
Using Machine Learning Algorithms to Predict Hospital Acquired Thrombocytopenia after Operation in the Intensive Care Unit: A Retrospective Cohort Study

 , ,
, ,
Abstract
:1. Introduction
2. Methods
2.1. Study Design
2.2. Data Collecting and Predictors
2.3. Endpoint
2.4. Machine Learning
2.5. Derivation and Test Set and Cross-Validation
2.6. Feature Selection and Oversampling
2.7. Statistical Analysis
3. Results
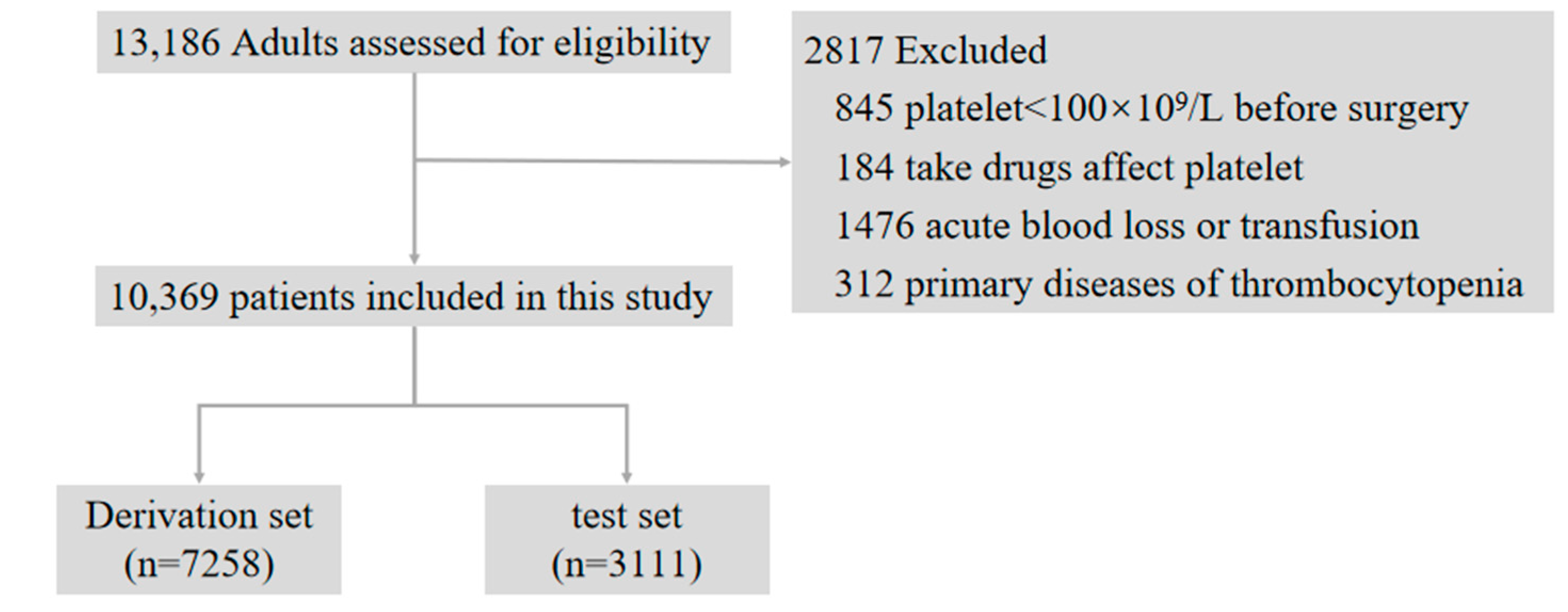
3.1. Study Population
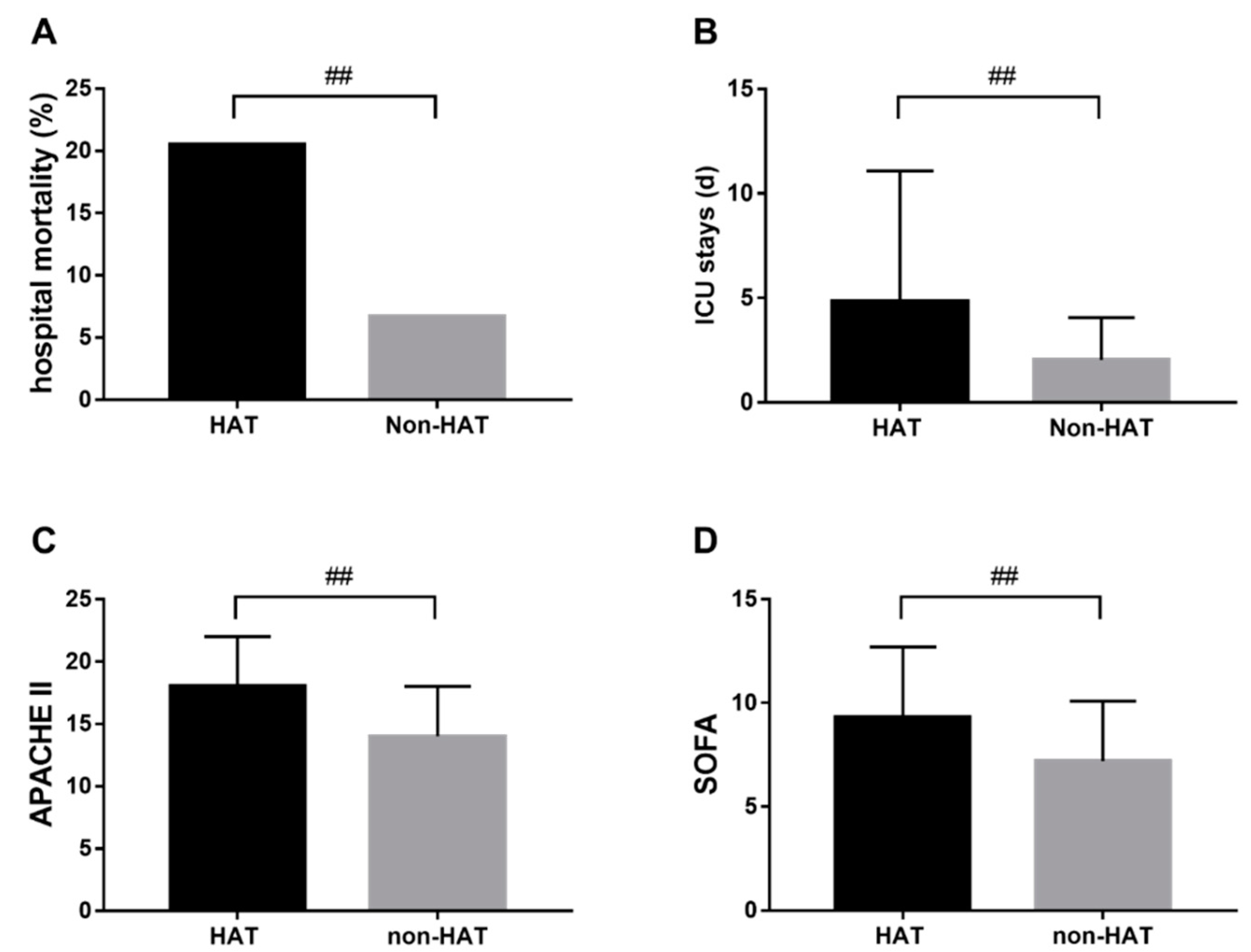
3.2. HAT and Adverse Outcomes
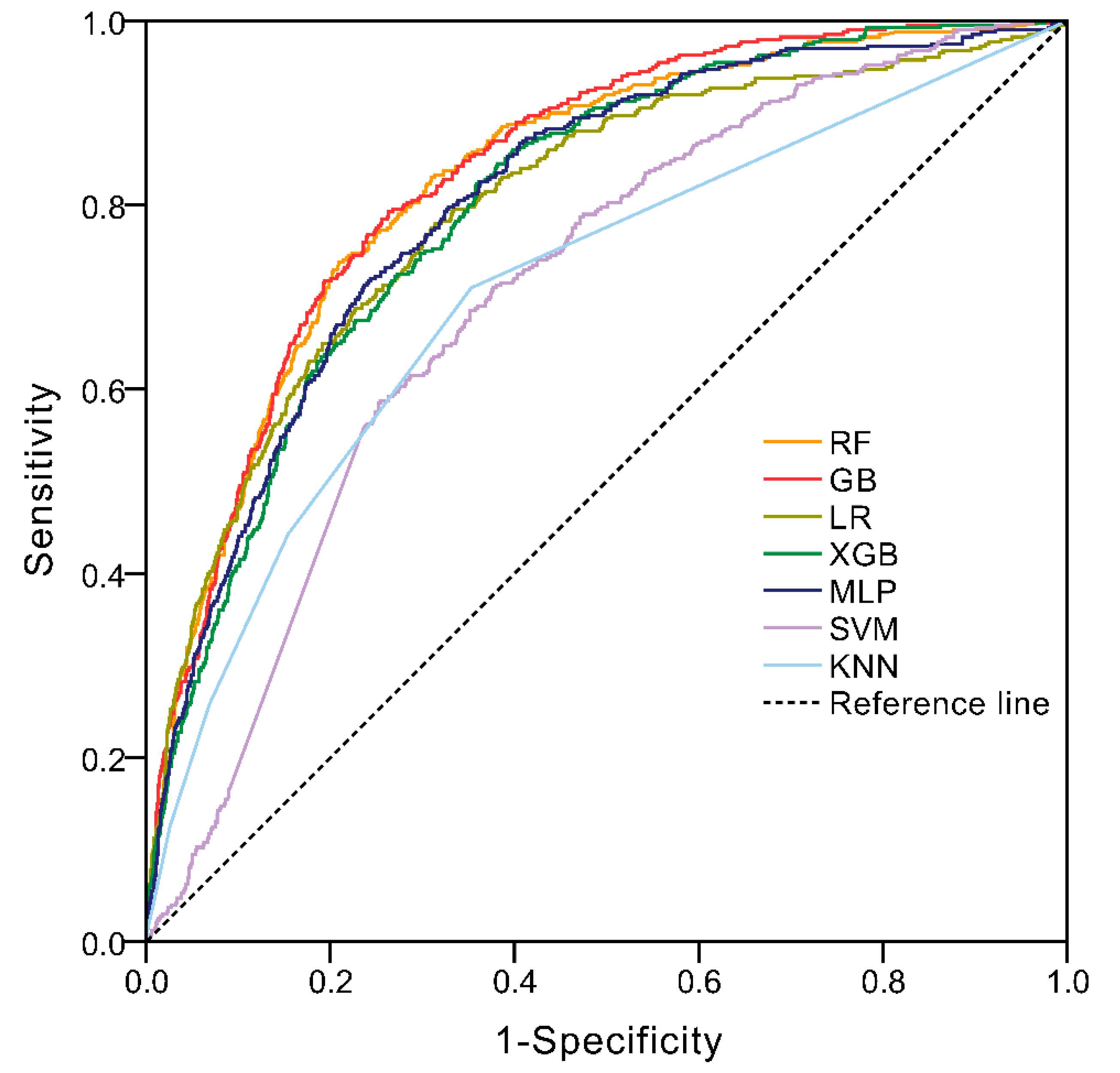
3.3. Performance of ML Models
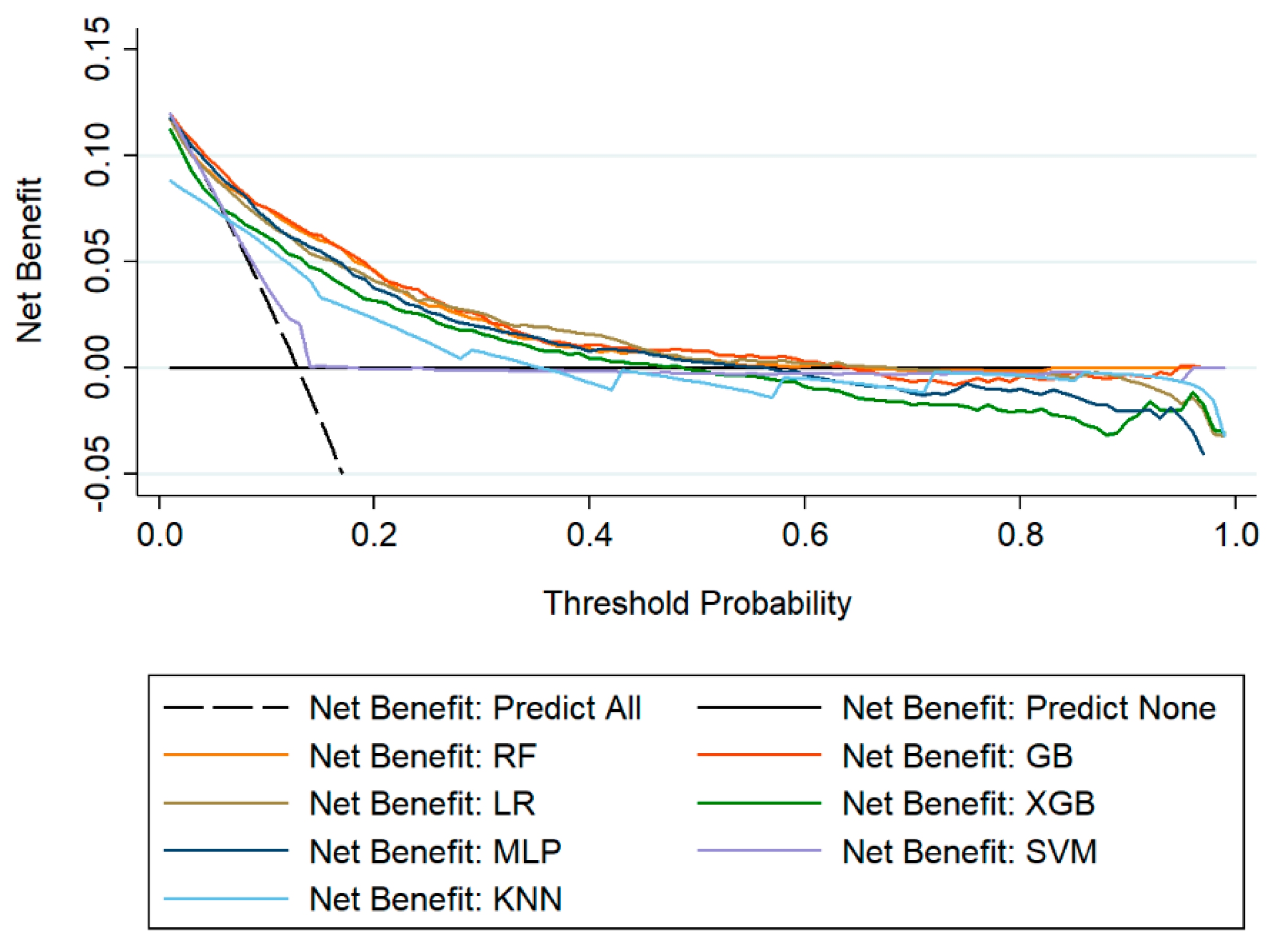
3.4. The Comparison of Machine Learning Models
3.5. Important Features of ML Models
4. Discussion
5. Summary
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Thachil, J.; Warkentin, T.E. How do we approach thrombocytopenia in critically ill patients? Br. J. Haematol. 2017, 177, 27–38. [Google Scholar] [CrossRef] [PubMed]
- Williamson, D.R.; Lesur, O.; Tétrault, J.-P.; Nault, V.; Pilon, D. Thrombocytopenia in the critically ill: Prevalence, incidence, risk factors, and clinical outcomes. Can. J. Anaesth. 2013, 60, 641–651. [Google Scholar] [CrossRef]
- Zarychanski, R.; Houston, D.S. Assessing thrombocytopenia in the intensive care unit: The past, present, and future. Hematol. Am. Soc. Hematol. Educ. Progr. 2017, 2017, 660–666. [Google Scholar] [CrossRef] [Green Version]
- Lauzier, F.; Arnold, D.M.; Rabbat, C.; Heels-Ansdell, D.; Zarychanski, R.; Dodek, P.; Ashley, B.J.; Albert, M.; Khwaja, K.; Ostermann, M.; et al. Risk factors and impact of major bleeding in critically ill patients receiving heparin thromboprophylaxis. Intensive Care Med. 2013, 39, 2135–2143. [Google Scholar] [CrossRef]
