

Energy Consumption Forecasting in a University Office by Artificial Intelligence Techniques: An Analysis of the Exogenous Data Effect on the Modeling

Abstract
:1. Introduction
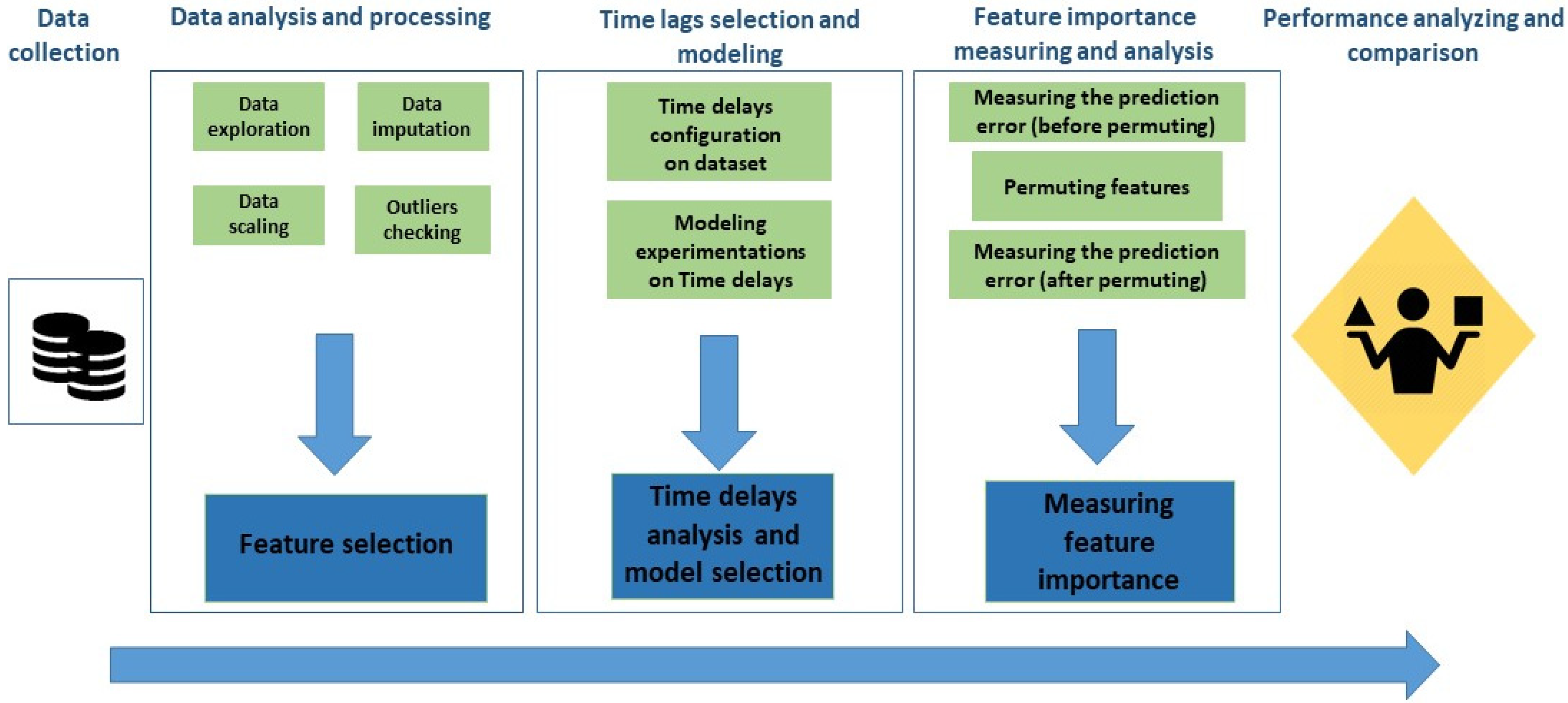
2. Methods and Protocols
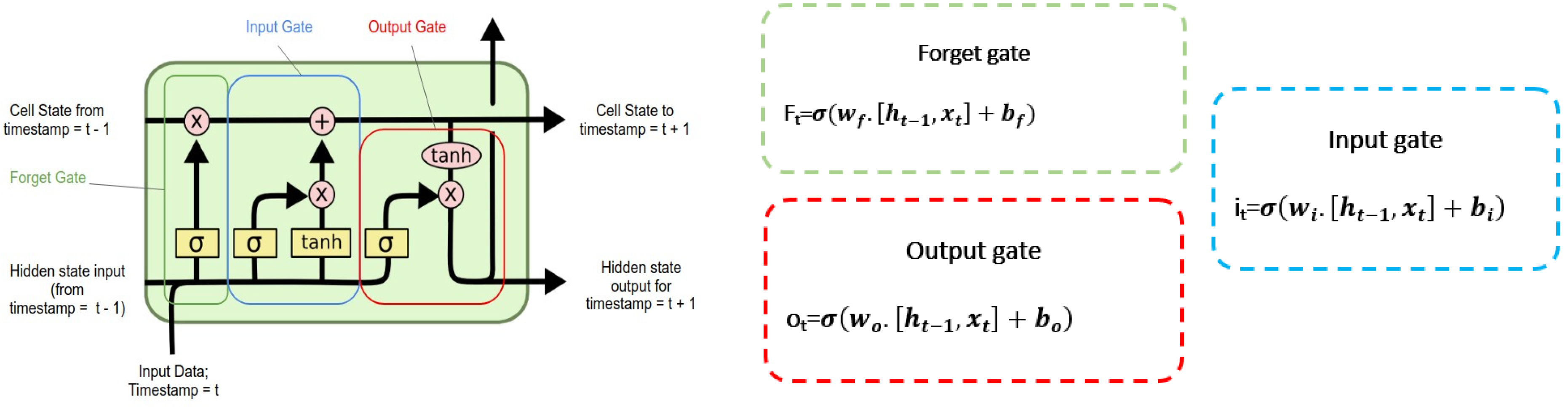
