1. Introduction
The field of robotics is very extensive with respect to robot design, as it is necessary to investigate and analyse the different types of mechanisms that a robot could eventually integrate. Mobile robots can move around their environment using different mechanisms, such as wheels, caterpillars and others [
1,
2,
3,
4]. Mobile robots include robots with a spherical shape, that roll to move, like a football. This type of robot represents a particular challenge because it must roll with all of its components inside [
5,
6]. Examples of this kind of robot can be found in the literature with different driving/steering mechanisms, including single wheels [
7,
8], pendulums [
9,
10,
11], and omnidirectional wheel mechanisms [
12].
It is well-known that, currently, advanced robots are very expensive and can be exposed to damage during laboratory experimentation. For this reason, simulators are very important in this field. Virtual laboratories using these simulators offer significant benefits for robotics education [
13]. Using such virtual laboratories, students can test and gain an understanding of concepts that are not easy to follow in the classroom, at any time and pace, and from anywhere [
14,
15]. They can also design and test control strategies before implementing them in an actual robot in the laboratory without risk of damage to the physical device.
Currently, there are many simulators for different areas of robotics. For example, Argos [
16], Webots [
17], RFCSIM [
18], and CoppeliaSim (formerly V-REP) [
19], to mention only those most used. Some of these platforms have licenses that can be used free of charge for educational purposes. They have competitive functionalities with various components that can interact with each other and can be programmed with different programming languages.
The CoppeliaSim simulator deserves special attention for being one of the most widely used for pedagogical purposes today. This simulator provides a versatile and scalable framework for creating 3D simulations in a relatively short period of time. CoppeliaSim has an integrated development environment (IDE) that is based on a distributed and scripted architecture—each scene object can have a built-in script attached, all operating at the same time, in the form of threads. CoppeliaSim contains a wealth of examples, robot models, sensors, and actuators to create and interact with a virtual world at run-time. New models can be designed and added to CoppeliaSim to implement custom-designed simulation experiments [
20,
21]. CoppeliaSim has an extensive list of mobile robots, among which there is no spherical robot. Therefore, it would be interesting to add a model of a spherical robot so that it would be available and could be used by the community for experiments.
In our laboratory, we have recently developed a spherical mobile robot that can be easily reproduced with a 3D-printer and some basic electronic components. Our idea was to develop and test the simulation model for this robot, as we did in previous investigations [
14,
15] with a model of the Khepera IV robot in the CoppeliaSim simulator. In the model, the physical properties and components, such as mass, dimensions, and other variables were carefully taken into account. This model was tested with several control strategies under different scenarios. The results obtained with the model were very similar to those obtained with the actual Khepera IV robot with the same control algorithms and experimental conditions [
22]. We expect the resulting new model to be very similar to the physical robot, based on our previous results obtained with the Khepera IV robot.
This paper presents the development and testing of a model of a spherical robot whose movement is based on an internal pendulum. The robot consists of a spherical-shaped cover that protects the pendulum and the internal circuitry and allows it to roll to move from one place to another. This type of morphology has a fundamental advantage in that there is no possibility of the robot tipping over, which gives it certain stability in movement. At the same time, it has certain disadvantages with respect to sliding on the surface and difficulties with the presence of obstacles or irregularities in the terrain [
9,
12,
23].
The main contribution of this article is the modelling and control of a non-linear model of a spherical robot that does not exist in the CoppeliaSim simulator. This is a challenging task due to the complexity of the spherical robot model. The developed model is controlled under different scenarios with several control algorithms implemented by the authors in previous studies, including Villela [
24], IPC (integral proportional controller) [
25], and reinforcement learning (RL) [
26,
27]. The experiments undertaken to test the robot model included investigation of position control, path-following and formation control. As a result of this work, the model and some examples are available online for use by the community that works with mobile robots.
The article is organised as follows:
Section 2 describes the model of the spherical robot and its design and implementation in CoppeliaSim.
Section 3 describes the control laws and experiments implemented with the spherical robot.
Section 4 shows the tests performed on position control, path-following and formation control. Finally,
Section 5 presents the conclusions and discusses future work.
2. Spherical Robot Model
This section presents the details of the mathematical model of the spherical robot in different situations.
2.1. Robot Description
A spherical robot is a mobile machine that has a spherical casing with a single contact with the surface on which it rests. The housing not only allows the robot to be in a balanced state, but also enables the robot to roll from one place to another without sliding.
Figure 1 shows a picture of the actual robot in the laboratory.
For practical purposes, the mechanism that moves the robot and maintains balance is based on a pendulum and three motors. One motor operates the pendulum and modifies the centre of gravity of the robot; the other motors are connected to the casing-sphere, which allows its movement using rotation. The design of this robot is based on [
28].
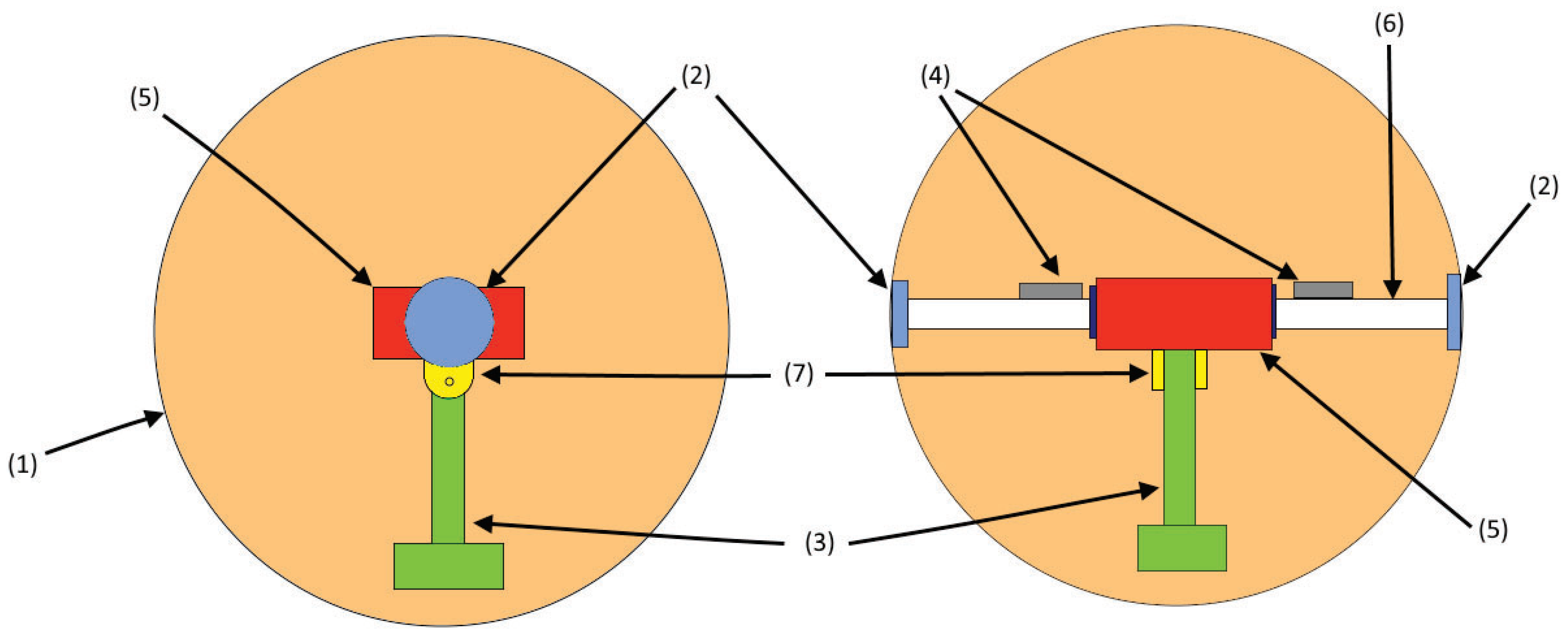
Figure 2 shows a schematic view of the robot, where the right side is the front view and the left side is the lateral view. The components are as follows: (1) casing sphere, a 3D-printed shell which is the body of the robot; (2) bearings, the joins of the case with the shaft; (3) pendulum, which is a stick that allows the robot to turn; (4) counterweights, which are two body masses to improve the stability of the robot; (5) circuitry box, is a small space that contains all the electronic components; (6) shaft (fixed axle), which is the join between the circuit box and the case; and (7) articulation, which is the join between the pendulum and the shaft.
