

A Hybrid Model of VMD-EMD-FFT, Similar Days Selection Method, Stepwise Regression, and Artificial Neural Network for Daily Electricity Peak Load Forecasting
 , ,
, ,
Abstract
:1. Introduction
2. Methods
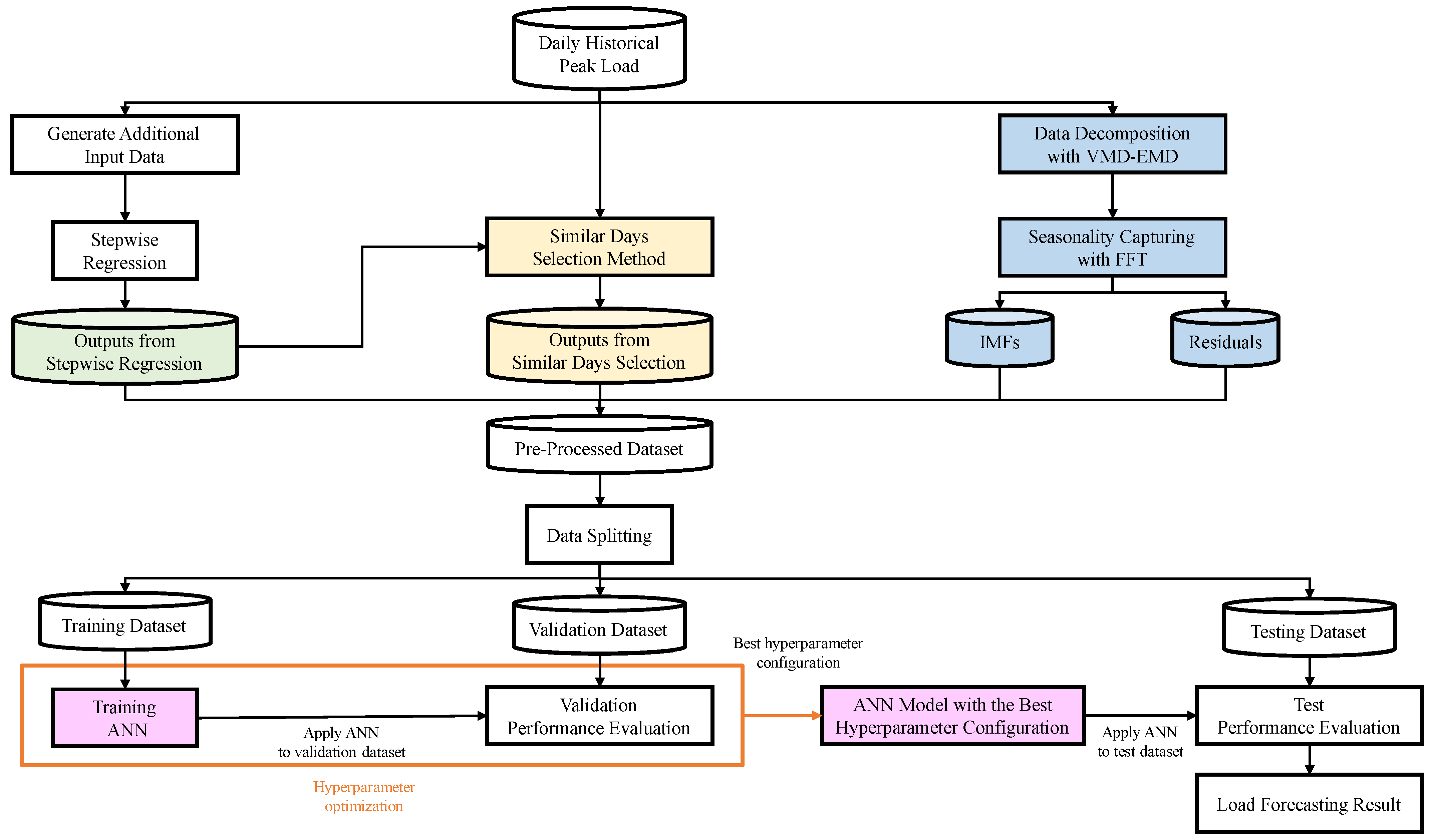
2.1. Architecture of the Proposed Model
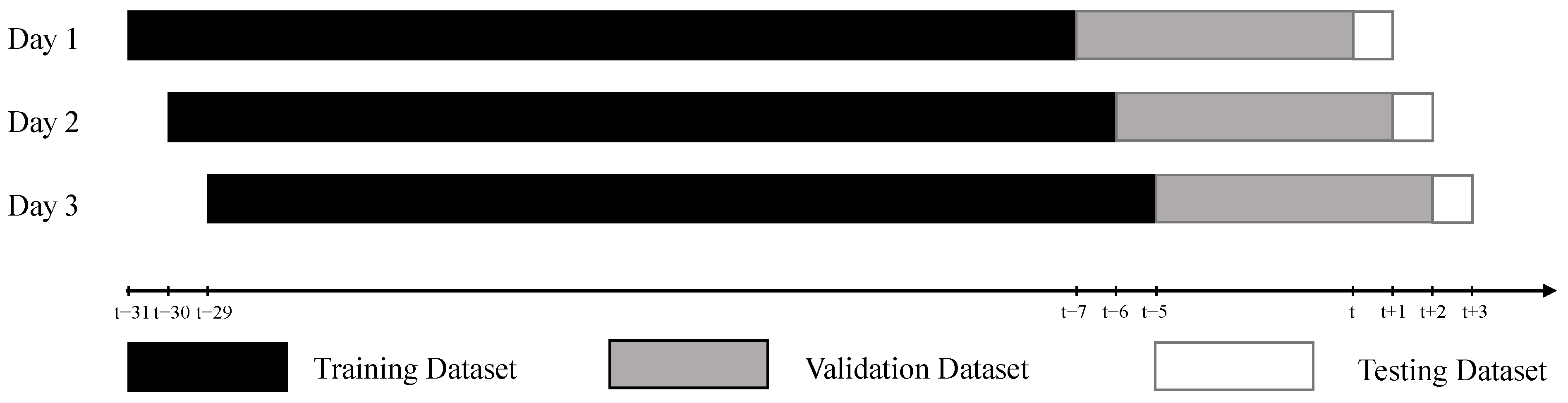
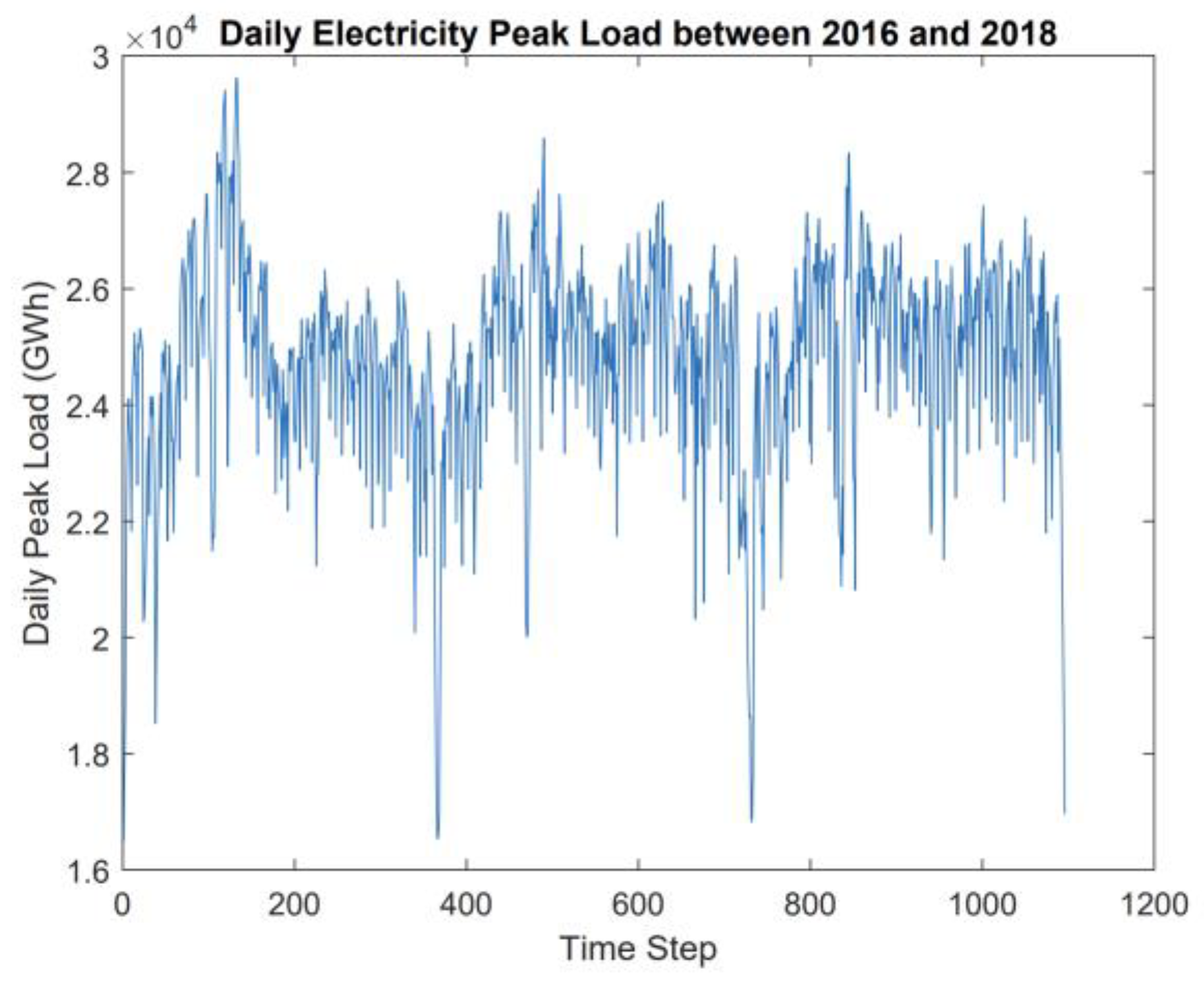
2.2. Data Preparation
2.3. Input Variable Selection
2.3.1. Additional Input Data Generation
2.3.2. Stepwise Regression
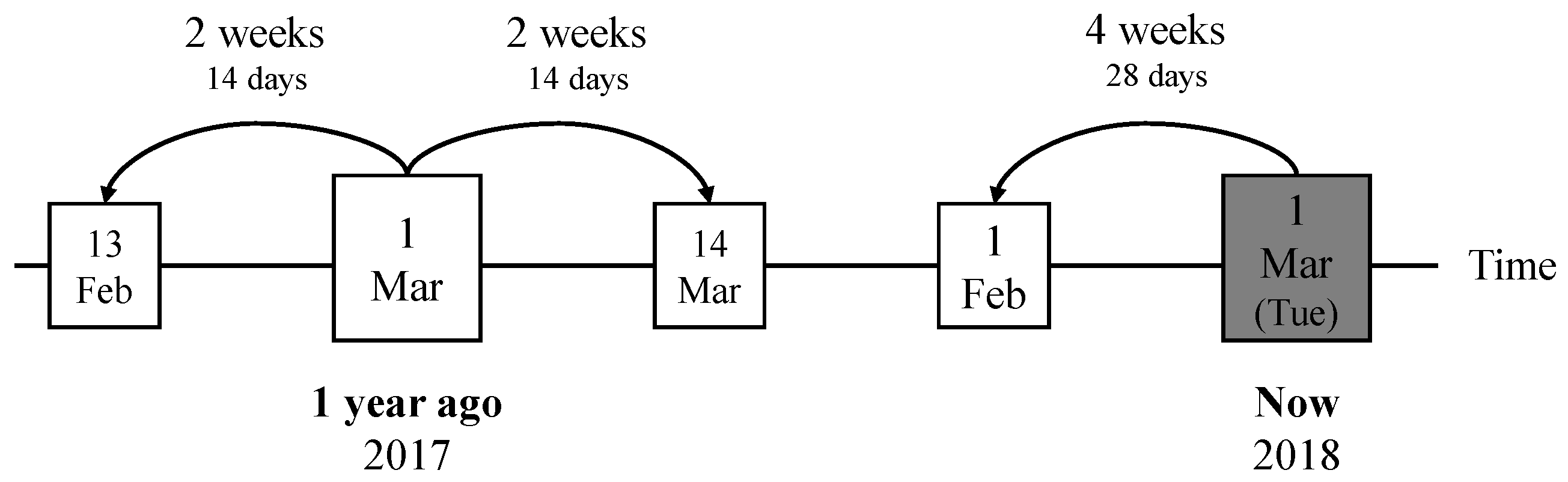
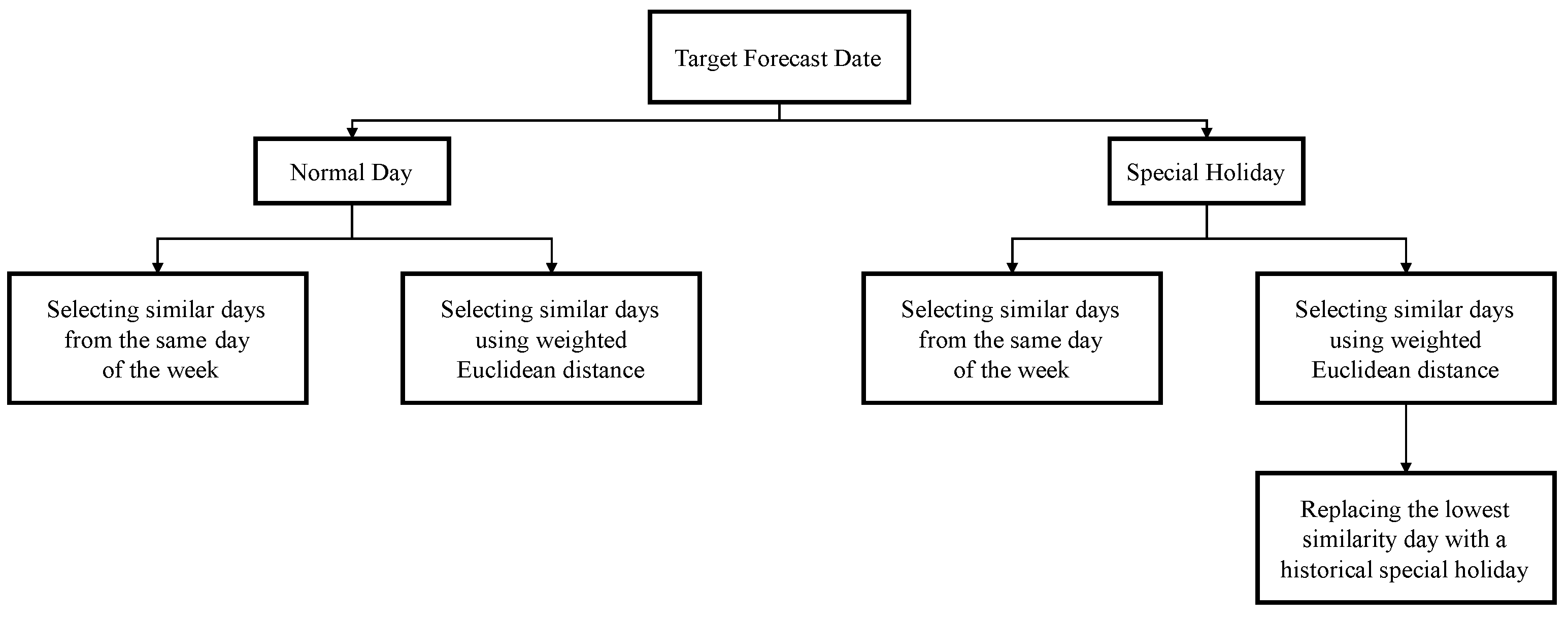
2.3.3. Similar Days Selection Method
- For a given target forecast date, rank the weighted Euclidean distance (WED) from minimum to maximum;
- Find the difference in the WED between the day with adjacent ranks in the top n days that have the lowest WED;
- Find the largest jump (largest difference) among the differences from Step 2 in the top n days. The number of selected days is the number of days before the occurrence of the largest jump;
- Repeat Steps 1 to 3 for a year (365 target dates). After completing this step, there are 365 values of the number of selected days;
- Find the frequency di for each possible value of the number of selected days, i = 1, 2, …, N;
- Calculate the weighted average number of selected days, , using Equation (5);
- Each value for the number of selected days has the weight that can be computed according to Equation (6).