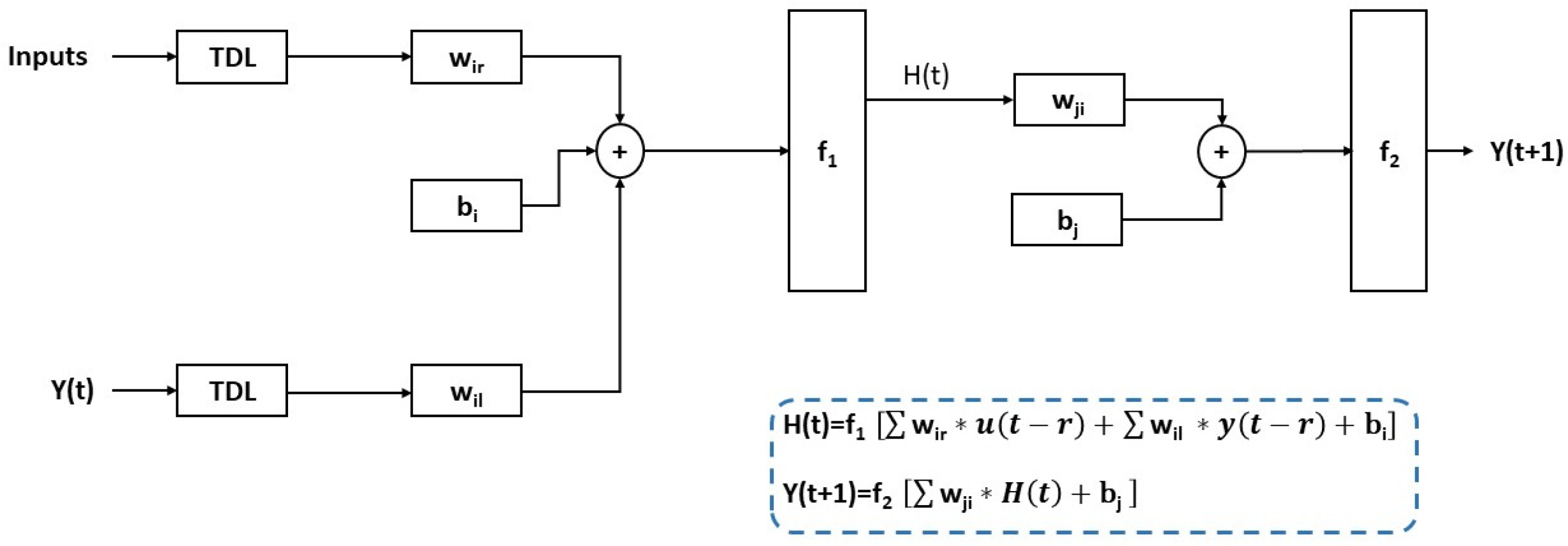
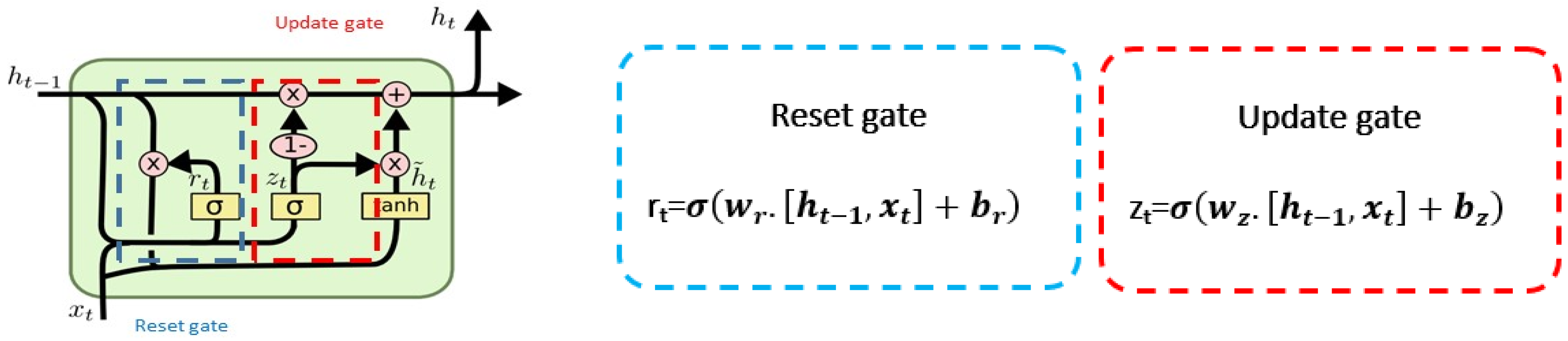
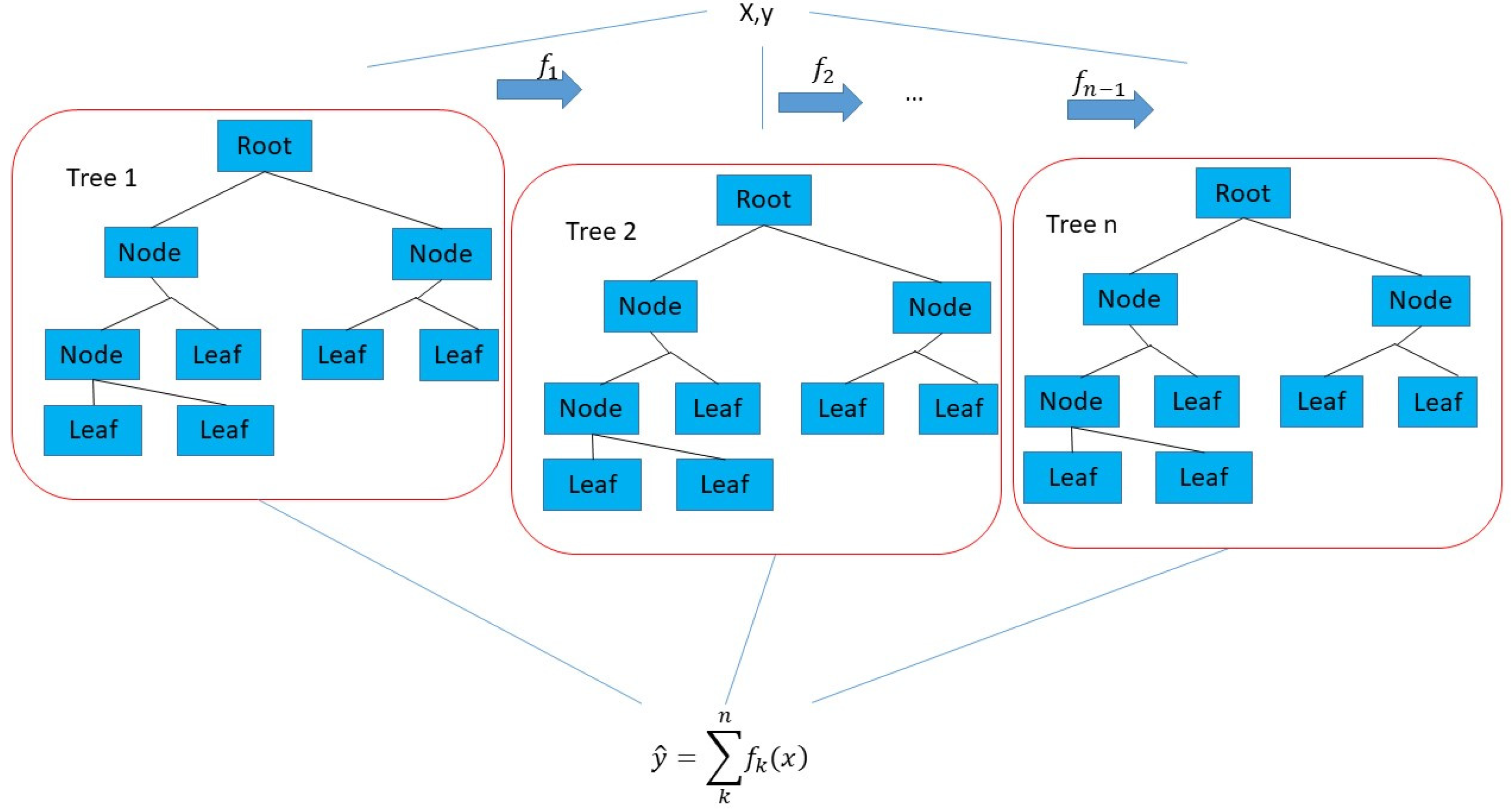
2.1. Machine Learning Algorithms for Modeling Energy Consumption Forecaster
2.2. Feature Importance Analysis by “Model Reliance” Method
