

A Two-Step Feature Selection Radiomic Approach to Predict Molecular Outcomes in Breast Cancer

 , , ,
, , ,  , ,
, ,  , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Patients
2.3. MRI Acquisition
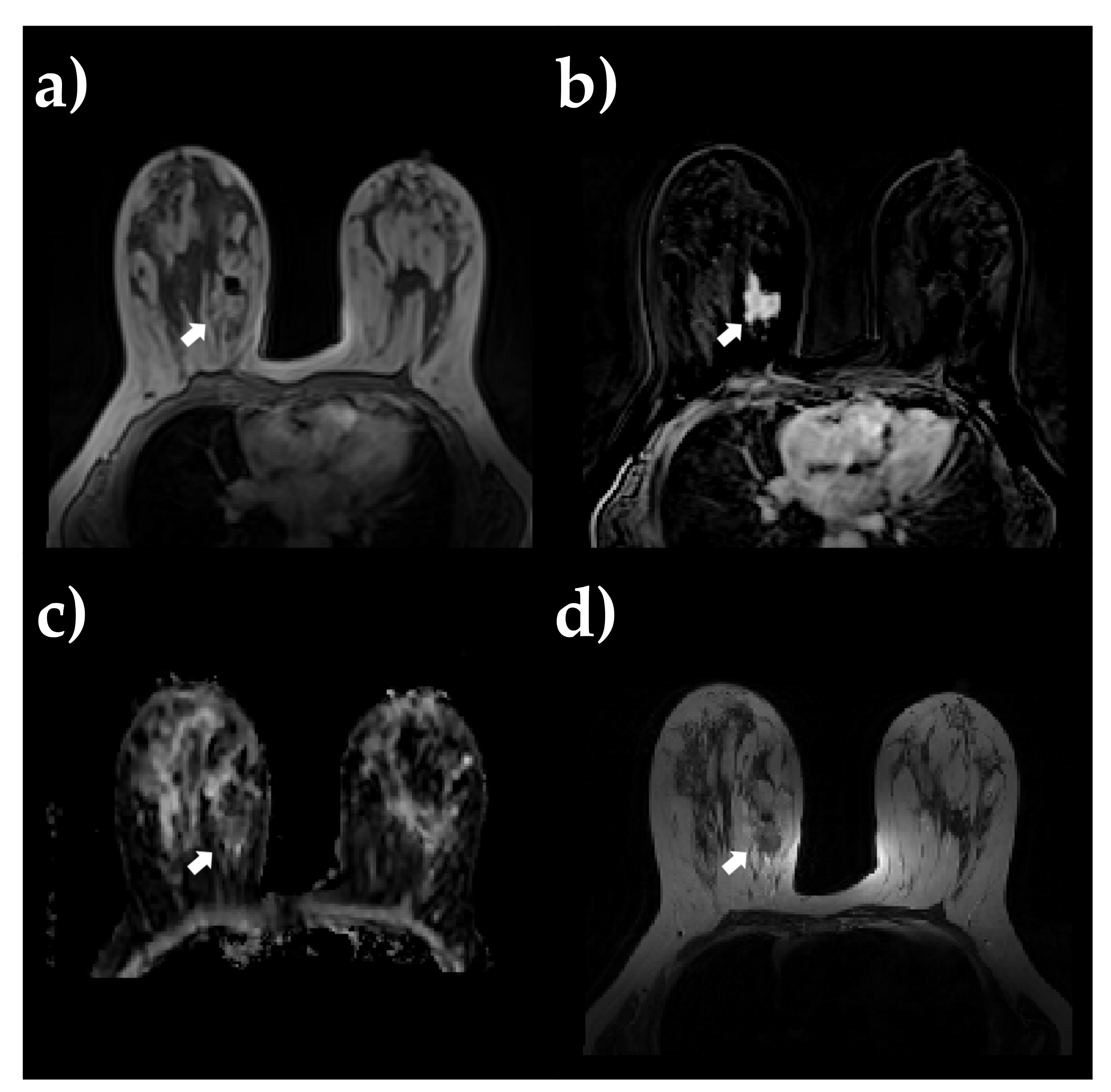
