
Ambient Sound Recognition of Daily Events by Means of Convolutional Neural Networks and Fuzzy Temporal Restrictions


Abstract
:1. Introduction
- Collecting a dataset of audio samples of events related to activities of daily living which are generated within indoor spaces;
- Integrating a fog–edge architecture with the IoT boards where the audio samples are collected to provide real-time recognition of audio events;
- Evaluating the performance of deep learning models for offline and real-time recognition of ambient daily living events in naturalistic conditions;
- A straightforward fuzzy processing of audio event streams is described by means of temporal restrictions which are modeled on linguistic protoforms to improve the audio recognition.
Related Works
2. Materials and Methods
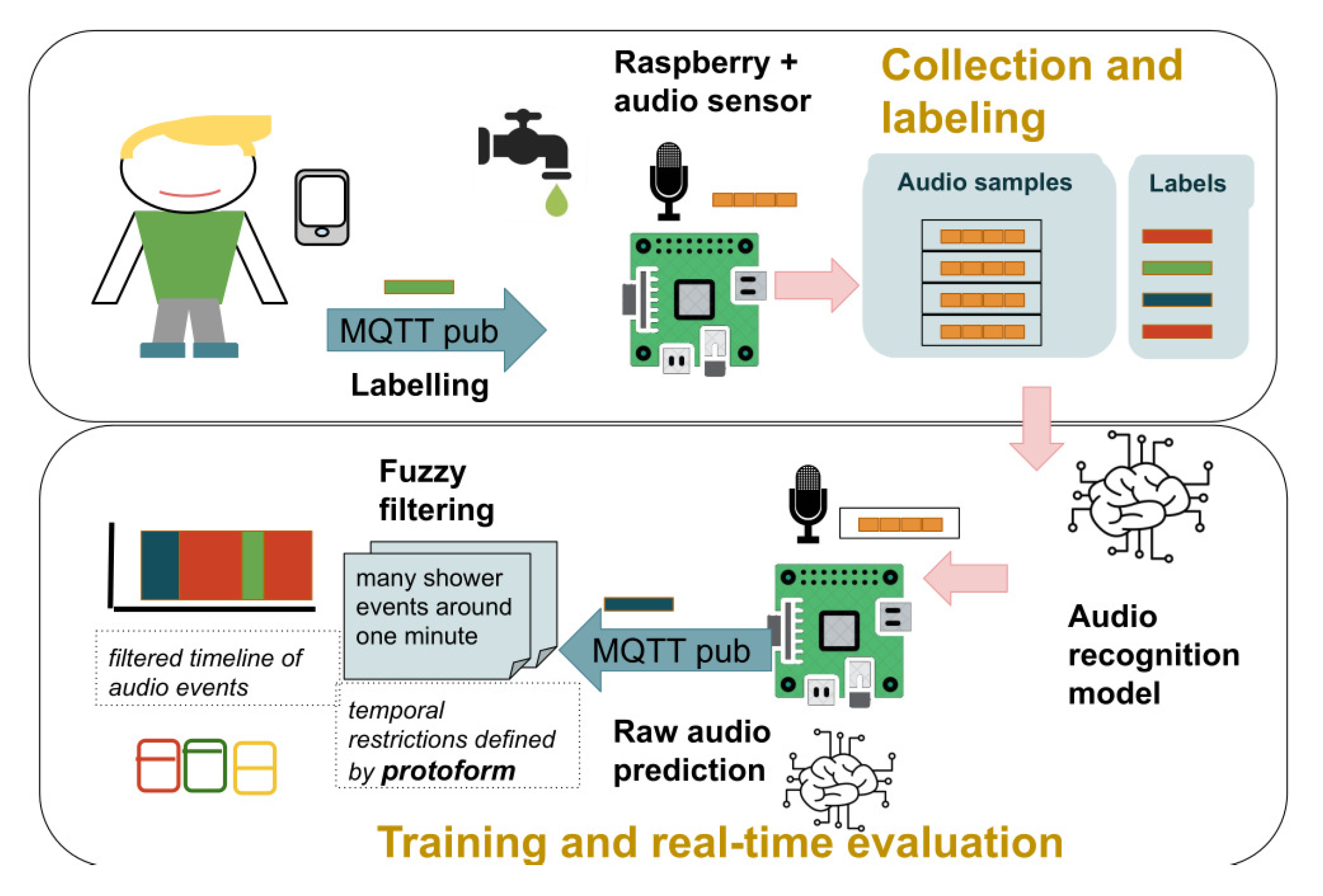
2.1. Materials: Devices and Architecture
2.2. Deep Learning Model for Ambient Sound Recognition of Daily Events
- Log-mel spectrogram (LM) was calculated for time–frequency representation of audio signals using a log power spectrum on a nonlinear Mel scale of frequency. When defining the length of the fast Fourier transform window to 2048, it produces images sized 128 × 130.
