Frequency-Temporal Disagreement Adaptation for Robotic Terrain Classification via Vibration in a Dynamic Environment

 , ,
, ,
Abstract
:1. Introduction
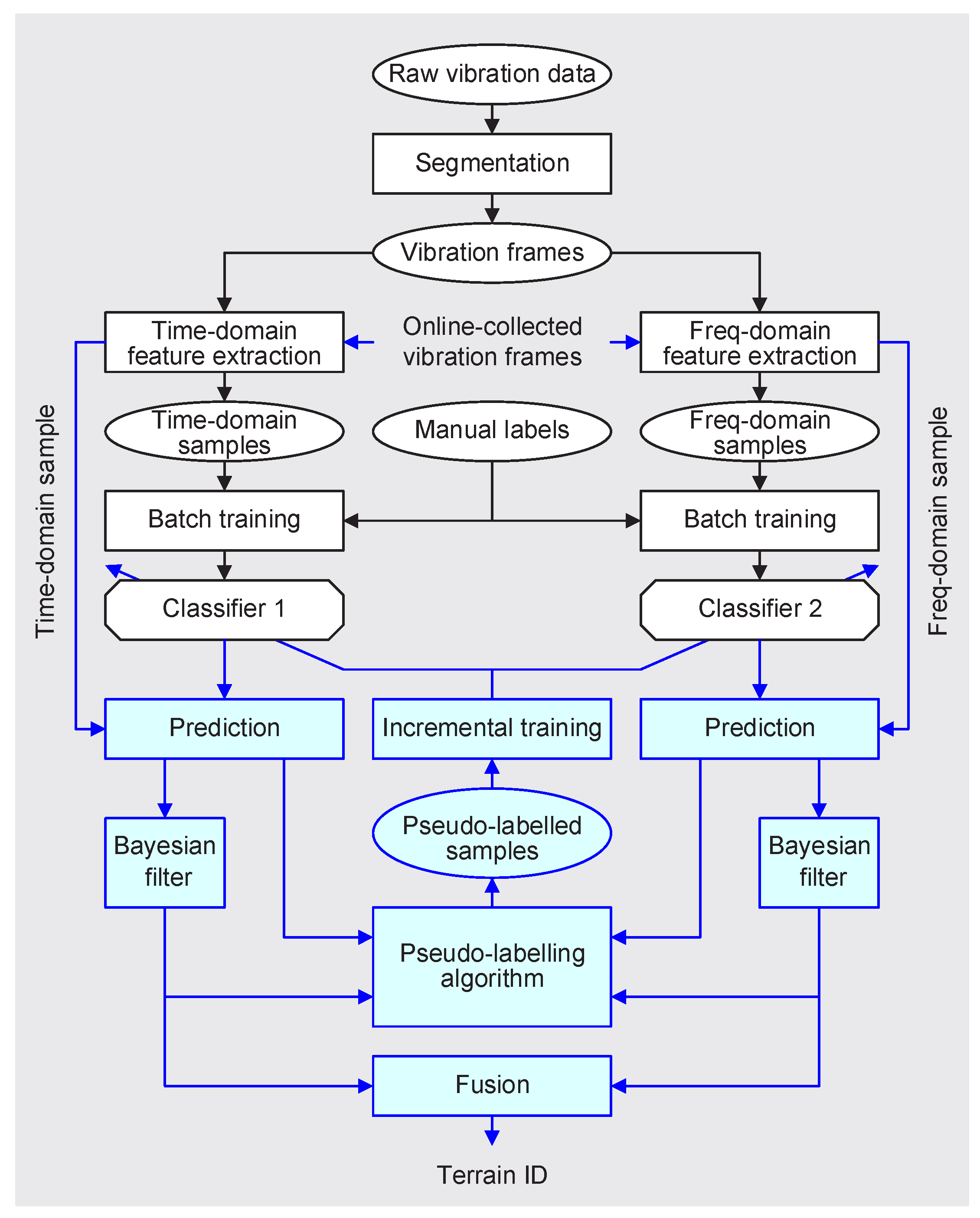
2. Methodology
2.1. Feature Extraction
2.1.1. Frequency-Domain Features
2.1.2. Time-Domain Features
2.2. Support Vector Machine
2.3. Bayesian Filter
2.4. Pseudo-Labeling Algorithm
- If one domain (denoted as the 1st domain) appears in-disagreement at a certain time, the sample is likely to be a key sample of the 1st domain.
- Based on the first rule, if at the same time, the other domain (denoted as the 2nd domain) does not appear in-disagreement, and there is no a posteriori ex-disagreement between the two domains, then the 2nd-domain terrain prediction is likely to be a reliable label to the 1st-domain key sample.
- If in-disagreement appears in both domains, but there is no a posteriori ex-disagreement, the filter-output terrain prediction can be used to label the samples from both domains.
- If neither in-disagreement nor ex-disagreement appears at a certain time, the sample is likely to be classified correctly, thus not a key sample.
| Algorithm 1 In- and Ex-Disagreement-Based Pseudo-Labeling Algorithm (IE) |
| Input: The unlabeled samples and , the a priori terrain predictions and , the a posteriori terrain predictions and , where . Output: Pseudo-labeled sample sets and , for time and frequency domain, respectively.
