2.2. Sources of Data and Measures
We obtained health data from 2017 release of the Centers for Disease Control and Prevention (CDC) 500 Cities Project [
39]. The CDC generated small area estimates (census tract and city-wide) of health by linking geocoded health surveys and high spatial resolution population demographic and socioeconomic data, while accounting for associations between individual health outcomes, individual characteristics, and spatial contexts [
40,
41]. The data used in these estimates is from the CDC’s Behavioral Risk Factor Surveillance System (BRFSS), which is based on phone interviews conducted with more than 400,000 adults each year in all 50 states [
41]. The BRFSS recruitment methodology has been refined since this survey’s initial launch in 1984 and is now considered a gold standard in telephone-based health surveys [
42]. As the median nationwide response rate is around 47%, the total number of respondents is close to 200,000 individuals [
43]. A 2014 meta-analysis comparing nationwide BRFSS data to other health data confirmed that the BRFSS measures included in the current study were moderately to highly reliable and valid [
44]. The 500 Cities Project data have also been used in at least four peer-reviewed articles, largely in medical journals, since their release approximately 1.5 years ago [
45,
46,
47,
48].
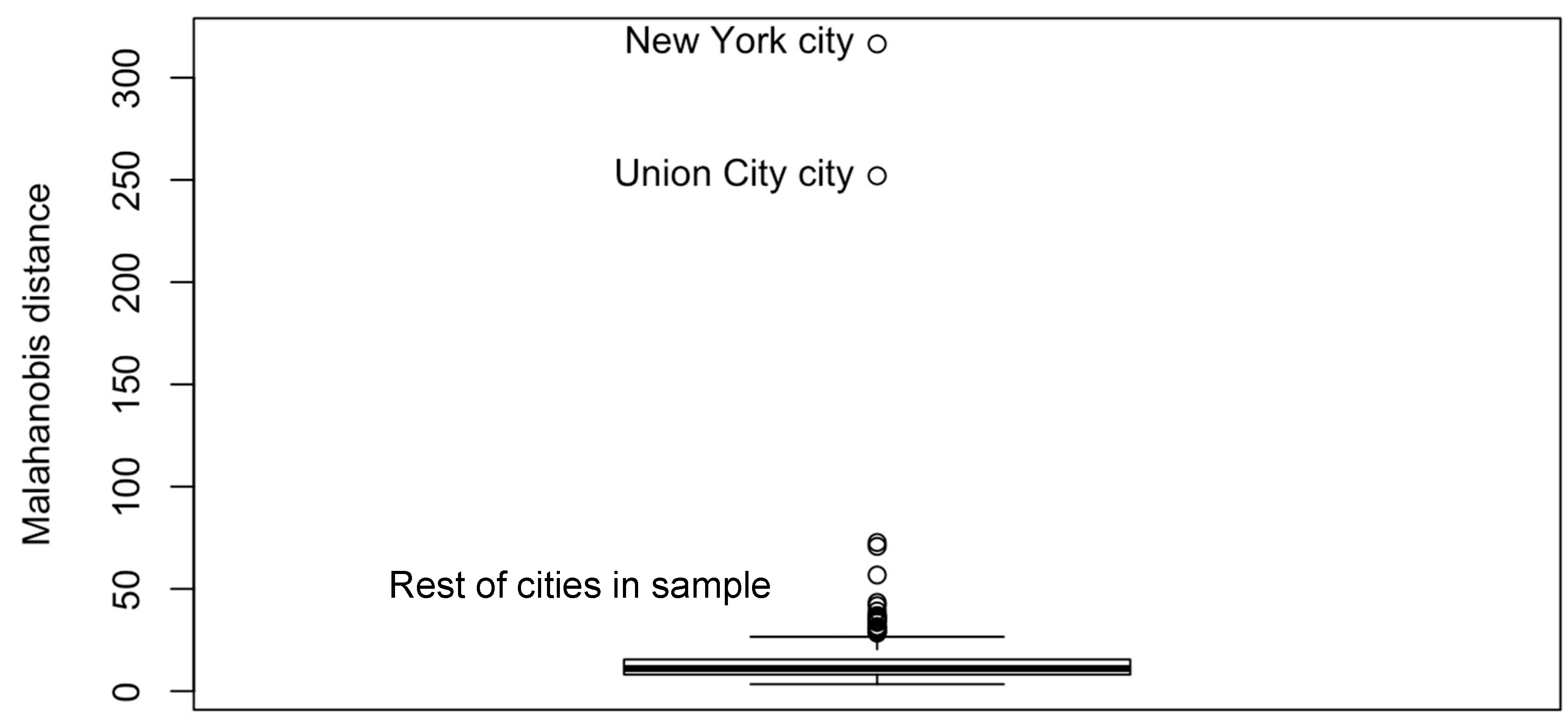
City-level estimates for health outcomes from the 500 Cities Project have very small margins of errors, while tract-level values have much larger errors due to the smaller sample size [
