
A Top-N Movie Recommendation Framework Based on Deep Neural Network with Heterogeneous Modeling

 , , , , and
, , , , and
Abstract
:1. Introduction
- We exploit both explicit and implicit feedback information to obtain the user’s preference information and the underlying characteristics of the item based on the meta-path selection results. Additionally, in order to obtain explicit feedback information, two bias factors are introduced according to the individual characteristics of the user–item information.
- We fuse MF and DNN to mine the potential features of users and items from both linear and nonlinear perspectives. MF and DNN learning are independently embedded to better capture user preference information and the potential feature information of items.
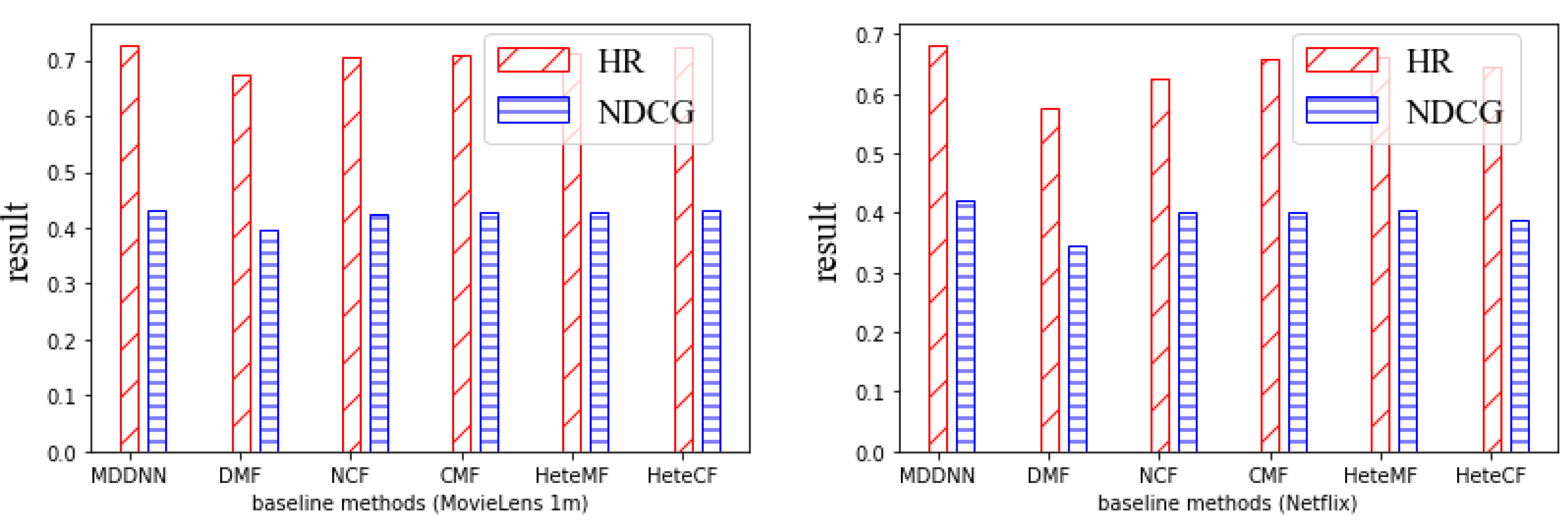
- Using the leave-one-out evaluation method, we combine explicit and implicit feedback results to obtain the top-N recommendation list for target users and adopt the HR and NDCG metrics to evaluate the proposed model.
2. Related Work
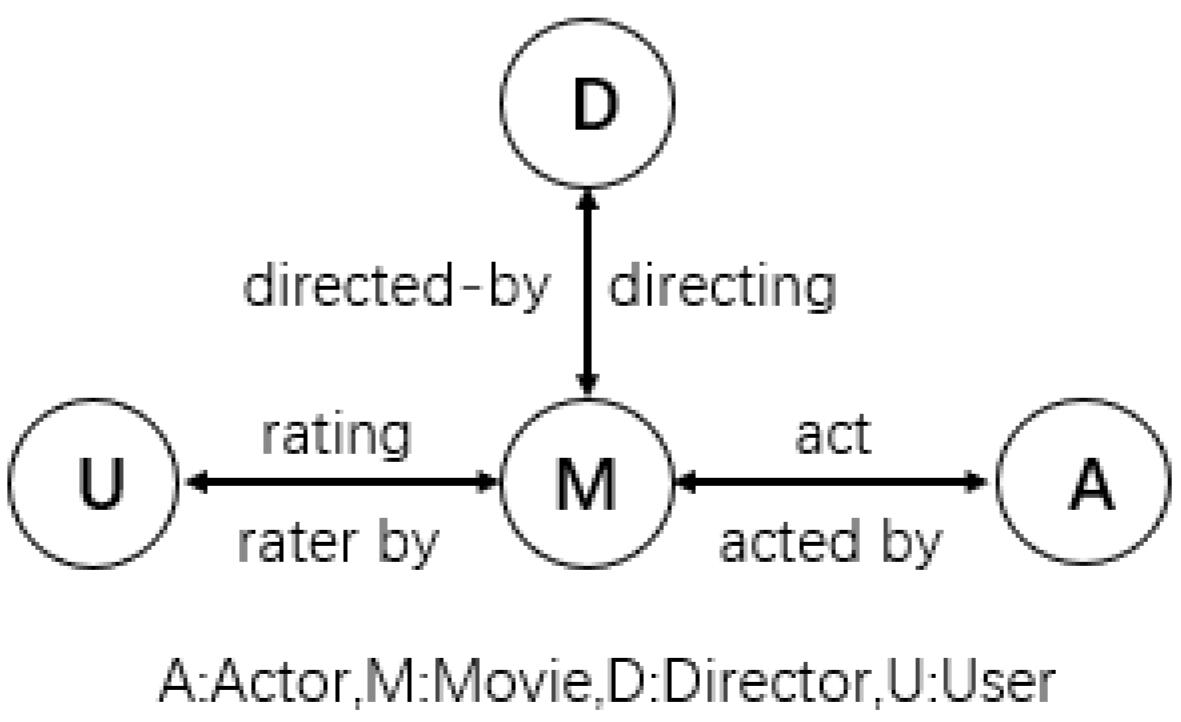
3. Our Approach: MFDNN
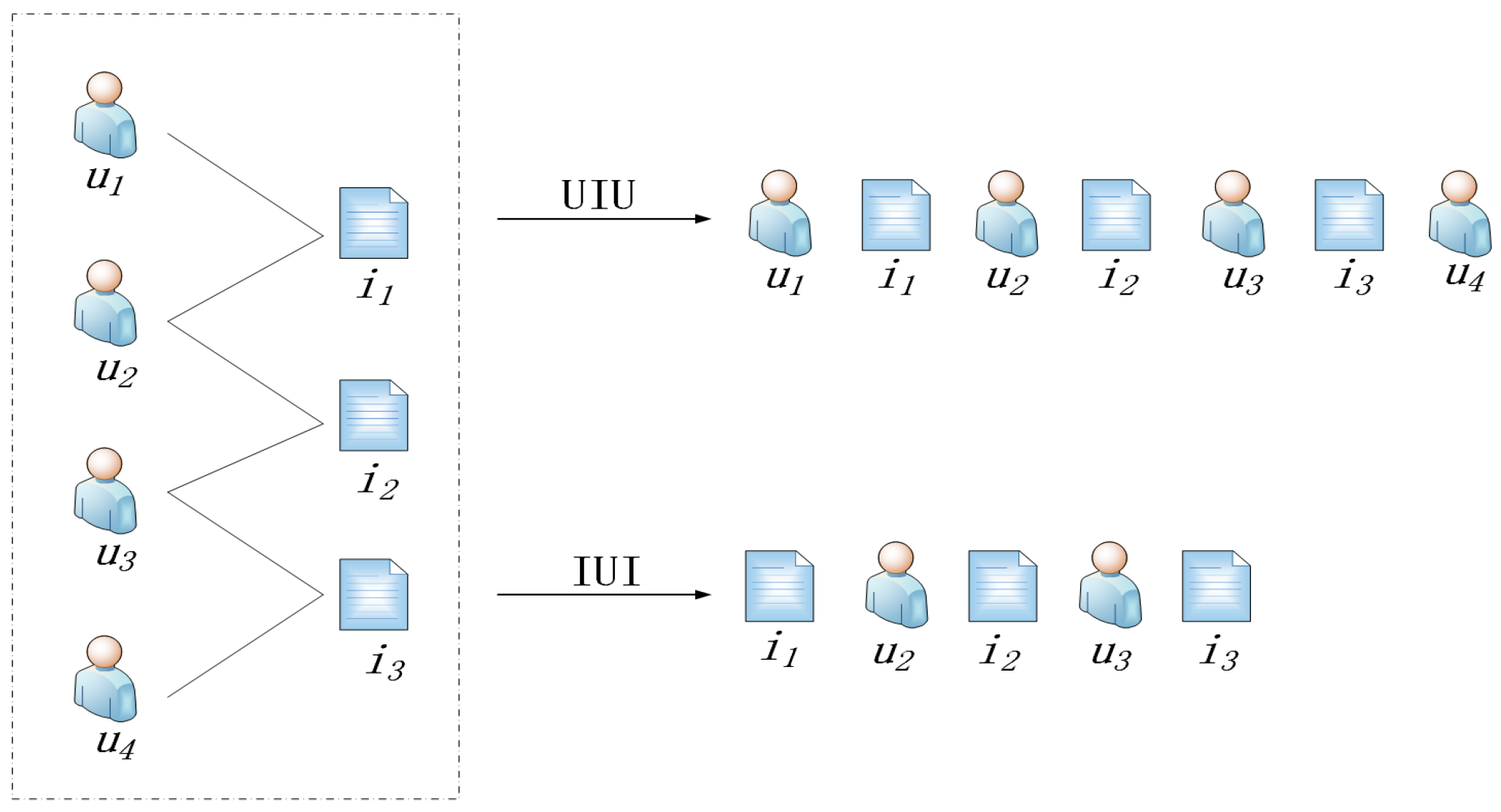
3.1. Problem Definition
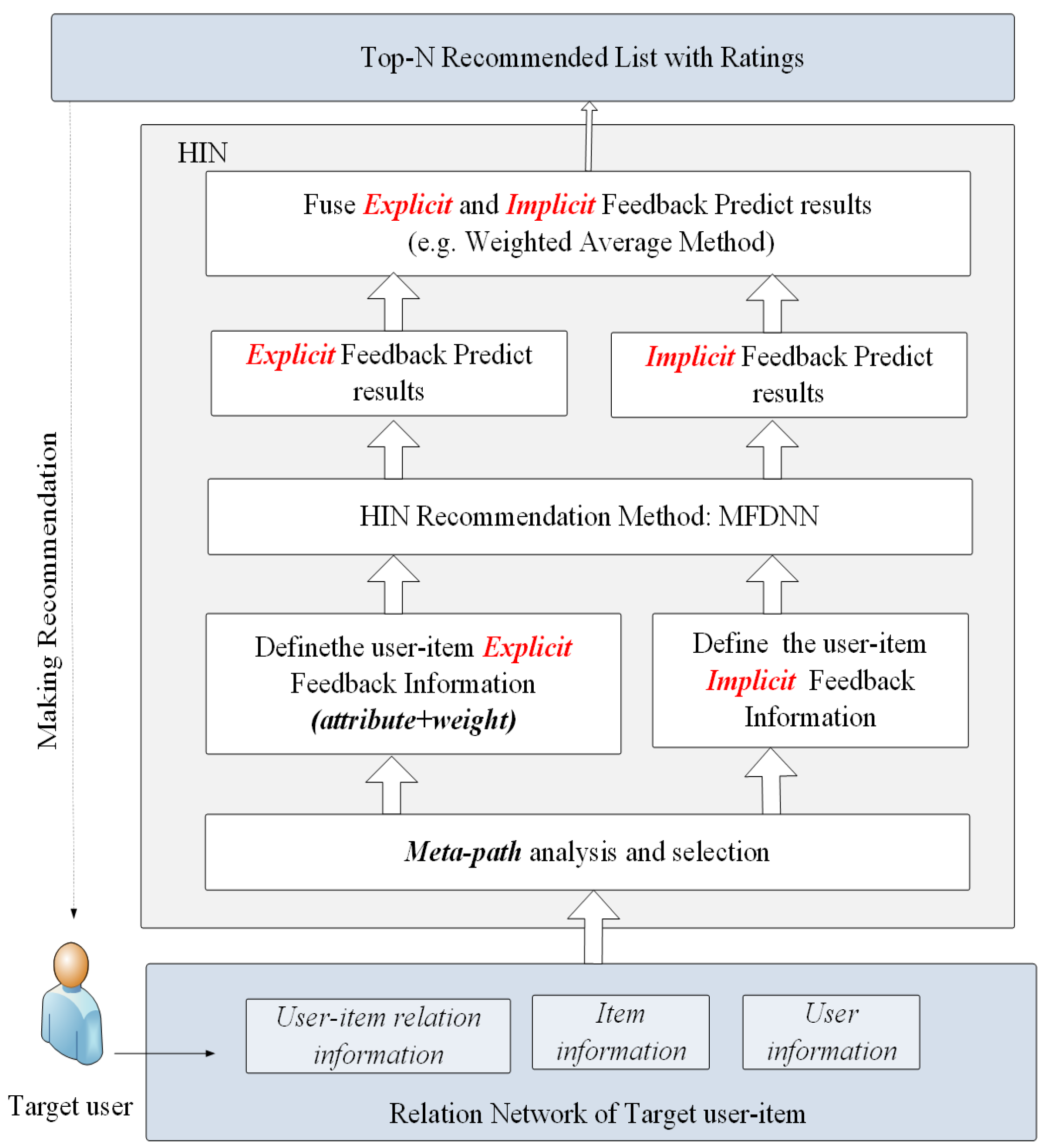
3.2. Top-N Recommendation Architecture
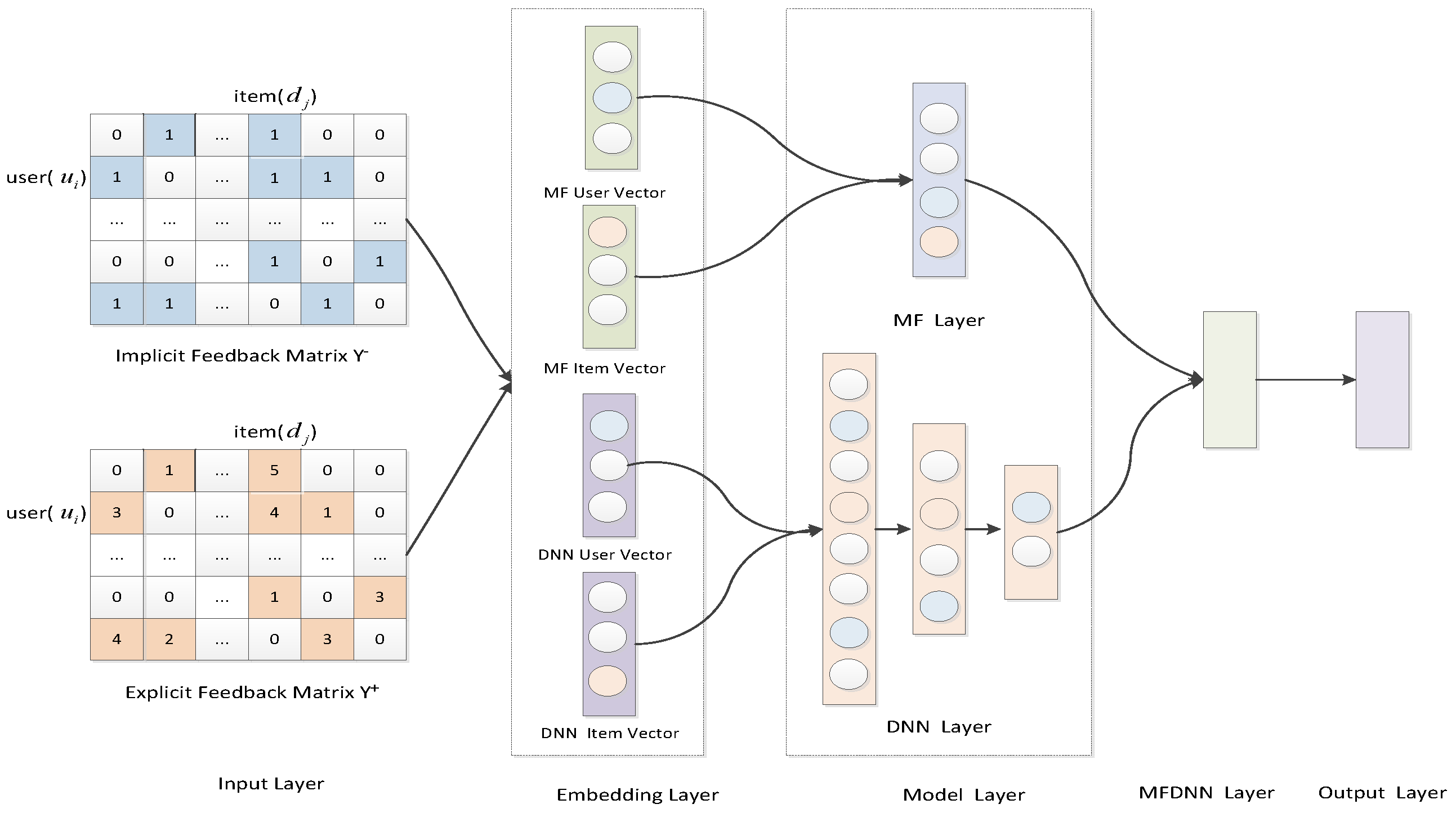
3.3. Framework of MFDNN
3.4. Implementation of MFDNN
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Baseline Methods
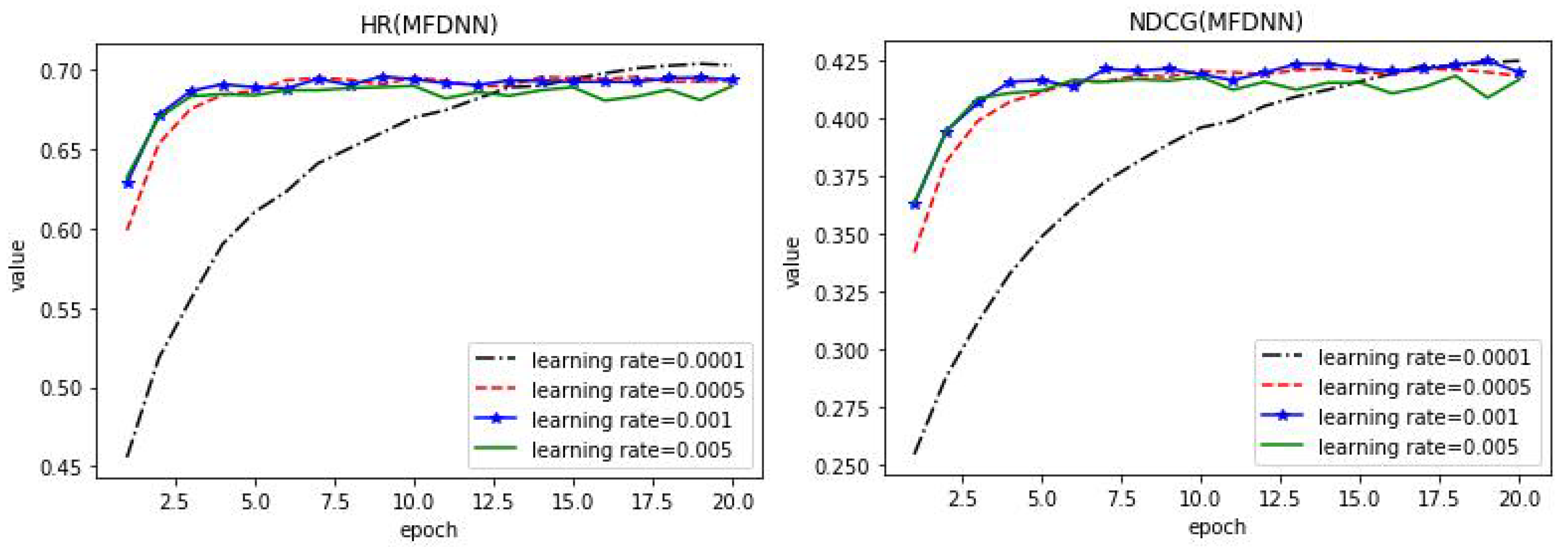
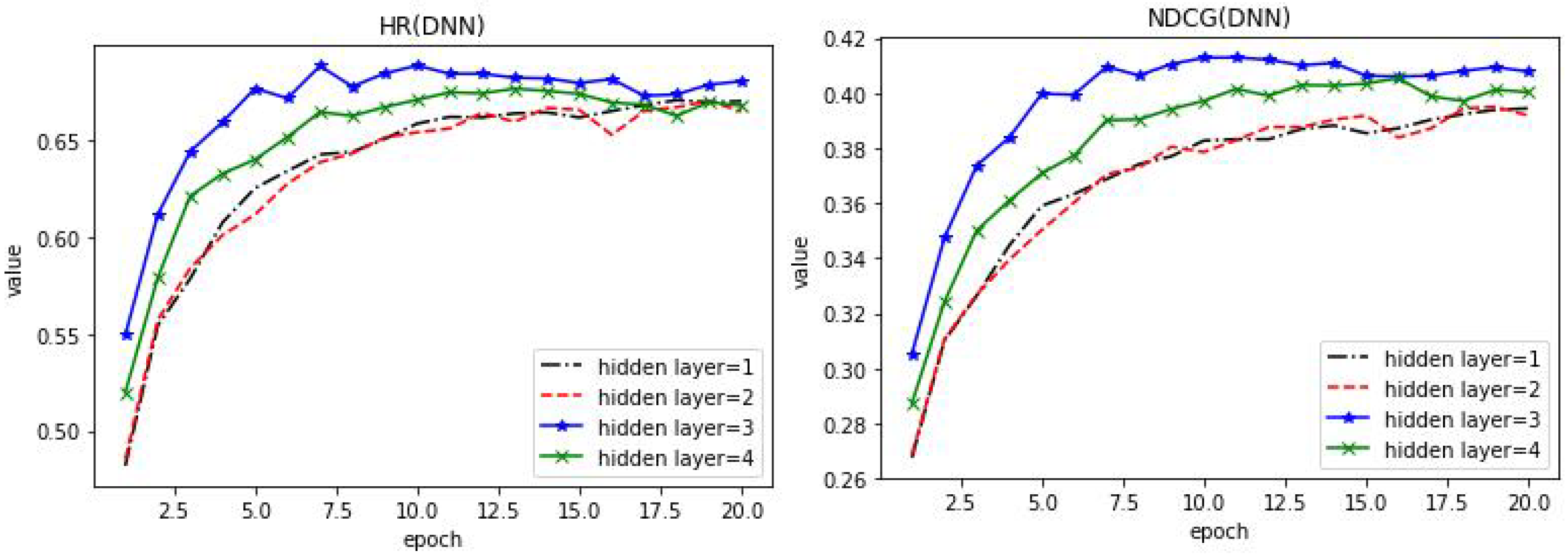
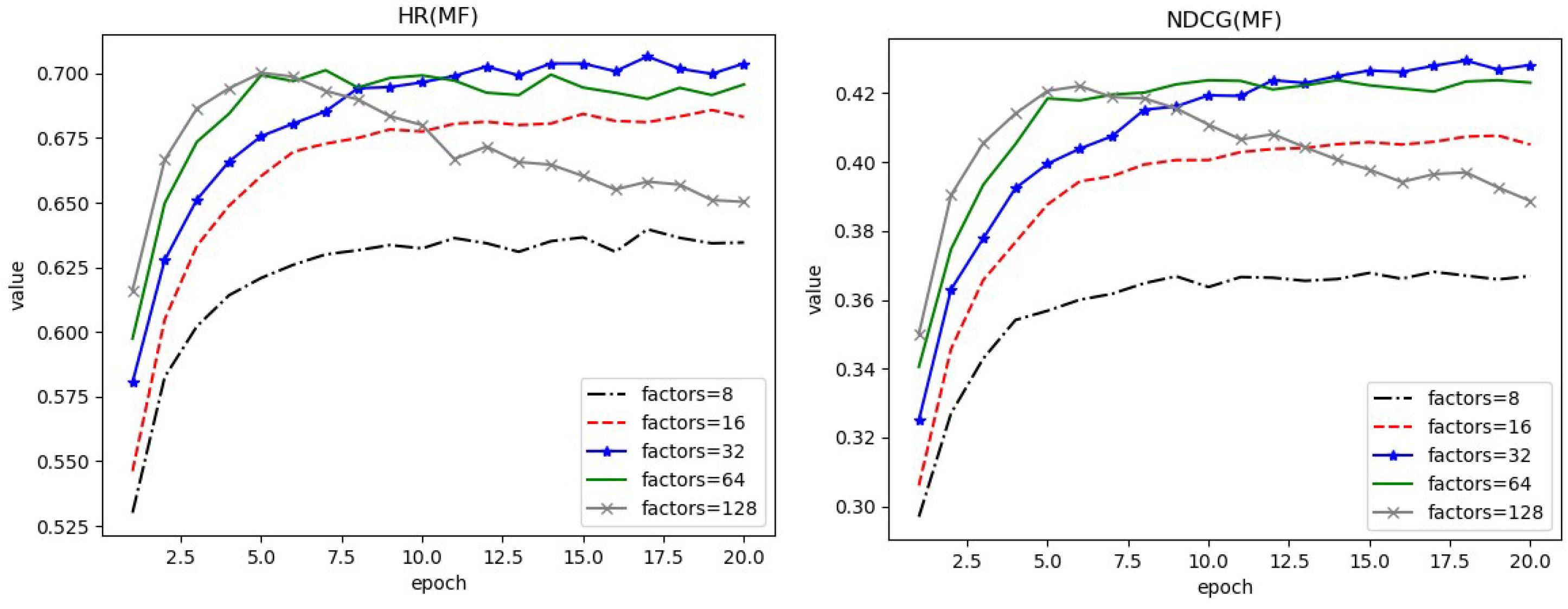
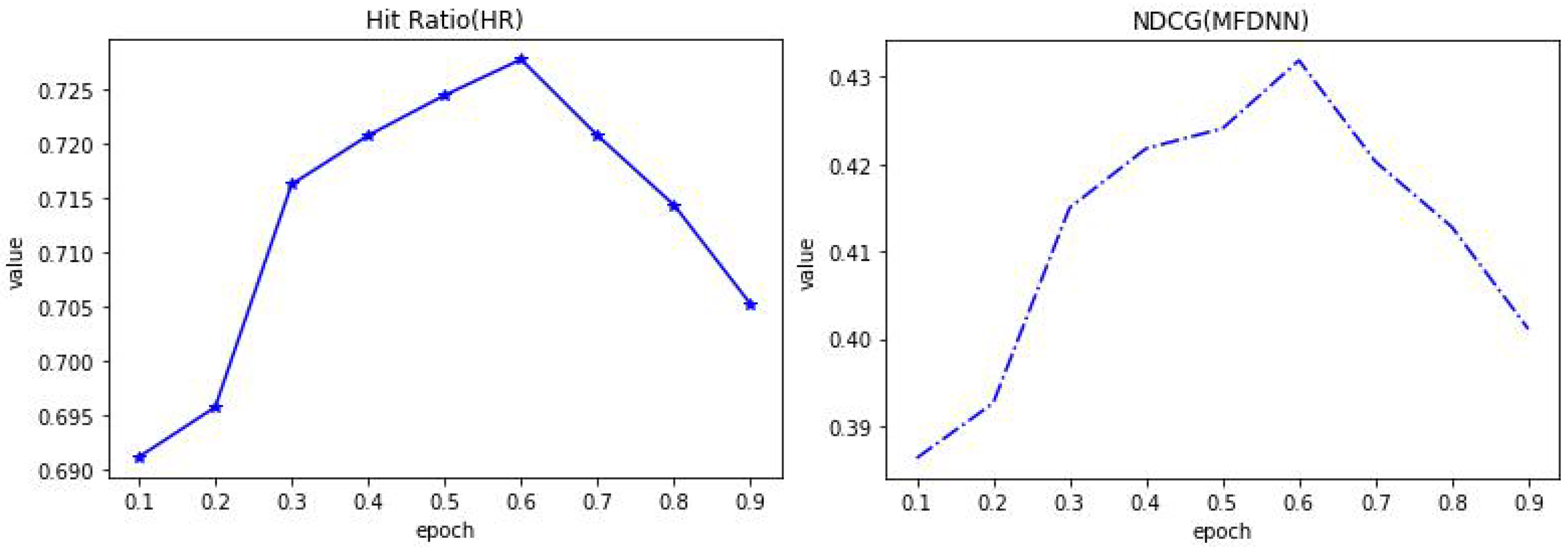
4.2. Parameters Analysis
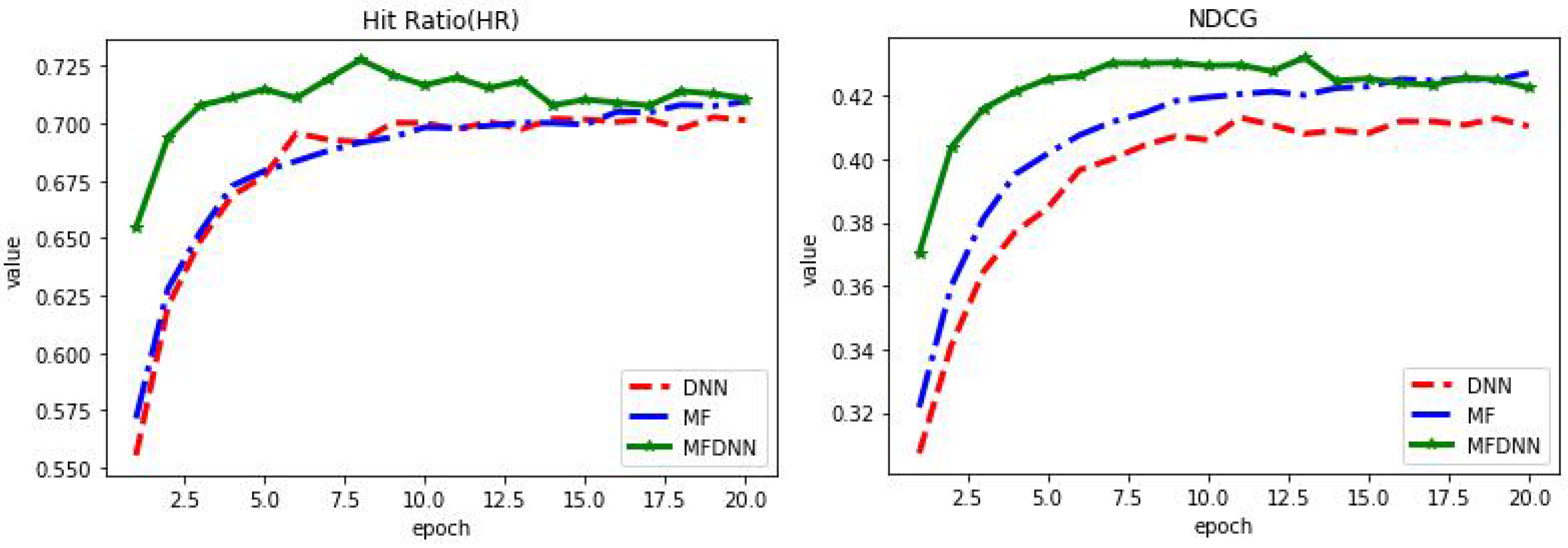
4.3. Performance and Comparison
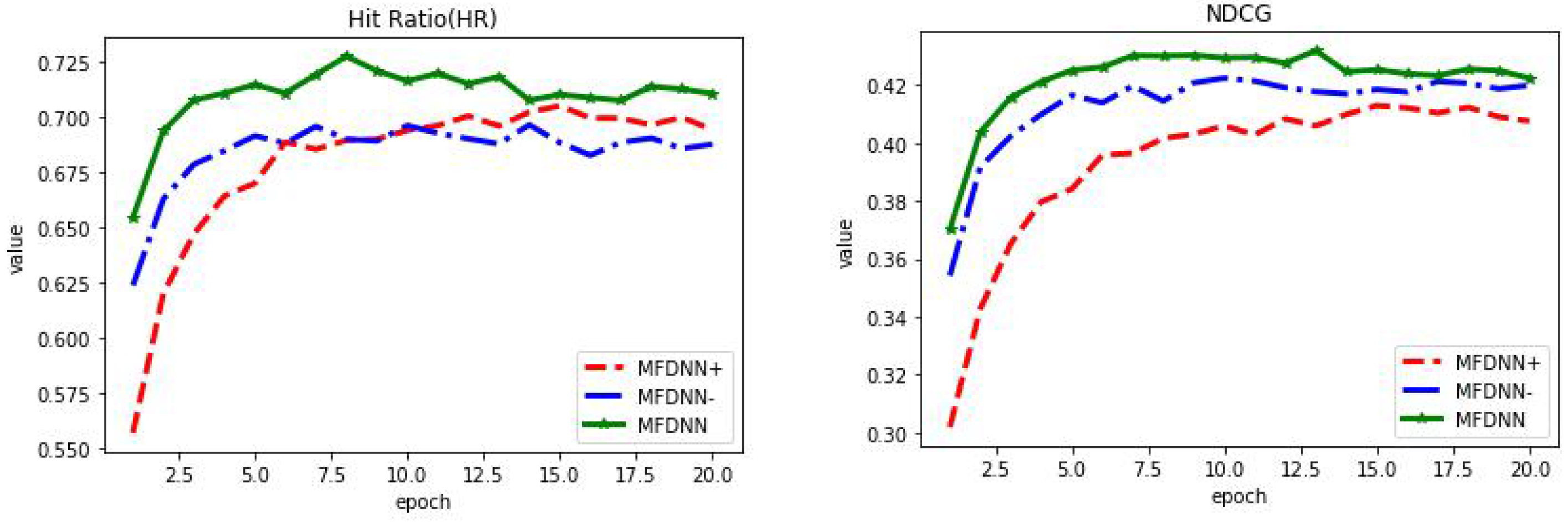
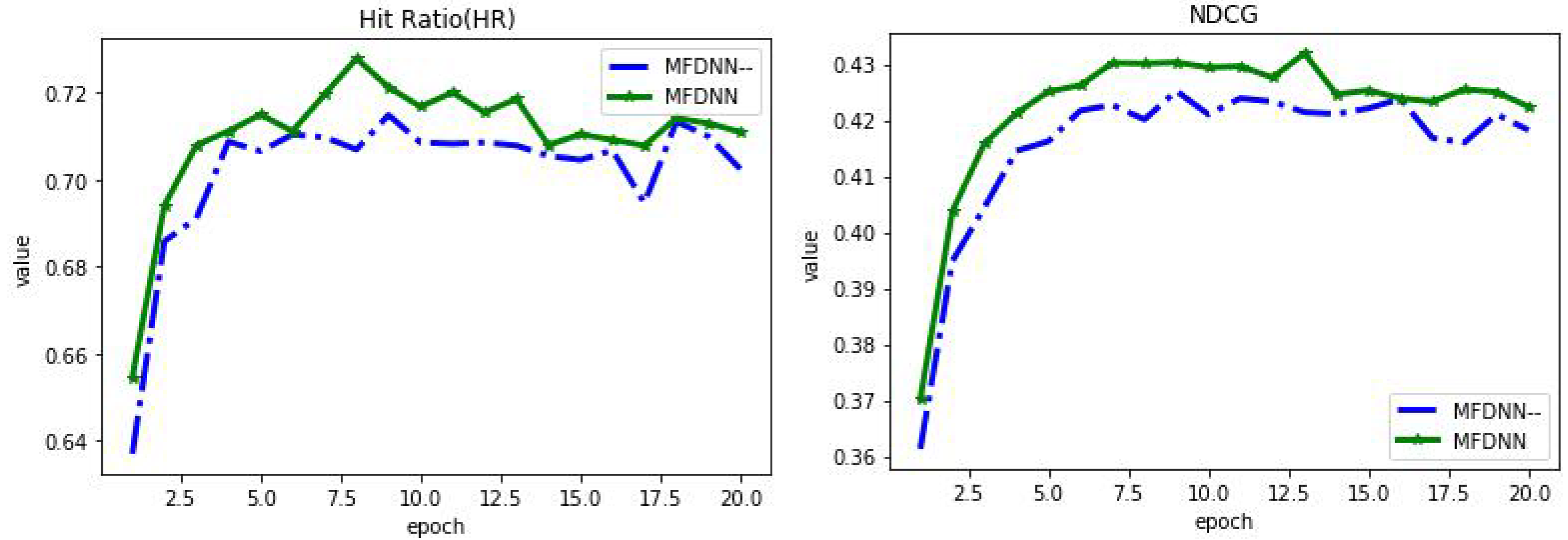
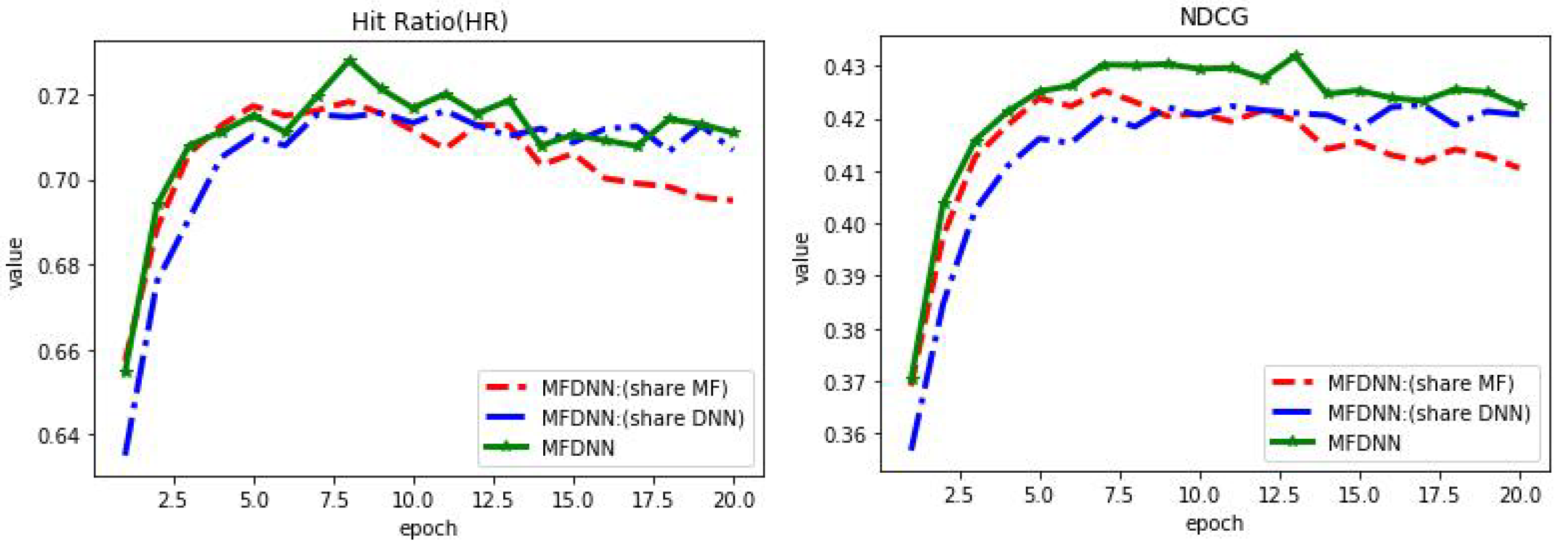
4.4. Discussions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Beheshti, A.; Yakhchi, S.; Mousaeirad, S.; Ghafari, S.; Goluguri, S.; Edrisi, M. Towards cognitive recommender systems. Algorithms 2020, 13, 176. [Google Scholar] [CrossRef]
- Jing, X.; Tang, J. Guess You Like: Course Recommendation in MOOCs. In Proceedings of the IEEE/WIC/ACM International Conferences on Web Intelligence, Leipzig, Germany, 23 August 2017; pp. 783–789. [Google Scholar]
- Diao, Q.; Qiu, M.; Wu, C.Y.; Smola, A.J.; Jiang, J.; Wang, C. Jointly modeling aspects, ratings and sentiments for movie recommendation (JMARS). In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24 August 2014; pp. 193–202. [Google Scholar]
