3.1. The Distribution Characteristics of NAIs at Different Time Scales
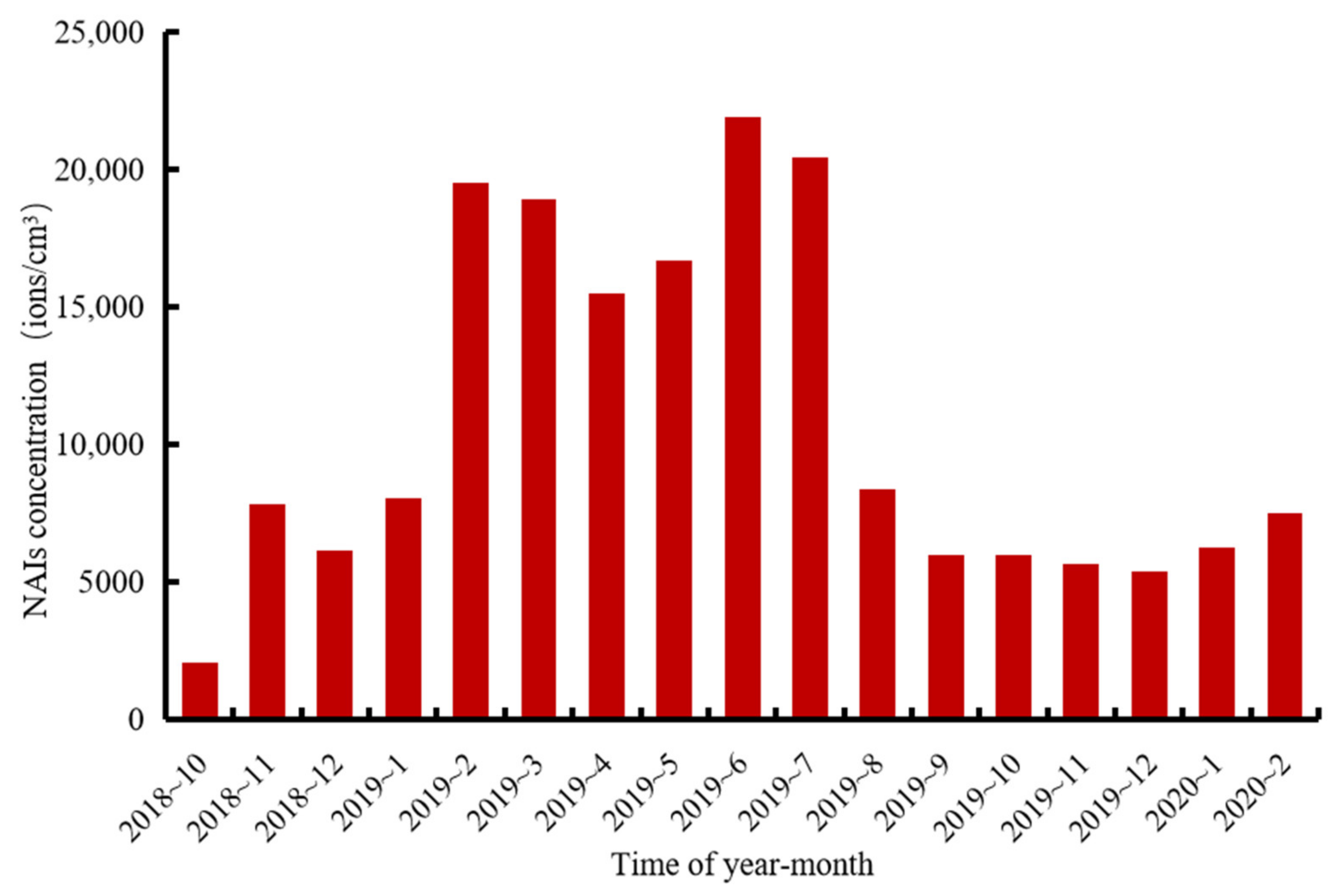
By analyzing the monthly data of NAI concentrations from October 2018 to January 2020 (as shown in
Figure 4), we could see that NAI concentrations from February to July 2019 were much higher than in other time periods, while NAI concentrations were low in October 2018 to January 2019 and August 2019 to February 2020. The above two figures showed clear seasonality in the monthly distribution of NAIs concentrations, with higher concentrations in spring and summer and lower concentrations in autumn and winter. We also found that the lower NAI concentrations occurred in the summer months of August.
