
Smart Energy Management: A Comparative Study of Energy Consumption Forecasting Algorithms for an Experimental Open-Pit Mine

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
- (a)
- This study presents one of the few studies made to forecast the energy consumption behavior in the mining industry and in particular the open-pit mines. It presents a comparison of some of the well-known ML techniques and evaluates their performance.
- (b)
- Four ML algorithms namely, Artificial Neural Network, Support Vector Machine, Random Forest, and Decision Tree were applied to a dataset acquired from an experimental open-pit mine. The different models were trained, tested, and then evaluated.
- (c)
- Four metrics were used to assess the models’ performance, namely correlation, root mean squared error, mean absolute error, and root relative squared error. After parameter tuning, Random Forest showed the best performance among all four algorithms.
- (d)
- Managers, technicians, and supervisors will be able to view real-time energy consumption, analyze future warnings based on the current condition of load consumption and make timely decisions.
2. Related Works
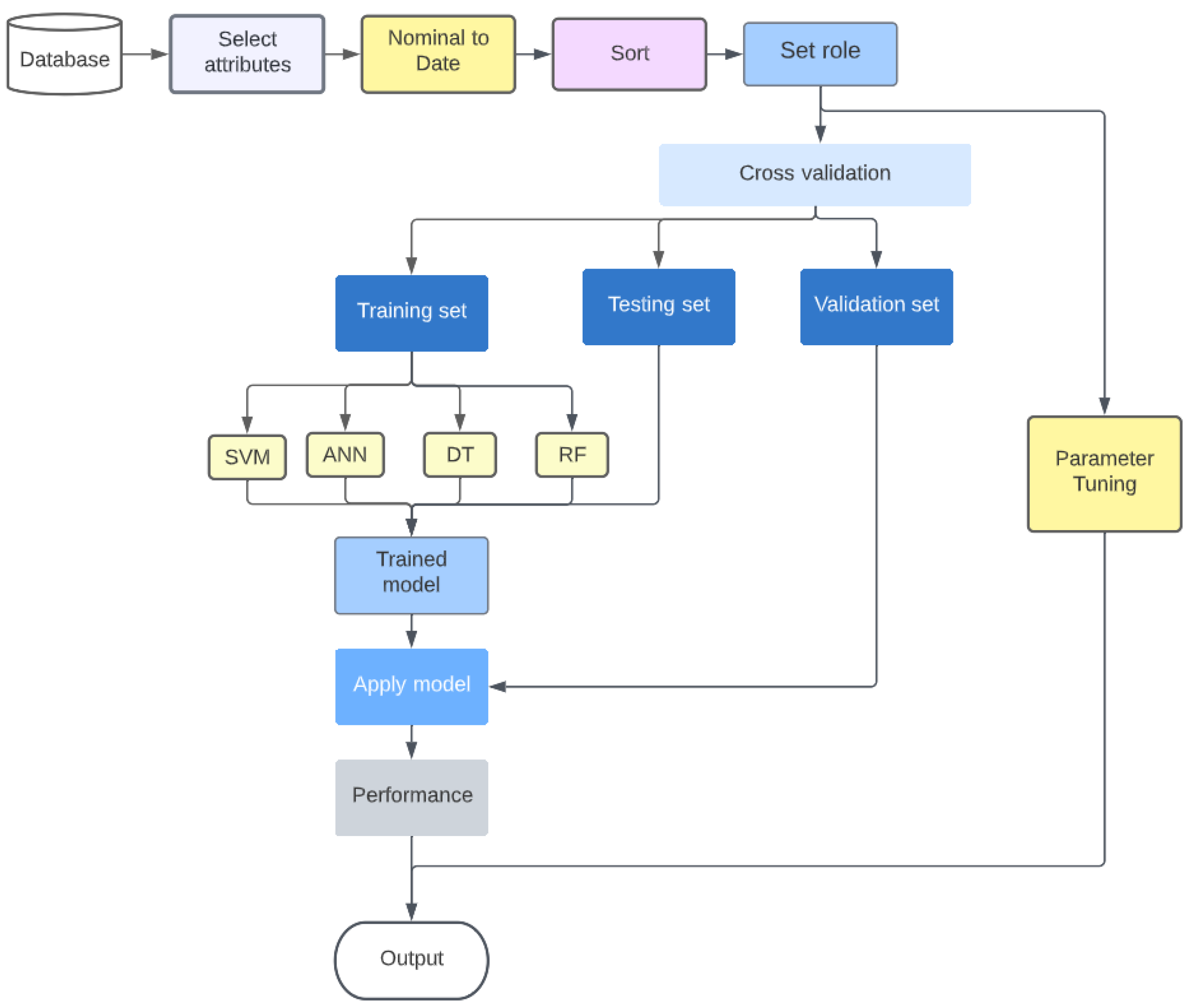
3. Materials and Methods
3.1. Data Description
3.2. Support Vector Machine
3.2.1. Definition
3.2.2. Support Vector Machine Parameters
- Kernel type: This parameter determines the type of kernel function to be used. The following kernel types can be used: multiquadric, dot, radial, polynomial, neural, anova, epachnenikov, gaussian combination.
- Kernel cache: It is an expert parameter. It determines the cache size in megabytes for kernel evaluations.
- C: This is the SVM complexity constant that determines the misclassification tolerance, with larger C values allowing for ‘softer’ bounds and lower values allowing for ‘harder’ limits. Over-fitting can occur when the complexity constant is too large, while over-generalization can occur when the complexity constant is too small. The Range is real.
- Convergence epsilon: This is an optimizer parameter. It specifies the precision of the KKT conditions.
- Max iterations: This is an optimizer parameter. It specifies to stop iterations after a specified number of iterations. Range: integer.
3.3. Artificial Neural Network
3.3.1. Definition
3.3.2. Artificial Neural Network Parameters
- Hidden layers: The name and size of all hidden levels are described by this parameter. This option allows the user to define the neural network’s structure. Each entry in the list describes a different hidden layer. The name and size of the concealed layer are required for each entry. The name of the layer can be chosen at will. It is simply used to show the model, the Range is real.
