
Automatic Segmentation and Classification Methods Using Optical Coherence Tomography Angiography (OCTA): A Review and Handbook

 ,
,  ,
, 
Abstract
:Featured Application
Abstract
1. Introduction

2. Materials and Methods
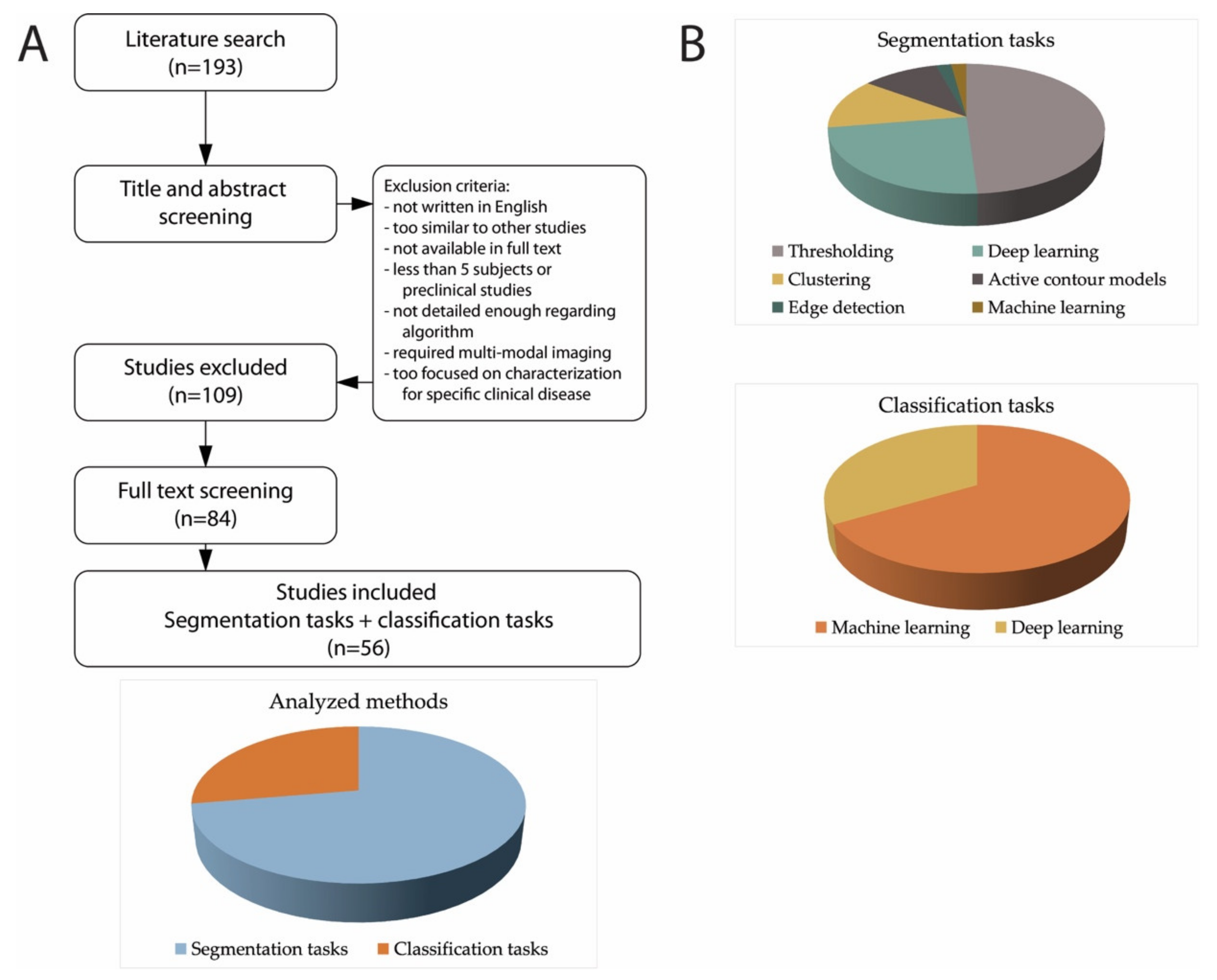
2.1. Literature Search Strategy and Study Selection
2.2. Data Extraction
3. Results
3.1. Segmentation Tasks
3.1.1. Thresholding
3.1.2. Deep Learning
3.1.3. Clustering
3.1.4. Active Contour Models
3.1.5. Edge Detection
3.1.6. Machine Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Method | First Author (Year) | Database 2D/3D Field of View (FOV) | Description | Results |
|---|---|---|---|---|---|
| Eye vasculature | Thresholding | Chu 2016 [39] | 5 subjects 2D 6.72 × 6.72 mm2 | Global threshold to remove FAZ, Hessian filter, local mean adaptive threshold, skeletonization. | No segmentation validation. Repeatability and usefulness of parameters. |
| Kim 2016 [40] | 84 DR, 14 healthy 2D 3 × 3 mm2 | Global threshold to remove FAZ, Hessian filter, local median adaptive threshold—top hat filter and combination of binarized images. | No segmentation validation. Negative correlation between DR severity and SD, VD, FD; positive correlation with VDI. | ||
| Alam 2017 [28] | 36 SCR patients, 26 healthy 2D 3 × 3 mm2 | Global thresholding, morphological functions, and fractal dimension analysis. | No segmentation validation. Avascular density was more sensitive to SCR presence than vessel tortuosity and mean diameter. | ||
| Ong 2017 [29] | 38 glaucoma, 120 non glaucoma 2D 6 × 6 mm2 | Global thresholding, morphological dilation, closing. | No segmentation validation. Method proposed for classification. | ||
| Aharony 2019 [21] | 20 DR, 6 AMD, 4 RVO, 26 healthy 2D 3 × 3 mm2 | Frangi filter, Otsu thresholding. | No segmentation validation. Method proposed for classification. | ||
| Alam 2019a [30] | 100 images/50 subjects 2D 8 × 8 mm2 | bias field correction, matched filtering method, bottom hat filtering, global thresholding + adaptive thresholding, morphological operations. | No segmentation validation. Method proposed for classification. | ||
| Alam 2019b [42] | 60 DR, 90 SCR, 40 healthy 2D 6 × 6 mm2 | Frangi filter, adaptive thresholding with morphological functions, skeletonization. | No segmentation validation. Method proposed for classification. | ||
| Pappelis 2019 [31] | 30 healthy 2D 6 × 6 mm2 | Local Otsu thresholding for all vessels, big blood vessels masked out through Frangi and global thresholding. | No segmentation validation. Repeatability of vessel density and flux. | ||
| Xu 2019 [22] | 123 DR, 108 healthy 2D 6 × 6 mm2 | Multi-scale line detector, Otsu thresholding for large vessel segmentation. Frangi Hessian filter and global thresholding for all vessels segmentation, skeletonization. | No segmentation validation. Repeatability and differences between healthy and diseased. | ||
| Abdelsalam 2020 [32] | 30 DR, 30 NPDR, 40 healthy 2D 3 × 3 mm2 | Contrast and resolution enhancement, Frangi filter, global thresholding. | No segmentation validation. Method proposed for classification. | ||
| Andrade De Jesus 2020 [24] | 82 glaucoma, 39 healthy 2D 3 × 3 mm2 | Microvasculature: Foveal disc axis correction, global thresholding (88th percentile of image intensity histogram), morphological opening and closing, small object removal. Choroid: global thresholding (lower 40th percentile), keep largest connected component. | No segmentation validation. Method proposed for classification. | ||
