
ADT-Det: Adaptive Dynamic Refined Single-Stage Transformer Detector for Arbitrary-Oriented Object Detection in Satellite Optical Imagery


Abstract
:1. Introduction
- Large-scale difference. Objects in satellite images vary in size hugely [5]. There are small objects such as cars, ships, aircraft, and small houses in satellite images, as well as large objects such as ports, airports, ground track fields, bridges, and large buildings. In addition, the size of objects within the same category (such as large aircraft and small aircraft) in the same image also varies greatly.
- Dense distribution. There are many densely distributed objects in satellite optical images, such as cars and ships [5].
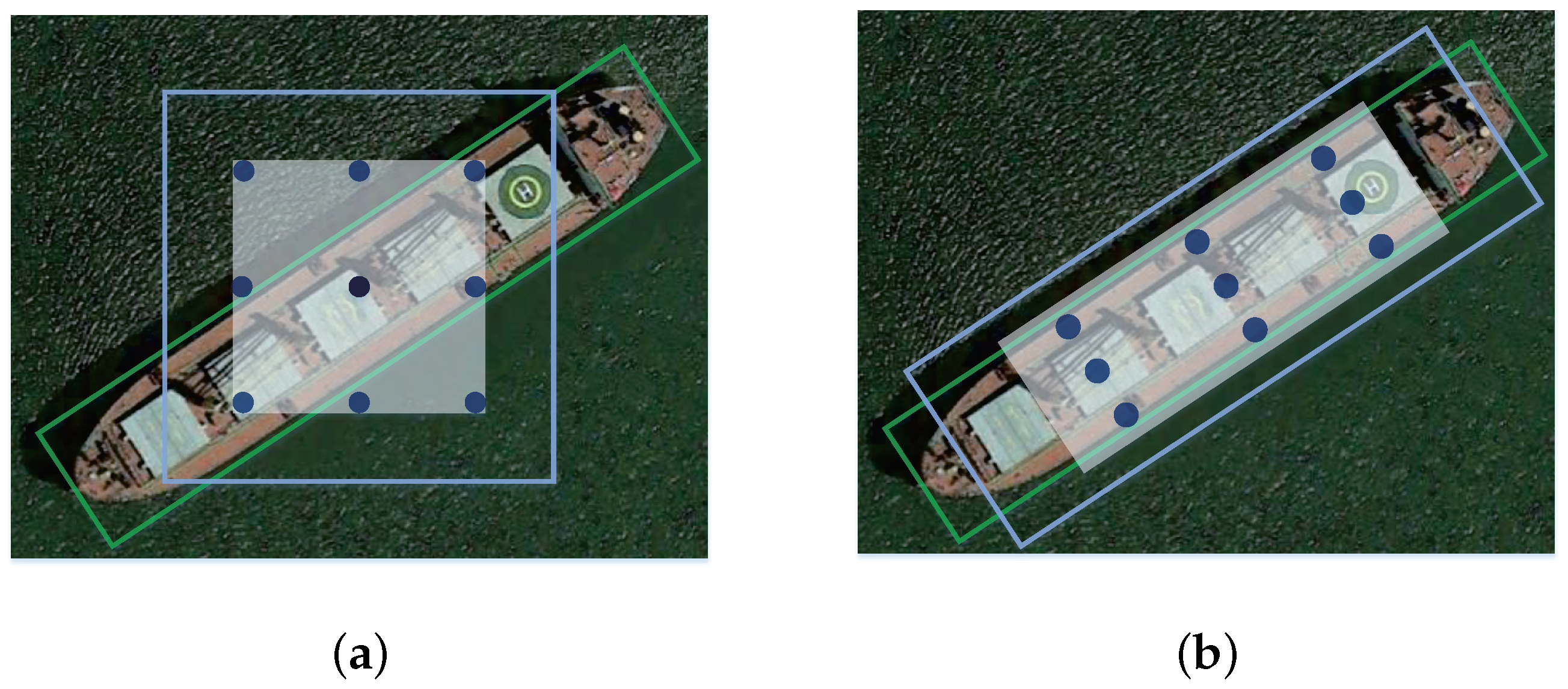
- Large aspect ratio. There are lots of objects with large aspect ratios, such as large vehicles, ships, harbors, and bridges in satellite optical images. The mismatch between the ground truth bounding box and the predicted bounding box of these objects is very sensitive to the rotation angle of objects [4].
- Category imbalance. Satellite optical imagery datasets are long-tailed, and the number of instances in each category varies greatly. For example, the amount of small vehicles is about 105 times larger than that of soccer ball fields in satellite optical imagery.