- Su, J.H.; Chang, W.Y.; Tseng, V.S. Integrated Mining of Social and Collaborative Information for Music Recommendation. Data Sci. Pattern Recognit. 2017, 1, 13–30. [Google Scholar]
- Liu, Y.; Peng, H.; Guo, J.; He, T.; Li, X.; Song, Y.; Li, J. Event detection and evolution based on knowledge base. Proc. Kbcom 2018, 2018, 1–7. [Google Scholar]
- Rizkallah, S.; Atiya, A.; Shaheen, S. New Vector-Space Embeddings for Recommender Systems. Appl. Sci. 2021, 11, 6477. [Google Scholar] [CrossRef]
- Zdziebko, T.; Sulikowski, P. Monitoring Human Website Interactions for Online Stores. In New Contributions in Information Systems and Technologies; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2015; Volume 354, pp. 375–384. [Google Scholar]
- Sulikowski, P.; Zdziebko, T. Horizontal vs. Vertical Recommendation Zones Evaluation Using Behavior Tracking. Appl. Sci. 2021, 11, 56. [Google Scholar] [CrossRef]
- Bin, S.; Sun, G. Matrix Factorization Recommendation Algorithm Based on Multiple Social Relationships. Math. Probl. Eng. 2021, 2021, 6610645. [Google Scholar] [CrossRef]
- Shu, J.; Shen, X.; Liu, H.; Yi, B.; Zhang, Z. A content-based recommendation algorithm for learning resources. Multimed. Syst. 2018, 24, 163–173. [Google Scholar] [CrossRef]
- Peng, H.; Li, J.; Gong, Q.; Song, Y.; Ning, Y.; Lai, K.; Yu, P. Fine-grained Event Categorization with Heterogeneous Graph Convolutional Networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, Macao, China, 13 July 2019; pp. 3238–3245. [Google Scholar]
- Liang, H.; Xu, Y.; Li, Y.; Nayak, R.; Tao, X. Connecting users and items with weighted tags for personalized item recommendations. In Proceedings of the ACM conference on Hypertext and hypermedia, Toronto, ON, Canada, 13–16 June 2010; pp. 51–60. [Google Scholar]
- Liu, Y.; Peng, H.; Li, J.; Song, Y.; Li, X. Event detection and evolution in multi-lingual social streams. Front. Comput. Sci. 2020, 5, 1–15. [Google Scholar] [CrossRef]
- Sulikowski, P. Evaluation of Varying Visual Intensity and Position of a Recommendation in a Recommending Interface Towards Reducing Habituation and Improving Sales. In International Conference on e-Business Engineering; Springer: Cham, Switzerland, 2019; pp. 208–218. [Google Scholar]
- Bell, R.; Koren, Y. Scalable collaborative filtering with jointly derived neighborhood interpolation weights. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 43–52. [Google Scholar]