|
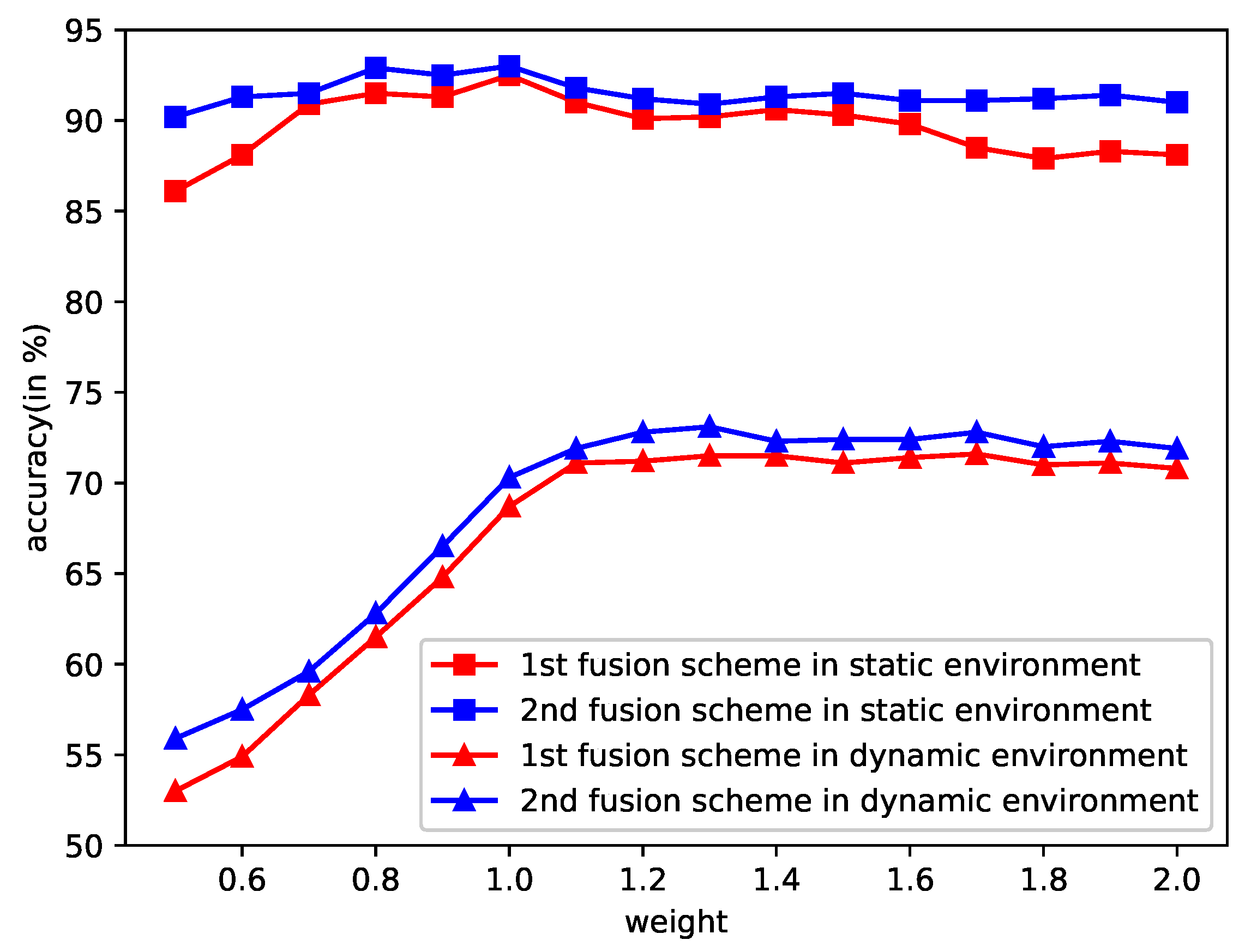
2.5. Fusion of Terrain Predictions
3. Experimental Verification
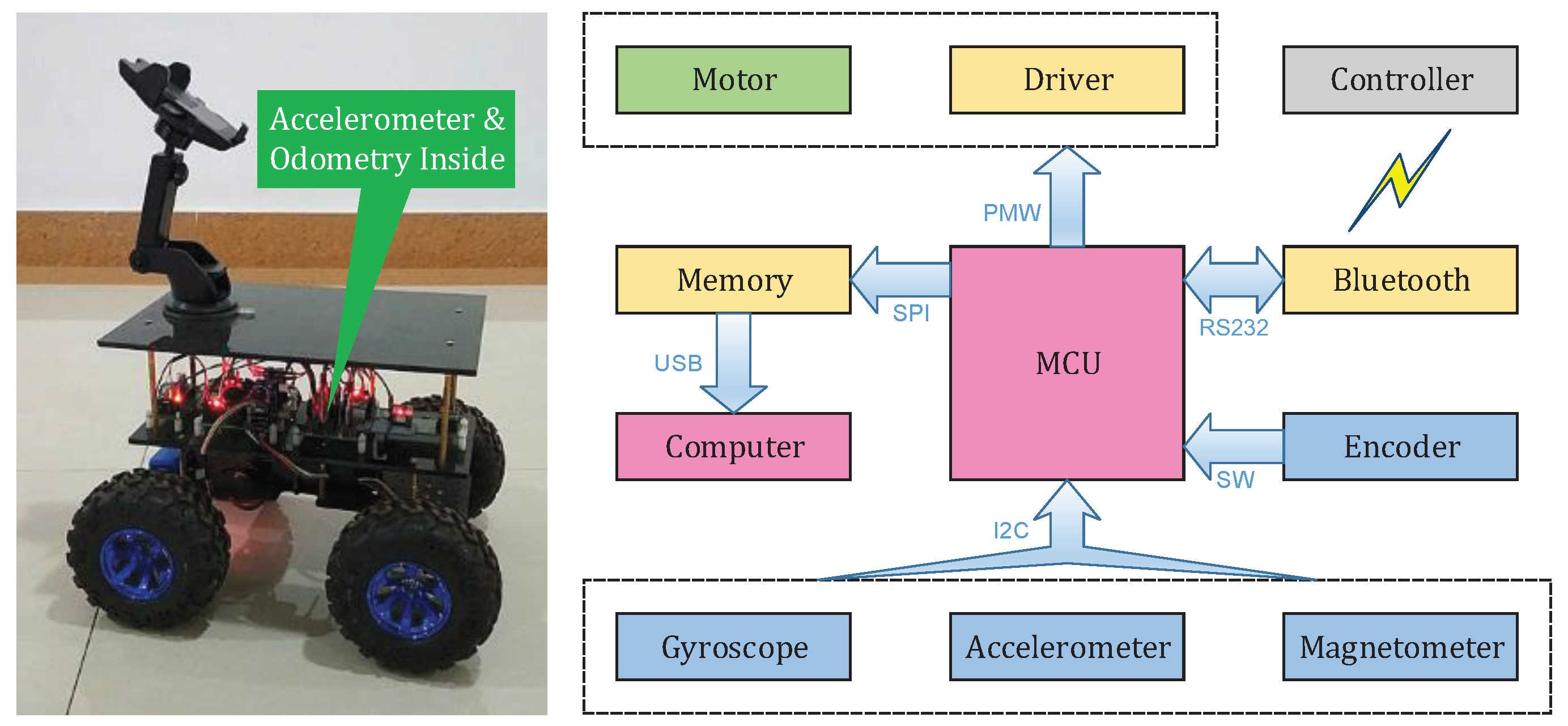
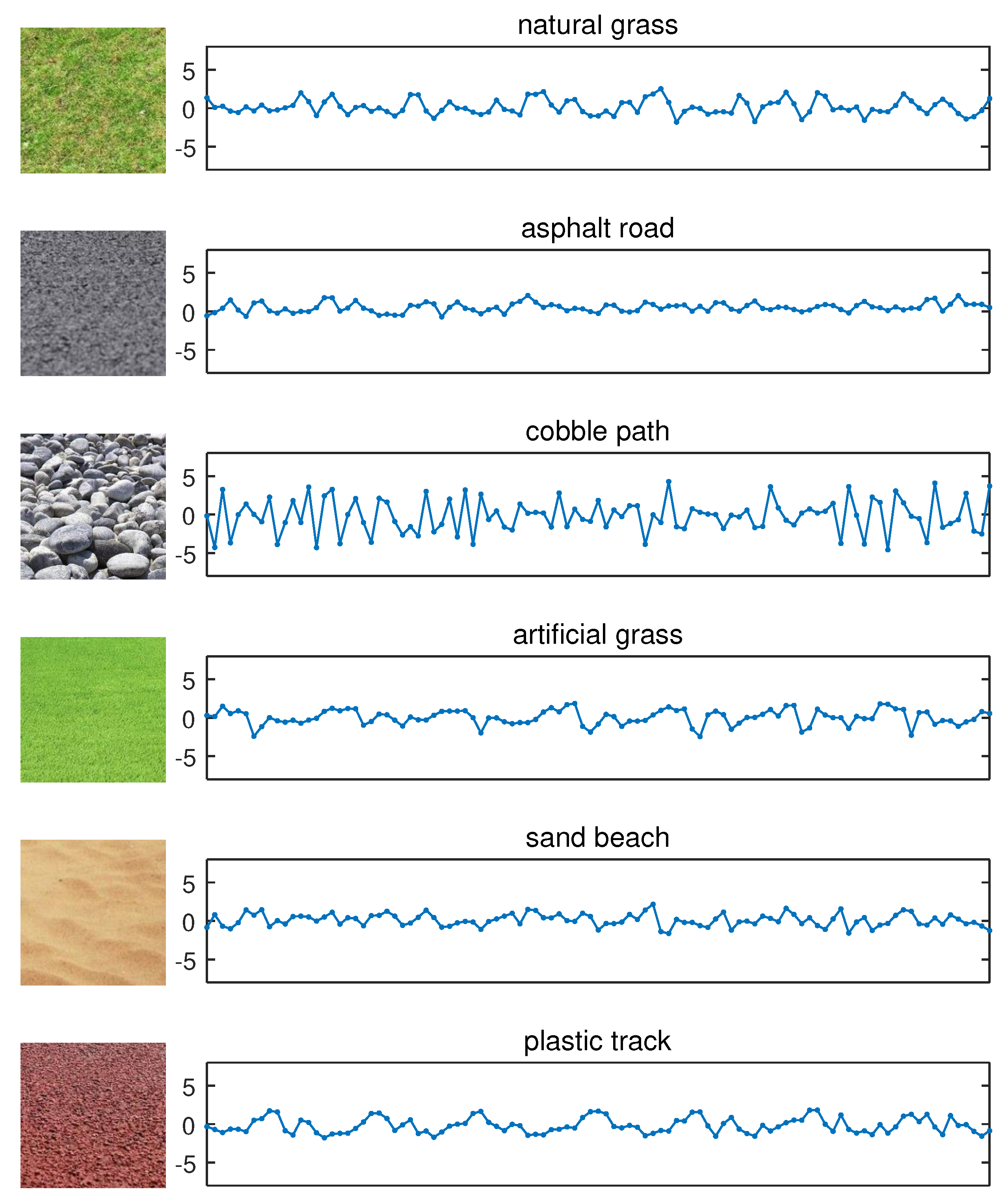
3.1. Experimental Data Collection
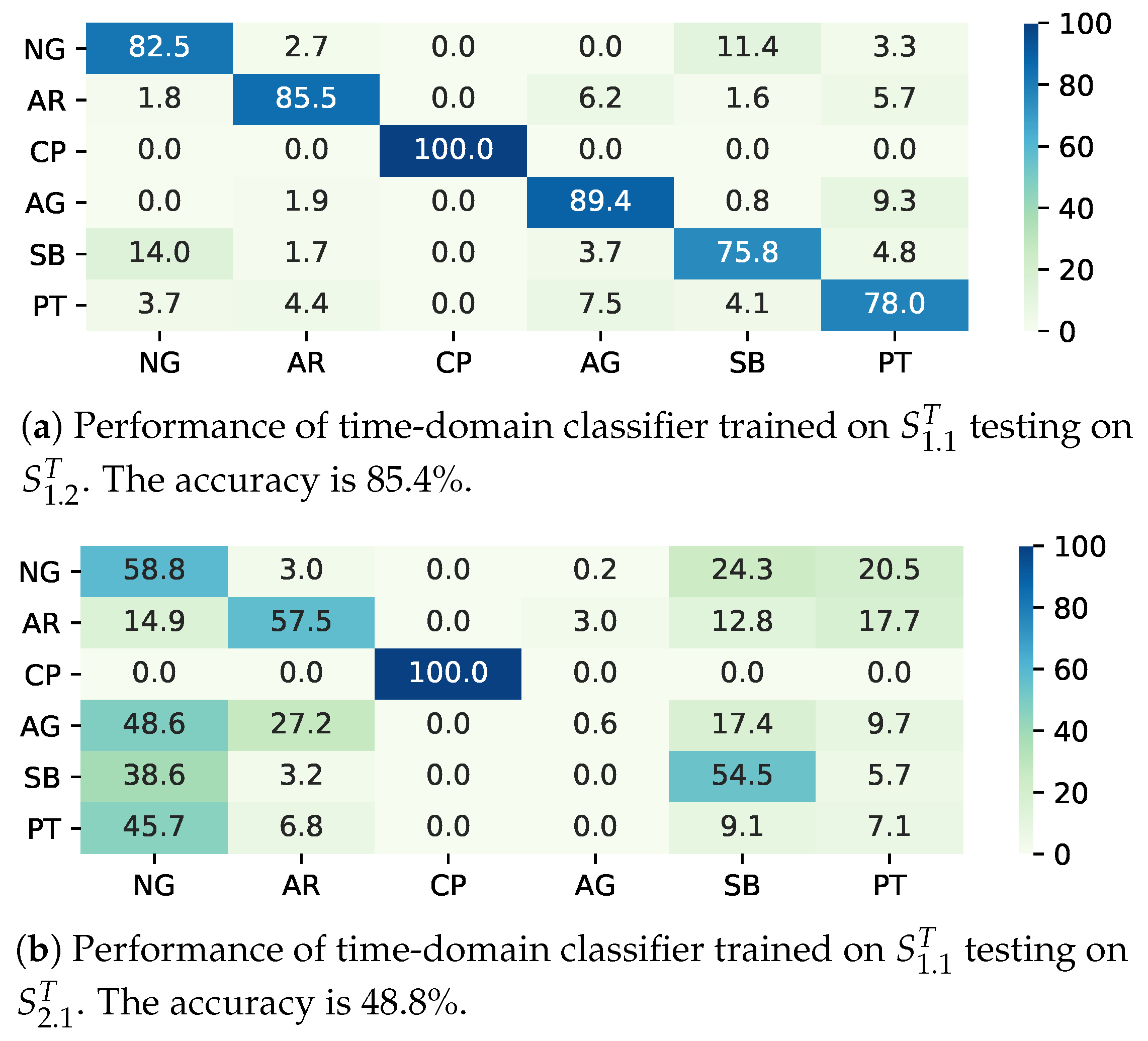