| Borrelli 2020 [34] | 15 NPDR, 15 healthy 3D 3 × 3 mm2 | Projection removal algorithm, global default thresholding. | No segmentation validation. The 3D vascular volume and 3D perfusion density were reduced in DR eyes. | ||
| Mehta 2020 [44] | 13 healthy 2D 3 × 3 mm2 | Histogram normalizatioon, CLAHE, linear registration.11 binarization techniques: global default, global Huang, global IsoData, global mean, global Otsu, local Bernsen, local mean, local median, local Niblack, local Otsu, and local Phansalkar. | No segmentation validation. No thresholding method is highly repeatable across contrast changes. Quantification is more repeatable when using local thresholds. | ||
| Su 2020 [37] | 25 high myopic, 25 moderate, 25 healthy 2D 6 × 6 mm2 | Binarization through combination of (1) Hessian filter, Huang’s fuzzy thresholding method, (2) median local thresholding. | No segmentation validation. Flow deficit evaluation (mean subfoveal choroidal thickness). | ||
| Terheyden 2020 [20] | 26 images 2D - | Comparison between Manual, Huang, Li, Otsu, Moments, Mean, Percentile thresholding techniques. | No segmentation validation. Reproducibility was higher with automated methods vs. manual. | ||
| Zhang 2020 [27] | 20 NPDR, 40 PDR, 40 controls 3D 3 × 3 × 2 mm3 | Curvelet denoising and optimally oriented flux (OOF) filtering, global thresholding (threshold = 0.14). | DSC = 0.8587 for normal, 0.8520 for severe NPDR, 0.8434 for PDR, using 2D projections. | ||
| Abdelsalam 2021 [33] | 80 DR, 90 healthy 2D 3 x 3 mm2 | Contrast and resolution enhancement, global thresholding. | No segmentation validation. Method proposed for classification. | ||
| Wu 2021 [23] | 14 subjects 2D 6 × 6 mm2 | Matched filtering vs. preprocessing: image cropping and color space conversion, Otsu thresholding, skeletonizationo, artefacts elimination. | No segmentation validation. Analysis of NVC with PRD treatment. | ||
| Clustering | Khansari 2017 [64] | 41 subjects 2D 3 × 3 mm2 & 6 × 6 mm2 | K-means clustering for segmentation, morphological operators. | No segmentation validation. Vessel tortuosity index comparison and correlation. | |
| Engberg 2019 [68] | 10 patients, 10 healthy 2D 3 × 3 mm2 | Dictionary-based method using pre-annotated data and then processing unseen images | On one validation image: DSC = 0.82 for larger vessels, 0.71 for capillaries, and 0.76 for background. | ||
| Cano 2020 [65] | 33 no DR, 26 mild NPDR, 13 PDR, 22 healthy 2D 6 × 6 mm2 | K- means clustering. | No segmentation validation. Method proposed for classification. | ||
| Chavan 2021 [63] | 41 subjects 2D 6 × 6 mm2 | Multiscale and multi span line detectors, k-means clustering into 2 classes, morphological closing. | No segmentation validation. Comparison between parameters and male and female, age, etc. | ||
| Active Contour Models | Eladawi 2017 [69] | 24 diabetic, 23 healthy 2D 6 × 6 mm2 | GGMRF model for contrast improvement, joint Markov Gibbs model to segment, hOMGRF moodel to overcome low contrast, segmentation refinement with 2D connectivity filter. | DSC = 0.9504 ± 0.0375 | |
| Sandhu 2018 [70] | 82 mild DR, 23 healthy 2D 6 × 6 mm2 | GGMRF model for contrast improvement, joint Markov Gibbs model to segment, hOMGRF moodel to overcome low contrast, segmentation refinement with 2D connectivity filter. | DSC = 0.9502 ± 0.0443 | ||