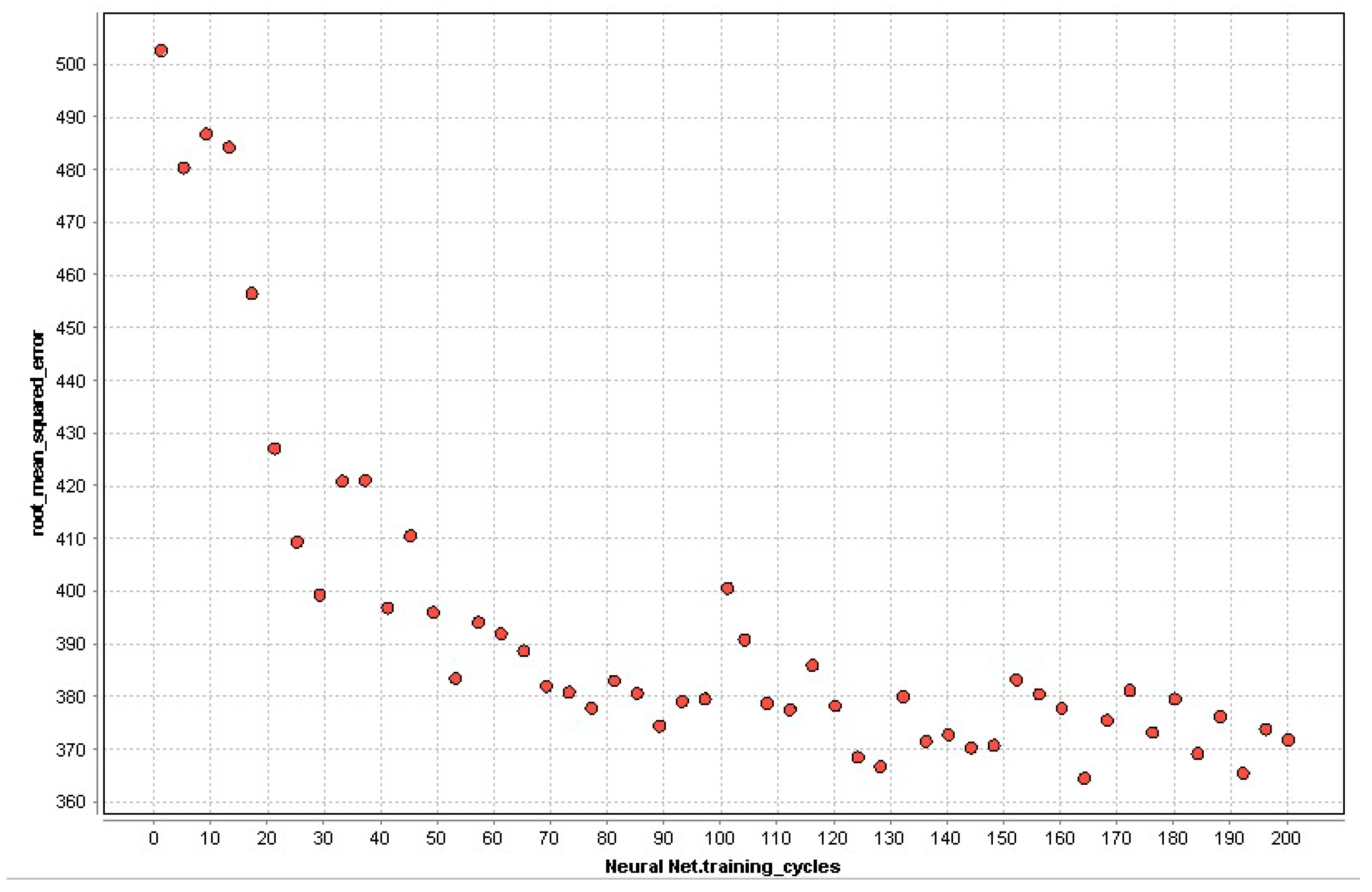
- Training cycles: The number of training cycles utilized to train the neural network is specified by this parameter. Back-propagation compares the output values to the correct solution in order to compute the value of a preset error function. The error is subsequently relayed to the rest of the network. The algorithm modifies the weights of each link based on this information in order to minimize the error function’s value by a tiny amount. This procedure is repeated an undetermined number of times n. This argument can be used to specify the number n. The Range is real.
- Learning rate: This parameter controls how much the weights are changed at each phase. It must not be zero. The Range is real.
- Momentum: The momentum merely adds a percentage of the previous weight update to the new one. Hence, local maxima are avoided, and optimization paths are smoothed. The Range is real.
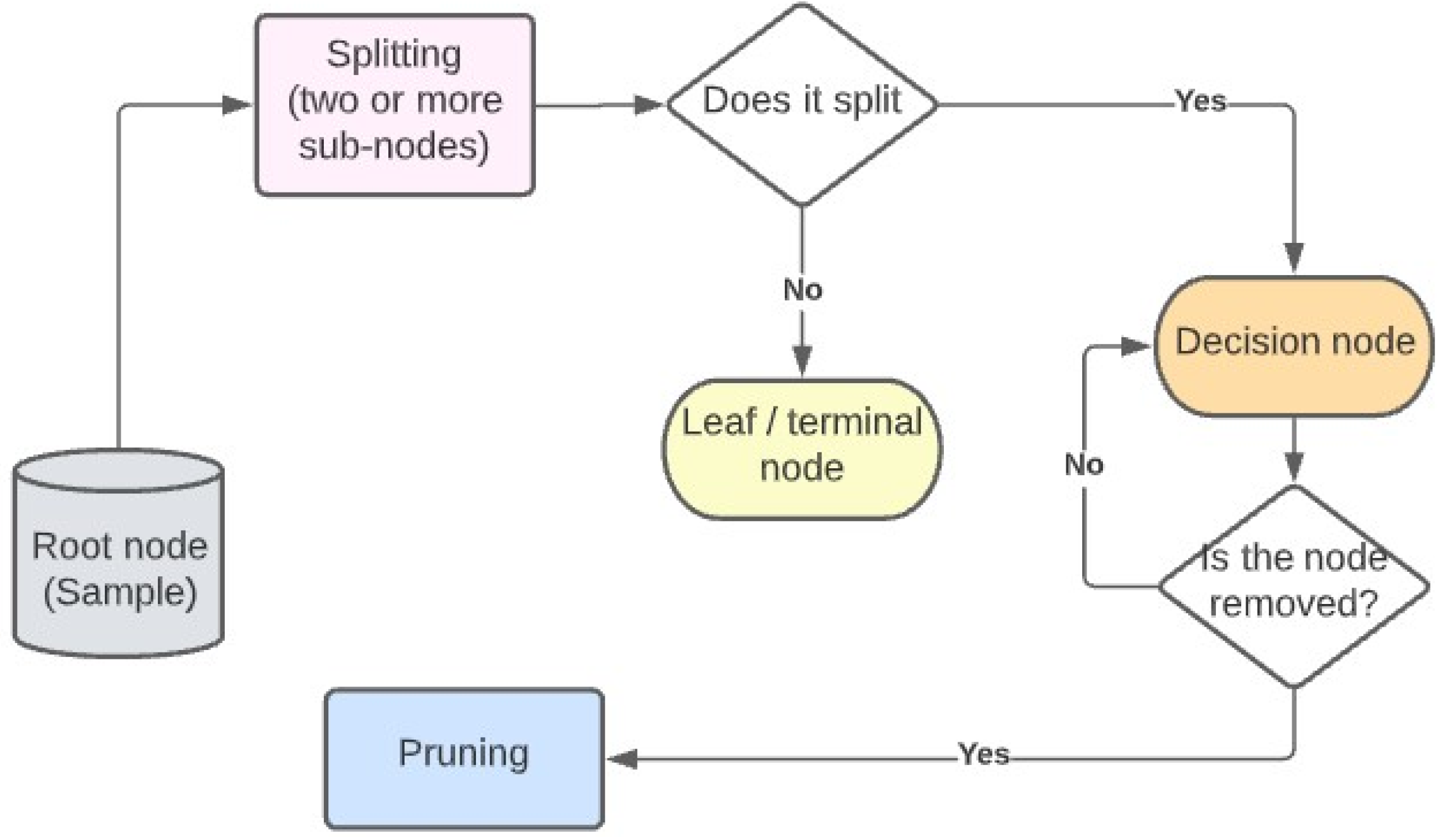
3.4. Decision Tree
3.4.1. Definition
3.4.2. Decision Tree Parameters
- Criterion: Selects the criterion by which Attributes will be separated based on. The split value is optimized for each of these criteria in relation to the chosen criterion. Information gain, gain ratio, gini index, accuracy, and least square are some of its variables.
- Maximal depth: The size and properties of the ExampleSet determine the depth of the tree. This parameter is used to limit the decision tree’s depth. If it is set to ‘−1’, the maximal depth parameter has no effect on the tree’s depth. The tree is created in this situation until additional halting requirements are met. A tree with a single node is formed if its value is set to ‘1’.
