
Deep Reinforcement Learning–Based Online One-to-Multiple Charging Scheme in Wireless Rechargeable Sensor Network


1
Yunnan Key Laboratory of Computer Technology Applications, Kunming University of Science and Technology, Kunming 650500, China
2
School of Computer Science and Engineering, University of Electronic Science and Technology of China, Chengdu 611731, China
*
Author to whom correspondence should be addressed.
Sensors 2023, 23(8), 3903; https://0-doi-org.brum.beds.ac.uk/10.3390/s23083903
Submission received: 20 January 2023
/
Revised: 22 February 2023
/
Accepted: 27 March 2023
/
Published: 12 April 2023
(This article belongs to the Special Issue Machine Learning and Intelligent Optimization Data Aggregation in Internet of Things 2022)
Abstract
:Wireless rechargeable sensor networks (WRSN) have been emerging as an effective solution to the energy constraint problem of wireless sensor networks (WSN). However, most of the existing charging schemes use Mobile Charging (MC) to charge nodes one-to-one and do not optimize MC scheduling from a more comprehensive perspective, leading to difficulties in meeting the huge energy demand of large-scale WSNs; therefore, one-to-multiple charging which can charge multiple nodes simultaneously may be a more reasonable choice. To achieve timely and efficient energy replenishment for large-scale WSN, we propose an online one-to-multiple charging scheme based on Deep Reinforcement Learning, which utilizes Double Dueling DQN (3DQN) to jointly optimize the scheduling of both the charging sequence of MC and the charging amount of nodes. The scheme cellularizes the whole network based on the effective charging distance of MC and uses 3DQN to determine the optimal charging cell sequence with the objective of minimizing dead nodes and adjusting the charging amount of each cell being recharged according to the nodes’ energy demand in the cell, the network survival time, and MC’s residual energy. To obtain better performance and timeliness to adapt to the varying environments, our scheme further utilizes Dueling DQN to improve the stability of training and uses Double DQN to reduce overestimation. Extensive simulation experiments show that our proposed scheme achieves better charging performance compared with several existing typical works, and it has significant advantages in terms of reducing node dead ratio and charging latency.
1. Introduction
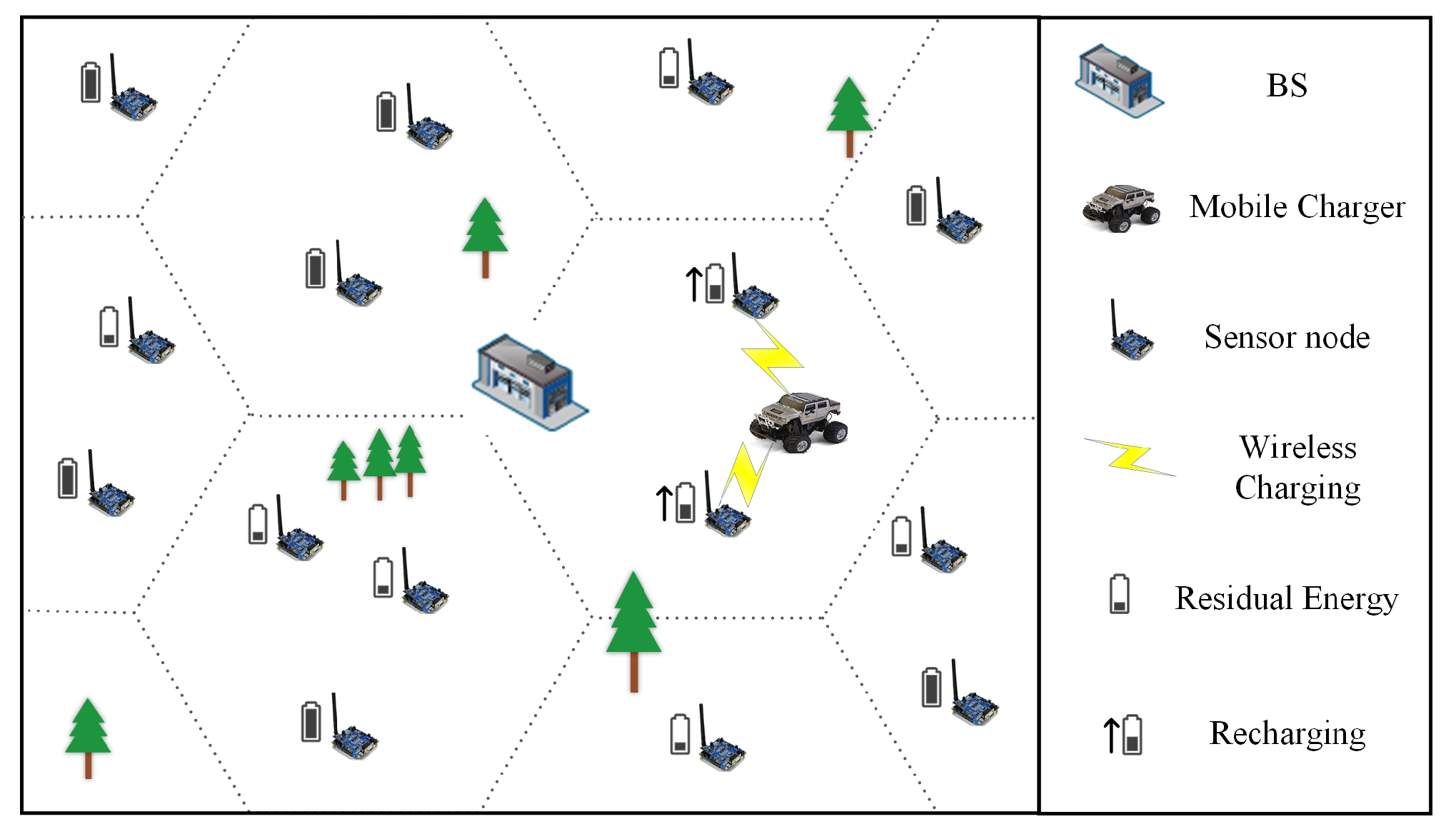
Wireless sensor networks (WSN) have gradually served as an essential infrastructure and have been widely used in modern defense, national health, intelligent transportation, environmental monitoring, and so on [1,2]. For a long time, however, the limited battery energy of sensor nodes has been a key factor in restricting the performance and popularization of WSN. Benefiting form the breakthrough of wireless charging technology, a novel and practical solution is to deploy charging systems for WSN to form wireless rechargeable sensor networks (WRSN) [3], which consist of one or more mobile chargers (MC) with high-capacity batteries, a base station (B), a service station (S) that can recharge MC, and lots of sensor nodes. The base station and the service station are usually at the same location, collectively known as BS. MC can move autonomously and is equipped with a wireless charging device to replenish energy for nodes by wireless charging to reduce the number of dead nodes.
Since the death of nodes in WSN may lead to serious consequences such as link disconnection, how to optimize the scheduling of MC to reduce the number of node deaths has become critical and has attracted much attention from the research community. Many studies have been conducted to explore the charging schemes for WRSN, which can be divided into two main categories: offline schemes [4,5,6,7,8,9] and online schemes [10,11,12,13,14,15,16,17]. In the offline schemes, it is assumed that the energy consumption rates of sensor nodes are fixed or regular, and thus, MC can plan its charging path in advance and moves periodically along the planned path to replenish energy for the sensor nodes. Offline schemes usually study a fixed charging path that minimizes MC travel distance while minimizing the number of dead nodes. For example, work of [5] is to calculate a charging path that minimizes node mortality while reducing MC travel distance. However, due to WRSNs usually being deployed in close contact with the environment, the energy consumption of sensor nodes is dynamic and diverse in practice, affected by the surrounding environment, which shows that the pre-defined charging scheduling in the offline schemes cannot well adapt to the dynamicity of the surroundings, leading to a lack of flexibility and to inefficiency.
Unlike the offline schemes, in online schemes, each sensor node monitors its residual energy and proactively sends a charging request to MC once it falls below a threshold. MC will make real-time scheduling to choose a charging candidate node among the receiving requests. Therefore, due to the different request times of charging nodes, the number of request nodes is different, and a fixed charging path cannot be calculated for online charging scheme. Therefore, the optimization objective of the online charging scheme is not the charging path, but the charging sequence. Since the online charging schemes are closely linked to the environment, online charging schemes can be well adapted to the changing energy demand of the WRSN, which can further reduce node dead ratio, but the existing online works still have performance problems for the following reasons. Firstly, most of them do not take the optimization of the charging path into account in whole, which could bring about unnecessary movement of MC and thus increase charging cost. For example, the classical online charging scheme NJNP [18] only considers the spatial position relationship between nodes and MC, and ignores the influence of node remaining power.
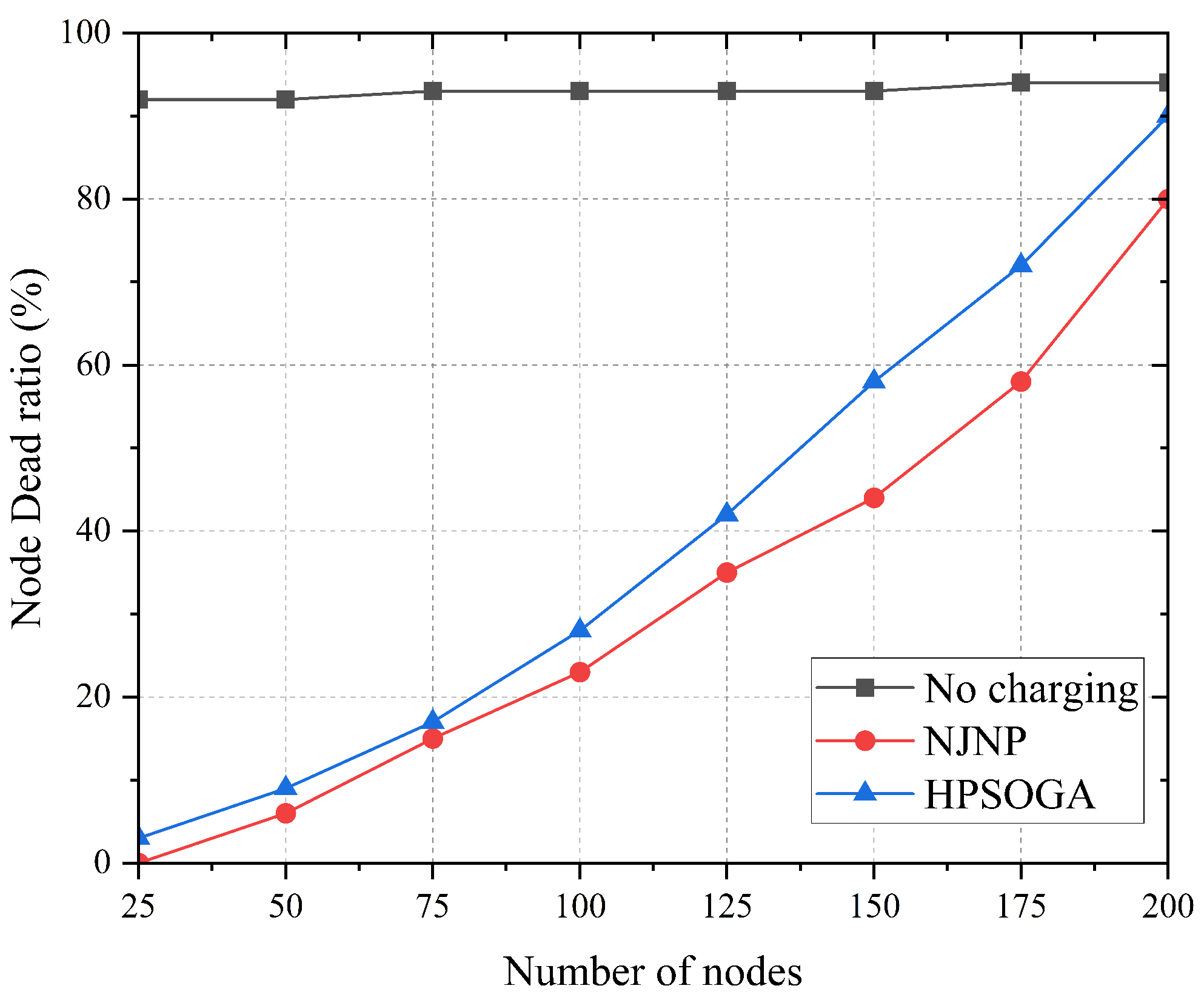
Secondly, most existing online schemes are based on one-to-one charging, by which MC can only charge one sensor at a time, making it prone to resulting in node failure for too long waiting time for charging, and is thus only suitable for small-scale WRSN. Figure 1 depicts the performance under the charging schemes HPSOGA [19] and NJNP using one-to-one charging scheme. As shown in Figure 1, HPSOGA and NJNP significantly reduce the node dead ratio when the number of nodes is small; however, its performance decreases severely as the network size increases. When the number of network nodes exceeds 100, the node dead ratio increases significantly and HPSOGA cannot effectively reduce the node dead ratio.
