1. Introduction
Estimating the fair price of a company or the Enterprise Value (EV) is a major issue in academic and business literature, as it has relevant impact in a number of situations. Global corporate operations, mergers and acquisitions, alliances and joint ventures, corporate bond issuing, international public offerings (commonly IPOs), banking credit, portfolio management, risk assessment, and in some cases the top-management bonus, require fair valuations compelling with well-founded and generally accepted systematic assessments [
1,
2,
3,
4,
5,
6,
7]. Investors, analysts, and sometimes academics tend to approach this objective focusing in public companies, for which a large amount of information and knowledge is available. However, this working line conveys the development of tight tailored models, with relevant chances to overfit the selected target, and subsequently lacking generalization capability over time, sector, market, or region. In this category we can include the investment banks’ Investor Research (IR) reports and the Technical Analysis (TA) reports [
8,
9,
10,
11,
12,
13,
14,
15].
Starting with this second group, TA reports support their models on market behavior and heuristic estimates, solely funded on historical price-volume data. In this case, forecasting estimates rely on trading rules attached to chart patterns fully dissociated from fundamental business data. Alternatively, investment banks and consultancy firms base their IR reports on deep industry knowledge and on available business information. This way of proceeding is generally known as Fundamental Analysis (FA), as it uses historical and solid financial statements (fundamentals), as well as commercial business forecasts [
1,
7,
16,
17,
18]. This methodology offers a much more rigorous and deeper understanding of the company real activity, although such a deep knowledge may limit the generalization capabilities.
Additionally to these very well established and known approaches, academics have also proposed statistical and mathematical methods with the aim of dissociating the tailoring and tight-fitting approach of IR and FA reports. This particular setting is especially noticeable in recent studies where machine learning techniques are applied to credit risk assessment and stock pricing forecast [
19,
20,
21,
22]. Under this view, in an attempt to categorize these methods, and attending to the nature of the supporting variables, we propose to classify them into three basic categories, namely, balance-sheet statements, Income Statements (also known as multiples), and value-creation approaches [
23], as shown in
Table 1.
The first set of methods, or balance-sheet based methods, are based on pre-existing accounting information in company records and they are strongly supported by balance-sheet statements and book value related ratios [
24]. These methods usually define and apply specific corrections to actual statements by incorporating contextual factors, such as future taxes, good-will, unrealized capital gains, or project finance associated variables. A remarkable reference, and probably the most cited academic work in this area, is the Adjusted Book Value proposed by Graham in its different editions [
14,
25]. The second set of methods are the multiples based methods, also known as comparable methods, which use the effective value of other operations as a benchmark to extrapolate to current valuations. Examples of references for benchmarking purposes are stock price, comparable corporate operations, balance-sheet ratios, and consensus investor-related valuation reports. IR reports always incorporate this information as a back reference for validation and support for the valuations stated in the reporting document [
7,
26,
27].
The third set, or value-creation based methods, includes the Discounted Cash Flow (DCF) as the most remarkable and frequently used tool for large-company valuation [
16,
28,
29,
30,
31,
32]. Another method also included in this set is the now popular Residual Income Model (RIM) [
33,
34,
35,
36]. Both DCF and RIM are based on the discount to date of future economic flows, and specifically the Free Cash Flow (FCF) for the DCF method, and the net future residual income plus the capital of the firm in the case of RIM method [
4]. The DCF method is essentially the actual discount of future FCF, which stands for the company cash flows that are real and effectively free and available to be applied in favor of shareholders. The nature of this model is independent from the effective payback strategy that the company finally executes, understanding that it would always be the most adequate and profitable one for equity holders.