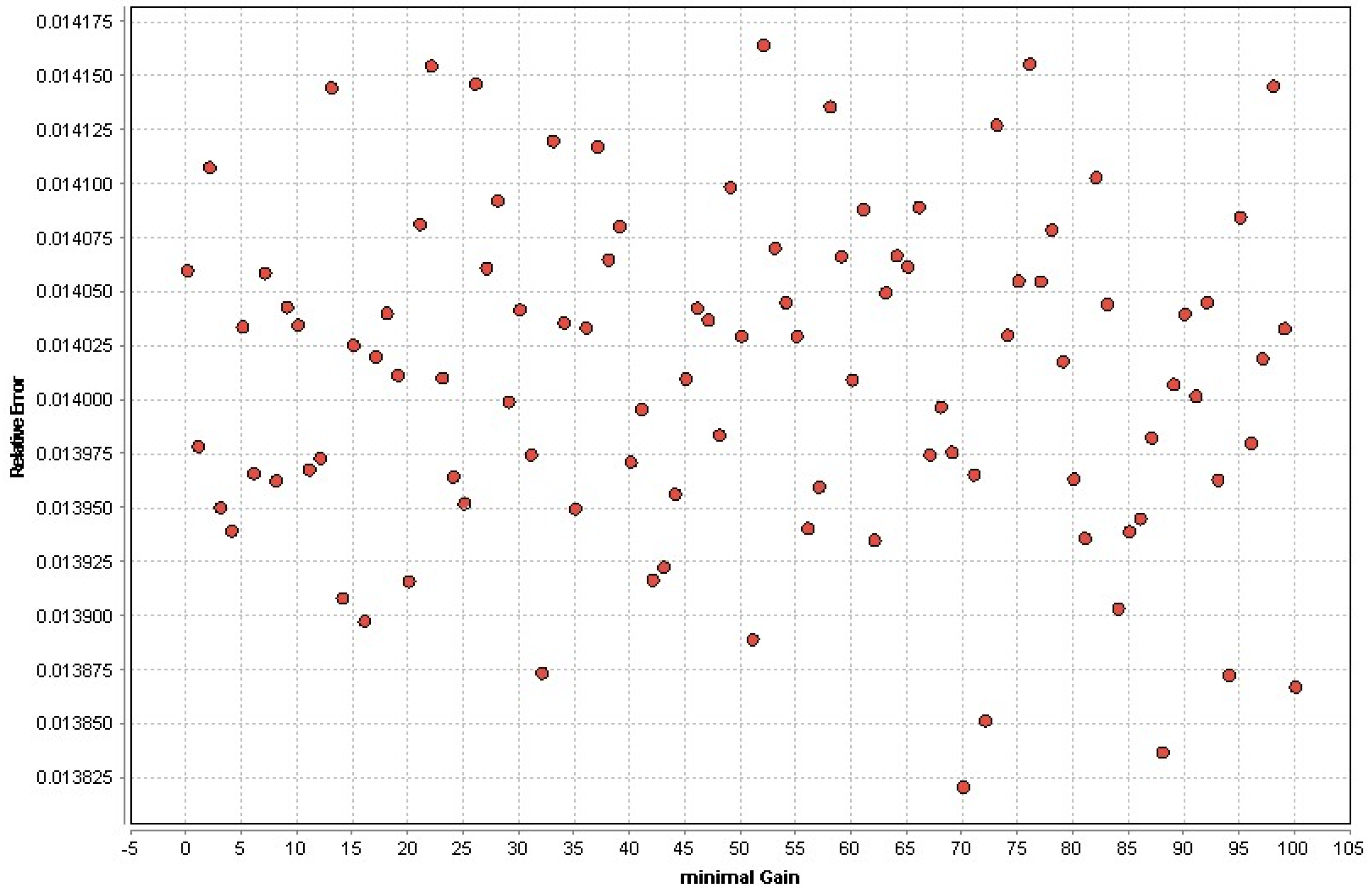
- Minimal gain: Before dividing a node, its gain is determined. If the node’s gain exceeds the minimal gain, it is divided. A greater minimal gain value means fewer splits and, as a result, a smaller tree. A value that is too high prevents splitting fully, resulting in a single-node tree.
- Minimal leaf size: The number of Examples in a leaf’s subset determines its size. Every leaf has at least the minimum leaf size number of Examples when the tree is constructed.
- Minimal size for split: The number of Examples in a node’s subset determines its size. Only nodes with a size larger than or equal to the split parameter’s minimum size are split.
- Number of prepruning alternatives: This option adjusts the amount of alternative nodes tested for splitting when split is stopped by prepruning at a specific node. As the tree creation process is paralleled by prepruning, this occurs. This could prohibit splitting at certain nodes if splitting at that node does not improve the tree’s discriminative capacity. Alternative nodes are tried for splitting in this situation.
3.5. Random Forest
3.5.1. Definition
3.5.2. Random Forest Parameters
- Number of trees: The number of random trees to generate is specified by this parameter. Bootstrapping is used to select a subset of Examples for each tree. The trees are trained in parallel across available processor threads if the parameter enable parallel execution is checked.
- Confidence: This option sets the level of confidence utilized in the pruning pessimistic error calculation.
- Random splits: If this parameter is enabled, numerical Attribute splits are picked at random rather than being optimized. A uniform sample between the least and maximal value for the current Attribute is conducted for random selection.
3.6. Rapid Miner
- The Repository stores data, procedures, and results.
- Operators are the critical components of any workflow.
- Operators are linked through ports. The first’s output is used as the second’s input.
- An Operator’s behavior can be altered by altering its settings.
- Reading the Help can help you understand how an Operator behaves.
