
Daily Prediction and Multi-Step Forward Forecasting of Reference Evapotranspiration Using LSTM and Bi-LSTM Models

 , ,
, , 
 and
and
Abstract
:1. Introduction
2. Material and Methods
2.1. Study Area and the Data
2.2. Prediction Models
2.2.1. Long Short-Term Memory (LSTM) Networks
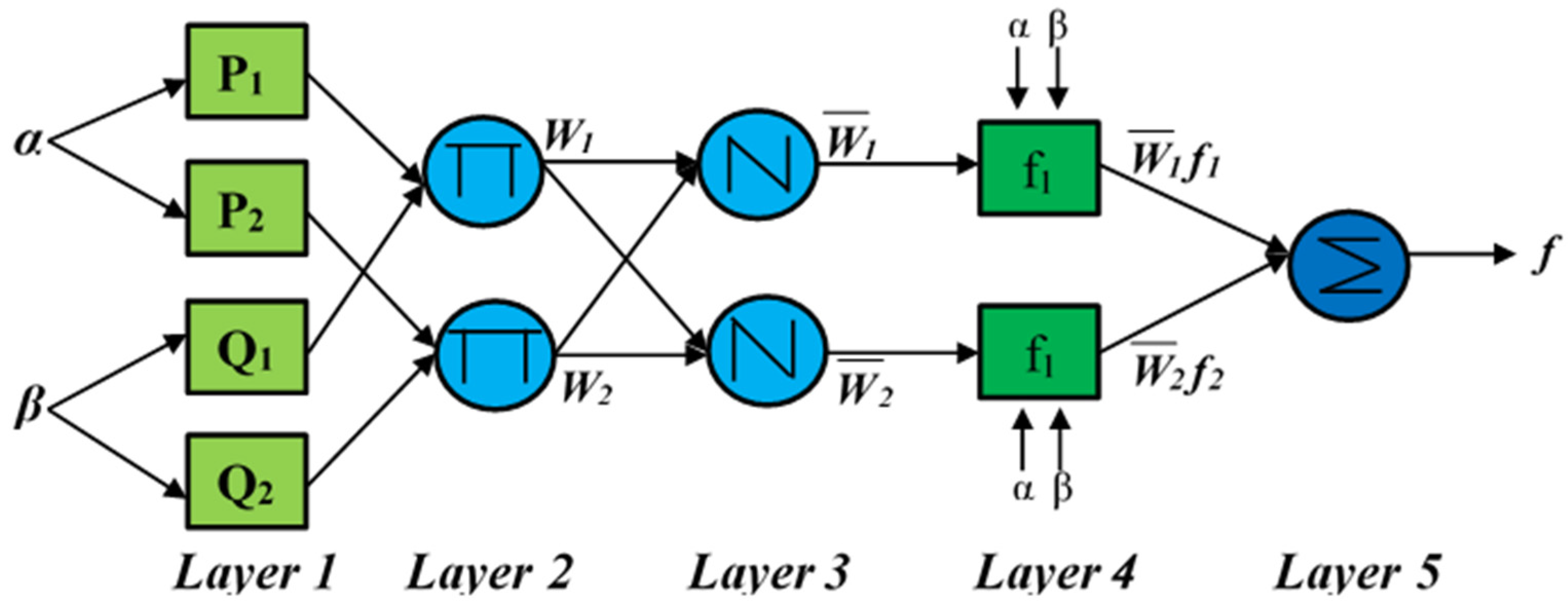
2.2.2. Adaptive Neuro-Fuzzy Inference System (ANFIS)
2.2.3. Gaussian Process Regression (GPR)
2.2.4. M5 Model Trees (M5 Tree)
2.2.5. Multivariate Adaptive Regression Spline (MARS)
2.2.6. Probabilistic Linear Regression (PLR)
2.2.7. Support Vector Regression (SVR)
2.3. Ranking of the ET0 Prediction Models: Shannon’s Entropy
2.4. Selection of Input Variables for Daily Predictions
2.5. Model Performance Evaluation
- -
- Correlation coefficient, R
- -
- Nash–Sutcliffe efficiency coefficient, NS [120]
- -
- Index of agreement, IOA [121]
- -
- Root mean square error, RMSE [122]
- -
- Normalized RMSE, NRMSE
- -
- Maximum absolute error, MAE
- -
- Median absolute deviation, MAD
3. Results and Discussion
3.1. Daily Prediction of ET0 Using Various Machine Learning Algorithms at the Training Station (Gazipur Sadar)
3.2. One-Step-Ahead Prediction of ET0 Using Different Modeling Approaches at the Training Station (Gazipur Sadar)
3.2.1. One-Step-Ahead Forecast Using Sequence to Sequence Regression LSTM (SSR-LSTM) Network
3.2.2. One-Step-Ahead Forecast Using ANFIS, LSTM, and Bi-LSTM Models
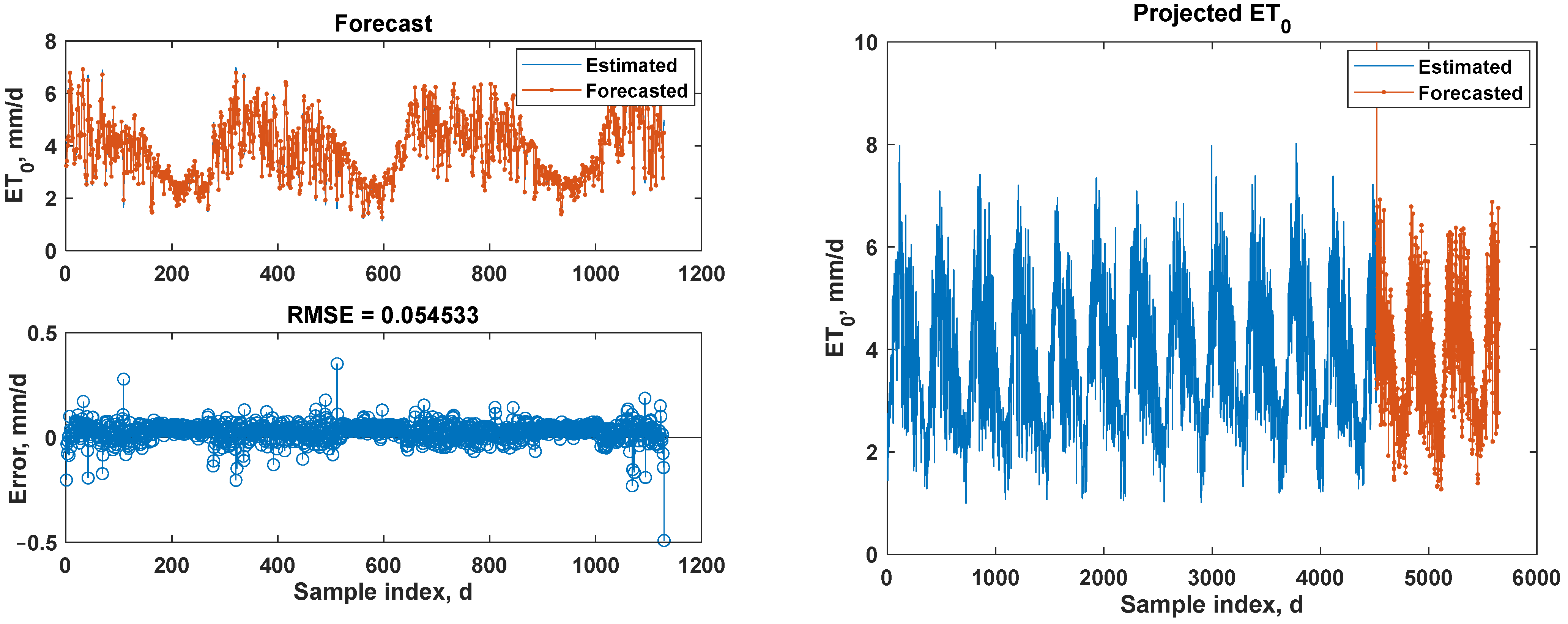
3.3. Multi-Step (5 Day-Ahead) Forecasting Using the Bi-LSTM Model
3.4. Generalization Capability of the Proposed Best ET0 Prediction Models
3.4.1. Generalization Capability of Proposed Best LSTM Model: Daily Prediction of ET0
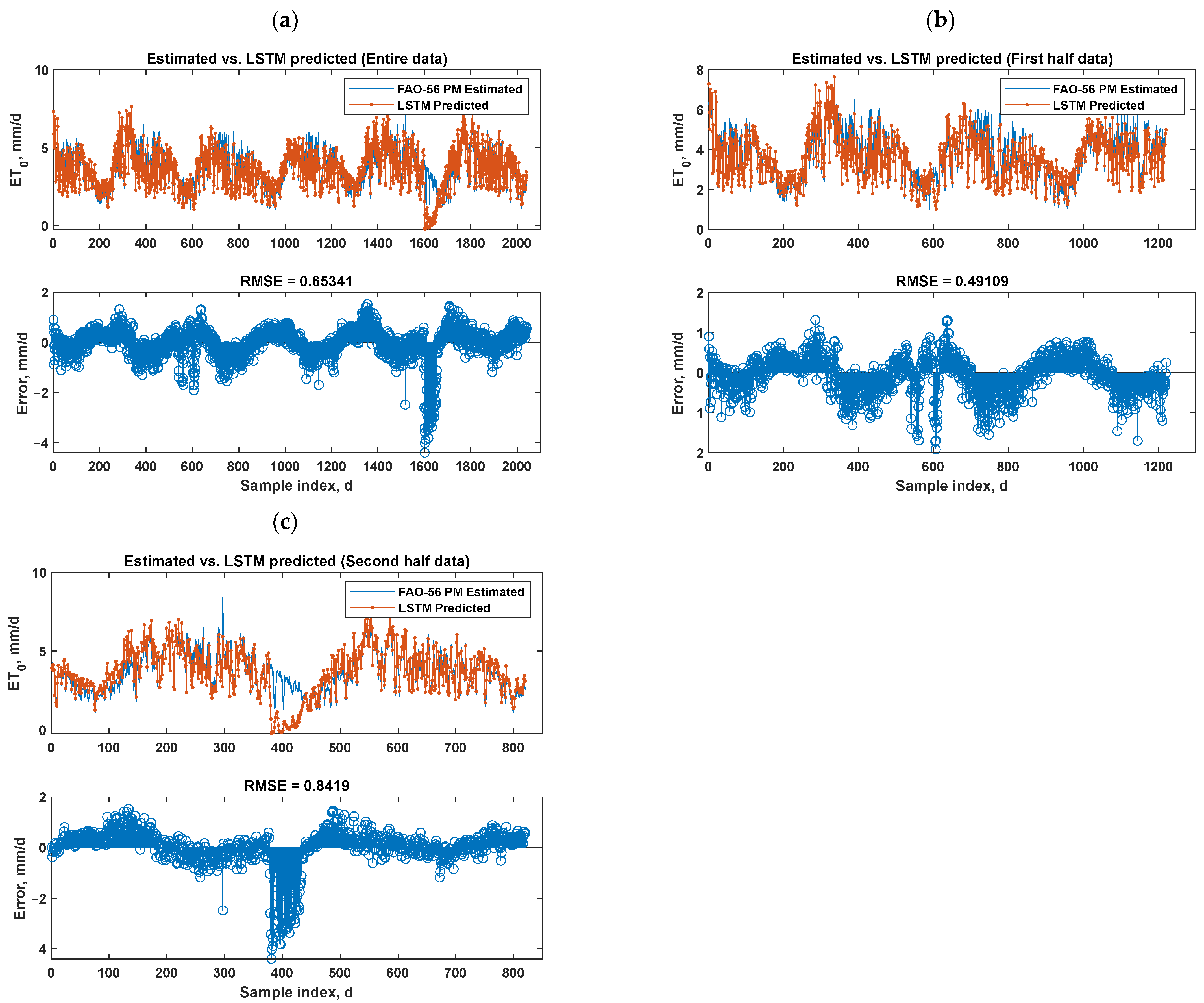
3.4.2. Generalization Capability of Proposed Best Bi-LSTM Model: Multi-Step (Multi-Day)-Ahead ET0 Forecasting
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, S.M.; Xu, Z.W.; Zhu, Z.L.; Jia, Z.Z.; Zhu, M.J. Measurements of evapotranspiration from eddy-covariance systems and large aperture scintillometers in the Hai River Basin, China. J. Hydrol. 2013, 487, 24–38. [Google Scholar] [CrossRef]
- Kisi, O. Modeling reference evapotranspiration using three different heuristic regression approaches. Agric. Water Manag. 2016, 169, 162–172. [Google Scholar]
- Kool, D.; Agam, N.; Lazarovitch, N.; Heitman, J.L.; Sauer, T.J.; Ben-Gal, A. A review of approaches for evapotranspiration partitioning. Agric. For. Meteorol. 2014, 184, 56–70. [Google Scholar] [CrossRef]
- Martí, P.; González-Altozano, P.; López-Urrea, R.; Mancha, L.A.; Shiri, J. Modeling reference evapotranspiration with calculated targets. Assessment and implications. Agric. Water Manag. 2015, 149, 81–90. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, Y.; Xu, D.; Zhao, N.; Lei, B.; Rosa, R.D.; Paredes, P.; Paço, T.A.; Pereira, L.S. The dual crop coefficient approach to estimate and partitioning evapotranspiration of the winter wheat–summer maize crop sequence in North China Plain. Irrig. Sci. 2013, 31, 1303–1316. [Google Scholar] [CrossRef]
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M. Crop Evapotranspiration-Guidelines for Computing crop Water Requirements; FAO: Rome, Italy, 1998. [Google Scholar]
- Ding, R.; Kang, S.; Zhang, Y.; Hao, X.; Tong, L.; Du, T. Partitioning evapotranspiration into soil evaporation and transpiration using a modified dual crop coefficient model in irrigated maize field with ground-mulching. Agric. Water Manag. 2013, 127, 85–96. [Google Scholar] [CrossRef]
- Landeras, G.; Ortiz-Barredo, A.; López, J.J. Comparison of artificial neural network models and empirical and semi-empirical equations for daily reference evapotranspiration estimation in the Basque Country (Northern Spain). Agric. Water Manag. 2008, 95, 553–565. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F.; Fernandes Filho, E.I. Exploring machine learning and multi-task learning to estimate meteorological data and reference evapotranspiration across Brazil. Agric. Water Manag. 2022, 259, 107281. [Google Scholar] [CrossRef]
- Kelley, J.; Pardyjak, E.R. Using neural networks to estimate site-specific crop evapotranspiration with low-cost sensors. Agronomy 2019, 9, 108. [Google Scholar] [CrossRef] [Green Version]
- Yassin, M.A.; Alazba, A.A.; Mattar, M.A. Modelling daily evapotranspiration using artificial neural networks under hyper arid conditions. Pak. J. Agric. Sci. 2016, 53, 695–712. [Google Scholar]