2.3.4. Numerical Example of Input Variable Selection
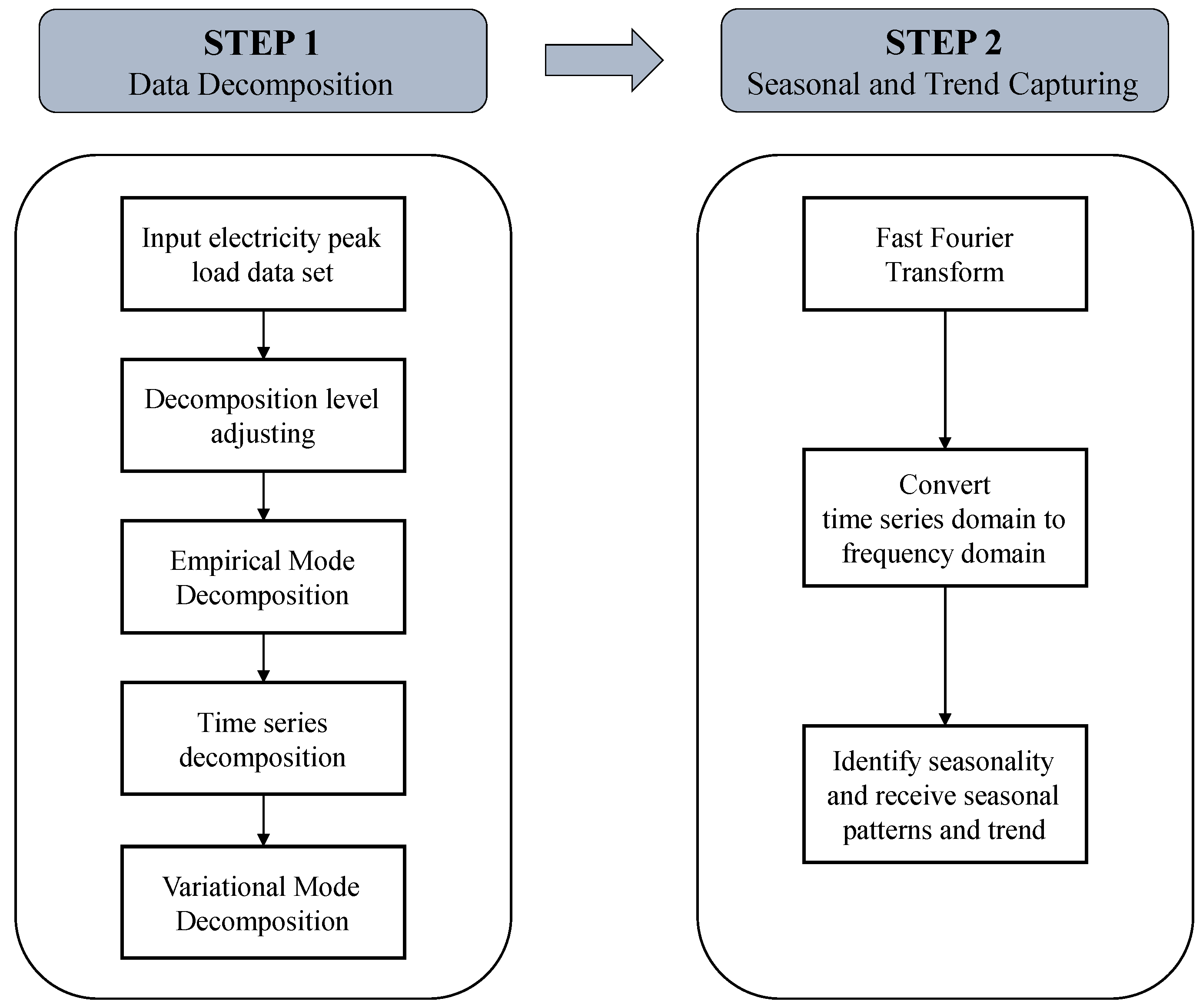
2.4. Data Decomposition and Seasonality Capturing
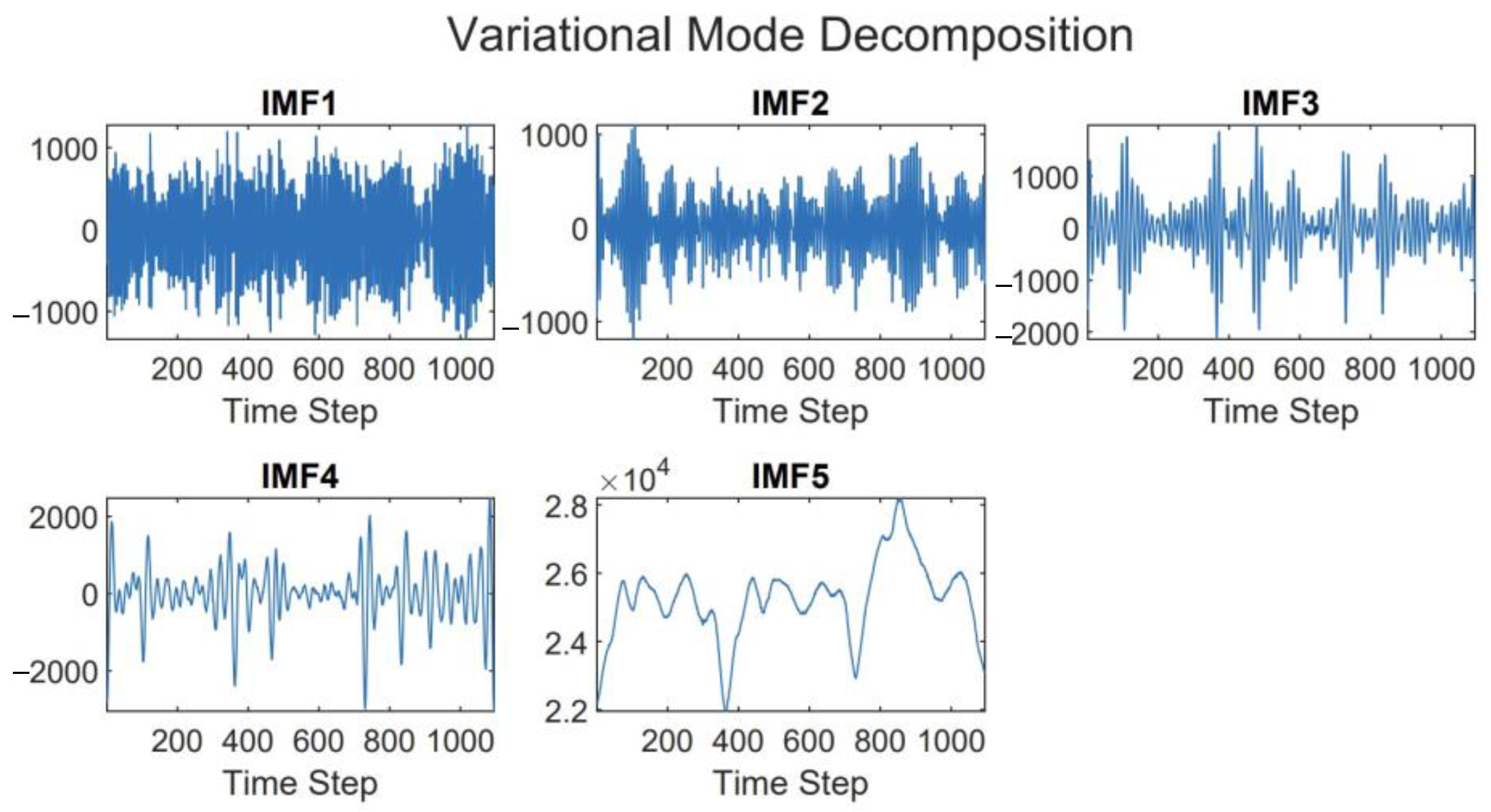
2.4.1. Variational Mode Decomposition
- In each mode (uk), the Hilbert transform is applied to obtain a unilateral frequency spectrum that is computed from its analytical signal;
- Estimate the center frequency by applying an exponential turned to shift the model’s frequency spectrum to the baseband;
- Compute the bandwidth of each mode by applying the optimal-solution processing based on Gaussian smoothing. The mathematical expression of the constrained variational problem is as follows:
- 4.
