
Consecutive Pre-Training: A Knowledge Transfer Learning Strategy with Relevant Unlabeled Data for Remote Sensing Domain

Abstract
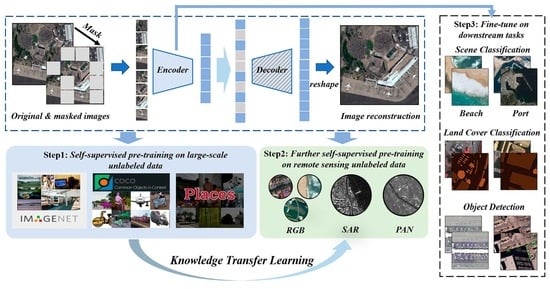
:
1. Introduction
- For the current knowledge transfer learning strategy from the natural scene domain to the RSD, the severe domain gap is analyzed in detail. In addition, a concise and effective knowledge transfer learning strategy called CSPT is proposed to gradually bridge the domain gap and then efficiently transfer the domain-level knowledge of large-scale unlabeled data such as ImageNet [18] into the specific RSD. Meanwhile, the designed CSPT is a promising method to release the huge potential of unlabeled data for task-aware model training in the RSD.
- Based on the MIM of task-agnostic representation, the impact of adding extra task-related unlabeled data and waiting for more iterative epochs on further self-supervised pre-training step of the proposed CSPT are studied. Then, we find that the designed CSPT can be a more unified and feasible way to promote the fine-tuning performance of various downstream tasks.
- Extensive experiments were conducted, which include three downstream tasks (e.g., scene classification, object detection and land cover classification) and two kinds of imaging data (e.g., optical and SAR) in the RSD. The experimental results show that the designed CSPT can mitigate task-aware discrepancy and bridge the domain gap to advance the performance of diverse downstream tasks and reach competitive results in comparison with SOTA methods. Finally, we make the pre-trained model weights freely available at https://github.com/ZhAnGToNG1/transfer_learning_cspt (accessed on 11 August 2022) to the remote sensing community. In addition, the research can also follow the designed CSPT to train their own ViT model weights for specific downstream tasks in other imaging data or application scenarios.
2. Related Work
2.1. Knowledge Transfer Learning
2.2. Self-Supervised Pre-Training
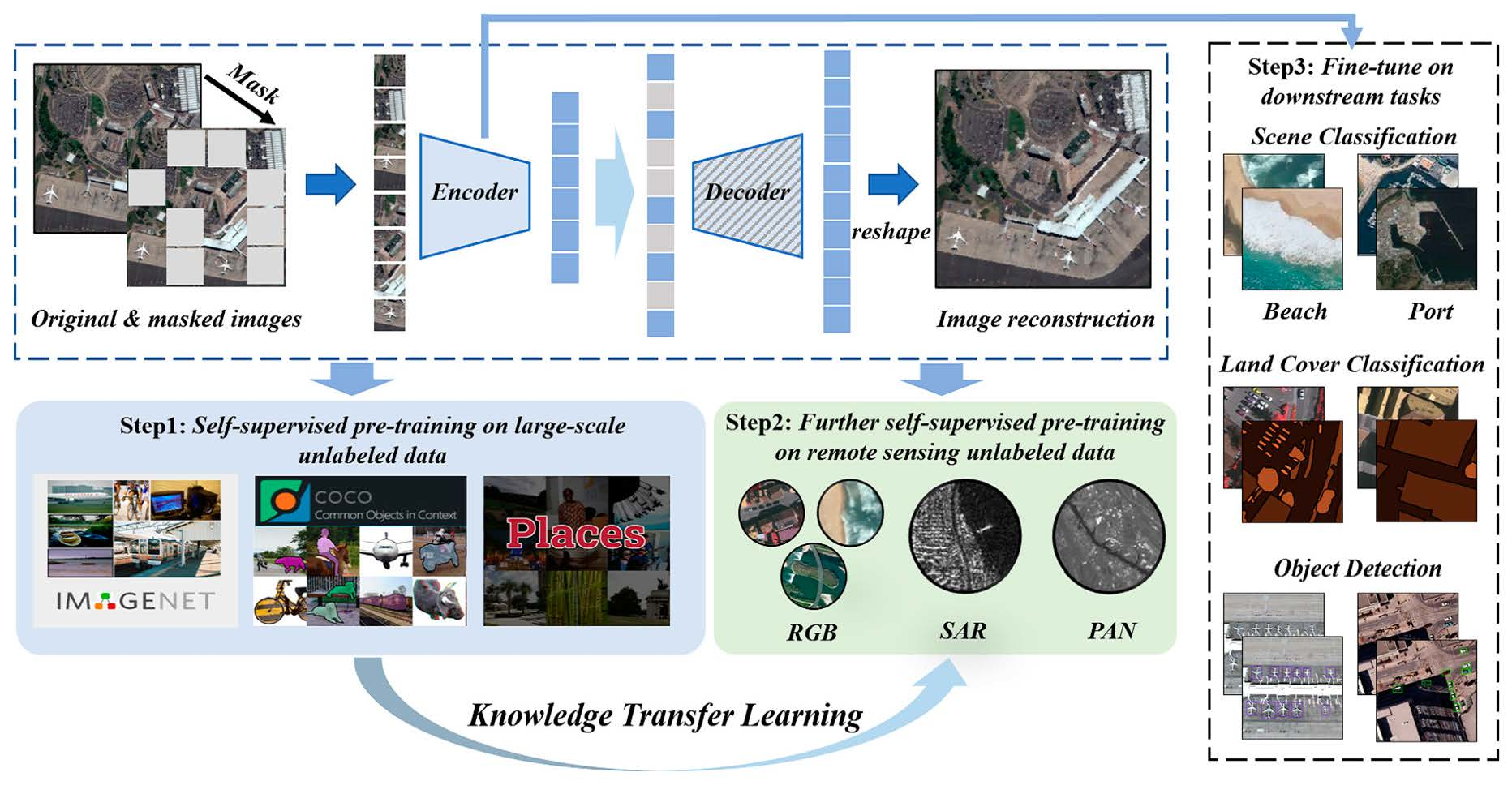
3. Knowledge Transfer Learning Strategy
