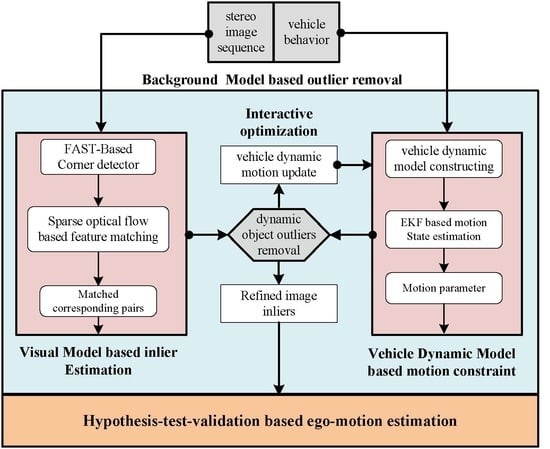
2.2. Data Association of Forward-Facing and Backward-Facing Cameras
With the purpose of fitting and fusing the data of a backward-facing monocular camera and forward-facing stereo camera, the key point of data synchronization both in spatial and temporal space must be solved beforehand, which is shown
Figure 2.
Within the stereo camera, left frame and right frame are triggered at the same time by the hardware flip-flop circuit. Then, we can assume that they were hardware synchronized and have the same timestamps. Hence, we only need to synchronize the data between monocular camera and stereo camera both in spatial and temporal space.
Using the camera intrinsic and extrinsic parameters, the data association in spatial space can be easily calculated and it will not change over time because of the rigid body motion assumption. Second, in temporal synchronization, we assume that the ego-motion has the same velocity between two consequent frames of stereo camera. So, after transforming the data from space into the space, there are two temporal synchronization steps that need to be dealt with—translation synchronization step and rotation synchronization.
In the translation synchronization step, linear interpolation method was given under the constant velocity assumption. In our method, we transform the data from monocular camera into stereo camera coordinate, as follows.
Here,
and
is the consecutive timestamps of stereo camera frames,
is the timestamp of monocular camera frame pending to be associated.
is the time difference calculated by
(in Equation (
1), we take
for example).
is the velocity value in this time gap.
and
are the motion states in the time
and
of stereo camera.
When it comes to the rotation synchronization step, however, the rotation matrix has a universal locking problem and cannot be directly used for interpolation. In our method, we use the spherical linear interpolation method with the rotation angles transformed to the unit quaternion representation space. Assuming