3.7. Performance Metrics
3.7.1. Correlation Coefficient
3.7.2. Mean Absolute Error
3.7.3. Root Mean Square Error
3.7.4. Root Relative Squared Error
4. Results and Discussion
4.1. Parameter Tuning Results
4.2. Performance Results
4.3. Statistical Results
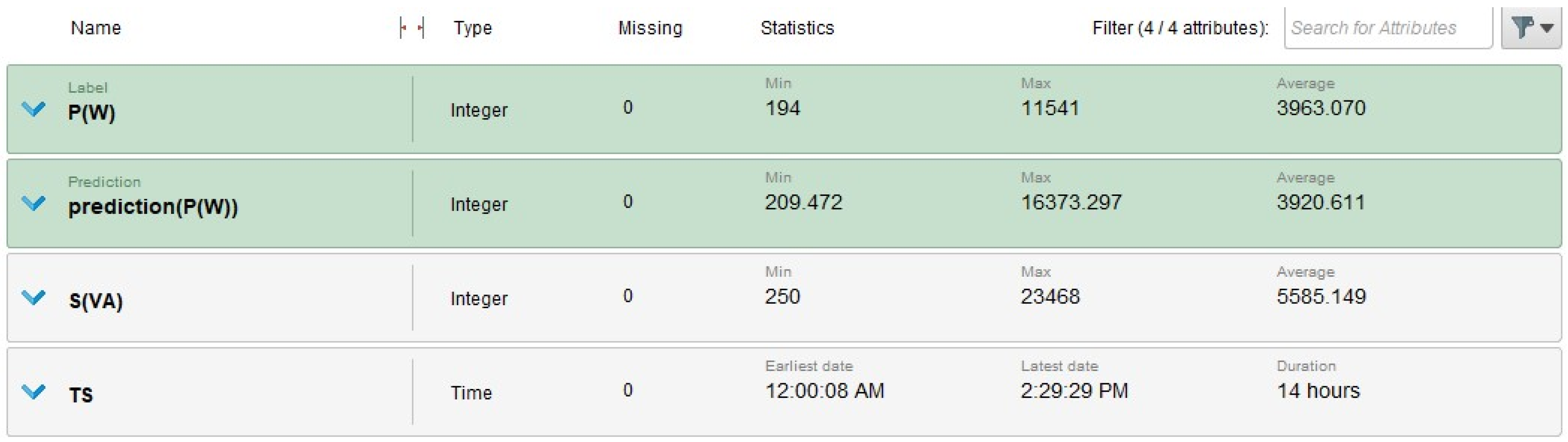
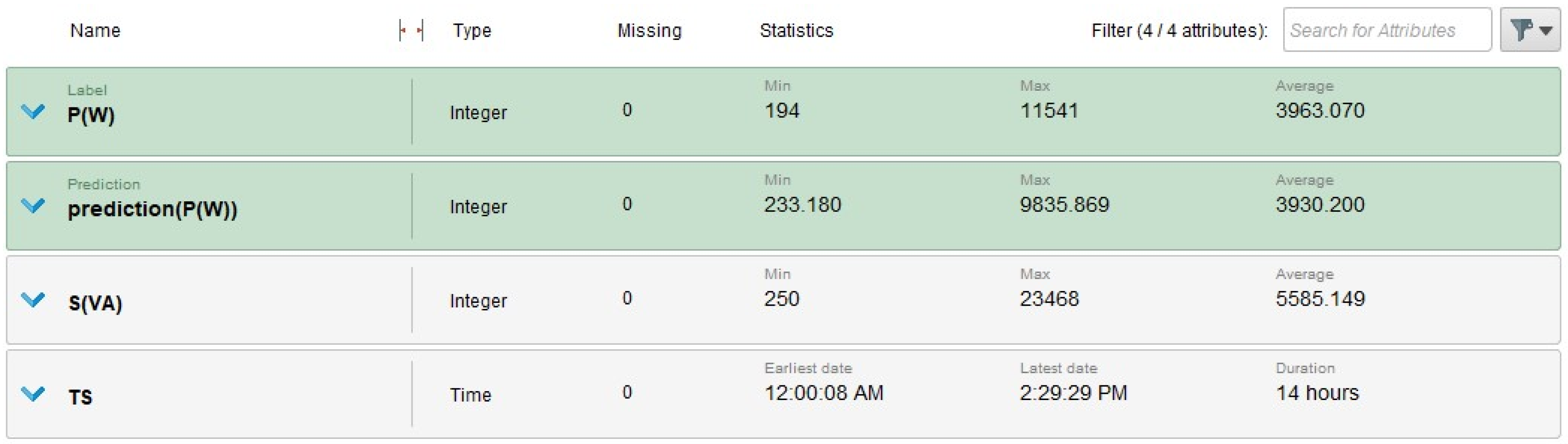
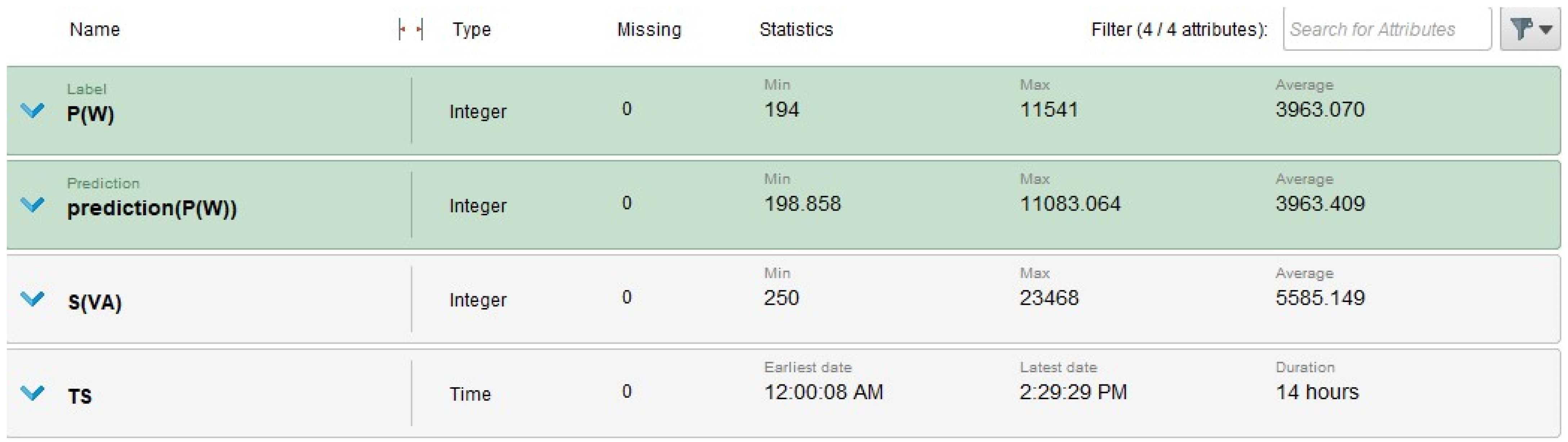
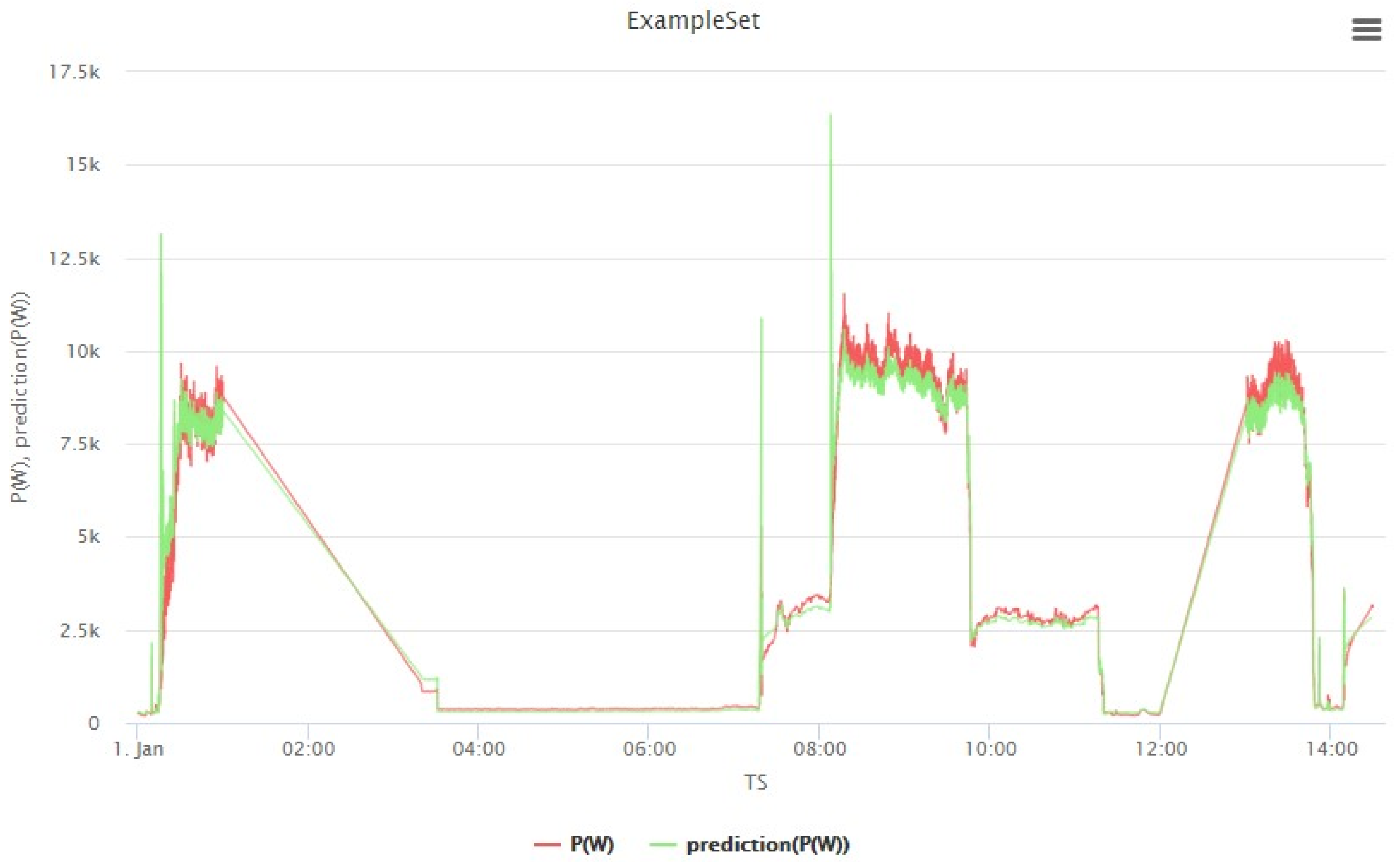
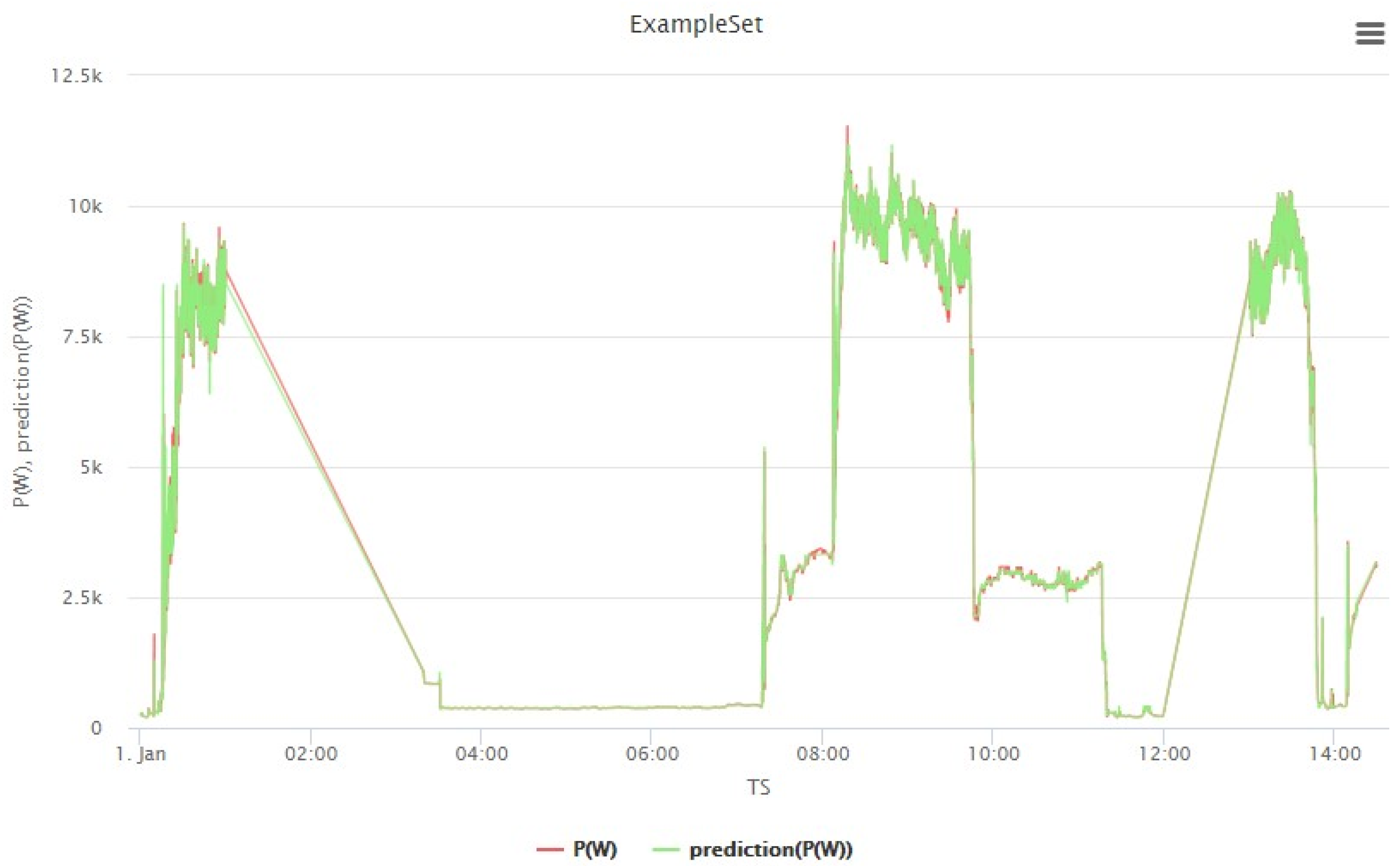
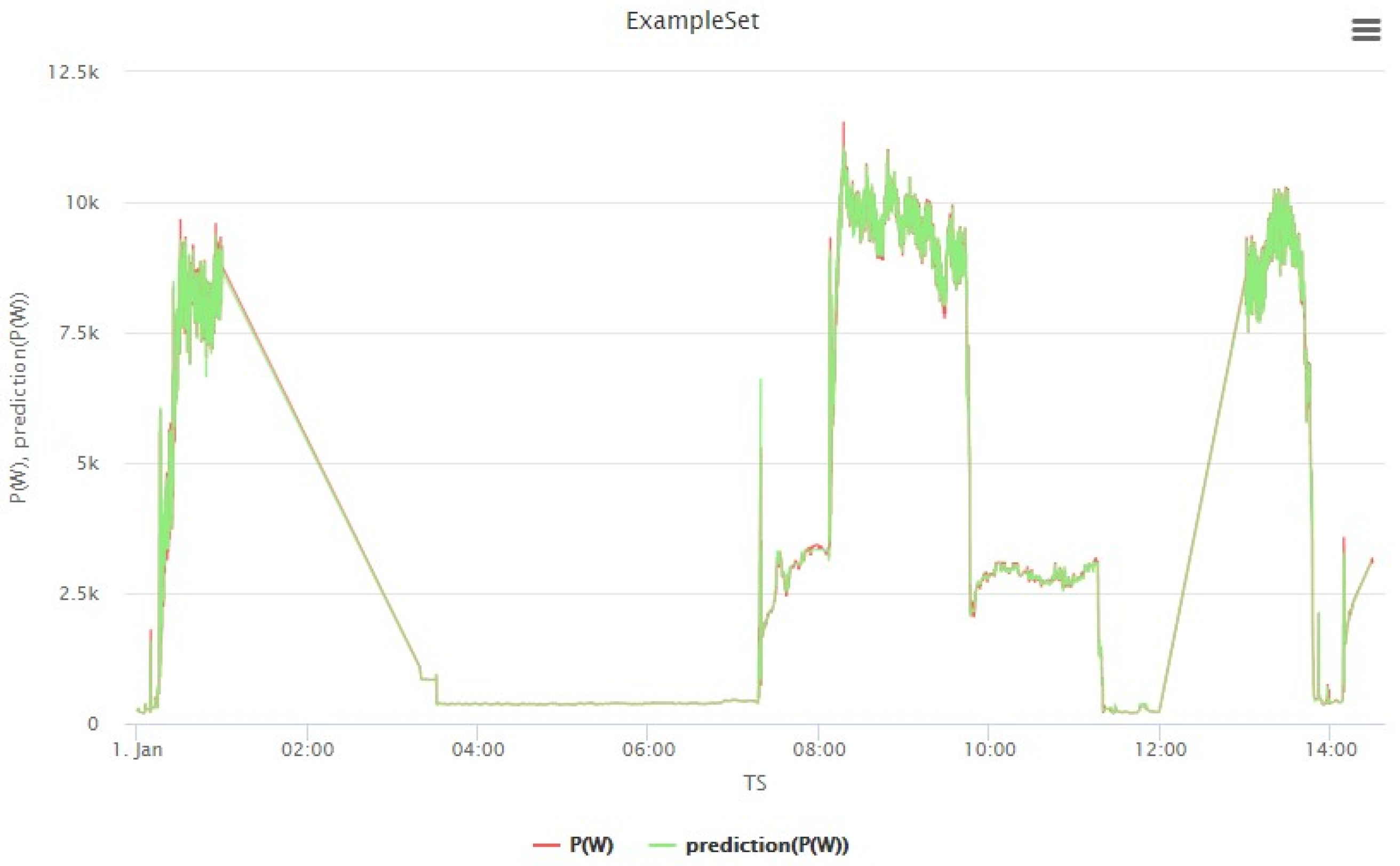
4.4. Visualization Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANFIS | Adaptive Network-based Fuzzy Inference System |
| ANN | Artificial Neural Network |
| AR | Auto Regressive |
| ARIMA | Auto Regressive Integrated Moving Average |
| BPNN | Back Propagation Neural Network |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| DRL | Deep Reinforcement Learning |
| DT | Decision Tree |
| FFNN | Feed Forward Neural Network |
| IoT | Internet of Things |
| ISO | International Standardization Organization |
| KKT | Karush–Kuhn–Tucker |
| KPI | Key Performance Indicator |
| LS | Least Square |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| MLP | Multi-Layer Perceptron |
| MLR | Multiple Linear Regression |
| NARX | Nonlinear Auto-Regressive Network Exogenous |
| OLS | Ordinary Least Squares |
| PUK | Pearson VII Universal Kernel |
| RBF | Radial Basis Function |
| RBM | Restricted Boltzmann Machine |
| RF | Random Forest |
| RMSE | Root Mean Square Error |
| RRSE | Root Relative Square Error |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| YALE | Yet Another Learning Environment |
References
- OECD. Key World Energy Statistics 2015; Organisation for Economic Co-Operation and Development: Paris, France, 2015. [Google Scholar]
- Statistical Review of World Energy, Energy Economics, Home Page. Available online: https://www.bp.com/en/global/corporate/energy-economics/statistical-review-of-world-energy.html (accessed on 28 February 2022).
- Darling, P. Mining: Ancient, modern and beyond. In SME Mining Engineering Handbook; Society for Mining, Metallurgy, and Exploration, Inc.: Englewood, CO, USA, 2011; pp. 3–9. [Google Scholar]
- Open Pit Mining|IntechOpen. Available online: https://www.intechopen.com/chapters/71931 (accessed on 29 April 2022).
- Grewal, G.S.; Rajpurohit, B.S. Efficient Energy Management Measures in Steel Industry for Economic Utilization. Energy Rep. 2016, 2, 267–273. [Google Scholar] [CrossRef] [Green Version]
- Norgate, T.; Haque, N. Energy and Greenhouse Gas Impacts of Mining and Mineral Processing Operations. J. Clean. Prod. 2010, 18, 266–274. [Google Scholar] [CrossRef]
- Rábago, K.R.; Lovins, A.B.; Feiler, T.E. Energy and Sustainable Development in the Mining and Minerals Industrie; Report for The Mining, Minerals and Sustainable Development Project; Rocky Mountain Institute: Snowmass Village, CO, USA, 2001. [Google Scholar]
- Marimon, F.; Casadesús, M. Reasons to Adopt ISO 50001 Energy Management System. Sustainability 2017, 9, 1740. [Google Scholar] [CrossRef] [Green Version]
- Hasan, A.S.M.M.; Trianni, A. A Review of Energy Management Assessment Models for Industrial Energy Efficiency. Energies 2020, 13, 5713. [Google Scholar] [CrossRef]
