
Efficient Construction of the Equation Automaton


1
Department of Computer Science, Faculty of Sciences, Mohammed V University in Rabat, Rabat 10000, Morocco
2
EA 4491-LISIC-Lab., Laboratoire d’Informatique Signal et Image de la Côte d’Opale Université Littoral Côte d’Opale, 62100 Calais, France
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Algorithms 2021, 14(8), 238; https://0-doi-org.brum.beds.ac.uk/10.3390/a14080238
Submission received: 27 May 2021
/
Revised: 27 July 2021
/
Accepted: 6 August 2021
/
Published: 11 August 2021
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:This paper describes a fast algorithm for constructing directly the equation automaton from the well-known Thompson automaton associated with a regular expression. Allauzen and Mohri have presented a unified construction of small automata and gave a construction of the equation automaton with time and space complexity in , where m denotes the number of Thompson automaton transitions. It is based on two classical automata operations, namely epsilon-removal and Hopcroft’s algorithm for deterministic Finite Automata (DFA) minimization. Using the notion of c-continuation, Ziadi et al. presented a fast computation of the equation automaton in time complexity. In this paper, we design an output-sensitive algorithm combining advantages of the previous algorithms and show that its computational complexity can be reduced to , where denotes the number of states of the equation automaton, by an epsilon-removal and Bubenzer minimization algorithm of an Acyclic Deterministic Finite Automata (ADFA).
1. Introduction
The equation automaton (also known as derived terms automaton or Antimirov automaton) was first introduced in Mirkin’s paper [1]. In [2], Antimirov introduced the notion of partial derivative of a regular expression, that lead to another definition and construction of the equation automaton. It is an -free NFA which has in general smaller number of states and transitions than the well-known position automaton [3,4,5]. The complexity of the original construction algorithm of [2], which is based on the computation of the set of partial derivatives of the expression, is in , where n denotes the size of the regular expression. In 2001, Champarnaud and Ziadi [6] introduced the notion of canonical derivatives and constructed a new automaton called the c-continuation automaton. They also proved that this automaton is isomorphic to the position automaton and that the equation automaton is its quotient for some equivalence relation.
The notion of c-derivative has been introduced in [6] to derive the equation automaton from the position automaton via the c-continuation automaton. A unique regular expression over indexed and ordered letters, called c-continuation, is assigned to each state of the position automaton. The resulting automaton is called the c-continuation automaton [6]. After that, one can define the equivalence relation between two c-continuations i.e., two states of the c-continuation automaton as follows: if deleting the indices of letters from two c-continuations results in the same regular expression, they correspond to the same partial derivative. Hence, the equation automaton would be a quotient of the c-continuation automaton w.r.t. the previously defined equivalence relation. From the algorithmic point of view, this result allows the construction of the equation automaton in time and space [6,7]. Therefore, this improves the Antimirov’s algorithm by a factor of .
In [8], Allauzen and Mohri present simple and unified constructions of the position automata [3,4,5], follow automata [9,10], and the equation automata [2,6,7] from regular expressions. Their algorithms are based on two standard automata operations applied to the Thompson automata [11,12] called: epsilon-remove and Hopcroft’s algorithm for DFA minimization [13]. The complexity of their construction for the equation automaton is in , where m is the number of Thompson automaton transitions. Notice that, by construction the number of transitions of the Thompson automaton m and the size of a regular expression n are proportional. Thus, we have .
To improve the time complexity of computing the equation automaton from a regular expression E, we design an algorithm, combining advantages of previous methods [6,7,8], with a worst-case time complexity in , where denotes the number of its states. Our approach is based on Bubenzer minimization of an acyclic DFA instead Hopcroft’s algorithm for DFA minimization step used in Allauzen and Mohri’s method. The main idea is to associate implicitly each c-continuation to a corresponding state, called position state in the Thompson automaton by a special marking of -transitions. As a consequence of this marking, the right language of each position state in the Thompson automaton represents implicitly its c-continuation, called pseudo-continuation. After that, we disable temporarily the cyclic -transition in the Thompson automaton and perform Bubenzer minimization of an acyclic DFA to compute efficiently partial derivatives equivalence relation over the set of position states. Finally, we remove indexed -transitions, enable the cyclic -transition and then compute the -closure of states in the produced automaton from the previous step to get the equation automaton. The implementation of the proposed algorithm is available under the repository https://github.com/FaissalOuardi/Equation-automaton, (accessed on 27 May 2021).
The paper is organized as follows. Section 2 contains some basic definitions and necessary preliminaries. Section 3 summarizes theoretical results that lead to c-continuations of a regular expression, and their relations with the partial derivatives. The definition of the c-continuation automaton is recalled, as well as the way it is connected to the equation automaton. Section 4 is a recall to the algorithm due to Allauzen and Mohri. We detail then in Section 5 the algorithmic refinements leading to an time complexity of the efficient construction of the equation automaton where is the number of its states.
2. Preliminaries
In this section, we introduce briefly the notion of finite automata. For further details on formal aspects of finite automata theory, we particularly recommend reading classical books [14,15].
2.1. Regular Expressions and Finite Automata
Let A be a non-empty finite set of letters, called an alphabet. The set of all words over A is denoted by . is the empty word. A language over A is a subset of .
2.1.1. Regular Expressions and Languages
A regular expression over the alphabet A is a term of the algebra defined over the set with the symbols of functions where ∗ is unary and + and · are binary. Properties of the constants and the operators , and · lead to identities on this algebra. Each regular expression denotes a language. L is the function that assigns to each regular expression the regular language it denotes. is defined as follows:
The following identities are classically used:
Let E be a regular expression. The set of letters occurring in E is denoted by . To specify their position in the expression, letters are subscripted following the order of reading. The resulted expression is the linearized form of E, denoted by . For example, starting from , one obtains the linearized version of E. The subscripted letters are called positions; the set of all position in the expression E is denoted by . For the previous example, we have . If F is a subexpression of E, we denote by the subset of positions of E that are letters of F. We say that a regular expression is in linear form if each letter of the expression occurs only once. We denote by h the function that maps each position in to the letter of that appears at this position in E. For , we have and . The size of the regular expression E, denoted by , is the number of nodes in its syntax tree. We call alphabetic width of E, denoted by , the number of occurrences of letters in the expression i.e., the cardinality of . The alphabetic width of the expression is equal to 5; its size is equal to 12.
Notice that the alphabetic width and the size of a regular expression are independent parameters. Therefore complexities are expressed w.r.t. both of these two parameters. However, it is usual to preprocess the input expression in order to reduce its size and to make its size proportional to its alphabetic width. So, if we consider a reduced regular expression E w.r.t. the following rules:
- ,
- ,
- E is in Star-Normal Form (SNF) [16].
Thus, we have in this case . It is known that regular expressions can be transformed to SNF in linear time [16]. denote the null term of E, that is
By we denote the syntax tree associated with the regular expression E. A node in will be denoted by . We write for the set of nodes of . If is a node in and denote respectively the symbol, the father and the right son of the node . If is an operator, will denote the subexpression that corresponds to the subtree with the root .
2.1.2. Finite Automata and Recognizable Languages
A nondeterministic finite automaton (NFA) is a quintuple where Q is a finite set of states, A is the alphabet, is the initial state, is the set of final states, and is the transition function. The size of an automaton , denoted by , is the number of its states. The automaton is called deterministic (DFA) if there is only one initial state, and , for any , for any . A path in is a sequence , of consecutive transitions. Its label is the word . A word is recognized by the automaton if there exists a path labeled w such that and .
