
An Adaptive Lp Norm Minimization Algorithm for Direction of Arrival Estimation


The College of Information and Communication Engineering, Harbin Engineering University, Harbin 150001, China
*
Author to whom correspondence should be addressed.
Remote Sens. 2022, 14(3), 766; https://0-doi-org.brum.beds.ac.uk/10.3390/rs14030766
Submission received: 29 December 2021
/
Revised: 29 January 2022
/
Accepted: 4 February 2022
/
Published: 7 February 2022
(This article belongs to the Special Issue Recent Advances in Signal Processing and Radar for Remote Sensing)
Abstract
:In this paper, we propose a new direction of arrival (DOA) estimation algorithm, in which DOA estimation is achieved by finding the sparsest support set of multiple measurement vectors (MMV) in an over-complete dictionary. The proposed algorithm is based on norm minimization, which belongs to non-convex optimization. Therefore, the quasi-Newton method is used to converge the iterative process. There are two advantages of this algorithm: one is the higher possibility and resolution of distinguishing closely spaced sources, and the other is the adaptive regularization parameter adjustment. Moreover, an accelerating strategy is applied in the computation, and a weighted method of the proposed algorithm is also introduced to improve the accuracy. We conducted experiments to validate the effectiveness of the proposed algorithm. The performance was compared with several popular DOA estimation algorithms and the Cramer–Rao bound (CRB).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
With extensive applications, including radar, sonar, wireless communication and remote sensing, DOA estimation has traditionally been a popular branch in the field of array signal processing [1,2]. As a key technology in passive radar, DOA estimation is being extensively developed to locate targets in complex electromagnetic environments without being perceived.
Considering problems, such as distinguishing coherence sources and separating spatial closely sources, sparse reconstruction theory plays an important role in DOA estimation [3,4]. In dividing the whole spatial domain of interests into a discrete set of potential grids, a traditional estimation module can be converted into an ill-posed inverse problem. The specific physical model will be introduced in Section 2.
The MMV data module of a M sensor array takes the following form:
where and are matrices of measurements and noise. The dictionary matrix consists of N steering vectors. These vectors are determined by N different angles. In addition, is a K-row sparse matrix that represents a K sources spatial spectrum.
Note that the dictionary matrix is fat; hence, the equation has infinitely many exact solutions. To reconstruct the sparse signal, a simple and intuitive measure of sparsity is -norm. The Lagrangian relaxation problem with the mixed norm is as follows:
Note that the mixed-norm means a sparse spatial domain but closely related time domain. That is to say, norm gathers the snapshots of to obtain a spatial spectrum , and norm measures the sparsity of . The general formula is:
Considering solving (2) directly is an NP-hard problem, alternative approaches are often studied. One alternative method is the greedy algorithm, OMP [5] pursued the current optimal value in every iteration. Another method is an approximate norm method, such as SL0 [6].
A common convex approximation of the -pseudo-norm that is known to promote sparse solution is the -norm.
Convex optimization algorithms are always convergent to the global optimal solution. This feature makes convex optimization algorithms well-studied. Malioutov et al. proposed a heuristic approach, named -SVD [7], using a reduction of the dimension of measurement matrix by SVD and adaptive grid refinement. However, for a large number of snapshots L or large number of candidate frequencies K, the problem becomes computationally intractable.
Different from other sparse reconstruction fields, in the DOA estimation, atoms of dictionary are completely determined and fixed by the discrete spatial grid. Highly correlated atoms in the dictionary makes it difficult to separate adjusted vectors. This is far from the “approximate orthogonality” condition, which was introduced in the Restricted Isometry Property (RIP) [8]. However, norm optimization has a greater possibility of obtaining a sparse solution, which is usually used in imagery target detection [9]. Thereby, norm optimization also can be used to distinguish closely spaced sources.
Hence, in the -constrained problem we search for an N-row sparse solution that minimizes the fitting error. Algorithms, such as iterative reweighted least squares (IRLS) [10] and FOCUSS [11] are popular in DOA estimation. They both approximate the norm with a weighted norm.
The goal of this paper is to find a practical sparse reconstruction method that fills the missing application scenario of traditional DOA estimation algorithm. The main contribution of the paper is a method for the automatic selection of the regularization parameter.
In contrast to other existing methods, the proposed method works completely in the iterative process, which means better adaptability to different situations. The key ingredient of the proposed method is the use of the quasi-Newton algorithm. Without losing accuracy, the iterative process is optimized, and the computation is reduced by a matrix inverse lemma, even with dense grids. In addition, we introduce the improvement of the weighted algorithm. Last but not least, the array does not have to be linear, and the sources can be coherent.
The rest of the paper is organized as follows. The processing of the proposed algorithm and innovative details are considered in Section 2. Potential application scenarios are discussed. Section 3 provides experimental results to compare the proposed algorithm with other DOA estimators. Our conclusions are contained in Section 4.
2. The Proposed Algorithm
The physical meaning of all parameters in the DOA estimation mathematical model will be explained here briefly. The array with all omnidirectional sensors receives plane waves from the far field of the narrow-band signal source. All signals are impinging with different angles . The phase difference between two adjacent sensors is defined as
where denotes the wavelength. Let the sensor at the coordinate origin be the reference. The direction vector can be expressed as , and thus the manifold matrix can be expressed as .
