1. Introduction
Proteins are complex molecules that govern much of how cells work, in humans, plants, and microbes. They are made of a succession of simple molecules called
-amino acids. All
-amino acids share a common constant linear body and a variable sidechain. The sidechain defines the nature of the amino acid. There are 20 natural amino acid types, each with a distinct sidechain offering specific physico-chemical properties. In a protein, the successive amino acids are connected one to the other by peptidic bonds, defining a long linear polymer called the protein backbone. In solution, most proteins fold into a 3D shape, determined by the physico-chemical properties of their amino acid sidechains. Because of their wide variety of functions, and their potentials for applications in medicine, environment, biofuels, green chemistry, etc., new protein sequences are sought that present desired new or enhanced properties and functions. As function is closely related to three-dimensional (3D) structure [
1], computational protein design (CPD) methods aim at finding a sequence that folds into a target 3D structure that corresponds to the desired properties and functions. A general formulation of this problem being highly intractable, simplifying assumptions have been made (see
Figure 1): the target protein structure (or backbone) is often assumed to be rigid, the continuous space of flexibility of amino acids sidechains is represented as a discrete set of conformations called rotamers and the atomic forces that control the protein stability are represented as a decomposable energy function, defined as the sum of terms involving at most two bodies (amino acids). The problem of design is then reduced to a purely discrete optimization problem: given a rigid backbone, one must find a combination of discrete sidechain natures and conformations (rotamers) that minimizes the energy. The resulting sequence and associated sidechain conformations define the Global Minimum Energy Conformation (GMEC) for the target backbone. A rotamer library for all 20 natural amino acids containing typically a few hundreds of conformations, the discrete search space becomes very quickly challenging to explore and the problem has been shown to be NP-hard [
2] (decision NP-complete). It has been naturally approached by stochastic optimization techniques such as Monte Carlo simulated annealing [
3], as in the commonly used Rosetta software [
4]. Such stochastic methods offer only asymptotic optimality guarantees. Another possible approach is to use provable optimization techniques that instead offer finite-time deterministic guarantees. In the last decade, Constraint programming-based algorithms for solving the weighted constraint satisfaction problem (WCSP) on cost function networks (CFN) have been proposed to tackle CPD instances [
5,
6]. These provable methods have shown unprecedented efficiency at optimizing decomposable force fields on genuine protein design instances [
6], leading to successfully characterized new proteins [
7]. Cost Function Networks are one example of a larger family of mathematical models that aim at representing and analyzing decomposable functions, called graphical models [
8,
9].
Even if provable methods definitely remove the possibility of failed optimization, they cannot fight the simplifying assumptions that appear in the CPD problem formulation. First, the optimized pairwise decomposed energetic criterion only approximates the actual molecule energy. Then, the rigid backbone and discrete-chain conformations ignore the actual continuous protein flexibility [
10]. Ultimately, even with a perfect energy function, an alternative backbone structure may well exist that gives the GMEC sequence an even better energy. This usually requires expensive post hoc filtering based on structure prediction (forward folding [
11]). Therefore, even with provable methods, a library of highly relevant mutants is usually produced for further experimental testing, with the hope that the probability of identifying a functional protein will be increased. Provable Branch-and-Bound-based WCSP algorithms have the native ability of enumerating solutions within a threshold of the optimal solution. Empirically, one can observe that the set of sequences that lie within this threshold grows very quickly in size with the energy threshold, but is mostly composed of sequences that are very similar to the optimal GMEC sequence. Ideally, a design library should be a set of low energy but also diverse solutions. With yeast-display capacity to simultaneously express and test thousands of proteins, libraries of diversified designs become increasingly important. The hope is that sequence diversity will improve the likelihood that a protein endowed of desired function is found. In this paper, we are therefore interested in algorithmic methods that can provide such a set of guaranteed diverse low-energy solutions and then to empirically check if enforcing diversity in a library while optimizing energy does improve the protein design process.
Because of their important applications, protein sequences can be subject to patents. Ideally, a newly designed sequence should satisfy a
minimum Hamming distance constraint to existing patented sequences. Specific design targets may need to escape known patterns such as e.g., antigenic sub-sequences that would be recognized by the Major Histocompatibility Complexes [
12]. This again raises the need to produce sequences satisfying minimum distance requirement to given sequences. Finally, CPD input structures often come from existing, experimentally resolved natural (or native) proteins. In this case, a native sequence exists that has usually acquired desirable properties following the billions of years of natural evolution and optimization it has been through. In many cases, to avoid disrupting the native protein properties (e.g., catalytic capacities), the protein designer may want to bound the maximum number of mutations introduced in the design. This raises the need to produce sequences satisfying
maximum distance requirement to given sequences.
In this paper, given an initial rigid backbone, we consider the problem of producing a set of diverse low-energy sequences that also provably satisfy a set of minimum and maximum distance requirements regarding given sequences. We observe that beyond structural biology and bioinformatics, this problem of producing a set of diverse solutions of a graphical model has been considered by many authors, either on discrete Boolean graphical models such as constraint networks (used in constraint programming), or on stochastic graphical models such as Markov random fields. Although this shows that the interest for the problem of diverse solutions generation goes well beyond computational protein design, we observe that these approaches either offer no guarantee, or are limited to specific tractable sub-classes of functions, such as submodular functions [
13]. Our approach instead relies on the reduction of distance requirements to discrete automaton-based constraints that can be decomposed and compressed into three-bodies (ternary) or two-bodies (binary) terms, using suitable dual and hidden encoding [
14,
15]. These constraints can then be processed natively by existing WCSP algorithms. Although our approach is general and generally applicable to the production of libraries of solutions of arbitrary discrete graphical models, its design is motivated by computation protein design. We therefore empirically evaluate this approach for the generation of a library of diverse sequences on a set of protein design problems. We first observe that this approach can produce provably diverse sets of solutions on computational protein design problems of realistic sizes in reasonable time. Going back to our initial aim, we also observe that sufficiently diverse libraries do offer better Native Sequence Recovery rates (NSR), a usual metric for protein design methods evaluation that measures how well it is able to reproduce nature’s optimization.
