1. Introduction
The prevention and early detection of diseases that affect health will always be a priority in the life of any person, given that poor health not only causes harm to each individual but also increases the costs of health institutions in each country. Information collected in 2019 by the World Health Organization (WHO), cardiovascular diseases, and diabetes mellitus are among the ten leading causes of death worldwide. Meanwhile, vehicle accidents are a cause of death in the vast majority of countries regardless of their level of economic income [
1]. These conditions can lead to cerebrovascular diseases [
2,
3,
4], which generally present in a condition known as intracranial hemorrhage or cerebral hemorrhage. Unfortunately, for those who suffer from this condition, the warning signs or symptoms with a slight degree of hemorrhage are practically imperceptible, which in many occasions generates the aggravation of the disease.
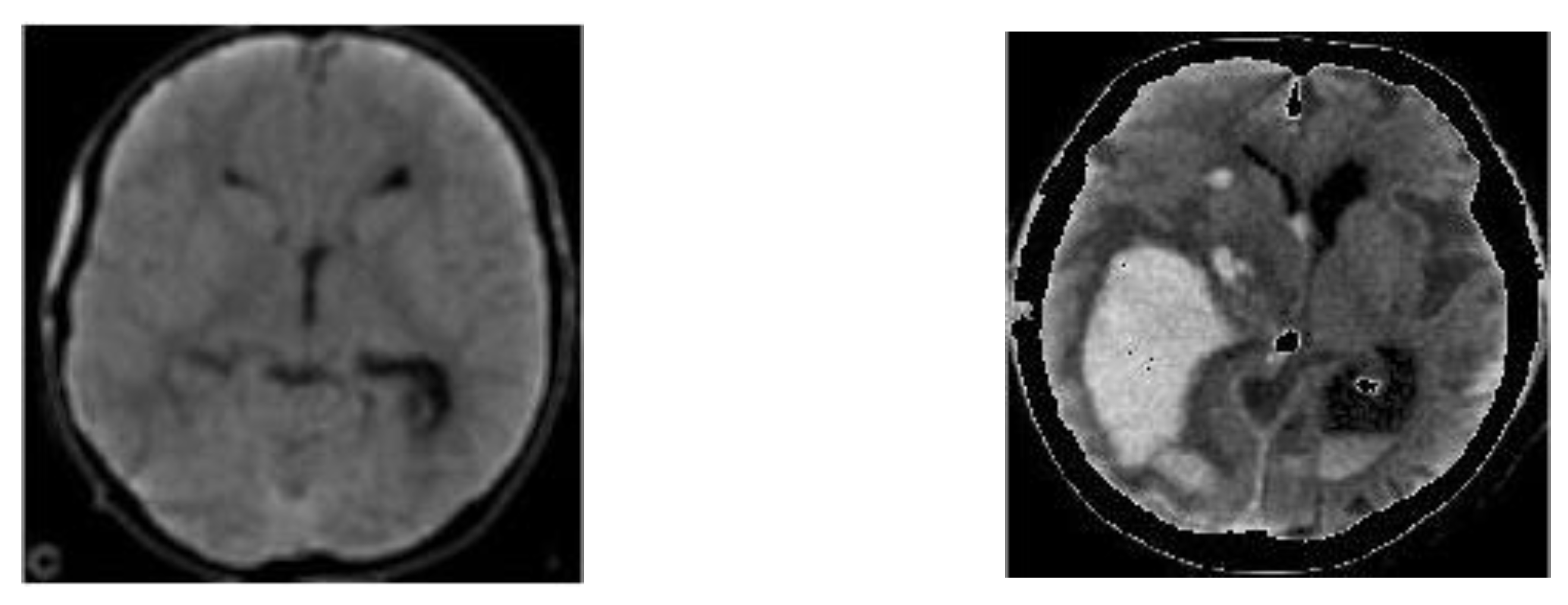
Normally, the initial evaluation of these kinds of organic anomalies by medical specialists is usually performed by means of diagnostic imaging techniques, commonly Magnetic Resonance Imaging (MRI) and Computed Tomography (CT). These two modalities are widely used to produce images with great quality and detail of brain structures, because through the use of contrasts applied to patients, it is possible to differentiate the elements that make up the anatomical structure of human beings. CT is particularly useful in identifying patients in whom brain damage or injury has occurred, who regularly demonstrate some degree of cerebral hemorrhage, as well as ventricular abnormalities. MRI has the characteristic of better and more sensitive imaging of different areas of the brain, such as white matter, gray matter, corpus callosum, deeper areas, ventricular areas, and the brainstem; nowadays, more patients undergo MR imaging after having suffered an injury [