- Log-scaled Mel-Frequency cepstral coefficients (MFCCs) with 13 components from the raw audio signals, which computes the spectrum of sound using a linear cosine transform of a log power spectrum on a nonlinear Mel scale of frequency [52]. As traditional MFCCs use between 8 and 13 cepstral coefficients [53], we proposed 13 features to provide the most representative information of audio samples. Based on this configuration, the resulting MFCC spectrogram of positive frequencies developed images sized 13 × 130.
Fuzzy Protoforms to Describe Daily Events from Audio Recognition Streams
- defines a crisp term, whose value is directly related to a recognised event r.
- defines a fuzzy temporal window (FTW) j where the audio event is aggregated. The FTWs are described according to the distance from the current time to a given timestamp as using the membership function , which defines a degree of relevance between for the time elapsed between the point of time current time .
- We defined an aggregation function of over which computes a unique aggregation degree of the occurrence of the event within a temporal window . Therefore, the following t-norm and t-conorm are defined to aggregate a linguistic term and temporal window:where we use Fuzzy weighted average (FWA) [55] to compute the degree of the linguistic term in the temporal window. In this way, the t-norm computes the temporal degree for each point of time of the temporal window, and the co-norm aggregates these computed degrees in the whole temporal window in a unique representative degree.
3. Results
3.1. Offline Case Study Evaluation
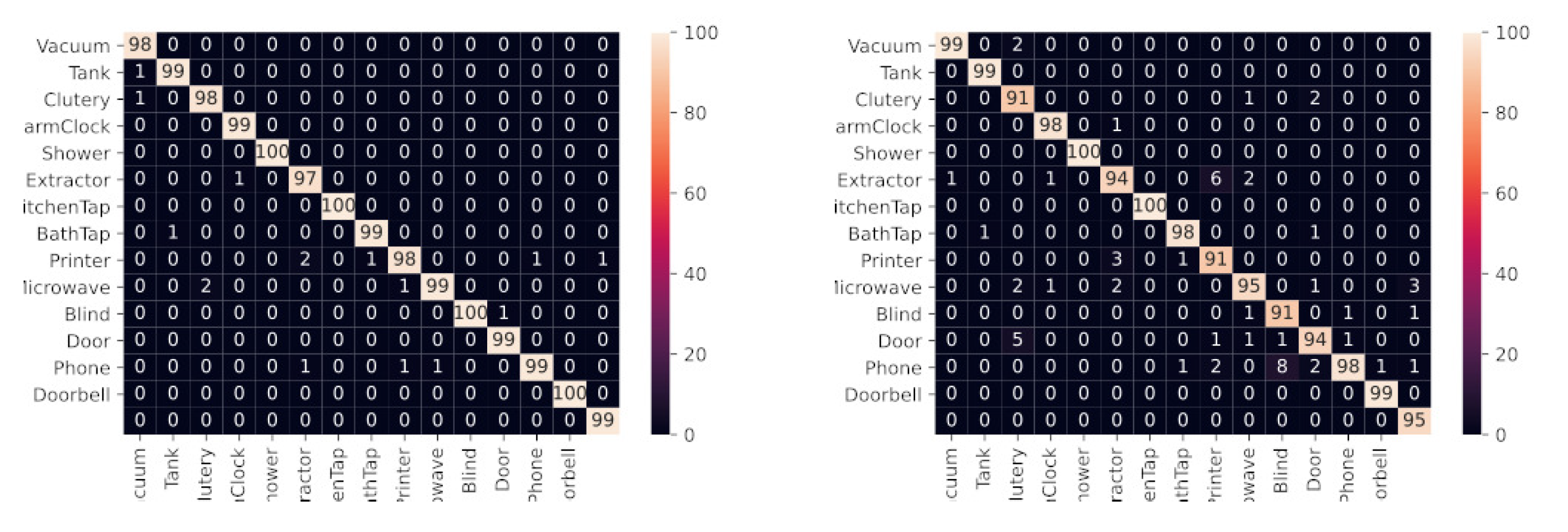
- Ad hoc ambient audio dataset. In this case, the dataset includes audio samples which have been collected in a single home and were labelled with an explicit segmentation of 3 s for events occurred in controlled conditions using the approach described in Section 2.1. All classes described in Table 2 are included in the dataset.