2.2. Horizontal Motion Equations
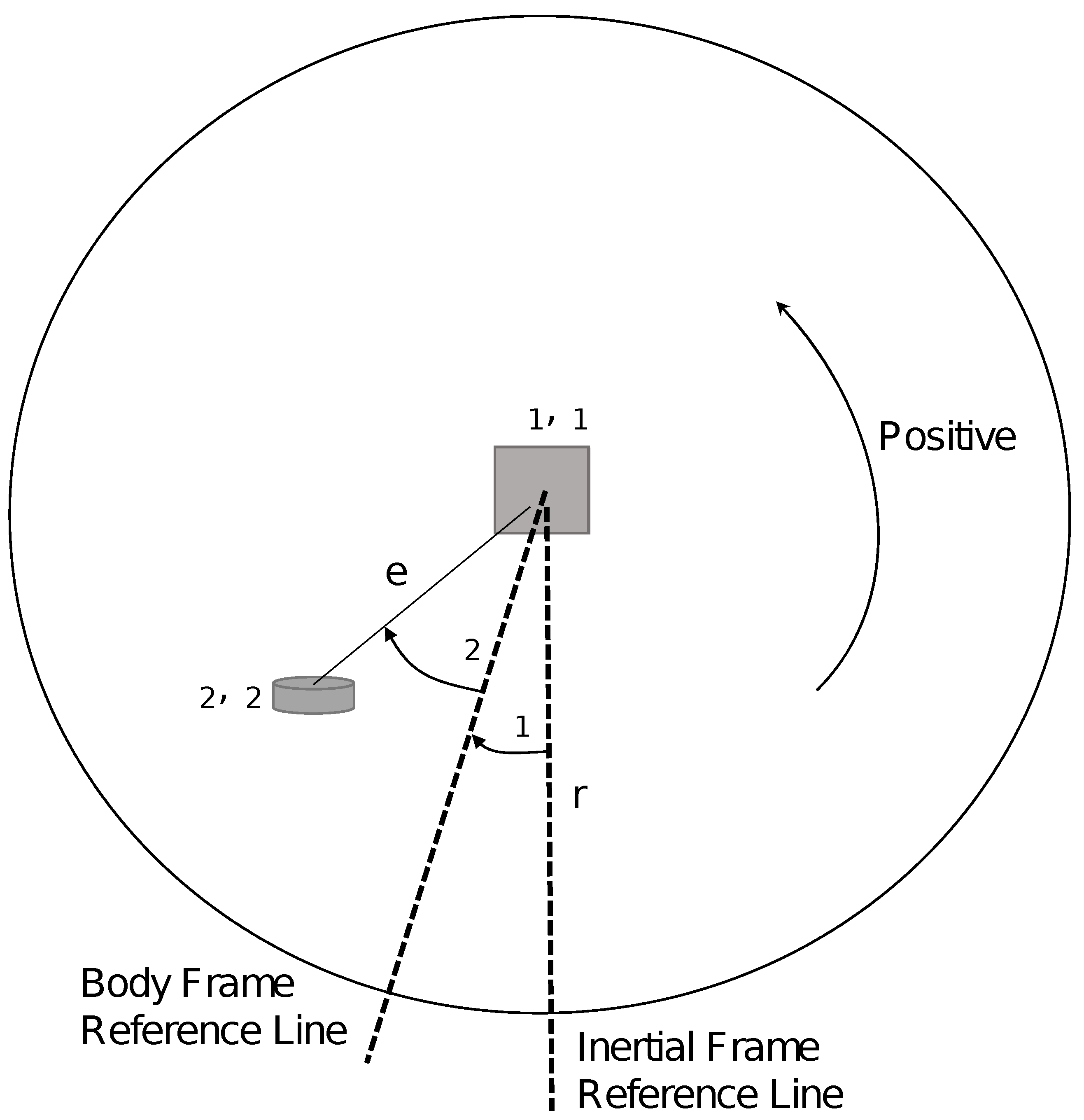
A simplified model of the robot can be seen in
Figure 3, which is based on [
28]. The model considers moments of inertia, the radius of the sphere, masses of the elements that make up the robot, angles, and the direction of linear velocity.
In this model, it is considered that the casing is always in contact with the surface, which allows the robot to roll without slipping. The dynamic model of the spherical robot for a horizontal movement considers the balance of potential energy, kinetic energy and rotational energy, respectively, as can be seen in Equations (
1)–(
3):
where the main variables are the following:
: is the potential energy of the spherical housing with respect to the height of its centroid.
: is the potential energy of the pendulum with respect to the height of the centroid of the spherical casing.
: is the kinetic energy of the spherical shell.
: is the kinetic energy of the pendulum.
: is the rotational energy of the spherical shell.
: is the rotational energy of the pendulum.
e: is the distance between the centroid of the spherical shell and the pendulum.
: is the mass of the spherical shell.
: is the mass of the pendulum.
The Lagrange equations are calculated as follows:
where t is the independent variable of time, T is the torque applied between the casing and the circuitry, and
is the torque that appears with the friction force that occurs between the casing and the ground. Solving the Equations (
5) and (
6), we obtain:
This last equation is useful to determine which motor may be used for the construction of the spherical robot and to consider its design.
2.3. Robot Turning Equations
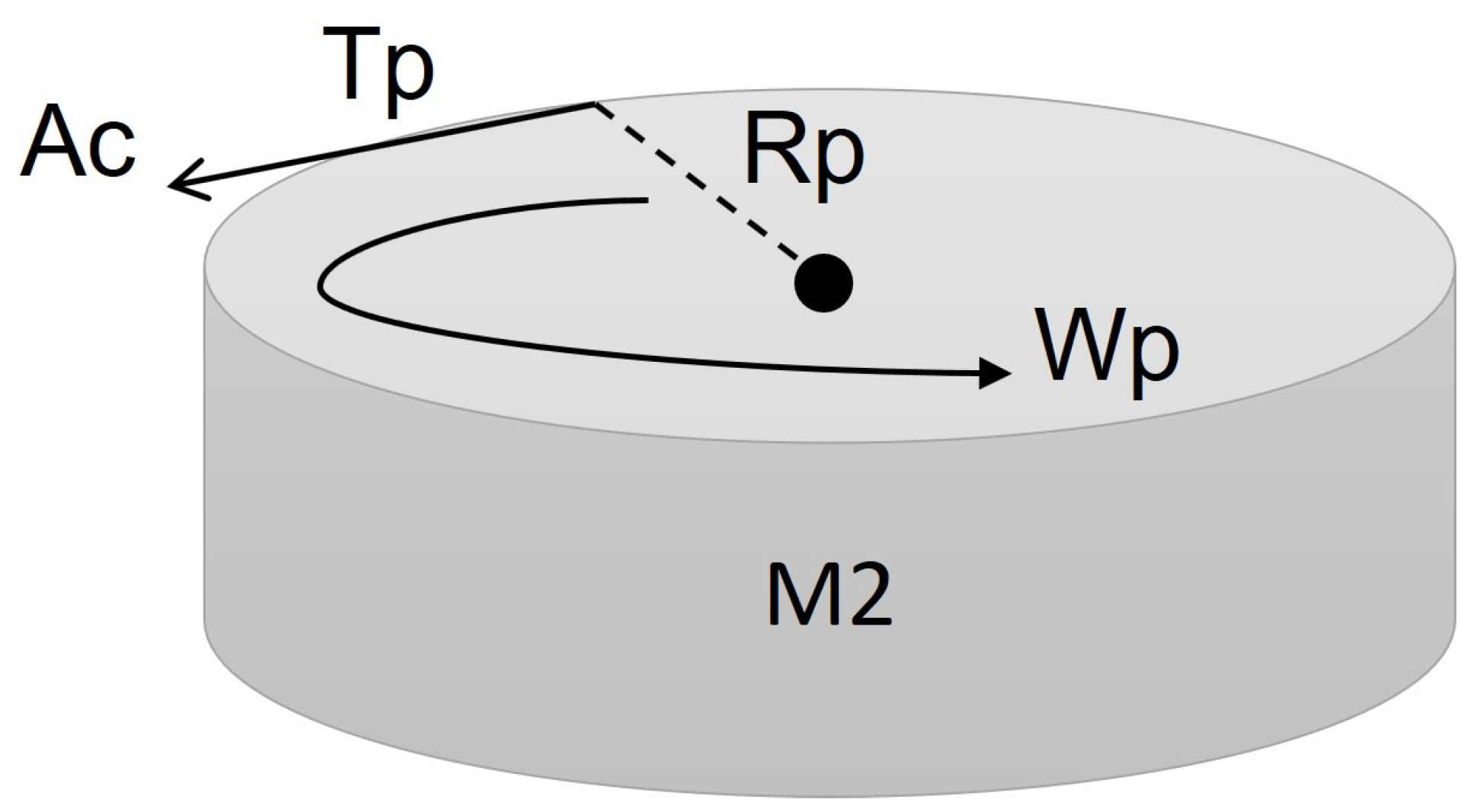
The motion that allows changing the direction of the spherical robot is based on the mass of the pendulum using a CMG (control moment gyroscope). The calculation of this motion is based on a torsion pendulum, as shown in
Figure 4.