The language recognized by the automaton , denoted by , is the set of words it recognizes. The right language of a state q in the automaton , denoted by , is obtained by setting q to be the initial state, i.e., .
We say that is acyclic if the underlying graph is acyclic. The language associated with an acyclic automaton is finite.
Let ∼ be an equivalence relation over Q. For , denotes the equivalence class of q w.r.t. ∼ and, for denotes the quotient set . We say that ∼ is right invariant w.r.t. if and only if the following conditions hold:
- (final and non-final states are not ∼-equivalent),
- for any , , if , then .
2.2. Thompson Automaton
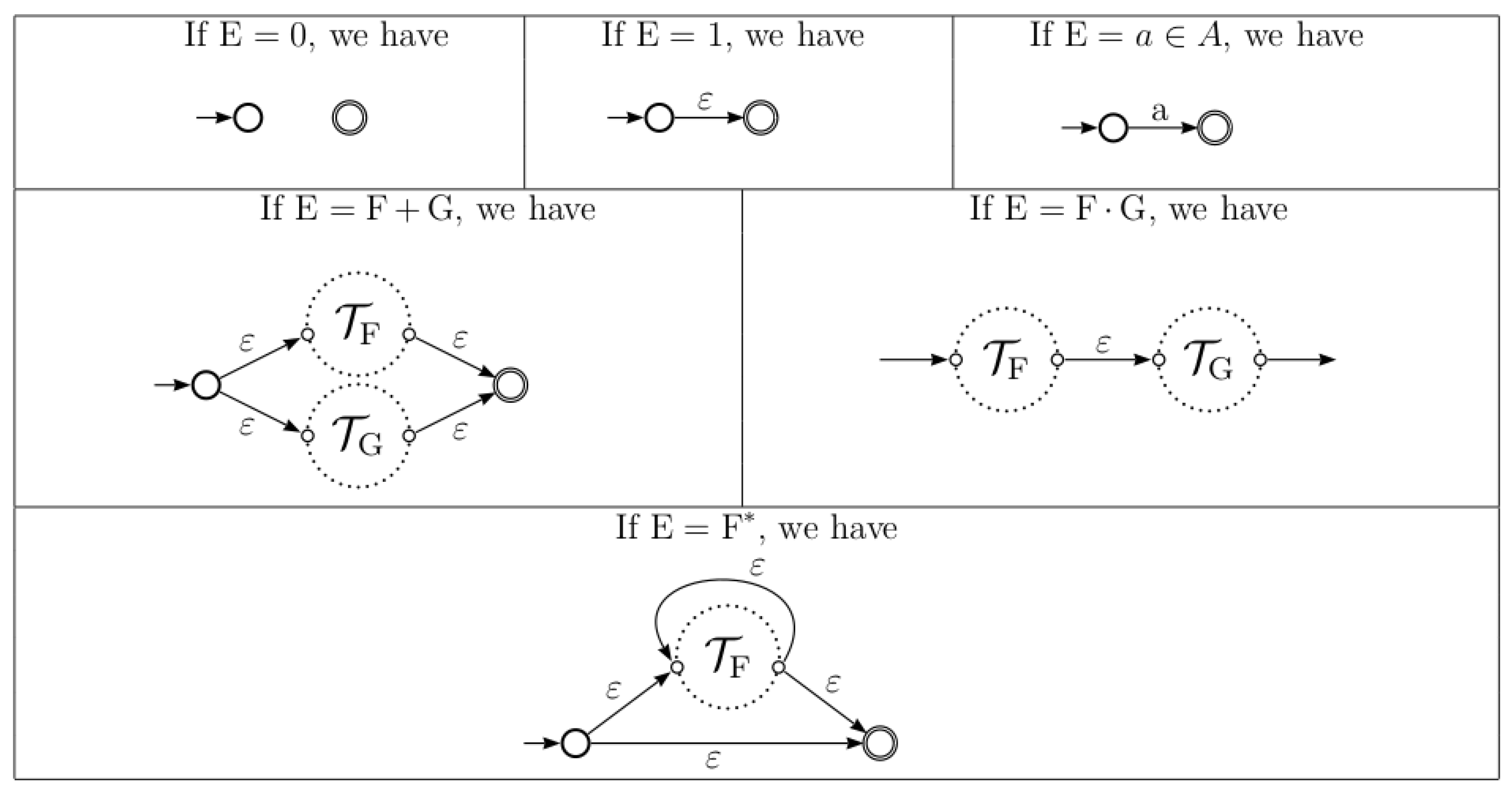
In [12], Thompson gave a linear time and space algorithm to convert a regular expression E to an NFA with -transitions, denoted by . The recursive steps of the construction of Thompson NFA are pictured in Figure 1.
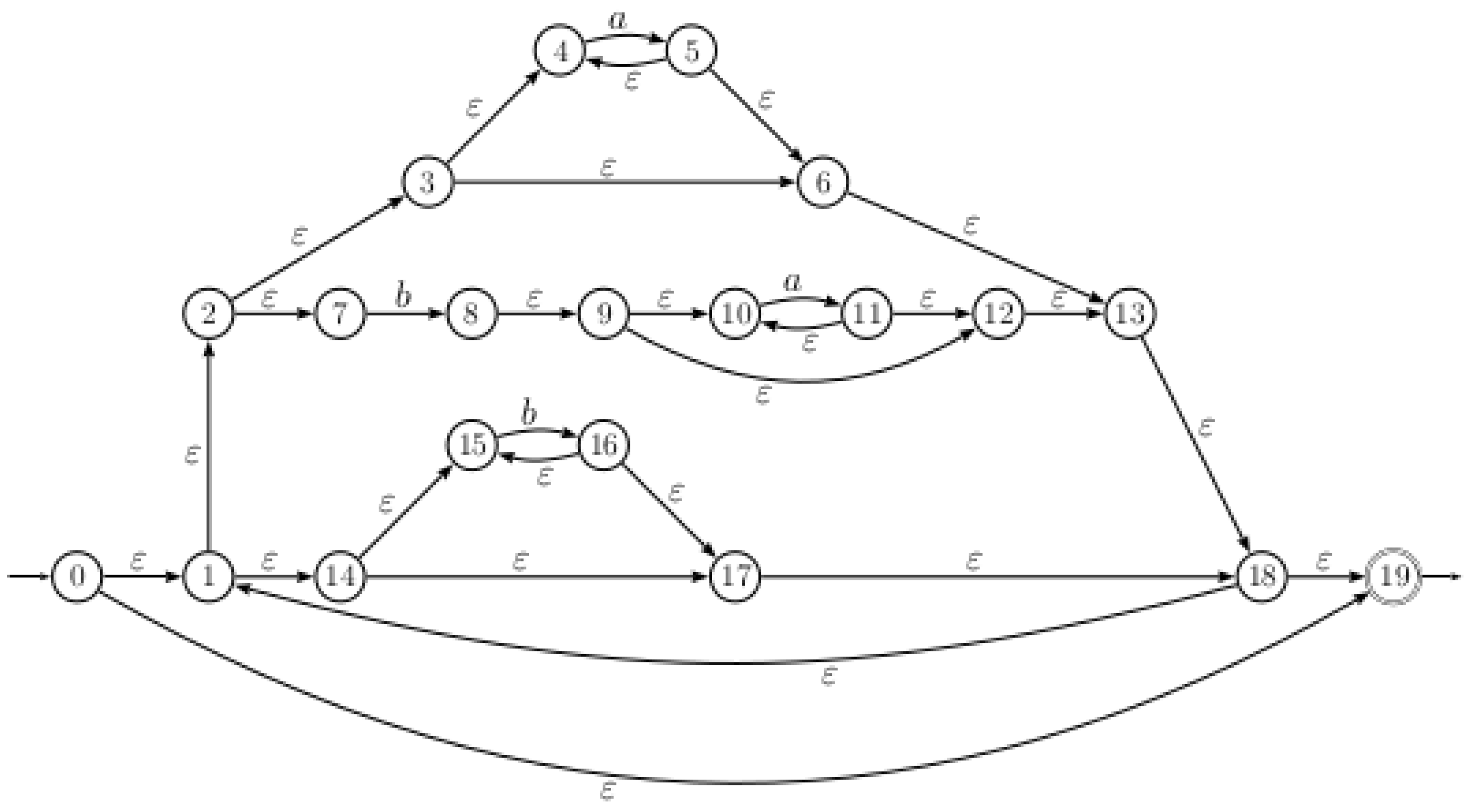
Example 1.
