2.1. The Multilevel and Multilevel Quasi Monte Carlo Methods
Let
, or
for short, be the expected value of a particular quantity of interest
P depending on a set of random variables
, discretized on mesh
L. The standard MC estimator for
using
samples on mesh
L, denoted as
, can be written as
The MLMC method, on the other hand, starts from a reformulation of
as a telescoping sum. The expected value of the quantity of interest on the finest mesh
L is expressed as the expected value of the quantity of interest on the coarsest mesh, plus a series of correction terms (or
differences), i.e.,
where we defined
with
.
Each term on the right-hand side is then estimated separately by a standard MC estimator with
samples, i.e.,
where
is the MLMC estimator for the expected value
, which is a discrete approximation for the expected value of the quantity of interest,
. The MLMC estimator in Equation (
3) can be written as a sum of
estimators for the expected value of the difference on each level, i.e.,
where we defined
with
.
Because of the telescoping sum property, i.e., Equation (
2), the MLMC estimator is an unbiased estimator for the quantity of interest on the finest mesh, i.e.,
The error is controlled by imposing a tolerance
on the mean square error (MSE) of the estimator, defined as
The right-hand side of Equation (
6) consists of two parts: the variance of the estimator,
, and the squared bias,
. The stopping criterion for multilevel schemes is typically based on the requirements that both terms are less than
. The root mean square error (RMSE) is defined as,
.
The variance of the estimator satisfies
with
the variance of the difference, which is used to determine the number of samples
needed on each level
ℓ. This is done by following the classic argument by Giles in [
8], where the total cost of the MLMC estimator,
is minimized, with
denoting the cost to compute a single realization of the difference
, subjected to the constraint
When treating the
as continuous variables, one finds
The second term in Equation (
6) is used to determine the maximum number of levels
L. A typical MLMC implementation is level-adaptive, i.e., starting from a coarse finite element mesh, finer meshes are only added if required to reach a certain accuracy. Assuming that the convergence
is bounded as
, then we can use the heuristic
and check for convergence using
, see [
8] for details.
The MLQMC estimator has a similar formulation as MLMC. It differs in that it uses an average over a number of shifts
on each level, and a set of deterministic sample points
, i.e.,
This can again be rewritten as a sum of
estimators, analogous as in Equation (
4),
where we defined
with
.
The major difference between MLMC and MLQMC is the choice of the sample points. For the MLMC estimator in Equation (
3), the sample points
are chosen at random from a given distribution. For MLQMC however, the sample points
are optimally chosen in the stochastic space, based on a deterministic rule. Here, we use a rank-1 lattice rule, similar to [
9]. By using these deterministic points, three practicalities must be addressed in order for MLQMC to work.
The first practicality pertains to the additional bias that is being generated on the stochastic quantities of the computed solution when using these deterministic points. In order to recover unbiased estimates, a number of random shifts
with
, has to be introduced on each level. This leads to the extra summation in the MLQMC estimator in Equation (
12), see Section 2.9 of [
18].
The representation of the MLQMC sample points with inclusion of the aforementioned random shifts is as follows:
where
,
is an
s-dimensional vector of positive integers and
N is the number of points in the lattice rule.
The second practicality relates to the number of points computed according to Equation (
14). It is clear that the total number of points
N needs to be known beforehand and thus cannot increase adaptively. Such a type of
closed lattice rule cannot easily be used in an adaptive algorithm where additional samples are added on the fly. By rewriting Equation (
14) as
with
the radical inverse function in base 2, it is however possible to obtain an
open lattice rule, i.e., removing the need to know
N beforehand [
19]. The radical inverse function in base 2 mirrors the binary representation of a number around its binary point ensuring that
.
The third practicality concerns the computation of the points
. These points are spatially located in the unit cube, that is
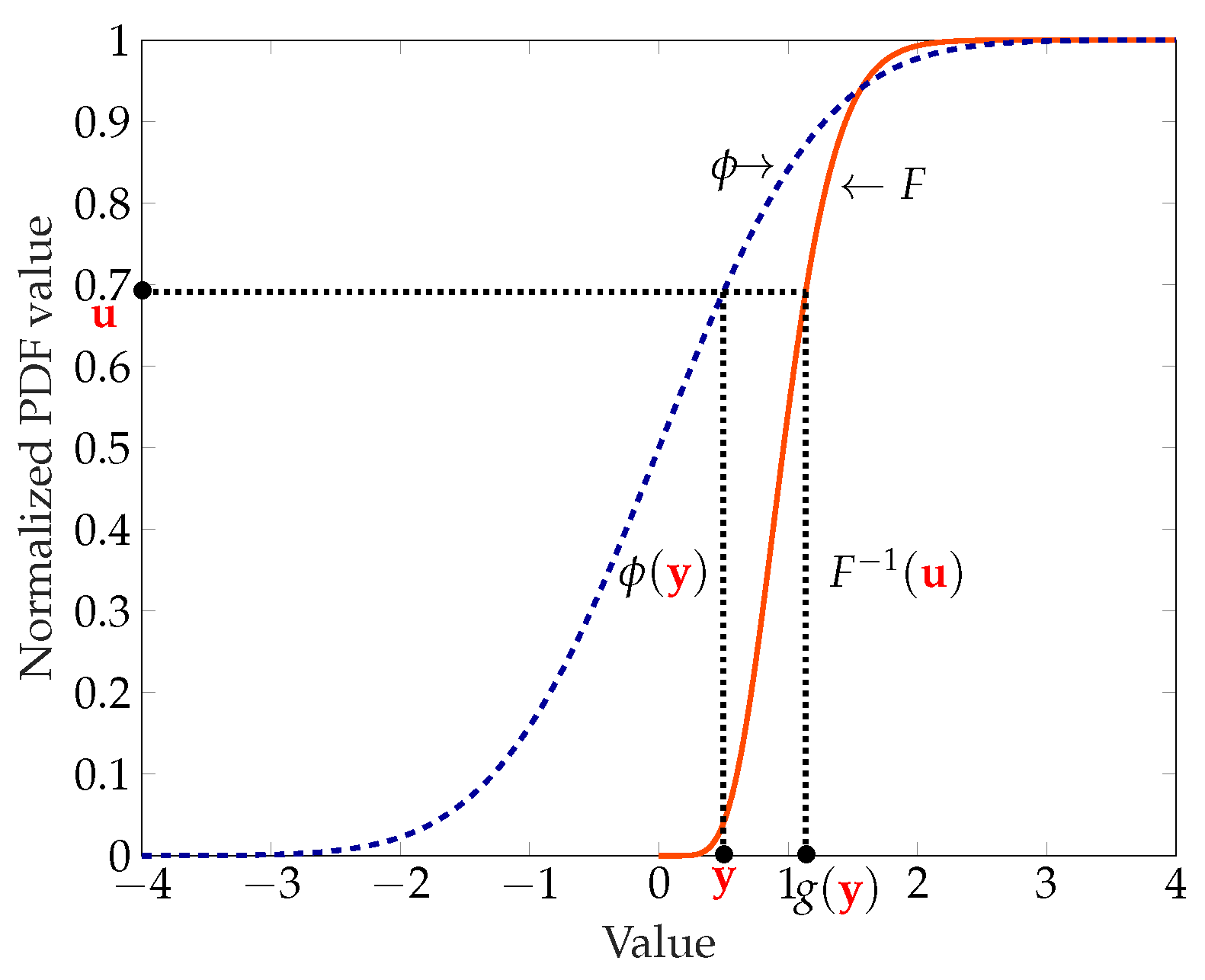
. In order to use these points in a Monte Carlo simulation that uses normally distributed random numbers, every set of points must be mapped from the
to
. For this the inverse,
, of the univariate standard normal cumulative distribution function,
, is applied point wise to Equation (
15), see [
20]. This is written as
The discussion pertaining to MLMC is applicable to MLQMC, with the exception of the part related to the computation of the number of samples. Unlike MLMC, the number of samples for MLQMC is not based on a formula as in Equation (
10). In order to satisfy the statistical constraint, i.e., Equation (
9), an adaptive algorithm is used, see [
9]. Starting with an initial number of samples, this algorithm multiplies the number of samples on the level with maximum ratio
with a constant factor until the variance of the estimator
is smaller than
. In our implementation this multiplication constant is chosen as
, and
is computed as
and
The number of samples is multiplied by 1.2 (instead of the naive value 2) because, in the current setting where each sample involves the solution of a complex PDE, an exponential growth with a doubling of the number of samples is a dramatic event that causes huge jumps in the total cost of the estimator. Reducing this value from 2 to 1.2, as in, for example [
21], is a compromise that causes a more gradual increase of the computational cost of the estimator, while, at the same time ensuring that enough progress is made. Note that increasing the amount of samples one at the time, i.e., the other extreme, would not be efficient in a parallel implementation, such as the one in this paper. We note that if the updated number of samples is not an integer, the least integer greater than this value is taken in order to have an integer value as updated number of samples.
In this work, we use a shifted rank-1 lattice rule in order to generate the MLQMC sample points
, as is commonly done in other work regarding MLQMC, see for example [
9,
10,
22]. Rank-1 lattice rules belong to one of two major classes of QMC points, i.e. lattices. The other class consists of digital nets/sequences, of which Sobol’ sequences are one of the oldest example, see [
23]. One of the major differences between these two classes, is that rank-1 lattice rules rely on a generating vector
to construct the points, while digital nets/sequences rely on a set of generating matrices
. The shifting procedure, also referred to as randomization, as done in Equation (
14) for rank-1 lattice rules, also differs for both classes. Shifting in rank-1 lattice rules is mathematically easier than digital shifting or scrambling in digital nets/sequences. (Digital) shifting allows for a faster convergence rate compared to the standard Monte Carlo method if the function under consideration is sufficiently smooth. We note that scrambling, which is only applicable to digital nets/sequences, can further improve the QMC convergence rate. For a more thorough discussion on this subject, we refer to [
18].
The generating vector
we use for p-MLQMC is available from [
24]. This vector was constructed with the component-by-component (CBC) algorithm with decreasing weights,
.