The NAI concentration value of August 2019 was much lower than July 2019. We further verified this phenomenon using correlation analysis between NAIs and meteorological factors in
Table 1 based on raw hourly data. Specifically, we divided 1 December 2018 at 0:00 to 30 November 2019 into four parts according to the seasons. From 1 December 2018 to 28 February 2019 was defined as winter, from 1 March 2019 to 31 May 2019 was defined as spring, from 1 June 2019 to 31 August 2019 was defined as summer and from 1 September 2019 to 30 November 2019 was defined as autumn. We matched hourly data for meteorological factors with hourly data for NAIs on a time series. For missing values of NAIs, we censored the meteorological data for the same time and matched them.
The results showed that different meteorological factors influenced NAIs in different seasons, with relative humidity being significantly (positively) correlated (
p < 0.01) with NAI concentrations in all seasons. The (positive) correlation (
p < 0.05) between precipitation and NAI concentrations occurred only in spring. The fact that rainfall had less impact on NAI concentrations was due to the drought suffered in summer and autumn 2019, as shown in
Table 1. Remarkably, the highest the value of Pearson correlation for meteorological factors was 0.306 from RHU in winter, so we used a multiple linear regression model to further explore the contribution of meteorological factors to NAIs.
The study further analyzed the contribution of the meteorological factors with
p < 0.01 in
Table 1 to the NAIs using the multiple linear regression model as shown in
Table 2. The meteorological factors in winter contributed the most to NAI concentrations, and the value of R
2 was 0.224. Meteorological factors in other seasons contributed less to NAI concentrations.
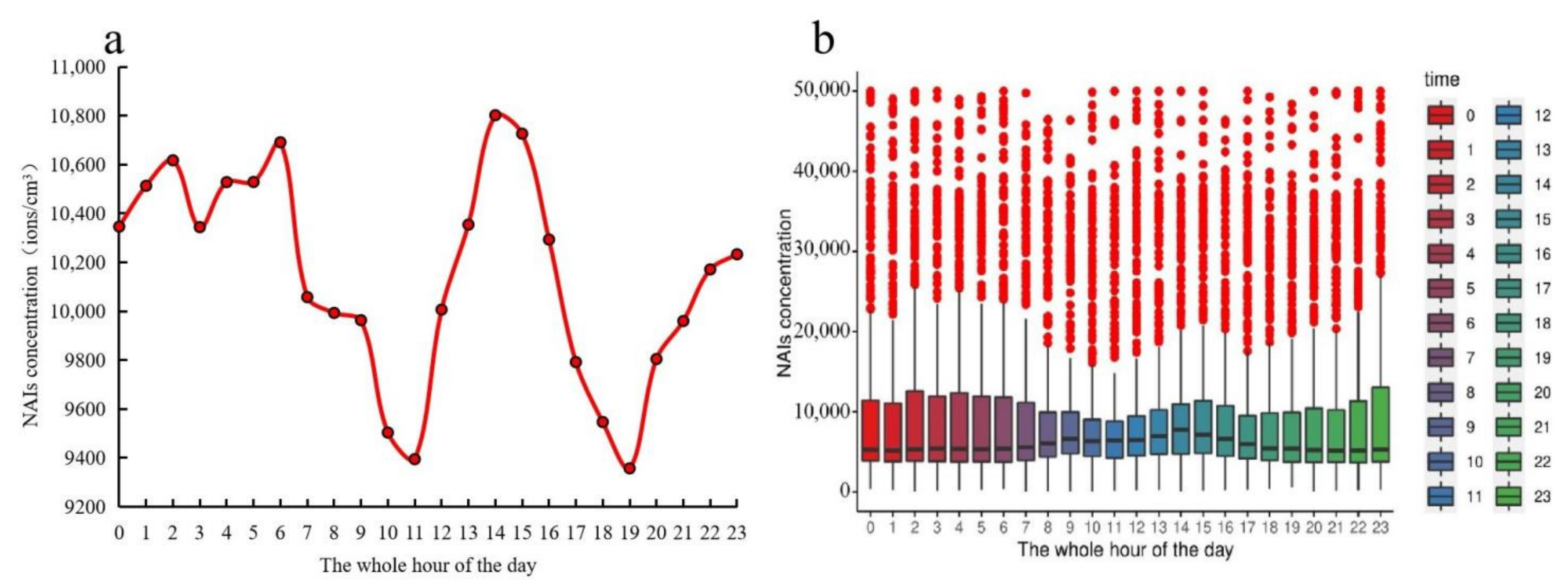
The average hourly value of NAI concentration distribution a day showed an approximate increasing trend from 19:00–6:00 and was much higher in 6:00 and 14:00–15:00. Overall, NAI concentrations were higher at midday and in the afternoon and were lower in 10:00–11:00 in the morning and 19:00 (
Figure 5a). Due to the excessive amount of data, the data overlaps, so we calculated the mathematical statistics for the raw hourly data based on the boxplot (
Figure 5b). The value of the boxplot includes the maximum, third quartile, medium, first quartile, minimum and outliers. The maximum NAI concentration in the figure is 50,000, which is because the range of the negative oxygen ion monitoring instrument that can be monitored is 0–50,000. We can see that the value of the median, maximum, third quartile and first quartile of the hour of the day was roughly similar to the trend in
Figure 5a.
