
An Information-Theoretic Perspective on Proper Quaternion Variational Autoencoders


Department of Information Engineering, Electronics and Telecommunications, Sapienza University of Rome, Via Eudossiana 18, 00184 Rome, Italy
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(7), 856; https://0-doi-org.brum.beds.ac.uk/10.3390/e23070856
Submission received: 30 May 2021
/
Revised: 24 June 2021
/
Accepted: 1 July 2021
/
Published: 3 July 2021
(This article belongs to the Special Issue Adaptive Signal Processing and Machine Learning Using Entropy and Information Theory)
Abstract
:Variational autoencoders are deep generative models that have recently received a great deal of attention due to their ability to model the latent distribution of any kind of input such as images and audio signals, among others. A novel variational autoncoder in the quaternion domain , namely the QVAE, has been recently proposed, leveraging the augmented second order statics of -proper signals. In this paper, we analyze the QVAE under an information-theoretic perspective, studying the ability of the -proper model to approximate improper distributions as well as the built-in -proper ones and the loss of entropy due to the improperness of the input signal. We conduct experiments on a substantial set of quaternion signals, for each of which the QVAE shows the ability of modelling the input distribution, while learning the improperness and increasing the entropy of the latent space. The proposed analysis will prove that proper QVAEs can be employed with a good approximation even when the quaternion input data are improper.
1. Introduction
Generative learning models have been recently gained considerable attention due to their surprising performance in producing highly realistic signals of various types [1,2,3,4]. They have been successfully employed in a wide variety of applications, such as image-to-image translation [5], image fusion [6], face de-identification [7], natural language generation [8], data augmentation on ancient handwritten characters [9], MRI super-resolution [10], brain tumor growth prediction [11], generative modeling of structured-data [12].
Among such generative methods, the variational autoencoders (VAEs) have been proven to perform stochastic variational inference and learning even for large datasets and intractable posterior distributions [13]. The main advantages of the VAEs rely on their capability of learning smooth latent representations of the input data. This has led VAEs to be used in several fields of applications, including high-quality image generation [14], speech enhancement [15], music style transfer [16], data augmentation [17], 3D scene generation [18], gesture similarity analysis [19], text generation [20] and sequential recommendation [21], among others.
Recent advances on VAEs focus both on theoretical aspects, such as the improvement of the stochastic inference approach [22], and on architectural aspects, such as the use of different types of latent variables to learn local and global structures [23], the definition of hierarchical schemes [24], rather than the use of a multi-agent generator [25]. Among the most recent VAE models, we focus on the quaternion-valued variational autoencoder (QVAE), which exploits the properties of quaternion algebra to improve performance, on one hand, and to significantly reduce the overall number of network parameters [26], on the other hand.
The basic approach on which relies the QVAE is the learning in the quaternion domain, which results in significant advantages in the presence of multidimensional input data (mainly 3D and 4D data) showing some inter-channel correlations. This properties have been widely exploited in shallow learning models, such as linear and nonlinear adaptive filters [27,28,29,30,31,32,33,34]. Another fundamental property of quaternion-valued learning is the Hamilton product, which has recently favored the proliferation of convolutional neural networks in the quaternion domain [35,36,37,38]. Due to their capabilities, quaternion-valued learning methods have been applied in several applications, including spoken language understanding [39], color image processing [40,41], 3D audio [42,43], speech recognition [44], image generation [45], quantum mechanics [46], risk diversification [47], gait data analysis [48].
As with any other complex-valued and hypercomplex-valued algebra, the quaternion-valued learning can rely on the properties of the second-order statistics, which are fundamental to characterize the input data based on their correlation. A characterization of correlation is achieved in terms of covariance and pseudo-covariance. In particular, random variables and processes with a vanishing pseudo-covariance are called proper [49,50,51]. Properness is preserved under affine transformations. Moreover, it should be considered that the multivariate Gaussian density assumes a natural form only for proper random variables. Properness in the quaternion domain, also denoted as -properness, is based on the vanishing of three different complementary covariance matrices [51]. In the case of possibly improper random variables, we need to take into account the quaternion conjugate and augmented second-order statistics [51,52,53]. The degree of improperness of a quaternion random vector can be measured in several ways. An interesting approach is to use an improperness measure based on the Kullback–Leibler (KL) divergence between the augmented covariance matrix and its closest proper version in the KL sense [51]. Quaternion second-order statistics have been used in several applications, from independent component analysis to canonical transform [54,55], from linear to nonlinear adaptive filtering [56,57,58].
Recently, augmented quaternion second-order statistics have been also exploited for the first time for the development of a deep learning model, the QVAE [26]. Deep VAEs should model long-range correlations in data [59] and quaternion layers allow to leverage internal latent relations between input features. The QVAE also leads to a significant reduction in the number of parameters, which may benefit the decoder. A full improper QVAE should be developed to completely exploit correlated multidimensional input data, such as color images. However, on one hand an improper QVAE may be too complex due to the sophisticated structure of the complete covariance matrix. On the other hand, the proper QVAEs may represent a good tradeoff between complexity and performance, even when input data are improper. To this end, an information-theoretic analyses, thanks to its relation with improperness measures, may help in understanding how good such approximation may be in terms of properness [60,61].
In order to understand and demystify the theoretical capabilities of generating data with a proper model when the input data is either proper or improper, in this paper we investigate the proper QVAE from an information-theoretic perspective. To this end, we show how the KL divergence may establish a relation between the loss function of the QVAE and the improperness measure. We exploit the KL-based measure to show the entropy loss due to the improperness of the quaternion random vector input of the QVAE, or equivalently, the mutual information among the quaternion random vector and its involutions over three pure unit quaternions [51,52]. We show how the entropy in input data plays an important role in the generation of improper signals. Furthermore, we illustrate how the improperness can be calibrated in the latent space in order to enhance its differential entropy. Simulation results on artificial signals will prove the ability of the proper QVAE to be adopted with a good approximation for the generation of improper signals. Moreover, results will show how the properness is preserved by the model, even if it is composed of several nonlinearities.
The paper is organized as follows. In Section 2, we briefly introduce the main properties of quaternion algebra that are exploited in quaternion-valued processing. In Section 3, we analyze the quaternion properness and the augmented second-order statistics of quaternion-valued signals, which are then exploited to define the quaternion variational autoencoders. In particular, the proper QVAE is described in Section 4, while in Section 5 we define the relation between the loss function of the QVAE and the properness measures of the involved signals by using the quaternion-valued entropy. Experimental simulations are shown in Section 6, while final conclusions are derived in Section 7.
2. Fundamental Properties of Quaternion Algebra
Quaternions are hypercomplex numbers consisting of four components, a scalar part and three imaginary ones, and elements of : The quaternion domain is an extension of the complex domain . A quaternion is identified as
in which are real coefficients and imaginary units. A quaternion without the scalar part is named pure quaternion and represents a vector in since the imaginary units play the role of orthonormal basis, being . The quaternions’ peculiarity is the relation among imaginary components which comply with the following properties:
The fundamental properties of quaternion operations are then described below.
Addition and subtraction of two quaternions. Addition and subtraction among quaternions q and p are performed component-wise:
Scalar product of two quaternions. As for addition and subtraction, the scalar product is also an element-wise operation:
Vector product of two quaternions. Due to the relations among imaginary units in (2) and the non commutative properties of vector product in the hypercomplex domain, a new kind of vector multiplication has to be introduced. The Hamilton product, denoted by ⊗, is at the core of quaternion neural networks and it is described by the following equation:
The Hamilton product can also be written in concise form:
from which it is straightforward obtaining the Hamilton product for pure quaternions, by fixing :
Conjugate of a quaternion. The conjugate of a quaternion number is obtained by subtracting the imaginary units instead of adding them to the scalar part:
Norm of a quaternion. The norm of a quaternion is simply the euclidean norm in , thus .
Quaternion polar form. Quaternions admit an Euler representation, so considering a quaternion q, an angle and a pure unit quaternion , the polar form is:
in this setting, and .