- Audioset dataset (Repository: https://research.google.com/audioset/ (last access 15 July 2021)). This public dataset provides videos from YouTube and labelling in the segment where a given sound occurs. From the categories of the dataset, we selected 12 events related to our classes which are included in the dataset: “Toilet flush”, “Conversation”, “Dishes, pots, and pans”, “Alarm clock”, “Water”, “Water tap”, “Printer”, “Microwave oven”, “Doorbell”, “Door”, “Telephone ringing” and “Silence”. The sounds collected from Audioset correspond to a balanced dataset with 60 files for each class which includes an explicit segmentation of the sound events.
3.2. Real-Time Case Study Evaluation
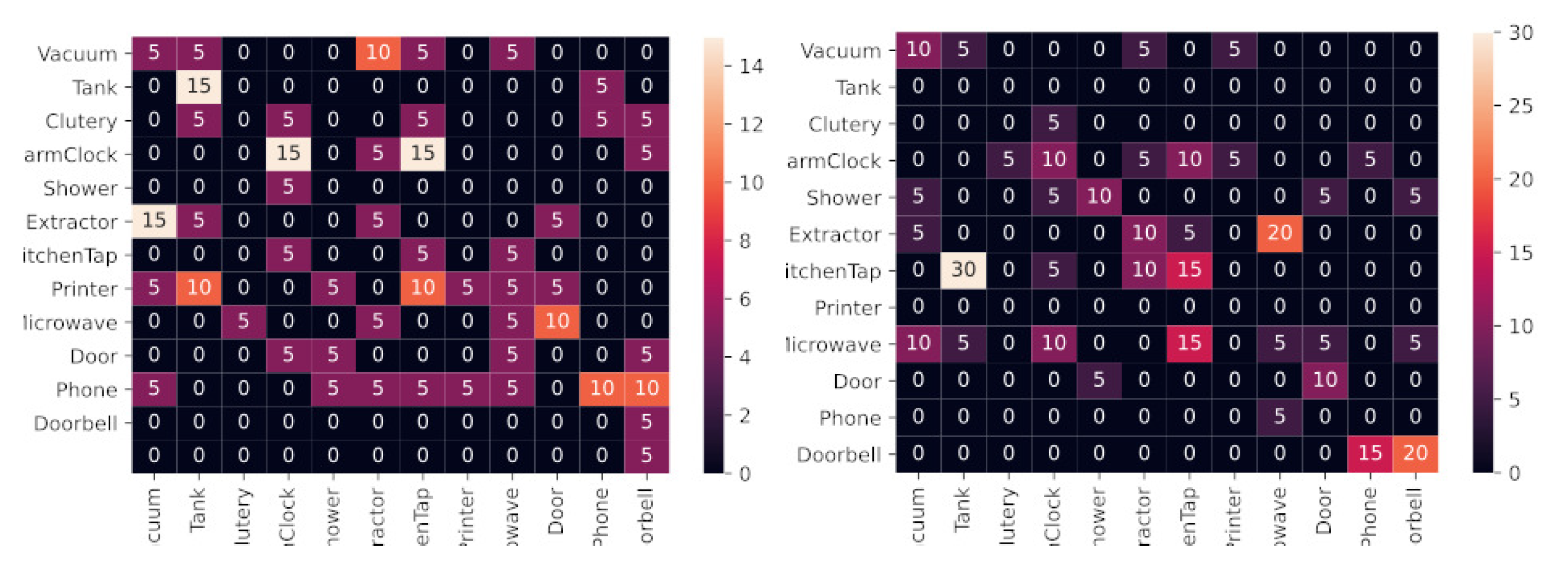
- (Scene 1) The inhabitant arrived home, went to the kitchen and started talking, then started using cutlery, then turned on the extractor fan for a long while, then turned on the tap, turned on the microwave, and was called on the phone.