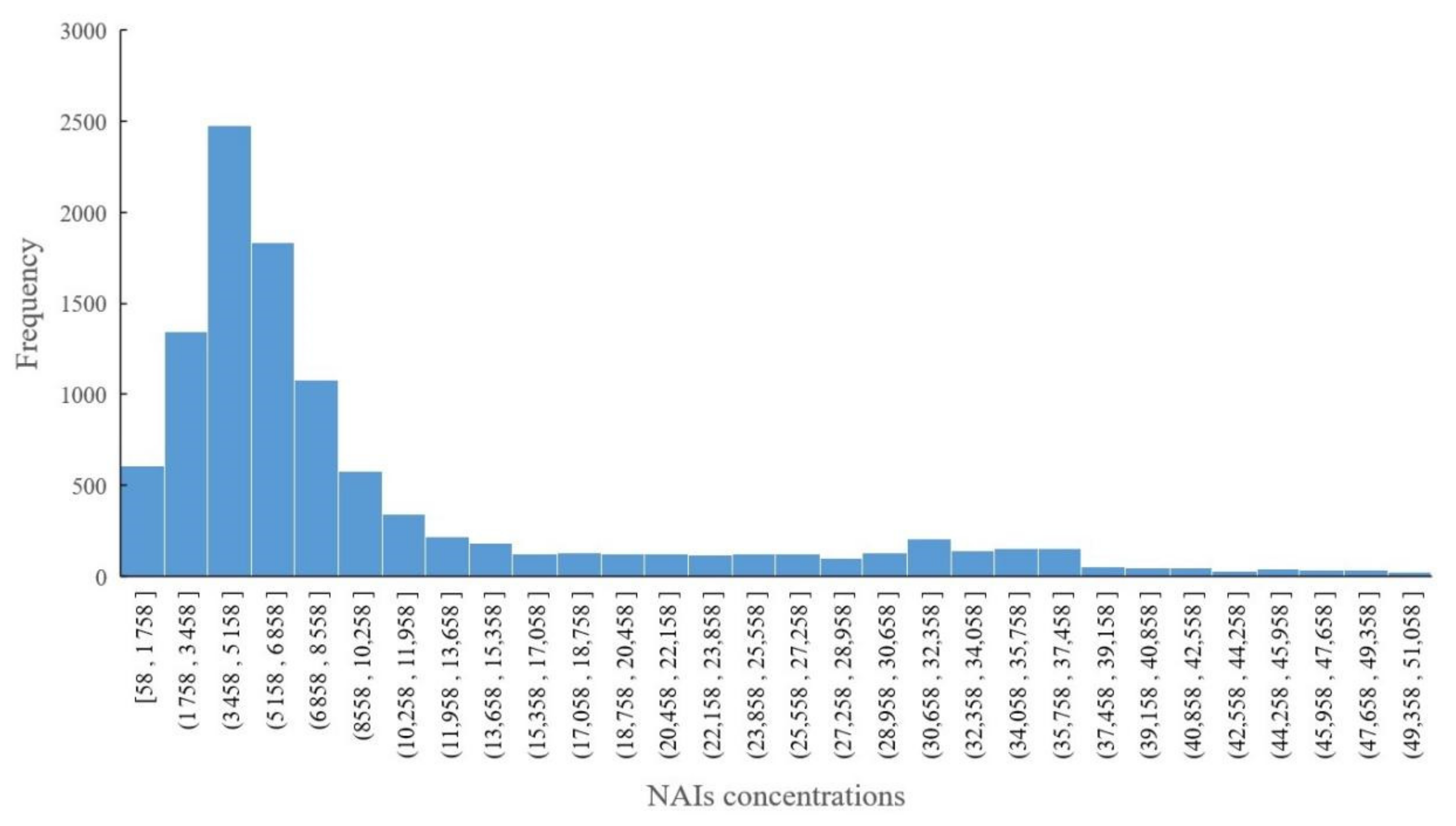
We calculated the frequency of NAI concentration intervals based on hourly data from 1 November 2018 00:00 to 20 February 2020 20:00, as shown in
Figure 6. The NAI concentration range of its frequency over 500 includes [58, 1758], (1758, 3458], (3458, 5158], (5158, 6858], (6858, 8558] and (8558, 10,258]; these interval segments are connected to each other, and connecting them to each other forms a new interval, which is (58, 10,258). Among [58, 10258], the interval [3458, 5158] has the highest frequency, reaching 2477. These results show that as the concentration of NAIs increases, the frequency also becomes very low, and the frequency of outliers in NAI concentrations is also relatively small.
