1. Introduction
Object detection in remote sensing images plays an important role in several civilian and military applications, such as urban planning, geographic information system updating, and search-and-rescue operations. Compared with the traditional methods (template-matching-based methods [
1,
2], knowledge-based methods [
3,
4], etc.), the deep-learning-based methods automatically extract features from raw data by shifting the burden of manual feature design to the underlying learning system, enabling a more powerful feature representation to extract higher semantic levels of feature maps. With this advantage, deep-learning-based detection approaches have achieved great success in both the computer vision and remote sensing community [
5,
6].
Unlike the natural scene image, remotely sensed images have larger scale variations and more feature complexity under different observation conditions, requiring higher generalization of object detectors. DNN-based detection approaches have recently been introduced from the computer vision field to the remote sensing field and achieved top scores on multiclass object detection. Many fundamental issues of deep learning object detection for remote sensing images are addressed, such as the lack of sufficient training samples [
7,
8], the poor performance of the small object detection [
9,
10,
11], and rotation characteristics of the object in satellite image [
12,
13]. The comprehensive review, written in 2020, can be found in article [
5].
Nevertheless, the large variation of object scales in multiresolution remote sensing images still poses a great challenge for object detectors. Recently, a number of studies have explored the possibility of solving this problem from different aspects, which can be summarized into three categories. (1) Feature fusion with different levels: in this category, many fusion models are created to extract multi-scale feature hierarchy to improve the model performance on both small and large objects. The representative studies include the cross-scale feature fusion (CSFF) [
14], the polarization attention mechanism module based on dual feature pyramid network (FPN) [
15], feature-fusion architecture(FFA) [
16], multi-patch feature pyramid network [
17], and Quad-FPN [
18]. (2) Improving the region proposal network to generate more suitable anchors: these models address the mismatch problem of the anchor size and object sizes in multi-scale images, such as the self-adaptive aspect ratio anchor (SARA) [
19], the multi-scale spatial attention region proposal network [
20], and the size folding operation (SF) [
21]. (3) Establishing parallel networks to detect objects of different scales: one of the representative works is the multi-expert detection network (MEDNet) [
22].
The above methods mainly focus on feature extraction and feature matching between objects of different scales. In addition to that, the imbalance of the positive and negative samples is another reason that the model fails to detect objects across different scales [
23]. Compared to small objects, large objects are more likely to be identified as positive samples with higher precision. When applying the model pre-trained by high-resolution images to low-resolution images, most large objects become small objects, leading to too few positive samples to effectively train the model.
In anchor-based detectors, an intersection-over-union (IoU) threshold is usually used to distinguish positive/negative samples, which also defines the detection quality [