2. Related Studies
2.1. The Mainstream Detectors for Object Detection in Satellite Optical Imagery
2.2. General Designs for DCNN-Based Object Detection in Satellite Optical Imagery
2.2.1. Feature Pyramid Networks (FPN)
2.2.2. Spatial Transformer Network
2.2.3. Refined Object Detectiors
3. Methodology
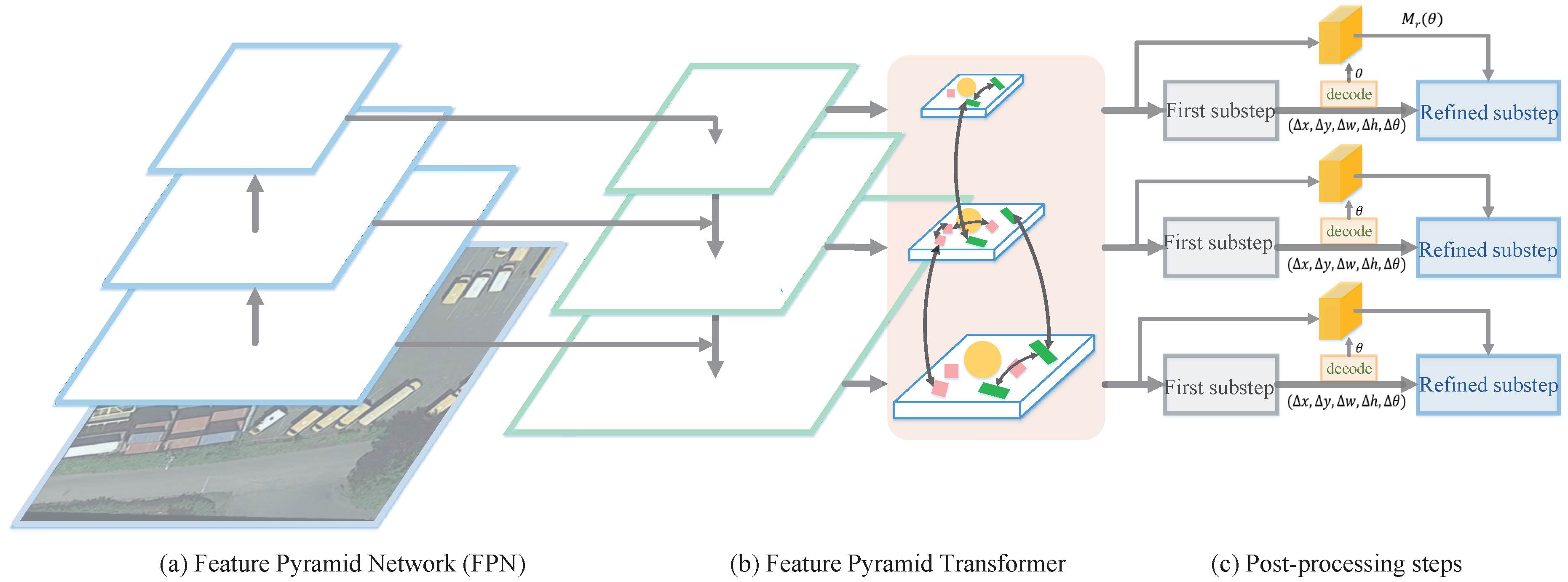
3.1. Network Architecture
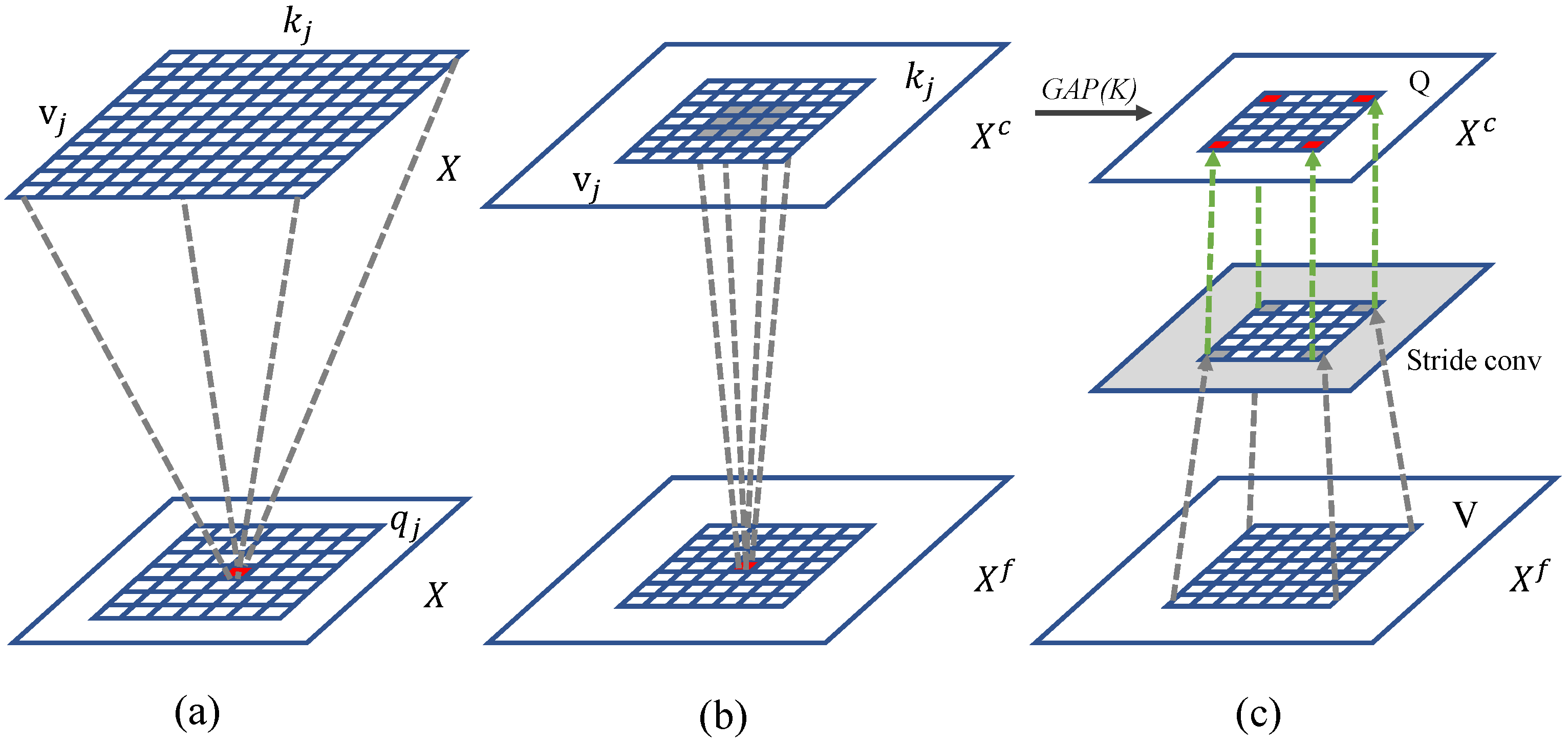
3.2. Feature Pyramid Transformer
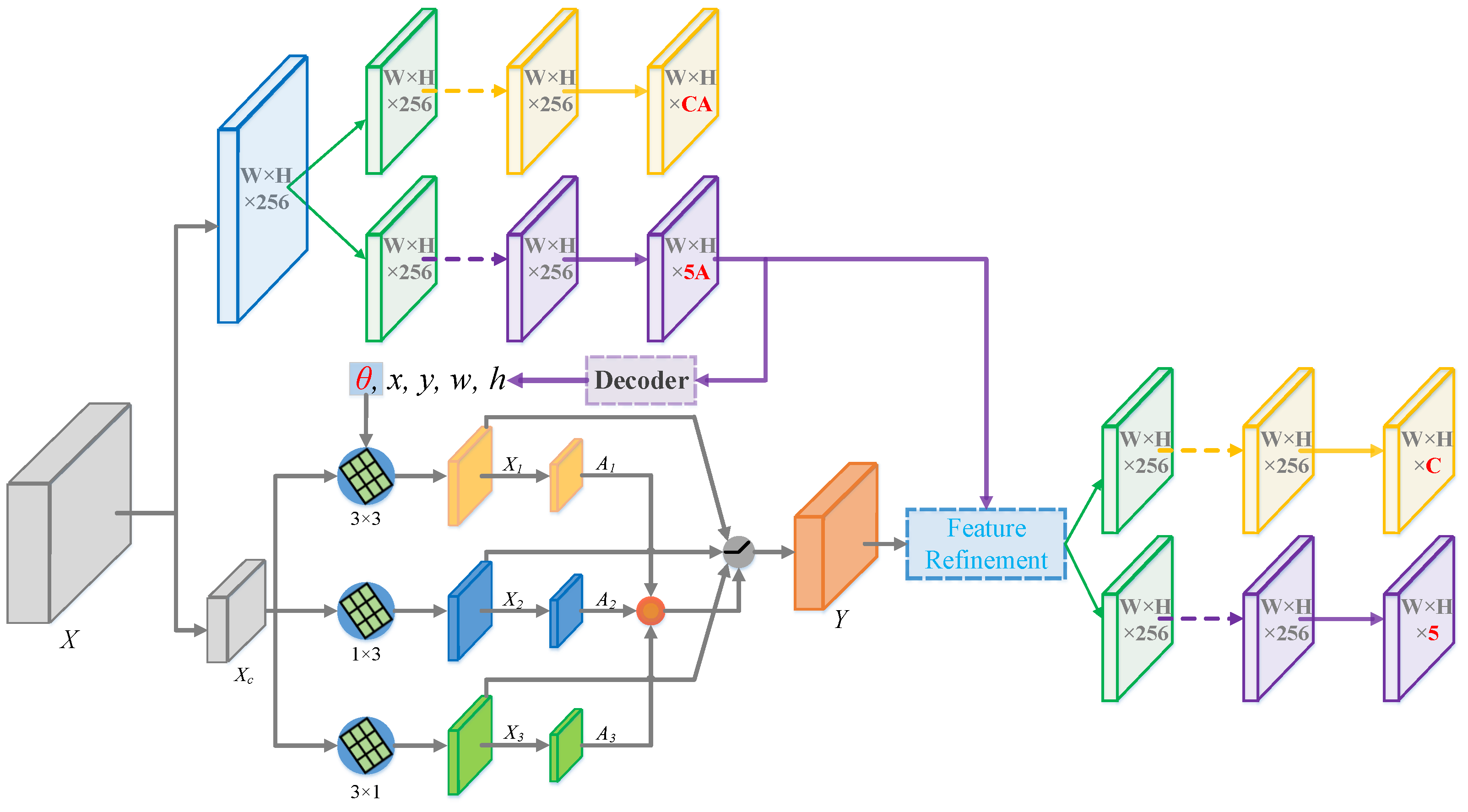
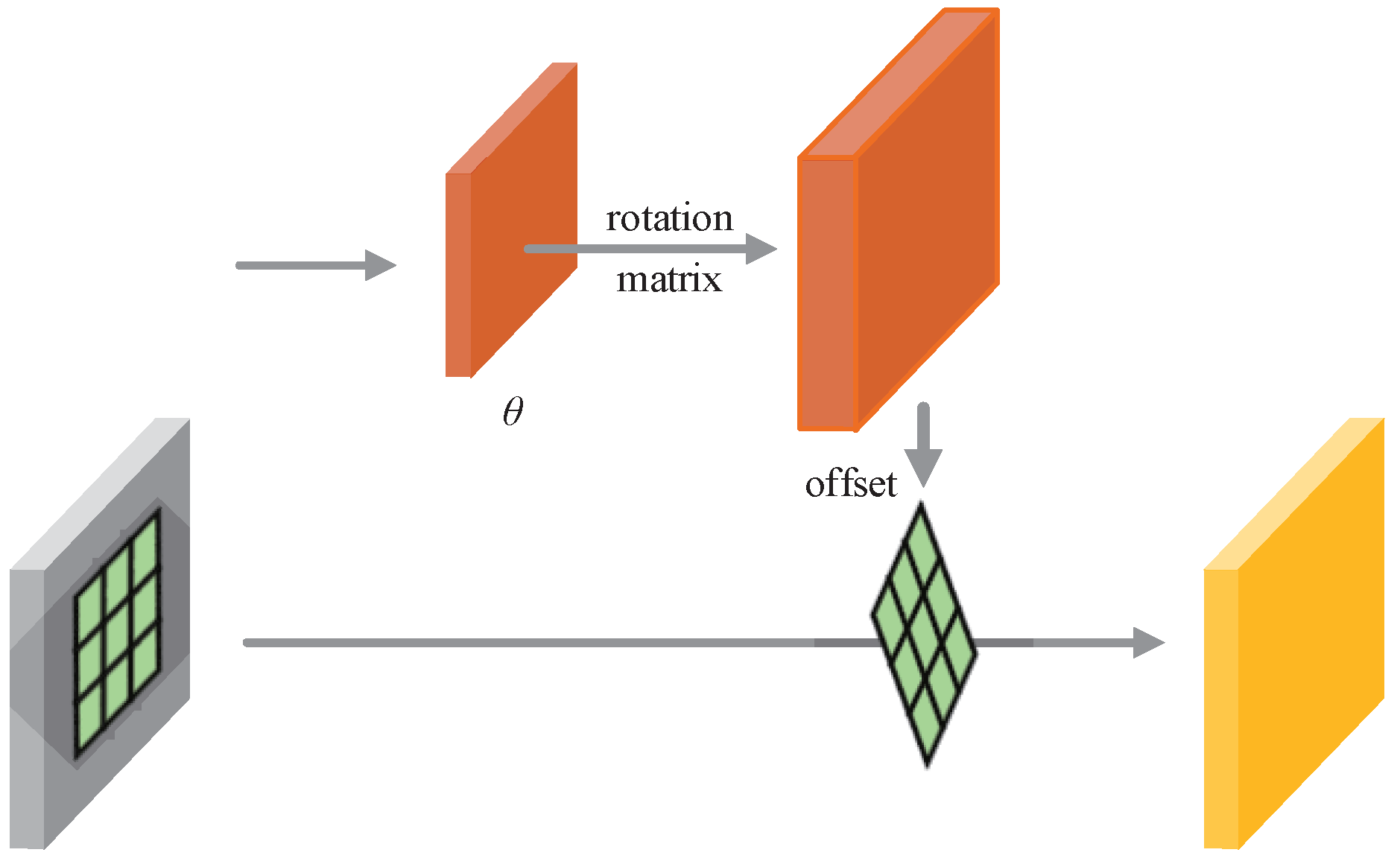
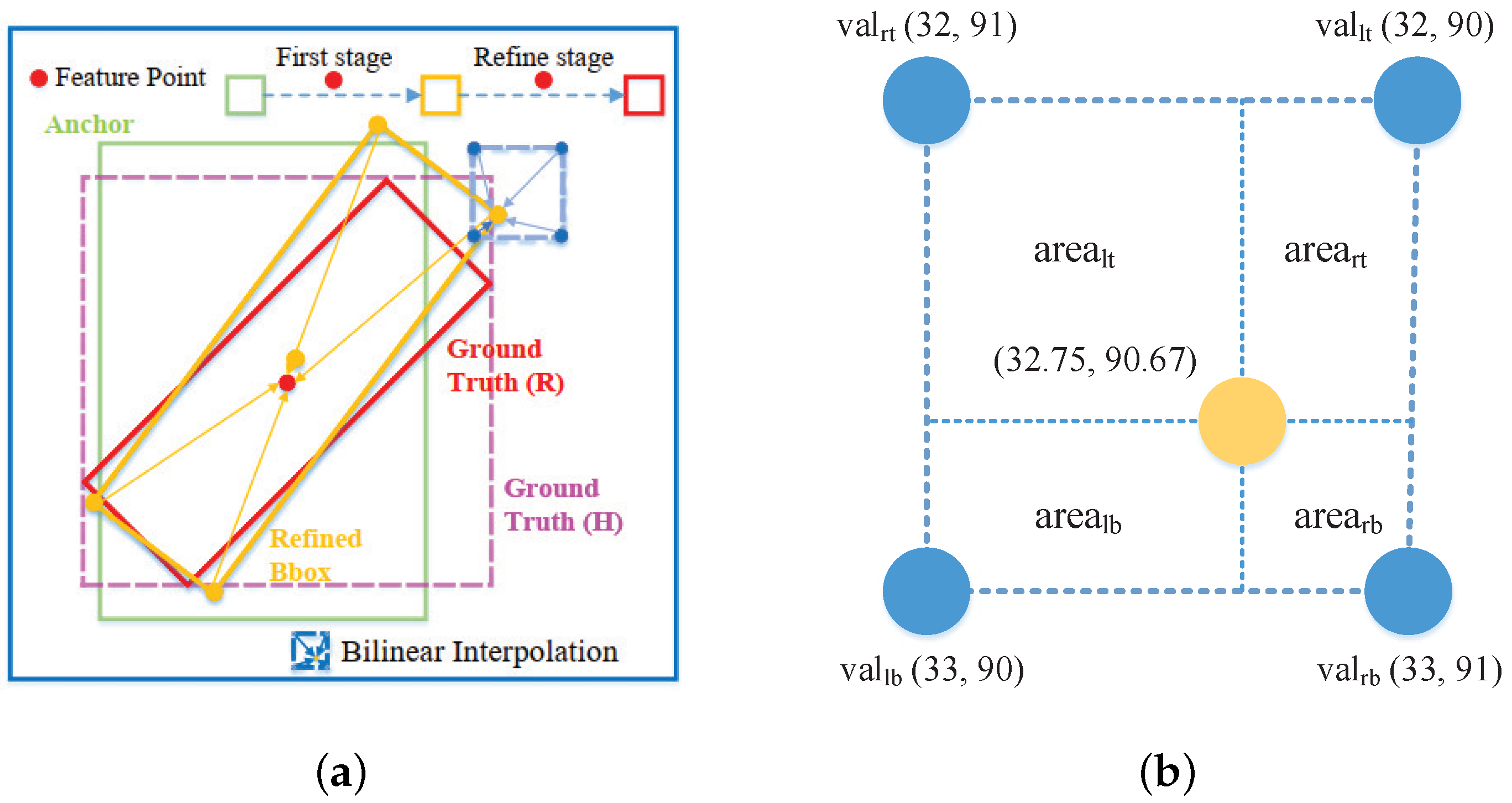
3.3. Dynamic Feature Refinement
3.4. RetinaNet-Based Rotation Detection and Loss Function
4. Experiments and Analysis
4.1. Benchmark Datasets
4.2. Implementation Details
4.3. Ablation Study
4.3.1. Ablation Study for DFR
4.3.2. Ablation Study on FPT
4.3.3. Ablation Study for Data Augmentation
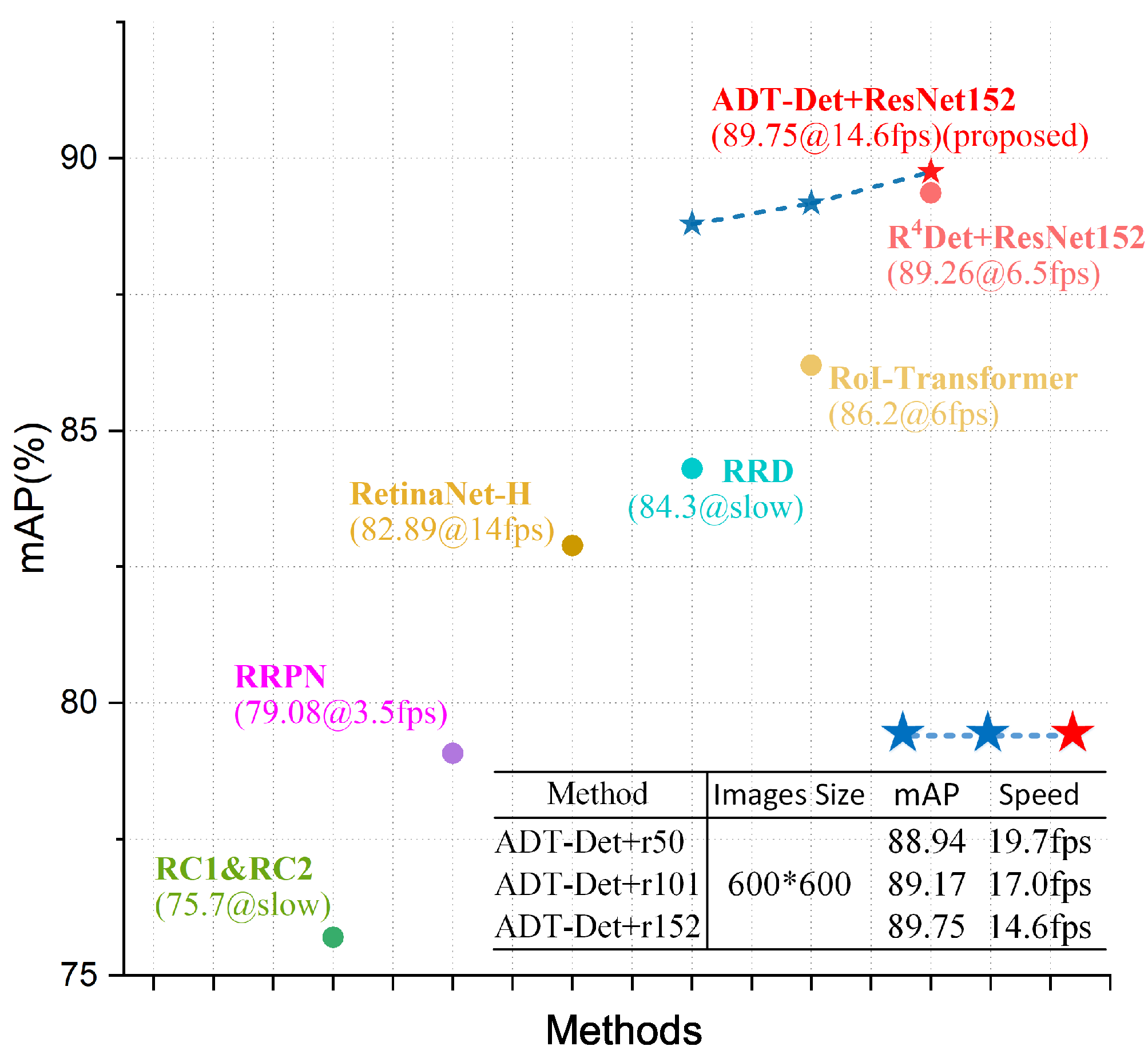
4.4. Comparison to State of the Art
4.4.1. Results on DOTA
4.4.2. Result on HRSC2016
4.4.3. Speed Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar]