The discount rate to be applied to FCF, and generally referred as Weighted Average Cost of Capital (WACC) [
29] requires especial remark at this point. This rate, in its closed form, includes two particular sensitive parameters, namely the risk-free rate (or the expected returns of an asset that is considered risk-free) and the risk premium of the company (or the differential among expected return of the specific commodity and the risk-free asset), also called beta (
) [
37]. Academics generally agree on the WACC closed form, although there is not a consensus on how to evaluate or estimate the mentioned specific components [
30,
31]. This fact has led to a wide extend of unrelated application of value creation models. Meanwhile the RIM model is also centered on the creation of value to shareholder, but in this case it is defined as the effective accounting earnings of the year. Accounting earnings are discounted to date using the cost of equity (
), which is one of the components of WACC. The RIM model very much compares with DCF model, since it is based on the same idea, but it focuses on shareholders value creation, so that it is directly linked to market value. One important drawback of value creation methods is the requirement of information such as forward statements, forecast, or detailed information effectively only available for large and public companies, but rarely for private entities.
In addition to the previously mentioned methods, statistical learning and Machine Learning (ML) techniques have received increasing attention in the financial field over the years [
38]. Examples of these applications are the prediction of bankruptcy [
39,
40], debt and credit rating classification, or follow-up analysis and pattern detection in stock-quote series [
41,
42]. However, and to the best of our knowledge, no prior analysis have been effectively implemented using these techniques in the company-valuation field [
43,
44]. This might be due to the relevant complexity and the large number of variables involved. Hence, we can argue that there is still room for development in terms of how statistical learning algorithms could eventually contribute to this end, as it has been the case in other relevant disciplines [
45,
46].
All things considered, the main goal of this work is to analyze and propose an unbiased quantitative systematic company-valuation model [
1,
4,
27,
30,
35,
47,
48], which should be able to approximate company value based on current financial information, historical accounting records, global economy framework information, as well as market trend by sector and region. To do so, and bearing in mind that the value-creation approach (and more precisely DCF) is probably the most described and applied model, we proposed to analyze this method applying a number of different strategies for standard FCF forecasting and WACC computation, while leveraging strictly on reported historical financial statements extracted from Thomson Reuters Database. For this study we took into account the full balance sheet and profit-and-loss statements in 30 consecutive years for a representative set of 42 companies, from five industrial sectors and within five market regions. In an additional final analysis included in this paper, we presented our first step into a more complex mathematical implementation, as an starting point toward more sophisticated methods, by incorporating exogenous variables together with the previously obtain features in order to build and asses the incremental generalization capabilities of linear regression techniques.
In the companion paper [
49], and once having developed and compared in this current work different company-valuation strategies and their ability to generalize the intrinsic value of companies, we present a deep and thoughtful comparative of ML techniques in this setting. In particular, we extend therein the analysis to nonlinear regression techniques using the variables that in this work were proven to be more closely related to the actual EV. Furthermore, we include a set of endogenous and exogenous variables with documented influence on the valuation according to the literature [
50].
This paper is organized as follows. In
Section 2, we describe the tools and databases, the DCF implemented methodology, and the Linear Regression Techniques used in this work. In
Section 3, we present several relevant experimental results, namely, FCF forecasting benchmarking, WACC inverse method analysis, DCF valuation results, and linear regression analysis. In
Section 4, we present the discussion and the main conclusions.
3. Results
This section includes the results of the experiments performed in this work to either validate or reject the hypothesis that it is possible to conduct an unbiased company valuation without being subject to qualitative aspects which are hardly quantifiable. Toward that end, we used stock market EV as the target, using exclusively the information that was available for both listed and unlisted companies, and supported on the mostly accepted ones by investors and analysts thoroughgoing developed DCF valuation model. To do so, and with the aim of evaluating the behavior of key variables of DCF model, we first scrutinized the existence of applying an effective WACC for each sector, market, and region that fit the model by matching the EV through different systematic cash flow forecasting methods. Specifically, the proposed implementation approach exercised the inverse method to estimate the WACC that better approximated current EV, considering a number of different FCF forecasting strategies that are described in
Table 1. In a second approach we applied the direct method based on the reference WACC values reported in literature to better assess again the right EV over the mentioned forecasting strategies. Finally, we started to explore the potential of the ML techniques, limiting ourselves here to the linear regression capabilities for the very same aim, and not only including intrinsic variables but also extending the potential enhancement of these techniques by adding external information into the model. Specific analyses were staged by sectors and market regions.