2. Computational Protein Design
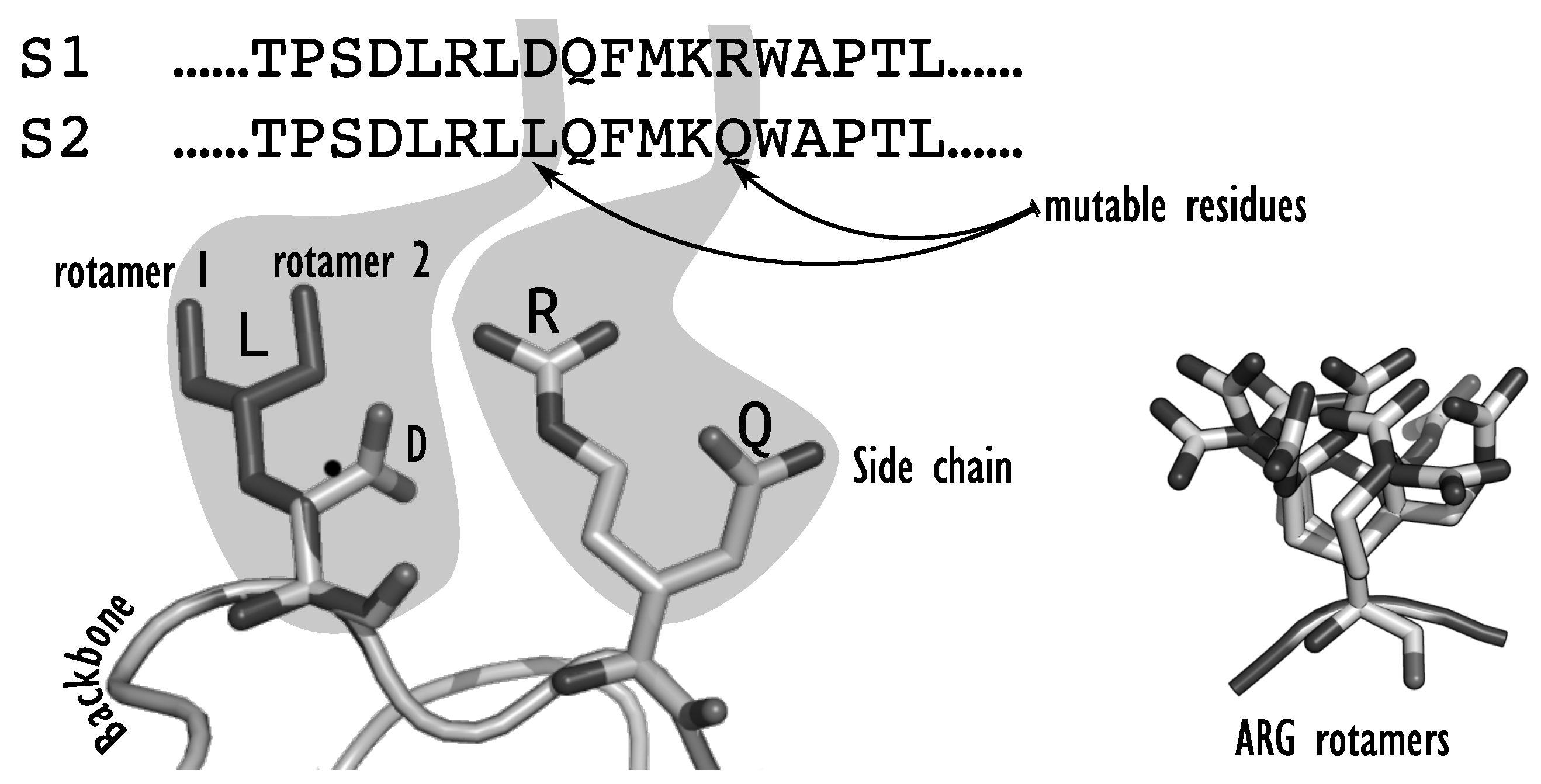
A CPD instance is first composed of an input target 3D structure, defined by the Cartesian coordinates of all the atoms in the protein backbone. The target protein structure can come from an existing protein backbone that was determined experimentally on an existing protein; or from a model that can be derived from existing 3D structures of similar proteins; or from a completely new structure, as it is done in
de novo design. Once a backbone has been chosen, the design space must be fixed. One may choose to do a full redesign, where the amino acids at all positions of the protein can be changed, or redesign only a subset of all positions, focusing on positions that are key for the targeted function. Overall, each position in the protein sequence will be set by the designer as either
fixed,
flexible, or
mutable. If the position is
fixed, the sidechain is fixed and rigid: the amino acid type and orientation are determined in the input target structure. If the position is
flexible, the residue type is fixed to the amino acid type of the input structure, but the sidechain might adopt several conformations in space. If the position is
mutable, all or a restricted set of amino acid types are allowed at the position, along with different conformations of their sidechain. Because of the supposed rigidity of the backbone, the sequence-conformation search space is therefore characterized by two decision levels: the sequence space, which corresponds to all the possible sequences
enabled by the mutable positions, and the conformation space, which must be searched to identify the best sidechain conformation at each flexible or mutable position. The possible conformations, or rotamers, for each amino acid are indexed in
rotamer libraries, such as the Dunbrack [
16] or the Penultimate libraries [
17]. Each library gathers a finite set of conformations, capturing a representative subset of all frequently adopted conformations in experimentally determined structures. In the Rosetta design software [
4] that relies on the Dunbrack library, a fully mutable position will be typically associated with around 400 possible rotamers. Designing a 10-residue peptide actually requires the exploration of
conformations.
Given a backbone structure and a rotamer library, the CPD problem seeks a stable and functional sequence-conformation. The protein functionality is assumed to result from its conformation and its stability is captured by an energy function
E that allows computation of the energy of any sequence-conformations on the target backbone. The task at hand is the minimization of this energy function. The optimal sequence is the best possible choice for the target rigid backbone. To model the energy, score functions are used. They can be physics-based, as the energetic force fields AMBER [
18] and CHARMM [
19]. They capture various atomic interactions including bond and torsion angle potentials, van der Waals potentials, electrostatic interactions, hydrogen bonds forces and entropic solvent effects. Score functions may also be enriched by “knowledge-based” energy terms that result from the statistical analysis of known protein structures. For instance, Rosetta
ref2015 and
beta_nov_16 score functions [
4,
20] also integrate rotamer log-probabilities of apparition in natural structures, as provided in the Dunbrack library, in a specific energy term. To be optimized, the energy function should be easy to compute while remaining as accurate as possible, to predict relevant sequences. To try to meet these requirements,
additive pairwise decomposable approximations of the energy have been chosen for protein design approaches [
6,
21]. The decomposable energy
E of a sequence-conformation
where
is the rotamer used at the position
i in the protein sequence can be written as:
The term
is a constant that captures interactions within the rigid backbone. For
, the unary (or one body) terms
capture the interactions between the rotamer
at position
i and the backbone, as well as interactions internal to the rotamer
. For
, the binary terms
capture the interactions between rotamers
and
at positions
i and
j respectively. These energy terms only vary with the rotamers, thanks to the rigid backbone assumption. Protein design dedicated software, such as OSPREY [
22] or Rosetta [
4], compute all the constant, unary, and binary energy terms, for each rotamer and combination of rotamers, for each position and pair of positions. While this requires quadratic time in the protein length in the worst case, distance cutoffs make these computations essentially linear in this length. Once computed, these values are stored in energy matrices. During the exploration of the sequence-conformation space, conformation energies can be efficiently computed by summing the relevant energy terms fetched from the energy matrix. CPD methods aim at finding the optimum conformation, called the
global minimum energy conformation (GMEC). Despite all these simplifications, this problem remains decision NP-complete [
23].
3. CPD as a Weighted Constraint Satisfaction Problem
A cost function network (CFN)
is a mathematical model that aims at representing functions of many discrete variables that decompose as a sum of simple functions (with small arity or concise representation). It is a member of a larger family of mathematical models called graphical models [
9] that all rely on multivariate function decomposability. A CFN is defined as a triple
where
is a set of variables,
is a set of finite domains, and
is a set of cost functions. Each variable
takes its values in the domain
. Each cost function
is a non-negative integer function that depends on the variables in
, called the scope of the function. Given a set of variables
, the set
denotes the Cartesian product of the domains of the variables in
. For a tuple
, with
, the tuple
denotes the projection of
over the variables of
. A cost function
maps tuples of
to integer costs in
. In this paper, we assume, as is usual in most graphical models, that the default representation of a cost function
is a multidimensional cost table (or tensor) that contains the cost of every possible assignment of the variables in its scope. This representation requires space that grows exponentially in the cost function arity
which explains why arity is often assumed to be at most two. The joint function is defined as the bounded sum of all cost functions in
:
where the bounded sum
is defined with
. The maximum cost
is used for forbidden partial assignments and represents a sort of infinite or unbearable cost. Cost functions that take their values in
represent hard constraints. The weighted constraint satisfaction problem consists of finding the assignment of all the variables in
with minimum cost:
Notice that when the maximum cost
, the cost function network becomes a constraint network [
24], where cost functions encode only constraints. Tuples that are assigned cost 0 are valid, i.e., they satisfy the constraint, and tuples that are assigned cost
are forbidden. The Constraint Satisfaction Problem then consists of finding a satisfying assignment, one that satisfies all the constraints.
Graphical models also encompass stochastic networks, such as discrete Markov random fields (MRF) and Bayesian Nets [
25]. A discrete
Markov Random Field is a graphical model
where
is a set of random variables,
is a set of finite domains, and
Φ is a set of potential functions. A potential function
maps
to
. The
joint potential function is defined as:
Instead of the sum used to combine functions in cost function networks, the product is used here. The normalization of the potential function P by the partition function defines the probability function of the MRF. The Maximum A Posteriori probability corresponds to the assignment with maximum probability (and maximum potential) .
MRF can also be expressed using additive energy functions , a logarithmic transformation of the potential functions. The potential function is then an exponential of the energy . Although potential functions are multiplied together, energies simply add up. Therefore, cost function networks are closely related to the energetic expression of Markov random fields. The main difference lies in the fact that CFNs deal with non-negative integers only, whereas MRF energies are real numbers. If , a CFN can be transformed into an MRF through an exponential transformation, and given a precision factor, an MRF can be transformed into a CFN through a log transform. Zero potentials are mapped to cost ⊤ and minimum energy means maximum probability.
Given a cost function network, the weighted constraint satisfaction problem can be answered by the exploration of a search tree in which nodes are CFNs induced by conditioning, i.e., domain reductions on the initial network. A Branch-and-Bound strategy is used to explore the search tree, which relies on a lower bound on the optimum assignment cost in the current subtree. If the lower bound is higher than the best joint cost found so far, it means that no better solution is to be found in the subtree, and it can be pruned. Each time a new solution is found, the maximum cost ⊤ is updated to the corresponding cost, as we are only interested in finding solutions with lower cost. Ordering strategies are crucial and can lead to huge improvement in the empirical computation time: decisions should be made that lead to low-cost solutions (and decrease the maximum cost ⊤) and that enable early pruning.
