
Predicting the 14-Day Hospital Readmission of Patients with Pneumonia Using Artificial Neural Networks (ANN)

 ,
,
Abstract
:1. Introduction
1.1. Related Work
1.1.1. Hospital Readmissions Are Harmful to Patients
1.1.2. Traditional Solutions Required for Hospital Readmissions
1.1.3. Modern Prediction Models Used for Hospital Readmissions
1.1.4. Topic Selection in Pneumonia
1.2. Study Objectives
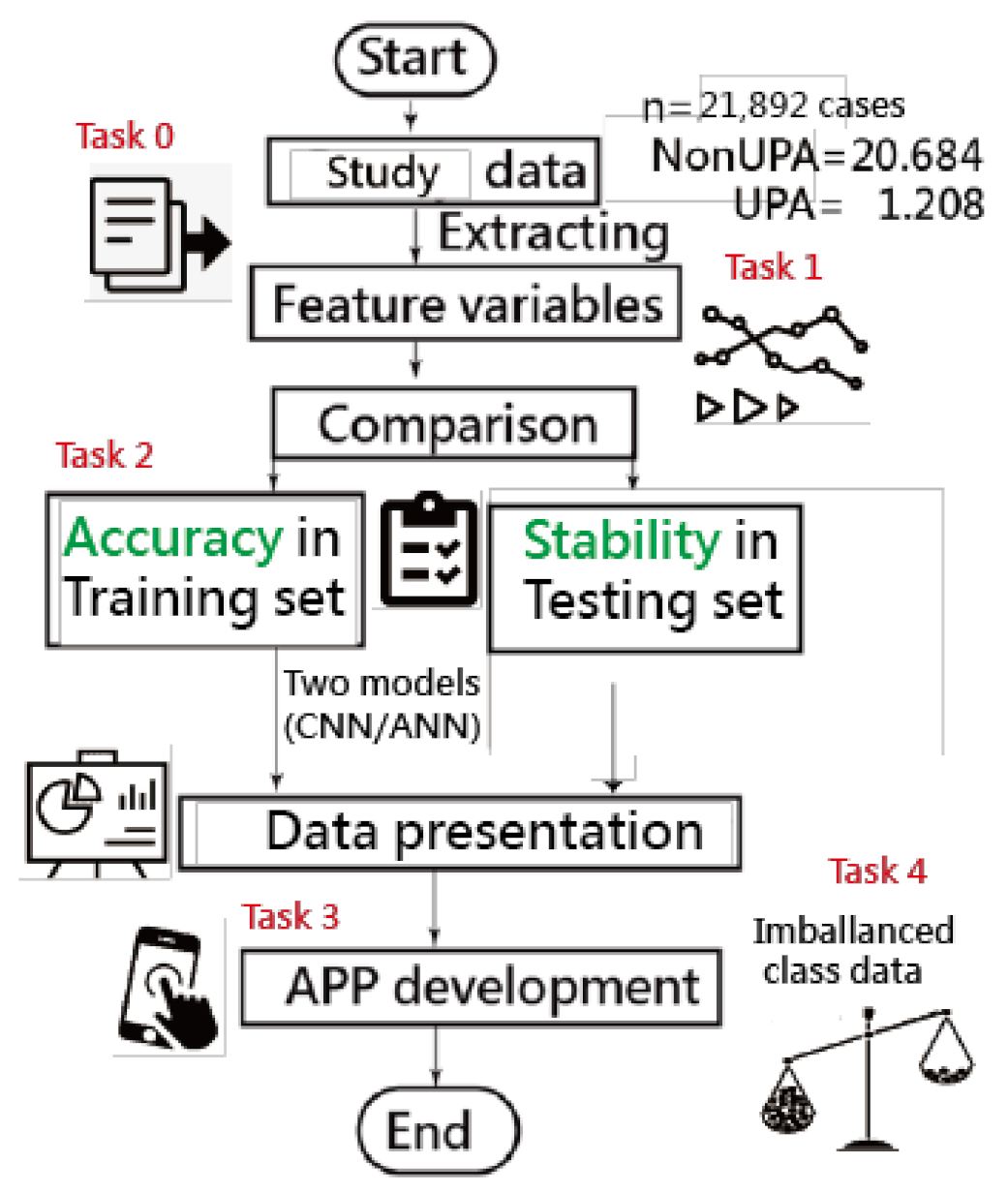
2. Materials and Methods
2.1. Study Sample and Demographic Data
2.2. Feature Variables (Task 1)
2.3. Model Building and Scenarios in Comparison (Task 2)
2.3.1. Models in Comparison
2.3.2. Scenarios in Comparison
2.4. Data Presentations in Results
2.4.1. Presentation 1: Comparison of Accuracy on Two Models
2.4.2. Presentation 2: Comparison of Prediction Models Referring to Algorithms in Weka Software
2.4.3. Presentation 3: Developing an App for Predicting UPRA (Task 3)
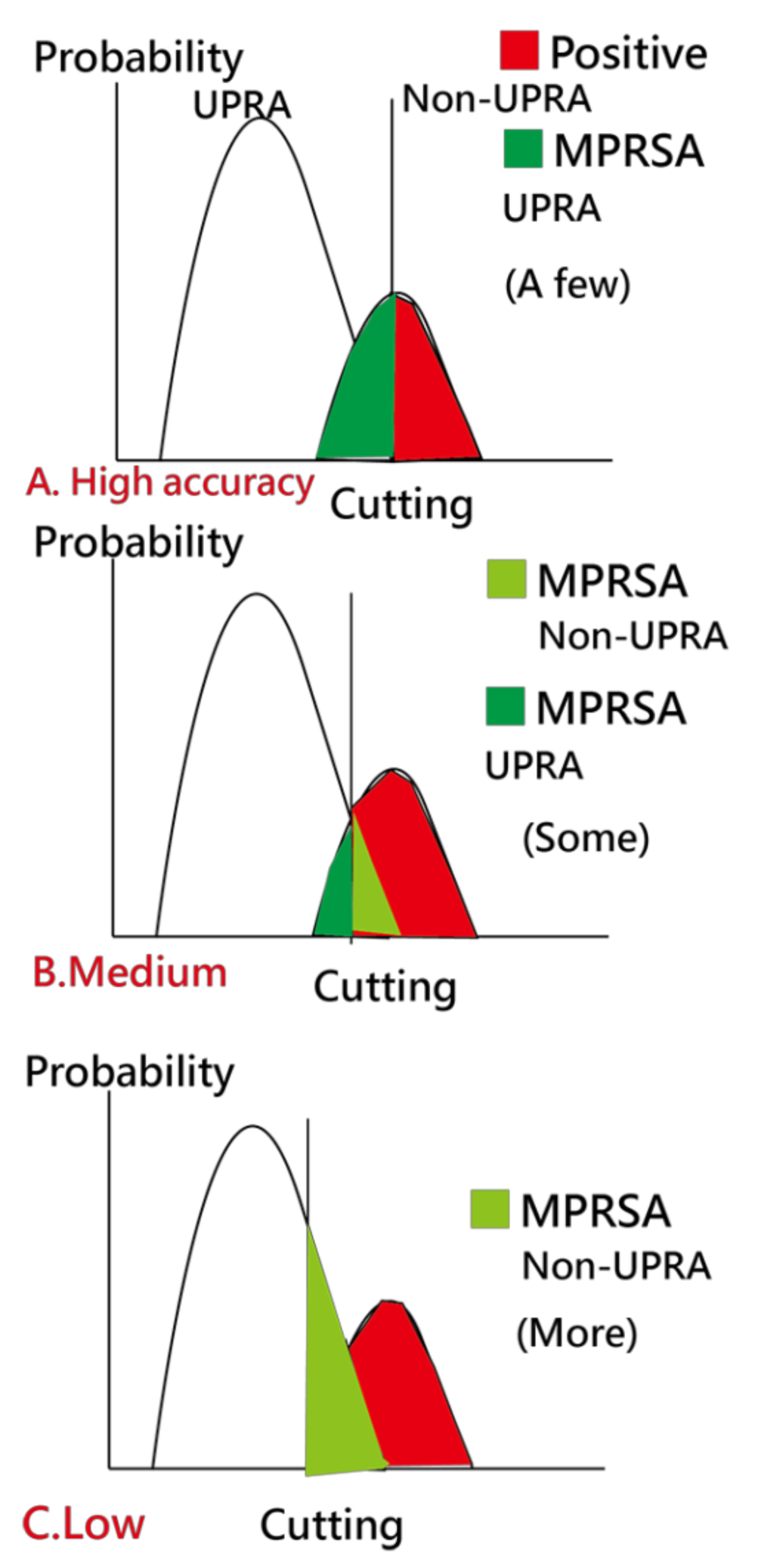
2.4.4. Caution in Estimation of Model Parameters (Task 4)
2.5. Statistical Tools and Data Analysis
3. Results
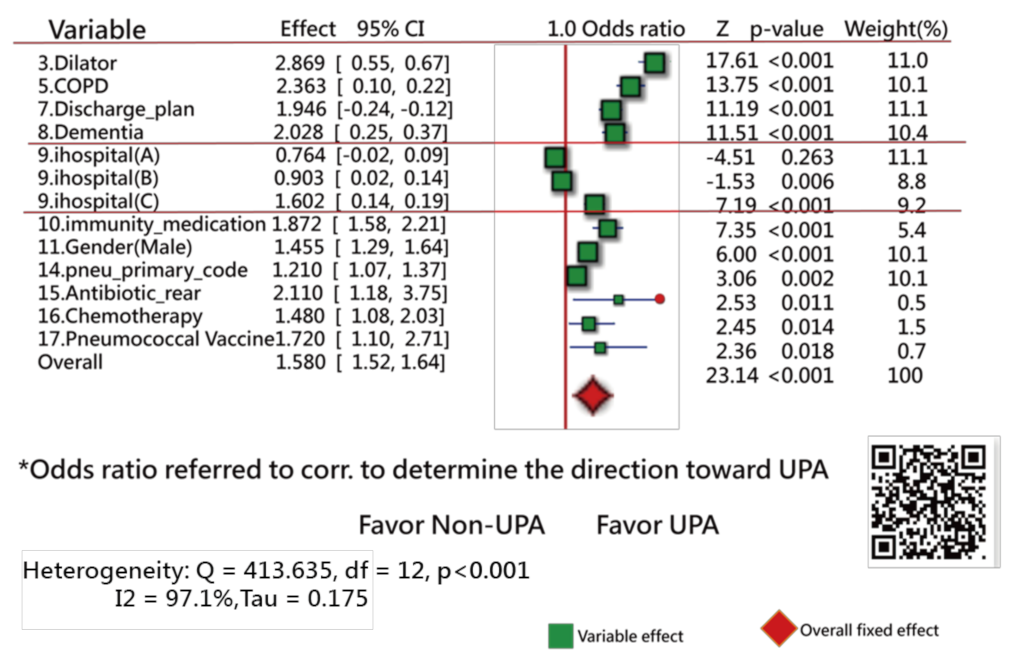
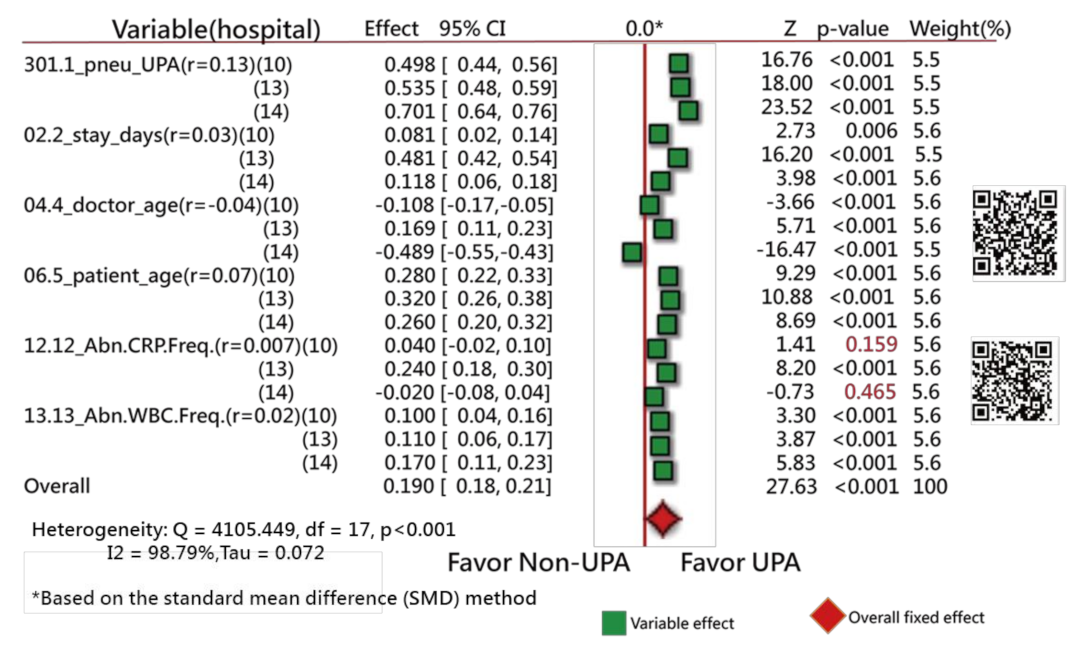
3.1. Task 1: Feature Variables Extracted from the Data