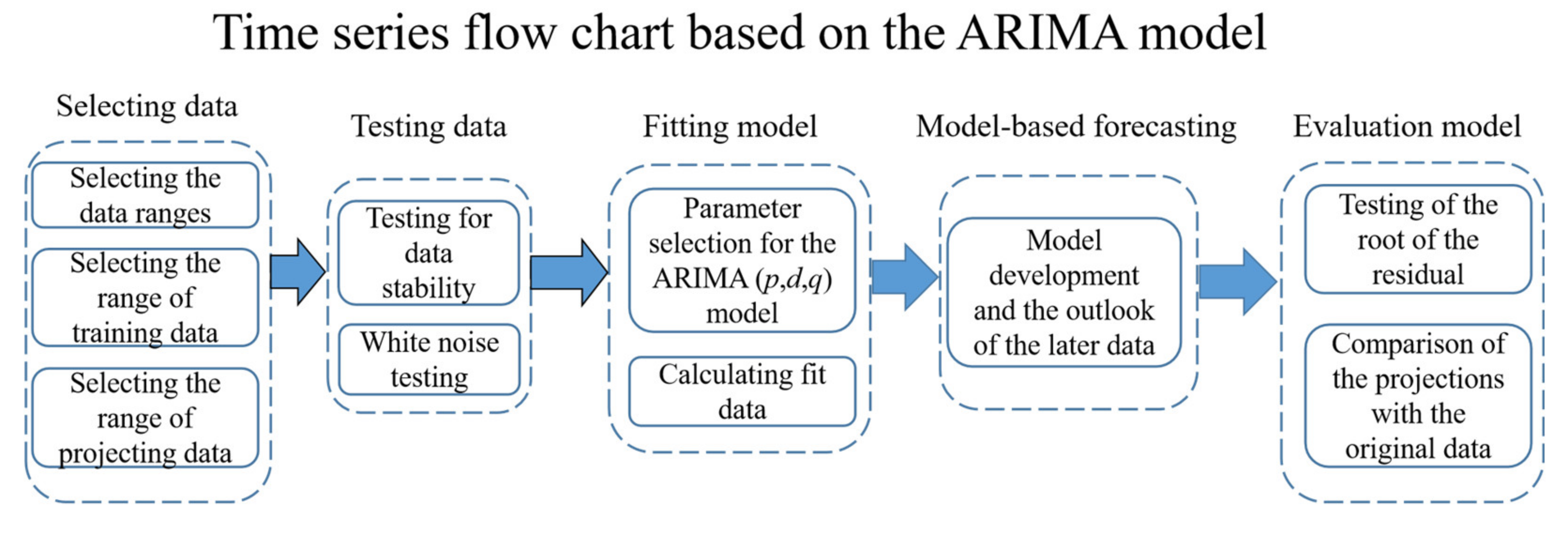
3.2. Filling in Missing Values of NAI Concentrations by Developing ARIMA Time Series Models
We used the average weekly value as weekly values and combined them into 68 weeks of data. The first 55 weeks were the training data, and the NAIs were predicted for 56–68 weeks.
