1. Introduction
Among our gadgets, smartphones are our closest companions. They provide the primary access into the Internet and modern amenities, they hold our private data and are becoming one of the primary means of attack against the user, be it through power viruses (or other means to consume resources) or more ordinary malware menaces (calling or texting tolled numbers, install unwanted software, send the attacker private information about the device or its owner, spy on the owner using the camera or microphone, etc.).
For our research we picked an Android smartphone over an iPhone, primarily due to the open access into its software stack. This open source stack, provided by Google for their devices via Android Open Source Project (AOSP), includes a high-level Android framework, and an open source kernel. This level of openness into the source code of the stack allows access into both public and non-public API information, allowing for the purpose of our research access into the smartphone sensors. It also consists of the basis of the infrastructure of data collection architecture (used to obtain the raw data behind the initial dataset for this paper) described in [
1] with an application for malware detection [
2], using measurable events collected for a set of Android applications including both samples obtained from scientists in the field (Malgenome application set described by the authors of [
3]) as well as more recent Internet sources (including [
4,
5] and Google Play for benign Android samples).
The purpose of this study was to assess if anomalous behavior could be detected through machine-learning classifiers based on input data sources from a variety of sensors within the device. We took into consideration that the smartphone phone itself can provide a large pool of data sources about runtime behavior. Some of this data is accessible through public APIs and an additional set can become accessible by making suitable changes into the smartphone software stack. While typical developers do not have access to non-public APIs, such an approach could provide benefits for telecom or smartphone manufacturers which have access to the AOSP stack or its equivalent from the smartphone system-on-chip (SoC) manufacturers or similar providers. By adding such an application within their phone, smartphone manufacturers could increase the intrinsic value of their product.
Many recent papers are trying to tackle the problem of detecting anomalous behavior in modern smartphones using software sensors (measurable events). For modern smartphones approaches vary but usually involve a combination of static and dynamic behavioral extraction of interesting data pertaining to sensors of the target smartphone application.
The measurable sources of data used in static analysis fall into 4 categories according to a recent study of over 80 frameworks by Bakour et al. [
6]: manifest-based, code-based, semantic-based, or application metadata-based. According to the same authors, using this data requires offline processing and is prone to weakness when obfuscation techniques are employed by the developers of malicious applications.
Recent frameworks use a combination of static [
7,
8,
9] and dynamic [
8,
9] extraction of data from sensors before being processed through machine-learning techniques. SandDroid is a recent sandbox analysis project classifying Android applications on a set of features using both static and dynamic analysis [
8].
Current anomaly-detection applications span a wide array of technical solutions, from traditional machine learning and statistics, to deep learning models for computer vision related tasks, with applications in virtually all fields of technology [
10,
11,
12].
Gaussian Mixture Models (GMMs) are one of the traditional approaches to anomaly detection. Zong et al. [
13] use a deep auto-encoder to generate a low-dimensional representation, which is further fed into a GMM for unsupervised anomaly detection in medical applications. Aljawarneh et al. [
14] use a Gaussian dissimilarity measure for anomaly detection in Internet of Things (IoT) systems, while Li et al. [
15] use GMM-based clustering for an application of early warning in civil aviation.
In viewing anomaly detection more as a classification problem, there are many options for the choice of classifier. Erfani et al. [
16] use Support Vector Machines and Deep Belief Networks to mitigate the impact of high dimensionality in large-scale anomaly detection. Li et al. [
17] use a modified Support Vector Machine (SVM) as an alternative to computer and information system security. The excellent surveys by Chalapathy [
10] and Ye [
11] give a detailed outlook of possible applications using deep learning and data mining solutions.
The literature involving detection of anomalies in modern smartphones usually focuses on centralized large-scale frameworks or collaborative efforts. Centralized frameworks are used for either static code analysis [
7,
8] or dynamic analysis using virtual machines on host systems [
8], highly efficient in running Android apps in emulation. Collaborative efforts, such as Contagio [
18] rely on a mix of online tools and offline community support. We considered the approach of running applications within an actual smartphone, as there are specific limitations (e.g., thermal throttling) or information (e.g., device identifiers) that do not appear in virtual machine simulation but make an impact on application behavior on real hardware (through metrics such as CPU load, network data frequency, and throughput of which we planned on measuring through our experiments). We used as starting points data acquired on actual smartphones, not via simulated/virtualized frameworks. In this way our environment also took into consideration the influence of additional constraint factors within the smartphone (such as thermal throttling, dynamic frequency changes and overall other types of computation throttling) which can modify an application resource requirements and through this means influence the collected raw data that are used as input for the machine-learning algorithms. Virtualized infrastructures do not simulate specific smartphone behavior such as thermal throttling, dynamic processor frequency changes etc.
Furthermore, the use of such methods, as described in the paper, is relatively limited in the context of smartphone technology. Most smartphone applications tend to veer towards classical anomaly detection and statistics, such as GMMs [
13,
14,
15] or Hidden Markov Models (HMMs) [
19], data mining and deterministic decision systems [
20,
21], or hybrid algorithms that incorporate learning classifiers (usually a version of SVMs) and belief networks [
16,
17,
22,
23]. An extensive literature review has found no comparative studies using the proposed methods on a challenging dataset, which is itself unique, as obtained through the methods described above, and very few instances of any one of the proposed methods being employed in anomaly detection on smartphones, despite their otherwise ubiquitous presence in machine-learning and anomaly-detection applications.
While all detections are aimed at malware applications, the detection itself is done through looking for patterns of anomalous behavior, as captured by the measurable sources of information (i.e., software sensors). The use of the proposed class of methods has to do with the way in which such potentially anomalous behavior could be learned, therefore it is intentionally modelled as a classification problem, rather than a standard anomaly-detection problem (for example through GMMs), due to the format of the data and the underlying assumptions of the learning model.
The choice of algorithm has very much to do with the available dataset. For the purposes of this paper, deep learning and some data mining solutions are not well suited to a small- to medium-sized dataset. In addition, GMMs are most frequently used when there is a large non-anomalous subset to train on, or when the dataset itself is imbalanced, and when it is thought that a classifier is unlikely to learn a coherent model for the positive (anomalous) samples, which is not the case here. As such, the paper investigates three types of classifiers for the machine-learning application: Logistic Regression, a shallow neural network for pattern recognition, and SVMs. The three are evaluated on several metrics, most important of which being the F1 score on the test set. The full details of the design, implementation, and evaluation of the learning algorithms are presented in their respective sections. Finally, the results show that all the three investigated algorithms perform reasonably well, with SVMs having a slight edge.
The remainder of the paper is divided as follows: Chapter 2 outlines the acquired data and the steps taken to curate the dataset, as well as giving a brief theoretical overview of the design of the classifier learning methods involved. Chapter 3 discusses the particulars of implementation and the obtained results for each model. Chapter 4 discusses the highlighted results and attempts to draw a conclusion based on the work reported. Opportunities and directions for future research are also discussed.