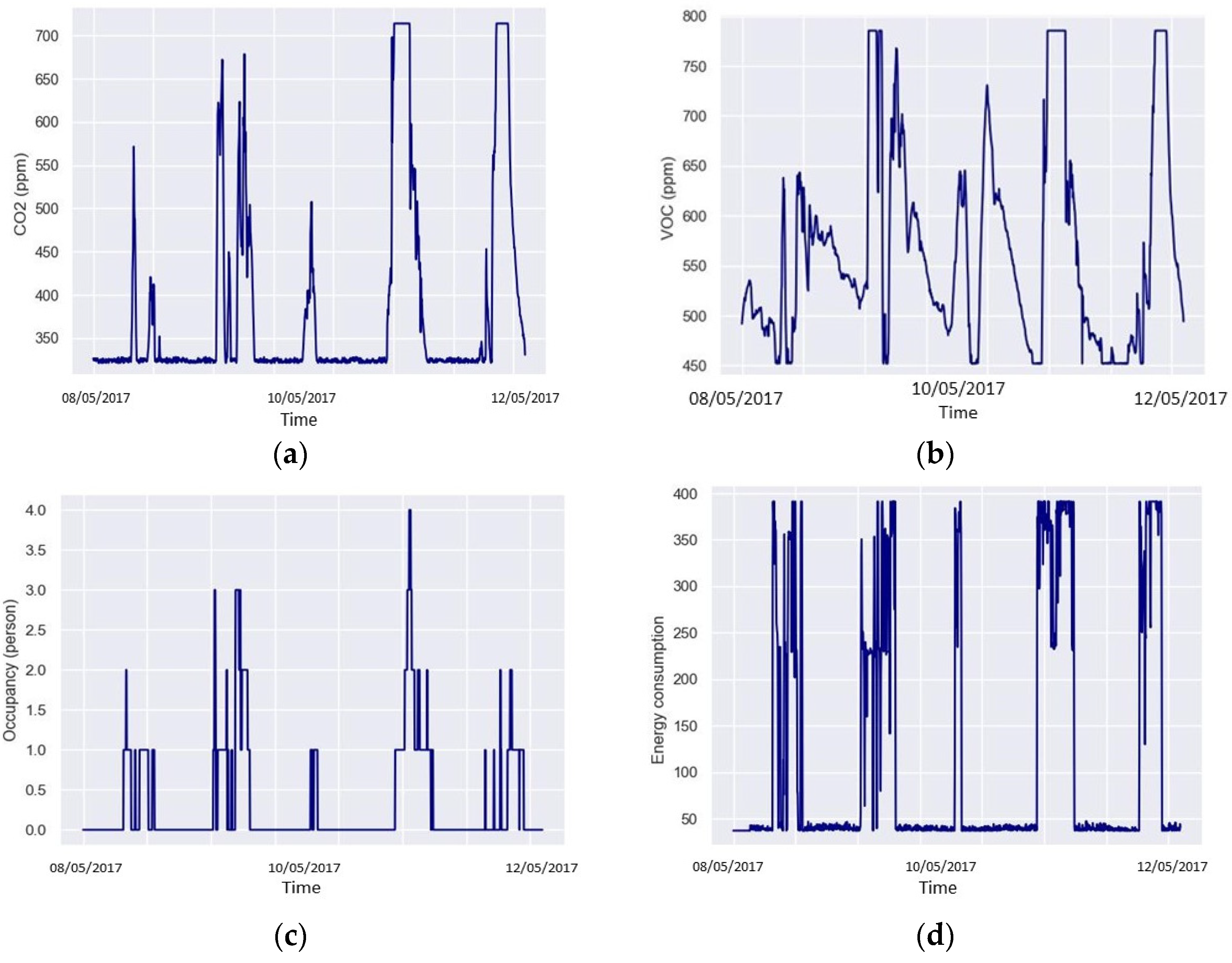
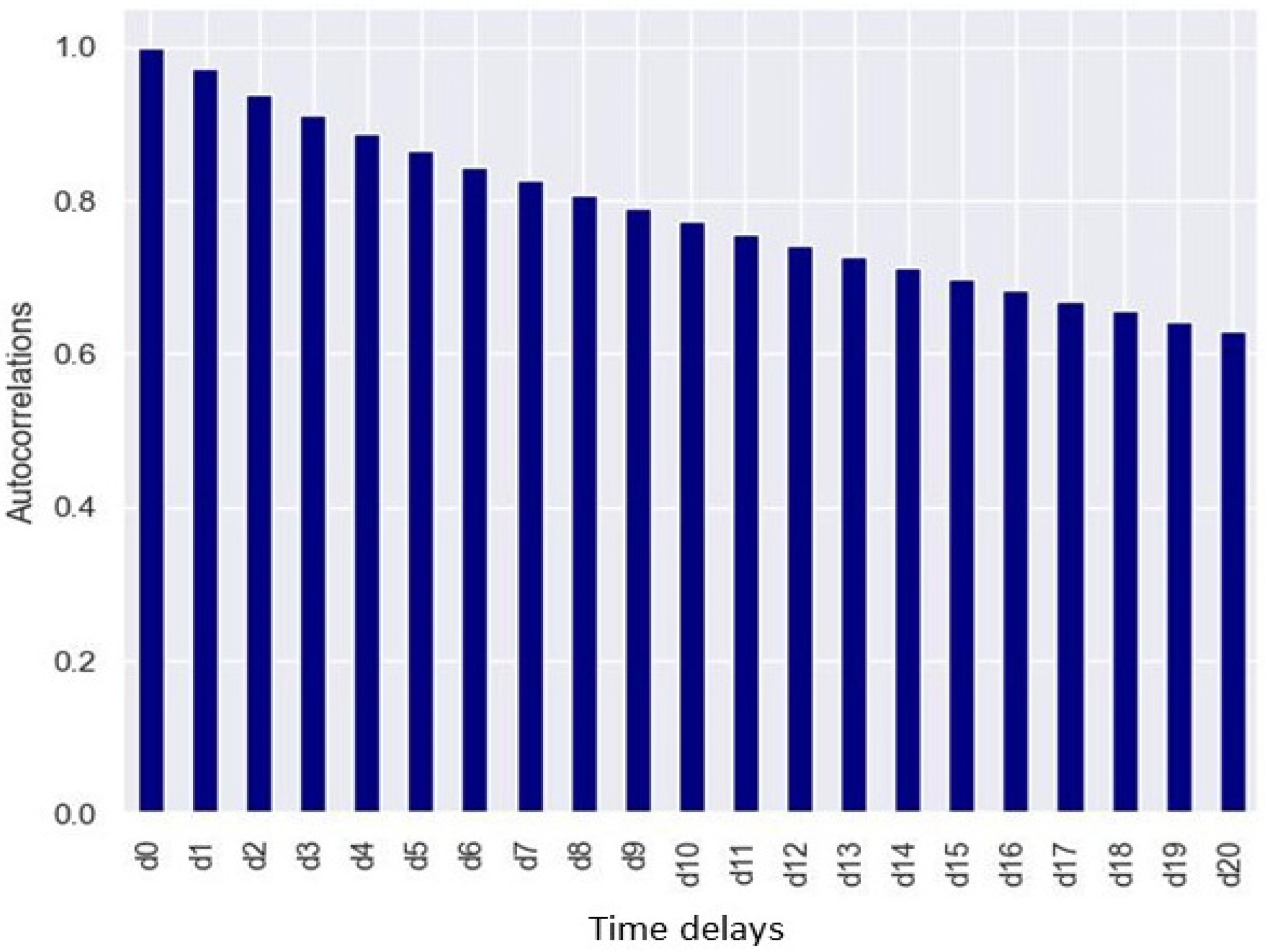
3. Dataset Presentation, Analysis, and Processing
3.1. Dataset Presentation
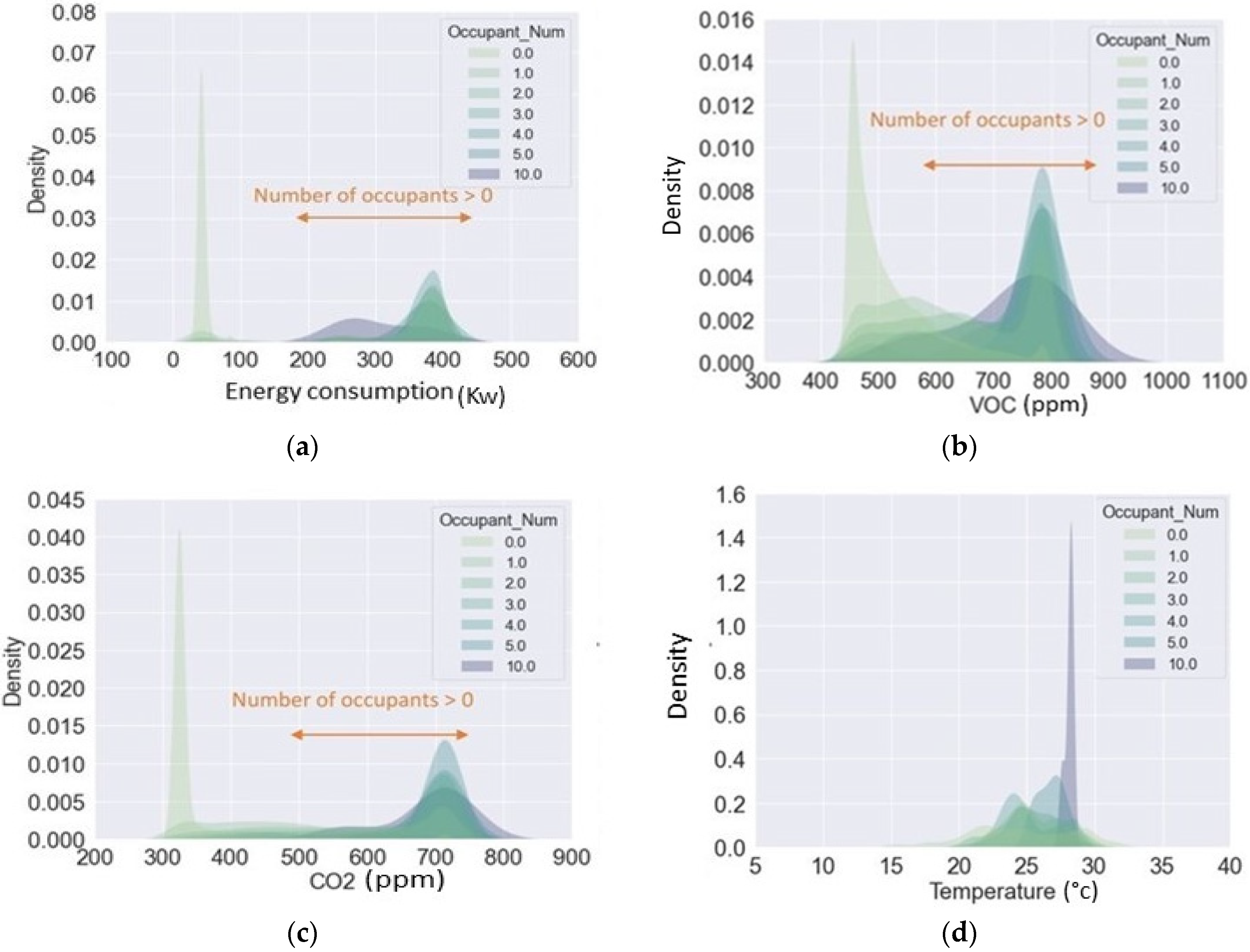
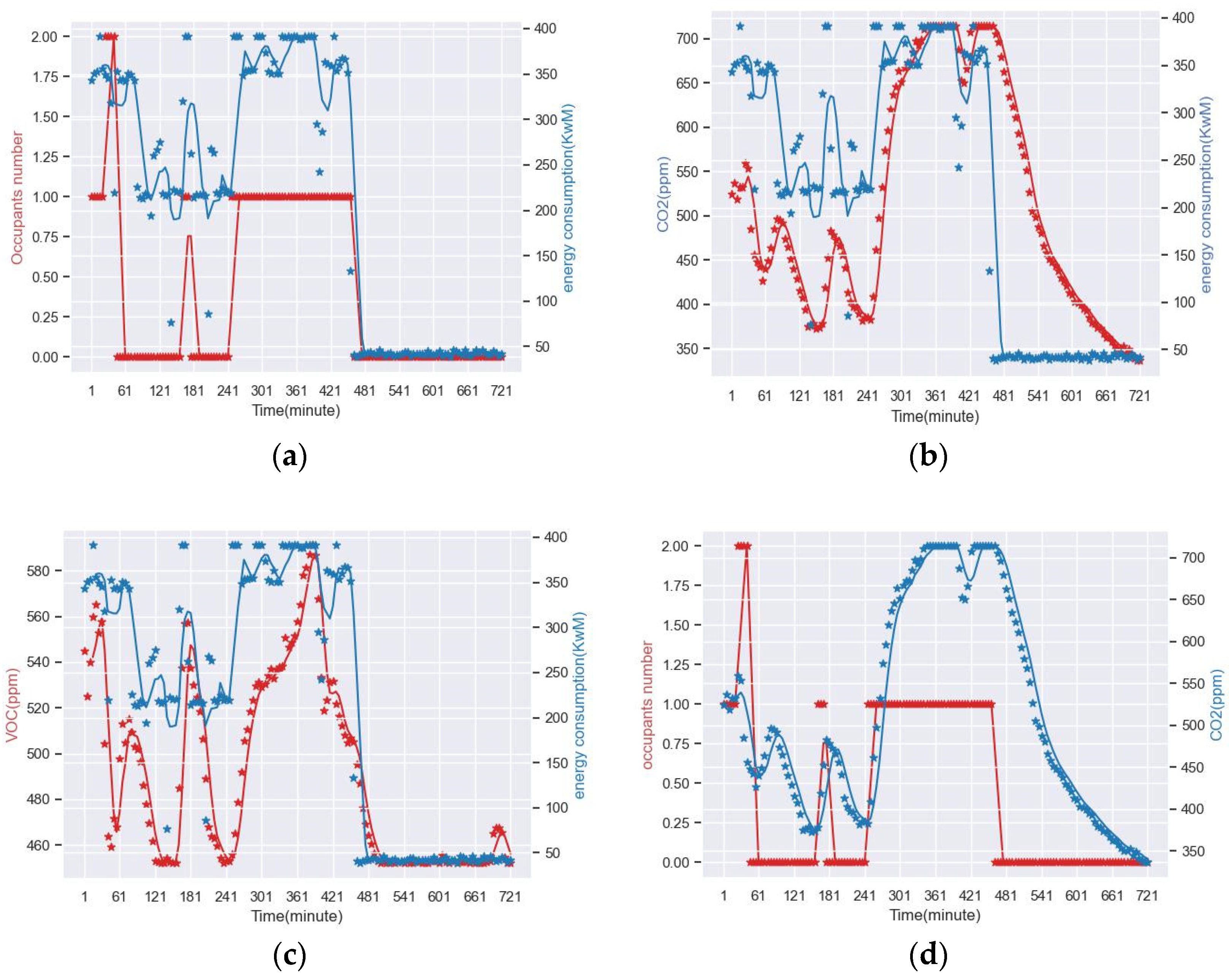
3.2. Dataset Analysis and Processing