3.1. Company Valuation Based on DCF
In an attempt to validate DCF as an standalone valuation model, we analyze here how it fits to the actual EV in listed companies. For this purpose, we used Equation (
5) to apply the different FCF forecasting strategies mentioned in
Table 3, which were singularly based just on historical accounting information. Implied valuation results for the listed companies (NPV) were then benchmarked against market capitalization including the required liabilities adjustment. From an analytical point of view, it is a general consensus that all the variables included in Equation (
5) are directly reported in the balance sheet and in the income statement. Due to all the difficulties for the projection of the FCF [
62], different projection strategies are proposed to obtain a closer estimate of EV. The only exception to this statement is the WACC, given that there is no simple and direct approach to obtain it, as previously mentioned. Therefore, in this section we took a twofold approach to methodologically overcome this uncertainty: (i) by using the inverse method to back-obtain the effective discount rate that matches the actual market valuation; (ii) by using the reference WACC reported in literature.
Inverse Method. In this experiment, we applied the previously described Inverse Method to estimate the implicit WACC that would eventually be applied to forecasted FCF to get the actual valuation for each company, year, and DCF model. As an example of the Inverse Method implementation,
Figure 1 shows the effective WACC for 3MCo in 1992 when applying the five evaluated forecasting strategies. In this example WACC ranged from 6% to 10%. Special mention requires the fact that M4 and M5 provided the very same value. A wider extension of this analysis for the same company over all available years provided a much wider variability of WACC, ranging from values between close to 0% up to 33%. Statistical perspective shows again that methods M4 and M5 offered a more limited variability, closing the figures from 4% to 9%.
Figure 2 provides an over-the-years and companies-wide outlook of the implicit effective WACC by forecasting strategies. WACC values over 70% were considered outliers and they are removed from the samples. Panels (d) and (e), corresponding to methods M4 and M5, respectively, show more restricted dynamic behavior for WACCs, exhibiting as a consequence much lower variability, which is consistent with previous visual inspections and with the statistical results shown in
Table 4. As a summary, we can argue that although variability, expressed as the Standard Deviation (STD), was high in all methods accounting for over 50% of mean or median, models M4 and M5 significantly outperformed the others. It is relevant to mention that M1 presented the poorest results in terms of stability. An empirical analysis of the previously mentioned companies (Inditex, 3MCo, and Coca-Cola) for 12 years in a row (see in
Table 5) showed a very stable Year-on-Year (YoY) behavior for the M4 model. This result can be recognized as a positive contribution, as it validates the aforementioned forecasting strategies to be considered as a valid feature to be incorporated in subsequent valuation models.
Consolidated analysis for sectors, market, and regions are shown in
Figure 3 and
Figure 4. Visual inspection of these figures does not anticipate any specific pattern for any of the analyzed models. The statistical view of WACC obtained with the Inverse Method are represented in
Table 6, which confirms these expectations and the difficulty to set an effective WACC that across companies can fit any region or sector. This fact is numerically verified because the STD accounts for almost over half of the mean or of the median, not offering better results than the global view presented earlier.
As for major findings of the application of the Inverse Method of the DCF model, and for a wide set of companies from different regions, sectors, and years, we can state the following ones. First, we validated the overall approach of DCF as the generally accepted valuation method by obtaining stable behavior for a number of individual companies. Second, we can agree that, although it is true for single companies, the consolidated conduct over any of region, sectors, or years, which would eventually allow us to generalize with confidence into non-traded companies such as private equity, did not offer an endorsed perspective to confirm the existence of consistent effective WACC values over mentioned directions. This statement should be understood if it is at least exclusively based on actual financial variables reported by companies. Finally, the consistent over-performance of M4 and M5 models can be appreciated. This finding can be taken into account as a priority in subsequent efforts.