The efficiency of the branch-and-bound strategy relies on strength of the lower bound on solution costs. In CFNs, since cost functions are non-negative, the empty-scoped cost function
provides a naive lower bound on the optimum cost. To efficiently compute tight lower bounds, local reasoning strategies are used that aim at pushing as much cost as possible in the constant cost
, for better pruning. They are based on
equivalence preserving transformations that perform cost transfers between cost functions, while maintaining the solutions’ joint costs unchanged [
26], i.e., the joint cost function is preserved (these operations are called reparameterizations in MRFs). Specific sequences of equivalence preserving transformations can be applied to a CFN to improve the lower bound
until a specific target property is reached on the CFN. These properties, called
local consistencies, aim at creating zero costs, while improving
. These sequences of operations should converge to a fixpoint (closure). Various local consistency properties have been introduced, as node consistency, arc consistency, full directional arc consistency, existential directional arc consistency, or virtual arc consistency [
26]. For binary CFNs that involve functions of arity at most two, these properties can be enforced in polynomial time in the size of the network. Among these, Virtual arc consistency has been shown to solve the WCSP on networks composed of submodular functions [
27]. Note however that the complexity of local consistency enforcing remains exponential in the arity of the cost functions (as is the size of the corresponding tensors).
Sometimes, one may need to include specific functions with a large scope in the description of the joint function. Because of the exponential size of the tensor description, these global cost functions must be represented with dedicated concise descriptions and require dedicated algorithms for local consistency propagation. More formally, a global cost function, denoted GCF , is a family of cost functions, with scope and possible parameters . A global cost function is said to be tractable when its minimum can be computed in polynomial time.
The CFN formulation of computational protein design is straightforward [
5,
6,
28,
29] (see
Figure 2): given a CPD instance with pairwise decomposable energy function
, let
be a cost function network with variables
, with one variable
for each flexible or mutable position
i in the protein sequence, domains
where the domain
of the variable
consists of the available rotamers at position
i, i.e., the amino acid types and their sidechain conformations. The cost functions are the empty-scoped, unary and binary energy terms:
Energy terms, which are floating-point numbers, are transformed into non-negative integer values by being shifted by a constant, multiplied by a large precision factor, and having their residual decimal truncated.
In this encoding, variables represent rotamers, combining information on the nature and the geometry (conformation) of the sidechain. In practice, it is often useful to add extra variables that represent the sequence information alone. The CFN can be transformed into , that embeds sequence variables, as follows:
- Variables
We add sequence variables to the network: , where . The value of represents the amino acid type of the rotamer value of .
- Domains
where where the domain of is the set of available amino acid types at position i.
- Constraints
The new set of cost functions is made of the initial functions ; and sequence constraints that ensure that is the amino acid type of rotamer . Such a function just forbids (map to cost ⊤) pairs of values where the amino acid identity of rotamer r does not match a. All other pairs are mapped to cost 0.
Such sequence variables depend functionally on the rotamer variables. They do not modify the search space and merely offer a facility to define properties on the protein sequence, if needed, as will be the case here.
4. Diversity and Optimality
In this section, we assume that we have a CFN and we want to express diversity requirements on the values taken by variables in . In the case of CPD, these variables will be the previously introduced sequence variables.
4.1. Measuring Diversity
The task at hand is the production of a set of diverse and low-cost solutions of . First, we need a measure of diversity between pairs of solutions, and among sets of solutions.
The simplest diversity measure between pairs of solutions is the Hamming distance, defined hereafter. It counts the number of variables in that take different values in two solutions. In the CPD framework, sequence variables represent amino acid identities: the Hamming distance measures the number of introduced mutations (or substitutions), a very usual notion in protein engineering.
Definition 1. Given a set of variables and two assignments and , the Hamming distance
between and is defined as follows: The Hamming distance can be generalized to take into account dissimilarity scores between values. The resulting distance is a semi-metric, defined as a sum of variable-wise dissimilarities, as follows:
Definition 2. Given a zero-diagonal symmetric positive matrix D that defines value dissimilarities, and two assignments , the weighted-Hamming distance
between and is defined as: In computational biology, protein sequences are often compared using dedicated similarity matrices, such as the BLOSUM62 matrix [
30]. A protein similarity matrix
S can be transformed into a dissimilarity matrix
D such that
.
Definition 3. Given a set of solutions, we define:
its average dissimilarity:
its minimum dissimilarity:
We are aiming at producing a library of solutions that is guaranteed to be diverse. The average dissimilarity does not match this need: a set of solutions might have a satisfying average dissimilarity value, with several occurrences of the same assignment, and one or a few very dissimilar ones. Therefore, to guarantee diversity, the minimum dissimilarity will be the diversity measure used throughout this paper.
Therefore, producing a set of diverse solutions requires that all solution pairs have their distance above a given threshold. This can be encoded in cost functions representing constraints, taking their values in only:
Definition 4. Given two sets of variables of the same cardinality, a dissimilarity matrix D and a diversity threshold δ, we define the global cost function: Allowing both positive and negative threshold
allows the
Dist cost function to express either minimum or maximum diversity constraints. When
, the cost function expresses a minimum dissimilarity requirement between the assignments
and
:
If
, the cost function represents the fact that
and
must be similar, with a dissimilarity lower than the absolute value of
:
If needed, both maximum and minimum requirements can be imposed using two constraints.
4.2. Diversity Given Sequences of Interest
In the CPD context, minimum and maximum distance requirements with known sequences may be useful in practice in at least two situations.
A native functional sequence is known for the target backbone. The designer wants that less than mutations be introduced on some sensitive region of the native protein, to avoid disrupting a crucial protein property.
A patented sequence exists for the same function, and sequences with more than mutations are required for the designed sequence to be usable without requiring a license.
The distance here is the Hamming distance based on matrix H which equals 1 everywhere except for its zero diagonal. Using sequence variables, the following diversity constraint-encoding cost functions need to be added to the CFN model:
4.3. Sets of Diverse and Good Quality Solutions
The problem of producing a set of diverse and good quality solutions, i.e., such that all pairs of solutions satisfy the diversity constraint, and the solutions have minimum cost, can be expressed as follows:
Definition 5 (DiverseSet). Given a dissimilarity matrix D, an integer M and a dissimilarity threshold δ, the problem DiverseSet consists of producing a set of M solutions of such that:
- Diversity
For all , , i.e., .
- Quality
The solutions have minimum cost, i.e., is minimum.
For a CFN with n variables, solving DiverseSet requires simultaneously deciding the value of variables. It can be solved by making M copies of with variable sets to and adding constraints for all . If the upper bound ⊤ is finite, all its occurrences must be replaced by . Although very elegant, this approach yields a CFN instance where the number of variables is multiplied by the number of wanted solutions. The WCSP and CPD problems being NP-hard, one can expect that the resulting model will be quickly challenging to solve. We empirically confirmed this on very tiny instances: we tested it on problems with 20 variables and maximum domain size bounded by six, asking for just for four 15-diverse solutions. This elegant approach took more than 23 h to produce 4 solutions. We therefore decided to solve a relaxed version of DiverseSet: an iterative algorithm provides a greedy approximation of the problem that preserves most of the required guarantees. Using this approach, the problem of producing four 15-diverse solutions of the above tiny problem takes just 0.28 s.
Definition 6 (DiverseSeq Given a dissimilarity matrix D, an integer M and a dissimilarity threshold δ, the set of assignments of DiverseSeq is built recursively:
The first solution is the optimum of
When solutions are computed, is such that:
for all and has minimum cost.
That is, is the minimum cost solution, among assignments that are at distance at least δ from all the previously computed solutions.
The set of solutions DiverseSeq needs to optimally assign n variables M times, instead of the variables. Given the NP-hardness of the WCSP, solving DiverseSeq may be exponentially faster than DiverseSet while still providing guarantees that distance constraints are satisfied together with a weakened form of optimality, conditional on the solutions found in previous iterations. The solution set is still guaranteed to contain the GMEC (the first solution produced).