| Wu 2020 [71] | 30 images 2D 3 × 3 mm2 | Stripe removal and segmentation using global minimization of the active contour model (GMAC). | Accuracy = 0.93 | ||
| Deep Learning | Prentasic 2016 [58] | 80 images/6 subjects 2D 1 × 1 mm2 | Custom architecture: Square filters convolutions (ReLU), max pooling, dropout layer, two fully connected layers, final fully connected layer. Three fold cross validation. | Mean accuracy = 0.83 F1 measure = 0.67 | |
| Giarratano 2020 [11] | 50 ROIs on images 2D 6 × 6 mm2 | UNet, CS-NET + thresholding, morphological opening. | UNet DSC = 0.89 CS-Net DSC = 0.89 | ||
| Li 2020 [54] | 316 volumes 3D to 2D 6 × 6 × 2 mm3 | VGG projection learning module (unidirectional pooling layer). Input 3D data and output 2D segmentation. | DSC = 0.8815 | ||
| Lo 2020 [50] | Test: 28 DR, 8 healthy 2D 6 × 6 mm2 | UNet variation, adapted for vessel and background. Fine-tuned network using a transfer learning method. | SCP DSC = 0.8599 DVC DSC = 0.7986 | ||
| Pissas 2020 [51] | 50 subjects 2D & 3D 8 × 8 mm2 | UNet modified architecture with iterative refinement (stacked hourglass network SHN distinct cascaded UNet modules, and single network employed by recurrently feeding intermediate predictions in the network to obtain refined predictions (iUNet). | DSC = 0.8540 | ||
| Ma 2021 [13] | 229 images 2D 3 × 3 mm2 | OCTA-Net: ResNet style. Coarse stage (split-based coarse segmentation (SCS) module to produce preliminary confidence maps) and fine stage (split-based refined segmentation (SRS) module to fuse vessel confidence maps to produce the final optimized results). | SVC DSC = 0.7597 DVC DSC = 0.7074 Both DSC = 0.7576 | ||
| Li preprint [55] | 500 images 3D to 2D 3 × 3 mm2 & 6 × 6 mm2 | IPN-V2: addition of plane perceptron to enhance the perceptron ability in the horizontal direction + global retraining. 3D volume to 2D segmentation. | 6x6 DSC = 0.8941 3x3 DSC = 0.9274 | ||
| Yu 2021 [52] | 80 images 2D to 3D 3 × 3 mm2 | Structure-constraint UNet architecture with feature encoder module, feature decoder module, and structure constraint blocks (SCB) for depth map estimation. From 2D segmentation to 3D space. | No segmentation validation. Depth prediction method is validated. | ||
| Foveal Avascular Zone (FAZ) | Thresholding | Alam 2017 [28] | 36 SCR, 26 healthy 2D 3 × 3 mm2 | Global thresholding, morphological functions, and fractal dimension analysis. | No segmentation validation. FAZ contour irregularity was more sensitive to SCR presence then FAZ area. |
| Xu 2019 [22] | 123 DR, 108 healthy 2D 6 × 6 mm2 | Multi-scale line detector, Otsu thresholding for large vessel segmentation. Frangi Hessian filter and global thresholding for all vessels segmentation, skeletonization. | DSC = 0.90 | ||
| Edge detector | Diaz 2019 [75] | 213 subjects 2D 3 × 3 mm2 & 6 × 6 mm2 | Morphological operators, white top-hat operator, Canny edge detector, morphological closing, inversion, removal of small objects. | Jaccard = 0.82 | |
| Active Contour Models | Lu 2018 [73] | 66 DR, 19 healthy 2D 3 × 3 mm2 | GGVF snake model. | Jaccard = 0.87 ± 0.06 (healthy) 0.86 ± 0.09 (diabetes with DR) 0.89 ± 0.05 (mild NPDR) 0.83 ± 0.09 (sever NPDR or PDR) | |
| Sandhu 2018 [70] | 82 mild DR, 23 healthy 2D 6 × 6 mm2 | GGMRF model for contrast improvement, joint Markov Gibbs model to segment, hOMGRF moodel to overcome low contrast, segmentation refinement with 2D connectivity filter. | DSC = 0.93 ± 0.06 | ||
| Lin 2020 [72] | 20 training / 37 test 2D 3 × 3 mm2 | Level Set model (ImageJ). | DSC = 0.9243 | ||
