
Clustering Informed MLP Models for Fast and Accurate Short-Term Load Forecasting

 , , , , and
, , , , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Clustering Methods for Short-Term Load Forecasting
2.1.1. K-Means Clustering Algorithm
2.1.2. Fuzzy C-Means Clustering Algorithm
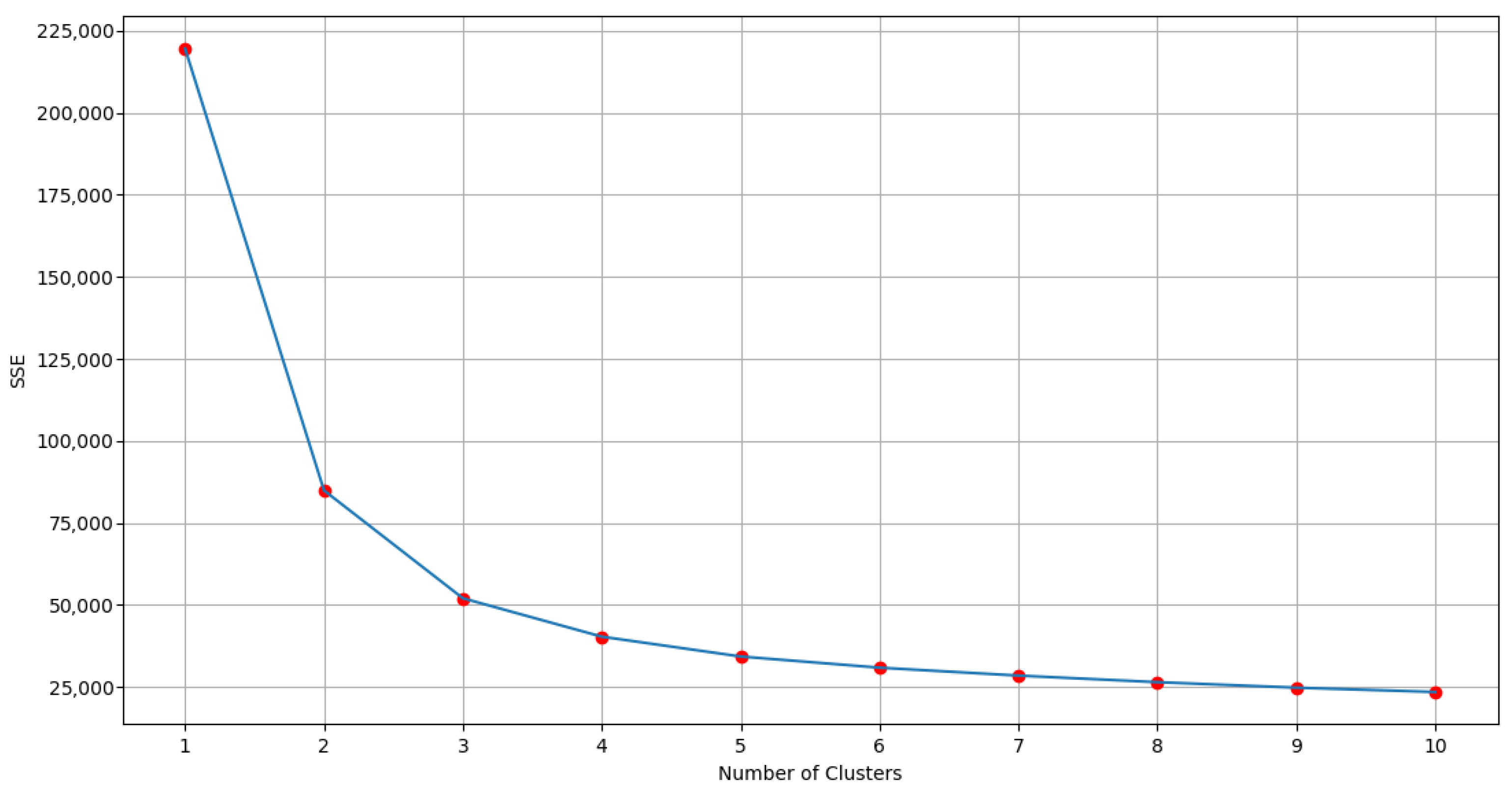
2.2. Elbow Optimization Method
2.3. Performance Metrics
2.4. Problem Formulation
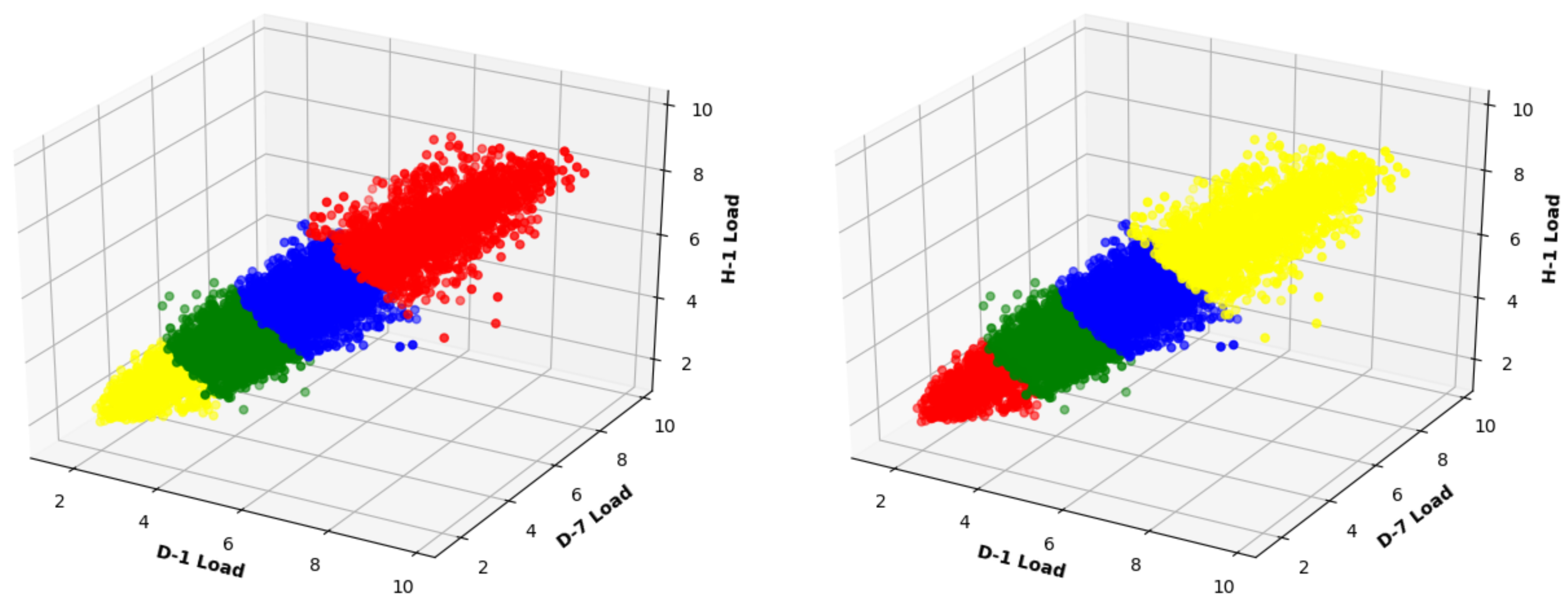
2.4.1. Calculation of Optimum Number of Clusters
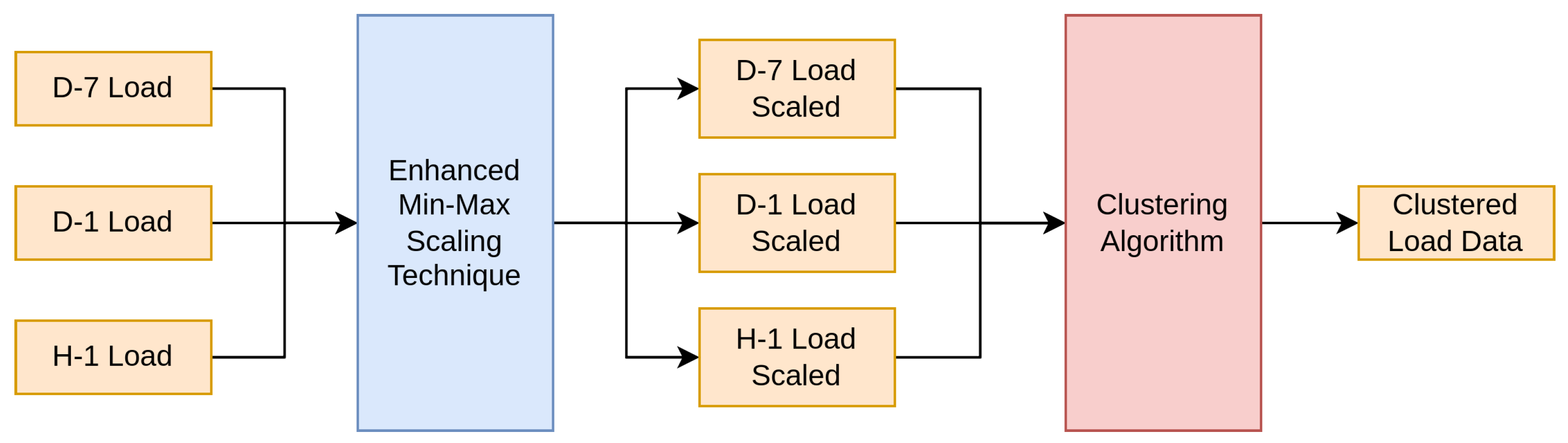
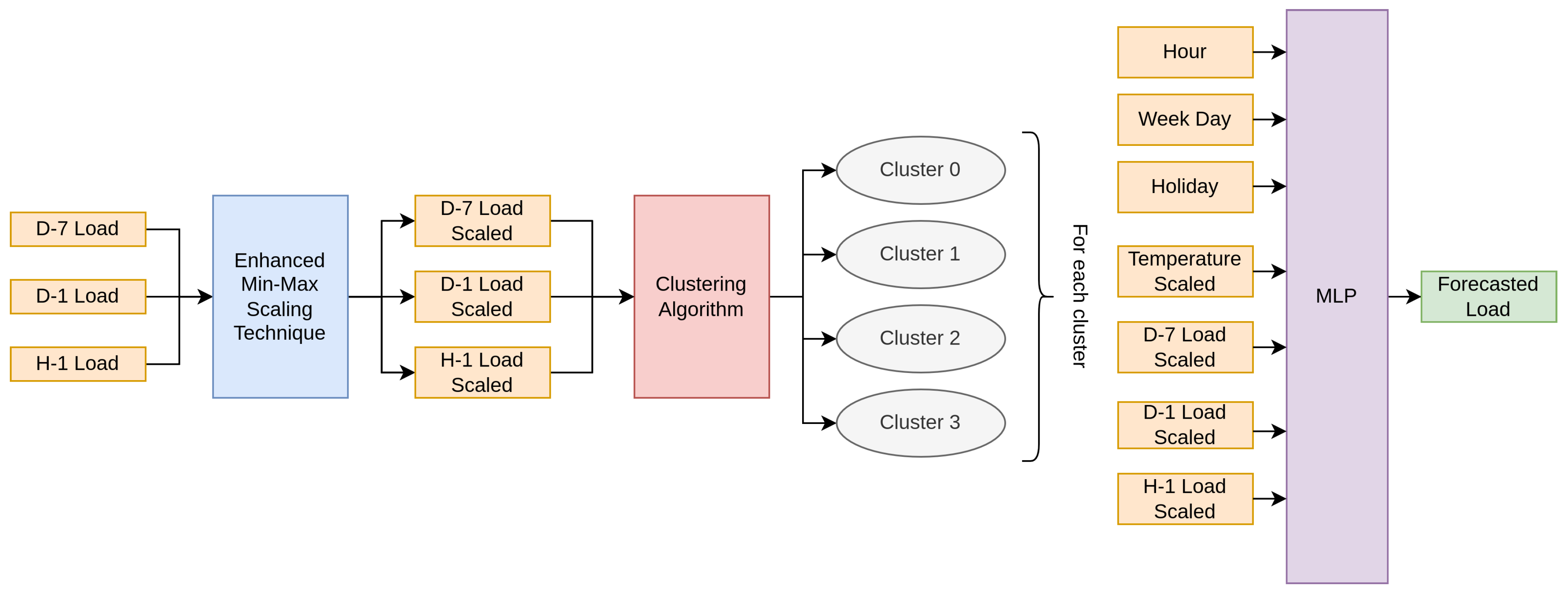
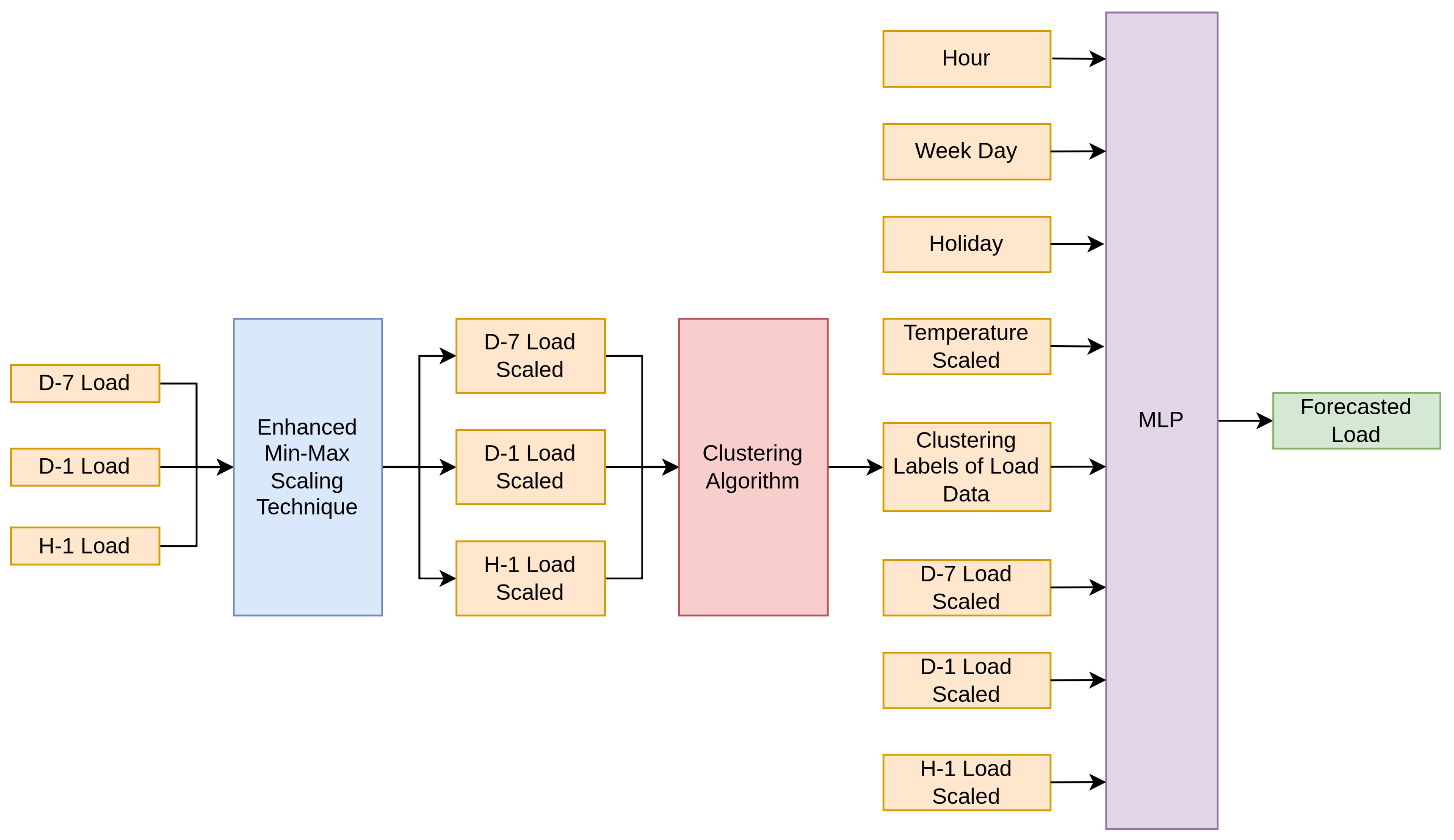
2.4.2. Short-Term Load Forecasting Approaches in Conjunction with Clustering Techniques
- Hour: Input variable within the range [0, 23] indicating the load forecast’s time of day;
- Week Day: Input variable denoting the day of the week, within the range [1, 7] (1 corresponding to Sunday, and so on);
- Holiday: Binary values are used to indicate whether a day is a holiday (1), which includes Greek state holidays, religious holidays and the weekends, or a normal working day (0);
- Temperature: Input variable indicating the temperature of the hour (in Celsius) for which the load is predicted, scaled by min-max technique;
- D-7 Load: Input variable denoting the corresponding load at the same hour on the same day in the prior week;
- D-1 Load: Input variable denoting the corresponding load at the same hour in the prior day;