39]. For example, for Birmingham, AL, USA, the margin of error at the city-level for percent poor mental health is ±0.25% (the estimate is 17%). For the same variable in Birmingham, the margin of error for census tracts is, on average, ±1.65% and as high as ±2.9%. Thus, for certain census tracts, estimates of percent poor mental health varied between 14.9% and 20.7%. Given these relatively large margins of errors for census tract estimates, and given the aforementioned changes in funding for greenspace and health promotion, we decided that a city-level study would be more rigorous and compelling.
We focused on two health measures for respondents aged 18 and over in each city: obesity and poor mental health. Obesity refers to the percentage of people who had a body mass index (BMI) larger than or equal to 30.0 kg/m
2 as calculated from their self-reported weight and height. Pregnant women and respondents reporting extremely high or extremely low values for height and weight were excluded from this calculation. Poor mental health describes the percentage of people who reported that their mental health was not good in 14 or more of the past 30 days. Both obesity and mental health measures were, therefore, binary variables during data collection (obese-levels of BMI or not; good or not good mental health). When aggregated to the city-level, they became continuous variables (percentages of obese residents and percentage of residents with poor mental health). Among the various health measures reported in the 500 Cities Project dataset, we chose obesity and poor mental health because we were interested in studying health outcomes for which the greenspace-health link is well studied but with mixed findings (see
Section 1.1.3). In particular, we aimed to ground our study in a substantial body of literature to uncover, for obesity and mental health, how the type of indicator of greenspace exposure, the unit of analysis, and moderators influenced the greenspace-health link.
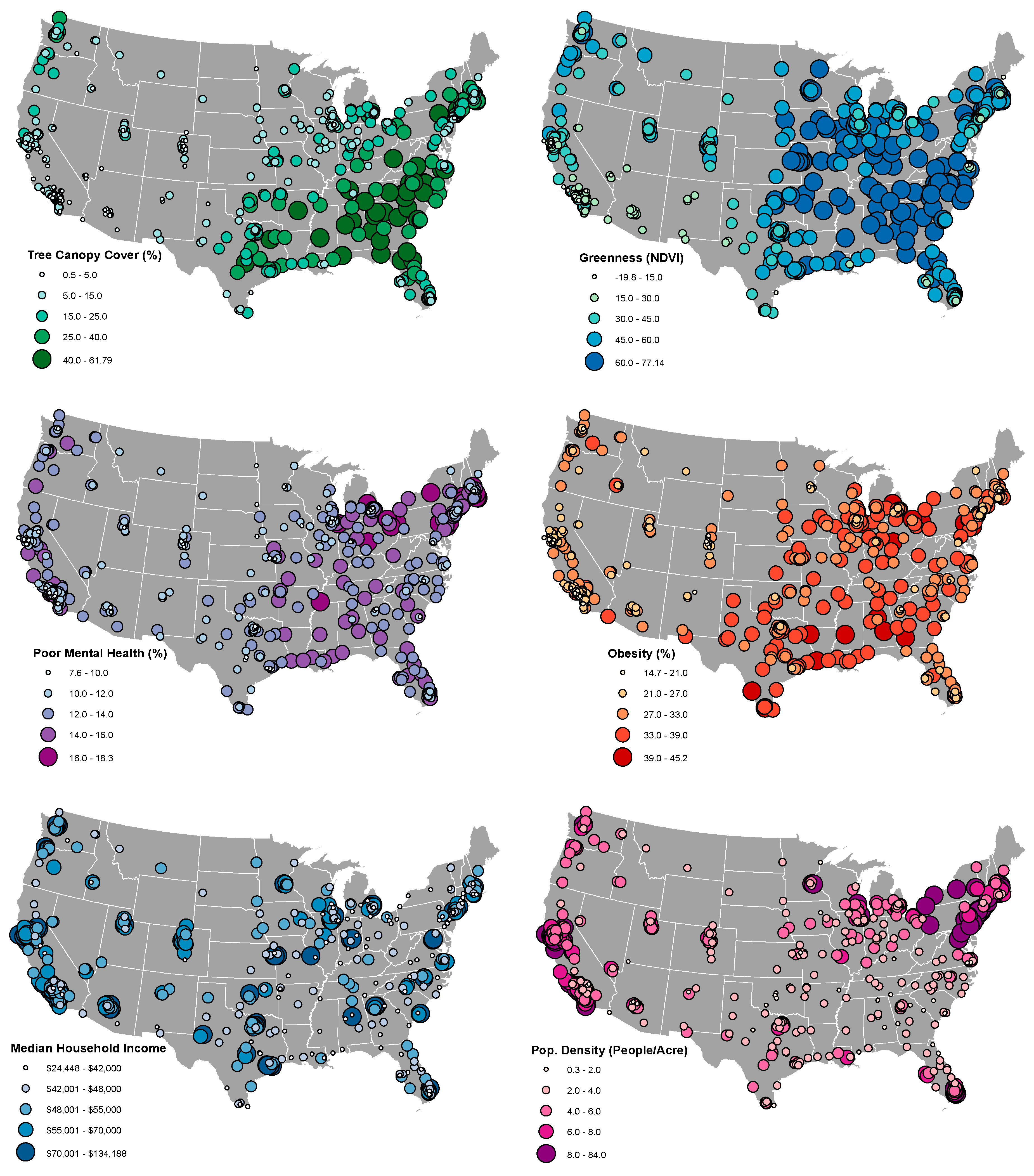