The data for week 28 were null, and we took the ARIMA model in the short-range to fill the missing values from the R package “forecast”. We used the predicted value output by the ARIMA model to fill in missed values. First, we performed the stationarity test and white noise test on the data of 1–27 weeks and fitted the ARIMA (p, d, q) model. The smoothness test result was p-value = 0.4322 > 0.05, so we needed to perform one differentiation in the time series. After one differentiation, we secondly performed the smoothness test and the result was p-value = 0.05, which passed the smoothness test, but it did not pass the white noise test because p-value = 0.08486 > 0.05. The new series passed the smoothness test with p-value = 0.01203 < 0.05 and the white noise test with p = 0.004859 < 0.05. Finally, we defined the d value of ARIMA (p, d, q), which was 2.
We fitted different ARIMA models to compare their accuracy measures, as shown in
Table 3. For parameter
p and
q, we simulated the
p,
q values in different models and chose the most appropriate model by comparing the Akaike information criterion (AIC), mean error (ME), root mean squared error (RMSE), mean absolute error (MAE), maximum permissible error (MPE), mean absolute percentage error (MAPE, %), the mean absolute scaled error (MASE) and ACF1 (auto correlation of errors at lag 1). We found that the RMSE and AIC was smallest when (
p,
d,
q) was (
0,
2,
2) and used 2,6238.82 to be the predicted value of this model to fill the missed value.
After completing the model, we tested the fit model consisting of a white noise test on the residual test series. The “white noise” was different from the white noise before modeling, and we hoped that the residuals of the model were completely random series, i.e., the white noise series. The residual white noise of ARIMA (0, 2, 2) model was tested by the Ljung–Box test; the p-value was 0.803, which indicated that the residuals were not autocorrelated, and the residual was a sequence of the white noise.
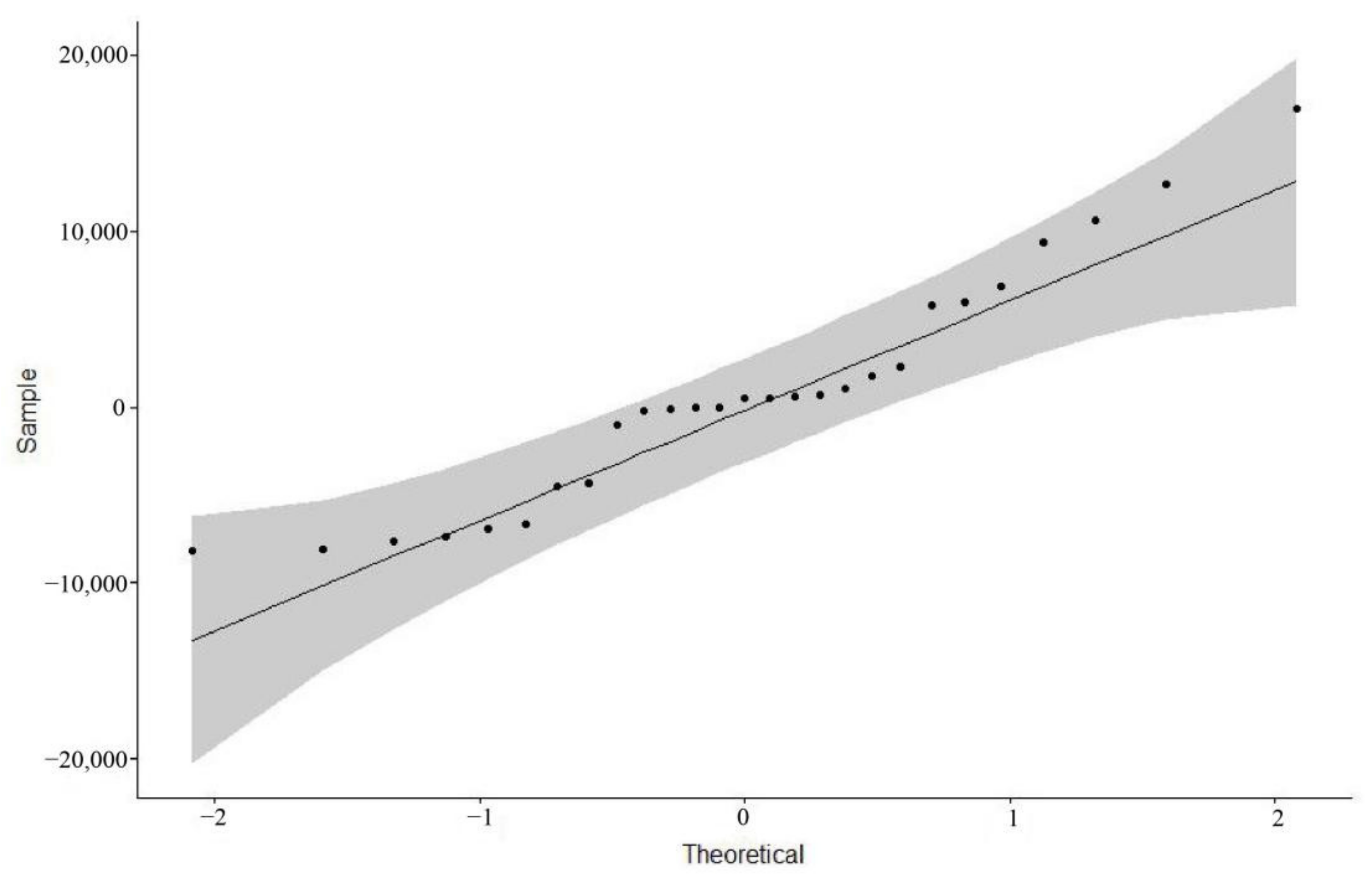
Then, we tested the residuals of the ARIMA (