and
are the unit quaternion for the timestamps
and
, the rotation synchronization value
can be calculated by the following equation.
In this equation, e is the interpolation coefficient and it can be calculated by . can be obtained from the inverse trigonometric function . It has the advantage of convenient calculation and good performance.
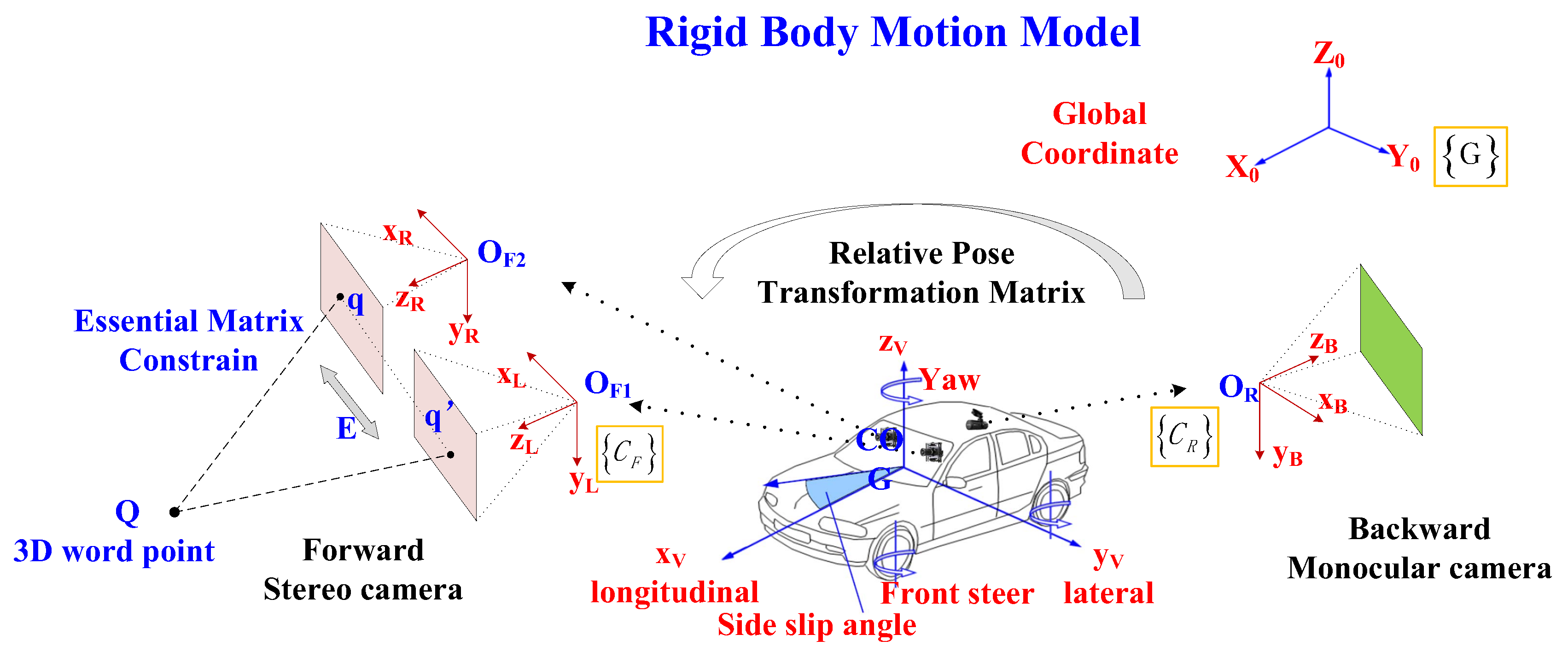
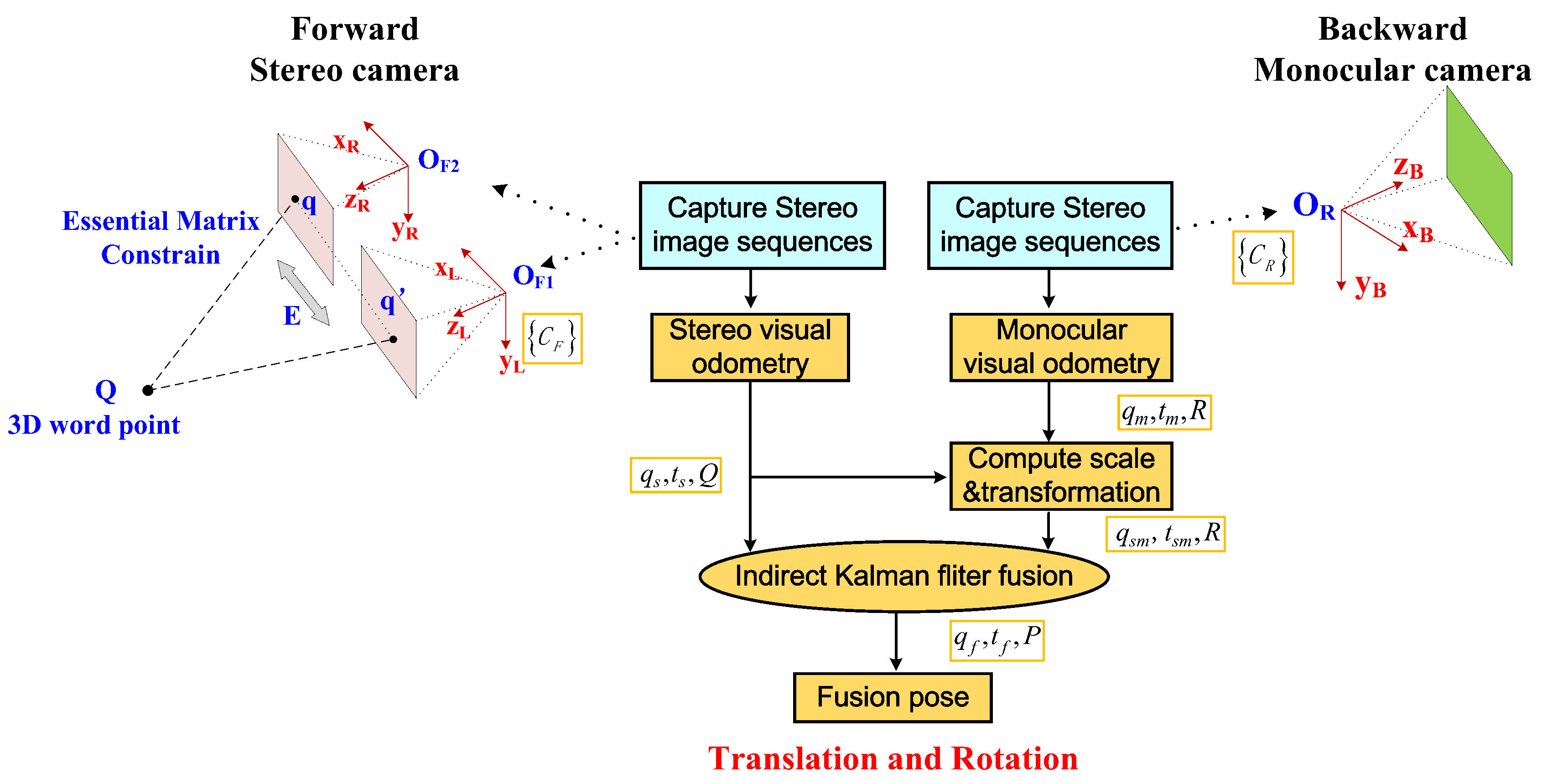
2.3. Loosely Coupled Framework for Trajectory Fusion
The detail fusion processing of forward stereo camera and backward monocular camera is shown in
Figure 3. It shows that our approach runs separate the stereo visual odometry and monocular visual odometry and fusion in the decision level. Therefore, it should be classified to loosely coupled fusion method.
This framework choice would bring several good features. At first, loosely coupled fusion method support the stereo visual odometry and monocular visual odometry working as independent modules, which bring the fusion system with the capability of handing camera module degradation. Second, with the opposite orientation of forward and backward, the fusion pipeline can comprehensively utilize the nearby environment information and take advantage of the time difference from front forward stereo camera to rear backward monocular camera. Third, the system cost is much lower than other construction scheme, such as two sets of stereo vision system, lidar based odometry, or other kinds of precise localization sensor based systems.
2.4. Basic Visual Odometry Method
In our proposed loosely coupled fusion method, featured-based visual odometry was used as the fundamental motion estimation method to compute the translation and rotation of both forward facing stereo camera and backward facing monocular camera and it has a deep influence on the correctness and effectiveness of our method. It has three modules including feature extraction and matching, pose tracking, and local bundle adjustment.