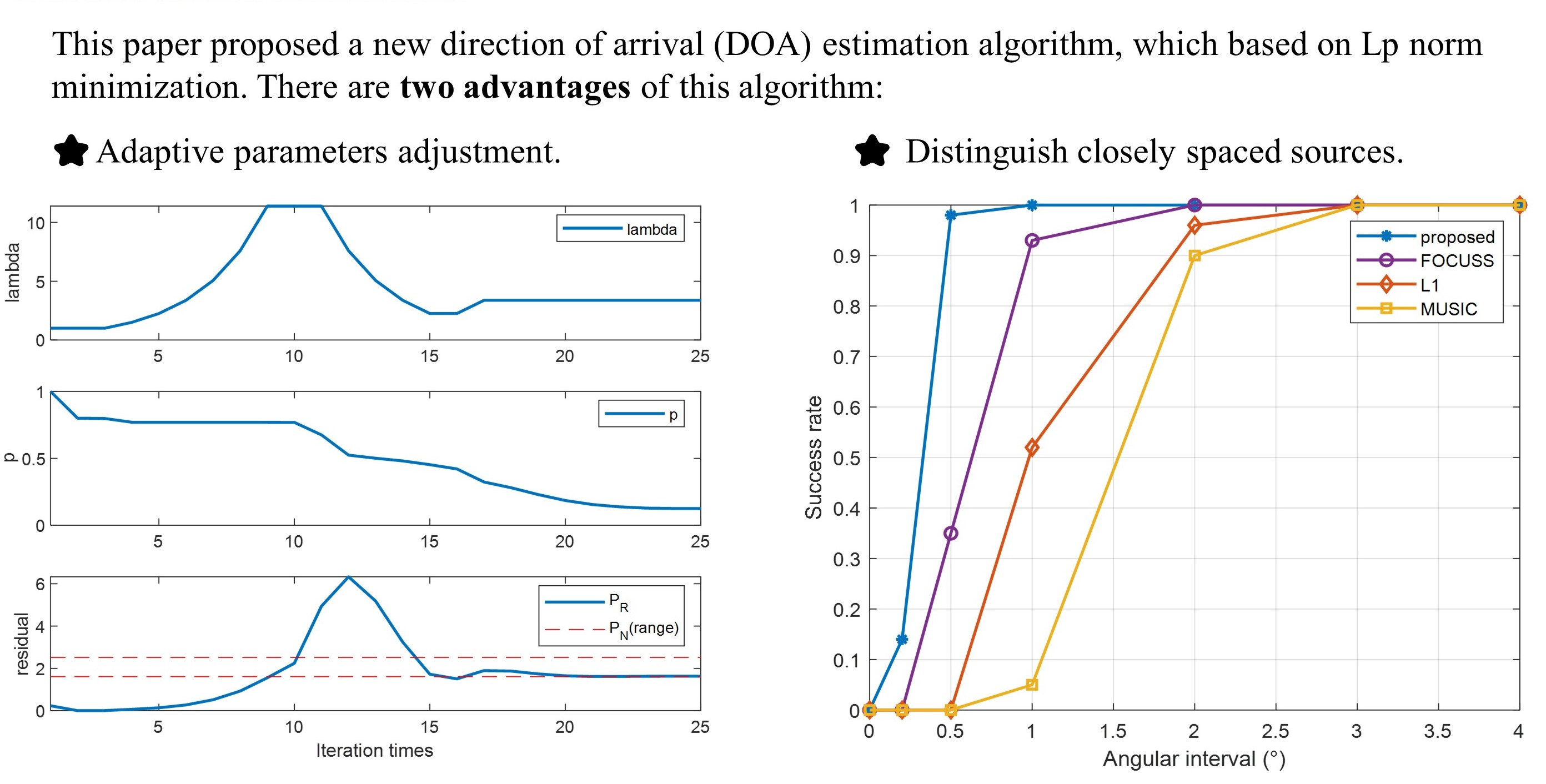
Figure 1 shows the whole processing of DOA estimation. In order of the subplots, first, the signal space can be divided to N grids; therefore, the dictionary matrix can be expressed as . Then, the sensor data matrix is the input data of the proposed algorithm. M denotes the number of sensors, and L denotes the number of samples. Finally, with a proper coefficient, linear combinations of atoms in the dictionary can reconstruct the signal. As long as the sparsest coefficient vector can be found, the direction of sources can be known from the index of the non-zero support set.
2.1. The Norm Minimization Algorithm
Due to , cost function (5) is not differentiable at . The authors in [12] proved a differentiable approximation suiting our purpose well:
where is the smoothing parameter that controls the trade-off between smoothness and approximation. Usually the value of is set to in the DOA estimation background. If is too large, the approximation is not good, and if is too small, the inverse of (11) will be singular.
The Jacobian matrix of the objective function is
where the superscript represents the conjugate transpose operation and
The Hessian matrix of the objective function is
However, the Newton method is not convergent due to the non-positive definiteness of . A positive definite approximation of can be obtained by simply removing the negative part in (11).
Note that
In DOA estimation, the dimension of is affected by the number of grids, usually , which causes heavy computation. Considering consists of and a diagonal matrix , the matrix inversion lemma is introduced to optimize the inversion
Note that
Applying (14) can reduce the dimension of the inverse matrix from to ; thus, the computational complexity decreases to from . In order to facilitate the subsequent measurement of residuals and introduce (14) to reduce the computational burden, the Newton direction in the proposed algorithm can be expressed as:
where are repeated parts in calculating and will be used to obtain the noisy parameter in section B.