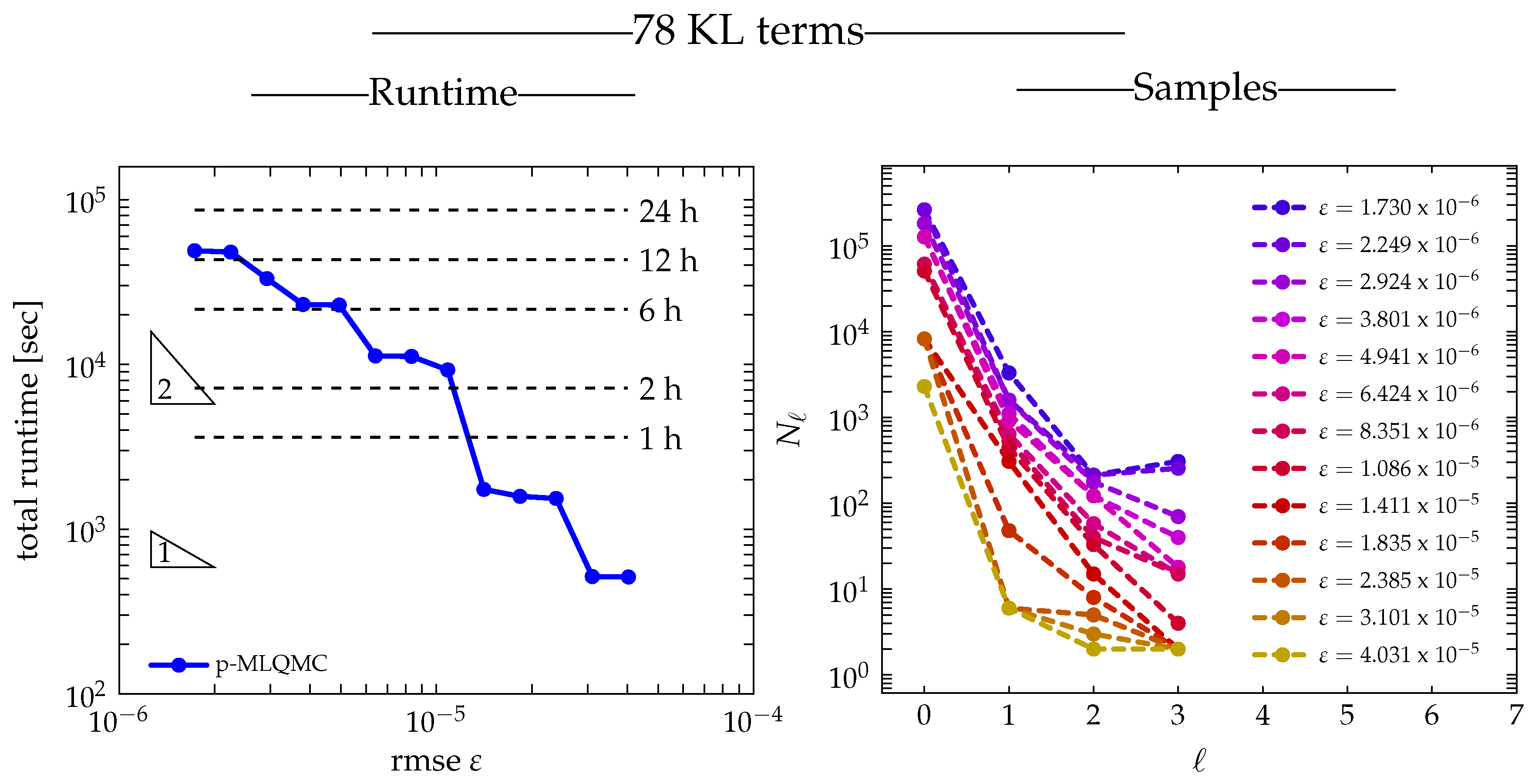
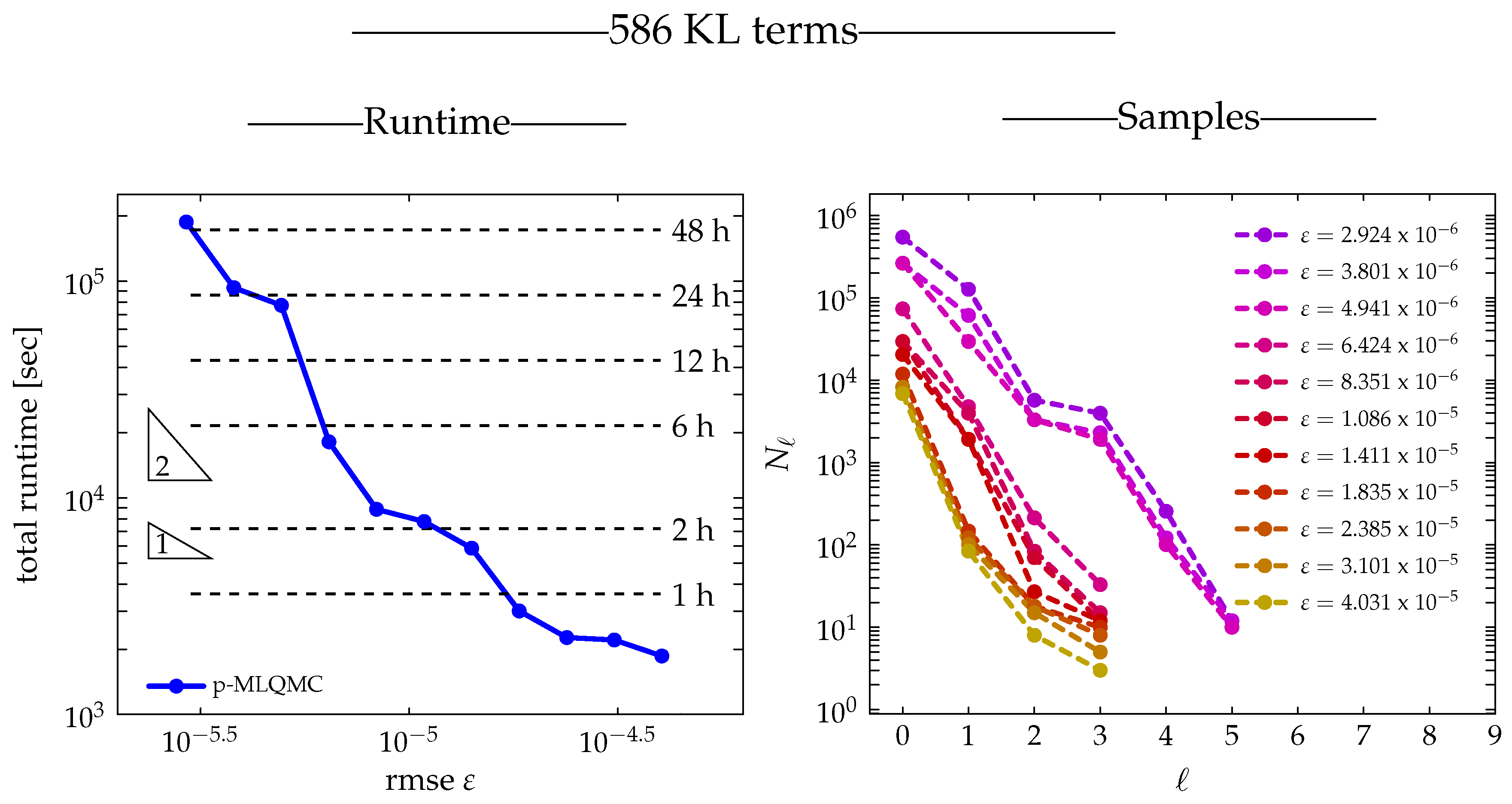
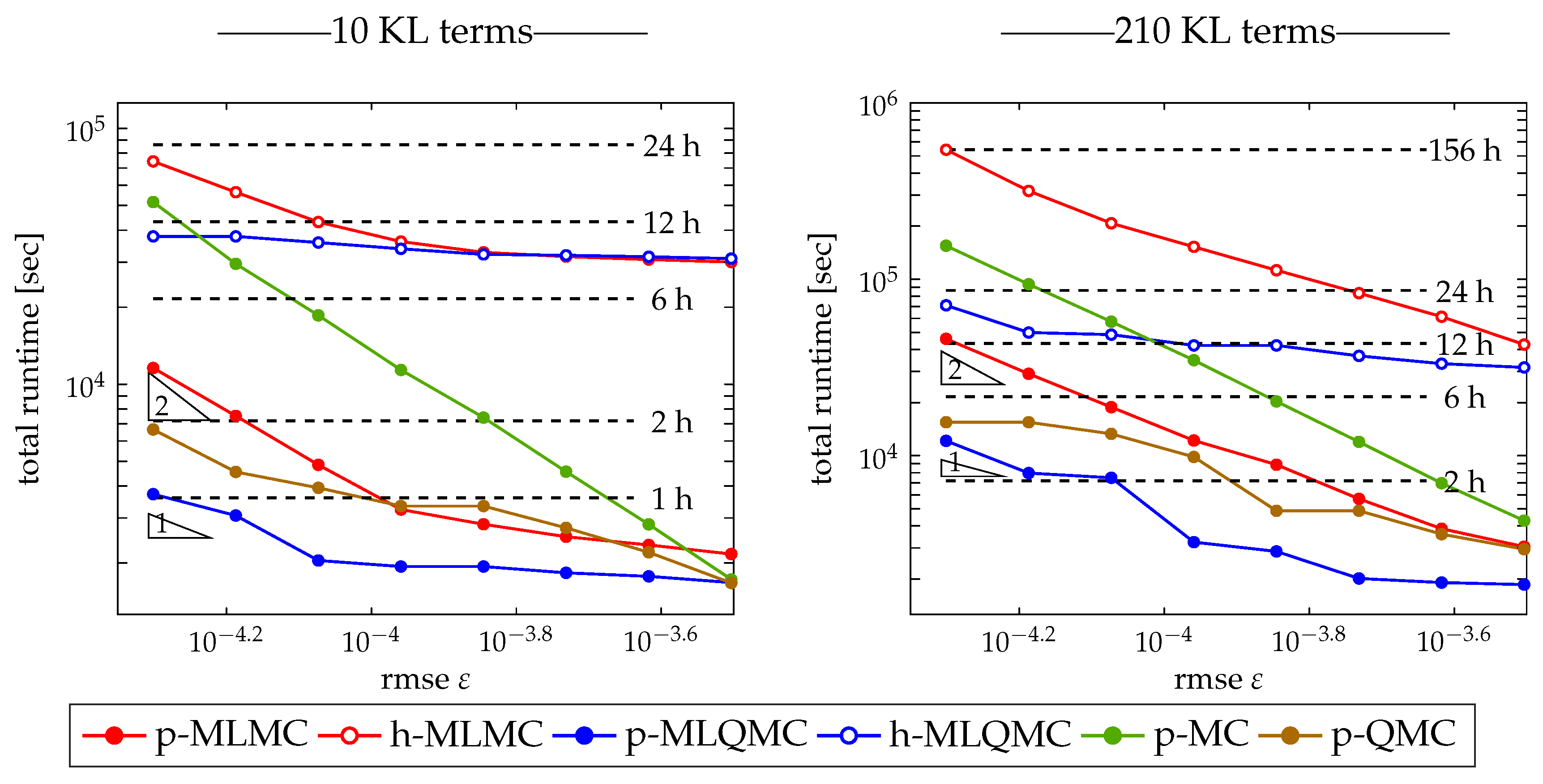
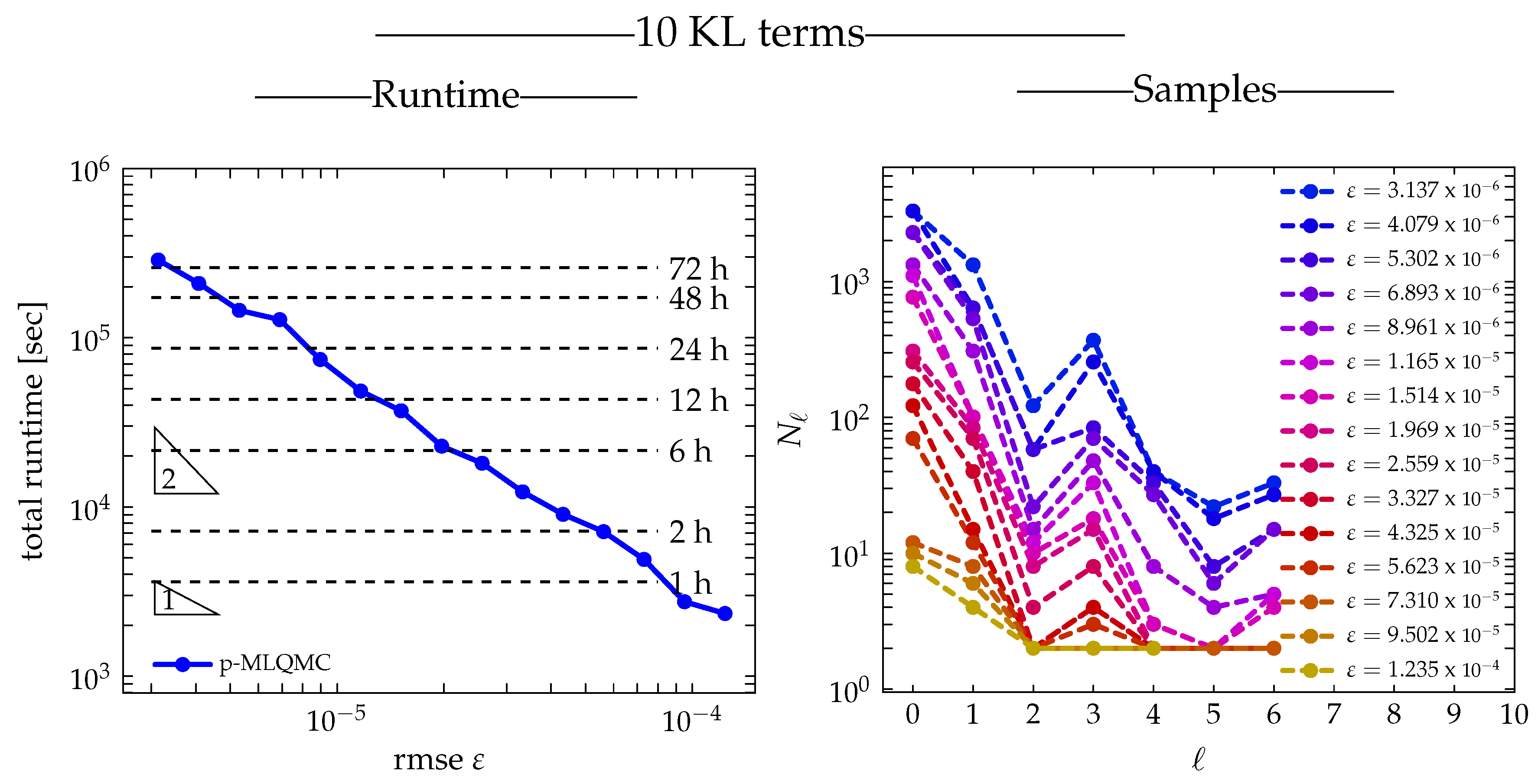
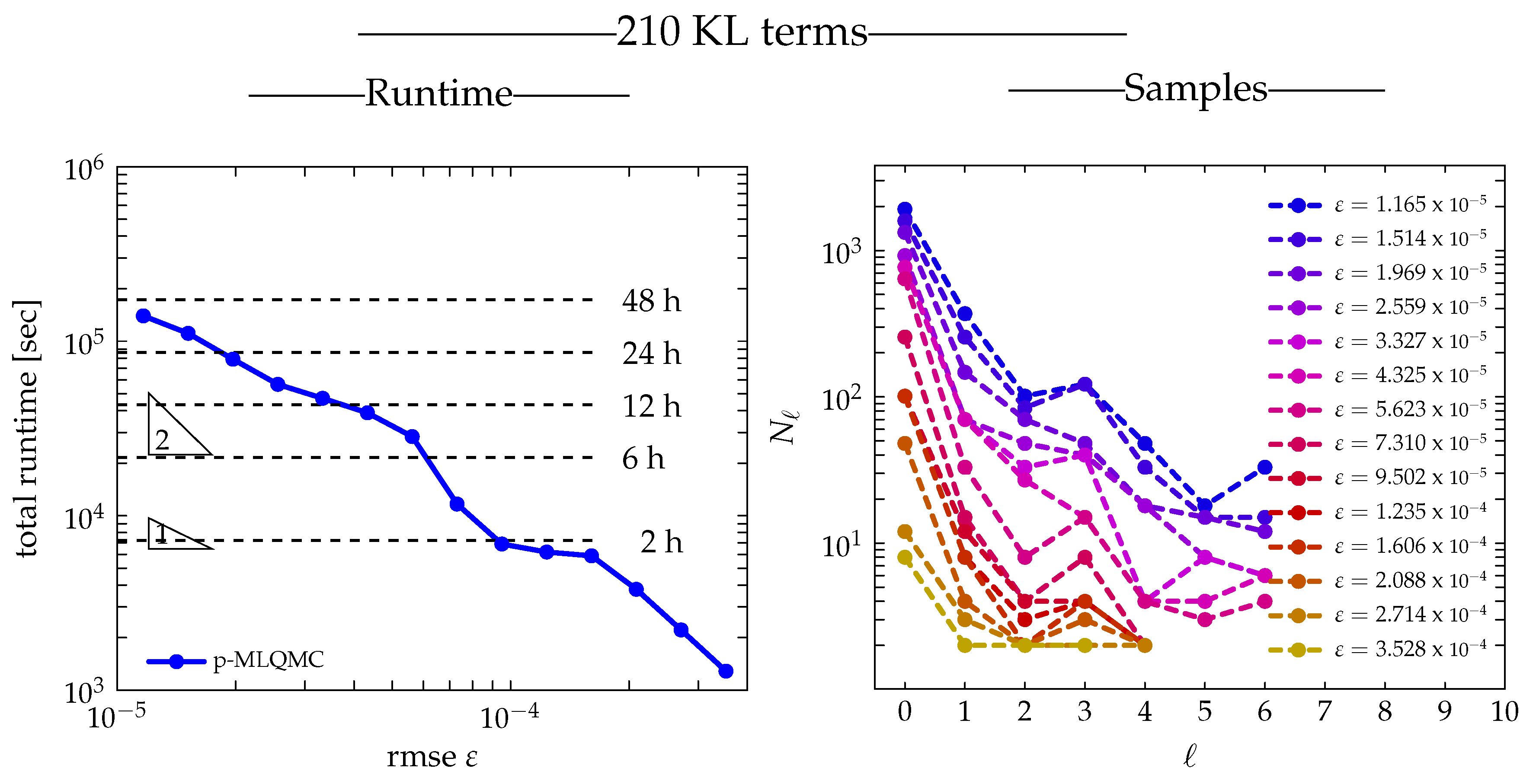
2.3. Algorithm
Algorithm 1 describes the implementation for p-MLQMC. The output produced by the algorithm consists of the expected value of the estimator for a given tolerance
on the root mean square error. The algorithm computes the expected value of the estimator and its variance on each level according to Equations (
17) and (
18). The algorithm starts with
and
on each level
ℓ. The value of
is typically chosen to be small, in the range of 10 to 32, in order to have a fair comparison with MLMC, see ([
28], page 3678) and ([
9], page 6). In Algorithm 1, the bias
B is evaluated by Equation (
11). The expected value
, where
follows from Equation (
17).