Feature Extraction and Matching: In order to extract and match feature points rapidly, ORB points (Oriented Fast and Rotated BRIEF) were selected as image features, which have good multi-scale and oriented invariance to viewpoints. In the implementation, feature points in each layer of image pyramid space were extracted respectively and the maximum feature points in the unit grid were set to less than five points, making them uniform-distributed. Specifically, for the stereo camera, feature points in the left and right images were extracted simultaneously using two parallel threads and the matching process was employed to delete the isolate points under the epipolar geometry constraints. In the feature matching stage, the Hamming distance was applied to measure the distance of feature points and the best matching should not exceed 30%. Meanwhile, the Fast Library for Approximate Nearest Neighbors (FLANN) method was also used to speed up the feature matching process.
Pose Tracking: The motion model and keyframe based pose tracking method were used to estimate the successive pose of ego vehicle. Firstly, the uniform motion model was used to track feature points and get matching pairs in successive frames with the help of observed 3D map points. With the matching pairs, we can estimate the camera motion using PnP optimization method of minimizing the reprojection errors of all matching point pairs. However, if the matching point pairs are less than certain threshold, the keyframe based pose tracking method woude be activated. Using bag of words(BOW) mode, it can track and match the feature points between the current frame and the closest keyframe.
Local Bundle Adjustment: In this step, the 3D map points observed by closest keyframes were mapped to the current feature points and the poses and 3D map points were adjusted and optimized simultaneously to minimize the reprojection errors. In the application, in order to keep a real-time performance for the system, the maximum number of iterations should be set to a certain value.
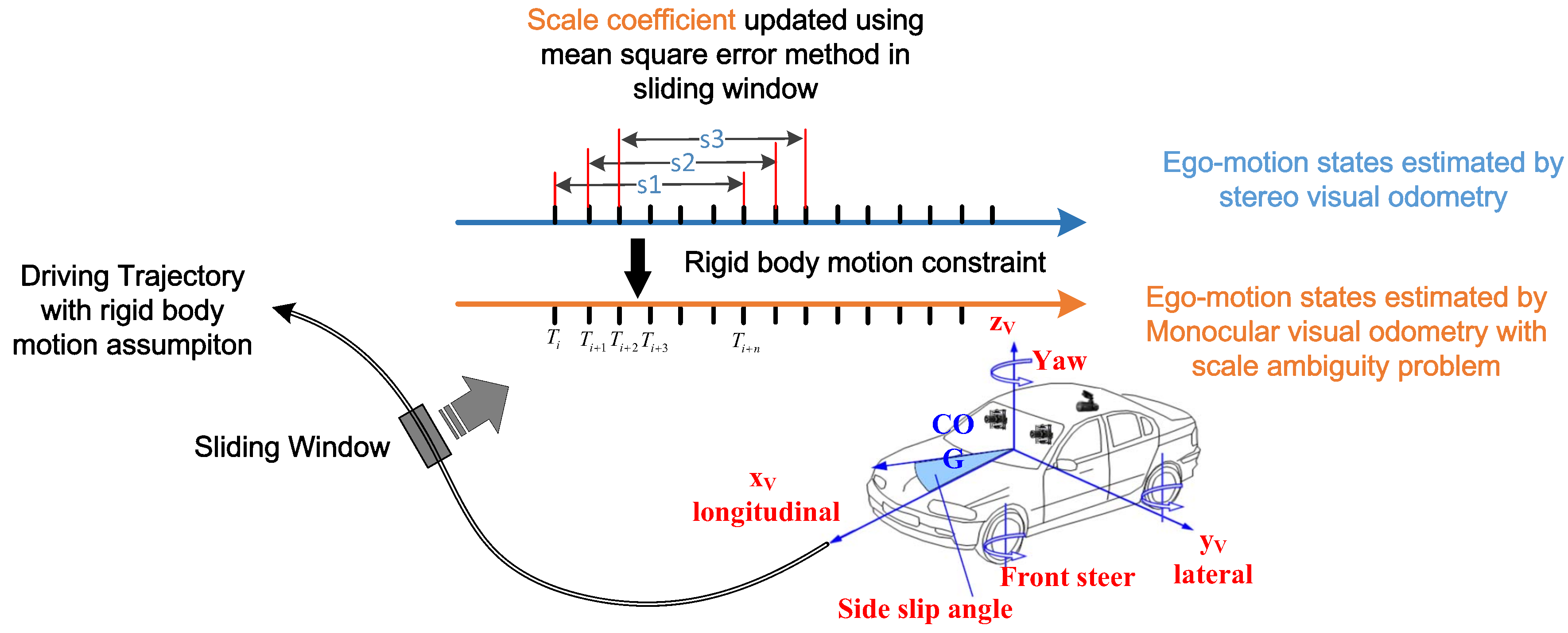
2.5. Scale of Monocular Visual Odometry
To avoid the scale ambiguity in the monocular visual odometry and make it work independently, we use the sliding window based scale estimation method. In the sliding window, mean square error (MSE) was used to dynamically correct and update the scale coefficient under the rigid body motion assumption, as shown in
Figure 4.
In the sliding window, we assume that there are
n monocular visual odometry states of
and
n stereo visual odometry states
. Here, it is noteworthy that, the states of stereo visual odometry has been synchronized to monocular visual odometry states both in spatial and temporal space. Unbiased estimation of the mathematical expectations of those states can be calculated as follows:
The above states can be data centralized to
and
by:
Theoretically, under the rigid body assumption, the relative move distance of the forward stereo camera and backward monocular camera should be equal to each other within the sliding window. So, the problem can be transformed to align the n monocular visual odometry states to the corresponding n points in stereo visual odometry states space.
In practice, there must be some alignment bias and the objective of optimization function should be the minimization of alignment bias. Here, MSE was employed to solve the issue, as in the following equation.
In the equation,
is the alignment bias,
s is the real scale coefficient of monocular visual odometry,
R is the rotation matrix obtained from camera calibration,
is the data centralized result of translation value. In order to minimize the alignment bias
, we can set
equal to 0. Then, we get the following equation.