- Yassin, M.A.; Alazba, A.A.; Mattar, M.A. Artificial neural networks versus gene expression programming forestimating reference evapotranspiration in arid climate. Agric. Water Manag. 2016, 163, 110–124. [Google Scholar] [CrossRef]
- Kumar, M.; Raghuwanshi, N.S.; Singh, R.; Wallender, W.W.; Pruitt, W.O. Estimating evapotranspiration using artificial neural network. J. Irrig. Drain. Eng. 2002, 128, 224–233. [Google Scholar] [CrossRef]
- Feng, Y.; Cui, N.; Gong, D.; Zhang, Q.; Zhao, L. Evaluation of random forests and generalized regression neural networks for daily reference evapotranspiration modelling. Agric. Water Manag. 2017, 193, 163–173. [Google Scholar] [CrossRef]
- Feng, Y.; Peng, Y.; Cui, N.; Gong, D.; Zhang, K. Modeling reference evapotranspiration using extreme learning machine and generalized regression neural network only with temperature data. Comput. Electron. Agric. 2017, 136, 71–78. [Google Scholar] [CrossRef]
- Gocić, M.; Arab Amiri, M. Reference evapotranspiration prediction using neural networks and optimum time lags. Water Resour. Manag. 2021, 35, 1913–1926. [Google Scholar] [CrossRef]
- Doğan, E. Reference evapotranspiration estimation using adaptive neuro-fuzzy inference systems. Irrig. Drain. 2009, 58, 617–628. [Google Scholar] [CrossRef]
- Dou, X.; Yang, Y. Evapotranspiration estimation using four different machine learning approaches in different terrestrial ecosystems. Comput. Electron. Agric. 2018, 148, 95–106. [Google Scholar] [CrossRef]
- Gavili, S.; Sanikhani, H.; Kisi, O.; Mahmoudi, M.H. Evaluation of several soft computing methods in monthly evapotranspiration modelling. Meteorol. Appl. 2018, 25, 128–138. [Google Scholar] [CrossRef] [Green Version]
- Roy, D.K.; Lal, A.; Sarker, K.K.; Saha, K.K.; Datta, B. Optimization algorithms as training approaches for prediction of reference evapotranspiration using adaptive neuro fuzzy inference system. Agric. Water Manag. 2021, 255, 107003. [Google Scholar] [CrossRef]
- Roy, D.K.; Barzegar, R.; Quilty, J.; Adamowski, J. Using ensembles of adaptive neuro-fuzzy inference system and optimization algorithms to predict reference evapotranspiration in subtropical climatic zones. J. Hydrol. 2020, 591, 125509. [Google Scholar] [CrossRef]
- Shiri, J.; Marti, P.; Nazemi, A.H.; Sadraddini, A.A.; Kisi, O.; Landeras, G.; Fakheri Fard, A. Local vs. external training of neuro-fuzzy and neural networks models for estimating reference evapotranspiration assessed through k-fold testing. Hydrol. Res. 2013, 46, 72–88. [Google Scholar] [CrossRef]
- Tabari, H.; Kisi, O.; Ezani, A.; Hosseinzadeh, T.P. SVM, ANFIS, regression and climate based models for reference evapotranspiration modeling using limited climatic data in a semi-arid highland environment. J. Hydrol. 2012, 444–445, 78–89. [Google Scholar] [CrossRef]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of CatBoost method for prediction of reference evapotranspiration in humid regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Wu, T.; Zhang, W.; Jiao, X.; Guo, W.; Alhaj Hamoud, Y. Evaluation of stacking and blending ensemble learning methods for estimating daily reference evapotranspiration. Comput. Electron. Agric. 2021, 184, 106039. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Z.; Zheng, J. CatBoost: A new approach for estimating daily reference crop evapotranspiration in arid and semi-arid regions of Northern China. J. Hydrol. 2020, 588, 125087. [Google Scholar] [CrossRef]
- Lu, X.; Fan, J.; Wu, L.; Dong, J. Forecasting multi-step ahead monthly reference evapotranspiration using hybrid extreme gradient boosting with grey wolf optimization algorithm. Comput. Model. Eng. Sci. 2020, 125, 699–723. [Google Scholar]
- Abdullah, S.S.; Malek, M.A.; Abdullah, N.S.; Kisi, O.; Yap, K.S. Extreme Learning Machines: A new approach for prediction of reference evapotranspiration. J. Hydrol. 2015, 527, 184–195. [Google Scholar] [CrossRef]
- Feng, Y.; Cui, N.; Zhao, L.; Hu, X.; Gong, D. Comparison of ELM, GANN, WNN and empirical models for estimating reference evapotranspiration in humid region of Southwest China. J. Hydrol. 2016, 536, 376–383. [Google Scholar] [CrossRef]
- Wu, L.; Zhou, H.; Ma, X.; Fan, J.; Zhang, F. Daily reference evapotranspiration prediction based on hybridized extreme learning machine model with bio-inspired optimization algorithms: Application in contrasting climates of China. J. Hydrol. 2019, 577, 123960. [Google Scholar] [CrossRef]