Quaternion involutions. A quaternion involution is generally defined as a mapping which is its own inverse or self-inverse mapping. Quaternions have infinite involutions that can be generalized by [62]:
in which q is the quaternion to be involved and is the axis of the involution. Interestingly, the scalar part of the quaternion is invariant to any kind of involution while the imaginary parts are reflected across the axis of the involution. Consequently, the conjugate of a quaternion is an involution since the scalar part remains unchanged while the imaginary units are reflected through the axis. Together with the conjugate, there are three crucial involutions we have to consider, which are perpendicular involutions:
In the perpendicular involutions, the quaternion is involved across its imaginary units.
3. Augmented Second-Order Statistics and Quaternion Properness
3.1. Statistics for Quaternion Random Signals
In order to understand the behavior of a signal, it is often crucial to study its statistics. A generic Gaussian signal can be completely described by the mean and the covariance matrix. For quaternion random variables, the mean can be easily derived by (3), resulting in another quaternion:
in which is the average of each quaternion component. Conversely, deriving second-order statistics for quaternion signals requires more detailed computations due to the interactions among components. As previously demonstrated for complex numbers [49], the covariance matrix is not able to describe the second-order information and the complementary covariance matrix needs to be considered too. Consequently, taking the standard covariance matrix of a quaternion signal into account is not sufficient to cover the complete second-order statistics; thus, the information is augmented through three complementary covariance matrices [52]. In order to build this complete statistical description, we need to introduce the information brought by the perpendicular involutions introduced in (8). The matrices to be considered are then:
which are, respectively, the standard covariance matrix and the three complementary matrices. Note that is the conjugate transpose operator. These matrices are still quaternions, so they comprise a real part and three imaginary units. As an example, we analyze the first matrix . It is composed by the covariance matrices of the quaternion components as follows:
Similarly, also the matrices can be determined and written in the above quaternion form.
The composition and the combination of the standard covariance matrix and of the complementary covariance matrices give rise to the augmented covariance matrix which recovers the complete second-order information of the augmented quaternion vector [52]. The matrices in (10) have interesting properties: each component of the matrix is symmetric but the component corresponding to the involved imaginary unit is, instead, skew-symmetric. These characteristics are included in the Hermitian property, according to which is -Hermitian, is -Hermitian and is -Hermitian. The derived augmented covariance matrix follows.
By means of the mean and augmented covariance matrix and following [52], it is now possible to define a generic quaternion Gaussian distribution , which is Gaussian if its components are jointly normal:
where the mean is the mean of the augmented quaternion and N the number of samples.
3.2. -Properness
In the previous subsection, we describe the complete second-order information of a quaternion signal by means of the augmented covariance matrix which is comprised of the covariance matrices of the quaternion with its perpendicular involutions. Due to the four degrees of freedom in quaternions, the domain includes manifold properness definitions that are employed to characterize the relation of with in some particular cases.
The lighter condition is described in the -properness, which holds for a signal that is uncorrelated with one of its perpendicular involutions, leading to the cancellation of either one of the complementary covariance submatrices . A slightly harder constraint is brought by the -properness which claims the nullification of two of the three complementary covariance submatrices. A composition of the two already defined properties gives rise to the strongest properness condition, the -properness. The latter holds when each complementary covariance matrix vanishes, that is . However, according to [52], an -proper variable has also several other features that are reported in Table 1. An -proper signal is then uncorrelated with its perpendicular involutions and, according to the second property in Table 1, it also has uncorrelated components which have equal variance . From these assumptions, we can derive the corresponding augmented covariance matrix for -proper signals which will be symmetric and positive definite:
The structure of the matrix is invariant to any linear transformation where is a quaternion weight matrix [54], thus ensuring that the quaternion properness is preserved by linear layers in neural networks.
As for improper signals in Section 3.1, a probability density function can be derived for -proper signals too. In this framework, the distribution is described by the covariance matrix in (14) which is equal to and by the mean of the quaternion component in (9):
In order to evaluate the properness of an augmented zero-mean quaternion random vector, a simple and fast coefficient was proposed in [32]. It indicates the correlation of the signal with its perpendicular involutions through the complementary covariance matrices. Note that the coefficient is bounded in and it is 0 in the case of -proper signals, while it is equal to 1 for improper ones. It is defined as
In our experiments, since we are dealing with -proper signals, we can just report the average of the three coefficients, simply denoted as I. Conversely, if we evaluate or proper signals, we should consider each coefficient independently.
4. The -Proper Variational Autoencoder
Originally introduced in [26] (the implementation of the QVAE is available online at: https://github.com/eleGAN23/QVAE, accessed on 1 July 2021), the quaternion variational autoencoder (QVAE) is a generative model which learns and controls the latent distribution of an n-dimensional -proper quaternion input. Once the distribution is learnt, then the model is able to generate new samples from it thanks to the probabilistic relation between the two quaternion spaces of the input and of the latent distribution.
Similar to the variational autoencoder (VAE) for real-valued distributions in [13], the QVAE grasps the mapping of the original quaternion input into the latent space described by a prior distribution , with . Then, it learns the conditional distribution of the input with respect to the latent vector , that is the prior distribution adjusted with the statistics learnt by the encoder. However, due to the intractability of the mapping distribution , the QVAE introduces an approximation to encode the input into the latent vector, as in its real-valued counterpart [13]. The parameters of this recognition model (or inference model) are then optimized to match the true intractable conditional distribution as . By employing this approximation, it is possible to express the marginal likelihood
where is the so called evidence lower bound (ELBO) [13] with respect to the parameters and , which is a lower bound on the log-likelihood of the data distribution [63]. is the KL divergence between the -proper centered isotropic Gaussian variable and the -proper Gaussian , with taking the form of (14) and . The KL divergence in the quaternion domain takes the following form:
The optimization of the QVAE cost function (17) goes through the minimization of the KL divergence, through which the QVAE forces the recognition model to be as close as possible to the prior distribution by operating on the statistics and .
5. Kullback–Leibler Divergence as Entropy Loss Due to Improperness
The KL divergence in (17) can be indeed seen as a measure of the improperness of the recognition model. As defined in [51], the measure is described by:
where is the set of all the augmented covariance matrices respecting one of the quaternion propernesses introduced in Section 3.2. This measure estimates the distance of the recognition model with an augmented covariance matrix from the -proper isotropic Gaussian variable described by the augmented covariance matrix , by assuming .
Since we are considering distributions with zero mean, the first term in the second line of the KL Equation (17) vanishes. Furthermore, Equation (18) minimizes the divergence over the set ; thus, in the -proper case, the matrix which minimizes (18) is the diagonal covariance matrix defined in (14). Employing these considerations and with some computations, we can reduce the improperness measure to:
If the signal for which we want to measure the improperness, i.e., the recognition model , is -proper, then the measure will be close to 0 since will be close to in the KL sense. Conversely, if the signal is improper, will be far from 0.
By defining the improperness measure through the KL, it is possible to leverage the relation among the divergence and the entropy and exploring the mutual information of the signal. Therefore, we can use the definition of the differential entropy for a generic quaternion vector [51,52] to compute the entropy of the recognition model :
The entropy expression can be simplified for isotropic -proper variables such as the prior distribution , by replacing the value of the determinant from (14), which is equal to .
In [52], the authors proved that the differential entropy is maximum for -proper signals. Thus, (21) is an upper bound for the general entropy definition (20), hence: .
Then, according to [51], the improperness measure can be rewritten through the difference between the entropy of the generic augmented quaternion and the entropy of the isotropic variable:
This formulation elegantly evaluates the loss of entropy that is due to the improperness of the recognition model. Therefore, we can measure the properness of the recognition model and compute the QVAE entropy loss due to the measure of properness (or improperness) of . Thus, when optimizing the QVAE cost function during training, together with the ELBO minimization, through the KL divergence we are jointly minimize also the difference between the Gaussian distributions and and the entropy loss of the latter.
Since the KL under the information theoretic perspective allows the QVAE to deal also with improper signals, although the QVAE is originally set up for -proper distributions, by means of an approximation it can be employed also for improper random variables. Let us consider an incoming improper signal , so both the recognition model and the generative model are represented by improper distributions too. We leave instead unchanged the prior distribution , which is the centered isotropic -proper distribution. On the training stage, the KL divergence of the QVAE will move the improper distribution towards the -proper prior distribution. While the distribution learning is well performed by the model, the KL takes care of increasing the entropy by slightly reducing the improperness. However, the overall original (improper) structure of the signal is preserved by the QVAE which just aims at enhancing the entropy of the recognition model, while leaving free the generative model.
