
Analysis of SARS-CoV-2 Population Genetics from Samples Associated with Huanan Market and Early Cases Identifies Substitutions Associated with Future Variants of Concern

Abstract
:1. Introduction
2. Materials and Methods
2.1. Consensus Genome and Minor Variations
2.2. Insertion, Deletion, and Fusion
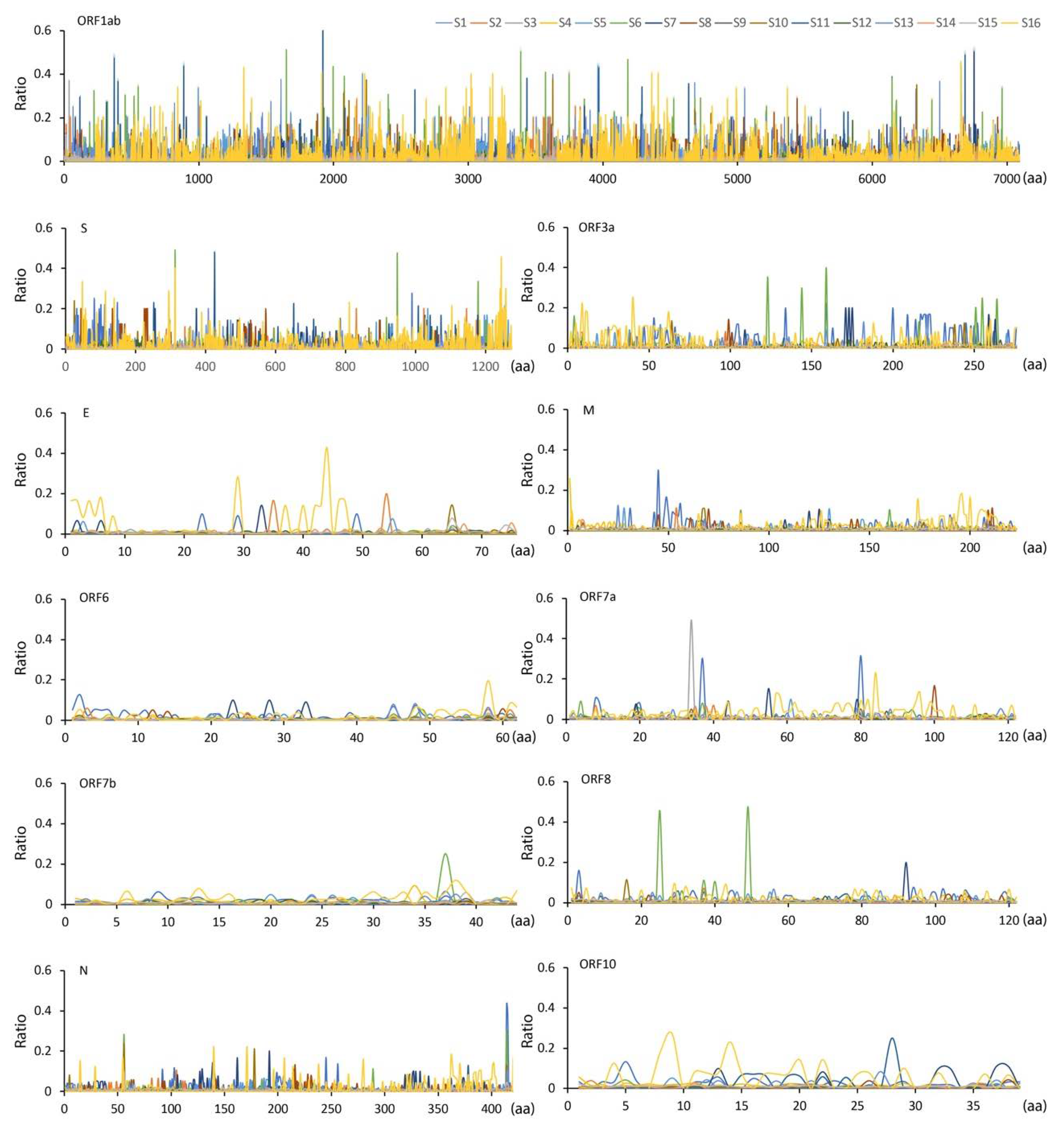
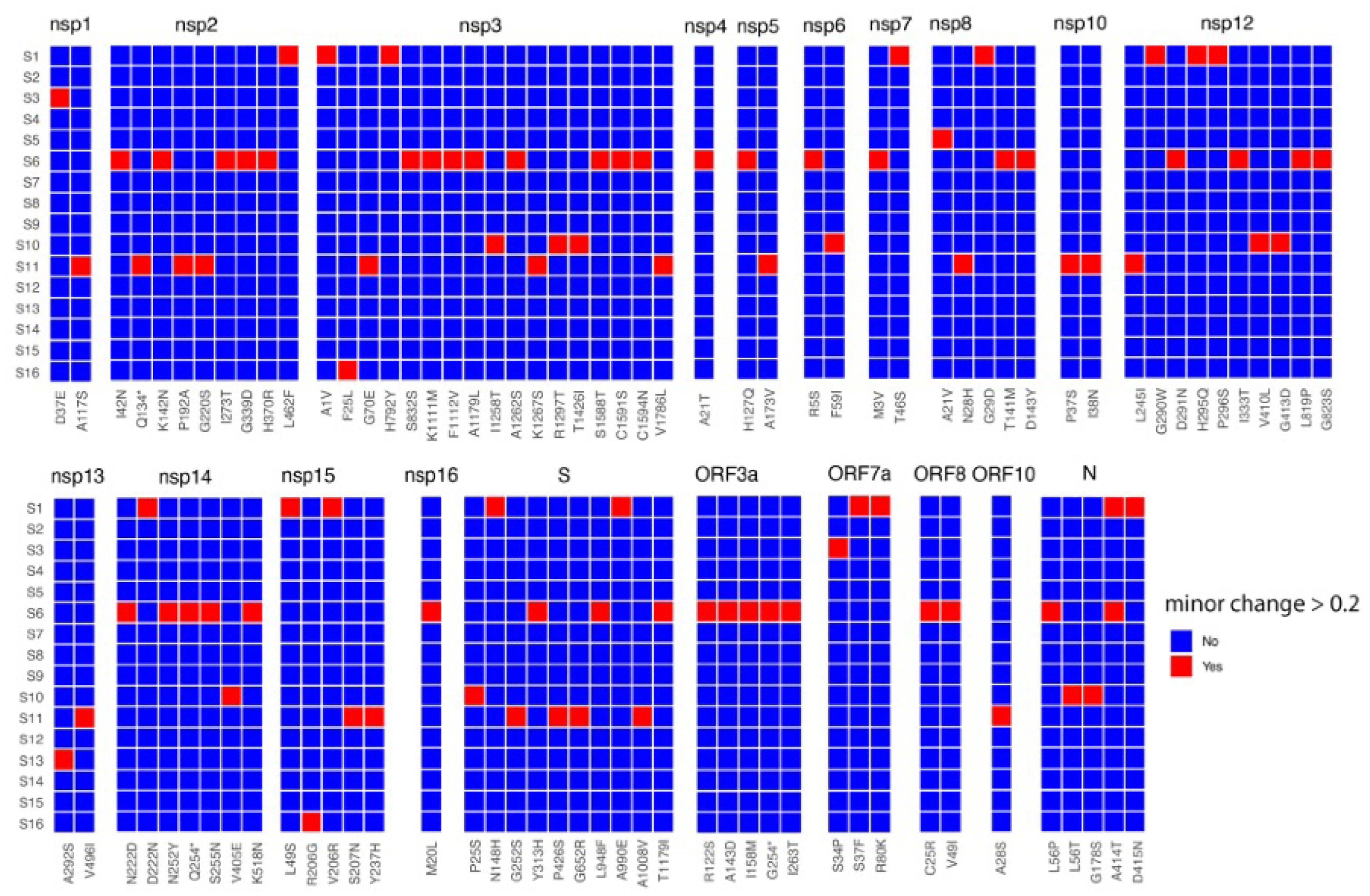
3. Results and Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, F.; Zhao, S.; Yu, B.; Chen, Y.M.; Wang, W.; Song, Z.G.; Hu, Y.; Tao, Z.W.; Tian, J.H.; Pei, Y.Y.; et al. A new coronavirus associated with human respiratory disease in China. Nature 2020, 579, 265–269. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef] [Green Version]
- Pekar, J.E.; Magee, A.; Parker, E.; Moshiri, N.; Izhikevich, K.; Havens, J.L.; Gangavarapu, K.; Serrano, L.M.M.; Crits-Christoph, A.; Matteson, N.L.; et al. SARS-CoV-2 emergence very likely resulted from at least two zoonotic events. Zenodo 2022. preprint. [Google Scholar] [CrossRef]
- Worobey, M.; Levy, J.I.; Malpica Serrano, L.M.; Crits-Christoph, A.; Pekar, J.E.; Goldstein, S.A.; Rasmussen, A.L.; Kraemer, M.U.; Newman, C.; Koopmans, M.P.G.; et al. The Huanan market was the epicenter of SARS-CoV-2 emergence. Zenodo 2022. preprint. [Google Scholar] [CrossRef]
- Korber, B.; Fischer, W.M.; Gnanakaran, S.; Yoon, H.; Theiler, J.; Abfalterer, W.; Hengartner, N.; Giorgi, E.E.; Bhattacharya, T.; Foley, B.; et al. Tracking Changes in SARS-CoV-2 Spike: Evidence that D614G Increases Infectivity of the COVID-19 Virus. Cell 2020, 182, 812–827.e19. [Google Scholar] [CrossRef] [PubMed]
- Volz, E.; Hill, V.; McCrone, J.T.; Price, A.; Jorgensen, D.; O’Toole, A.; Southgate, J.; Johnson, R.; Jackson, B.; Nascimento, F.F.; et al. Evaluating the Effects of SARS-CoV-2 Spike Mutation D614G on Transmissibility and Pathogenicity. Cell 2021, 184, 64–75.e11. [Google Scholar] [CrossRef] [PubMed]
- Lu, R.; Zhao, X.; Li, J.; Niu, P.; Yang, B.; Wu, H.; Wang, W.; Song, H.; Huang, B.; Zhu, N.; et al. Genomic characterisation and epidemiology of 2019 novel coronavirus: Implications for virus origins and receptor binding. Lancet 2020, 395, 565–574. [Google Scholar] [CrossRef] [Green Version]