- (Scene 2) The inhabitant arrived home, went to the living room and started talking, then started vacuuming, then opened and closed the window blinds and then was called on the phone.
- (Scene 3) The inhabitant arrived home, went to the bedroom and started talking, then started vacuuming, then the alarm clock went off for a long while, then printed some documents, and finally, the individual opened and closed the window blinds.
- (Scene 4) The inhabitant went to the fourth bathroom and started talking, then turned on the tap, then took a shower for a long while, then vacuumed and, finally, flushed the toilet.
- (Scene 5) The inhabitant was talking in the kitchen, then started vacuuming, then talked again and started using cutlery, then opened and closed the window blinds, then turned on the tap and, finally, used the microwave.
- (Scene 6) The inhabitant was in the bathroom vacuuming and started talking, then he took a shower for a long while, then was called on the phone and afterward turned on the tap; finally, the individual left the room closing the door.
3.3. Fuzzy Protoforms and Fuzzy Rules
3.4. Limitations of the Work
4. Conclusions and Ongoing Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
Abbreviations
| CCN | convolutional neural network |
| IoT | Internet of Things |
| MFCC | Mel-Frequency cepstral coefficient |
| AR | activity recognition |
| FWA | |
| TS | |
| TR |
References
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Espinilla, M.; Martínez, L.; Medina, J.; Nugent, C. The experience of developing the UJAmI Smart lab. IEEE Access 2018, 6, 34631–34642. [Google Scholar] [CrossRef]
- Bravo, J.; Fuentes, L.; de Ipina, D.L. Theme Issue: “Ubiquitous Computing and Ambient Intelligence”. Pers. Ubiquitous Comput. 2011, 15, 315–316. Available online: http://www.jucs.org/jucs_11_9/ubiquitous_computing_in_the/jucs_11_9_1494_1504_jbravo.pdf (accessed on 22 July 2021).