- Yan, K.; Zhou, X.; Chen, J. Collaborative Deep Learning Framework on IoT Data with Bidirectional NLSTM Neural Networks for Energy Consumption Forecasting. J. Parallel Distrib. Comput. 2022, 163, 248–255. [Google Scholar] [CrossRef]
- Biswas, M.A.R.; Robinson, M.D.; Fumo, N. Prediction of Residential Building Energy Consumption: A Neural Network Approach. Energy 2016, 117, 84–92. [Google Scholar] [CrossRef]
- Jin, N.; Yang, F.; Mo, Y.; Zeng, Y.; Zhou, X.; Yan, K.; Ma, X. Highly Accurate Energy Consumption Forecasting Model Based on Parallel LSTM Neural Networks. Adv. Eng. Inform. 2022, 51, 101442. [Google Scholar] [CrossRef]
- González-Briones, A.; Hernández, G.; Corchado, J.M.; Omatu, S.; Mohamad, M.S. Machine Learning Models for Electricity Consumption Forecasting: A Review. In Proceedings of the 2019 2nd International Conference on Computer Applications Information Security (ICCAIS), Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–6. [Google Scholar]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building Energy Load Forecasting Using Deep Neural Networks. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 7046–7051. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Kim, T.-Y.; Cho, S.-B. Predicting Residential Energy Consumption Using CNN-LSTM Neural Networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Wu, B.; Wang, L.; Wang, S.; Zeng, Y.-R. Forecasting the U.S. Oil Markets Based on Social Media Information during the COVID-19 Pandemic. Energy 2021, 226, 120403. [Google Scholar] [CrossRef]
- Somu, N.; Raman, M.R.G.; Ramamritham, K. A Deep Learning Framework for Building Energy Consumption Forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Liu, L.; Wu, L. Forecasting the Renewable Energy Consumption of the European Countries by an Adjacent Non-Homogeneous Grey Model. Appl. Math. Model. 2021, 89, 1932–1948. [Google Scholar] [CrossRef]
- Liu, T.; Tan, Z.; Xu, C.; Chen, H.; Li, Z. Study on Deep Reinforcement Learning Techniques for Building Energy Consumption Forecasting. Energy Build. 2020, 208, 109675. [Google Scholar] [CrossRef]
- Singh, S.; Yassine, A. Big Data Mining of Energy Time Series for Behavioral Analytics and Energy Consumption Forecasting. Energies 2018, 11, 452. [Google Scholar] [CrossRef] [Green Version]
- Boogen, N.; Datta, S.; Filippini, M. Dynamic Models of Residential Electricity Demand: Evidence from Switzerland. Energy Strategy Rev. 2017, 18, 85–92. [Google Scholar] [CrossRef] [Green Version]
- Abulibdeh, A. Modeling Electricity Consumption Patterns during the COVID-19 Pandemic across Six Socioeconomic Sectors in the State of Qatar. Energy Strategy Rev. 2021, 38, 100733. [Google Scholar] [CrossRef]
- Laayati, O.; Bouzi, M.; Chebak, A. Smart Energy Management System: Design of a Monitoring and Peak Load Forecasting System for an Experimental Open-Pit Mine. Appl. Syst. Innov. 2022, 5, 18. [Google Scholar] [CrossRef]
- Laayati, O.; Bouzi, M.; Chebak, A. Smart Energy Management: Energy Consumption Metering, Monitoring and Prediction for Mining Industry. In Proceedings of the 2020 IEEE 2nd International Conference on Electronics, Control, Optimization and Computer Science (ICECOCS), Kenitra, Morocco, 2–3 December 2020; pp. 1–5. [Google Scholar]