5]. However, the preparation for acquiring these images is much more complex than CT, so in acute phases, CT is the modality of choice when brain injury is suggested [
6]. Unfortunately, however, these imaging techniques are sometimes not sufficient to determine the suspicion of a brain anomaly, and it is essential to obtain more information about its characteristics, requiring the invasion of the tissue by means of a craniotomy, so that the specialist can make a detailed diagnosis [
7].
CT images for the diagnosis of cerebral hemorrhages are the most widely used for the detection of this condition due to their high quality. These cerebral hemorrhages have various causes of occurrence, such as cranioencephalic trauma, hypertension, or intracranial tumors. In general, they are usually divided into five types of hemorrhages, depending mainly on the area where they occur [
8].
- -
Epidural Hemorrhage (HED);
- -
Subdural Hemorrhage (SDH);
- -
Subarachnoid Hemorrhage (SAH);
- -
Intracerebral Hemorrhage (ICH); and
- -
Intraventricular Hemorrhage (IVH).
By implementing images captured by increasingly sophisticated means, such as MRI and CT, together with engineering technologies and Artificial Intelligence (AI), it has been possible to generate a large number of computer vision applications, where intelligent computation can be integrated with these images to design and develop complex diagnostic systems and thus help physicians to increase the diagnostic accuracy of early detection of various diseases. Techniques such as Artificial Neural Networks (ANN), Support Vector Machines (SVM), and Deep Learning algorithms have been applied to visual pattern recognition, as in the case of brain hemorrhages [
9,
10].
The main disadvantage of Deep Learning algorithms is that they work ideally with a very large number of training instances or examples, and in particular examples, the deeper a network is, the more accurate it will be [
11]. However, this makes it practically impossible to know how these algorithms converge to a solution, which turns them into a Black Box.