0, 2, 2) model for normality by plotting a QQ plot of the normality test, by drawing a 45-degree line relative to the x and y axes and visually observing whether the points representing the residuals fell on or near the 45-degree line, and the grey area in the graph represents the 95% confidence interval of the normal distribution (
Figure 7). All values were inside the grey area. Our result indicated that the residuals passed the normality test and showed that the established ARIMA (
0, 2, 2) model was reasonable.
3.3. Making the Outlook of NAIs Concentrations by Developing ARIMA Time Series Models
After filling in the missing data from week 28 using ARIMA (0, 2, 2), we started to make the outlook the data from weeks 56–68 based on the ARIMA model for data from weeks 1–55. According to the smoothness test for the raw data, its p-value was 0.6033, which was greater than 0.05, then it failed to do the smoothness test. We needed to differentiate the data to make it stable.
Next, we differenced the data once, then the p-value was less than 0.05, which passed the smoothness test, and the differenced time series was a smooth time series. The differential data were tested for white noise (p-value = 0.002258) and passed the white noise test, so the data were smooth non-white noise data and could be fitted to the ARIMA model.
Here, we selected the ARIMA (
p,
d,
q) model parameters, where
d = 1 since the previous data were differenced once. For parameter
p and
q, we simulated the
p,
q values in different models and chose the most appropriate model by comparing the Akaike information criterion (AIC), mean error (ME), root mean squared error (RMSE), mean absolute error (MAE), maximum permissible error (MPE), mean absolute percentage error (MAPE, %), the mean absolute scaled error (MASE) and ACF1 (auto correlation of errors at lag 1), as shown in
Table 4. We found that the RMSE and AIC was smallest when (
p,
d,
q) was (
1,
1,
1), (
0,
1,
1), (
0,
1,
2), (
2, 1, 0) and
(2,
1, 1). Combining the other metrics, we finally chose (
0,
1,
1) as the (
p,
d,
q) value of the model.