Our goal is to solve the scale coefficient of
s and we found that the above equation is a bivariate linear equation, with the following form.
with
Then, through solving the bivariate linear problem, we can get the result of the scale coefficient of
s as:
However, in Equation (
8), the scale coefficient of
s is not symmetric. It means that, there is no reciprocal relation between
s (projecting data from monocular visual odometry to stereo visual odometry) and
(projecting data from stereo visual odometry to monocular visual odometry). So, we rewrite the alignment bias
into the following form.
Then, the Equation (
7) turns to:
Then, we can get the new result of scale coefficient of
and take it as the scale of current monocular visual odometry sliding window end state
:
By comparing Formulas (8) and (11), we can know that the new Equation (
11) can calculate the scale coefficient
without solving the rotation matrix
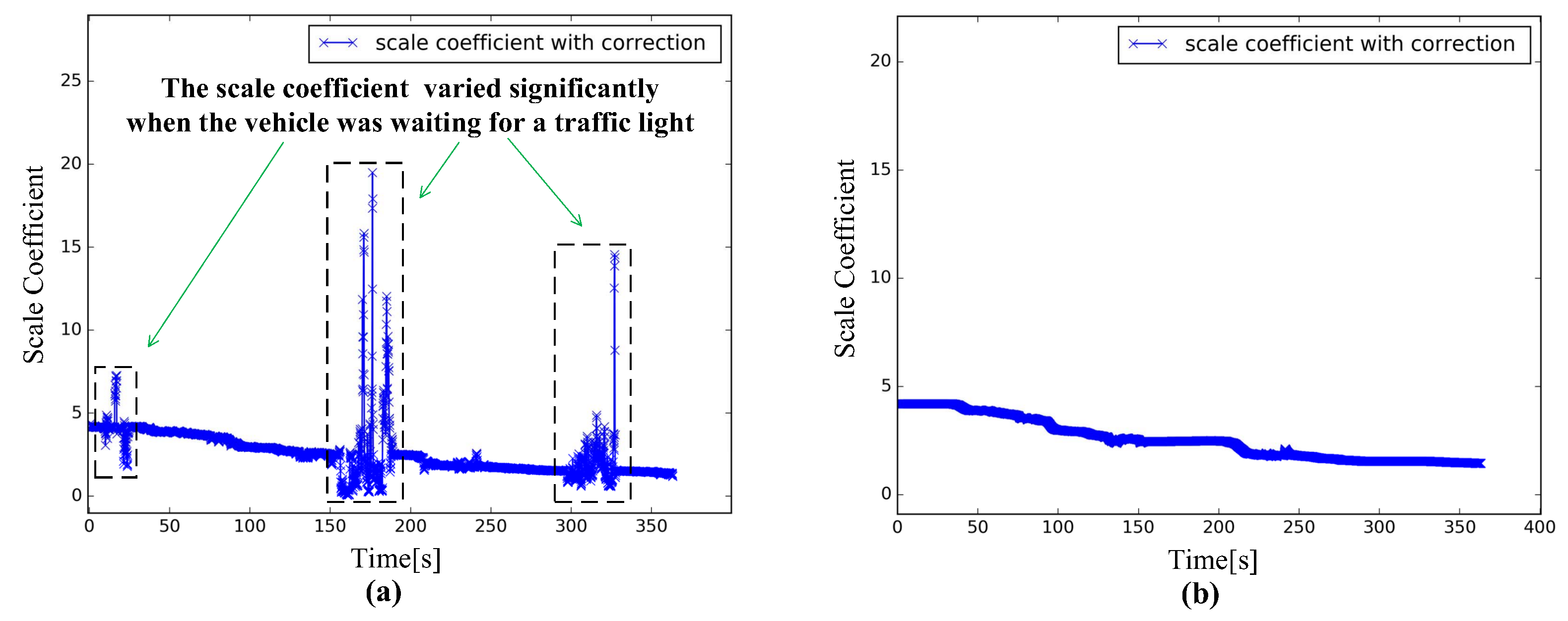
R. In practice, the scale estimation method is influenced seriously by vehicle motion state, especially stationary state or the changes of motion state. Therefore, we adjust the strategy of scale estimation and correct monocular scale step by step by considering the effect of vehicle motion state.
In this equation,
is the scale updating factor, and
is the updating scale coefficient of monocular visual odometry. The velocity
is computed in the following steps. At first, computing the initial velocity
according to aligning stereo visual odometry position based on the uniform velocity model,
Then, we compare the initial velocity
with the velocity threshold
(0.04–0.06 m/s in our evaluation) and get the final velocity
,
Finally, the real value trajectory of monocular visual odometry can be calculated using the updated scale coefficient
, as shown in the following equation.
In this equation, is the transformation matrix from forward stereo camere to the backward monocular camera. is the transformation matrix for the different initialization time points. is the transformation matrix from the monocualr coordinate to the coordinate which is opposite to the global coordinate on X-O-Y plane.