- Sun, P.; Zheng, Y.; Zhou, Z.; Xu, W.; Ren, Q. R4 Det: Refined single-stage detector with feature recursion and refinement for rotating object detection in aerial images. Image Vis. Comput. 2020, 103, 104036. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Hou, J.B.; Zhu, X.; Yin, X.C. Self-Adaptive Aspect Ratio Anchor for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 1318. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine Feature Pyramid Network and Multi-Layer Attention Network for Arbitrary-Oriented Object Detection of Remote Sensing Images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 8232–8241. [Google Scholar]
- Lee, J.; Kim, D.; Ponce, J.; Ham, B. Sfnet: Learning object-aware semantic correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2278–2287. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2117–2125. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature pyramid transformer. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 323–339. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3684–3692. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 16–18 June 2020; pp. 11207–11216. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, SCITEPRESS, Porto, Portugal, 24–26 February 2017; Volume 2, pp. 324–331. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Zhu, Y.; Du, J.; Wu, X. Adaptive period embedding for representing oriented objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7247–7257. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Feng, P.; Guan, J. IENet: Interacting embranchment one stage anchor free detector for orientation aerial object detection. arXiv 2019, arXiv:1912.00969. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Liu, L.; Pan, Z.; Lei, B. Learning a rotation invariant detector with rotatable bounding box. arXiv 2017, arXiv:1711.09405. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.s.; Bai, X. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5909–5918. [Google Scholar]
- Wang, J.; Yang, W.; Li, H.C.; Zhang, H.; Xia, G.S. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 5, 4307–4323. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP | FRM | DFR | FPT | Data Aug. |
|---|---|---|---|---|---|
| RetinaNet [23] | 62.22 | × | - | - | - |
| RDet [4] | 71.69 | √ | - | - | - |
| 73.10 | - | √ | × | × | |
| ADT-Det (ours) | 73.77 | - | √ | √ | × |
| 76.89 | - | √ | √ | √ |
| Methods | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FRM | 89.54 | 81.99 | 48.46 | 62.52 | 70.48 | 74.29 | 77.54 | 90.80 | 81.39 | 83.54 | 61.79 | 59.82 | 65.44 | 67.46 | 60.05 | 71.69 |