Let us consider the regular expression . The Thompson automaton associated with E is shown in the Figure 2.
There are some disadvantages of Thompson’s NFA when it is used in practice: it has many redundant states and -transitions, its number of states is in while other constructions offer NFAs with states.
In the next section, we will present the construction of a reduced -free automaton, named equation automaton, sometimes called Antimirov automaton or derived terms automaton.
3. Equation Automaton
The equation automaton has been introduced for the first time by Mirkin in [1]. In 1996, Antimirov introduced the notion of partial derivatives and used it to define the equation automaton [2]. Champarnaud and Ziadi [6] defined the notion of canonical derivatives of a linear expression and constructed a new automaton called the c-continuation automaton. They also proved that this automaton is isomorphic to the position automaton in the sense that the two automata have identical sets of states, identical initial and final states, and transitions Theorem 6 in [6]. Using an equivalence relation over the set of states of the c-continuation automaton, they derive the equation automaton in quadratic time.
The definition of the equation automaton of a regular expression is based on that of the partial derivatives of regular expressions, which are multisets of regular expressions over A. The partial derivative of E with respect to is defined recursively on the structure of E as follows:
The partial derivative of E with respect to the string is denoted by and recursively defined by and .
Let .
Theorem 1.
(Antimirov [2]). The cardinality of the set of all partial derivatives of a regular expression E is less than or equal to .
The equation automaton of E is defined by:
- ,
- .
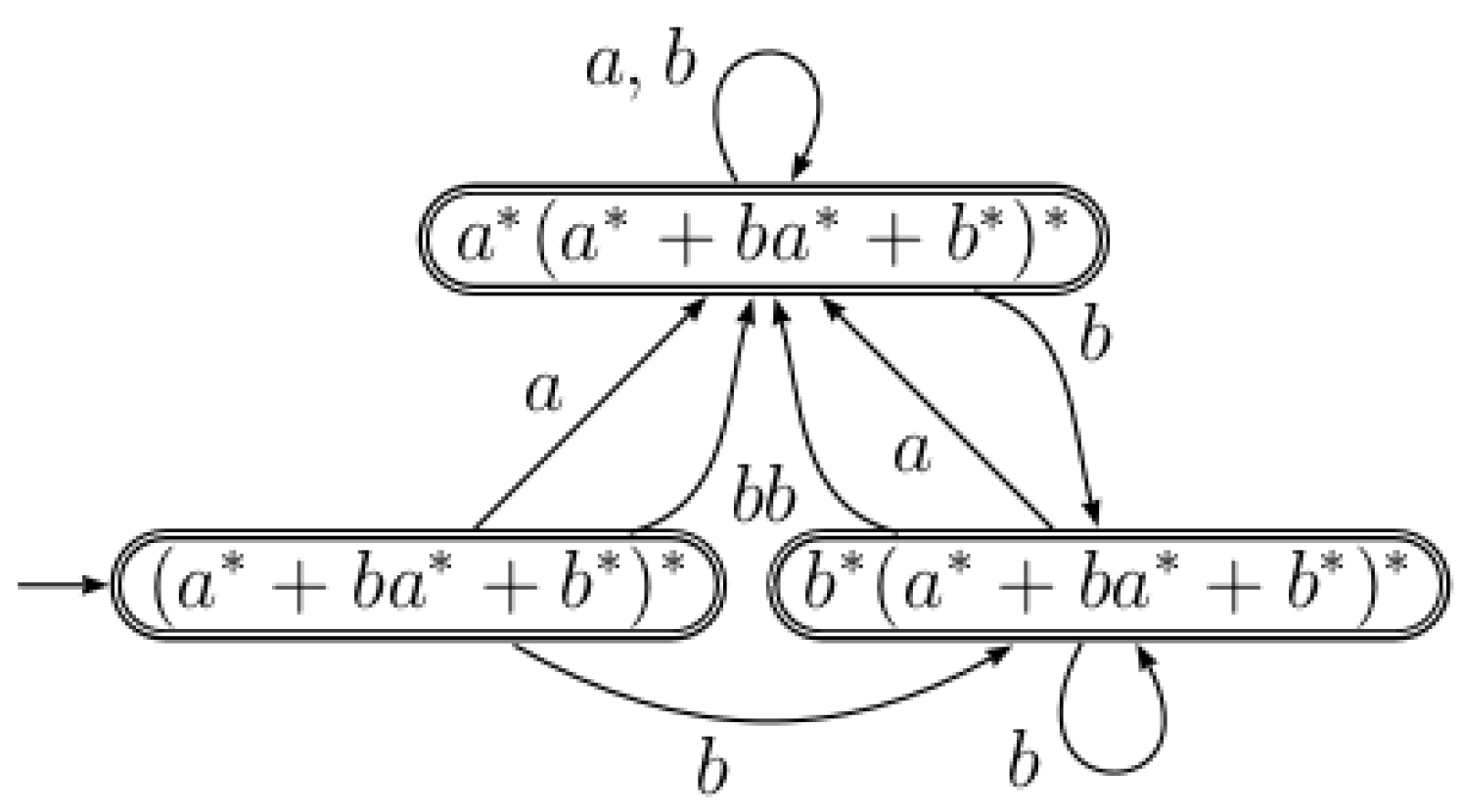
Example 2.