- Zhou, P.; Yang, X.L.; Wang, X.G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.R.; Zhu, Y.; Li, B.; Huang, C.L.; et al. A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature 2020, 579, 270–273. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Munoz-Basagoiti, J.; Rickett, N.Y.; Pollakis, G.; Paxton, W.A.; Günther, S.; Kerber, R.; Ng, L.F.; Elmore, M.J.; Magassouba, N.F. Variation around the dominant viral genome sequence contributes to viral load and outcome in patients with Ebola virus disease. Genome Biol. 2020, 21, 238. [Google Scholar] [CrossRef]
- Dowall, S.D.; Matthews, D.A.; Garcia-Dorival, I.; Taylor, I.; Kenny, J.; Hertz-Fowler, C.; Hall, N.; Corbin-Lickfett, K.; Empig, C.; Schlunegger, K.; et al. Elucidating variations in the nucleotide sequence of Ebola virus associated with increasing pathogenicity. Genome Biol. 2014, 15, 540. [Google Scholar] [CrossRef]
- Carroll, M.W.; Matthews, D.A.; Hiscox, J.A.; Elmore, M.J.; Pollakis, G.; Rambaut, A.; Hewson, R.; García-Dorival, I.; Bore, J.A.; Koundouno, R. Temporal and spatial analysis of the 2014–2015 Ebola virus outbreak in West Africa. Nature 2015, 524, 97. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Langmead, B.; Salzberg, S.L. HISAT: A fast spliced aligner with low memory requirements. Nat. Methods 2015, 12, 357–360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R. The sequence alignment/map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Töpfer, A.; Zagordi, O.; Prabhakaran, S.; Roth, V.; Halperin, E.; Beerenwinkel, N. Probabilistic inference of viral quasispecies subject to recombination. J. Comput. Biol. 2013, 20, 113–123. [Google Scholar] [CrossRef]
- Morelli, M.J.; Wright, C.F.; Knowles, N.J.; Juleff, N.; Paton, D.J.; King, D.P.; Haydon, D.T. Evolution of foot-and-mouth disease virus intra-sample sequence diversity during serial transmission in bovine hosts. Vet. Res. 2013, 44, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garrison, E.; Marth, G. Haplotype-based variant detection from short-read sequencing. arXiv 2012, arXiv:1207.3907. [Google Scholar]
