In order to tailor the method to predict traffic flow for the coastal beaches of Portugal, firstly, we performed the activity of selecting the available data in the surrounding area of the two selected beaches. Then, we assessed whether the available data were relevant enough to handle the prediction models’ induction.
The following subsections describe in detail each one of the steps presented in the methodology.
3.1. Data Selecting
The original Telemetry dataset contains more than 170 million records (170,158,409) considering the years of 2019, 2020, and 2021 and is composed of parking sensors and radars data. For the goal of this work, just radar data were selected, resulting in 155,432,185 records.
Table 3 presents the attributes of the original data. Each record is produced at a frequency of 100 ms and contains the identification of the moving object, ID and coordinates of the radar, timestamp, and the
x-
y axis speed component.
The meteorological dataset used in this work was provided by the Portuguese Institute of Sea and Atmosphere (IPMA) [
23]. IPMA maintains an up-to-date climate dataset with information such as air temperature, wind speed, and direction, light radiation and so forth.
Figure 1b presents the two meteorological stations near to the radars used in this work. One is placed at the University in Aveiro, and the other is at Dunas de Mira.
Table 4 presents the attributes of the meteorological data. Each record is produced at a frequency of ten minutes.
3.2. Data Preprocessing
The radar data are produced at a frequency of 100 ms; however, the meteorological data are generated at a frequency of 10 min. The adjustment of the difference in the granularity (100 ms × 10 min) among the two datasets is one of the tasks executed in the preprocessing phase.
Before adjusting the granularity, other derived radas data were produced; year, month, day, hour, weekday, and minute attributes were calculated from the timestamp. Addutionally, the xSpeed and ySpeed attributes result in the Speed measure. Negative values for Speed represent the measure of the speed of an object approximating the radar, and positive values represent the object moving away; the in_out logical attribute stores this situation.
Using the identification, speed, and direction of the moving object, for each radar, it is possible to compute the quantity and speed (
maximal,
mean, and
minimal) at the level of the
radar,
year,
month,
day,
hour and
minutes (ten minute intervals).
Table 5 presents the resulting format of the processing radar data, and each record represents measures aggregated for ten minutes at the hour.
Figure 1a presents the localization of the radars named “
pasmoradar03pontepraias”, “
pasmoradar02poste12” and “
pasmoradar01riativa”. The first one occurs before entering the bridge; the second one is in the interconnection segment between Barra and Costa Nova, and the third one is at the urban limit to the south of Costa Nova.
This work aims to develop a model to forecast the traffic flow in Barra and Costa Nova, considering the meteorological environment and level of speed vehicles approximating and leaving the radars. Then, two new measures were computed to represent the traffic flow in the regions
TF_Barra and
TF_Costa.
where
= the quantity of objects approximating the radar
i, and
= the quantity of objects detaching from the radar
i, computed by
with
i as the identification of the radar,
j as the interval minute (0, 10, …, 50),
obj_count_A as the value of the
count_obj attribute where
in_out = 1, and
obj_count_D as value of the
count_obj attribute where
in_out = 0.
Therefore,
TF_Barra and
TF_Costa can be positive or negative values. A positive
TF value represents an increase in the traffic flow for that region, and negative values can express a reduction. Additionally, new speed measures were computed considering the movement of approximation and detaching for each radar.
with
n as the quantity of records representing the
attribute with
= 1.
with
i as the identification of the radar,
j as the interval minute, and
n as the quantity of records representing the
attribute with
= 0.
In Equations (
5)–(
10),
i represents the identification of the radar, and
j represents the interval minute. Equations (
7) and (
9) consider the records with
= 1, while for Equations (
8) and (
10),
= 0.
Table 6 presents the final processed radar data.
Figure 1b presents the two meteorological stations collecting environment measures. Each record represents one observation every ten minutes for each hour of the day. The processing of the meteorological data was focused on two goals: (1) correcting the lack of measures of the stations, and (2) transforming the wind direction values from degree to cardinal values.
In situation (1), some records are incomplete in one station but complete in another. In this case, considering that the meteorological stations are close and the variation of the measures is not significant, the procedure was to complete the fault value by using the value of the other station.
Wind direction values recorded in degree are a potential problem at the moment to execute the data mining tasks (situation 2). For instance, the direction North (cardinal) represents the degree interval between 348.75 and 11.25. Therefore, considering the direction, a value of 5 degrees represents the same direction as a value of 359 degrees. However, the two values could represent two different environments in the execution of mining tasks. The solution was to transform the values into eight cardinal points (N, NE, E, SE, S, SW, W, NW) defined by a 45 degree interval.
Table 7 presents the processed meteorological data. The next step is to concatenate the two datasets: radars and meteorological.
3.4. Model Training
The dataset was not randomly shuffled before splitting. The final dataset that was preprocessed in the previous steps was divided into training, validation, and testing sets, composed of 70, 20, and 10% of time-ordered records. The time ordering is necessary to build windows of consecutive records, and it is a way to execute training, evaluation, and testing steps more realistically due to the time series form of the data. In addition to the radar information, the dataset contains contextual data [
3]: weekday, temperature, solar radiation, speed and wind direction, and precipitation. These attributes can improve the performance of the predictive models; however, they are related to the year’s seasons. Therefore, to ensure that the model considers records of all seasons, the training set was defined with 70% of the dataset; it is equivalent to the interval between January and December of 2020.
Figure 3 presents the complete dataset divided into subsets; the
x-axis represents the time and the
y-axis the traffic flow values.