Greenspace data were drawn from two sources to compare between overall “greenness” and tree cover. Greenness was obtained from 250 m NASA’s Moderate Resolution Imaging Spectroradiometer (MODIS) Vegetation Indices [
49]. We calculated the Normalized Difference Vegetation Index (NDVI) from MODIS imagery in the summer months with the most leaf cover (June and July). NDVI shows the density of “greenness” and is calculated with the visible and near-infrared light reflected by vegetation. NDVI typically ranges from −1.0 to 1.0 where −1.0 represents complete cover by water, snow, ice, or rock and 1.0 represents complete cover by healthy green vegetation. We multiplied these values by 100 to create a range more similar to the scales of other variables. Tree cover was obtained from the most recently available nationwide dataset of tree canopy cover at moderately high resolution: the US Forest Service Percent Tree Canopy layer provided by the Multi-Resolution Land Characteristics Consortium in their 2011 National Land Cover Database. These 30 m resolution data used standardized preparation, classification, and quality control protocols to develop a percentage (from 0 to 100%) of tree cover in 65 distinct mapping zones for the continental US from Landsat-5 and Landsat-7 imagery. The resulting data have an average error ranging from 6% to 17% [
50], although underestimates are more common in urban than rural areas [
51]. Citywide greenspace values for both greenness and tree cover were the mean value of all overlapping pixels within municipal boundaries provided by the US Census Bureau’s Topologically Integrated Geographic Encoding and Referencing system [
52]. These calculations were performed with the zonal statistics tool in ArcGIS 10.5.1 (ESRI, Redlands, CA, USA).