| DFR | 88.99 | 79.42 | 50.52 | 68.62 | 78.19 | 77.09 | 86.96 | 90.85 | 79.82 | 85.45 | 58.99 | 62.66 | 66.01 | 67.56 | 55.45 | 73.10 |
| Methods | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two-stage methods | ||||||||||||||||
| R-FCN [12] | 37.80 | 38.21 | 3.64 | 37.26 | 6.74 | 2.60 | 5.59 | 22.85 | 46.93 | 66.04 | 33.37 | 47.15 | 10.60 | 25.19 | 17.96 | 26.79 |
| FR-H [5] | 47.16 | 61.00 | 9.80 | 51.74 | 14.87 | 12.80 | 6.88 | 56.26 | 59.97 | 57.32 | 47.83 | 48.70 | 8.23 | 37.25 | 23.05 | 32.29 |
| FR-O [5] | 79.09 | 69.12 | 17.17 | 63.49 | 34.20 | 37.16 | 36.20 | 89.19 | 69.60 | 58.96 | 49.40 | 52.52 | 46.69 | 44.80 | 46.30 | 52.93 |
| IE-Net [37] | 80.20 | 64.54 | 39.82 | 32.07 | 49.71 | 65.01 | 52.58 | 81.45 | 44.66 | 78.51 | 46.54 | 56.73 | 64.40 | 64.24 | 36.75 | 57.14 |
| RCNN [11] | 80.94 | 65.67 | 35.34 | 67.44 | 59.92 | 50.91 | 55.81 | 90.67 | 66.92 | 72.39 | 55.06 | 52.23 | 55.14 | 53.35 | 48.22 | 60.67 |
| RoI-Transformer [2] | 88.64 | 78.54 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| SCRDet [15] | 89.98 | 80.65 | 52.09 | 68.36 | 68.83 | 60.36 | 72.41 | 90.85 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 |