- Selleng, S.; Malowsky, B.; Strobel, U.; Wessel, A.; Ittermann, T.; Wollert, H.G.; Warkentin, T.E.; Greinacher, A. Early-onset and persisting thrombocytopenia in post-cardiac surgery patients is rarely due to heparin-induced thrombocytopenia, even when antibody tests are positive. J. Thromb. Haemost. 2010, 8, 30–36. [Google Scholar] [CrossRef]
- Griffin, B.R.; Bronsert, M.; Reece, T.B.; Pal, J.D.; Cleveland, J.C.; Fullerton, D.A.; Gist, K.M.; Jovanovich, A.; Jalal, D.; Faubel, S.; et al. Thrombocytopenia After Cardiopulmonary Bypass Is Associated With Increased Morbidity and Mortality. Ann. Thorac. Surg. 2020, 110, 50–57. [Google Scholar] [CrossRef] [PubMed]
- Tew, S.; Fontes, M.L.; Greene, N.H.; Kertai, M.D.; Ofori-Amanfo, G.; Jaquiss, R.D.B.; Lodge, A.J.; Ames, W.A.; Homi, H.M.; Machovec, K.A.; et al. Natural history of nonimmune-mediated thrombocytopenia and acute kidney injury in pediatric open-heart surgery. Paediatr. Anaesth. 2017, 27, 305–313. [Google Scholar] [CrossRef] [PubMed]
- Lo, G.K.; Juhl, D.; Warkentin, T.E.; Sigouin, C.S.; Eichler, P.; Greinacher, A. Evaluation of pretest clinical score (4 T’s) for the diagnosis of heparin-induced thrombocytopenia in two clinical settings. J. Thromb. Haemost. 2006, 4, 759–765. [Google Scholar] [CrossRef]
- Lillo-Le Louët, A.; Boutouyrie, P.; Alhenc-Gelas, M.; Le Beller, C.; Gautier, I.; Aiach, M.; Lasne, D. Diagnostic score for heparin-induced thrombocytopenia after cardiopulmonary bypass. J. Thromb. Haemost. 2004, 2, 1882–1888. [Google Scholar] [CrossRef]
- Paydary, K.; Banwell, E.; Tong, J.; Chen, Y.; Cuker, A. Diagnostic accuracy of the PLASMIC score in patients with suspected thrombotic thrombocytopenic purpura: A systematic review and meta-analysis. Transfusion 2020, 60, 2047–2057. [Google Scholar] [CrossRef]
- Dvir, D.; Généreux, P.; Barbash, I.M.; Kodali, S.; Ben-Dor, I.; Williams, M.; Torguson, R.; Kirtane, A.J.; Minha, S.a.; Badr, S.; et al. Acquired thrombocytopenia after transcatheter aortic valve replacement: Clinical correlates and association with outcomes. Eur. Heart J. 2014, 35, 2663–2671. [Google Scholar] [CrossRef] [Green Version]
