1. Introduction
Reservoir characterization is the process of preparing a comprehensive quantitative representation of a reservoir using data from a variety of disciplines, such as geology, petrophysics, geochemistry, and petroleum engineering [
1]. A typical forward-modeling approach utilizes the reservoir characteristics and project design parameters as input, to predict the field response. This is accomplished by either solving the system of flow equations analytically or using a numerical reservoir simulator. More recently, machine learning techniques have been utilized to predict production using reservoir characteristics as input [
2,
3,
4,
5,
6,
7,
8]. Traditionally, reservoir characterization is performed by integrating all available seismic, geological, well logs, and core data, which is updated throughout the life of the field as more data becomes available. This makes field-scale dynamic characterization studies labor-intensive, time-consuming, and expensive [
1].
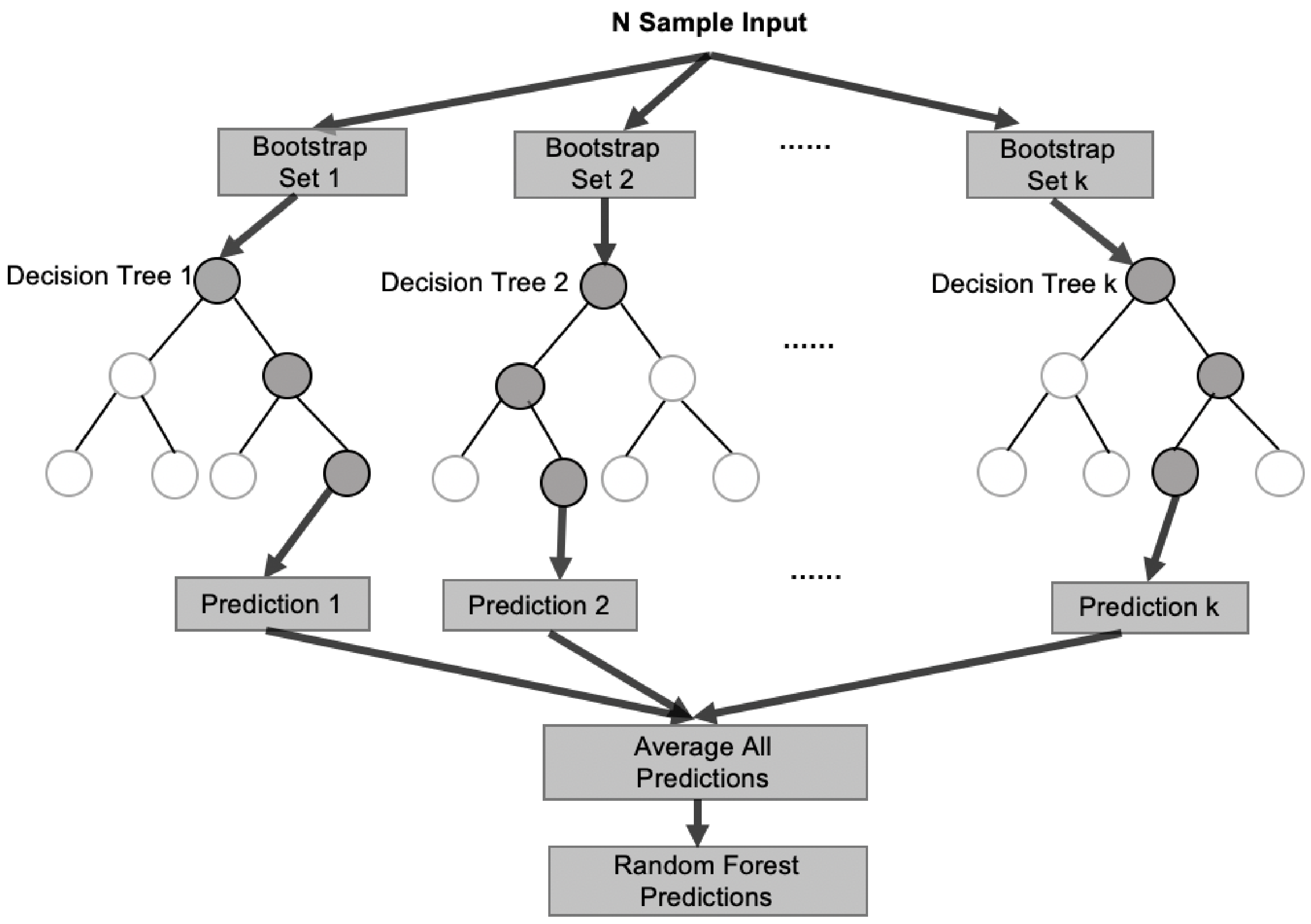
In this study, we utilize the random forest ensemble machine learning method to implement an inverse-modeling approach that uses the actual field production and injection data (measured at the surface) as the inputs to predict the time-lapse saturation profiles. Accurate estimation of fluid saturation is an important step in the dynamic reservoir characterization process, as it is one of the reservoir properties that changes over time and directly impacts well performance. Saturation measurements at a well location are useful for estimating remaining reserves, predicting production rates, planning workover activity, assessing drainage efficiency, performing economic analysis, and diagnosing production problems [
1]. Traditionally, oil saturation at a wellbore location is estimated using wireline logging techniques such as thermal decay logging, carbon-oxygen logging, resistivity, etc. However, wireline logging suffers from several limitations such as production/injection interruption, tool operational limits, technical challenges in highly deviated wells, and the need to pull the tubing pump in some cases [
9]. Well intervention can also be prohibitively expensive and operationally risky, especially in offshore environments and deviated well trajectories, which limits the frequency of data acquisition.
Machine learning techniques have been increasingly used in recent years for data-driven reservoir characterization, and specifically for saturation prediction, as summarized in
Table 1. Several studies have utilized Neural Networks (NN) for predicting water or oil saturation using well logs and core data as inputs and demonstrated superior performance compared to conventional methods [
10,
11,
12,
13,
14,
15,
16,
17,
18]. Algorithms such as functional networks [
19], support vector machine [
20], long short-term memory [
21], and decision trees [
22] have also been successfully used to predict fluid saturation in a variety of formation types using petrophysical well logs as input. The use of seismic data for estimating fluid saturations in machine learning models has also been reported [
23,
24]. Recently, researchers developed an analytical model to estimate water saturation by using capacitance-resistance model (CRM) and traditional resistivity logs [
25]. Only a handful of studies [
9,