2.2. Adaptive Method for p
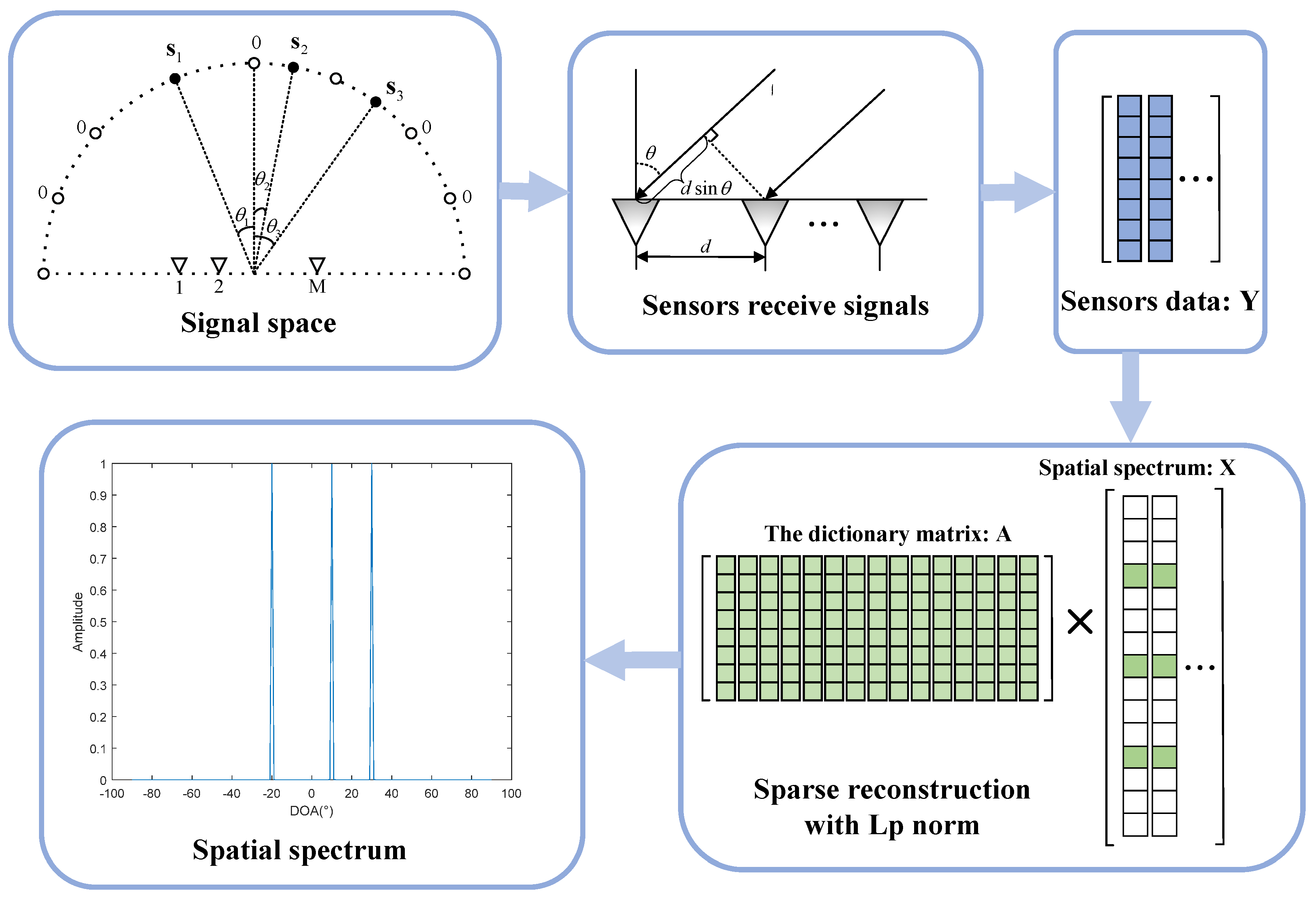
The ability to estimate the DOAs of two closely spaced sources is always an important indicator of the DOA estimation algorithm. Figure 2 is a norm ball of space. The curves show that, the lower the p value, the easier it is to find a sparser solution. When faced with closely spaced sources, norm optimization has a greater possibility of obtaining a sparse solution, thereby, distinguishing two sources.
As stated in the RIP condition, the uniqueness solution can be characterized in terms of the of matrix . Recall the smallest constants for which the matrix satisfies the RIP of order K, that is
It is clear that any K-sparse vector is recovered via the norm minimization if and only if the strict inequality holds. Define a new parameter to represent the RIP condition of matrix
The quantity can be made arbitrarily close to 1 by when the is orthogonal column by column. As stated in [12], given , if (20) for some integer , then every K-sparse vector is exactly recovered by solving the norm minimization.
When , condition (20) becomes
From (21), when , the right side of the inequality becomes , which means the RIP condition number . That is to say, the smaller the value of p, the lower the ’approximate orthogonal’ requirement of sparse reconstruction for matrix . From the perspective of DOA estimation, as long as p is small enough, the ability of the algorithm to overcome the high correlation between adjacent columns in over-complete basis is stronger, and the ability of separating spatial closely sources is stronger.
When the penalty of norm is close to norm. However, too small p may lead the algorithm to converge to a local optimization. The common norm optimization algorithms, such as FOCUSS usually choose based on experience [13]. In order to make p sensitive to the spectrum convergence and find a sparser solution, this section defines a decreasing processing of p by variation of the spectrum until .
where . When , proves that the spectrum variation of this iteration is too large, then we directly reduce the p value to half of the previous time. Thus, the stopping criteria of the proposed algorithm is , and is a small constant.
2.3. Adaptive Regularization Parameter Adjustment
According to (5), the regularization parameter has a significant influence on the optimization process. However, balancing the relationship between residuals and sparsity is a difficult problem. At present, the methods for selecting regularization parameters include Generalized Cross Validation (GCV) [14], L-curve [15] etc. However, the above methods usually require massive data for prior computation and are, thus, not suitable for real-time DOA estimation. Another computational algorithm L1-SRACV [16], which considers the covariance matrix distribution, can also avoid the regularization parameters.
This section will provide a practical procedure for adjusting in iteration. This method balances residuals and sparsity adaptively without massive prior simulation and working in the iteration process.
The covariance matrix of receiving data:
The ascending sorted eigenvalues can be obtained by eigenvalue decomposition of R. Therefore, the expected value of the noise energy is:
If source number K is unknown, there are two alternative methods. Under a low-SNR scenario, can be expressed by the minimal eigenvalue . Under a high-SNR scenario, the source number K can be roughly estimated by the slope mutation of .
In a convergent and stationary iterative process with accurate estimation results, the power of residual must converge to the noise power. Therefore, can be the measurement indicator of proposed algorithm, which should be controlled within a certain range. Considering the calculation error of and residual, the range of is determined to be after many simulation experiments.
The details are: in the kth iteration, if , this indicates an overemphasis on the influence of sparsity on the optimal value—the model is poorly fitting—thus, we reduce . If , this indicates an overemphasis on the influence of noise—the model is over fitting—thus we enlarge . If , the descent direction works well, and nothing has to change. When the support set of the spectrum is determined, will not have obvious fluctuations, which indicates the convergence of this computation.