3.1. Problem Analysis
3.2. Consecutive Pre-Training for Knowledge Transfer Learning
3.3. Revisiting Masked Image Modeling
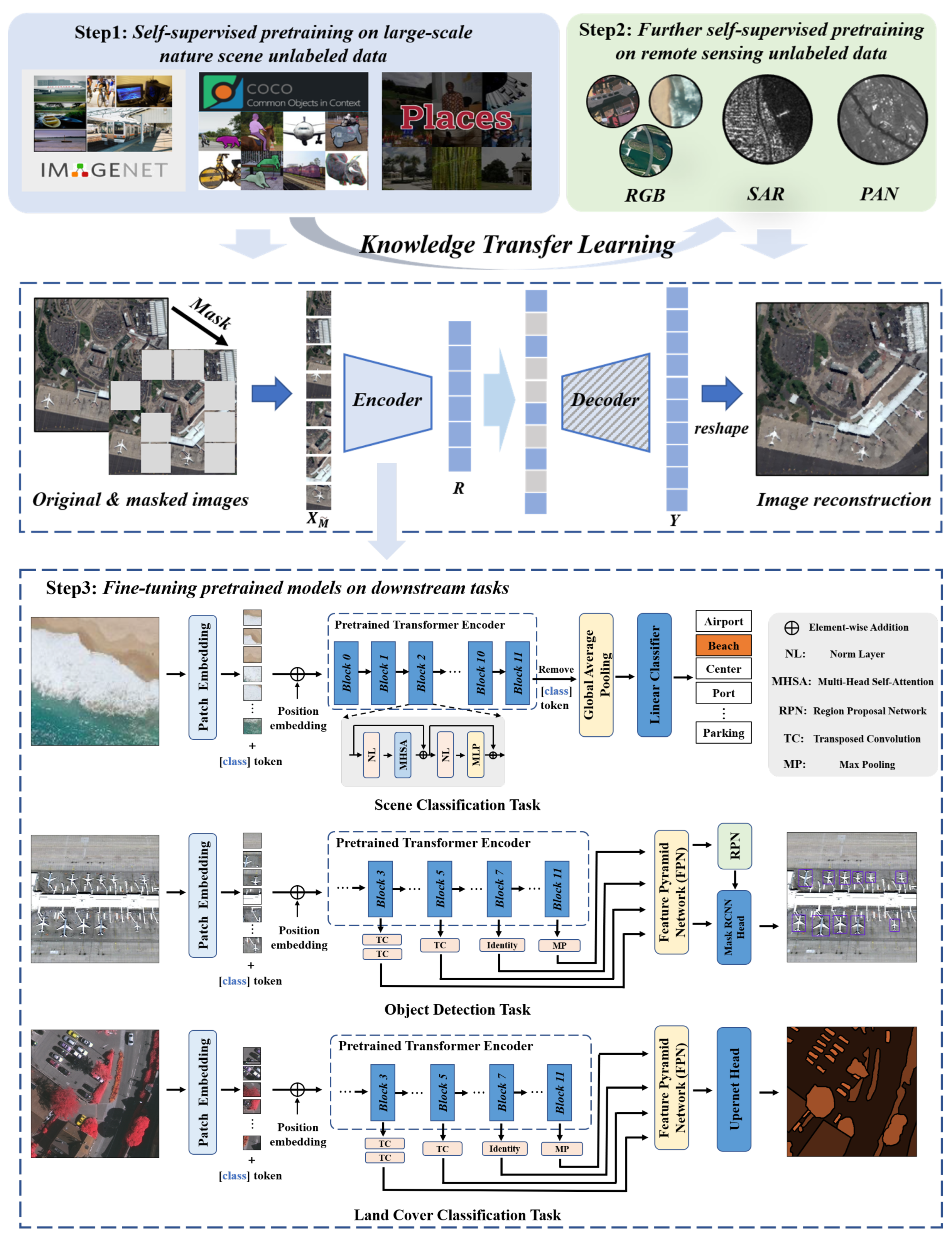
4. Experiments and Analysis
4.1. Datasets Description
4.2. Implementation Details
4.2.1. Pre-Training Setting
4.2.2. Fine-Tuning Setting
4.3. Transfer Learning Ability Comparison
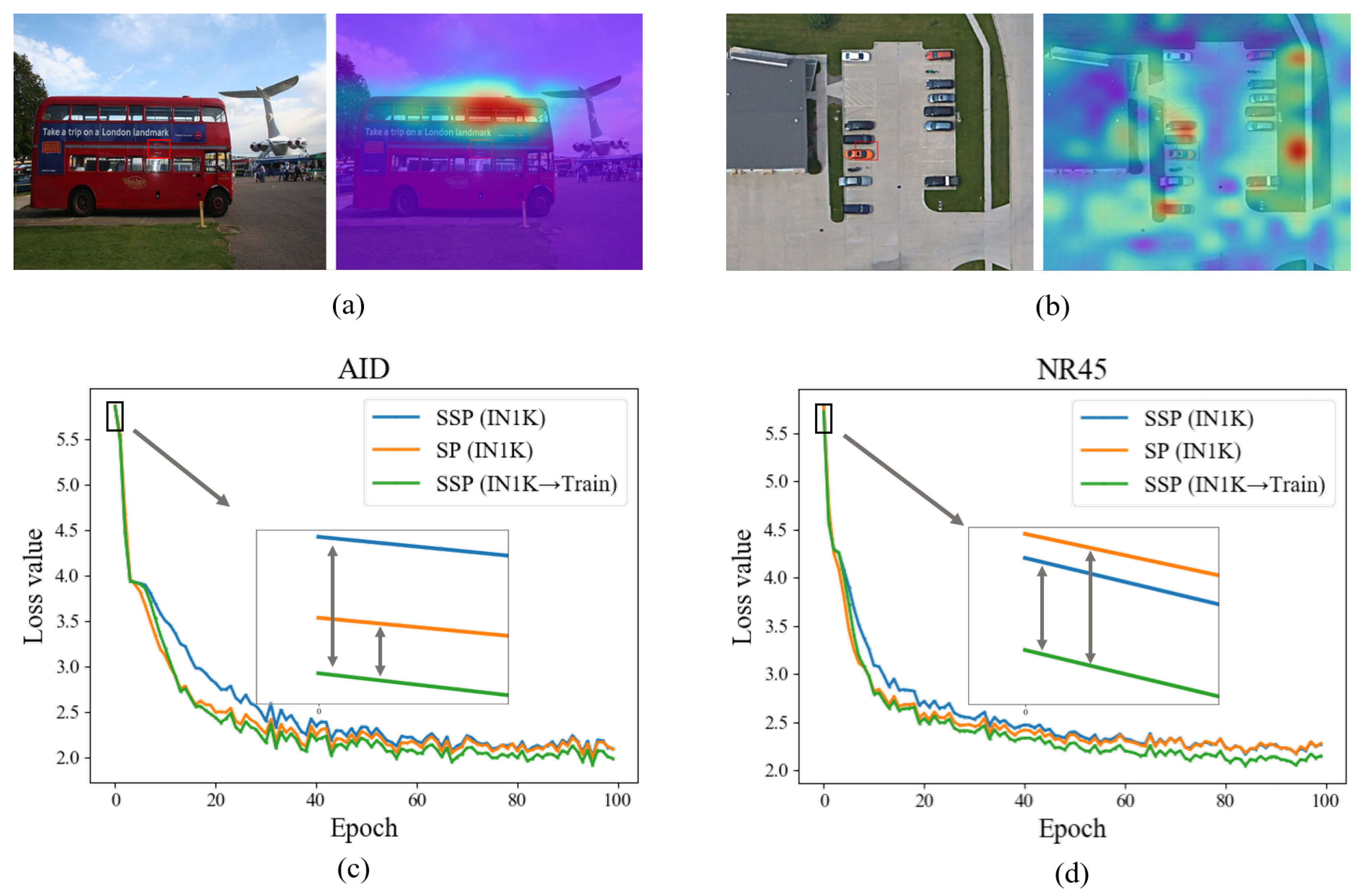
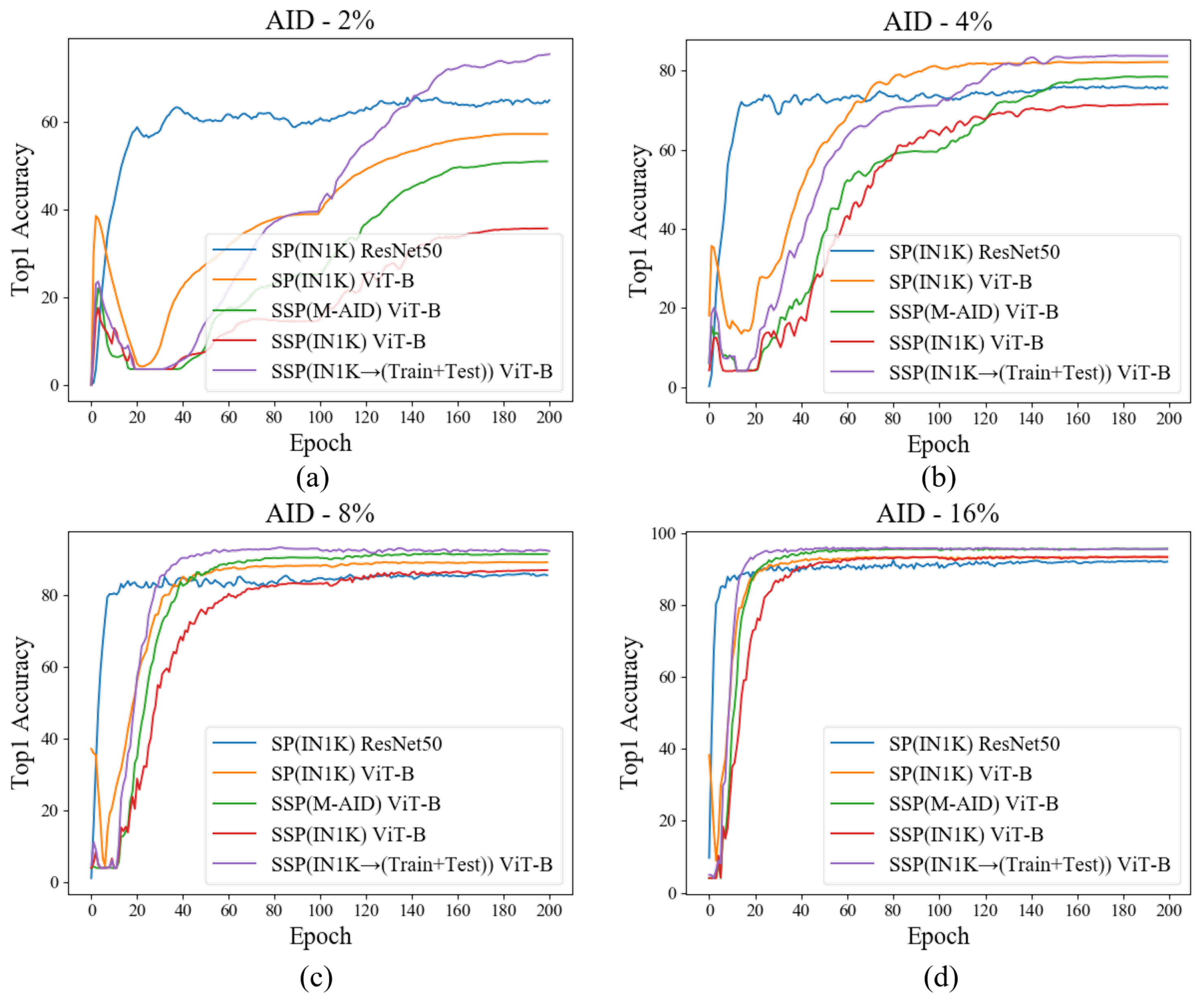
4.4. Scalability of Data Quantity
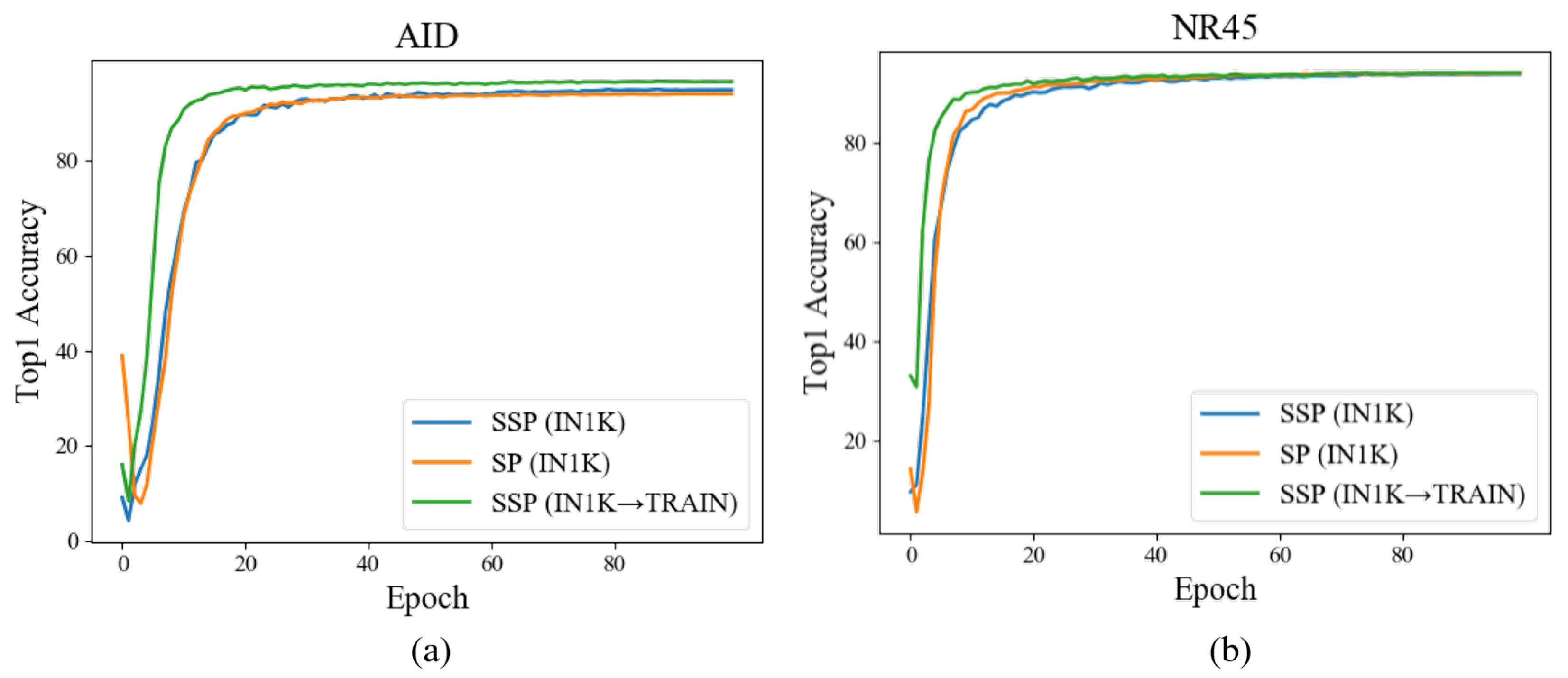
4.4.1. Discussion on Further Self-Supervised Pre-Training Step
4.4.2. Discussion on Fine-Tuning Step
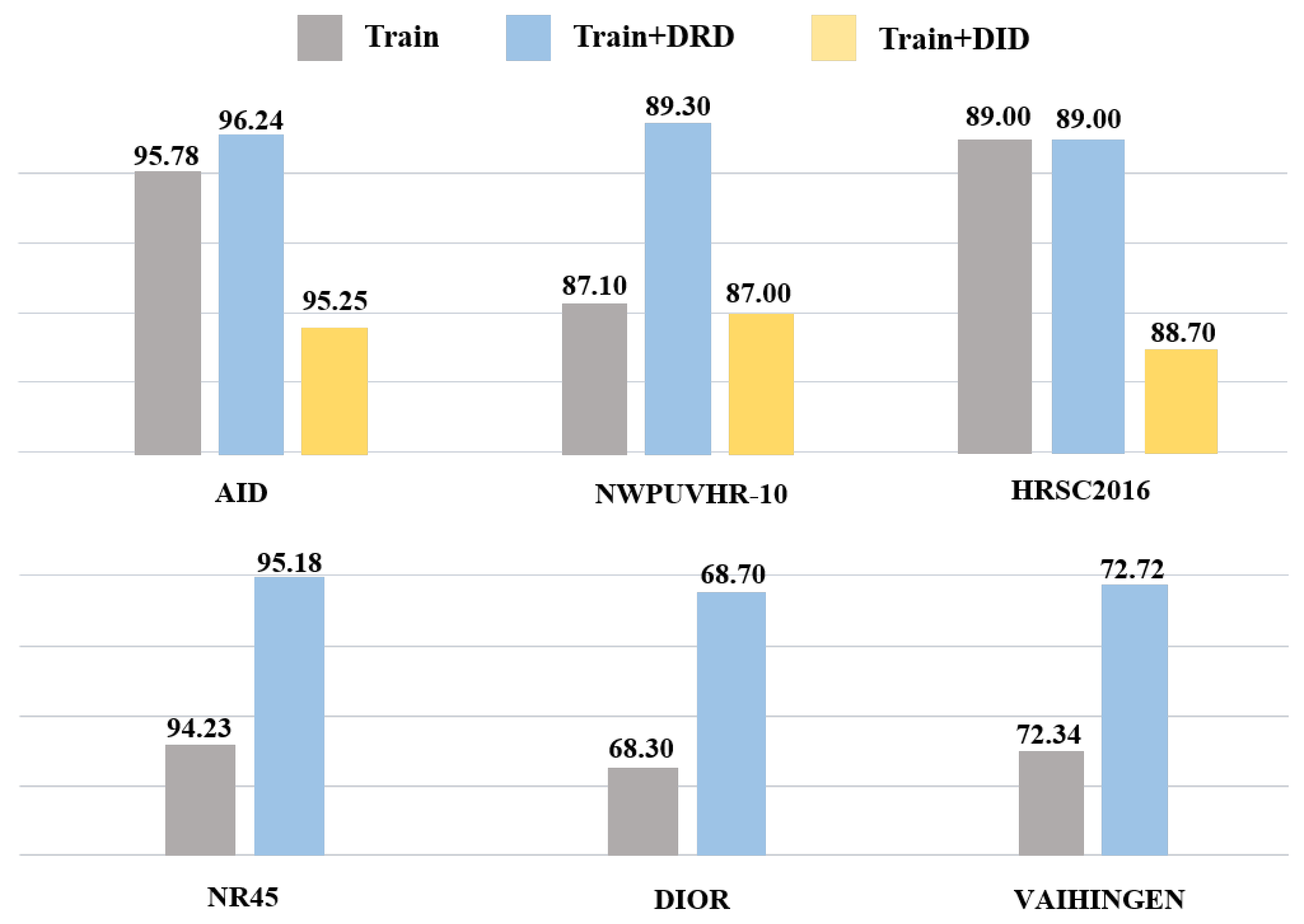
4.5. Scalability on SAR Imaging Data
4.6. Comparison Experiment Analysis
4.6.1. Scene Classification
4.6.2. Object Detection
4.6.3. Land Cover Classification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Li, Z.; Wei, B.; Li, X.; Fu, B. Seismic vulnerability assessment at urban scale using data mining and GIScience technology: Application to Urumqi (China). Geomat. Nat. Hazards Risk 2019, 10, 958–985. [Google Scholar] [CrossRef] [Green Version]
- Rathore, M.M.; Ahmad, A.; Paul, A.; Rho, S. Urban planning and building smart cities based on the Internet of Things using Big Data analytics. Comput. Netw. Int. J. Comput. Telecommun. Netw. 2016, 101, 63–80. [Google Scholar] [CrossRef]
- Ozdarici-Ok, A.; Ok, A.O.; Schindler, K. Mapping of Agricultural Crops from Single High-Resolution Multispectral Images—Data-Driven Smoothing vs. Parcel-Based Smoothing. Remote Sens. 2015, 7, 5611. [Google Scholar] [CrossRef] [Green Version]
- Sadgrove, E.J.; Falzon, G.; Miron, D.; Lamb, D.W. Real-time object detection in agricultural/remote environments using the multiple-expert colour feature extreme learning machine (MEC-ELM). Comput. Ind. 2018, 98, 183–191. [Google Scholar] [CrossRef]