| RSDet [4] | 90.10 | 82.00 | 53.80 | 68.5 | 70.20 | 78.7 | 73.6 | 91.2 | 87.1 | 84.7 | 64.31 | 68.2 | 66.1 | 69.3 | 63.7 | 74.1 |
| Gliding Vertex [10] | 89.64 | 85.00 | 52.26 | 77.34 | 73.01 | 73.14 | 86.82 | 90.74 | 79.02 | 86.81 | 59.55 | 70.91 | 72.94 | 70.86 | 57.32 | 75.02 |
| FFA [38] | 90.10 | 82.70 | 54.20 | 75.20 | 71.00 | 79.90 | 83.50 | 90.70 | 83.90 | 84.60 | 61.20 | 68.0 | 70.70 | 76.00 | 63.70 | 75.00 |
| APE [36] | 89.96 | 83.64 | 53.42 | 76.03 | 74.01 | 77.16 | 79.45 | 90.83 | 87.15 | 84.51 | 67.72 | 60.33 | 74.61 | 71.84 | 65.55 | 75.75 |
| Anchor-free methods | ||||||||||||||||
| DRN [32] | 89.71 | 82.34 | 47.22 | 64.10 | 76.22 | 74.43 | 85.84 | 90.57 | 86.18 | 84.89 | 57.65 | 61.93 | 69.30 | 69.63 | 58.48 | 73.23 |
| Single-stage methods | ||||||||||||||||
| SSD [21] | 39.57 | 9.09 | 0.64 | 13.18 | 0.26 | 0.39 | 1.11 | 16.24 | 27.57 | 9.23 | 27.16 | 9.09 | 3.03 | 1.05 | 1.01 | 10.59 |
| YOLO v2 [19] | 39.49 | 20.29 | 36.58 | 23.42 | 8.85 | 2.09 | 4.82 | 44.34 | 38.35 | 34.65 | 16.02 | 37.62 | 47.23 | 25.5 | 7.45 | 21.39 |
| RDet [4]-ResNet152 | 89.49 | 81.17 | 5.53 | 66.10 | 70.92 | 78.66 | 78.21 | 90.81 | 85.26 | 84.23 | 61.81 | 63.77 | 68.16 | 68.83 | 67.17 | 73.73 |