Proper initialization can considerably reduce the running time of the quasi-Newton method, and it has a much lower possibility to become trapped in a local minimum. The product of the dictionary and receiving data can be the initialization
The proposed Algorithm 1 is described as follows.
| Algorithm 1 The improved norm DOA estimator with adaptive regularization parameter adjustment. |
|
2.4. Weighted Method
The weighted algorithm adds a weight in front of the spatial spectrum, which is a simple strategy to accelerate convergence and obtain higher resolution.
Set a small weight in the place where the signal may occur, and set a large weight in the place where there is no signal so that the small value of the spatial spectrum is smaller, the large value is larger and the overall solution is more sparse. Normally, the spatial spectrum of CAPON algorithm is used as the weight.
The weighted method can not only accelerate the iteration but also improve the accuracy of the algorithm. Although the weighted method will increase the computational complexity, it can improve the estimated success rate even in worse situations.
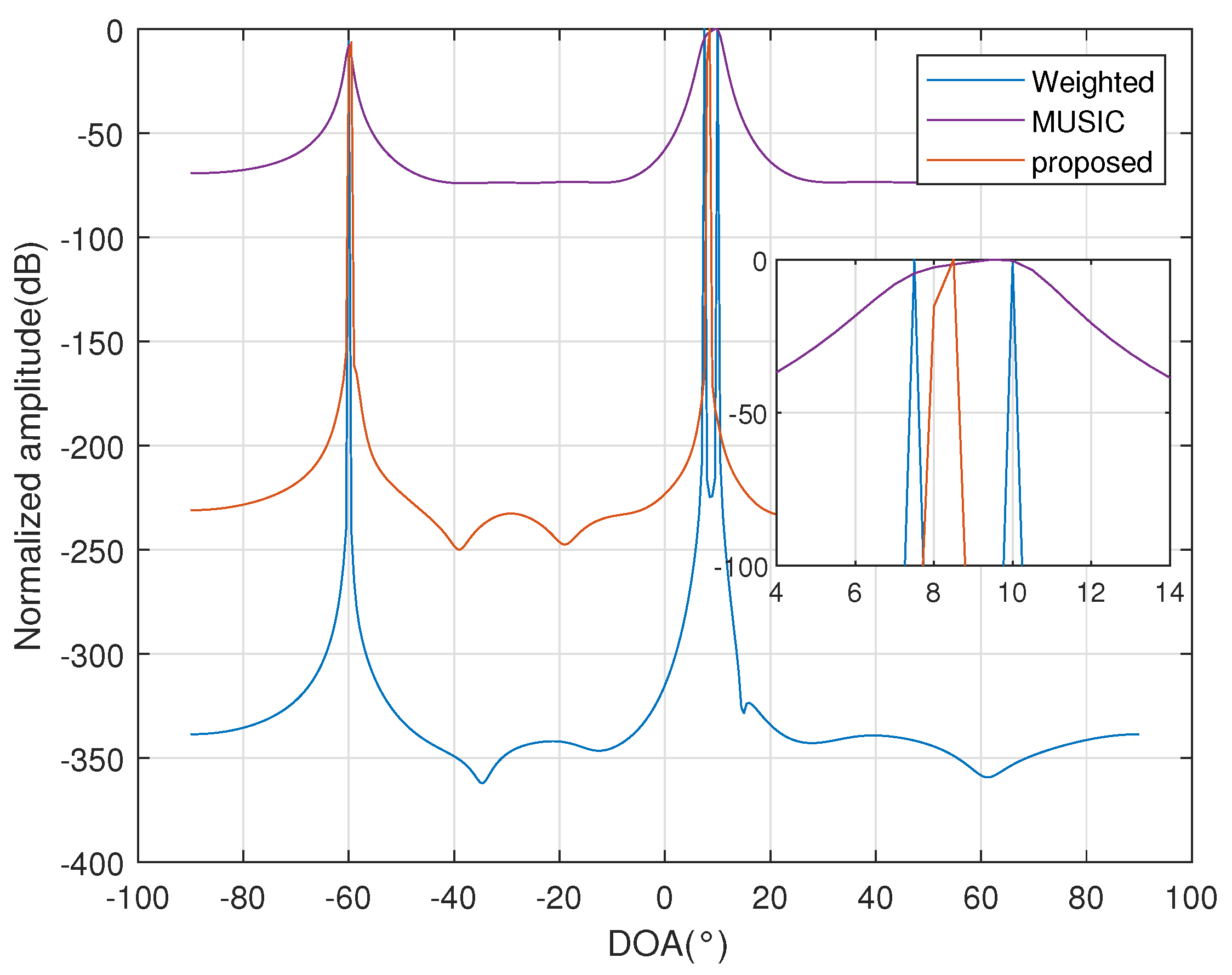
In Figure 3, the simulation is based on a eight-sensor uniform linear array with half-wavelength sensor spacing. The results show that the weighted method can distinguish two sources separated only by 3° with 200 snapshots and .
3. Experimental Results
In this section, the empirical performance of the proposed algorithm is investigated and compared with those of MUSIC, FOCUSS and L1-SVD ( norm optimization by CVX toolbox [17]). The simulations are based on a 12-sensor uniform linear array with half-wavelength sensor spacing. All methods here use a grid of 1801 points in the range of , which means .
Considering the stability and good performance of all algorithms, the regularization parameter of FOCUSS and L1-SVD was selected by the empirical value and for the FOCUSS algorithm. For the proposed method, we used adaptive and p. The signal waveform was modeled as a complex circular Gaussian random variable . The variance of Gaussian white noise is determined by the SNR. According to , sensor data modeled as random variable .