24]. Choosing an appropriate threshold is a compromise between detection quality and precision, because the lower IoU threshold brings more potential region proposals of the object, but with more noisy samples, which leads to unreliable detection results. However, using a high IoU threshold in training results in too few positive samples, leading to model overfitting.
To achieve high precision, the IoU threshold must closely match the quality of detector hypotheses [
25]. Cascade R-CNN [
25], as an extension of two-stage anchor-based detectors, uses a three-stage cascaded structure to address the above issue, where the IoU of training samples (i.e., the quality of the hypotheses) can be progressively improved by cascaded bounding box regression. This cascaded structure sequentially improves the quantity and quality of positive training samples to reduce the overfitting problem. In experiments with natural scene images, the cascaded structure achieves better precision in the detection of objects of different scales. However, in the original structure of Cascade R-CNN, the maximum number of the cascade component is three. The overall detection performance declines when the fourth stage is added [
25]. This limits the extension of cascaded detectors to achieve better detection performance.
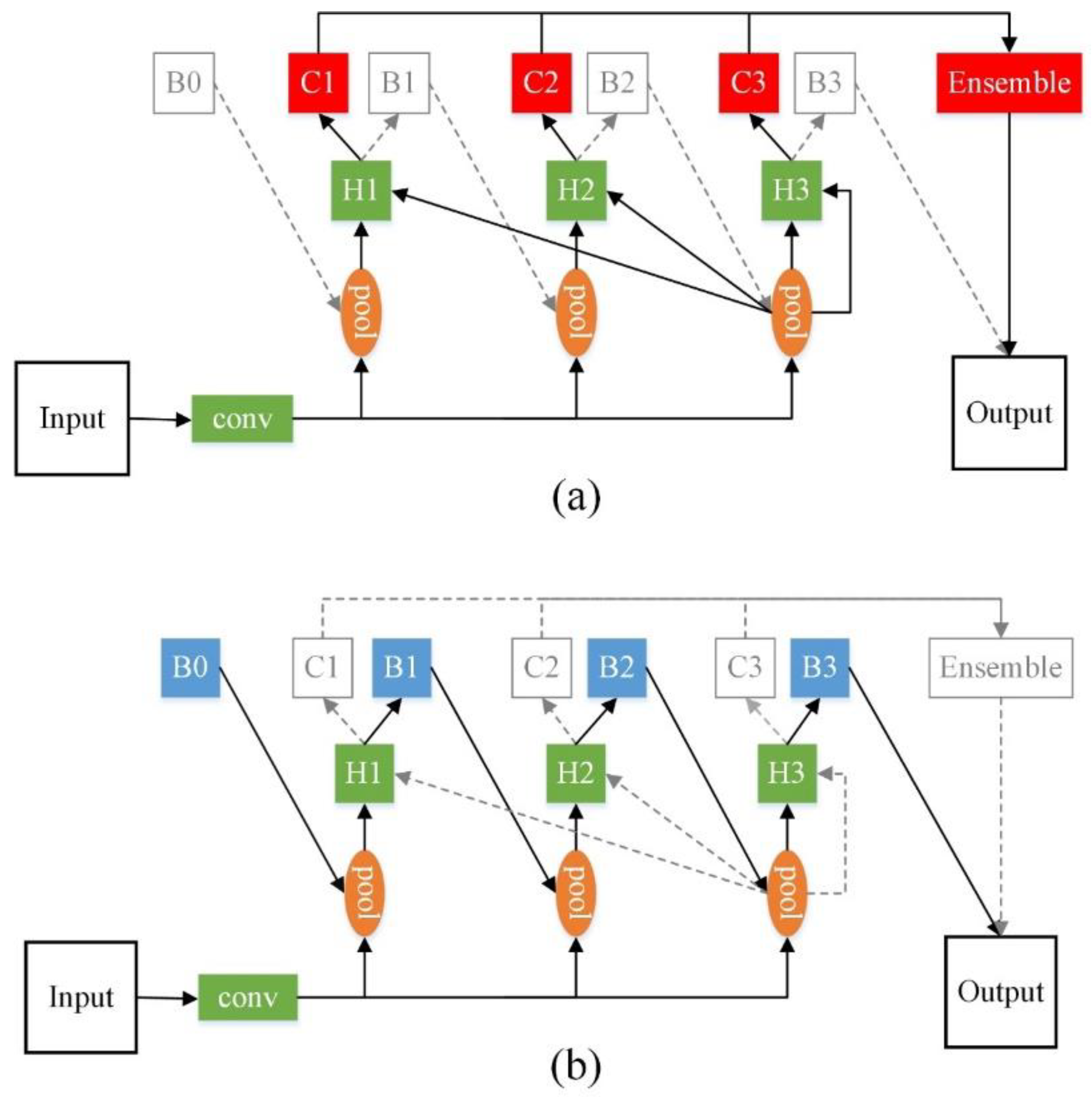
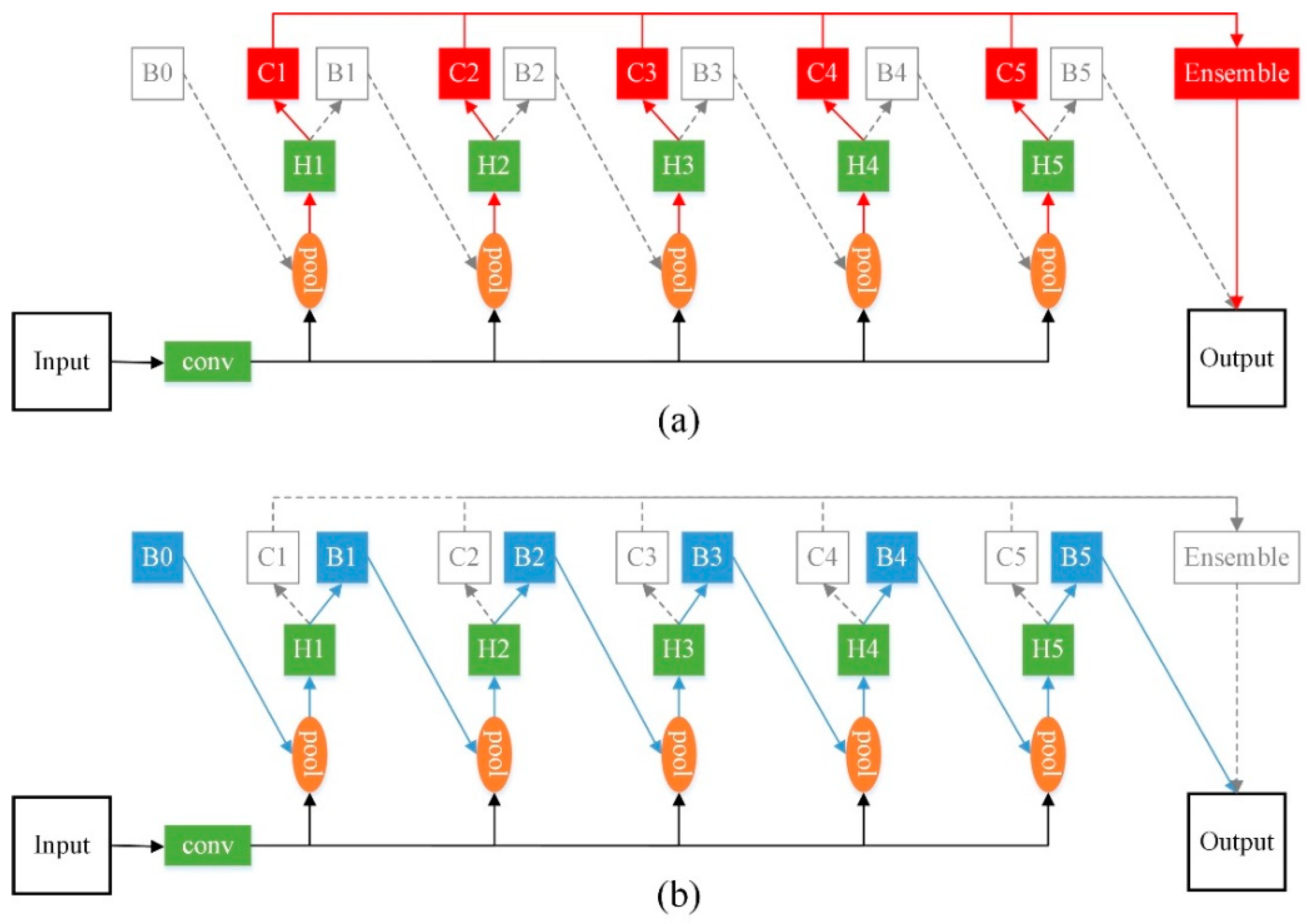
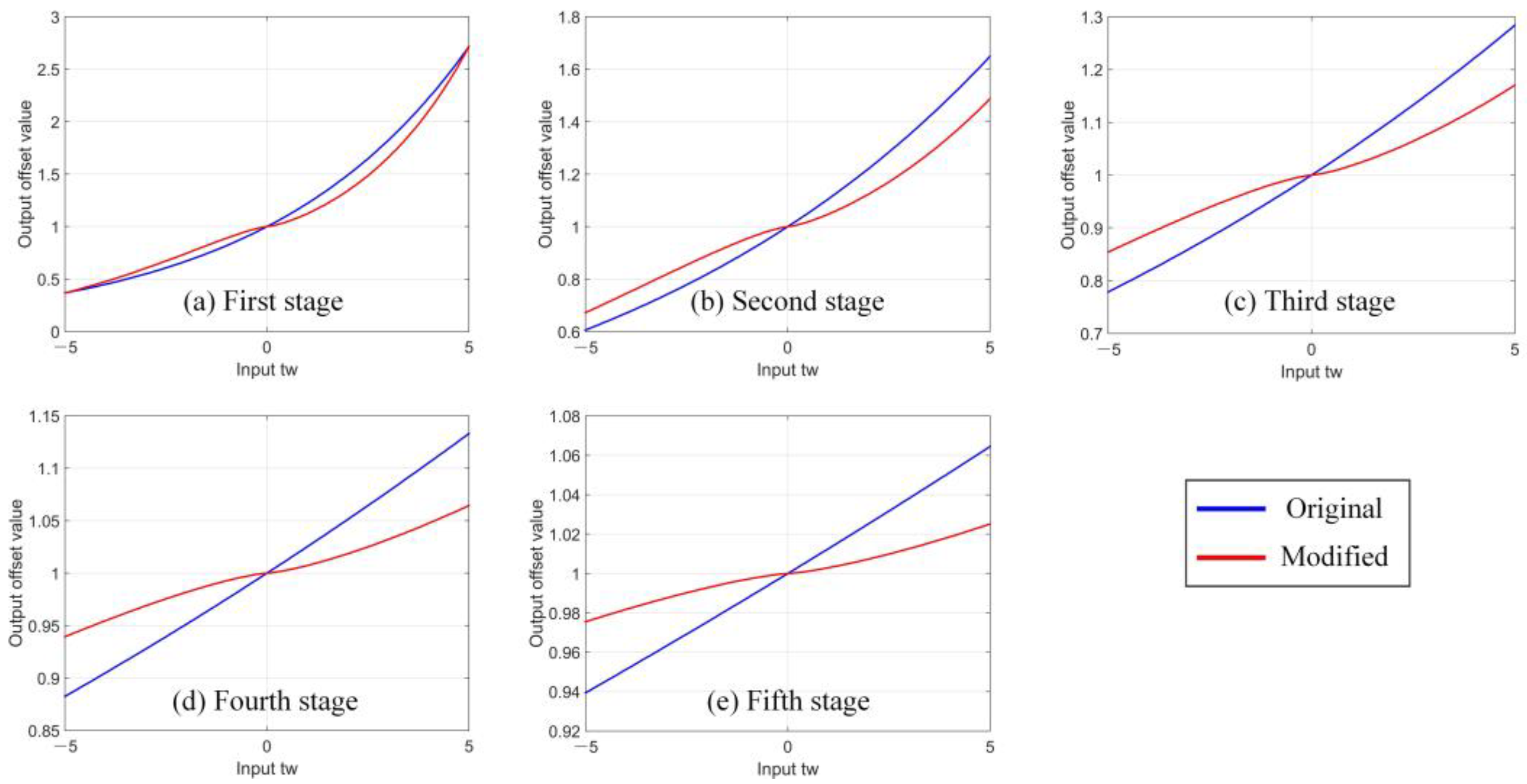
In this paper, we investigated the causes of performance degradation when adding more cascaded stages. We found that at inference, the original ensemble strategy in Cascade R-CNN introduces a mismatch between the classifier and region of interest (RoI) vectors, decreasing the classification accuracy.