Within the context of Artificial Neural Networks, this is where most of the efforts of the scientific community have been focused, specifically for the classification of images by Convolutional Neural Networks (CNN). This is due to the marvelous performance they have maintained for the aforementioned task, and the large number of models that currently exist; compared to methodologies based on the study of the characteristics of an image, such as the radionomic study of an image, the performance of algorithms based on Machine Learning [
12] is far superior. However, a very important concept in data analysis is neglected: simplicity.
The excellent performance of these Deep Learning algorithms is not really up for debate, but their opacity and comprehensibility leave a virgin space within the area of Artificial Intelligence. In view of this, and with the efforts of several organizations worldwide, a new current was generated, which was called eXplainable Artificial Intelligence (XAI).
XAI was created with the primary intention of generating AI systems that provide accessible explanations of the way in which algorithms make a given decision, thus creating systems that are highly reliable and, in turn, more transparent compared to the usual AI systems.
Naturally, an important question arises: when can an algorithm be considered explainable? In response to this question, extensive discussions have led to the establishment of five characteristics that these models must satisfy [
11].
- -
Interpretability means providing explanations to end users for a particular decision or process.
- -
Transparency quantitatively measures the ease or accessibility of a model or algorithm.
- -
Explainability allows an explanation to be given of how a particular model has taken a particular solution.
- -
Contestability means that any XAI user can affirm or reject a decision taken.
- -
Justifiability indicates an understanding of the case to support a particular outcome.