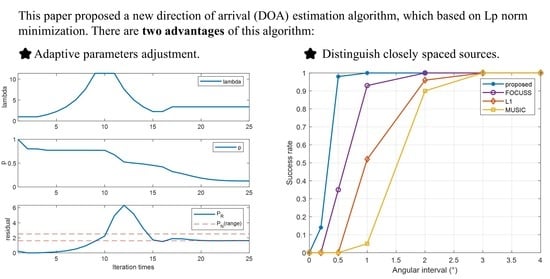
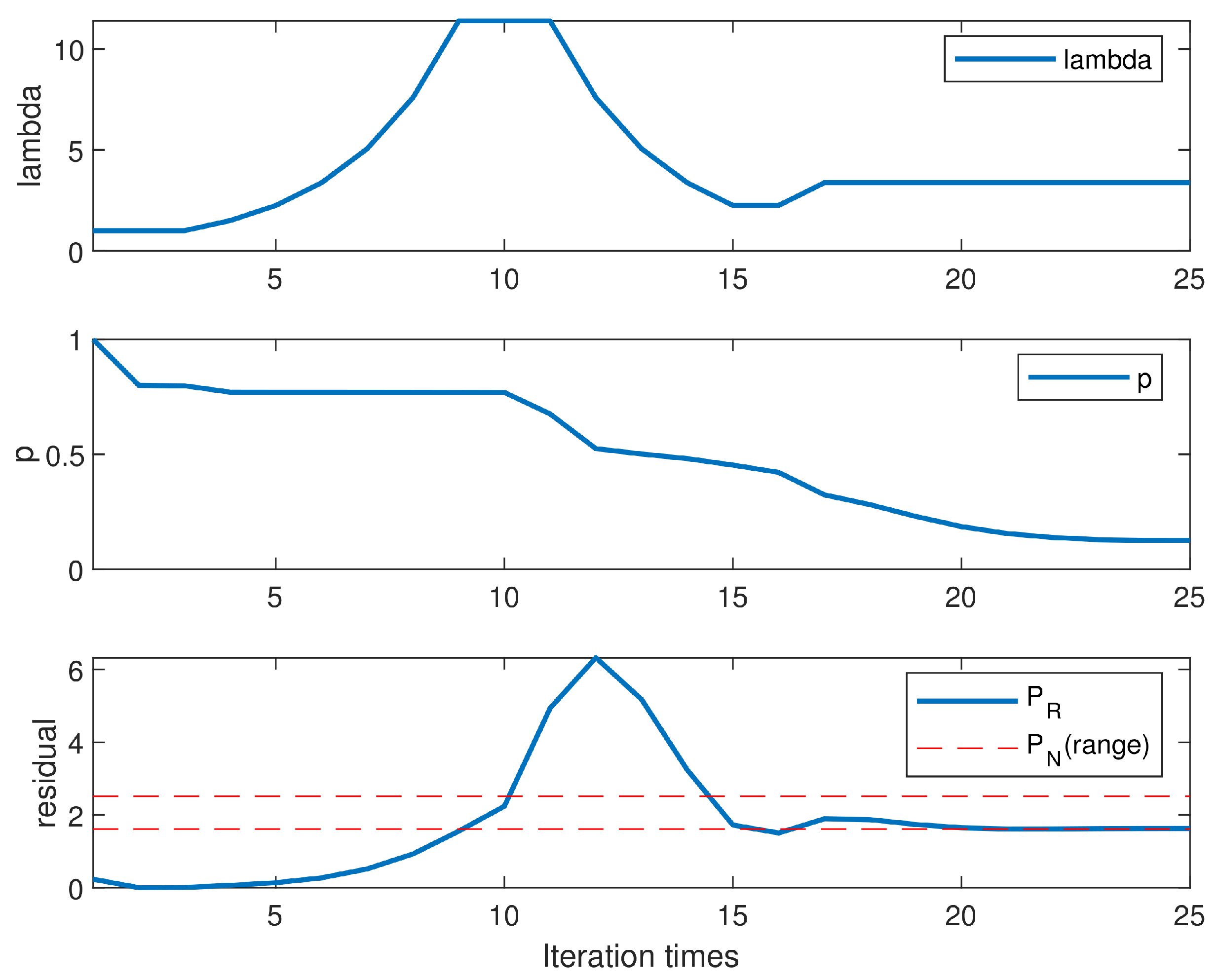
First, the highlight of the proposed algorithm is adaptive adjustment of parameters in the iterative process. The proposed algorithm automatically adjusts according to the expectation power of residual and adjusts p according to the variation of spatial spectrum as shown in Figure 4 with . The top subplot shows the variation of , the middle subplot shows the variation of p, and the bottom subplot indicates the convergence procedure of the residual.
In Figure 4, we examine how the proposed method can adjust and p to provide a convergence result. From the beginning, the result is too close to the least squares solution, which usually has a small residual. In order to obtain a sparser solution, is increased to emphasize the importance of sparsity in iterations. For the whole process, the adaptive method maintains the residuals within expectations as much as possible until iteration convergence.