- Rashidi, P.; Mihailidis, A. A survey on ambient-assisted living tools for older adults. IEEE J. Biomed. Health Inform. 2012, 17, 579–590. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruiz, A.R.J.; Granja, F.S. Comparing ubisense, bespoon, and decawave uwb location systems: Indoor performance analysis. IEEE Trans. Instrum. Meas. 2017, 66, 2106–2117. [Google Scholar] [CrossRef]
- Xu, X.; Tang, J.; Zhang, X.; Liu, X.; Zhang, H.; Qiu, Y. Exploring techniques for vision based human activity recognition: Methods, systems, and evaluation. Sensors 2013, 13, 1635–1650. [Google Scholar] [CrossRef] [PubMed]
- Cruz-Sandoval, D.; Beltran-Marquez, J.; Garcia-Constantino, M.; Gonzalez-Jasso, L.A.; Favela, J.; Lopez-Nava, I.H.; Cleland, I.; Ennis, A.; Hernandez-Cruz, N.; Rafferty, J.; et al. Semi-automated data labeling for activity recognition in pervasive healthcare. Sensors 2019, 19, 3035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- López-Medina, M.; Espinilla, M.; Cleland, I.; Nugent, C.; Medina, J. Fuzzy cloud-fog computing approach application for human activity recognition in smart homes. J. Intell. Fuzzy Syst. 2020, 38, 709–721. [Google Scholar] [CrossRef]
- Medina-Quero, J.; Zhang, S.; Nugent, C.; Espinilla, M. Ensemble classifier of long short-term memory with fuzzy temporal windows on binary sensors for activity recognition. Expert Syst. Appl. 2018, 114, 441–453. [Google Scholar] [CrossRef]
- Krishnan, N.C.; Cook, D.J. Activity recognition on streaming sensor data. Pervasive Mob. Comput. 2014, 10, 138–154. [Google Scholar] [CrossRef] [Green Version]
- Radu, V.; Lane, N.D.; Bhattacharya, S.; Mascolo, C.; Marina, M.K.; Kawsar, F. Towards multimodal deep learning for activity recognition on mobile devices. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12 September 2016; pp. 185–188. [Google Scholar]
- Weiser, M. The Computer for the Twenty-First Century; Scientific American: New York, NY, USA, 1991. [Google Scholar]
- Van Kasteren, T.; Englebienne, G.; Kröse, B.J. An activity monitoring system for elderly care using generative and discriminative models. Pers. Ubiquitous Comput. 2010, 14, 489–498. [Google Scholar] [CrossRef] [Green Version]
- Ordóñez, F.; De Toledo, P.; Sanchis, A. Activity recognition using hybrid generative/discriminative models on home environments using binary sensors. Sensors 2013, 13, 5460–5477. [Google Scholar] [CrossRef]
- Ann, O.C.; Theng, L.B. Human activity recognition: A review. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Penang, Malaysia, 28–30 November 2014; pp. 389–393. [Google Scholar]
- Laput, G.; Zhang, Y.; Harrison, C. Synthetic sensors: Towards general-purpose sensing. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6 May 2017; pp. 3986–3999. [Google Scholar]
- Shi, W.; Dustdar, S. The promise of edge computing. Computer 2016, 49, 78–81. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the first edition of the MCC workshop on Mobile cloud Computing, Helsinki, Finland, 17 August 2012; pp. 13–16. [Google Scholar]
- Kortuem, G.; Kawsar, F.; Sundramoorthy, V.; Fitton, D. Smart objects as building blocks for the internet of things. IEEE Internet Comput. 2009, 14, 44–51. [Google Scholar] [CrossRef] [Green Version]
