
Haphazard Intentional Sampling in Survey and Allocation Studies on COVID-19 Prevalence and Vaccine Efficacy †



Abstract
:1. Introduction
2. Haphazard Intentional Sampling Method: Two-Group Allocation
2.1. Pure Intentional Sampling Formulation
2.2. Haphazard Formulation
2.3. Case Study: Estimating SARS-CoV-2 Infection Prevalence
2.3.1. Auxiliary Regression Model for SARS-CoV-2 Prevalence
- : simulated SARS-CoV-2 prevalence in sector i;
- : income in census sector i;
- : zero-income population percentage in census sector i;
- : percentage of households with two or more bathrooms in census sector i.
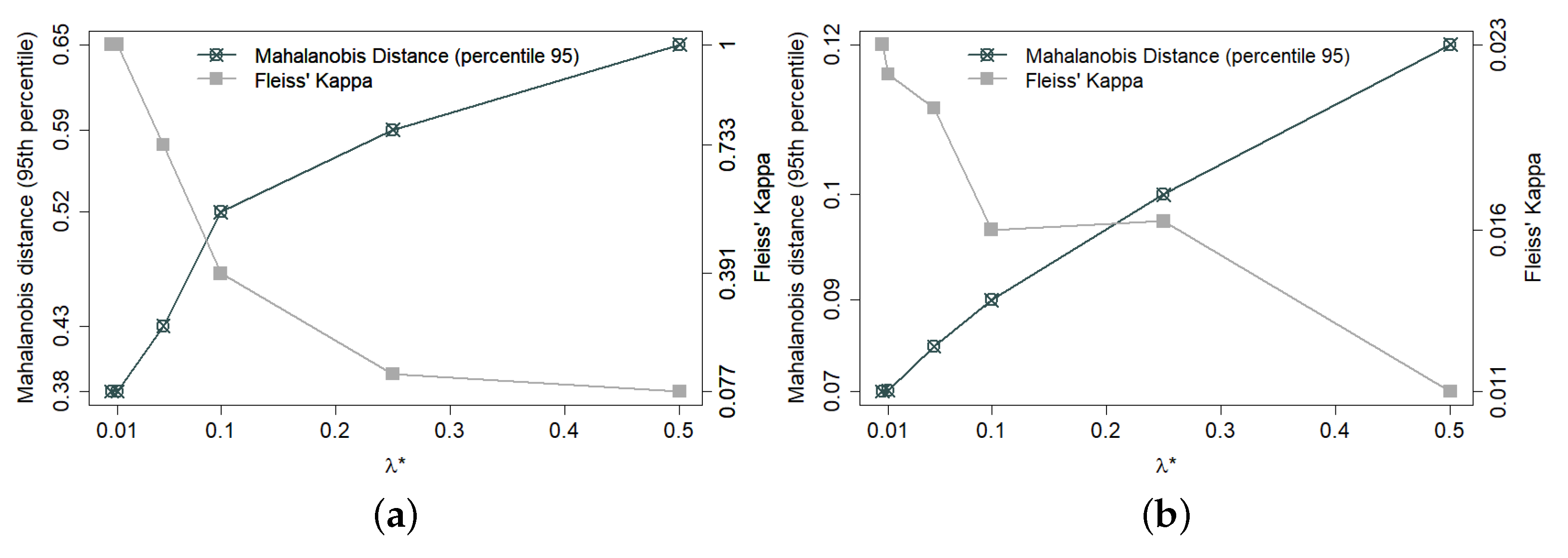
2.3.2. Balance and Decoupling Trade-Off in the Haphazard Method
2.3.3. Benchmark Experiments and Computational Setups
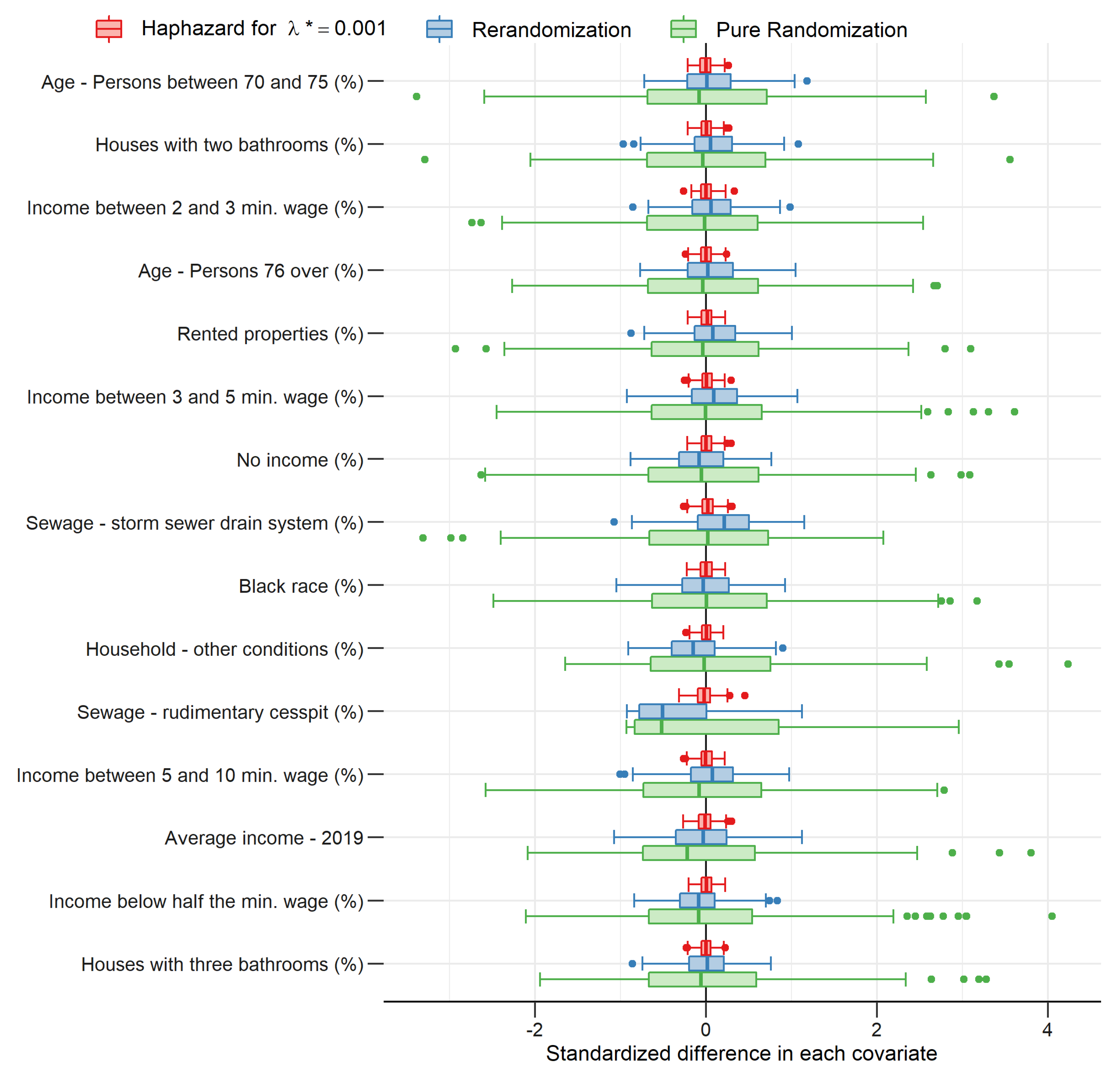