- Reilly, V.; Idrees, H.; Shah, M. Detection and tracking of large number of targets in wide area surveillance. In Computer Vision—ECCV 2010. ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6313, pp. 186–199. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhang, Q.; Xu, Y.; Zhang, J.; Tao, D. Vitaev2: Vision transformer advanced by exploring inductive bias for image recognition and beyond. arXiv 2022, arXiv:2202.10108. [Google Scholar]
- Gao, P.; Lu, J.; Li, H.; Mottaghi, R.; Kembhavi, A. Container: Context aggregation network. arXiv 2021, arXiv:2106.01401. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Gong, C.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D. ISPRS semantic labeling contest. ISPRS Leopoldshöhe Ger. 2014, 1, 4. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In International Conference on Pattern Recognition Applications and Methods; SciTePress: Porto, Portugal, 2017; Volume 2, pp. 324–331. [Google Scholar]
- Ross, T.D.; Worrell, S.W.; Velten, V.J.; Mossing, J.C.; Bryant, M.L. Standard SAR ATR evaluation experiments using the MSTAR public release data set. In Algorithms for Synthetic Aperture Radar Imagery; International Society for Optics and Photonics: Bellingham, WA, USA, 1998; Volume 3370, pp. 566–573. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Long, Y.; Xia, G.S.; Zhang, L.; Cheng, G.; Li, D. Aerial Scene Parsing: From Tile-level Scene Classification to Pixel-wise Semantic Labeling. arXiv 2022, arXiv:2201.01953. [Google Scholar]
- Ranjan, P.; Patil, S.; Ansari, R.A. Building Footprint Extraction from Aerial Images using Multiresolution Analysis Based Transfer Learning. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020; pp. 1–6. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-end airplane detection using transfer learning in remote sensing images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Zhang, J.; Du, B.; Xia, G.S.; Tao, D. An Empirical Study of Remote Sensing Pre-Training. arXiv 2022, arXiv:2204.02825. [Google Scholar]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision–ECCV 2014. ECCV 2014; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–21 June 2021; pp. 8748–8763. [Google Scholar]