Thirdly, the existing online charging schemes lack explicitly analyzing and optimizing the charging amount that MC transfers to the sensor node(s) in each charging task. The charging amount is an important factor in determining the performance of the charging scheme; specifically, too much charging amount can lead to a long charging time, causing uncharged nodes to die before they are charged, while too little charging amount can make it difficult for nodes to run efficiently for a long time.
Aiming at the above problems, this paper proposes a novel solution. First of all, one-to-multiple charging [20], i.e., MC can charge multiple sensor nodes simultaneously, is adopted to increase the rate of energy replenishment of MC. Then, a new scheduling scheme is proposed to optimize both the charging sequence and the charging amount to improve performance. Classical optimization methods [21,22] are usually difficult to converge when tackling the above optimization problem with the large dimensionality of dynamic environment state, while reinforcement learning (RL) [23] uses a trial-and-error approach that allows agents to continuously learn as they interact with the environment in order to achieve a specific goal.
In classical RL process, the agent perceives state s from the environment and then selects action a based on state s and its own parameters; after performing action a, the environment state transitions from state s to the next state and provides a reward value . The intelligent body learns between state transitions in the form of a sequence and continuously optimizes its own parameters. Thus, RL has adaptability to dynamic environments and powerful decision-making capabilities, and is thus more suitable for optimizing MC scheduling. For example, the work of [15] uses reinforcement learning Q-learning, which combines RL and MC to reduce node mortality while increasing MC autonomy. However, the work of [15] is an offline charging scheme, which is difficult to apply in a dynamic WRSN environment.
Classical reinforcement learning, such as Q-learning, is only applicable to problems with limited state space and action space; it requires a data approximation function approach to deploy value functions and perform state updates, and requires manual design of high-quality learning features. In WRSN, with the large variety and number of sensor nodes and the large amount of continuous high-dimensional data such as residual energy, RL is difficult to apply to such problems. Deep learning [24], with its rapid development, has more powerful processing ability for continuous high-dimensional data. Therefore, reinforcement learning can be combined with deep learning to form deep reinforcement learning (DRL) with both high-dimensional continuous data processing ability and powerful decision-making ability. Therefore, DRL utilizes deep learning for high-dimensional continuous data processing and reinforcement learning for real-time decision making, which can well solve the problem of optimizing MC for scheduling in WRSN.
Specifically, in this paper, we propose an online one-to-multiple (OTM) charging scheme based on Double Dueling Deep Q-Network (3DQN), called OTM3DQN. Based on the effective charging distance of MC, OTM3DQN cellularizes the whole network and then uses 3DQN to determine the optimal charging cell sequence from the global consideration to minimize the node dead ratio. Meanwhile, in order to improve the charging efficiency, this scheme calculates the charging amount of each cell being recharged according to the nodes’ energy demand in the cell, the network survival time, and MC’s remaining energy. Moreover, the scheme further utilizes Double DQN and Dueling DQN to reduce overestimation to speed up the training process. The main contributions of this paper are as follows:
- In contrast to existing work, this paper considers both the optimization of charging sequences and the charging amount in one-to-multiple charging. To the best of our knowledge, we present for the first time an optimization scheme that dynamically adjusts the one-to-many charging sequence and the charging amount according to the real-time network state.
- We use the 3DQN algorithm to decide the next charging cell from the candidate charging cells and to calculate the optimized amount of charging for the sensor nodes in the cell to improve the performance when avoiding node failure.
- Finally, we conducted comprehensive tests to evaluate the performance of our charging scheme under various input parameters and compared our charging scheme with existing typical schemes to determine the superiority of our charging scheme.
The paper is organized as follows: Section 2 briefly reviews the related work. In Section 3, we provide the network model and the problem formulation. Section 4 presents the detailed process of using 3DQN to optimize the charging sequences. Then, Section 5 gives the proposed charging framework and the optimization of node charge amount. In Section 6, the simulation experiment setup is described and the simulation results are discussed. Finally, Section 7 concludes the paper and presents future work.
2. Related Work
In recent years, there has been much research on the charging schemes for WRSN, which are classified into two main categories: offline schemes and online schemes.
2.1. Offline Schemes
Offline schemes usually assume that the energy consumption rate of the node is constant or varies regularly and focus on how to calculate a fixed charging sequence to achieve the minimum node dead ratio and minimum traveling distance. In order to ensure that the sensor is not dead before charging while minimizing as much as possible the number of MC, the work of [4] combined charging path optimization and depot site issues. In [5], Y. Ma et al. studied a charging strategy that maximizes the cumulative utility gain of MC while reducing the travel cost during charging and gave a constant approximation algorithm for these two problems. The authors of [6] used a multi-charger approach and provided an approximation with a proven performance ratio for the NP-hardness longest delay minimization problem. To minimize the total charging delay, C. Lin et al. combined the distance from the node to MC and the angle between the node and MC in [7] and proposed a unique energy model. In addition, they introduced a linear programming framework for determining the optimal solution and proposed a method for minimizing the complexity based on a constant approximation method. The authors of [25] proposed a bidirectional charging strategy to minimize the MC traversal path length, energy consumption, and completion time. A clustering-based approach was also proposed to reduce the total MC travel distance and reduce the energy consumed by MC charging and the total single-round completion time. The WSN was split into a few charging zones by the authors in [8]; they set the charging time to ensure that the nodes in the charging area are fully charged while minimizing the number of dead nodes. The authors of [9] cooperated to determine which sensors should be charged and when these sensors should be charged. They devised a surrogate function to characterize task collaboration. They then used the closest neighbor rule to approximate the optimization issue. Wei Z. et al. in [15] studied how to choose the optimal charging point; they used Q-learning to solve this problem.
2.2. Online Schemes
In the online schemes, when the remaining energy of a sensor falls below a certain level, MC will receive a charging request sent by the sensor. In [10], the authors set the charging probability for each requesting charging node; when the remaining energy of the requesting node is lower and the distance from MC is shorter, then the charging probability of the requesting charging node is higher. In [11,12], the authors developed a two-fold warning threshold charging technique to improve charging throughput. In order to reduce the charging latency, the authors of [13] proposed a gravity-searching scheme to optimize the charging order of the nodes that need to be charged. The work of [26] significantly improves charging throughput by optimizing the Fruit Fly optimization (FFO) algorithm and combining it with a threshold-based path selection algorithm to jointly optimize MC scheduling.
The authors of [16] proposed a reward function by which the reward function produces reward value to measure the performance of the charging scheme. To maximize the reward value, they used deep reinforcement learning to optimize MC scheduling and maximize the reward during the charging process. Compared with the deep reinforcement learning used by [16], Yang et al. proposed a new Actor–Critic reinforcement learning algorithm (ACRL) in [17]. In order to speed up the model training, they added the GRU layer to the Actor network, which can also schedule MC more efficiently. In [27], Banoth et al. proposed a DQN-based dynamic partial mobile charging scheduling method, where MC can interrupt the charging process of the current node, select another key node to replenish its energy, use the algorithm to predict the charging duration of the node, and collect data to train itself while performing the charging task. The authors of [28] developed a sensor energy consumption prediction model, and based on this model, the MC is efficiently scheduled, significantly improving the sensor survival rate. In [14], in order to reduce node dead ratio, the authors used fuzzy logic to establish the sequence of sensor exhaustion. The goal of [29] was to reduce the node dead ratio and increase the charging times of MC.
Several recent papers have looked at WRSN with multiple MCs [30,31]. How to coordinate and schedule MCs and cooperate with each other is the difficulty of this problem. The authors of [30] divided the network area into several regions and proposed an allocation algorithm that allowed each MC to charge several regions. In [31], in order to reduce the traveling distance by MCs, the authors proposed the idea of path merging. They made each MC responsible for a different region and assigned the same path to MC that departed for charging and MC that returned for charging.
Although a lot of works have been done on the charging scheduling of WRSN, most of the works are based on one-to-one charging technology with limited charging capacity. That leads to these works being difficult to meet the huge energy demand in large-scale WRSN. Some studies have adopted more efficient one-to-multiple charging technology to enhance charging capability. However, the schemes overlook the optimization of the charging amount that MC transfers to sensor nodes, and thus still have performance limitations. Aiming at the above problems, the paper utilizes DRL algorithms to optimize both the one-to-multiple charging sequence and the charging amount in order to further improve the charging performance in WRSN. Table 1 shows how the related work differs from our scheme.
3. Network Model and Problem Formulation
3.1. Network Structure
As shown in Figure 2, there are n sensor nodes and one MC in the WRSN. All sensor nodes whose locations can be accurately determined are placed on a two-dimensional map without obstacles. The location of sensor node is . We divide the two-dimensional map by a regular hexagonal cell with side length D; D is the charging range of MC. We call the hexagonal cell containing the nodes the charging cell. The charging cells are denoted as and the center position of is denoted by . The set of nodes within charging cell is . The charging cell has nodes. Table 2 lists the important notations used in this paper. In the sensor network, each sensor node consumes energy when collecting data and sending data. If the node works for a long time, it may die due to insufficient energy. Due to the limited capacity of MC battery, it cannot work permanently in WRSN, and some nodes may die because they cannot obtain energy supplements in time; nevertheless, a proper charging method can minimize the node dead ratio.