5. Relation with Existing Work
In the case of Boolean functions (
), the work of [
31] considers the optimization of the solution set cardinality
M or the diversity threshold
using average or minimum dissimilarity. The authors prove that enforcing arc consistency on a constraint requiring sufficient average dissimilarity
is polynomial but NP-complete for minimum dissimilarity
. They evaluate an algorithm for incremental production of a set maximizing
. The papers [
32,
33] later addressed the same problems using global constraints and knowledge compilation techniques. Being purely Boolean, these approaches cannot directly capture cost (or energy) which is crucial for CPD. More recently, ref. [
34] proposed a Constraint Optimization Problem approach to provide diverse high-quality solutions. Their approach however trades diversity for quality while diversity is a requirement in our case.
The idea of producing diverse solutions has also been explored in the more closely related area of discrete stochastic graphical models (such as Markov random fields). In the paper of Batra et al. [
35], the Lagrangian relaxation of minimum dissimilarity constraints is shown to add only unary cost functions to the model. This approach can be adapted to cost function networks, but a non-zero duality gap remains and ultimately, no guarantee can be offered. This work was extended in [
36] using higher-order functions to
approximately optimize a trade-off between diversity and quality. More recently, ref. [
37] addressed the
DiverseSet problem, but using optimization techniques that either provide no guarantee or are restricted to tractable variants of the WCSP problem, defined by submodular functions [
13].
In the end, we observe that none of these approaches simultaneously provides guarantees on quality and diversity. Closest to our target, ref. [
38] considered the problem of incrementally producing the set of the best
M-modes of the joint distribution
.
Definition 7 ([
39]).
A solution is said to be a δ-mode iff there exists no better solution than in the Hamming ball of radius δ centered in (implying that is a local minimum). In [
38,
39,
40,
41], an exact dynamic programming algorithm, combined with an A* heuristic search and tree-decomposition was proposed to exactly solve this problem with the Hamming distance. This algorithm relies however on NP-complete lower bounds and is restricted to a fixed variable order, a restriction that is known to often drastically hamper solving efficiency. It however provides a diversity guarantee: indeed, a
-mode will always be
strictly more than
away from another one and will be produced by greedily solving
DiverseSeq.
Theorem 1. Given a cost function network , a diversity threshold δ, and the Hamming dissimilarity matrix, for any δ-mode , there exists a value such that the solution of DiverseSeq contains .
Proof. If a -mode is not in the solution of DiverseSeq , this must be because it is forbidden by a constraint. Consider the iteration i which forbids for the first time: a solution with a cost lower than the cost of was produced (else would have been produced instead) but this solution is strictly less than away from (since is forbidden). However, this contradicts the fact that is a -mode. □
For a sufficiently large M, the sequence of DiverseSeq solutions will therefore contain all -modes and possibly some extra solutions. Interestingly, it is not difficult to separate modes from non-modes.
Theorem 2. Any assignment of a CFN is a δ-mode iff it is an optimal solution of the CFN
For bounded δ, this problem is in P.
Proof. The function restricts to be within of . If is an optimal solution of then there is no better assignment than in the -radius Hamming ball and is a -mode.
For bounded , a CFN with n variables and at most d values in each domain, there is tuples within the Hamming ball, because from , we can pick any variable (n choices) and change its value (d choices), times. Therefore, the problem of checking if is optimal is in P.
□
6. Representing the Diversity Constraint
The key to guaranteeing quality and diversity of solutions in a cost function network is the dissimilarity cost function . Given a complete assignment , a dissimilarity D and a threshold , we need to concisely encode the global diversity constraint .
6.1. Using Automata
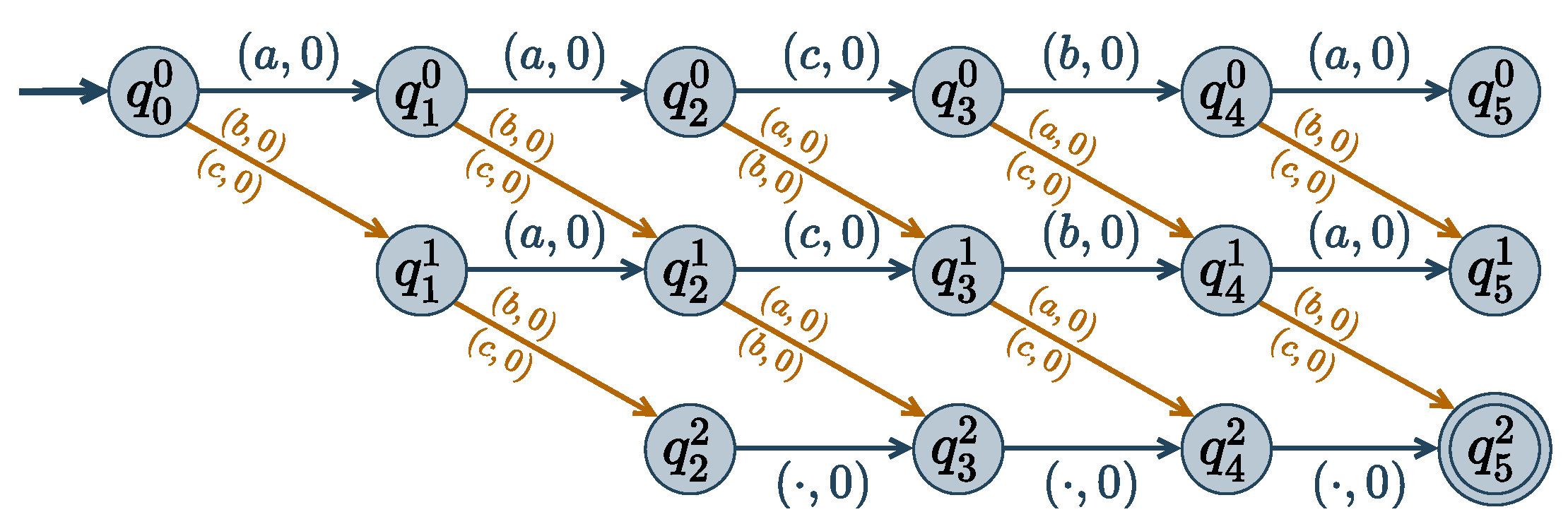
Given a solution , a dissimilarity matrix D and a diversity threshold , the cost function needs to be added to the cost function network. Please note that the function may involve all the network variables: it is a global cost function and its representation as one huge, exponential size tensor is not possible.
To encode this function concisely, we exploit the fact that the set of authorized tuples defines a regular language that can be encoded into a finite state automaton and then decomposed in ternary functions [
42,
43]. Here, we use a weighted automaton to define the weighted regular language of all tuples with their associated cost. A weighted automaton
encoding
can be defined as follows:
The alphabet is the set of possible values, i.e., the union of the variable domains
The set of states
gathers
states denoted
:
that represent the fact that the first
i values of
have distance
d to the first
i values of
. For
, automaton state
represents the fact that the first
i values of
have distance
to the first
i values of
.
In the initial state, no value of
has been read, and the dissimilarity is 0:
The assignment is accepted if it has dissimilarity from
higher than the threshold
, hence the accepting state:
For every value r of , the transition function defines a 0-cost transition from to . All other transitions have infinite cost ⊤.
This weighted automaton contains
finite cost transitions, were
d is the maximum domain size. An assignment
of
is accepted if and only if
; and the automaton represents the
cost function. An example of a
Dist encoding automaton is given in
Figure 3.
6.2. Exploiting Automaton Function Decomposition
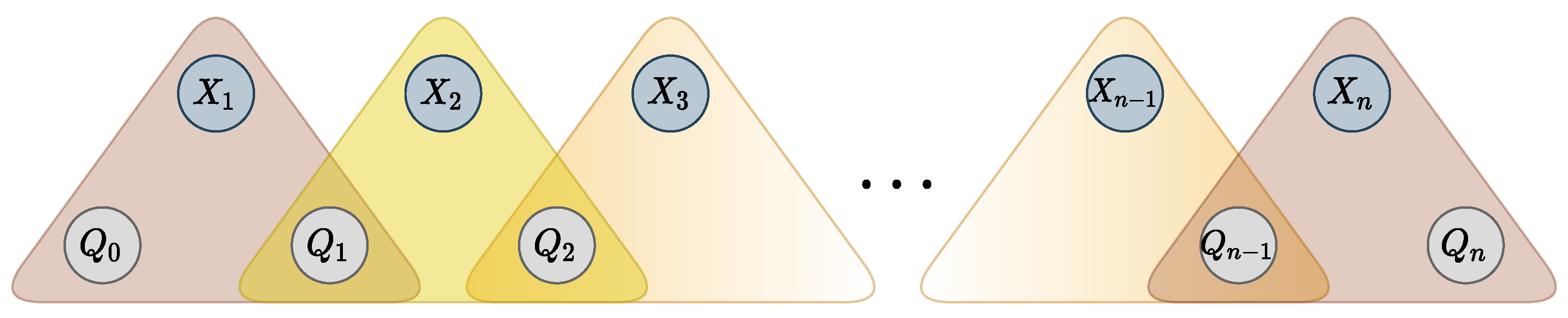
It is known that the
WRegular cost function, encoding automaton
, can be decomposed into a sequence of ternary cost functions [
43]. The decomposition is achieved by adding
state variables
, and
n ternary cost functions
, such that
if and only if there exists a transition from
to
in
labeled with value
and cost
c. Variable
is restricted to the starting states and variable
to the accepting states. Additional variables and ternary functions are represented in
Figure 4. The resulting set of ternary functions is logically equivalent to the original global constraint.