3.2. Task 2: Comparisons of Accuracies in Training and Test Samples
3.3. Task 3: Web-Based Assessment of the App for Predicting UPRA
3.4. Task 4: Cautions Addressed in Estimation of Model Parameters
4. Discussion
4.1. Principal Findings
4.2. What This Finding Adds to What We Already Knew
4.2.1. Literature Reviews of Feature Variables
4.2.2. Comparison of Variables in Different Count Events in Two Groups
4.2.3. Comparison of Model Accuracies in the Literature
4.3. Contributions from This Study
4.3.1. ANN Module Developed on MS Excel
4.3.2. The Imbalanced-Class Data Considered in Estimation of Model Parameters
4.3.3. An App Developed to Predict the UPRA Using Online Visualization
4.3.4. The Forest Plot Used to Interpret the Feature Variables
4.4. Implications and Future Work
4.5. Limitations and Suggestions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Ethics Approval and Consent to Participate
Abbreviations
| AI | artificial intelligence |
| ANN | artificial neural network |
| AUC | area under ROC curve |
| CNN | convolutional neural network |
| KNN | k-nearest neighbor algorithm |
| MPRSA | matching personal response to adapt for the correct classification |
| SD | standard deviation |
| SVM | support vector machines |
| TGHIA | the Taiwan government-run health insurance administration |
| UPRA | unplanned readmission |
Appendix A
Appendix B
Appendix C
References
- Mitchell, R.; Harvey, L.; Stanford, R.; Close, J. Health outcomes and costs of acute traumatic spinal injury in New South Wales, Australia. Spine J. 2018, 18, 1172–1179. [Google Scholar] [CrossRef] [PubMed]
- Chien, T.W. Over 8,818 Articles Searched by the Keyword of Patient Readmission [MeSH Major Topic] Were Found in Pubmed library. Available online: https://pubmed.ncbi.nlm.nih.gov/?term=Patient+Readmission%5BMeSH+Major+Topic%5D (accessed on 20 November 2020).
- Hospital Quality Initiative-Outcome Measures 2016 Chart Book. Available online: https://www.cms.gov/Medicare/Quality-Initiatives-Patient-Assessment-Instruments/HospitalQualityInits/OutcomeMeasures.html (accessed on 20 November 2020).
- Jencks, S.F.; Williams, M.V.; Coleman, E.A. Rehospitalizations among Patients in the Medicare Fee-for-Service Program. N. Engl. J. of Med. 2009, 360, 1418–1428. [Google Scholar] [CrossRef] [PubMed]