- To convert the constrained variational problem above into an unconstrained variation problem, the penalty term (α) and the Lagrange multiplier, λ(t), are applied to the model as follows:
- 5.
- To find the optimal solution of the problem, the saddle point of the enlarged Lagrange function is obtained from the Alternate Direction Method (ADM) as follows:
2.4.2. Fast Fourier Transform
2.5. Artificial Neural Network
3. Results
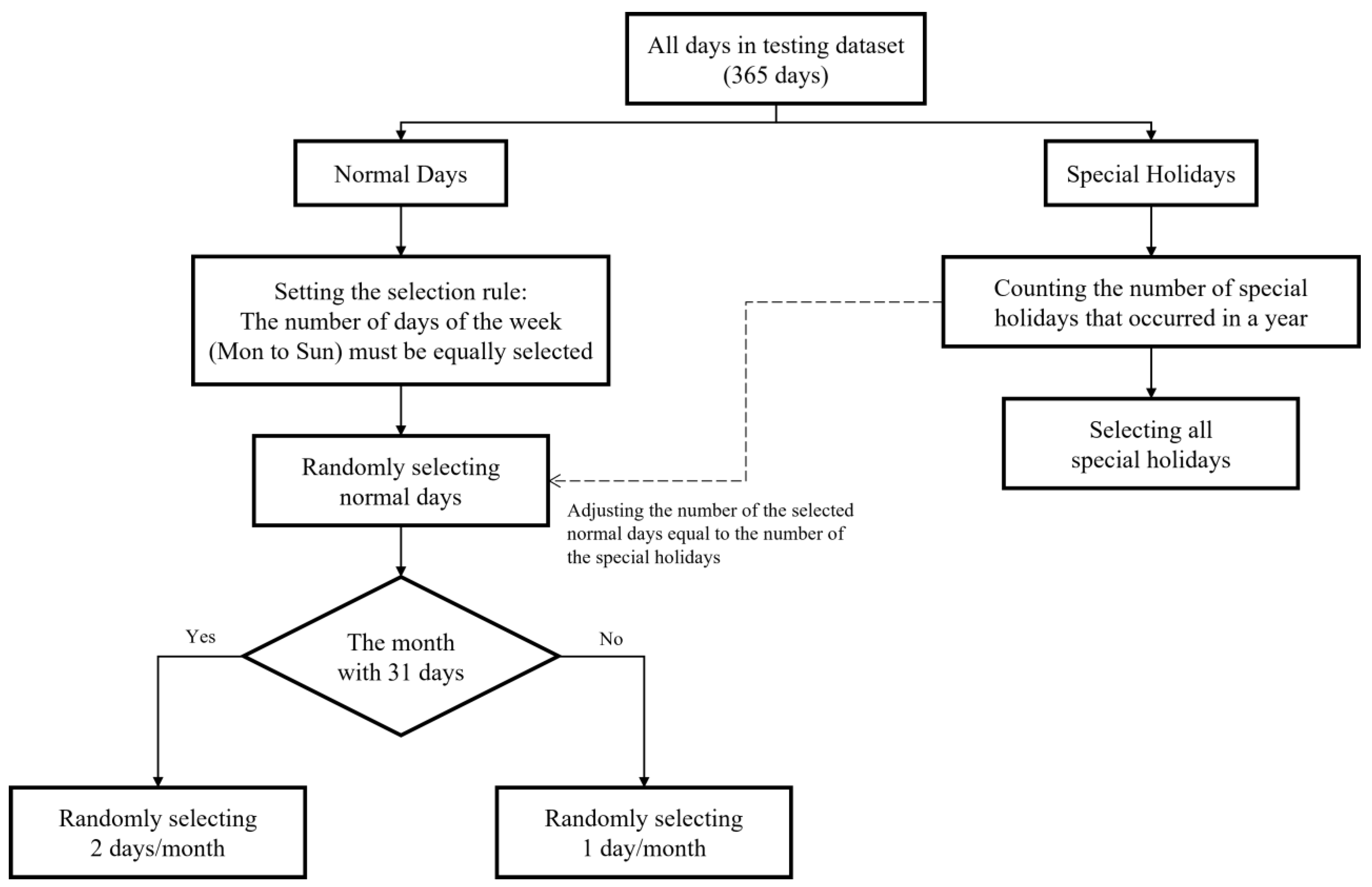
3.1. Target Forecast Date
3.1.1. Input Variables Selection
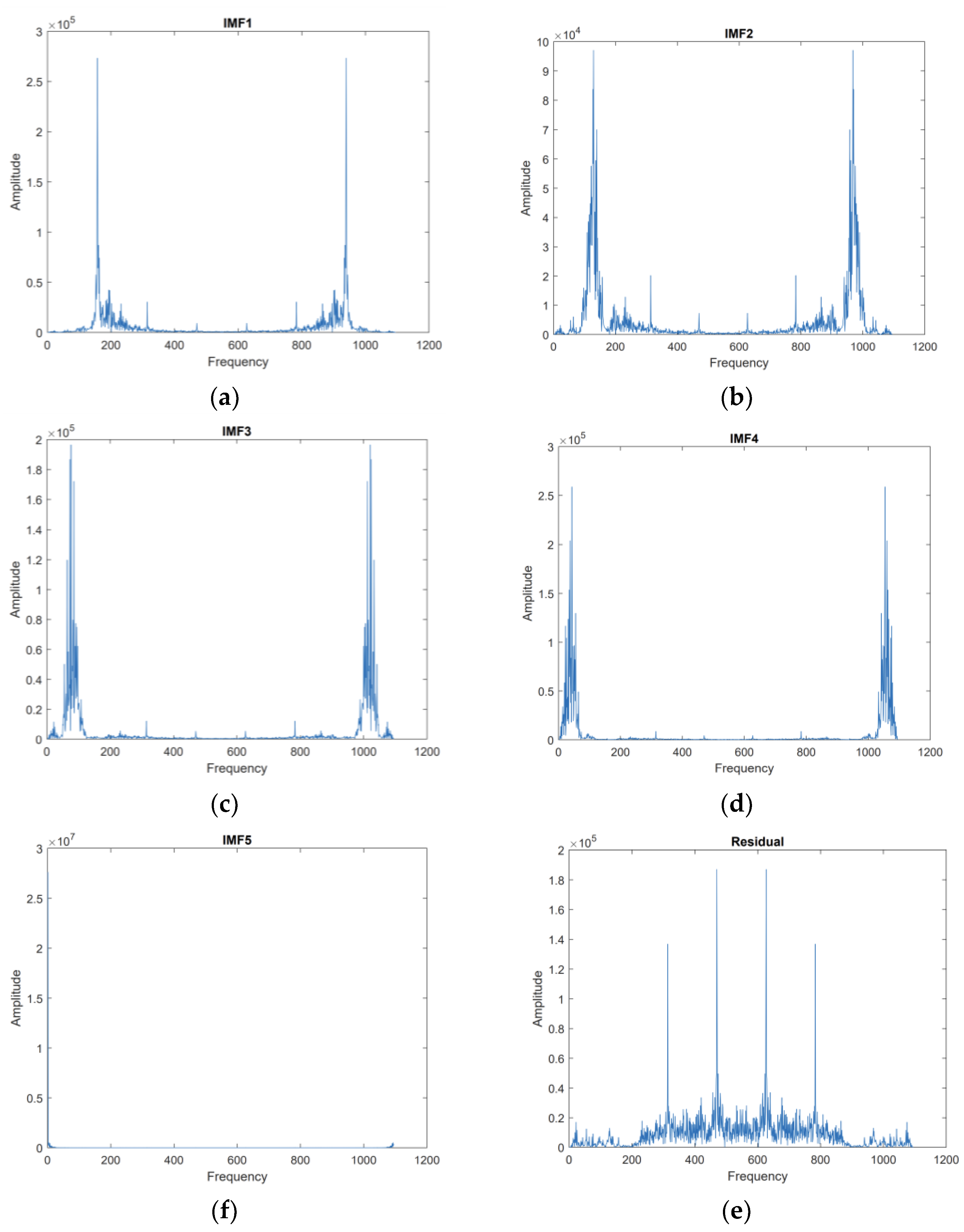
3.1.2. Data Denoising
3.1.3. Seasonality and Trend Capturing
3.2. Performance Measures
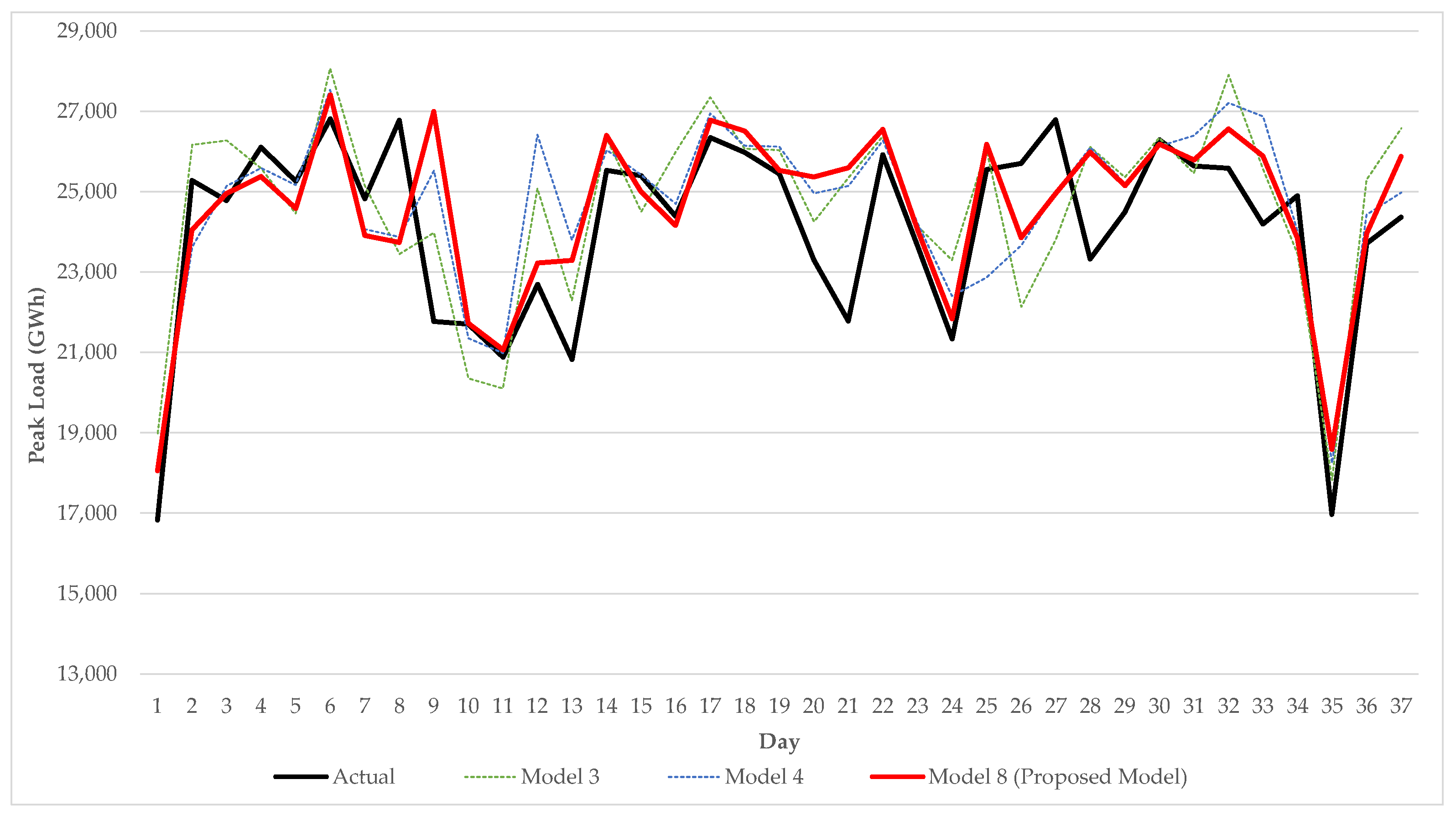
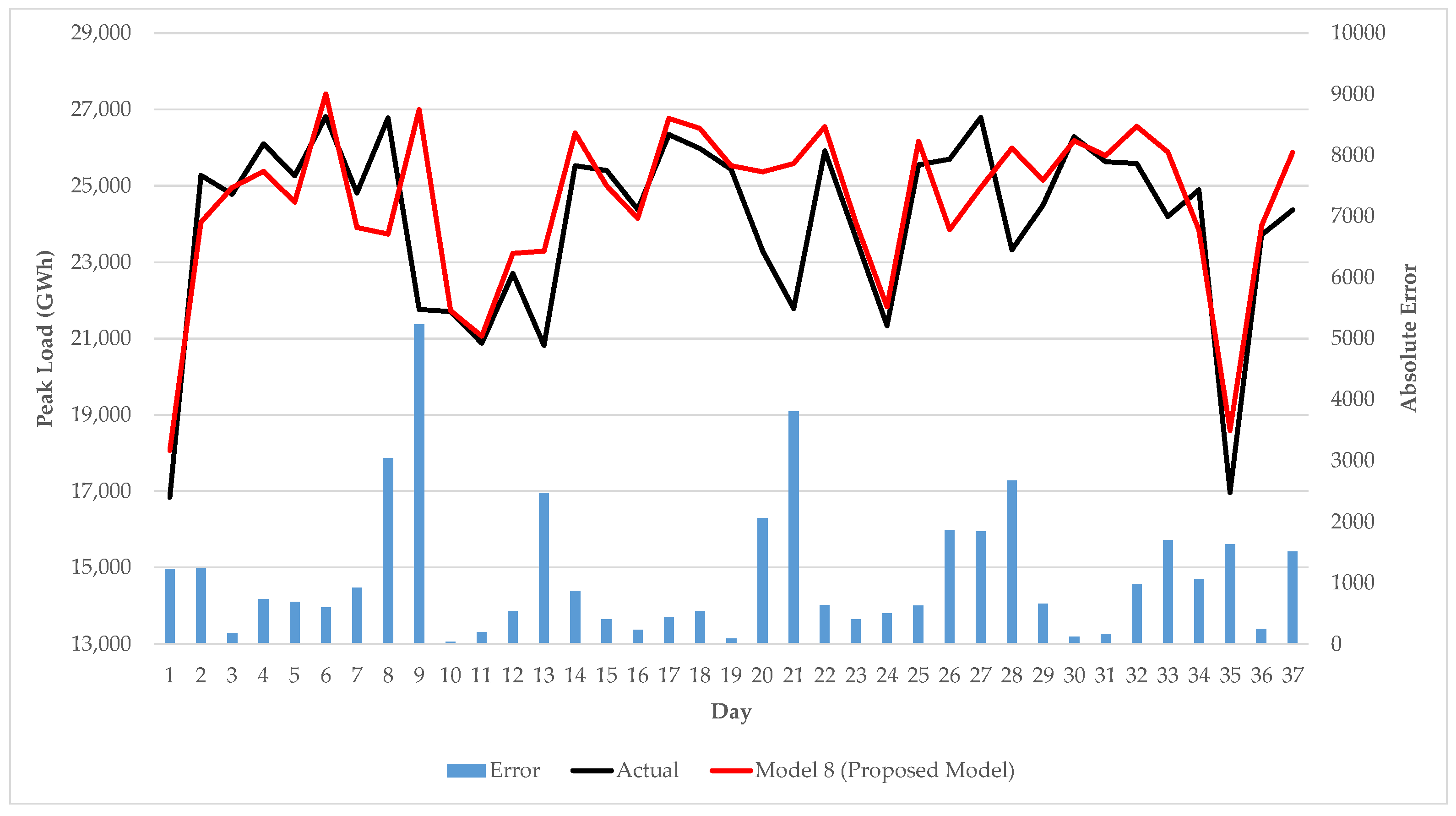
3.3. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Y.; Yang, Y.; Liu, C.; Li, C.; Li, L. A hybrid application algorithm based on the support vector machine and artificial intelligence: An example of electric load forecasting. Appl. Math. Model. 2015, 39, 2617–2632. [Google Scholar] [CrossRef]
- Al-Musaylh, M.S.; Deo, R.C.; Li, Y.; Adamowski, J.F. Two-phase particle swarm optimized-support vector regression hybrid model integrated with improved empirical mode decomposition with adaptive noise for multiple-horizon electricity demand forecasting. Appl. Energy 2018, 217, 422–439. [Google Scholar] [CrossRef]
- Li, L.-L.; Sun, J.; Wang, C.-H.; Zhou, Y.-T.; Lin, K.-P. Enhanced Gaussian process mixture model for short-term electric load forecasting. Inf. Sci. 2019, 477, 386–398. [Google Scholar] [CrossRef]
- Singh, P.; Dwivedi, P. A novel hybrid model based on neural network and multi-objective optimization for effective load forecast. Energy 2019, 182, 606–622. [Google Scholar] [CrossRef]
- Al-Musaylh, M.S.; Deo, R.C.; Adamowski, J.F.; Li, Y. Short-term electricity demand forecasting with MARS, SVR and ARIMA models using aggregated demand data in Queensland, Australia. Adv. Eng. Inform. 2018, 35, 1–16. [Google Scholar] [CrossRef]
- Zheng, H.; Yuan, J.; Chen, L. Short-Term Load Forecasting Using EMD-LSTM Neural Networks with a Xgboost Algorithm for Feature Importance Evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef]
- Yukseltan, E.; Yucekaya, A.; Bilge, A.H. Forecasting electricity demand for Turkey: Modeling periodic variations and demand segregation. Appl. Energy 2017, 193, 287–296. [Google Scholar] [CrossRef]
- Son, H.; Kim, C. Short-term forecasting of electricity demand for the residential sector using weather and social variables. Resour. Conserv. Recycl. 2017, 123, 200–207. [Google Scholar] [CrossRef]
- Jiang, W.; Wu, X.; Gong, Y.; Yu, W.; Zhong, X. Holt–Winters smoothing enhanced by fruit fly optimization algorithm to forecast monthly electricity consumption. Energy 2020, 193, 116779. [Google Scholar] [CrossRef]
- Pappas, S.S.; Ekonomou, L.; Karamousantas, D.C.; Chatzarakis, G.E.; Katsikas, S.K.; Liatsis, P. Electricity demand loads modeling using AutoRegressive Moving Average (ARMA) models. Energy 2008, 33, 1353–1360. [Google Scholar] [CrossRef]
- Hamzacebi, C.; Es, H.A. Forecasting the annual electricity consumption of Turkey using an optimized grey model. Energy 2014, 70, 165–171. [Google Scholar] [CrossRef]
- Vilar, J.M.; Cao, R.; Aneiros, G. Forecasting next-day electricity demand and price using nonparametric functional methods. Int. J. Electr. Power Energy Syst. 2012, 39, 48–55. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, R.C. Neural Networks for Short-Term Load Forecasting: A Review and Evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar] [CrossRef]
- González, C.; Mira-McWilliams, J.; Juárez, I. Important variable assessment and electricity price forecasting based on regression tree models: Classification and regression trees, Bagging and Random Forests. IET Gener. Transm. Distrib. 2015, 9, 1120–1128. [Google Scholar] [CrossRef]