2.4. Image Processing and 3D ROI Segmentation
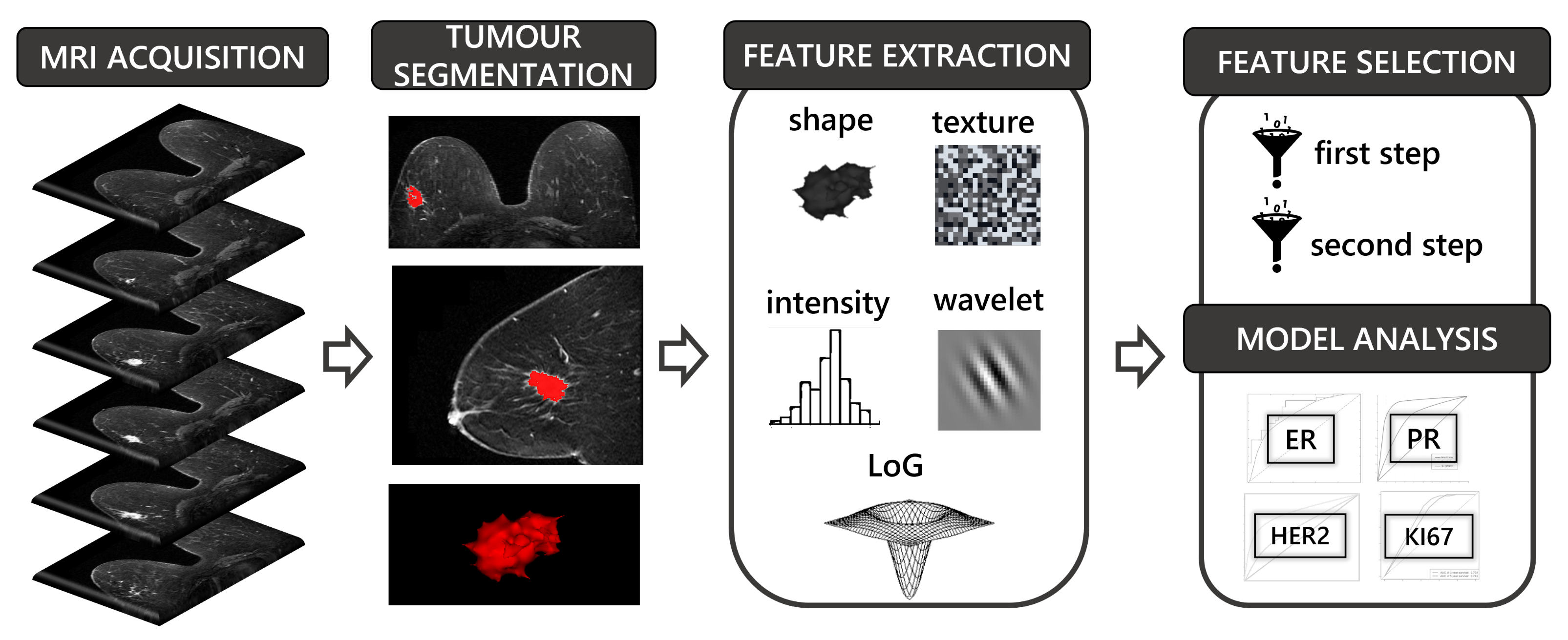
2.5. Feature Extraction
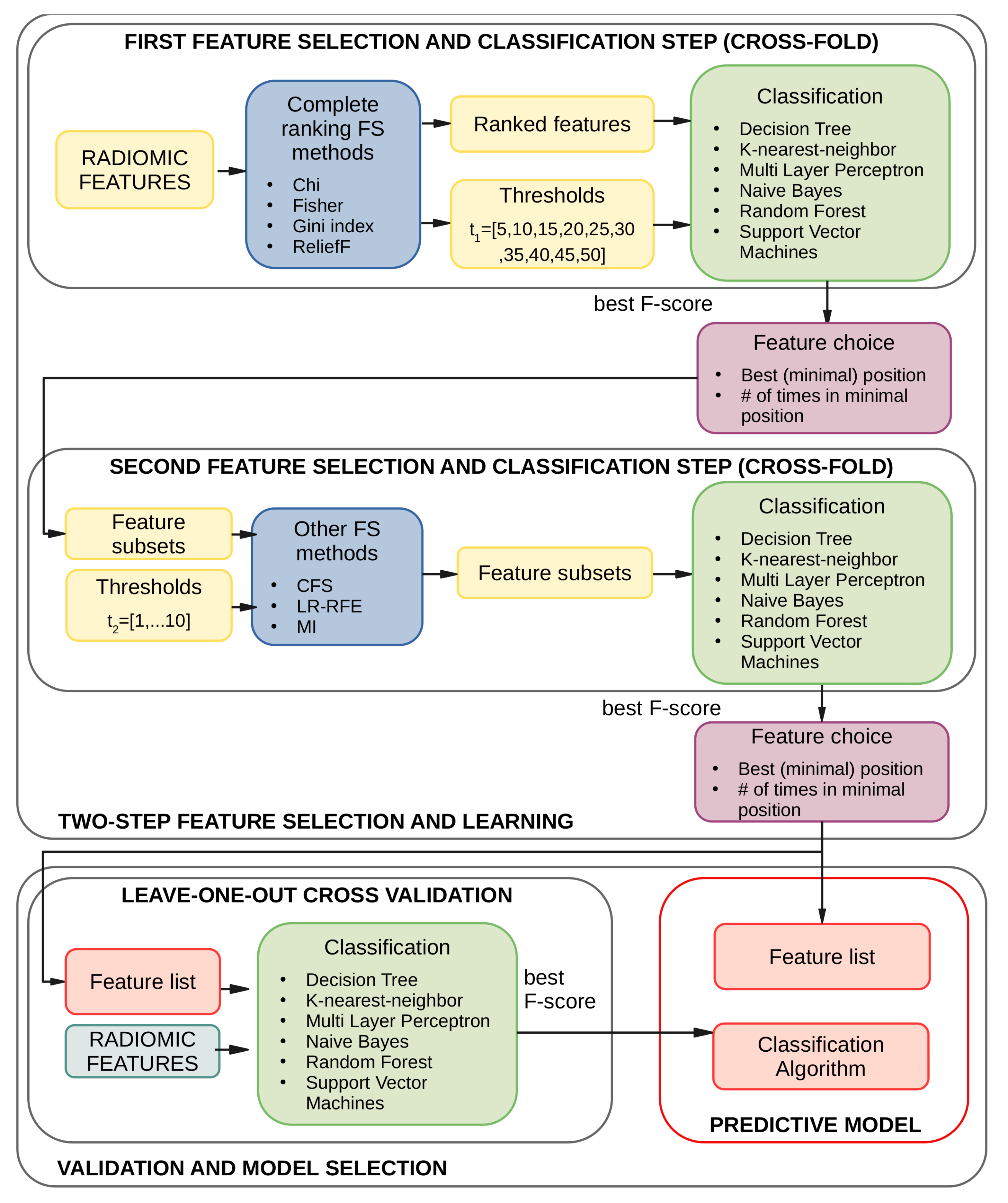
2.6. Two-Step Feature Selection and Learning
2.7. Model Selection and Validation
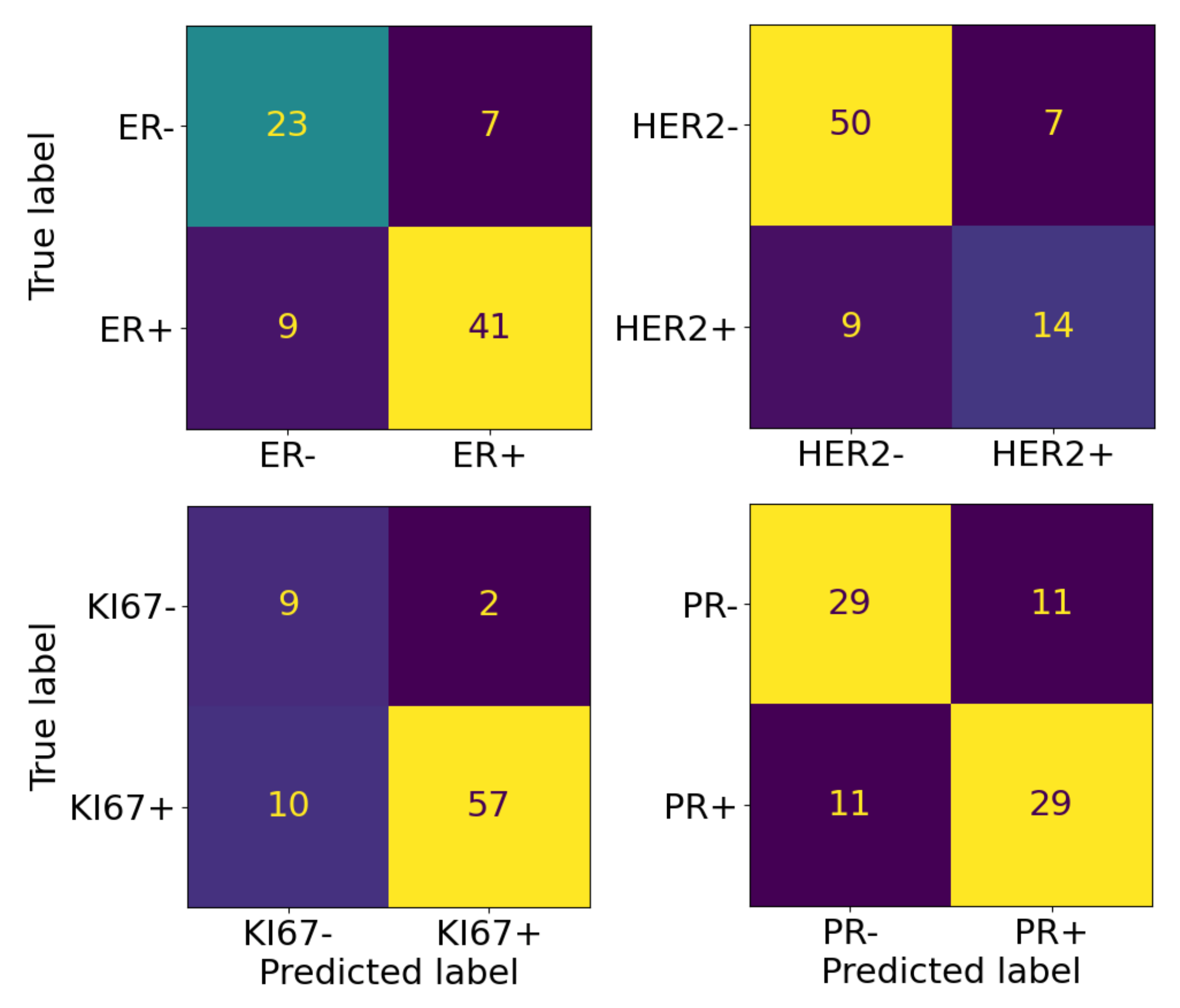
3. Results
3.1. Experiments and Settings
- Radiomics from a single MRI sequence;
- Radiomics from all MRI sequences;
- Radiomics from a ingle MRI sequence + clinical information (i.e., patient’s age);
- Radiomics from all MRI sequences + clinical information (i.e., patient’s age).