- Yin, Z.; Feng, Q.; Yang, L.; Deo, R.C.; Wen, X.; Si, J.; Xiao, S. Future projection with an extreme-learning machine and support vector regression of reference evapotranspiration in a mountainous inland watershed in north-west China. Water 2017, 9, 880. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi, F.; Mehdizadeh, S.; Mohammadi, B.; Pham, Q.B.; Doan, T.N.C.; Vo, N.D. Application of an artificial intelligence technique enhanced with intelligent water drops for monthly reference evapotranspiration estimation. Agric. Water Manag. 2021, 244, 106622. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F.; de Oliveira, R.A.; Fernandes Filho, E.I. Estimation of reference evapotranspiration in Brazil with limited meteorological data using ANN and SVM—A new approach. J. Hydrol. 2019, 572, 556–570. [Google Scholar] [CrossRef]
- Torres, A.F.; Walker, W.R.; McKee, M. Forecasting daily potential evapotranspiration using machine learning and limited climatic data . Agric. Water Manag. 2011, 98, 553–562. [Google Scholar] [CrossRef]
- Gocić, M.; Motamedi, S.; Shamshirband, S.; Petković, D.; Ch, S.; Hashim, R.; Arif, M. Soft computing approaches for forecasting reference evapotranspiration. Comput. Electron. Agric. 2015, 113, 164–173. [Google Scholar] [CrossRef]
- Karbasi, M. Forecasting of Multi-Step Ahead Reference Evapotranspiration Using Wavelet- Gaussian Process Regression Model. Water Resour. Manag. 2018, 32, 1035–1052. [Google Scholar] [CrossRef]
- Kisi, O.; Keshtegar, B.; Zounemat-Kermani, M.; Heddam, S.; Trung, N.T. Modeling reference evapotranspiration using a novel regression-based method: Radial basis M5 model tree. Theor. Appl. Climatol. 2021, 145, 639–659. [Google Scholar] [CrossRef]
- Mattar, M.A. Using gene expression programming in monthly reference evapotranspiration modeling: A case study in Egypt. Agric. Water Manag. 2018, 198, 28–38. [Google Scholar] [CrossRef]
- Mattar, M.A.; Alazba, A.A. GEP and MLR approaches for the prediction of reference evapotranspiration. Neural Comput. Appl. 2019, 31, 5843–5855. [Google Scholar] [CrossRef]
- Alazba, A.A.; Yassin, M.A.; Mattar, M.A. Modeling daily evapotranspiration in hyper-arid environment using gene expression programming. Arab J. Geosci. 2016, 9, 202. [Google Scholar] [CrossRef]
- Yassin, M.A.; Alazba, A.A.; Mattar, M.A. Comparison Between Gene Expression Programming and Traditional Models for Estimating Evapotranspiration under Hyper Arid Conditions. Water Resour. 2016, 43, 412–427. [Google Scholar] [CrossRef]
- Shiri, J.; Sadraddini, A.A.; Nazemi, A.H.; Kişi, Ö.; Landeras, G.; Fakheri Fard, A.; Marti, P. Generalizability of Gene Expression Programming-based approaches for estimating daily reference evapotranspiration in coastal stations of Iran. J. Hydrol. 2014, 508, 1–11. [Google Scholar] [CrossRef]
- Shiri, J.; Kişi, Ö.; Landeras, G.; López, J.J.; Nazemi, A.H.; Stuyt, L.C.P.M. Daily reference evapotranspiration modeling by using genetic programming approach in the Basque Country (Northern Spain). J. Hydrol. 2012, 414–415, 302–316. [Google Scholar] [CrossRef]
- Wang, S.; Lian, J.; Peng, Y.; Hu, B.; Chen, H. Generalized reference evapotranspiration models with limited climatic data based on random forest and gene expression programming in Guangxi, China. Agric. Water Manag. 2019, 221, 220–230. [Google Scholar] [CrossRef]
- Wang, S.; Fu, Z.-Y.; Chen, H.-S.; Nie, Y.-P.; Wang, K.L. Modeling daily reference ET in the karst area of northwest Guangxi (China) using gene expression programming (GEP) and artificial neural network (ANN). Theor. Appl. Climatol. 2016, 126, 493–504. [Google Scholar] [CrossRef]
- Roy, D.K.; Saha, K.K.; Kamruzzaman, M.; Biswas, S.K.; Hossain, M.A. Hierarchical fuzzy systems integrated with particle swarm optimization for daily reference evapotranspiration prediction: A novel approach. Water Resour. Manag. 2021, 35, 5383–5407. [Google Scholar] [CrossRef]
- Yan, S.; Wu, L.; Fan, J.; Zhang, F.; Zou, Y.; Wu, Y. A novel hybrid WOA-XGB model for estimating daily reference evapotranspiration using local and external meteorological data: Applications in arid and humid regions of China. Agric. Water Manag. 2021, 244, 106594. [Google Scholar] [CrossRef]
- Başağaoğlu, H.; Chakraborty, D.; Winterle, J. Reliable evapotranspiration predictions with a probabilistic machine learning framework. Water 2021, 13, 557. [Google Scholar] [CrossRef]
- Fu, T.; Li, X.; Jia, R.; Feng, L. A novel integrated method based on a machine learning model for estimating evapotranspiration in dryland. J. Hydrol. 2021, 603, 126881. [Google Scholar] [CrossRef]