- Garrison, E.; Kronenberg, Z.N.; Dawson, E.T.; Pedersen, B.S.; Prins, P. A spectrum of free software tools for processing the VCF variant call format: Vcflib, bio-vcf, cyvcf2, hts-nim and slivar. PLoS Comput. Biol. 2022, 18, e1009123. [Google Scholar] [CrossRef]
- Li, H.; Durbin, R. Fast and accurate short read alignment with Burrows–Wheeler transform. Bioinformatics 2009, 25, 1754–1760. [Google Scholar] [CrossRef] [Green Version]
- Faust, G.G.; Hall, I.M. SAMBLASTER: Fast duplicate marking and structural variant read extraction. Bioinformatics 2014, 30, 2503–2505. [Google Scholar] [CrossRef] [Green Version]
- Rausch, T.; Zichner, T.; Schlattl, A.; Stütz, A.M.; Benes, V.; Korbel, J.O. DELLY: Structural variant discovery by integrated paired-end and split-read analysis. Bioinformatics 2012, 28, i333–i339. [Google Scholar] [CrossRef] [Green Version]
- Schirmer, M.; D’Amore, R.; Ijaz, U.Z.; Hall, N.; Quince, C. Illumina error profiles: Resolving fine-scale variation in metagenomic sequencing data. BMC Bioinform. 2016, 17, 125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldswain, H.; Dong, X.; Penrice-Randal, R.; Alruwaili, M.; Shawli, G.T.; Prince, T.; Williamson, M.K.; Raghwani, J.; Randle, N.; Jones, B. The P323L substitution in the SARS-CoV-2 polymerase (NSP12) confers a selective advantage during infection. Genome Biol. 2023, 24, 47. [Google Scholar] [CrossRef]
- Gribble, J.; Stevens, L.J.; Agostini, M.L.; Anderson-Daniels, J.; Chappell, J.D.; Lu, X.; Pruijssers, A.J.; Routh, A.L.; Denison, M.R. The coronavirus proofreading exoribonuclease mediates extensive viral recombination. PLoS Pathog. 2021, 17, e1009226. [Google Scholar] [CrossRef]
- Sawicki, S.G.; Sawicki, D.L.; Siddell, S.G. A contemporary view of coronavirus transcription. J. Virol. 2007, 81, 20–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, X.; Penrice-Randal, R.; Goldswain, H.; Prince, T.; Randle, N.; Donovan-Banfield, I.; Salguero, F.J.; Tree, J.; Vamos, E.; Nelson, C.; et al. Analysis of SARS-CoV-2 known and novel subgenomic mRNAs in cell culture, animal model, and clinical samples using LeTRS, a bioinformatic tool to identify unique sequence identifiers. Gigascience 2022, 11, giac045. [Google Scholar] [CrossRef] [PubMed]