| RDet [3]-ResNet152 | 88.96 | 85.42 | 52.91 | 73.84 | 74.86 | 81.52 | 80.29 | 90.79 | 86.95 | 85.25 | 64.05 | 60.93 | 69.00 | 70.55 | 67.76 | 75.84 |
| ADT-Det (no Multi-Scale Training) | 88.99 | 79.42 | 50.52 | 68.62 | 78.19 | 77.09 | 86.96 | 90.85 | 79.82 | 85.45 | 58.99 | 62.66 | 66.01 | 67.56 | 55.45 | 73.10 |
| ADT-Det-ResNet50 | 89.28 | 83.97 | 51.44 | 79.12 | 78.31 | 82.18 | 87.79 | 90.82 | 84.84 | 87.46 | 65.47 | 64.23 | 71.87 | 71.40 | 65.08 | 76.89 |
| ADT-Det-ResNet101 | 89.62 | 84.70 | 51.88 | 77.43 | 77.88 | 80.54 | 88.22 | 90.85 | 84.18 | 86.68 | 66.30 | 69.17 | 76.34 | 70.91 | 63.01 | 77.18 |
| ADT-Det-ResNet152 | 89.61 | 84.59 | 53.18 | 81.05 | 78.31 | 80.86 | 88.22 | 90.82 | 84.80 | 86.89 | 69.97 | 66.78 | 76.18 | 72.10 | 60.03 | 77.43 |
| ADT-Det (with Feature Recursion) | 89.71 | 84.71 | 59.63 | 80.94 | 80.30 | 83.53 | 88.94 | 90.86 | 87.06 | 87.81 | 70.72 | 70.92 | 78.66 | 79.40 | 65.99 | 79.95 |
| Methods | RC1&RC2 [39] | RRPN [13] | RRD [40] | RoI-Trans. [2] | DRN [32] | CenterMap-Net [41] | RDet [4] | RDet [3] | ADT-Det | |
|---|---|---|---|---|---|---|---|---|---|---|