| Algorithm 1: p-MLQMC. |
![Algorithms 13 00110 i001]() |
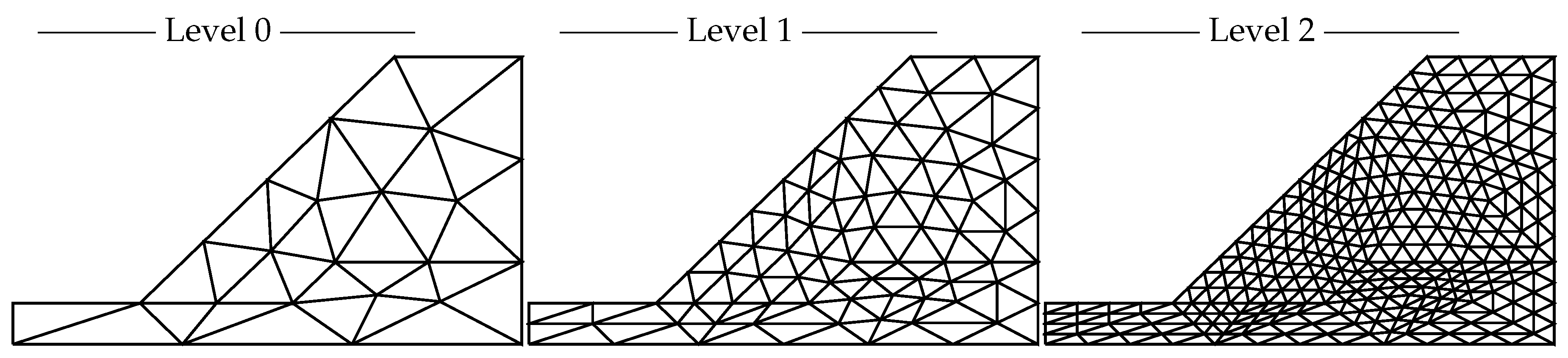
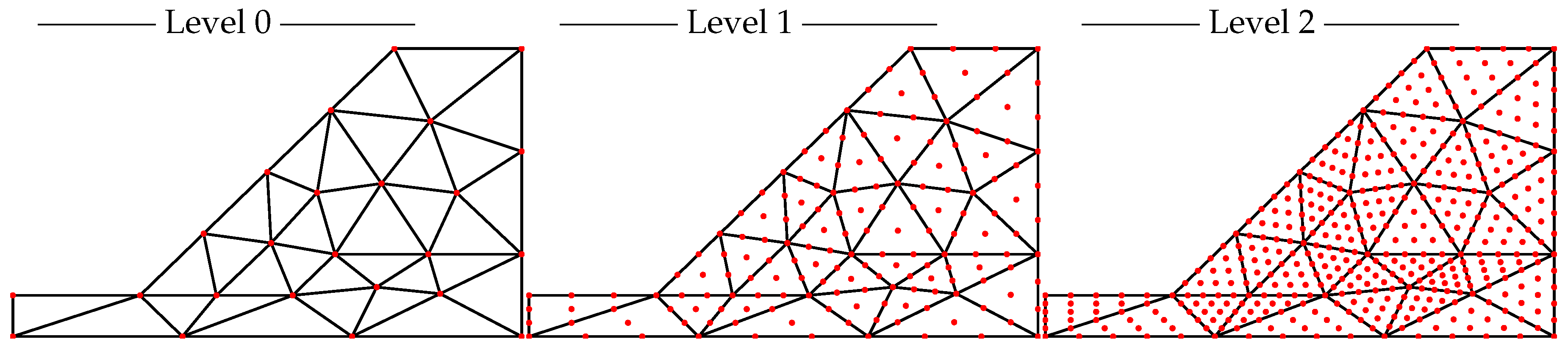
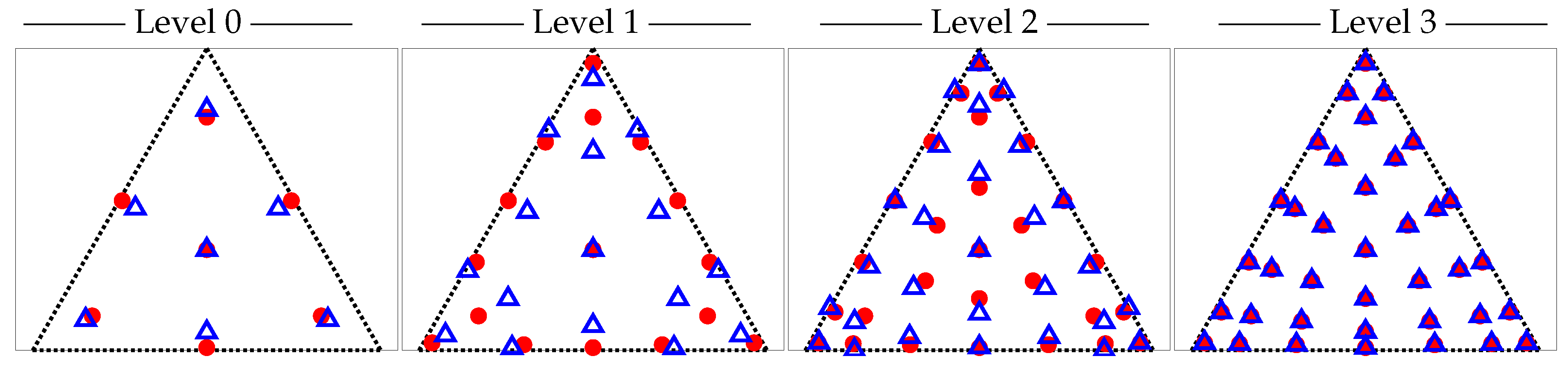
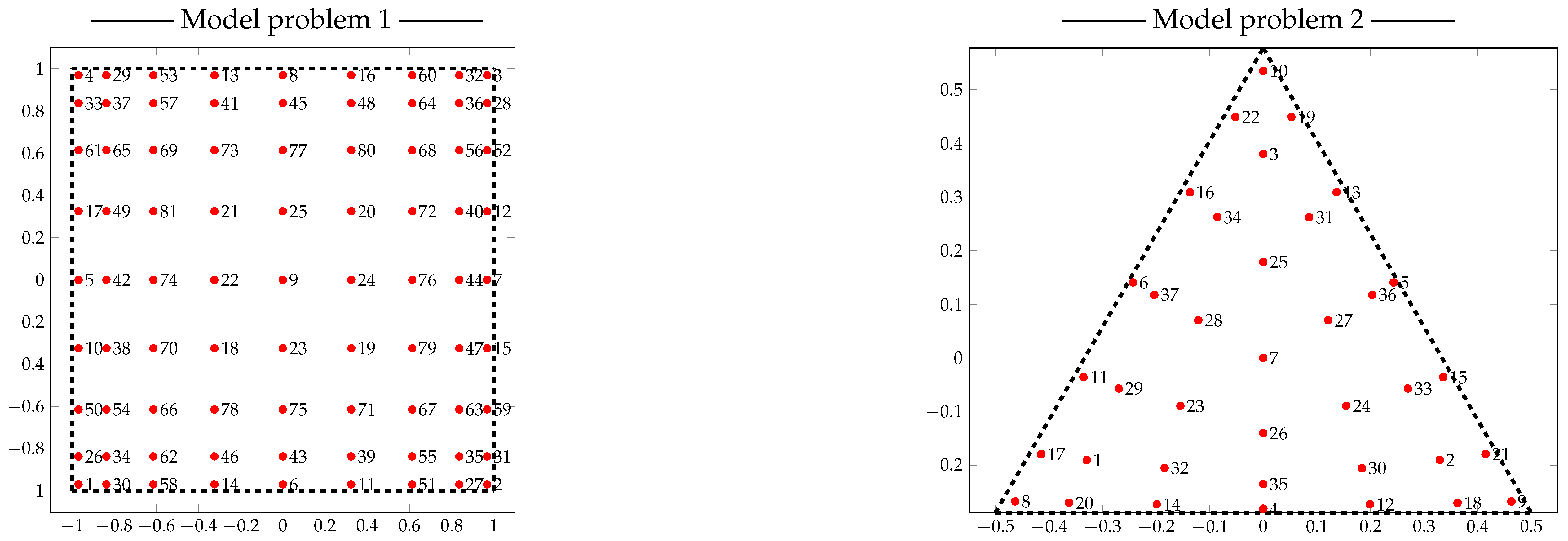
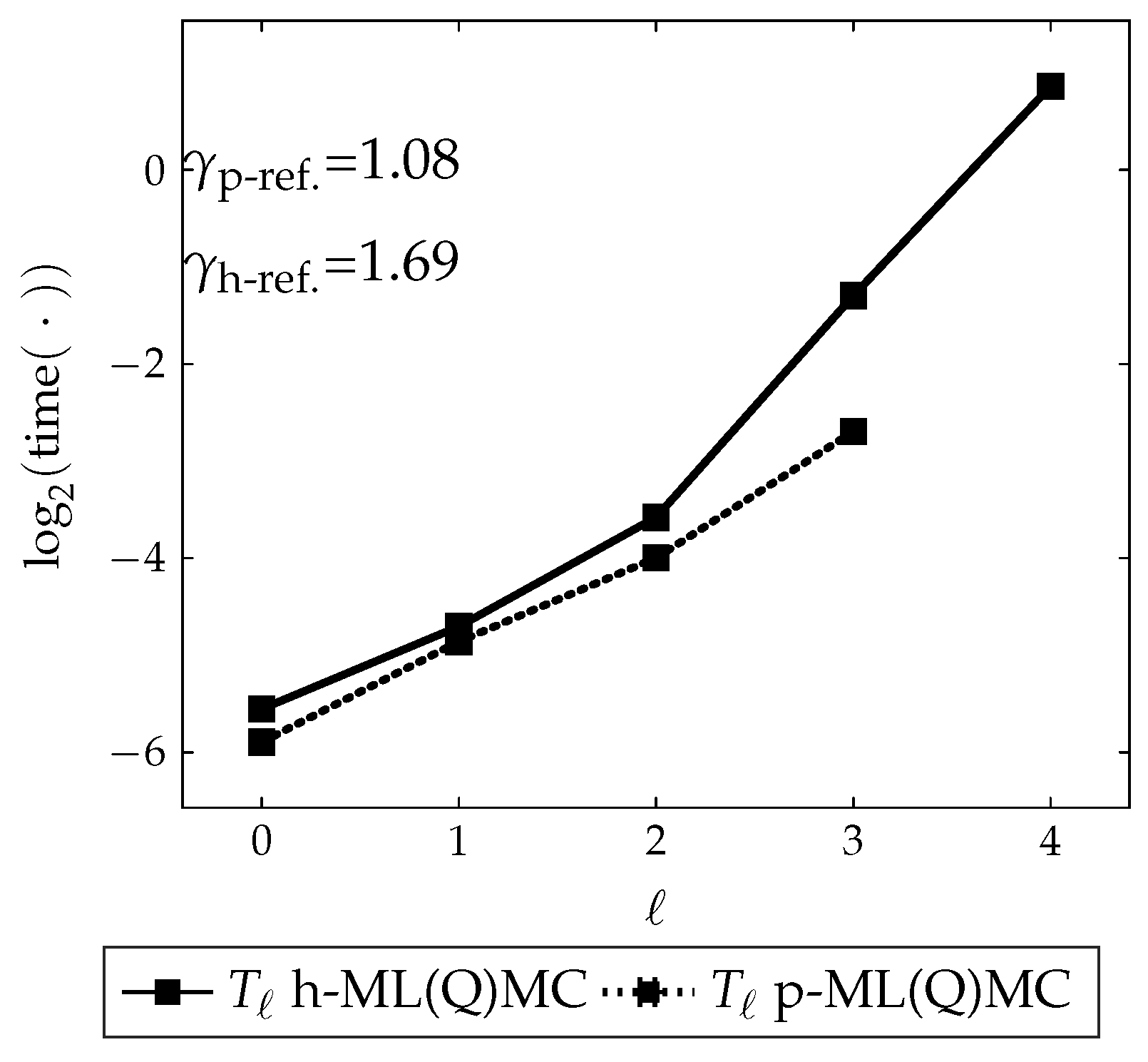
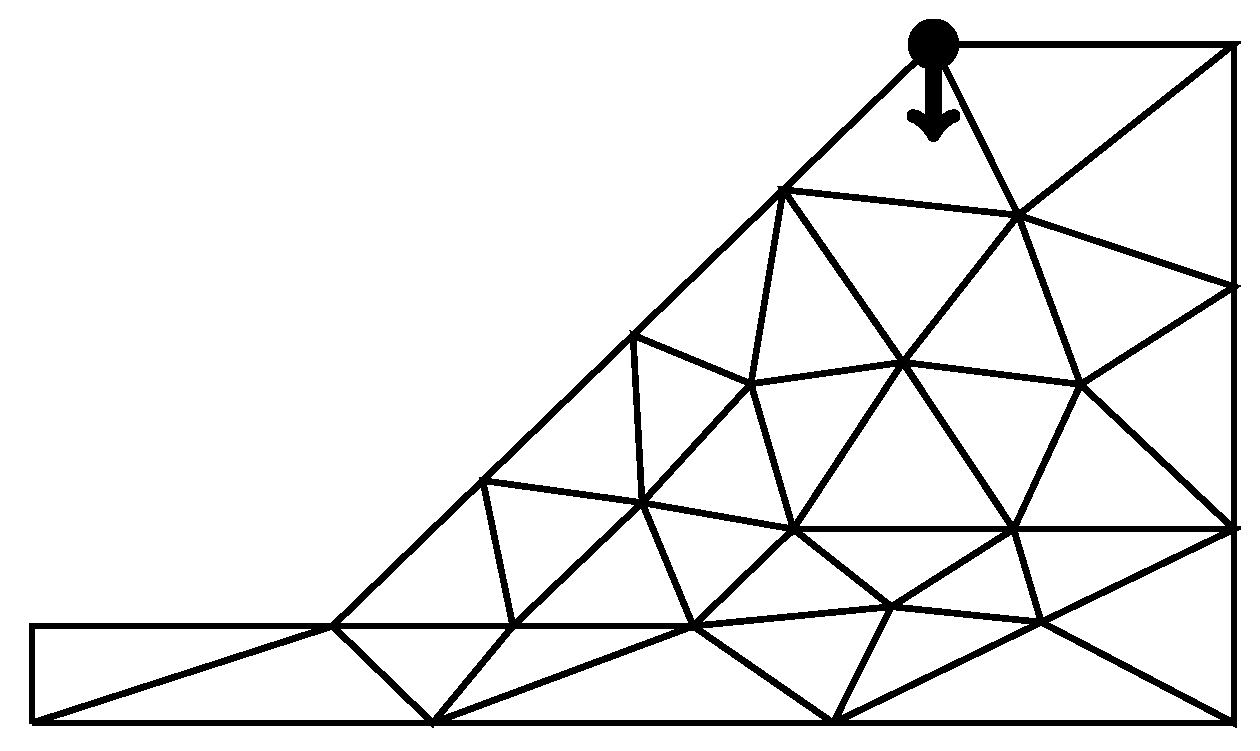
For this p-MLQMC algorithm to be able to work well, it is important to adequately generate the mesh hierarchy based on p-refinement. The challenge consists of selecting adequate points, on each level, in which to compute the discrete values of the random field. We generate these points starting from a given Gauss quadrature set on the finest level, i.e., level 3 for both our model problems. This is illustrated for one element for model problem 1 in
Figure 5 and for model problem 2 in
Figure 6. The
☐ and
∆, respectively represent the location of the actual Gauss quadrature points for a square and a triangular element, while the
● represent the location of the points where the values of the random field will be computed. This approach contrasts with a more intuitive one, which would consist of selecting the location of the actual Gauss quadrature points for the generation of the values of the random field. We observed numerically that our approach yields a larger decay of the expected value and variance of the multilevel differences compared to choosing the actual Gauss quadrature points for sampling from the random field, since, in that case the sets of quadrature points on different levels are not contained in each other, i.e.,
☐0 ⊈
☐ℓ ⊈ … ⊈
☐L. Such an inclusion property does hold however for our sets of random field evaluation points, i.e.,
●0 ⊆
●ℓ ⊆ … ⊆
●L. This implies that the sets of random values that are generated in these sets of points will also be included in one another. This will lead to a good decrease of
, as is required by the multilevel methodology. Note that on level 3, both
☐ and
∆ have the same spatial location as
●. We use the Gauss quadrature set on the finest mesh as a starting point for the construction of subsets on coarser meshes. The computed discrete random values are used during the numerical integration of the element stiffness matrix by means of Gauss quadrature points, see
Section 2.6 for further details.