The
Dist function satisfies however several properties that can be exploited to further improve its space and time efficiency. One can first notice that the set of forbidden solutions does not depend on the order of the variables (the distance measure is the sum of independent variable-wise dissimilarities). Therefore, the order of the variables in the automaton can be chosen freely. We can use the DAC-ordering [
43]. This order is known to preserve the strength of the lower bounds produced by CFN local consistencies when applied to the decomposition (instead of the initial full
Dist function, with its potentially exponential size table).
Then, in the case of the Dist cost function, each state variable has values (the number of states in the automaton) and each ternary function cost table describes costs of tuples, where d is the domain size. To speed up the resolution through better soft local consistency enforcing, we exploit the properties of Dist and the dissimilarity matrix D.
6.3. Compressing the Encoding
The encoding of a Dist cost function in a sequence of n ternary functions, described in cost tables of size can be reduced along several lines.
First, for
Dist, we know that states
can only be reached after
i transitions, i.e., the reachable states of variable
are the states in the
i-th column in the
Dist automaton (see
Figure 3). The domains of the variables
can be reduced to the
states
:
Furthermore, our semi-metrics are defined by a non-decreasing sum of non-negative elements of D. Therefore, any state can reach the accepting state if and only if the maximum dissimilarity that can be achieved from variable i to variable n is larger than the remaining diversity to reach . All such maximum dissimilarities can be pre-computed in one pass over all variables in as follows:
In the Hamming case, the distance can increase by 1 at most, i.e., , therefore .
A symmetric argument holds for the starting state . These simplifications reduce ternary cost tables to .
For a given dissimilarity matrix D, let denote the number of distinct values that appear in D. If variables have domains of maximum size d and ignoring the useless 0 matrix, we know that . However, distance matrices are usually more structured. For example, the BLOSUM62 similarity matrix leads to levels.
In the Hamming case, there are
dissimilarity levels. This means that a state
can only reach states
or
. This sparsity of the transition matrix can be exploited, provided it is made visible. This can be achieved using extended variants of the
dual and
encoding of constraint networks [
14,
15]. These transformations, detailed hereafter, are known to preserve the set of solutions and their costs.
In constraint networks, the dual representation of a constraint network is a new network with:
One variable
per constraint
:
Domain
of variable
is the set of tuples
that satisfy the constraint
:
For each pair of constraints
with overlapping scopes
, there is a constraint
that ensures that tuples assigned to
and
are compatible, i.e., they have the same values on the overlapping variables:
where
We apply this transformation to the reduced
functions (see
Figure 5). The dual variable of
is a variable
that contains all pairs
such that there is a transition from
q to
in
. For the Hamming case, the variable
has at most
values. It is connected to
by a pairwise function:
where
is the weighted transition function of the automaton
.
In this new dual representation, for every pair of consecutive dual variables
and
, we add a function on these two variables to ensure that the arriving state of
is the starting state of
:
In the worst case, this function has size ( in the Hamming case). Only n extra variables are required.
The hidden representation of a constraint network is a network with:
All the variables in
and the variables
from the dual network (and associated domains):
For any dual variable
, and each
, the set of constraints
contains a function involving
and
:
As before, this transformation is applied to the reduced
functions only (see
Figure 5). In this new hidden representation, we keep variables
and create two pairwise functions involving each
and respectively
and
:
These functions ensure that the state value of is consistent with the arriving state of the transition represented in and the starting state of . In the worst case, these functions have size ( in the Hamming case).
The dedicated dual and hidden representations require the description of and tuples respectively (it is in the Hamming case), instead of the tuples in .
8. Results
We implemented the iterative approach described above in its direct (ternary) decomposition, hidden and dual representations in the CFN open-source solver toulbar2 and experimented with it on various CFNs representing real Bayesian Networks [
44]. All three decompositions offered comparable efficiency but empirically, as expected, the dual encoding was almost systematically more efficient. It is now the default for diversity encoding in toulbar2. All toulbar2 preprocessing algorithms dedicated to exact optimization that do not preserve suboptimal solutions were deactivated at the root node (variable elimination, dead-end elimination, variable merging). We chose to enforce strong virtual arc consistency (flag
-A in toulbar2). The computational cost of VAC, although polynomial, is high, but amortized over the
M resolutions. During tree search, the default existential directional arc consistency (EDAC) was used. All experiments were performed on one core of a Xeon Gold 6140 CPU at 2.30 GHz. Wall-clock times could be further reduced using a parallel implementation of the underlying Hybrid Best-First search engine [
45], currently under development in
toulbar2.
Following our main motivation for protein design, we extracted two sets of prepared protein backbones for full redesigns from the benchmark sets built by [
46,
47] with the aim of checking if, as expected, diverse libraries can improve the overall design process. In the benchmark of monomeric proteins of less than 100 residues, with an X-ray resolved structure below 2 Å, with no missing or nonstandard residues and no ligand from [
46], we selected the 20 proteins that had required the least CPU-time to solve, as indicated in the Excel sheet provided in the supplementary information of paper [
46]. The harder instances from [
47] correspond to proteins with diverse secondary structure compositions and fold classes. We selected the 17 instances that required less than 24 h of CPU-time for the full redesigned GMEC to be computed by toulbar2. These instances are listed in
Table 1.
Full redesign was performed on each protein structure, and CFN instances were generated using the Dunbrack library [
16] and Rosetta
ref2015 score function [
48]. Alternate rotamer libraries and score functions can be used if required as the algorithms presented here are not specialized for Rosetta (and not even for CPD, see [
44]). The resulting networks have from 44 to 87 rotamer variables, and maximum domain sizes range from 294 to 446 rotamers. The number of variables is doubled after sequence variables are added.
Predictive bounding contribution
solutions with diversity threshold
for each problem from [
46] were generated, with and without predictive bounding. The worst CPU-time spent on the resolution without predictive bounding was 32 min. It was reduced to 17 min with predictive bounding. The average computation time was 201s per problem. This shows that predictive bounding provides a simple and efficient boost and that real CPD instances can be solved in a reasonable time, even when relatively large diversity requirements are used.
Diversity improves prediction quality
For all instances, sets of solutions were generated with diversity threshold ranging from 1 to 15. For , the set of solutions produced is just the set of the 10 best (minimum energy) sequences.
These CPD problems use real protein backbones, determined experimentally. A native sequence exists for these backbones, therefore it is possible to measure the improvements diversity brings in terms of recovering native sequences, known to be folded and functional. Two measures are often used to assess computational protein design methods. The Native Sequence Recovery (NSR) is the percentage of amino acid residues in the designed protein which are identical to the amino acid residues in the native sequence that folds on the target backbone. The NSR can be enhanced by taking into account
similarity scores between the amino acid types. Such scores are provided by similarity matrices, such as BLOSUM62 [
30]. The
Native Sequence Similarity Recovery (NSSR) is the fraction of positions where the designed and native sequences have a positive similarity score. NSR and NSSR measure how much the redesigned protein resembles the natural in terms of sequence. Although often used, these measures have their own limitations: while protein design targets maximal stability, natural protein only require sufficient marginal stability. In the end, they therefore provide a useful but imperfect proxy for computation protein design evaluation: a perfect (100%) recovery would not necessarily indicate the best algorithm (also because the approximate energy function plays a major role here).