- Almazan, F.; Galan, C.; Enjuanes, L. The nucleoprotein is required for efficient coronavirus genome replication. J Virol 2004, 78, 12683–12688. [Google Scholar] [CrossRef] [Green Version]
- Zahradnik, J.; Marciano, S.; Shemesh, M.; Zoler, E.; Harari, D.; Chiaravalli, J.; Meyer, B.; Rudich, Y.; Li, C.; Marton, I.; et al. SARS-CoV-2 variant prediction and antiviral drug design are enabled by RBD in vitro evolution. Nat. Microbiol. 2021, 6, 1188–1198. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample ID | Accession ID | SRA ID | WHO ID | ID in Article | Virus Strain | Lineage | Gender | Age | Onset Date | Collection Date | Wuhan Seafood Market | ICU | Sample | Sequencing Method | Publication Link |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | SRX7705833 | SRR11059945 | - | - | nCov-RNA-3 | B | male | 40 | 15 December 2019 | 30 December 2019 | - | yes | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa207 accessed on 1 May 2022 |
| S2 | SRX7730880 | SRR11092063 | WHO_S04 | ICU-04 | WIV02 | B | male | 32 | 19 December 2019 | 30 December 2019 | Vendor | yes | BAL | Illumina HiSeq 3000 paired end sequencing | https://0-www-nature-com.brum.beds.ac.uk/articles/s41586-020-2012-7 accessed on 1 May 2022 |
| S3 | SRX7705834 | SRR11059944 | - | - | nCov-RNA-4 | B | male | 61 | 19 December 2019 | 1 January 2020 | Visitor | yes | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa203 accessed on 1 May 2022 |
| S4 | SRX7636886 | SRR10971381 | WHO_S06 | - | Hu-1 | B | male | 41 | 20 December 2019 | 26 December 2019 | Worker | - | BAL | Illumina MiniSeq paired end sequencing | https://0-www-nature-com.brum.beds.ac.uk/articles/s41586-020-2008-3 accessed on 1 May 2022 |
| S5 | SRX7730884 | SRR11092059 | WHO_S08 | ICU-10 | WIV07 | B | male | 56 | 20 December 2019 | 30 December 2019 | Vendor | yes | BAL | Illumina HiSeq 3000 paired end sequencing | https://0-www-nature-com.brum.beds.ac.uk/articles/s41586-020-2012-7 accessed on 1 May 2022 |
| S6 | SRX7705836 | SRR11059942 | - | - | nCov-RNA-6 | B | male | 56 | 20 December 2019 | 30 December 2019 | - | yes | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa209 accessed on 1 May 2022 |