2. Materials and Methods
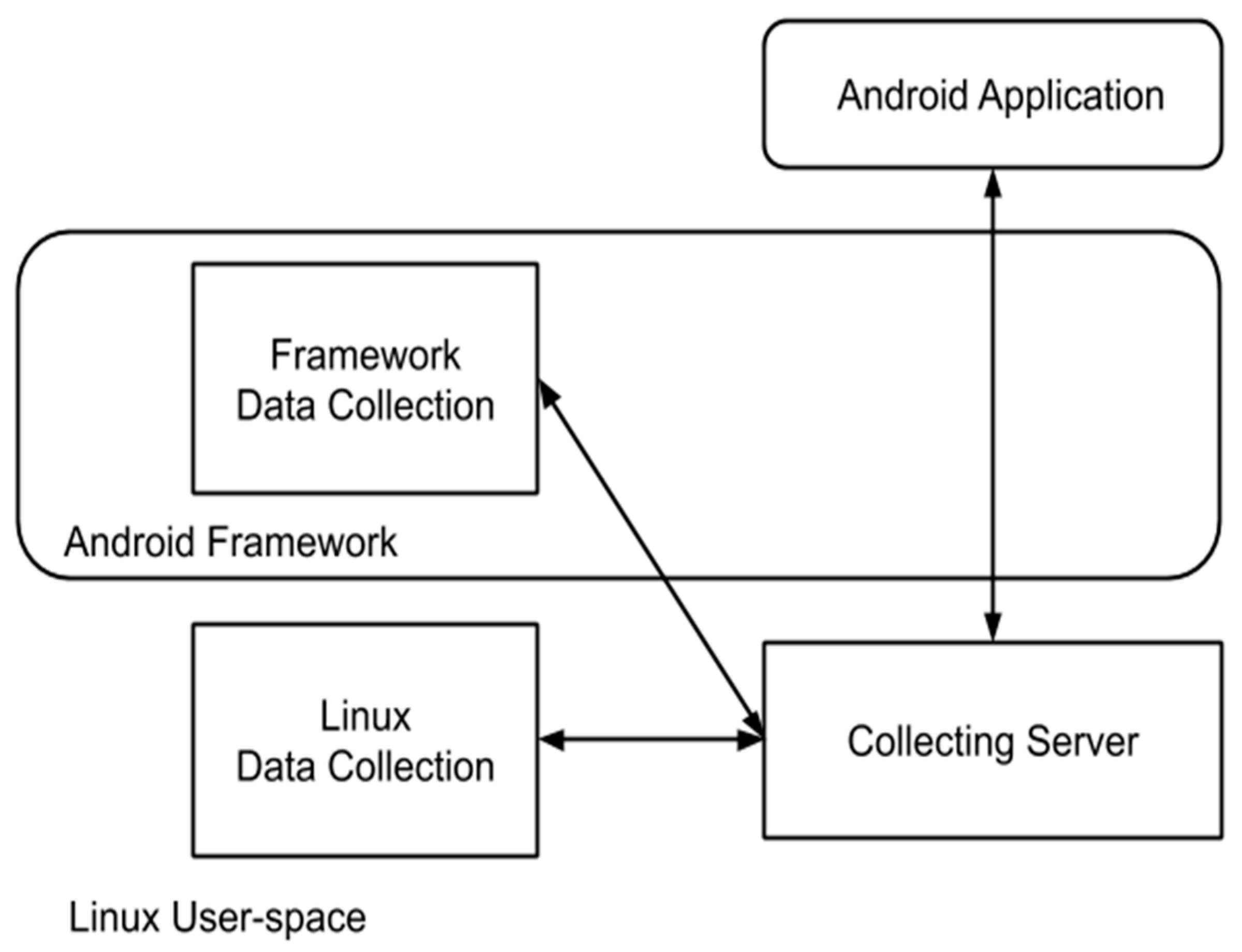
The general architecture, described in [
1] includes measurable events as sources of data, extracted with a set of data collectors [
1] into a server for further processing, as shown in
Figure 1. The sources of data are made available through the Android framework or Linux user-space (via procfs virtual file system entries) and are provided originally by hardware sensors or software hooks added into the framework.
Synthesizing the information available in [
1],
Table 1 below shows the measurable events that were collected on a Nexus 4 smartphone running Android 4.2.2 JellyBean.
As said in [
1] for the “SMS” event there are hooks for destination number and message content. For the “Call” event there is a hook for the destination number. For “WiFi”, “Camera”, “NFC”, as well as “Bluetooth” we get information about sensor activity (turning on/off). “Sensors” offer information about what peripherals are registered as sensors in the Android framework terminology as well as real-time data from them. “Camera” indicates if the application wishes to access the camera peripheral or photo content within the phone.
Through the data acquisition procedure, the smartphone remained mostly stationary, in an artificially lit room with weak GPS reception. As such, the device was not able to offer pertinent GPS or other motion (accelerometer, gyroscope, magnetometer) or lighting (ambient light) information for our experiments. We chose not to include in our smartphone a functionality (normally missing from commercial devices) that artificially injects GPS data, considering that by itself any additional GPS data injection component would represent an example of atypical application (hard to install by regular users) and behavior (and also being potentially hazardous if requiring administrative privileges into the phone in order to operate). For our research we focused on the scenarios that for malware applications the abnormal behavior would manifest primarily through disguising themselves as top (or banking) applications (for the purpose of extracting confidential login data) or by sending phone information to toll numbers or various URLs.
Another reason not to include GPS information was that for the majority of applications in our pool this information was not required, the main part of the experiments not including applications focused on user movement information (whether it is from GPS or other types of movement based sensors).
“App Install” detects the installation of a new application within the smartphone and it offers the app name for it. “Activity” intercepts information regarding the state of the Android application: “Create”, “Start”, “Stop”, “Pause”, “Resume” and “Destroy”. The “Runtime Crash” detects the similarly named event at runtime. The “ANR” intercepts “Application Not Responding” type events generated by the Android framework following an application entering a freezing/non-functioning state. These hooks were implemented in Java and they offer the ability to acquire data for the data collection server upon request, for the purpose of detecting anomalous behavior.
Due to the user experience oriented programming in modern smartphone apps, each feature is accessible within a short number of Graphical User Interface (GUI) interactions (for example in email apps you have login, message lists, folders/categories, individual email widows and a limited set of clicking and scrolling to do in each such window), in our case exposing behavior coded within Android applications to our software sensors. Empirically, as a trade-off between time spent collecting data for each target application and the implication on overall collecting time spent on the entire application pool we studied and collected data for, we found that approximately 5 min was considered enough to stop acquiring new types of events, and thus new type of behavior, from the application.
The final application set comprises 361 Android applications; however not all of them were installed at once, but consecutively during the experiments. For each sample application, during the dataset acquisition the procedure involved side-loading (installing Android applications in apk format via the adb interface), starting the sample application and monitoring its behavior while interacting with it manually (in foreground/background) for a short period of time (approximately 5 min), then uninstalling it.
The initial data was collected through the framework described in [
1,
2] which relies on a data collection framework within the smartphone and the installation of an additional application that performs the real-time monitoring while running in background (called AMDS in [
2]). The application pool was built by using both reputable applications (the ones that the phone came with, top Google Play applications, or similar stores for other markets such as SlideMe [
4]) as well as known malware applications. The data acquisition process involved installing new applications one by one, manually interacting with each in application-specific manner (e.g., clicking buttons, swiping) while also toggling between foreground/background for the duration of the experiment (around 5 min for each app). After this step the target application was uninstalled, to prevent both reaching lack of storage space during the experiment as well as preventing some applications from influencing one another and the next target application from the list was installed and experimented with. During the training phase a data of monitoring each target application was stored locally in the phone, and during testing phase a different pool of applications was used, each application installed, monitored, local data stored updated, while the real-time monitoring application described at large in [
2], was running in background, and if abnormal behavior was detected this application would be prevented from running, it would be flagged to the user who would make the final decision (to continue preventing the application from running or allow it to continue) on a case by case basis.
The raw data obtained from the experimentation is organized as a set of unique application names, a set of labels for each application (clean or malware) and 19 sets of feature data, one for each investigated feature. Inside the feature data, there are multiple values for the same {application name; feature} pair, due to multiple sensor interrogations for the same feature on the particular application.
Table 2 shows an example of the raw data obtained from the sensors.
Table 3 shows the investigated features for which sensor triggers were programmed and a short description, as detailed in [
1,
2].