- Goecks, J.; Jalili, V.; Heiser, L.M.; Gray, J.W. How Machine Learning Will Transform Biomedicine. Cell 2020, 181, 92–101. [Google Scholar] [CrossRef] [PubMed]
- Dourthe, C.; Julien, C.; Di Tommaso, S.; Dupuy, J.-W.; Dugot-Senant, N.; Brochard, A.; Le Bail, B.; Blanc, J.-F.; Chiche, L.; Balabaud, C.; et al. Proteomic profiling of hepatocellular adenomas paves the way to new diagnostic and prognostic approaches. Hepatology 2021. [Google Scholar] [CrossRef]
- Choudhury, A.; Theophanous, S.; Lønne, P.-I.; Samuel, R.; Guren, M.G.; Berbee, M.; Brown, P.; Lilley, J.; van Soest, J.; Dekker, A.; et al. Predicting outcomes in anal cancer patients using multi-centre data and distributed learning—A proof-of-concept study. Radiother. Oncol. 2021, 159, 183–189. [Google Scholar] [CrossRef] [PubMed]
- Xiang, L.; Wang, H.; Fan, S.; Zhang, W.; Lu, H.; Dong, B.; Liu, S.; Chen, Y.; Wang, Y.; Zhao, L.; et al. Machine Learning for Early Warning of Septic Shock in Children With Hematological Malignancies Accompanied by Fever or Neutropenia: A Single Center Retrospective Study. Front. Oncol. 2021, 11, 678743. [Google Scholar] [CrossRef] [PubMed]
- Than, M.P.; Pickering, J.W.; Sandoval, Y.; Shah, A.S.V.; Tsanas, A.; Apple, F.S.; Blankenberg, S.; Cullen, L.; Mueller, C.; Neumann, J.T.; et al. Machine Learning to Predict the Likelihood of Acute Myocardial Infarction. Circulation 2019, 140, 899–909. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thiele, T.; Selleng, K.; Selleng, S.; Greinacher, A.; Bakchoul, T. Thrombocytopenia in the intensive care unit-diagnostic approach and management. Semin. Hematol. 2013, 50, 239–250. [Google Scholar] [CrossRef]
- Ozelo, M.C.; Colella, M.P.; de Paula, E.V.; do Nascimento, A.C.K.V.; Villaça, P.R.; Bernardo, W.M. Guideline on immune thrombocytopenia in adults: Associação Brasileira de Hematologia, Hemoterapia e Terapia Celular. Project guidelines: Associação Médica Brasileira—2018. Hematol. Transfus. Cell Ther. 2018, 40, 50–74. [Google Scholar] [CrossRef] [PubMed]