3.2. Results of the First Feature Selection Step
3.3. Results of the Second Feature Selection Step
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADC | Apparent Diffusion Coefficient |
| AUC | Area Under Receiver Operator Characteristic (ROC) Curve |
| BC | Breast Cancer |
| CFS | Correlation-based Feature Selection |
| CNN | Convolutional Neural Network |
| DCE | Dynamic Contrast-Enhanced |
| DICOM | Digital Imaging and COmmunications in Medicine |
| DWI | Diffusion Weighted Imaging |
| DT | Decision Tree |
| ER | Estrogen Receptor |
| FSA | Feature Selection Algorithm |
| GLCM | Gray-Level Co-occurrence Matrix |
| GLDM | Gray-Level Dependence Matrix |
| GLRLM | Gray-Level Run-Length Matrix |
| GLSZM | Gray-Level Size Zone Matrix |
| HER2 | Human Epidermal growth factor Receptor |
| IBSI | Image Biomarker Standardization Initiative |
| KNN | K-Nearest Neighbors |
| LA | Learning Algorithm |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| LOOCV | Leave-One-Out Cross-Validation |
| LR | LASSO Regression |
| MI | Mutual Information |
| ML | Machine Learning |
| MLP | Multi Layer Perceptron |
| mpMRI | multiparametric MRI |
| MRI | Magnetic Resonance Imaging |
| NB | Naive Bayes |
| NIfTI | Neuroimaging Informatics Technology Initiative |
| NGTDM | Neighbouring Gray-Tone Difference Matrix |
| PC | Post Contrast |
| PR | Progesterone Receptor |
| RF | Random Forest |
| RFE | Recursive Features Elimination |
| ROC | Receiver Operator Characteristic |
| ROI | Region Of Interest |
| SUB | Subtracted |
| SVM | Support Vector Machine |
| SMOTE | Synthetic Minority Oversampling TEchnique |
| T2 | T2-weighted |
| TCIA | The Cancer Imaging Archive |
| TCGA-BRCA | The Cancer Genome Atlas BReast Invasive CArcinoma |
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Wang, L. Early diagnosis of breast cancer. Sensors 2017, 17, 1572. [Google Scholar] [CrossRef] [Green Version]
- Tirada, N.; Aujero, M.; Khorjekar, G.; Richards, S.; Chopra, J.; Dromi, S.; Ioffe, O. Breast cancer tissue markers, genomic profiling, and other prognostic factors: A primer for radiologists. Radiographics 2018, 38, 1902–1920. [Google Scholar] [CrossRef] [Green Version]
- Woeckel, A.; Albert, U.S.; Janni, W.; Scharl, A.; Kreienberg, R.; Stueber, T. The screening, diagnosis, treatment, and follow-up of breast cancer. Dtsch. Ärzteblatt Int. 2018, 115, 316. [Google Scholar]
- Fisher, R.; Pusztai, L.; Swanton, C. Cancer heterogeneity: Implications for targeted therapeutics. Br. J. Cancer 2013, 108, 479–485. [Google Scholar] [CrossRef] [Green Version]
- Van’t Veer, L.J.; Dai, H.; Van De Vijver, M.J.; He, Y.D.; Hart, A.A.; Mao, M.; Peterse, H.L.; Van Der Kooy, K.; Marton, M.J.; Witteveen, A.T.; et al. Gene expression profiling predicts clinical outcome of breast cancer. Nature 2002, 415, 530–536. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aiello, M. Is Radiomics Growing towards Clinical Practice? J. Pers. Med. 2022, 12, 1373. [Google Scholar] [CrossRef] [PubMed]
- Lambin, P.; Rios-Velazquez, E.; Leijenaar, R.; Carvalho, S.; Van Stiphout, R.G.; Granton, P.; Zegers, C.M.; Gillies, R.; Boellard, R.; Dekker, A.; et al. Radiomics: Extracting more information from medical images using advanced feature analysis. Eur. J. Cancer 2012, 48, 441–446. [Google Scholar] [CrossRef] [Green Version]
- Incoronato, M.; Aiello, M.; Infante, T.; Cavaliere, C.; Grimaldi, A.M.; Mirabelli, P.; Monti, S.; Salvatore, M. Radiogenomic analysis of oncological data: A technical survey. Int. J. Mol. Sci. 2017, 18, 805. [Google Scholar] [CrossRef] [Green Version]
- Monti, S.; Aiello, M.; Incoronato, M.; Grimaldi, A.M.; Moscarino, M.; Mirabelli, P.; Ferbo, U.; Cavaliere, C.; Salvatore, M. DCE-MRI pharmacokinetic-based phenotyping of invasive ductal carcinoma: A radiomic study for prediction of histological outcomes. Contrast Media Mol. Imaging 2018, 2018, 5076269. [Google Scholar] [CrossRef]
- Hylton, N. Dynamic contrast-enhanced magnetic resonance imaging as an imaging biomarker. J. Clin. Oncol. 2006, 24, 3293–3298. [Google Scholar] [CrossRef]
- Romeo, V.; Cavaliere, C.; Imbriaco, M.; Verde, F.; Petretta, M.; Franzese, M.; Stanzione, A.; Cuocolo, R.; Aiello, M.; Basso, L.; et al. Tumor segmentation analysis at different post-contrast time points: A possible source of variability of quantitative DCE-MRI parameters in locally advanced breast cancer. Eur. J. Radiol. 2020, 126, 108907. [Google Scholar] [CrossRef] [PubMed]