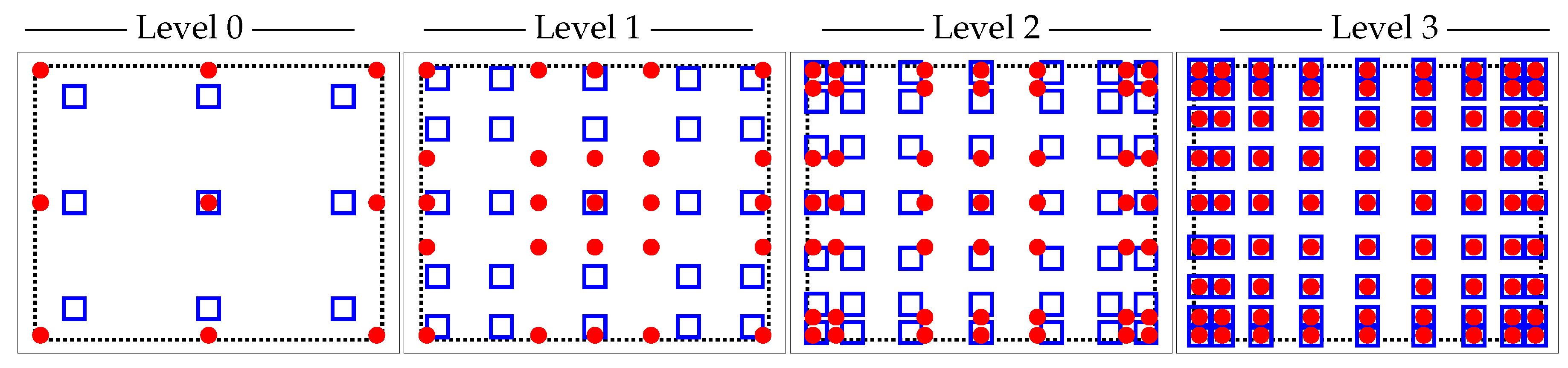
We will now describe an algorithm which generates the location of the points in which the discrete values of the random field are to be computed.
Figure 5 and
Figure 6, show the location of these points
●. As input to this algorithm, we require a set of Gauss quadrature points in natural coordinates for one element of the finest considered mesh. An algorithm for generating the point sets on each level is given in Algorithm 2. The output consists of a vector of points in which the discrete values of the random field are to be computed. This vector contains all the locations of the points on the finest level. Because the vector is sorted, taking subsets hereof gives the locations of the points on the coarser levels.
Figure 7 shows in which sequence the points are chosen on a unit square and on a unit triangle. For example, for model problem 2, the evaluation points at the coarsest level are points
, the second coarsest level points
, the third coarsest level points
, and at the finest level points
. See also
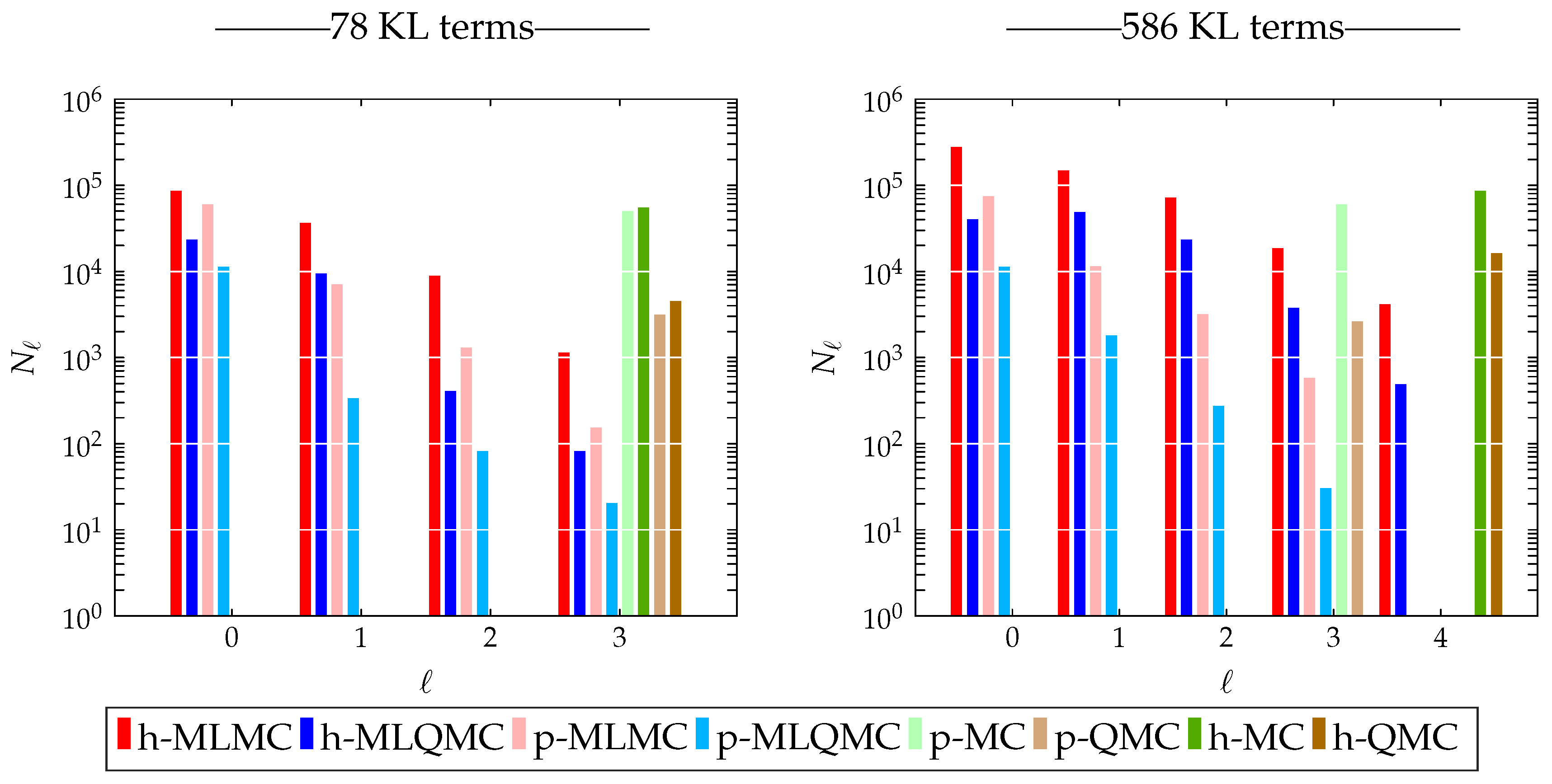
Table 1 and
Table 2 which, among other, list the number of quadrature points used per level. Once the locations of the points for one element in natural coordinates for each level have been obtained, the points are mapped to each element of the mesh by means of a transformation matrix. This results in a point set, listing the locations in global coordinates where the discrete values of the random field for the model problem are to be computed. As such, Algorithm 2 only works for two dimensional problems. Algorithm 2 consists of two main loops, the first loop starts on line 3, and returns a set of points which are closest to points of a given quadrature set on level
ℓ. The second loop, starting on line 12, reorders the obtained set of closest points as in
Figure 7, following the principle illustrated in
Figure 8. Extending Algorithm 2 for three dimensions can be done be rewriting lines 12 to 24 to accommodate a reordering in three dimensions or to not consider a reordering at all. This would mean that lines 12 to 24 have to be omitted when computing the locations for the points in three dimensions.
| Algorithm 2: Point Set Generation |
![Algorithms 13 00110 i002]() |
In its current form, Algorithm 1 is level-adaptive, in the sense that levels are added to the estimator () only when needed to reduce the bias. This means that the maximum level L that satisfies the bias constraint is not known a priori. The p-MLQMC method in Algorithm 1 takes as input a number of meshes with maximum L, generated during a preprocessing step using the point selection method in Algorithm 2. If the bias constraint were not satisfied with the predefined maximum level L, it would force us to recompute a hierarchy of meshes with a higher level L by means of Algorithm 2, and restart Algorithm 1 with these new meshes. The implication hereof is that samples from earlier runs of Algorithm 1 with maximum level L cannot be reused when restarting Algorithm 1 with maximum level . The reason is that the inclusion principle is needed for the locations where discrete values of the random field are generated, as stated here above. In our implementation, we run Algorithm 2 only once for an a priori determined maximum level L, so that the set of points where the random field must be computed on each level remains the same during the course of Algorithm 1.