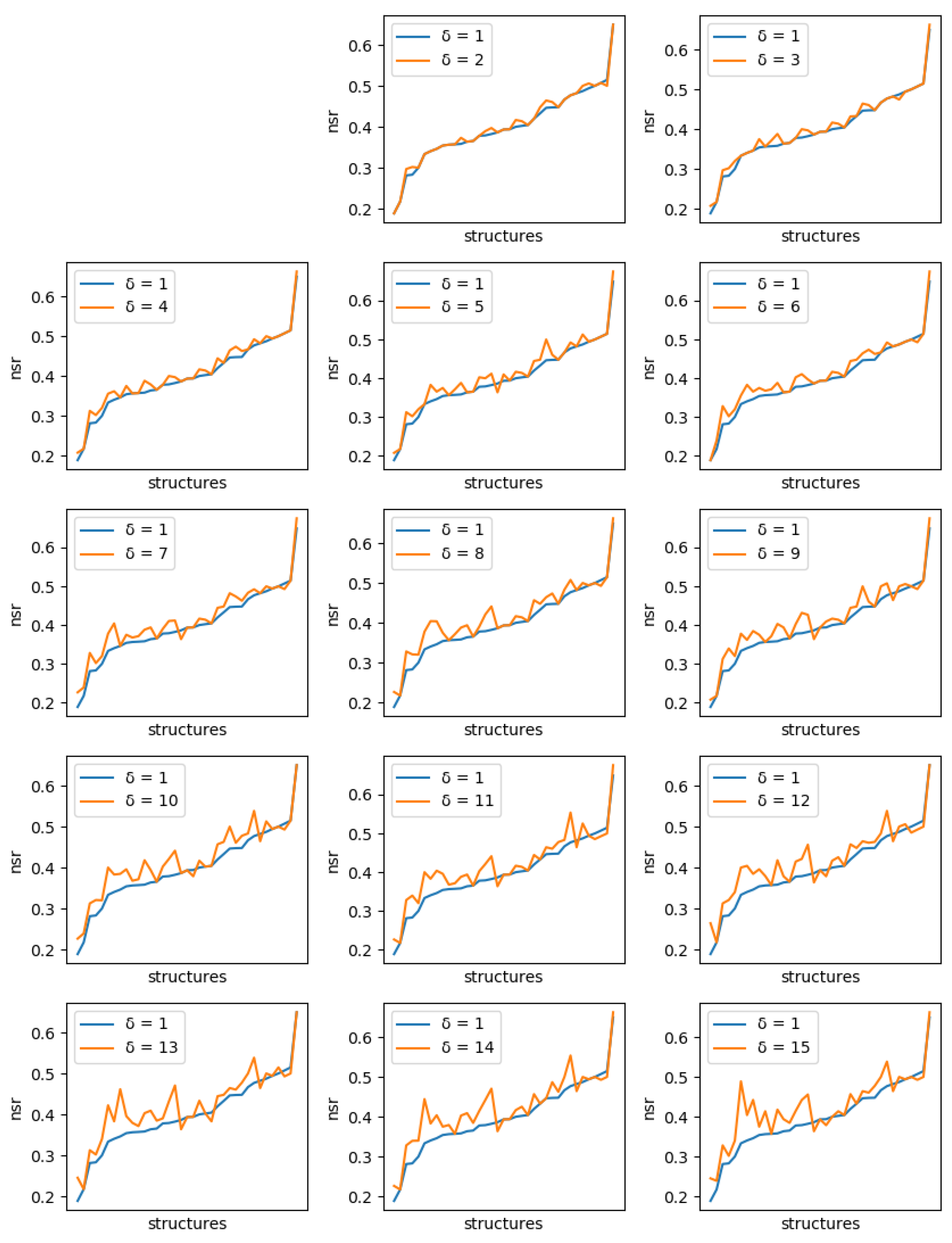
If solution diversity helps, the maximum NSR/NSSR over the 10 sequences should improve when is large compared to when , as long as the costs remain close to the optimum. A solution cost too far from the optimum, which could be generated because of a diversity threshold set too high, would mean a poor quality of the solution. Even with , the maximum difference in energy we observed with the global minimum energy never exceeded kcal/mol (with an average of 2.1 kcal/mol).
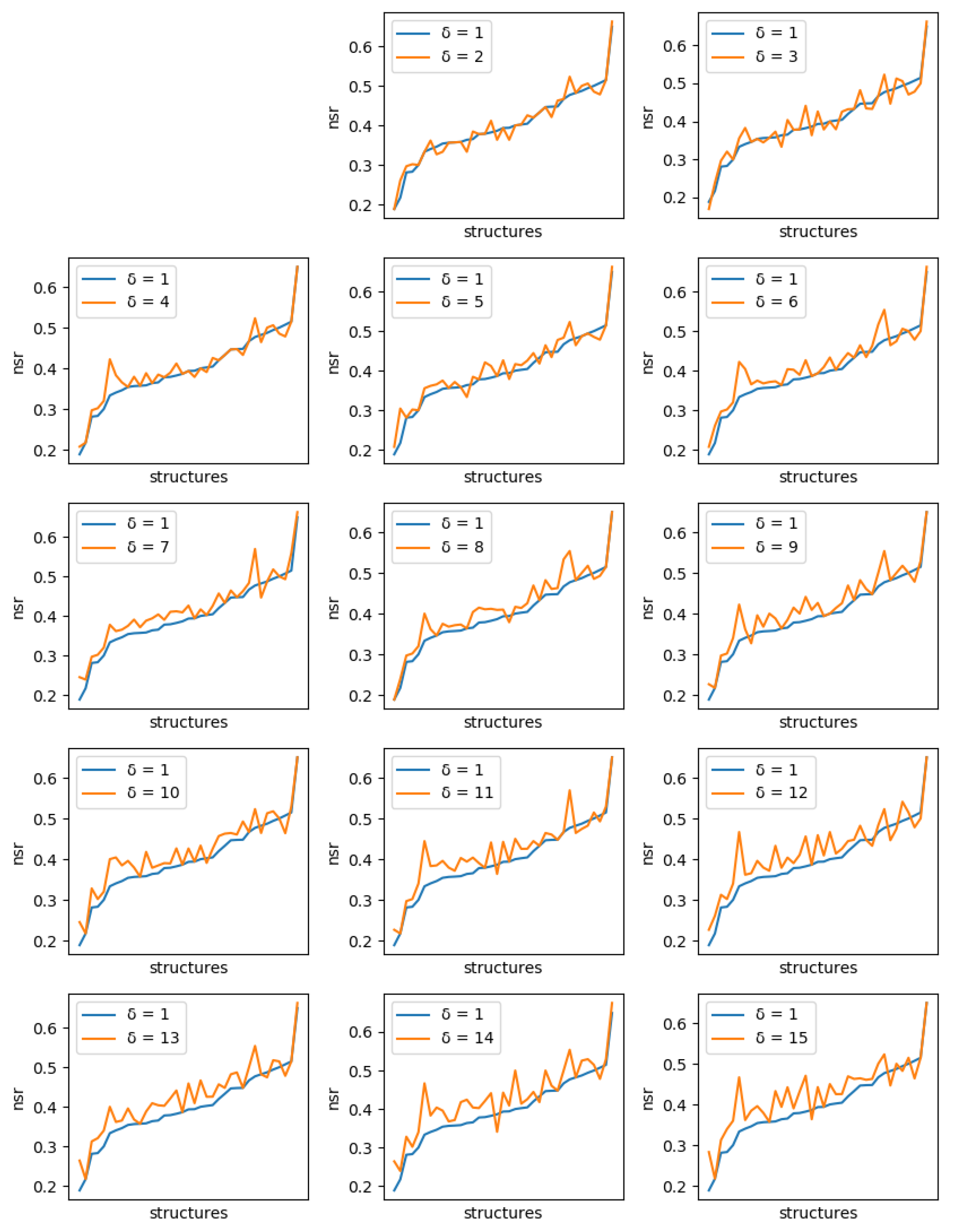
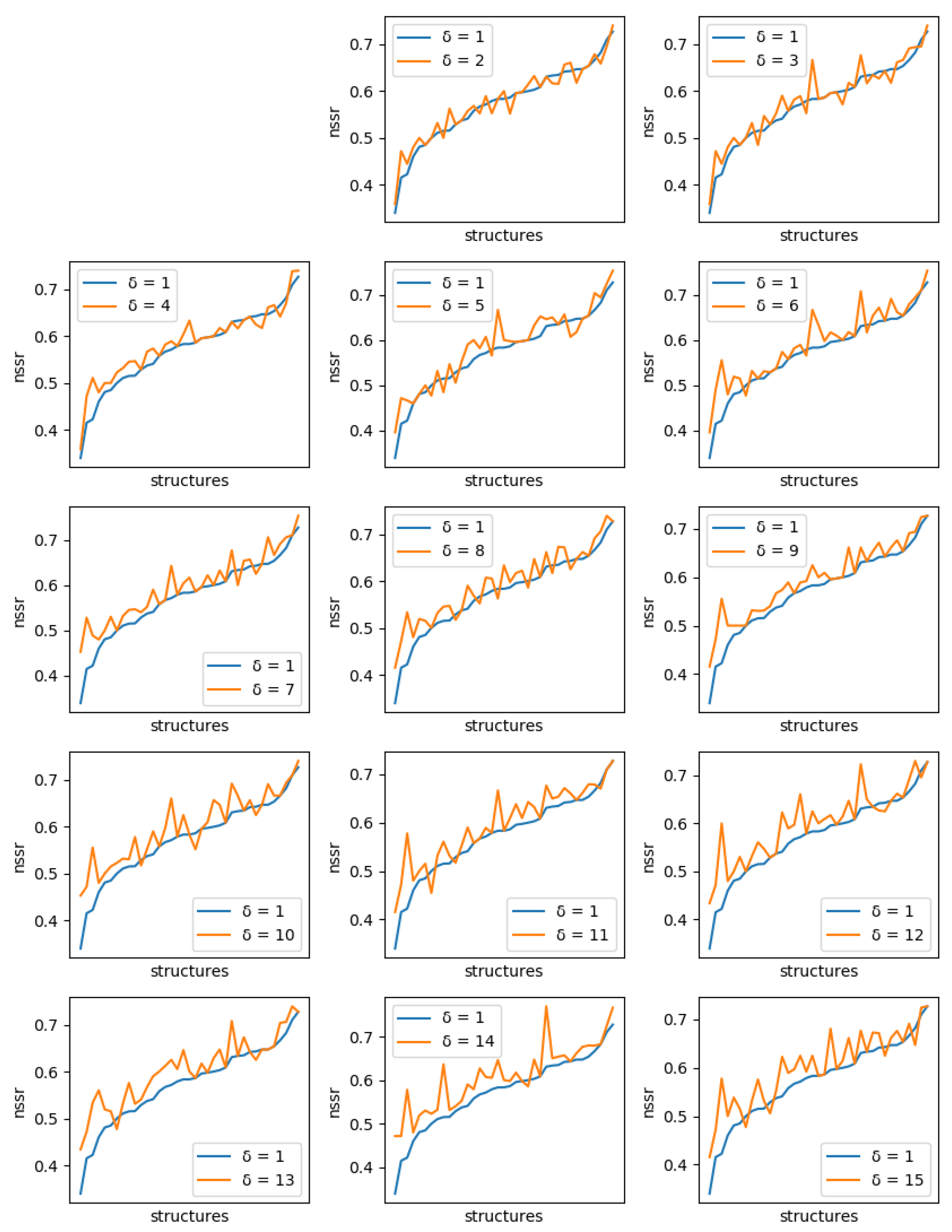
For each protein, and each diversity threshold
, we compared the best NSR (resp. NSSR) that could be obtained with
to the best obtained with diversity threshold 1, i.e., the simple enumeration of the 10 best sequences. Results are plotted in
Figure 6 (resp.
Figure 7). Although somewhat noisy, they show a clear general increase in the best NSR (resp. NSSR) when diverse sequences are produced, even with small
. To validate the statistical significance of the diversity improvement of sequence quality,
p-values for a unilateral Wilcoxon signed-rank test comparing the sample of best NSR (resp. NSSR) for each
with
were computed. They are shown in
Table 2 and confirm the improvement brought by increasingly diverse libraries.
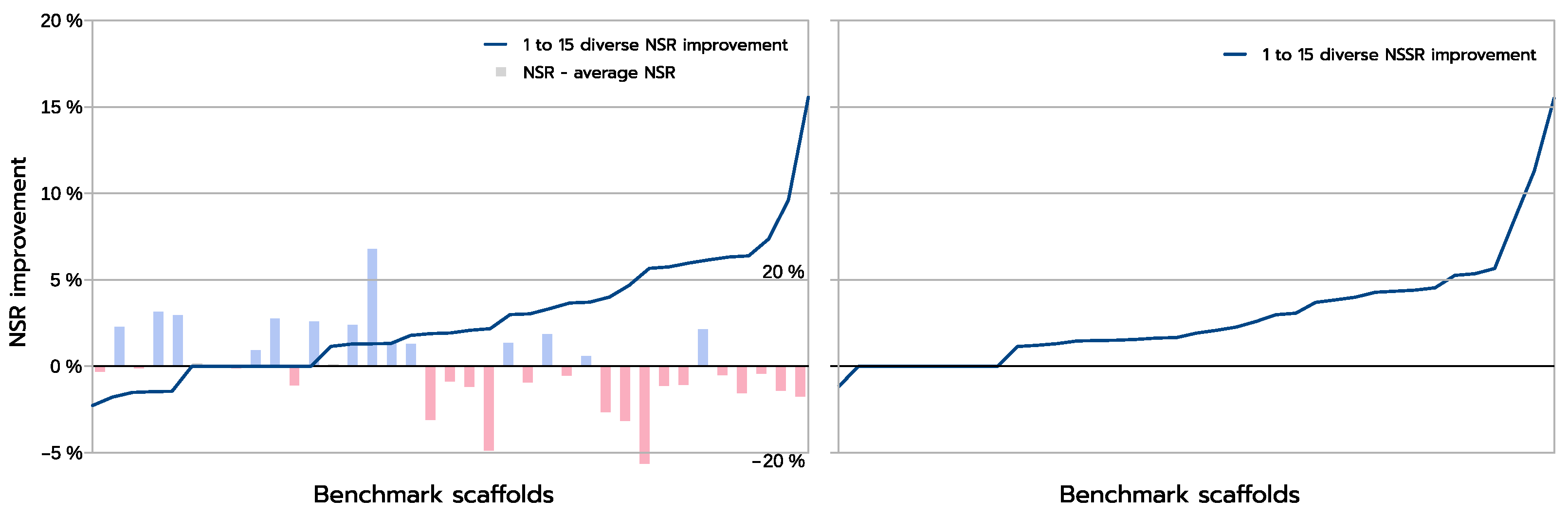
The improvements are more clearly visible when one compares the absolute improvement in NSR (and NSSR) obtained when one compares the best sequences produced inside a library using a guaranteed diversity of 15 versus just 1, as illustrated in
Figure 8. On most backbones (X-axis), the increased diversity yields a clear improvement in the NSR (Y-axis), with the largest absolute improvement exceeding 15% in NSR. For a small fraction of backbones, there is absolutely no improvement. These are backbones for which the GMEC actually provides