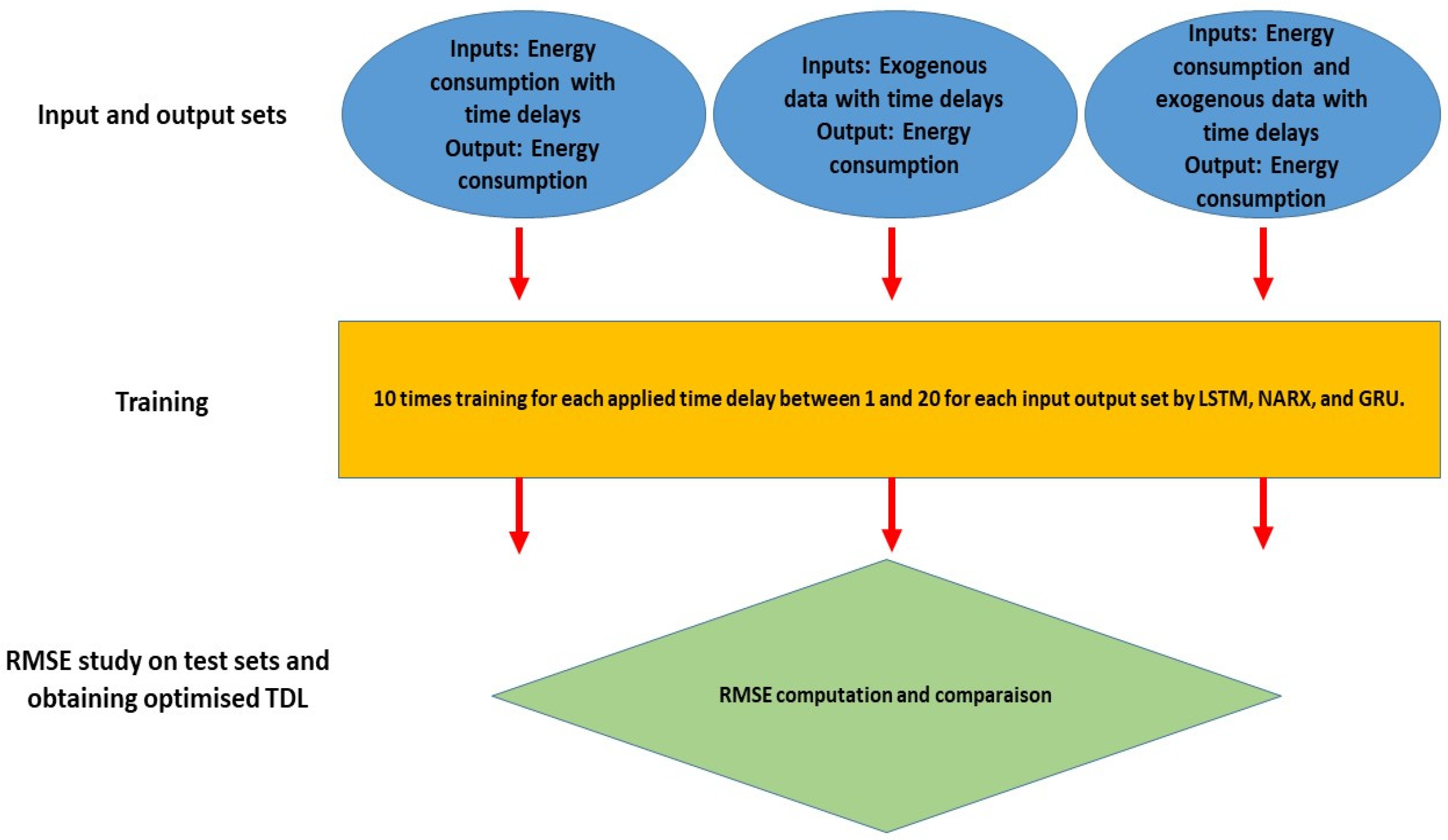
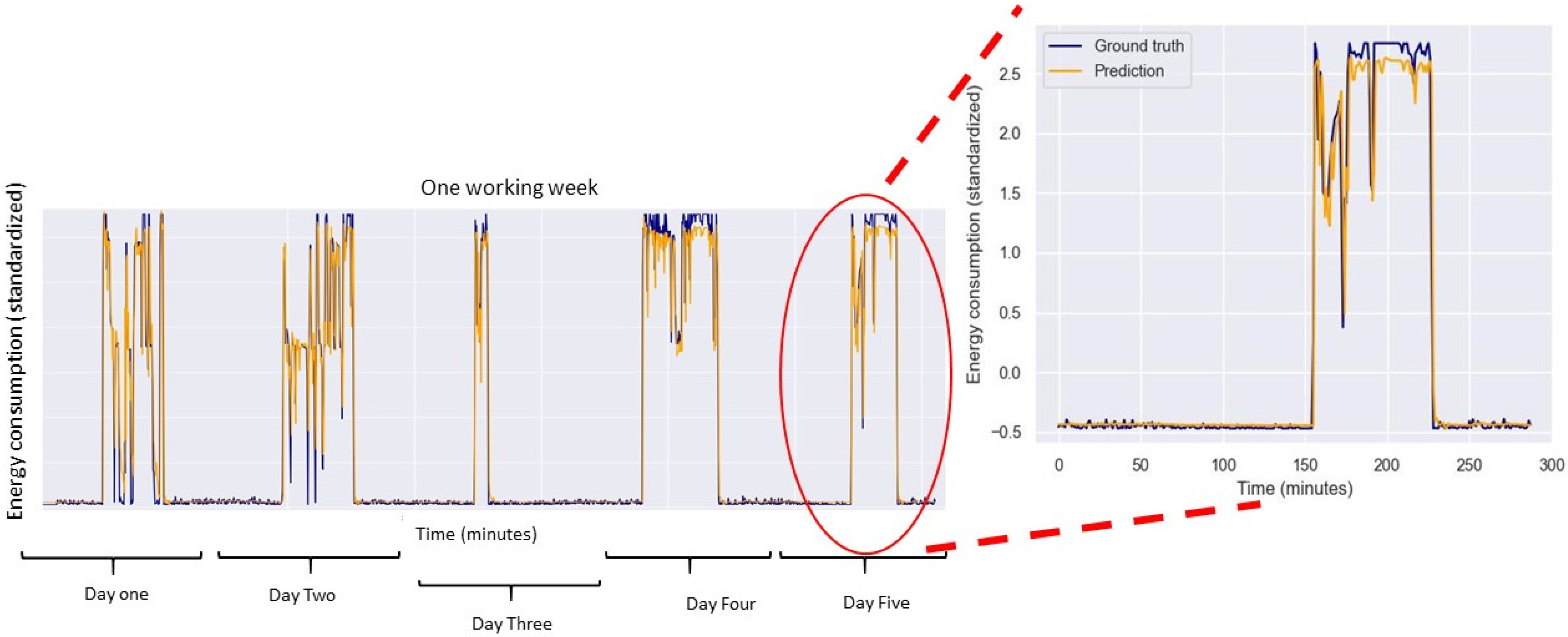
4. Experimentation and Results
- The first set of input features is the energy consumption with applied time lags (ECTL) to predict the energy consumption in their next steps.