- Solomon, D.; Winter, R.; Boulanger, A.; Anderson, R.; Wu, L. Forecasting Energy Demand in Large Commercial Buildings Using Support Vector Machine Regression; CUCS-040-11; Department of Computer Science, Columbia University: New York, NY, USA, 2011. [Google Scholar]
- Edwards, R.E.; New, J.; Parker, L.E. Predicting Future Hourly Residential Electrical Consumption: A Machine Learning Case Study. Energy Build. 2012, 49, 591–603. [Google Scholar] [CrossRef]
- Dagnely, P.; Ruette, T.; Tourwé, T.; Tsiporkova, E.; Verhelst, C. Predicting Hourly Energy Consumption. Can Regression Modeling Improve on an Autoregressive Baseline? In Proceedings of the Data Analytics for Renewable Energy Integration; Woon, W.L., Aung, Z., Madnick, S., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 105–122. [Google Scholar]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Short-Term Load Forecasting in a Non-Residential Building Contrasting Models and Attributes. Energy Build. 2015, 92, 322–330. [Google Scholar] [CrossRef] [Green Version]
- Borges, C.; Penya, Y.; Agote, D.; Fernandez, I. Short-Term Load Forecasting in Non-Residential Buildings. In Proceedings of the IEEE Africon’11 Conference, Victoria Falls, Zambia, 13–15 September 2011. [Google Scholar]
- Zhao, H.X.; Magoulès, F. Parallel Support Vector Machines Applied to the Prediction of Multiple Buildings Energy Consumption. 2010. Available online: https://0-journals-sagepub-com.brum.beds.ac.uk/doi/10.1260/1748-3018.4.2.231 (accessed on 28 February 2022).
- Paudel, S.; Nguyen, P.H.; Kling, W.L.; Elmitri, M.; Lacarrière, B.; Corre, O.L. Support Vector Machine in Prediction of Building Energy Demand Using Pseudo Dynamic Approach. arXiv 2015, arXiv:1507.05019. [Google Scholar]
- Jain, R.K.; Smith, K.; Culligan, P.J.; Taylor, J.E. Forecasting Energy Consumption of Multi-Family Residential Buildings Using Support Vector Regression: Investigating the Impact of Temporal and Spatial Monitoring Granularity on Performance Accuracy. Appl. Energy 2014, 123, 168–178. [Google Scholar]
- Mena, R.; Rodríguez, F.; Castilla, M.; Arahal, M.R. A Prediction Model Based on Neural Networks for the Energy Consumption of a Bioclimatic Building. Energy Build. 2014, 82, 142–155. [Google Scholar] [CrossRef]
- Penya, Y.K.; Borges, C.E.; Agote, D.; Fernández, I. Short-term load forecasting in air-conditioned non-residential Buildings. In Proceedings of the 2011 IEEE International Symposium on Industrial Electronics, Gdansk, Poland, 27–30 June 2011; pp. 1359–1364. [Google Scholar] [CrossRef] [Green Version]
- González, P.A.; Zamarreño, J. Prediction of Hourly Energy Consumption in Buildings Based on a Feedback Artificial Neural Network. Energy Build. 2005, 37, 595–601. Available online: https://0-www-sciencedirect-com.brum.beds.ac.uk/science/article/pii/S0378778804003032 (accessed on 9 March 2022). [CrossRef]
- Fernández, I.; Borges, C.E.; Penya, Y.K. Efficient Building Load Forecasting. In Proceedings of the ETFA2011, Toulouse, France, 5–9 September 2011; pp. 1–8. [Google Scholar]
- Escrivá-Escrivá, G.; Álvarez-Bel, C.; Roldán-Blay, C.; Alcázar-Ortega, M. New Artificial Neural Network Prediction Method for Electrical Consumption Forecasting Based on Building End-Uses. Energy Build. 2011, 43, 3112–3119. [Google Scholar] [CrossRef]