3.2. Energy Consumption Model
The sensor node carries a battery with capacity of E. Each sensor node can calculate its own data acquisition frequency and data transmission rate when working and then predict its own residual energy. For each node , energy is used mainly for sending and receiving data. The energy consumed for the node to send data is:
where and represent the data transfer amount an unit time from nodes to and B, respectively. is the energy required to transmit a unit of data from to (B). Especially, ; is the distance between and ; and are hyper-parameters and fixed values. The energy consumed for a node to receive data is:
the energy consumed by the received unit data is a fixed value, expressed as . The final energy consumption rate of the node is:
3.3. One-to-Multiple Charging Model
The coordinate of MC’s position is . MC moving speed is v, and the energy consumption is c per unit distance. The transmit power of MC is a fixed value, which is , and MC itself carries battery energy of . MC is equipped with a wireless charging device and replenishes the nodes with wireless charging. Current wireless energy transfer technologies are classified as inductive coupling, electromagnetic radiation and magnetic resonance coupling. Since inductive coupling has limitations such as the need for close contact and accurate alignment of the charging direction, while electromagnetic radiation is less efficient, inductive coupling and electromagnetic radiation are not applicable to this paper. Therefore, the magnetic resonance coupling wireless charging technology with longer charging distance and higher charging efficiency becomes a more suitable choice.
MC replenishes energy for nodes, and when the energy of MC is insufficient, MC returns to the S to replenish its own energy. Compared with that charging process, the time for MC to replenish energy can be neglected; thus, MC cannot consume the time to replenish energy in the S, and the location of S is . According to [32], we ignore the factors affecting charging efficiency and use the following one-to-multiple charging model.
When MC is in a charging cell, denote to be the distance from to MC. All nodes in the charging cell turn on the energy receiver in preparation for charging, and MC can recharge all nodes within the charging range that are ready to be charged. Then, the received power of the is , where is the efficiency of wireless power transfer, and is the decreasing function with respect to [32], specifically:
According to the conclusion obtained by [33], we believe that, when MC is charging multiple nodes at the same time, the nodes do not affect each other.
3.4. Problem Formulation
In the problem formulation, since MC has limited energy, MC will return to the service station to replenish energy when it is low. We define the time interval between the departure of MC from the service station and its return to the service station as follows:
Definition (CR): The process from when MC leaves the service station and performs a charging task to when MC is at low energy and returns to the service station is called a charging round (CR ).
Definition (Charging latency): The time interval between the node sending a charge request message and the node starting to be charged by MC.
In this paper, the primary goal is to reduce number of dead nodes, defined as . We define that a node has two states: dead and active. Thus, maximizing the proportion of active nodes while reducing the proportion of dead nodes is our primary goal. We use to indicate that the is active and to indicate that the is dead. Therefore, the goal of our scheme may be formalized as follows:
subject to
where is the energy consumed by MC moving, and is the energy consumed by MC charging nodes.
4. Optimized Charging Sequence
In this paper, we combine DQN, Dueling DQN, and Double DQN into the 3DQN model. In this section, we explain in detail the 3DQN network model, the construction of the learning model, and how to optimize the charging sequence by 3DQN.
4.1. Learning Model Construction
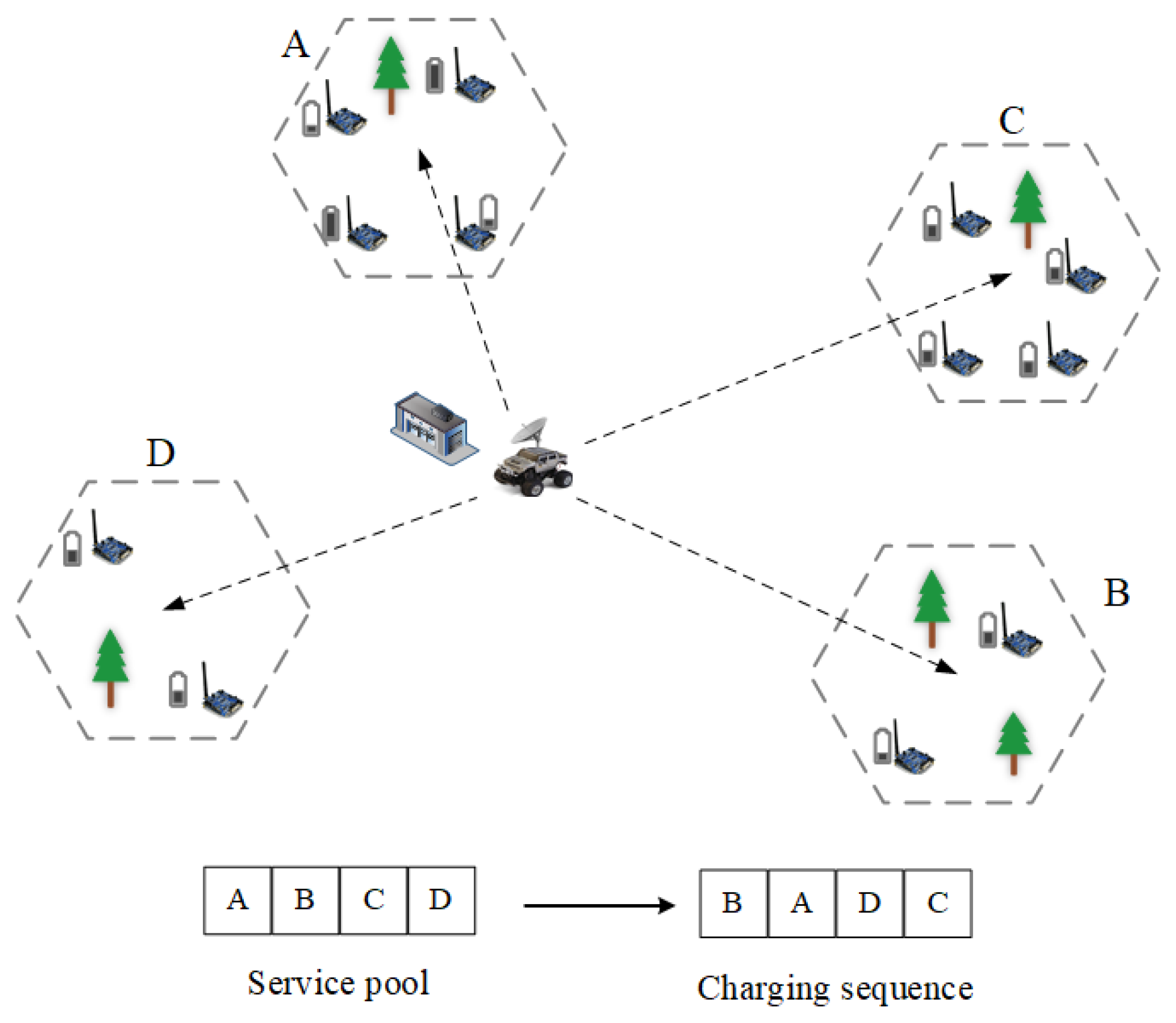
MC will not perform the next charging task until it has performed one; therefore, the online one-to-multiple charging scheme is one that contains sequence of decisions. The charging process is shown in Figure 3. Suppose MC receives charging requests from A, B, C, and D, then MC scheduling is optimized by optimizing the charging decision sequence as B, A, D, and C. Since RL has a natural advantage for optimizing decision sequences, we use RL to optimize MC charging sequences.
In WRSN, traditional RL is difficult to be applied to such problems because of the presence of large and high-dimensional data. However, deep learning has a powerful high-dimensional data processing capability. Therefore, RL can be combined with deep learning to form deep reinforcement learning with both high-dimensional continuous data processing capability and powerful decision-making capability, which can well solve the optimization problem of scheduling MC in WRSN. As shown in Figure 4, we have the following definition.
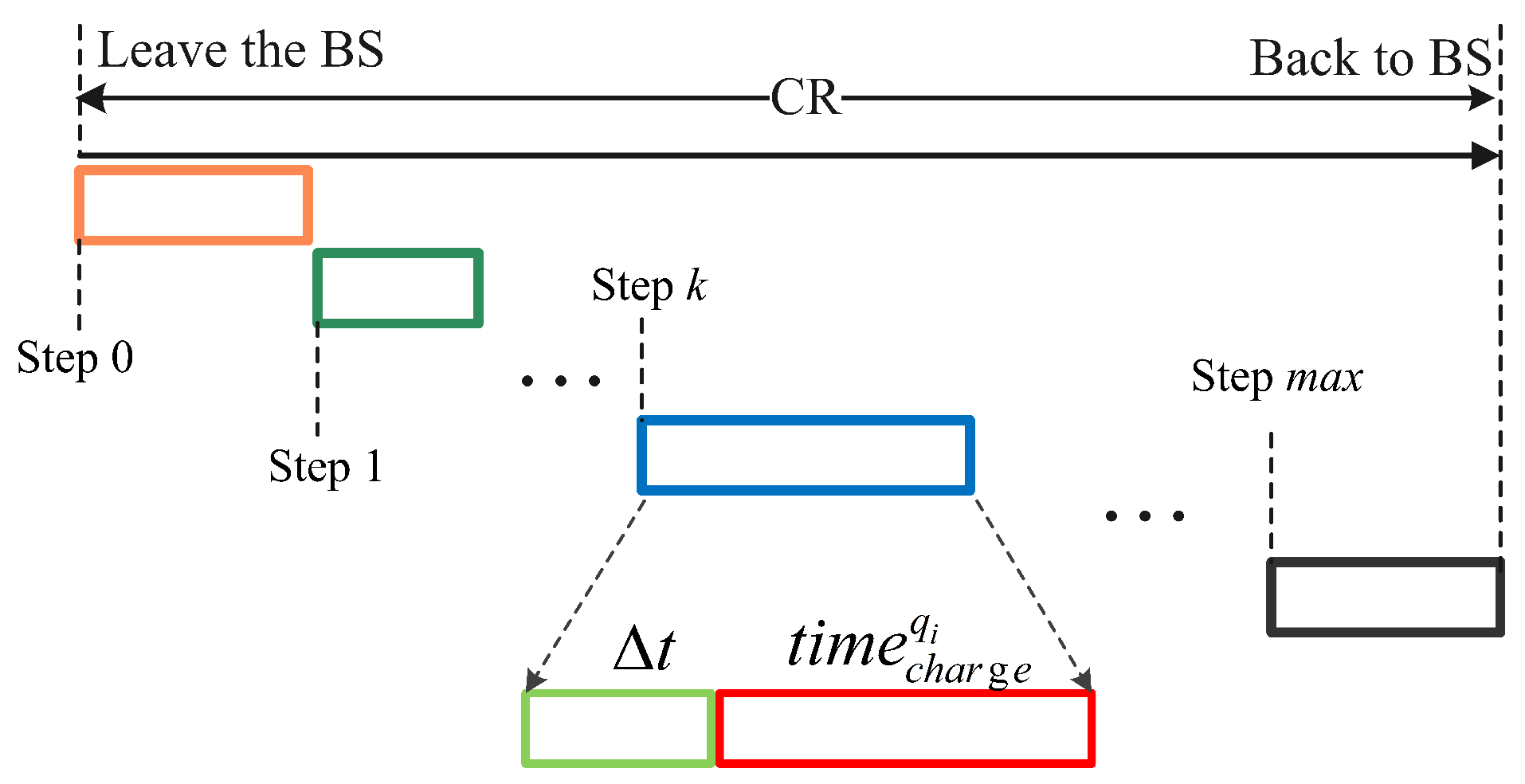
Definition (Step): The moment at which MC makes a charging decision based on the current state.