- Hines, A.L.; Barrett, M.L.; Jiang, H.J.; Steiner, C.A. Conditions with the Largest Number of Adult Hospital Readmissions by Payer, 2011; Agency for Healthcare Research and Quality: Rockville, MD, USA, 2014. Available online: http://www.hcup-us.ahrq.gov/reports/statbriefs/sb172-Conditions-Readmissions-Payer.pdf (accessed on 20 November 2020).
- Flanagan, J.; Stamp, K.D.; Gregas, M.; Shindul-Rothschild, J. Predictors of 30-Day Readmission for Pneumonia. J. Nurs. Adm. 2016, 46, 69–74. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Covinsky, K.E.; Pierluissi, E.; Johnston, C.B. Hospitalization-associated disability:"She was probably able to ambulate, but I’m not sure". JAMA 2011, 306, 1782–1793. [Google Scholar] [CrossRef]
- National Priorities Partnership. National Priorities and Goals: Aligning Our Efforts to Transform America’s Healthcare; National Quality Forum: Washington, DC, USA, 2008. [Google Scholar]
- The Patient Protection and Affordable Care Act. Available online: https://www.govinfo.gov/content/pkg/PLAW-111publ148/pdf/PLAW-111publ148.pdf (accessed on 20 November 2020).
- Readmissions Reduction Program (HRRP). Available online: https://www.cms.gov/medicare/medicare-fee-for-service-payment/acuteinpatientpps/readmissions-reduction-program.html (accessed on 20 November 2020).