- Kamaev, V.A.; Shcherbakov, M.V.; Panchenko, D.P.; Shcherbakova, N.L.; Brebels, A. Using Connectionist Systems for Electric Energy Consumption Forecasting in Shopping Centers. Autom. Remote Control 2012, 73, 1075–1084. [Google Scholar] [CrossRef]
- Bagnasco, A.; Fresi, F.; Saviozzi, M.; Silvestro, F.; Vinci, A. Electrical Consumption Forecasting in Hospital Facilities: An Application Case. Energy Build. 2015, 103, 261–270. [Google Scholar] [CrossRef]
- Borges, C.E.; Penya, Y.K.; Fernández, I.; Prieto, J.; Bretos, O. Assessing Tolerance-Based Robust Short-Term Load Forecasting in Buildings. Energies 2013, 6, 2110–2129. [Google Scholar] [CrossRef] [Green Version]
- Lai, F.; Magoulés, F.; Lherminier, F. Vapnik’s Learning Theory Applied to Energy Consumption Forecasts in Residential Buildings. Int. J. Comput. Math. 2008, 85, 1563–1588. [Google Scholar]
- Farzana, S.; Liu, M.; Baldwin, A.; Hossain, M.U. Multi-Model Prediction and Simulation of Residential Building Energy in Urban Areas of Chongqing, South West China. Energy Build. 2014, 81, 161–169. [Google Scholar] [CrossRef]
- Yuan, J.; Farnham, C.; Azuma, C.; Emura, K. Predictive Artificial Neural Network Models to Forecast the Seasonal Hourly Electricity Consumption for a University Campus. Sustain. Cities Soc. 2018, 42, 82–92. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, H.; Li, X.; Huang, J.; Wang, W. Machine Learning Method for Energy Consumption Prediction of Ships in Port Considering Green Ports. J. Clean. Prod. 2020, 264, 121564. [Google Scholar] [CrossRef]
- Shao, M.; Wang, X.; Bu, Z.; Chen, X.; Wang, Y. Prediction of Energy Consumption in Hotel Buildings via Support Vector Machines. Sustain. Cities Soc. 2020, 57, 102128. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Magoulès, F. A Review on the Prediction of Building Energy Consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A Review of Data-Driven Approaches for Prediction and Classification of Building Energy Consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- RapidMiner Documentation. Support Vector Machine. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/predictive/support_vector_machines/support_vector_machine.html (accessed on 1 March 2022).
- Amasyali, K.; El-Gohary, N.M. A Review of Data-Driven Building Energy Consumption Prediction Studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Bourhnane, S.; Abid, M.R.; Lghoul, R.; Zine-Dine, K.; Elkamoun, N.; Benhaddou, D. Machine Learning for Energy Consumption Prediction and Scheduling in Smart Buildings. SN Appl. Sci. 2020, 2, 297. [Google Scholar] [CrossRef] [Green Version]
- Bourdeau, M.; Zhai, X.Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and Forecasting Building Energy Consumption: A Review of Data-Driven Techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs. Neurons: Comparison between Random Forest and ANN for High-Resolution Prediction of Building Energy Consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- RapidMiner Documentation. Neural Net. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/predictive/neural_nets/neural_net.html (accessed on 1 March 2022).