26] have incorporated production and injection data in the machine learning workflow for saturation prediction. However, these studies also require other input parameters derived from core, petrophysical logs, or seismic data. This limits the implementation of these models in field cases where such input data is not readily or reliably available, often due to the acquisition costs. A key distinction of this study is the use of only the field injection and production data, which are often readily available, as the key input feature for predicting time-lapse oil saturation profiles without requiring detailed geophysical inputs, as highlighted in
Table 1.
Fluid production is an important reflection of the dynamic reservoir properties [
27]. Moreover, production data is typically the most frequently and reliably measured quantity throughout the life of a field. Although oil saturation is influenced by a number of parameters such as the capillary pressure, drainage, injection, wettability, etc., the direct relationship between the changing reservoir fluid saturations and surface production can be illustrated from mass conservation as the production of fluids at the surface results in a change in reservoir saturations. However, it is a complex non-linear time-dependent relationship as the fluid saturation is affected by the field-wide drainage and injection over time. Supervised machine learning algorithms have been demonstrated to effectively “learn” the complex relationship between a given set of target prediction output and input features. In this study, a random forest ensemble machine learning algorithm is implemented using the actual field-wide production and injection data as the inputs, to predict the time-lapse wellbore oil saturation profiles. Static geological parameters such as absolute permeability, porosity, lithology, etc. are not included as input features because they do not typically change significantly over time at a given well location (except in some cases such as during fracking, high rate injection, and others) and they are also not measured frequently over the life of an operation. Other dynamic data such as downhole or surface pressures and temperatures are also not included as inputs to demonstrate the broad applicability of the algorithm when such data is not easily available, or not collected frequently.
Since the time-lapsed oil saturation data is not collected in the subject offshore field, it is synthetically generated for training and testing the random forest algorithm through full-field numerical reservoir simulation. The simulation model is history-matched by adjusting reservoir parameters to ensure a reasonable agreement between the nine years of observed historical field behavior and simulation output, to establish a satisfactory representation of the field. Although the algorithm is demonstrated using synthetic saturation data, the workflow can also be implemented with actual field saturation profiles, if available. Three and a half years of historical field production, injection, and synthetic oil saturation trends (from the history-matched simulation model) are used for training, and about one year of data is used for the blind testing. The workflow is successfully demonstrated for predicting time-lapse saturation profiles at four deviated well locations, each representing a unique well trajectory, complex reservoir structure, and geological heterogeneity. In addition to demonstrating the workflow using the actual field production and injection data with simulated saturation data, it is also tested with the production, injection, and saturation data all from the simulation model. Very similar results are obtained (as illustrated in the
Supplementary Material Figures S1 and S2) which is expected as the simulation model is history matched with the field data.