- Lopez Medina, M.A.; Espinilla, M.; Paggeti, C.; Medina Quero, J. Activity recognition for iot devices using fuzzy spatio-temporal features as environmental sensor fusion. Sensors 2019, 19, 3512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Medina-Quero, J.M.; Burns, M.; Razzaq, M.A.; Nugent, C.; Espinilla, M. Detection of falls from non-invasive thermal vision sensors using convolutional neural networks. Multidiscip. Digit. Publ. Inst. Proc. 2018, 2, 1236. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Wyse, L. Audio spectrogram representations for processing with convolutional neural networks. arXiv 2017, arXiv:1706.09559. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Kim, J. Urban sound tagging using multi-channel audio feature with convolutional neural networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events, Tokyo, Japan, 2–3 November 2020. [Google Scholar]
- Lasseck, M. Acoustic bird detection with deep convolutional neural networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), Surrey, UK, 19–20 November 2018; pp. 143–147. [Google Scholar]
- Choi, K.; Fazekas, G.; Sandler, M. Automatic tagging using deep convolutional neural networks. arXiv 2016, arXiv:1606.00298. [Google Scholar]
- Pons, J.; Slizovskaia, O.; Gong, R.; Gómez, E.; Serra, X. Timbre analysis of music audio signals with convolutional neural networks. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 2744–2748. [Google Scholar]
- Su, Y.; Zhang, K.; Wang, J.; Madani, K. Environment sound classification using a two-stream CNN based on decision-level fusion. Sensors 2019, 19, 1733. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beltrán, J.; Chávez, E.; Favela, J. Scalable identification of mixed environmental sounds, recorded from heterogeneous sources. Pattern Recognit. Lett. 2015, 68, 153–160. [Google Scholar] [CrossRef]
- Beltrán, J.; Navarro, R.; Chávez, E.; Favela, J.; Soto-Mendoza, V.; Ibarra, C. Recognition of audible disruptive behavior from people with dementia. Pers. Ubiquitous Comput. 2019, 23, 145–157. [Google Scholar] [CrossRef]
- Laput, G.; Ahuja, K.; Goel, M.; Harrison, C. Ubicoustics: Plug-and-play acoustic activity recognition. In Proceedings of the 31st Annual ACM Symposium on User Interface Software and Technology, Berlin, Germany, 14 October 2018; pp. 213–224. [Google Scholar]
- Le Yaouanc, J.M.; Poli, J.P. A fuzzy spatio-temporal-based approach for activity recognition. In International Conference on Conceptual Modeling; Springer: Berlin/Heidelberg, Germany, 2012; pp. 314–323. [Google Scholar]
- Medina-Quero, J.; Martinez, L.; Espinilla, M. Subscribing to fuzzy temporal aggregation of heterogeneous sensor streams in real-time distributed environments. Int. J. Commun. Syst. 2017, 30, e3238. [Google Scholar] [CrossRef] [Green Version]
- Hamad, R.A.; Hidalgo, A.S.; Bouguelia, M.R.; Estevez, M.E.; Medina-Quero, J. Efficient activity recognition in smart homes using delayed fuzzy temporal windows on binary sensors. IEEE J. Biomed. Health Inform. 2019, 24, 387–395. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Cruz, C.; Medina-Quero, J.; Serrano, J.M.; Gramajo, S. Monwatch: A fuzzy application to monitor the user behavior using wearable trackers. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Al-Sharman, M.K.; Emran, B.J.; Jaradat, M.A.; Najjaran, H.; Al-Husari, R.; Zweiri, Y. Precision landing using an adaptive fuzzy multi-sensor data fusion architecture. Appl. Soft Comput. 2018, 69, 149–164. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, L.A. Generalized theory of uncertainty: Principal concepts and ideas. In Fundamental Uncertainty; Springer: Berlin/Heidelberg, Germany, 2011; pp. 104–150. [Google Scholar]
- Zadeh, L.A. A prototype-centered approach to adding deduction capability to search engines-the concept of protoform. In Proceedings of the 2002 Annual Meeting of the North American Fuzzy Information Processing Society Proceedings, NAFIPS-FLINT 2002 (Cat. No. 02TH8622), New Orleans, LA, USA, 27–29 June 2002; pp. 523–525. [Google Scholar]