6. Experimental Results
In this section, we report the sets of experiments we performed for testing the reliability of the improperness measures and the performances of the -proper variational autoencoder in learning proper as well as improper distributions.
6.1. Proper and Improper Test Signals
We consider two proper signals and two improper signals and we evaluate the improperness coefficient (16), the differential entropy (20), the improperness measure (18) and the entropy loss (22). We expect that the proper signals have improperness measure and coefficients close to 0, as well as the entropy loss. On the contrary, the entropy should be greater than for the corresponding improper signals.
As input signals, we consider:
- -proper signal with independent Gaussian components defined as:with .
- -proper filtered signal from a colored Gaussian noise as [31]:with .
- Improper signal from a quaternion with components:and composed as:
- Improper filtered signal from a Gaussian noise as:with and .
Mild improper signals (i.e., with different from 0 and to 1) can be generated by varying the coefficient b in the improper signal I2. As an example, by setting , it is possible to obtain a mild-improper signal with . However, we want to stress the -proper QVAE with completely improper cases that are the extreme and most difficult cases. For this reason, we only consider improper signals with .
We compute the measures defined in Section 5 for each of these signal by using the Quaternion Toolbox for MATLAB (S. J. Sangwine and N. Le Bihan. Quaternion Toolbox for MATLAB, Version 2 with support for Octonions, 2013. First public release 2005. Software library available online at: http://qtfm.sourceforge.net/, accessed on 1 July 2021) and report the results in Table 2. As we expect, the proper signals have low improperness coefficients, meaning that the complementary covariances are sparse, while the coefficients for the improper signals are reasonably equal to 1. On the other hand, the differential entropy is low and negative for the improper signals, while it is highest for the proper ones, proving that (21) is an upper bound for the generic differential entropy. Moreover, the entropy loss is almost 0 for proper signals, confirming that there is no loss of entropy due to the improperness. On the contrary, the improper signals come at the cost of a high entropy drop.
6.2. Proper and Improper Signals for an -Proper QVAE
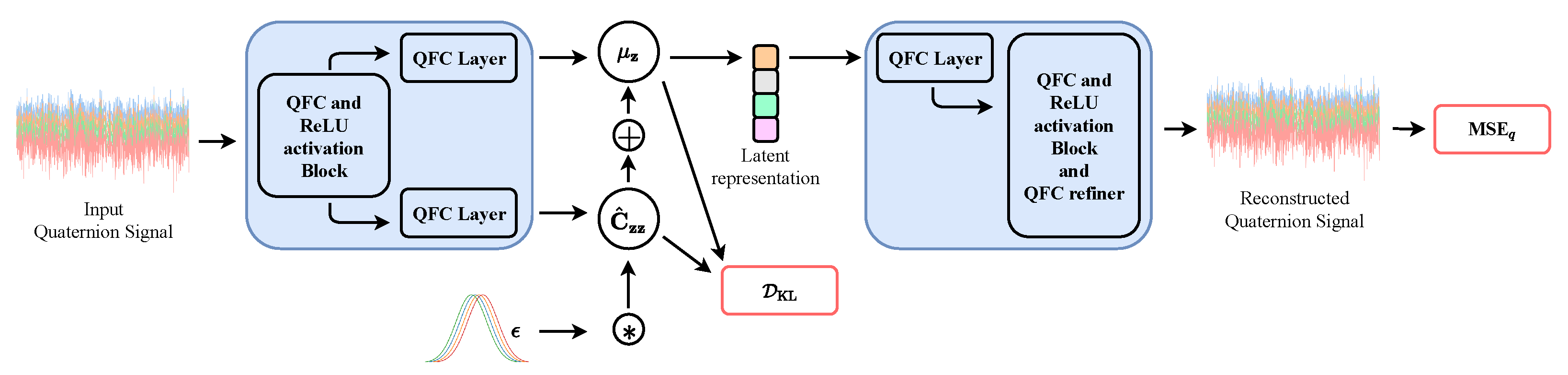