This paper uses state, action, and reward, and the state after the action is performed to define one-to-multiple charge scheme [34]. The states, actions, and rewards of a one-to-many charging scheme are defined below.
State: In online one-to-multiple charging, we take the status information of MC and nodes as the status space of WRSN, which is specifically . is the specific position coordinate of MC. contains node status information and charging cell location information, which is formulated as . , where is the node location and remaining energy in the , specifically .
Action: MC makes a decision based on the current state, which is an action. In one-to-multiple charging, it is decided that the charging cell to be charged is one action, and the number of charging cells are the same as the number of action spaces.
Reward: The reward is obtained by MC after completing the action and is used to evaluate the action. The main objective of this paper is to optimize the scheduling of MC in order to decrease the node dead ratio in WRSN. Reducing charging latency is a secondary goal. We utilize the trip length of MC, the node dead ratio, and the request charging cell ratio in online one-to-multiple charging. The reward is defined as:
where is the distance MC moves between adjacent steps. is the node dead ratio. The number of charging cells requesting charging is expressed as , and m is the total number of charging cells.
At the initial state, MC is in the service station. When MC is working, MC will select a charging cell to charge or will go back to S due to its low energy. As shown in Figure 4, during a CR, at step k, the state of WRSN is ; thus, MC determines action and executes it. MC obtains and next state after performing the action [17]. We assume that MC chooses to charge at step k; in the process of MC moving and charging the charging cell , the remaining nodes consume energy in the waiting process. After charging the charging cell , energy updates of nodes in the charging cell are as follows:
The energy of the remaining nodes is updated as follows:
MC consumes energy due to movement and charging, and its energy updates are as follows:
where is time spent by MC to move and is MC’s charging time in . Compared to the traveling time, the movement time of MC in the charging cell can be ignored. MC will return to the service station to replenish its energy due to lack of energy. After returning to the service station to replenish its energy, MC’s energy will be updated as follows:
According to Formulas (12) and (13), when the node is within the charging range, its energy will increase. On the contrary, nodes not within the charging range will reduce their energy due to the waiting process. At the same time, the maximum residual energy of a node is E when supplementing energy, and the minimum residual energy of a node is 0 when consuming energy.
We applied some criteria for training and creating suitable solutions, namely:
- When the remaining energy of MC is sufficient, MC can charge any of the charging cells.
- MC does not consume energy when not moving and not charging.
- MC does not accept charging requests during the charging process.
- MC cannot be interrupted during the charging process.
- If the residual energy of MC cannot support the charging task, it must return to the S to replenish the energy.
4.2. Deep Q-Networks
Q-learning is the classical method for charging sequential decision problems [15]. Under the following policy , the expected value of the total return obtained by choosing a series of actions is called the -value, and then the sequential decision problem can be solved by learning bootstrap estimates based on the -value. An action a in state s follows the ground-truth value of policy as
where represents the discount factor. The discount factor’s function is to provide incentives received at various points in the future with various weights and values. The best value is . Since the -table can only calculate -values for a limited state space, it is difficult to apply in the constantly varying WRSN environment; thus, deep neural networks are used as a nonlinear function to approximate -values, i.e., deep neural networks are combined with classical -learning to form a deep -network (DQN).
The DQN improves training efficiency and reduces fluctuations by means of experience replay buffer and dual networks [35]. The neural network used to estimate the -value function is the main network with parameters of , and the neural network used to output iterative learning target values is the target network with parameters of . We randomly take a certain number of b groups of samples from the for gradient descent calculation to train the main network and eliminate the correlation between the sample data to improve the learning efficiency. The target value of iterative learning is expressed as:
The main network parameter update formula is as follows:
where is the learning rate; the main network updates the parameters to the target network every n steps.
4.3. Double Dueling Deep Q-Networks
To pick and evaluate the greedy action, the maximized operators in Formula (17) employ identical values. Since action selection and evaluation use the same network, it is more likely that an overestimation of the true action value is generated because of bootstrapping. The double deep -network (DDQN) [36] has two DQN networks; the main DQN network outputs the actions and the target DQN network computes the target values for iterative learning to avoid bootstrapping and reduce overestimation. Therefore, the DDQN updates the objective as:
It can be seen from Formula (19) that we use the main network to select the action and the target network to participate in the calculation of the updated target value. The main network parameters are likewise updated to the target network every n steps.
In order to further improve its steady-state control, we combine DDQN and Dueling DQN [37] to produce the Double Dueling Deep -Network (3DQN) to attain better outcomes. We further stabilize the training process with 3DQN, which contains two different estimators: is used to estimate the state value and is the action advantage function. Finally, the output values of the two functions are combined as follows:
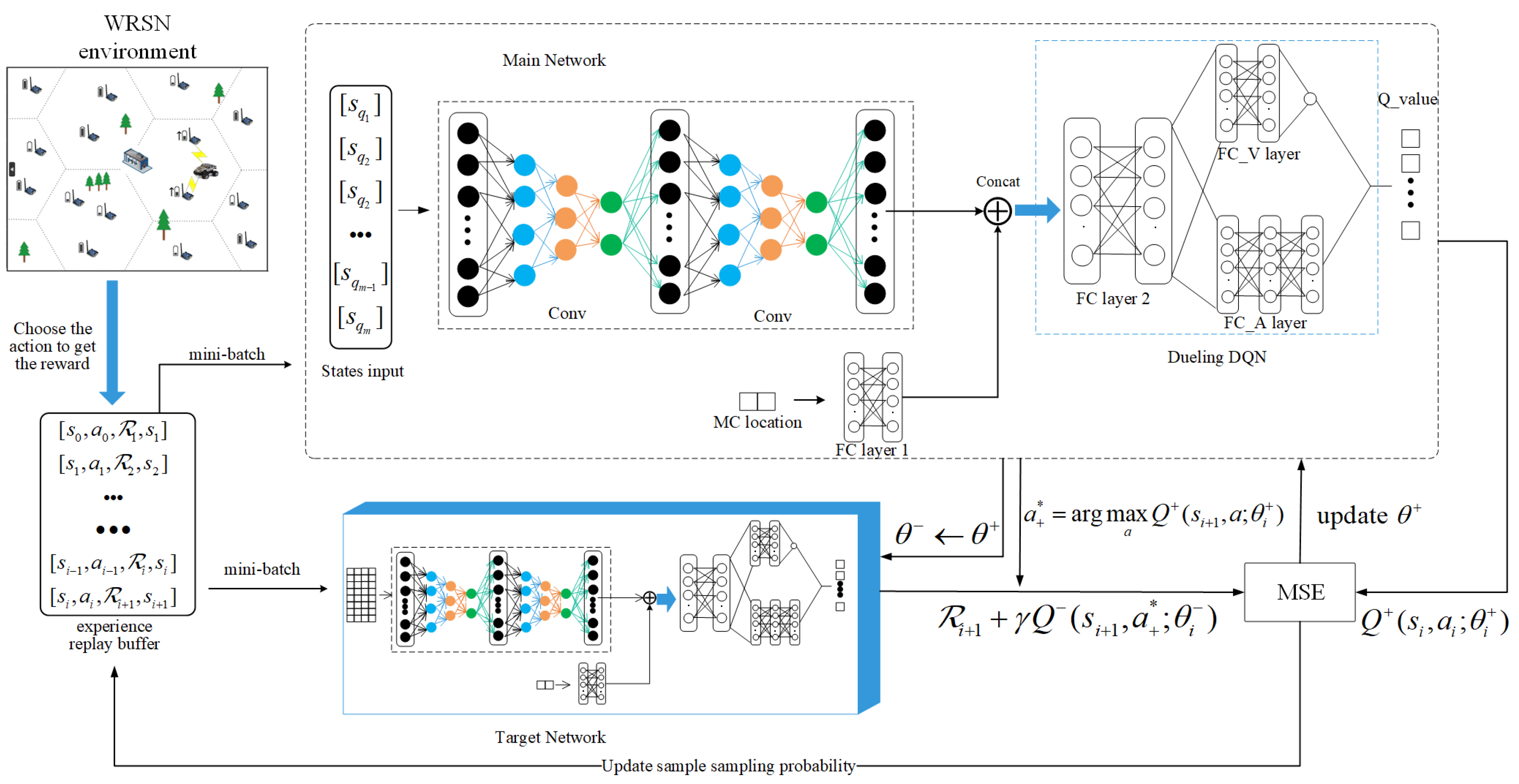
where is a scalar and is a -dimensional vector, the and are output by two independent streams, and the last hidden layer of the original DQN is divided into these two independent streams. The suggested 3DQN’s design is shown in Figure 5. The main network is in the upper part of Figure 5, and the target network is in the lower part of Figure 5. Two DQNs have Dueling structures and are jointly trained to represent two Q-valued functions, but they are structurally independent.
4.4. Training with 3DQN
As shown in Figure 5, we combine the and the into , which is the input of the convolution layer. After passing through the fully connected layer, MC position information is combined with the convolution layer’s output as the next layer’s input.
In 3DQN, the main network is represented by , and the target network is represented by . At each step, the generated by the -greedy policy is executed, and the value of decreases monotonically with the training process, with a minimum value of 0.01. Then, through the reward function, we obtain the reward value , and obtain the next state . We store as a tuple into .
In the process of training, a certain number of samples are randomly taken from the for gradient descent calculation each time, which is less efficient in learning the differences of effects produced by different actions in the samples. Therefore, a weighted sample pool (Prioritized experience replay) [38] is introduced to set different sampling weights for different samples. The worse the performance of an action in a sample, i.e., the greater the deviation relative to the estimate, the greater the probability that it will be selected by the action to improve learning efficiency. In this paper, we use a stepwise approach to calculate the sampling weights of the samples. The estimation error of sample i is as follows:
The sampling weight of the sample set is the inverse of the estimation error of the sample, and then the sampling probability of sample i can be obtained as:
where indicates the magnitude of the action of the sampling weights. When , the weighted sampling becomes ordinary random sampling. The OTM3DQN training is described in detail in Algorithm 1.
| Algorithm 1: OTM3DQN |
 |
5. Charging Scheme Details and Procedures
This section describes the specific steps of the charging scheme in this paper, which includes how to calculate the charging request threshold and the node charging amount, which are aimed at reducing the sensor node dead ratio. For the former, we calculate the node charging threshold by computing the node’s minimum tolerated charging time and determining the conditions under which charging cells send charging requests based on the node charging threshold. In particular, the charging requests for the charging cells are sent by the aggregation nodes. For the node charging amount, we calculate it from three perspectives: individual node demand, average residual time of all nodes in the whole WRSN, and MC’s residual energy, which changes dynamically according to the network state. Then the center of gravity method is used to adjust the charging location based on the node charging amount. In addition, since MC energy is limited, MC will determine whether its energy is sufficient before performing the charging task. Section 5.2 describes the charging request threshold. Section 5.3 and Section 5.4 calculate the node charging amount and MC charging location. Section 5.5 determines whether MC performs the next charging task.