| Input size | 300 × 300 | 800 × 800 | 384 × 384 | 512 × 800 | 768 × 768 | 768 × 768 | 800 × 800 | 800 × 800 | 600 × 600 | 80 0× 800 |
| AP | 75.7 | 79.08 | 84.3 | 86.20 | 92.7 * | 92.8 * | 89.26 | 89.56 | 88.96 | 89.75/93.47 * |
| Speed | Slow(<1 fps) | 3.5fps | Slow(<1 fps) | 6 fps | - | - | 10 fps | 6.5 fps | 14.6 fps | 12 fps |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Sun, P.; Zhou, Z.; Xu, W.; Ren, Q. ADT-Det: Adaptive Dynamic Refined Single-Stage Transformer Detector for Arbitrary-Oriented Object Detection in Satellite Optical Imagery. Remote Sens. 2021, 13, 2623. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13132623
Zheng Y, Sun P, Zhou Z, Xu W, Ren Q. ADT-Det: Adaptive Dynamic Refined Single-Stage Transformer Detector for Arbitrary-Oriented Object Detection in Satellite Optical Imagery. Remote Sensing. 2021; 13(13):2623. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13132623
Chicago/Turabian StyleZheng, Yongbin, Peng Sun, Zongtan Zhou, Wanying Xu, and Qiang Ren. 2021. "ADT-Det: Adaptive Dynamic Refined Single-Stage Transformer Detector for Arbitrary-Oriented Object Detection in Satellite Optical Imagery" Remote Sensing 13, no. 13: 2623. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13132623