- Chakraborty, S.; Uzkent, B.; Ayush, K.; Tanmay, K.; Sheehan, E.; Ermon, S. Efficient conditional pre-training for transfer learning. arXiv 2020, arXiv:2011.10231. [Google Scholar]
- Ericsson, L.; Gouk, H.; Hospedales, T.M. How well do self-supervised models transfer? In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5414–5423. [Google Scholar]
- Kotar, K.; Ilharco, G.; Schmidt, L.; Ehsani, K.; Mottaghi, R. Contrasting contrastive self-supervised representation learning pipelines. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9949–9959. [Google Scholar]
- Asano, Y.M.; Rupprecht, C.; Zisserman, A.; Vedaldi, A. PASS: An ImageNet replacement for self-supervised pre-training without humans. arXiv 2021, arXiv:2109.13228. [Google Scholar]
- Stojnic, V.; Risojevic, V. Self-supervised learning of remote sensing scene representations using contrastive multiview coding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1182–1191. [Google Scholar]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and local contrastive self-supervised learning for semantic segmentation of HR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote sensing image scene classification with self-supervised paradigm under limited labeled samples. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Li, W.; Chen, K.; Chen, H.; Shi, Z. Geographical Knowledge-Driven Representation Learning for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Manas, O.; Lacoste, A.; Giro-i Nieto, X.; Vazquez, D.; Rodriguez, P. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9414–9423. [Google Scholar]
- Reed, C.J.; Yue, X.; Nrusimha, A.; Ebrahimi, S.; Vijaykumar, V.; Mao, R.; Li, B.; Zhang, S.; Guillory, D.; Metzger, S.; et al. Self-supervised pre-training improves self-supervised pre-training. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 2584–2594. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. arXiv 2021, arXiv:2111.06377. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. arXiv 2021, arXiv:2111.09886. [Google Scholar]
- Gao, P.; Ma, T.; Li, H.; Dai, J.; Qiao, Y. ConvMAE: Masked Convolution Meets Masked Autoencoders. arXiv 2022, arXiv:2205.03892. [Google Scholar]