- Liu, N.; Xiang, E.; Zhao, M.; Yang, Q. Unifying explicit and implicit feedback for collaboratie filtering. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 1445–1448. [Google Scholar]
- Pan, W.; Liu, Z.; Ming, Z.; Zhong, H.; Wang, X.; Xu, C. Compressed knowledge transfer via factorization machine for heterogeneous collaborative recommendation. Knowl.-Based Syst. 2015, 85, 234–244. [Google Scholar] [CrossRef]
- Li, G.; Chen, Q. Exploiting explicit and implicit feedback for personalized ranking. Math. Probl. Eng. 2016, 2016, 2535329. [Google Scholar] [CrossRef] [Green Version]
- Ding, D.; Zhang, M.; Li, S.Y.; Tang, J.; Chen, X.; Zhou, Z.H. BayDNN: Friend Recommendation with Bayesian Personalized Ranking Deep Neural Network. In Proceedings of the Twenty-Sixth Conference on Information and Knowledge Management (CIKM’ 17), California, CA, USA, 6–10 November 2017; pp. 1479–1488. [Google Scholar]
- Nguyen, H.T.; Wistuba, M.; Grabocka, J.; Drumond, L.R.; Drumond, L.R.; Schmidt-Thieme, L. Personalized Deep Learning for Tag Recommendation. Knowl. Discov. Data Min. 2017, 6, 186–197. [Google Scholar]
- Wang, F.; Qu, Y.; Zheng, L.; Lu, C.T.; Philip, S.Y. Deep and Broad Learning on Content-aware POI Recommendation. In Proceedings of the IEEE 3rd International Conference on Collaboration and Internet Computing, FUTO, Nigeria, 14 June 2017; pp. 369–378. [Google Scholar]
- Kelen, D.; Daróczy, B.; Ayala-Gómez, F.; Ország, A.; Benczúr, A. Session Recommendation via Recurrent Neural Networks over Fisher Embedding Vectors. Sensors 2019, 19, 3498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, T.; He, L.; Lu, C.T.; Chen, L.; Philip, S.Y.; Wu, J.; Chen, L.; Philip, S.Y.; Wu, J. A Broad Learning Approach for Context-Aware Mobile Application Recommendation. ICDM 2017, 5, 955–960. [Google Scholar]
- Hakan, B.; Pinar, K. Context-aware friend recommendation for location based social networks using random walk. In Proceedings of the International Conference on World Wide Web, New York, NY, USA, 11–15, April 2016; pp. 531–536. [Google Scholar]
- Zheng, J.; Bhuiyan, M.Z.A.; Liang, S.; Xing, X.; Wang, G. Auction-based adaptive sensor activation algorithm for target tracking in wireless sensor networks. Future Gener. Comput. Syst. 2014, 39, 88–99. [Google Scholar] [CrossRef]
- Wang, Z.J.; Chen, K.M.; He, L. AsySIM: Modeling Asymmetric Social Influence for Rating Prediction. Data Sci. Pattern Recognit. 2018, 2, 25–40. [Google Scholar]