Where
is the torque of the pendulum;
is the radius of the pendulum;
is the angular velocity of the pendulum;
is the swing acceleration of the pendulum; and
is the mass of the pendulum. The equation of the rotational motion of the pendulum is as follows:
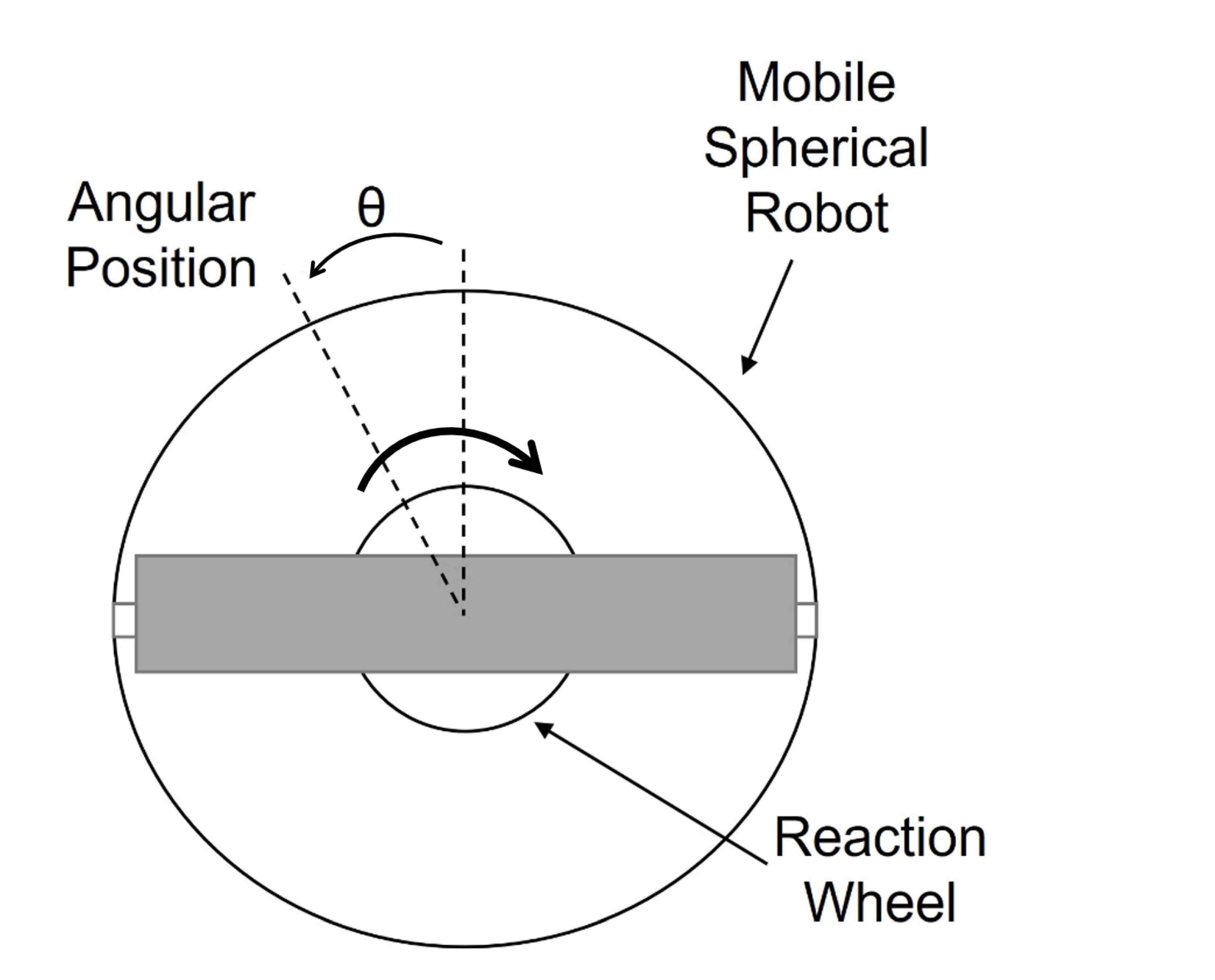
Figure 5 shows an angle
corresponding to the angular position of a spherical mobile robot, whose orientation is controlled by varying the speed of a reaction wheel. The angular velocity of the reaction wheel, relative to the spherical mobile robot, can be varied by varying the voltage applied to the electric motor. This means that, if the motor rotates clockwise, the spherical robot will orient itself in the opposite direction. The effect is achieved by analysing the angular momentum at the axis of rotation; as the speed of the wheel varies, the speed of the mobile robot will also start to vary so that the momentum remains constant.
The equations governing this phenomenon are obtained after analysing the momentum of the spherical robot and the reaction wheel around the axis of rotation. As shown below:
where the main variables are the following:
is the angle of the spherical robot casing (robot angle);
is the angular velocity of the spherical robot;
is the angular velocity of the pendulum wheel;
is the moment of inertia of the spherical robot casing;
is the moment of inertia of the pendulum wheel of the spherical robot; and
is the equivalent moment of inertia where:
.
2.4. Building the Model of the Robot
The parts of the spherical robot were designed using the 3D design software Autodesk Fusion 360 [
29] based on the actual robot shown in
Figure 2. These parts were then imported into the CoppeliaSim simulator [
30] working environment and the robot was assembled manually.
Figure 6 shows the process of building the robot.
As can be seen, on the right side, the imported parts of the robot are shown (i.e., housing, pendulum motor, housing motors). On the left side, the result of the robot assembly is shown. The total diameter of the robot is 18 centimetres. Note that the motors and internal elements were built in the same software.
3. Experiments with the Spherical Robot
In this section, some tests/experiments implemented with the robot are presented and commented on.
3.1. Position Control
This experiment consisted of getting the robot to move from one point C (current position) to another
(target point) in the most efficient way possible, which implies that it does so by following the shortest path to the destination point. Note that this robot can rotate without displacement, which means that its model is holonomic. To add complexity to the experiment, we imposed non-holonomic constraints on the model. This means that the robot has to move in order to rotate (it cannot rotate about its own position).
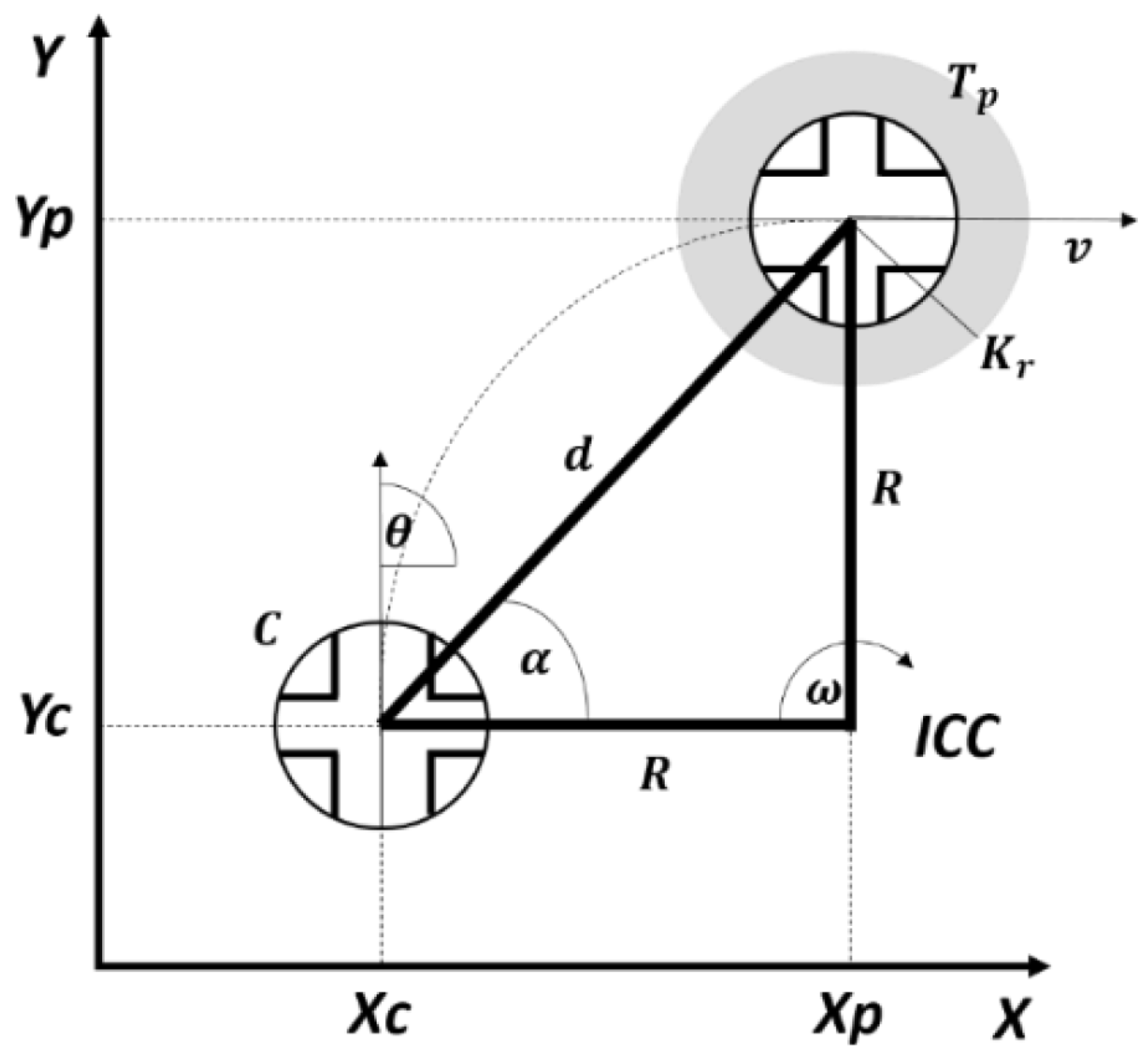
Figure 7 shows a representation of this experiment.
As can be seen, the variables involved in this experiment were, on one hand, the pose
C(
), which includes the position (
x,
y) and the orientation angle (
) of the robot; on the other hand, the distance (
d) and the angle (
) at which the target point is located. These variables are calculated as follows:
The control law is calculated using the angular error as input (
) and obtaining as outputs the linear velocity (
) and the angular velocity of the robot (
). Then the corresponding values for the housing motor and pendulum are calculated for the robot to move with these angular and linear velocities. As a result, the robot is positioned in a new pose C (
x,
y,
), which is used to recalculate the values described above.