- Urruticoechea, A.; Smith, I.E.; Dowsett, M. Proliferation marker Ki-67 in early breast cancer. J. Clin. Oncol. 2005, 23, 7212–7220. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Li, H.; Zhu, Y.; Lan, L.; Yang, S.; Drukker, K.; Morris, E.A.; Burnside, E.S.; Whitman, G.J.; Giger, M.L.; et al. Prediction of clinical phenotypes in invasive breast carcinomas from the integration of radiomics and genomics data. J. Med. Imaging 2015, 2, 041007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grimm, L.J.; Zhang, J.; Mazurowski, M.A. Computational approach to radiogenomics of breast cancer: Luminal A and luminal B molecular subtypes are associated with imaging features on routine breast MRI extracted using computer vision algorithms. J. Magn. Reson. Imaging 2015, 42, 902–907. [Google Scholar] [CrossRef]
- Mazurowski, M.A.; Zhang, J.; Grimm, L.J.; Yoon, S.C.; Silber, J.I. Radiogenomic analysis of breast cancer: Luminal B molecular subtype is associated with enhancement dynamics at MR imaging. Radiology 2014, 273, 365–372. [Google Scholar] [CrossRef]
- Sutton, E.J.; Oh, J.H.; Dashevsky, B.Z.; Veeraraghavan, H.; Apte, A.P.; Thakur, S.B.; Deasy, J.O.; Morris, E.A. Breast cancer subtype intertumor heterogeneity: MRI-based features predict results of a genomic assay. J. Magn. Reson. Imaging 2015, 42, 1398–1406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sutton, E.J.; Dashevsky, B.Z.; Oh, J.H.; Veeraraghavan, H.; Apte, A.P.; Thakur, S.B.; Morris, E.A.; Deasy, J.O. Breast cancer molecular subtype classifier that incorporates MRI features. J. Magn. Reson. Imaging 2016, 44, 122–129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, H.; Zhu, Y.; Burnside, E.S.; Huang, E.; Drukker, K.; Hoadley, K.A.; Fan, C.; Conzen, S.D.; Zuley, M.; Net, J.M.; et al. Quantitative MRI radiomics in the prediction of molecular classifications of breast cancer subtypes in the TCGA/TCIA data set. NPJ Breast Cancer 2016, 2, 16012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sung, J.S.; Jochelson, M.S.; Brennan, S.; Joo, S.; Wen, Y.H.; Moskowitz, C.; Zheng, J.; Dershaw, D.D.; Morris, E.A. MR imaging features of triple-negative breast cancers. Breast J. 2013, 19, 643–649. [Google Scholar] [CrossRef]
- TCGA-BRCA. Available online: https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=3539225 (accessed on 1 May 2021).
- Esposito, G.; Pagliari, G.; Randon, M.; Mirabelli, P.; Lavitrano, M.; Aiello, M.; Salvatore, M. BCU Imaging Biobank, an Innovative Digital Resource for Biomedical Research Collecting Imaging and Clinical Data From Human Healthy and Pathological Subjects. Open J. Bioresour. 2021, 8, 4. [Google Scholar] [CrossRef]
- Genomic Data Commons Data Portal. Available online: https://portal.gdc.cancer.gov/ (accessed on 1 May 2021).
- TCGA-Breast-Radiogenomics. Available online: https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=19039112 (accessed on 1 May 2021).
- Haga, A.; Takahashi, W.; Aoki, S.; Nawa, K.; Yamashita, H.; Abe, O.; Nakagawa, K. Standardization of imaging features for radiomics analysis. J. Med. Investig. 2019, 66, 35–37. [Google Scholar] [CrossRef]
- Yu, J.S.; Chung, J.J.; Hong, S.W.; Chung, B.H.; Kim, J.H.; Kim, K.W. Prostate cancer: Added value of subtraction dynamic imaging in 3T magnetic resonance imaging with a phased-array body coil. Yonsei Med. J. 2008, 49, 765–774. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fedorov, A.; Vangel, M.G.; Tempany, C.M.; Fennessy, F.M. Multiparametric magnetic resonance imaging of the prostate: Repeatability of volume and apparent diffusion coefficient quantification. Investig. Radiol. 2017, 52, 538. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brancato, V.; Aiello, M.; Basso, L.; Monti, S.; Palumbo, L.; Di Costanzo, G.; Salvatore, M.; Ragozzino, A.; Cavaliere, C. Evaluation of a multiparametric MRI radiomic-based approach for stratification of equivocal PI-RADS 3 and upgraded PI-RADS 4 prostatic lesions. Sci. Rep. 2021, 11, 643. [Google Scholar] [CrossRef]
- Welcome to pyradiomics documentation! Available online: https://pyradiomics.readthedocs.io (accessed on 1 May 2021).