We considered the possibility that while there is a usual correlation between the number of packets and bytes transferred via WiFi, in the case of applications disguising themselves as another application, there may be a difference in communication protocols between the fake and original application that could influence the correlation between number of packets and bytes transferred. Generally speaking, even if the two features were to be correlated, the presence of two correlated features among a total of 19 would not adversely affect the learning process to any significant extent. In this particular case, however, the possible lack of correlation could, potentially, in itself be a valuable learnable pattern for detecting behavior. Therefore, it was believed that including both features would result in new information being available to the model.
The measurable events pool provided by the infrastructure described in detail in [
1] and used through the monitoring application described in [
2] includes events collectable from Android (e.g., SMS, Bluetooth, Call etc.), events collectable from Linux user-space (e.g., via procfs, including CPU load, memory load etc.) and there were non-numerical metrics (e.g., app name, version) which were eliminated when we curated the data set. Features for which data was not available in all instances were then eliminated to preserve the integrity of the dataset, as a fully numeric, complete set of samples is required for the learning process.
As stated in [
1,
2] our collection infrastructure includes data collectors, a collection server, and an Android monitoring application. Data is acquired for both Android events (SMS, WiFi, and Bluetooth) as well as Linux user-space (CPU load, memory load, and network statistics) and kernel-space metrics (performance counters). The collection server maintains the list of running Android applications (and correlation with corresponding process identification numbers) and based on application state manages monitoring via the data collectors. The Android application usually resides in background and allows high-level user interaction and control (including picking the infrastructure operating mode: idle, training, testing on a system-wide and per application level). Furthermore, part of the initial pre-processing of the dataset is that clearly anomalous readings are eliminated as data-points. This is partly achieved in the initial composition of the dataset, and partly done automatically when processing the numerical data.
The ground-truth target labels were manually set. Applications downloaded from reputable sources (top Google Applications) were marked as clean, while applications from the known malware sources (e.g., applications from the Malgenome set) were considered malware.
The dataset is first processed by parsing the feature data and identifying all the values associated with a unique application name on a particular feature set. These values are then averaged to obtain a single value for the {application name; feature} pair. The average value is obtained by running a first pass on the values and calculating their mean and variance, after which a new mean is computed, taking into consideration only the values that fall within a 95% confidence interval from the natural mean. In the extreme case that no values fall within this range, the median value of the set is selected instead. This contributes to the rejection of extreme sensor values, which are thought to most likely be the result of erroneous momentary interrogation.