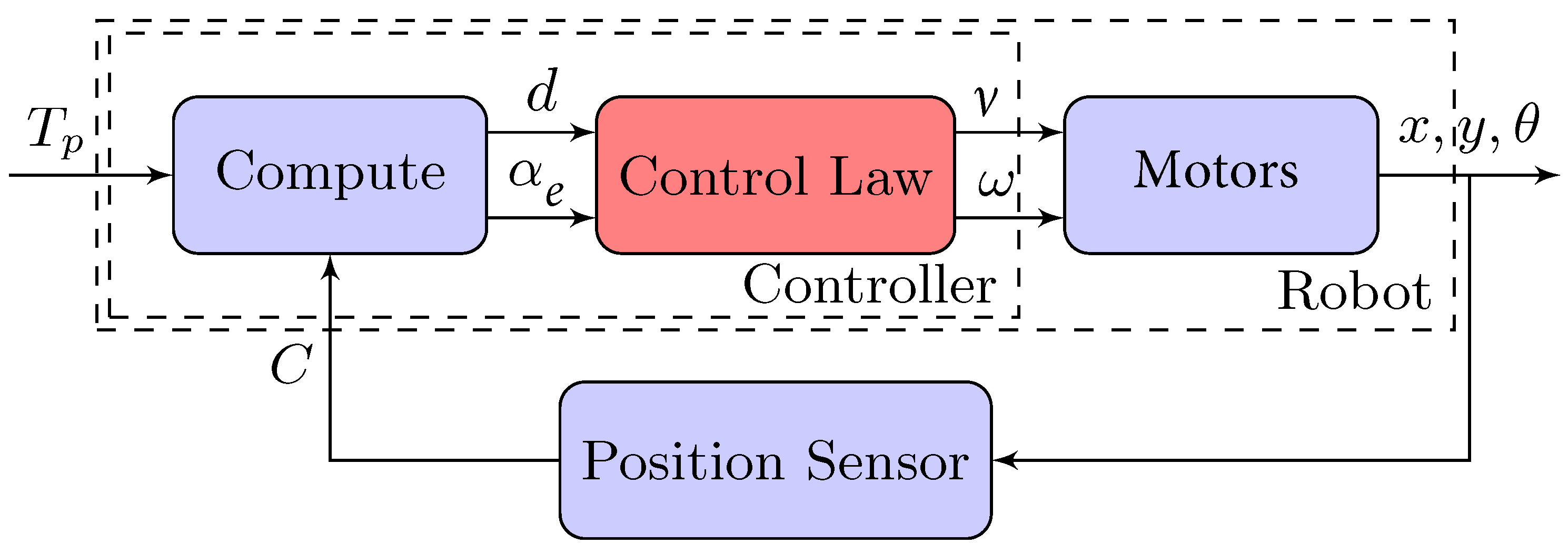
Figure 8 shows the block diagram of the control loop for this experiment. Where the block Compute implements Equations (
12) and (
13); while the Control Law block can be implemented in different ways, with artificial intelligence or conventional control law approaches, as is explained in the next subsections.
In the case of the spherical robot, the linear velocity (
) is applied as a voltage to the servomotors of
Figure 2, which allows movement of the pendulum backwards or forwards to change the centre of gravity of the robot and to make the robot move in one of those directions. The angular velocity (
) is applied to the DC motor of the pendulum, which allows the robot to rotate clockwise or counter-clockwise.
In addition to this experiment, the model was tested with other approaches: (1) path-following and (2) formation control. In the first case, the robot must control its position by following a trajectory received as a reference. In the second experiment, more robots were added to the scenario. One of them acts as the leader and the rest as followers. The followers use the position of the leader to make a formation around the leader.
3.2. Reinforcement Learning Approach
Reinforcement learning is able to provide an optimal solution despite the complexity of the system. The system learns by acting on the environment while operating in real-time. This is an advantage of traditional optimization methods that rely on a mathematical model and are tuned backwards in time [
31,
32].
The reinforcement learning approach for this research, called Q-learning, is based on solving the Bellman equation, and the principle of optimality. This technique allows an optimal learning process to be carried out during regular operation, based on the robot’s dynamics, and continuous-time signals. In the limit, the Q-matrix captures a discretized version of the optimal action-state combination in terms of the highest long-term reward.
Given a system described by the dynamics
and a reward function
, where
is the state of the system, and
the control policy, a long-term reward can be defined by Equation (
14):
where
is a discount factor required to penalize future rewards and to ensure convergence of the summation. This expression represents the discounted accumulated rewards starting from the current state
and the application of the policy
.
To apply Bellman’s optimality principle, the previous long-term reward expression (
14) is redefined in terms of the function
, called action-value, which allows for the splitting of the reward assignment into two consecutive steps. This action-value function conveys the long-term reward by the contribution of the immediate reward due to applying an arbitrary action
while in the state
, and by the discounted accumulated reward continuing with the control policy
. This is as shown in (
15) starting from
:
The optimal value is obtained by maximizing the future rewards; using the optimal policy defined by
, a recursive equation is obtained:
This equation captures the optimal principle by stating that future optimal control actions are not specified by past optimal values, but, instead, only by the current state. The major advance in these calculations is the viability of forward-in-time learning, as opposed to a standard optimal search performed backwards-in-time. This method is also known as Q-learning. From (
16), the following recursive equation can be devised that asymptotically converges to the fixed manifold
[
33,
34]:
The term
is typically labeled temporal difference
, or error between the target value
and the current value
, with
a learning rate. The expression (
17) resembles a gradient descend numerical search. Another interpretation of (
17) is the structure of a low-pass filter, by rearranging it as
. The learning rate
, or numerical search step size, establishes the effect of new information overriding previous information. A small value will reduce the rate of learning, while a larger value will rely more heavily on new data, despite what was previously learned.
3.3. Control Laws: Villela and IPC Approaches
As was mentioned before, the Control Law block of
Figure 9 can be implemented with traditional control laws or with a machine learning approach. In this subsection, we show both control laws that will later be implemented in the robot. For example, the Villela control law [
24], named after its author, was used previously with different kinds of robots with good results [
15,
18,
22]. It calculates the linear velocity (
) and the angular velocity (
) of the robot, as shown in Equations (
18).
where
is the maximum linear velocity,
is the radius of a docking area (around the target point) and
is the maximum angular velocity of the robot.
Based on the Villela control law, in a previous study, we developed what we term an integral proportional controller IPC [
25], which was compared with the Villela algorithm and was found to produce better results. The controller implements the velocities as follows in Equation (
19):
where
, for
and
,
, and
are tuning parameters of the control law. We tested this control law with a differential wheeled mobile robot, so it is challenging to implement this controller with a spherical robot.
4. Results
In this section, the results of the implementation of the control experiments with the developed model are presented.
4.1. Reinforcement Learning Results
This subsection shows the simulation results for different tests in several iterations to build the Q-matrix. The Q-matrix was obtained in MATLAB during the learning stage and exported to Python (Spyder-Anaconda IDE). The CoppeliaSim software was connected to Spyder via remote API, which ensured it was compatible with Python programming. The experiments were performed with the CoppeliaSim simulator using the developed spherical robot model.
In the learning stage, the algorithm builds the Q-matrix to learn how to reach the destination point. To this end, the angle error () is used to obtain the angular velocity () in order to control the position of the robot. Note that, initially, the linear velocity () is kept constant at its maximum value until the robot reaches the docking area.
The Q-matrix is composed of the sets (state, action), where the state is the angle error (), and the action is the angular velocity (). The criterion for obtaining the rewards of the Q-matrix is to penalize significant changes in the angle error and small changes in the angular velocity of the pendulum. In this case, the matrix Q has a size of 126 × 41, where 126 states are generated linearly spaced between and , and 41 actions linearly spaced between and . The array is made up of initial reward values. These initial values are adjusted according to the number of iterations of the algorithm based on a learning rate, a discount rate and a coefficient of relationship between exploration and use. They explore and use values to allow the robot to explore the space to complete knowledge of it and later use that knowledge.