- Foster, K.R.; Koprowski, R.; Skufca, J.D. Machine learning, medical diagnosis, and biomedical engineering research-commentary. Biomed. Eng. Online 2014, 13, 94. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.A. Feature Extraction: Foundations and Applications; Springer: Berlin/Heidelberg, Germany, 2008; Volume 207. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Urso, A.; Fiannaca, A.; La Rosa, M.; Ravì, V.; Rizzo, R. Data Mining: Classification and Prediction. In Encyclopedia of Bioinformatics and Computational Biology; Elsevier: Amsterdam, The Netherlands, 2019; pp. 384–402. [Google Scholar] [CrossRef]
- Dasarathy, B.V. Nearest Neighbor (NN) Norms: NN Pattern Classification Techniques; IEEE Computer Society Tutorial; IEEE Computer Society: Washington, DC, USA, 1991. [Google Scholar]
- Langley, P.; Iba, W.; Thompson, K. An analysis of Bayesian classifiers. In Proceedings of the AAAI, San Jose, CA, USA, 12–16 July 1992; Citeseer: Princeton, NJ, USA, 1992; Volume 90, pp. 223–228. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Magee, J.F. Decision Trees for Decision Making; Harvard Business Review: Brighton, MA, USA, 1964. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Technical report; California University San Diego La Jolla Inst for Cognitive Science: La Jolla, CA, USA, 1985. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 1, pp. 278–282. [Google Scholar]
- Ge, R.; Zhou, M.; Luo, Y.; Meng, Q.; Mai, G.; Ma, D.; Wang, G.; Zhou, F. McTwo: A two-step feature selection algorithm based on maximal information coefficient. BMC Bioinform. 2016, 17, 142. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Zhang, C.; Zhang, L.; Gao, R. A two-step feature selection method to predict cancerlectins by multiview features and synthetic minority oversampling technique. BioMed Res. Int. 2018, 2018, 9364182. [Google Scholar] [CrossRef] [Green Version]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Santucci, D.; Faiella, E.; Cordelli, E.; Sicilia, R.; de Felice, C.; Zobel, B.B.; Iannello, G.; Soda, P. 3T MRI-Radiomic approach to predict for lymph node status in breast Cancer patients. Cancers 2021, 13, 2228. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2018, 50, 94. [Google Scholar] [CrossRef] [Green Version]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Huang, Y.; Wei, L.; Hu, Y.; Shao, N.; Lin, Y.; He, S.; Shi, H.; Zhang, X.; Lin, Y. Multi-parametric MRI-based radiomics models for predicting molecular subtype and androgen receptor expression in breast cancer. Front. Oncol. 2021, 11, 706733. [Google Scholar] [CrossRef] [PubMed]
- Mann, R.M.; Kuhl, C.K.; Kinkel, K.; Boetes, C. Breast MRI: Guidelines from the European society of breast imaging. Eur. Radiol. 2008, 18, 1307–1318. [Google Scholar] [CrossRef] [Green Version]
- Kayadibi, Y.; Kocak, B.; Ucar, N.; Akan, Y.N.; Akbas, P.; Bektas, S. Radioproteomics in breast cancer: Prediction of Ki-67 expression with MRI-based radiomic models. Acad. Radiol. 2022, 29, S116–S125. [Google Scholar] [CrossRef]
- Fan, M.; Yuan, W.; Zhao, W.; Xu, M.; Wang, S.; Gao, X.; Li, L. Joint prediction of breast cancer histological grade and Ki-67 expression level based on DCE-MRI and DWI radiomics. IEEE J. Biomed. Health Informatics 2019, 24, 1632–1642. [Google Scholar] [CrossRef] [Green Version]
- Zhong, S.; Wang, F.; Wang, Z.; Zhou, M.; Li, C.; Yin, J. Multiregional Radiomic Signatures Based on Functional Parametric Maps from DCE-MRI for Preoperative Identification of Estrogen Receptor and Progesterone Receptor Status in Breast Cancer. Diagnostics 2022, 12, 2558. [Google Scholar] [CrossRef]
- Fang, J.; Zhang, B.; Wang, S.; Jin, Y.; Wang, F.; Ding, Y.; Chen, Q.; Chen, L.; Li, Y.; Li, M.; et al. Association of MRI-derived radiomic biomarker with disease-free survival in patients with early-stage cervical cancer. Theranostics 2020, 10, 2284. [Google Scholar] [CrossRef]