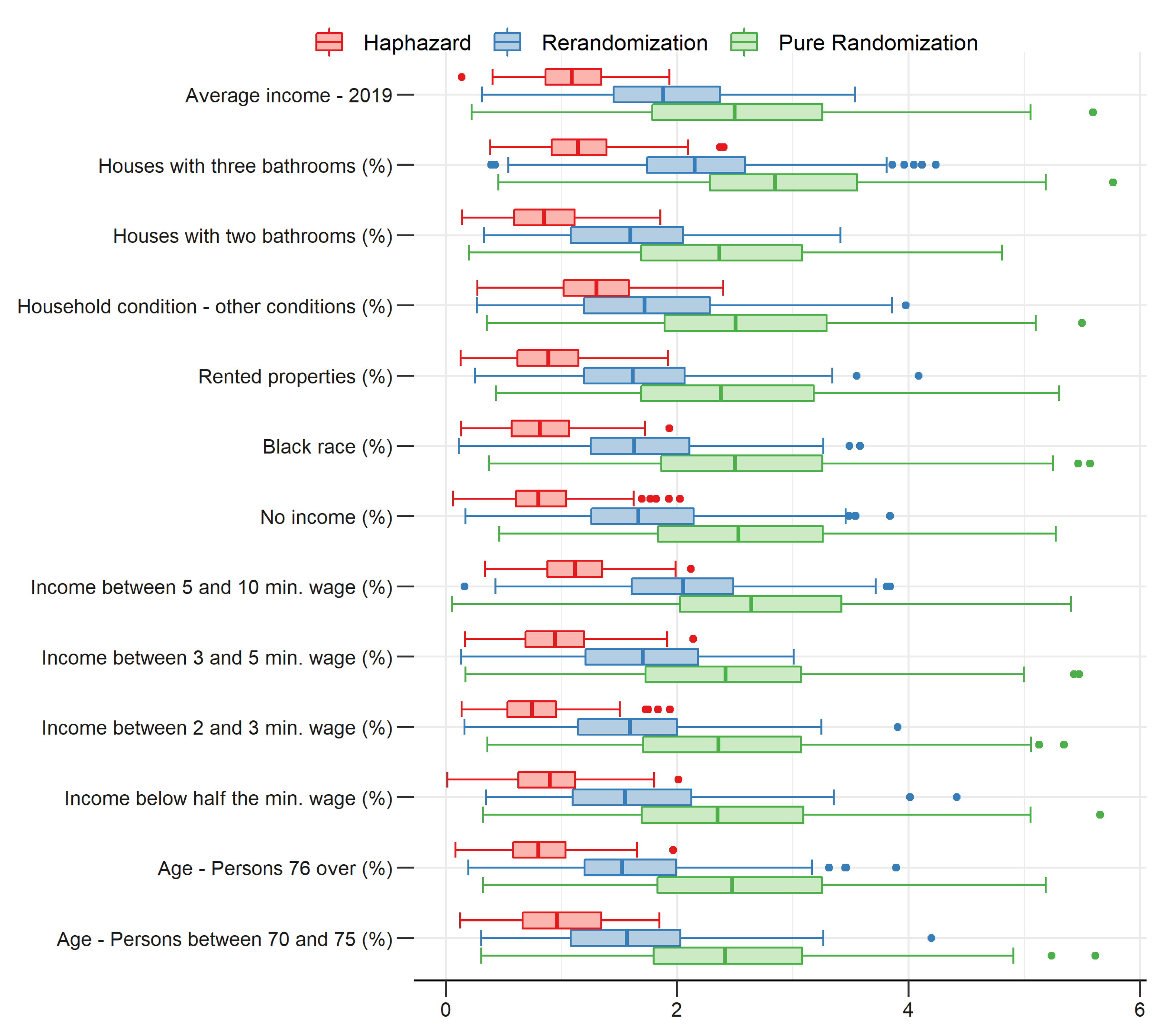
2.4. Experimental Results
2.4.1. Group Unbalance among Covariates
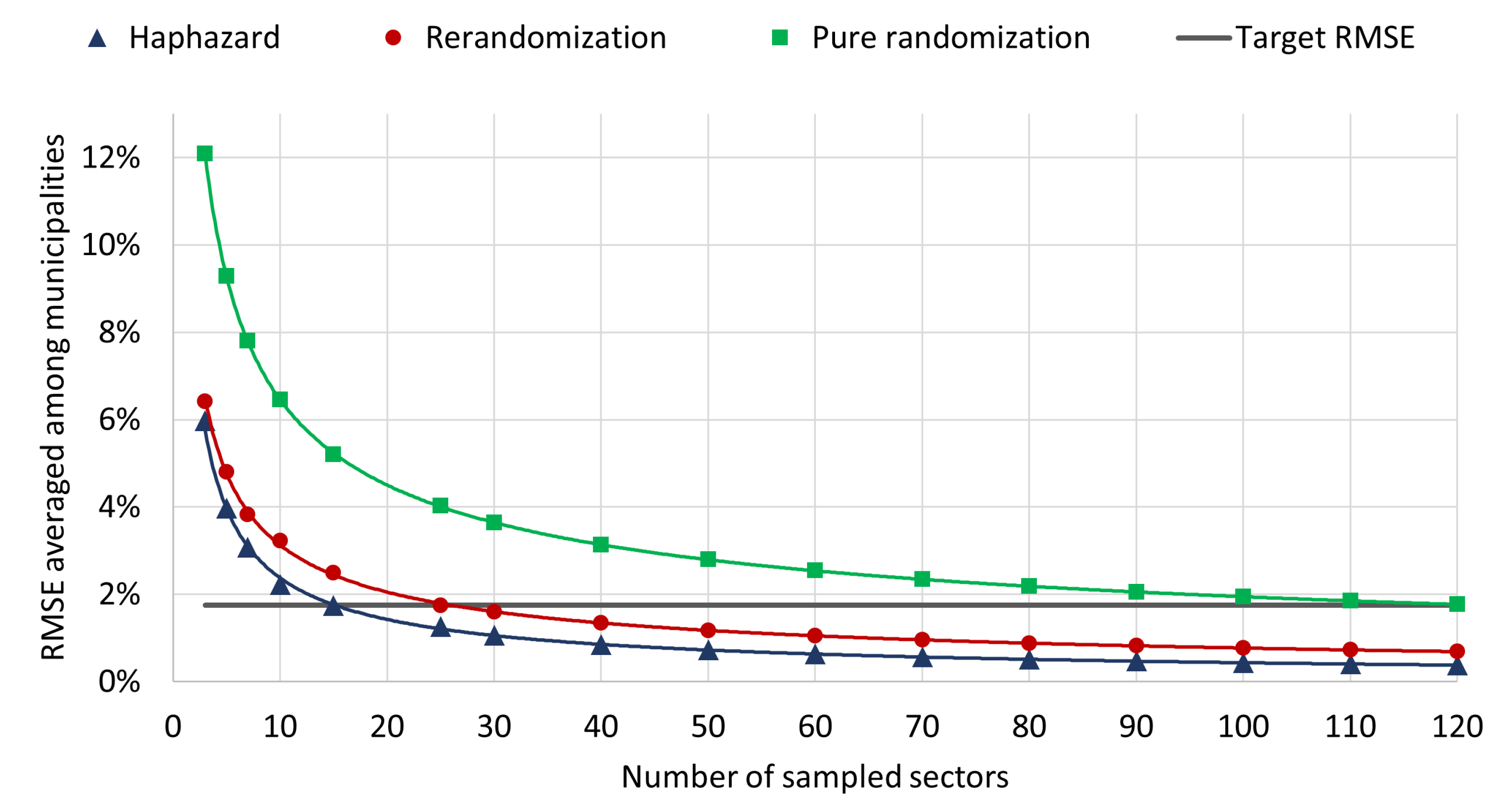
2.4.2. Root Mean Square Errors of Simulated Estimations
3. Multiple-Group Allocation
3.1. Case Study: Vaccine Efficacy Testing
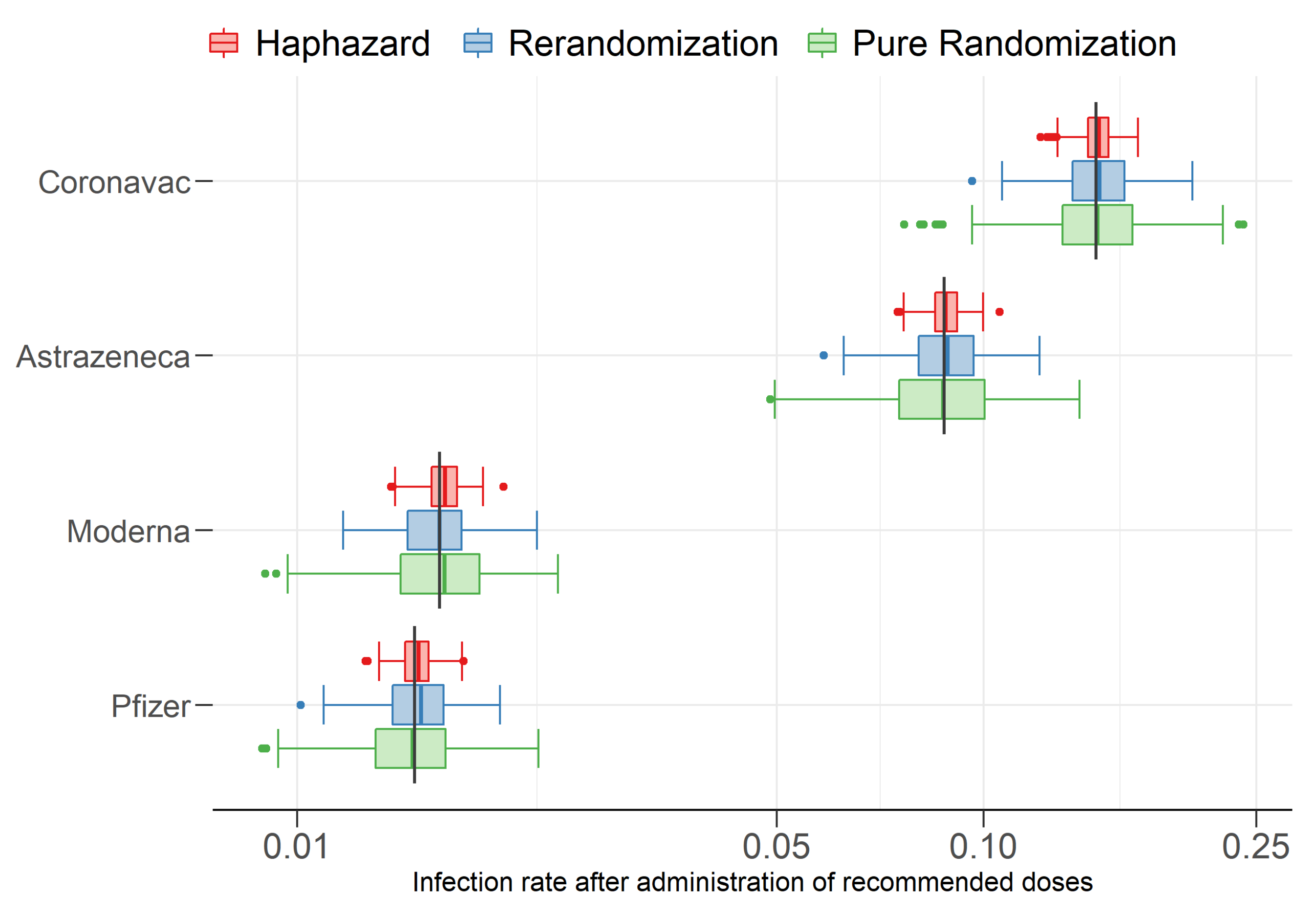
3.2. Experimental Results
4. Discussion
5. Final Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IBGE | Instituto Brasileiro de Geografia e Estatística |
| (Brazilian Institute of Geography and Statistics) | |
| IBOPE | Instituto Brasileiro de Opinião Pública e Estatística |
| (Brazilian Institute of Public Opinion and Statistics) | |
| MILP | Mixed-Integer Linear Programming |
| MIQP | Mixed-Integer Quadratic Programming |
| RMSE | Root mean square error |
| SD | Standard deviation |
References