Consolidated Discount Rate. As earlier mentioned, although it is possible formulate the WACC in a closed form, there is no precise consensus on how some of its components should be calculated. The previous experiment validated the existence of certain reference WACC estimated through the Inverse Method for specific companies. In this direction, more studies and various databases offer consolidated values from this variable by sector, market, and region [
63,
64]. These reports are based on massive data analysis including thousands of companies at a global level, where risk-free rates are calculated based on the cost of debt of sovereign bonds, and final figures are adjusted to incorporate region, market inflation, and investors opportunity cost. Following that line, the next experiment aims to evaluate the effectiveness of the registered reference WACCs for the 42 companies included in our study.
Table 7 shows the reference WACCs to estimate EV, obtained from [
63], in order to follow the same strategy presented in last experiment.
To analyze the performance of reference WACC, we conducted the DCF model using all the previously evaluated models. Resulting errors are computed as the difference between estimated EV and real EV for each year and company (see
Figure 5).
Table 8 and
Table 9 summarizes the statistical errors consolidated by sectors and regions. These results exhibited close correspondence with the previous experiment, showing that M4 and M5 outperform the other methods. In particular, the STD of the errors for them were generally under three percentage digits, while the rest of the methods were largely over 100%.
Based on these last results, we should argue that even the application of strongly sustained and widely used published reference WACCs does not lead to accurate valuation of companies. This fact drives the concept supported earlier about the difficulty to extend WACC analysis to sectors or regions. It is also proven in this experiment the better performance of models M4 and M5 than the others, which is consistent with the previous findings in the preceding experiment.
As a summarizing result of this section, we can state that the use of the DCF model based exclusively on intrinsic information, regardless of how intensive were the efforts to set a right WACC, could not offer an accurate model to estimate cross-company valuations. Additional information and other techniques were required for an effective unbiased valuation. Hence, we propose in the next section to investigate and use other techniques, such us ML, which together with extrinsic information could better suit each specific company, sectors, markets, or regions.
3.2. Estimation Based on Linear Regression
In this subsection, we scrutinize the possibilities of a statistical learning technique, namely linear regression, to estimate the company EV, and for this aim several experiments are carried out. The real company EVs are identified as the desired output , and the estimated values are represented by in vector form. Different input variables are explored to analyze the performance of the estimation models. We followed three steps. Firstly, we proposed a model that considered exclusively endogenous variables obtained directly or indirectly from the balance sheet and the income statement. For better performance of ML, specific variables developed in previous sections, such as previous years FCFs and the net debt, were also incorporated as entries for the model. The underling rationale was that these variables are constitutive elements of DCF, they are a-priori knowledgeable, and their incorporation could drive increased accuracy toward the solution.
Secondly, we extended the experiments by incorporating exogenous variables, namely, GDP, CPI, and RIR from markets where companies operated. Although these variables were not directly linked with the business relation at the current day, they were well related to business perspectives, and so to certainly stain what companies could do in the future, with compliance with the past, hence improving or worsening the FCF. Thirdly, we analyzed endogenous and exogenous variables combined, and how this blended set of information could improve the effectiveness in fitting market valuations. Particularly in our analysis, we considered the variables previously selected and calculated for the DCF model i.e., the four designated exogenous variables from previous experiments.
The training phase of the company-valuation model was done with 70% of the total sample data (677 samples), whereas the model was tested using the remaining 30% [
65,
66]. The dataset was normalized in two different ways to better adjust the company-valuation model, namely, statistically and operationally. The first normalization attended to standard re-scaling for application of this set of techniques, while the second one was strictly attached to the normalization against a key operational variable, namely the Earnings before Interest, Taxes, Depreciation, and Amortization (EBITDA).