- Bhuiyan, M.Z.A.; Wang, G.; Vasilakos, A.V. Local Area Prediction-Based Mobile Target Tracking in Wireless Sensor Networks. IEEE Trans. Comput. 2015, 64, 1968–1982. [Google Scholar] [CrossRef]
- Sheng, Y.; Wu, T.; Wang, X. Incorporating term definitions for taxo-nomic relation identification. In Proceedings of the 9th Joint International Semantic Technology Conference (JIST), Hangzhou, China, 25–27 November 2019; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Xue, H.J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep Matrix Factorization Models for Recommender Systems. Int. Jt. Conf. Artif. Intell. 2017, 17, 3203–3209. [Google Scholar]
- Mao, Q.; Li, J.; Wang, S.; Zhang, Y.; Peng, H.; He, M.; Wang, L. Aspect-based sentiment classification with attentive neural turing machines. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 5139–5145. [Google Scholar]
- Peng, H.; Bao, M.; Li, J.; Bhuiyan, M.Z.A.; Liu, Y.; He, Y.; Yang, E. Incremental term representation learning for social network analysis. FGCS 2018, 86, 1503–1512. [Google Scholar] [CrossRef]
- Peng, H.; Li, J.; Wang, S.; Wang, L.; Gong, Q.; Yang, R.; Li, B.; He, L.; Yu, P.S. Hierarchical taxonomy-aware and attentional graph capsule rcnns for large-scale multi-label text classification. IEEE Trans. Knowl. Data Eng. 2020, 33, 2505–2519. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.Y.; Lin, I.C.; Wu, H.J. Recommendation System to Identify Collusive Users in Online Auctions Using the Pollution Diffusion Method. J. Internet Technol. 2019, 20, 353–358. [Google Scholar]
- Sun, Y.Z.; Han, J.W.; Yan, X.F.; Yu, P.S.; Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, Z.Q.; Luo, P.; Yu, P.S.; Yue, Y.; Wu, B. Semantic Path based Personalized Recommendation on Weighted Heterogeneous Information Networks. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management (CIKM’ 15), Melbourne, Australia, 18–23 October 2015; pp. 453–462. [Google Scholar]
- Shi, C.; Kong, X.; Huang, Y.; Philip, S.Y.; Wu, B. A general framework for relevance measure in heterogeneous networks. IEEE Trans. Knowl. Data Eng. 2014, 26, 2479–2492. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Z.; Liu, H.; Fu, B.; Wu, Z.; Zhang, T. Recommendation in heterogeneous information networks based on generalized random walk model and bayesian personalized ranking. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 288–296. [Google Scholar]