5.1. The Charging Scheme Overview
Our charging scheme is described as follows: we use MC effective charging distance as the side length of the regular hexagonal division network; the hexagon with internal nodes is named as the charging cell and expressed as . MC maintains the 3DQN algorithm and a service pool , and when a charging cell reaches the charging request condition, it will send a message to MC with the request to charge, then MC receives this message, updates the service pool, and then performs the following operations:
- MC obtains the optimal or nearly optimal charging cell by using 3DQN algorithm;
- MC determines whether to go to charging cell according to Section 5.5;
- After MC reaches the center of the charging cell , the charging amount of nodes within the charging cell is derived according to Section 5.3, and the charging position is derived according to Section 5.4;
- MC decides whether to charge the nodes in charging cell according to Section 5.5;
As the proposed scheme is non-preemptive, MC performs a new charging task only after the current charging task is completed. After performing the charging task, MC obtains the current WRSN state as an input to the 3DQN algorithm and derives the next optimal charging cell.
5.2. Charging Request Threshold
The charging request threshold (defined as ) determines when a cell sends a charging request. The node residual energy reaches threshold when the node residual energy falls below a certain level, so the threshold for node is
where is the threshold factor. If whole charging cell is considered, a simple analysis from Formula (23) shows that the threshold for sending a charging request from the charging cell should be a simple sum of the thresholds of each node:
This paper takes into account that, when more than half of the number of sensor nodes within the charging cell residual energy drop below the threshold, or the value of the residual energy within the charging cell is below the , then this charging cell sends a charging request. Therefore, the service pool of MC is expressed as:
5.3. Charging Amount of Nodes
In previous studies, both the full and partial charging schemes of sensor nodes have significant limitations which cannot meet the dynamic WRSN environment. The charging amount of node is discussed from three aspects below.
- (1)
- Analysis from individual sensor node
Since lowering the node dead ratio as much as feasible is the aim of this paper, the energy replenished to each sensor node should be as much as possible to ensure that it does not die before the next charging service; thus, the value of for is taken as follows:
The charging amount of the where is located is:
- (2)
- Analysis from all charging cells
When charging the charging cell, the energy variation of the sensor nodes in the other charging cells should be considered by MC and it should not lose sight of them. After MC finishes this charging task, MC still needs to go to . We use to represent the distance between and centers; thus, the distance matrix between the centers of charging cells in WRSN is:
The matrix column summation is:
Then, Matrix row summation is . Thus, the average distance between the center positions of any two charging cells is:
We replace the average length of the movement in MC charging task with d. Considering only the latency of MC movement, the average waiting time of sensor nodes in the network waiting for MC charging is:
The overall residual energy of the is expressed as . Similarly, the received power of the is . The average energy surplus of charging cells in the WRSN is:
We use the total energy consumption rate of the internal nodes of the charging cell to represent the energy consumption rate of the charging cell. Therefore, the energy consumption of is , and the energy consumption rate of charging cells in the WRSN is:
Then the average network survival time is . So that not too many sensor nodes die in the network, there is the following equation:
The equation can be rectified to obtain:
After obtaining the energy required for the charging cell, the energy required for each node within the charging cell can be calculated. In this paper, according to the principle that, the longer the survival time, the less energy is allocated, and the survival time of is , therefore, the energy that should be allocated to in is:
- (3)
- Analysis from MC residual energy
To minimize the node dead ratio and simultaneously increase MC’s energy efficiency, the service time of MC to perform a charging task must be manageable. The average charging efficiency of the charging cells in the network is:
Assume that the number of charging cells in the service pool requesting charging is x. Therefore, we have the following equation:
where is the residual energy of MC, the of is obtained as:
According to the above analysis, the value of should be the median of the values taken by the three formulas of (27), (35), and (39). If the value of is greater than the value found in Formula (27), then . Otherwise, the value of is obtained according to Formula (36), and the energy is allocated according to the principle of energy consumption rate of sensor nodes. Algorithm 2 presents the algorithm’s pseudo-code.
5.4. Mc Charging Location Determination
Through the analysis in Section 5.3, MC obtains the charging amount of node. Then, MC determines the appropriate charging location to replenish nodes in the charging cell with the energy they need. The coordinates of in the in 2D are , and the required energy is the weight; the center of gravity of the object in the solution plane are:
Therefore, the adjusted charging position of MC after reaching the to be charged is:
| Algorithm 2: Charging amount of nodes determination |
 |
5.5. Analyze Whether MC Returns to the S
After selecting the next charging cell to be recharged, MC will check whether it has enough energy before recharging. MC can check whether its energy is enough in two steps. First, MC can judge whether its energy is enough to go to the charging cell center and return to the S. The energy for MC to move from the current position to the center of is
The energy returned to the S from the charging cell center is
If , MC returns to S and this CR ends. Otherwise, MC heads to the charging cell center.
If MC has enough energy to return to S, it should also be determined whether MC has enough energy to perform the charging task. The energy of MC moving from the charging cell center to the charging position is . The charging time of MC in the is
The energy consumed by MC replenishes energy for sensor nodes in . From the charging position of the , the energy returned by MC to the S is . Therefore, if , MC returns to S and this CR ends. Otherwise, the nodes in the charging cell are charged by MC. The specifics are explained in Algorithm 3.
| Algorithm 3: Whether MC returns S |
 |
6. Experiment
In this section, we analyze our proposed scheme through experiments. We provide further experimental information, along with a comparison of several approaches.
6.1. Experimental Settings
We take into account three networks of varying sizes, with 50, 100, and 200 sensor nodes. A 3.7 V/450 mAh alkaline rechargeable battery powers the node. Therefore, maximum energy capacity of node is E = 3.7 V × 0.45 A × 3600 s = 6 kJ. In that initial state of the network environment, the node positions are uniformly and randomly drawn in the square area with a side length of 1000 m, and the BS is located at (500,500). The energy of the node is randomly distributed between 500 and 6000 J. The capacity of MC is = 25 × 3.7 V × 3 A × 3600 s = 1000 kJ since it has 25 Li-ion batteries, each of which has a voltage and power of 3.7 V and 3000 mAh, respectively. The speed of MC is 5 m/s, the transmit power of MC is 20 w, and the energy consumption of MC is 50 J/m. We use the Python simulator (Python v3.6.8) and Pytorch 1.7.0 to build the simulation environment
In the training process, we use a mini-batch size of 32 as the input, 1D convolution layer as the input layer of the neural network, and the dimension of the input layer is the same as that of the state s. We combine the MC position information processed by the fully connected layer with the state-of-nodes information processed by the convolutional layer as the input of the following fully connected layer.
The main network has four hidden layers: two convolutions, one fully connected layer, and two parallel fully connected layers outputting A and V, respectively. The number of output channels of A is the same as the action space, and V has only single output channel. Finally, these two values are calculated by Formula (20) to obtain the Q. All networks use the ReLU activation. We used the Adam optimizer to train our model, and the 1 × learning rate was applied to the training of all scale networks. The target network structure is the same as the main network structure. The OTM3DQN is trained for 1200 CRs on 100 nodes, 150 nodes, and 200 nodes, respectively. The experimental parameters are shown in Table 3.
6.2. Result of Comparison with Others
We carry out comparison experiments to show the performance of our proposed scheme, OTM3DQN. The charging schemes we compare include the Greedy scheme and the FCFS scheme. We apply two deep reinforcement learning algorithms RMP-RL [16] and ACRL [17] in this paper, they schedule MC to move to center of charging cell and apply the fully charging method. The FCFS scheme and the Greedy scheme are introduced as follows.
(1) FCFS scheme: In the FCFS scheme, when the charging cell meets the conditions for entering MC service pool, the charging cell sends a charging request. Then, MC inserts the charging cell identification that sent the charging request into after receiving the request. Charging cells are selected on a first-come, first-served basis. MC selects a charging cell from and goes to the center of the charging cell to fully charge all nodes in the charging cell. After charging is complete, MC removes the charging cell identification from and continues to receive charging requests.
(2) Greedy scheme: In the Greedy scheme, when the charging cell meets the conditions for entering the MC service pool, the charging cell sends a charging request. Then, MC inserts the charging cell identification that sent the charging request into after receiving the request. At each step, with the Greedy scheme min , MC selects a charging cell from and goes to the center of the charging cell to fully charge all nodes in the charging cell. After charging is complete, MC removes the charging cell identification from and continues to receive charging requests.