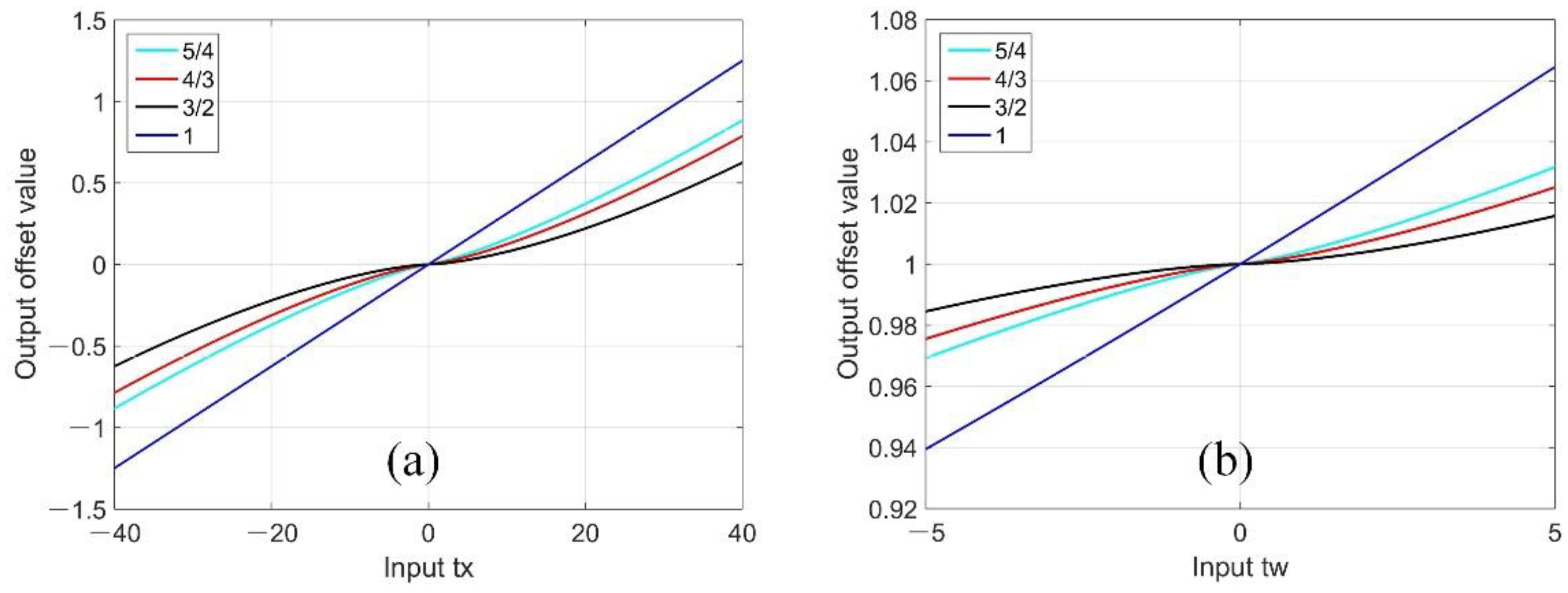
To overcome this limitation, we propose a new ensemble strategy for cascaded classification by taking the RoI features produced by the same stage for classification, rather than uniformly using those from the final stage. The final classification results are obtained by integrating the classifier outputs of all stages. In addition, the loss function of bounding box regression [
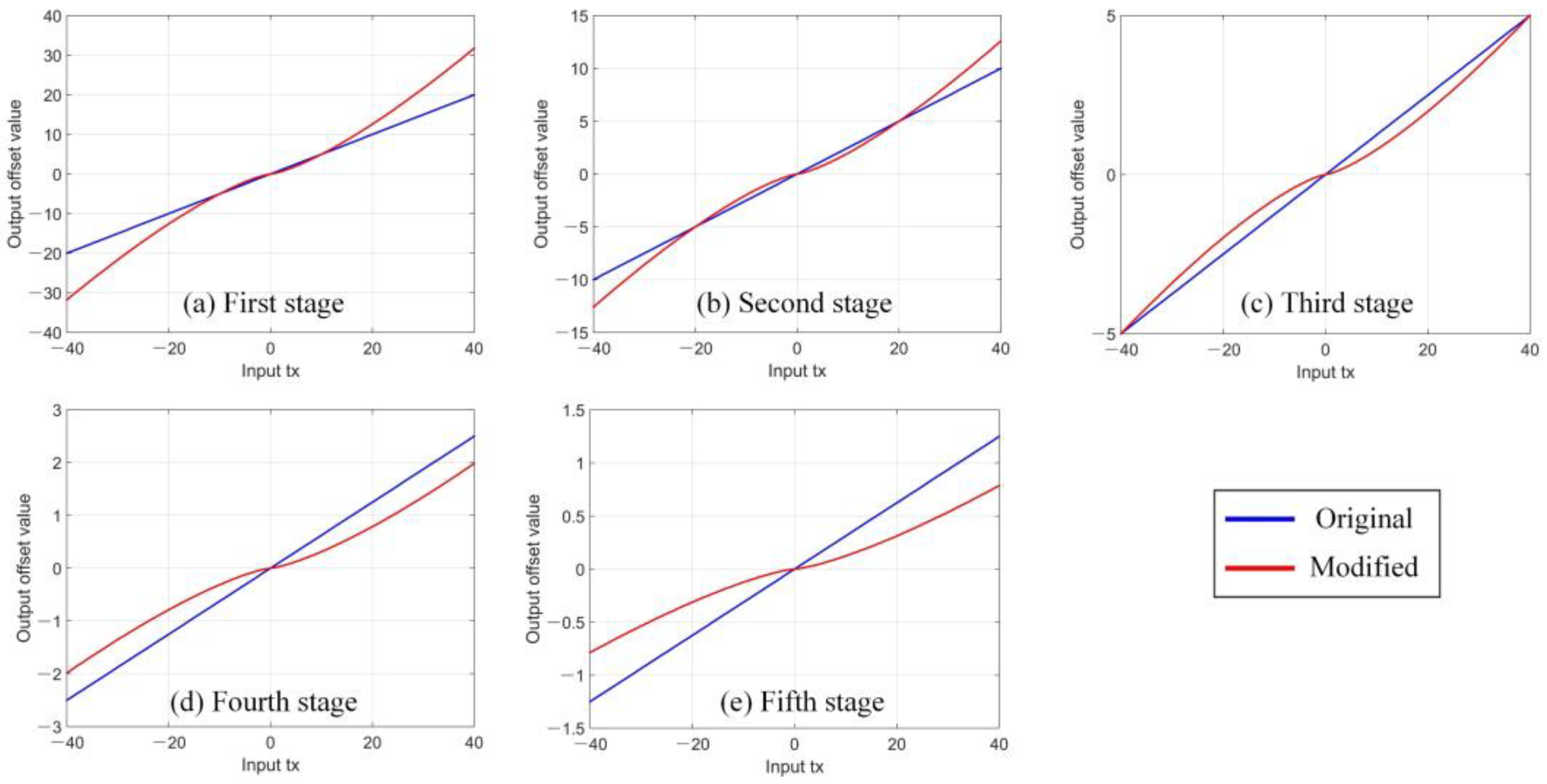
26] is modified to improve sensitivity, allowing the cascaded regressor to further converge as the number of stages increases. The modified cascade structure is denoted as Cascade R-CNN++ throughout this paper.