Figure 4 presents similar data distributions of the subsets.
This work aims to develop regression models for forecasting the traffic flow in the Barra and Costa Nova regions. Regression models consider predictor and target variables; in this case, TF_Barra and TF_Costa dataset attributes were the target variables, and others, e.g., month, day, weekday, hour, minute, temperature, speed, and wind, were used as predictors. Each record presents the values (predicted and targeted) aggregated by ten-minute intervals; therefore, a sequence of six records represents the behavior of that environment during one hour.
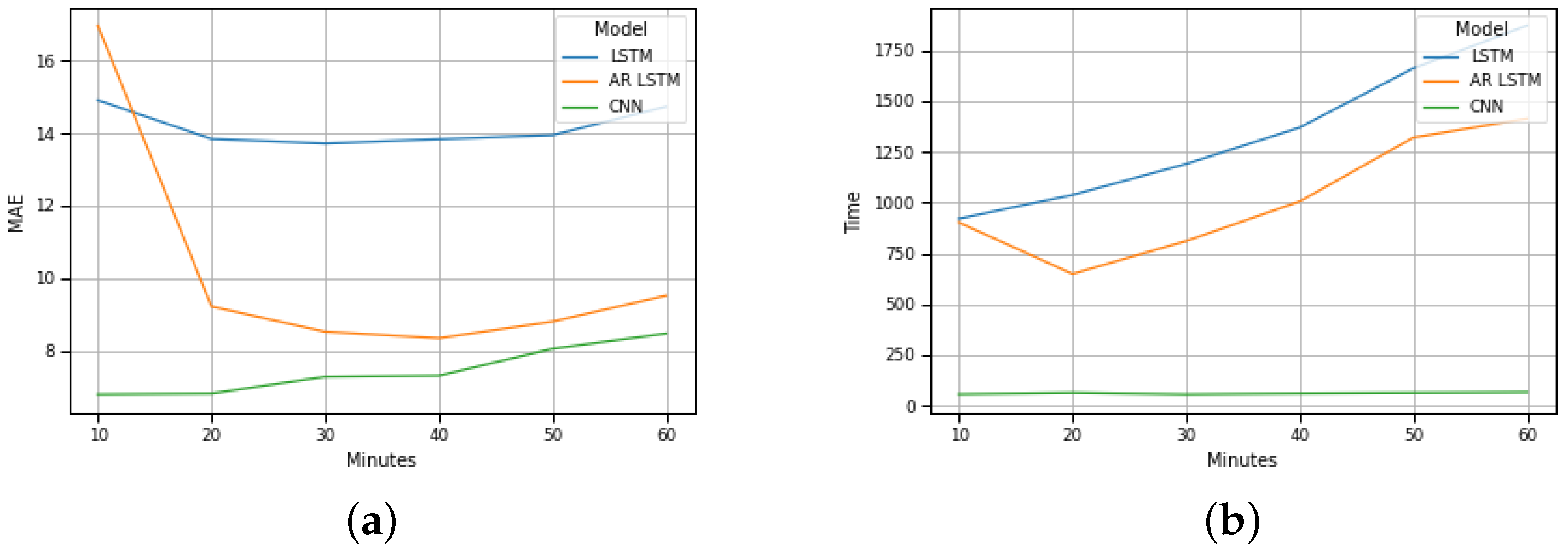
We conducted experiments using three deep-learning regression methods (
LSTM, AR-LSTM, CNN) to forecast the traffic flow;
mean absolute error (
MAE) was used as a performance metric. Each model was constructed considering the best configuration, defined as the result of an optimization phase by using the hyperparameter options (
neurons, activation function, optimizer function, dropout, batch size, filter map, and kernel size). Each model was trained to find the best number of epochs, considering the limit of 200 epochs. For each method, six different time intervals were considered: (1,1), (2,2), (3,3), (4,4), (5,5), and (6,6), where (1,1) means one previous record (ten minutes) and one (ten minute) traffic flow predicted. Therefore, this work presents results to forecast the traffic flow between ten and sixty minutes (one hour) considering a multi-step model. In a multi-step model, the proposal is to build a model where it is possible to consider the changing of the input features along the time to forecast the sequence values.
Figure 5 presents the single and multi-step models.
The CNN model was defined with a convolutional layer with 64 filter maps, a Relu activation function, and a kernel size of the same length as the time interval value, e.g., kernel size = 6, where the time interval was 6 (one hour). A dense layer was used with the number of nodes defined by the product between the time interval value and the number of features, e.g., considering the dataset with 43 features and one hour as the period to forecast, the number of nodes was 258 (43 × 6). Finally, the last layer converted the format to present the predicted traffic flow values.
The LSTM method has been used to analyze time-series datasets; the proposal is to accumulate the internal state during the time interval and then compute the forecast for the next time interval. In this work, the LSTM model had a first layer with 32 neurons and was configured to return the output at the final time step. There was a dense layer with the same configuration as the CNN in the sequence. The number of nodes was defined by the product between the time interval value and the number of features, e.g., considering the dataset with 43 features and one hour as the period to forecast, the number of nodes was 258 (43 × 6). Finally, the last layer converts the format to present the predicted traffic flow values.
Finally, the AR-LSTM model decomposed the prediction into individual time steps. The approach was to use each model output to feed back into itself. Therefore, the forecasting could be done considering the previous result. In the same way, as in the LSTM model, the LSTM layer contains 32 neurons.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}