- Zurada, J.M. Introduction to Artificial Neural Systems, 1st ed.; West Publishing Co.: New York, NY, USA, 1992; pp. 26–89. [Google Scholar]
- Amjady, N. Day-ahead price forecasting of electricity markets by a new fuzzy neural network. IEEE Trans. Power Appar. Syst. 2006, 21, 887–896. [Google Scholar] [CrossRef]
- Dedinec, A.; Filiposka, S.; Dedinec, A.; Kocarev, L. Deep belief network based electricity load forecasting: An analysis of Macedonian case. Energy 2016, 115, 1688–1700. [Google Scholar] [CrossRef]
- Khan, A.; Chiroma, H.; Imran, M.; Khan, A.; Bangash, J.I.; Asim, M.; Hamza, M.F.; Aljuaid, H. Forecasting electricity consumption based on machine learning to improve performance: A case study for the organization of petroleum exporting countries (OPEC). Comput. Electr. Eng. 2020, 86, 106737. [Google Scholar] [CrossRef]
- Pannakkong, W.; Harncharnchai, T.; Buddhakulsomsiri, J. Forecasting Daily Electricity Consumption in Thailand Using Regression, Artificial Neural Network, Support Vector Machine, and Hybrid Models. Energies 2022, 15, 3105. [Google Scholar] [CrossRef]
- Wang, D.; Luo, H.; Grunder, O.; Lin, Y.; Guo, H. Multi-step ahead electricity price forecasting using a hybrid model based on two-layer decomposition technique and BP neural network optimized by firefly algorithm. Appl. Energy 2017, 190, 390–407. [Google Scholar] [CrossRef]
- Wang, G.; Wang, X.; Wang, Z.; Ma, C.; Song, Z. A VMD–CISSA–LSSVM Based Electricity Load Forecasting Model. Mathematics 2022, 10, 28. [Google Scholar] [CrossRef]
- Szkuta, B.R.; Sanabria, L.A.; Dillon, T.S. Electricity Price Short-Term Forecasting Using Artificial Neural Networks. IEEE Trans. Power Appar. Syst. 1999, 14, 851–857. [Google Scholar] [CrossRef]
- Brzostowski, K.; Świątek, J. Dictionary adaptation and variational mode decomposition for gyroscope signal enhancement. Appl. Intell. 2021, 51, 2312–2330. [Google Scholar] [CrossRef]
- Zhengkun, L.; Ze, Z. The Improved Algorithm of the EMD Endpoint Effect Based on the Mirror Continuation. In Proceedings of the 2016 Eighth International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Macau, China, 11–12 March 2016. [Google Scholar]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011. [Google Scholar]
- Chaitanya, B.K.; Yadav, A.; Pazoki, M.; Abdelaziz, A.Y. A comprehensive review of islanding detection methods. In Uncertainties in Modern Power Systems, 1st ed.; Zobaa, A.F., Abdel Aleem, S.H.E., Eds.; Academic Press: Cambridge, MA, USA, 2021; pp. 211–256. [Google Scholar]
- Xiao, Q.; Li, J.; Sun, J.; Feng, H.; Jin, S. Natural-gas pipeline leak location using variational mode decomposition analysis and cross-time–frequency spectrum. Measurement 2018, 124, 163–172. [Google Scholar] [CrossRef]
- Jiang, P.; Li, R.; Liu, N.; Gao, Y. A novel composite electricity demand forecasting framework by data processing and optimized support vector machine. Appl. Energy 2020, 260, 114243. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhu, Z. A hybrid method for noise suppression using variational mode decomposition and singular spectrum analysis. Appl. Geophys. 2019, 161, 105–115. [Google Scholar] [CrossRef]
- Natarajan, Y.J.; Nachimuthu, D.S. New SVM kernel soft computing models for wind speed prediction in renewable energy applications. Soft Comput. 2020, 24, 11441–11458. [Google Scholar] [CrossRef]
- Chen, X.; Ding, K.; Zhang, J.; Han, W.; Liu, Y.; Yang, Z.; Weng, S. Online prediction of ultra-short-term photovoltaic power using chaotic characteristic analysis, improved PSO and KELM. Energy 2022, 248, 123574. [Google Scholar] [CrossRef]
- Leles, M.C.R.; Sansão, J.P.H.; Mozelli, L.A.; Guimarães, H.N. A new algorithm in singular spectrum analysis framework: The Overlap-SSA (ov-SSA). SoftwareX 2018, 8, 26–32. [Google Scholar] [CrossRef]