We consider a plain QVAE with a quaternion encoder network and a quaternion decoder network. The first model is comprised of a stack of five quaternion fully connected layers (QFC) with an increasing number of weights , as in [26,64] and split ReLU activation function as the PixelHVAE in [65]. The statistics of the latent distribution are learnt through two additionally quaternion linear layers with number of weights equal to 4 times the latent dimension, which we fix to 25. The decoder has a mirrored structure, and thus quaternion fully connected layers are piled up as , with an additional refiner layer at the end of the stack. We do not consider including the quaternion batch normalization [38,45] since it can introduce randomness which may affect the correct learning of the distribution statistics [24,66]. For every experiment, the prior distribution is a centered isotropic -proper quaternion Gaussian distribution, as described in Section 4. We employ a training signal with 1000 samples, a validation set of 500 and a test set of 1000 without mini batches and we perform 5k iterations with Adam having a learning rate equal to . As in the original QVAE [26], the cost function is a weighted sum of a quaternion mean squared error as defined in [37], and the KL divergence of Section 5, for which we fix the scale parameter equal to . Figure 1 shows the architecture of the QVAE we consider in our tests.
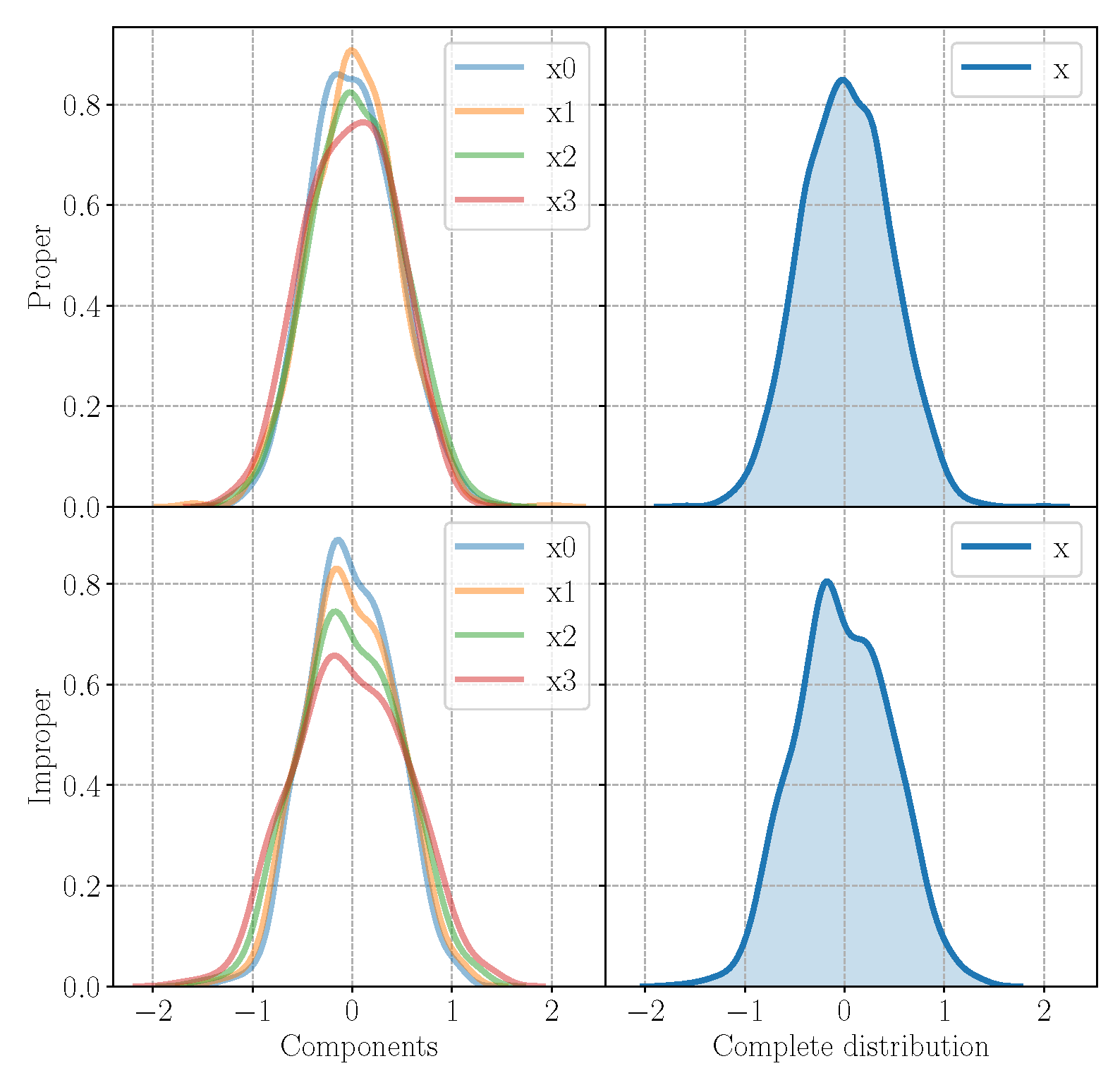
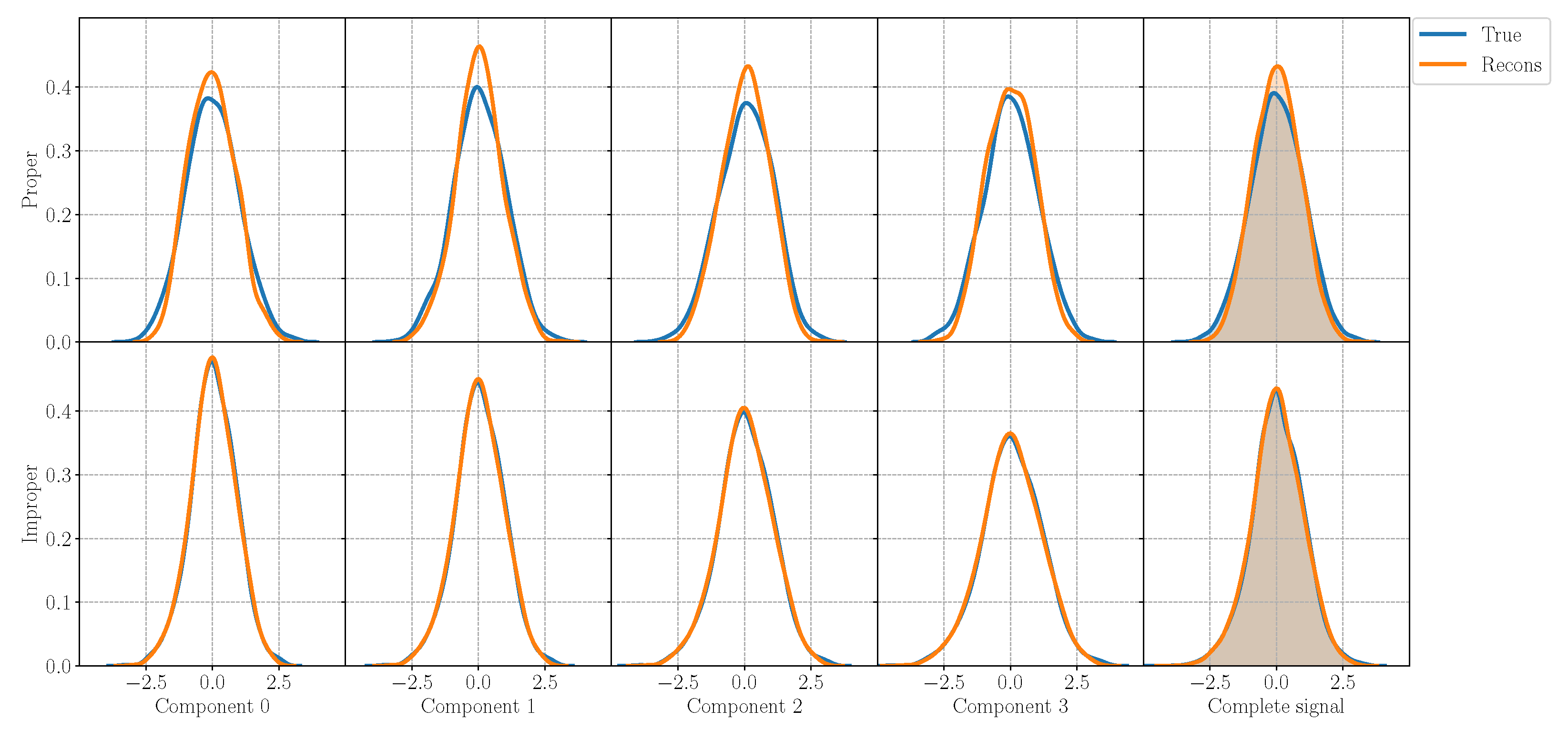
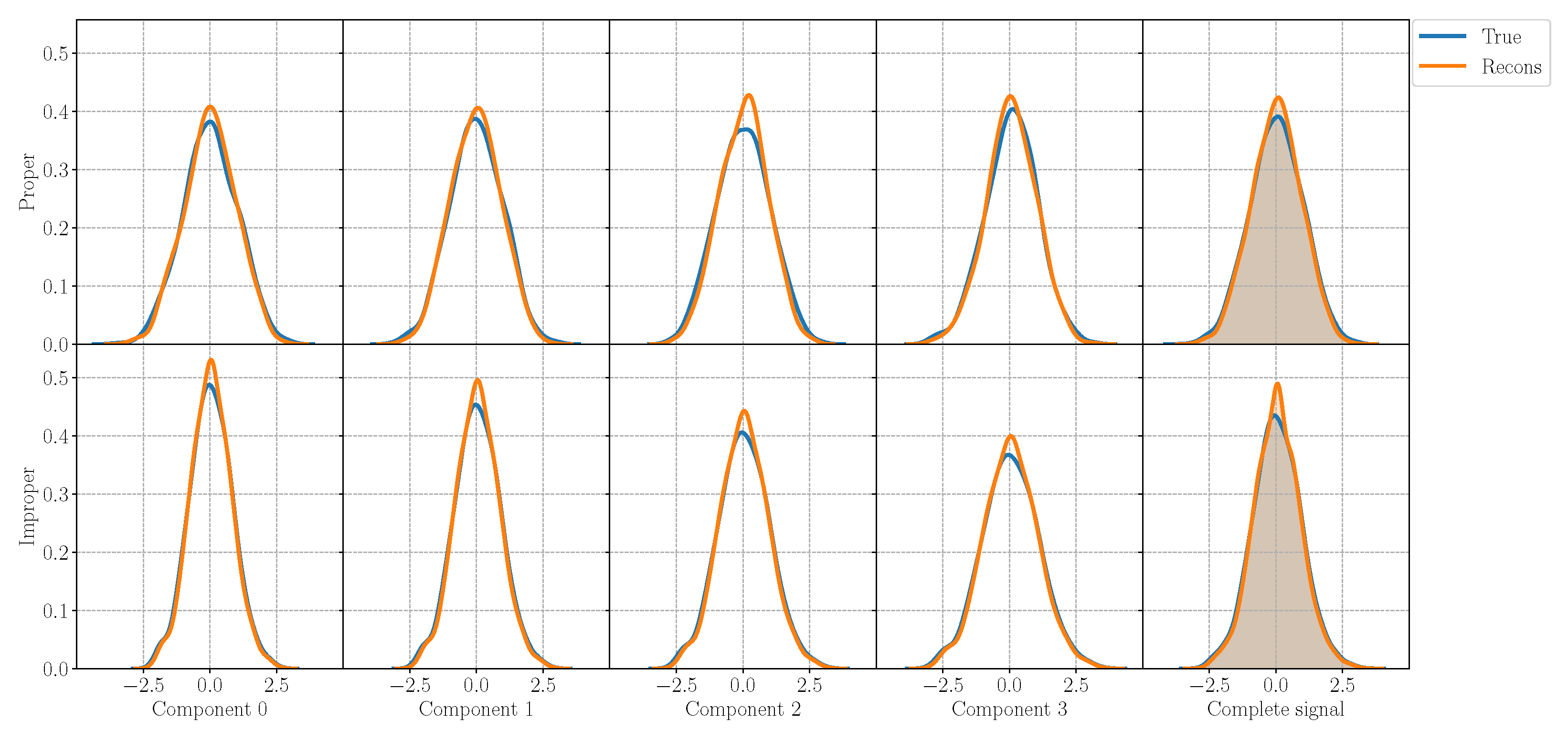
For each experiment, we evaluate the performance of the model in the reconstruction task and generation task as well as on the ability of preserving the properness or the improperness of the incoming signal. In order to assess the generation ability of the model, in Figure 2, we plot the generated components and the complete signal sampling from the model trained on a proper signal and on an improper signal. While the components of the improper signal show different variances, the ones from the proper signal has the same variance according to the properties in Table 1. Figure 3 reports instead the original and reconstructed distributions for the proper and improper case, in the first and in the second line, respectively, with an MSE equal to for the proper signal and to for the improper one. In the figure, the first four columns represent the four components , while the last one displays the distribution of the complete signal . The -QVAE is able to perfectly reconstruct the input distribution even in the improper case, grasping the different variances in each component and learning the complete signal. Thus, the QVAE is effective even if approximated for improper distributions, for which it is capable of learning the correct statistics of each component.