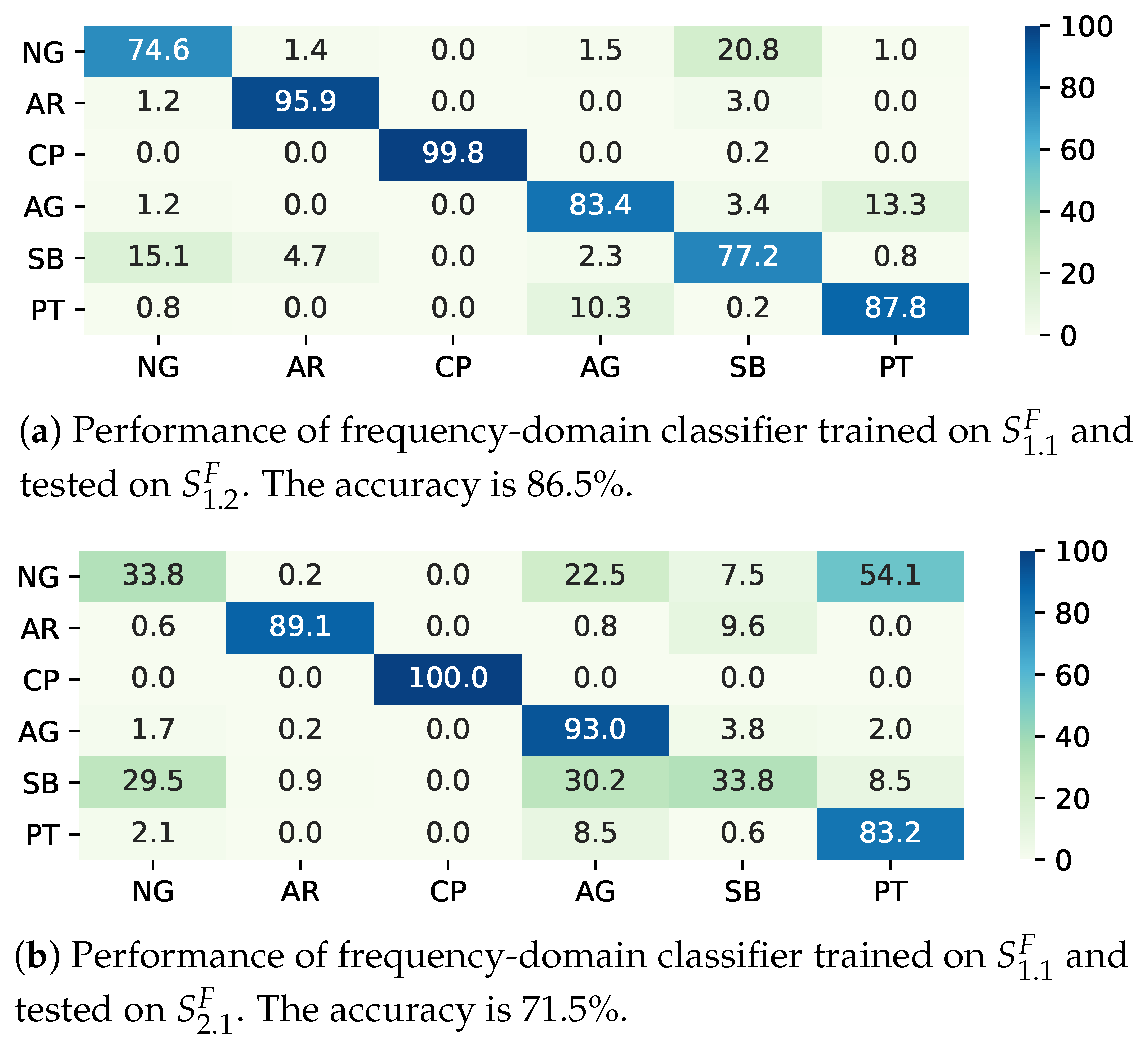
3.2. Performance Evaluation of Classifier
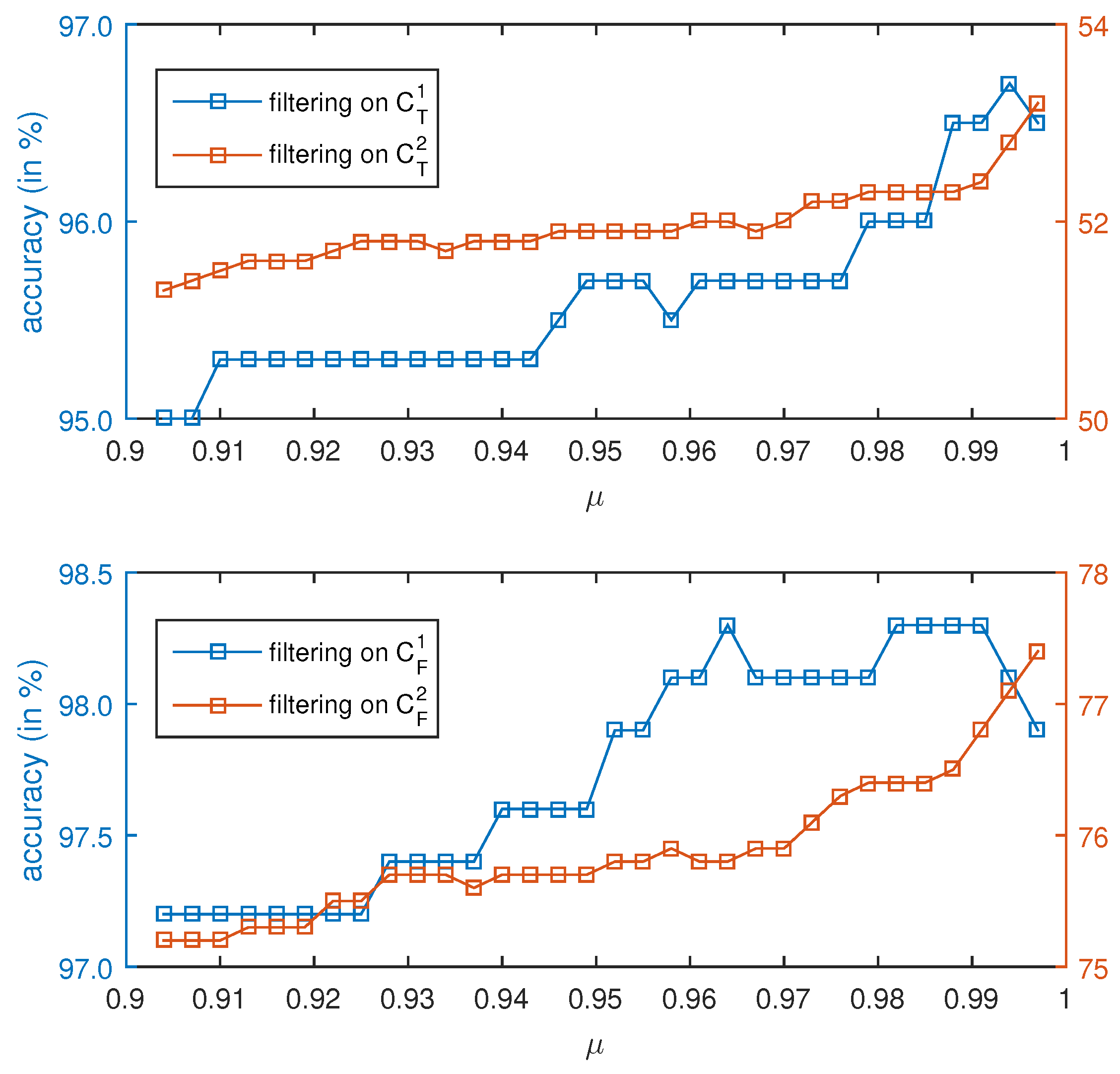
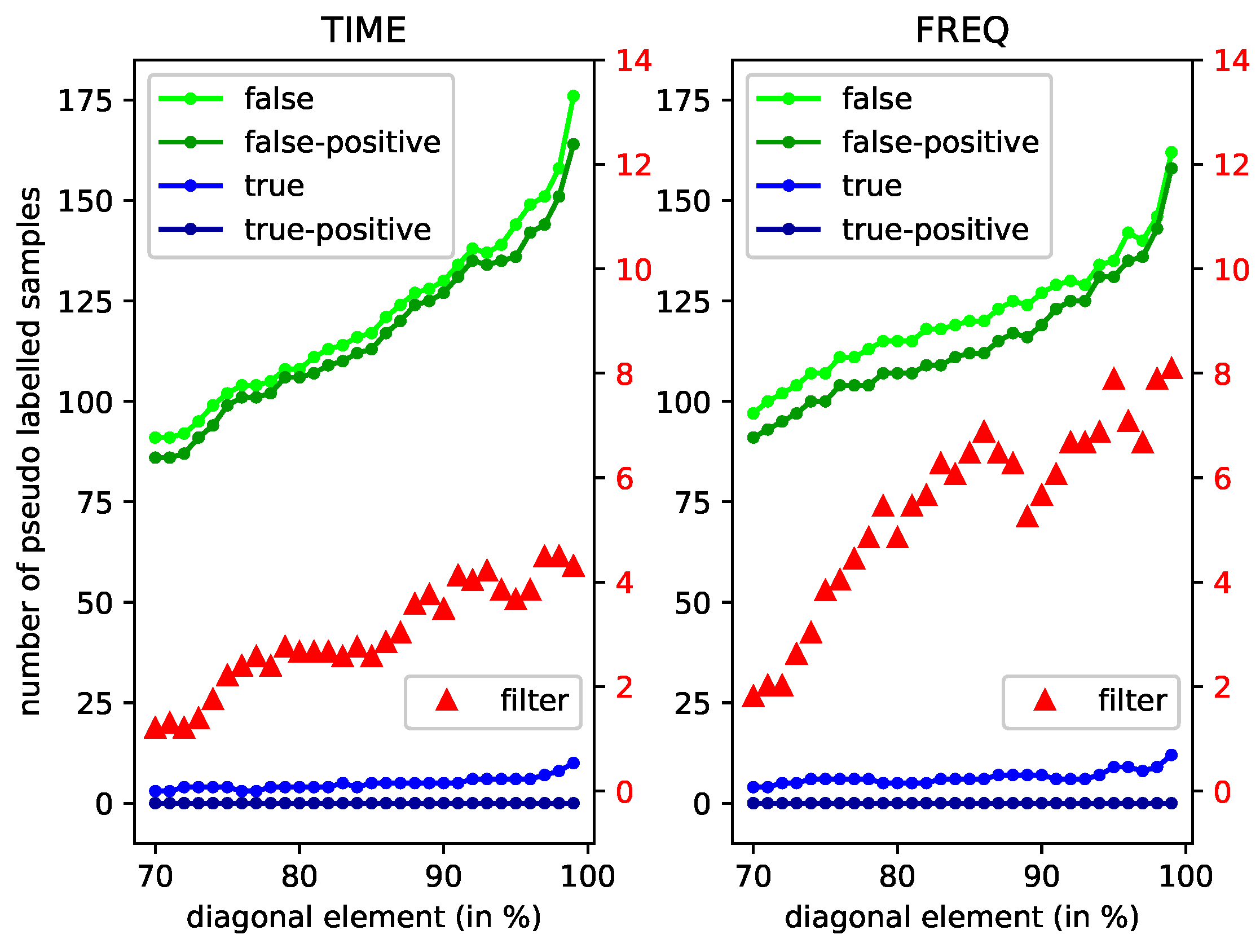
3.3. Performance Evaluation of Bayesian Filter
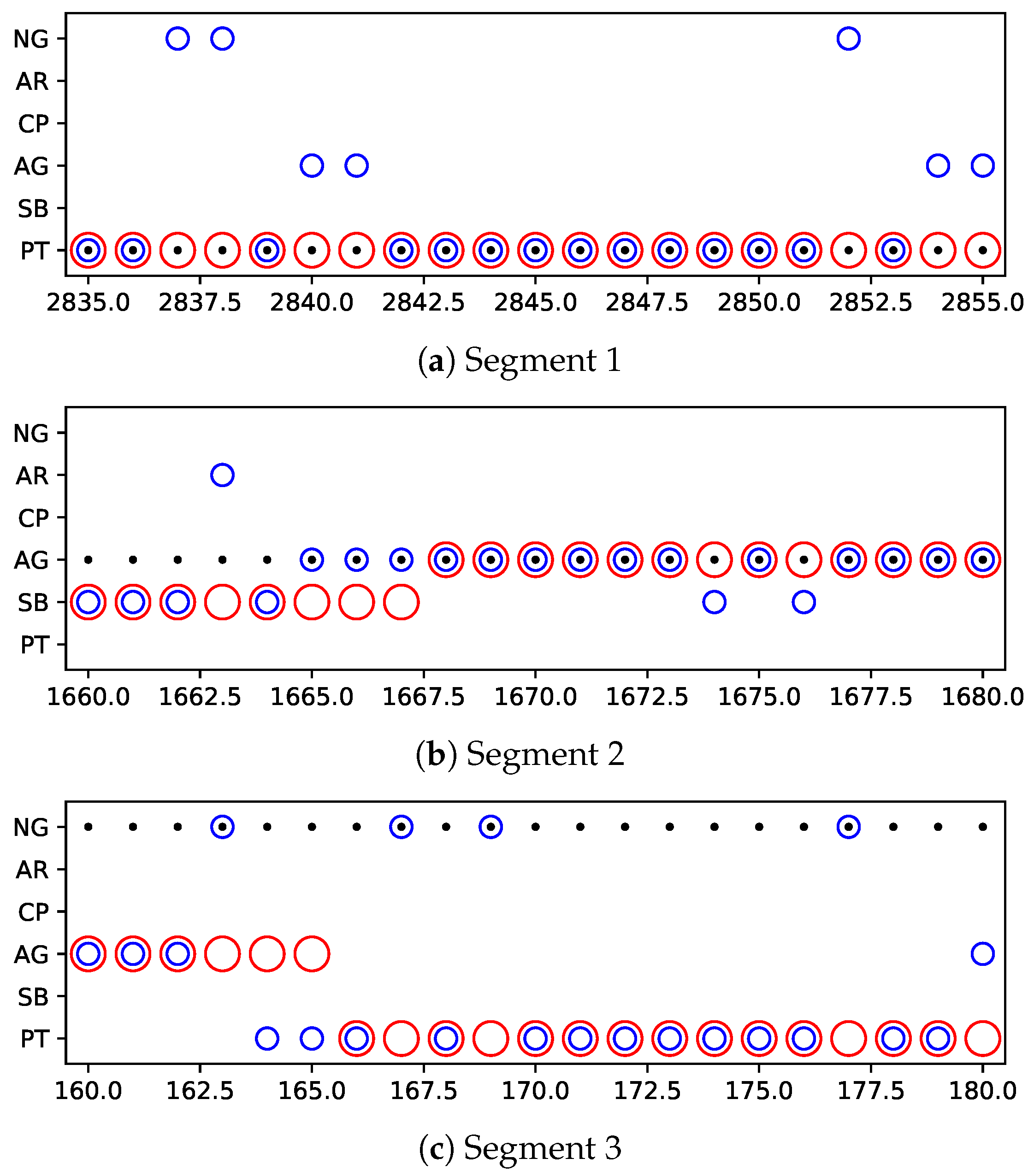