- Lauretto, M.S.; Nakano, F.; Pereira, C.A.B.; Stern, J.M. Intentional Sampling by goal optimization with decoupling by stochastic perturbation. AIP Conf. Proc. 2012, 1490, 189–201. [Google Scholar]
- Lauretto, M.S.; Stern, R.B.; Morgan, K.L.; Clark, M.H.; Stern, J.M. Haphazard intentional allocation and rerandomization to improve covariate balance in experiments. AIP Conf. Proc 2017, 1853, 050003. [Google Scholar]
- Fossaluza, V.; Lauretto, M.S.; Pereira, C.A.B.; Stern, J.M. Combining optimization and randomization approaches for the design of clinical trials. In Interdisciplinary Bayesian Statistics; Springer: New York, NY, USA, 2015; pp. 173–184. [Google Scholar]
- Stern, J.M. Decoupling, sparsity, randomization, and objective Bayesian inference. Cybern. Hum. Knowing 2008, 15, 49–68. [Google Scholar]
- Lauretto, M.S.; Stern, R.B.; Ribeiro, C.O.; Stern, J.M. Haphazard intentional sampling techniques in network design of monitoring stations. Proceedings 2019, 33, 12. [Google Scholar] [CrossRef] [Green Version]
- Morgan, K.L.; Rubin, D.B. Rerandomization to improve covariate balance in experiments. Ann. Stat. 2012, 40, 1263–1282. [Google Scholar] [CrossRef]
- Stern, J.M. Symmetry, invariance and ontology in Physics and Statistics. Symmetry 2011, 3, 611–635. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2012. [Google Scholar]
- Wolsey, L.A.; Nemhauser, G.L. Integer And Combinatorial Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Ward, J.; Wendell, R. Technical Note-A New norm for measuring distance which yields linear location problems. Oper. Res. 1980, 28, 836–844. [Google Scholar] [CrossRef]