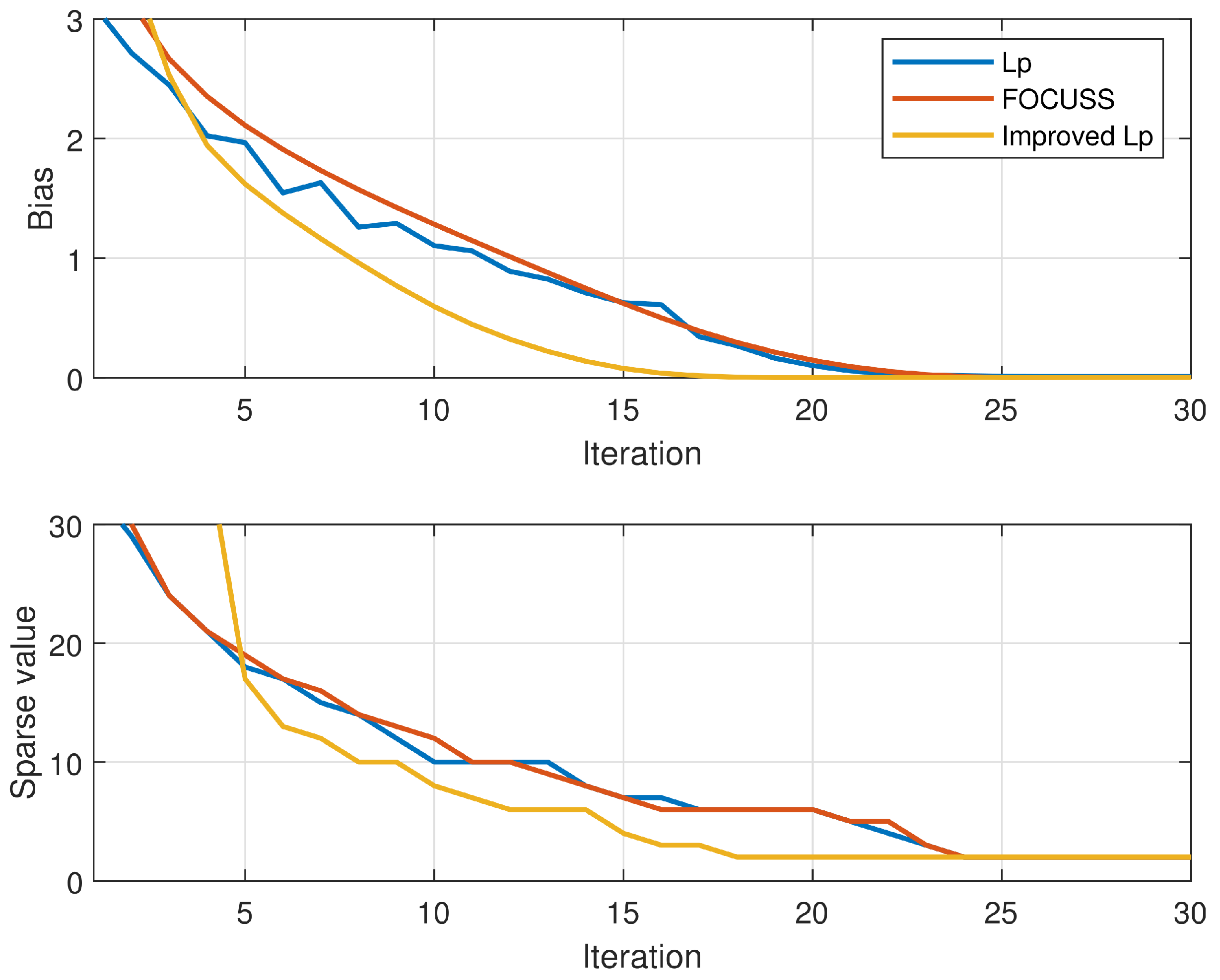
The adaptive methods can not only reduce the influence of the artificial selection of parameters on the results but also speed up the algorithm convergence to a certain extent. The convergence speed of the proposed algorithm was improved under the combined effect of acceleration strategy and adaptive methods. Figure 5 shows that the improved method will converge before 18 iterations, and the original method of and the FOCUSS algorithm requires nearly 24 iterations to converge.
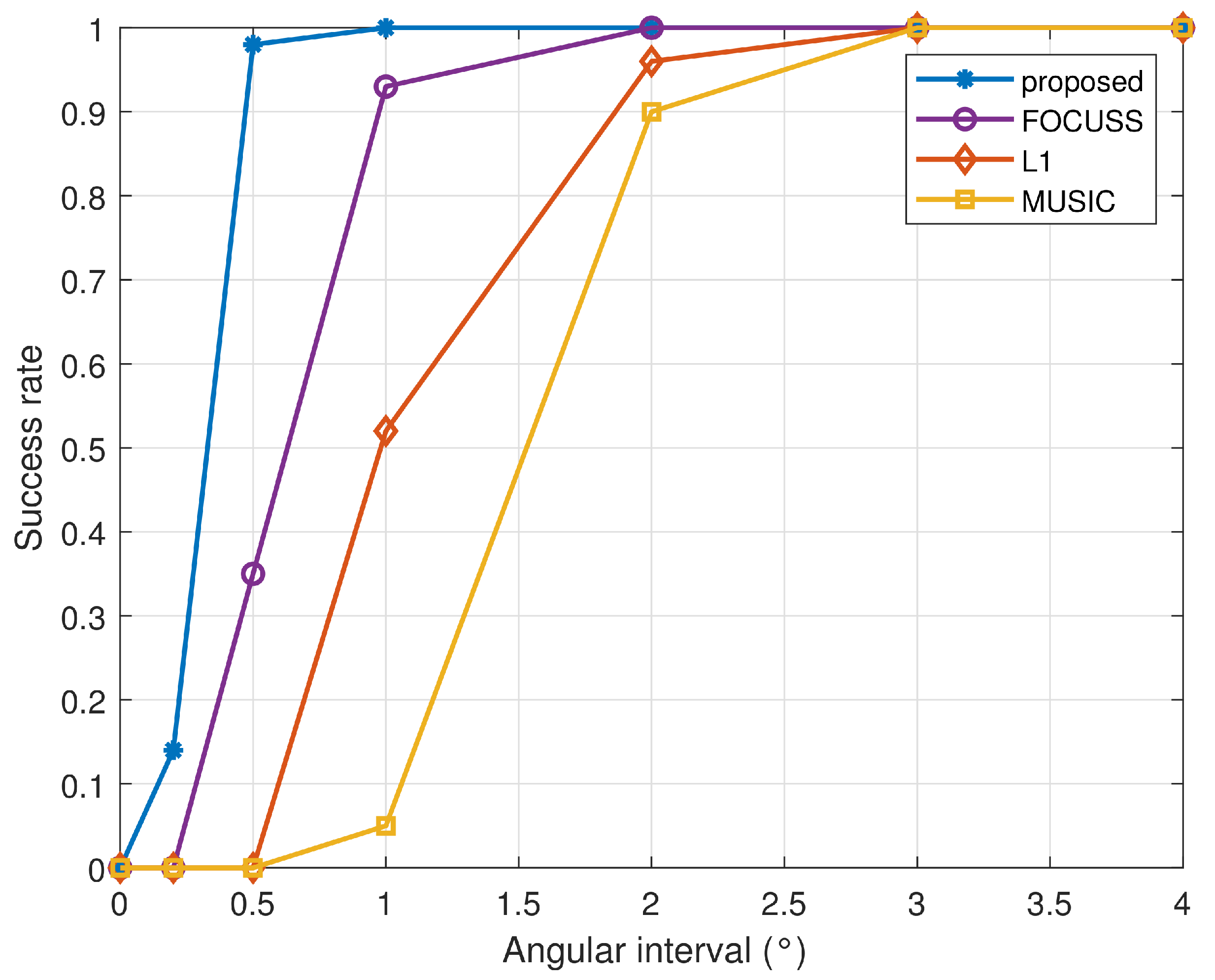
Assume two equal-power uncorrelated signals arrive from 0° and , respectively, where is varied from to 4°. The SNR is set to 0 dB, and the number of snapshots is 200. The statistical result obtained via 200 multi-snapshot trials is shown in Figure 6 with the correct rate versus angular separation. As is clear from the figure, the proposed algorithm had a better ability to distinguish two closely spaced signals.