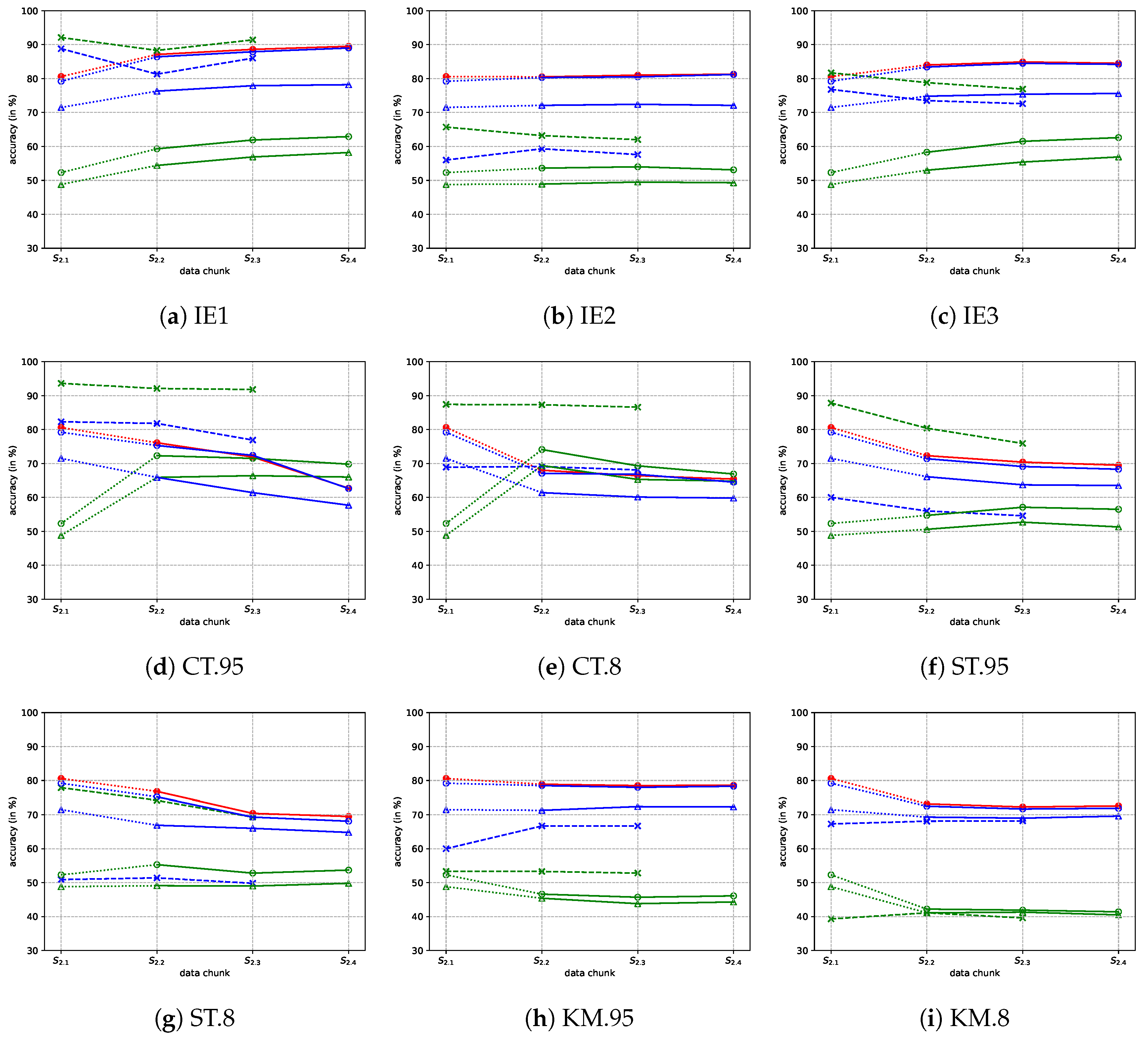
3.4. Comparative Study of Adaptation in a Dynamic Environment
- IE1: The proposed DyVTC. IE is the abbreviation of in- and ex-disagreement.
- IE2: Similar to IE1, we use the a priori ex-disagreement, instead of a posteriori ex-disagreement.
- IE3: Similar to IE1, we use both a priori and a posteriori ex-disagreement, which are combined using logical OR.
- CT.95: Using co-training algorithm (see [47]) to tackle such a terrain classification problem. The confidence threshold is 0.95.
- CT.8: Similar to CT.95, but the confidence threshold is 0.8.
- ST.8: Similar to ST.95, but the confidence threshold is 0.8.
- KM.95: Using an advanced fuzzy k means (see [48]) semi-supervised clustering algorithm to label the newly collected samples. The confidence threshold is 0.95.