Once all unique {application name; feature} values are parsed for a particular feature, the application names are checked against the existing list and only the pairs for which the application name already exists are kept. This is done to ensure the integrity of the dataset, in which all samples (i.e., applications) must have existing values for all features. The end result is a dataset with 361 samples for 19 features, plus the target labels, which are the inputs to the learning algorithms.
The features are all numeric, so there is no need to apply any type of coding for categorical variables. The target class labels are either clean (coded to 0) or malware (coded to 1).
The final dataset has its features normalized. The value for each sample within a feature is updated by subtracting the mean (
) and dividing by the standard deviation (
) of that feature (
j), as shown below.
This ensures that all input features are of similar range and centered on zero, which helps the speed and convergence of the learning process, as well as removing potential biases caused by the varying magnitudes. A cross-section of the dataset is exemplified in
Table 4. Notice that the unique application names have been removed and each sample is now uniquely identifiable only implicitly through its row number. The actual data used for training is structured with samples as rows and features as columns, but is shown here transposed, for readability. It also includes an intercept term, which is a column of 1-s, not shown here. The sample and feature labels are not present in the actual dataset and are shown in the table only for convenience.
The dataset is then split into three sets, for training, cross-validation, and testing. The training set is used to learn the optimized parameters of the prediction model, the cross-validation set is used to tune its meta-parameters, and the testing set is used exclusively to rate the model performance on data it had not previously seen. The parameters and meta-parameters differ for each learning model and are explained in their respective sections.
The split is done randomly each time the overall script starts, so the data is different for each complete run which learns and evaluates the three models, meaning the overall results differ slightly at each run. However, the same training, cross-validation, and test sets are used for learning and evaluation on each of the three learning models, within a complete run of the script, so that their performance can be properly compared.
The samples are split into 70% for the training set, 15% for the validation set and 15% for testing. This is done by generating a random index with the same length as the number of samples and then taking the appropriate percentage splits, using the index as the row number inside the dataset. In the context of 361 total samples, this works out to 253 samples for training, 54 samples for validation, and 54 samples for testing.
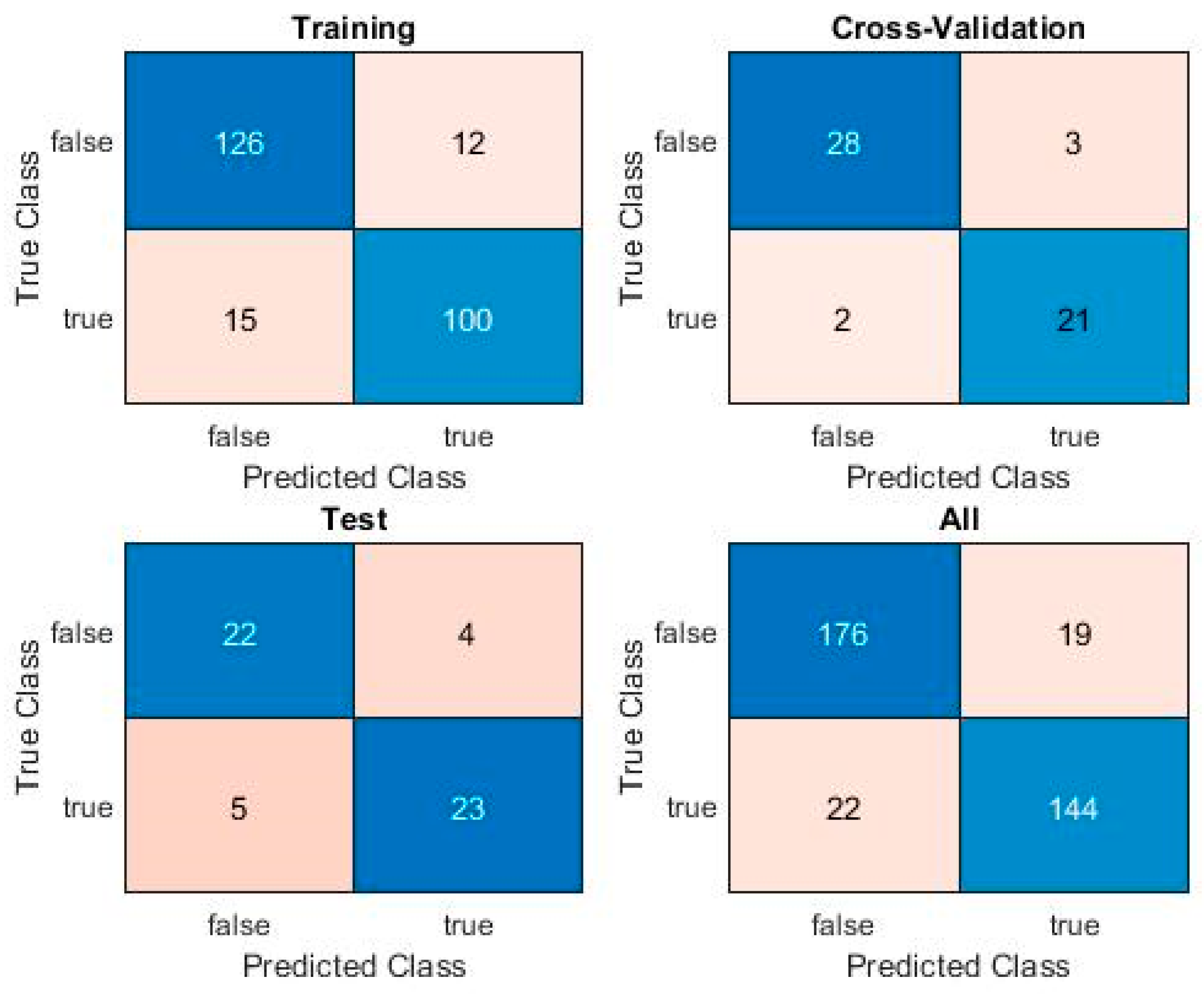
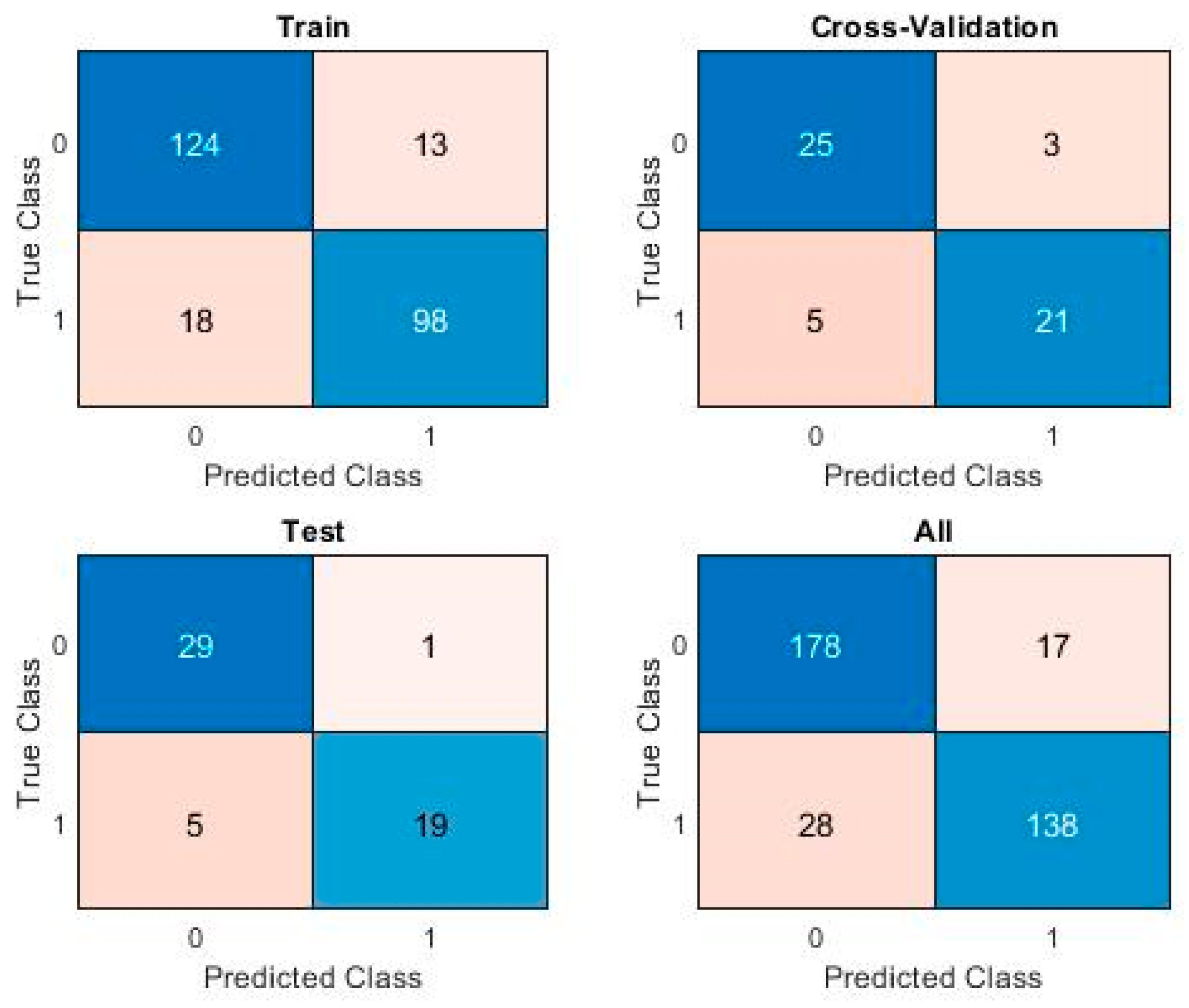
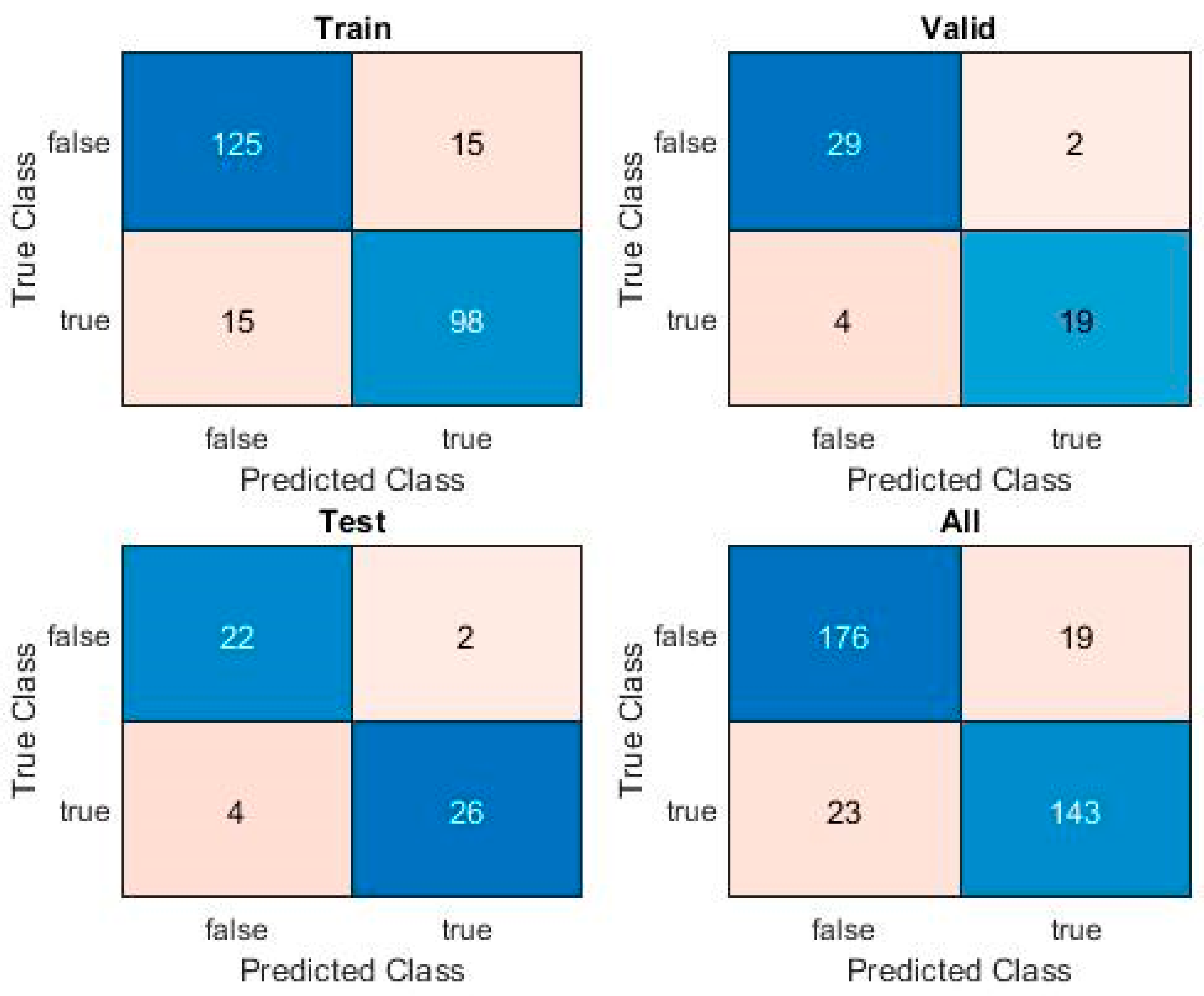
A True Positive (TP) is a sample correctly identified as malware, a True Negative (TN) is a sample correctly classified as clean, a False Positive (FP) is a clean sample misclassified as malware, and a False Negative (FN) is a malware sample misclassified as clean. A chart showing the number and rates of samples thus classified is called a Confusion Matrix. The results of each algorithm include such a chart for each sample set and for the overall set.