- Alexandridis, G.; Siolas, G.; Stafylopatis, A. Accuracy versus novelty and diversity in recommender systems: A nonuniform random walk approach. In Recommendation and Search in Social Networks; Springer: Cham, Switzerland, 2015; pp. 41–57. [Google Scholar]
- Alexandridis, G.; Siolas, G.; Stafylopatis, A. A biased random walk recommender based on Rejection Sampling. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara, ON, Canada, 25–28 August 2013; pp. 648–652. [Google Scholar]
- Wang, Z.; Liu, H.; Du, Y.; Wu, Z.; Zhang, X. Unified embedding model over heterogeneous information network for personalized recommendation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3813–3819. [Google Scholar]
- Liu, J.; Shi, C.; Hu, B.B.; Liu, S.; Philip, S.Y. Personalized Ranking Recommendation via Integrating Multiple Feedbacks. In Proceedings of the Knowledge Discovery and Data Mining, Halifax, Canada, 13–17 August 2017; pp. 131–143. [Google Scholar]
- He, X.N.; Liao, L.Z.; Zhang, H.W.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web (WWW’ 17), Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Luo, C.; Pang, W.; Wang, Z.; Lin, C. Social-based collaborative filtering recommendation using heterogeneous relations. In Proceedings of the International Conference on Data Mining (ICDM), Washington, WA, USA, 14–17 December 2014; pp. 917–922. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Liu, J.; Tang, M.; Zheng, Z.; Liu, X.; Lyu, S. Location-aware and personalized collaborative filtering for web service recommendation. IEEE Trans. Serv. Comput. 2016, 9, 686–699. [Google Scholar] [CrossRef]
- Benedikt, L.; Katja, H.; Jürgen, Z. Blended recommending: Integrating interactive information filtering and algorithmic recommender techniques. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 975–984. [Google Scholar]
- Wei, J.; He, J.H.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative filtering and deep learning based recommendation system for cold start items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef] [Green Version]
- Suraj, S.; Babu, R.V. Deep Learning in Neural Networks: An Overview. Comput. Sci. 2015, 61, 85–117. [Google Scholar]
- Sun, Z.Q.; Li, F.; Huang, H.F. Large Scale Image Classification Based on CNN and Parallel SVM. In Proceedings of the International Conference on Neural Information Processing, California, CA, USA, 4 December 2017; pp. 545–555. [Google Scholar]