The main contributions of this study are as follows: (1) we investigated the causes of performance degradation in cascaded detectors when more stages are added, (2) we propose a new ensemble strategy to minimize the mismatch between the classifiers and input RoIs at inference and to improve classification accuracy, and (3) we propose a modified loss function for bounding box regression to enable further convergence of bounding box regression with more stages built. The proposed Cascade R-CNN++ approach can achieve state-of-the-art detection performance on the remote sensing dataset DOTA [
27,
28]. It can be implemented in most cases where region-proposal-based methods are needed. In experiments with multiresolution remote sensing images, the proposed approach outperforms Cascade R-CNN both in detection quality and precision.
The rest of this paper is arranged as follows.
Section 2 reviews previous studies most relevant to this research.
Section 3 introduces the employed dataset and evaluation metrics.
Section 4 analyzes the reasons for performance degradation when more stages are added in Cascade R-CNN.
Section 5 describes the proposed method, Cascade R-CNN++.
Section 6 presents experimental results with discussion, and
Section 7 draws the conclusions.
2. Related Works
In the computer vision field, deep-learning-based detectors can be generally divided into two categories. The first is one-stage approaches that are more efficient with simpler structures, represented by YOLO [
29,
30,
31], single-shot detection (SSD) [
32], and RetinaNet [
33]. The other category is two-stage approaches (i.e., region-proposal-based methods), represented by region-based convolutional neural networks (R-CNNs) [
26], Fast R-CNN [
34], Faster R-CNN [
35], Feature Pyramid Network (FPN) [
36] and Cascade R-CNN [
24]. In the second category, the multi-scale region proposals are produced firstly, followed by the feature extraction and bounding box regression procedure. Although one-stage models have achieved high precision in object detection, two-stage methods can generally be more flexible and extensible across different computer vision tasks, such as objection detection, instance segmentation and key point detection. Thus, this research focuses on two-stage detectors and aims to alleviate the problem limiting the further extension of the cascaded structure.
R-CNN [
26] was proposed in 2014. It employs a two-stage structure for object detection, combining region proposals with CNN extracted features. R-CNN employs selective search algorithms to generate approximately 2000 candidate region proposals from the input image and applies CNNs to create feature vectors for each object proposal. The performance of R-CNN was validated on natural scene images using the PASCAL VOC 2012 dataset, reaching a mean Average Precision (mAP) of 53.3%. Fast R-CNN [
34] improves computational efficiency by integrating the three training stages in R-CNN, achieving a mAP of 68.4% on PASCAL VOC 2012 test. R-CNN and Fast R-CNN both employ the selective search approach to generate object proposals, which is more computationally expensive. Faster R-CNN [
35] replaces the selective search algorithm with a region proposal network (RPN), introducing anchors to identify region proposals using a fully convolutional network and significantly reduces time consumption. It achieved detection accuracy of 70.4% mAP on PASCAL VOC 2012 dataset. RPN has a fixed receptive field size, where objects are of various scales.
Only using the topmost feature layer for proposal generation can lead to missed detection of small objects. FPN [
36] can extract top-down multiscale feature layers for RPN to generate region proposals. As different layers have different receptive fields, a combination of FPN and Faster R-CNN can better adapt to the detection of objects of different scales. Faster R-CNN & FPN achieved AP of 35.8% on the COCO detection benchmark [
36]. More recent studies also contributed to improve the feature pyramid for object detection in optical remote sensing images, such as aware feature pyramid network (AFPN) [
37] and Feature Enhancement Network (FENet) [
38], achieving 74.3% and 74.89% mAP (PASCAL VOC metric) on DOTA-v1.0 dataset, respectively.
Besides two-stage architectures, multistage detectors, including Cascade R-CNN [
24,
25], have recently been proposed. Cascade R-CNN uses a three-stage structure and can achieve better performance than two-stage detectors through cascaded bounding box regression and an ensemble of cascaded classification results. In the design of cascaded detectors, regressed bounding boxes from the previous stage act as region proposals for the current stage to progressively improve the quality of region proposals in the cascaded structure. Linearly increased IoU thresholds (0.5, 0.6, and 0.7) are used for training at each stage to better match the quality of input proposals to train high-quality detectors. Cascade R-CNN obtained 38.9% AP on MS-COCO 2017. However, degraded performance is observed when the fourth stage is added to Cascade R-CNN [
25].