Covariate data, including those for possible moderators, were collected from the US Census Bureau’s American Community Survey (ACS) for 2012–2016 (5-year estimates) [
53]. Each year, the US Census Bureau surveys approximately two million US residents to gauge the latest demographics, housing, and employment information. To minimize margins of errors, data for geographies with less than 65,000 people are aggregated for 5-year periods (e.g., 2011–2016). Although 5-year estimates for small geographies, such as block groups or census tracts, have shown very large margins of errors in some circumstances, estimates for larger geographies such as cities have acceptable margins of error [
54]. We collected ACS data for a number of variables describing urban sprawl and socio-demographics factors. For sprawl, we considered
population density (people per acre),
residential density (housing units per acre), and
percent drivers (percentage of people who drive to work alone).
Percent drivers is associated with measures of sprawl, such as population density [
22,
23], as more decentralized and less densely populated cities make public transit less economically viable and likely require more residents to commute via car; therefore,
percent drivers has been used as a proxy for sprawl [
8,
55]. We considered cities with either a high percentage of driving commuters or a higher density as being characterized by higher urban sprawl. We found that
population density and
residential density were highly correlated (
r = 0.94) and, further, that including both measures in initial multivariate models resulted in multicollinearity—Variance Inflation Factor (VIF) values for both variables were over 14.0. Because
population density was more strongly correlated with health outcome variables, we did not use
residential density as a predictor in multivariate analyses but used it instead as one of the moderators (see
Section 2.3). In contrast,
percent drivers showed modest correlation with
population density (
r = −0.63) and including both in multivariate models did not cause multicollinearity. Therefore, both were used in the reported analyses below.
Key demographic variables describing income and race and ethnicity include
median income and
percent White.
Median income describes the citywide median household income values expressed in US dollars, which is a key descriptor of a city’s socioeconomic status.
Percent White describes the percentage of non-Hispanic White residents. In the US, non-Hispanic Whites are the largest racial-ethnic group, making up 61.3% of the total population in 2016 [
53]. Throughout the paper, we use the phrase “race and ethnicity” rather than one of the two terms because
percent White includes elements of both: White (characterized as race) and non-Hispanic (characterized as ethnicity). Over the course of US history, structural racism against racial and ethnic minority people (e.g., non-Hispanic Blacks and Hispanics/Latinos) has led to health inequities, with non-Hispanic Whites experiencing significantly better health outcomes [
56]. Such health inequities, combined with uneven greenspace provisions that also put non-Hispanic Whites at an advantage [
36], warrant the use of
median income and
percent White as moderators of the greenspace-health link.
Other covariates include
percent female (percentage of female residents),
median age (median age of city residents),
total population (number of people permanently residing within city limits),
percent degree (percentage of people aged 25 and older with a bachelor degree or higher), and
median age of housing. We used
median age of housing to model a city’s development timeline: Cities with older residential buildings were likely founded earlier than those with newer residential buildings. Different development timelines might impact the provision of greenspace, as older cities were planned with walkable pocket parks, while newer cities tend to contain larger but less diffuse greenspaces that are intended to be accessible via car [
8]. Lastly,
percent inactive was drawn from the CDC 500 Cities Project. This measure was the percentage of BRFSS respondents who answered “no” to the following question: “During the past month, other than your regular job, did you participate in any physical activities or exercises such as running, calisthenics, golf, gardening, or walking for exercise?”
Table 1 summarizes the variables included in this study.
Datasets were obtained for the closest possible years of overlap. The 2012–2016 ACS data can be considered as an average of 2014 demographic data, which is the temporal midpoint between the two extreme years of data collection. The midpoint matches with the CDC data, which was collected in 2014 and 2015. MODIS data for NDVI-derived greenness were collected during the final year of ACS data, while NLCD tree cover data were collected for the most recent year available (2011). The moderate-resolution remote sensing measures of greenspace coverage do not seem to change much in a 5-year time period, even in cities with intensive urban greening efforts [
57].