Two standard loss functions are used for the classification algorithms, Cross-Entropy Loss and Hinge Loss. Cross-entropy is the default loss function used for binary classification problems. It is intended for use with binary classification where the target values are in the set {0, 1}, as is the default coding in our dataset. It is used for the Logistic Regression and Pattern net learning algorithms [
24]. Using Cross-Entropy Loss, the cost function to be minimized is shown below.
is the hypothesis outputted by the model (see also Equation (5)) and
is the ground-truth label for that sample.
where
.
Hinge Loss is an alternative to cross-entropy for binary classification problems, primarily developed for use with SVM models. It is intended for use with binary classification where the target values are in the set {−1, 1}, which are set automatically by the learning algorithm. The Hinge Loss function encourages examples to have the correct sign, assigning more error when there is a difference in the sign between the actual and predicted class values [
24]. The formula of the Hinge Loss function is shown below.
where
,
being the similarity (kernel) function [
25,
26,
27].
The following metrics are used for evaluation, as shown in
Table 5.
Accuracy is the rate of correctly classified instances, irrespective of class. Precision is the fraction of relevant instances among the retrieved instances, i.e., the number of correctly predicted positives out of the samples that were predicted positive. Recall is the fraction of total relevant instances retrieved, i.e., the number of correctly predicted positives out of the samples that actually were positive. The F1 score is the harmonic mean of precision and recall [
28].
Table 6 below gives an overview of the parameters and criteria used for optimization at each level of the training process.
Logistic Regression is used to obtain a model for the classification and prediction of a binary outcome from a set of samples, in the presence of more than one explanatory variable. The procedure is quite similar to multiple linear regression, with the exception that the response variable is binomial [
29,
30].
The optimization problem is described as
, where
X is the input data, namely the dependent variables, containing all data-points, plus an intercept term, which helps prevent overfitting.
Y is the output data that the algorithm is trying to learn, and θ is the matrix of coefficients used to estimate
Y from
X. The challenge is finding the best coefficients, which minimizes the error between the actual
Y and the estimate. This is obtained from
, or, in extended form:
Once the best available set of coefficients (
θ) is found, a prediction for a given sample is done using the function:
where
and
th is the prediction threshold.
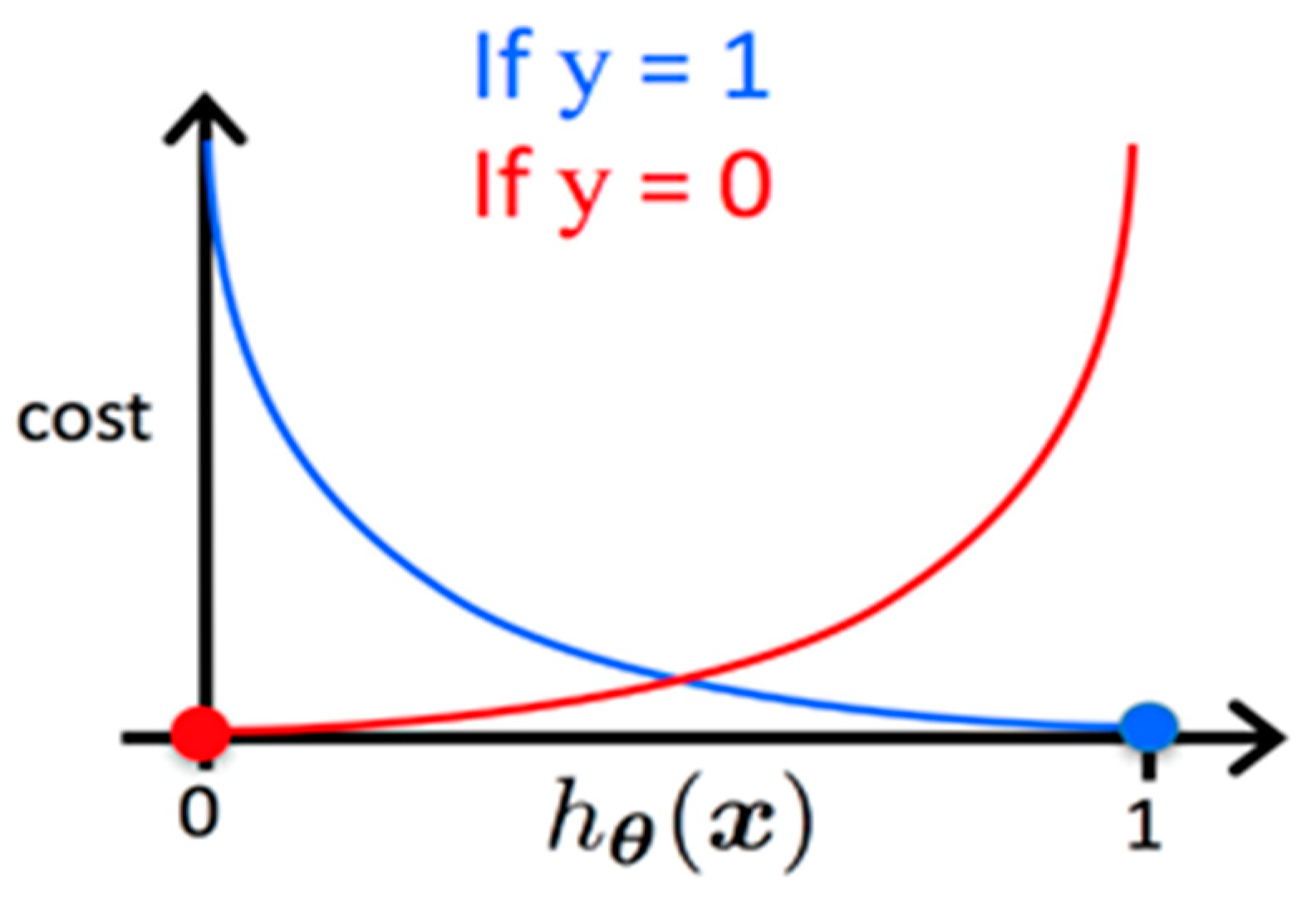
The cost function, shown previously in Equation (2), is computed as a measure of the difference between estimated values and the ground truth for the input data. A visualization of the cost for a particular sample is shown in
Figure 2, where
y is the ground truth and
is the hypothesis outputted by our model [
25].
If there are too many features, the learned hypothesis may fit the training set very well, but fail to generalize to new examples, which is called overfitting [
26]. Conversely, if there are not enough representative features or if the number of the training examples is not large enough to correctly create the model, it would underfit. Parameters such as alpha (α), the learning rate, or lambda (λ), the regularization parameter, must also be taken into account. The learning rate, α, should not be too large, because it could lead the algorithm to diverge, yet a value too small would cause slow learning and the cost function can get stuck in local minima [
31]. Faster gradient descent can be obtained via an adaptive learning rate. Lambda (λ) is the regularization parameter and it determines how strongly a model is penalized for fitting too closely the learned features on the available data [
25].