- Zhang, X.; Miao, Q.; Zhang, H.; Wang, L. A parameter-adaptive VMD method based on grasshopper optimization algorithm to analyze vibration signals from rotating machinery. Mech. Syst. Signal Process. 2018, 108, 58–72. [Google Scholar] [CrossRef]
- Ding, J.; Xiao, D.; Li, X. Gear Fault Diagnosis Based on Genetic Mutation Particle Swarm Optimization VMD and Probabilistic Neural Network Algorithm. IEEE Access 2020, 8, 18456–18474. [Google Scholar] [CrossRef]
- Gai, J.B.; Shen, J.X.; Hu, Y.F.; Wang, H. An integrated method based on hybrid grey wolf optimizer improved variational mode decomposition and deep neural network for fault diagnosis of rolling bearing. Measurement 2020, 162, 107901. [Google Scholar] [CrossRef]
- Yang, J.; Zhou, C.; Li, X. Research on Fault Feature Extraction Method Based on Parameter Optimized Variational Mode Decomposition and Robust Independent Component Analysis. Coatings 2022, 12, 419. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, P.; Zhao, Y.; Sun, Y. A Denoising Method for Mining Cable PD Signal Based on Genetic Algorithm Optimization of VMD and Wavelet Threshold. Sensors 2022, 22, 9386. [Google Scholar] [CrossRef] [PubMed]
- Venter, G. Review of optimization techniques. In Encyclopedia of Aerospace Engineering, 1st ed.; Bleckley, R., Shyy, W., Eds.; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2010. [Google Scholar]
- Fallah, S.N.; Ganjkhani, M.; Shamshirband, S.; Chau, K.-w. Computational Intelligence on Short-Term Load Forecasting: A Methodological Overview. Energies 2019, 12, 393. [Google Scholar] [CrossRef]
- Mandal, P.; Senjyu, T.; Funabashi, T. Neural networks approach to forecast several hour ahead electricity prices and loads in deregulated market. Energy Convers. Manag. 2006, 47, 2128–2142. [Google Scholar] [CrossRef]
- Chen, Y.; Luh, P.B.; Guan, C.; Zhao, Y.; Michel, L.D.; Coolbeth, M.A.; Friedland, P.B.; Rourke, S.J. Short-Term Load Forecasting: Similar Day-Based Wavelet Neural Networks. IEEE Trans. Power Syst. 2010, 25, 322–330. [Google Scholar] [CrossRef]
- Mu, Q.; Wu, Y.; Pan, X.; Huang, L.; Li, X. Short-term Load Forecasting Using Improved Similar Days Method. In Proceedings of the 2010 Asia-Pacific Power and Energy Engineering Conference (APPEEC), Chengdu, China, 28–31 March 2010. [Google Scholar]
- Park, R.-J.; Song, K.-B.; Kwon, B.-S. Short-Term Load Forecasting Algorithm Using a Similar Day Selection Method Based on Reinforcement Learning. Energies 2020, 13, 2640. [Google Scholar] [CrossRef]
- Senjyu, T.; Takara, H.; Uezato, K.; Funabashi, T. One-hour-ahead load forecasting using neural network. IEEE Trans. Power Syst. 2002, 17, 113–118. [Google Scholar] [CrossRef]
- The Asia Foundation. Available online: https://asiafoundation.org/where-we-work/thailand/ (accessed on 21 February 2022).
- Kaastra, I.; Boyd, M. Designing a neural network for forecasting financial and economic time series. Neurocomputing 1996, 10, 215–236. [Google Scholar] [CrossRef]
- Yildiz, B.; Bilbao, J.I.; Sproul, A.B. A review and analysis of regression and machine learning models on commercial building electricity load forecasting. Renew. Sust. Energy Rev. 2017, 73, 1104–1122. [Google Scholar] [CrossRef]
- Smith, G. Step away from stepwise. J. Big Data 2018, 5, 32. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Zhou, F.; Zhou, H.; Li, Z.; Zhao, K. Multi-Step Ahead Short-Term Electricity Load Forecasting Using VMD-TCN and Error Correction Strategy. Energies 2022, 15, 5375. [Google Scholar] [CrossRef]
- Musbah, H.; El-Hawary, M. SARIMA Model Forecasting of Short-Term Electrical Load Data Augmented by Fast Fourier Transform Seasonality Detection. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019. [Google Scholar]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks, 1st ed.; MIT Press: Cambridge, MA, USA, 1995; pp. 35–54. [Google Scholar]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building energy load forecasting using Deep Neural Networks. In Proceedings of the IECON 42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 7046–7051. [Google Scholar]