3. Datasets and Evaluation Metrics
The DOTA-v1.5 dataset [
27], which contains 2806 images and 403,318 instances, was employed in this study, in
Section 4,
Section 6 and
Section 7. It consists of 16 categories of objects, i.e., airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool, and container crane. The proportions of the training, validation, and testing sets are 1/2, 1/6, and 1/3, respectively.
Another remote sensing dataset, NWPU VHR-10 [
6,
12,
39], was also used in the comparison with state-of-the-art detectors in
Section 6. NWPU VHR-10 dataset is a publicly available geospatial object detection dataset. It contains 800 very-high-resolution (VHR) remote sensing images cropped from Google Earth and Vaihingen dataset and annotated by experts. The dataset consists of 10 categories of objects, including airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, and vehicle.
In this research, Intersection over Union (IoU) was used to measure the amount of overlap between the predicted and ground truth bounding box. It is a ratio from 0 to 1 that specifies the accuracy of object localization. The IoU threshold used in training defines the detection quality. The metrics of AP, AP
50, AP
75, AP
90, AP
S, AP
M and AP
L, as defined in the metric standard of MS COCO object detection challenge [
40], were taken to assess the detection precision. The abovementioned metrics have been widely used to evaluate object detection tasks.
7. Discussion
In this section, we discuss the impacts of IoU thresholds on the detection performance of cascaded detectors.
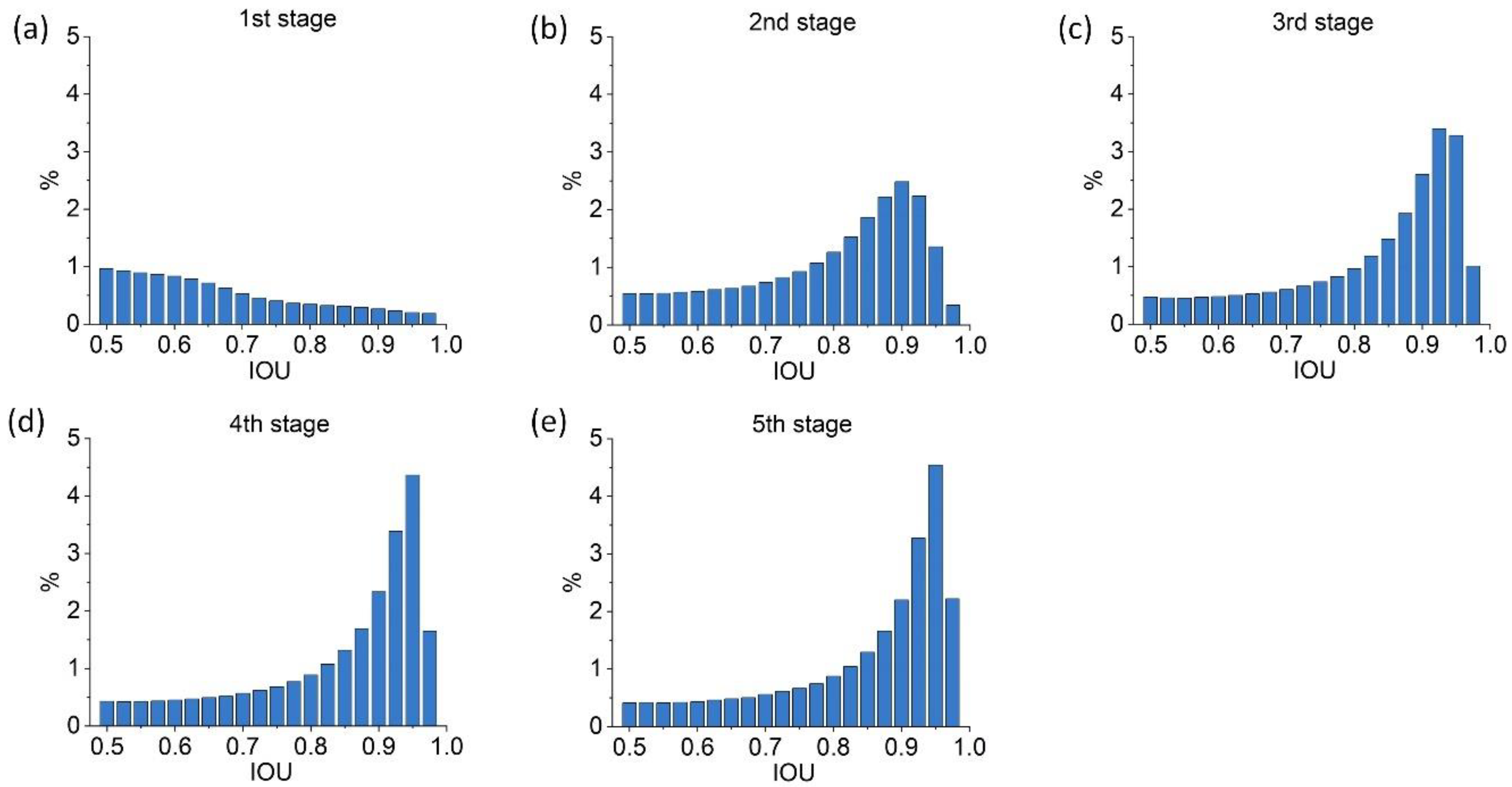
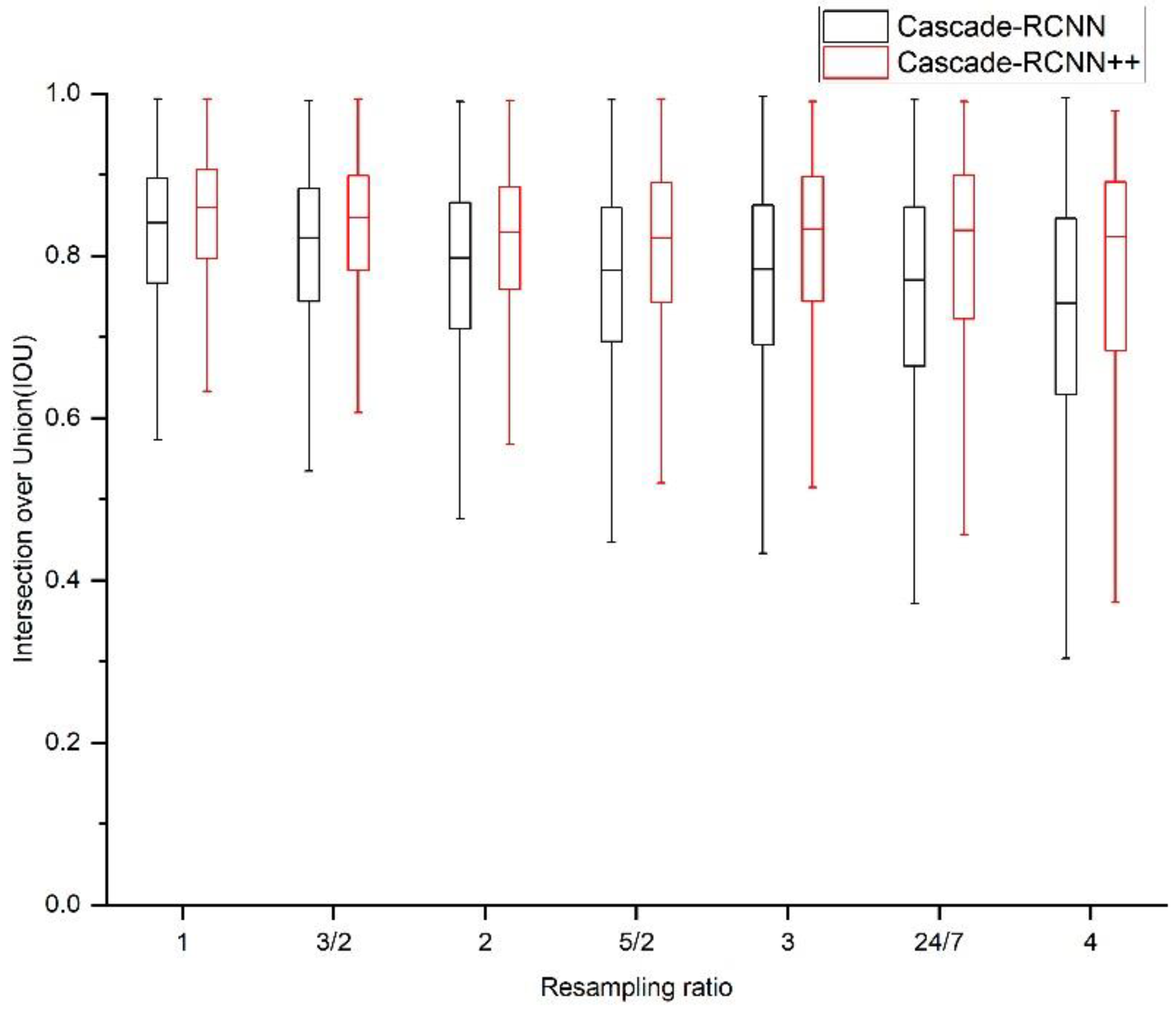