| Deep learning | Guo 2019 [60] | 405 images 2D 3 × 3 mm2 | UNet, thresholding and largest connected region extraction and hole filling. | DSC = 0.9760 | |
| Li 2020 [54] | 316 volumes 3D to 2D 6 × 6 × 2 mm3 | VGG projection learning module (unidirectional pooling layer). Input 3D data and output 2D segmentation. | DSC = 0.8861 | ||
| Guo 2021 [57] | 80 subjects 2D 3 × 3 mm2 | Normalization, custom made network: boundary alignment module (BAM) implemented to extract global information. | DSC = 0.88 | ||
| Li preprint [55] | 500 images 3D to 2D 3 × 3 mm2 & 6 × 6 mm2 | IPN-V2: addition of plane perceptron to enhance the perceptron ability in the horizontal direction + global retraining. 3D volume to 2D segmentation. | 6x6 DSC = 0.9084 3x3 DSC = 0.9755 | ||
| CNV / Choriocapillaris | Thresholding | Cheng 2019 [18] | 17 CNV 2D - | CIELAB color space transformation, Otsu thresholding, majority, size filter. | No segmentation validation. Discussion of features |
| Laiginhas 2020 [19] | 18 images 2D - | Projection artefact removal, local thresholding (Phansalkar, mean, Niblack) and global thresholding (mean, default, Otsu). | No segmentation validation. Local thresholding methods are more robust and reproducible. | ||
| Clustering | Taibouni 2019 [66] | 54 patients 2D 3 × 3 mm2 | Frangi filter, Gabor wavelets and fuzzy c-means classification. | No segmentation validation. Quantitative parameters compared with manual software. | |
| Xue 2019 [67] | 48 AMD 2D - | Global threshold (0.3), median filter, grid tissue-like membrane system modified CLIQUE clustering algorithm. | DSC = 0.84 | ||
| Machine learning | Gao 2017 [77] | 30 images/19 CNV 2D 6 × 6 mm2 | Random forest classifier (structural OCT images, inner retinal and choroidal angiograms, standard deviation, and directional Gabor filters at multiple scales). | Jaccard = 0.81 ± 0.12 | |
| Deep learning | Wang 2020 [61] | Test 100 CNV, 120 non-CNV 2D 3 × 3 mm2 | Custom CNNs: one for CNV membrane identification and segmentation and one for pixel wise vessel segmentation. | Max IoU = 0.88 | |
| Skin vasculature | Thresholding | Liew 2012 [76] | 8 scar patients 2D MIP 4 × 1.5 × 3 mm3 | Tissue surface segmentation (Canny edge), global thresholding, skeletonization. | No segmentation validation. Parameter analysis for normal vs. scar tissue |
| Meiburger 2019 [25] | 7 BCC patients 3D 10 x 10 x 1.2 mm3 | Frangi, global thresholding per image slice, adaptive among volume, skeletonization. | Validation of parameters vs semi-automated segmentation. High intra-operator variability for semi-automatic segmentation. | ||
| Zhang 2020 [41] | 10 subjects–2 sites 3D 2.5 × 2.5 × 2.5 mm3 | ID-BISIM threshold: SNR adaptive binarization method based on the linear boundary of static signals in ID space | Sensitivity = 0.83 ± 0.15 Specificity = 0.98 ± 0.01 |
3.2. Classification Tasks
3.2.1. Machine Learning
3.2.2. Deep Learning
| Task | Method | First Author (Year) | Database 2D/3D Field of View (FOV) | Description | Results |
|---|---|---|---|---|---|
| Diabetic retinopathy classification | Machine learning | Sandhu 2018 [70] | 82 DR, 23 healthy 2D 6 × 6 mm2 | Features: blood vessel density, blood vessel caliber, distance map of FAZ area. Classifier: SVM classifier with RBF. | AUC = 95.22% |
| Aharony 2019 [21] | 20 DR, 6 AMD, 4 RVO, 26 healthy 2D 3 × 3 mm2 | Features: mean, standard deviation, skewness, and kurtosis of gray level histogram. No formal classifier. | Accuracy = 83.9% | ||