- Goldstein, B.A.; Navar, A.M.; Carter, R.E. Moving beyond regression techniques in cardiovascular risk prediction: Applying machine learning to address analytic challenges. Eur. Heart J. 2017, 38, 1805–1814. [Google Scholar] [CrossRef] [Green Version]
- Frizzell, J.D.; Liang, L.; Schulte, P.J.; Yancy, C.W.; Heidenreich, P.A.; Hernandez, A.F.; Bhatt, D.L.; Fonarow, G.C.; Laskey, W.K. Prediction of 30-Day All-Cause Readmissions in Patients Hospitalized for Heart Failure: Comparison of Machine Learning and Other Statistical Approaches. JAMA Cardiol. 2017, 2, 204–209. [Google Scholar] [CrossRef] [Green Version]
- Ubels, J.; Schaefers, T.; Punt, C.; Guchelaar, H.-J.; de Ridder, J. RAINFOREST: A random forest approach to predict treatment benefit in data from (failed) clinical drug trials. Bioinformatics 2020, 36, i601–i609. [Google Scholar] [CrossRef]
- Hinselmann, G.; Rosenbaum, L.; Jahn, A.; Fechner, N.; Ostermann, C.; Zell, A. Large-scale learning of structure-activity relationships using a linear support vector machine and problem-specific metrics. J. Chem. Inf. Model 2011, 51, 203–213. [Google Scholar] [CrossRef] [PubMed]
- Al’Aref, S.J.; Maliakal, G.; Singh, G.; van Rosendael, A.R.; Ma, X.; Xu, Z.; Alawamlh, O.A.H.; Lee, B.; Pandey, M.; Achenbach, S.; et al. Machine learning of clinical variables and coronary artery calcium scoring for the prediction of obstructive coronary artery disease on coronary computed tomography angiography: Analysis from the CONFIRM registry. Eur. Heart J. 2020, 41, 359–367. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lorencin, I.; Anđelić, N.; Španjol, J.; Car, Z. Using multi-layer perceptron with Laplacian edge detector for bladder cancer diagnosis. Artif. Intell. Med. 2020, 102, 101746. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of Support Vector Machine (SVM) Learning in Cancer Genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Li, Y.; Zhang, T. Deep neural mapping support vector machines. Neural Netw. 2017, 93, 185–194. [Google Scholar] [CrossRef] [PubMed]