- In the second model, only the exogenous data with applied time lags (ETL), which lacks the energy consumption data, are utilized as inputs to study the model performance and the association of exogenous data.
- In the third model, energy consumption and exogenous data with applied time lags (ECETL) are used as the inputs to study their roles in the final model’s performance.
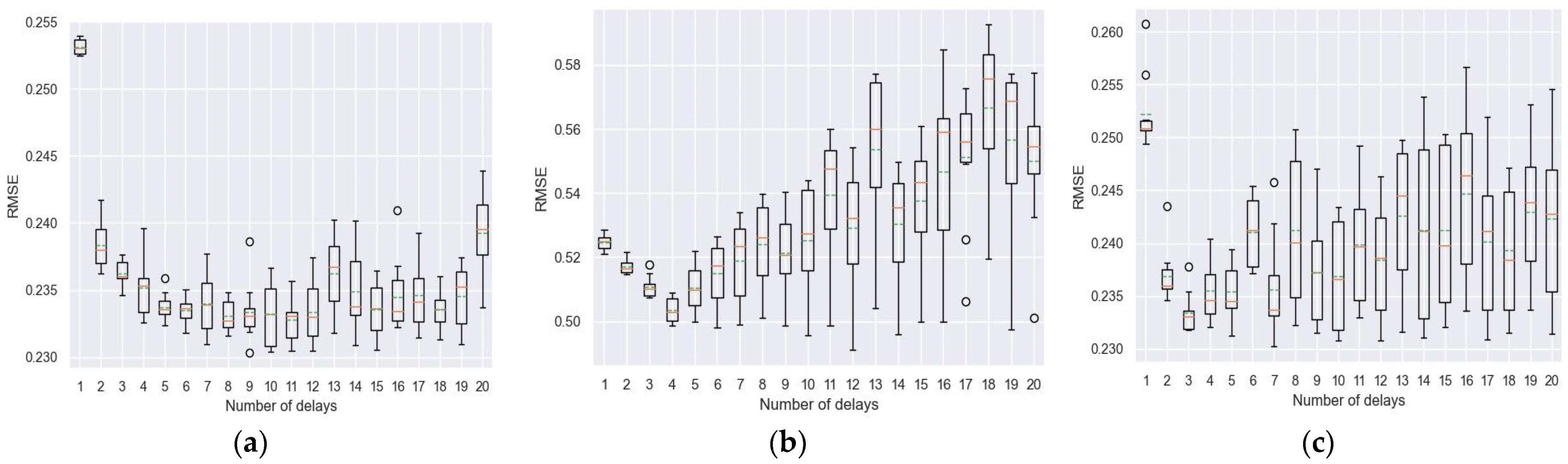
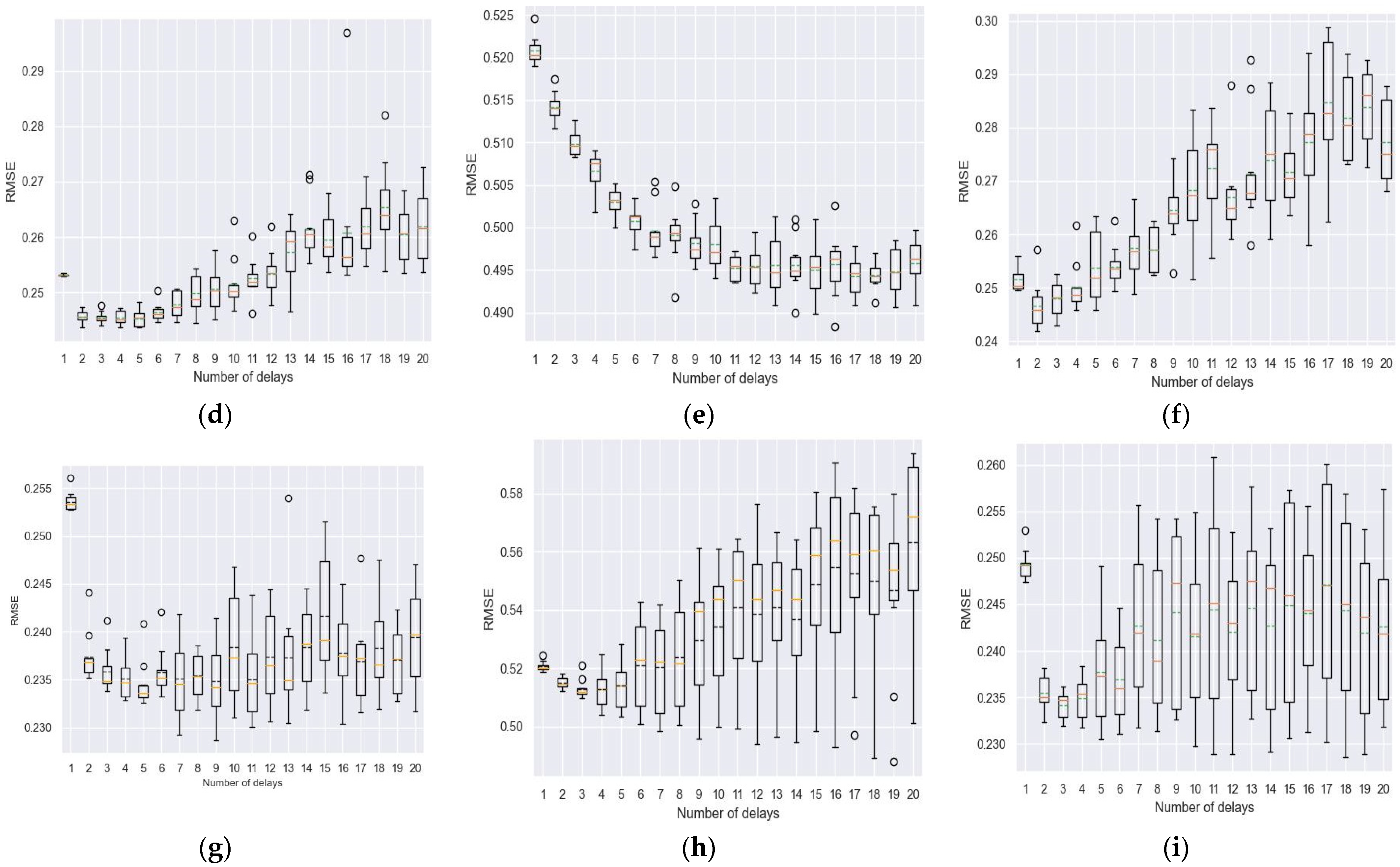
4.1. Experimentation to Realize Tapped Delay Line (TDL)
4.2. Experimental Results Regarding Model Reliance
- 1.