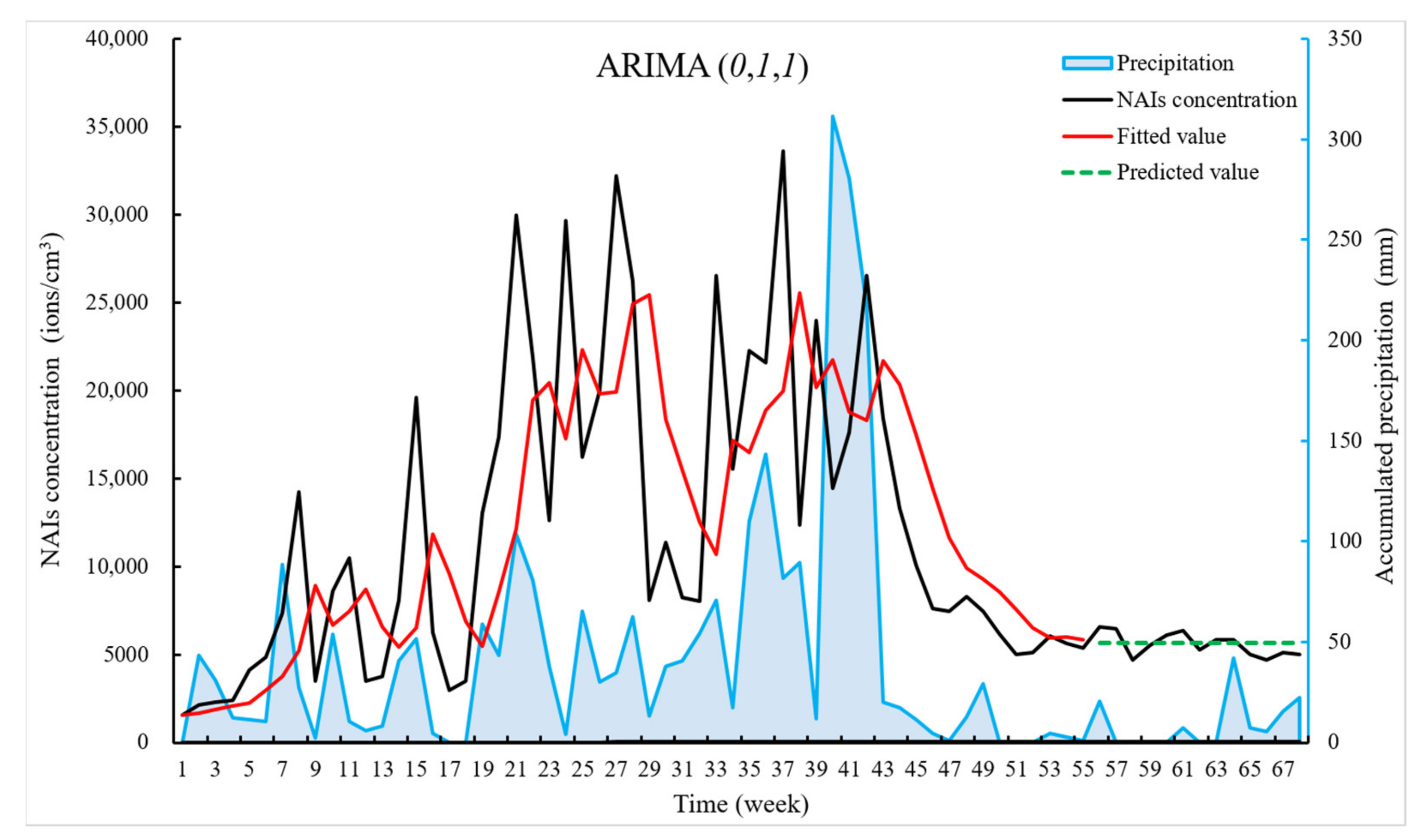
We predicted NAI concentrations for 56–68 weeks and plotted them in a time series plot based on the ARIMA (
0, 1, 1) model, as shown in
Figure 8. ARIMA (
0, 1, 1), compared to the other ARIMA series model, had fitted values for 1–55 weeks that were relatively rightward skewed due to the one difference, which had less impact on the results. The ARIMA (
0, 1, 1) model had relatively low values of AIC, RMSE, etc., and could largely predict trends in NAIs well over the next 13 weeks.
Besides, the study found that the weekly precipitation and weekly NAI concentration have similar trends in the time series. Both precipitation and NAIs show a low and gentle trend in the later periods, as shown in
Figure 8. There may be some connection between NAIs and the weekly data of accumulated precipitation. The meteorological factors were linked to the NAIs in some way, so we next tested the weekly data on meteorological factors and NAIs for correlation as shown in
Table 5.
As seen in
Table 5, the study showed a significant correlation between the concentrations of NAIs and cumulative precipitation, mean atmospheric pressure, and mean relative humidity.
To further explore the contribution of meteorological factors to weekly NAI concentrations, we performed a multiple linear regression analysis using the meteorological factors with the highest correlations in
Table 6 (PRE_W, PRS_W, RHU_W) and NAI concentrations. We can see that the value of R
2 is 0.349. This means that the meteorological factors (PRE_W, PRS_W and RHU_W) contribute 34.9% to NAIs.
After completing the model, we tested the fit model consisting of a white noise test on the residual test series. The “white noise” was different from the white noise before modeling, and we hoped that the residuals of the model are completely random series, i.e., the white noise series. The residual white noise of the ARIMA (0, 1, 1) model was tested by the Ljung–Box test; the p-value was 0.9571, which indicated that the residuals were not autocorrelated, and the residual was a sequence of the white noise.