The next section describes the subject field and the available data, this is followed by the description of the machine learning algorithm and feature selection in
Section 3, and the model prediction results and discussion in
Section 4, and finally the conclusions in
Section 5.
2. Field Overview and Data Description
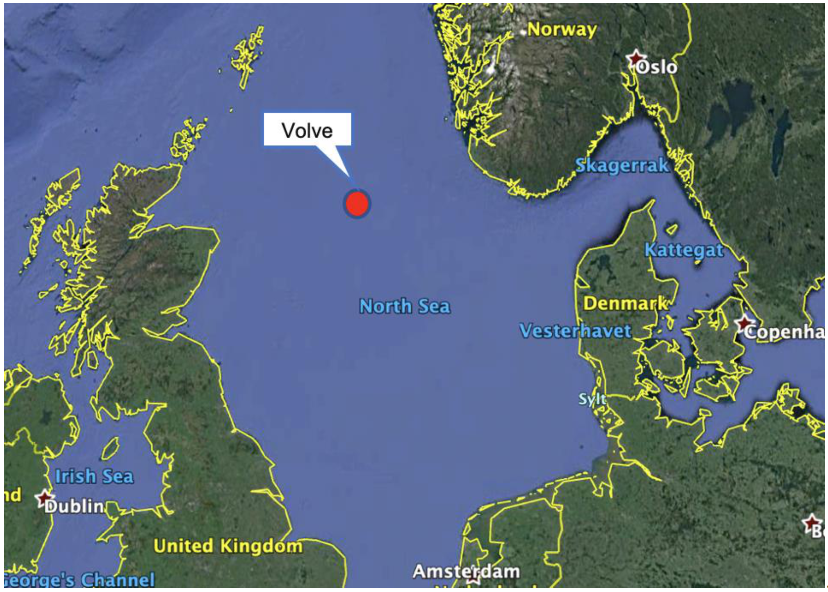
This study utilizes data from the Volve oil field, located in the central part of the North Sea, at the southern end of the Norwegian sector as shown in
Figure 1. This offshore oil field was discovered in 1993, and the plan for development was approved in 2005 [
28]. Field production started in early 2008, achieving 56,000 bbl/day of peak oil rate. New wells were drilled up until 2012–2013, which contributed to the increased recovery rate and extended life of the field. The main drainage strategy was pressure maintenance by water injection, with production wells placed high on the structure and water injectors at the flanks. The Volve field is described as a fault block structure with an initial estimation of 173 million bbl of oil in place [
29]. The reservoir is a small dome-shaped structure and is believed to be formed due to the collapse of adjacent salt ridges during the Middle Jurassic age [
29,
30]. Oil was produced from the sandstone of Middle Jurassic age in the Hugin formation at an average depth of 2700 to 3100 m true vertical depth (TVD) below sea level. There is no known aquifer support, so the drainage was primarily dependent on reservoir depressurization and hydrocarbon displacement by water injection. The field was decommissioned in September 2016 after roughly nine years in operation that delivered a cumulative oil production of 63 million barrels, achieving a recovery rate of 54% [
31].
Equinor (previously known as Statoil), the operator of Volve field, together with the Volve license partners released all subsurface and production datasets from the field in 2018 to support research, learning, and innovation for the energy future. The released dataset [
29] includes production and injection data through the life of the operation (from 2008 to 2016), well trajectories, completion string design, seismic data, well logs (petrophysical and drilling), geological and stratigraphic data, static and dynamic models, surface and grid data.