| S7 | SRX7730882 | SRR11092061 | WHO_S11 | ICU-08 | WIV05 | B | female | 52 | 22 December 2019 | 30 December 2019 | Vendor | yes | BAL | Illumina HiSeq 3000 paired end sequencing | https://0-www-nature-com.brum.beds.ac.uk/articles/s41586-020-2012-7 accessed on 1 May 2022 |
| S8 | SRX7730883 | SRR11092060 | WHO_S12 | ICU-09 | WIV06 | B | male | 40 | 22 December 2019 | 30 December 2019 | Vendor | yes | BAL | Illumina HiSeq 3000 paired end sequencing | https://0-www-nature-com.brum.beds.ac.uk/articles/s41586-020-2012-7 accessed on 1 May 2022 |
| S9 | SRX7705831 | SRR11059947 | - | - | nCov-RNA-1 | B | female | 49 | 22 December 2019 | 30 December 2019 | - | no | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa205 accessed on 1 May 2022 |
| S10 | SRX7705832 | SRR11059946 | - | - | nCov-RNA-2 | B | female | 52 | 22 December 2019 | 30 December 2019 | - | yes | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa206 accessed on 1 May 2022 |
| S11 | SRX7705835 | SRR11059943 | - | - | nCov-RNA-5 | B | male | 40 | 22 December 2019 | 30 December 2019 | - | no | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa208 accessed on 1 May 2022 |
| S12 | SRX7730881 | SRR11092062 | WHO_S10 | ICU-06 | WIV04 | B | female | 49 | 23 December 2019 | 30 December 2019 | Vendor | yes | BAL | Illumina HiSeq 1000 paired end sequencing | https://0-www-nature-com.brum.beds.ac.uk/articles/s41586-020-2012-7 accessed on 1 May 2022 |
| S13 | SRX7705837 | SRR11059941 | - | - | nCov-RNA-7 | B | female | 53 | 24 December 2019 | 1 January 2020 | No | no | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa204 accessed on 1 May 2022 |
| S14 | SRX7705838 | SRR11059940 | - | - | nCov-RNA-8 | B | male | 41 | 26 December 2019 | 30 December 2019 | - | no | BAL | Illumina HiSeq 2500 paired end sequencing | https://0-doi-org.brum.beds.ac.uk/10.1093/cid/ciaa210 accessed on 1 May 2022 |
| S15 | SRX8032203 | SRR11454614 | - | - | HBCDC-HB-01/2019 | B | female | 49 | - | 30 December 2019 | - | - | BAL | Illumina MiSeq paired end sequencing | |
| S16 | SRX8032205 | SRR11454612 | - | - | HBCDC-HB-04/2019 | B | male | - | - | 30 December 2019 | - | - | sputum | Illumina MiSeq paired end sequencing |