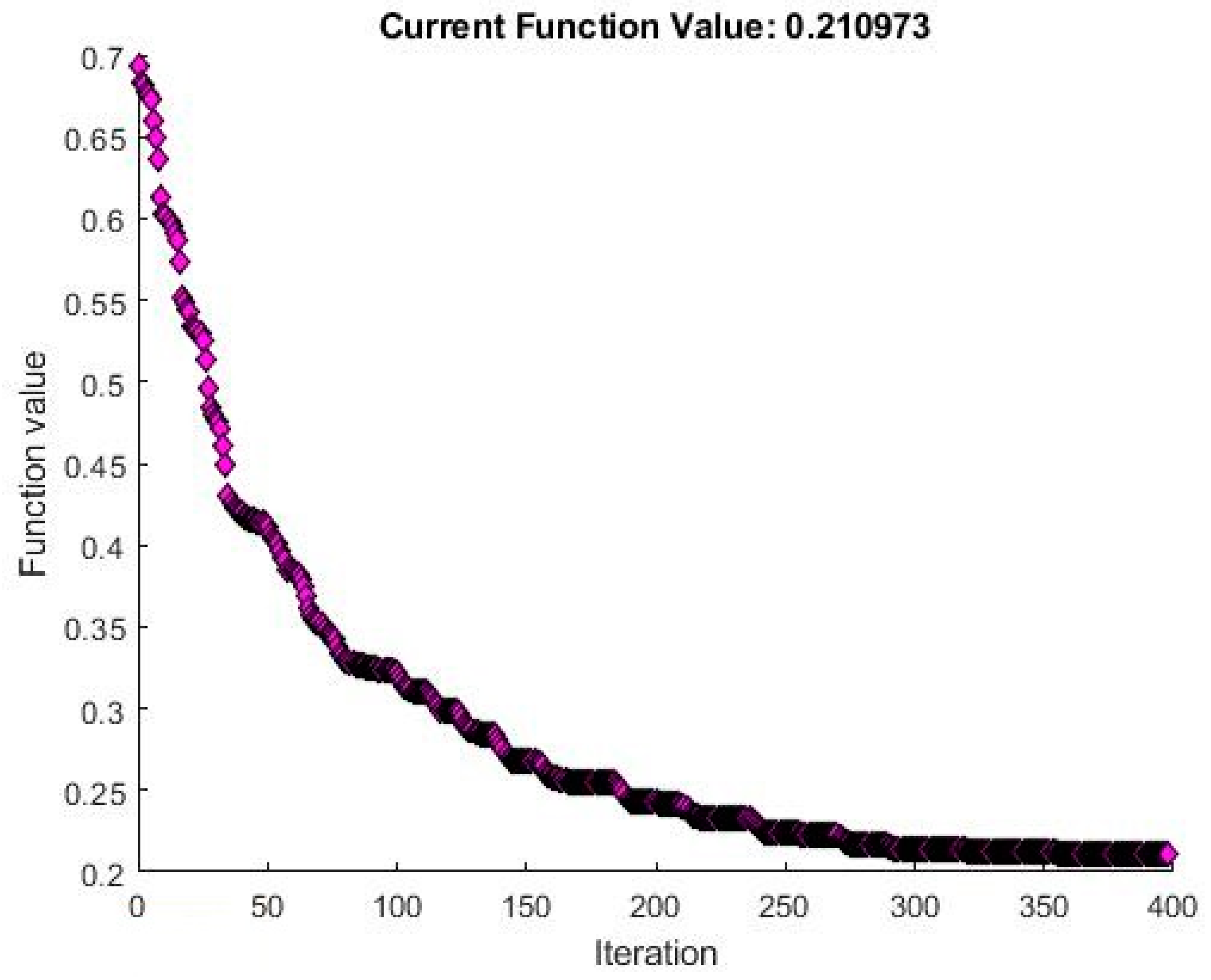
Gradient descent is an optimization algorithm where the potential solution is improved each iteration by moving along the feature gradient in the variable space. While it requires that the target function be differentiable and it is somewhat susceptible to local minima, gradient descent provides a stable and computationally inexpensive algorithm for function optimization.
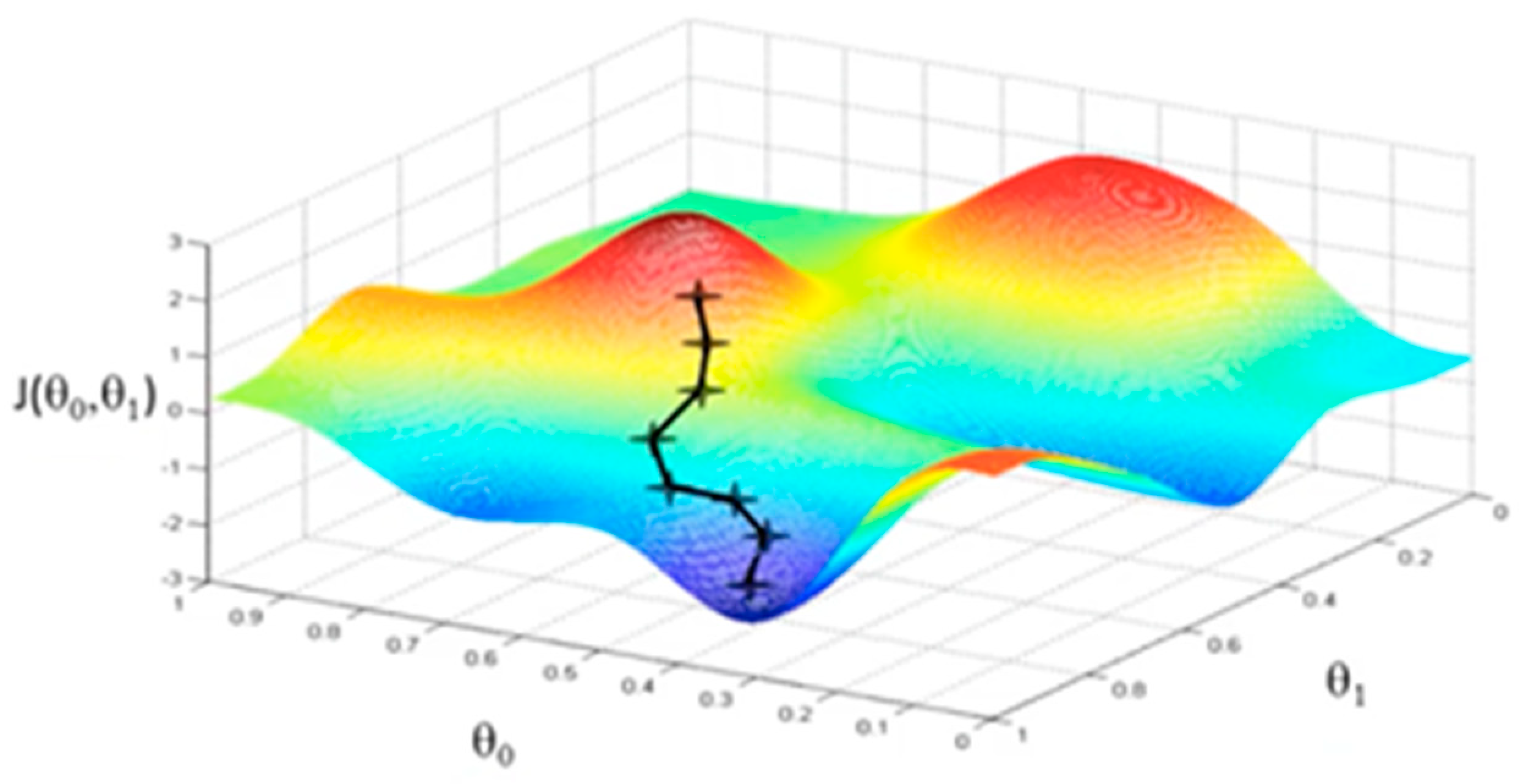
Figure 3 shows a visualization of the Gradient Descent algorithm, for two thetas [
25]. This would correspond to a one variable learning problem, for which
is the coefficient of the independent variable x, and
is the intercept term.
is the associated cost for each tuple of the two theta parameters, shown as the landscape on which the gradient descent algorithm searches for optima.