2.6. Kalman Filter Based Trajectory Fusion
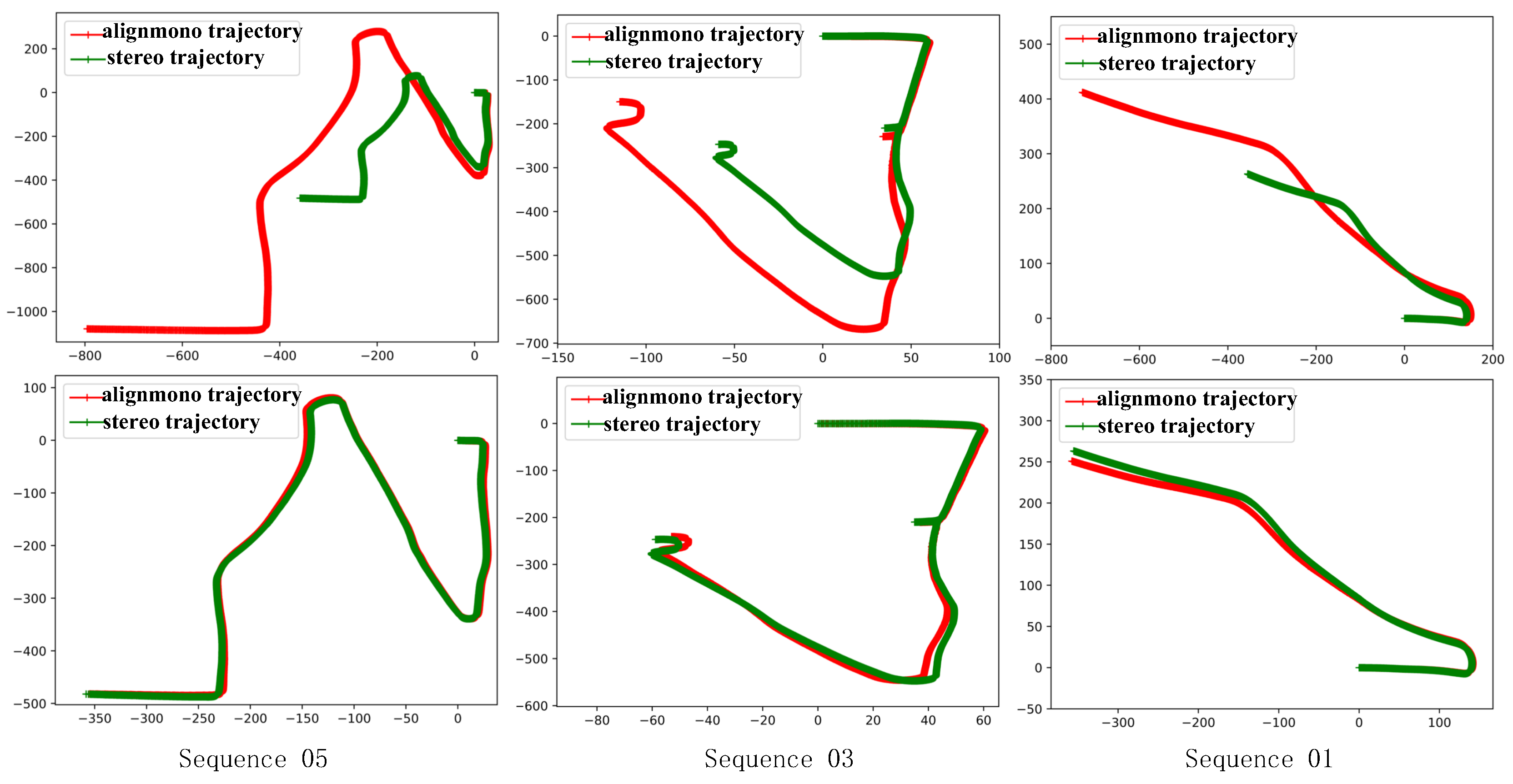
After giving a dynamically updated scale coefficient to the backward monocular visual odometry, the absolute ego-motion estimation can be correctly obtained. Then, in the sliding window, loosely coupled trajectory fusion was operated to get precise ego-motion estimation, using two-layers Kalman filter method.
2.6.1. Prediction Equation and Observation Equation
In the sliding window
, we first take the ego-motion state from forward stereo camera
as the state variable and establish state prediction equation as Formula (14). Then, we take the ego-motion state from backward monocular camera
as the observation and establish observation equation as Formula (15).
Here, is white Gaussian noise of state prediction equation, with covariance matrix of ; is white Gaussian noise of observation equation, with covariance matrix of . I is an identity matrix.
2.6.2. Calculation of Covariance Matrix
Accurately determining the covariance matrix Q and R would affect the accuracy of the trajectory fusion results. In the proposed method, the matching error of all image frames in the sliding window is considered during the calculation of visual odometry. We use minimum optimization error of each frame to measure the accuracy of the matching confidence and determine the covariance matrix.
Feature points based visual odometry is applied for both forward stereo camera and backward monocular camera and sparse 3-D map points are also reconstructed by different approaches. Here, we use back projection method for stereo camera and use triangulating method for monocular camera. By tracking the feature pairs between sequential images, the ego-motion estimation can be described as a 3D-to-2D problem. In the problem, the RANSAC method is employed to remove outliers. The 3D-to-2D feature pairs from both cameras are all considered in the same optimization function, shown in Equation (
16), which tries to minimize the reprojection error of the images and will concern the rigid constraint of the system.
where,
is total reprojection error,
R and
t are the rotation matrix and translation matrix between successive frames,
is the number of inliners of the visual odometry,
represent the indexes of feature points in the frame that matching the 3D map points.
represent the matched feature points in the frame,
are the corresponding 3D points in the 3D sparse map space.
is the projection function from 3D to 2D.
is the total projection error.
From the optimization function Equation (
16), we found that the more accuracy of the matching between 3D sparse map points and the corresponding 2D frame point, the better output of the pose obtained by solving the optimization equation. In practice, for the principle of comparability, we take into account of the number of frames in the sliding window and then we can get the mean reprojection error
as:
where
is the correction coefficient,
n is the number of frames in the sliding window,
when it represents stereo visual odometry and
for monocular visual odometry. Then, we can use
as diagonal elements to construct the covariance matrix
Q for process noise
w and can use
as diagonal elements to construct the covariance matrix
R for measurement noise
v.