- H-1 Load: Input variable denoting the corresponding load in the prior hour.
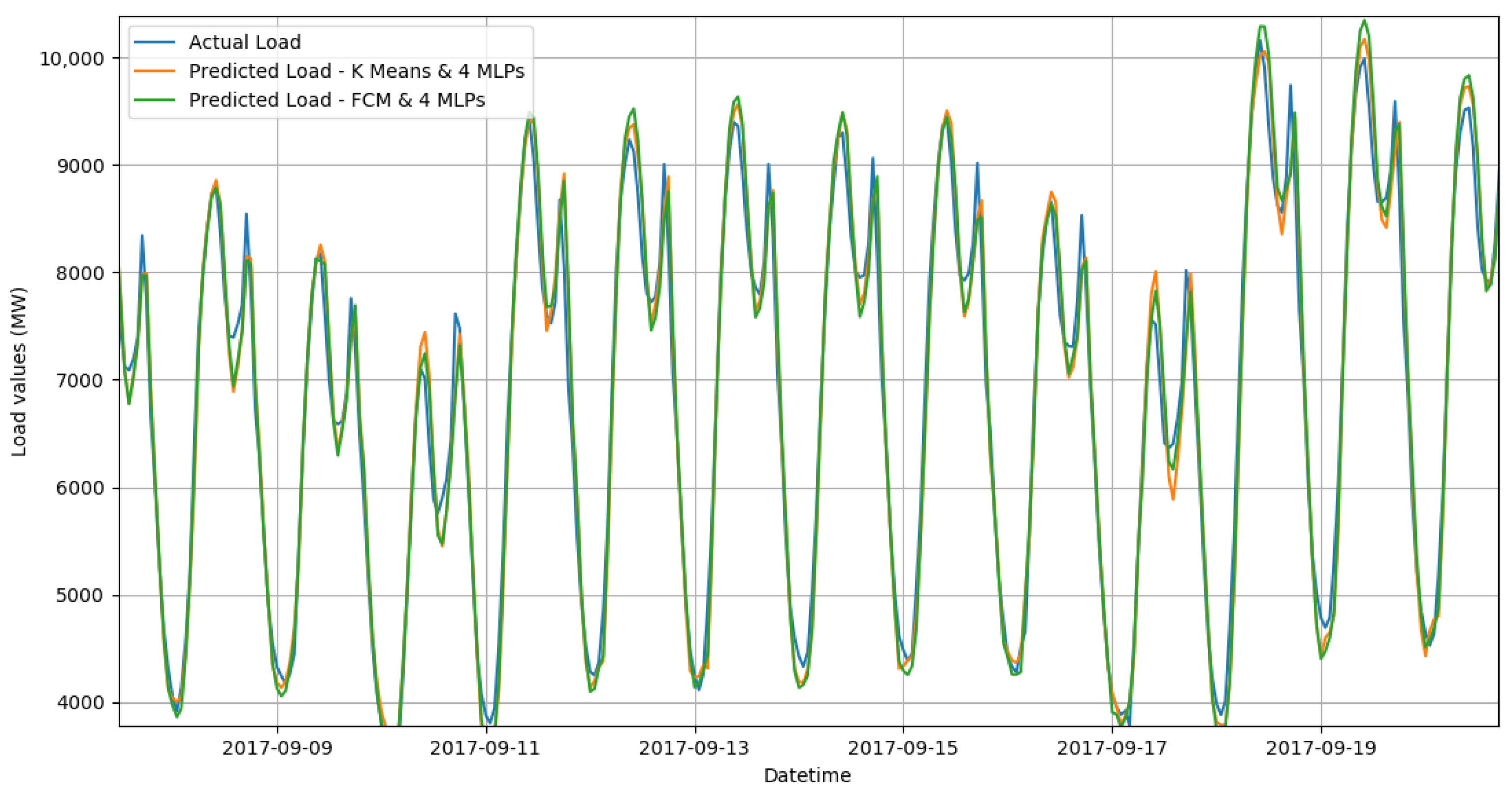
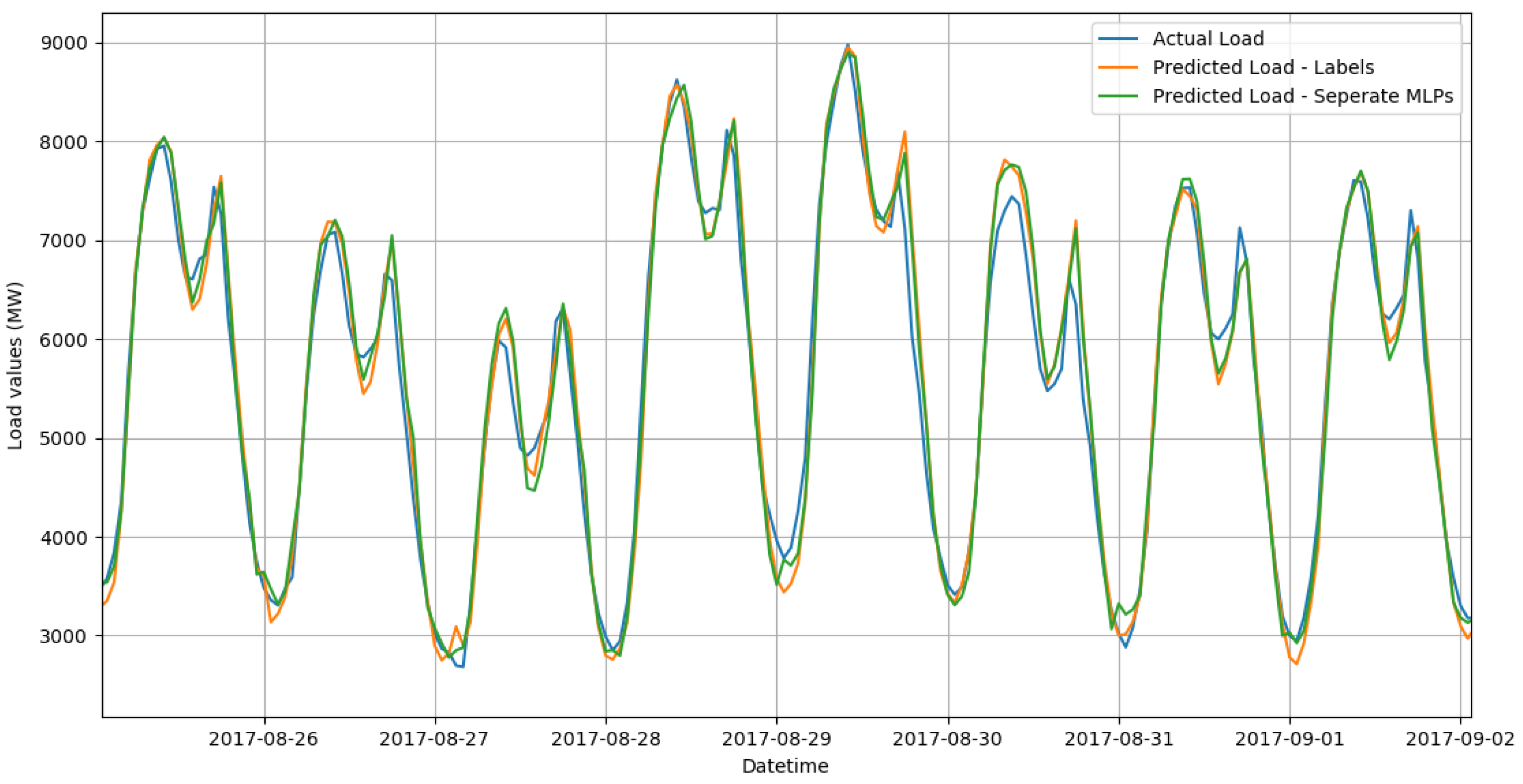
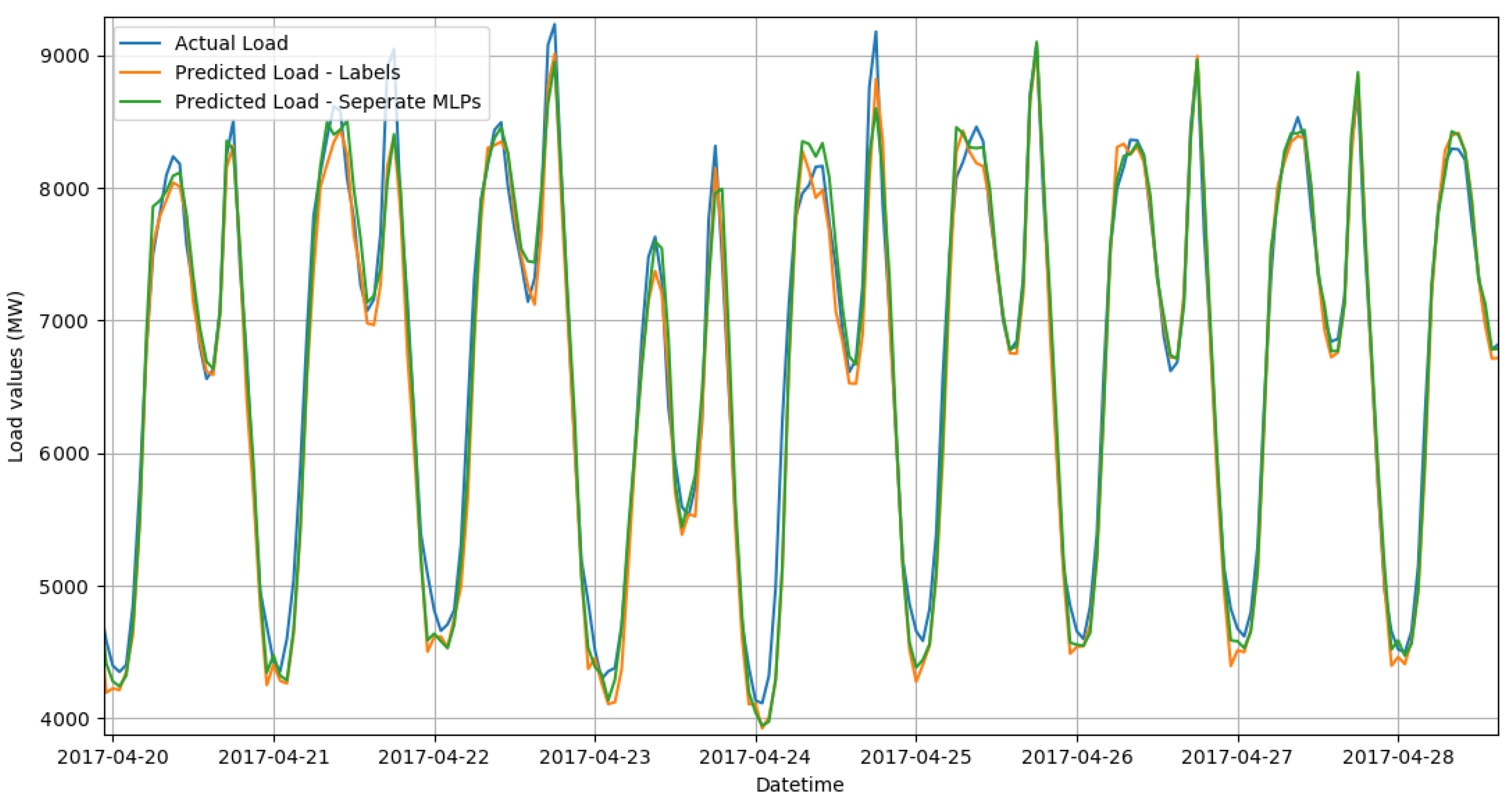
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kalakova, A.; Nunna, H.S.S.K.; Jamwal, P.K.; Doolla, S. Genetic Algorithm for Dynamic Economic Dispatch with Short-Term Load Forecasting. In Proceedings of the 2019 IEEE Industry Applications Society Annual Meeting, Baltimore, MD, USA, 29 September–3 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Laitsos, V.M.; Bargiotas, D.; Daskalopulu, A.; Arvanitidis, A.I.; Tsoukalas, L.H. An Incentive-Based Implementation of Demand Side Management in Power Systems. Energies 2021, 14, 7994. [Google Scholar] [CrossRef]
- Alamaniotis, M.; Ikonomopoulos, A.; Alamaniotis, A.; Bargiotas, D.; Tsoukalas, L.H. Day-ahead electricity price forecasting using optimized multiple-regression of relevance vector machines. In Proceedings of the 8th Mediterranean Conference on Power Generation, Transmission, Distribution and Energy Conversion (MEDPOWER 2012), Cagliari, Italy, 1–3 October 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Alamaniotis, M.; Bargiotas, D.; Bourbakis, N.G.; Tsoukalas, L.H. Genetic Optimal Regression of Relevance Vector Machines for Electricity Pricing Signal Forecasting in Smart Grids. IEEE Trans. Smart Grid 2015, 6, 2997–3005. [Google Scholar] [CrossRef]