| Sample | Position | Site Coverage | C8782U | U28144C |
|---|---|---|---|---|
| S01 | 8782 | 16 | 0.00% | 0.00% |
| S02 | 8782 | 1 | 0.00% | 0.00% |
| S03 | 8782 | 846 | 0.12% | 0.07% |
| S04 | 8782 | 209 | 0.00% | 0.00% |
| S05 | 8782 | 16 | 0.00% | 0.00% |
| S06 | 8782 | 5 | 0.00% | 0.00% |
| S07 | 8782 | 3 | 0.00% | 0.00% |
| S08 | 8782 | 5 | 0.00% | 0.00% |
| S09 | 8782 | 28619 | 0.16% | 0.18% |
| S10 | 8782 | 1413 | 0.07% | 0.19% |
| S11 | 8782 | NA | NA | NA |
| S12 | 8782 | 82 | 0.00% | 0.00% |
| S13 | 8782 | 9 | 0.00% | 0.00% |
| S14 | 8782 | 63 | 0.00% | 0.00% |
| S15 | 8782 | 2781 | 0.07% | 0.27% |
| S16 | 8782 | 3 | 0.00% | 0.00% |
| Sample | Position | Gene | Reference | Alternative | Inserted Nucleotide | Deleted Nucleotide | Quality Score |
|---|---|---|---|---|---|---|---|
| S1 | 8084 | nsp3 | GAAAAACT | GAAAACT | - | A | 4290.82 |
| S1 | 18976 | nsp14 | CAACACA | CAAACACA | A | - | 452.059 |
| S6 | 8837 | nsp4 | ATA | AA | - | T | 22.9267 |
| S6 | 13884 | nsp12 | ATA | AA | - | T | 43.2573 |
| S6 | 13893 | nsp12 | TTG | TATG | - | A | 21.4099 |
| S11 | 2550 | nsp2 | TAAACCAACCAT | TACCAACCAT | - | AA | 1276.76 |
| S11 | 6023 | nsp3 | TATCCAA | TATCAA | - | C | 1001.59 |
| S11 | 10024 | nsp4 | ACA | ATCA | T | - | 330.538 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, X.; Hiscox, J.A. Analysis of SARS-CoV-2 Population Genetics from Samples Associated with Huanan Market and Early Cases Identifies Substitutions Associated with Future Variants of Concern. Viruses 2023, 15, 1728. https://0-doi-org.brum.beds.ac.uk/10.3390/v15081728
Dong X, Hiscox JA. Analysis of SARS-CoV-2 Population Genetics from Samples Associated with Huanan Market and Early Cases Identifies Substitutions Associated with Future Variants of Concern. Viruses. 2023; 15(8):1728. https://0-doi-org.brum.beds.ac.uk/10.3390/v15081728
Chicago/Turabian StyleDong, Xiaofeng, and Julian A. Hiscox. 2023. "Analysis of SARS-CoV-2 Population Genetics from Samples Associated with Huanan Market and Early Cases Identifies Substitutions Associated with Future Variants of Concern" Viruses 15, no. 8: 1728. https://0-doi-org.brum.beds.ac.uk/10.3390/v15081728