SVMs, also called Large Margin Classifiers, are supervised learning models used for classification and regression. The input data is classified by optimizing the hyperplane equation so that the distance to the data representing the classes is maximum [
32]. In addition to performing linear classification, SVMs can efficiently perform a non-linear classification using kernels, implicitly mapping their inputs into high-dimensional feature spaces [
25].
Having the training data, the problem is to determine the parameters of the hyperplane that best separates the data into classes. The cost function for SVMs was shown previously in Equation (3). The parameter C is important for the system because it is responsible for finding the minimum of the cost function, as well as providing regularization. If the value of C is too large then the SVM will change the decision boundary in an intent to integrate the outliers which produces overfitting, but if C is too small, there is a risk of high bias [
25]. The similarity function, named kernel, is used by the SVM to draw the decision boundary. Kernels must be semi-positive and symmetrical. The paper investigates the use of three of the most common options: linear, polynomial, and Gaussian (Radial Basis Function), in order to find normally distributed features across the feature map, while also being able to find features that have unusual values [
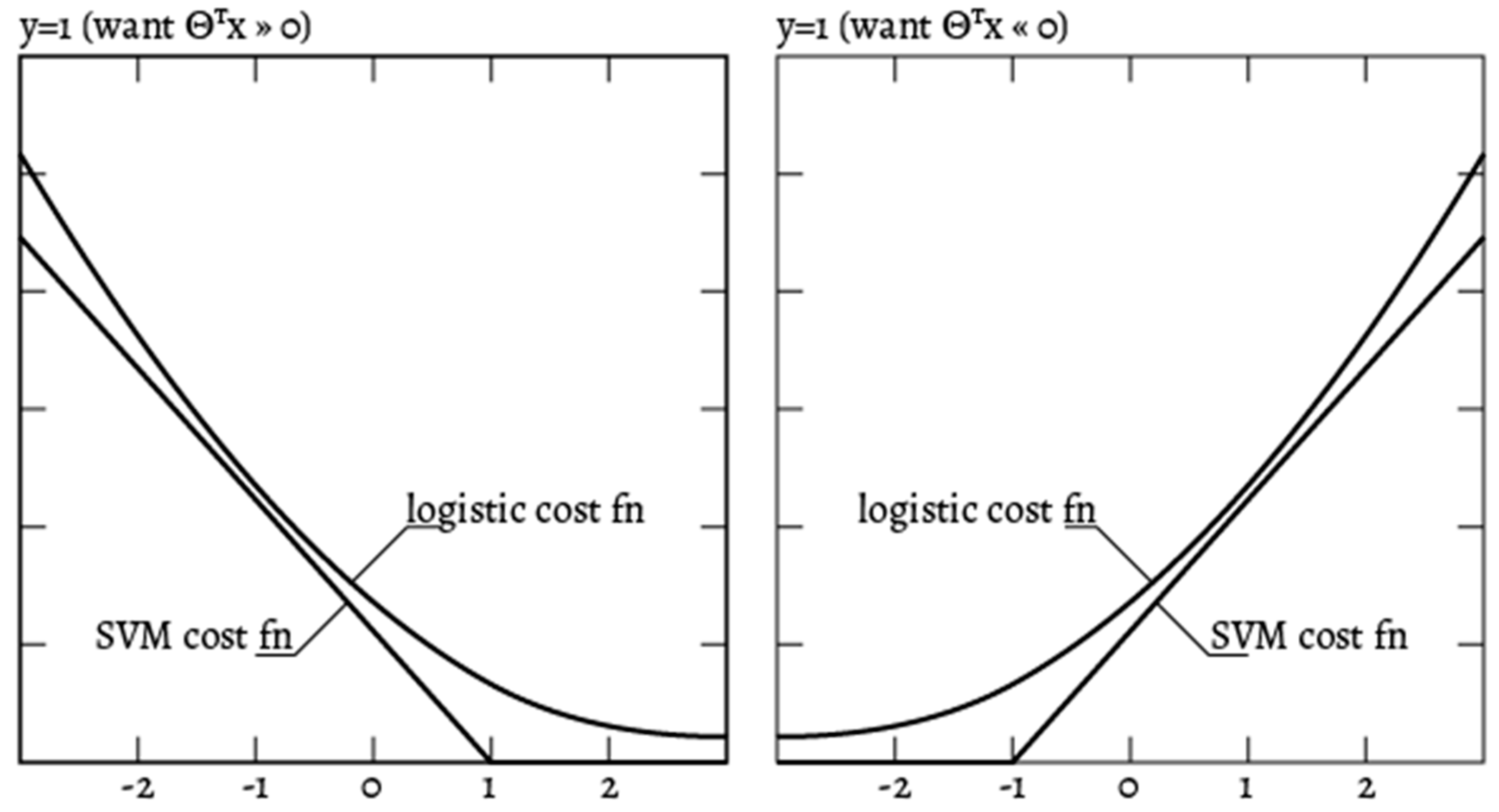
33]. Because of faster execution, an SVM with a Gaussian kernel might outperform Logistic Regression for a medium-sized dataset. SVM finds a solution hyperplane which is as far as possible for the two categories while Logistic Regression does not have this property. In addition, Logistic Regression is more sensitive to outliers than SVM, because the Logistic cost function diverges faster than Hinge Loss [
33].
Figure 4 provides a visual representation of the difference between the two cost functions, using the notations of
y and
discussed earlier in the paper [
34].