the best NSR in both the 1-diverse and the 15-diverse cases. Then an even smaller fraction of backbones shows an actual decrease in NSR: one close to GMEC solution did better than any of the 15-diverse sequences. The degradation here is very limited and likely corresponds to substitutions to similar amino acids. This is confirmed by the NSSR curve that takes into account amino acid properties through the underlying BLOSUM62 matrix used. Here, only one case shows a degradation in NSSR.
Diversity also has the advantage that it is more likely to provide improved sequences when the predicted 1-diverse sequences are poor. Indeed, with an initial sequence with NSR equal to
r, the introduction of a random mutation will move us away from the native in
r% of cases (we mutate a correct amino acid) and otherwise (we mutate a wrong amino acid) leave us with a wrong amino acid again (in
cases, leaving the NSR unchanged) or bring us closer to the native sequence with
probability. On average, a mutation should therefore decrease the number of correct positions with probability
, which increases with
r and is positive as soon as the sequence has NSR higher than 5% (
). Our results confirm this trend, as shown in the NSR figure on the left of
Figure 8: among the ten backbones with the highest improvement in NSR, nine had a 1-diverse NSR below the average 1-diverse NSR. Conversely, only 50% of the ten less improved backbones had a below-average 1-diverse NSR. Although these improvements underline the approximate nature of the energy function, showing that it is often worth to explore the sequence space beyond the GMEC, they also confirm that energy, on average, does guide us towards native sequences: instead of degrading NSR as soon as
, energy optimization pushes the introduced mutations to improve NSR in most cases, even with 15 introduced mutations and initial NSRs ranging from 20 to 60%.