The bias curves in Figure 7 were obtained via 200 independent trials. Every multi-snapshots trial had a different DOA, and , drawn within the intervals and , and the snapshot number was 200. The root mean square error (RMSE) curves for different SNRs show that the resolution of the proposed algorithm meets the existing sparse reconstruction algorithm standards. Since the set grid size is , when the SNR is high, the resolution of these algorithms is limited by the grid, and the curves will gradually become flat.
In conventional DOA estimation, this degree of error can generally be regarded as a correct estimation. The RMSE of the algorithm does not fully reflect the ability of DOA estimation. Sometimes, it is more meaningful to distinguish two sources in a certain spatial range with low resolution than to obtain only one estimation result with high resolution, which means that the latter option loses a target.
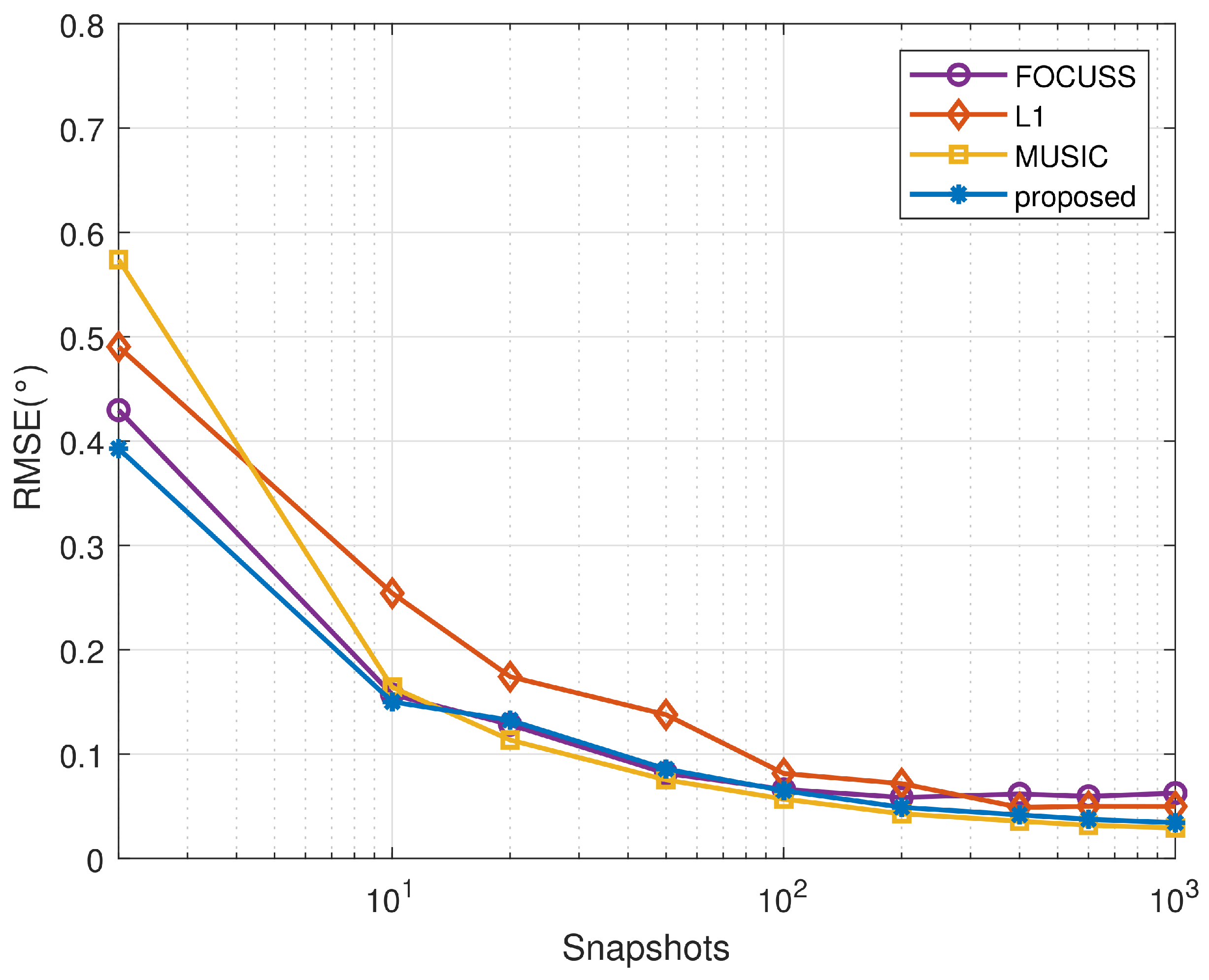
This section will close by examining the impact of the size of the data snapshot on the error-suppression criterion of the adaptive method. Consider two uncorrelated signals arriving from and , where the SNR is fixed at 0 dB, the number of data snapshots is varied from 2 to 1000, and the remaining conditions are identical to those above. Figure 8 shows that, compared to the other methods, the proposed algorithm is stable in small and large snapshots.