This need to make Machine Learning models more transparent and explainable has inspired us to carry out this work, as we naturally think that the task of image classification is complex and, above all, extensive in its development. This motivated us to develop a methodology that makes use of two of the most relevant measures within an image [
12], and the automation of the classification task by means of an unconventional paradigm, which is known as Minimalist Machine Learning. This timely algorithm allows us to go beyond simplicity, of course without leaving aside the excellent results that our main proposal allows us to achieve, compared to algorithms that currently obtain very good results. Among these algorithms are mainly CNNs, whose creation is focused on the classification of images, mainly in the detection of diseases [
12,
13], as the great effectiveness and versatility shown has been evident [
13]. However, consequently, it has sacrificed simplicity in its learning and understanding, becoming practically a black box, of which what goes in and what comes out is known to perfection, but unfortunately, what happens inside is difficult to understand.
In the same way, it is important to mention that in the field of Deep Learning, efforts are being made to take these models based on Artificial Neural Networks to the path of explainability, mainly in areas of major relevance such as health [
14].
A clear example of this is the work done by Wang et al. In this work, the efficient detection of small brain hemorrhages is achieved by analyzing structural abnormalities found on MR images. The authors succeeded in developing a practical model with very good performance. They achieve this with a nine-layer [
15] CNN model, obtaining values above 97% in four different performance measures. Subsequently, Doke et al. carried out a work dedicated to the classification of micro-bleeds at the brain level using Convolutional Neural Networks and Bayesian optimization [