- Ballas, S.K.; Lusardi, M. Hospital readmission for adult acute sickle cell painful episodes: Frequency, etiology, and prognostic significance. Am. J. Hematol. 2005, 79, 17–25. [Google Scholar] [CrossRef] [PubMed]
- Emerson, C.B.; Eyzaguirre, L.M.; Albrecht, J.S.; Comer, A.C.; Harris, A.D.; Furuno, J.P. Healthcare-associated infection and hospital readmission. Infect. Control. Hosp. Epidemiol. 2012, 33, 539–544. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kripalani, S.; Theobald, C.N.; Anctil, B.; Vasilevskis, E.E. Reducing hospital readmission rates: Current strategies and future directions. Annu. Rev. Med. 2014, 65, 471–485. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hansen, L.O.; Young, R.S.; Hinami, K.; Leung, A.; Williams, M.V. Interventions to reduce 30-day rehospitalization: A systematic review. Ann. Intern. Med. 2011, 155, 520–528. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Della, P.R.; Roberts, P.; Goh, L.; Dhaliwal, S.S. Utility of models to predict 28-day or 30-day unplanned hospital readmissions: An updated systematic review. BMJ Open 2016, 6, e011060. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Cui, Z.; Chen, Y.; Avidan, M.; Abdallah, A.B.; Kronzer, A. Predicting Hospital Readmission via Cost-Sensitive Deep Learning. IEEE ACM Trans. Comput. Biol. Bioinform. 2018, 15, 1968–1978. [Google Scholar] [CrossRef] [PubMed]
- Hanley, J.A.; McNeil, B.J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 1983, 148, 839–843. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Z.; Peng, H.; Lan, C.; Zheng, Y.; Fang, L.; Li, J. Imbalance learning for the prediction of N6-Methylation sites in mRNAs. BMC Genom. 2018, 19, 574, PMCID:PMC6090857. [Google Scholar] [CrossRef] [PubMed]
- Lei, T.; Sun, H.; Kang, Y.; Zhu, F.; Liu, H.; Zhou, W.; Wang, Z.; Li, D.; Li, Y.; Hou, T. ADMET Evaluation in Drug Discovery. 18. Reliable Prediction of Chemical-Induced Urinary Tract Toxicity by Boosting Machine Learning Approaches. Mol Pharm. 2017, 14, 3935–3953. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Xiong, Y.; Zhang, Z.Y.; Guo, Q.; Xu, Q.; Liow, H.H.; Zhang, Y.H.; Wei, D.Q. Improved feature-based prediction of SNPs in human cytochrome P450 enzymes. Interdiscip Sci. 2015, 7, 65–77. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Jin, Y.; Zhang, Q. DeepPred-SubMito: A Novel Submitochondrial Localization Predictor Based on Multi-Channel Convolutional Neural Network and Dataset Balancing Treatment. Int. J. Mol. Sci. 2020, 21, 5710. [Google Scholar] [CrossRef] [PubMed]
- Horne, B.D.; Budge, D.; Masica, A.L.; Savitz, L.A.; Benuzillo, J.; Cantu, G.; Bradshaw, A.; McCubrey, R.O.; Bair, T.L.; Roberts, C.A.; et al. Early inpatient calculation of laboratory-based 30-day readmission risk scores empowers clinical risk modification during index hospitalization. Am. Heart J. 2017, 185, 101–109. [Google Scholar] [CrossRef] [PubMed]
- Cronin, P.R.; Greenwald, J.L.; Crevensten, G.C.; Chueh, H.C.; Zai, A.H. Development and Implementation of a Real-Time 30-Day Readmission Predictive Model. AMIA Annu. Symp. Proc. 2014, 2014, 424–431. [Google Scholar] [PubMed]
- Yale New Haven Health Services Corporation–Center for Outcomes Research & Evaluation (YNHHSC/CORE). 2018 Condition-Specific Measures Updates and Specifications Report Hospital-Level 30-Day Risk-Standardized Readmission Measures; Center for Outcomes Research and Evaluation: New Haven, CT, USA, 2018. [Google Scholar]
- Magill, S.S.; Edwards, J.R.; Bamberg, W. Emerging Infections Program Healthcare-Associated Infections and Antimicrobial Use Prevalence Survey Team. Multistate point-prevalence survey of health careassociated infections. N. Engl. J. Med. 2014, 370, 1198–1208. [Google Scholar] [CrossRef] [Green Version]
- Medscape. What Is the Global Prevalence of Pneumonia? Available online: https://www.medscape.com/answers/967822-23537/what-is-the-global-prevalence-of-pneumonia#qna (accessed on 20 November 2020).
- Papazian, L.; Klompas, M.; Luyt, C.E. Ventilator-associated pneumonia in adults: A narrative review. Intensive Care Med. 2020, 46, 888–906, PMCID:PMC7095206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tedja, R.; Gordon, S. Hospital-Acquired, Health Care-Associated, and Ventilator-Associated Pneumonia. 2013. Available online: https://teachmemedicine.org/cleveland-clinic-2/ (accessed on 20 November 2020).
- Markar, S.R.; Walsh, S.R.; Griffin, K.; Khandanpour, N.; Tang, T.Y.; Boyle, J.R. Assessment of a multifactorial risk index for predicting postoperative pneumonia after open abdominal aortic aneurysm repair. Vascular 2009, 17, 36–39. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Ian, H. The WEKA Data Mining Software: An Update. SIGKDD Explor. 2009, 11. Available online: https://www.kdd.org/exploration_files/p2V11n1.pdf (accessed on 20 November 2020).