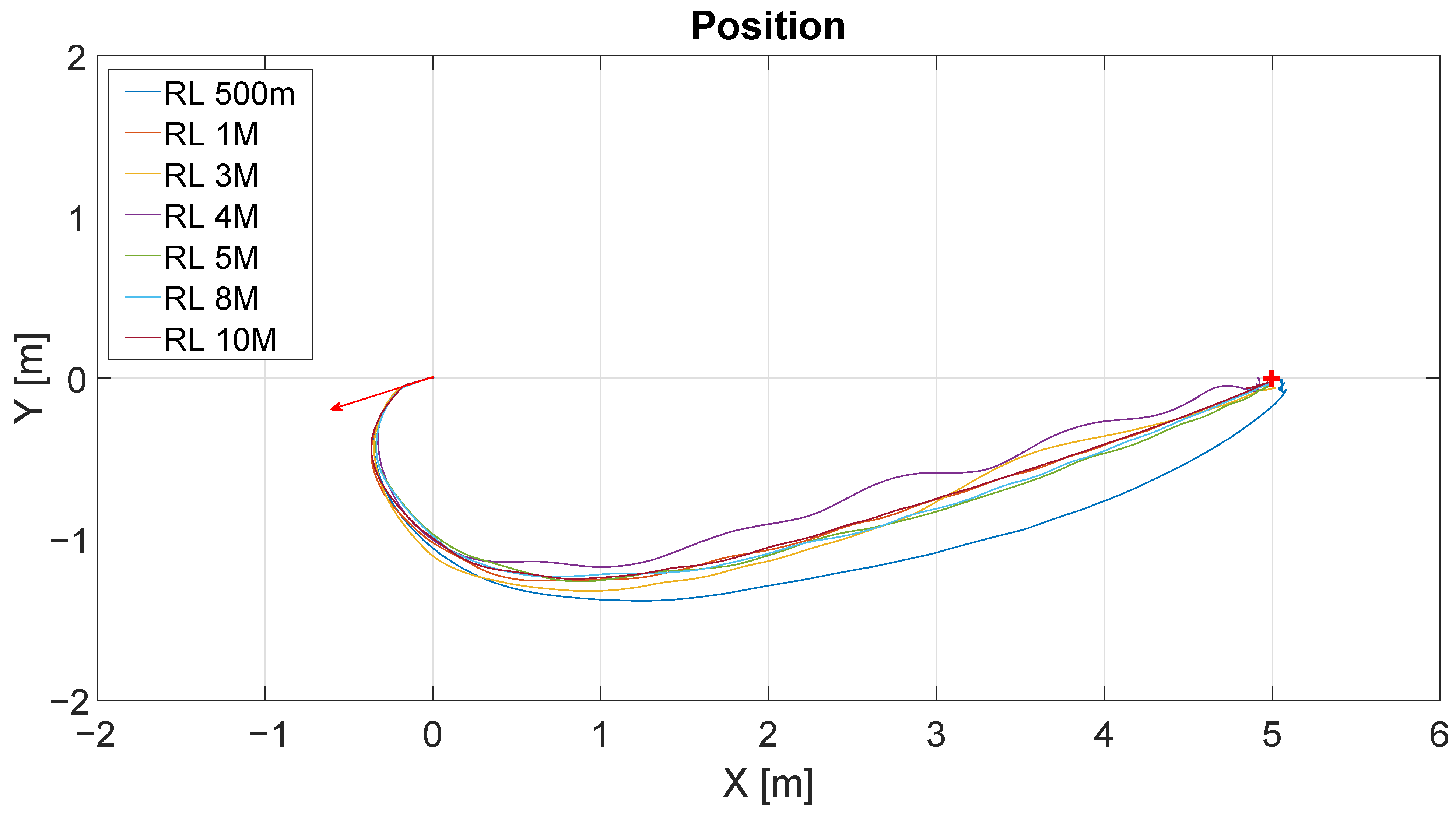
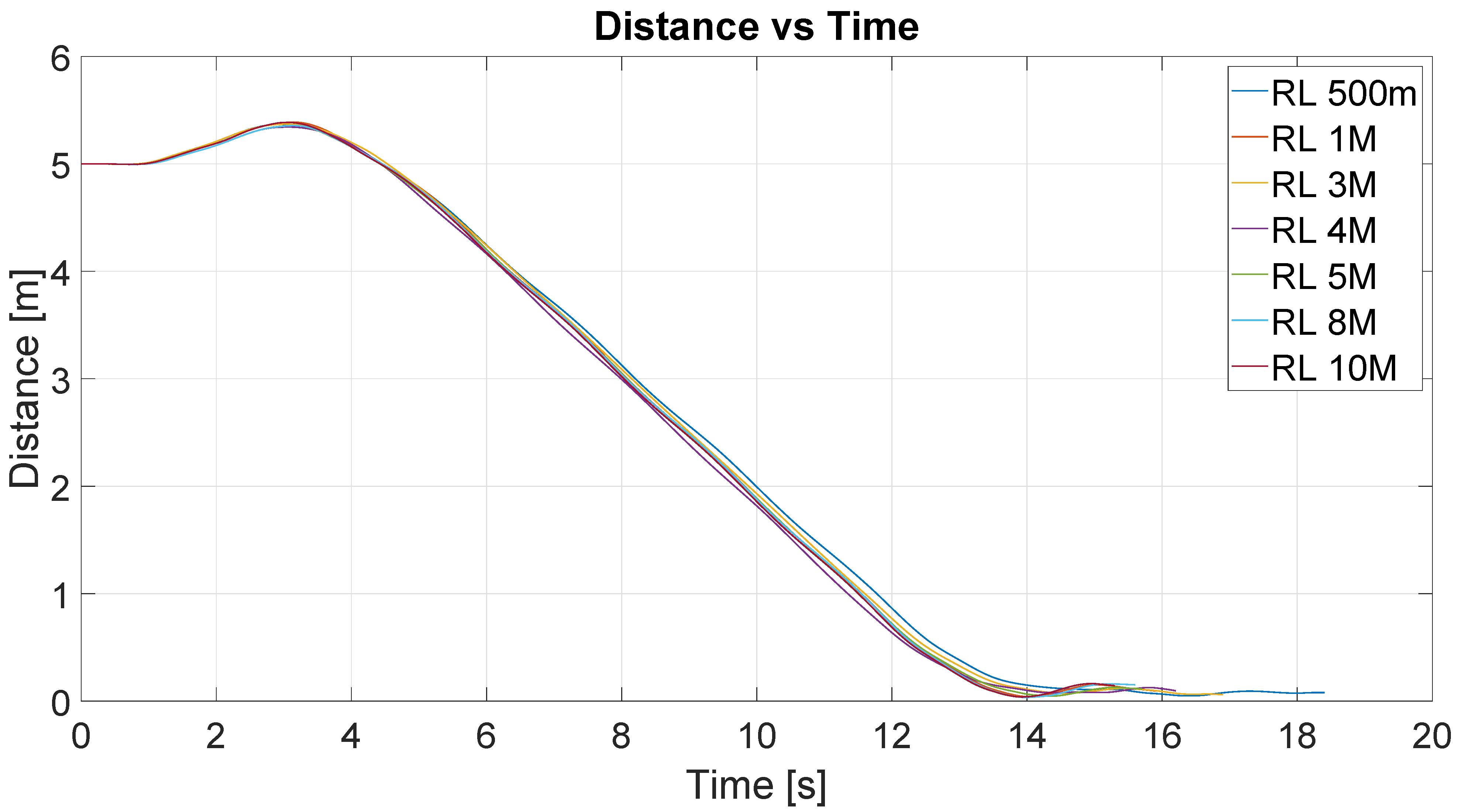
Figure 9 shows the results of the position control experiment for different iterations of the RL algorithm (RL 500 m-500.000 iterations, RL 1M-1.000.000 iterations, and so on). The lines describe the trajectories followed by the robot for each value of iteration. The initial position of the robot is represented by the base of the red arrow at (
), and the target point is represented by the red cross located at (
). The direction of the arrow represents the initial orientation of the robot.
Figure 10 shows the distance to the destination point for these experiments. The y-axis represents the distance in meters and the x-axis represents the time in seconds. As can be seen, for all experiences, the time to arrive at the destination was similar, around 14 s. This would be expected given the similarity between the trajectories shown in the figure above.
The quality of each control algorithm can be evaluated using performance indexes. These indexes use the integral of the error, which is, in our case, the distance to the target point. The performance indexes considered in this work are the following: (1) integral square error (ISE), (2) integral absolute error (IAE), (3) integral time squared error (ITSE), and (4) integral time absolute error (ITAE). Note that the last two also include the time in the analysis [
35].
Table 1 shows the performance indexes to compare the results of each algorithm. Note that all the indexes showed similar results, which is logical in view of the above results. The best performance was shown by the RL4M algorithm. For that reason, we selected this algorithm to compare with the other approaches.
4.2. Comparison between Different Approaches (RL, Villela and IPC)
To establish a basis for comparison of the results of the different control algorithms with the spherical robot, in addition to the RL, the Villela and the IPC algorithms were selected. In both algorithms, the parameters were selected based on our previous experience with the implementation of these experiments with the Khepera IV robot (see for example [
25,
27]). In the Villela algorithm, the parameters were the following:
and
. For the IPC algorithm, the parameters were the following:
,
,
,
and
.