- Zhang, R.; Guo, Z.; Gao, P.; Fang, R.; Zhao, B.; Wang, D.; Qiao, Y.; Li, H. Point-M2AE: Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training. arXiv 2022, arXiv:2205.14401. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t stop pre-training: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Dery, L.M.; Michel, P.; Talwalkar, A.; Neubig, G. Should we be pre-training? an argument for end-task aware training as an alternative. arXiv 2021, arXiv:2109.07437. [Google Scholar]
- Anand, M.; Garg, A. Recent advancements in self-supervised paradigms for visual feature representation. arXiv 2021, arXiv:2111.02042. [Google Scholar]
- Ericsson, L.; Gouk, H.; Loy, C.C.; Hospedales, T.M. Self-Supervised Representation Learning: Introduction, Advances and Challenges. arXiv 2021, arXiv:2110.09327. [Google Scholar] [CrossRef]
- Tao, C.; Qia, J.; Zhang, G.; Zhu, Q.; Lu, W.; Li, H. TOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-supervised Learning. arXiv 2022, arXiv:2204.04716. [Google Scholar]
- Xu, Y.; Sun, H.; Chen, J.; Lei, L.; Ji, K.; Kuang, G. Adversarial Self-Supervised Learning for Robust SAR Target Recognition. Remote Sens. 2021, 13, 4158. [Google Scholar] [CrossRef]
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-aware self-supervised learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10181–10190. [Google Scholar]
- Wang, L.; Liang, F.; Li, Y.; Ouyang, W.; Zhang, H.; Shao, J. RePre: Improving Self-Supervised Vision Transformer with Reconstructive Pre-training. arXiv 2022, arXiv:2201.06857. [Google Scholar]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model. arXiv 2022, arXiv:2208.03987. [Google Scholar]
- Zhou, L.; Liu, H.; Bae, J.; He, J.; Samaras, D.; Prasanna, P. Self Pre-training with Masked Autoencoders for Medical Image Analysis. arXiv 2022, arXiv:2203.05573. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.141655. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Contributors, M. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 22 January 2022).