Table 3 presents the results of the improperness and entropy analysis on the reconstructed and generated signals on the test set. As for the original samples in Table 2, we compute the improperness coefficient (16), the differential entropy (20), the improperness measure (18) and the entropy loss (19). It is worth noting that the QVAE trained on -proper signals still generates and reconstruct -proper signals, as measured by the improperness measures and the entropy loss. Moreover, the entropy of this kind of signal is higher than the entropy of the improper samples. While we already knew that -properness is preserved by linear transformations, this result asserts that it is maintained also for non-linear transformations brought by activation functions in neural networks, adding an important milestone in the study of -proper signals.
Another interesting result comes when the QVAE is trained on improper signals. While the improperness coefficients of both reconstructed and generated signals are close to the coefficients of their respective original signals in Table 2, indicating the improperness of these random variable, the entropy values and losses values are intriguing. Indeed, the differential entropy is increased with respect to the input signal (originally, ≈−51 and ≈−45), approaching values from ≈−10 up to 0, meaning that the -proper structure of the QVAE works towards an increase in entropy and an improperness reduction in the input signal. Confirming this, the loss of entropy was drastically reduced with respect to the original signal, ranging from approximately 8 and 13 while the input entropy loss is around ≈51.
Hence, the -proper QVAE can be approximated to learn improper distributions, on which it preserves the original structure of the signal while increasing the entropy of the latent space, at the cost of a limited improperness reduction. Although the slight modification on the distribution, the QVAE is still able to catch the correct statistics and to perform a good generation as well as a precise reconstruction, as Figure 2 and Figure 3 show.
To further assess the performance of the QVAE and provide a comparison with its real-valued counterpart, we test a real-valued VAE on the same signal benchmarks. We expect that the real-valued VAE performs similar to the QVAE in the proper case, but that the quaternion model outperforms the real-valued one when dealing with improper signals. Indeed, thanks to the quaternion algebra properties, the QVAE is able to learn intra-component correlations while the VAE do not catch them. Thus, in cases with no correlation among components i.e., proper signals, the two models should have similar performances. On the contrary, in the improper case where the correlation among components is higher the QVAE gains advantages from the quaternion algebra and obtains better performances. Results and details are reported in the Appendix A. However, thanks to the quaternion algebra properties, the QVAE has just of free parameters with respect to its real-valued counterpart.
7. Conclusions
In this paper, we have conducted a thorough analysis on a -proper quaternion-valued variational autoencoder (QVAE) under an information-theoretic perspective, investigating the entropy loss of the model due to the measure of improperness in the input signal. We have proved that the QVAE can be approximated for improper signals, for which it increases the entropy of the latent space by slightly reducing the improperness. Moreover, it is worth noting that, in each of our experiments, the properness is preserved also for nonlinear transformations brought by activation functions and not only for simple quaternion linear operations. As a conclusion, the QVAE is able to learn the correct distribution of both -proper and improper random variables, while the measure of improperness, as well as the entropy of the latent space, can be calibrated through the KL divergence in the cost function.
Author Contributions
Conceptualization, E.G. and D.C.; methodology, E.G. and D.C.; software, E.G.; validation, E.G. and D.C.; formal analysis, E.G. and D.C.; investigation, E.G., D.C. and A.U.; resources, D.C.; data curation, E.G. and D.C.; writing—original draft preparation, E.G. and D.C.; writing—review and editing, D.C.; visualization, E.G. and D.C.; supervision, D.C. and A.U.; project administration, D.C.; funding acquisition, A.U. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by “Progetti di Ricerca” of Sapienza University of Rome under grant numbers RM120172AC5A564C and RG11916B88E1942F.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Evaluation of the Real-Valued VAE on Proper and Improper Signals
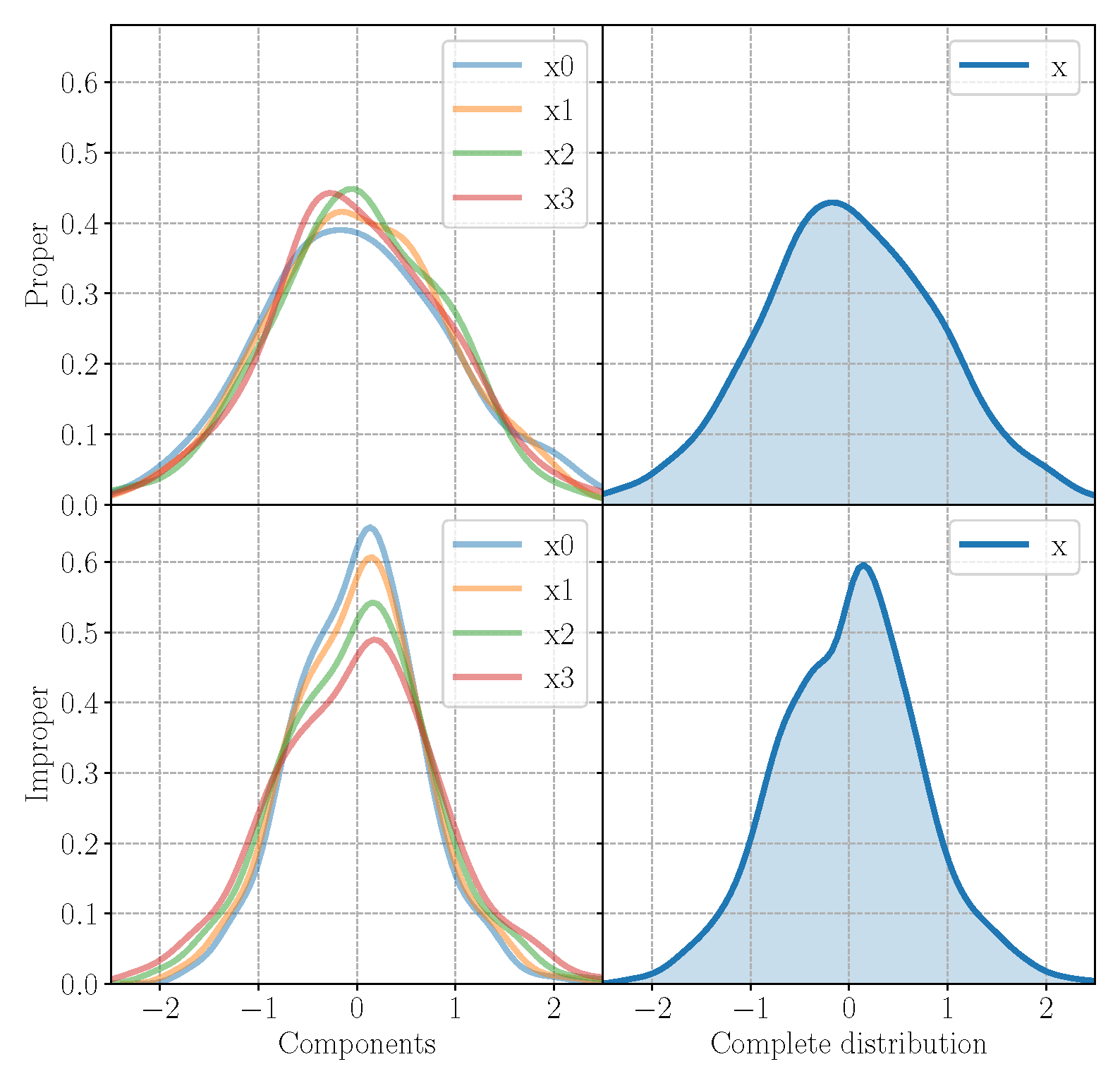
In order to further assess the performance of the -proper QVAE, we perform a set of experiments with a real-valued VAE on the same benchmarks. In order to make a fair comparison, the hyperparameters are the same as for the QVAE, while the architecture is built with real-valued blocks. Moreover, the KL divergence is the standard divergence in [13]. However, due to the algebra in real domain, the VAE has parameters while the QVAE has just , thus the proposed model in the quaternion domain has exactly the of parameters with respect to its real-valued counterpart. Thus, the QvAE is able to learn the improperness of the input signal and to generate or to reconstruct precise signals while requiring parameters and memory. Moreover, the QVAE is able to perfectly reconstruct the improper signal, as shown in Figure 3, while the real-valued VAE makes some errors. These results can be seen in Figure A1 and Figure A2. As we expect, the QVAE outperform the real-valued VAE when dealing with correlated signals i.e., improper cases, since the proposed method leverages the quaternion algebra properties, including the Hamilton product, to learn intra-components relations, while the real-valued VAE is not able to catch them. Thus, while for proper signals the performances between VAE and QVAE are similar, in the improper cases the QVAE has better performances thanks to the Hamilton product in its core blocks. Finally, the improperness measures and corresponding entropy loss for each of the signals considered are reported in Table A1.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Average improperness coefficient I (16), differential entropy (20), improperness measure (19) and entropy loss (22) for different output from the real-valued VAE (Recons stands for the reconstructed signal, Sample for the generated one) with different kinds of -proper and improper signals. As the QVAE, also the VAE, which is however larger in terms of free parameters, is able to learn the improperness of the input.