- Kacprzyk, J.; Zadrożny, S. Linguistic database summaries and their protoforms: Towards natural language based knowledge discovery tools. Inf. Sci. 2005, 173, 281–304. [Google Scholar] [CrossRef]
- Peláez-Aguilera, M.D.; Espinilla, M.; Fernández Olmo, M.R.; Medina, J. Fuzzy linguistic protoforms to summarize heart rate streams of patients with ischemic heart disease. Complexity 2019, 2019, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Akhoundi, M.A.A.; Valavi, E. Multi-sensor fuzzy data fusion using sensors with different characteristics. arXiv 2010, arXiv:1010.6096. [Google Scholar]
- Upton, E.; Halfacree, G. Raspberry Pi User Guide; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Monteiro, A.; de Oliveira, M.; de Oliveira, R.; Da Silva, T. Embedded application of convolutional neural networks on Raspberry Pi for SHM. Electron. Lett. 2018, 54, 680–682. [Google Scholar] [CrossRef]
- Monk, S. Programming the Raspberry Pi: Getting Started with Python; McGraw-Hill Education: New York, NY, USA, 2016. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Hunkeler, U.; Truong, H.L.; Stanford-Clark, A. MQTT-S—A publish/subscribe protocol for Wireless Sensor Networks. In Proceedings of the 2008 3rd International Conference on Communication Systems Software and Middleware and Workshops (COMSWARE’08), Bangalore, India, 6–10 January 2008; pp. 791–798. [Google Scholar]
- Medina, J.; Espinilla, M.; Zafra, D.; Martínez, L.; Nugent, C. Fuzzy fog computing: A linguistic approach for knowledge inference in wearable devices. In International Conference on Ubiquitous Computing and Ambient Intelligence; Springer: Berlin/Heidelberg, Germany, 2017; pp. 473–485. [Google Scholar]
- Darwin, I.F. Android Cookbook: Problems and Solutions for Android Developers; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Logan, B. Mel frequency cepstral coefficients for music modeling. Ismir. Citeseer 2000, 270, 1–11. [Google Scholar]
- Rao, K.S.; Vuppala, A.K. Speech Processing in Mobile Environments; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, high performance convolutional neural networks for image classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Dong, W.; Wong, F. Fuzzy weighted averages and implementation of the extension principle. Fuzzy Sets Syst. 1987, 21, 183–199. [Google Scholar] [CrossRef]
- Delgado, M.; Ruiz, M.D.; Sánchez, D.; Vila, M.A. Fuzzy quantification: A state of the art. Fuzzy Sets Syst. 2014, 242, 1–30. [Google Scholar] [CrossRef]
- Medina-Quero, J.; Espinilla, M.; Nugent, C. Real-time fuzzy linguistic analysis of anomalies from medical monitoring devices on data streams. In Proceedings of the 10th EAI International Conference on Pervasive Computing Technologies for Healthcare, Cancun, Mexico, 16–19 May 2016; pp. 300–303. [Google Scholar]
- Polo-Rodriguez, A.; Cruciani, F.; Nugent, C.D.; Medina, J. Domain Adaptation of Binary Sensors in Smart Environments through Activity Alignment. IEEE Access 2020, 8, 228804–228817. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Architecture from Model CNN + MFCC | |
|---|---|
| Input | 13 × 130 × 1 |
| Conv(3 × 3) | 11 × 128 × 16 |
| Conv(3 × 3) | 9 × 126 × 16 |
| Conv(3 × 3) | 7 × 124 × 32 |
| Conv(3 × 3) | 5 × 122 × 64 |
| Conv(3 × 3) | 3 × 120 × 128 |
| Conv(3 × 3) | 1 × 118 × 256 |
| GlobalAvgPool2D | 256 |
| Dense | 1024 |
| Dense | 15 |
| Network Architecture from Model CNN + LM | |
| Input | 128 × 130 × 1 |
| Conv(2 × 2) | 127 × 129 × 16 |
| Max-Pool(2 × 2) | 63 × 64 × 16 |
| Conv(2 × 2) | 62 × 63 × 32 |
| Max-Pool(2 × 2) | 31 × 31 × 32 |
| Conv(2 × 2) | 30 × 30 × 64 |
| Max-Pool(2 × 2) | 15 × 15 × 64 |
| Conv(2 × 2) | 14 × 14 × 128 |
| Conv(2 × 2) | 13 × 13 × 128 |
| Flatten | 21,632 |
| Dense | 1024 |
| Dense | 1024 |