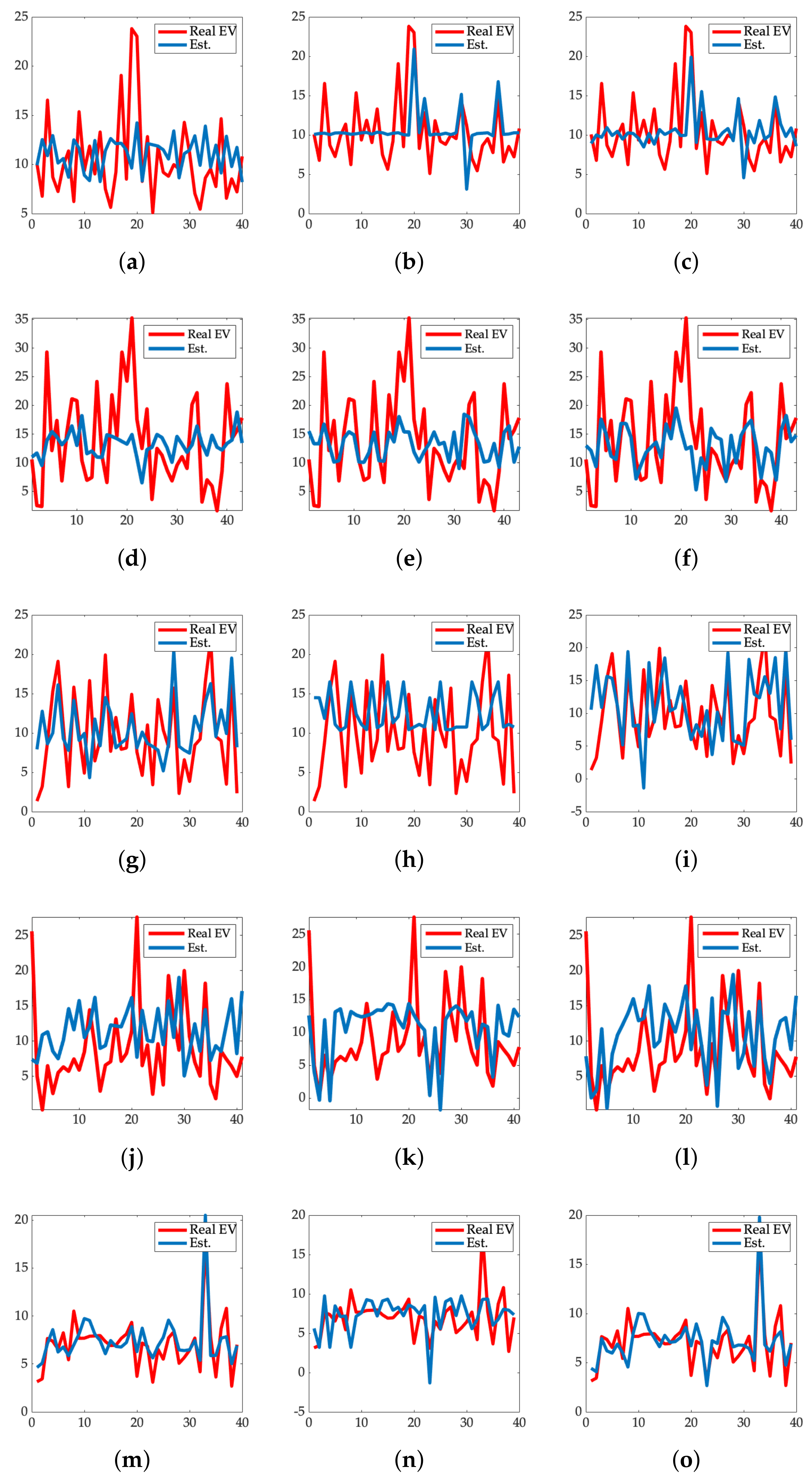
Figure 6 shows the real normalized EV values (in red) and the estimated ones (in blue). Panel (a) presents the results when incorporating as entry just the endogenous variables of the DCF valuation method. In Panel (b), the results for just the exogenous variables were considered, while Panel (c) incorporated both endogenous and exogenous as input variables for the analysis. Visual inspection of these three figures shows that estimates on Panel (c) better tacked the real valuations. In a second level, estimates on Panel (a) also followed up the real values to a certain extent, while the estimated EV only based on exogenous variables on Panel (b) resulted in the worst model, as expected. These visual results are consistent with expectations in all settings as the incorporation of exogenous information was supplying the model with additional prediction capabilities.
Table 10 shows the estimated figures of merit (MSE, MAE, and RMSE) for EV accuracy in linear regression for the implemented methods described earlier. Statistical error figures supported the visual inspection findings, offering better results for the model that incorporates the endogenous and exogenous variables simultaneously. In particular, lower error was obtained when considering both sets of variables, showing a RMSE of 6.51.