- KM.8: Similar to KM.95, but the confidence threshold is 0.8.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Song, W.; Cho, K.; Um, K.; Won, C.S.; Sim, S. Complete scene recovery and terrain classification in textured terrain meshes. Sensors 2012, 12, 11221–11237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reina, G. Cross-coupled control for all-terrain rovers. Sensors 2013, 13, 785–800. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reinstein, M.; Kubelka, V.; Zimmermann, K. Terrain adaptive odometry for mobile skid-steer robots. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 4706–4711. [Google Scholar]
- Brooks, C.A.; Iagnemma, K. Vibration-based terrain classification for planetary exploration rovers. IEEE Trans. Robot. 2005, 21, 1185–1191. [Google Scholar] [CrossRef]
- Lv, W.; Kang, Y.; Zhao, Y. Self-tuning asynchronous filter for linear Gaussian system and applications. IEEE/CAA J. Autom. Sin. 2018, 5, 1054–1061. [Google Scholar] [CrossRef]
- Pentzer, J.; Brennan, S.; Reichard, K. Model-based Prediction of Skid-steer Robot Kinematics Using Online Estimation of Track Instantaneous Centers of Rotation. J. Field Robot. 2014, 31, 455–476. [Google Scholar] [CrossRef]
- Lv, W.; Kang, Y.; Qin, J. FVO: Floor Vision Aided Odometry. Sci. China Inf. Sci. 2019, 62, 12202. [Google Scholar] [CrossRef] [Green Version]
- Lv, W.; Kang, Y.; Zhao, Y.B.; Wu, Y.; Zheng, W.X. A Novel Inertial-Visual Heading Determination System for Wheeled Mobile Robots. IEEE Trans. Control Syst. Technol. 2020, 1–8. [Google Scholar] [CrossRef]
- Pentzer, J.; Reichard, K.; Brennan, S. Energy-based path planning for skid-steer vehicles operating in areas with mixed surface types. In Proceedings of the 2016 American Control Conference, Boston, MA, USA, 6–8 July 2016; pp. 2110–2115. [Google Scholar]
- Lee, J.; Lim, J.; Lee, J. Compensated Heading Angles for Outdoor Mobile Robots in Magnetically Disturbed Environment. IEEE Trans. Ind. Electron. 2018, 65, 1408–1419. [Google Scholar] [CrossRef]
- Lv, W.; Kang, Y.; Qin, J. Indoor Localization for Skid-Steering Mobile Robot by Fusing Encoder, Gyroscope, and Magnetometer. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1241–1253. [Google Scholar] [CrossRef]
- Chen, M. Disturbance attenuation tracking control for wheeled mobile robots with skidding and slipping. IEEE Trans. Ind. Electron. 2017, 64, 3359–3368. [Google Scholar] [CrossRef]
- Lv, W.; Kang, Y.; Zhao, Y. FVC: A Novel Nonmagnetic Compass. IEEE Trans. Ind. Electron. 2019, 66, 7810–7820. [Google Scholar] [CrossRef]
- Gonzalez, R.; Apostolopoulos, D.; Iagnemma, K. Slippage and immobilization detection for planetary exploration rovers via machine learning and proprioceptive sensing. J. Field Robot. 2017, 35, 231–247. [Google Scholar] [CrossRef]
- Anantrasirichai, N.; Burn, J.; Bull, D. Terrain classification from body-mounted cameras during human locomotion. IEEE Trans. Cybern. 2015, 45, 2249–2260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Filitchkin, P.; Byl, K. Feature-based terrain classification for littledog. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 1387–1392. [Google Scholar]
- Zhu, Y.; Luo, K.; Ma, C.; Liu, Q.; Jin, B. Superpixel segmentation based synthetic classifications with clear boundary information for a legged robot. Sensors 2018, 18, 2808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, Y.; Guo, W.; Zha, F.; Liu, Y.; Chen, C.; Sun, L. A Vision-Based Two-Stage Framework for Inferring Physical Properties of the Terrain. Appl. Sci. 2020, 10, 6473. [Google Scholar] [CrossRef]
- Zou, Y.; Chen, W.; Xie, L.; Wu, X. Comparison of different approaches to visual terrain classification for outdoor mobile robots. Pattern Recognit. Lett. 2014, 38, 54–62. [Google Scholar] [CrossRef]
- Kurban, T.; Beşdok, E. A comparison of RBF neural network training algorithms for inertial sensor based terrain classification. Sensors 2009, 9, 6312–6329. [Google Scholar] [CrossRef] [Green Version]
- Christie, J.; Kottege, N. Acoustics based terrain classification for legged robots. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 3596–3603. [Google Scholar]
- Valada, A.; Burgard, W. Deep spatiotemporal models for robust proprioceptive terrain classification. Int. J. Robot. Res. 2017, 36, 1521–1539. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.A.; Huh, T.M.; Mukherjee, R.; Cutkosky, M. Integrated Ground Reaction Force Sensing and Terrain Classification for Small Legged Robots. IEEE Robot. Autom. Lett. 2016, 1, 1125–1132. [Google Scholar] [CrossRef]
- Walas, K. Terrain classification and negotiation with a walking robot. J. Intell. Robot. Syst. 2015, 78, 401–423. [Google Scholar] [CrossRef] [Green Version]
- Otte, S.; Weiss, C.; Scherer, T.; Zell, A. Recurrent Neural Networks for fast and robust vibration-based ground classification on mobile robots. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 5603–5608. [Google Scholar]
- Bermudez, F.L.G.; Julian, R.C.; Haldane, D.W.; Abbeel, P.; Fearing, R.S. Performance analysis and terrain classification for a legged robot over rough terrain. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 513–519. [Google Scholar]
- Libby, J.; Stentz, A.J. Using sound to classify vehicle-terrain interactions in outdoor environments. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 3559–3566. [Google Scholar]
- Hoepflinger, M.A.; Remy, C.D.; Hutter, M.; Spinello, L.; Siegwart, R. Haptic terrain classification for legged robots. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 2828–2833. [Google Scholar]
- Weiss, C.; Frohlich, H.; Zell, A. Vibration-based terrain classification using support vector machines. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 4429–4434. [Google Scholar]
- Mei, M.; Chang, J.; Li, Y.; Li, Z.; Li, X.; Lv, W. Comparative study of different methods in vibration-based terrain classification for wheeled robots with shock absorbers. Sensors 2019, 19, 1137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dutta, A.; Dasgupta, P. Ensemble Learning With Weak Classifiers for Fast and Reliable Unknown Terrain Classification Using Mobile Robots. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 2933–2944. [Google Scholar] [CrossRef]
- Bai, C.; Guo, J.; Guo, L.; Song, J. Deep Multi-Layer Perception Based Terrain Classification for Planetary Exploration Rovers. Sensors 2019, 19, 3102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Kodagoda, S.; Shi, L.; Wang, H. Road-Terrain Classification for Land Vehicles: Employing an Acceleration-Based Approach. IEEE Veh. Technol. Mag. 2017, 12, 34–41. [Google Scholar] [CrossRef]