Let us consider the regular expression . The partial derivatives of E are as follows:
The computation of the transitions of the equation automaton are as follows:
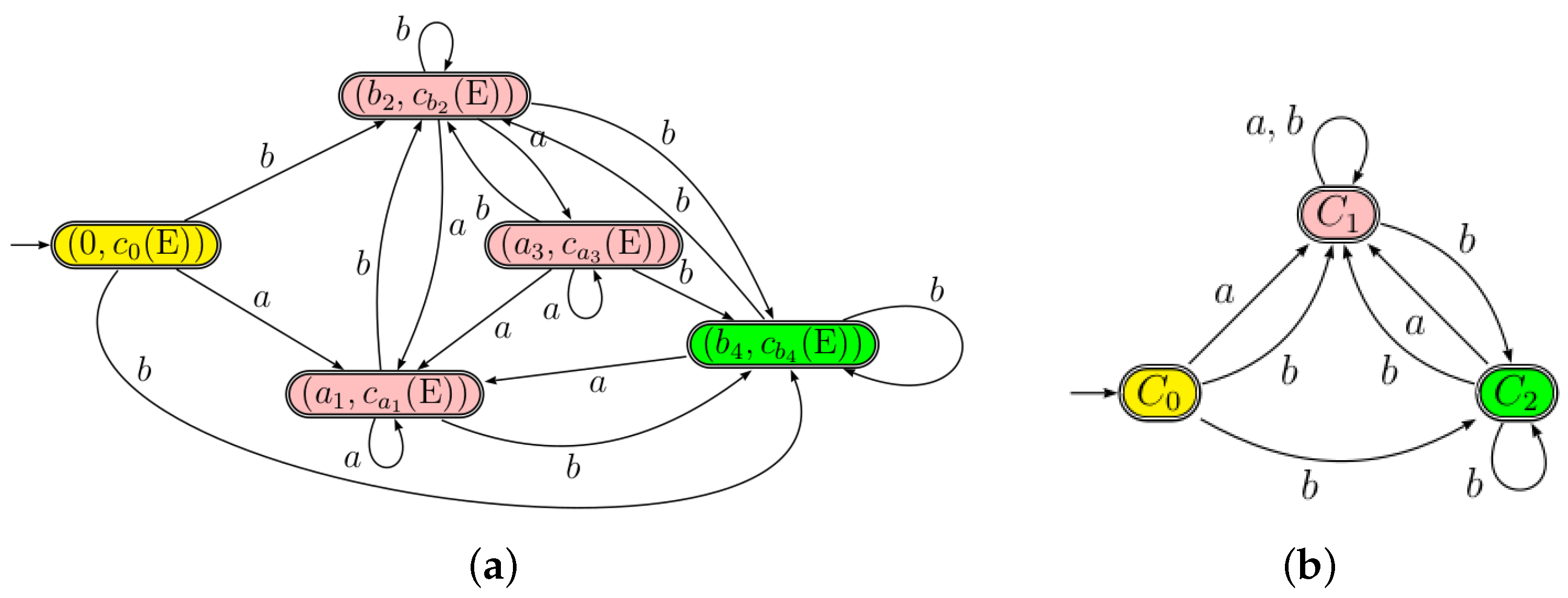
The equation automaton associated with E is shown in Figure 3.
In the following, we recall the definition and properties of the c-continuation automaton. Next, we show how it can be bound to the equation automaton.
3.1. C-Continuation Automaton
This automaton has been introduced by Champarnaud and Ziadi [6] to efficiently compute the equation automaton. Let us recall the notion of c-derivative, c-continuation and c-continuation automaton.
Definition 1.
(c-derivative with respect to a letter). The c-derivative of a regular expression E with respect to a letter a is the regular expression defined by:
The c-derivative with respect to a word is defined recursively by the rules: and
Theorem 2.
(Theorem 4 in [6]). Let E be a linear regular expression and a be a letter from E. Then all non-zero c-derivatives of the form , where u is an arbitrary word, are equal.
Theorem 2 allows us to define the c-continuation of a in a linear expression E as the unique value of the non-zero c-derivatives .
Proposition 1.
(Proposition 6 in [6]). For every letter a of a linear expression E, the c-continuation is such that:
Corollary 1.
(Corollary 5 in [6]). For every letter a of a linear expression E, the c-continuation is either 1 or a subexpression of E or a product of subexpressions.
More precisely, for a linear regular expression E, we have , where is a subexpression of E, for all .
We now consider a regular expression E over A. Let be the linearized form of E over and h be the mapping from onto .
In order to simplify the writing for a regular expression E, we consider by convention that and will denote .
Definition 2.
(c-continuation automaton) The c-continuation automaton of E, , , is defined by:
- ,
- ,
- ,
- .
We note that the number of states of is exactly .
Corollary 2.
(Corollary 7 in [6]). Let E be a regular expression. One has: .
Example 3.
Let us consider the regular expression from Example 1. The linearized form of E is and the c-continuations of E are as follows:
The outgoing transitions from the state are computed using the c-derivatives of as follows:
Then we get the c-continuation automaton in Figure 4.
3.2. Equation Automaton as a Quotient of C-Continuation Automaton
Champarnaud and Ziadi [6] have proved that the equation automaton is a quotient of the c-continuation automaton. Let us consider the equivalence relation defined by
Sometimes we write .
Proposition 2.
The relation is right-invariant, i.e., for all letters a in A, for all pairs of states in Q such that , we have: .
Moreover, if two states are equivalent w.r.t. , then they are either both final or both non-final, since .
The equivalence class of the state is represented by . Since the relation is right-invariant, we can define the quotient automaton as follows:
- ,
- ,
- ,
- .
Theorem 3.
(Theorem 10 in [6]). Let E be a regular expression. The automaton deduced from the c-continuation automaton is isomorphic to the equation automaton .
We note that the number of states of is majorized by .
Example 4.
Let us consider the regular expression from Example 1. There are three -equivalence classes when applying the function h that remove indices from letters for different c-continuations of E:
The c-continuation automaton and the quotient automaton which is isomorphic to the equation automaton are schematized in Figure 5:
4. Allauzen and Mohri’s Algorithm
In [8], Allauzen and Mohri compute the equation automaton from the Thompson automaton of a regular expression E in time. Their algorithm is based on some combinations of -transitions removal and Hopcroft’s algorithm for DFA minimization to the classical Thompson automata [13]. In the next, we briefly describe their method.
Let . We denote by the automaton over obtained by recursively marking some of the -transitions of the Thompson automaton as follows:

Allauzen and Mohri have shown that the equation automaton can be obtained using some -transitions marking of the Thompson automaton and then apply two classical automata operations, namely epsilon removal, denoted by the function (resp. the function for marked epsilon removal) and the Hopcroft’s algorithm for DFA minimization [13], denoted by .
Proposition 3.
(Proposition 3 in [8]). We have .
Note that after removing -transitions from the automaton , we obtain a deterministic finite automaton . After that, the Hopcroft’s algorithm for DFA minimization is applied to derive the automaton such that the set of its states is in bijection with the set of partial derivatives of E. Finally, to compute transitions of the equation automaton from , marked -transitions are removed using operation.
Theorem 4.
(Theorem 3 in [8]). Let E be a regular expression over A. The equation automaton of E can be computed in time.
5. Efficient Conversion Algorithm
In this section, we will show that the equation automaton of a regular expression E can be deduced from the associated Thompson automaton in time, where denotes the number of states of . Algorithm 1 summarizes the different steps of our approach.
| Algorithm 1 Computation of the equation automaton. |
| input: The Thompson automaton associated with a regular expression E. output: The equation automaton associated with E. /* Computation of states */ |
| Compute ): |
 |
| Compute : |
| • Compute pseudo-continuations for all position states of . • Merge equivalent states having the same pseudo-continuation. /* Computation of transitions and final states /* |
| Compute : |
| • Perform epsilon removal operation using function over . |
For convenience, we assume that the k states of a given finite automaton are identified by the integers .