- Chia, M.Y.; Huang, Y.F.; Koo, C.H. Resolving data-hungry nature of machine learning reference evapotranspiration estimating models using inter-model ensembles with various data management schemes. Agric. Water Manag. 2022, 261, 107343. [Google Scholar] [CrossRef]
- Pasqualotto, N.; D’Urso, G.; Bolognesi, S.F.; Belfiore, O.R.; Van Wittenberghe, S.; Delegido, J.; Pezzola, A.; Winschel, C.; Moreno, J. Retrieval of evapotranspiration from sentinel-2: Comparison of vegetation indices, semi-empirical models and SNAP biophysical processor approach. Agronomy 2019, 9, 663. [Google Scholar] [CrossRef] [Green Version]
- Rodrigues, G.C.; Braga, R.P. A Simple application for computing reference evapotranspiration with various levels of data availability—ETo tool. Agronomy 2021, 11, 2203. [Google Scholar] [CrossRef]
- Rodrigues, G.C.; Braga, R.P. Estimation of daily reference evapotranspiration from NASA POWER reanalysis products in a hot summer mediterranean climate. Agronomy 2021, 11, 2077. [Google Scholar] [CrossRef]
- Zheng, S.; Ni, K.; Ji, L.; Zhao, C.; Chai, H.; Yi, X.; He, W.; Ruan, J. Estimation of evapotranspiration and crop coefficient of rain-fed tea plants under a subtropical climate. Agronomy 2021, 11, 2332. [Google Scholar] [CrossRef]
- Bellido-Jiménez, J.A.; Estévez, J.; García-Marín, A.P. New machine learning approaches to improve reference evapotranspiration estimates using intra-daily temperature-based variables in a semi-arid region of Spain. Agric. Water Manag. 2021, 245, 106558. [Google Scholar] [CrossRef]
- Vásquez, C.; Célleri, R.; Córdova, M.; Carrillo-Rojas, G. Improving reference evapotranspiration (ETo) calculation under limited data conditions in the high Tropical Andes. Agric. Water Manag. 2022, 262, 107439. [Google Scholar] [CrossRef]
- Nourani, V.; Elkiran, G.; Abdullahi, J. Multi-step ahead modeling of reference evapotranspiration using a multi-model approach. J. Hydrol. 2020, 581, 124434. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, J.; Asteris, P.G.; Jahed Armaghani, D.; Tahir, M.M. Supervised machine learning techniques to the prediction of tunnel boring machine penetration rate. Appl. Sci. 2019, 9, 3715. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.-F.; Chen, Y.-P.P. Hybrid deep learning and empirical mode decomposition model for time series applications. Expert Syst. Appl. 2019, 120, 128–138. [Google Scholar] [CrossRef]
- Fang, W.; Zhong, B.; Zhao, N.; Love, P.E.D.; Luo, H.; Xue, J.; Xu, S. A deep learning-based approach for mitigating falls from height with computer vision: Convolutional neural network. Adv. Eng. Inform. 2019, 39, 170–177. [Google Scholar] [CrossRef]
- Fan, L.; Zhang, T.; Zhao, X.; Wang, H.; Zheng, M. Deep topology network: A framework based on feedback adjustment learning rate for image classification. Adv. Eng. Inform. 2019, 42, 100935. [Google Scholar] [CrossRef]
- Cummins, N.; Baird, A.; Schuller, B.W. Speech analysis for health: Current state-of-the-art and the increasing impact of deep learning. Methods 2018, 151, 41–54. [Google Scholar] [CrossRef] [PubMed]
- Plappert, M.; Mandery, C.; Asfour, T. Learning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks. Rob. Auton. Syst. 2018, 109, 13–26. [Google Scholar] [CrossRef] [Green Version]
- Bowes, B.D.; Sadler, J.M.; Morsy, M.M.; Behl, M.; Goodal, J.L. Forecasting groundwater table in a flood prone coastal city with long short-term memory and recurrent neural networks. Water 2019, 11, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Supreetha, B.S.; Shenoy, N.; Nayak, P. Lion algorithm-optimized long short-term memory network for groundwater level forecasting in Udupi District, India. Appl. Comput. Intell. Soft Comput. 2020, 2020, 8685724. [Google Scholar] [CrossRef] [Green Version]
- Barzegar, R.; Aalami, M.T.; Adamowski, J. Short-term water quality variable prediction using a hybrid CNN–LSTM deep learning model. Stoch. Environ. Res. Risk Assess. 2020, 34, 415–433. [Google Scholar] [CrossRef]