- Exploring the model reliance score on input features.
- 2.
- Exploring the model reliance score on time delay layers.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Herrington, G. Update to limits to growth: Comparing the World3 model with empirical data. J. Ind. Ecol. 2021, 25, 614–626. [Google Scholar] [CrossRef]
- Ministry of Ecological and Solidarity Transition. Multi Annual Energy Plan; Ministre de la Transition Ecologique et Solidaire: Paris, France, 2019; p. 342. [CrossRef]
- Énergie dans les Bâtiments|Ministères Écologie Énergie Territoires (n.d.). Available online: https://www.ecologie.gouv.fr/energie-dans-batiments (accessed on 22 September 2022).
- Koschwitz, D.; Frisch, J.; van Treeck, C. Data-driven heating and cooling load predictions for non-residential buildings based on support vector machine regression and NARX Recurrent Neural Network: A comparative study on district scale. Energy 2018, 165, 134–142. [Google Scholar] [CrossRef]
- Rahman, A.; Srikumar, V.; Smith, A.D. Predicting electricity consumption for commercial and residential buildings using deep recurrent neural networks. Appl. Energy 2018, 212, 372–385. [Google Scholar] [CrossRef]
- Xue, P.; Jiang, Y.; Zhou, Z.; Chen, X.; Fang, X.; Liu, J. Multi-step ahead forecasting of heat load in district heating systems using machine learning algorithms. Energy 2019, 188, 116085. [Google Scholar] [CrossRef]
- De Silva, M.; Sandanayake, Y. Building Energy Consumption Factors: A Literature Review and Future Research Agenda. 2012. Available online: http://dl.lib.uom.lk/handle/123/12050 (accessed on 8 December 2022).
- Hadjout, D.; Torres, J.F.; Troncoso, A.; Sebaa, A.; Martínez-Álvarez, F. Electricity consumption forecasting based on ensemble deep learning with application to the Algerian market. Energy 2022, 243, 123060. [Google Scholar] [CrossRef]
- Chi, D. Research on electricity consumption forecasting model based on wavelet transform and multi-layer LSTM model. Energy Rep. 2022, 8, 220–228. [Google Scholar] [CrossRef]
- Dong, B.; Liu, Y.; Mu, W.; Jiang, Z.; Pandey, P.; Hong, T.; Olesen, B.; Lawrence, T.; O’Neil, Z.; Andrews, C.; et al. A Global Building Occupant Behavior Database. Sci. Data 2022, 9, 369. [Google Scholar] [CrossRef]
- Chen, S.; Ren, Y.; Friedrich, D.; Yu, Z.; Yu, J. Prediction of office building electricity demand using artificial neural network by splitting the time horizon for different occupancy rates. Energy AI 2021, 5, 100093. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N. Building Lighting Energy Consumption Prediction for Supporting Energy Data Analytics. Procedia Eng. 2016, 145, 511–517. [Google Scholar] [CrossRef]
- Faiq, M.; Geok Tan, K.; Pao Liew, C.; Hossain, F.; Tso, C.P.; Li Lim, L.; Khang Wong, A.Y.; Mohd Shah, Z. Prediction of energy consumption in campus buildings using long short-term memory. Alex. Eng. J. 2023, 67, 65–76. [Google Scholar] [CrossRef]
- Mahjoub, S.; Chrifi-Alaoui, L.; Marhic, B.; Delahoche, L. Predicting Energy Consumption Using LSTM, Multi-Layer GRU and Drop-GRU Neural Networks. Sensors 2022, 22, 4602. [Google Scholar] [CrossRef]
- Lin, X.; Yu, H.; Wang, M.; Li, C.; Wang, Z.; Tang, Y. Electricity consumption forecast of high-rise office buildings based on the long short-term memory method. Energies 2021, 14, 4785. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Tang, X.; Dai, Y.; Wang, T.; Chen, Y. Short-term power load forecasting based on multi-layer bidirectional recurrent neural network. Undefined 2019, 13, 3847–3854. [Google Scholar] [CrossRef]
- Vanishing and Exploding Gradients in Deep Neural Networks (n.d.). Available online: https://www.analyticsvidhya.com/blog/2021/06/the-challenge-of-vanishing-exploding-gradients-in-deep-neural-networks/ (accessed on 19 September 2022).
- Wang, J.Q.; Du, Y.; Wang, J. LSTM based long-term energy consumption prediction with periodicity. Energy 2020, 197, 117197. [Google Scholar] [CrossRef]
- LSTM RNN in Keras: Examples of One-to-Many, Many-to-One & Many-to-Many–Weights & Biases (n.d.). Available online: https://wandb.ai/ayush-thakur/dl-question-bank/reports/LSTM-RNN-in-Keras-Examples-of-One-to-Many-Many-to-One-Many-to-Many---VmlldzoyMDIzOTM (accessed on 8 December 2022).