- Madrid, E.A.; Antonio, N. Short-Term Electricity Load Forecasting with Machine Learning. Information 2021, 12, 50. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Date | No. | Past Date | WED | ||
|---|---|---|---|---|---|
| 1 January 2018 | 1 | 1 January 2017 (Weekday) | 0 | 0 | 0 |
| (Weekday) | 2 | 2 January 2017 (Weekday) | 0 | 0 | 0 |
| 3 | 3 January 2017 (Weekday) | 0 | 0 | 0 | |
| 4 | 4 January 2017 (Weekday) | 0 | 0 | 0 | |
| 5 | 5 January 2017 (Weekday) | 0 | 0 | 0 | |
| 6 | 6 January 2017 (Weekend) | 1 | 993 | 31.51 | |
| 7 | 7 January 2017 (Weekend) | 1 | 993 | 31.51 |
| Target Date | No. | Generated Additional Dates | WED (Ranked) | WED Difference |
|---|---|---|---|---|
| 1 January 2018 | 1 | 3 January 2017 | 584.77 | - |
| 2 | 31 December 2016 | 1135.79 | 551.02 | |
| 3 | 1 January 2017 | 1190.57 | 54.78 | |
| 4 | 2 January 2017 | 1196.36 | 5.79 | |
| 5 | 30 December 2017 | 1541.40 | 345.04 | |
| 6 | 31 December 2017 | 1595.00 | 53.60 | |
| 7 | 29 December 2017 | 2020.71 | 425.72 |
| Number of Days until the Biggest Jump Occurs | 1 Day | 2 Days | 3 Days | 4 Days | 5 Days | 6 Days | 7 Days |
|---|---|---|---|---|---|---|---|
| 133 | 70 | 48 | 38 | 20 | 33 | 23 | |
| wi | 0.36 | 0.19 | 0.13 | 0.10 | 0.05 | 0.09 | 0.06 |
| 2.823 ≅ 3 | |||||||
| Target Date | 1 January 2018 (Mon) (New Year’s Day) | |
|---|---|---|
| Similar day selected from the same day of the week | SD1 | 25 December 2017 (Mon) |
| SD2 | 18 December 2017 (Mon) | |
| SD3 | 11 December 2017 (Mon) | |
| SD4 | 4 December 2017 (Mon) | |
| SD5 | 19 December 2016 (Mon) | |
| SD6 | 26 December 2016 (Mon) | |
| SD7 | 2 January 2017 (Mon) | |
| SD8 | 9 January 2017 (Mon) | |
| Similar day selected based on WED | SD9 | 3 January 2017 |
| SD10 | 31 December 2016 | |
| SD11 | 1 January 2017 (previous New Year’s Day) | |
| Month | Target Dates | |||||
|---|---|---|---|---|---|---|
| Normal Day | Special Day | |||||
| Jan. | 22 January 2018 (Mon.) | 27 January 2018 (Sat.) | 1 January 2018 (New Year’s Day) | |||
| Feb. | 20 February 2018 (Tue.) | |||||
| Mar. | 7 March 2018 (Wed.) | 25 March 2018 (Sun.) | 1 March 2018 (Makha Bucha Day) | |||
| Apr. | 12 April 2018 (Thu.) | 6 April 2018 (Chakri Day) | 13 April 2018 (Songkran) | 14 April 2018 (Songkran) | 15 April 2018 (Songkran) | |
| May | 21 May 2018 (Mon.) | 18 May 2018 (Fri.) | 1 May 2018 (Labor Day) | 4 May 2018 (Coronation Day) | 14 May 2018 (Farmer’s Day) | 29 May 2018 (Visakha Bucha Day) |
| June | 16 June 2018 (Sat.) | |||||
| Jul. | 10 July 2018 (Tue.) | 15 July 2018 (Sun.) | 27 July 2018 (Asarnha Bucha Day) | 28 July 2018 (King’s Brithday) | 28 July 2018 (Buddhist Lent Day) | |
| Aug. | 20 August 2018 (Mon.) | 1 August 2018 (Wed.) | 12 August 2018 (Mother’s Day) | |||
| Sep. | 11 September 2018 (Tue.) | |||||
| Oct. | 10 October 2018 (Wed.) | 25 October 2018 (Thu.) | 13 October 2018 (Memorial Day) | 23 October 2018 (Piyamaharaj Day) | ||
| Nov. | 22 November 2018 (Thu.) | |||||
| Dec. | 14 December 2018 (Fri) | 8 December 2018 (Sat.) | 5 December 2018 (Father’s Day) | 10 December 2018 (Ratthathammanoon Day) | 31 December 2018 (New Year’s Day) | |
| Variable Type | Generated Additional Input Variable | Significant Input Variable |
|---|---|---|
| Day of the week indicators | Mon., Tue., …, Sun. (7 variables) | Mon., Tue., Fri., Sun. (4 variables) |
| Weekend indicator | 0, 1 (2 variables) | 0, 1 (2 variables) |
| Historical peak load | T − 1, T − 2, …, T − 10 (10 variables) | T − 1, T − 2, T − 6, T − 7 (4 variables) |
| LPI | Weekly LPI, Monthly LPI (2 variables) | Weekly SI (1 variable) |
| MA(L) | MA(2), MA(3), …, MA(7) (6 variables) | None |
| Expr. | Stepwise | SD | VMD-EMD-FFT | Train | Validate | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAPE | RMSE | MAE | MAPE | RMSE | MAE | MAPE | RMSE | MAE | ||||