2.4. Cost Complexity Theorem
Having introduced the p-MLQMC method, we now present a complexity theorem for MLQMC, which also covers the MLMC method, when
. More details can be found in [
22] and in ([
29], page 76). We refer to [
8] for the original MLMC complexity theorem and its generalization on which the current theorem is based, see [
17].
Theorem 1. Given the positive constants such that with , and assume that the following conditions hold:
- 1.
,
- 2.
and
- 3.
.
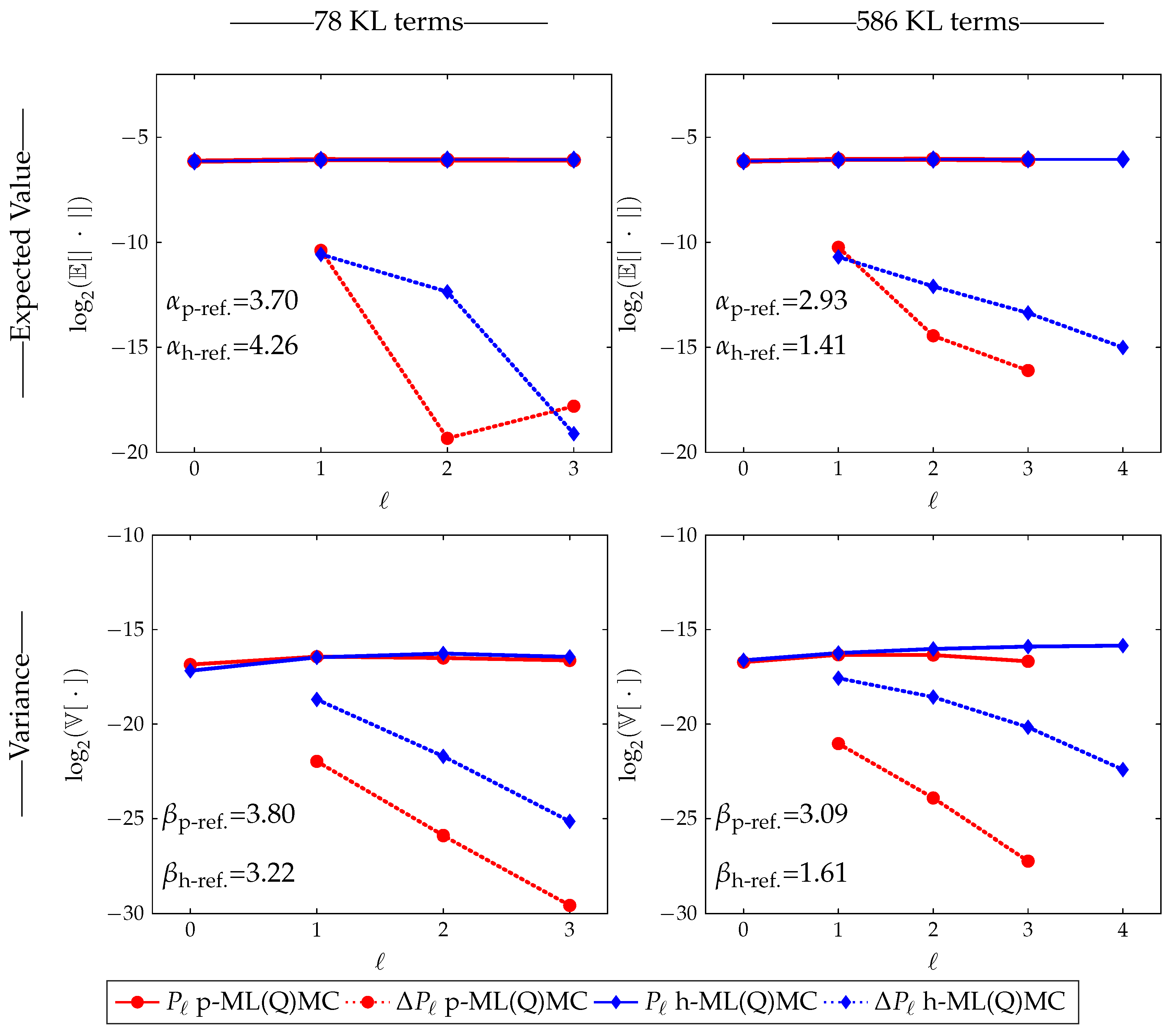
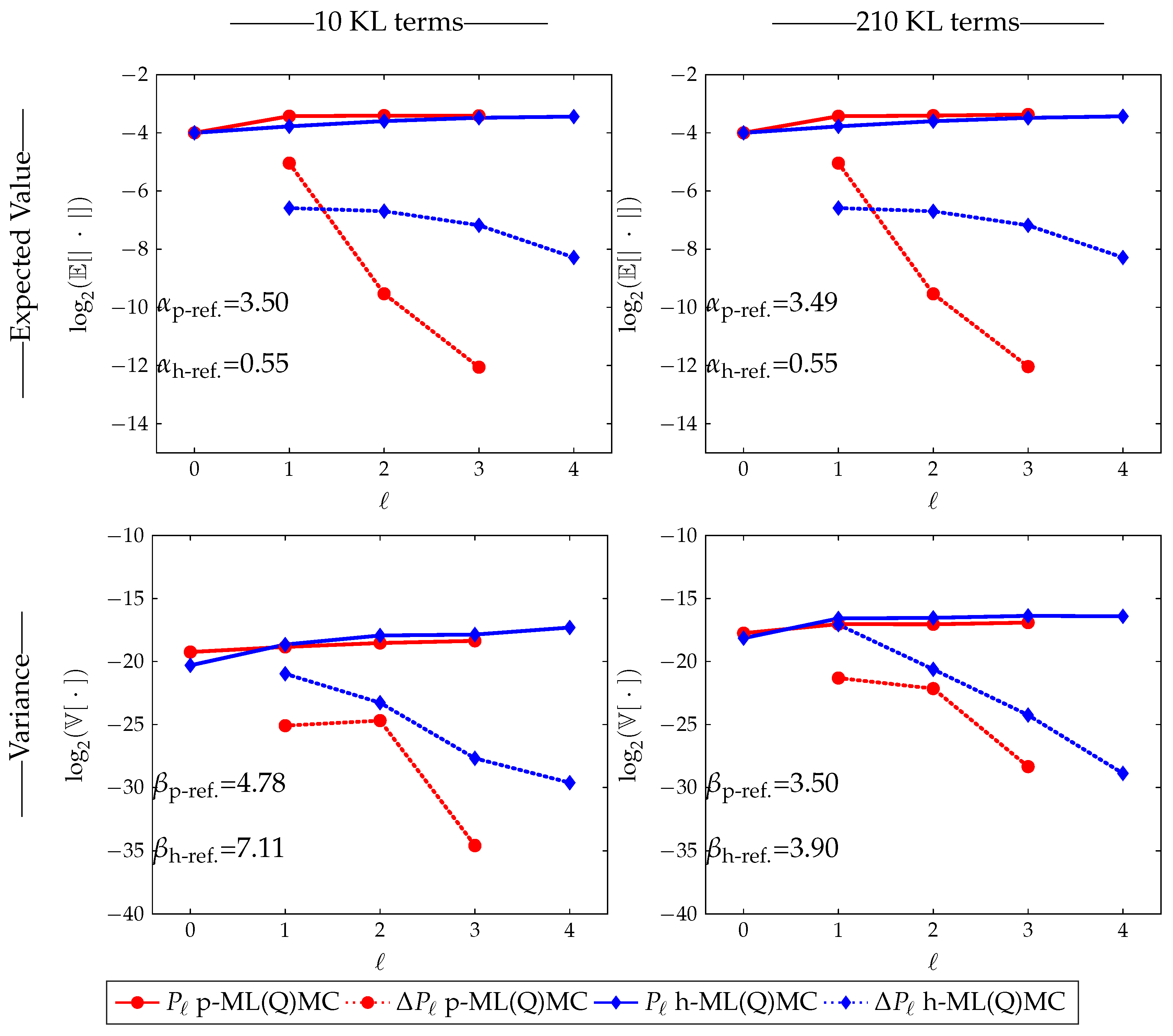
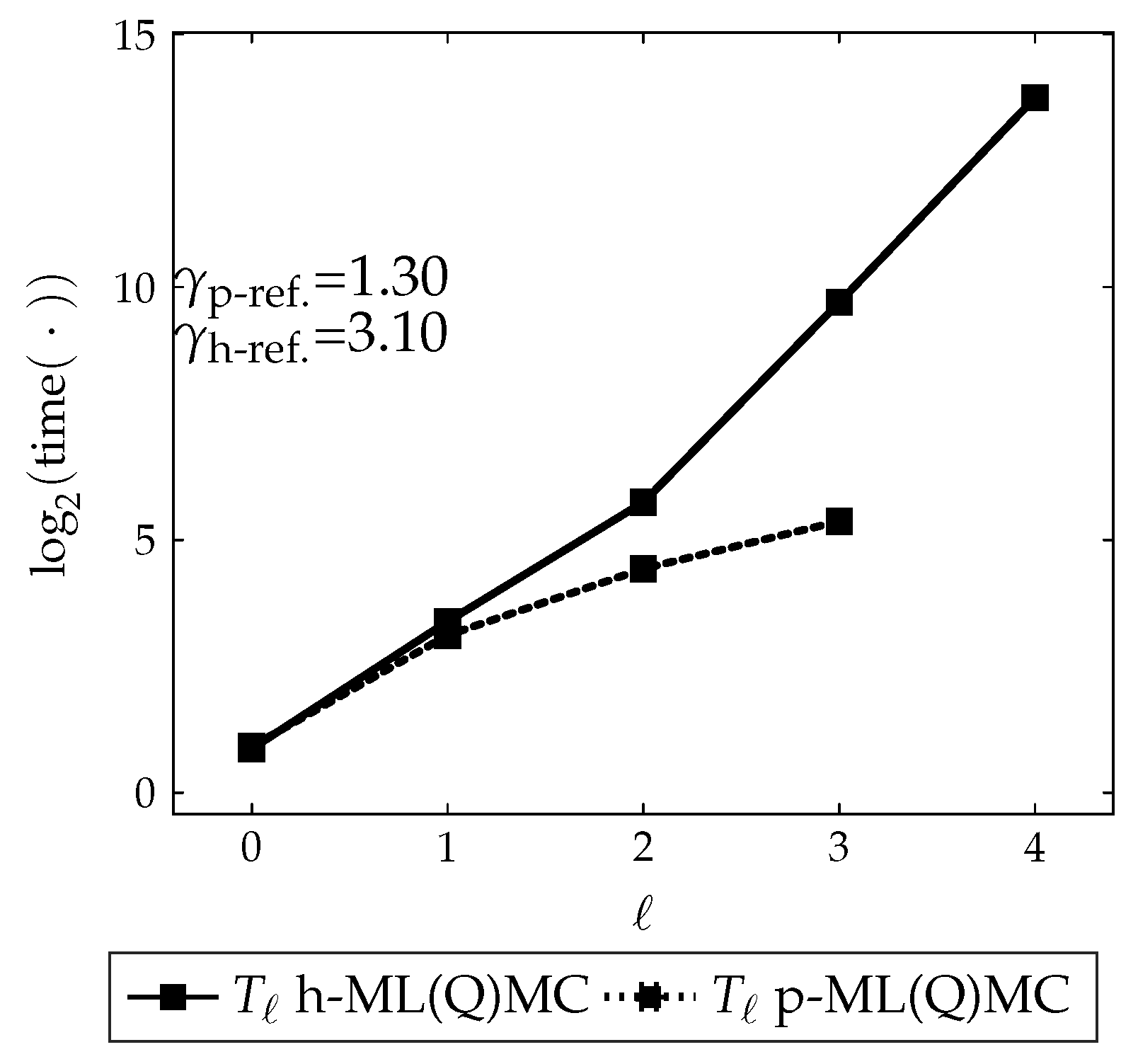
Then, there exists a positive constant such that for any there exists an L and a sequence for which the multilevel estimator, has an , and The constant in Assumption 1 of Theorem 1, represents the rate at which decreases with increasing level ℓ. The constant in Assumption 2, stands for the decay rate of , i.e., the variance of the estimator of the difference on level ℓ. The constant in Assumption 3, is determined by the efficiency of the solver. This factor will be different for h-refinement and p-refinement. All three factors will be estimated on the fly in our numerical experiments. The parameter depends on the Quasi-Monte Carlo (QMC) rule used.