- Alamaniotis, M.; Tsoukalas, L.H. Implementing smart energy systems: Integrating load and price forecasting for single parameter based demand response. In Proceedings of the 2016 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), Ljubljana, Slovenia, 9–12 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kyriakides, E.; Polycarpou, M. Short Term Electric Load Forecasting: A Tutorial. In Trends in Neural Computation; Chen, K., Wang, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 391–418. [Google Scholar] [CrossRef]
- Alamaniotis, M.; Bargiotas, D.; Tsoukalas, L.H. Towards Smart Energy Systems: Application of Kernel Machine Regression for Medium Term Electricity Load Forecasting. SpringerPlus 2016, 5, 58. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kontogiannis, D.; Bargiotas, D.; Daskalopulu, A. Fuzzy Control System for Smart Energy Management in Residential Buildings Based on Environmental Data. Energies 2021, 14, 752. [Google Scholar] [CrossRef]
- Kontogiannis, D.; Bargiotas, D.; Daskalopulu, A.; Tsoukalas, L.H. A Meta-Modeling Power Consumption Forecasting Approach Combining Client Similarity and Causality. Energies 2021, 14, 88. [Google Scholar] [CrossRef]
- Hua, Y.; Wang, N.; Zhao, K. Simultaneous Unknown Input and State Estimation for the Linear System with a Rank-Deficient Distribution Matrix. Math. Probl. Eng. 2021, 2021, 6693690. [Google Scholar] [CrossRef]
- Liu, C.; Li, Q.; Wang, K. State-of-charge estimation and remaining useful life prediction of supercapacitors. Renew. Sustain. Energy Rev. 2021, 150, 111408. [Google Scholar] [CrossRef]