2.3. Analyses
We first performed bivariate analyses to test associations between health, greenspace, and covariates. We used Pearson product correlations at an alpha level of p < 0.05. Next, we created multivariate models with each health and each greenspace variable while adjusting for covariates and spatial patterns in the data. Each model included one dependent variable (obesity or poor mental health), one independent variable (greenness or tree cover), and all covariates. Initial analyses with ordinary least squares (OLS) regression showed high variance inflation factor (VIF) values for percent degree and median income. Because the latter was more highly correlated with health and greenspace, percent degree was removed from subsequent models. This solved multicollinearity concerns and all subsequent model VIF values were 3.5 or lower. OLS models also showed that spatial autocorrelation was present in model residuals (Moran’s I for obesity and poor mental health models were statistically significant, p < 0.001). In other words, cities that were closer together shared more similar demographic, health, and greenness characteristics than cities farther away, which, if not corrected for, introduced non-random bias in beta coefficients of regression models.
Given the potential for spatial autocorrelation issues, we used more advanced spatial models. We first ran the LaGrange Multiplier Test to determine which spatial regressions were most likely to resolve spatial autocorrelation concerns [
58]. We then tested how the model fit, as measured by AIC (Akaike Information Criterion), and spatial autocorrelation, as measured by Moran’s I, varied between models. We found that spatial moving average (SMA) models showed moderately higher (poorer) model fit values than some other spatial regression techniques but also non-significant Moran’s I values in greenspace-health models (see
Appendix A,
Table A1), which indicated that spatial autocorrelation effects were resolved. SMA models integrate a kernel function that smooths out random noise across a geographic space while preserving the underlying covariance function [
59]. We thus report our findings based on the SMA models. The comparative model fits, rather than effect sizes or variance, are explained in these models because SMA models use maximum likelihood estimates and introduce kernel smoothing. However, the coefficients for significant greenspace-health relationships are somewhat consistent between models, and OLS models suggested that each 10% increase in greenspace was associated with a 0.2% decrease in obesity, before adjusting for spatial effects.
We then performed moderation tests to examine how the greenspace-health relationship varied across levels of income, race and ethnicity, and sprawl. Flips in the direction of the association between two variables are possible from both moderation and mediation effects, and both effects likely play roles in the greenspace-health relationship. For many epidemiological studies, moderation is more suitable for statistical testing [
4]. Mediation implies that there is a cause-and-effect relationship between the independent variable of interest (i.e., greenspace) and the mediator (i.e., income), whereas moderation does not require a causal relationship [