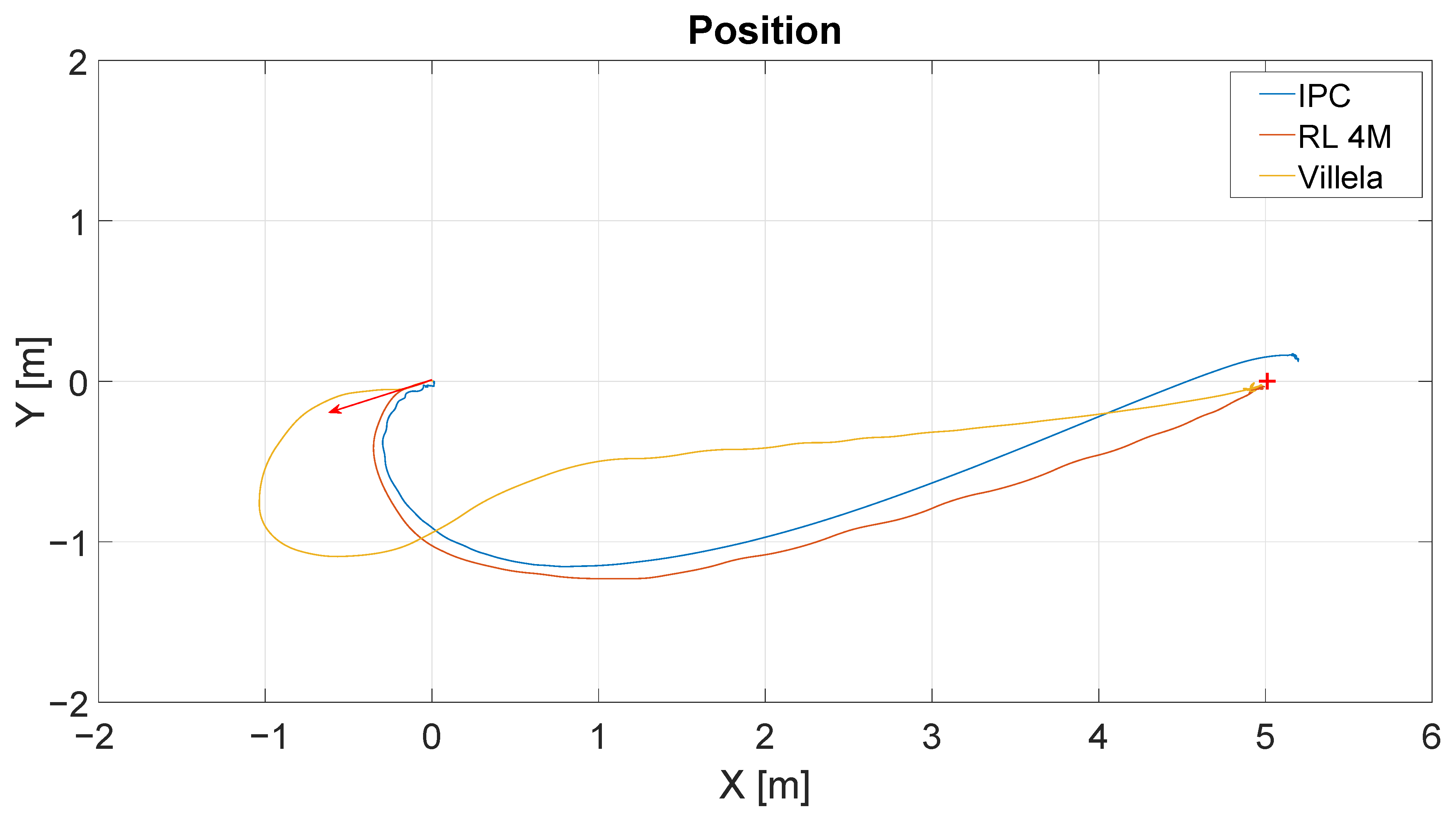
Figure 11 shows the results of the position control experiment for the different algorithms (Villela, IPC, and RL). As in the previous case, the red arrow represents the initial orientation of the robot and the red cross represents the target point. The lines describe the trajectories followed by the robot for each control law. The initial position of the robot is represented by the base of the arrow at (
), and the target point located at (
).
As can be seen, the IPC and RL4M algorithms describe similar trajectories, while Villela’s approach shows the worst trajectory. In order to provide a better comparison, we can analyze the graph of distance vs. time.
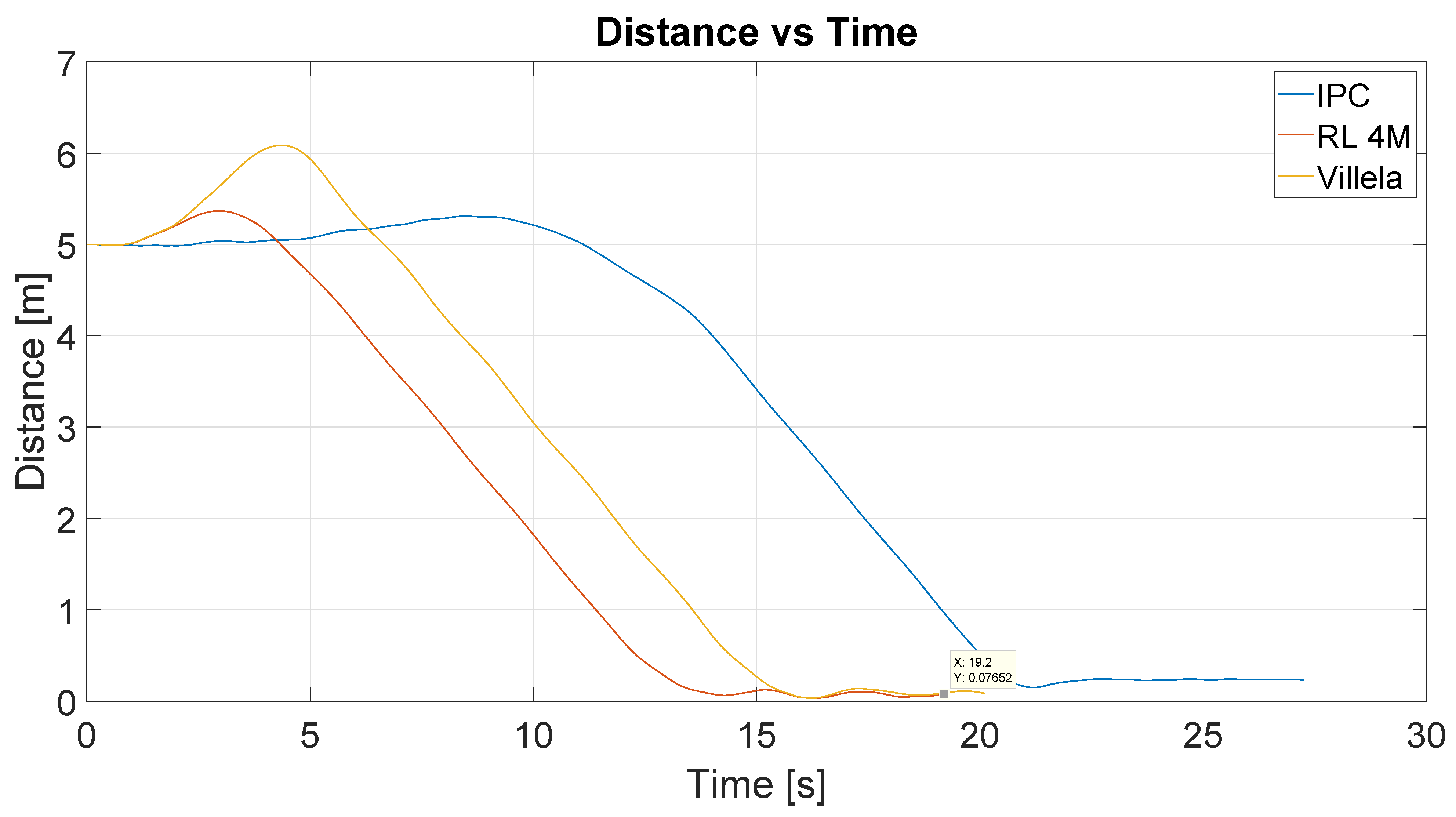
Figure 12 shows the distance to the destination point for these experiments. The y-axis represents the distance in meters and the x-axis represents the time in seconds.
As can be seen, the better performance was demonstrated by the RL4M algorithm, which took around 14 s to reach the destination point. Note that, in the previous figure, it appears that IPC had a similar trajectory to RL4M, but when the time is taken into account in the analysis, the differences are clearer. With the IPC algorithm, the robot took more than 20 s to reach the destination point. So the trajectory was similar but took more time and the performance was the worst of all, while RL4M showed the best behaviour.
Table 2 shows the performance indexes for all algorithms. As can be seen, as was expected, the best performance was shown by the RL4M algorithm, which confirms the previous results.
4.3. Path Following
To test the control strategies in a different scenario, we implemented a path-following example [
36,
37,
38]. This experiment is widely known in the field of mobile robot control because it is used to demonstrate the behaviour of the implemented control algorithm. It consists of “dynamic” position control of the robot in which the reference point constantly changes to describe a trajectory by joining all points. The result is that the robot follows the points one by one to create the trajectory.