- Hamling, J.; Lee, P.; Weitkunat, R.; Ambühl, M. Facilitating meta-analyses by deriving relative effect and precision estimates for alternative comparisons from a set of estimates presented by exposure level or disease category. Stat Med. 2008, 27, 954–970. [Google Scholar] [CrossRef]
- Chen, C.J.; Wang, L.C.; Kuo, H.T.; Fang, Y.C.; Lee, H.F. Significant effects of late evening snack on liver functions in patients with liver cirrhosis: A meta-analysis of randomized controlled trials. J. Gastroenterol Hepatol. 2019, 34, 1143–1152. [Google Scholar] [CrossRef]
- Lalkhen, A.G. Statistics V: Introduction to clinical trials and systematic reviews. Contin. Educ. Anaesth. Crit. Care Pain 2008, 8, 143–146. [Google Scholar] [CrossRef]
- Linarcre, J.M. Logit and Probit: What Are They? Available online: https://www.winsteps.com/winman/whatisalogit.htm (accessed on 20 October 2020).
- Camilli, G. Origin of the Scaling Constant d=1.7 in Item Response Theory. J. Educ. Behav. Stat. 1994, 19, 293–295. [Google Scholar] [CrossRef]
- Norman, D.; VerhelstI, W.; Molenaar. Logit based parameter estimation in the Rasch model. Stat. Neerl. 1988, 42, 273–295. [Google Scholar]
- Wright, B.D. Solving measurement problems with the Rasch model. J. Educ. Meas. 1977, 14, 97–116. [Google Scholar] [CrossRef]
- Ma, S.C.; Chou, W.; Chien, T.W.; Chow, J.C.; Yeh, Y.T.; Chou, P.H.; Lee, H.F. An App for Detecting Bullying of Nurses Using Convolutional Neural Networks and Web-Based Computerized Adaptive Testing: Development and Usability Study. JMIR Mhealth Uhealth 2020, 8, e16747. [Google Scholar] [CrossRef]
- Lee, Y.L.; Chou, W.; Chien, T.W.; Chou, P.H.; Yeh, Y.T.; Lee, H.F. An App Developed for Detecting Nurse Burnouts Using the Convolutional Neural Networks in Microsoft Excel: Population-Based Questionnaire Study. JMIR Med. Inform. 2020, 8, e16528, PMCID:PMC7243132. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.H.; Chien, T.W.; Yeh, Y.T.; Chou, W.; Hsing, S.C. An App for Classifying Personal Mental Illness at Workplace Using Fit Statistics and Convolutional Neural Networks: Survey-Based Quantitative Study. JMIR Mhealth Uhealth 2020, 8, e17857. [Google Scholar] [CrossRef]
- Chou, P.H.; Chien, T.W.; Yang, T.Y.; Yeh, Y.T.; Chou, W.; Yeh, C.H. Predicting Active NBA Players Most Likely to Be Inducted into the Basketball Hall of Famers Using Artificial Neural Networks in Microsoft Excel: Development and Usability Study. Int. J. Environ. Res. Public Health 2021, 18, 4256. [Google Scholar] [CrossRef]
- Rasch, G. Probabilistic Models for Some Intelligence and Attainment Tests; University of Chicago Press: Chicago, IL, USA, 1980. [Google Scholar]
- Chien, T.W. Video Abstract on UPRA App. Available online:https://youtu.be/Xj9pJMxfs0o (accessed on 14 April 2021).
- Chien, T.W. UPRA App on Forest Plot for Discrete Feature Variables. Available online: http://www.healthup.org.tw/gps/UPA14daysfeature2020.htm (accessed on 14 April 2021).
- Chien, T.W. UPRA App on Forest Plot for Continuous Feature Variables. Available online: http://www.healthup.org.tw/gps/UPA14daysfeature20202.htm (accessed on 14 April 2021).
- Chien, T.W. UPRA App Version of Using Paste Function. Available online: http://www.healthup.org.tw/irs/annreadimision14.asp (accessed on 14 April 2021).
- Chien, T.W. UPRA App Version of Using Input Data Approach. Available online: http://www.healthup.org.tw/irs/irsin_e.asp?type1=94 (accessed on 14 April 2021).