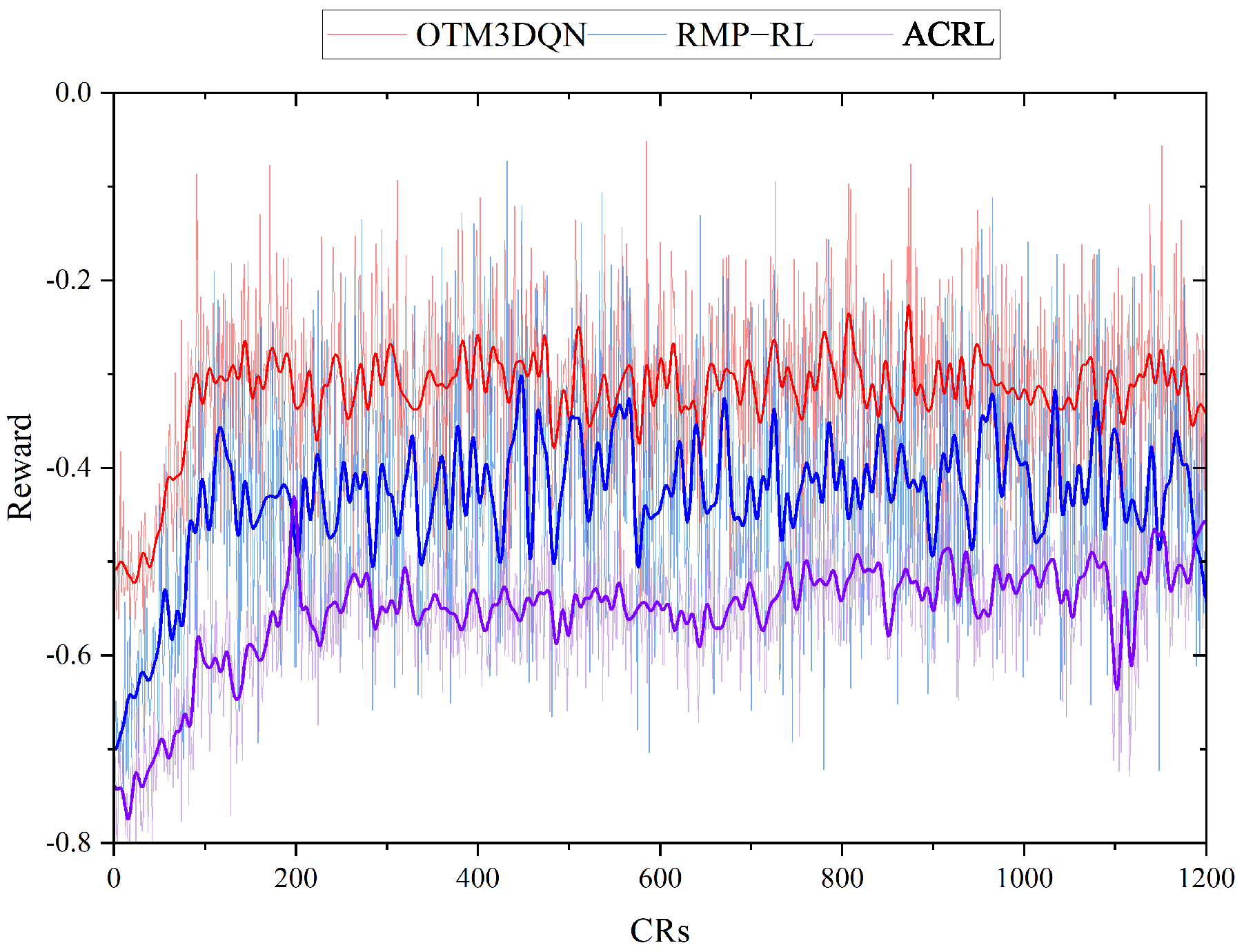
We first compare the performance of two deep reinforcement learning algorithms RMP-RL and ACRL in training; these two schemes were studied for 1200 CRs. Figure 6 shows the change in reward values during training for OTM3DQN, RMP-RL, and ACRL at the scale of 100 nodes, MC speed of 5 m/s, and transmit power of 20 w. As shown in Figure 6, the performance of OTM3DQN is the highest and most stable. OTM3DQN has a higher reward value because MC supplements a more reasonable energy value for the node when charging the node, thus reducing charging time which can replenish energy for other nodes in time and reduce node dead ratio. Meanwhile, OTM3DQN is more stable and faster than RMP-RL because OTM3DQN uses Double DQN to alleviate the overestimation caused by bootstrap operation during training, and then uses Dueling DQN to improve the stability of training, which makes OTM3DQN obtain a faster convergence rate and better stability.
ACRL has the best stability during training, but the reward value is lower than RMP-RL because RMP-RL selects actions based on value. In contrast, ACRL selects actions based on probability during training. In the process of training, when performing an action yields a higher reward, ACRL will increase the probability of the action choice; this will give ACRL a greater probability of selecting some of the better-performing actions. Therefore, the ACRL training has good stability, but it can also lead to the appearance of fear forward and fear backward when facing unknown strategies. With unknown strategies, this makes it possible that there are better policies that are not being executed, which is the reason for the lower ACRL reward value.
6.3. Impact of MC Transmitting Power
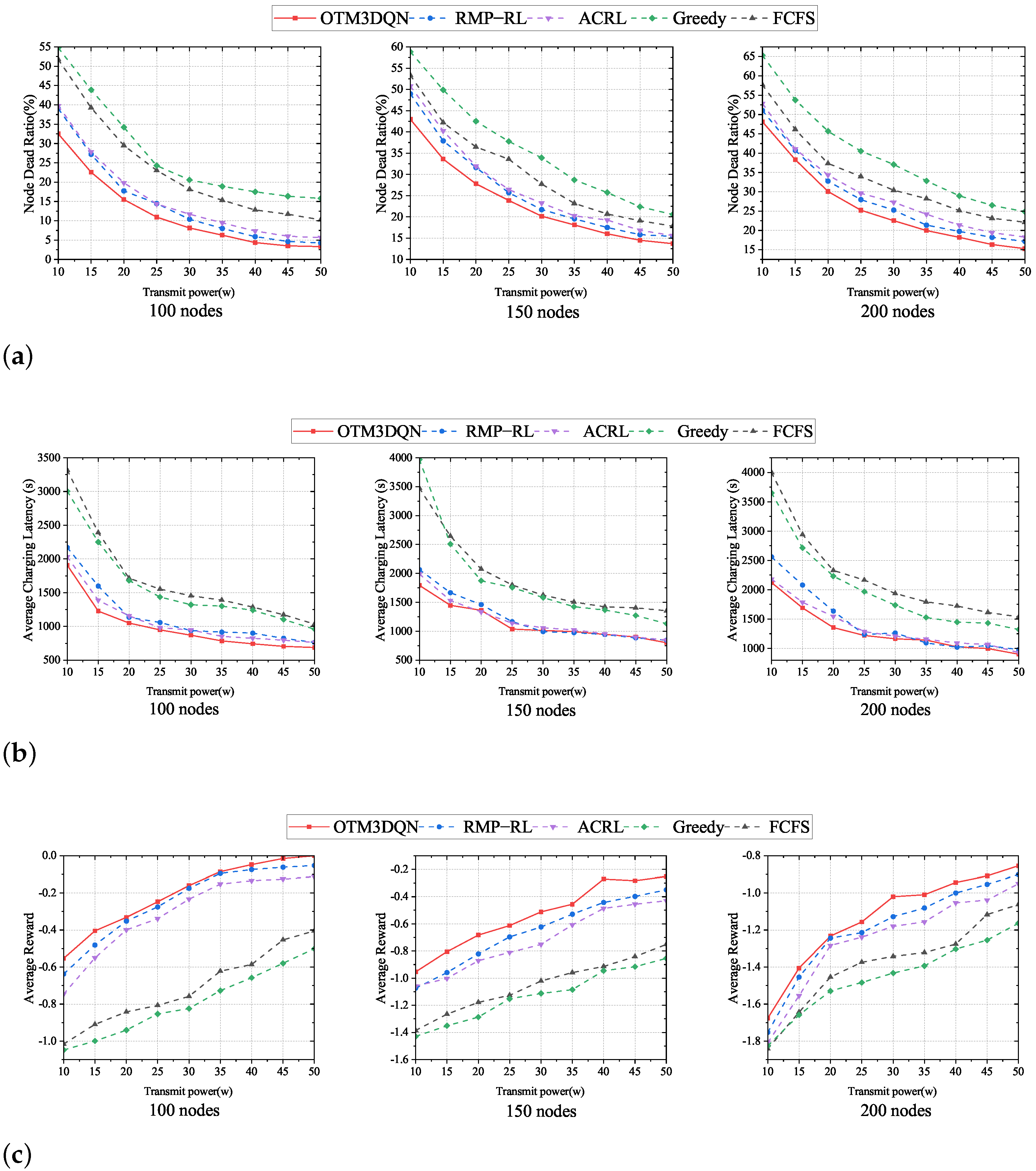
We mainly talk about how MC transmitting power affects charging effectiveness. The movement speed of MC is fixed at 5 m/s. The value of uniformly increases from 10 w to 50 w. We count the number of dead nodes at the completion of each charging task of the MC and calculate the node dead ratio when MC returns to S. In Figure 7, we show the comparison results with OTM3DQN, RMP-RL, ACRL, Greedy, and FCFS in networks with different numbers of sensor nodes.
As depicted in Figure 7a,b, in 100, 150, and 200 nodes, the three different network sizes, we observe that node dead ratio and average charging latency are relatively high at the beginning at lower , and node dead ratio and average charging latency show decreasing trend as increases. The reason is that, when is too small, resulting in longer charging time, the residual energy of subsequent nodes rapidly decreases, leading to more nodes with insufficient energy, a sharp increase in charging requests, a sharp increase in node dead ratio, and a rapid increase in the average charging latency. With the gradual increase of , MC can replenish energy for nodes faster, with more energy remaining in subsequent nodes and shorter waiting time for charging, leading to a lower node dead ratio and average charging latency.
It can be seen from Figure 7a,b that OTM3DQN has the lowest node dead ratio and the lowest average charging latency among the five charging schemes. This is because OTM3DQN uses the 3DQN algorithm to select the optimal charging cell from the global perspective, rather than just calculating the next charging cell from the data in the , which takes into account the nodes that are likely to fall into energy deficit, thus reducing the node dead ratio. At the same time, OTM3DQN analyzes the three aspects to derive a reasonable node charging amount, thus making MC not spend too much time charging, allowing subsequent nodes to wait less time, and also then renewing nodes to have more energy to support until the next charge, which results in less node dead ratio and average charging latency.
Although the reward value function is used to guide the deep reinforcement learning training process, Greedy and FCFS can still derive data, such as the number of dead nodes, which can be substituted into the reward function to derive the reward value. To unify the reward values, we use n for 100 and m for 32. In Figure 7c, comparing the three network scales, we observed that the average reward for all five charging schemes tends to increase as . This is because, when increases, nodes can replenish their energy faster. The remaining nodes will have a shorter waiting time, resulting in fewer dead nodes and requesting cells and a rise in the average reward value.
We find that there is no optimal value of transmitting power, but after reaching a specific value, the tendency of various indexes to improve with increasing transmitting power becomes slower. For a network size of 100 nodes using the OTM3DQN charging scheme, this value is about 35 w, which varies for different network sizes and charging schemes, but is about 25 w to 40 w, and this range should continue to increase as the network size continues to expand. We can also see that all three charging schemes using deep reinforcement learning outperform the traditional charging schemes, with the OTM3DQN charging scheme performing the best. It can also be seen in Figure 7c that the traditional charging schemes have substantial limitations due to the overemphasis on one aspect, such as the Greedy, because the Greedy charging scheme averages the traveling distance weight and the residual energy weight of the nodes and focuses only on the charging cells in the , making the Greedy charging scheme short-sighted.