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-Attention-Based DenseNet Network for Remote Sensing Image Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, J.; Luo, Z.; Li, J.; Chen, C. Remote sensing image scene classification based on an enhanced attention module. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1926–1930. [Google Scholar] [CrossRef]
- Chen, S.B.; Wei, Q.S.; Wang, W.Z.; Tang, J.; Luo, B.; Wang, Z.Y. Remote Sensing Scene Classification via Multi-Branch Local Attention Network. IEEE Trans. Image Process. 2021, 31, 99–109. [Google Scholar] [CrossRef]
- Zhao, Q.; Ma, Y.; Lyu, S.; Chen, L. Embedded Self-Distillation in Compact Multi-Branch Ensemble Network for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar]
- Zhang, G.; Xu, W.; Zhao, W.; Huang, C.; Yk, E.N.; Chen, Y.; Su, J. A Multiscale Attention Network for Remote Sensing Scene Images Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9530–9545. [Google Scholar] [CrossRef]
- Wang, S.; Guan, Y.; Shao, L. Multi-Granularity Canonical Appearance Pooling for Remote Sensing Scene Classification. IEEE Trans. Image Process. 2020, 29, 5396–5407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; An, W.; Sun, J.; Wu, H.; Zhang, W.; Du, Y. Best representation branch model for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9768–9780. [Google Scholar] [CrossRef]
- Li, F.; Feng, R.; Han, W.; Wang, L. High-Resolution Remote Sensing Image Scene Classification via Key Filter Bank Based on Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8077–8092. [Google Scholar] [CrossRef]
- Chen, X.; Xie, S.; He, K. An empirical study of training self-supervised visual transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, QC, Canada, 11–17 October 2021; pp. 9640–9649. [Google Scholar]
- Guo, Y.; Xu, M.; Li, J.; Ni, B.; Zhu, X.; Sun, Z.; Xu, Y. HCSC: Hierarchical Contrastive Selective Coding. arXiv 2022, arXiv:2202.00455. [Google Scholar]
- Peng, X.; Wang, K.; Zhu, Z.; You, Y. Crafting Better Contrastive Views for Siamese Representation Learning. arXiv 2022, arXiv:2202.03278. [Google Scholar]
- Deng, P.; Xu, K.; Huang, H. When CNNs meet vision transformer: A joint framework for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; TaoXie; Michael, K.; Fang, J.; imyhxy; et al. ultralytics/yolov5: V6.2—YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci.ai Integrations. 2022; Available online: https://0-doi-org.brum.beds.ac.uk/10.5281/zenodo.7002879 (accessed on 17 August 2022).
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhang, T.; Zhuang, Y.; Wang, G.; Dong, S.; Chen, H.; Li, L. Multiscale Semantic Fusion-Guided Fractal Convolutional Object Detection Network for Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–20. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Chen, Y.; Jiao, L.; Shang, R. Cross-layer attention network for small object detection in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 2148–2161. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. FSoD-Net: Full-scale object detection from optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October 2019–2 November 2019. [Google Scholar]
- Chen, F.; Liu, H.; Zeng, Z.; Zhou, X.; Tan, X. BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation. Remote Sens. 2022, 14, 1638. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Payload | Task | Dataset | Resolution (m) | Classes | # Trainval | # Test |
|---|---|---|---|---|---|---|---|
| Natural Scene | RGB | Classification | ImageNet [18] | - | 1000 | 1,331,167 | 100,000 |
| Place365 [36] | - | 365 | 1,803,460 | 36,500 | |||
| Detection/Segmentation | COCO [37] | - | 80 | 123,287 | 40,670 | ||
| PASCAL VOC [35] | - | 20 | 11,530 | - | |||
| Remote Sensing | Optical | Classification | AID [19] | 0.5 to 8 | 30 | 2000 | 8000 |
| NWPU-RESISC45 [20] | 0.2 to 30 | 45 | 9450 | 22,000 | |||
| Segmentation | POTSDAM [21] | 0.05 | 6 | 3456 | 2016 | ||
| VAIHINGEN [21] | 0.09 | 6 | 344 | 398 | |||
| GID [22] | 0.8 to 3.24 | 15 | 4368 | 2912 | |||
| Detection | DIOR [23] | 0.5 to 30 | 20 | 11,725 | 11,738 | ||
| NWPUVHR-10 [24] | 0.5 to 2 | 10 | 1479 | 1279 | |||
| UCAS-AOD [25] | - | 2 | 6489 | 2824 | |||
| HRSC2016 [26] | 0.4 to 2 | 1 | 617 | 438 | |||
| SAR | Classification | MSTAR [27] | 0.3 | 8 | 1890 | 7576 | |
| Detection | SSDD [29] | 1 to 15 | 1 | 812 | 348 | ||
| HRSID [28] | 0.5 to 3 | 1 | 3642 | 1962 |