- Huang, K.W.; Lin, C.C.; Lee, Y.M.; Wu, Z.X. A Deep Learning and Image Recognition System for Image Recognition. Data Sci. Pattern Recognit. 2019, 3, 1–11. [Google Scholar]
- He, Y.; Li, J.; Song, Y.; He, M.; Peng, H. Time-evolving Text Classification with Deep Neural Networks. Int. Jt. Conf. Artif. Intell. 2018, 18, 2241–2247. [Google Scholar]
- Arif, M.H.; Li, J.; Iqbal, M.; Peng, H. Optimizing XCSR for text classification. IEEE Symp. Serv. Oriented Syst. Eng. (Sose) 2017, 8, 86–95. [Google Scholar]
- Peng, H.; Li, J.; He, Y.; Liu, Y.; Bao, M.; Wang, L.; Song, Y.; Yang, Q. Large-scale hierarchical text classification with recursively regularized deep graph-cnn. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1063–1072. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Xie, Z.; Zeng, Z.; Zhou, G.; Wang, W. Topic enhanced deep structured semantic models for knowledge base question answering. Sci. China Inf. Sci. 2017, 60, 1–15. [Google Scholar] [CrossRef]
- Zhao, Y.Y.; Qin, B.; Liu, T. Encoding syntactic representations with a neural network for sentiment collocation extraction. Sci. China Inf. Sci. 2017, 60, 110101. [Google Scholar] [CrossRef] [Green Version]
- Qu, Y.R.; Cai, H.; Ren, K.; Zhang, W.; Yu, Y.; Wen, Y.; Wang, J. Product-based neural networks for user response prediction. In Proceedings of the IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1149–1154. [Google Scholar]
- Zhang, W.N.; Du, T.M.; Wang, J. Deep learning over multi-field categorical data. A case study on user response prediction. In Proceedings of the 38th European Conference on Information Retrieval Research (ECIR), Padua, Italy, 20–23 March 2016; pp. 45–57. [Google Scholar]
- Wang, C.; Liu, J.; Luo, F.; Tan, Y.; Deng, Z.; Hu, Q.N. Pairwise input neural network for target-ligand interaction prediction. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine, Belfast, UK, 2–5 November 2014; pp. 67–70. [Google Scholar]
- Ning, X.; Karypis, G. Slim: Sparse linear methods for top-n recommender systems. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining(ICDM), Vancouver, BC, Canada, 11 December 2011. [Google Scholar]
- Cheng, Y.; Yin, L.; Yu, Y. LorSLIM: Low rank sparse linear methods for top-N recommendations. In Proceedings of the International Conference on Data Mining (ICDM), Washington, DC, USA, 14–17 December 2014. [Google Scholar]