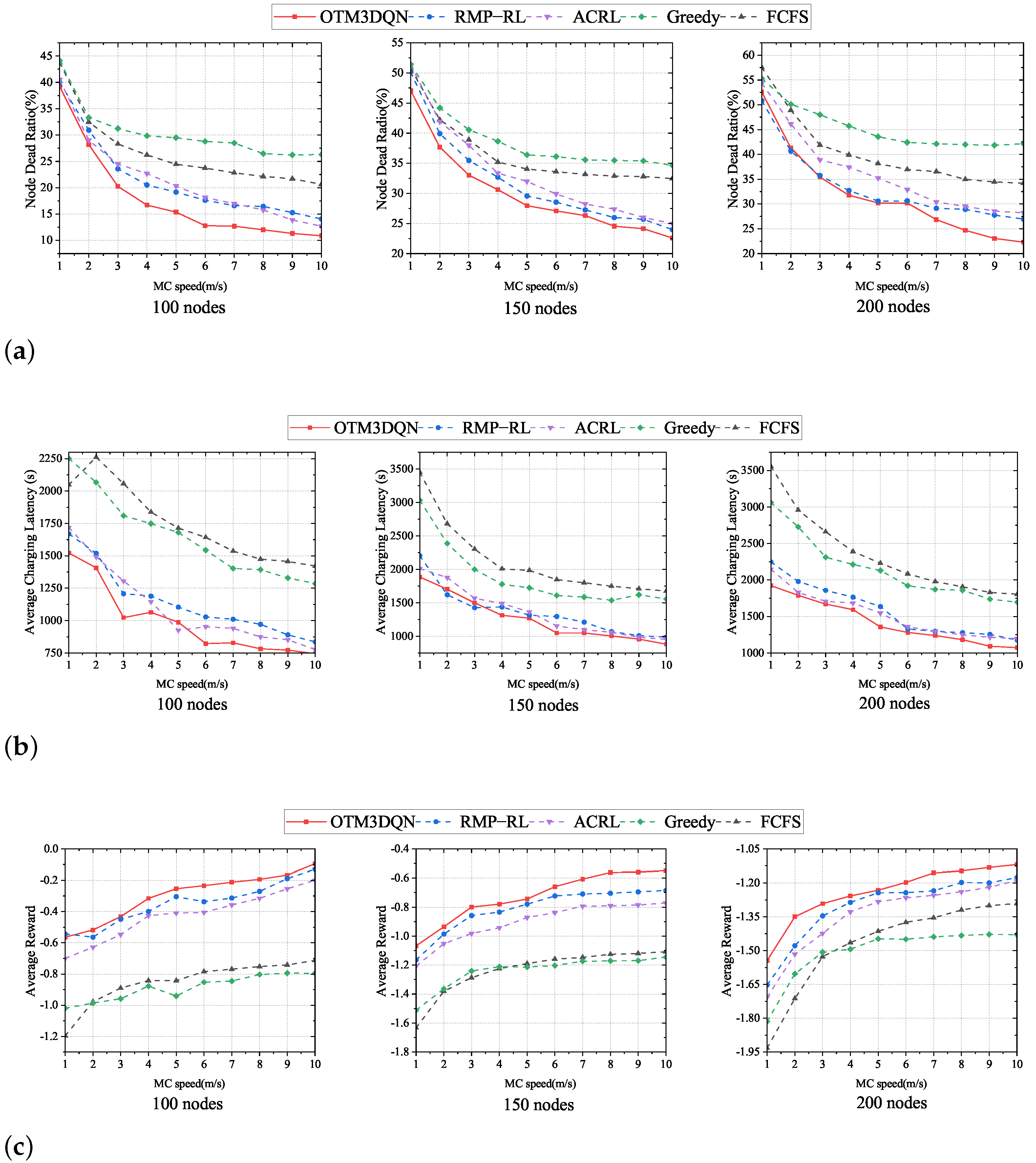
6.4. Impact of MC Speed
We analyze the performance of the three metrics for five charging schemes with a range of MC speed as a sequence of arithmetic progression from 1 m/s to 10 m/s, and we fix MC transmitting power is 20 w. From Figure 8, we can observe that the node dead ratio and average charging latency decrease with the increase of MC movement speed. The average reward also increases with the increase of MC movement speed. The OTM3DQN continues to be the best performer among the five charging schemes, again because OTM3DQN uses the 3DQN algorithm and analyzes the node charging amount, making the selection of charging cells and charging amounts more reasonable, and thus reducing node dead ratio and average charging latency.
It can be seen from Figure 8 that the performance of FCFS and Greedy charging schemes almost do not improve with the increase of MC speed after reaching a specific value, which is due to the short-sightedness caused by the limitations of FCFS and Greedy. Since FCFS only focuses on the residual energy, and Greedy, although it considers both the traveling distance and the residual energy, cannot dynamically adjust the weights between the traveling distance and the residual energy, MC only moves between a few charging cells under these two schemes, thus making FCFS and Greedy fall into local optimal solutions.
Meanwhile, in Figure 8c, it can be observed that, when MC speed is low, the enhancement of the performance of the charging schemes by increasing the speed is pronounced. However, as MC speed increases, the enhancement of charging schemes’ performance by increasing the speed is too limited. It can be concluded that, when MC speed reaches a specific range, it is difficult to improve the charging efficiency by increasing MC speed.
6.5. Charging Cost and Energy Efficiency
Table 4 shows the average travel length and energy efficiency obtained by different schemes for 100, 150, and 200 nodes, MC speed of 5 m/s, and transmit power of 20 w. The average travel length is called average cost. Energy efficiency is the ratio of the replenishment energy of the sensor node to the maximum available energy of MC in CR. We observe that the OTM3DQN charging scheme outperforms the remaining four charging schemes in terms of energy efficiency and average cost. In contrast, the Greedy charging scheme performs just below the OTM3DQN charging scheme in terms of energy efficiency over 100 and 150 nodes. This is because the Greedy charging scheme averages the traveling distance weight and the residual energy weight of the nodes and focuses only on the charging cells in the , making the Greedy charging scheme short-sighted. In other words, the OTM3DQN charging scheme is more long-term by dynamically adjusting the traveling distance weight and node residual energy weight from a global perspective. The FCFS charging scheme performs the worst since the FCFS charging scheme only focuses on the residual energy of the nodes. As a result, MC charges only a few charging cells in WRSN, which consumes much energy during the movement, leading to higher average cost and lower energy efficiency. We also observe that the Greedy and FCFS charging schemes perform worse as the network size increases, while the OTM3DQN charging scheme performs better, which proves the superiority and scalability of our charging scheme.
7. Conclusions and Future Work
In this paper, we have proposed a novel one-to-multiple charging scheduling optimization scheme based on DRL, called OTM3DQN, for WRSN. Different from the existing one-to-multiple works that only optimize the charging sequence, OTM3DQN explicitly analyzes the charging amount that MC transfers to the sensor node(s) in each charging task and utilizes Double Dueling DQN (3DQN) to optimize the scheduling of charging sequences of MC in order to improve the overall charging performance. The proposed scheme further utilizes Double DQN to reduce overestimation caused by bootstrapping to lower the error and thus achieve better performance. In addition, OTM3DQN makes use of the Dueling DQN structure to improve the stability of training and uses the prioritized experience replay to improve the training efficiency. Extensive simulation experiments have been conducted to evaluate the performance of the proposed scheme. The results show that, in large-scale WRSN, OTM3DQN has better performance in reducing node dead ratio and charging latency compared with several existing typical works.
In the future, we will work on complex WRSN with multiple MCs to achieve lower node mortality for a larger network. Our goal also includes applying the algorithm to real-world environments in the future.
Author Contributions
Conceptualization, Z.G.; Data curation, Z.G. and H.W.; Funding acquisition, Y.F.; Methodology, Z.G. Project administration, Y.F. and N.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62062047 and the major scientific and technological projects in Yunnan Province under No. 202202AD080006.
Data Availability Statement
The data are not publicly available due to it is not permitted.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhu, H.; Zhuo, Y.; Liu, Q.; Chang, S. π-Splicer: Perceiving Accurate CSI Phases with Commodity WiFi Devices. IEEE Trans. Mob. Comput. 2018, 17, 2155–2165. [Google Scholar] [CrossRef]
- Qin, J.; Zhu, H.; Zhu, Y.; Lu, L.; Xue, G.; Li, M. POST: Exploiting Dynamic Sociality for Mobile Advertising in Vehicular Networks. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1770–1782. [Google Scholar] [CrossRef]
- He, S.; Chen, J.; Jiang, F.; Yau, D.K.; Xing, G.; Sun, Y. Energy Provisioning in Wireless Rechargeable Sensor Networks. IEEE Trans. Mob. Comput. 2013, 12, 1931–1942. [Google Scholar] [CrossRef]
- Jiang, G.; Lam, S.K.; Sun, Y.; Tu, L.; Wu, J. Joint charging tour planning and depot positioning for wireless sensor networks using mobile chargers. IEEE/ACM Trans. Netw. 2017, 25, 2250–2266. [Google Scholar] [CrossRef]
- Ma, Y.; Liang, W.; Xu, W. Charging utility maximization in wireless rechargeable sensor networks by charging multiple sensors simultaneously. IEEE/ACM Trans. Netw. 2018, 26, 1591–1604. [Google Scholar] [CrossRef]
- Xu, W.; Liang, W.; Kan, H.; Xu, Y.; Zhang, X. Minimizing the longest charge delay of multiple mobile chargers for wireless rechargeable sensor networks by charging multiple sensors simultaneously. In Proceedings of the IEEE 39th International Conference on Distributed Computing Systems, Dallas, TX, USA, 7–9 July 2019; pp. 881–890. [Google Scholar]
- Lin, C.; Yang, Z.; Dai, H.; Cui, L.; Wang, L.; Wu, G. Minimizing charging delay for directional charging. IEEE/ACM Trans. Netw. 2021, 29, 2478–2493. [Google Scholar] [CrossRef]
- Malebary, S. Wireless mobile charger excursion optimization algorithm in wireless rechargeable sensor networks. IEEE Sens. J. 2020, 20, 13842–13848. [Google Scholar] [CrossRef]
- Wu, T.; Yang, P.; Dai, H.; Xu, W.; Xu, M. Collaborated tasks-driven mobile charging and scheduling: A near optimal result. In Proceedings of the IEEE INFOCOM, Paris, France, 29 April–2 May 2019; pp. 1810–1818. [Google Scholar]
- Zhu, J.; Feng, Y.; Liu, M.; Chen, G.; Huang, Y. Adaptive online mobile charging for node failure avoidance in wireless rechargeable sensor networks. Comput. Commun. 2018, 126, 28–37. [Google Scholar] [CrossRef]
- Lin, C.; Sun, Y.; Wang, K.; Chen, Z.; Xu, B.; Wu, G. Double warning thresholds for preemptive charging scheduling in wireless rechargeable sensor networks. Comput. Netw. 2019, 148, 72–87. [Google Scholar] [CrossRef]
- Lin, C.; Zhou, J.; Guo, C.; Song, H.; Wu, G.; Obaidat, M.S. TSCA: A Temporal-Spatial Real-Time Charging Scheduling Algorithm for On-Demand Architecture in Wireless Rechargeable Sensor Networks. IEEE Trans. Mob. Comput. 2018, 17, 211–224. [Google Scholar] [CrossRef]
- Kaswan, A.; Tomar, A.; Jana, P.K. An efficient scheduling scheme for mobile charger in on-demand wireless rechargeable sensor networks. J. Netw. Comput. Appl. 2018, 114, 123–134. [Google Scholar] [CrossRef]
- Tomar, A.; Muduli, L.; Jana, P.K. An efficient scheduling scheme for on-demand mobile charging in wireless rechargeable sensor networks. Pervasive Mob. Comput. 2019, 59, 101074. [Google Scholar] [CrossRef]
- Wei, Z.; Liu, F.; Lyu, Z.; Ding, X.; Shi, L.; Xia, C. Reinforcement learning for a novel mobile charging strategy in wireless rechargeable sensor networks. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Tianjin, China, 20–22 June 2018; pp. 485–496. [Google Scholar]
- Cao, X.; Xu, W.; Liu, X.; Peng, J.; Liu, T. A deep reinforcement learning-based on-demand charging algorithm for wireless rechargeable sensor networks. Ad Hoc Netw. 2021, 110, 102278. [Google Scholar] [CrossRef]