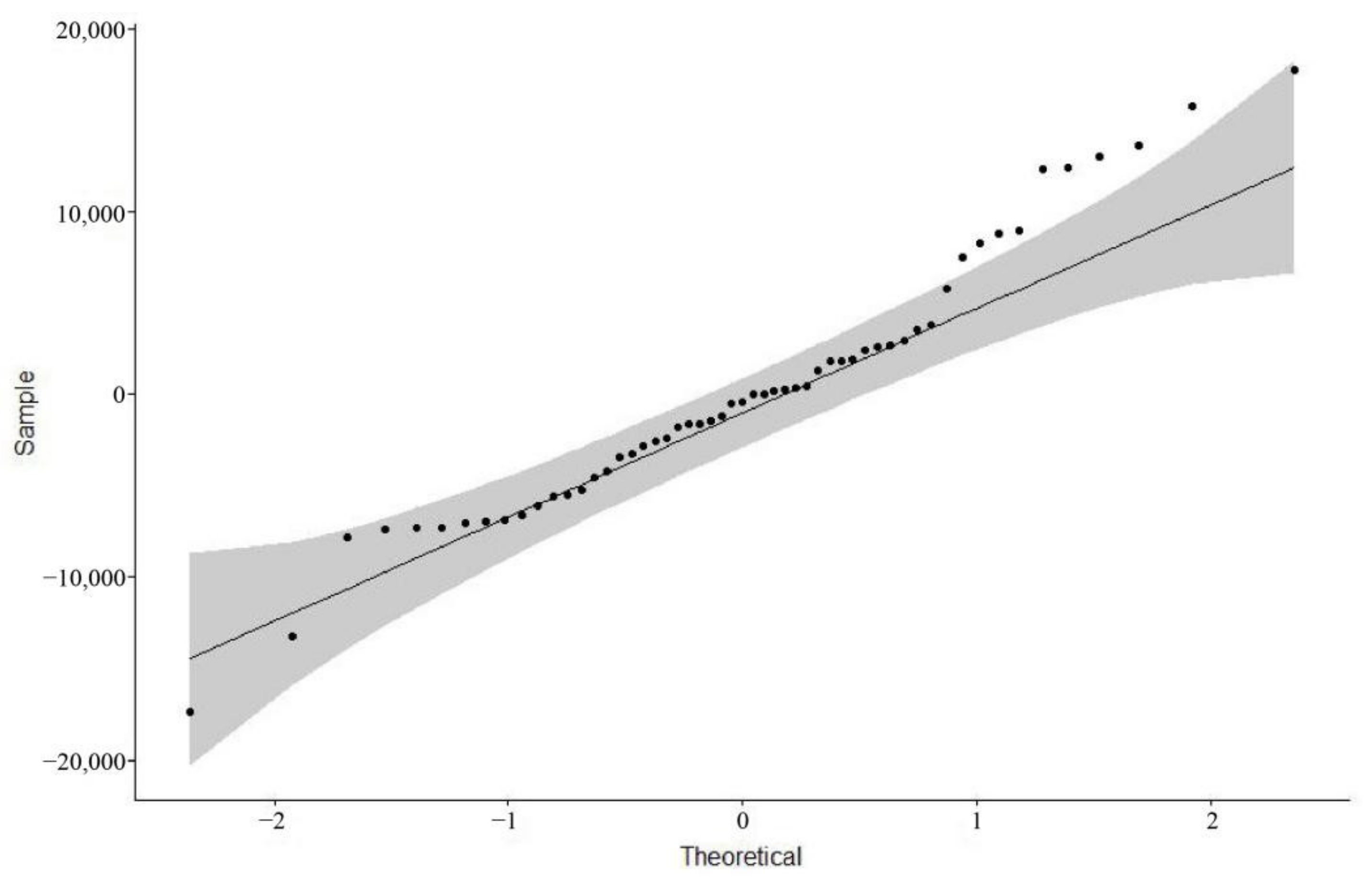
Then, we tested the residuals of the ARIMA (
0, 1, 1) model for normality by plotting a QQ plot of the normality test, by drawing a 45-degree line relative to the x and y axes and visually observing whether the points representing the residuals fell on or near the 45-degree line, and the grey area in the graph represents the 95% confidence interval of the normal distribution (
Figure 9). Although a small number of values were outside the gray area, most values were around the 45% line and inside the grey area. Our result indicated that the residuals largely passed the normality test. Overall, we used the ARIMA (
0,
2,
2) model to fill in the week 28 data based on the weeks 1–27 data. Then, the ARIMA (
0,
1,
1) model was used to predict the week 56–68 data based on the week 1–55 data. Our results showed that the established ARIMA (
0,
2,
2) and ARIMA (
0, 1, 1) model was reasonable.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}