- Park, H.; Lim, Y.; Ko, E.S.; Cho, H.h.; Lee, J.E.; Han, B.K.; Ko, E.Y.; Choi, J.S.; Park, K.W. Radiomics Signature on Magnetic Resonance Imaging: Association with Disease-Free Survival in Patients with Invasive Breast CancerRadiomics Signature on MRI for DFS in Invasive Breast Cancer. Clin. Cancer Res. 2018, 24, 4705–4714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, T.; Wang, Z.; Zhao, Q.; Bai, Q.; Zhou, X.; Gu, Y.; Peng, W.; Wang, H. Machine learning-based analysis of MR multiparametric radiomics for the subtype classification of breast cancer. Front. Oncol. 2019, 9, 505. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Li, Z.; Qu, J.; Zhang, R.; Zhou, X.; Li, L.; Sun, K.; Tang, Z.; Jiang, H.; Li, H.; et al. Radiomics of multiparametric MRI for pretreatment prediction of pathologic complete response to neoadjuvant chemotherapy in breast cancer: A multicenter study. Clin. Cancer Res. 2019, 25, 3538–3547. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ni, M.; Zhou, X.; Liu, J.; Yu, H.; Gao, Y.; Zhang, X.; Li, Z. Prediction of the clinicopathological subtypes of breast cancer using a fisher discriminant analysis model based on radiomic features of diffusion-weighted MRI. BMC Cancer 2020, 20, 1073. [Google Scholar] [CrossRef]
- Saha, A.; Harowicz, M.R.; Grimm, L.J.; Kim, C.E.; Ghate, S.V.; Walsh, R.; Mazurowski, M.A. A machine learning approach to radiogenomics of breast cancer: A study of 922 subjects and 529 DCE-MRI features. Br. J. Cancer 2018, 119, 508–516. [Google Scholar] [CrossRef] [Green Version]
- Ubaldi, L.; Valenti, V.; Borgese, R.; Collura, G.; Fantacci, M.; Ferrera, G.; Iacoviello, G.; Abbate, B.; Laruina, F.; Tripoli, A.; et al. Strategies to develop radiomics and machine learning models for lung cancer stage and histology prediction using small data samples. Phys. Medica 2021, 90, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Granzier, R.; Ibrahim, A.; Primakov, S.; Keek, S.; Halilaj, I.; Zwanenburg, A.; Engelen, S.; Lobbes, M.; Lambin, P.; Woodruff, H.; et al. Test–Retest Data for the Assessment of Breast MRI Radiomic Feature Repeatability. J. Magn. Reson. Imaging 2021, 56, 592–604. [Google Scholar] [CrossRef]
- Van Griethuysen, J.J.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.; Fillion-Robin, J.C.; Pieper, S.; Aerts, H.J. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef] [Green Version]
- Zwanenburg, A.; Vallières, M.; Abdalah, M.A.; Aerts, H.J.; Andrearczyk, V.; Apte, A.; Ashrafinia, S.; Bakas, S.; Beukinga, R.J.; Boellaard, R.; et al. The image biomarker standardization initiative: Standardized quantitative radiomics for high-throughput image-based phenotyping. Radiology 2020, 295, 328–338. [Google Scholar] [CrossRef] [Green Version]
- Lambin, P.; Leijenaar, R.T.; Deist, T.M.; Peerlings, J.; De Jong, E.E.; Van Timmeren, J.; Sanduleanu, S.; Larue, R.T.; Even, A.J.; Jochems, A.; et al. Radiomics: The bridge between medical imaging and personalized medicine. Nat. Rev. Clin. Oncol. 2017, 14, 749–762. [Google Scholar] [CrossRef] [Green Version]
- Parmar, C.; Rios Velazquez, E.; Leijenaar, R.; Jermoumi, M.; Carvalho, S.; Mak, R.H.; Mitra, S.; Shankar, B.U.; Kikinis, R.; Haibe-Kains, B.; et al. Robust radiomics feature quantification using semiautomatic volumetric segmentation. PLoS ONE 2014, 9, e102107. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | TR (ms) | TE (ms) | FA () | Slices | ST (mm) | Voxel Size | Matrix | FOV (mm) | Aver. | Meas. | Time (min) | b-Value (s/mm) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TSE T2 | 5440 | 81 | 80 | 40 | 4.0 | 0.8 × 0.8 | 448 | 340 | 2 | - | 03:34 | - |
| DWI ax | 9600 | 74 | 90 | 25 | 4.0 | 1.8 × 1.8 | 192 | 340 | 3 | - | 04:48 | 50/500/800 |
| DCE | 5.47 | 1.75 | 20 | 36 (slab1) | 3.6 | 1.7 × 1.7 | 192 | 320 | 1 | 60 | 09:39 | - |
| HR Vibe T1-w fat sat | 8.69 | 4.33 | 15 | 176 (slab1) | 0.9 | 0.8 × 0.8 | 448 | 340 | 1 | - | 03:21 | - |
| Algorithm | Type (Ranker/Subset) | Approach (Filter/Wrapper) | Result (Complete/Partial) |
|---|---|---|---|
| Chi Squared | Ranker | Filter | Complete |
| Fisher Score | Ranker | Filter | Complete |
| Gini Index | Ranker | Filter | Complete |
| Mutual Information | Ranker | Filter | Partial |
| ReliefF | Ranker | Filter | Complete |
| LR-RFE | Ranker | Wrapper | Partial |
| CFS | Subset | Filter | Partial |
| Marker Name | Total Samples | Positive Threshold | Sample Class # (%) | |
|---|---|---|---|---|
| Negative | Positive | |||
| ER | 80 | ≥ | ||
| HER2 | 80 | ≥2 | ||
| Ki67 | 78 | ≥ | ||
| PR | 80 | ≥ | ||