- Abu Alfeilat, H.A.; Hassanat, A.B.A.; Lasassmeh, O.; Tarawneh, A.S.; Alhasanat, M.B.; Eyal Salman, H.S.; Prasath, V.B.S. Effects of Distance Measure Choice on K-Nearest Neighbor Classifier Performance: A Review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef] [Green Version]
- Pérez-Guaita, D.; Quintás, G.; Kuligowski, J. Discriminant analysis and feature selection in mass spectrometry imaging using constrained repeated random sampling—Cross validation (CORRS-CV). Anal. Chim. Acta 2020, 1097, 30–36. [Google Scholar] [CrossRef] [PubMed]
- Rossi, R.M.; Requarth, E.W.; Warshak, C.R.; Dufendach, K.; Hall, E.S.; DeFranco, E.A. Predictive Model for Failed Induction of Labor Among Obese Women. Obstet. Gynecol. 2019, 134, 485–493. [Google Scholar] [CrossRef]
- Jani, K.H.; Jones, K.A.; Jones, G.W.; Amiel, J.; Barron, B.; Elhadad, N. Machine learning to extract communication and history-taking skills in OSCE transcripts. Med. Educ. 2020, 54, 1159–1170. [Google Scholar] [CrossRef] [PubMed]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Taft, L.M.; Evans, R.S.; Shyu, C.R.; Egger, M.J.; Chawla, N.; Mitchell, J.A.; Thornton, S.N.; Bray, B.; Varner, M. Countering imbalanced datasets to improve adverse drug event predictive models in labor and delivery. J. BioMed. Inform. 2009, 42, 356–364. [Google Scholar] [CrossRef] [Green Version]
- Le, N.Q.K.; Do, D.T.; Hung, T.N.K.; Lam, L.H.T.; Huynh, T.-T.; Nguyen, N.T.K. A Computational Framework Based on Ensemble Deep Neural Networks for Essential Genes Identification. Int. J. Mol. Sci. 2020, 21, 9070. [Google Scholar] [CrossRef] [PubMed]