From Corollary 1, the c-continuation associated with a position x is a concatenation of distinct subexpressions of E, possibly reduced to a single subexpression or to 1. In the Thompson automaton , we can associate a position x to a particular state q, called position state and define the associated pseudo-continuation , where denotes the integer that identify the initial state of the Thompson automaton . So, the first step, compute , of our algorithm consists on computing the function such that for two subexpressions and of E, we have: . This step can be done using a special marking of the -transitions of that makes it acyclic and deterministic and such that the right languages of its states represent the structure of the corresponding subexpressions. In the next step, Compute , we re-mark the -transitions such that the resulted automaton is acyclic and deterministic and the right language of a position state in represents a pseudo-continuation. After that, one can merge equivalent position states having the same right language. The final step is the computation of final states and transitions of the equation automaton using an epsilon removal operation, denoted by , from the resulted automaton in the previous step.
In the next, we will show that the equation automaton can be computed efficiently from the Thompson automaton using the following operations .
5.1. Computation of States
In the following, We will show that the computation of the relation over the states of the Thompson automaton can be performed in linear time w.r.t. the size of the expression using the minimization of an acyclic deterministic finite automaton. This minimization can be performed efficiently in time using Bubenzer’s algorithm [17,18].
Before computing the equivalence classes over states of the Thompson automaton, we will perform a preprocessing step to identify all identical sub-expressions of E. In the next, we will show that this identification can be done in time.
5.1.1. Sub-Expressions Identification
Let Exp the set of all subexpressions of E. In this preprocessing step, we will mark each state in the Thompson automaton by a unique letter in the set .
Let us define a bijection N between the set Exp and a finite set of letters . Consequently, if and are two sub-expressions of E, then we have:
Based on the parsing method, introduced in Section 6 in [19], that derive an equivalent regular expression from Thompson automaton, each subexpression of E is associated with an integer identifying the initial state in the Thompson automaton .
Let q be a state in , we denote by the subexpression associated with q, if it exists. For abbreviation, represents .
In the following, we will show that the computation of the function N over the states of turns into a minimization of the acyclic deterministic sub-automaton of the Thompson automaton, , defined by:
- where l (resp. r), denote left (resp. right),
- , i.e., a state in is augmented by the letter .
- The transition function is defined over the Thompson automaton as follows:

Notice that this automaton is an acyclic deterministic sub-automaton of the Thompson automaton where -transitions are indexed and the cyclic transitions in the case when are temporarily disabled.
To compute identical subexpressions, we define the equivalence relation ∼ over the states of as follows:
Thus we have:
Lemma 1.
Let q and be two states in . We have:
Proof.
Obvious, by construction. □
Proposition 4.
The function can be computed over in time.
Proof.
Let q and two states in . One has:
Example 5.
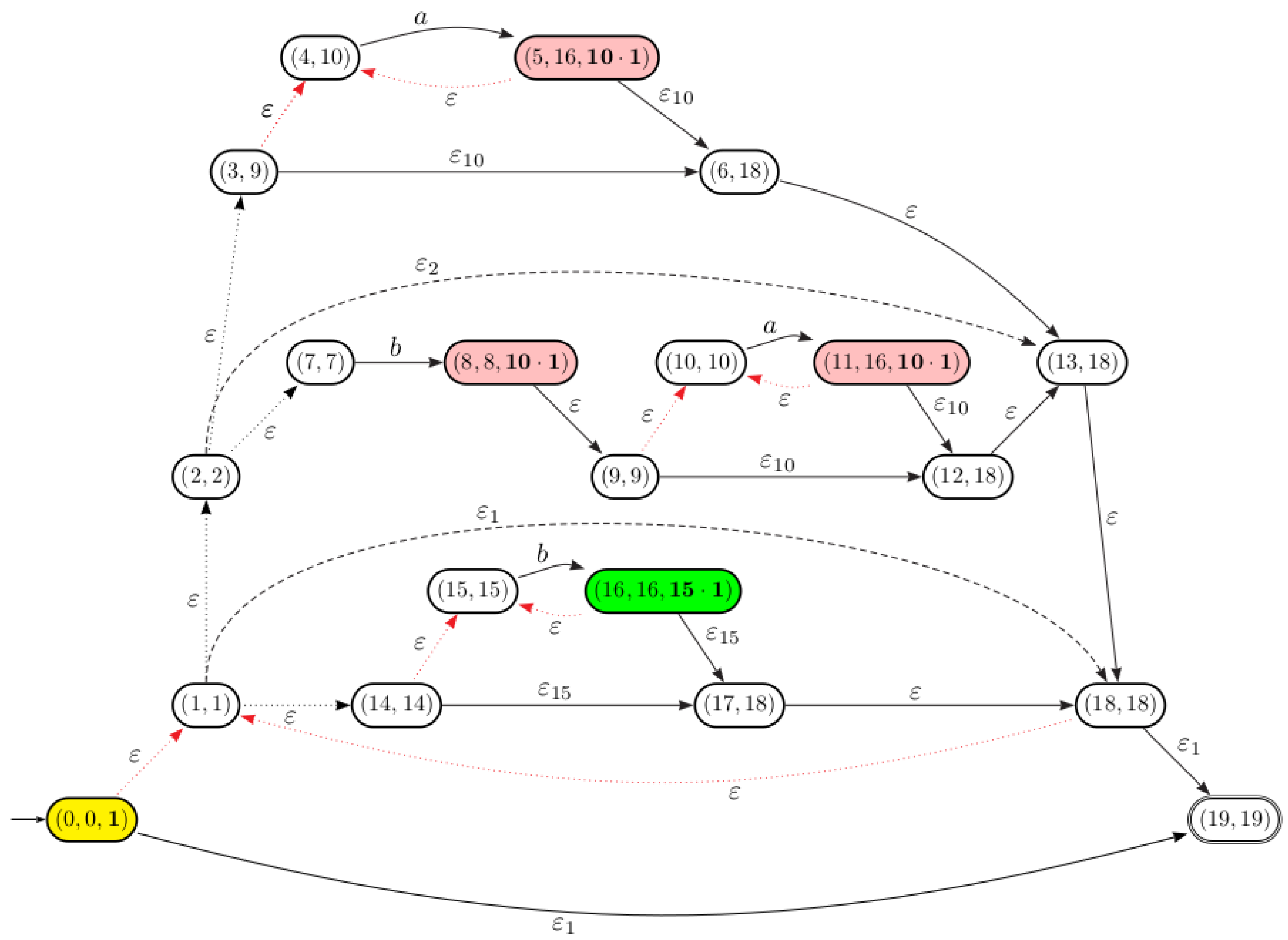
The automaton obtained after performing the subexpression identification step for the regular expression through .
As shown in Figure 6, for the states 3 and 9 we have:
As a consequence, we have .
5.1.2. -Equivalent States Merging
Let us now turn to the computation of the set of states of the equation automaton. From Corollary 1, the c-continuation is a concatenation of distinct subexpressions of E, possibly reduced to a single subexpression or to 1. The following proposition shows that the c-continuation can be computed over the syntactic tree associated with the linearized version .
Proposition 5.
(Ref. [6]). Let E be a regular expression and x a position in . Let be a node in such that . The c-continuation is as follows:
where ⊙ is the concatenation operator.
The function is defined as follows:
with ⊥ is an artificial node such that .
Using Proposition 5, the computation of the set of states requires time and space complexity. This is due to the fact that the size of a c-continuation is in . In order to reduce this complexity, we introduce a modified definition of pseudo-continuation introduced in [6] over an acyclic deterministic sub-automaton of the Thompson automaton, denoted by . When merging -equivalent states over , we get the automaton . This step requires a linear time w.r.t the size of E using Bubenzer’s algorithm [17], since the automaton is acyclic and deterministic.