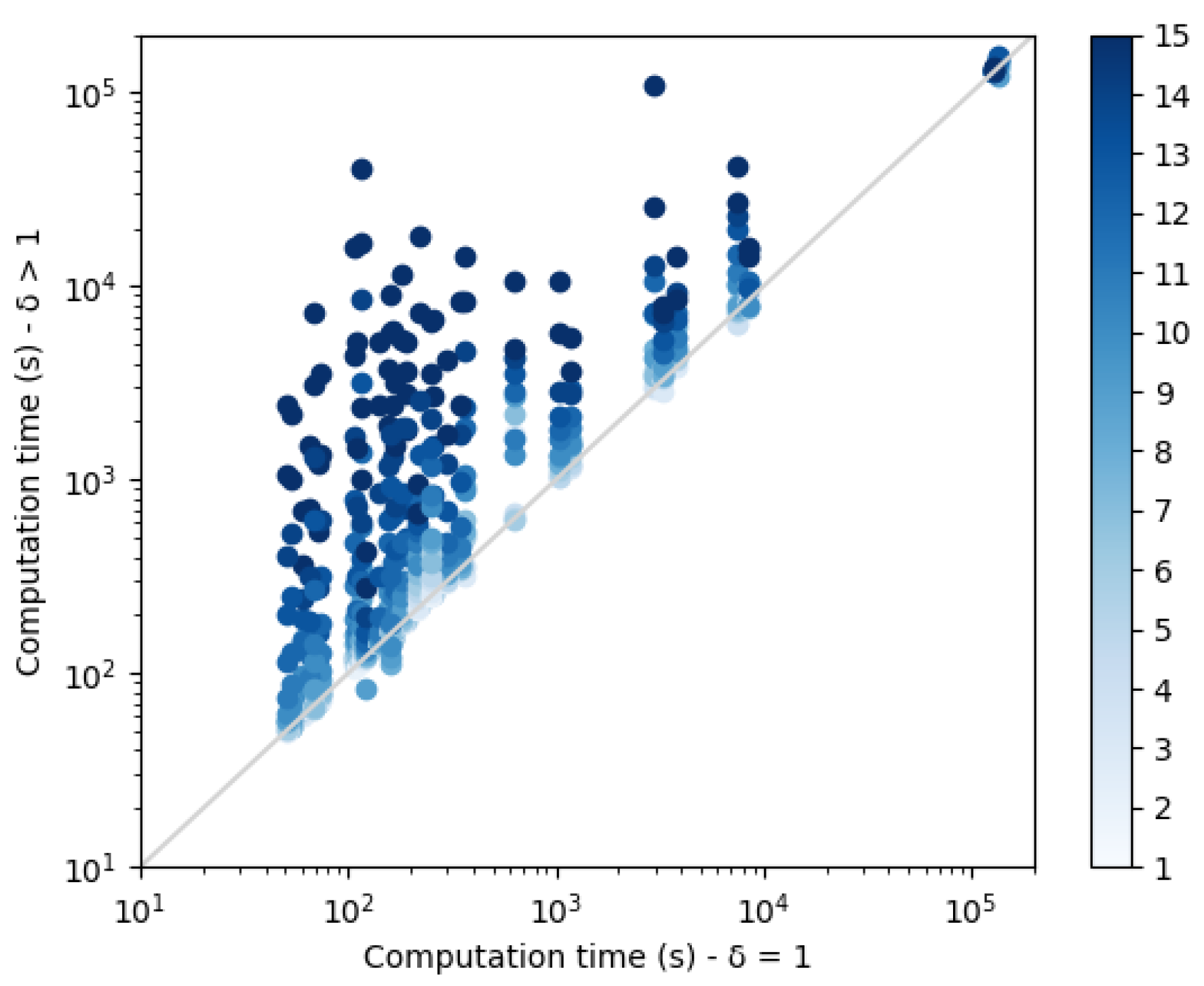
Each dissimilarity constraint adds
n extra variables to the network (with the dual representation). These variable domain sizes increase with the diversity threshold
and contribute to the construction of increasingly large CFN instances that need to be solved. Computation times are plotted in
Figure 9. As expected, a threshold increase leads to an exponential increase in the computation time. The small set of points on the top right corner of the plot correspond to the protein structure 3FYM. This protein, with 70 amino acids, is not the largest in our benchmark set, a reminder that size is not necessarily the best predictor of empirical computational cost in NP-hard problem solving. On this backbone, for high diversity thresholds, the 24 h computation time limit was reached and less than 10 sequences were produced.
Given that the optimized function is an approximation of the real intractable energy, solving the problem to optimality might seem exaggerated. The requirement for optimality that we have used in previous experiments can be trivially relaxed to a relative or absolute approximation guarantee using artificially tightened pruning rules as originally proposed in [
49] in the Weighted-A* algorithm. This pruning mechanism is already implemented in the toulbar2 solver (using the
-rgap and
-agap flags respectively).
For diversity threshold , we generated sets of 10 suboptimal diverse sequences that satisfy the diversity constraints, but allowing for a 3 kcal/mol energy gap to the optimum. Our optimizations are still provable, but the optimality guarantee is now reduced to a bounded sub-optimality guarantee. Empirically, the maximum energy degradation we observed with the global minimum energy over the 10 diverse sequences produced never exceeded 5.65 kcal/mol (with an average energy difference of 3.86 kcal/mol). This is only slightly more than the 4.3 kcal/mol worse degradation (average 2.1 kcal/mol) of the resolution, when exact optimum are used.
We compared these samples of suboptimal sequences to the set of 10 exact best sequences. Results for NSR and NSSR are shown in
Figure 10 and
Figure 11 respectively, and corresponding
p-values are displayed in
Table 2 (unilateral Wilcoxon signed-rank test). With dissimilarity threshold
, it is clear that the set of diverse suboptimal sequences have better quality than the 10 best enumerated sequences. Moreover, as shown in
Figure 12, for harder instances, suboptimal diverse resolution becomes faster than exact enumeration.
Therefore, when predicting a library of sequences, if the instance is hard, it seems empirically wise to generate suboptimal diverse sequences, instead of enumerating minimum energy sequences, without diversity. Doing so, there is a higher chance of predicting better sequences “in practice” faster.
9. Conclusions
Producing a library of diverse solutions is a very usual requirement when an approximate or learned model is used for optimal decoding. In this paper, we show that with an incremental provable CFN approach that directly tackles a series of decision NP-complete problems, using diversity constraints represented as weighted automata that are densely encoded in a dedicated dual encoding together with predictive bounding, it is possible to produce sequences of solutions that satisfy guarantees on diversity on realistic full redesign computational protein design instances. This guarantee is obtained on dense problems, with non-permutated-submodular functions while also guaranteeing that each new solution produced is the best given the previously identified solutions.
We also showed that the stream of diverse solutions that our algorithm produces can be filtered and each solution efficiently identified as being a -mode or not. -mode represent local minima, each defining its own basin in the protein sequence energy landscape. Beyond their direct use for design, the guaranteed diversity provided by our algorithm could also be of interest to perform more systematic analyses of such energy landscapes.
On real protein design problems, we observe that small and large diversity requirements do improve the quality of sequence libraries when native proteins are fully redesigned. Moreover, large diversity requirements on suboptimal sequences also improve the quality of sequence libraries, compared to a simple enumeration of the minimum energy sequences. In the context of optimizing an approximate or learned function, the requirement for an optimal cost solution may be considered to be exaggerated. Our guaranteed suboptimal resolution is useful, given that even computationally expensive approaches with asymptotic convergence results such as simulated annealing may fail with unbounded error [
46].
Two directions could extend this work. Beyond the language of permutated submodular functions, the other important tractable class of CFN is the class of CFN with a graph of bounded tree-width. This parameter is exploited in several protein packing [
50] and design [
51] algorithms and is also exploited in dedicated branch-and-bound algorithms, also implemented in toulbar2 [
45,
52]. These tree-search algorithms can trade space for time and are empirically usable on problems with a tree-width that is too large to make pure dynamic programming applicable, mostly because of its space-complexity (in
where
d is the domain size and
w is the width of the tree-decomposition used). On such problems, it would be desirable to show that the decomposed ternary or binary functions we use for encoding
can be arranged in such a way that tree-width can be preserved or more likely, not exaggeratedly increased. This would enable the efficient production of diverse solutions for otherwise unsolved structured instances.
Another direction would be to identify a formulation of the Dist (and possibly ) constraints that would provide better pruning or avoid the introduction of extra variables that often disturb dynamic variable ordering heuristics. One possibility would be to encode these using linear (knapsack) constraints for which dedicated propagators would need to be developed.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}