- Murtagh, B.A. Advanced Linear Programming: Computation and Practice; McGraw-Hill International Book Co.: New York, NY, USA, 1981. [Google Scholar]
- EPICOVID19. Available online: http://www.epicovid19brasil.org/?page_id=472 (accessed on 21 August 2020).
- Draper, N.R.; Smith, H. Applied Regression Analysis, 3rd ed.; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Am. Psychol. Assoc. 1971, 76, 378–382. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Gurobi Optimization Inc. Gurobi: Gurobi Optimizer 9.01 Interface, R package version 9.01; Gurobi Optimization Inc.: Beaverton, OR, USA, 2021. [Google Scholar]
- Morgan, K.L.; Rubin, D.B. Rerandomization to balance tiers of covariates. J. Am. Stat. Assoc. 2015, 110, 1412–1421. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lock, K.F. Rerandomization to Improve Covariate Balance in Randomized Experiments. Ph.D. Thesis, Harvard University, Cambridge, MA, USA, 2011. [Google Scholar]
- Blum, A.; Hopcroft, J.; Kannan, R. Foundations Of Data Science; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Cruz, E.P. Brazilian institute to start production of vaccine CoronaVac. Agência Brasil. 2020. Available online: https://agenciabrasil.ebc.com.br/en/saude/noticia/2020-12/brazilian-institute-start-production-vaccine-coronavac (accessed on 14 December 2021).
- Instituto Butantan. S Project. Available online: https://projeto-s.butantan.gov.br/ (accessed on 14 December 2021). (In Portuguese)
- World Health Organization. Vaccine Efficacy, Effectiveness and Protection. 2020. Available online: https://www.who.int/news-room/feature-stories/detail/vaccine-efficacy-effectiveness-and-protection (accessed on 20 December 2021).