| Abdelsalam 2020 [32] | 30 DR, 30 NPDR, 40 healthy 2D 3 × 3 mm2 | Features: mean of the intercapillary areas, FAZ perimeter, circularity index, and vascular density. Classifier: neural network | Total Accuracy = 97% Precision = 95.2% (healthy vs. diabetic) 96.7% (DR vs. NPDR) | ||
| Cano 2020 [65] | 33 no DR, 26 mild NPDR, 13 PDR, 22 healthy 2D 6 × 6 mm2 | Features: Vessel tortuosity, fractal dimension ratio (FDR). Classifier: Ordinary least squares modeling method. | PDR Accuracy = 94% Mild NPDR vs. healthy Accuracy = 91% | ||
| Abdelsalam 2021 [33] | 80 DR, 90 healthy 2D 3 × 3 mm2 | Features: multifractal parameter computation (maximum, shift, width, lacunarity, box counting dimension, information dimension, correlation dimension). Classifier: SVM. | Accuracy = 98.5% | ||
| Liu 2021 [84] | 114 DR, 132 healthy 2D 3 × 3 mm2 | Features: wavelet transform on SVP, DVP, RVN. Classifiers: LR, LR-EN, SVM, XGBoost. | Sensitivity = 84% Specificity = 80% | ||
| Deep learning | Heisler 2020 [86] | 463 volumes 2D 3 × 3 mm2 | VGG19, ResNet50, and DenseNet with superficial and deep plexus images, majority soft voting. | Ensemble network accuracy = 92 ± 1.92% | |
| Le 2020 [89] | 75 DR, 24 diabetes, 32 healthy 2D 6 × 6 mm2 | VGG16. | Accuracy = 87.27% AUC = 0.97 (healthy) 0.98 (no DR) 0.97 (DR) | ||
| Zang 2021 [90] | 303 images 2D 3 × 3 mm2 | A densely and continuously connected neural network with adaptive rate dropout (DcardNet). | Accuracy = 96.5% (two class) 80.0% (three classes) 67.9% (four classes) | ||
| Glaucoma classification | Machine learning | Ong 2017 [29] | 38 glaucoma, 120 healthy 2D 6 × 6 mm2 | Features: Haralick’s texture features, inverse difference normalized and inverse difference moment normalized features, global features (including mean, standard deviation, skewness, kurtosis, and entropy), local structure features, thresholded cumulative count of microvasculature pixels). Classifier: SVM. | Specificity = 0.95 Sensitivity = 0.87 AUC = 0.98 |
| Andrade De Jesus 2020 [24] | 82 glaucoma, 39 healthy 2D 3 × 3 mm2 | Features: microvascular intensity median computed on 6 layers and 7 sectors. Classifiers: SVM, random forest, and gradient boosting. | AUC = 0.76± 0.06 (xGB) AUC = 0.67± 0.06 (RNFL) | ||
| Age-Related Macular Degeneration Classification | Machine learning | Alfahaid 2018 [83] | 92 AMD, 92 healthy 2D - | Features: rotation invariant uniform local binary pattern texture features. Classifier: KNN classifier | Accuracy = 89% (all layers) 89% (superficial) 94% (deep) 98% (outer) 100% (choriocapillaris) |
| Deep learning | Thakoor 2021 [91] | 160 non-NV-AMD, 80 NV-AMD, 97 healthy 2D - | Custom-made 3D CNN, consisting of 4 3D convolutional layers, two dense layers, and final softmax classification. | Accuracy = 93.4% (NV-AMD vs. healthy) 77.8% (NV-AMD vs. non-NV-AMD vs. healthy) | |
| Artery/vein classification | Machine learning | Alam 2019 [30] | 100 images 2D 8 × 8 mm2 | Features: ratio of vessel width to central reflex, average of maximum profile brightness, average of median profile intensity, optical density of vessel boundary intensity compared to background intensity. Classifier: K-means clustering | All vessel Sensitivity = 0.9679 Specificity = 0.9572 Accuracy = 96.57% AUC = 98.05% |
| Deep learning | Alam 2020 [78] | 30 DR, 20 healthy 2D 6 × 6 mm2 | Enface fully connected network based on UNet | Accuracy = 86.75% | |