- Barman, N.N.; Patil, S.S.; Kurli, R.; Deka, P.; Bora, D.P.; Deka, G.; Ranjitha, K.M.; Shivaranjini, C.; Roy, P.; Suresh, K.P. Meta-analysis of the prevalence of livestock diseases in North Eastern Region of India. Vet. World 2020, 13, 80–91, PMCID:PMC7020116. [Google Scholar] [CrossRef] [PubMed]
- Prescott, H.C.; Sjoding, M.W.; Iwashyna, T.J. Diagnoses of early and late readmissions after hospitalization for pneumonia. A systematic review. Ann. Am. Thorac. Soc. 2014, 11, 1091–1100, PMCID:PMC4214054. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bohannon, R.W.; Maljanian, R.D. Hospital readmissions of elderly patients hospitalized with pneumonia. Conn. Med. 2003, 67, 599–603. [Google Scholar] [PubMed]
- Mather, J.F.; Fortunato, G.J.; Ash, J.L.; Davis, M.J.; Kumar, A. Prediction of pneumonia 30-day readmissions: A single-center attempt to increase model performance. Respir Care 2014, 59, 199–208. [Google Scholar] [CrossRef] [PubMed]
- Dobler, C.C.; Hakim, M.; Singh, S.; Jennings, M.; Waterer, G.; Garden, F.L. Ability of the LACE index to predict 30-day hospital readmissions in patients with community-acquired pneumonia. ERJ Open Res. 2020, 6, 00301–2019, PMCID:PMC7369430. [Google Scholar] [CrossRef] [PubMed]
- Makam, A.N.; Nguyen, O.K.; Clark, C.; Zhang, S.; Xie, B.; Weinreich, M.; Mortensen, E.M.; Halm, E.A. Predicting 30-Day Pneumonia Readmissions Using Electronic Health Record Data. J. Hosp. Med. 2017, 12, 209–216, PMCID:PMC6296251. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weinreich, M.; Nguyen, O.K.; Wang, D.; Mayo, H.; Mortensen, E.M.; Halm, E.A.; Makam, A.N. Predicting the Risk of Readmission in Pneumonia. A Systematic Review of Model Performance. Ann. Am. Thorac. Soc. 2016, 13, 1607–1614, PMCID:PMC5059500. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tonkikh, O.; Shadmi, E.; Flaks-Manov, N.; Hoshen, M.; Balicer, R.D.; Zisberg, A. Functional status before and during acute hospitalization and readmission risk identification. J. Hosp. Med. 2016, 11, 636–641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, K.-P.; Chen, P.-C.; Huang, L.-Y.; Mao, H.-C.; Chan, D.-C.D. Predicting Inpatient Readmission and Outpatient Admission in Elderly: A Population-Based Cohort Study. Medicine 2016, 95, e3484. [Google Scholar] [CrossRef] [PubMed]
- Shorr, A.F.; Zilberberg, M.D.; Reichley, R.; Kan, J.; Hoban, A.; Hoffman, J.; Micek, S.T.; Kollef, M.H. Readmission following hospitalization for pneumonia: The impact of pneumonia type and its implication for hospitals. Clin. Infect. Dis. 2013, 57, 362–367. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andruska, A.; Micek, S.T.; Shindo, Y.; Hampton, N.; Colona, B.; McCormick, S.; Kollef, M.H. Pneumonia Pathogen Characterization Is an Independent Determinant of Hospital Readmission. Chest 2015, 148, 103–111, PMCID:PMC7127757. [Google Scholar] [CrossRef] [PubMed]
- Kansagara, D.; Englander, H.; Salanitro, A.; Kagen, D.; Theobald, C.; Freeman, M.; Kripalani, S. Risk prediction models for hospital readmission: A systematic review. JAMA 2011, 306, 1688–1698. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mellors, B.O.L.; Spear, A.M.; Howle, C.R.; Curtis, K.; Macildowie, S.; Dehghani, H. Machine learning utilising spectral derivative data improves cellular health classification through hyperspectral infrared spectroscopy. PLoS ONE 2020, 15, e0238647. [Google Scholar] [CrossRef]
- Singh, V.K.; Maurya, N.S.; Mani, A.; Yadav, R.S. Machine learning method using position-specific mutation based classification outperforms one hot coding for disease severity prediction in haemophilia ‘A’. Genomis 2020, 12, 5122–5128. [Google Scholar] [CrossRef]
- Frenkenfield, J. Artificial neural network (ANN). Available online: https://www.investopedia.com/terms/a/artificial-neural-networks-ann.asp (accessed on 10 October 2020).
- Zhang, Z.; Lim, G.; Falissard, L.; Morgand, C.; Roussel, S.; Imbaud, C.; Ghosn, W.; Bounebache, K.; Rey, G. A Deep Artificial Neural Network−Based Model for Prediction of Underlying Cause of Death From Death Certificates: Algorithm Development and Validation. JMIR Med. Inform. 2020, 8, e17125, PMCID:PMC7218605. [Google Scholar] [CrossRef] [PubMed]
- Chien, T.W. Comparison of Feature Variables among Groups. Available online: http://www.healthup.org.tw/gps/UPPhopitalvar.htm (accessed on 20 November 2020).
- Chien, T.W. Comparison of Feature Variables among Groups. Available online: http://www.healthup.org.tw/gps/UPPhopitalvar2.htm (accessed on 20 November 2020).