The majority of the region proposals produced by RPN or selective search have low quality, showing distribution concentrated around low IoU values. A high threshold will lead to too few positive samples, resulting in model overfitting. A low threshold will produce noisy detections. The IoU threshold of 0.5 is a standard compromise widely used in object detection models. This value is used as the initial threshold for the first stage, both in Cascade R-CNN and the proposed Cascade R-CNN++ model.
In the original Cascade R-CNN, the IoU thresholds for the second and third stages were empirically set as 0.6 and 0.7, increasing linearly by a step size of 0.1. In
Section 4.1, it was found that with the number of cascades increases, the improvement in the IoU distribution of training samples becomes smaller. Thus, for the five-stage model in
Section 4, the IoU thresholds for the fourth and fifth stages were empirically set as 0.75 and 0.85. We conducted a comparison on the detection performance under different IoU threshold settings on the proposed Cascade R-CNN++ structure, with results shown in
Table 6, where the “empirical thresholds” are represented by
, and the “auto determined thresholds” are denoted by
, which are the thresholds automatically determined by the 20% quantile of IoU distribution at each stage except the first stage, as described in
Section 6.1.
In
Table 6, it is shown that under the same conditions, auto determined thresholds achieved better overall performance. It is likely that the thresholds estimated using the IoU distribution better matches the quality of training samples, and thus achieved a better balance between effective training and high-quality detection.