- Chang, F.-J.; Chang, L.-C.; Huang, C.-W.; Kao, I.-F. Prediction of monthly regional groundwater levels through hybrid soft-computing techniques. J. Hydrol. 2016, 541, 965–976. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater level forecasting using artificial neural networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Guzman, S.M.; Paz, J.O.; Tagert, M.L.M. The use of NARX neural networks to forecast daily groundwater levels. Water Resour. Manag. 2017, 31, 1591–1603. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. Learn. Syst. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep learning with a long short-term memory networks approach for rainfall-runoff simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef] [Green Version]
- Liang, C.; Li, H.; Lei, M.; Du, Q. Dongting lake water level forecast and its relationship with the three Gorges dam based on a long short-term memory network. Water 2018, 10, 1389. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Xu, Y.-P.; Yang, Z.; Wang, G.; Zhu, Q. Integration of a parsimonious hydrological model with recurrent neural networks for improved streamflow forecasting. Water 2018, 10, 1655. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Majhi, B.; Naidu, D.; Mishra, A.P.; Satapathy, S.C. Improved prediction of daily pan evaporation using Deep-LSTM model. Neural Comput. Appl. 2020, 32, 7823–7838. [Google Scholar] [CrossRef]
- Hu, X.; Shi, L.; Lin, G.; Lin, L. Comparison of physical-based, data-driven and hybrid modeling approaches for evapotranspiration estimation. J. Hydrol. 2021, 601, 126592. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F. New approach to estimate daily reference evapotranspiration based on hourly temperature and relative humidity using machine learning and deep learning. Agric. Water Manag. 2020, 234, 106113. [Google Scholar] [CrossRef]
- Roy, D.K. Long short-term memory networks to predict one-step ahead reference evapotranspiration in a subtropical climatic zone. Environ. Process. 2021, 8, 911–941. [Google Scholar] [CrossRef]
- Ferreira, L.B.; da Cunha, F.F. Multi-step ahead forecasting of daily reference evapotranspiration using deep learning. Comput. Electron. Agric. 2020, 178, 105728. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Deo, R.C.; Feng, Q.; Ghahramani, A.; Raj, N.; Yin, Z.; Yang, L. Hybrid deep learning method for a week-ahead evapotranspiration forecasting. Stoch. Environ. Res. Risk Assess. 2021, 36, 831–849. [Google Scholar] [CrossRef]
- Saggi, M.K.; Jain, S. Reference evapotranspiration estimation and modeling of the Punjab Northern India using deep learning. Comput. Electron. Agric. 2019, 156, 387–398. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F. Forecasting evapotranspiration in different climates using ensembles of recurrent neural networks. Agric. Water Manag. 2021, 255, 107040. [Google Scholar] [CrossRef]
- Maroufpoor, S.; Bozorg-Haddad, O.; Maroufpoor, E. Reference evapotranspiration estimating based on optimal input combination and hybrid artificial intelligent model: Hybridization of artificial neural network with grey wolf optimizer algorithm. J. Hydrol. 2020, 588, 125060. [Google Scholar] [CrossRef]
- Yu, H.; Wen, X.; Li, B.; Yang, Z.; Wu, M.; Ma, Y. Uncertainty analysis of artificial intelligence modeling daily reference evapotranspiration in the northwest end of China. Comput. Electron. Agric. 2020, 176, 105653. [Google Scholar] [CrossRef]
- Estévez, J.; García-Marín, A.P.; Morábito, J.A.; Cavagnaro, M. Quality assurance procedures for validating meteorological input variables of reference evapotranspiration in mendoza province (Argentina). Agric. Water Manag. 2016, 172, 96–109. [Google Scholar] [CrossRef]
- Allen, R.G.; Pereira, L.S.; Raes, D. Evapotranspiracion ´Del Cultivo. Guías Para la Determinacion´ de Los Requerimientos de Agua de Los Cultivos (Technical Report); FAO: Roma, Italia, 2006. [Google Scholar]
- Shiri, J.; Nazemi, A.H.; Sadraddini, A.A.; Landeras, G.; Kişi, O.; Fakheri Fard, A.; Marti, P. Comparison of heuristic and empirical approaches for estimating reference evapotranspiration from limited inputs in Iran. Comput. Electron. Agric. 2014, 108, 230–241. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Muhammad Adnan, R. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Jang, J.-S.R.; Sun, C.T.; Mizutani, E. Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence; Prentice Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Sugeno, M.; Yasukawa, T. A fuzzy-logic-based approach to qualitative modeling. IEEE Trans. Fuzzy Syst. 1993, 1, 7. [Google Scholar] [CrossRef] [Green Version]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man. Cybern. 1985, SMC-15, 116–132. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- MATLAB Version R2019b; The MathWorks, Inc.: Natick, MA, USA, 2019.
- Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man. Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K. Gaussian Process for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 16–18 November 1992; pp. 343–348. [Google Scholar]
- Wang, Y.; Witten, I. Induction of model trees for predicting continuous classes. Work. Pap. 1996, 96, 23. [Google Scholar]
- Bhattacharya, B.; Solomatine, D.P. Neural networks and M5 model trees in modelling water level–discharge relationship. Neurocomputing 2005, 63, 381–396. [Google Scholar] [CrossRef]
- Solomatine, D.P.; Dulal, K. Model trees as an alternative to neural networks in rainfall-runoff modelling. Hydrol. Sci. J. 2003, 48, 399–411. [Google Scholar] [CrossRef]
- Solomatine, D.P.; Yunpeng, X. M5 model trees and neural networks: Application to flood forecasting in the upper reach of the Huai River in China. J. Hydrol. Eng. 2004, 9, 491–501. [Google Scholar] [CrossRef]
- Jekabsons, G. M5PrimeLab: M5’ Regression Tree, Model Tree, and Tree Ensemble Toolbox for Matlab/Octave; The MathWorks, Inc.: Natick, MA, USA, 2020; Available online: http://www.cs.rtu.lv/jekabsons/regression.html (accessed on 23 December 2021).
- Friedman, J.H. Multivariate adaptive regression splines (with discussion). Ann. Stat. 1991, 19, 1–67. [Google Scholar]
- Bera, P.; Prasher, S.O.; Patel, R.M.; Madani, A.; Lacroix, R.; Gaynor, J.D.; Tan, C.S.; Kim, S.H. Application of MARS in simulating pesticide concentrations in soil. Trans. Asabe 2006, 49, 297–307. [Google Scholar]
- Salford-Systems. SPM Users Guide: Introducing MARS; Minitab, LLC.: State College, PA, USA, 2019; Available online: https://www.minitab.com/content/dam/www/en/uploadedfiles/content/products/spm/IntroMARS.pdf (accessed on 23 December 2021).
- Roy, D.K.; Datta, B. Multivariate adaptive regression spline ensembles for management of multilayered coastal aquifers. J. Hydrol. Eng. 2017, 22, 4017031. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. 1977, 39, 763–768. [Google Scholar]
- MacKay, D.J.C. The evidence framework applied to classification networks. Neural Comput. 1992, 4, 720–736. [Google Scholar] [CrossRef]
- Chen, M. Probabilistic Linear Regression. 2021. Available online: https://www.mathworks.com/matlabcentral/fileexchange/55832-probabilistic-linear-regression (accessed on 23 December 2021).
- Yu, P.-S.; Chen, S.-T.; Chang, I.-F. Support vector regression for real-time flood stage forecasting. J. Hydrol. 2006, 328, 704–716. [Google Scholar] [CrossRef]
- Yoon, H.; Jun, S.-C.; Hyun, Y.; Bae, G.-O.; Lee, K.-K. A comparative study of artificial neural networks and support vector machines for predicting groundwater levels in a coastal aquifer. J. Hydrol. 2011, 396, 128–138. [Google Scholar] [CrossRef]
- Basak, D.; Pal, S.; Patranabis, D.C. Support vector regression. Neural Inf. Process. 2007, 11, 203–224. [Google Scholar]
- Chevalier, R.F.; Hoogenboom, G.; McClendon, R.W.; Paz, J.A. Support vector regression with reduced training sets for air temperature prediction: A comparison with artificial neural networks. Neural Comput. Appl. 2011, 20, 151–159. [Google Scholar] [CrossRef]
- Zhang, G.; Ge, H. Prediction of xylanase optimal temperature by support vector regression. Electron. J. Biotechnol. 2012, 15, 7. [Google Scholar] [CrossRef]
- Wu, J.; Sun, J.; Liang, L.; Zha, Y. Determination of weights for ultimate cross efficiency using Shannon entropy. Expert Syst. Appl. 2011, 38, 5162–5165. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Willmot, C.J. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe Jr, G.J. Evaluating the use of “goodness-of fit” measuresin hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Tao, H.; Diop, L.; Bodian, A.; Djaman, K.; Ndiaye, P.M.; Yaseen, Z.M. Reference evapotranspiration prediction using hybridized fuzzy model with firefly algorithm: Regional case study in Burkina Faso. Agric. Water Manag. 2018, 208, 140–151. [Google Scholar] [CrossRef]
- Chia, M.Y.; Huang, Y.F.; Koo, C.H. Swarm-based optimization as stochastic training strategy for estimation of reference evapotranspiration using extreme learning machine. Agric. Water Manag. 2021, 243, 106447. [Google Scholar] [CrossRef]
- Mohammadi, B.; Mehdizadeh, S. Modeling daily reference evapotranspiration via a novel approach based on support vector regression coupled with whale optimization algorithm. Agric. Water Manag. 2020, 237, 106145. [Google Scholar] [CrossRef]
- Elbeltagi, A.; Deng, J.; Wang, K.; Malik, A.; Maroufpoor, S. Modeling long-term dynamics of crop evapotranspiration using deep learning in a semi-arid environment. Agric. Water Manag. 2020, 241, 106334. [Google Scholar] [CrossRef]
- Gao, L.; Gong, D.; Cui, N.; Lv, M.; Feng, Y. Evaluation of bio-inspired optimization algorithms hybrid with artificial neural network for reference crop evapotranspiration estimation. Comput. Electron. Agric. 2021, 190, 106466. [Google Scholar] [CrossRef]
- Yin, J.; Deng, Z.; Ines, A.V.; Wu, J.; Rasu, E. Forecast of short-term daily reference evapotranspiration under limited meteorological variables using a hybrid bi-directional long short-term memory model (Bi-LSTM). Agric. Water Manag. 2020, 242, 106386. [Google Scholar] [CrossRef]