- Kontogiannis, D.; Bargiotas, D.; Daskalopulu, A. Minutely Active Power Forecasting Models Using Neural Networks. Sustainability 2020, 12, 3177. [Google Scholar] [CrossRef] [Green Version]
- Arvanitidis, A.I.; Bargiotas, D.; Daskalopulu, A.; Laitsos, V.M.; Tsoukalas, L.H. Enhanced Short-Term Load Forecasting Using Artificial Neural Networks. Energies 2021, 14, 7788. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, D.; Yue, D. Rough Neuron Based RBF Neural Networks for Short-Term Load Forecasting. In Proceedings of the 2017 IEEE International Conference on Energy Internet (ICEI), Beijing, China, 17–21 April 2017; pp. 291–295. [Google Scholar] [CrossRef]
- Sadaei, H.J.; de Lima e Silva, P.C.; Guimarães, F.G.; Lee, M.H. Short-term load forecasting by using a combined method of convolutional neural networks and fuzzy time series. Energy 2019, 175, 365–377. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, Y.; Sun, J.; Cui, Z.; Wang, K. Stacked bidirectional LSTM RNN to evaluate the remaining useful life of supercapacitor. Int. J. Energy Res. 2021, 1–10. [Google Scholar] [CrossRef]
- Yang, A.; Li, W.; Yang, X. Short-term electricity load forecasting based on feature selection and Least Squares Support Vector Machines. Knowl.-Based Syst. 2019, 163, 159–173. [Google Scholar] [CrossRef]