- Le, N.Q.K.; Hung, T.N.K.; Do, D.T.; Lam, L.H.T.; Dang, L.H.; Huynh, T.-T. Radiomics-based machine learning model for efficiently classifying transcriptome subtypes in glioblastoma patients from MRI. Comput. Biol. Med. 2021, 132, 104320. [Google Scholar] [CrossRef]
- Vickers, A.J.; Elkin, E.B. Decision curve analysis: A novel method for evaluating prediction models. Med. Decis. Mak. 2006, 26, 565–574. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lebois, M.; Josefsson, E.C. Regulation of platelet lifespan by apoptosis. Platelets 2016, 27, 497–504. [Google Scholar] [CrossRef] [PubMed]
- Vinholt, P.J. The role of platelets in bleeding in patients with thrombocytopenia and hematological disease. Clin. Chem. Lab. Med. 2019, 57, 1808–1817. [Google Scholar] [CrossRef]
- Glance, L.G.; Blumberg, N.; Eaton, M.P.; Lustik, S.J.; Osler, T.M.; Wissler, R.; Zollo, R.; Karcz, M.; Feng, C.; Dick, A.W. Preoperative thrombocytopenia and postoperative outcomes after noncardiac surgery. Anesthesiology 2014, 120, 62–75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qureshi, A.I.; Zafar, A.; Miran, M.S.; Jani, V.B. Carotid Endarterectomy in Patients With Thrombocytopenia: Analysis of the National Surgical Quality Improvement Program Registry. Oper. Neurosurg. (Hagerstown) 2017, 13, 150–156. [Google Scholar] [CrossRef]
- Warner, M.A.; Jia, Q.; Clifford, L.; Wilson, G.; Brown, M.J.; Hanson, A.C.; Schroeder, D.R.; Kor, D.J. Preoperative platelet transfusions and perioperative red blood cell requirements in patients with thrombocytopenia undergoing noncardiac surgery. Transfusion 2016, 56, 682–690. [Google Scholar] [CrossRef] [Green Version]
- Doupe, P.; Faghmous, J.; Basu, S. Machine Learning for Health Services Researchers. Value Health 2019, 22, 808–815. [Google Scholar] [CrossRef] [PubMed]