In the following, a state in the automaton is called a position state, if there exists and such that . The state is also considered as a position state.
It is obvious to see that each position state is associated with a unique position in and then it’s can be associated with a c-continuation.
Let and two position states associated with the positions x and in . One can extend the relation over position states in as follows:
In the next, we will prove that the computation of the equivalence classes can be performed in a linear time w.r.t. the size of the regular expression over using the notion of pseudo-continuations.
For abbreviation, a state in will be denoted by q. We denote by the pseudo-continuation associated with the position state q which is an implicit representation of its c-continuation , where x is the position letter of q. We will show that the computation of the equivalence classes turns on the computation of pseudo-continuation over a particular -transitions marking of the automaton .
Definition 3.
The pseudo-continuation associated with a position state in is recursively defined by:
In order to compute efficiently the set of pseudo-continuations associated with the position states in , we define an acyclic deterministic sub-automaton of the Thompson automaton as follows:
- .
- , i.e., a state in is replaced by .
- The transition function is defined as follows:

Let us define the equivalence relation ≈ over the position states of as follows:
Thus we have:
Let be the application that maps a letter to the letter i. By construction, the following proposition holds.
Proposition 6.
Let be a position state in . We have:
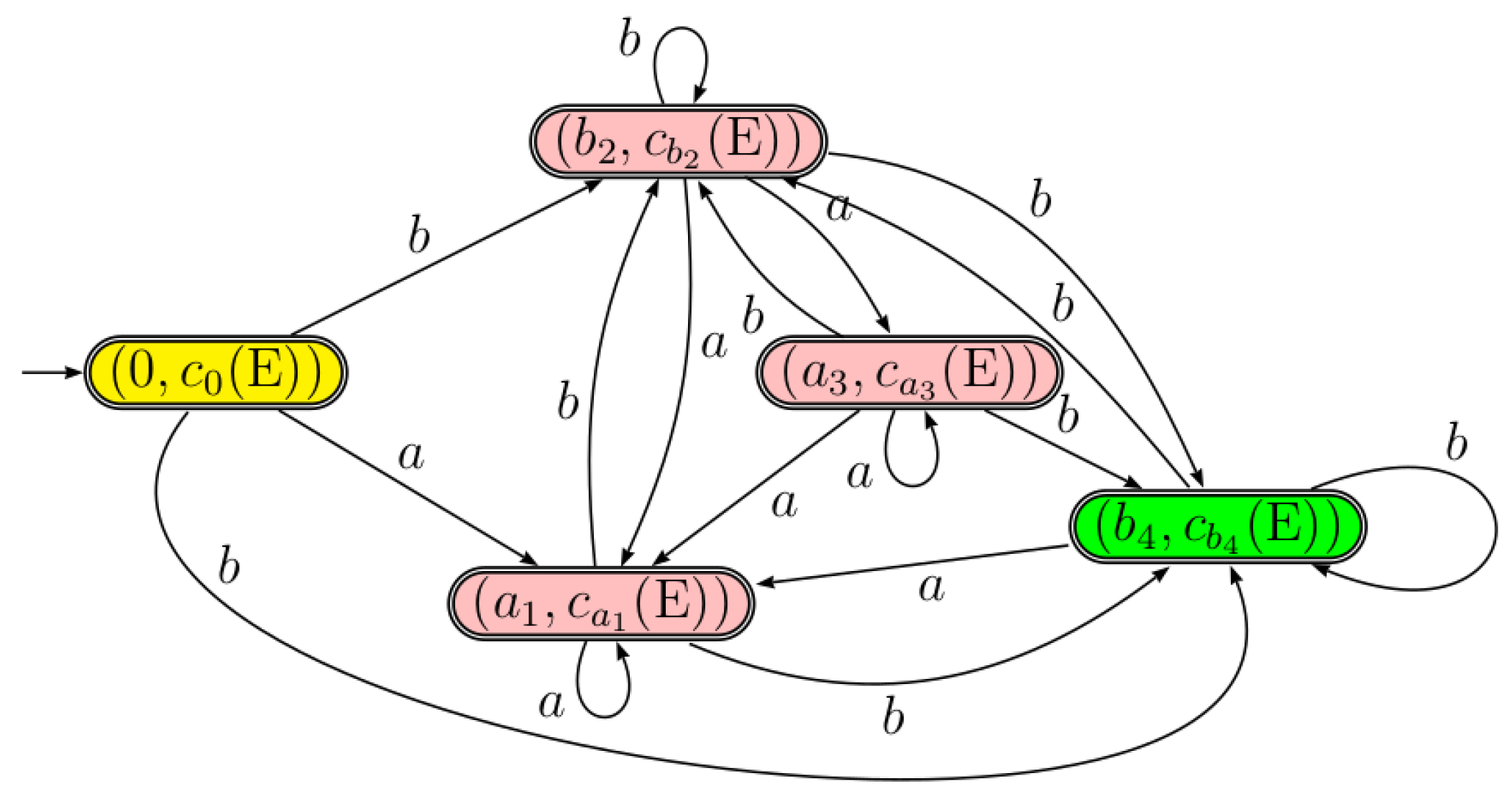
Example 6.
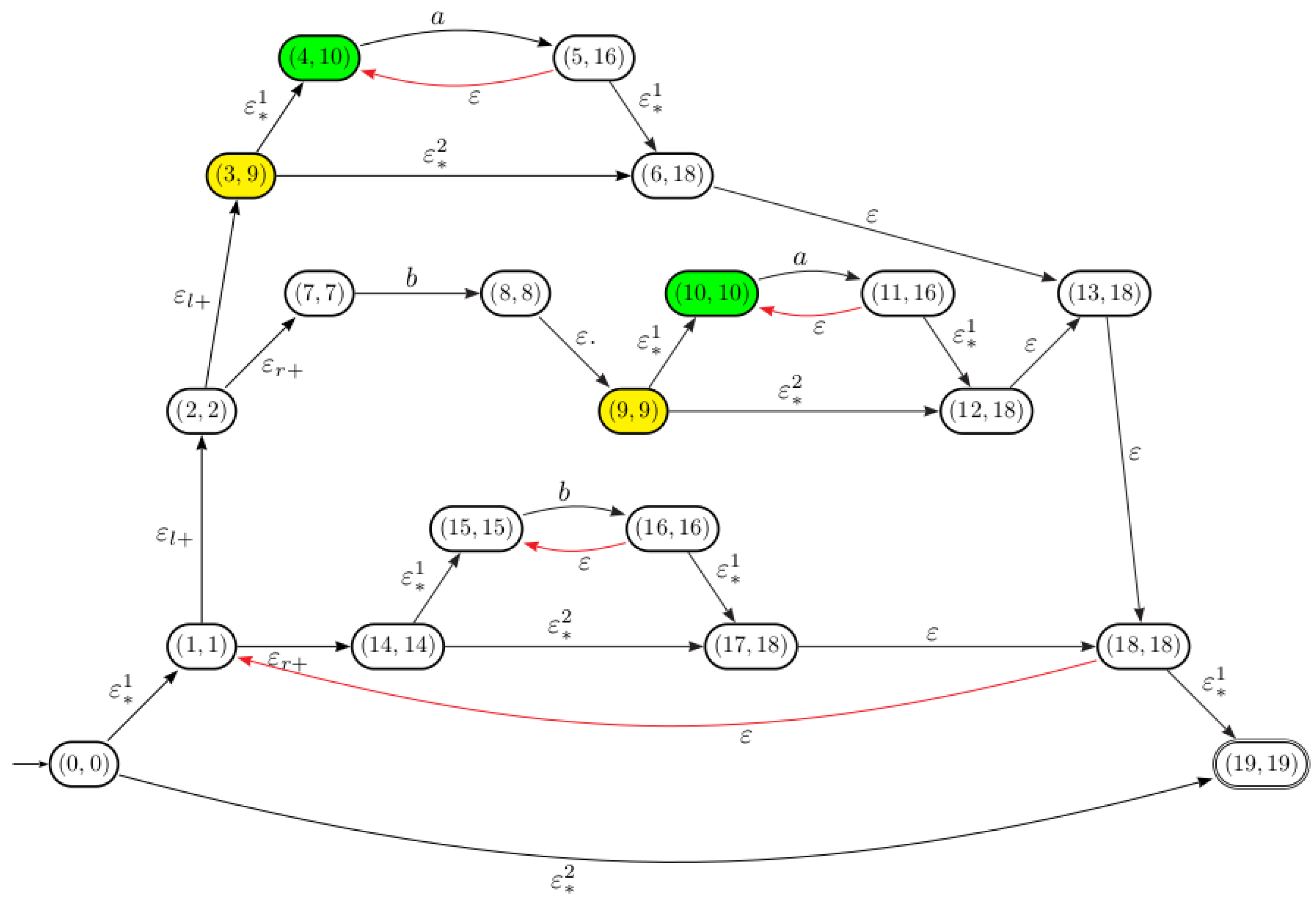
Let us consider the Thompson automaton defined in previous examples. Figure 7 schematizes the derived automaton from after pseudo continuations computation for position states.