For this study, the daily production and injection field data measured at the surface (from all six active producers and two active injectors) is used as input. Since saturation data is not measured directly in the Volve field, synthetic saturation profiles are generated using numerical reservoir simulation. A commercial simulator (CMG®) is used to create a black-oil heterogeneous reservoir model, as summarized in
Table 2. The geological properties, well surveys, operating parameters, and grid dimensions are imported from the Eclipse
® simulation model that is part of Equinor’s publicly released Volve dataset [
29]. The areal field map with the well locations is shown in
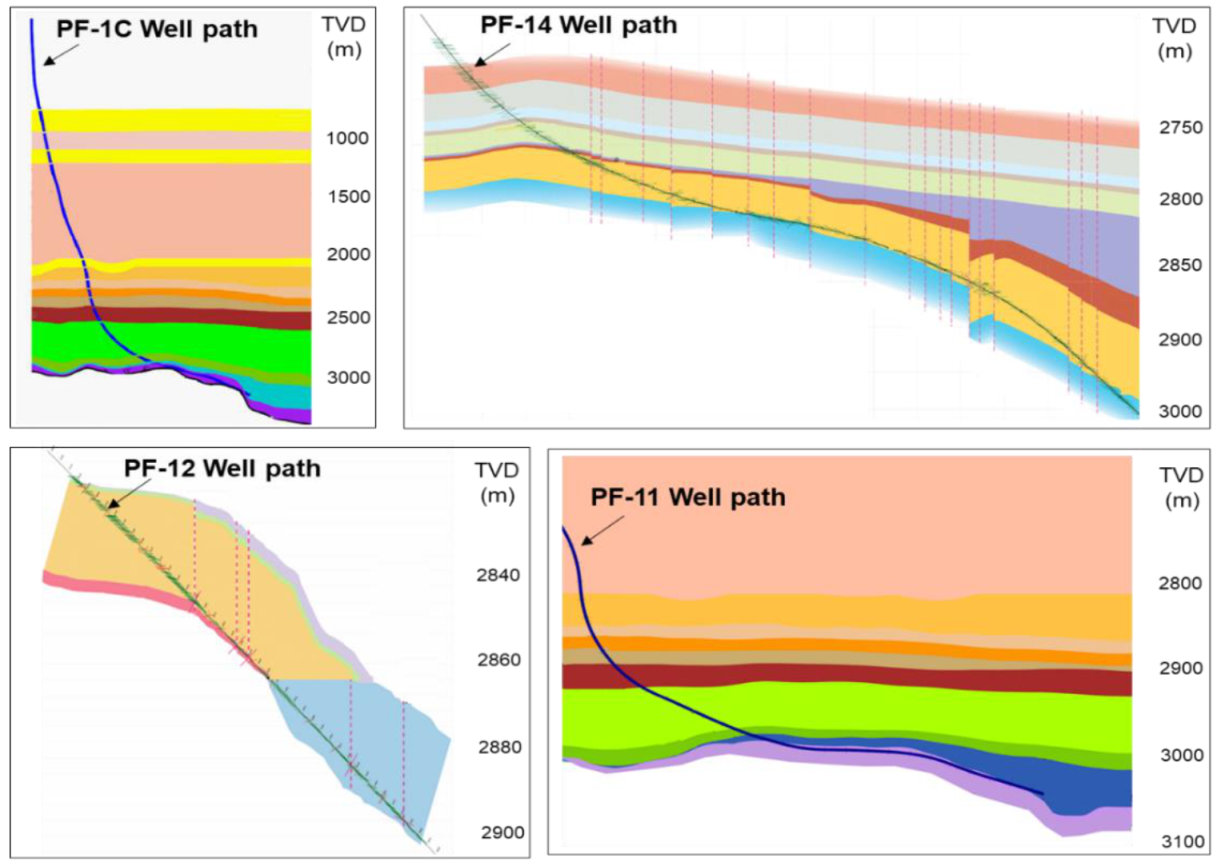
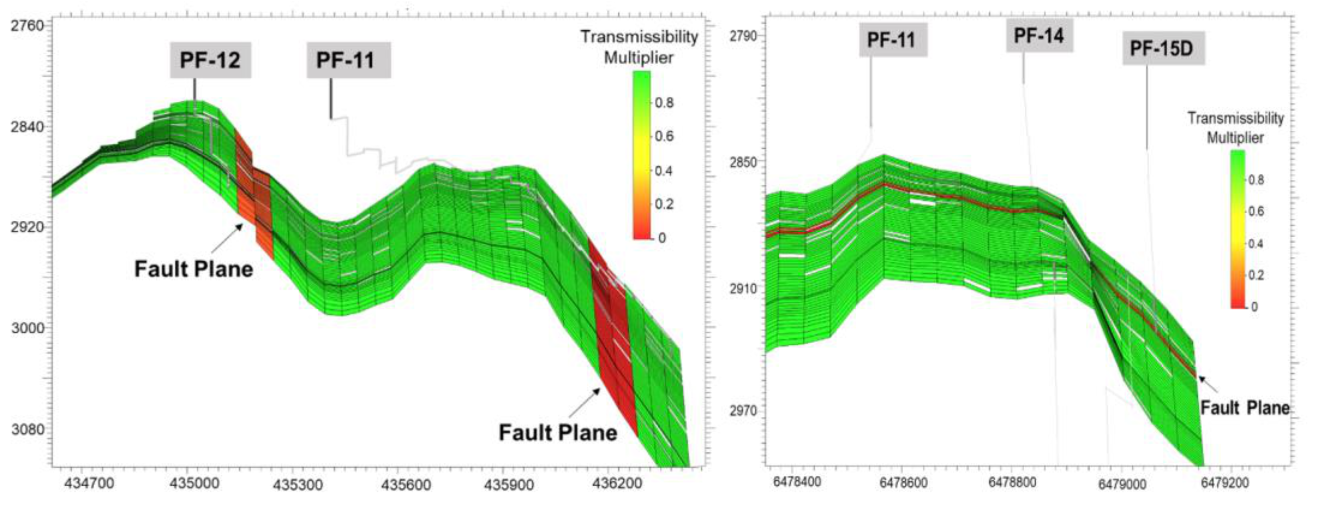
Figure 2. The prefix “P” or “I” are added to the well names to indicate a producer or injector, respectively, as one of the injectors (well F-5) is converted into a producer later. The western part of the reservoir structure is heavily faulted, as shown in
Figure 3, and communication across the faults is uncertain. The faults are represented using low transmissibility multipliers in the simulation model, consistent with the Volve simulation model developed by Equinor [
32]. The oil, water, and gas production rates from the simulation model showed a reasonable match with the nine years of historical Volve field data, as illustrated in
Figure 4 (where the monthly oil and water rates are expressed in thousands of stock tank barrels or MSTB, and the gas rate is expressed in millions of standard cubic feet or MMSCF). The objective of history matching is to ensure a reasonable representation of the Volve oil field. The saturation profiles from the history-matched simulation model, along with the actual field production (oil, water, gas) and injection (water) rates, are used for the training, validation, and testing of the ensemble machine learning model, as described in the next section. Although the algorithm is demonstrated using synthetic saturation data, the workflow can also be implemented with actual field saturation profiles, if available.
5. Conclusions