60]. The greenspace-health literature is dominated by cross-sectional studies such as the current study. Claiming that one variable caused a change in another is therefore not possible [
15,
29]. For this reason, we ran moderation tests rather than mediation tests.
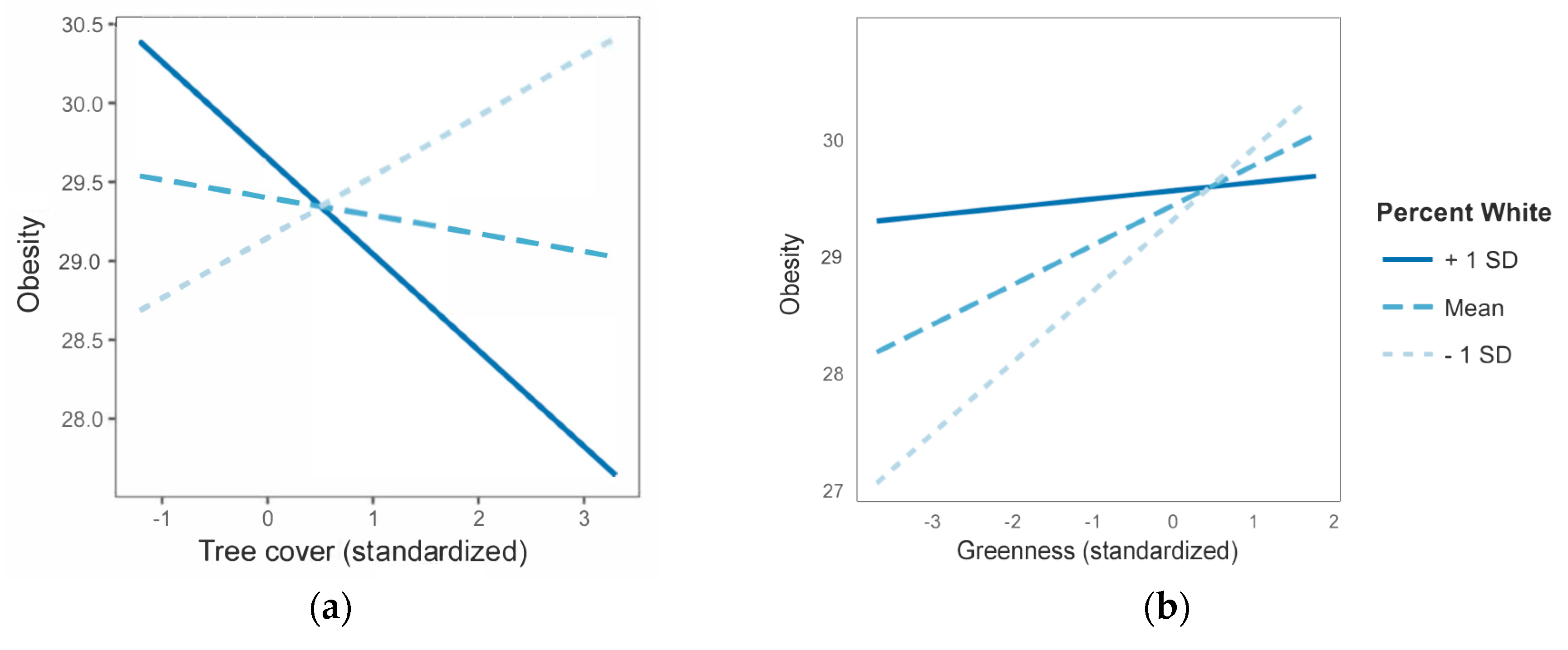
In this study, we tested the moderating effects of five possible variables (
median income,
percent White,
population density,
residential density, and
percent drivers) in each of the four greenspace-health main effect models. We centered and standardized greenspace and the moderators, and we added interaction terms to each model. Statistically significant interaction terms indicated that moderation was present. We then plotted the greenspace-health relationships for the moderators that were significant using line graphs at three values of the moderator: the mean, −1 standard deviations from the mean, and +1 standard deviations from the mean. These plots allowed us to visually examine how moderators impacted the slope and direction (direct or inverse) of the relationship between greenspace and health. Although not central to the research questions of the current study, we also considered
physical inactivity as a potential moderator because exercising in greenspace can improve health outcomes [
4]. However, because we found physical inactivity had no moderation effects on greenspace and
obesity or
poor mental health (data not shown), we do not report any further description of its moderation impact.
Because greenspace provision differs for cities with different racial-ethnic composition [
8], we examined how the greenspace-health relationship varies based on a city’s largest racial-ethnic group. First, as explained above, we tested the percentage of non-Hispanic Whites as a moderating variable in analyses with our full sample (
n = 496). Second, we tested for significant relationships between greenspace and health outcomes in smaller numbers of cities based on racial and ethnic composition. We split our sample into cities with a non-Hispanic Black majority (
n = 44), a Hispanic or Latino majority (
n = 103), or a non-Hispanic White majority (
n = 349). “Majority” was defined by which group had the largest percentage, not which group was 50% of the population or more. Thus, a city like Phoenix, AZ, which has 44% non-Hispanic White and 42% Hispanic, was classified as majority-non-Hispanic White. In summary, we conducted analyses of race-ethnicity with four samples of cities: (1) the entire set of 496 cities; (2) the 44 cities with a non-Hispanic Black population majority; (3) the 103 cities with a Hispanic or Latino population majority; and (4) the 349 cities with a non-Hispanic White population majority.
Analyses were performed using the R statistical software program Version 3.4.2 (R Foundation for Statistical Computing, Vienna, Austria) and RStudio Version 1.1.383 (RSTudio Team, Boston, MA, USA). Datasets were merged through a unique identifier provided for cities by the US Census Bureau.
Supplementary material associated with this article includes a programming script for R Studio Markdown, which details how we merged data and ran analyses included in this paper.



{kind=link}
{kind=link}
{kind=link}