16]. This excellent work is close to the fundamental concept of the development of this paper, as a simple CNN model is developed with only five layers, basic operators, and filters, which are developed in a very efficient way. These examples show the panorama of the increasingly extensive use of machine learning models in tasks such as anomaly detection or brain diseases, but they still leave a wide field in the generation of simpler and more practical algorithms, without neglecting efficiency, which is ultimately the main purpose of any of the classification models.
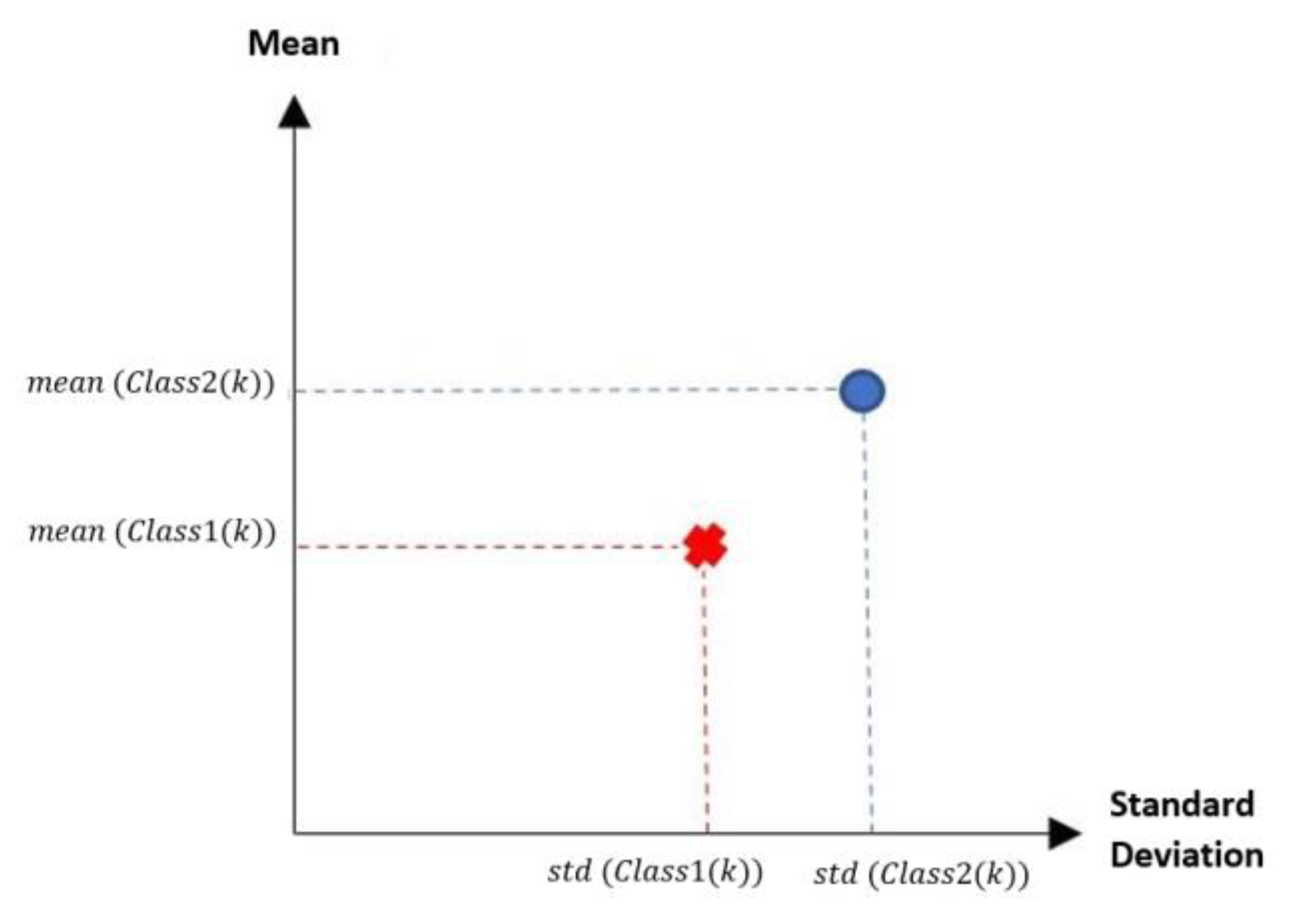
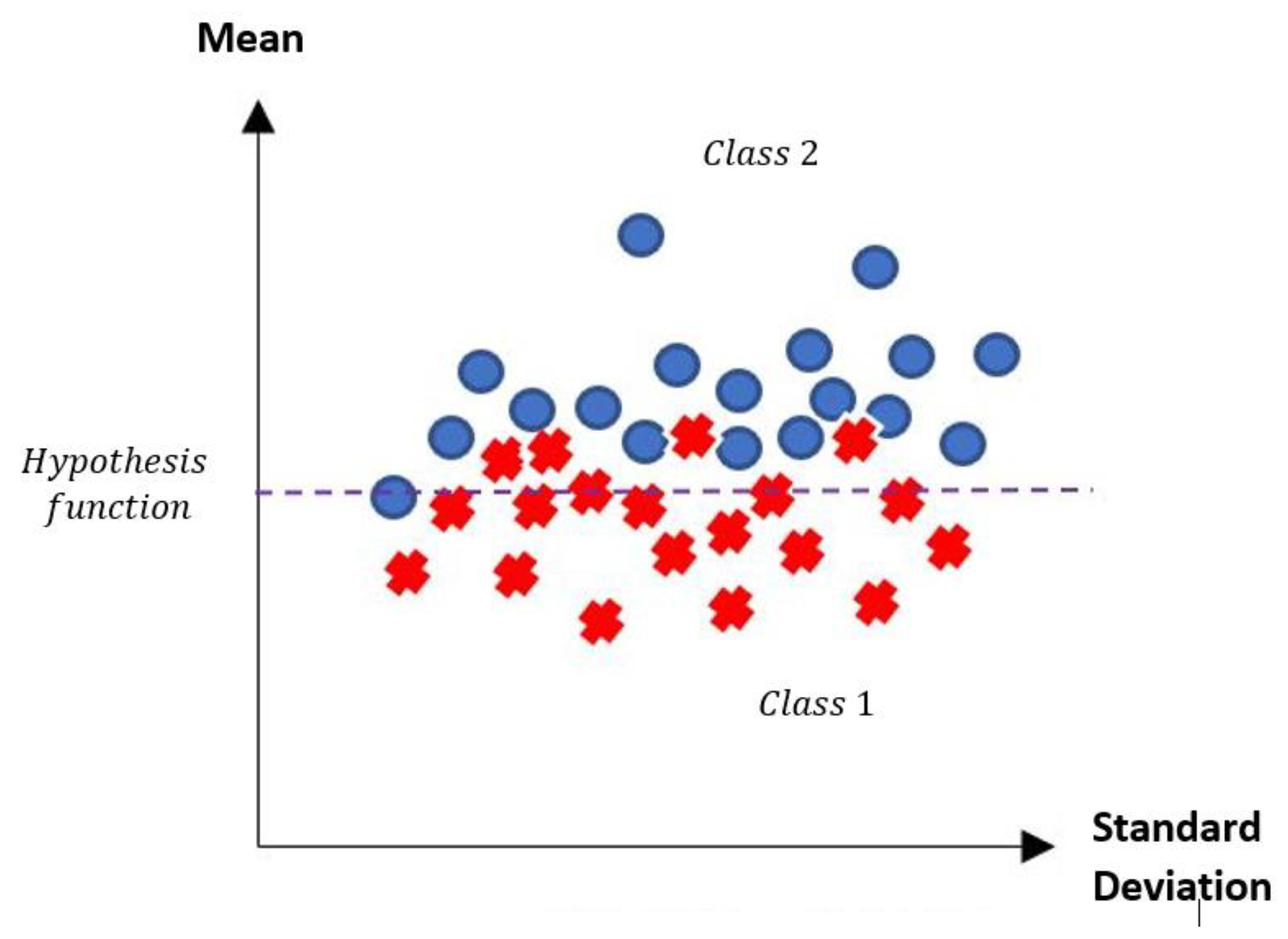
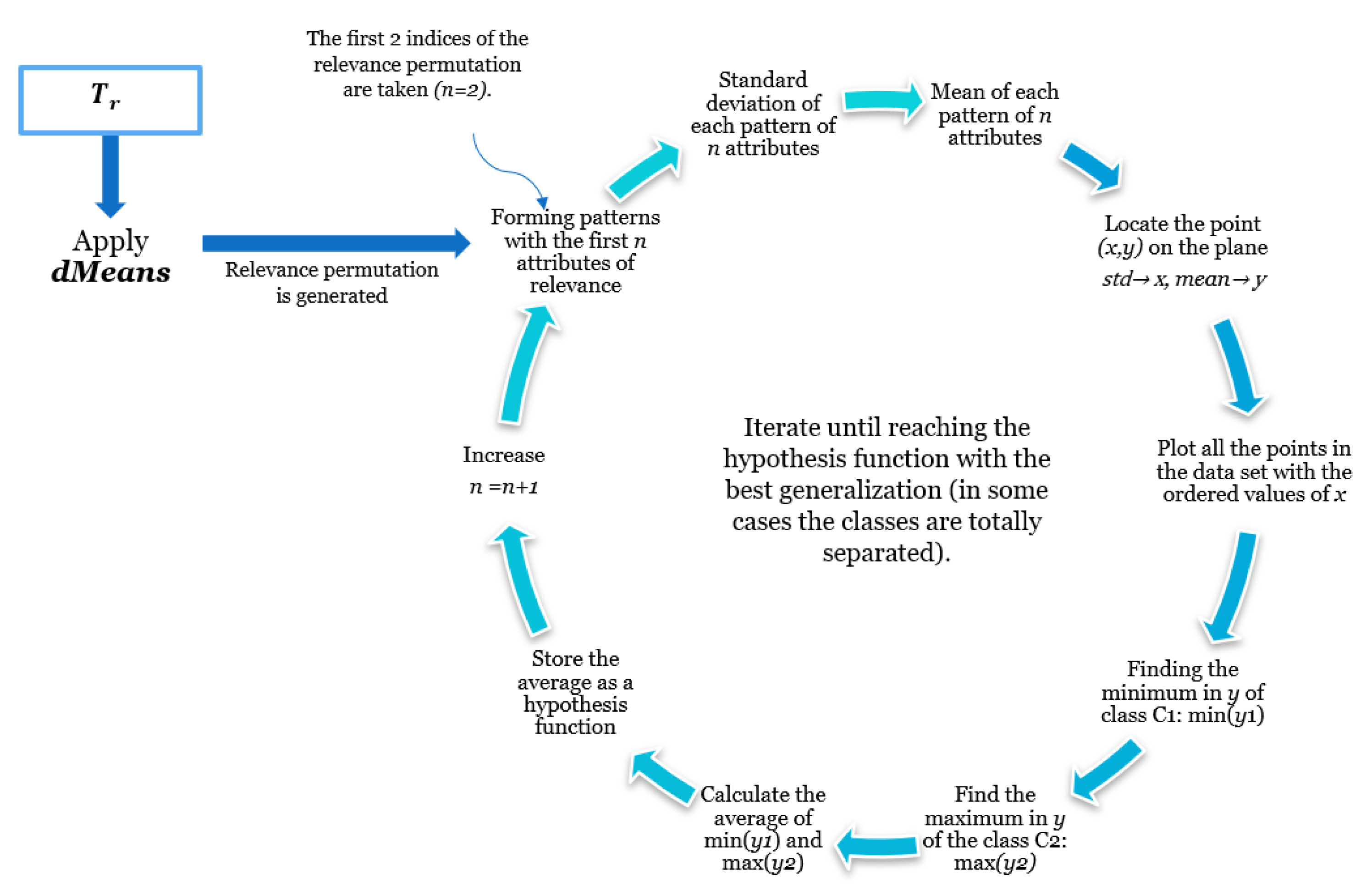
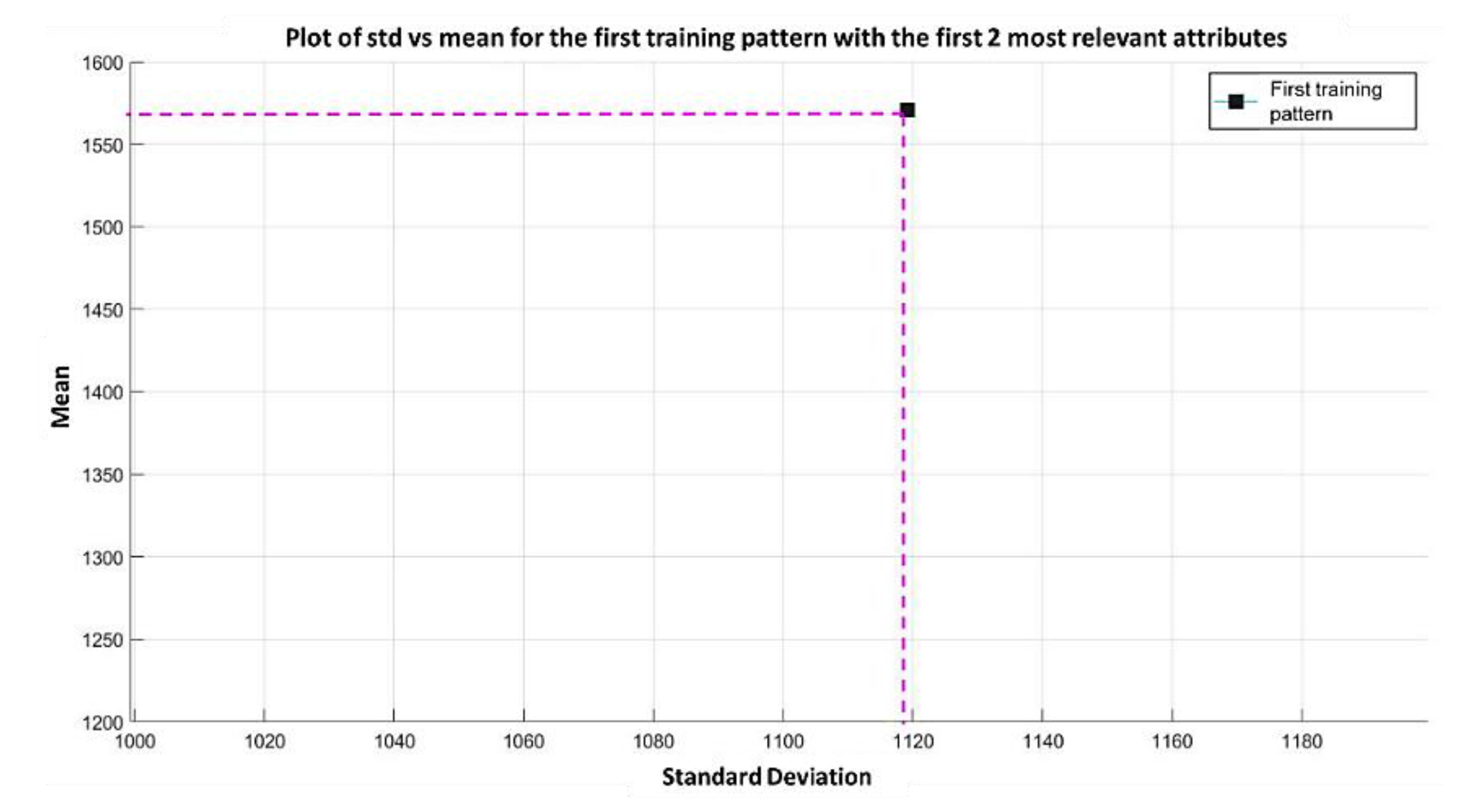
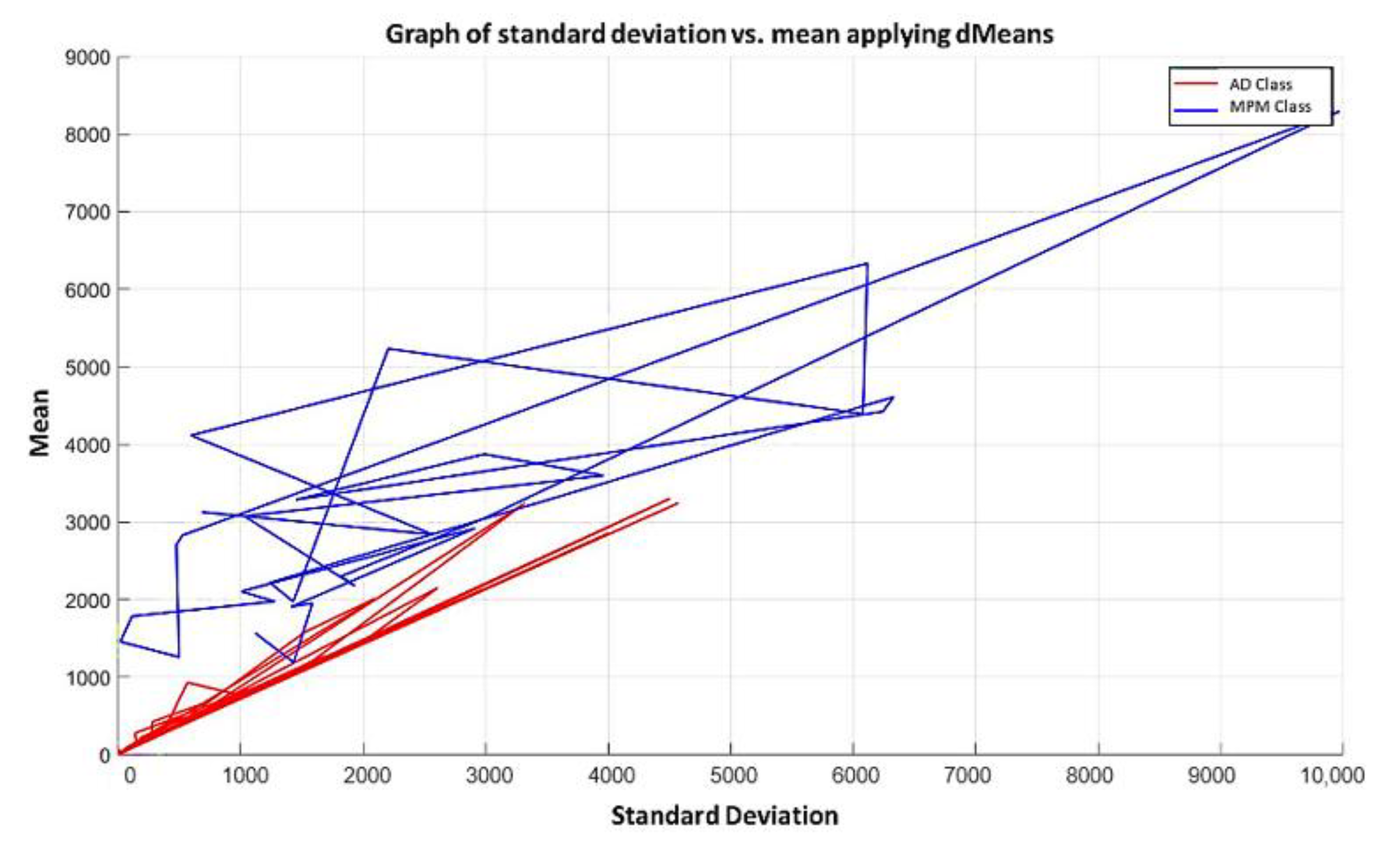
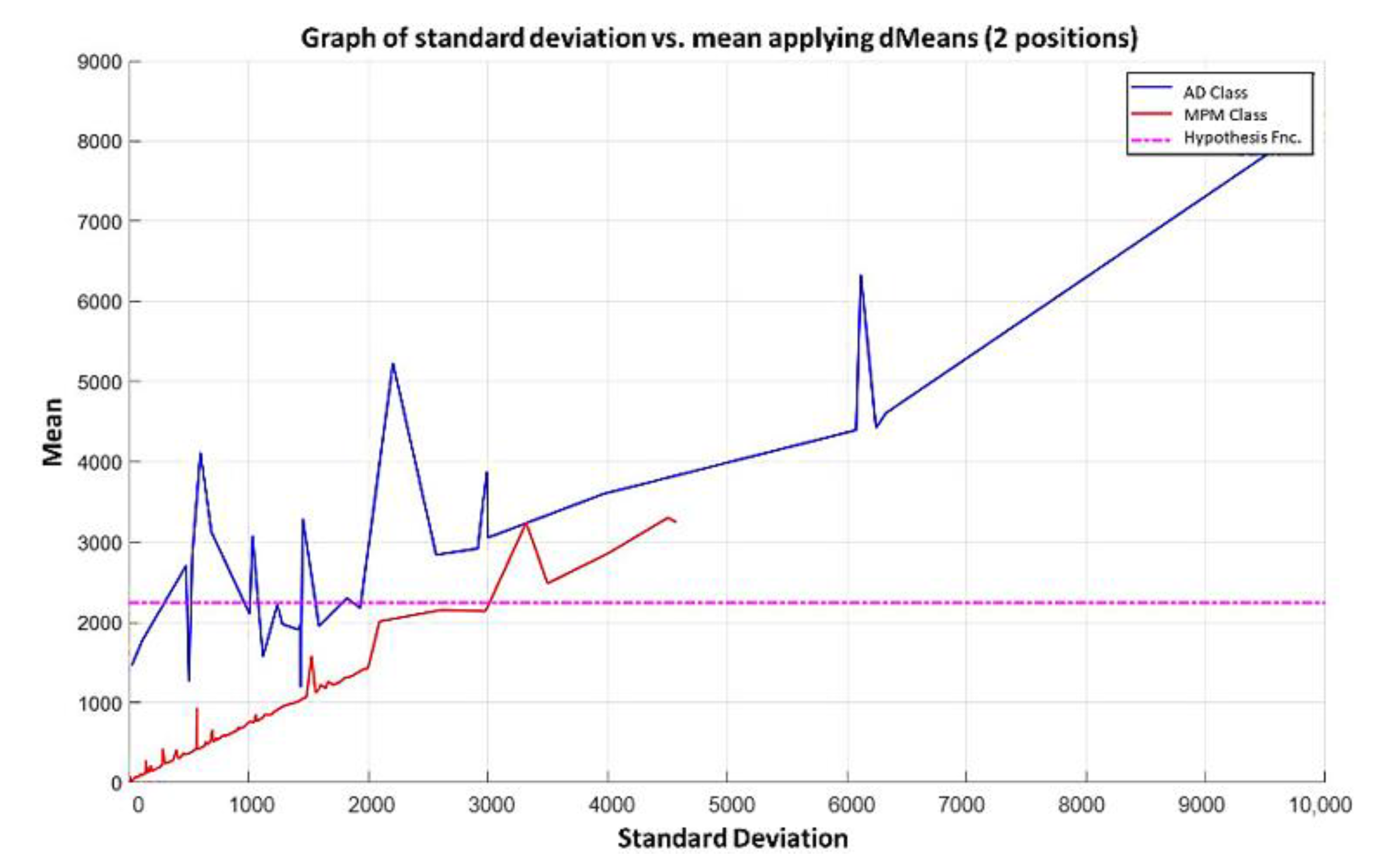
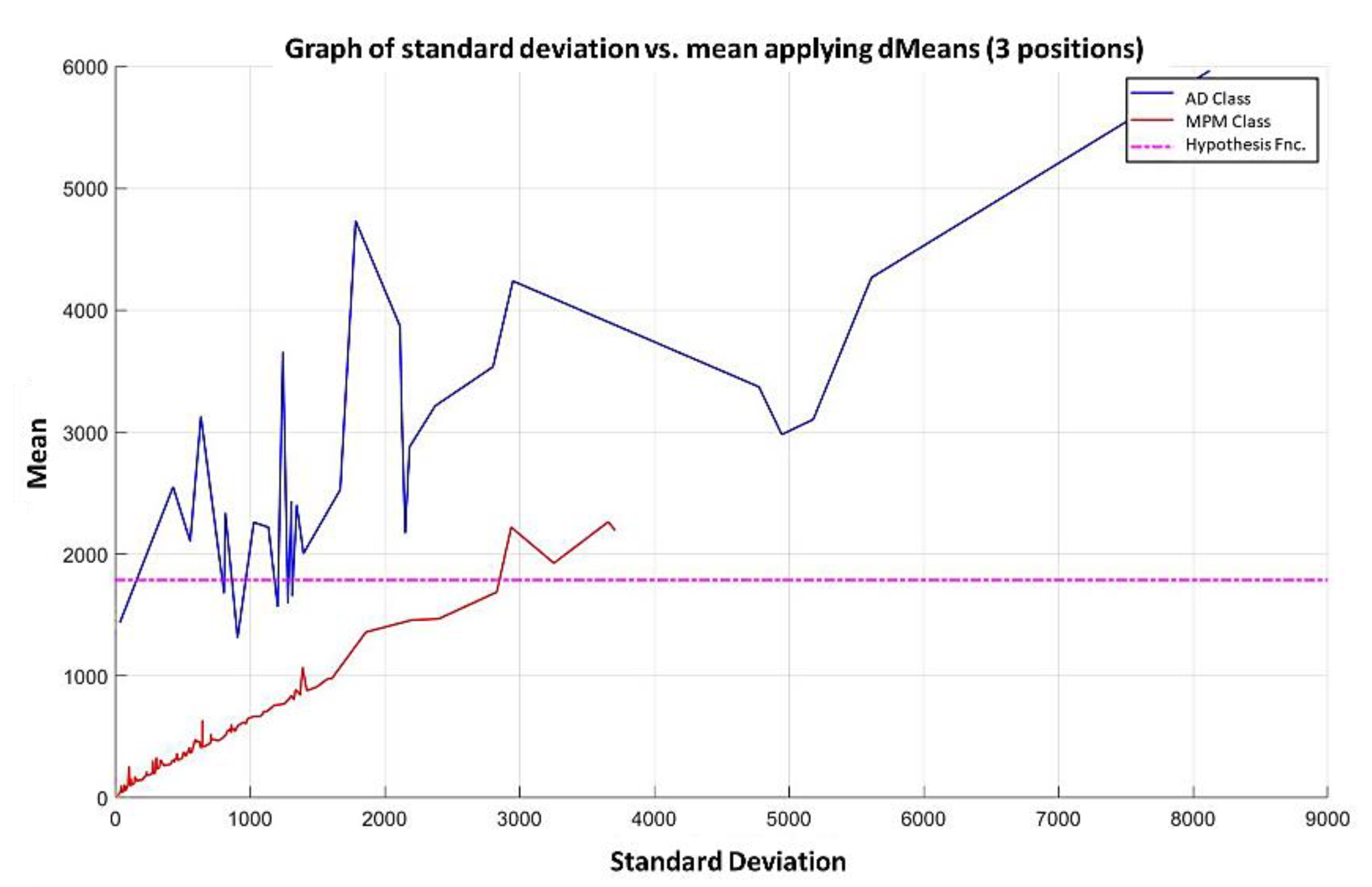
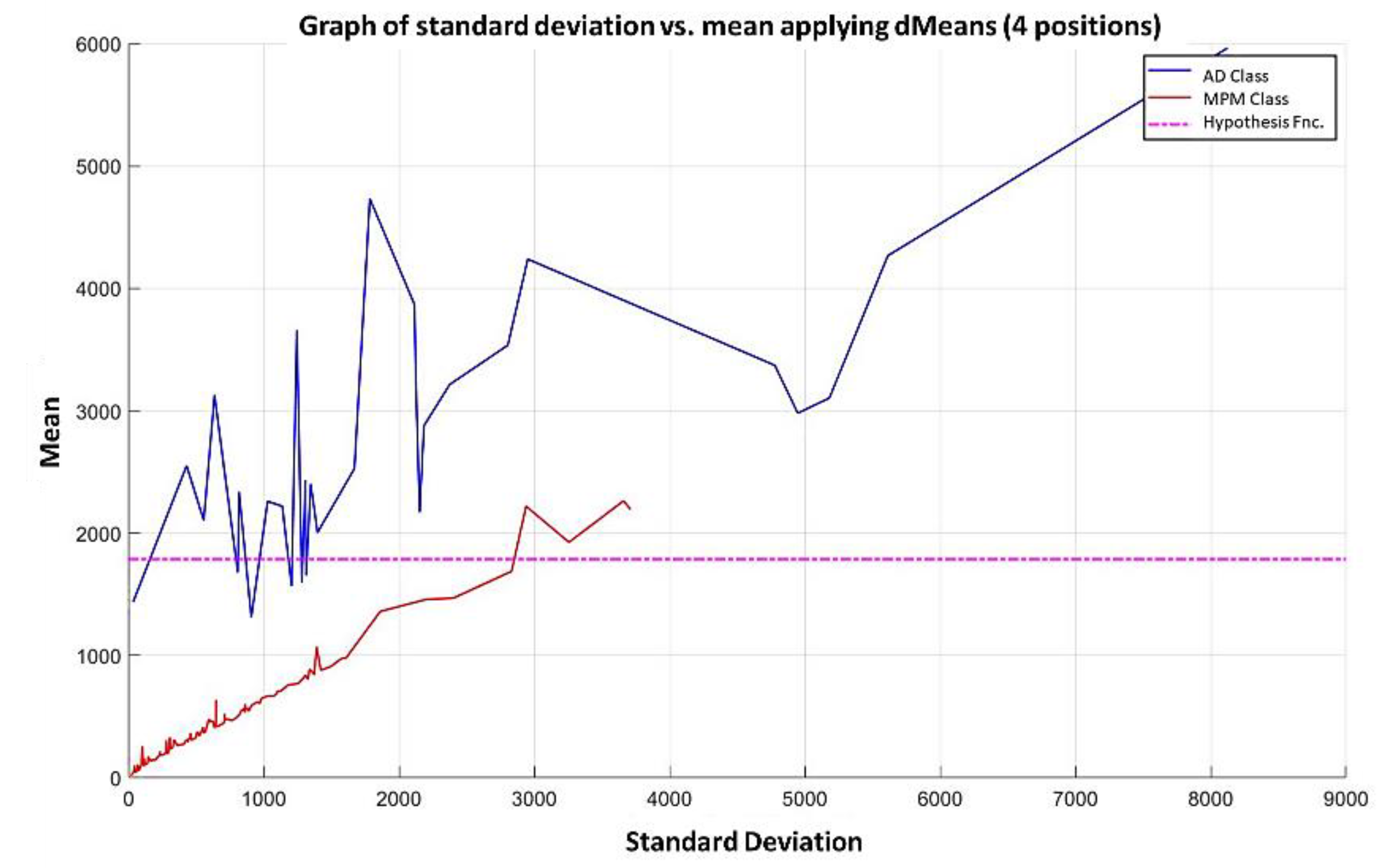
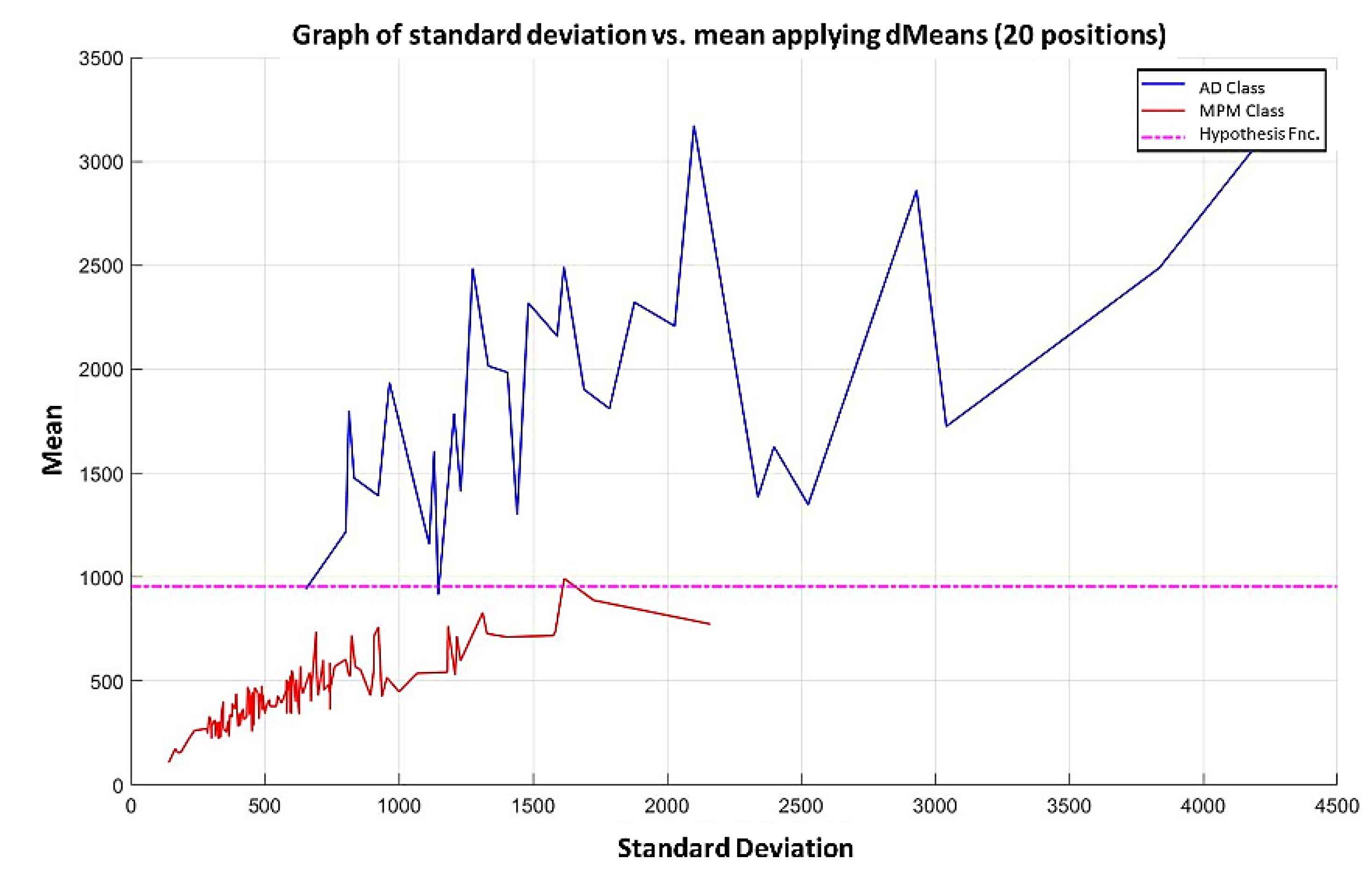
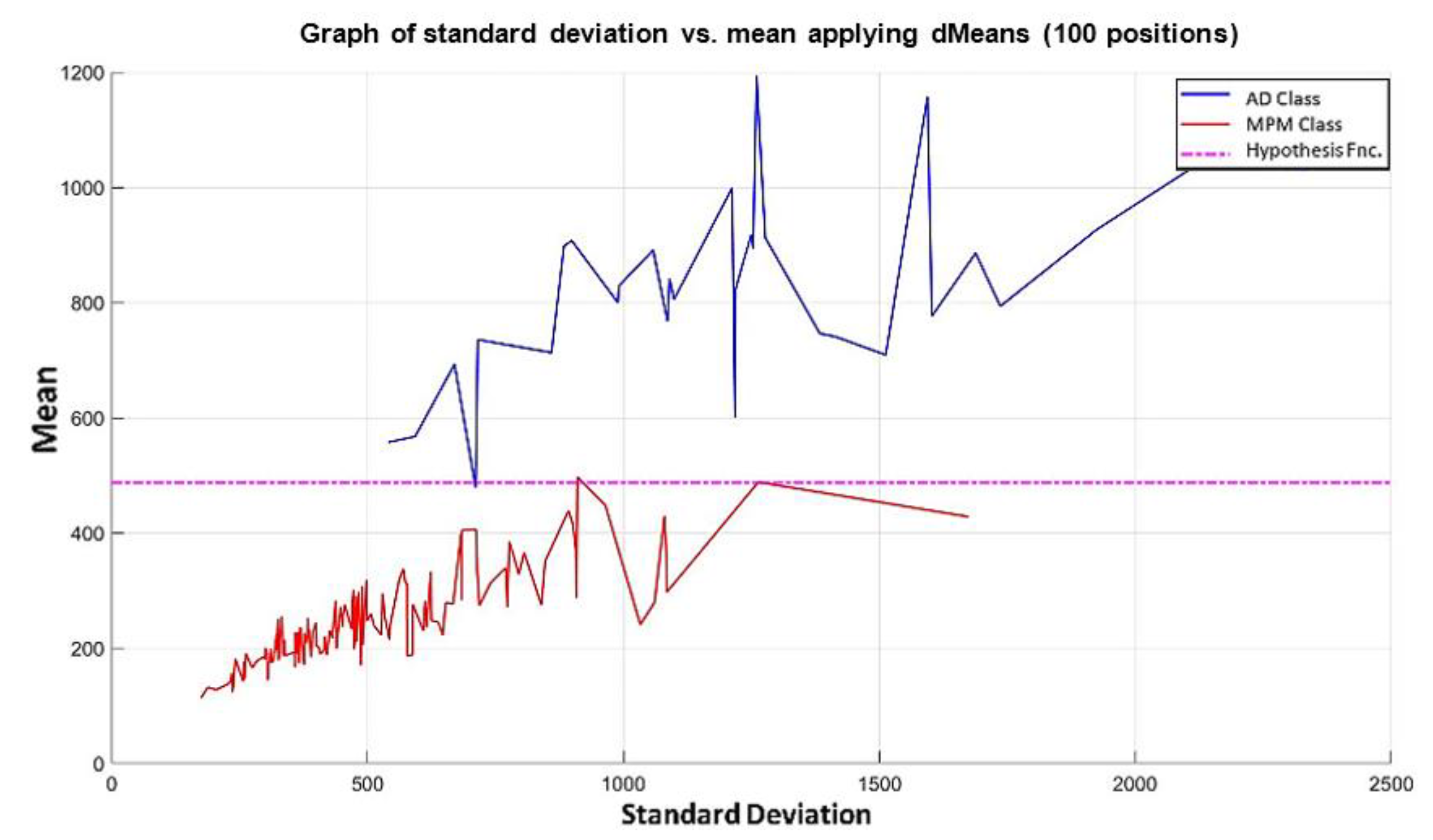
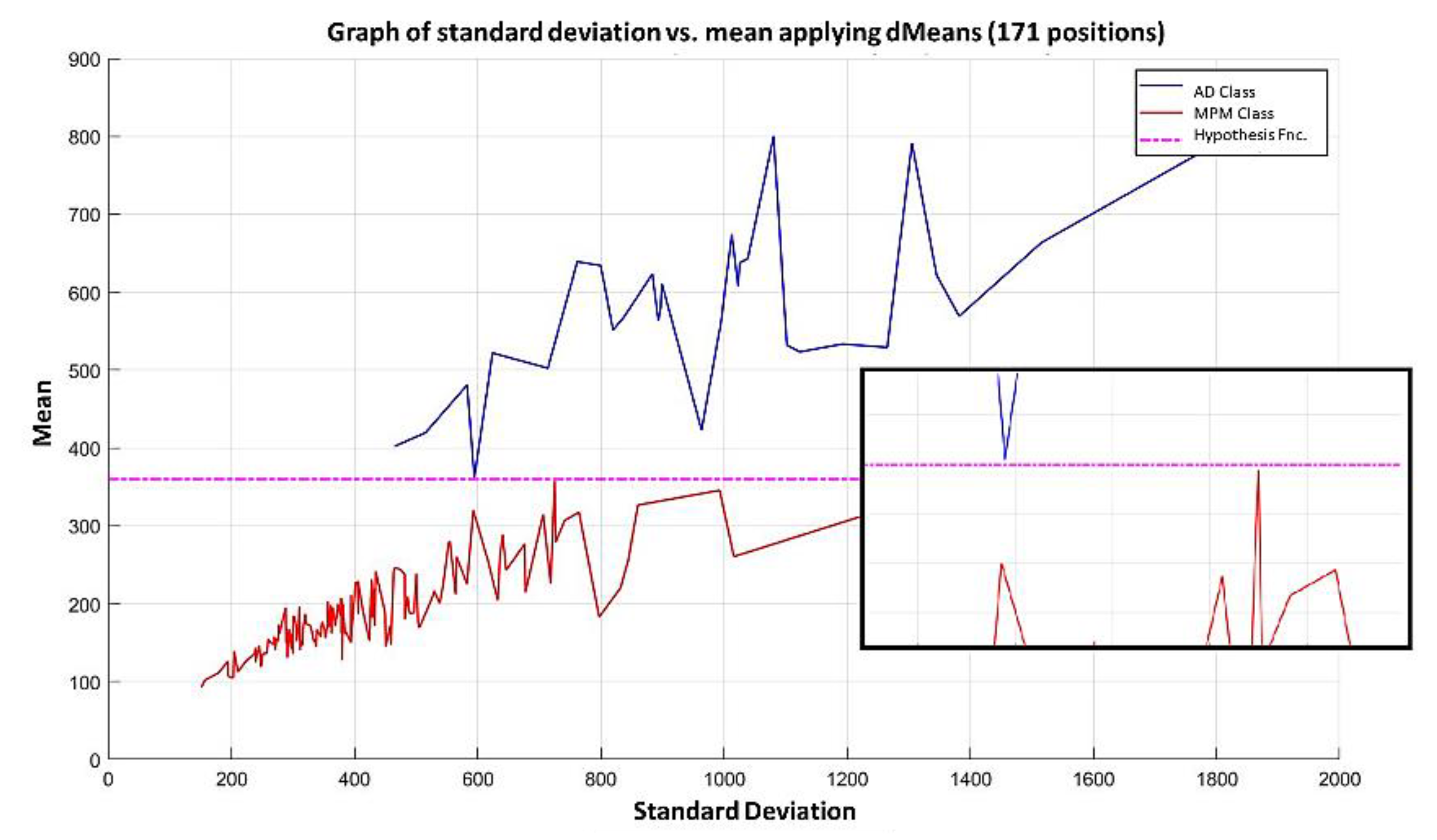
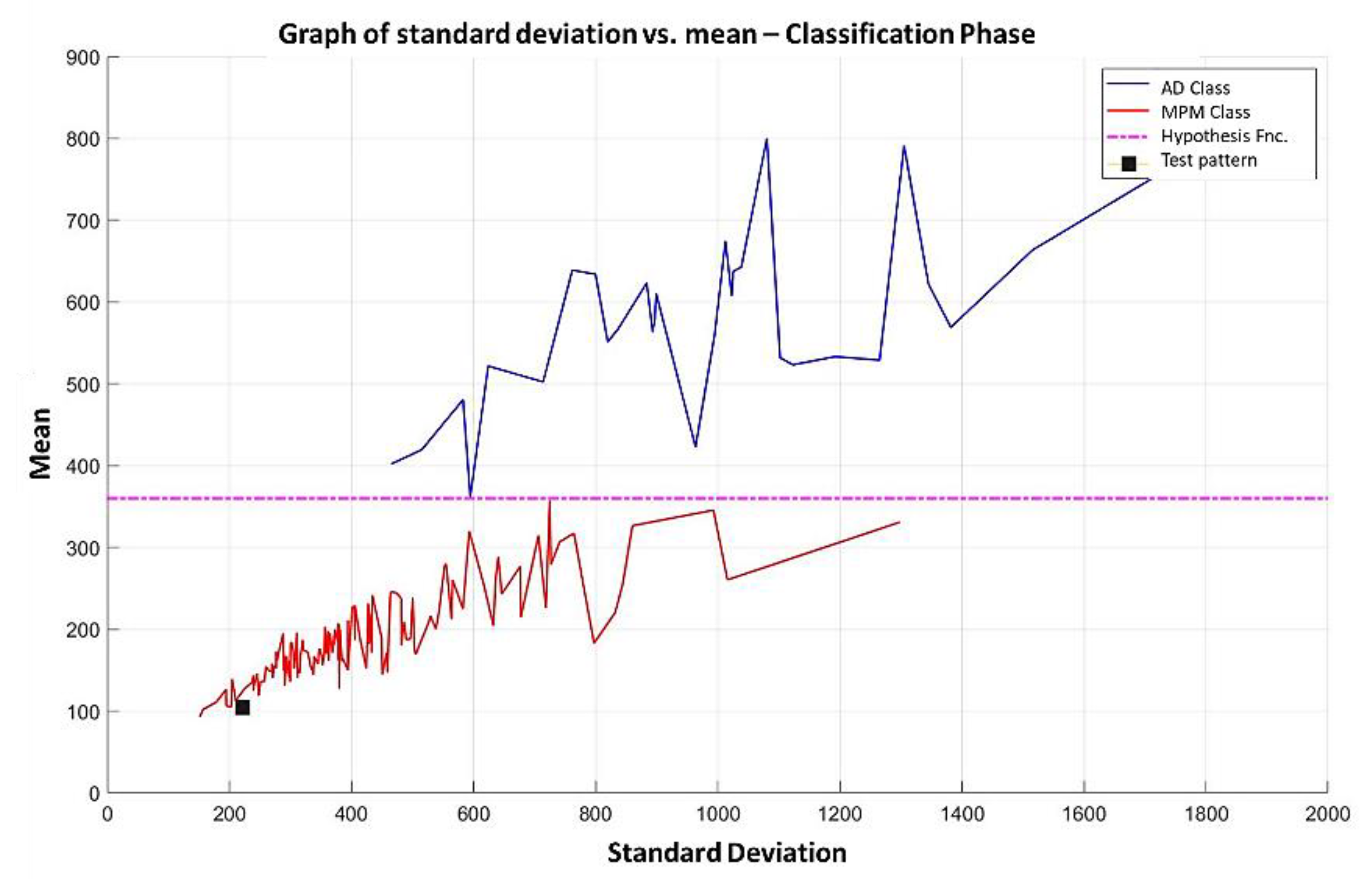
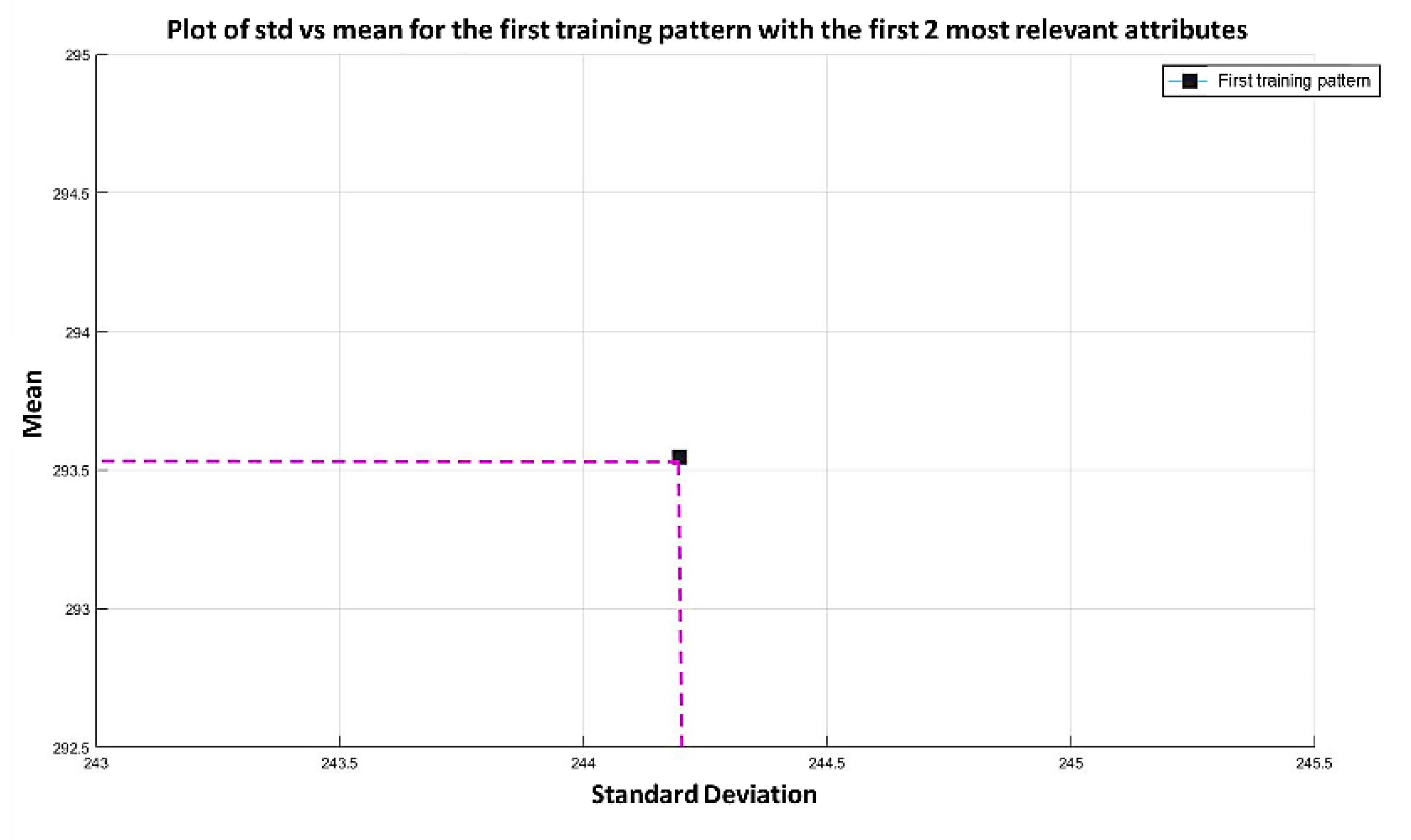
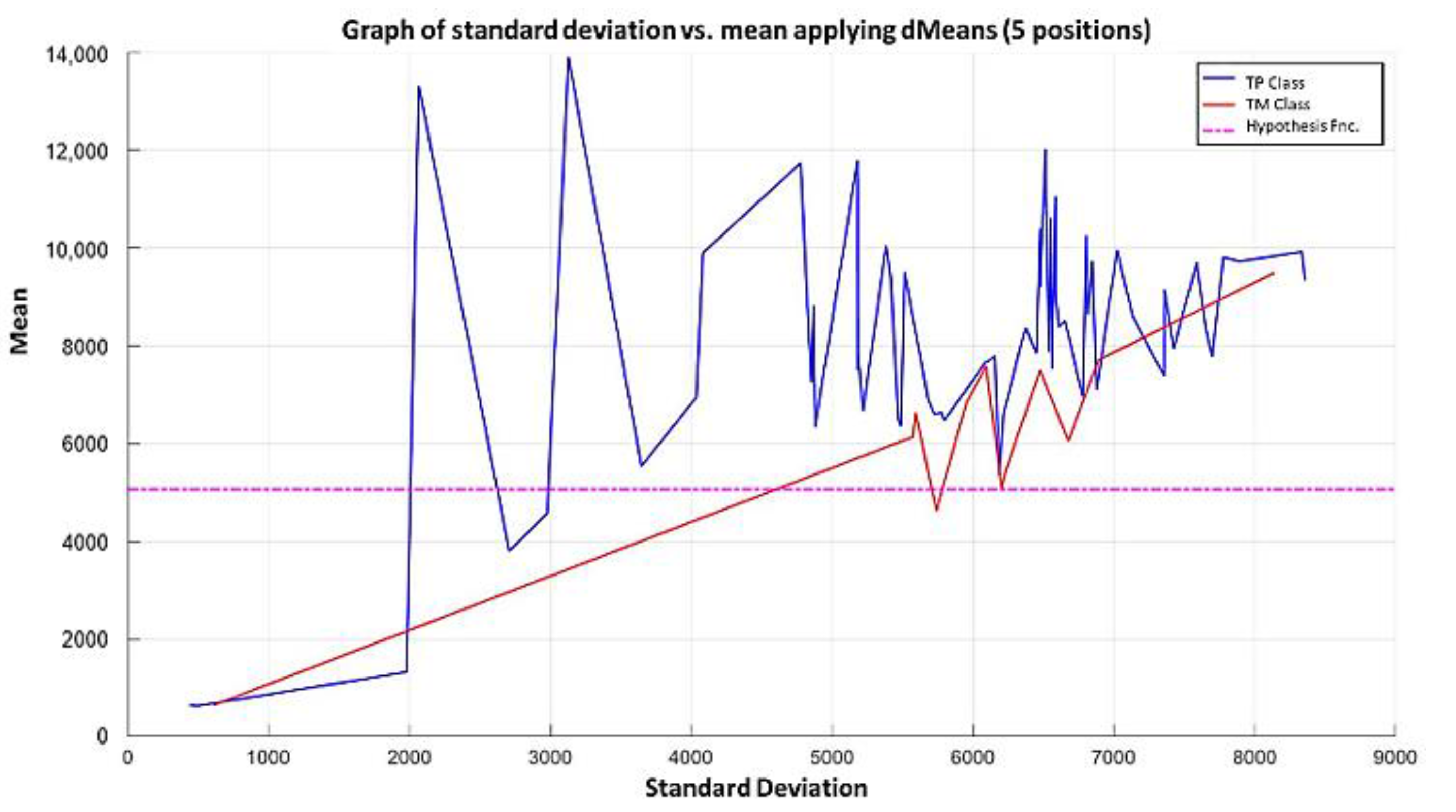
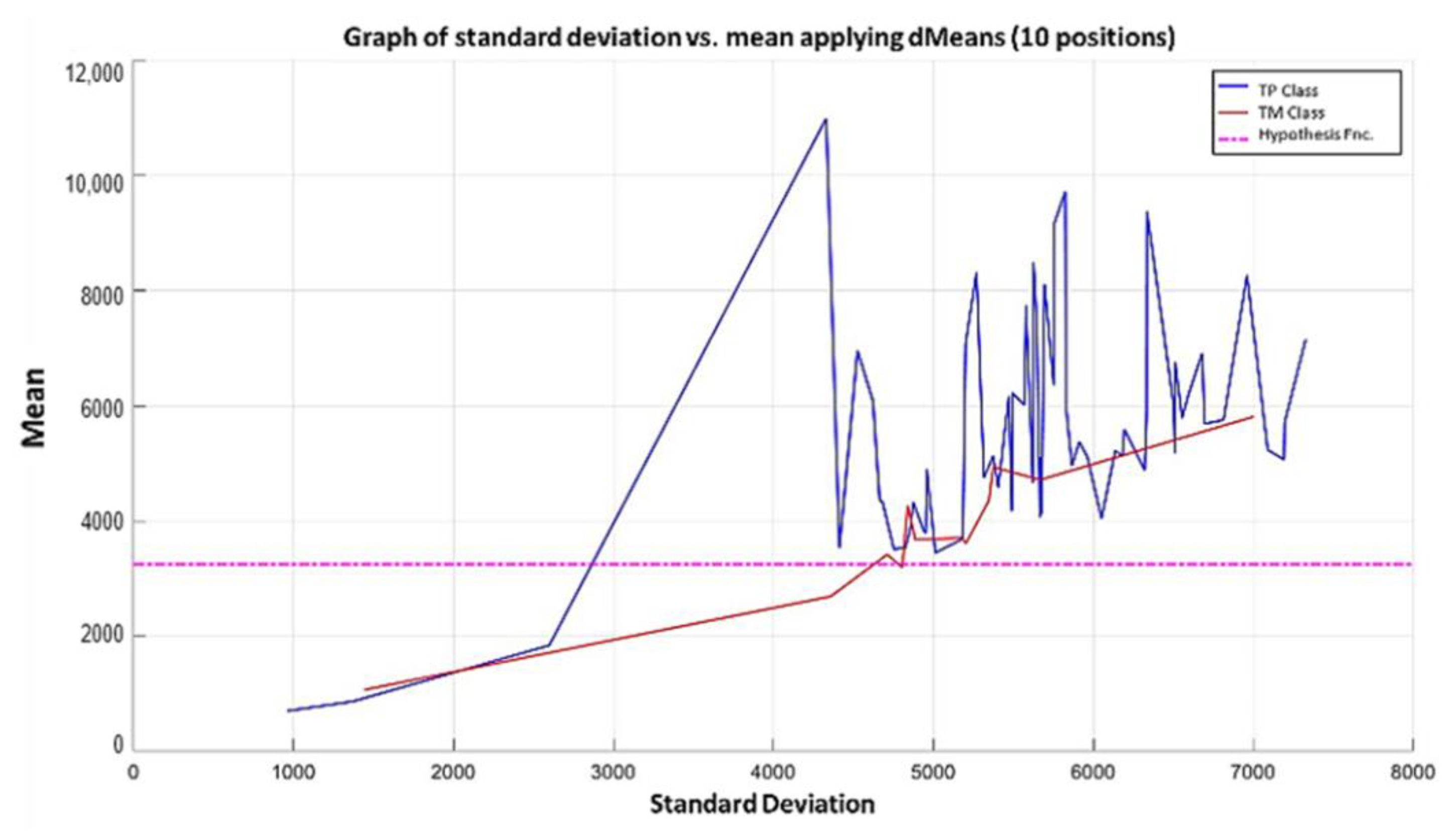
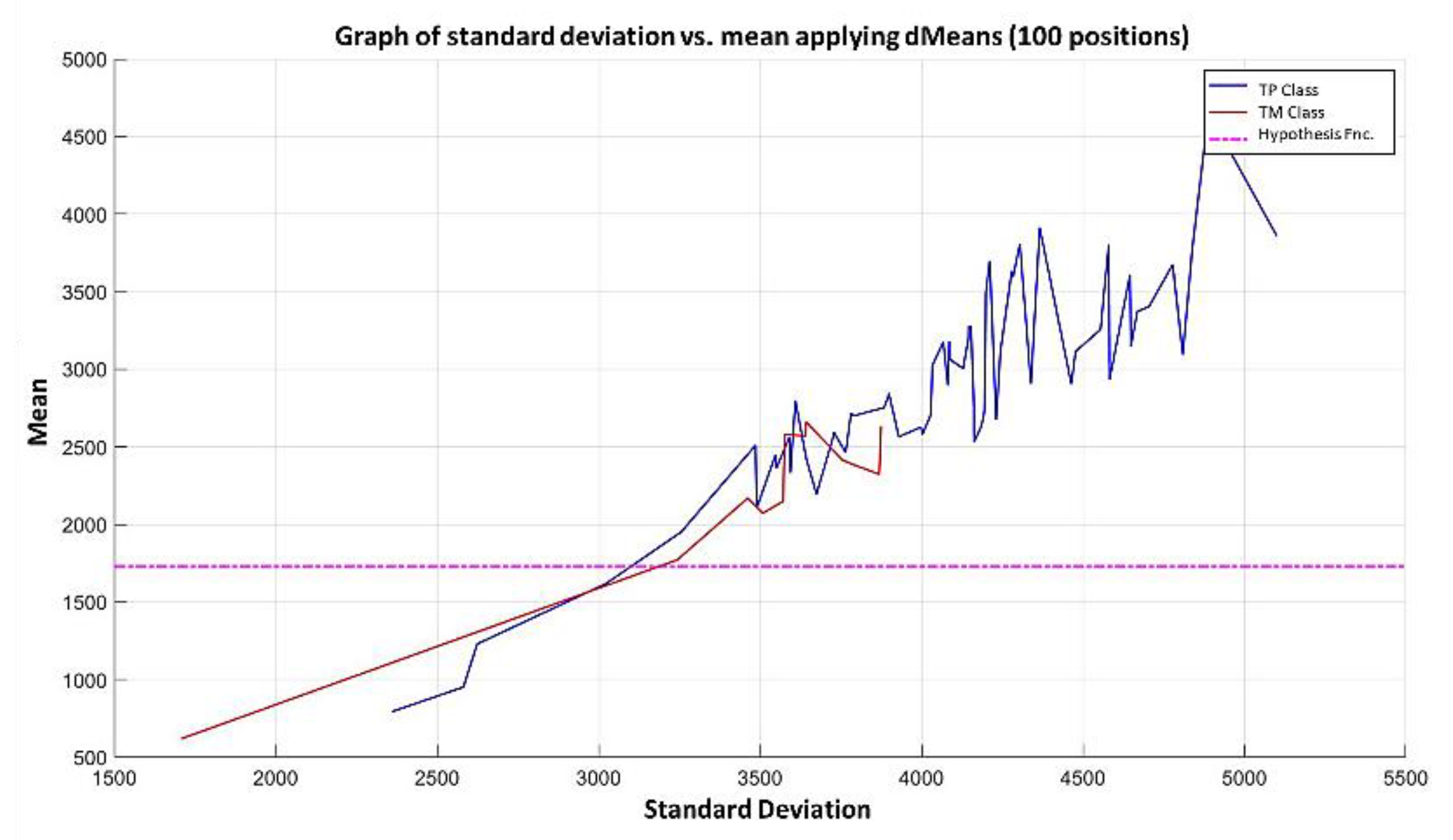
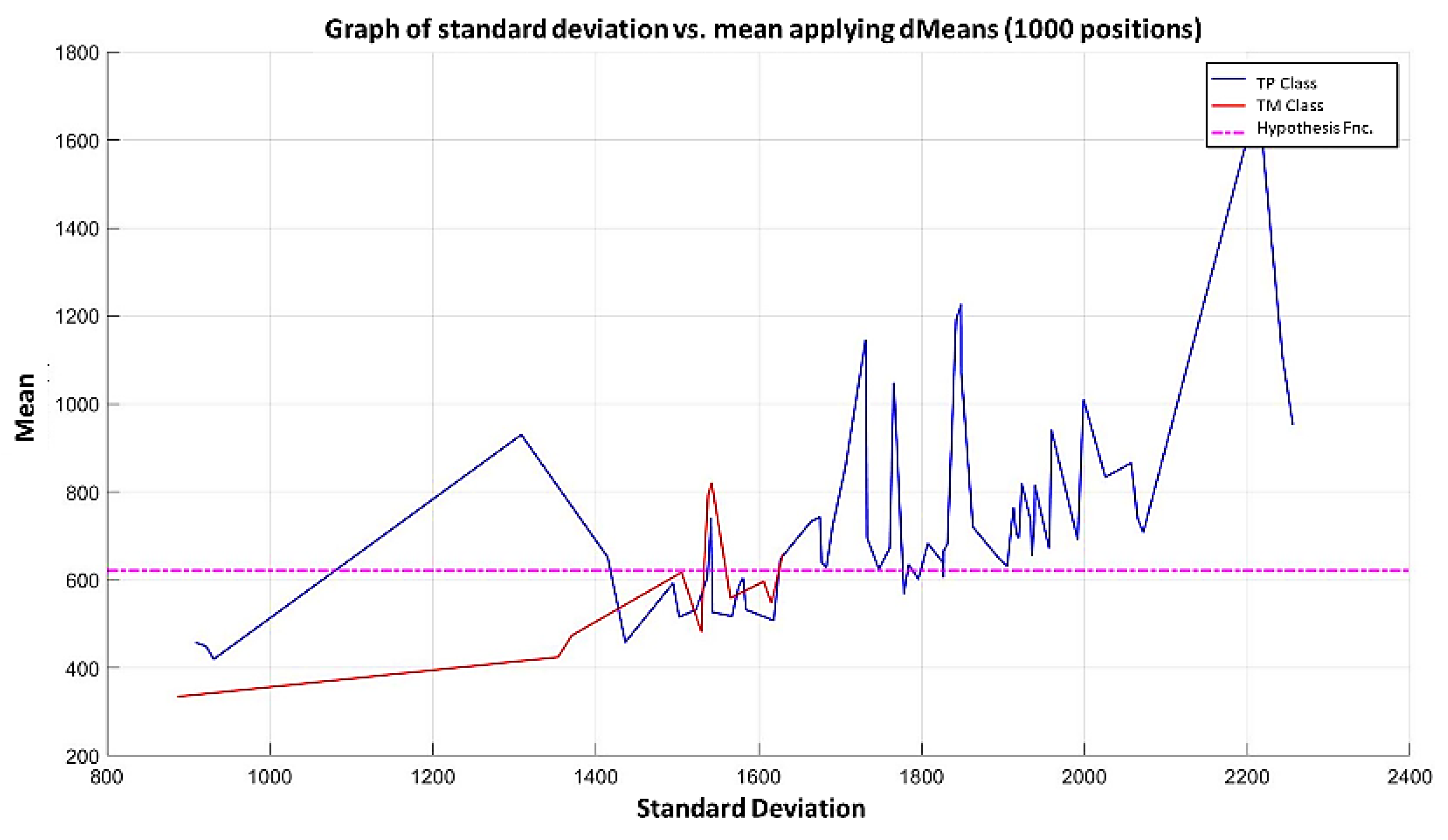
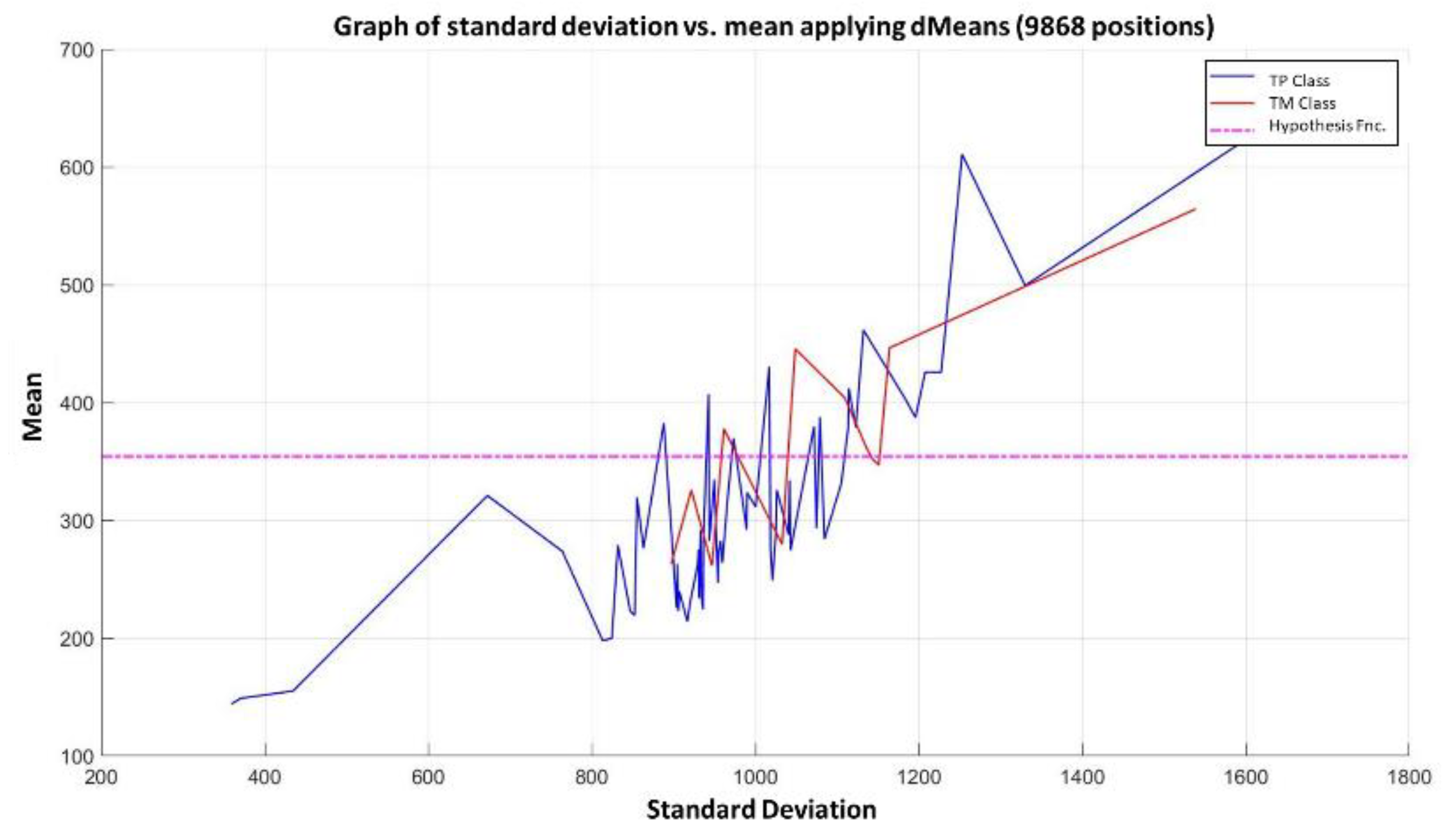
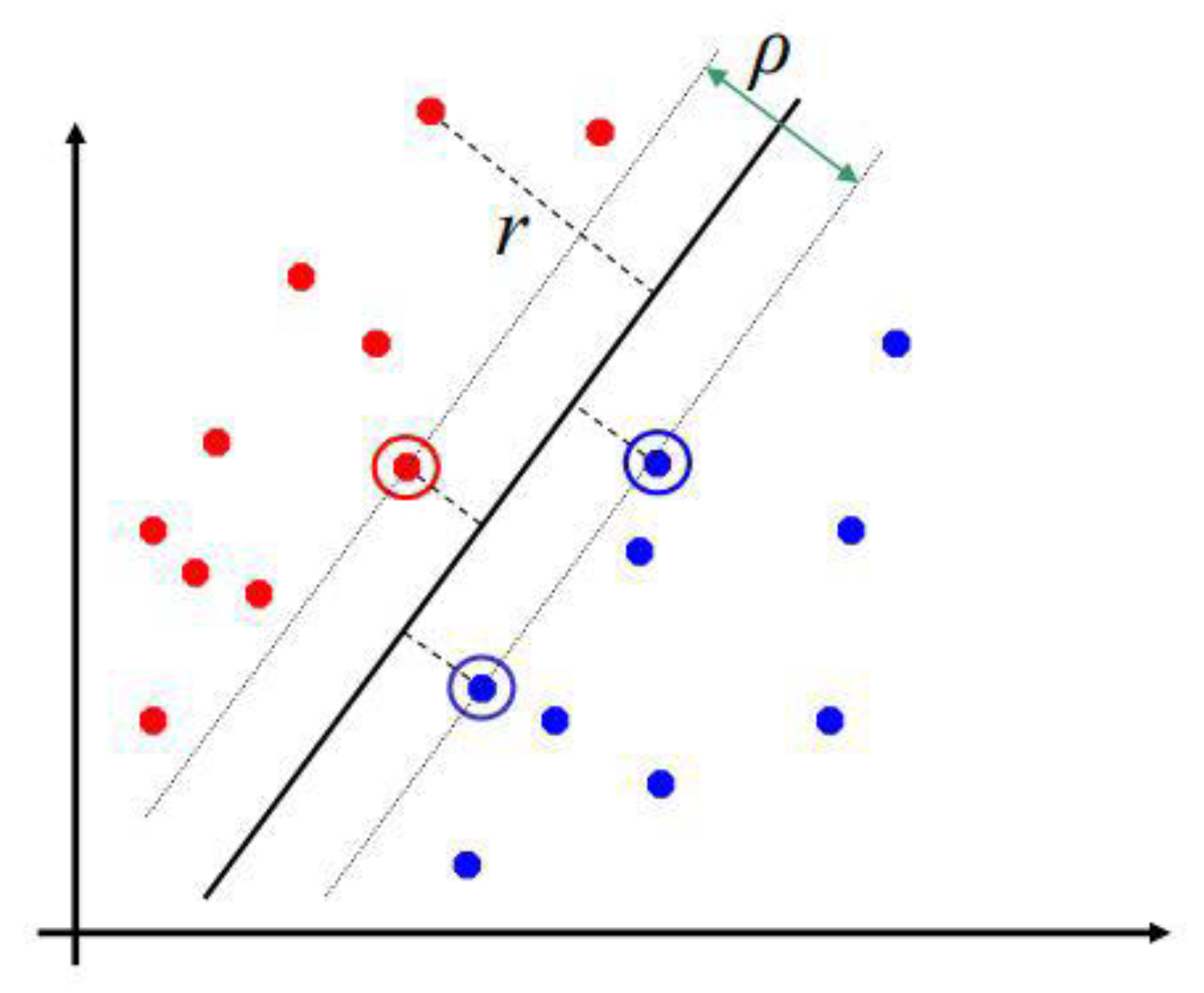
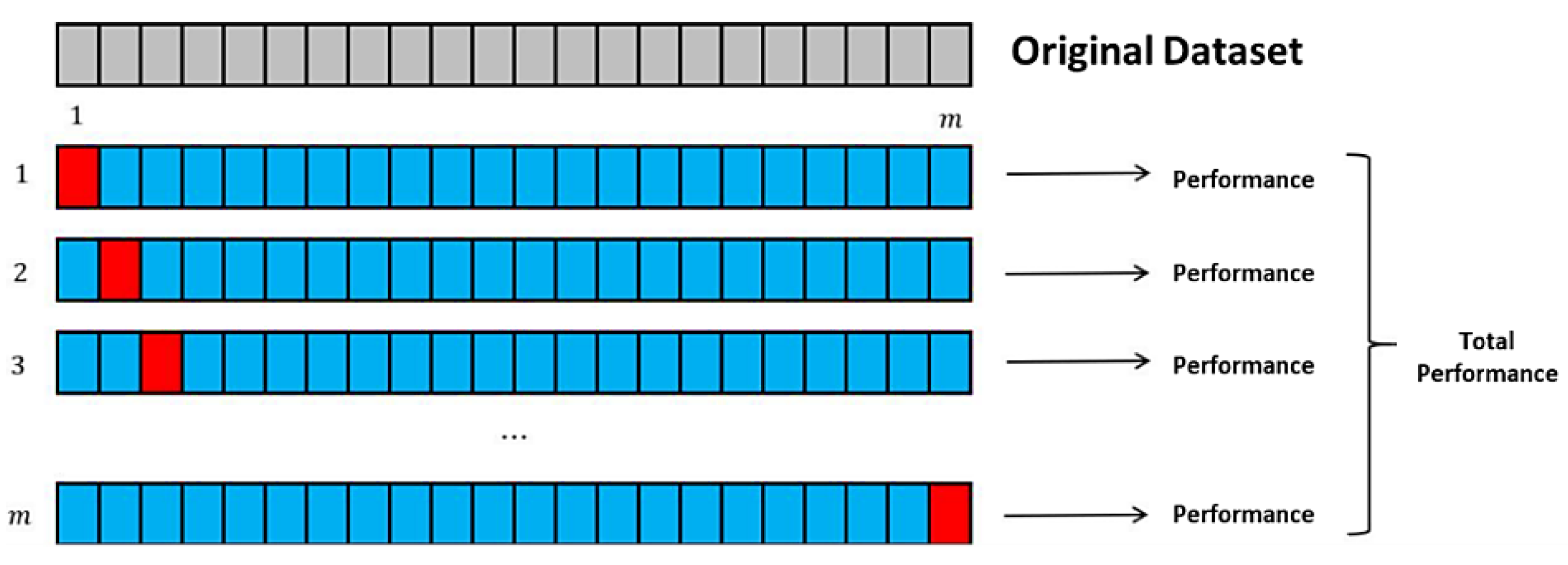
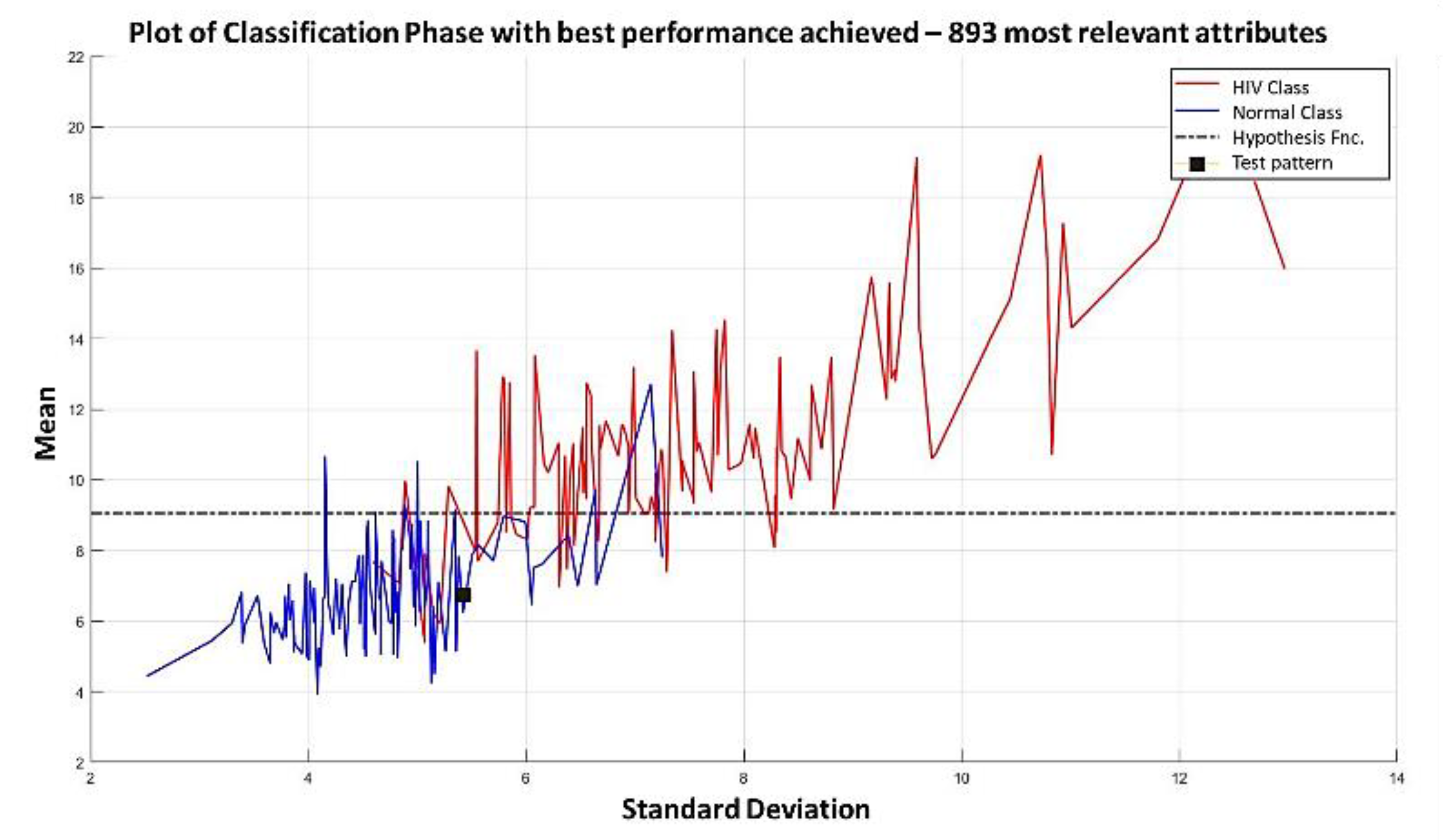
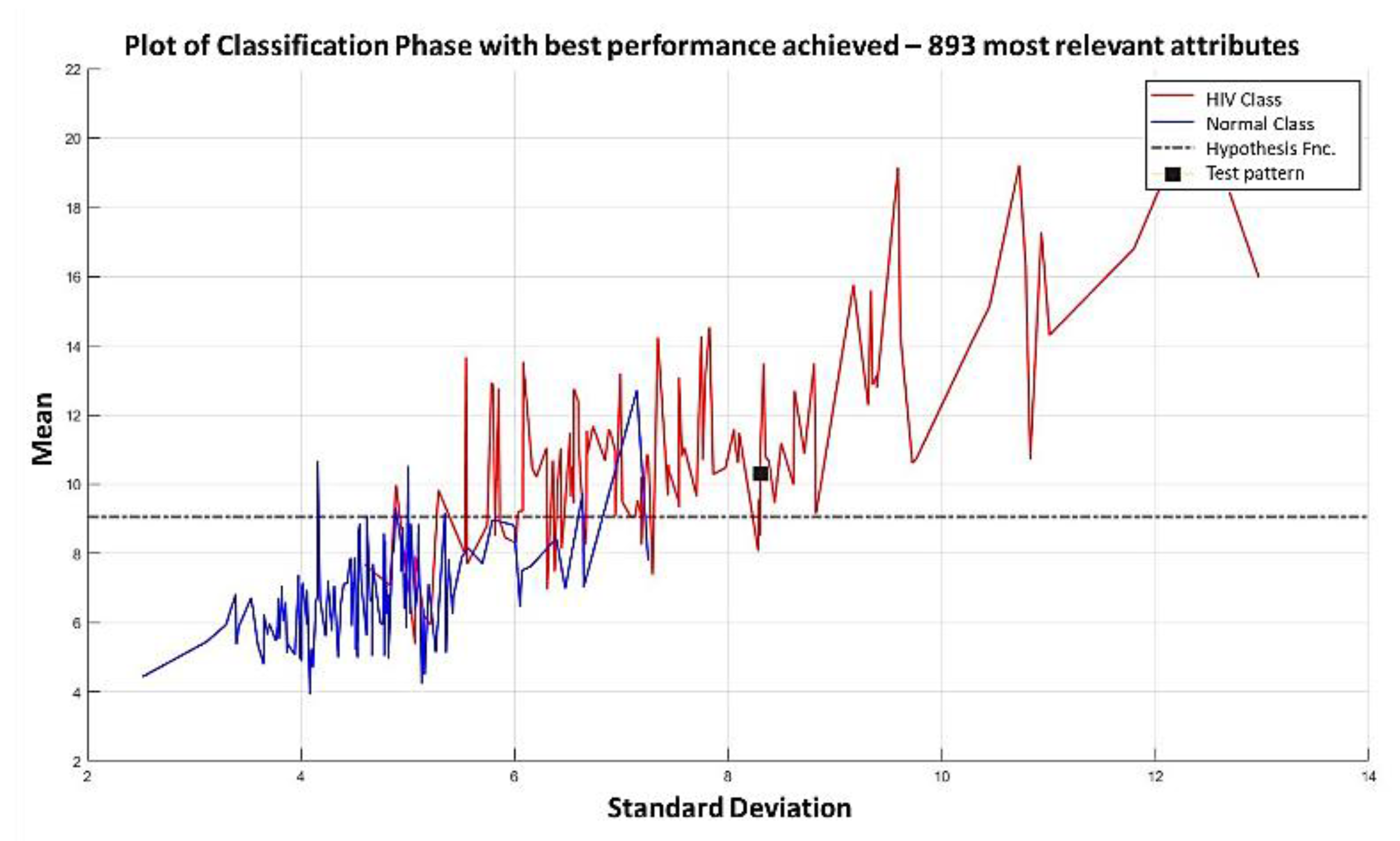
In the MML paradigm, one of the most applied tasks in the area of Pattern Recognition (PR) is performed: classification. An important characteristic of this paradigm is the ability to represent the results and data graphically in a Cartesian plane. In order to achieve this graphical representation, statistical measures are used to identify the classes, as reflected in the article Toward the Bleaching of the Black Boxes: Minimalist Machine Learning [
17], where the author obtains the statistical properties of the data: Arithmetic Mean and Standard Deviation.