As the focus of this paper is to improve the ability of the algorithm to distinguish closely spaced sources, the proposed algorithm and the conventional sparse reconstruction algorithms are essentially maintained in terms of the RMSE.
4. Conclusions
In this paper, an improved norm minimization DOA estimation algorithm was proposed. The proposed algorithm has two advantages: one is the greater ability to separate two closely spaced sources, and the other is the adaptive regularization parameter adjustment. The latter can reduce the impact of manual selection of on the results and can accelerate convergence. The main motivation of this work comes from the desire to increase the practicability of sparse reconstruction algorithms.
By applying norm minimization with the quasi-Newton method and acceleration strategies, the proposed algorithm was faster than L1-SVD, the convex optimization algorithm. In addition, the adaptive method of the regularization parameter can run stably in most non-extreme situations. Compared to other seriously time-consuming methods or by optimizing the inequality-constrained minimization problem directly, the proposed method is more practical.
Author Contributions
This work described in this article is the collaborative development of all authors. L.L. and Z.R. contributed to the idea of result processing and designed the experiment. Z.R. completed the first draft. L.L. reviewed the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The research was funded by “Aviation Foundation”, grant number 201901012005.
Acknowledgments
The authors would like to thank the support of the laboratory and university.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Krim, H.; Viberg, M. Two decades of array signal processing research: The parametric approach. IEEE Signal Process. Mag. 1996, 13, 67–94. [Google Scholar] [CrossRef]
- Del-Rey-Maestre, N.; Mata-Moya, D.; Jarabo-Amores, M.P.; Gómez-del Hoyo, P.J.; Bárcena-Humanes, J.L.; Rosado-Sanz, J. Passive Radar Array Processing with Non-Uniform Linear Arrays for Ground Target’s Detection and Localization. Remote Sens. 2017, 9, 756. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Li, J.; Stoica, P.; Xie, L. Chapter 11—Sparse methods for direction-of-arrival estimation. In Academic Press Library in Signal Processing, Volume 7; Chellappa, R., Theodoridis, S., Eds.; Academic Press: New York, NY, USA, 2018; pp. 509–581. [Google Scholar] [CrossRef] [Green Version]
- Paik, J.W.; Hong, W.; Lee, J.H. Direction-of-Departure and Direction-of-Arrival Estimation Algorithm Based on Compressive Sensing: Data Fitting. Remote Sens. 2020, 12, 2773. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal Recovery From Random Measurements Via Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef] [Green Version]
- Shah, J.A.; Haider, H.; Kadir, K.A.; Khan, S. Sparse signal reconstruction of compressively sampled signals using smoothed ℓ0-norm. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 61–65. [Google Scholar] [CrossRef]
- Malioutov, D.; Cetin, M.; Willsky, A. A sparse signal reconstruction perspective for source localization with sensor arrays. IEEE Trans. Signal Process. 2005, 53, 3010–3022. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Zhao, X.; Li, W.; Zhang, M.; Tao, R.; Ma, P. Adaptive Iterated Shrinkage Thresholding-Based Lp-Norm Sparse Representation for Hyperspectral Imagery Target Detection. Remote Sens. 2020, 12, 3991. [Google Scholar] [CrossRef]
- Chartrand, R.; Yin, W. Iteratively reweighted algorithms for compressive sensing. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 3869–3872. [Google Scholar] [CrossRef]
- Gorodnitsky, I.; Rao, B. Sparse signal reconstruction from limited data using FOCUSS: A re-weighted minimum norm algorithm. IEEE Trans. Signal Process. 1997, 45, 600–616. [Google Scholar] [CrossRef] [Green Version]
- Foucart, S.; Lai, M.J. Sparsest solutions of underdetermined linear systems via ℓq-minimization for 0 < q ≤ 1. Appl. Comput. Harmon. Anal. 2009, 26, 395–407. [Google Scholar] [CrossRef] [Green Version]
- Cotter, S.; Rao, B.; Engan, K.; Kreutz-Delgado, K. Sparse solutions to linear inverse problems with multiple measurement vectors. IEEE Trans. Signal Process. 2005, 53, 2477–2488. [Google Scholar] [CrossRef]
- Golub Gene, M.H.; Wahba, G. Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics 1979, 21, 215–223. [Google Scholar] [CrossRef]
- Rashno, A.; Tabataba, F.S.; Sadri, S. Regularization convex optimization method with l-curve estimation in image restoration. In Proceedings of the 2014 4th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 29–30 October 2014; pp. 221–226. [Google Scholar] [CrossRef]
- Yin, J.; Chen, T. Direction-of-Arrival Estimation Using a Sparse Representation of Array Covariance Vectors. IEEE Trans. Signal Process. 2011, 59, 4489–4493. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S. CVX: MATLAB Software for Disciplined Convex Programming, Version 2.0 Beta. Available online: http://cvxr.com/cvx (accessed on 25 September 2013).
Figure 1.
Schematic of the DOA estimation process.

Figure 2.
Unit norm ball.

Figure 3.
The spectrum of distinguishing closely spaced sources by the weighted method.

Figure 4.
The change of the , p and residual in the iteration process.

Figure 5.
The change of the spectrum bias and sparsity in the iteration process.

Figure 6.
The probability of separating two closely spaced sources as a function of the angular interval.
Figure 6.
The probability of separating two closely spaced sources as a function of the angular interval.

Figure 7.
The RMSE of the DOA estimates as a function of the SNR.

Figure 8.
The RMSE of the DOA estimates as a function of the snapshots.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, L.; Rao, Z. An Adaptive Lp Norm Minimization Algorithm for Direction of Arrival Estimation. Remote Sens. 2022, 14, 766. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14030766
AMA Style
Liu L, Rao Z. An Adaptive Lp Norm Minimization Algorithm for Direction of Arrival Estimation. Remote Sensing. 2022; 14(3):766. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14030766
Chicago/Turabian StyleLiu, Lutao, and Zejing Rao. 2022. "An Adaptive Lp Norm Minimization Algorithm for Direction of Arrival Estimation" Remote Sensing 14, no. 3: 766. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14030766
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.