- Golden, C.E.; Rothrock, M.J.; Mishra, A. Comparison between random forest and gradient boosting machine methods for predicting Listeria spp. prevalence in the environment of pastured poultry farms. Food Res. Int. 2019, 122, 47–55. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thomas, M.R.; Storey, R.F. The role of platelets in inflammation. Thromb. Haemost. 2015, 114, 449–458. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | HAT (n = 1354) | Non-HAT (9015) | p |
|---|---|---|---|
| Age, y | 57.9 ± 14.4 | 53.8 ± 15.2 | <0.001 |
| Male, n (%) | 795 (58.7) | 5322 (59.0) | 0.815 |
| BMI, kg/m2 | 22.98 ± 2.48 | 23.32 ± 2.56 | 0.283 |
| Hypertension, n (%) | 276 (20.4) | 1564 (17.3) | <0.001 |
| Diabetes, n (%) | 154 (11.4) | 785 (8.7) | <0.001 |
| Hemoglobin, g/L | 108.3 ± 23.0 | 115.4 ± 21.3 | <0.001 |
| Red blood cell, ×1012/L | 3.6 ± 0.8 | 3.9 ± 0.7 | <0.001 |
| MCHC, g/L | 327.9 ± 15.0 | 329.3 ± 13.7 | 0.001 |
| White blood cell, ×109/L | 12.0 ± 5.7 | 12.1 ± 5.0 | 0.102 |
| Platelet, ×109/L | 126 (111–152) | 172 (137–220) | <0.001 |
| Platelet crit | 0.17 ± 0.07 | 0.23 ± 0.08 | <0.001 |
| Platelet distribution width | 16.6 ± 4.0 | 15.3 ± 3.3 | <0.001 |
| Mean platelet volume, fl | 12.2 ± 1.5 | 11.7 ± 1.4 | <0.001 |
| Hematocrit, L/L | 0.33 ± 0.07 | 0.35 ± 0.06 | <0.001 |
| Direct bilirubin, μmol/L | 8.3 (5.5–14.5) | 6.1 (4.3–9.1) | <0.001 |
| Albumin, g/L | 30.7 ± 6.7 | 33.7 ± 6.4 | <0.001 |
| APTT, s | 39.1 ± 17.3 | 32.4 ± 10.6 | <0.001 |
| PT, s | 15.0 ± 6.3 | 13.0 ± 3.8 | <0.001 |
| Thrombin time, s | 21.7 ± 14.0 | 19.4 ± 8.3 | <0.001 |
| FDP, mg/L | 11.2 (6.1–21.5) | 6.9 (3.5–13.4) | <0.001 |
| Procalcitonin, ng/ml | 0.6 (0.1–3.0) | 0.2 (0.1–0.7) | <0.001 |
| Interleukin-6, pg/ml | 174.6 (54.7–567.4) | 97.5 (29.9–282.9) | <0.001 |
| Lactic acid, mmol/L | 2.0 (1.4–3.1) | 1.7 (1.3–2.7) | <0.001 |
| Chlorine, mmol/L | 108.1 ± 7.9 | 105.3 ± 6.4 | <0.001 |
| APACHE II | 18 (13–22) | 14 (9–18) | <0.001 |
| SOFA | 9.3 ± 3.4 | 7.2 ± 2.9 | <0.001 |
| Hospital days, d | 19 (13–28) | 16 (11–22) | <0.001 |