Figure 6 and
Table 11 shows the results of the linear regression modeling coefficients with the relationship among parameters (endogenous and exogenous variables) and the valuation itself. In the first method including only the endogenous variables, the last FCF, together with the actual debt, were the most influencing parameters in EV, whilst, when considering both spectra of variables, the most influencing ones were FCF, GDP, and WACC. The results obtained here are consistent with theoretical concepts experienced earlier and published in the literature.
Figure 7 and
Table 12 show the results and the statistical analysis, respectively, for EV estimation by sector. Utilities sector was confirmed to be the most accurately followed by the deployed model, with an RMSE of 1.1746 being the smallest one. This fact was visually verified in Panels (m,n,o). In these specific companies, the estimated EV (in blue) and real EV (in red) drew closer to each other than other represented sectors, and it was especially remarkable when endogenous and exogenous variables were simultaneously used, see Panel (o).
4. Discussion and Conclusions
All the previously presented results enable us to conclude that it is not possible to develop effectively an unbiased company-valuation model by leveraging exclusively on endogenous references, for a specific market-region, sector, company, or year, and by using the different proposed DCF models with different FCF forecasting strategies. One key restriction is the lack of generalized consensus of the application of an effective closed form to obtain a discount rate WACC and its corresponding constituents that can fit the real company valuation in stock markets. With respect to the WACC analysis performed in this paper through the Inverse Method and direct approach for individual companies, although offering relevant findings, it does not allow us to justify the existence of a single value of WACC under a global perspective, and either from the sector, region, or year perspectives. Additionally, two relevant conclusions arise from this analysis: First, FCF forecasting strategies using polynomial fitting are consistently offering better results in modeling companies’ valuation; second, it is possible to obtain a WACC that fits every single company and year, and this figure could eventually be persistent in certain companies over the years.
Earlier results were evidenced to be improved by further analysis incorporating not only endogenous, but also exogenous information as drivers of external market and business environment trends, and using simple statistical learning methods, specifically linear regression. We found that the MSE and the MAE showed higher magnitudes in the valuations. Better results were obtained through a double normalization of input space, namely a statistical description with zero mean and unit STD, and a standardization (operation-oriented normalization). In particular, input space operative normalization, and the statistical normalization in a lower extent, enhance the generalization capabilities by making them independent from volume or currency. Regression analysis with only endogenous variables obtained a RMSE of 6.99, whereas when exogenous variables were incorporated to the input space variability is improved, RMSE was reduced to 6.51, and the determination coefficient reached 0.28.
Hence, we can conclude from the results obtained that the operational variables and models evaluated in this work have been validated from an intrinsic valuation capabilities perspective, as it is viable to set the free parameters to match stock market pricing. Additionally, and in order to validate a systematic and unbiased model for companies’ valuation, we required supplementary exogenous variables complementing the historical financial statements, which can incorporate general market trends and investor business expectations. Furthermore, the application of simple statistical learning techniques for a bundled analysis boosted the results and performance.
The main contributions of this work could be considered in three directions. First, although we did not obtain statistically significance in specific cases, the implementation of the Inverse Method to estimate WACC across markets and industries can offer an alternative systematic tool for value assessment. Furthermore, we consider that the information obtained as a result of this effort could constitute additional valid features to be used in advanced valuation models using ML methods. Second, the published reference WACCs are hardly applicable in reality to accurately match market expectation, but offers a valid representation of global market expectation that again could be considered as part of the input space for applications beyond traditional approaches. Finally, as a first step toward a later in-depth study leveraging on ML methods presented in the companion paper, a linear regression scheme is introduced, with or without exogenous variables. This last analysis is carried out incorporating not only straight from the financial reports accounting data, but also the features obtained in the previous experiments. We expect that these three key findings pave the way toward more sophisticated developments in the valuation field. Therefore, we propose a deeper analysis of ML techniques in the companion paper [
49], leveraging on the valid results and conclusions of the present work.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}