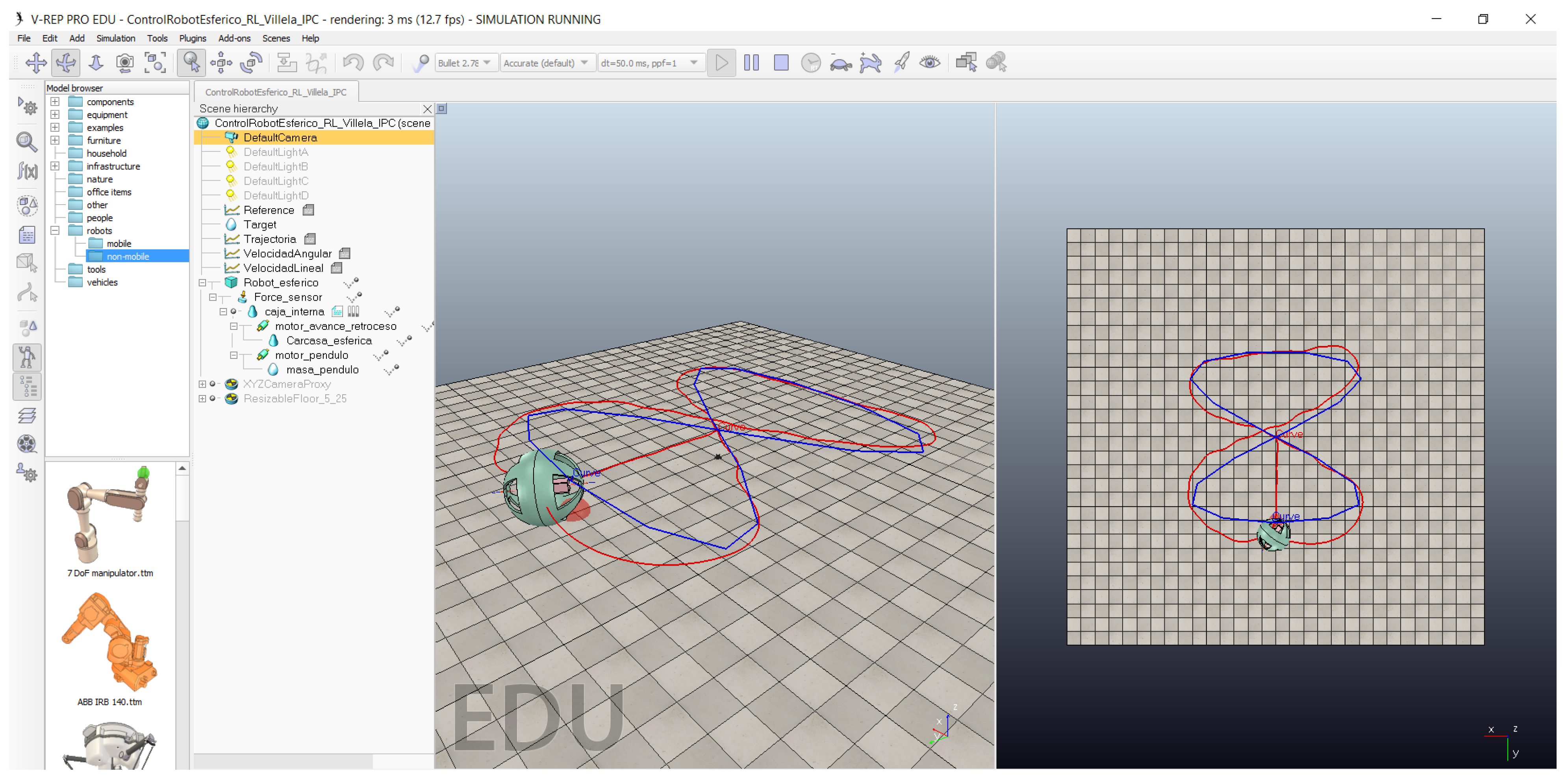
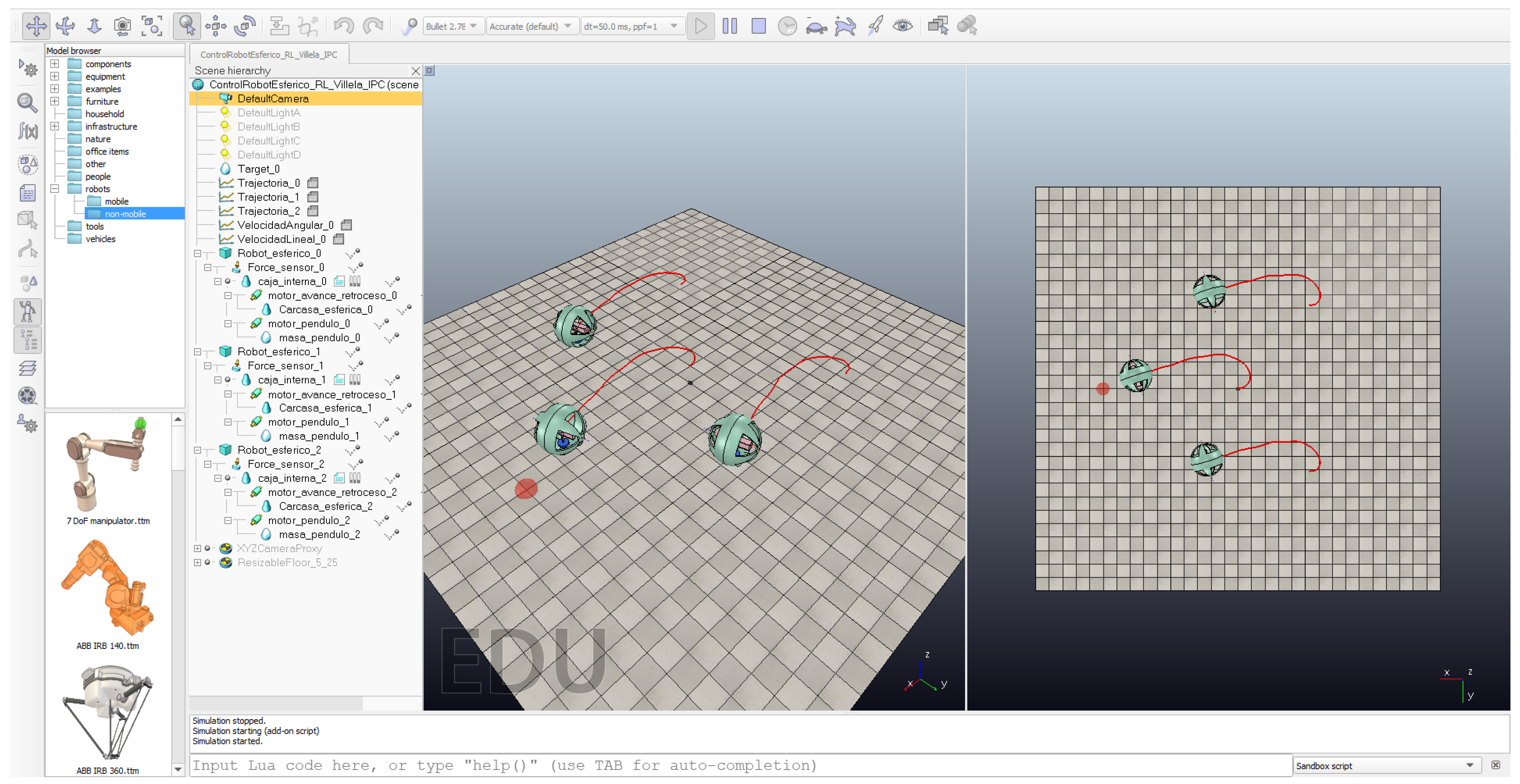
Figure 13 shows the implementation of this experiment with the spherical robot in CoppeliaSim.
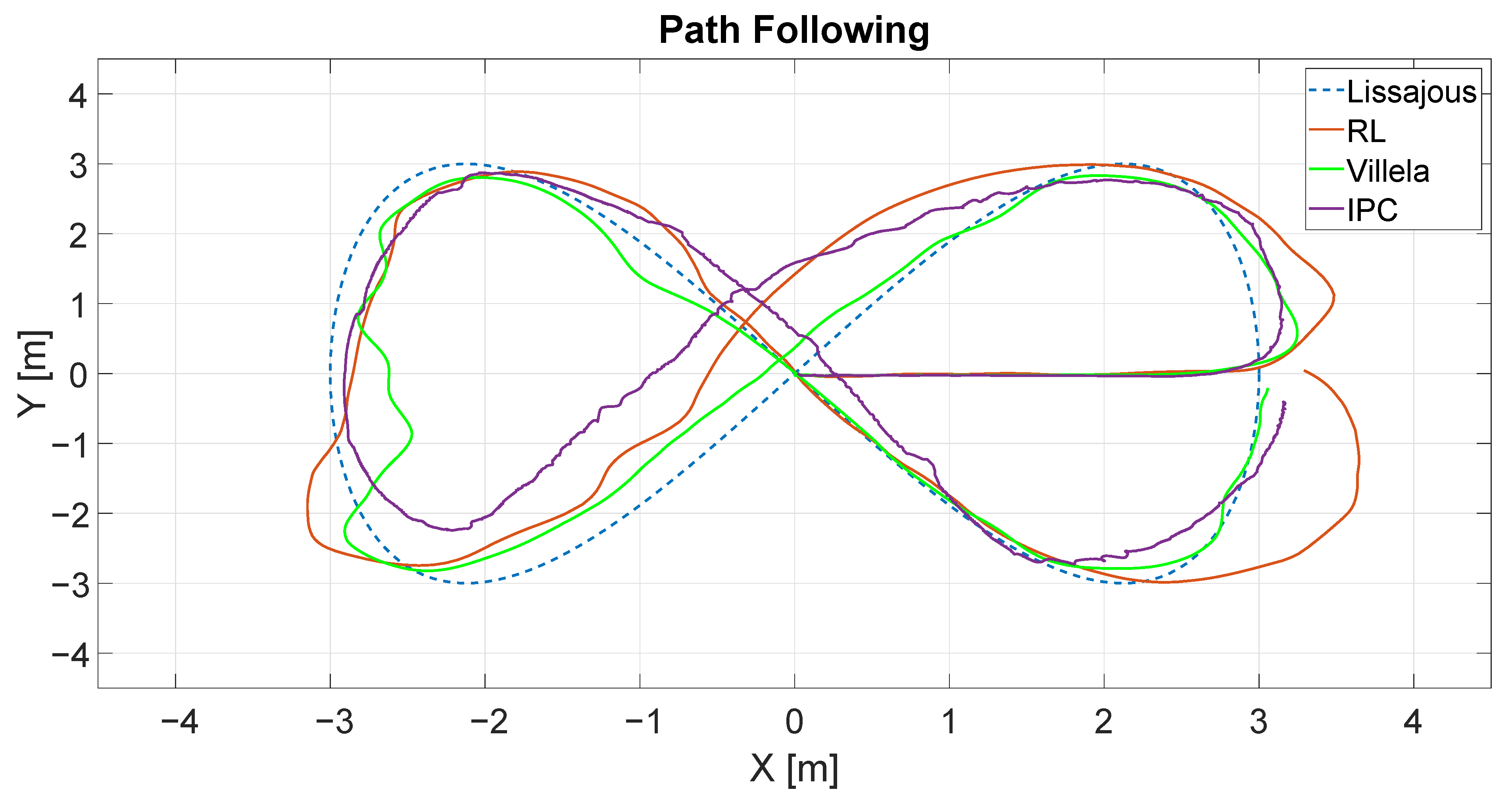
Figure 14 shows the trajectories described by the robot for different control algorithms: RL4M (red line), Villela (green line) and IPC (violet line). The dashed line represents the trajectory that the robot receives as a reference. As can be seen, the robot follows the trajectory with different behaviours for all the algorithms.