| ICU days, d | 4.8 (2.0–11.1) | 2.0 (1.0–4.1) | <0.001 |
| ML Algorithms | AUC | 95% CI | Sensitivity | PPV | Specificity | NPV |
|---|---|---|---|---|---|---|
| RF | 0.828 | 0.807–0.848 | 0.738 | 34.3 | 0.791 | 95.3 |
| GB | 0.834 | 0.815–0.853 | 0.793 | 30.7 | 0.737 | 96.0 |
| LR | 0.798 | 0.773–0.822 | 0.780 | 26.8 | 0.686 | 95.5 |
| XGB | 0.801 | 0.780–0.823 | 0.845 | 24.6 | 0.619 | 96.4 |
| MLP | 0.804 | 0.782–0.826 | 0.720 | 30.4 | 0.757 | 94.8 |
| SVM | 0.704 | 0.679–0.729 | 0.685 | 22.1 | 0.649 | 99.1 |
| KNN | 0.708 | 0.679–0.736 | 0.710 | 22.9 | 0.647 | 93.8 |
| GB | RF | XGB | |
|---|---|---|---|
| 1 | Platelet | Platelet | Platelet |
| 2 | Procalcitonin | Direct bilirubin | Procalcitonin |
| 3 | Direct bilirubin | Procalcitonin | Interleukin-6 |
| 4 | APTT | PT | APTT |
| 5 | PT | Interleukin-6 | PT |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Y.; Chen, C.; Yang, J.; Yang, H.; Fu, M.; Zhong, X.; Wang, B.; He, M.; Hu, Z.; Zhang, Z.; et al. Using Machine Learning Algorithms to Predict Hospital Acquired Thrombocytopenia after Operation in the Intensive Care Unit: A Retrospective Cohort Study. Diagnostics 2021, 11, 1614. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics11091614
Cheng Y, Chen C, Yang J, Yang H, Fu M, Zhong X, Wang B, He M, Hu Z, Zhang Z, et al. Using Machine Learning Algorithms to Predict Hospital Acquired Thrombocytopenia after Operation in the Intensive Care Unit: A Retrospective Cohort Study. Diagnostics. 2021; 11(9):1614. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics11091614
Chicago/Turabian StyleCheng, Yisong, Chaoyue Chen, Jie Yang, Hao Yang, Min Fu, Xi Zhong, Bo Wang, Min He, Zhi Hu, Zhongwei Zhang, and et al. 2021. "Using Machine Learning Algorithms to Predict Hospital Acquired Thrombocytopenia after Operation in the Intensive Care Unit: A Retrospective Cohort Study" Diagnostics 11, no. 9: 1614. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics11091614