| Central Serous Chorio- retinopathy classification | Deep learning | Aoyama 2021 [92] | 53 CSC, 47 healthy 2D 12 × 12 mm2 | VGG16 pretrained model | Accuracy = 95% |
| Sickle cell retinopathy classification | Machine learning | Alam 2017 [87] | 35 SCD, 14 healthy 2D - | Features: BVT, BVC, VPI, FAZ area, FAZ contour irregularity, PAD. Classifiers: SVM, KNN, discriminant analysis | Accuracy = 97% (SVM) 95% (KNN) 88% (discriminant analysis) |
| Retinopathy classification | Machine learning | Alam 2019 [42] | 60 DR, 90 SCR, 40 healthy 2D 6 × 6 mm2 | Features: BVT, BVC, VPI, BVD, FAZ area, FAZ contour irregularity. Classifier: SVM | Accuracy = 97.45% (healthy vs. disease) 94.32% (DR vs SCR) 89.60% (NPDR staging) 93.11% (SCR staging) |
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Spaide, R.F.; Fujimoto, J.G.; Waheed, N.K.; Sadda, S.R.; Staurenghi, G. Optical coherence tomography angiography. Prog. Retin. Eye Res. 2018, 64, 1–55. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Milner, T.E.; Srinivas, S.; Wang, X.; Malekafzali, A.; van Gemert, M.J.C.; Nelson, J.S. Noninvasive imaging of in vivo blood flow velocity using optical Doppler tomography. Opt. Lett. 1997, 22, 1119–1121. [Google Scholar] [CrossRef]
- Kashani, A.H.; Chen, C.L.; Gahm, J.K.; Zheng, F.; Richter, G.M.; Rosenfeld, P.J.; Shi, Y.; Wang, R.K. Optical coherence tomography angiography: A comprehensive review of current methods and clinical applications. Prog. Retin. Eye Res. 2017, 60, 66–100. [Google Scholar] [CrossRef]
- Wang, R.K. Optical Microangiography: A Label-Free 3-D Imaging Technology to Visualize and Quantify Blood Circulations Within Tissue Beds In Vivo. IEEE J. Sel. Top. Quantum Electron. 2010, 16, 545–554. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.; Tan, O.; Tokayer, J.; Potsaid, B.; Wang, Y.; Liu, J.J.; Kraus, M.F.; Subhash, H.; Fujimoto, J.G.; Hornegger, J.; et al. Split-spectrum amplitude-decorrelation angiography with optical coherence tomography. Opt. Express 2012, 20, 4710. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, M.; Drexler, W. Optical coherence tomography angiography and photoacoustic imaging in dermatology. Photochem. Photobiol. Sci. 2019, 18, 945–962. [Google Scholar] [CrossRef]
- Tey, K.Y.; Teo, K.; Tan, A.C.S.; Devarajan, K.; Tan, B.; Tan, J.; Schmetterer, L.; Ang, M. Optical coherence tomography angiography in diabetic retinopathy: A review of current applications. Eye Vis. 2019, 6, 1–10. [Google Scholar] [CrossRef]
- Sun, Z.; Yang, D.; Tang, Z.; Ng, D.S.; Cheung, C.Y. Optical coherence tomography angiography in diabetic retinopathy: An updated review. Eye 2021, 35, 149–161. [Google Scholar] [CrossRef]
- Perrott-Reynolds, R.; Cann, R.; Cronbach, N.; Neo, Y.N.; Ho, V.; McNally, O.; Madi, H.A.; Cochran, C.; Chakravarthy, U. The diagnostic accuracy of OCT angiography in naive and treated neovascular age-related macular degeneration: A review. Eye 2019, 33, 274–282. [Google Scholar] [CrossRef]
- Van Melkebeke, L.; Barbosa-Breda, J.; Huygens, M.; Stalmans, I. Optical Coherence Tomography Angiography in Glaucoma: A Review. Ophthalmic Res. 2018, 60, 139–151. [Google Scholar] [CrossRef] [PubMed]
- Giarratano, Y.; Bianchi, E.; Gray, C.; Morris, A.; Macgillivray, T.; Dhillon, B.; Bernabeu, M.O. Automated segmentation of optical coherence tomography angiography images: Benchmark data and clinically relevant metrics. Transl. Vis. Sci. Technol. 2020, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Yao, X.; Alam, M.N.; Le, D.; Toslak, D. Quantitative optical coherence tomography angiography: A review. Exp. Biol. Med. 2020, 245, 301–312. [Google Scholar] [CrossRef]