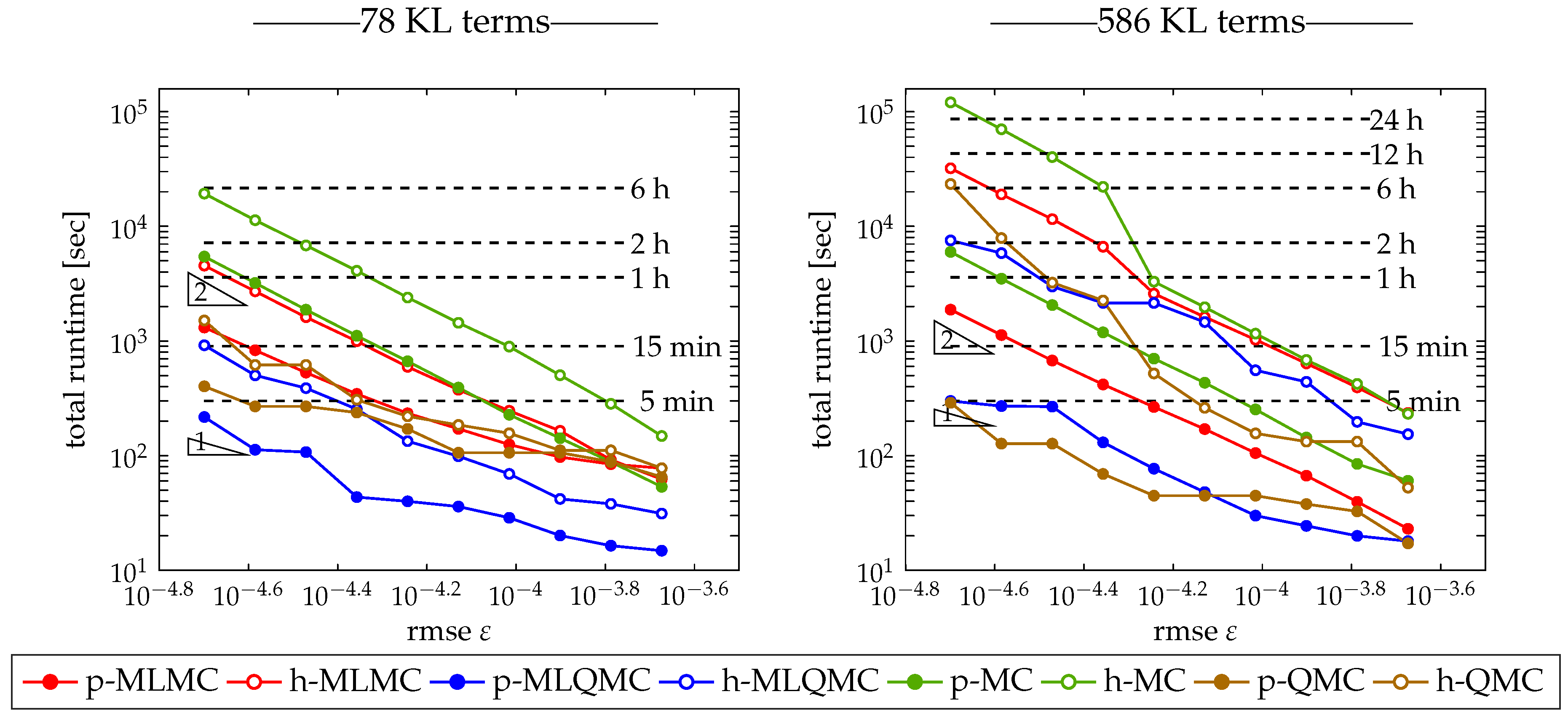
The theorem can now be interpreted as follows. When the variance decreases faster with increasing level ℓ than the cost increases, i.e., , the dominant computational cost is located on the coarsest level, which is small because is small. Conversely, if the variance decreases slower with increasing level ℓ than the cost increases, i.e., , the dominant computational cost will be located on the finest level. The cost will be small because is small.
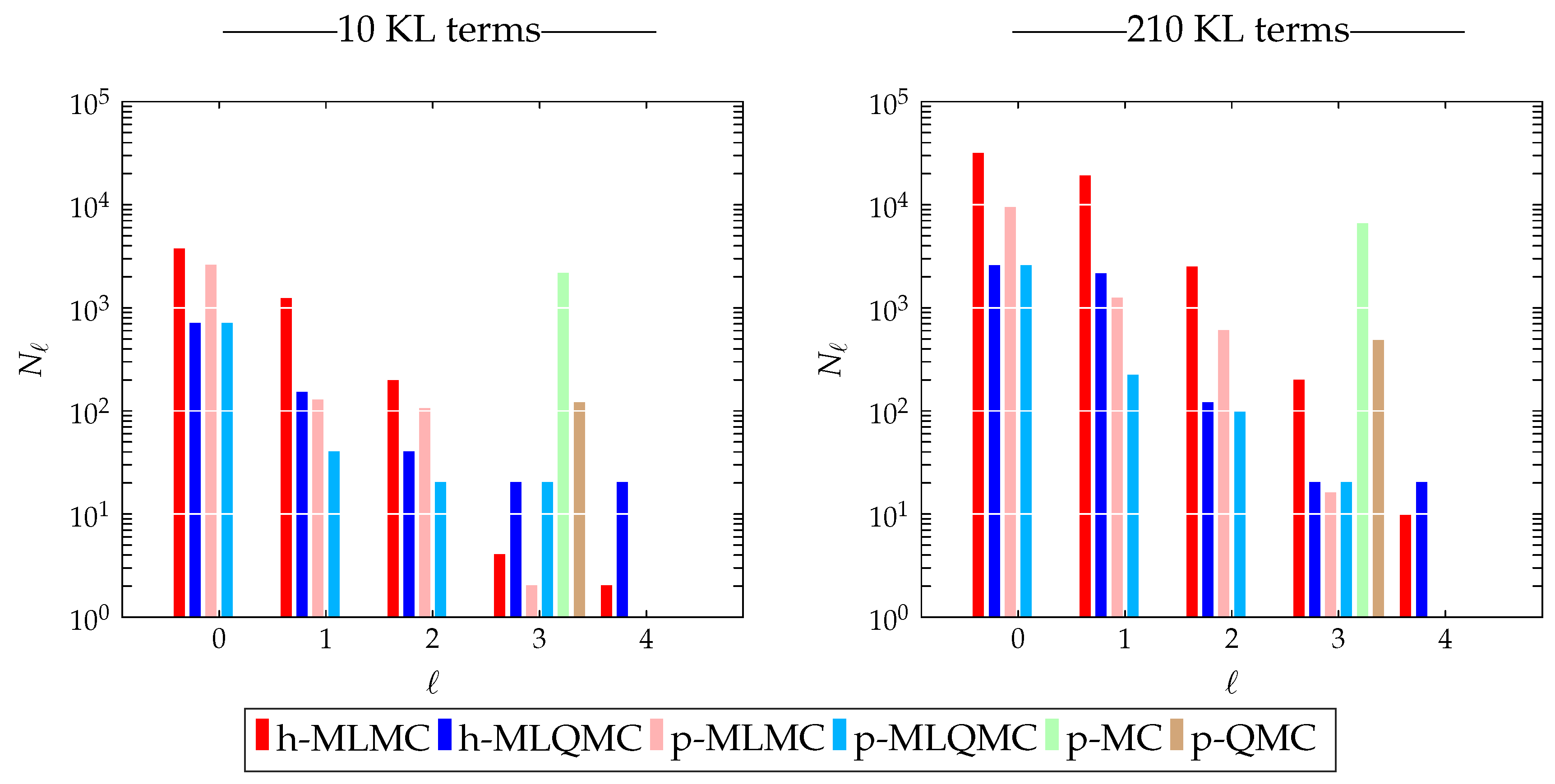
Observe that if
, then
, see Equation (
7), as
ℓ increases. Hence, the number of samples
will be a decreasing function of
ℓ. This means that most samples will be taken on the coarse mesh, where samples are cheap, whereas increasingly fewer samples are required on the finer, but more expensive meshes. In practice, the number of samples must be truncated to
, the smallest integer larger than or equal to
.
Using Equation (
10), the total cost of the MLMC estimator, from Equation (
8), can be written as
Following this theorem, we note that the optimal cost of the MLMC estimator, which corresponds to
, is proportional to
when the variance over the levels decreases faster than the cost per level increases, i.e.,
. Similarly for the MLQMC estimator, we can hope to achieve an optimal cost proportional to
. Note that this is only true in the limit when
. We will show in our numerical experiments that the theoretically derived asymptotic cost complexity is close to what we observe. Quasi-Monte Carlo methods work so well because they are based on the concept of
weighted function spaces and
low effective dimension. Not all higher stochastic dimensions are of equal importance. A series of decreasing weights can be used to quantify this importance. The idea is then to analyze the problem at hand in this
weighted function space. The weights can be used to design a good lattice rule that yields a good convergence of the QMC method. A more thorough analysis can be found in [
28,
30,
31].