| Task | Datasets | Transfer Learning Strategies (ViT-B [14]) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| - | Train | M-AID | IN1K | IN1K→Train | IN1K→(Train + Test) | |||||||
| From Scratch | Self-Sup. | Self-Sup. | Sup. | Self-Sup. | Self-Sup. | Self-Sup. | ||||||
| - | ep800 | ep1600 | - | ep800 | ep800 | ep1600 | ep2400 | ep800 | ep1600 | ep2400 | ||
| Scene Classification | NR45 [20] | 67.35 | 88.40 | 94.69 | 94.10 | 93.94 | 94.23 | 94.21 | 94.16 | 95.11 | 94.90 | 94.84 |
| AID [19] | 63.15 | 86.53 | 96.10 | 94.04 | 95.00 | 95.78 | 96.05 | 96.00 | 96.69 | 96.69 | 96.75 | |
| Land Cover Classification | POTSDAM [21] | 60.97 | 63.32 | 76.85 | 76.43 | 78.08 | 78.36 | 78.14 | 78.09 | 78.70 | 77.98 | 78.19 |
| VAIHINGEN [21] | 60.43 | 59.62 | 73.82 | 69.21 | 71.05 | 72.34 | 72.04 | 72.90 | 74.69 | 74.19 | 73.07 | |
| GID [22] | 44.70 | 46.08 | 60.96 | 62.64 | 62.93 | 64.97 | 62.82 | 63.58 | 63.31 | 64.69 | 64.55 | |
| Object Detection | NWPUVHR-10 [24] | 54.80 | 66.50 | 88.10 | 68.20 | 86.00 | 87.10 | 87.20 | 87.50 | 88.40 | 88.30 | 88.90 |
| DIOR [23] | 36.90 | 56.00 | 68.20 | 52.70 | 66.80 | 68.30 | 68.20 | 67.60 | 69.80 | 69.20 | 68.50 | |
| UCAS-AOD [25] | 49.00 | 59.40 | 89.60 | 83.30 | 88.70 | 89.40 | 90.00 | 89.30 | 90.00 | 90.10 | 90.30 | |
| HRSC2016 [26] | 30.00 | 49.30 | 86.50 | 82.60 | 83.00 | 89.00 | 89.40 | 89.20 | 89.60 | 89.90 | 90.10 | |
| Pre-Training Method | Architecture | NR45 | AID | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 2% | 4% | 8% | 16% | 2% | 4% | 8% | 16% | ||
| Train from scratch | ResNet-50 | 27.48 | 44.30 | 54.62 | 63.73 | 21.80 | 26.11 | 46.15 | 59.78 |
| ViT-B | 27.50 | 38.73 | 51.05 | 66.19 | 23.17 | 32.05 | 43.97 | 59.65 | |
| SP(IN1K) | ResNet-50 | 73.45 | 80.92 | 86.77 | 91.34 | 65.60 | 75.70 | 86.10 | 92.62 |
| ViT-B | 75.80 | 81.51 | 90.24 | 93.08 | 39.03 | 66.72 | 88.19 | 93.47 | |
| SSP(IN1K) | ViT-B | 59.36 | 85.92 | 88.38 | 92.58 | 17.59 | 42.38 | 83.29 | 93.44 |
| SSP(M-AID) | ViT-B | 70.77 | 87.17 | 91.26 | 93.51 | 25.26 | 59.63 | 90.45 | 95.70 |
| SSP(IN1K→(Train + Test)) | ViT-B | 80.43 | 89.66 | 92.56 | 94.33 | 42.79 | 73.69 | 93.23 | 96.10 |
| Task | Dataset | Self-Supervised Pre-Training | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M-AID | M-AID→Train | M-AID→(Train + Test) | IN1K | IN1K→Train | IN1K→(Train + Test) | ||||||||||
| ep1600 | ep800 | ep1600 | ep2400 | ep800 | ep1600 | ep2400 | ep800 | ep800 | ep1600 | ep2400 | ep800 | ep1600 | ep2400 | ||
| Target Classification | MSTAR [27] | 98.01 | 99.67 | 99.79 | 99.80 | 99.93 | 99.95 | 99.96 | 98.03 | 99.82 | 99.80 | 99.80 | 99.96 | 99.96 | 99.97 |
| Ship Detection | SSDD [29] | 90.60 | 91.10 | 91.10 | 90.90 | 91.60 | 91.40 | 91.20 | 90.90 | 91.80 | 91.50 | 91.30 | 91.00 | 91.70 | 91.80 |
| HRSID [28] | 68.30 | 68.60 | 68.90 | 69.30 | 68.60 | 69.60 | 69.60 | 68.70 | 68.90 | 69.10 | 69.90 | 69.00 | 69.70 | 70.20 | |
| Method | Publication | Setting | Network | Top-1 Accuracy (%) | |
|---|---|---|---|---|---|
| AID (2:8) | NR45 (2:8) | ||||
| MG-CAP [81] | TIP2020 | SP(IN1K) | VGG-16 | 93.34 | 92.95 |
| CAD [76] | JSTAR2020 | SP(IN1K) | DenseNet-121 | 95.73 | 94.58 |
| KFBNet [83] | TGRS2020 | SP(IN1K) | DenseNet-121 | 95.50 | 95.11 |
| F2BRBM [82] | JSTAR2021 | SP(IN1K) | ResNet-50 | 96.05 | 94.87 |
| MBLANet [78] | TIP2021 | SP(IN1K) | ResNet-50 | 95.60 | 94.66 |
| EAM [77] | GRSL2021 | SP(IN1K) | ResNet-101 | 94.26 | 94.29 |
| MSA-Net [80] | JSTAR2021 | SP(IN1K) | ResNet-101 | 93.53 | 93.52 |
| ESD-MBENet [79] | TGRS2021 | SP(IN1K) | DenseNet-121 | 96.39 | 95.36 |
| ASP [30] | arXiv2022 | SP(M-AID) | ResNet-101 | 95.40 | 94.20 |
| SeCo [47] | ICCV2021 | SSP(Sentinel-2) | ResNet-50 | 93.47 | 92.91 |
| MoCov3 [84] | ICCV2021 | SSP(IN1K) | ResNet-50 | 92.51 | 91.79 |
| Swin Transformer [15] | ICCV2021 | SP(IN1K) | Swin-T | 96.55 | 94.70 |
| Vision Transformer [14] | ICLR2021 | SP(IN1K) | ViT-B | 94.04 | 94.10 |
| CTNet [87] | GRSL2021 | SP(IN1K) | MobileNet-v2+ViT-B | 96.25 | 95.40 |
| ViTAEv2 [16] | arXiv2022 | SP(IN1K) | ViTAEv2-S | 96.61 | 95.29 |
| RSP [34] | arXiv2022 | SP(M-AID) | ViTAEv2-S-E40 | 96.72 | 95.35 |
| SimMIM [55] | CVPR2022 | SSP(IN1K) | ViT-B | 93.08 | 92.57 |
| MAE [53] | CVPR2022 | SSP(IN1K) | ViT-B | 95.00 | 93.94 |
| MAE [53] | CVPR2022 | SSP(IN1K) | ViT-L | 94.92 | 94.34 |
| CSPT | - | SSP(IN1K→(Train + DRD)) | ViT-B | 96.24 | 95.18 |
| CSPT | - | SSP(IN1K→(Train + Test)) | ViT-B | 96.75 | 95.11 |
| CSPT | - | SSP(IN1K→(Train + Test)) | ViT-L | 96.30 | 95.62 |