- Mohammadi, R.; Jain, S.; Namin, A.T.; Heller, M.S.; Palacholla, R.; Kamarthi, S.; Wallace, B. Predicting Unplanned Readmissions Following a Hip or Knee Arthroplasty: Retrospective Observational Study. JMIR Med. Inform. 2020, 8, e19761. [Google Scholar] [CrossRef] [PubMed]
- Chien, T.-W.; Lin, W.-S.; De Beurs, D.; Bidmon, S. Improving Inpatient Surveys: Web-Based Computer Adaptive Testing Accessed via Mobile Phone QR Codes. JMIR Med. Inform. 2016, 4, e8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hulin, C.; Drasgow, F.; Parsons, C. Item Response Theory: Applications to Psychological Measurement; Dow & Jones Irwin: Homewood, CA, USA, 1983. [Google Scholar]
- Vest, J.R.; Gamm, L.D.; Oxford, B.A.; Gonzalez, M.I.; Slawson, K.M. Determinants of preventable readmissions in the United States: A systematic review. Implement. Sci. IS 2010, 5, 88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berry, J.G.; Ziniel, S.I.; Freeman, L.; Kaplan, W.; Antonelli, R.; Gay, J.; Coleman, E.A.; Porter, S.; Goldmann, D. Hospital readmission and parent perceptions of their child’s hospital discharge. Int. J. Qual. Health Care 2013, 25, 573–581. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chien, T.W. 30-Day Readmission in Pubmed. Available online: https://pubmed.ncbi.nlm.nih.gov/?term=30-day+and+readmission+and+hospital&sort=date (accessed on 20 November 2020).
- Kim, H.; Hung, W.W.; Paik, M.C.; Ross, J.S.; Zhao, Z.; Kim, G.S.; Boockvar, K. Predictors and outcomes of unplanned readmission to a different hospital. Int. J. Qual. Health Care 2015, 27, 513–519. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Testing Set | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | n1 | SENS | SPEC | ACC | AUC | SENS | SPEC | ACC | AUC |
| A: Machine learning algorithms in the Weka software (based on maximum accuracy) | |||||||||
| BayesNet | 15,324 | 0.00 | 1.00 | 0.93 | 0.50 | ||||
| Logistic | 15,324 | 0.00 | 1.00 | 0.93 | 0.53 | ||||
| NaiveBayes | 15,324 | 0.01 | 0.99 | 0.93 | 0.53 | ||||
| SMO | 15,324 | 0.00 | 1.00 | 0.93 | 0.50 | ||||
| RandomForest | 15,324 | 0.00 | 1.00 | 0.93 | 0.50 | ||||
| MultiLayer | 15,324 | 0.00 | 1.00 | 0.93 | 0.63 | ||||
| REPTree | 15,324 | 0.00 | 1.00 | 0.93 | 0.50 | ||||
| JRIP | 15,324 | 0.00 | 1.00 | 0.93 | 0.50 | ||||
| LinSVM | 15,324 | 0.00 | 1.00 | 0.93 | 0.50 | ||||
| J48 (Tree) | 15,324 | 0.00 | 1.00 | 0.93 | 0.50 | ||||
| B. CNN & ANN | n1 n2 | ||||||||
| CNN | 15,324/6568 | 0.80 | 0.21 | 0.24 | 0.51 | 0.88 | 0.10 | 0.13 | 0.50 |
| ANN | 15,324/6568 | 0.80 | 0.70 | 0.70 | 0.75 * | 0.69 | 0.77 | 0.77 | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tey, S.-F.; Liu, C.-F.; Chien, T.-W.; Hsu, C.-W.; Chan, K.-C.; Chen, C.-J.; Cheng, T.-J.; Wu, W.-S. Predicting the 14-Day Hospital Readmission of Patients with Pneumonia Using Artificial Neural Networks (ANN). Int. J. Environ. Res. Public Health 2021, 18, 5110. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18105110
Tey S-F, Liu C-F, Chien T-W, Hsu C-W, Chan K-C, Chen C-J, Cheng T-J, Wu W-S. Predicting the 14-Day Hospital Readmission of Patients with Pneumonia Using Artificial Neural Networks (ANN). International Journal of Environmental Research and Public Health. 2021; 18(10):5110. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18105110
Chicago/Turabian StyleTey, Shu-Farn, Chung-Feng Liu, Tsair-Wei Chien, Chin-Wei Hsu, Kun-Chen Chan, Chia-Jung Chen, Tain-Junn Cheng, and Wen-Shiann Wu. 2021. "Predicting the 14-Day Hospital Readmission of Patients with Pneumonia Using Artificial Neural Networks (ANN)" International Journal of Environmental Research and Public Health 18, no. 10: 5110. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18105110