Table A1.
Average improperness coefficient I (16), differential entropy (20), improperness measure (19) and entropy loss (22) for different output from the real-valued VAE (Recons stands for the reconstructed signal, Sample for the generated one) with different kinds of -proper and improper signals. As the QVAE, also the VAE, which is however larger in terms of free parameters, is able to learn the improperness of the input.
| Signal | Out | I | |||
|---|---|---|---|---|---|
| P1. (proper) | Recons | 0.031 | 5.4547 | 0.0031 | 0.0030 |
| Sample | 0.0697 | 5.4498 | 0.0148 | 0.0147 | |
| P2. (proper) | Recons | 0.0396 | 4.8138 | 0.0050 | 0.0050 |
| Sample | 0.9879 | −21.2687 | 6.7205 | 6.7205 | |
| I1. (improper) | Recons | 0.9983 | −8.9158 | 14.0350 | 14.0350 |
| Sample | 0.9995 | −8.2952 | 16.1035 | 16.1035 | |
| I2. (improper) | Recons | 0.9984 | −9.0598 | 14.2591 | 14.2591 |
| Sample | 0.9977 | −9.2681 | 13.7240 | 13.7240 |
Figure A1.
Generated samples from the real-valued VAE trained on the proper signal P1 and on the improper signal I2. These model generates good samples (upper figure), even if the variance is larger with respect to the QVAE.
Figure A1.
Generated samples from the real-valued VAE trained on the proper signal P1 and on the improper signal I2. These model generates good samples (upper figure), even if the variance is larger with respect to the QVAE.

Figure A2.
Reconstructed distributions from the real-valued VAE on signal P1 (proper) in the upper line and I2 (improper) in the lower line. Although the larger number of parameters, the VAE commits some errors in both the signal for the reconstruction task, while the QVAE is able instead to perfectly reconstruct original signals. The MSE values are for the proper signal and for the improper one.
Figure A2.
Reconstructed distributions from the real-valued VAE on signal P1 (proper) in the upper line and I2 (improper) in the lower line. Although the larger number of parameters, the VAE commits some errors in both the signal for the reconstruction task, while the QVAE is able instead to perfectly reconstruct original signals. The MSE values are for the proper signal and for the improper one.

References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Rezende, D.J.; Metz, L.; Chintala, S. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Bond-Taylor, S.; Leach, A.; Long, Y.; Willcocks, C.G. Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models. arXiv 2021, arXiv:2103.04922v1. [Google Scholar]
- Ruiz-Garcia, A.; Schmidhuber, J.; Palade, V.; Took, C.C.; Mandic, D. Deep neural network representation and Generative Adversarial Learning. Neural Netw. 2021, 139, 199–200. [Google Scholar] [CrossRef]
- Fu, Y.; Ma, J.; Guo, X. Unsupervised Exemplar-Domain Aware Image-to-Image Translation. Entropy 2021, 23, 565. [Google Scholar] [CrossRef]
- Hou, J.; Zhang, D.; Wu, W.; Ma, J.; Zhou, H. A Generative Adversarial Network for Infrared and Visible Image Fusion Based on Semantic Segmentation. Entropy 2021, 23, 376. [Google Scholar] [CrossRef]
- Lin, J.; Li, Y.; Yang, G. FPGAN: Face de-identification method with generative adversarial networks for social robots. Neural Netw. 2021, 133, 132–147. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified Language Model Pre-training for Natural Language Understanding and Generation. arXiv 2019, arXiv:1905.03197. [Google Scholar]
- Grassucci, E.; Scardapane, S.; Comminiello, D.; Uncini, A. Flexible Generative Adversarial Networks with Non-Parametric Activation Functions. In Progress in Artificial Intelligence and Neural Systems. Smart Innovation, Systems and Technologies; Springer: Singapore, 2021; Volume 184. [Google Scholar]
- Sanchez, I.; Vilaplana, V. Brain MRI Super-Resolution Using 3D Generative Adversarial Networks. arXiv 2018, arXiv:1812.11440v1. [Google Scholar]
- Elazab, A.; Wang, C.; Gardezi, S.J.S.; Bai, H.; Hu, Q.; Wang, T.; Chang, C.; Lei, B. GP-GAN: Brain tumor growth prediction using stacked 3D generative adversarial networks from longitudinal MR Images. Neural Netw. 2020, 132, 321–332. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Yoo, J.; Lee, J.; Hong, S. SetVAE: Learning Hierarchical Composition for Generative Modeling of Set-Structured Data. arXiv 2021, arXiv:2103.15619v1. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114v10. [Google Scholar]
- Razavi, A.; van den Oord, A.; Vinyals, O. Generating Diverse High-Fidelity Images with VQ-VAE-2. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14866–14876. [Google Scholar]
- Sadeghi, M.; Alameda-Pineda, X. Robust Unsupervised Audio-Visual Speech Enhancement Using a Mixture of Variational Autoencoders. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7534–7538. [Google Scholar]
- Wu, S.L.; Yang, Y.H. MuseMorphose: Full-Song and Fine-Grained Music Style Transfer with Just One Transformer VAE. arXiv 2021, arXiv:2105.04090v1. [Google Scholar]
- Chadebec, C.; Thibeau-Sutre, E.; Burgos, N.; Allassonnière, S. Data Augmentation in High Dimensional Low Sample Size Setting Using a Geometry-Based Variational Autoencoder. arXiv 2021, arXiv:2105.00026v1. [Google Scholar]
- Kosiorek, A.R.; Strathmann, H.; Zoran, D.; Moreno, P.; Schneider, R.; Mokrá, S.; Rezende, D.J. NeRF-VAE: A Geometry Aware 3D Scene Generative Model. arXiv 2021, arXiv:2104.00587v1. [Google Scholar]
- Stewart, K.; Danielescu, A.; Supic, L.; Shea, T.; Neftci, E. Gesture Similarity Analysis on Event Data Using a Hybrid Guided Variational Auto Encoder. arXiv 2021, arXiv:2104.00165v1. [Google Scholar]
- Qian, D.; Cheung, W.K. Enhancing Variational Autoencoders with Mutual Information Neural Estimation for Text Generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4047–4057. [Google Scholar]
- Xie, Z.; Liu, C.; Zhang, Y.; Lu, H.; Wang, D.; Ding, Y. Adversarial and Contrastive Variational Autoencoder for Sequential Recommendation. arXiv 2021, arXiv:2103.10693v1. [Google Scholar]
- Gallego, V.; Ríos Insua, D. Variationally Inferred Sampling through a Refined Bound. Entropy 2021, 23, 123. [Google Scholar] [CrossRef]
- Sadeghi, H.; Andriyash, E.; Vinci, W.; Buffoni, L.; Amin, M.H. PixelVAE++: Improved PixelVAE with Discrete Prior. arXiv 2019, arXiv:1908.09948v1. [Google Scholar]
- Vahdat, A.; Kautz, J. NVAE: A Deep Hierarchical Variational Autoencoder. arXiv 2020, arXiv:2007.03898v1. [Google Scholar]
- Zhao, H.; Li, T.; Xiao, Y.; Wang, Y. Improving Multi-Agent Generative Adversarial Nets with Variational Latent Representation. Entropy 2020, 22, 1055. [Google Scholar] [CrossRef] [PubMed]
- Grassucci, E.; Comminiello, D.; Uncini, A. A Quaternion-Valued Variational Autoencoder. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Bülow, T.; Sommer, G. Hypercomplex Signal—A Novel Extension of the Analystic Signal to the Multidimensional Case. IEEE Trans. Signal Process. 2001, 49, 2844–2852. [Google Scholar] [CrossRef] [Green Version]
- Took, C.C.; Mandic, D.P. The Quaternion LMS Algorithm for Adaptive Filtering of Hypercomplex Processes. IEEE Trans. Signal Process. 2009, 57, 1316–1327. [Google Scholar] [CrossRef] [Green Version]