| Method | Setting | Backbone | mAP (%) | AL | AT | BF | BC | B | C | D | ESA | ETS | GC | GTF | HB | O | S | SD | ST | TC | TS | V | WM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster-RCNN [88] | SP(IN1K) | ResNet-101 | 53.6 | 51.3 | 61.6 | 62.2 | 80.6 | 26.9 | 74.2 | 37.3 | 53.4 | 45.1 | 69.6 | 61.8 | 43.7 | 48.9 | 56.1 | 41.8 | 39.5 | 73.8 | 44.7 | 33.9 | 65.3 |
| Mask-RCNN [71] | SP(IN1K) | ResNet-101 | 65.2 | 53.9 | 76.6 | 63.2 | 80.9 | 40.2 | 72.5 | 60.4 | 76.3 | 62.5 | 76.0 | 75.9 | 46.5 | 57.4 | 71.8 | 68.3 | 53.7 | 81.0 | 62.3 | 53.0 | 81.0 |
| YOLOv5 [89] | SP(IN1K) | CSPdarknet-53 | 68.5 | 87.3 | 61.7 | 73.7 | 90.0 | 42.6 | 77.5 | 55.2 | 63.8 | 63.2 | 66.9 | 78.0 | 58.1 | 58.1 | 87.8 | 54.3 | 79.3 | 89.7 | 50.2 | 53.9 | 79.6 |
| CenterNet [91] | SP(IN1K) | DLA-34 | 63.2 | 78.6 | 56.5 | 76.1 | 88.1 | 33.2 | 77.1 | 41.0 | 47.4 | 55.5 | 71.4 | 72.5 | 23.0 | 52.7 | 89.8 | 54.0 | 78.6 | 86.2 | 46.1 | 57.8 | 77.4 |
| CANet [93] | SP(IN1K) | ResNet-101 | 74.3 | 70.3 | 82.4 | 72.0 | 87.8 | 55.7 | 79.9 | 67.7 | 83.5 | 77.2 | 77.3 | 83.6 | 56.0 | 63.6 | 81.0 | 79.8 | 70.8 | 88.2 | 67.6 | 51.2 | 89.6 |
| PANet [90] | SP(IN1K) | ResNet-101 | 66.1 | 60.2 | 72.0 | 70.6 | 80.5 | 43.6 | 72.3 | 61.4 | 72.1 | 66.7 | 72.0 | 73.4 | 45.3 | 56.9 | 71.7 | 70.4 | 62.0 | 80.9 | 57.0 | 47.2 | 84.5 |
| MSFC-Net [92] | SP(IN1K) | ResNeSt-101 | 70.1 | 85.8 | 76.2 | 74.3 | 90.1 | 44.1 | 78.1 | 55.5 | 60.9 | 59.5 | 76.9 | 73.6 | 49.5 | 57.2 | 89.6 | 69.2 | 76.5 | 86.7 | 51.8 | 55.2 | 84.3 |
| FSoD [94] | SP(NR45) | MSE-Net | 71.8 | 88.9 | 66.9 | 86.8 | 90.2 | 45.5 | 79.6 | 48.2 | 86.9 | 75.5 | 67.0 | 77.3 | 53.6 | 59.7 | 78.3 | 69.9 | 75.0 | 91.4 | 52.3 | 52.0 | 90.6 |
| Mask-RCNN(MAE) [53] | SSP(IN1K) | ViT-B | 66.8 | 58.9 | 85.6 | 69.4 | 80.7 | 37.8 | 78.5 | 70.2 | 85.0 | 55.4 | 80.7 | 77.4 | 58.7 | 57.1 | 44.3 | 79.2 | 44.3 | 83.1 | 70.9 | 27.5 | 74.8 |
| Mask-RCNN(MAE) [53] | SSP(IN1K) | ViT-L | 68.3 | 66.1 | 86.5 | 73.3 | 83.6 | 41.4 | 81.6 | 72.2 | 86.2 | 58.3 | 79.2 | 78.7 | 60.3 | 61.1 | 60.1 | 73.4 | 42.1 | 83.3 | 71.3 | 28.9 | 78.7 |
| Mask-RCNN(MoCov3) [84] | SSP(IN1K) | ResNet-50 | 62.5 | 57.9 | 75.1 | 65.1 | 85.3 | 36.2 | 71.9 | 59.2 | 66.4 | 51.6 | 74.0 | 75.8 | 58.8 | 54.8 | 67.8 | 67.8 | 44.2 | 83.0 | 58.4 | 27.6 | 76.6 |
| Mask-RCNN(SimMIM) [55] | SSP(IN1K) | ResNet-50 | 63.5 | 59.6 | 80.4 | 69.7 | 77.0 | 34.5 | 77.5 | 64.9 | 77.6 | 52.4 | 76.8 | 74.4 | 52.0 | 55.5 | 59.6 | 70.8 | 40.5 | 80.2 | 64.4 | 27.1 | 75.0 |
| Mask-RCNN(CSPT) | SSP(IN1K→(Train + DRD)) | ViT-B | 68.7 | 69.9 | 87.7 | 70.8 | 81.2 | 41.6 | 80.5 | 74.8 | 86.0 | 58.8 | 78.9 | 75.6 | 60.6 | 58.9 | 60.8 | 78.3 | 44.6 | 84.1 | 76.2 | 29.0 | 76.4 |
| Mask-RCNN(CSPT) | SSP(IN1K→(Train + Test)) | ViT-B | 69.8 | 69.8 | 89.1 | 74.7 | 82.6 | 42.2 | 80.5 | 76.9 | 86.4 | 58.8 | 80.7 | 77.7 | 61.9 | 60.2 | 60.9 | 79.2 | 46.1 | 84.3 | 77.2 | 29.0 | 77.3 |
| Mask-RCNN(CSPT) | SSP(IN1K→(Train + Test)) | ViT-L | 71.7 | 74.1 | 89.9 | 81.2 | 86.2 | 44.5 | 81.9 | 74.8 | 90.1 | 61.3 | 81.9 | 79.6 | 61.6 | 61.0 | 61.0 | 83.7 | 44.5 | 88.1 | 78.9 | 29.2 | 79.9 |
| Method | Setting | Backbone | mIoU(%) |
|---|---|---|---|
| BES-Net [97] | SP(IN1K) | ResNet-18 | 78.21 |
| Deeplabv3+ [95] | SP(IN1K) | ResNet-50 | 75.21 |
| Upernet [73] | SP(IN1K) | ResNet-50 | 75.86 |
| GCNet [96] | SP(IN1K) | ResNet-101 | 75.38 |
| Upernet [73] | SP(IN1K) | ViT-B | 76.43 |
| Upernet(CSPT) | SSP(IN1K→Train) | ViT-B | 78.36 |
| Upernet(CSPT) | SSP(IN1K→(Train + Test)) | ViT-B | 78.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Gao, P.; Dong, H.; Zhuang, Y.; Wang, G.; Zhang, W.; Chen, H. Consecutive Pre-Training: A Knowledge Transfer Learning Strategy with Relevant Unlabeled Data for Remote Sensing Domain. Remote Sens. 2022, 14, 5675. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14225675
Zhang T, Gao P, Dong H, Zhuang Y, Wang G, Zhang W, Chen H. Consecutive Pre-Training: A Knowledge Transfer Learning Strategy with Relevant Unlabeled Data for Remote Sensing Domain. Remote Sensing. 2022; 14(22):5675. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14225675
Chicago/Turabian StyleZhang, Tong, Peng Gao, Hao Dong, Yin Zhuang, Guanqun Wang, Wei Zhang, and He Chen. 2022. "Consecutive Pre-Training: A Knowledge Transfer Learning Strategy with Relevant Unlabeled Data for Remote Sensing Domain" Remote Sensing 14, no. 22: 5675. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14225675