2.6.3. Two-Layers Kalman Filter Based Trajectory Fusion
After obtaining the parameters of prediction equation and observation equation, along with the covariance matrix Q and R, we can benefit from the data fusion pipeline. Here, we employed two fusion space for the motion propagation process of both the position estimation and orientation estimation.
In the first level of the fusion stage, the relative position
was estimated in the Euclidean linear space. In the sliding window, the Kalman filter was used to construct the prediction equation and observation equation. The detail was shown in
Table 1. Where,
is the estimation of changes of relative position within the sliding window,
and
are the estimation of ego-motion states. For the Kalman gain
, it is a diagonal matrix and all diagonal elements are same. Hence, we use
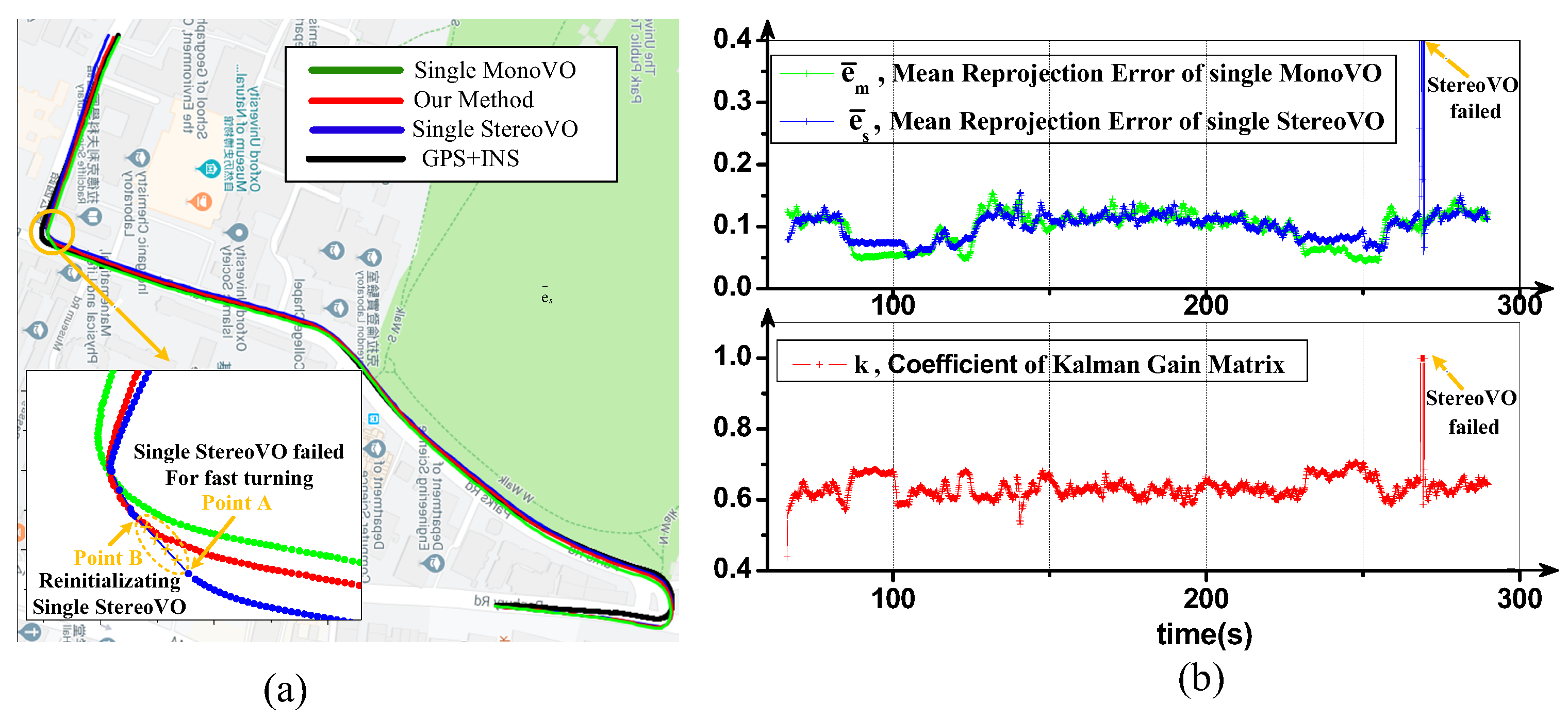
to represent diagonal matrix K and the k is the coefficient of Kalman gain matrix.
In the orientation estimation stage, we proposed an improved Kalman filter, which uses the orientation error space represented by unit quaternion as the state of the filter. In order to construct the motion propagation equation, the state vector of this filter need to be unified with four elements
, which can be described as follows:
where, ⊗ represents the multiplication of quaternion.Then, the estimation of orientation propagation states can be acquired by the following equation:
Here, is the estimation of relative orientation changes within the sliding window, are the estimation of ego-motion states represented by the unit quaternion. In this form, the state propagation model and measurement model would be much simpler. Moreover, the processing of the data fusion occurred in the error space was represented by the error quaternion, which could be closer to linear space and, thus, more suitable to the Kalman filter.