- Moon, J.; Kim, Y.; Son, M.; Hwang, E. Hybrid Short-Term Load Forecasting Scheme Using Random Forest and Multilayer Perceptron. Energies 2018, 11, 3283. [Google Scholar] [CrossRef] [Green Version]
- Almalaq, A.; Edwards, G. A Review of Deep Learning Methods Applied on Load Forecasting. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 511–516. [Google Scholar] [CrossRef]
- Koo, B.g.; Lee, S.W.; Kim, W.; Park, J.H. Comparative Study of Short-Term Electric Load Forecasting. In Proceedings of the 2014 5th International Conference on Intelligent Systems, Modelling and Simulation, Langkawi, Malaysia, 27–29 January 2014; pp. 463–467. [Google Scholar] [CrossRef]
- Hernández, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sánchez-Esguevillas, A.; Lloret, J. Artificial neural networks for short-term load forecasting in microgrids environment. Energy 2014, 75, 252–264. [Google Scholar] [CrossRef]
- Farfar, K.E.; Khadir, M. A two-stage short-term load forecasting approach using temperature daily profiles estimation. Neural Comput. Appl. 2019, 31. [Google Scholar] [CrossRef]
- Dong, X.; Qian, L.; Huang, L. Short-term load forecasting in smart grid: A combined CNN and K-means clustering approach. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 13–16 February 2017; pp. 119–125. [Google Scholar] [CrossRef]
- Ngo, M.D.; Yun, S.Y.; Choi, J.H.; Ahn, S.J. Short-Term Load Forecasting of Buildings Based on Artificial Neural Network and Clustering Technique. J. IKEEE 2018, 22, 672–679. [Google Scholar]