- Domingos, P. A Few Useful Things to Know about Machine Learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Yu, Z.; Haghighat, F.; Fung, B.C.M.; Yoshino, H. A Decision Tree Method for Building Energy Demand Modeling. Energy Build. 2010, 42, 1637–1646. [Google Scholar] [CrossRef] [Green Version]
- RapidMiner Documentation. Decision Tree. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/predictive/trees/parallel_decision_tree.html (accessed on 1 March 2022).
- Dai, Y.; Khandelwal, M.; Qiu, Y.; Zhou, J.; Monjezi, M.; Yang, P. A Hybrid Metaheuristic Approach Using Random Forest and Particle Swarm Optimization to Study and Evaluate Backbreak in Open-Pit Blasting. Neural Comput. Appl. 2022, 34, 6273–6288. [Google Scholar] [CrossRef]
- RapidMiner Documentation. Random Forest. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/predictive/trees/parallel_random_forest.html (accessed on 31 March 2022).
- Yadav, A.K.; Malik, H.; Chandel, S.S. Application of Rapid Miner in ANN Based Prediction of Solar Radiation for Assessment of Solar Energy Resource Potential of 76 Sites in Northwestern India. Renew. Sustain. Energy Rev. 2015, 52, 1093–1106. [Google Scholar] [CrossRef]
- Correlation Coefficient: Simple Definition, Formula, Easy Calculation Steps. Available online: https://www.statisticshowto.com/probability-and-statistics/correlation-coefficient-formula/ (accessed on 23 February 2022).
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another Look at Measures of Forecast Accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Root Relative Squared Error. Available online: https://www.gepsoft.com/GeneXproTools/AnalysesAndComputations/MeasuresOfFit/RootRelativeSquaredError.htm (accessed on 21 February 2022).
- Laayati, O.; El Hadraoui, H.; Guennoui, N.; Bouzi, M.; Chebak, A. Smart Energy Management System: Design of a Smart Grid Test Bench for Educational Purposes. Energies 2022, 15, 2702. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Team | Year | Application | Methodology | Reference |
|---|---|---|---|---|
| Solomon | 2011 | Large commercial building | SVM (RBF) | [26] |
| Edwards | 2012 | Residential building | ANN LS-SVM MLR | [27] |
| Dagnely | 2015 | Nonresidential building | OLS, SVM (RBF) | [28] |
| Massana | 2015 | Nonresidential building | MLR, ANN (MLP, SVM (PUK) | [29] |
| Penya | 2011 | Nonresidential building | Poly, Exponential, mixed, AR, ANN, SVM | [30] |
| Zhao | 2010 | Multiple buildings | SVM (RBF) | [31] |
| Paudel | 2015 | Building | SVM (RBF) | [32] |
| Jain | 2014 | Multifamily residential building | SVM (RBM) | [33] |
| Men | 2014 | Bioclimatic building | ANN (NARX) | [34] |
| Penya | 2011 | Air-conditioned nonresidential building | AR ARIMA, ANN, Bayesian Network | [35] |
| González | 2005 | Nonresidential building | ANN | [36] |
| Fernández | 2011 | Nonresidential building | AR, SVM (RBF), Poly, ANN | [37] |
| Escrivá | 2011 | Nonresidential building | ANN (MLP) | [38] |
| Kamaev | 2012 | Shopping center | ANN | [39] |
| Bagnasco | 2012 | Hospital facilities | ANN (BPNN) | [40] |
| Borges | 2013 | Multifamily residential building | SVM(RBF) AR | [41] |
| Lai | 2008 | Residential building | SVM | [42] |
| Farzana | 2014 | Residential building | ANN(BPNN) | [43] |
| Yuan | 2018 | University Campus | ANN | [44] |
| Yun | 2020 | Ships of green ports | ANN | [45] |
| Minglei | 2020 | Hotel | SVM | [46] |
| Model | Parameters | Default Value |
|---|---|---|
| SVM | Kernel type | Dot |
| Kernel cache | 200 | |
| C | 0.0 | |
| Convergence epsilon | 0.001 | |
| Max iterations | 100,000 | |
| ANN | Hidden layers size | 2 |
| Training cycle | 200 | |
| Learning rate | 0.01 | |
| Momentum | 0.9 | |
| DT | Criterion | Least square |
| Maximal depth | 10 | |
| Minimal gain | 0.01 | |
| Minimal leaf size | 2 | |
| Minimal size for split | 4 | |
| Number of prepruning alternatives | 3 | |
| RF | Number of trees | 100 |
| Criterion | Least square | |
| Maximal depth | 10 |
| Model | Parameter | Tuned Value |
|---|---|---|
| DT | Minimal gain | 0.0595 |
| RF | Minimal gain | 70 |
| ANN | Training cycles | 164 |
| SVM | Convergence epsilon | 88 |
| Model | Measure | Before Optimization | After Optimization | ||
|---|---|---|---|---|---|
| Testing Set | Validation Set | Testing Set | Validation Set | ||
| SVM | R | 0.984 | 0.994 | 0.984 | 0.994 |
| MAE | 0.0368 | 0.0291 | 0.0365 | 0.0282 | |
| RMSE | 518.695 | 421.49 | 516.44 | 415.86 | |
| RRSE | 0.183 | 0.112 | 0.182 | 0.111 | |
| ANN | R | 0.992 | 0.995 | 0.992 | 0.995 |
| MAE | 0.0265 | 0.0276 | 0.0267 | 0.0290 | |
| RMSE | 365.192 | 381.256 | 363.48 | 384.745 | |
| RRSE | 0.129 | 0.101 | 0.128 | 0.102 | |
| DT | R | 0.997 | 0.966 | 0.999 | 1 |
| MAE | 0.0093 | 0.0474 | 0.0050 | 0.0041 | |
| RMSE | 200.763 | 985.602 | 116.139 | 94.175 | |
| RRSE | 0.071 | 0.262 | 0.031 | 0.025 | |
| RF | R | 0.998 | 0.971 | 1 | 1 |
| MAE | 0.0079 | 0.0516 | 0.0038 | 0.0027 | |
| RMSE | 186.057 | 939.576 | 92.196 | 52.16 | |
| RRSE | 0.065 | 0.25 | 0.025 | 0.014 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Maghraoui, A.; Ledmaoui, Y.; Laayati, O.; El Hadraoui, H.; Chebak, A. Smart Energy Management: A Comparative Study of Energy Consumption Forecasting Algorithms for an Experimental Open-Pit Mine. Energies 2022, 15, 4569. https://0-doi-org.brum.beds.ac.uk/10.3390/en15134569
El Maghraoui A, Ledmaoui Y, Laayati O, El Hadraoui H, Chebak A. Smart Energy Management: A Comparative Study of Energy Consumption Forecasting Algorithms for an Experimental Open-Pit Mine. Energies. 2022; 15(13):4569. https://0-doi-org.brum.beds.ac.uk/10.3390/en15134569
Chicago/Turabian StyleEl Maghraoui, Adila, Younes Ledmaoui, Oussama Laayati, Hicham El Hadraoui, and Ahmed Chebak. 2022. "Smart Energy Management: A Comparative Study of Energy Consumption Forecasting Algorithms for an Experimental Open-Pit Mine" Energies 15, no. 13: 4569. https://0-doi-org.brum.beds.ac.uk/10.3390/en15134569