- Christakopoulou, E.; Karypis, G. HOSLIM: Higher-order sparse linear method for top-N recommender systems. In Proceedings of the Conference on Knowledge Discovery and Data Mining (PAKDD), New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Philip, S.Y. A Survey of Heterogeneous Information Network Analysis. IEEE Trans. Knowl. Data Eng. 2017, 29, 17–37. [Google Scholar] [CrossRef]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-Graph Based Recommendation Fusion over Heterogeneous Information Networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar]
- Zhene, Z.; Hao, P.; Lin, L.; Guixi, X.; Du, B.; Bhuiyan, M.Z.A.; Li, D. Deep Convolutional Mesh RNN for Urban Traffic Passenger Flows Prediction. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced&Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018. [Google Scholar]
- Du, B.; Peng, H.; Wang, S.; Bhuiyan, M.Z.A.; Wang, L.; Gong, Q.; Liu, L.; Li, J. Deep irregular convolutional residual lstm for urban traffic passenger flows prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 275–285. [Google Scholar] [CrossRef]
- Xu, X.; Wang, J.; Peng, H.; Wu, R. Prediction of academic performance associated with internet usage behaviors using machine learning algorithms. Comput. Hum. Behav. 2019, 98, 166–173. [Google Scholar] [CrossRef]
- Diederik, P.K.; Jimmy, B. Adam: A Method for Stochastic Optimization. In Proceedings of the ICLR, Santiago, MN, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Harper, F.M.; Joseph, A.K. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Yu, X.; Ren, X.; Gu, Q.; Sun, Y.; Han, J. Collaborative filtering with entity similarity regularization in Heterogeneous information networks. In Proceedings of the IJCAI-HINA Workshop, IJCAI, Beijing, China, 2–3 August 2013. [Google Scholar]
- Li, F.; Xu, G.; Cao, L. Coupled matrix factorization within non-iid context. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Ho Chi Minh, Vietnam, 1–22 May 2015; Springer: Cham, Switzerland, 2015; pp. 707–719. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Sheng, Y.; Xu, Z.; Wang, Y.; Melo, G.D. Murex: Multi-document semantic relation extraction for news analytics. WWW J. 2020, 23, 2043–2077. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Y | User–item interaction matrix |
| U | Set of users |
| I | Set of items |
| Final prediction results | |
| Implicit feedback prediction results | |
| Explicit feedback prediction results | |
| User–item relation matrix | |
| User–item rating matrix | |
| Final prediction results of MF | |
| Final prediction results of DNN | |