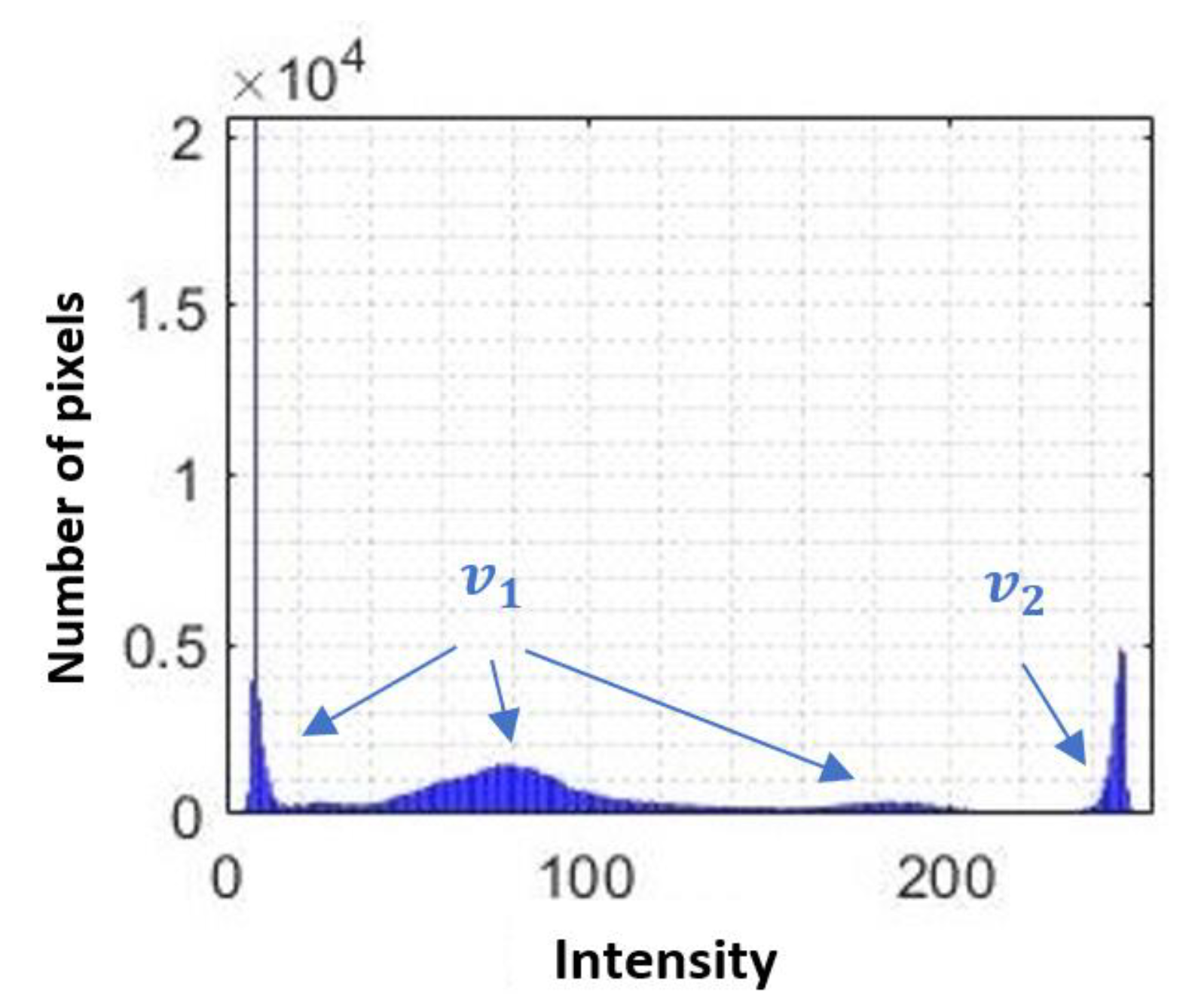
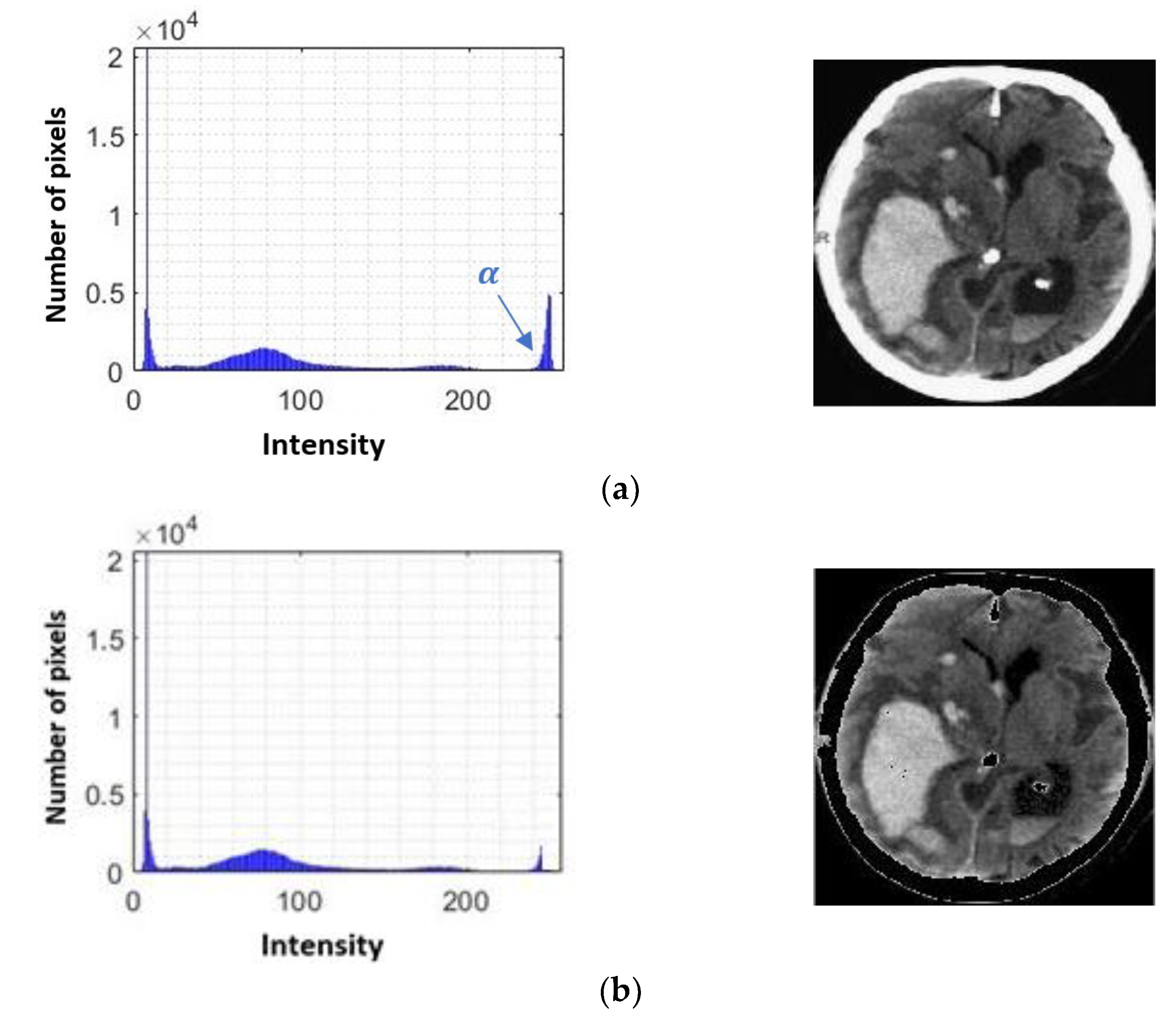
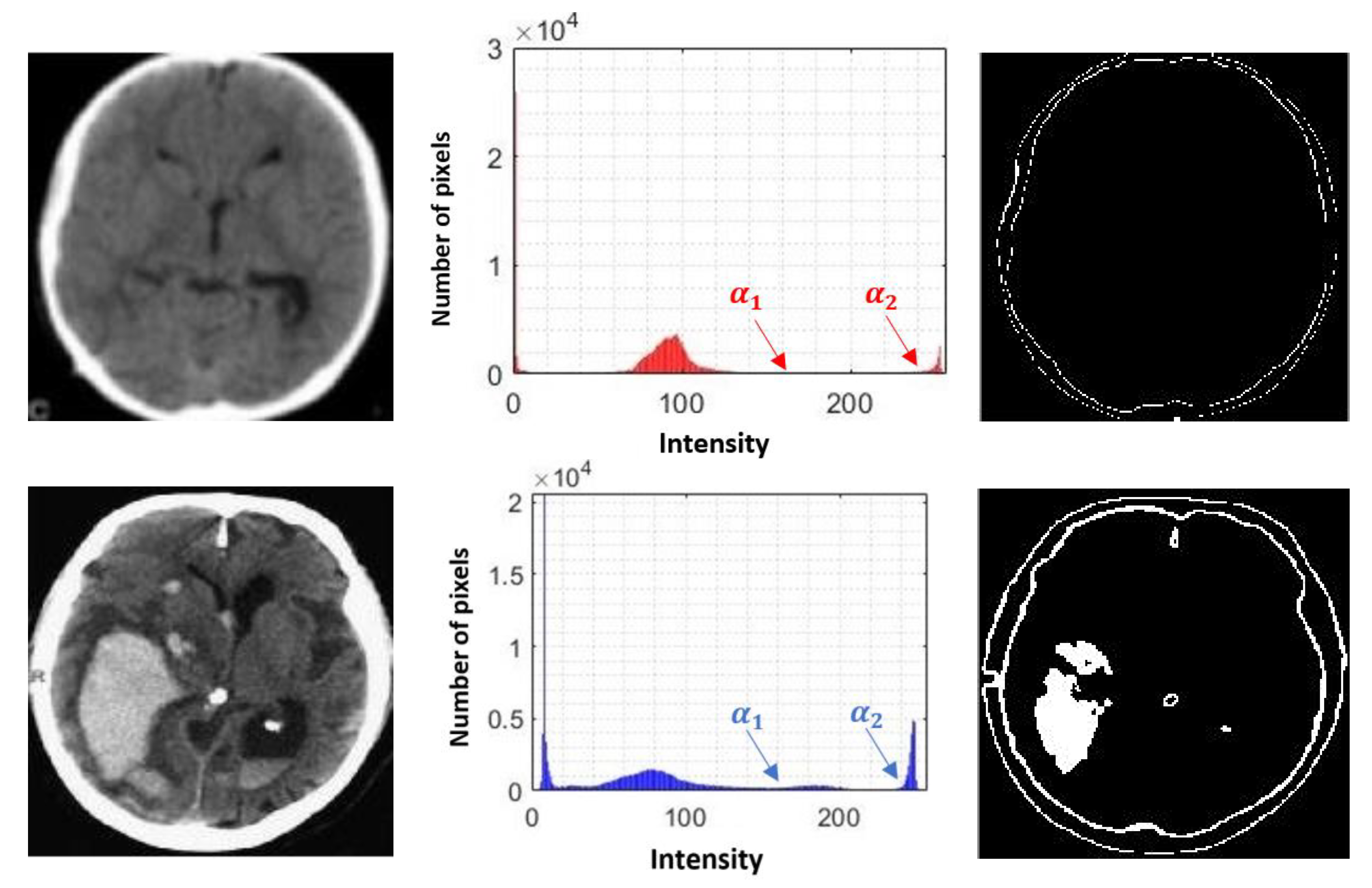
In the context of information obtained from images, it is possible to define a set of characteristics that can support the determination of the behavior of an image, presenting a series of elements that can distinguish a delimited set of instances, through more complex attributes not related to mathematical operations, with an observable behavior in all images. These quantifiable observations are areas, solidity, perimeters, contrast, energy, entropy, and orientation, to mention some of the most outstanding [
18].
By means of these attributes present in the images, each instance has the possibility of having different values for each behavioral attribute of the image, creating the possibility of being identifiable, identified, or classified by means of supervised learning algorithms.