| 1 | No | No | No | 0.109% | 33 | 26 | 0.066% | 26 | 16 | 6.482% | 1911 | 1498 |
| 2 | No | Yes | No | 0.063% | 16 | 15 | 0.042% | 16 | 10 | 6.523% | 2035 | 1526 |
| 3 | No | No | Yes | 0.084% | 27 | 20 | 0.062% | 23 | 15 | 5.987% | 1706 | 1408 |
| 4 | No | Yes | Yes | 0.067% | 21 | 16 | 0.124% | 18 | 27 | 5.257% | 1626 | 1218 |
| 5 | Yes | No | No | 0.633% | 259 | 150 | 0.366% | 156 | 89 | 7.530% | 2473 | 1717 |
| 6 | Yes | Yes | No | 0.073% | 18 | 17 | 0.067% | 25 | 16 | 6.324% | 1949 | 1474 |
| 7 | Yes | No | Yes | 0.080% | 21 | 19 | 0.068% | 26 | 16 | 6.192% | 1758 | 1423 |
| 8 | Yes | Yes | Yes | 0.069% | 18 | 17 | 0.059% | 23 | 14 | 4.894% | 1593 | 1135 |
| Hyperparameter | Optimization Range |
|---|---|
| Hidden node | 1, 5, 10 |
| Training cycle | 50, 100, 500, 1000, 1500 |
| Learning rate | 0.1, 0.01, 0.001, 0.0001, 0.00001 |
| Source | DF | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|
| Day | 36 | 1.60805 | 0.044668 | 9.71 | <0.00001 |
| Stepwise regression | 1 | 0.00009 | 0.000088 | 0.02 | 0.89 |
| SD | 1 | 0.02041 | 0.02041 | 4.44 | 0.037 |
| VMD-EMD-FFT | 1 | 0.02264 | 0.022637 | 4.92 | 0.028 |
| Day∗SD | 36 | 0.45167 | 0.012546 | 2.73 | <0.00001 |
| Day∗VMD-EMD-FFT | 36 | 0.51886 | 0.014413 | 3.13 | <0.00001 |
| Error | 184 | 0.84666 | 0.004601 | ||
| Total | 295 | 3.46838 |
| SD | N | Mean | Grouping | |
|---|---|---|---|---|
| No | 148 | 0.0535428 | A | |
| Yes | 148 | 0.0461328 | B | |
| VMD-EMD-FFT | N | Mean | Grouping | |
|---|---|---|---|---|
| No | 148 | 0.0537472 | A | |
| Yes | 148 | 0.0459434 | B | |
| Day | SD | Difference | |
|---|---|---|---|
| No | Yes | ||
| Songkran | 0.142428 | 0.035683 | 10.67% |
| Labor Day | 0.037857 | 0.206282 | −16.84% |
| Day | VMD-EMD-FFT | Difference | |
|---|---|---|---|
| No | Yes | ||
| Songkran | 0.167653 | 0.024599 | 14.31% |
| King’s Birthday | 0.030704 | 0.166523 | −13.58% |
| Expr. | Forecasting Model | Input Selected from | Test | ||||
|---|---|---|---|---|---|---|---|
| Lagged Value | SD | Data Decomposition | MAPE | RMSE | MAE | ||
| 8 | ANN | Stepwise | Proposed Similar Day Selection | VMD-EMD-FFT | 4.894% | 1593 | 1135 |
| 9 | ANN | Stepwise | Weighted Euclidean Distance [44] | VMD-EMD-FFT | 5.827% | 1612 | 1347 |
| 10 | ANN | Stepwise | Proposed Similar Days Selection | VMD-FFT [28] | 5.132% | 1601 | 1210 |
| 11 | ANN | Stepwise | Proposed Similar Days Selection | EMD [6] | 5.957% | 1720 | 1392 |
| 12 | LSTM [53] | [53] | No | No | 8.560% | 2370 | 1902 |
| 13 | XGBoost [54] | [54] | No | No | 6.147% | 1992 | 1547 |
| Model | MAPE | Number of Run per Experiment | Running Time per Experiment (Min.) | ||
|---|---|---|---|---|---|
| All Days | Special Days | Normal Days | |||
| Full Model | 6.143% | 7.636% | 4.728% | 365 | 500.05 |
| Proposed Model | 4.894% | 7.095% | 2.809% | 37 | 50.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aswanuwath, L.; Pannakkong, W.; Buddhakulsomsiri, J.; Karnjana, J.; Huynh, V.-N. A Hybrid Model of VMD-EMD-FFT, Similar Days Selection Method, Stepwise Regression, and Artificial Neural Network for Daily Electricity Peak Load Forecasting. Energies 2023, 16, 1860. https://0-doi-org.brum.beds.ac.uk/10.3390/en16041860
Aswanuwath L, Pannakkong W, Buddhakulsomsiri J, Karnjana J, Huynh V-N. A Hybrid Model of VMD-EMD-FFT, Similar Days Selection Method, Stepwise Regression, and Artificial Neural Network for Daily Electricity Peak Load Forecasting. Energies. 2023; 16(4):1860. https://0-doi-org.brum.beds.ac.uk/10.3390/en16041860
Chicago/Turabian StyleAswanuwath, Lalitpat, Warut Pannakkong, Jirachai Buddhakulsomsiri, Jessada Karnjana, and Van-Nam Huynh. 2023. "A Hybrid Model of VMD-EMD-FFT, Similar Days Selection Method, Stepwise Regression, and Artificial Neural Network for Daily Electricity Peak Load Forecasting" Energies 16, no. 4: 1860. https://0-doi-org.brum.beds.ac.uk/10.3390/en16041860