At first glance, it appears that the best performance was shown by the Villela algorithm. To perform a better comparison, we calculated the performance indexes for all algorithms.
Table 3 shows these results.
As can be seen, the lowest values in all indexes were for the Villela algorithm, which means that, for this algorithm, the robot followed the trajectory better.
4.4. Multi-Agent Formation Control
This experiment was based on [
22,
39] and consisted of making a formation in a cooperative and decentralized way. One robot acted as the leader and the rest as followers. The positions of the follower’s robots were controlled as in the previous experiment. To make a formation, the followers’ robots have to reach a position using the leader position as the reference. Equation (
20) shows how the velocity of the leader robot is calculated as a function of its own position error (
) and the followers’ errors in the formation (
).
The values of
and
are manually adjusted to control the influence of each error in the velocity of the leader robot. If
, the errors of the followers in the formation are not taken into account, and the control is made in a non-cooperative way because the leader robot does not consider the errors of the followers. Equation (
21) shows how the formation error is calculated.
Figure 15 shows this experiment in the CoppeliaSim simulator for the RL algorithm. For the leader robot, the reference is the target point at the left of the image (red semi-sphere) and, for the followers, the target points are their positions in the formation. In this case, the followers use the position of the leader to make a triangular formation around it. Both followers are situated at a fixed 4 m from the leader and
and −
behind it, respectively.
As can be seen, initially, the robots make a triangle using the leader robot as a reference. At the end of the experiment, the followers maintain the formation around the leader robot.
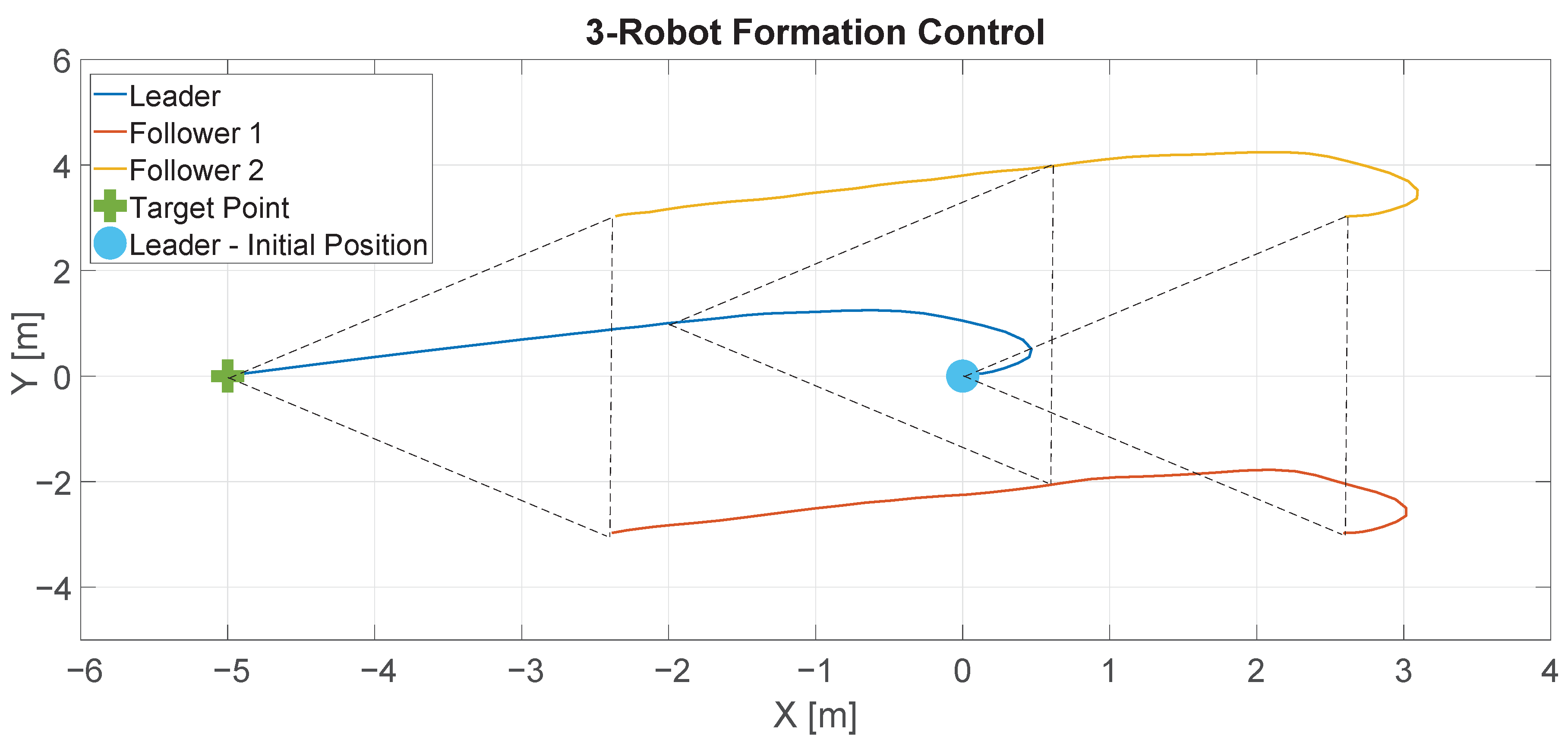
Figure 16 shows the data for this experiment. The blue small circle represents the initial position of the leader robot and the green cross represents the destination point. The blue line represents the trajectory described by the leader robot and the red and orange lines represent the trajectories described by the following robots. As can be seen, the robots maintain the formation during the experiment.
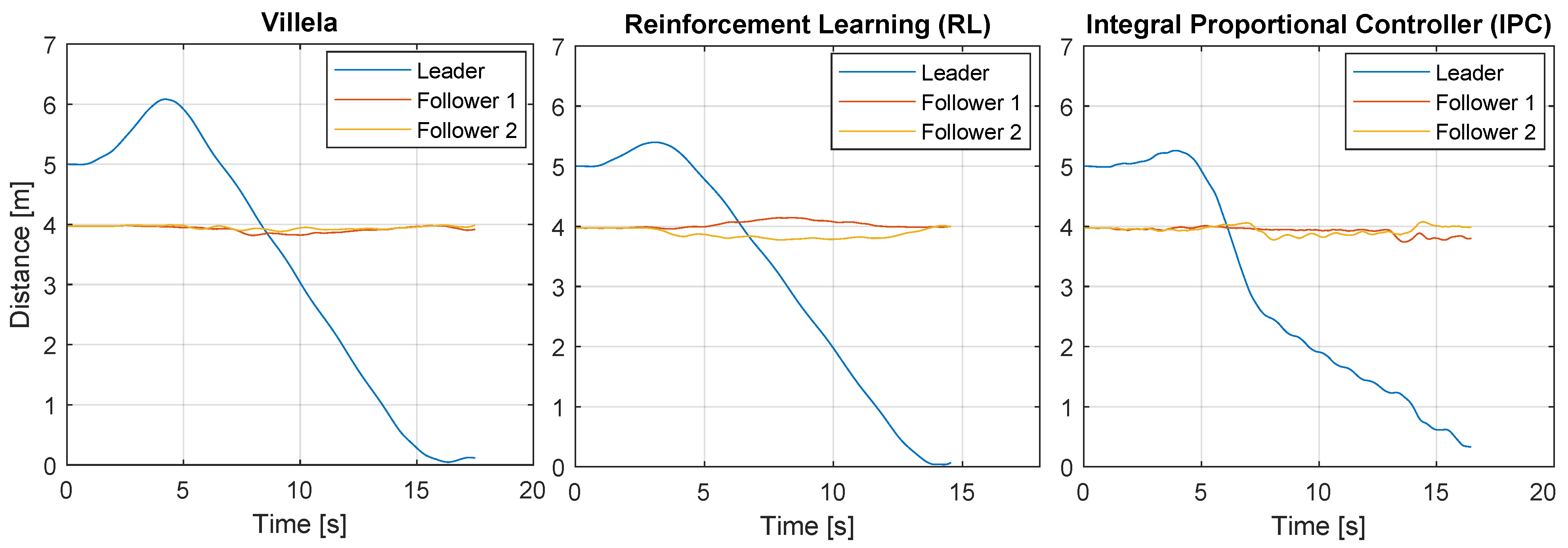
Figure 17 shows the results of this experiment for all the algorithms. The y-axis represents the distance travelled by the robots. The leader robot is represented by the blue lines and they show the distance from the robot to its target point. The followers are represented by the red and orange lines, which show the distance between each follower and the leader.
As can be seen, at the beginning, the leader robot moves away from the target because, initially, the target is at its back. After a few seconds, the leader reaches the destination point, while the followers maintain a constant distance to the leader (4 m), which means that the formation is maintained during the experience.
By simple visual inspection, it can be observed that the RL algorithm showed better performance because the leader robot reached the destination point in less time and travelled the shortest distance. However, to be on the safe side, we calculated the performance indexes for each experiment to establish a more accurate comparison.
Table 4,
Table 5 and
Table 6 show the performance indexes for each algorithm and robot in each experiment.
All experiences were generated with the same initial conditions, and only the control algorithm was changed in each case. We can then compare the results using Equation (
21), which is shown in the row Sum in
Table 4,
Table 5 and
Table 6. As can be seen, the least values in all cases for the Sum row were observed for the RL experiment, which confirms that the better performance was produced by this algorithm.



 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}