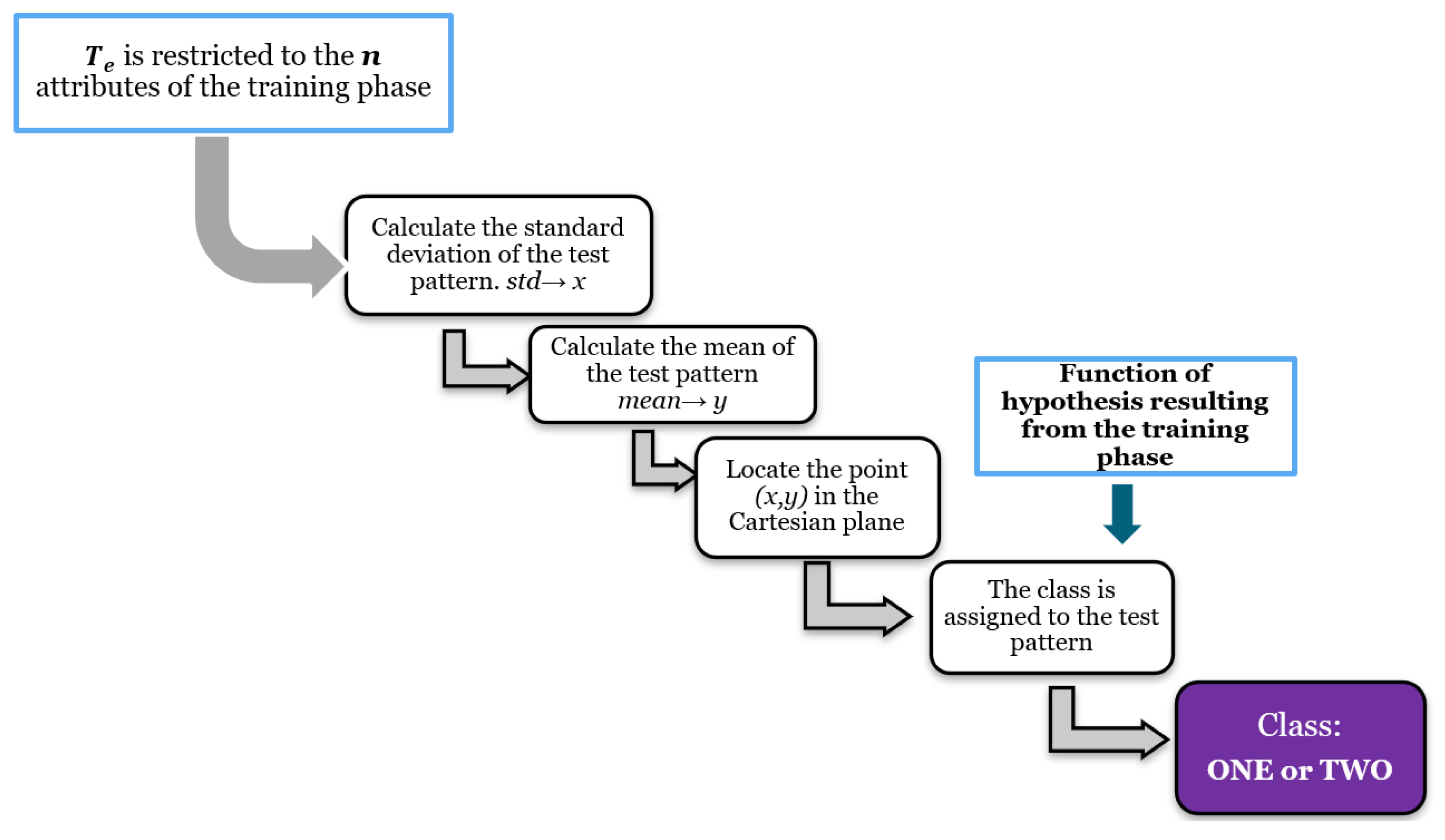
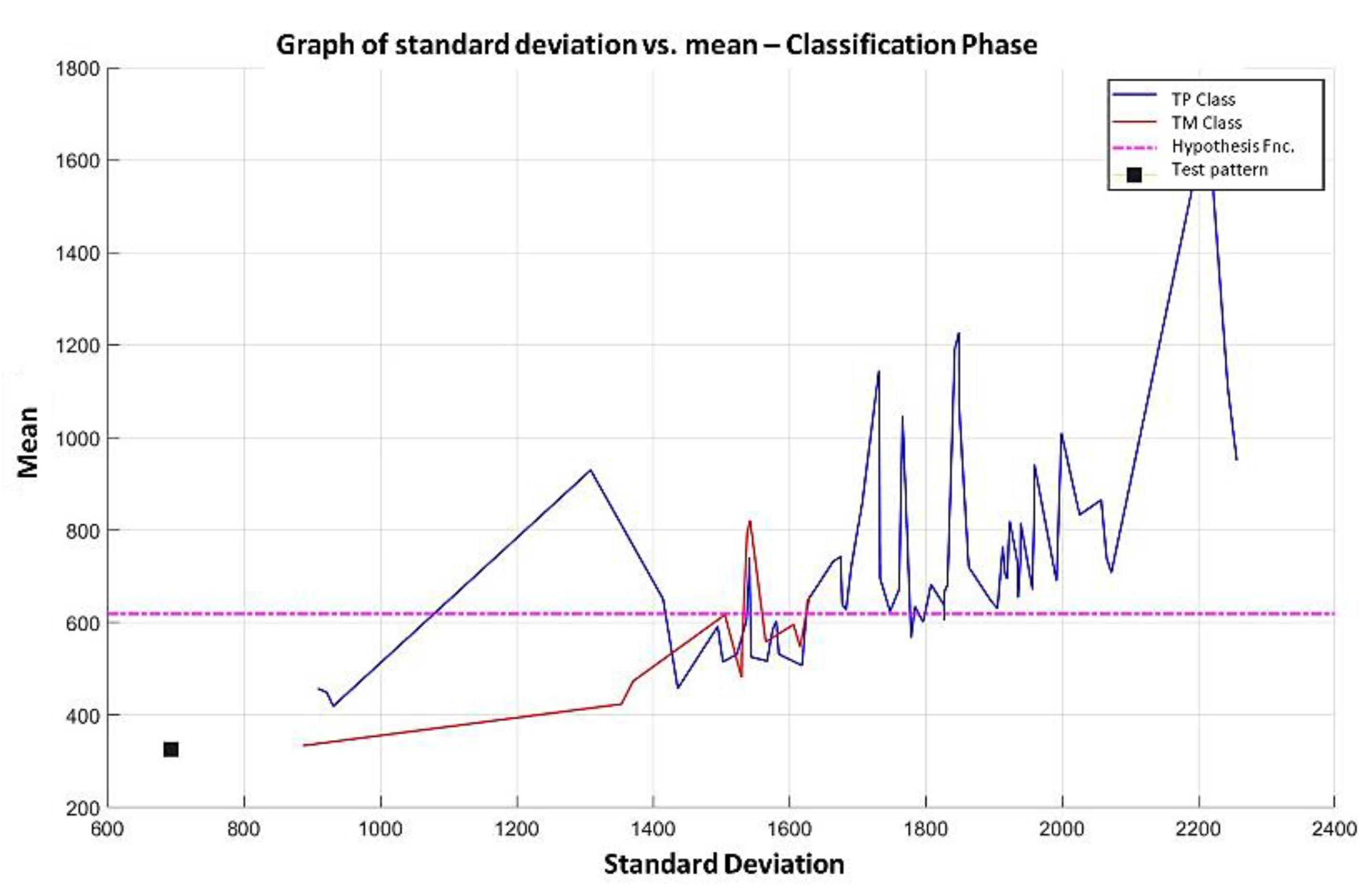
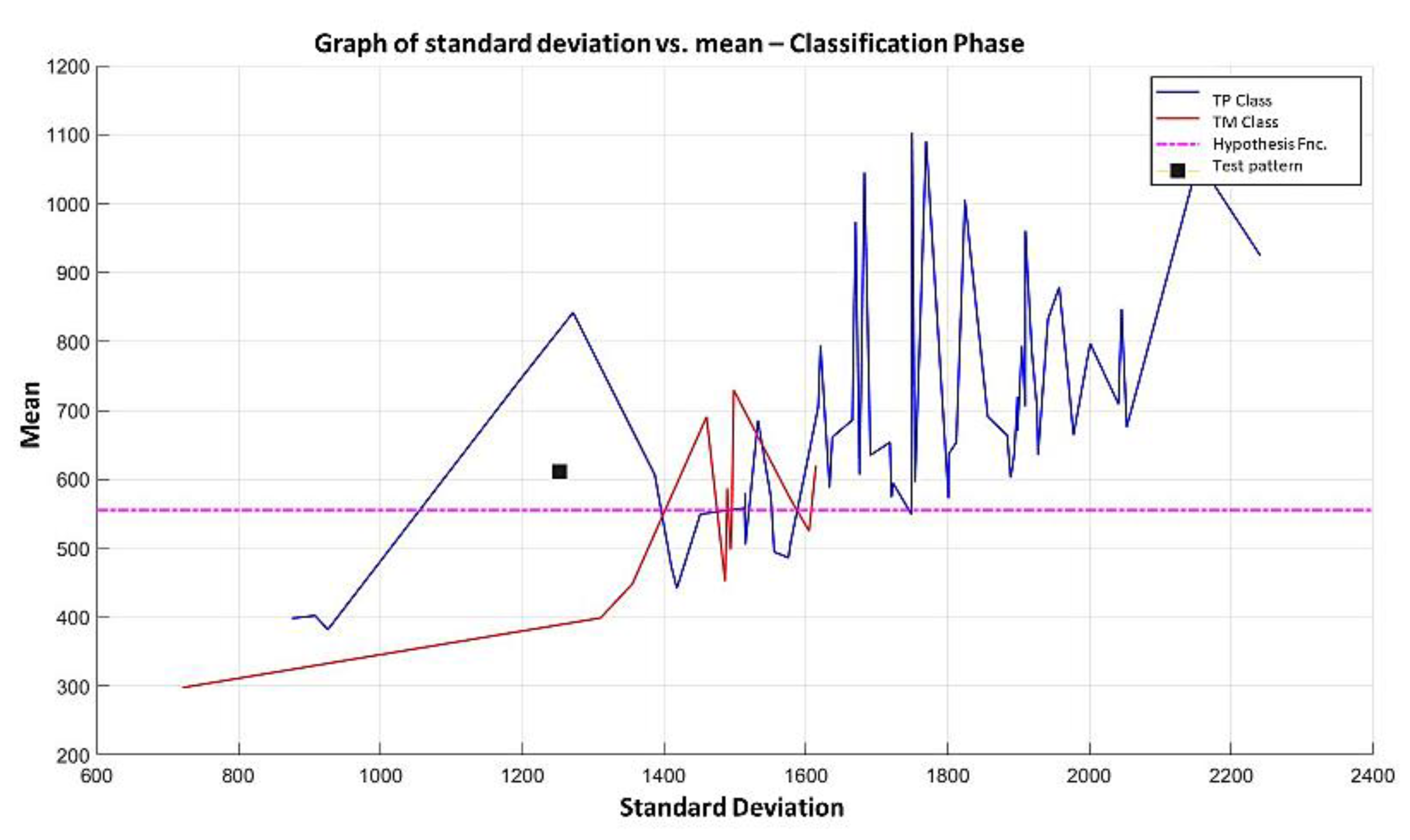
Supervised learning consists of training a set through operations or calculations, and this process is known as the training or learning phase, which allows obtaining an optimal hypothesis, which achieves the best generalization and approximation according to the training data; on the other hand, there is the test set, which consists of instances that will be subjected to a classification phase and compared with the hypothesis resulting from the training phase, in order to assign a label to this test element that was completely unknown during the learning phase [
19].
Based on the above, a classifier can be defined as a system that categorizes instances contained in a finite set of classes, which is fed by an array of attributes and whose output is a label associated to the input in question, which is assigned according to a maximum similarity function [
20]. A Pattern Recognition (PR) model must have the ability to decide which label to assign to a test pattern that has never before been observed by the system, given a finite set of data provided at the input of the classification model. In this classification model, the following tasks are performed [
21]: characterization and obtaining samples (always with the support and assistance of an expert in the field), grouping of the samples into their respective classes, according to the group formation criteria, training of the algorithm, and finally the validation of the model using validation methods, which allow evaluating the performance of the algorithm with test patterns whose class is unknown.
The main contribution of this paper is to present a simple and practical proposal for image classification, whose application in medical images simplifies the classification task and allows visualizing in a two-dimensional plane the behavior of a dataset, without leaving aside the very good performance achieved by this methodology compared to the state-of-the-art classifier algorithms.
The remainder of the paper consists of the following sections.
Section 2 includes some of the related methods that will support the work presented.
Section 2 is made up of four subsections, where some materials and methods are included.
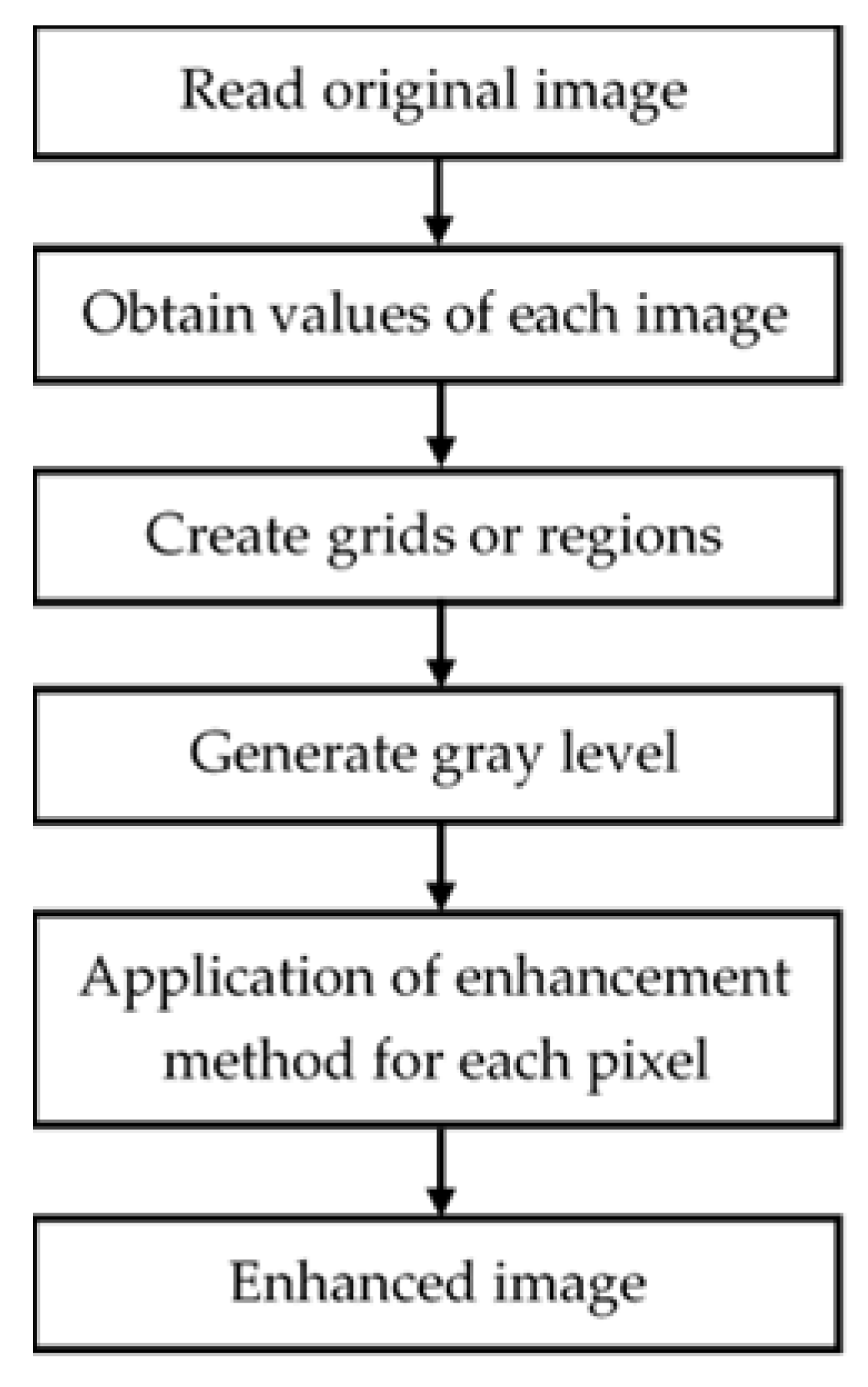
Section 2.1 includes brief information about various image enhancement techniques.
Section 2.2 describes the process followed for image segmentation based on the implementation of morphological operators.
Section 2.3 presents some theoretical advances that have allowed the generation of an efficient classification algorithm based on the MML paradigm. Moreover, the content of
Section 2.4 serves as a solid base on how the learning and classification process of a new classification algorithm of this new MML paradigm is carried out.
Section 3 presents the main proposed methodology of the work.
Section 3.1 deals with CT image enhancement and image segmentation.
Section 3.2 includes the methodology of applying the classification algorithm of the Minimalistic Machine Learning paradigm. Finally,
Section 3.3 describes by means of real examples with two numerical datasets the way this new paradigm works.
Section 4 presents the results.
Section 4.1 describes the image dataset that is evaluated under the MML paradigm. In
Section 4.2, we show in broad strokes the strong classifiers found in the state of the art, under which our results are compared.
Section 4.3 shows the performance achieved, performance measures, and a brief analysis of the different results achieved.
Section 5 contains conclusions and future work. Finally, references are included.