Notice that dotted ε-transitions are temporarily disabled and dashed ones are temporarily added.
The position states in the automaton are . According to the definition of a pseudo continuation (see Formula (7)), the pseudo-continuations associated with position states are computed over the automaton as follows:
On the other hand, we have:
The following proposition is fundamental to prove that the equivalence relation using the notion of c-continuation is the same when using pseudo-continuations .
Proposition 7.
Let q (resp. ) be a position state associated with a position (resp. ) in . One has:
As a consequence, the following proposition holds.
Proposition 8.
Let q and be two position states in . One has:
Theorem 5.
Let E be a regular expression and the associated Thompson automaton. The relation can be computed over in time.
Proof.
From Proposition 8, one can deduce that the computation of the equivalence relation , turn to apply the Myhill-Nerode relation on the states of the automaton . By definition, this last is acyclic and deterministic. Then, its minimization using Bubenzer’s algorithm [17] requires time and space complexity. □
Example 7
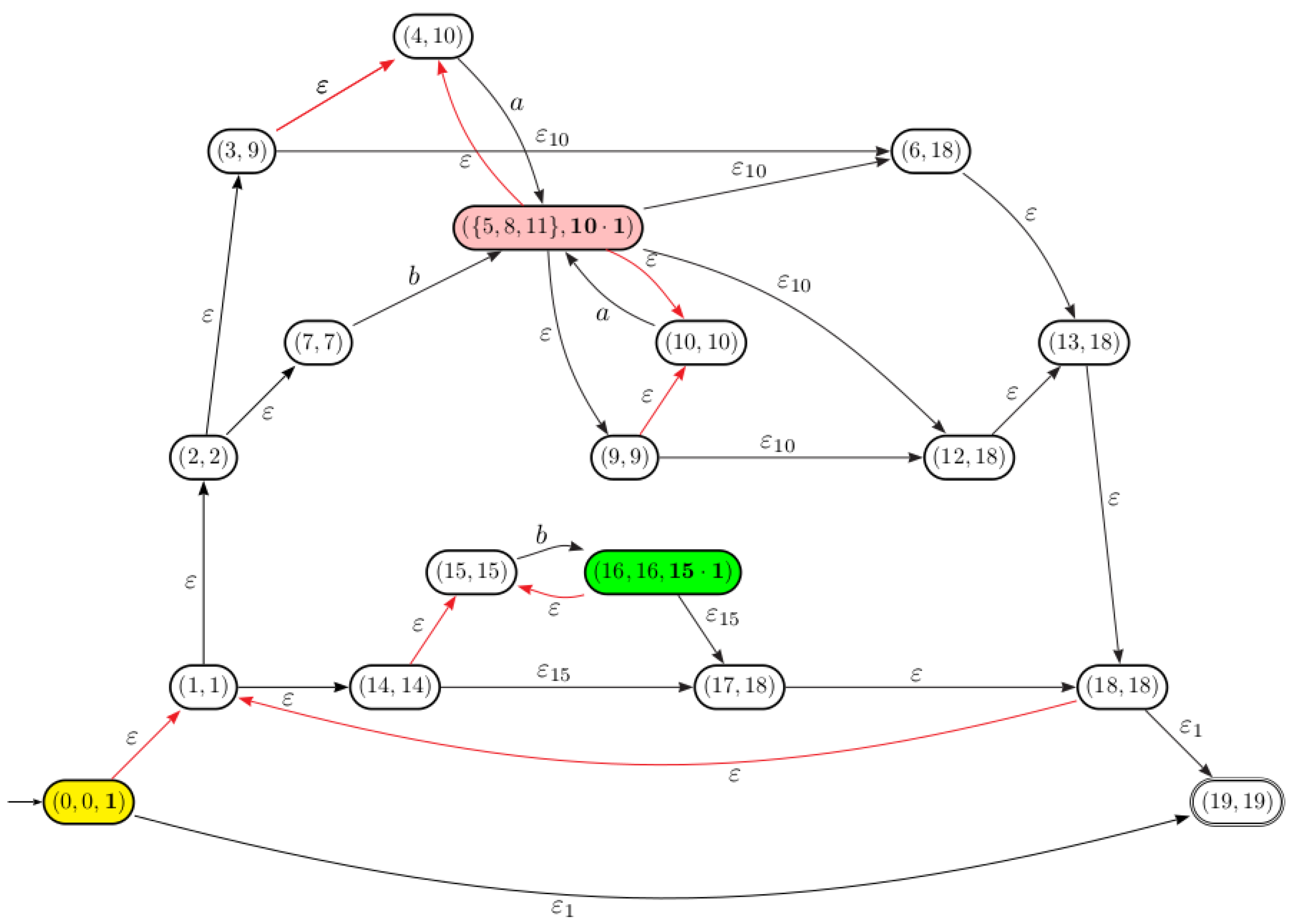
(Continues). The automaton , schematized in the Figure 8, is obtained from after merging -equivalent position states and 11.
The next step of our approach consists of the transitions and final states computation of the equation automaton using epsilon removal operation, denoted by , over the automaton .
5.2. Computation of Transitions and Final States
After merging -equivalent states in the previous step, we obtain a reduced automaton having the same set of states as the equation automaton. To compute the transition function, we first enable the cyclic transitions previously disabled in the case when on .
Let be the set of states of . Recall that epsilon removal operation is denoted by, for a state and denotes the resulted automaton after removing marked and non-marked -transitions from the automaton .
As a consequence of Lemma 5 from [8], the following Lemma yeilds.
Lemma 2.