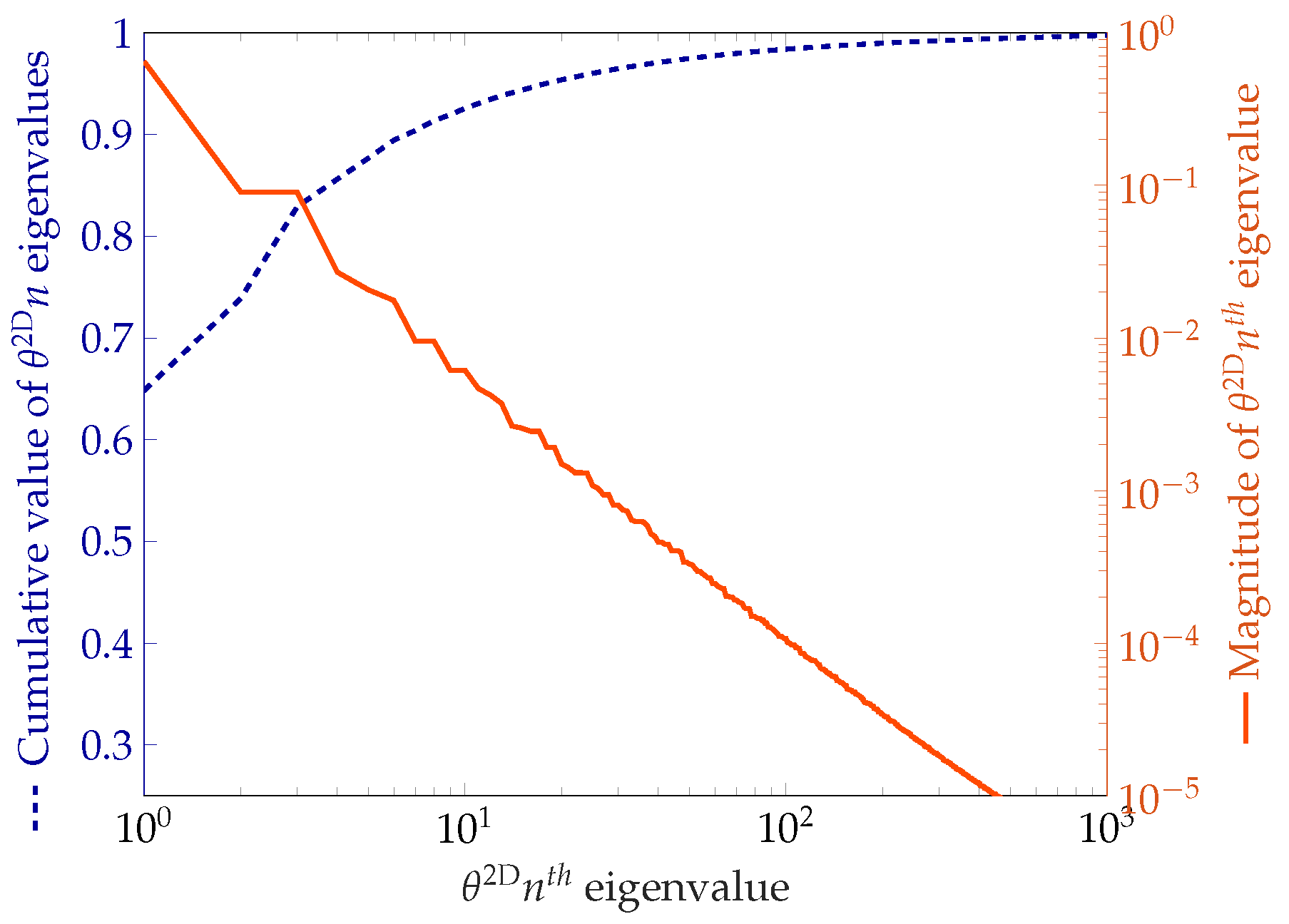
2.5. Modeling the Spatial Variability
The uncertain spatial variability of the Young’s modulus (model problem 1) and the soil’s cohesion (model problem 2) is represented by means of a random field. The Young’s modulus is represented as a gamma random field, while the soil’s cohesion is represented as a lognormal random field. The starting point for the construction of both fields is the generation of a (truncated) Gaussian random field. This is done by using a Karhunen–Loève (KL) expansion, see [
32].
Consider a Gaussian random field
, where
is a random variable with a given covariance kernel. For both cases we choose the Matérn covariance kernel,
with
the smoothness parameter,
the modified Bessel function of the second kind,
the variance and
the correlation length. The parameter values,
,
and
will be given later on for both cases. The KL expansion can be formulated as:
Here,
denotes the mean of the field, and is set to zero. The
denote i.i.d. standard normal random variables. The symbols
and
respectively denote the eigenvalues and eigenfunctions of the covariance kernel corresponding to Equation (
21). They are the solutions of the eigenvalue problem
These can be approximated by means of a numerical collocation scheme, i.e., by solving
in some well-chosen collocation points
. Following the Nyström method, see [
33], the integral in Equation (
24), is approximated by a numerical integration scheme which uses the collocation points as quadrature nodes, i.e.,
In matrix notation, this becomes
where
is a symmetric positive semi-definite matrix with entries
,
W is a diagonal matrix containing the weights
on its diagonal and
is a vector with entries
. The matrix eigenvalue problem, Equation (
26), can be reformulated as
where
and
. Matrix
is symmetric positive semi-definite. This implies that the eigenvalues
are nonnegative real and the eigenvectors
are orthogonal to each other. Using Equation (
25), the Nyström eigenfunctions
are obtained:
where
stands for the q-th element of eigenvector
. These eigenvalues and eigenfunctions can be used as an approximate eigenpair in the KL expansion after a suitable normalization.
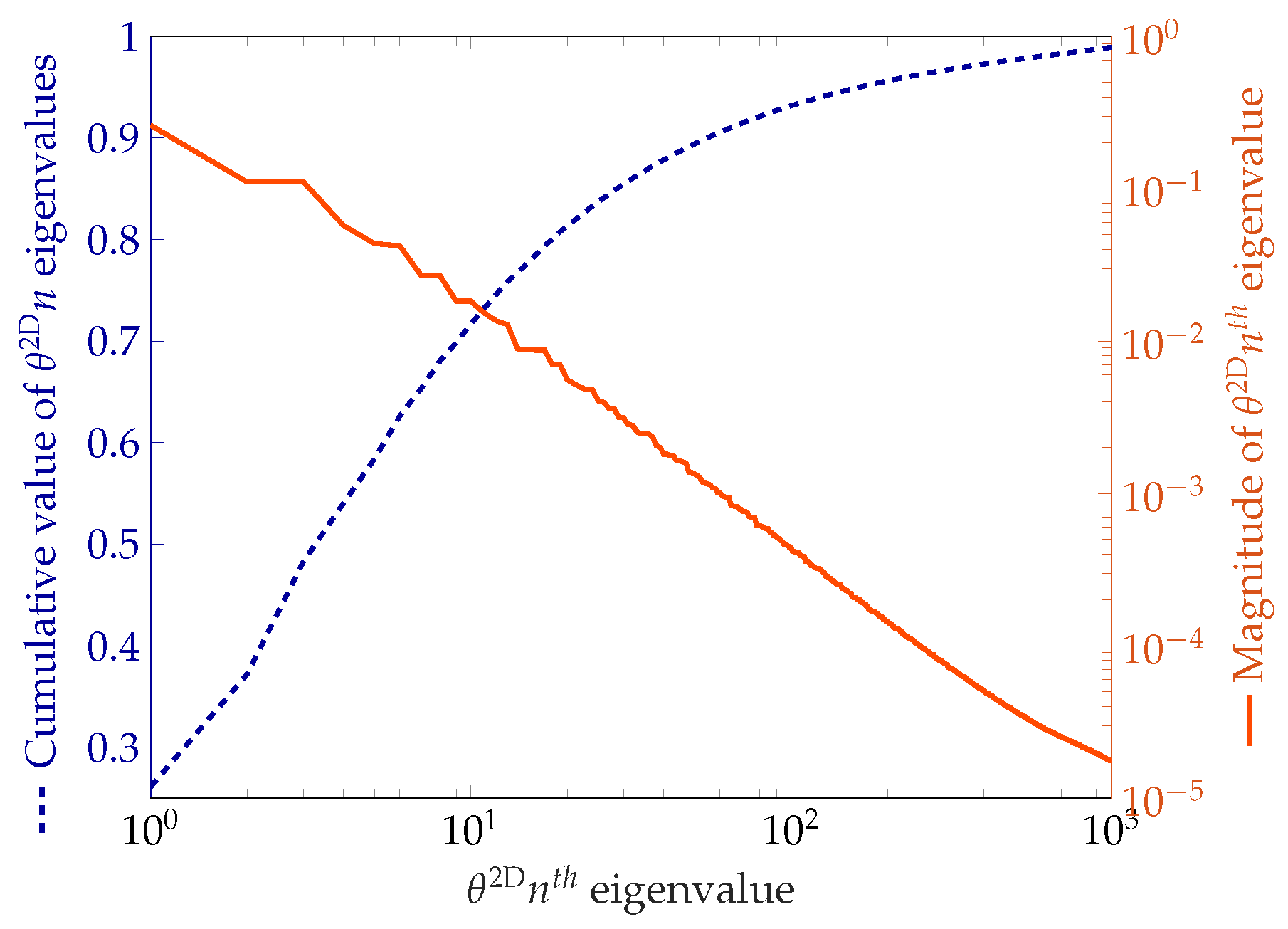
In an actual implementation, the number of KL terms in Equation (
22) is truncated to a finite value
s, representing the stochastic dimension, i.e.,
The transformation of a Gaussian random field to respectively a gamma and a lognormal random field is detailed in
Section 3.1.4 and
Section 3.3.4.

 ,
, 
































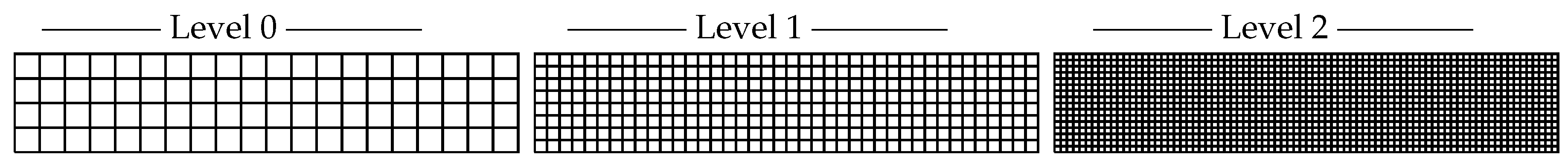{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}