| Dense | 15 |
| Class | Description |
|---|---|
| Vaccum cleaner | Audio sample of vacuuming |
| Tank | Audio sample of flushing toilet |
| Cutlery + pans | Audio sample of cutlery and pans |
| Alarm clock | Audio sample of alarm clock sound |
| Shower | Audio sample of shower |
| Extractor | Audio sample of an extractor fan |
| Kitchen tap | Audio sample of a kitchen tap |
| Bathroom tap | Audio sample of a bathroom tap |
| Printer | Audio sample of a printer operating |
| Microwave | Audio sample of a microwave operating |
| Blind | Audio sample of a window blind being moved |
| Door | Audio sample of a door being opened or closed |
| Phone | Audio sample of a phone ringing |
| Doorbell | Audio sample of a doorbell ringing |
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| CNN + MFCC model (ad hoc dataset) | 0.99 | 0.99 | 0.99 | 0.99 |
| CNN + LM model (ad hoc dataset) | 0.96 | 0.96 | 0.96 | 0.96 |
| CNN + MFCC model (Audioset) | 0.23 | 0.25 | 0.23 | 0.23 |
| CNN + LM model (Audioset) | 0.29 | 0.36 | 0.29 | 0.32 |
| Trainable Parameters | Learning Time | Millions of Instructions (MI) | Evaluation Time | |
|---|---|---|---|---|
| Model CNN + MFCC | 1.7 M | 96 min | MI | 2.53 s |
| Model CNN + LM | 23.3 M | 207 min | MI | 2.81 s |
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| Scene 1 | 0.95 | 0.97 | 0.95 | 0.96 |
| Scene 2 | 0.99 | 0.99 | 0.98 | 0.98 |
| Scene 3 | 0.97 | 0.98 | 0.97 | 0.98 |
| Scene 4 | 0.96 | 0.97 | 0.96 | 0.96 |
| Scene 5 | 0.91 | 0.93 | 0.91 | 0.92 |
| Scene 6 | 0.92 | 0.92 | 0.90 | 0.91 |
| Description in Natural Language | Type | |
|---|---|---|
| some | [0.25, 1] | |
| most | [0.5, 1] | |
| for a short time | [−6 s, −3 s, 3 s, 6 s] | |
| for a while | [−12 s, −6 s, 6 s, 12 s] |
| Event | Quantifier | FTW |
|---|---|---|
| Vaccum cleaner | most | for a short time |
| Tank | most | for a short time |
| Conversation | some | for a while |
| Cutlery + pans | most | for a short time |
| Alarm clock | most | for a short time |
| Shower | some | for a while |
| Extractor | some | for a while |
| Kitchen tap | most | for a short time |
| Bathroom tap | most | for a short time |
| Printer | most | for a short time |
| Microwave | some | for a while |
| Blind | most | for a short time |
| Door | most | for a short time |
| Phone | most | for a short time |
| Doorbell | most | for a short time |
| Idle | some | for a while |
| Raw | Fuzzy | |||
|---|---|---|---|---|
| FP | FN | FP | FN | |
| Printer | 6 | 0 | 0 | 0 |
| vacuum cleaner | 2 | 0 | 0 | 1 |
| blind | 3 | 0 | 0 | 0 |
| door bell | 1 | 0 | 0 | 0 |
| Kitchen tap | 6 | 0 | 0 | 0 |
| microwave | 1 | 0 | 0 | 0 |
| shower | 2 | 0 | 1 | 0 |
| tap wc | 3 | 0 | 1 | 0 |
| door | 0 | 0 | 0 | 1 |
| Total | 24 | 0 | 2 | 2 ] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Polo-Rodriguez, A.; Vilchez Chiachio, J.M.; Paggetti, C.; Medina-Quero, J. Ambient Sound Recognition of Daily Events by Means of Convolutional Neural Networks and Fuzzy Temporal Restrictions. Appl. Sci. 2021, 11, 6978. https://0-doi-org.brum.beds.ac.uk/10.3390/app11156978
Polo-Rodriguez A, Vilchez Chiachio JM, Paggetti C, Medina-Quero J. Ambient Sound Recognition of Daily Events by Means of Convolutional Neural Networks and Fuzzy Temporal Restrictions. Applied Sciences. 2021; 11(15):6978. https://0-doi-org.brum.beds.ac.uk/10.3390/app11156978
Chicago/Turabian StylePolo-Rodriguez, Aurora, Jose Manuel Vilchez Chiachio, Cristiano Paggetti, and Javier Medina-Quero. 2021. "Ambient Sound Recognition of Daily Events by Means of Convolutional Neural Networks and Fuzzy Temporal Restrictions" Applied Sciences 11, no. 15: 6978. https://0-doi-org.brum.beds.ac.uk/10.3390/app11156978