- Heinemann, A.B.; Oort, P.A.V.; Fernandes, D.S.; Maia, A. Sensitivity of APSIM/ORYZA model due to estimation errors in solar radiation. Bragantia 2012, 71, 572–582. [Google Scholar] [CrossRef] [Green Version]
- Li, M.-F.; Tang, X.-P.; Wu, W.; Liu, H.-B. General models for estimating daily global solar radiation for different solar radiation zones in mainland China. Energy Convers. Manag. 2013, 70, 139–148. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Climatic Variables | Min | Max | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|---|---|
| Data Range: 1 January 2004 to 30 June 2019 (5660 Daily Entries) | ||||||
| Minimum temperature, °C | 4.40 | 34.50 | 21.17 | 5.64 | −0.63 | −0.88 |
| Maximum temperature, °C | 12.00 | 53.00 | 30.93 | 3.92 | −1.10 | 2.11 |
| Relative humidity, % | 38.00 | 89.00 | 80.22 | 8.20 | −0.63 | 0.75 |
| Wind speed, m/s | 0.68 | 5.06 | 2.79 | 1.05 | −0.06 | −1.32 |
| Sunshine duration, h | 0.00 | 11.40 | 5.54 | 3.09 | −0.40 | −1.04 |
| Climatic Variables | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|
| Entire dataset (1 June 2015 to 31 December 2020: 2041 daily entries) | ||||
| Minimum temperature, °C | 21.37 | 5.98 | −0.73 | −0.76 |
| Maximum temperature, °C | 31.46 | 4.16 | −0.83 | 0.28 |
| Relative humidity, % | 78.89 | 12.18 | −1.23 | 1.93 |
| Wind speed, m/s | 1.43 | 0.23 | 0.07 | 0.22 |
| Sunshine duration, h | 5.90 | 3.19 | −0.41 | −0.71 |
| First half data (1 June 2015 to 3 October 2018: 1221 daily entries) | ||||
| Minimum temperature, °C | 21.06 | 6.08 | −0.65 | −0.92 |
| Maximum temperature, °C | 31.27 | 4.21 | −0.71 | 0.26 |
| Relative humidity, % | 80.06 | 11.30 | −1.24 | 2.25 |
| Wind speed, m/s | 1.43 | 0.23 | 0.06 | 0.35 |
| Sunshine duration, h | 5.75 | 3.18 | −0.42 | −0.98 |
| Second half data (4 October 2018 to 31 December 2020: 820 daily entries) | ||||
| Minimum temperature, °C | 21.69 | 5.87 | −0.83 | −0.56 |
| Maximum temperature, °C | 31.66 | 4.11 | −0.95 | 0.35 |
| Relative humidity, % | 77.71 | 12.89 | −1.18 | 1.54 |
| Wind speed, m/s | 1.44 | 0.23 | 0.09 | 0.08 |
| Sunshine duration, h | 6.05 | 3.19 | −0.39 | −0.44 |
| Training Options | Corresponding Parameter Values |
|---|---|
| Solver for optimization | ‘adam’ |
| Maximum number of epochs | 1000 |
| Gradient threshold value | 1 |
| Preliminary learning rate | 0.01 |
| Minimum size of the batch | 150 |
| Length of sequence | 1000 |
| Two-Input Combinations | Three-Input Combinations | Four-Input Combinations |
|---|---|---|
| Min temp, max temp | Min temp, max temp, humidity | Min temp, max temp, humidity, wind speed |
| Min temp, humidity | Min temp, max temp, wind speed | Min temp, max temp, humidity, sunshine hours |
| Min temp, wind speed | Min temp, max temp, sunshine hours | Min temp, max temp, wind speed, sunshine hours |
| Min temp, sunshine hours | Min temp, humidity, wind speed | Min temp, humidity, wind speed, sunshine hours |
| Max temp, humidity | Min temp, humidity, sunshine hours | Max temp, humidity, wind speed, sunshine hours |
| Max temp, wind speed | Min temp, wind speed, sunshine hours | |
| Max temp, sunshine hours | Max temp, humidity, wind speed | |
| Humidity, wind speed | Max temp, humidity, sunshine hours | |
| Humidity, sunshine hours | Max temp, wind speed, sunshine hours | |
| Wind speed, sunshine hours | Humidity, wind speed, sunshine hours |
| Model No. | Different Input Combinations | Test RMSE, mm/d | |
|---|---|---|---|
| LSTM | Bi-LSTM | ||
| Single Input Combinations | |||
| M1 | Min temp | 0.880 | 0.964 |
| M2 | Max temp | 0.775 | 0.781 |
| M3 | Humidity | 1.124 | 1.211 |
| M4 | Wind speed | 1.177 | 1.105 |
| M5 | Sunshine hours | 0.732 | 0.807 |
| Two Inputs combinations | |||
| M6 | Min temp, max temp | 0.765 | 0.779 |
| M7 | Min temp, humidity | 0.729 | 0.751 |
| M8 | Min temp, wind speed | 1.004 | 1.049 |
| M9 | Min temp, sunshine hours | 0.527 | 0.514 |
| M10 | Max temp, humidity | 0.634 | 0.602 |
| M11 | Max temp, wind speed | 0.734 | 0.743 |
| M12 | Max temp, sunshine hours | 0.501 | 0.430 |
| M13 | Humidity, wind speed | 0.727 | 0.760 |
| M14 | Humidity, sunshine hours | 0.531 | 0.983 |
| M15 | Wind speed, sunshine hours | 0.527 | 0.627 |
| Three Inputs Combinations | |||
| M16 | Min temp, max temp, humidity | 0.570 | 0.574 |
| M17 | Min temp, max temp, wind speed | 0.729 | 0.722 |
| M18 | Min temp, max temp, sunshine hours | 0.512 | 0.447 |
| M19 | Min temp, humidity, wind speed | 0.726 | 0.723 |
| M20 | Min temp, humidity, sunshine hours | 0.337 | 0.377 |
| M21 | Min temp, wind speed, sunshine hours | 0.470 | 0.501 |
| M22 | Max temp, humidity, wind speed | 0.567 | 0.566 |
| M23 | Max temp, humidity, sunshine hours | 0.300 | 0.239 |
| M24 | Max temp, wind speed, sunshine hours | 0.409 | 0.394 |
| M25 | Humidity, wind speed, sunshine hours | 0.337 | 0.333 |
| Four Inputs Combinations | |||
| M26 | Min temp, max temp, humidity, wind speed | 0.577 | 0.561 |
| M27 | Min temp, max temp, humidity, sunshine hours | 0.262 | 0.229 |
| M28 | Min temp, max temp, wind speed, sunshine hours | 0.382 | 0.404 |
| M29 | Min temp, humidity, wind speed, sunshine hours | 0.271 | 0.238 |
| M30 | Max temp, humidity, wind speed, sunshine hours | 0.107 | 0.116 |
| All Inputs | |||
| M31 | Min temp, max temp, humidity, wind speed, sunshine hours | 0.081 | 0.087 |
| Sl. No. | LSTM | Bi-LSTM | ||
|---|---|---|---|---|