| User embedding vector of MF | |
| Item embedding vector of MF | |
| User embedding vector of DNN | |
| Item embedding vector of DNN |
| Algorithm MFDNN algorithm |
| User–item relation matrix; |
| User–item rating matrix; |
| Parameter of regularization term; |
| Learning rate⇐0.001; |
| epochs ⇐ Number of iterations; |
| User embedding vector of MF; |
| Item embedding vector of MF; |
| User embedding vector of DNN; |
| Item embedding vector of DNN; |
| epochs Calculate Equations (8)–(10) |
| Calculate Equations (11)–(14) |
| Update MFDNN with Adam |
| Calculate Equation (7) |
| Calculate at the same way |
| Calculate Equation (15) |
| Top-N recommendation list |
| Aspect | MovieLens 1m | Netflix |
|---|---|---|
| #users | 6040 | 48,018 |
| #movies | 3706 | 17,770 |
| #ratings | 1,000,209 | 11,160,900 |
| Rating Density | 0.04468 | 0.01308 |
| MovieLens 1m | Netflix | |||
|---|---|---|---|---|
| Method | HR@10 | NDCG@10 | HR@10 | NDCG@10 |
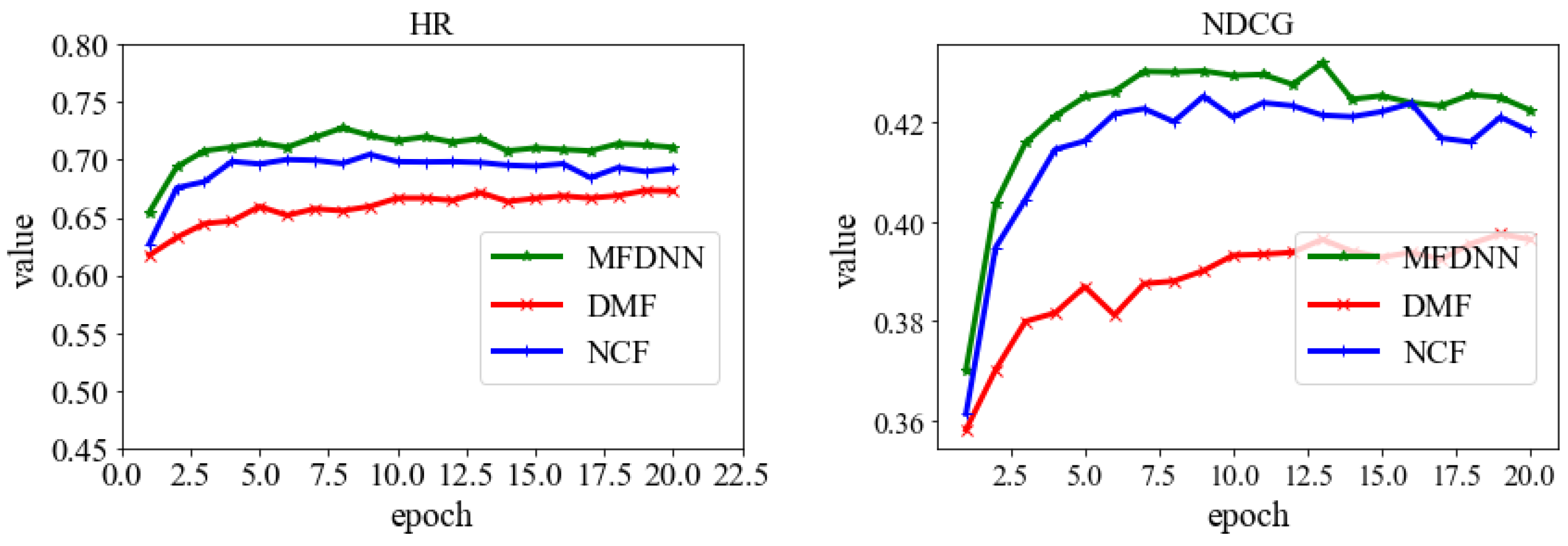
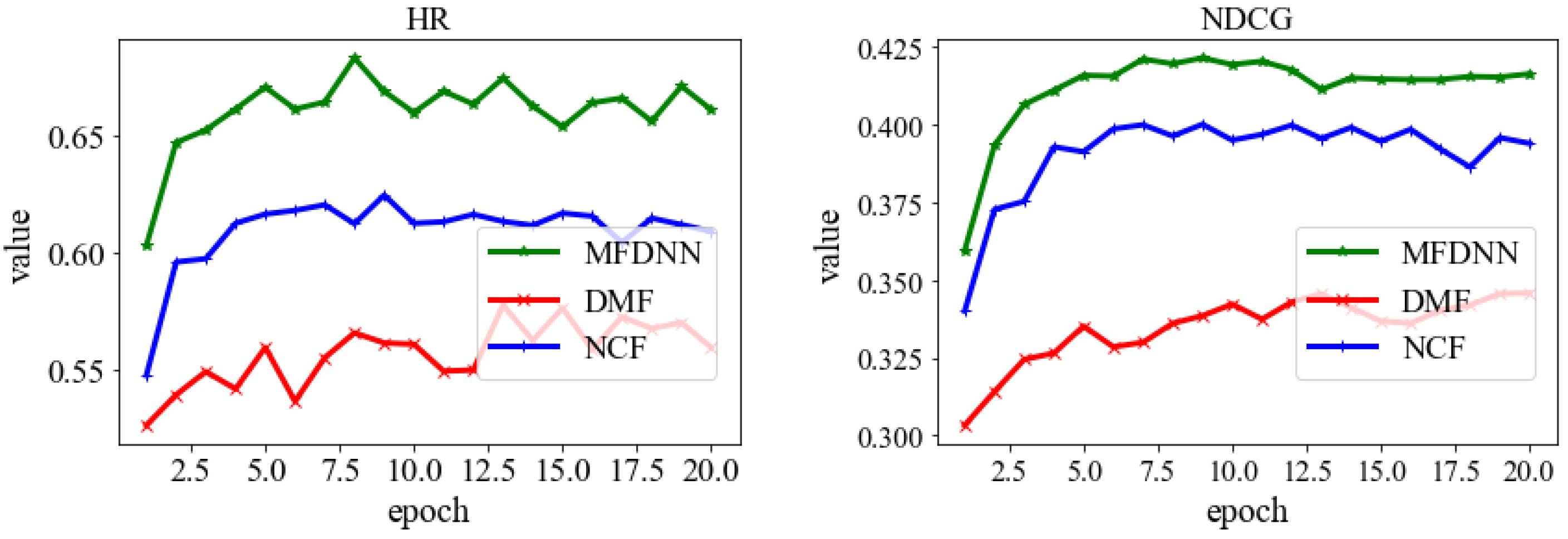
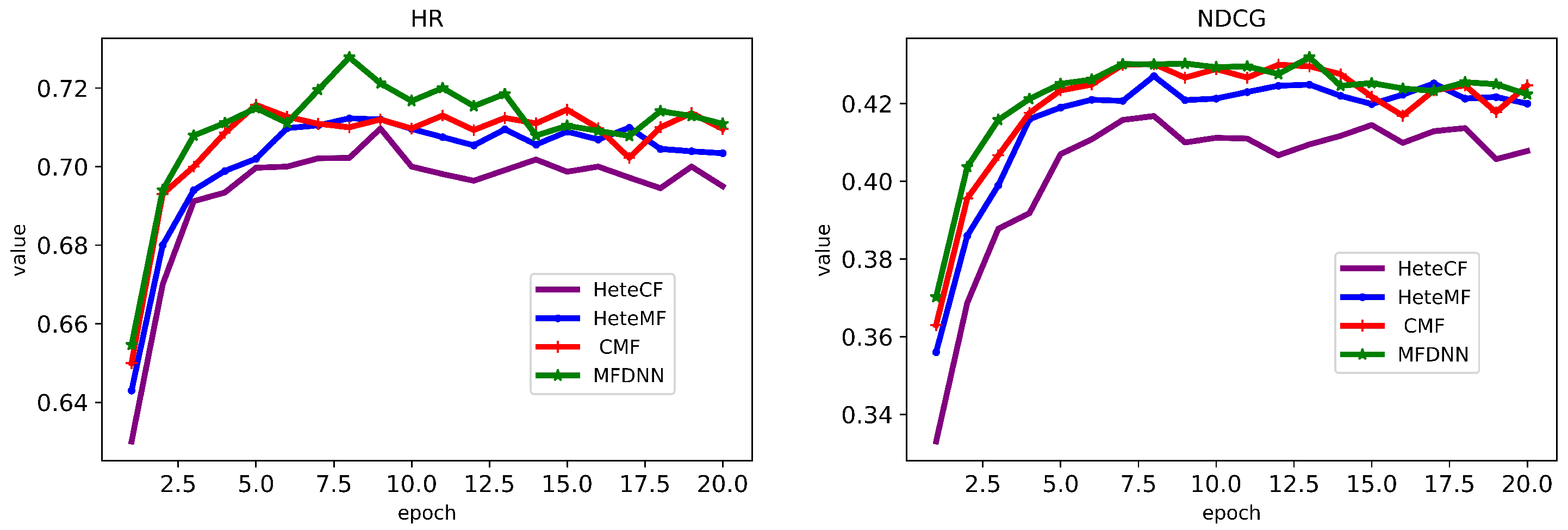
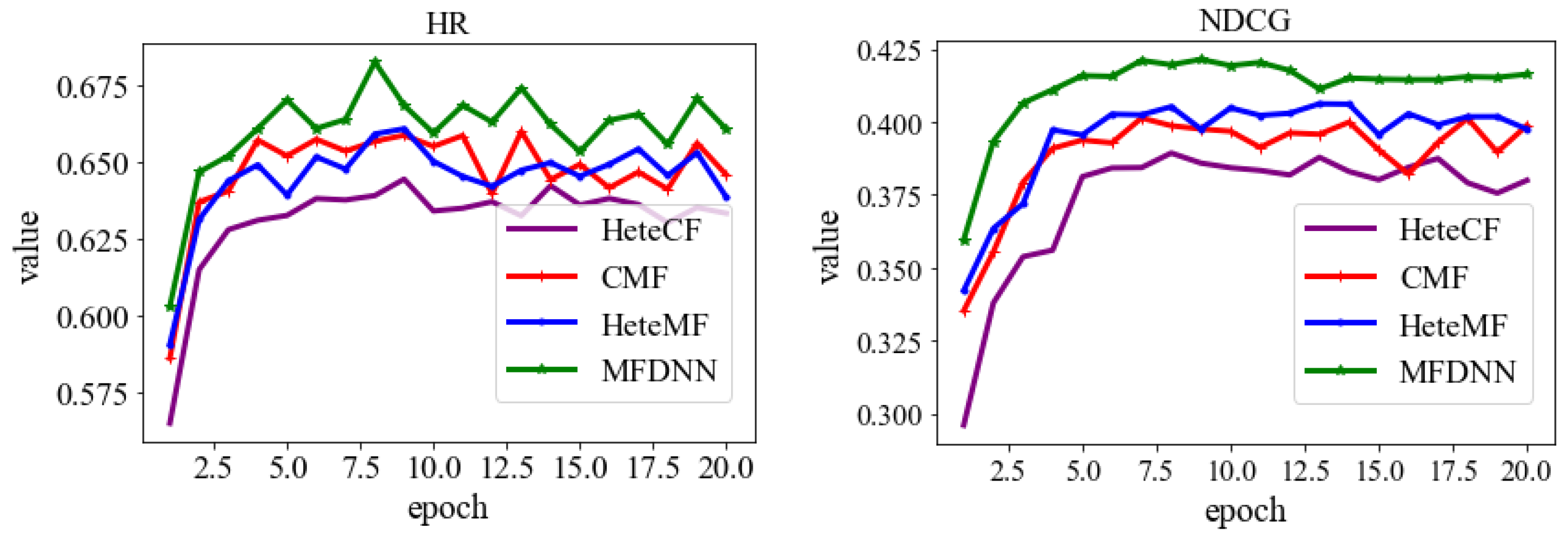
| MFDNN | 0.7278 | 0.4319 | 0.6828 | 0.4214 |
| DMF | 0.6735 | 0.3975 | 0.5776 | 0.3459 |
| NCF | 0.7048 | 0.4252 | 0.6245 | 0.4000 |
| HeteCF | 0.7097 | 0.4268 | 0.6601 | 0.4013 |
| HeteMF | 0.7123 | 0.4271 | 0.6609 | 0.4062 |
| CMF | 0.7235 | 0.4308 | 0.6445 | 0.3893 |
| MovieLens 1m | Netfilx | |||
|---|---|---|---|---|
| Top-N | HR | NDCG | HR | NDCG |
| N=5 | 0.5303 | 0.3672 | 0.4583 | 0.3058 |
| N=10 | 0.7279 | 0.4319 | 0.6828 | 0.4214 |
| N=15 | 0.7869 | 0.4443 | 0.7542 | 0.4386 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, J.; Zhang, X.; Li, Q.; Wang, C.; Song, Y.; Zhao, Z.; Wang, S. A Top-N Movie Recommendation Framework Based on Deep Neural Network with Heterogeneous Modeling. Appl. Sci. 2021, 11, 7418. https://0-doi-org.brum.beds.ac.uk/10.3390/app11167418
Gong J, Zhang X, Li Q, Wang C, Song Y, Zhao Z, Wang S. A Top-N Movie Recommendation Framework Based on Deep Neural Network with Heterogeneous Modeling. Applied Sciences. 2021; 11(16):7418. https://0-doi-org.brum.beds.ac.uk/10.3390/app11167418
Chicago/Turabian StyleGong, Jibing, Xinghao Zhang, Qing Li, Cheng Wang, Yaxi Song, Zhiyong Zhao, and Shuli Wang. 2021. "A Top-N Movie Recommendation Framework Based on Deep Neural Network with Heterogeneous Modeling" Applied Sciences 11, no. 16: 7418. https://0-doi-org.brum.beds.ac.uk/10.3390/app11167418