- Paul, T.K.; Ogunfunmi, T. A Kernel Adaptive Algorithm for Quaternion-Valued Inputs. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2422–2439. [Google Scholar] [CrossRef] [PubMed]
- Ortolani, F.; Comminiello, D.; Scarpiniti, M.; Uncini, A. Frequency Domain Quaternion Adaptive Filters: Algorithms and Convergence Performance. Signal Process. 2017, 136, 69–80. [Google Scholar] [CrossRef]
- Ortolani, F.; Comminiello, D.; Scarpiniti, M.; Uncini, A. Advances in Hypercomplex Adaptive Filtering for 3D Audio Processing. In Proceedings of the IEEE First Ukraine Conference on Electrical and Computer Engineering (UKRCON), Kyiv, Ukraine, 29 May–2 June 2017; pp. 1125–1130. [Google Scholar]
- Xiang, M.; Kanna, S.; Mandic, D.P. Performance Analysis of Quaternion-Valued Adaptive Filters in Nonstationary Environments. IEEE Trans. Signal Process. 2018, 66, 1566–1579. [Google Scholar] [CrossRef]
- Ogunfunmi, T.; Safarian, C. The Quaternion Stochastic Information Gradient Algorithm for Nonlinear Adaptive Systems. IEEE Trans. Signal Process. 2019, 67, 5909–5921. [Google Scholar] [CrossRef]
- Comminiello, D.; Scarpiniti, M.; Parisi, R.; Uncini, A. Frequency-Domain Adaptive Filtering: From Real to Hypercomplex Signal Processing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7745–7749. [Google Scholar]
- Gaudet, C.; Maida, A. Deep Quaternion Networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Parcollet, T.; Ravanelli, M.; Morchid, M.; Linarès, G.; Trabelsi, C.; De Mori, R.; Bengio, Y. Quaternion Recurrent Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–19. [Google Scholar]
- Parcollet, T.; Morchid, M.; Linarès, G. A Survey of Quaternion Neural Networks. Artif. Intell. Rev. 2019, 53, 2957–2982. [Google Scholar] [CrossRef]
- Vecchi, R.; Scardapane, S.; Comminiello, D.; Uncini, A. Compressing Deep-Quaternion Neural Networks with Targeted Regularisation. CAAI Trans. Intell. Technol. 2020, 5, 172–176. [Google Scholar] [CrossRef]
- Parcollet, T.; Morchid, M.; Linarès, G. Deep Quaternion Neural Networks for Spoken Language Understanding. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 504–511. [Google Scholar]
- Parcollet, T.; Morchid, M.; Linarès, G. Quaternion Convolutional Neural Networks for Heterogeneous Image Processing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8514–8518. [Google Scholar]
- Yin, Q.; Wang, J.; Luo, X.; Zhai, J.; Jha, S.K.; Shi, Y. Quaternion Convolutional Neural Network for Color Image Classification and Forensics. IEEE Access 2019, 7, 20293–20301. [Google Scholar] [CrossRef]
- Comminiello, D.; Lella, M.; Scardapane, S.; Uncini, A. Quaternion Convolutional Neural Networks for Detection and Localization of 3D Sound Events. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8533–8537. [Google Scholar]
- Ricciardi Celsi, M.; Scardapane, S.; Comminiello, D. Quaternion Neural Networks for 3D Sound Source Localization in Reverberant Environments. In Proceedings of the IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP), Espoo, Finland, 21–24 September 2020; pp. 1–6. [Google Scholar]
- Parcollet, T.; Zhang, Y.; Morchid, M.; Trabelsi, C.; Linarès, G.; De Mori, R.; Bengio, Y. Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition. arXiv 2018, arXiv:1806.07789. [Google Scholar]
- Grassucci, E.; Cicero, E.; Comminiello, D. Quaternion Generative Adversarial Networks. arXiv 2021, arXiv:2104.09630v1. [Google Scholar]
- Danielewski, M.; Sapa, L. Foundations of the Quaternion Quantum Mechanics. Entropy 2020, 22, 1424. [Google Scholar] [CrossRef]
- Sugitomo, S.; Maeta, K. Quaternion Valued Risk Diversification. Entropy 2020, 22, 390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szczęsna, A. Quaternion Entropy for Analysis of Gait Data. Entropy 2019, 21, 79. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neeser, F.; Massey, J. Proper complex random processes with applications to information theory. IEEE Trans. Inf. Theory 1993, 39, 1293–1302. [Google Scholar] [CrossRef] [Green Version]
- Le Bihan, N. The Geometry of Proper Quaternion Random Variables. Signal Process. 2017, 138, 106–116. [Google Scholar] [CrossRef]
- Vìa, J.; Ramìrez, D.; Santamarìa, I. Properness and Widely Linear Processing of Quaternion Random Vectors. IEEE Trans. Inf. Theory 2010, 56, 3502–3515. [Google Scholar] [CrossRef]
- Took, C.C.; Mandic, D.P. Augmented Second-Order Statistics of Quaternion Random Signals. Signal Process. 2011, 91, 214–224. [Google Scholar] [CrossRef] [Green Version]
- Navarro-Moreno, J.; Fernández-Alcalá, R.M.; Ruiz-Molina, J.C. A Quaternion Widely Linear Model for Nonlinear Gaussian Estimation. IEEE Trans. Signal Process. 2014, 62, 6414–6424. [Google Scholar] [CrossRef]
- Vìa, J.; Palomar, D.P.; Vielva, L.; Santamarìa, I. Quaternion ICA From Second-Order Statistics. IEEE Trans. Signal Process. 2011, 59, 1586–1600. [Google Scholar] [CrossRef]
- Zhang, Y.N.; Li, B.Z. Generalized Uncertainty Principles for the Two-Sided Quaternion Linear Canonical Transform. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4594–4598. [Google Scholar]
- Ortolani, F.; Comminiello, D.; Uncini, A. The Widely Linear Block Quaternion Least Mean Square Algorithm For Fast Computation In 3D Audio Systems. In Proceedings of the IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016. [Google Scholar]
- Ogunfunmi, T.; Safarian, C. A Quaternion Kernel Minimum Error Entropy Adaptive Filter. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4149–4153. [Google Scholar]
- Xia, Y.; Xiang, M.; Li, Z.; Mandic, D.P. Adaptive Learning Methods for Nonlinear System Modeling; Chapter Echo State Networks for Multidimensional Data: Exploiting Noncircularity and Widely Linear; Elsevier: Amsterdam, The Netherlands, 2018; pp. 267–288. [Google Scholar]
- Vahdat, A.; Andriyash, E.; Macready, W.G. Undirected Graphical Models as Approximate Posteriors. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 9680–9689. [Google Scholar]
- Smith, J.D. Some Observations on the Concepts of Information-Theoretic Entropy and Randomness. Entropy 2001, 3, 1–11. [Google Scholar] [CrossRef]
- Santamaria, I.; Crespo, P.M.; Lameiro, C.; Schreier, P.J. Information-Theoretic Analysis of a Family of Improper Discrete Constellations. Entropy 2018, 20, 45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ell, T.A.; Sangwine, S.J. Quaternion Involutions and Anti-Involutions. Comput. Math. Appl. 2007, 53, 137–143. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. Found. Trends Mach. Learn. 2019, 12, 307–392. [Google Scholar] [CrossRef]
- Hou, X.; Shen, L.; Sun, K.; Qiu, G. Deep Feature Consistent Variational Autoencoder. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1133–1141. [Google Scholar]
- Tomczak, J.M.; Welling, M. VAE with a VampPrior. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Spain, 9–11 April 2018; pp. 1214–1223. [Google Scholar]
- Maaløe, L.; Fraccaro, M.; Liévin, V.; Winder, O. BIVA: A Very Deep Hierarchy of Latent Variables for Generative Modeling. arXiv 2019, arXiv:1902.02102. [Google Scholar]
Short Biography of Authors