5. Conclusions and Future Works
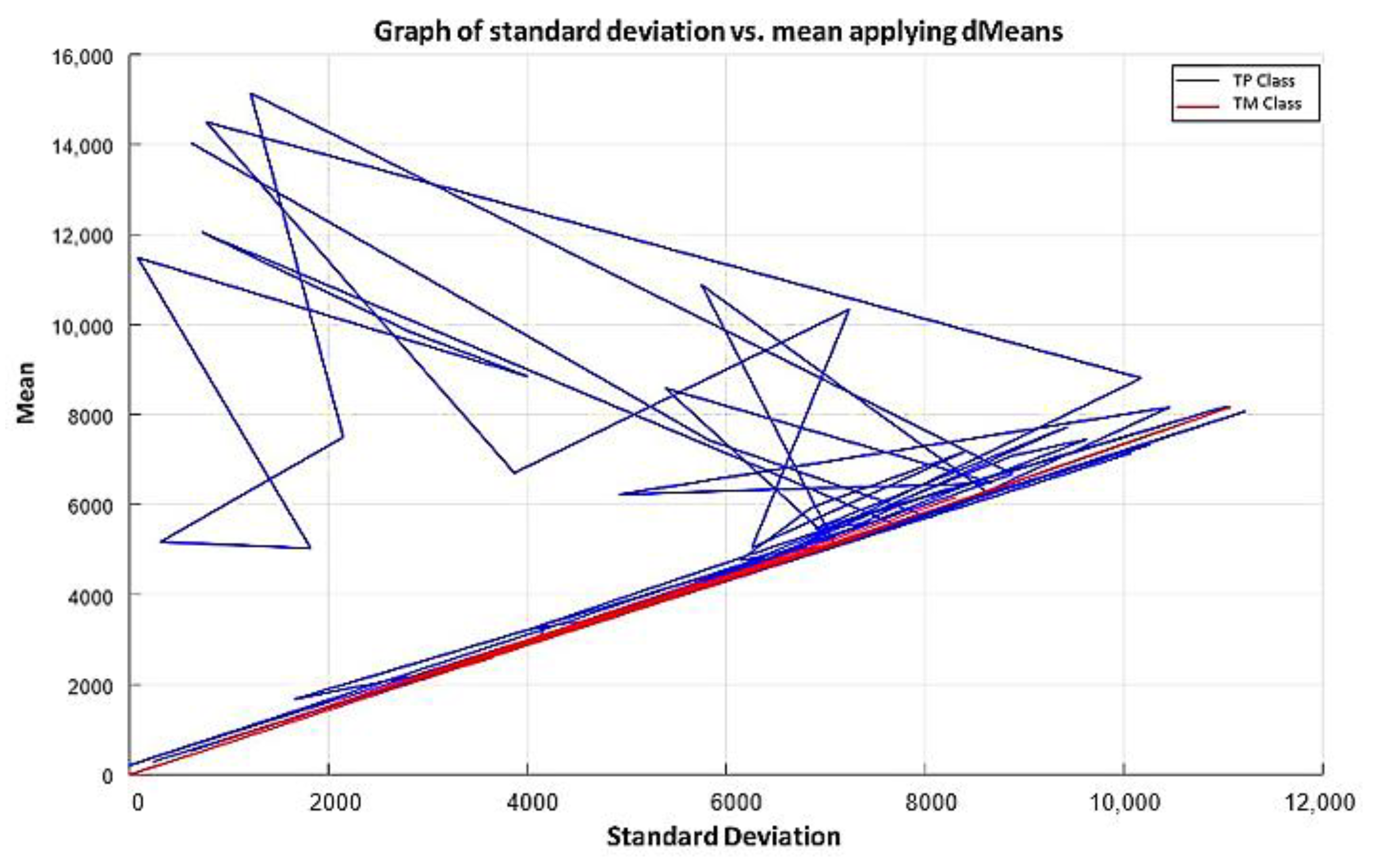
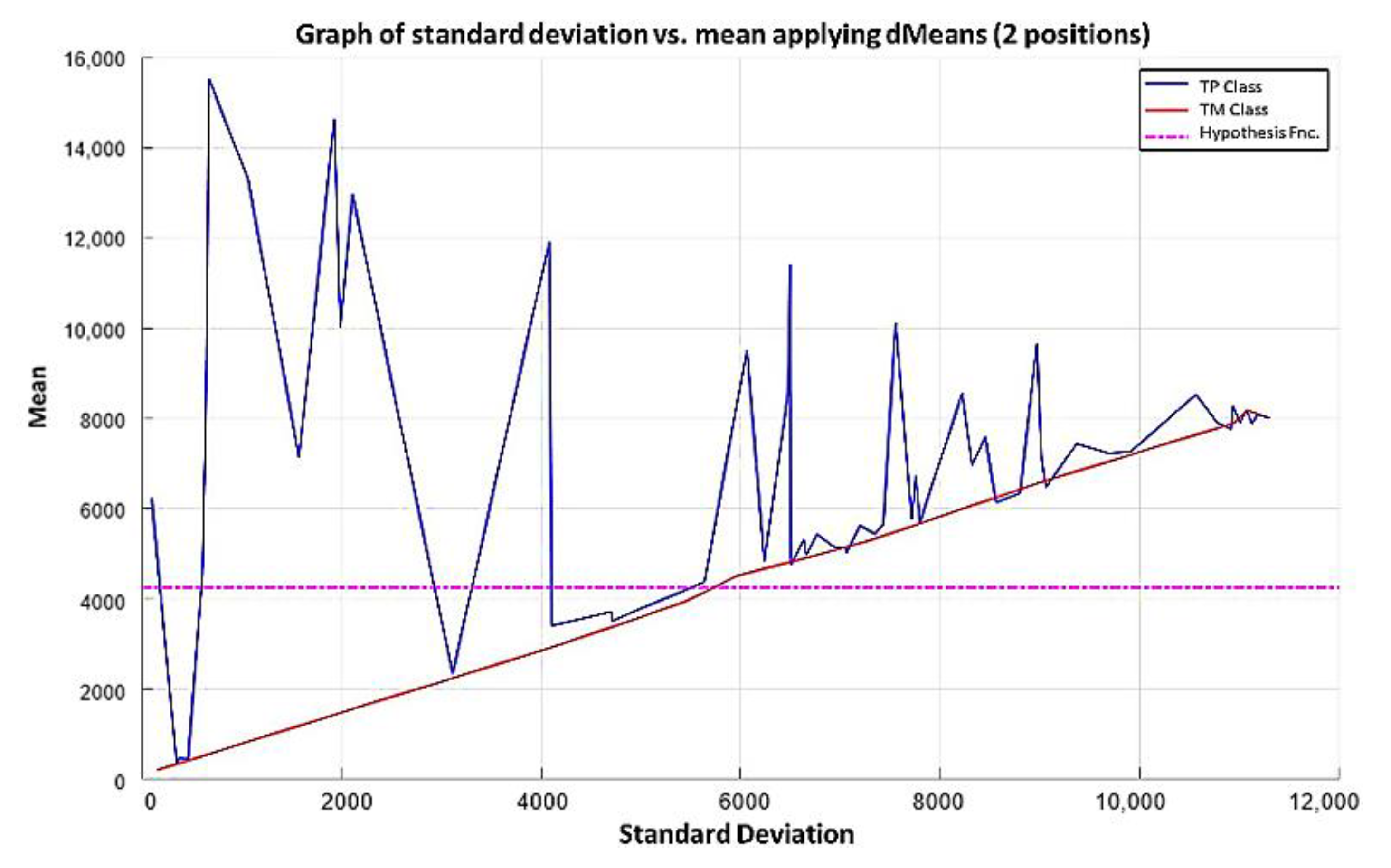
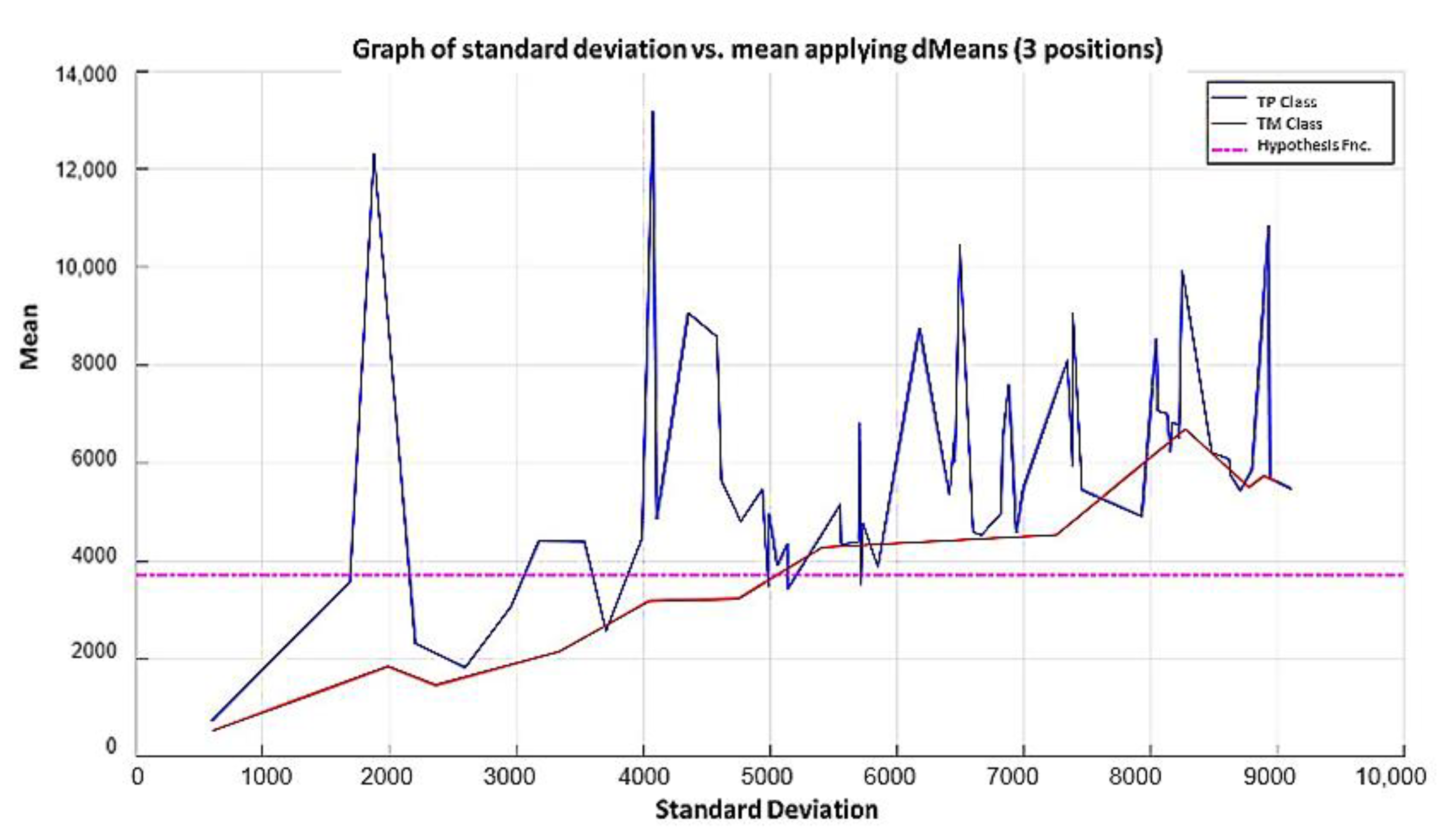
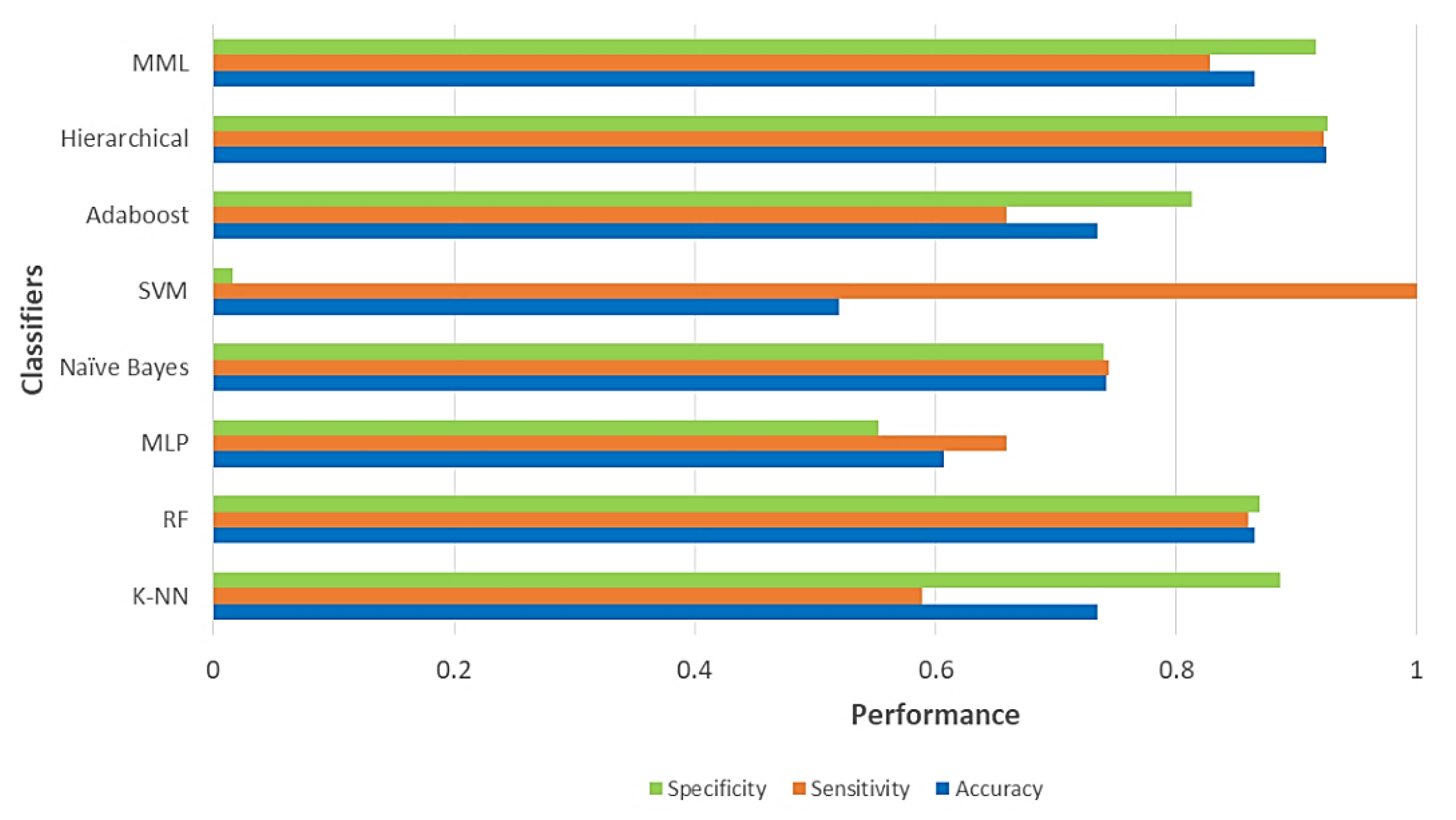
In this paper, we have introduced a new classification algorithm of the Minimalistic Machine Learning paradigm. The classification algorithm based on the MML paradigm was implemented on a set of brain images obtained by Computed Tomography. Derived from the experimental work, a series of enhancement techniques were applied to this set of images for the improvement and enhancement of the areas of interest, specifically the areas with possible hemorrhage. As a result of our methodology, it has been shown to be highly effective in classifying between people who present Intra-Ventricular Hemorrhages and people without hemorrhages. Observing that the proposed method is competitive with other classification algorithms as K-NN, MLP, Naïve Bayes, SVM, Adaboost, and Hierarchical algorithms, ranking second on two performance measures and second only to the Hierarchical classifier on these two measures applied to the same dataset. It was also observed that the training time was less than that the SVMs and Adaboost. The substantial difference of our proposal lies in the ease in which the behavior of the algorithm and its results can be observed through a two-dimensional representation in the Cartesian plane and the minimization of necessary features, through the application of the dMeans method. This substantial improvement could allow the application of this methodology for mobile devices or embedded systems.
As well as the important advances achieved, it is important to mention the main limitations that come with the application of this new methodology for image classification. As could be evidenced in the results section, the training time is considerably high, considering the low number of images. Therefore, when applied in conjunction with a larger number of images and higher resolution, it would generate an extremely high computational cost, which is objectively the weakest point of the application of this model. For this reason, constant development is being carried out to reduce this effect in the Minimalist Machine Learning methodology. However, the excellent news lies in the generation of a classification model that meets all the indispensable characteristics of an algorithm belonging to the XAI, being extremely easy to explain, the interpretation of results is even graphical, which helps greatly to its interpretability, it is completely transparent, justifiable, and contestable to the sample of the results of their decisions.
As for future work, we plan to generate new algorithms under this novel Minimalistic Machine Learning paradigm and to continue experimenting with more datasets from different domains. In addition, considering the main limitations of this methodology, hard work will be maintained to substantially decrease the training time on similar datasets and of course seek to improve on the results seen during the development of this paper. As previously discussed at the end of the results section, the results shown can most likely be improved by applying advanced image segmentation techniques and applied to datasets of different characteristics, such as multi-sequence MR images. In addition, we plan to generate new pattern classification algorithms, applying Genetic Programming algorithms.


 ,
, 












































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}