- Wang, C.; Lv, W.; Li, X.; Mei, M. Terrain Adaptive Estimation of Instantaneous Centres of Rotation for Tracked Robots. Complexity 2018, 2018, 4816712. [Google Scholar] [CrossRef]
- Otsu, K.; Ono, M.; Fuchs, T.J.; Baldwin, I.; Kubota, T. Autonomous terrain classification with co-and self-training approach. IEEE Robot. Autom. Lett. 2016, 1, 814–819. [Google Scholar] [CrossRef]
- Brooks, C.A.; Iagnemma, K. Self-supervised terrain classification for planetary surface exploration rovers. J. Field Robot. 2012, 29, 445–468. [Google Scholar] [CrossRef]
- Shi, W.; Li, Z.; Lv, W.; Wu, Y.; Chang, J.; Li, X. Laplacian Support Vector Machine for Vibration-Based Robotic Terrain Classification. Electronics 2020, 9, 513. [Google Scholar] [CrossRef] [Green Version]
- Lv, W.; Kang, Y.; Zheng, W.X.; Wu, Y.; Li, Z. Feature-temporal semi-supervised extreme learning machine for robotic terrain classification. IEEE Trans. Circuits Syst. II Express Briefs 2020. [Google Scholar] [CrossRef]
- Sheu, J.J.; Chu, K.T.; Li, N.F.; Lee, C.C. An efficient incremental learning mechanism for tracking concept drift in spam filtering. PLoS ONE 2017, 12, e0171518. [Google Scholar] [CrossRef]
- Hostetter, G. Recursive discrete Fourier transformation. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 184–190. [Google Scholar] [CrossRef]
- Li, Z.; Kang, Y.; Feng, D.; Wang, X.M.; Lv, W.; Chang, J.; Zheng, W.X. Semi-supervised learning for lithology identification using Laplacian support vector machine. J. Pet. Sci. Eng. 2020, 195, 107510. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. Acm Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Cauwenberghs, G.; Poggio, T. Incremental and decremental support vector machine learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001; pp. 409–415. [Google Scholar]
- Fang, H.; Tian, N.; Wang, Y.; Zhou, M.; Haile, M.A. Nonlinear Bayesian estimation: From Kalman filtering to a broader horizon. IEEE/CAA J. Autom. Sin. 2018, 5, 401–417. [Google Scholar] [CrossRef] [Green Version]
- Kittler, J.; Hatef, M.; Duin, R.; Matas, J. On combining classifiers. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 226–239. [Google Scholar] [CrossRef] [Green Version]
- Xue, J.; Zhang, H.; Dana, K. Deep texture manifold for ground terrain recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 558–567. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Gan, H.; Nong, S.; Rui, H.; Tong, X.; Dan, Z. Using clustering analysis to improve semi-supervised classification. Neurocomputing 2013, 101, 290–298. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Equation | Description |
|---|---|---|
| Zero-crossing number (ZCN) | is an indicator function, which outputs 1 if the expression in holds, or 0 otherwise. This feature is an approximation of the frequency of a. | |
| Mean | Although the gravitational acceleration has been subtracted, the mean of a may considerably diverge from zero for some course terrains. | |
| ZCN in | . is a complement to , which avoids for even high-frequency vibration signal when the robot is traversing coarse terrains. | |
| Variance | Intuitively, the variance is higher when the terrain becomes coarser. | |
| Autocorrelation | is an integer indicating time difference. As a measure of non-randomness, gets larger with a stronger dependency between and . | |
| Maximum | indicates the biggest bump of the terrain. | |
| Minimum | indicates the deepest puddle of the terrain. | |
| -norm | reflects the energy of a. If , has the similar function as . Instead, we can also use the -norm, i.e., . | |
| Impulse factor | measures the impact degree in a. | |
| Kurtosis | measures the deviation degree of the a with Gaussian distribution. |
| Sensor | Specifications |
|---|---|
| Odometry | 540 pulse per round; resolution: 0.67 deg. |
| Gyroscope | range: ±250 deg/s; initial ZRO * tolerance: ±5 deg/s; total RMS noise: 0.1 deg/s. |
| Accelerometer | range: ±2 g; initial ZGO tolerance: ±80 mg; total RMS noise: 8 mg. |
| Magnetometer | range: ±4800 uT. |
| Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IE1 | IE2 | IE3 | CT.95 | CT.8 | ST.95 | ST.8 | KM.95 | KM.8 | ||
| Time Domain | True True-Positive Accuracy | 8 0 0% | 71 71 100% | 79 71 89.8% | 753 702 93.2% | 1005 886 88.2% | 716 653 91.2% | 1096 868 79.2% | 658 610 92.7% | 1542 1071 69.5% |
| False False-Positive Accuracy | 157 152 96.8% | 37 0 0% | 194 152 78.4% | 491 462 94.1% | 963 834 86.6% | 155 112 72.3% | 503 378 75.1% | 566 43 7.6% | 1653 186 11.3% | |
| All All-Positive Accuracy | 165 152 92.1% | 108 71 65.7% | 273 223 81.7% | 1244 1164 93.6% | 1968 1720 87.4% | 871 765 87.8% | 1599 1246 77.9% | 1224 653 53.3% | 3195 1257 39.3% | |
| Freq Domain | True True-Positive Accuracy | 9 0 0% | 65 65 100% | 74 65 87.8% | 765 645 84.3% | 1232 881 71.5% | 1175 708 60.3% | 1691 862 51.0% | 5 3 60.0% | 2298 1985 86.4% |
| False False-Positive Accuracy | 146 143 97.9% | 51 0 0% | 197 143 72.6% | 98 65 66.3% | 354 211 59.6% | 75 43 57.3% | 260 132 50.8% | 0 0 0.0% | 910 175 19.2% | |
| All All-Positive Accuracy | 155 143 92.3% | 116 65 56.0% | 271 208 76.8% | 863 710 82.3% | 1586 1092 68.9% | 1250 751 60.0% | 1951 994 50.9% | 5 3 60.0% | 3208 2160 67.3% | |
| Method | Pseudo Labeling | Incremental Learning |
|---|---|---|
| IE1 | 12 | 584 |
| IE2 | 13 | 152 |
| IE3 | 16 | 651 |
| CT.95 | 62 | 195 |
| CT.8 | 147 | 237 |
| ST.95 | 73 | 213 |
| ST.8 | 196 | 281 |
| KM.95 | 359 | 204 |
| KM.8 | 838 | 323 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, C.; Chang, J.; Lv, W.; Wu, Y.; Li, K.; Li, Z.; Yuan, C.; Ma, S. Frequency-Temporal Disagreement Adaptation for Robotic Terrain Classification via Vibration in a Dynamic Environment. Sensors 2020, 20, 6550. https://0-doi-org.brum.beds.ac.uk/10.3390/s20226550
Cheng C, Chang J, Lv W, Wu Y, Li K, Li Z, Yuan C, Ma S. Frequency-Temporal Disagreement Adaptation for Robotic Terrain Classification via Vibration in a Dynamic Environment. Sensors. 2020; 20(22):6550. https://0-doi-org.brum.beds.ac.uk/10.3390/s20226550
Chicago/Turabian StyleCheng, Chen, Ji Chang, Wenjun Lv, Yuping Wu, Kun Li, Zerui Li, Chenhui Yuan, and Saifei Ma. 2020. "Frequency-Temporal Disagreement Adaptation for Robotic Terrain Classification via Vibration in a Dynamic Environment" Sensors 20, no. 22: 6550. https://0-doi-org.brum.beds.ac.uk/10.3390/s20226550