 | Eleonora Grassucci is a PhD student in Information and Communication Technologies with the Department of Information Engineering, Electronics and Telecommunications at Sapienza University of Rome, Italy. She earned a Master Degree in Data Science at Sapienza University of Rome. |
 | Danilo Comminiello is an Associate Professor with the Department of Information Engineering, Electronics and Telecommunications at Sapienza University of Rome. His current research interests deep learning and computational intelligence methodologies. Danilo Comminiello is a member of the IEEE Machine Learning for Signal Processing Technical Committee. He is one of the editors of the book “Adaptive Learning Methods for Nonlinear Modeling” (D. Comminiello and J. C. Principe, eds.), Elsevier, 2018. |
 | Aurelio Uncini is a Full Professor in Circuits Theory with the Department of Information Engineering, Electronics and Telecommunications at Sapienza University of Rome, Italy. He is author of more than 250 papers in the field of optimization algorithms for circuits design, signal processing, neural networks and audio signal processing. His present research interests include also linear and nonlinear adaptive filters, blind signal processing, adaptive audio and array processing, machine learning for signal processing. |
Figure 1.
Plain QVAE architecture. The input signal can be either proper or improper. The encoder network is composed of quaternion fully connected layers (QFC) and it learns the statistics of the original distribution and employs them to build the latent representation, on which the KL divergence acts. The representation is then passed to the decoder network which reconstruct the input signal, evaluating the result by means of a quaternion MSE loss (MSE).
Figure 1.
Plain QVAE architecture. The input signal can be either proper or improper. The encoder network is composed of quaternion fully connected layers (QFC) and it learns the statistics of the original distribution and employs them to build the latent representation, on which the KL divergence acts. The representation is then passed to the decoder network which reconstruct the input signal, evaluating the result by means of a quaternion MSE loss (MSE).

Figure 2.
Generated samples from the QVAE trained on the proper signal P1 (first line), and on the improper signal I2 (second line). On the left are the generated components, on the right are the complete distribution of the signal. While -proper components have the same variance, the improper ones have different variance values, respecting the properties of the original signal.
Figure 2.
Generated samples from the QVAE trained on the proper signal P1 (first line), and on the improper signal I2 (second line). On the left are the generated components, on the right are the complete distribution of the signal. While -proper components have the same variance, the improper ones have different variance values, respecting the properties of the original signal.

Figure 3.
Original and reconstructed distributions from the QVAE trained with the proper signal P1 in the first line, and with improper signal I2 in the second line. The QVAE is able to perfectly learn the different variance values for each of the four components, thus fully reconstructing the distribution of the input signal.
Figure 3.
Original and reconstructed distributions from the QVAE trained with the proper signal P1 in the first line, and with improper signal I2 in the second line. The QVAE is able to perfectly learn the different variance values for each of the four components, thus fully reconstructing the distribution of the input signal.

Table 1.
Fundamental properties of -proper random variables.
| , | |
Table 2.
In order to prove the measures and the assumptions presented in Section 5, we compute the average improperness coefficient I (16), the differential entropy (20), the improperness measure (19) and entropy loss (22) for different kinds of -proper and improper signals. The entropy is highest for the -proper signals, while the improperness measure and coefficients are close to 0. As is clear from and , there is a low entropy loss due to the improperness in the first two signals, while it is high for the last two, improper, random vectors.
Table 2.
In order to prove the measures and the assumptions presented in Section 5, we compute the average improperness coefficient I (16), the differential entropy (20), the improperness measure (19) and entropy loss (22) for different kinds of -proper and improper signals. The entropy is highest for the -proper signals, while the improperness measure and coefficients are close to 0. As is clear from and , there is a low entropy loss due to the improperness in the first two signals, while it is high for the last two, improper, random vectors.
| Signal | I | |||
|---|---|---|---|---|
| P1. (proper) | 0.0393 | 4.0177 | 0.0049 | 0.0049 |
| P2. (proper) | 0.0528 | 5.0174 | 0.0103 | 0.0103 |
| I1. (improper) | 1.0000 | −51.6040 | 50.9298 | 51.0691 |
| I2. (improper) | 0.9999 | −45.4454 | 51.3121 | 51.1843 |
Table 3.
Average improperness coefficient I (16), differential entropy (20), improperness measure (19) and entropy loss (22) for different outputs from the QVAE (Recons stands for the reconstructed signal, Sample for the generated one) with different kinds of -proper and improper signals. The QVAE preserves the structure of the signal, learning the properness and improperness nature of the input.
Table 3.
Average improperness coefficient I (16), differential entropy (20), improperness measure (19) and entropy loss (22) for different outputs from the QVAE (Recons stands for the reconstructed signal, Sample for the generated one) with different kinds of -proper and improper signals. The QVAE preserves the structure of the signal, learning the properness and improperness nature of the input.
| Signal | Out | I | |||
|---|---|---|---|---|---|
| P1. (proper) | Recons | 0.0287 | 5.1519 | 0.0030 | 0.0029 |
| Sample | 0.0537 | 2.3859 | 0.0096 | 0.0095 | |
| P2. (proper) | Recons | 0.0640 | 3.4614 | 0.0124 | 0.0123 |
| Sample | 0.1099 | −0.2705 | 0.0348 | 0.0347 | |
| I1. (improper) | Recons | 0.9989 | 0.3749 | 9.9700 | 9.9700 |
| Sample | 0.9930 | −3.6337 | 8.1208 | 8.1208 | |
| I2. (improper) | Recons | 0.9998 | −8.1100 | 13.0767 | 13.0767 |
| Sample | 0.9964 | −10.7147 | 12.1469 | 12.1469 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Grassucci, E.; Comminiello, D.; Uncini, A. An Information-Theoretic Perspective on Proper Quaternion Variational Autoencoders. Entropy 2021, 23, 856. https://0-doi-org.brum.beds.ac.uk/10.3390/e23070856
AMA Style
Grassucci E, Comminiello D, Uncini A. An Information-Theoretic Perspective on Proper Quaternion Variational Autoencoders. Entropy. 2021; 23(7):856. https://0-doi-org.brum.beds.ac.uk/10.3390/e23070856
Chicago/Turabian StyleGrassucci, Eleonora, Danilo Comminiello, and Aurelio Uncini. 2021. "An Information-Theoretic Perspective on Proper Quaternion Variational Autoencoders" Entropy 23, no. 7: 856. https://0-doi-org.brum.beds.ac.uk/10.3390/e23070856
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.