(Lemma 5 in [8]). Let q and be two position states in associated respectively with the positions x and in , we have:
The set of destination states of the outgoing transitions from a state is then equal to
Lemma 3.
Let q be a position state in associated with a position x in , we have:
Proposition 9.
We have
Example 8.
(Continues). Let us consider the automaton of the Example 7. The final states and the transitions of the equation automaton are computed over using epsilon removal operation as follows:
- The set of states of the equation automaton are .
- Since the final state of is the state 19 and , , and , then the set of final states are .
- There are two paths in from the state 0 to the state labeled respectively by and , then . Consequently, two transitions and are added to the equation automaton. The same process will be applied for other transitions.
Since there are states in and the operation is performed on exactly states, the following theorem holds.
Theorem 6.
Let E be a regular expression. The equation automaton of E can be computed in .
6. Conclusions
In this paper, we presented a fast and sophisticated construction of the equation automaton from a regular expression over its associated Thompson automaton. The time complexity of our algorithm is at least as favorable as that of the best previously known algorithm. It is based on the minimization of acyclic deterministic finite automata and epsilon removal operations. This allowed us a construction of the equation automaton in time and space complexity where denotes the number of transitions of the produced automaton. The implementation of the proposed algorithm is available under the following repository: https://github.com/FaissalOuardi/Equation-automaton (accessed on 27 May 2021).
Author Contributions
Conceptualization, F.O., Z.L. and B.E.; methodology, F.O., Z.L. and B.E.; validation, F.O., Z.L. and B.E.; formal analysis, F.O., Z.L. and B.E. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Source code can be found under the following link: https://github.com/FaissalOuardi/Equation-automaton (accessed on 27 May 2021).
Acknowledgments
We wish to thank the referees for the care they put into reading the previous versions of this manuscript. Their comments were invaluable in depth and detail, and the current version owes much to their efforts.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mirkin, B.G. Novyj algoritm postroéniá bazisa v ázyké régularnyh vyražénij. Izvéstiá Akadémii Nauk SSSR. Engineering cybernetics, no. 5 (1966). English translation of the preceding: Brzozowski, J. An algorithm for constructing a base in a language of regular expressions. pp. 110–116. J. Symb. Log. 1971, 36, 694. [Google Scholar]
- Antimirov, V. Partial derivatives of regular expressions and finite automaton constructions. Theor. Comput. Sci. 1996, 155, 291–319. [Google Scholar] [CrossRef] [Green Version]
- Glushkov, V.M. The abstract theory of automata. Russ. Math. Surv. 1961, 16, 1–53. Available online: https://0-iopscience-iop-org.brum.beds.ac.uk/article/10.1070/RM1961v016n05ABEH004112 (accessed on 27 May 2021). [CrossRef]
- McNaughton, R.F.; Yamada, H. Regular expressions and state graphs for automata. IEEE Trans. Electron. Comput. 1960, 9, 39–57. [Google Scholar] [CrossRef]
- Ziadi, D.; Ponty, J.-L.; Champarnaud, J.-M. A New Quadratic Algorithm to Convert a Regular Expression into an Automaton. In Proceedings of the Workshop on Implementing Automata, London, ON, Canada, 29–31 August 1996; pp. 109–119. [Google Scholar]
- Champarnaud, J.-M.; Ziadi, D. Canonical derivatives, partial derivatives and finite automaton constructions. Theor. Comput. Sci. 2002, 289, 137–163. [Google Scholar] [CrossRef] [Green Version]
- Khorsi, A.; Ouardi, F.; Ziadi, D. Fast equation automaton computation. J. Discret. Algorithms 2008, 6, 433–448. [Google Scholar] [CrossRef] [Green Version]
- Allauzen, C.; Mohri, M. A Unified Construction of the Glushkov, Follow, and Antimirov Automata. In Proceedings of the International Conference of Mathematical Foundations of Computer Science, Stará Lesná, Slovakia, 28 August–1 September 2006; pp. 110–121. [Google Scholar]
- Ilie, L.; Yu, S. Follow automata. Inf. Comput. 2003, 186, 140–162. [Google Scholar] [CrossRef] [Green Version]
- Champarnaud, J.-M.; Nicart, F.; Ziadi, D. From the ZPC Structure of a Regular Expression to its Follow Automaton. IJAC 2006, 16, 17–34. [Google Scholar] [CrossRef]
- Kleene, S. Representation of Events in Nerve Nets and Finite Automata; Automata Studies, Ann. Math. Studies 34; Princeton University Press: Princeton, NJ, USA, 1956; pp. 3–41. [Google Scholar]
- Thompson, K. Regular Expression Search Algorithm. Commun. ACM 1968, 11, 410–422. [Google Scholar] [CrossRef]
- Hopcroft, J. An n log n Algorithm for Minimizing States in a Finite Automaton; Technical Report; Stanford University, CS Dept.: Stanford, CA, USA, 1971. [Google Scholar]
- Hopcroft, J.E.; Ullman, J.D. Introduction to Automata Theory, Languages and Computation; Addison-Wesley: Reading, MA, USA, 1979. [Google Scholar]
- Sakarovitch, J.; Thomas, R. Elements of Automata Theory; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Brüggemann-Klein, A. Regular expressions into finite automata. Theor. Comp. Sci. 1993, 120, 117–126. [Google Scholar] [CrossRef] [Green Version]
- Bubenzer, J. Cycle-aware minimization of acyclic deterministic finite-state automata. J. Discret. Appl. Math. 2014, 163, 238–246. [Google Scholar] [CrossRef]
- Revuz, D. Minimization of acyclic deterministic automata in linear time. Theor. Comput. Sci. 1992, 92, 181–189. [Google Scholar] [CrossRef] [Green Version]
- Giammarresi, D.; Ponty, J.-L.; Wood, D.; Ziadi, D. A characterization of Thompson digraphs. Discret. Appl. Math. 2004, 134, 317–337. [Google Scholar] [CrossRef]
- Myhill, J. Finite automata and the representation of events. In WADD TR-57-624; Wright Patterson AFB: Dayton, OH, USA, 1957; pp. 112–137. [Google Scholar]
- Nerode, A. Linear automata transformation. Proc. AMS 1958, 9, 541–544. [Google Scholar] [CrossRef]
Figure 1.
Thompson construction of an NFA.

Figure 2.
Thompson automaton .

Figure 3.
The equation automaton .

Figure 4.
The c-continuation automaton .

Figure 5.
(a) The c-continuation automaton versus (b) The quotient automaton .

Figure 6.
The automaton associated with .

Figure 7.
Pseudo-continuations computation for position states in .

Figure 8.
The automaton associated with .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ouardi, F.; Lotfi, Z.; Elghadyry, B. Efficient Construction of the Equation Automaton. Algorithms 2021, 14, 238. https://0-doi-org.brum.beds.ac.uk/10.3390/a14080238
AMA Style
Ouardi F, Lotfi Z, Elghadyry B. Efficient Construction of the Equation Automaton. Algorithms. 2021; 14(8):238. https://0-doi-org.brum.beds.ac.uk/10.3390/a14080238
Chicago/Turabian StyleOuardi, Faissal, Zineb Lotfi, and Bilal Elghadyry. 2021. "Efficient Construction of the Equation Automaton" Algorithms 14, no. 8: 238. https://0-doi-org.brum.beds.ac.uk/10.3390/a14080238
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.