- Yang, M.; Liu, N.; Zuo, L.; Feng, Y.; Liu, M.; Gong, H.; Liu, M. Dynamic Charging Scheme Problem With Actor–Critic Reinforcement Learning. IEEE Internet Things J. 2021, 8, 370–380. [Google Scholar] [CrossRef]
- He, L.; Kong, L.; Gu, Y.; Pan, J.; Zhu, T. Evaluating the on-demand mobile charging in wireless sensor networks. IEEE Trans. Mob. Comput. 2014, 14, 1861–1875. [Google Scholar] [CrossRef]
- Lyu, Z.; Wei, Z.; Pan, J.; Chen, H.; Xia, C.; Han, J.; Shi, L. Periodic charging planning for a mobile WCE in wireless rechargeable sensor networks based on hybrid PSO and GA algorithm. Appl. Soft Comput. 2019, 75, 388–403. [Google Scholar] [CrossRef]
- Xie, L.; Shi, Y.; Hou, Y.T.; Lou, W.; Sherali, H.D.; Midkiff, S.F. On renewable sensor networks with wireless energy transfer: The multi-node case. In Proceedings of the 2012 9th Annual IEEE Communications Society Conference on Sensor, Mesh and ad hoc Communications and Networks (SECON), Seoul, Republic of Korea, 18–21 June 2012; pp. 10–18. [Google Scholar]
- Mavrovouniotis, M.; Li, C.; Yang, S. A survey of swarm intelligence for dynamic optimization: Algorithms and applications. Swarm Evol. Comput. 2017, 33, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Tang, K.; Menzel, S.; Yao, X. Dynamic Optimization in Fast-Changing Environments via Offline Evolutionary Search. IEEE Trans. Evol. Comput. 2021, 26, 431–445. [Google Scholar] [CrossRef]
- Gao, Y.; Chen, S.F.; Lu, X. Research on reinforcement learning technology: A review. Acta Autom. Sin. 2004, 30, 86–100. [Google Scholar]
- Duan, Y.; Lv, Y.; Zhang, J.; Zhao, X.; Wang, F. Deep learning for control: The state of the art and prospects. Acta Autom. Sin. 2016, 42, 643–654. [Google Scholar]
- Chen, T.S.; Chen, J.J.; Gao, X.Y.; Chen, T.C. Mobile Charging Strategy for Wireless Rechargeable Sensor Networks. Sensors 2022, 22, 359. [Google Scholar] [CrossRef] [PubMed]
- Susan, T.S.A.; Balasubramanian, N. Scheduling on-demand charging request in wireless rechargeable sensor network with fruit fly optimization-based path selection. Int. J. Inf. Technol. 2022, 14, 2377–2388. [Google Scholar] [CrossRef]
- Banoth, S.P.R.; Donta, P.K.; Amgoth, T. Dynamic mobile charger scheduling with partial charging strategy for WSNs using deep-Q-networks. Neural Comput. Appl. 2021, 33, 15267–15279. [Google Scholar] [CrossRef]
- Dudyala, A.K.; Ram, L.K. Improving the Lifetime of Wireless Rechargeable Sensors Using Mobile Charger in On-Demand Charging Environment Based on Energy Consumption Rate Prediction. In Proceedings of the First International Conference on Computational Electronics for Wireless Communications: ICCWC 2021, Haryana, India, 11–12 June 2021; Springer: Singapore, 2022; pp. 679–688. [Google Scholar]
- Liu, T.; Wu, B.; Zhang, S.; Peng, J.; Xu, W. An Effective Multi-node Charging Scheme for Wireless Rechargeable Sensor Networks. In Proceedings of the IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 2026–2035. [Google Scholar] [CrossRef]
- Lin, C.; Wang, Z.; Deng, J.; Wang, L.; Ren, J.; Wu, G. mTS: Temporal-and spatial-collaborative charging for wireless rechargeable sensor networks with multiple vehicles. In Proceedings of the IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 99–107. [Google Scholar]
- Ouyang, W.; Liu, X.; Obaidat, M.S.; Lin, C.; Zhou, H.; Liu, T.; Hsiao, K.F. Utility-aware charging scheduling for multiple mobile chargers in large-scale wireless rechargeable sensor networks. IEEE Trans. Sustain. Comput. 2020, 6, 679–690. [Google Scholar] [CrossRef]
- Xie, L.; Shi, Y.; Hou, Y.T.; Lou, W.; Sherali, H.D.; Midkiff, S.F. Multi-node wireless energy charging in sensor networks. IEEE/ACM Trans. Netw. 2014, 23, 437–450. [Google Scholar] [CrossRef]
- Sample, A.P.; Yeager, D.J.; Powledge, P.S.; Mamishev, A.V.; Smith, J.R. Design of an RFID-Based Battery-Free Programmable Sensing Platform. IEEE Trans. Instrum. Meas. 2008, 57, 2608–2615. [Google Scholar] [CrossRef]
- Hu, W.; Jin, Y.; Wen, Y.; Wang, Z.; Sun, L. Towards Wi-Fi AP-Assisted Content Prefetching for On-Demand TV Series: A Reinforcement Learning Approach. arXiv 2017, arXiv:1703.03530. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
Figure 1.
Impact of the number of nodes to the performance of the one-to-one charging scheme.

Figure 2.
Overview of environment.

Figure 3.
Charging sequence optimization.

Figure 4.
Charging sequence based on RL.

Figure 5.
Network model structure of the 3DQN.

Figure 6.
Training process average reward value for OTM3DQN, RMP-RL, and ACRL.

Figure 7.
Impact of MC transmitting power. (a) Node dead ratio under different MC transmitting power. (b) Average charging latency under different MC transmitting power. (c) Average reward under different MC transmitting power.
Figure 7.
Impact of MC transmitting power. (a) Node dead ratio under different MC transmitting power. (b) Average charging latency under different MC transmitting power. (c) Average reward under different MC transmitting power.

Figure 8.
Impact of MC speed. (a) Node dead ratio under different MC speed. (b) Average charging latency under different MC speed. (c) Average reward under different MC speed.
Figure 8.
Impact of MC speed. (a) Node dead ratio under different MC speed. (b) Average charging latency under different MC speed. (c) Average reward under different MC speed.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison of our charging scheme with existing schemes.
| Category | Charging Scheme | Charging Amount | Optimization Objective | Optimization Scheme | Paper |
|---|---|---|---|---|---|
| offline | One-to-One | fully charging | Charging path | Traditional heuristic method | [5,9,19] |
| Charging path, depot location | Traditional heuristic method | [4] | |||
| Charging path | RL | [15] | |||
| Online | Charging sequence | Traditional heuristic method | [10,12,13] | ||
| Charging sequence | Classical optimization method | [26] | |||
| Charging sequence | DRL | [27] | |||
| One-to-multiple | fixed ratio charging | Charging sequence | Traditional heuristic method | [14,29] | |
| dynamic charging amount | Charging sequence, Charging amount | DRL | Our charging scheme |
Table 2.
List of important notations.
| Notation | Definition |
|---|---|
| n | Number of sensors |
| m | Number of charging cells |
| Location of sensor node i | |
| Central location of the charging cell | |
| Set of sensor nodes in charging cell | |
| Number of sensor nodes in charging cell | |
| Energy consumption rate of sensor node i | |
| Residual energy of sensor node i | |
| Charging amount of sensor node i | |
| E | Maximum energy of sensor battery |
| Received power of sensor node i | |
| Transmit power of MC | |
| Residual energy of MC | |
| Maximum energy of MC | |
| v | Moving speed of MC |
| c | Energy consumption of MC |
| Location of MC |
Table 3.
Experiment parameters.
| Parameter | Value |
|---|---|
| L, The side length of the square area | 1000 m |
| D, Charging range of MC | 2.7 m |
| Number of Nodes | 100, 150, 200 |
| , MC maximum energy | 1000 kJ |
| v, Speed of MC | 5 m/s |
| , Transmit power of MC | 20 w |
| c, Energy consumption of MC | 50 J/m |
| E, Sensor maximum energy | 6000 J |
| , Threshold factor | 0.5 |
| , Energy consumption of sensor | 0.3∼1 J/s |
| , Initial Residual Energy of sensor | 500∼6000 J |
| b, Mini-batch | 32 |
| B, Capacity of buffer | 20,000 |
| , Discounted factor | 0.95 |
| , Learning rate for gradient descent | |
| , Probability of choosing a random action | [0.01, 1] |
| n, The steps change from 1 to 0.01 | 100 |
Table 4.
Average charging cost and energy efficiency.
| Schemes | 100 Nodes | 150 Nodes | 200 Nodes | |||
|---|---|---|---|---|---|---|
| Average Cost (m) | Energy Efficiency (%) | Average Cost (m) | Energy Efficiency (%) | Average Cost (m) | Energy Efficiency (%) | |
| OTM3DQN | 138.79 | 46.09% | 130.28 | 47.19% | 132.79 | 49.57% |
| RMP-RL | 140.00 | 41.96% | 132.82 | 43.56% | 138.91 | 46.59% |
| ACRL | 142.84 | 43.13% | 137.76 | 44.30% | 141.60 | 45.75% |
| Greedy | 143.61 | 45.81% | 141.88 | 44.53% | 145.91 | 45.26% |
| FCFS | 171.77 | 39.14% | 188.31 | 40.41% | 227.37 | 35.06% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gong, Z.; Wu, H.; Feng, Y.; Liu, N. Deep Reinforcement Learning–Based Online One-to-Multiple Charging Scheme in Wireless Rechargeable Sensor Network. Sensors 2023, 23, 3903. https://0-doi-org.brum.beds.ac.uk/10.3390/s23083903
AMA Style
Gong Z, Wu H, Feng Y, Liu N. Deep Reinforcement Learning–Based Online One-to-Multiple Charging Scheme in Wireless Rechargeable Sensor Network. Sensors. 2023; 23(8):3903. https://0-doi-org.brum.beds.ac.uk/10.3390/s23083903
Chicago/Turabian StyleGong, Zheng, Hao Wu, Yong Feng, and Nianbo Liu. 2023. "Deep Reinforcement Learning–Based Online One-to-Multiple Charging Scheme in Wireless Rechargeable Sensor Network" Sensors 23, no. 8: 3903. https://0-doi-org.brum.beds.ac.uk/10.3390/s23083903
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.