- Li, Z.; Bao, S.; Gao, Z. Short Term Prediction of Photovoltaic Power Based on FCM and CG-DBN Combination. J. Electr. Eng. Technol. 2019, 15, 333–341. [Google Scholar] [CrossRef]
- Yang, M.; Shi, C.; Liu, H. Day-ahead wind power forecasting based on the clustering of equivalent power curves. Energy 2021, 218, 119515. [Google Scholar] [CrossRef]
- Bian, H.; Zhong, Y.; Sun, J.; Shi, F. Study on power consumption load forecast based on K-means clustering and FCM-BP model. Energy Rep. 2020, 6, 693–700. [Google Scholar] [CrossRef]
- Lu, Y.; Zhang, T.; Zeng, Z.; Loo, J. An improved RBF neural network for short-term load forecast in smart grids. In Proceedings of the 2016 IEEE International Conference on Communication Systems (ICCS), Shenzhen, China, 14–16 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kuan, L.; Yan, Z.; Xin, W.; Yan, C.; Xiangkun, P.; Wenxue, S.; Zhe, J.; Yong, Z.; Nan, X.; Xin, Z. Short-term electricity load forecasting method based on multilayered self-normalizing GRU network. In Proceedings of the 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 26–28 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Jin, X.; Han, J. K-Means Clustering. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 563–564. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Bholowalia, P.; Kumar, A. EBK-means: A clustering technique based on elbow method and k-means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Hirth, L.; Mühlenpfordt, J.; Bulkeley, M. The ENTSO-E Transparency Platform—A review of Europe’s most ambitious electricity data platform. Appl. Energy 2018, 225, 1054–1067. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Number of Data | MAPE (%) | Score |
|---|---|---|---|
| Cluster 0 | 2052 | 1.66 | 0.95132 |
| Cluster 1 | 2330 | 1.76 | 0.89331 |
| Cluster 2 | 2955 | 1.67 | 0.88591 |
| Cluster 3 | 1423 | 1.65 | 0.88591 |
| Total | 8760 | 1.69 | 0.98643 |
| Cluster | Number of Data | MAPE (%) | Score |
|---|---|---|---|
| Cluster 0 | 1423 | 1.74 | 0.87951 |
| Cluster 1 | 2128 | 1.66 | 0.95198 |
| Cluster 2 | 2308 | 1.75 | 0.89383 |
| Cluster 3 | 2901 | 1.70 | 0.88200 |
| Total | 8760 | 1.71 | 0.98632 |
| Approach | MAPE (%) | Score |
|---|---|---|
| MLPs and K-Means—Labels are fed as input to MLP | 1.77 | 0.98583 |
| MLPs and Fuzzy C-Means—Labels are fed as input to MLP | 1.70 | 0.98678 |
| Approach | Time (s) |
|---|---|
| MLPs and K-Means—Individual MLP for each cluster | 1690.27835 |
| MLPs and Fuzzy C-Means—Individual MLP for each cluster | 1353.51278 |
| MLPs and K-Means—Labels are fed as input to MLP | 1223.64124 |
| MLPs and Fuzzy C-Means—Labels are fed as input to MLP | 808.320161 |
| Approach | Proposed by | MAPE (%) |
|---|---|---|
| SOM—K-Means—MLP | Hernandez et al. [21] | 3.18 |
| K-Means—Stacked Denoising Autoencoders - ANNs | Farfar et al. [22] | 1.85 |
| Sparsified K-Means—ANN | Seon-Ju Ahn et al. [24] | 2.06 |
| K-Means—SVM | Xishuang Dong et al. [23] | 2.92 |