- Ma, Y.; Hao, H.; Xie, J.; Fu, H.; Member, S.; Zhang, J.; Yang, J.; Wang, Z.; Liu, J.; Zheng, Y.; et al. ROSE: A Retinal OCT-Angiography Vessel Segmentation Dataset and New Model mentation models and our OCTA-Net on the constructed ROSE dataset. IEEE Trans. Med. Imaging 2021, 40, 928–939. [Google Scholar] [CrossRef]
- Schottenhamml, J.; Moult, E.M.; Ploner, S.B.; Chen, S.; Novais, E.; Husvogt, L.; Duker, J.S.; Waheed, N.K.; Fujimoto, J.G.; Maier, A.K. OCT-OCTA segmentation: Combining structural and blood flow information to segment Bruch’s membrane. Biomed. Opt. Express 2021, 12, 84. [Google Scholar] [CrossRef]
- Guo, Y.; Camino, A.; Zhang, M.; Wang, J.; Huang, D.; Hwang, T.; Jia, Y. Automated segmentation of retinal layer boundaries and capillary plexuses in wide-field optical coherence tomographic angiography. Biomed. Opt. Express 2018, 9, 4429. [Google Scholar] [CrossRef]
- EyeWiki. Available online: https://eyewiki.aao.org/File:2.jpg (accessed on 12 October 2021).
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man. Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Y.-S.; Lin, S.-H.; Hsiao, C.-Y.; Chang, C.-J. Detection of Choroidal Neovascularization by Optical Coherence Tomography Angiography with Assistance from Use of the Image Segmentation Method. Appl. Sci. 2020, 10, 137. [Google Scholar] [CrossRef] [Green Version]
- Laiginhas, R.; Cabral, D.; Falcão, M. Evaluation of the different thresholding strategies for quantifying choriocapillaris using optical coherence tomography angiography. Quant. Imaging Med. Surg. 2020, 10. [Google Scholar] [CrossRef]
- Terheyden, J.H.; Wintergerst, M.W.M.; Falahat, P.; Berger, M.; Holz, F.G.; Finger, R.P. Automated thresholding algorithms outperform manual thresholding in macular optical coherence tomography angiography image analysis. PLoS ONE 2020, 15, e0230260. [Google Scholar] [CrossRef] [Green Version]
- Aharony, O.; Gal-Or, O.; Polat, A.; Nahum, Y.; Weinberger, D.; Zimmer, Y. Automatic characterization of retinal blood flow using OCT angiograms. Transl. Vis. Sci. Technol. 2019, 8, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Chen, C.; Ding, W.; Yang, P.; Lu, H.; Xu, F.; Lei, J. Automated quantification of superficial retinal capillaries and large vessels for diabetic retinopathy on optical coherence tomographic angiography. J. Biophotonics 2019, 12. [Google Scholar] [CrossRef]
- Wu, S.; Wu, S.; Feng, H.; Hu, Z.; Xie, Y.; Su, Y.; Feng, T.; Li, L. An optimized segmentation and quantification approach in microvascular imaging for OCTA-based neovascular regression monitoring. BMC Med. Imaging 2021, 21, 1–9. [Google Scholar] [CrossRef]
- Andrade De Jesus, D.; Sánchez Brea, L.; Barbosa Breda, J.; Fokkinga, E.; Ederveen, V.; Borren, N.; Bekkers, A.; Pircher, M.; Stalmans, I.; Klein, S.; et al. OCTA multilayer and multisector peripapillary microvascular modeling for diagnosing and staging of glaucoma. Transl. Vis. Sci. Technol. 2020, 9, 1–22. [Google Scholar] [CrossRef]
- Meiburger, K.M.; Chen, Z.; Sinz, C.; Hoover, E.; Minneman, M.; Ensher, J.; Kittler, H.; Leitgeb, R.A.; Drexler, W.; Liu, M. Automatic skin lesion area determination of basal cell carcinoma using optical coherence tomography angiography and a skeletonization approach: Preliminary results. J. Biophotonics 2019, 12, 201900131. [Google Scholar] [CrossRef] [PubMed]