| Model | Ranking Value | Model | Ranking Value | |
| 1 | M31 | 0.996 | M31 | 0.966 |
| 2 | M30 | 0.906 | M30 | 0.913 |
| 3 | M27 | 0.702 | M27 | 0.704 |
| 4 | M23 | 0.687 | M23 | 0.696 |
| 5 | M20 | 0.657 | M29 | 0.688 |
| 6 | M29 | 0.652 | M25 | 0.642 |
| 7 | M25 | 0.640 | M20 | 0.621 |
| 8 | M28 | 0.604 | M24 | 0.600 |
| 9 | M24 | 0.600 | M28 | 0.594 |
| 10 | M21 | 0.584 | M12 | 0.581 |
| 11 | M12 | 0.563 | M18 | 0.576 |
| 12 | M18 | 0.561 | M21 | 0.563 |
| 13 | M14 | 0.560 | M26 | 0.557 |
| 14 | M22 | 0.558 | M9 | 0.555 |
| 15 | M26 | 0.556 | M22 | 0.551 |
| 16 | M15 | 0.555 | M16 | 0.551 |
| 17 | M9 | 0.555 | M10 | 0.535 |
| 18 | M16 | 0.554 | M15 | 0.522 |
| 19 | M10 | 0.535 | M17 | 0.488 |
| 20 | M11 | 0.496 | M19 | 0.485 |
| 21 | M17 | 0.493 | M11 | 0.482 |
| 22 | M19 | 0.491 | M7 | 0.478 |
| 23 | M13 | 0.491 | M13 | 0.475 |
| 24 | M7 | 0.483 | M6 | 0.462 |
| 25 | M5 | 0.482 | M2 | 0.460 |
| 26 | M6 | 0.470 | M5 | 0.451 |
| 27 | M2 | 0.470 | M14 | 0.384 |
| 28 | M1 | 0.415 | M1 | 0.376 |
| 29 | M8 | 0.364 | M8 | 0.336 |
| 30 | M3 | 0.306 | M4 | 0.311 |
| 31 | M4 | 0.209 | M3 | 0.256 |
| Model | Performance Evaluation Indices | |||||
|---|---|---|---|---|---|---|
| R | NS | IOA | NRMSE | MAE, mm/d | MAD, mm/d | |
| LSTM | 0.998 | 0.995 | 0.999 | 0.021 | 0.666 | 0.025 |
| Bi-LSTM | 0.998 | 0.995 | 0.999 | 0.023 | 0.582 | 0.027 |
| ANFIS | 0.991 | 0.981 | 0.995 | 0.043 | 0.706 | 0.061 |
| GPR | 0.993 | 0.985 | 0.996 | 0.038 | 0.650 | 0.052 |
| M5 Tree | 0.985 | 0.970 | 0.993 | 0.054 | 1.153 | 0.062 |
| MARS_C | 0.992 | 0.983 | 0.996 | 0.041 | 0.869 | 0.054 |
| MARS_L | 0.992 | 0.983 | 0.996 | 0.040 | 0.760 | 0.054 |
| PLR | 0.973 | 0.943 | 0.985 | 0.075 | 1.489 | 0.114 |
| SVR | 0.993 | 0.985 | 0.996 | 0.038 | 0.676 | 0.050 |
| Model | Shannon’s Entropy Value | Rank |
|---|---|---|
| LSTM | 0.979 | 1 |
| Bi-LSTM | 0.978 | 2 |
| ANFIS | 0.807 | 6 |
| GPR | 0.839 | 3 |
| M5 tree | 0.734 | 8 |
| MARS_C | 0.794 | 7 |
| MARS_L | 0.810 | 5 |
| PLR | 0.665 | 9 |
| SVR | 0.836 | 4 |
| Model | Performance Evaluation Indices | |||||
|---|---|---|---|---|---|---|
| R | NS | IOA | NRMSE | MAE, mm/d | MAD, mm/d | |
| ANFIS | 0.755 | 0.567 | 0.858 | 0.207 | 2.710 | 0.308 |
| Bi-LSTM | 0.999 | 0.998 | 0.999 | 0.014 | 0.491 | 0.017 |
| LSTM | 0.698 | 0.429 | 0.833 | 0.237 | 3.047 | 0.334 |
| SSR-LSTM | 0.818 | 0.666 | 0.898 | 0.184 | 2.687 | 0.279 |
| Model | Shannon’s Entropy Value | Rank |
|---|---|---|
| Bi-LSTM | 1.00 | 1 |
| SSR-LSTM | 0.30 | 2 |
| ANFIS | 0.27 | 3 |
| LSTM | 0.24 | 4 |
| Forecasting Horizon | Training RMSE, mm/d | Validation RMSE, mm/d |
|---|---|---|
| 1 day | 0.08 | 0.11 |
| 2 days | 0.12 | 0.17 |
| 3 days | 0.09 | 0.18 |
| 4 days | 0.10 | 0.22 |
| 5 days | 0.10 | 0.28 |
| Indices | Forecasting Horizon | ||||
|---|---|---|---|---|---|
| 1 Day | 2 Days | 3 Days | 4 Days | 5 Days | |
| RMSE, mm/d | 0.11 | 0.17 | 0.18 | 0.22 | 0.28 |
| NRMSE | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 |
| R | 1.00 | 0.99 | 0.99 | 0.98 | 0.97 |
| MAD, mm/d | 0.03 | 0.04 | 0.04 | 0.06 | 0.08 |
| MAE, mm/d | 0.07 | 0.08 | 0.10 | 0.13 | 0.17 |
| NS | 0.99 | 0.98 | 0.98 | 0.97 | 0.95 |
| IOA | 1.00 | 0.99 | 0.99 | 0.99 | 0.99 |
| Performance Indices | Entire Dataset | First Half Data | Second Half Data |
|---|---|---|---|
| RMSE, mm/d | 0.65 | 0.49 | 0.84 |
| NRMSE | 0.18 | 0.13 | 0.23 |
| R | 0.87 | 0.92 | 0.83 |
| MAD, mm/d | 0.18 | 0.18 | 0.20 |
| MAE, mm/d | 0.44 | 0.39 | 0.52 |
| NS | 0.72 | 0.84 | 0.57 |
| IOA | 0.97 | 0.98 | 0.96 |
| Forecasting Horizon | Training RMSE, mm/d | Validation RMSE, mm/d |
|---|---|---|
| 1 day | 0.09 | 0.12 |
| 2 days | 0.10 | 0.17 |
| 3 days | 0.11 | 0.29 |
| 4 days | 0.12 | 0.56 |
| 5 days | 0.10 | 0.73 |
| Indices | Forecasting Horizon | ||||
|---|---|---|---|---|---|
| 1 Day | 2 Days | 3 Days | 4 Days | 5 Days | |
| RMSE, mm/d | 0.12 | 0.17 | 0.29 | 0.56 | 0.73 |
| NRMSE | 0.03 | 0.05 | 0.08 | 0.16 | 0.20 |
| R | 1.00 | 0.99 | 0.98 | 0.90 | 0.86 |
| MAD, mm/d | 0.04 | 0.05 | 0.08 | 0.14 | 0.24 |
| MAE, mm/d | 0.09 | 0.12 | 0.19 | 0.37 | 0.56 |
| NS | 0.99 | 0.98 | 0.95 | 0.81 | 0.69 |
| IOA | 1.00 | 1.00 | 0.99 | 0.95 | 0.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, D.K.; Sarkar, T.K.; Kamar, S.S.A.; Goswami, T.; Muktadir, M.A.; Al-Ghobari, H.M.; Alataway, A.; Dewidar, A.Z.; El-Shafei, A.A.; Mattar, M.A. Daily Prediction and Multi-Step Forward Forecasting of Reference Evapotranspiration Using LSTM and Bi-LSTM Models. Agronomy 2022, 12, 594. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy12030594
Roy DK, Sarkar TK, Kamar SSA, Goswami T, Muktadir MA, Al-Ghobari HM, Alataway A, Dewidar AZ, El-Shafei AA, Mattar MA. Daily Prediction and Multi-Step Forward Forecasting of Reference Evapotranspiration Using LSTM and Bi-LSTM Models. Agronomy. 2022; 12(3):594. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy12030594
Chicago/Turabian StyleRoy, Dilip Kumar, Tapash Kumar Sarkar, Sheikh Shamshul Alam Kamar, Torsha Goswami, Md Abdul Muktadir, Hussein M. Al-Ghobari, Abed Alataway, Ahmed Z. Dewidar, Ahmed A. El-Shafei, and Mohamed A. Mattar. 2022. "Daily Prediction and Multi-Step Forward Forecasting of Reference Evapotranspiration Using LSTM and Bi-LSTM Models" Agronomy 12, no. 3: 594. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy12030594