| K-Means—MLP | Xishuang Dong et al. [23] | 3.12 |
| K-Means—CNN | Xishuang Dong et al. [23] | 3.06 |
| K-Means—FCM—MLP | Bian Haihong et al. [27] | 2.15 |
| Enhanced STLF via MLPs | Arvanitidis et al. [13] | 1.80 |
| MLPs and K-Means—Individual MLP for each cluster | Proposed algorithm | 1.69 |
| MLPs and Fuzzy C-Means—Individual MLP for each cluster | Proposed algorithm | 1.71 |
| MLP and K-Means—Labels are fed as input to MLP | Proposed algorithm | 1.77 |
| MLP and Fuzzy C-Means—Labels are fed as input to MLP | Proposed algorithm | 1.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arvanitidis, A.I.; Bargiotas, D.; Daskalopulu, A.; Kontogiannis, D.; Panapakidis, I.P.; Tsoukalas, L.H. Clustering Informed MLP Models for Fast and Accurate Short-Term Load Forecasting. Energies 2022, 15, 1295. https://0-doi-org.brum.beds.ac.uk/10.3390/en15041295
Arvanitidis AI, Bargiotas D, Daskalopulu A, Kontogiannis D, Panapakidis IP, Tsoukalas LH. Clustering Informed MLP Models for Fast and Accurate Short-Term Load Forecasting. Energies. 2022; 15(4):1295. https://0-doi-org.brum.beds.ac.uk/10.3390/en15041295
Chicago/Turabian StyleArvanitidis, Athanasios Ioannis, Dimitrios Bargiotas, Aspassia Daskalopulu, Dimitrios Kontogiannis, Ioannis P. Panapakidis, and Lefteri H. Tsoukalas. 2022. "Clustering Informed MLP Models for Fast and Accurate Short-Term Load Forecasting" Energies 15, no. 4: 1295. https://0-doi-org.brum.beds.ac.uk/10.3390/en15041295