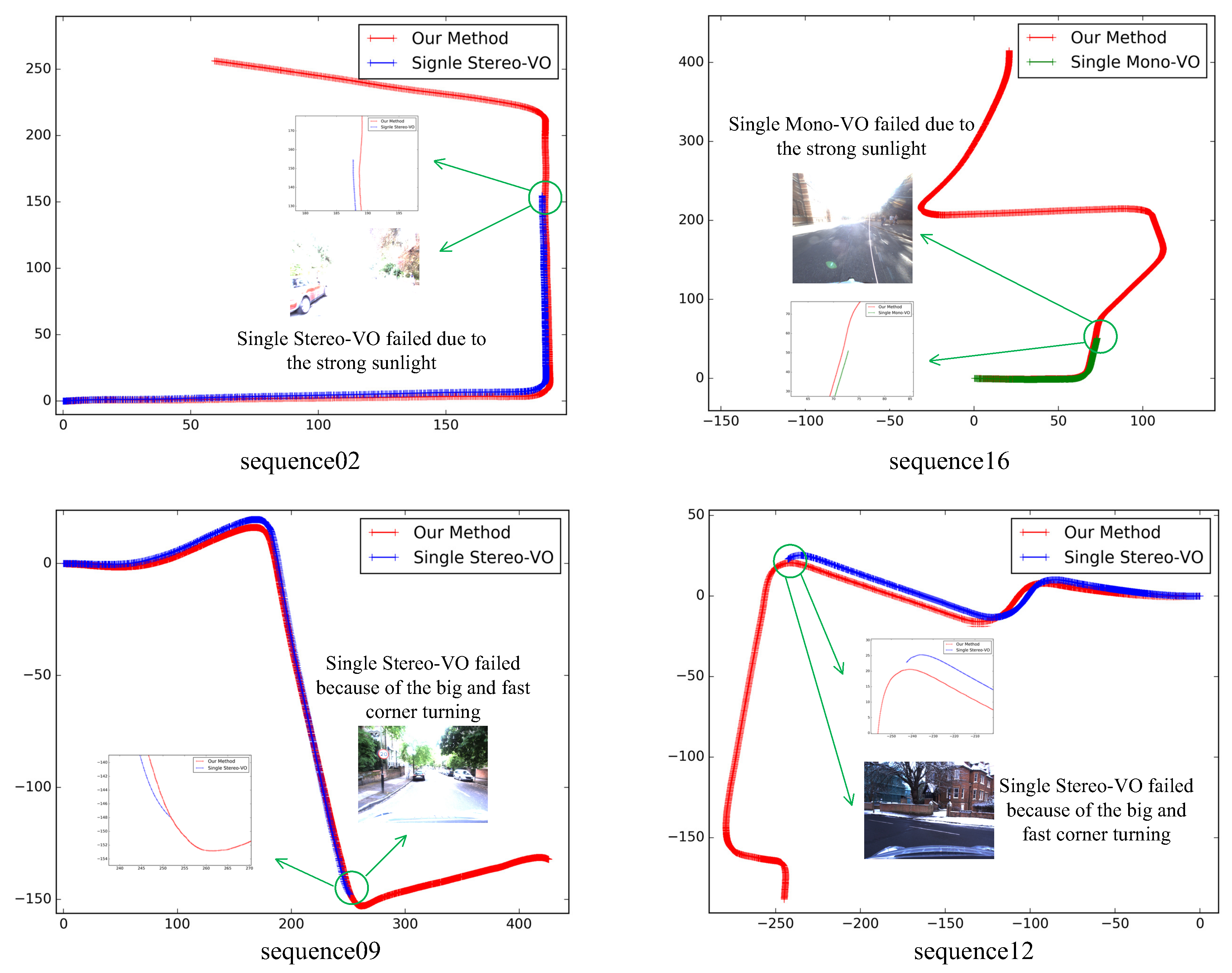
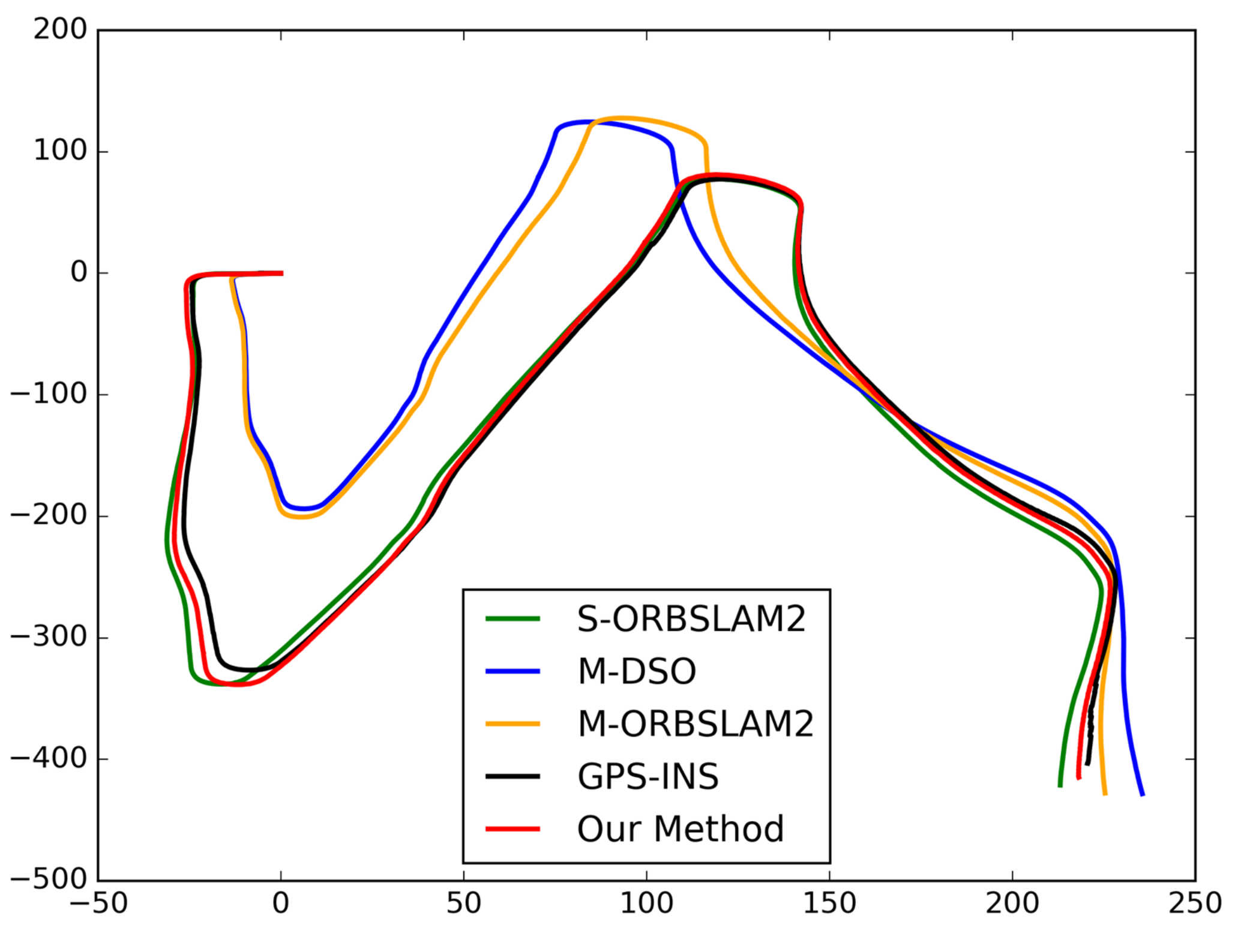
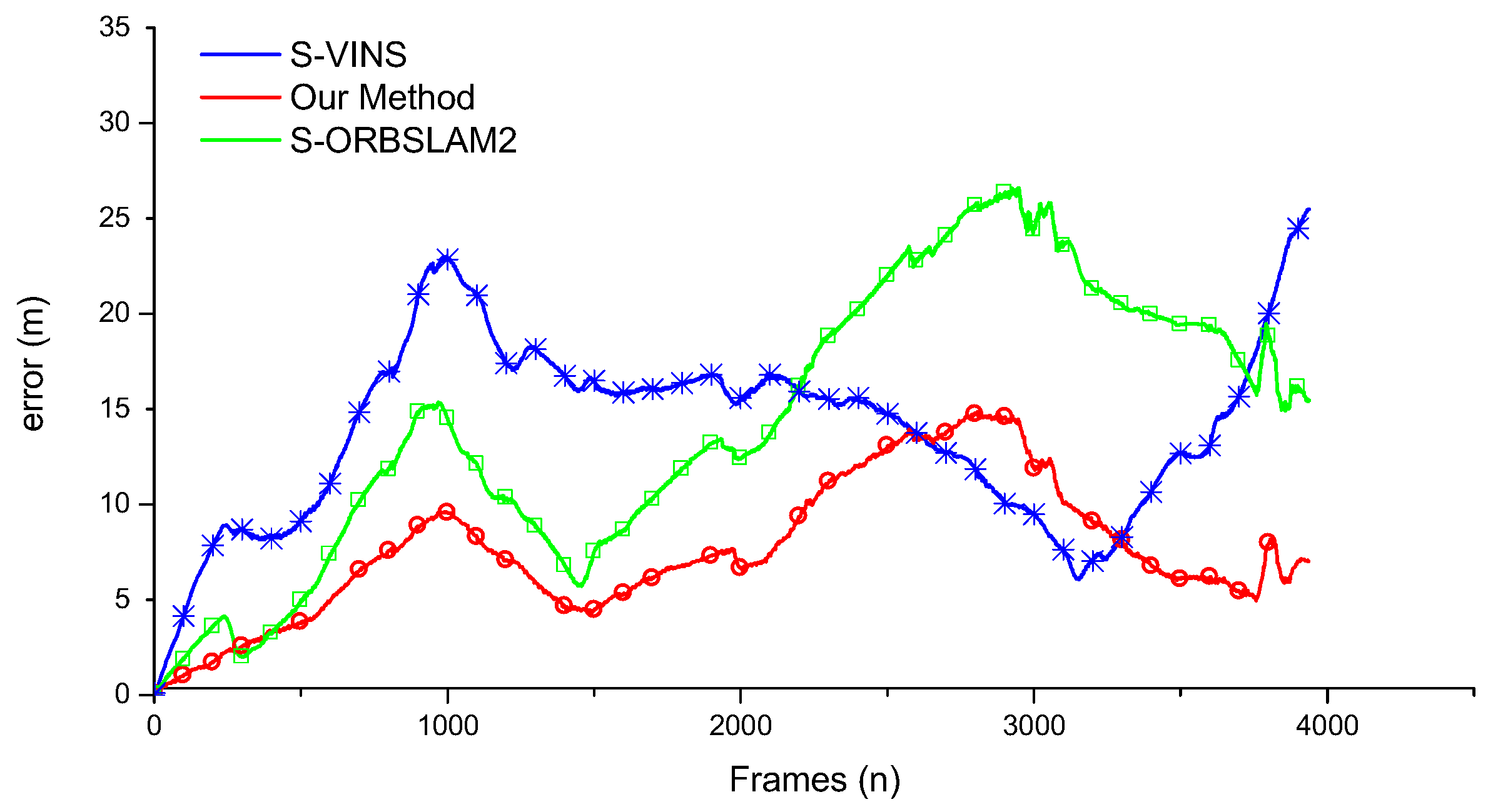
With the proposed trajectory fusion method, the ego-motion states can be computed accurately. When one of the forward-facing stereo camera or backward-facing monocular camera fails, the Kalman filter can automatically update the Kalman gain and reduce the credibility of the impaired camera naturally. It means that the proposed pipeline can fully or partially bypass failure modules and make use of the rest of the pipeline handle sensor degradation.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}