In this study, we develop an ensemble machine learning method to implement an inverse-modeling approach that uses the field-wide production and injection data as the main inputs to predict the time-lapse saturation profiles. Other dynamic reservoir parameters such as pressures, temperatures, and static geological attributes such as permeability, porosity, etc. are not included as inputs to demonstrate the broad applicability of the algorithm when such data is not easily or reliably available. The workflow is demonstrated using actual field injection and production data measured at the surface from a structurally complex, heterogeneous, and heavily faulted offshore oil field. The oil saturation data for training and testing the machine learning model is synthetically generated through full-field history-matched numerical reservoir simulation, as time-lapsed saturation data is not measured directly in the subject field.
The random forest model predicted dynamic saturation profiles at four deviated well locations, each representing a unique well trajectory, complex reservoir structure, and geological heterogeneity, with over 90% R-square, less than 0.07 MAPE and less than 0.06 RMSE in all cases. The results demonstrate the effectiveness of our simple and intuitive modeling approach that captures the dynamic relationship between the field production, injection, and oil saturation trends.
The proposed workflow is demonstrated for a waterflood operation but it can also be adopted for primary production, which will be a special case for no water injection. For other enhanced oil recovery (EOR) processes (such as polymer, steam, or gas injection), the key criteria that will determine whether or not our model can be applied are the recovery mechanisms. For instance, if a process significantly alters the reservoir properties, like permeability (in case of fracking) or temperatures (in case of a steam flood) then the model will need to incorporate those changes, as the current model does not include permeability or temperature as an input feature. This study uses simulated oil saturation data. In the future, we plan to extend this by using saturation data from well logs and also implement the workflow in other oil and gas fields.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}