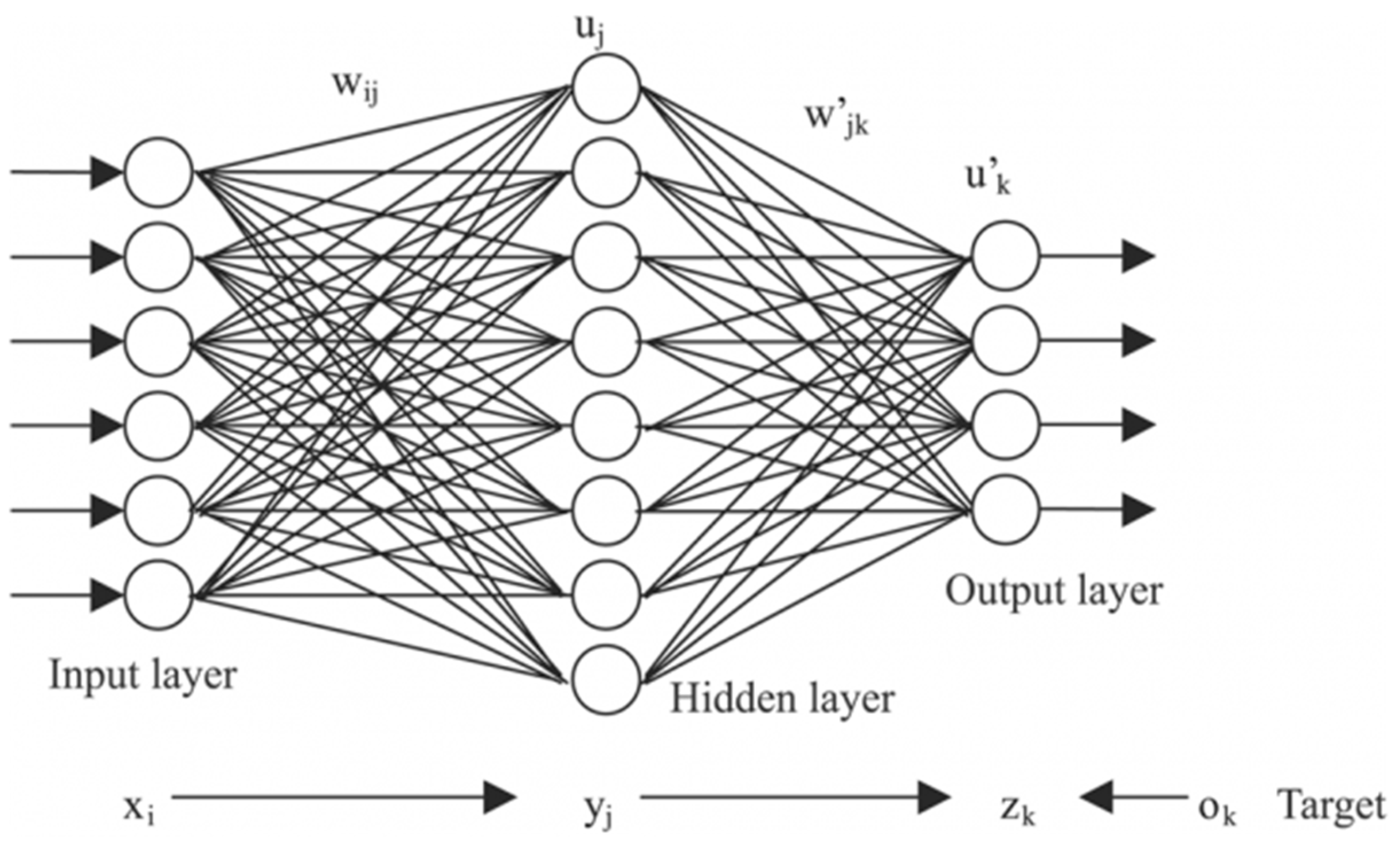
Artificial neural network models are based on a layer of hidden features (i.e., neurons), which replace the specific features used in other models, and which control the classification. Neural networks have an input layer that matches the dimension of an input sample and an output layer which matches the target variable. The model is optimized by successively tuning the weights of these neurons, through a process called back-propagation. A standard neural network is exemplified in
Figure 5 [
35,
36], where
are the features of the input layer, i.e., the dataset features shown previously,
are the weights associated with the transition of from the input layer to the hidden layer,
are the artificial features of the hidden layer, the number of which is an important meta-parameter, to be chosen by the designer,
are the weights associated with the transition from the hidden layer to the output layer, and
are the output features, or dependent variables, of which there is only one (
y) in the case of binary classification, such as presented in this paper.
4. Discussion
Table 11 provides an overall comparison of obtained metrics on the training, validation, and test sets, for each proposed model, using the meta-parameter values selected during validation. The results show that all of the three investigated algorithms perform reasonably well on a challenging dataset, with SVMs having an edge in performance on the test set, as well as maintaining a good equilibrium between the training, cross-validation, and test results.
A Cochran’s Q test [
37,
38] was performed to evaluate the results, with the null hypothesis being that the three algorithms have similar performance in classification. The test obtains a
p-value of
and a Cochran Q value of 42.5614, for which the null hypothesis can be safely rejected at the
significance level, providing proof that the SVM model significantly outperforms the others.
Furthermore, a comparative post-hoc analysis of the statistical significance of the results obtained through the three models was performed using three McNemar tests [
39,
40] for each of the three pairs of models. The tests are undertaken on pairs of models, since a McNemar Test can only be run on two models at a time. The first test (exact–conditional McNemar) compares the accuracies of the two models, while the second (Asymptotic McNemar) and third (Mid-
p-value McNemar) tests assess whether one model classifies better than the other. The null hypothesis for the first test is that the two models have equal predictive accuracies. The null hypothesis for the second and third tests is that one of the models is significantly less accurate than the other. The comparison is not cost sensitive, i.e., it assigns the same penalty for different types of misclassification. Detailed descriptions of McNemar tests and the procedure used can be seen in [
40,
41].
Table 12 shows the results of the statistical significance tests, where h is the hypothesis test result (
indicates the rejection of the null hypothesis, while
indicates a failure to reject the null hypothesis), p is the
p-value of the test, and e1 and e2 are the classification losses or misclassification rates of the respective two models (which are the same, irrespective of test).
The comparison between Logistic Regression and PatternNet is somewhat inconclusive. While the exact–conditional test cannot reject the null hypothesis, that the two methods have similar accuracies, neither can the other two tests reject the assumption that one test performs better than the other, although it should be noted that the p-value of the first test is twice as large as the values for the second and third tests. However, in the comparisons with the SVM model, both for Logistic Regression, as well as for PatternNet, the null hypothesis of the first test is rejected, meaning that the two methods have dissimilar accuracies. This is further collaborated by the second and third tests, where there is strong evidence that the null hypothesis cannot be rejected, meaning that the SVM model significantly outperforms both the Logistic Regression, as well as the PatternNet, models.
The obtained
p-values of the exact–conditional McNemar tests are manually corrected using the Discrete Bonferroni–Holm Method for Exact McNemar tests [
42,
43,
44]. As stated by Holm (1979) [
42], “except in trivial non-interesting cases the sequentially rejective Bonferroni test has strictly larger probability of rejecting false hypotheses and thus it ought to replace the classical Bonferroni test at all instants where the latter usually is applied”.
Table 13 shows the corrected
p-values and the resulting decision on the significance of the test.
The corrected
p-values are obtained as described in Westfall et al. [
43] and implemented in [
44]. For the test result to be considered significant, its corrected
p-value should be below the
threshold. The first test is evaluated as expected, since the initial series of McNemar tests showed that there is no statistical difference in the performance of Logistic Regression and PatternNet, by a very high
p-value, in relation to the threshold. The second test is most interesting, as the hypothesis that the Logistic Regression model and the SVM model have significantly different performance is now rejected, upon strengthening the test. However, it should be noted that it is a borderline decision, and the test would have been accepted at a
significance level. The third test reinforces the conclusion that the SVM model performs significantly better, this time compared to the PatternNet model, meeting the significance requirement by a wide margin.
However, all their performances are satisfactory and comparable on the initial metric used. The intention is that the dataset be expanded in the future, at which time further testing will be undertaken to evaluate the ability of each model to generalize, as well as the performance of various ensemble methods, possibly comprising two or more of these same models.
The literature review has yielded few comparable studies for the chosen methods on smartphone applications, without even taking into account the considerably different datasets, features, extraction techniques, etc. that other studies work with. Most papers discuss detection accuracy, with very few using the F1 score metric. The reported accuracy also varies considerably across methods and especially datasets. The final metric values, on the test set, for the linear kernel SVM, compare favorably with most papers in the literature review, for which similar metrics were available. The closest comparison is the application described in [
2], which obtains slightly higher metrics on a previous version of the dataset.
While the final hard numbers of the F1 score metric and the statistical significance tests clearly favor the SVM implementation, the difference in performance is oftentimes a relatively small number of misclassified samples, which is one of the issues to keep in mind when working with a small number of data-points.
Therefore, one of the main directions for future research is expanding the dataset, both in terms of the number of data-points (samples), as well as the number of features, where applicable. This would be a great benefit to the ability to train and test the models, as well as allow the investigation of deeper and more complex model architectures, some of which were touched upon in the discussion on the state of the art.
Another interesting future option is ensemble learning, which leverages the positive results of having three good classifiers, whose outputs can then be composed into a final prediction. This is particularly appealing, given the comparatively small difference in accuracies of the three investigated models.
In addition, detection of anomalous behavior from the user’s interaction pattern standpoints could be a promising topic for further research, starting from the framework already described.
The obvious future step for the application is that of actual hardware implementation on a working prototype, through which future data can also be more easily gathered. The dataset split procedure, which was discussed at length throughout the paper, should give the model a good ability to generalize to as yet unseen data.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}