- Fiolet, T.; Kherabi, Y.; MacDonald, C.-J.; Ghosn, J.; Peiffer-Smadja, N. Comparing COVID-19 vaccines for their characteristics, efficacy and effectiveness against SARS-CoV-2 and variants of concern: A narrative review. Clin. Microbiol. Infect. 2022, 28, 202–221. [Google Scholar] [CrossRef]
- Azevedo, T.C.P.; Freitas, P.V.; Cunha, P.H.P.; Moreira, E.A.P.; Rocha, T.J.M.; Barbosa, F.T.; Sousa-Rodrigues, C.F.; Ramos, F.W.S. Efficacy and landscape of COVID-19 vaccines: A review article. Rev. Assoc. Med. Bras. 2021, 67, 474–478. [Google Scholar] [CrossRef]
- Morar, F.; Iantovics, L.B.; Gligor, A. Analysis of phytoremediation potential of crop plants in industrial heavy metal contaminated soil in the upper Mures River basin. J. Environ. Inform. 2018, 31, 1–14. [Google Scholar]
- Iantovics, L.B.; Rotar, C.; Morar, F. Survey on establishing the optimal number of factors in exploratory factor analysis applied to data mining. WIREs Data Min. Knowl Discov. 2019, 9, e1294. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sectors | Time (s) | |
|---|---|---|
| <50 | 0.1 | 5 |
| 50–4000 | 0.01 | 30 |
| >4000 | 0.001 | 120 |
| City | Haphazard | Rerandomization | Pure Randomization | |||
|---|---|---|---|---|---|---|
| RMSE | SD | RMSE | SD | RMSE | SD | |
| São Paulo | 1.6558% | 1.6516% | 2.4683% | 2.3900% | 4.9930% | 4.9899% |
| Rorainópolis | 0.8582% | 0.7487% | 1.5116% | 1.4310% | 3.0028% | 3.0008% |
| Rio de Janeiro | 1.3864% | 1.3310% | 1.9441% | 1.9394% | 4.6324% | 4.6216% |
| Oiapoque | 1.3887% | 1.3835% | 1.7651% | 1.7509% | 3.2107% | 3.2107% |
| Marília | 1.1624% | 1.1603% | 1.4787% | 1.4737% | 3.4950% | 3.4919% |
| Iguatu | 0.8329% | 0.8196% | 1.3029% | 1.3025% | 3.9094% | 3.9003% |
| Cruzeiro do Sul | 1.3873% | 1.3489% | 2.0482% | 2.0457% | 5.0029% | 5.0003% |
| Corrente | 0.7496% | 0.7000% | 1.0708% | 1.0665% | 2.8250% | 2.8230% |
| Campos dos Goytacazes | 0.9419% | 0.9350% | 1.8786% | 1.8522% | 4.4839% | 4.4829% |
| Brasília | 1.7978% | 1.3434% | 1.5739% | 1.5299% | 3.9608% | 3.9539% |
| Vaccine | Efficacy (%) |
|---|---|
| CORONAVAC/SINOVAC (control) | 50.4 |
| ASTRAZENECA/OXFORD | 70.4 |
| MODERNA | 94.5 |
| PFIZER/BIONTECH | 95 |
| Group | Haphazard | Rerandomization | Pure Randomization | |||
|---|---|---|---|---|---|---|
| RMSE | SD | RMSE | SD | RMSE | SD | |
| 1—Coronavac (Sinovac) | 0.867% | 0.859% | 1.881% | 1.880% | 2.872% | 2.872% |
| 2—Pfizer/Biontech | 0.092% | 0.091% | 0.182% | 0.181% | 0.260% | 0.260% |
| 3—AstraZeneca/Oxford | 0.499% | 0.499% | 1.133% | 1.130% | 1.696% | 1.696% |
| 4—Moderna | 0.102% | 0.102% | 0.200% | 0.198% | 0.311% | 0.311% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miguel, M.G.R.; Waissman, R.P.; Lauretto, M.S.; Stern, J.M. Haphazard Intentional Sampling in Survey and Allocation Studies on COVID-19 Prevalence and Vaccine Efficacy. Entropy 2022, 24, 225. https://0-doi-org.brum.beds.ac.uk/10.3390/e24020225
Miguel MGR, Waissman RP, Lauretto MS, Stern JM. Haphazard Intentional Sampling in Survey and Allocation Studies on COVID-19 Prevalence and Vaccine Efficacy. Entropy. 2022; 24(2):225. https://0-doi-org.brum.beds.ac.uk/10.3390/e24020225
Chicago/Turabian StyleMiguel, Miguel G. R., Rafael P. Waissman, Marcelo S. Lauretto, and Julio M. Stern. 2022. "Haphazard Intentional Sampling in Survey and Allocation Studies on COVID-19 Prevalence and Vaccine Efficacy" Entropy 24, no. 2: 225. https://0-doi-org.brum.beds.ac.uk/10.3390/e24020225