8. Conclusions
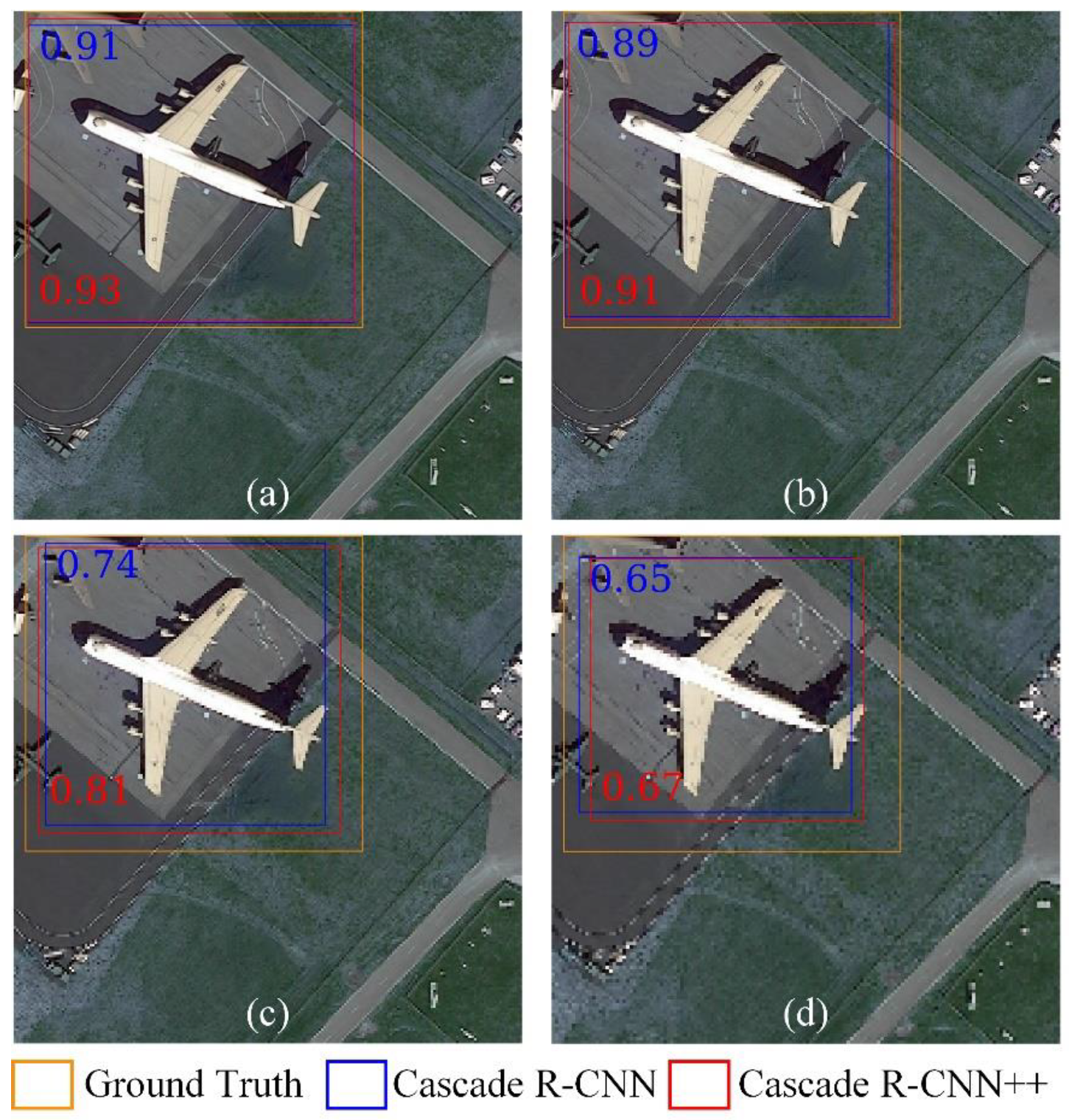
In this study, we proposed Cascade R-CNN++ as an improved cascade structure, to achieve high-quality object detection across multiresolution remote sensing image. The new model overcomes the extension problem of the original Cascade R-CNN by employing a new ensemble strategy for classification at inference, which eliminated the mismatch between the classifier and RoI features. Further, we modified the loss function of bounding box regression to achieve higher sensitivity around zero, which allowed further convergence with an increase in the cascaded stage. The effectiveness of the proposed method was verified using DOTA-v1.5 and NWPU VHR-10 datasets. Cascade R-CNN++ could achieve higher precision with an increase of stages, and significant improvements were achieved in high-quality detection (e.g., AP90). We conducted further analysis on detection quality to verify model transferability across multiresolution remote sensing images. Comparing to Cascade R-CNN, the proposed Cascade R-CNN++ achieved higher IoU values on the detection of different categories of objects across multiresolution images. This trend becomes more significant as the image resolution decreases.
Owing to limited variability of remote sensing training dataset, the transferability of the deep learning model between multiresolution imagery is essential for remote sensing object detection. “Training once, apply to multiscale” is the ultimate goal. The cascade structure and loss function presented in this paper can help the model to improve transferability across multiresolution images. They are independent components that can further be applied to another multistage model. In the future, we will explore the use of cascaded structure in other tasks, such as instance segmentation and key point detection.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}