| Marker | Feature Type | Image Modality | Feature Selection Algorithm | Feature Threshold t1 | F1-Score ± Variance |
|---|---|---|---|---|---|
| ER | radiomics from single modalities | T2 | fisher | 45 | 0.69 ± 0.02 |
| radiomics from single modalities/clinical | T2 | fisher | 25 | ||
| radiomics/clinical | ALL | chi | 50 | ||
| radiomics | ALL | chi | 25 | ||
| HER2 | radiomics from single modalities | ADC | reliefF | 30 | 0.7 ± 0.03 |
| radiomics from single modalities/clinical | ADC | reliefF | 10 | ||
| radiomics/clinical | ALL | gini index | 10 | ||
| radiomics | ALL | reliefF | 30 | ||
| Ki67 | radiomics from single modalities | PC | chi | 10 | |
| radiomics from single modalities/clinical | PC | gini index | 5 | ||
| radiomics/clinical | ALL | chi | 50 | ||
| radiomics | ALL | fisher | 20 | 0.79 ± 0.05 | |
| PR | radiomics from single modalities | PC | fisher | 5 | 0.73 ± 0.03 |
| radiomics from single modalities/clinical | PC | fisher | 5 | 0.73 ± 0.03 | |
| radiomics/clinical | ALL | reliefF | 15 | ||
| radiomics | ALL | reliefF | 15 |
| Best Training Results | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Marker Name | 1st Step Results | 2nd Step Results | LOO Results | |||||||
| Feat. Type | FSA | F1-Score ±var | FSA | F1-Score ±var | LA | Feat. # | F1-Score pos/neg | |||
| ER | T2 | fisher | 45 | lr rfe | 10 | svm | 11 | 0.85/0.81 | ||
| HER2 | ALL | gini | 10 | cfs | 5 | rf | 5 | 0.64/0.86 | ||
| Ki67 | PC | chi | 10 | cfs | 1 | mlp | 2 | 0.9/0.84 | ||
| PR | PC | fisher | 5 | lr rfe | 3 | mlp | 3 | 0.73/0.73 | ||
| Best Training Results (Other Metrics) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Marker Name | 1st Step Result | 2nd Step Result | LOO Result | ||||||
| acc ± var | prec ± var | rec ± var | acc ± var | prec ± var | rec ± var | acc | prec | rec | |
| ER | 0.73 ± 0.02 | 0.72 ± 0.02 | 0.7 ± 0.02 | 0.74 ± 0.01 | 0.74 ± 0.02 | 0.72 ± 0.01 | 0.81 | 0.87 | 0.82 |
| HER2 | 0.73 ± 0.02 | 0.71 ± 0.02 | 0.71 ± 0.02 | 0.8 ± 0.02 | 0.75 ± 0.04 | 0.77 ± 0.04 | 0.8 | 0.67 | 0.61 |
| KI67 | 0.89 ± 0.01 | 0.76 ± 0.06 | 0.8 ± 0.06 | 0.87 ± 0.02 | 0.78 ± 0.05 | 0.84 ± 0.05 | 0.85 | 0.97 | 0.85 |
| PR | 0.74 ± 0.03 | 0.77 ± 0.03 | 0.74 ± 0.03 | 0.75 ± 0.02 | 0.79 ± 0.02 | 0.75 ± 0.02 | 0.73 | 0.73 | 0.73 |
| ER |
|---|
| original_shape_Flatness |
| T2_original_glcm_Idmn |
| T2_wavelet-LHH_glszm_ZoneEntropy |
| T2_wavelet-LHH_gldm_LargeDependenceLowGrayLevelEmphasis |
| T2_wavelet-LLH_glszm_SmallAreaLowGrayLevelEmphasis |
| T2_wavelet-LLH_gldm_SmallDependenceLowGrayLevelEmphasis |
| T2_wavelet-LLH_firstorder_Skewness |
| T2_log-sigma-4-0-mm-3D_glcm_Imc2 |
| T2_log-sigma-4-0-mm-3D_firstorder_Skewness |
| T2_log-sigma-5-0-mm-3D_glszm_SmallAreaEmphasis |
| T2_log-sigma-5-0-mm-3D_firstorder_Skewness |
| HER2 |
| T2_original_glrlm_RunVariance |
| T2_original_glrlm_LongRunEmphasis |
| T2_original_glszm_ZonePercentage |
| T2_original_gldm_DependenceNonUniformityNormalized |
| ADC_wavelet-LLH_firstorder_Minimum |
| Ki67 |
| PC_wavelet-LHH_gldm_DependenceEntropy |
| PC_wavelet-HHL_gldm_SmallDependenceLowGrayLevelEmphasis |
| PR |
| original_shape_Flatness |
| PC_wavelet-LLH_glcm_Correlation |
| PC_wavelet-HHH_ngtdm_Busyness |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brancato, V.; Brancati, N.; Esposito, G.; La Rosa, M.; Cavaliere, C.; Allarà, C.; Romeo, V.; De Pietro, G.; Salvatore, M.; Aiello, M.; et al. A Two-Step Feature Selection Radiomic Approach to Predict Molecular Outcomes in Breast Cancer. Sensors 2023, 23, 1552. https://0-doi-org.brum.beds.ac.uk/10.3390/s23031552
Brancato V, Brancati N, Esposito G, La Rosa M, Cavaliere C, Allarà C, Romeo V, De Pietro G, Salvatore M, Aiello M, et al. A Two-Step Feature Selection Radiomic Approach to Predict Molecular Outcomes in Breast Cancer. Sensors. 2023; 23(3):1552. https://0-doi-org.brum.beds.ac.uk/10.3390/s23031552
Chicago/Turabian StyleBrancato, Valentina, Nadia Brancati, Giusy Esposito, Massimo La Rosa, Carlo Cavaliere, Ciro Allarà, Valeria Romeo, Giuseppe De Pietro, Marco Salvatore, Marco Aiello, and et al. 2023. "A Two-Step Feature Selection Radiomic Approach to Predict Molecular Outcomes in Breast Cancer" Sensors 23, no. 3: 1552. https://0-doi-org.brum.beds.ac.uk/10.3390/s23031552