- Broujeny, R.S.; Madani, K.; Chebira, A.; Amarger, V.; Hurtard, L. Data-driven living spaces’ heating dynamics modeling in smart buildings using machine learning-based identification. Sensors 2020, 20, 1071. [Google Scholar] [CrossRef] [Green Version]
- Ng, B.C.; Darus, I.Z.M.; Jamaluddin, H.; Kamar, H.M. Dynamic modeling of an automotive variable speed air conditioning system using nonlinear autoregressive exogenous neural networks. Appl. Therm. Eng. 2014, 73, 1255–1269. [Google Scholar] [CrossRef]
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. arXiv 2018, arXiv:1801.01489. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- ASHRAE Global Occupant Behavior Database|Kaggle (n.d.). Available online: https://www.kaggle.com/datasets/claytonmiller/ashrae-global-occupant-behavior-database (accessed on 21 September 2022).
- Mora, D.; Fajilla, G.; Austin, M.C.; de Simone, M. Occupancy patterns obtained by heuristic approaches: Cluster analysis and logical flowcharts. A case study in a university office. Energy Build. 2019, 186, 147–168. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S.; Wang, D. Short-term electricity demand forecasting using components estimation technique. Energies 2019, 12, 2532. [Google Scholar] [CrossRef] [Green Version]
- Diebold, F.X.; Mariano, R.S. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 2002, 20, 134–144. [Google Scholar] [CrossRef]
- Diebold, F.X. Comparing Predictive Accuracy, Twenty Years Later: A Personal Perspective on the Use and Abuse of Diebold–Mariano Tests. J. Bus. Econ. Stat. 2015, 33, 1. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Algorithm | Time Lags | RMSE-MIN | RMSE-MAX | MAE-MIN | MAE-MAX | R2-MIN | R2-MAX |
|---|---|---|---|---|---|---|---|---|
| LSTM | 10 | 0.23 | 0.234 | 0.072 | 0.085 | 0.95 | 0.95 |
| NARX | 4 | 0.243 | 0.247 | 0.077 | 0.082 | 0.944 | 0.946 | |
| GRU | 3 | 0.23 | 0.24 | 0.069 | 0.078 | 0.94 | 0.95 | |
| Decision tree | 7 | 0.234 | 0.072 | 0.95 | ||||
| XGboost | 8 | 0.232 | 0.073 | 0.95 | ||||
| LSTM | 4 | 0.49 | 0.50 | 0.22 | 0.24 | 0.76 | 0.77 |
| NARX | 15 | 0.48 | 0.50 | 0.21 | 0.23 | 0.77 | 0.78 | |
| GRU | 5 | 0.50 | 0.52 | 0.20 | 0.24 | 0.74 | 0.77 | |
| Decision tree | 12 | 0.50 | 0.22 | 0.77 | ||||
| XGboost | 18 | 0.48 | 0.22 | 0.78 | ||||
| LSTM | 3 | 0.23 | 0.237 | 0.07 | 0.08 | 0.94 | 0.95 |
| NARX | 3 | 0.24 | 0.25 | 0.08 | 0.089 | 0.942 | 0.946 | |
| GRU | 3 | 0.23 | 0.236 | 0.07 | 0.09 | 0.94 | 0.95 | |
| Decision tree | 2 | 0.234 | 0.072 | 0.95 | ||||
| XGboost | 10 | 0.22 | 0.073 | 0.95 | ||||
| Models | Algorithms | XGboost | LSTM | NARX | GRU | ||||
|---|---|---|---|---|---|---|---|---|---|
| DM | p-Value | DM | p-Value | DM | p-Value | DM | p-Value | ||
| LSTM | −1.86 | 0.031 | --- | --- | --- | --- | --- | --- |
| NARX | 5.35 | 0.99 | 6.56 | 1 | --- | --- | --- | --- | |
| GRU | 0.86 | 0.8 | 2.51 | 0.99 | −5.28 | 6.42 | --- | --- | |
| Decision tree | 1.047 | 0.85 | 2.42 | 0.99 | −4.83 | 6.85 | 0.277 | 0.609 | |
| LSTM | 4.53 | 0.99 | --- | --- | --- | --- | --- | --- |
| NARX | 0.70 | 0.75 | −3.88 | 5.22 | --- | --- | --- | --- | |
| GRU | 8 | 1 | 2.8 | 0.99 | 6.45 | 1 | --- | --- | |
| Decision tree | 5.4 | 0.99 | 0.52 | 0.701 | 4.56 | 0.99 | −1.3 | 0.096 | |
| LSTM | 2.03 | 0.97 | --- | --- | --- | --- | --- | --- |
| NARX | 7.78 | 1 | 6.17 | 1 | --- | --- | --- | --- | |
| GRU | 2.87 | 0.99 | 0.135 | 0.55 | −5.55 | 1.43 | --- | --- | |
| Decision tree | 3.05 | 0.99 | 1.39 | 0.91 | −3.49 | 0.0002 | 1.288 | 0.90 | |
| Model Reliance Score | ||||||
|---|---|---|---|---|---|---|
| Models | Algorithm | Time Lags | Energy Consumption | VOC | CO2 | Occupancy |
| LSTM | 10 | 4.95 | --- | --- | --- |
| NARX | 4 | 6.50 | --- | --- | --- | |
| GRU | 3 | 4.92 | --- | --- | --- | |
| Decision tree | 7 | 6.88 | --- | --- | --- | |
| XGboost | 8 | 6.92 | --- | --- | --- | |
| LSTM | 4 | --- | 1.11 | 1.35 | 1.98 |
| NARX | 15 | --- | 1.064 | 1.14 | 2.81 | |
| GRU | 5 | --- | 1.083 | 1.24 | 1.99 | |
| Decision tree | 12 | --- | 1.11 | 1.23 | 2.83 | |
| XGboost | 18 | --- | 1.25 | 1.57 | 2.73 | |
| LSTM | 3 | 4.68 | 1.018 | 1.005 | 1.10 |
| NARX | 3 | 6.15 | 1.007 | 1.03 | 1.22 | |
| GRU | 3 | 4.71 | 1.011 | 1.003 | 1.11 | |
| Decision tree | 2 | 6.58 | 1.001 | 1.004 | 1.41 | |
| XGboost | 10 | 6.78 | 1.003 | 1.012 | 1.17 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadeghian Broujeny, R.; Ben Ayed, S.; Matalah, M. Energy Consumption Forecasting in a University Office by Artificial Intelligence Techniques: An Analysis of the Exogenous Data Effect on the Modeling. Energies 2023, 16, 4065. https://0-doi-org.brum.beds.ac.uk/10.3390/en16104065
Sadeghian Broujeny R, Ben Ayed S, Matalah M. Energy Consumption Forecasting in a University Office by Artificial Intelligence Techniques: An Analysis of the Exogenous Data Effect on the Modeling. Energies. 2023; 16(10):4065. https://0-doi-org.brum.beds.ac.uk/10.3390/en16104065
Chicago/Turabian StyleSadeghian Broujeny, Roozbeh, Safa Ben Ayed, and Mouadh Matalah. 2023. "Energy Consumption Forecasting in a University Office by Artificial Intelligence Techniques: An Analysis of the Exogenous Data Effect on the Modeling" Energies 16, no. 10: 4065. https://0-doi-org.brum.beds.ac.uk/10.3390/en16104065