- Salvi, M.; Molinari, F. Multi-tissue and multi-scale approach for nuclei segmentation in H&E stained images. Biomed. Eng. Online 2018, 17, 89. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Qiao, Y.; Sarabi, M.S.; Khansari, M.M.; Gahm, J.K.; Kashani, A.H.; Shi, Y. 3D Shape Modeling and Analysis of Retinal Microvasculature in OCT-Angiography Images. IEEE Trans. Med. Imaging 2020, 39, 1335–1346. [Google Scholar] [CrossRef]
- Alam, M.; Thapa, D.; Lim, J.I.; Cao, D.; Yao, X. Quantitative characteristics of sickle cell retinopathy in optical coherence tomography angiography. Biomed. Opt. Express 2017, 8, 1741. [Google Scholar] [CrossRef] [Green Version]
- Ong, E.P.; Cheng, J.; Wong, D.W.K.; Liu, J.; Tay, E.L.T.; Yip, L.W.L. Glaucoma classification from retina optical coherence tomography angiogram. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Korea, 11–15 July 2017; pp. 596–599. [Google Scholar] [CrossRef]
- Alam, M.; Toslak, D.; Lim, J.I.; Yao, X. OCT feature analysis guided artery-vein differentiation in OCTA. Biomed. Opt. Express 2019, 10, 2055. [Google Scholar] [CrossRef]
- Pappelis, K.; Jansonius, N.M.; Pap-Pelis, K. Quantification and Repeatability of Vessel Density and Flux as Assessed by Optical Coherence Tomography Angiography. Transl. Vis. Sci. Technol. 2019, 8, 3. [Google Scholar] [CrossRef]
- Abdelsalam, M.M. Effective blood vessels reconstruction methodology for early detection and classification of diabetic retinopathy using OCTA images by artificial neural network. Inform. Med. Unlocked 2020, 20, 100390. [Google Scholar] [CrossRef]
- Abdelsalam, M.M.; Zahran, M.A. A Novel Approach of Diabetic Retinopathy Early Detection Based on Multifractal Geometry Analysis for OCTA Macular Images Using Support Vector Machine. IEEE Access 2021, 9, 22844–22858. [Google Scholar] [CrossRef]
- Borrelli, E.; Sacconi, R.; Querques, L.; Battista, M.; Bandello, F.; Querques, G. Quantification of diabetic macular ischemia using novel three-dimensional optical coherence tomography angiography metrics. J. Biophotonics 2020, 13, e202000152. [Google Scholar] [CrossRef]
- Phansalkar, N.; More, S.; Sabale, A.; Joshi, M. Adaptive local thresholding for detection of nuclei in diversity stained cytology images. In Proceedings of the ICCSP 2011—2011 International Conference on Communications and Signal Processing, Kerala, India, 10–12 February 2011; pp. 218–220. [Google Scholar]
- Mehta, N.; Liu, K.; Alibhai, A.Y.; Gendelman, I.; Braun, P.X.; Ishibazawa, A.; Sorour, O.; Duker, J.S.; Waheed, N.K. Impact of Binarization Thresholding and Brightness/Contrast Adjustment Methodology on Optical Coherence Tomography Angiography Image Quantification. Am. J. Ophthalmol. 2019, 205, 54–65. [Google Scholar] [CrossRef] [PubMed]
- Su, L.; Ji, Y.S.; Tong, N.; Sarraf, D.; He, X.; Sun, X.; Xu, X.; Sadda, S.V.R. Quantitative assessment of the retinal microvasculature and choriocapillaris in myopic patients using swept-source optical coherence tomography angiography. Graefe’s Arch. Clin. Exp. Ophthalmol. 2020, 258, 1173–1180. [Google Scholar] [CrossRef]
- Chu, Z.; Cheng, Y.; Zhang, Q.; Zhou, H.; Dai, Y.; Shi, Y.; Gregori, G.; Rosenfeld, P.J.; Wang, R.K. Quantification of Choriocapillaris with Phansalkar Local Thresholding: Pitfalls to Avoid. Am. J. Ophthalmol. 2020, 213, 161–176. [Google Scholar] [CrossRef] [PubMed]
- Chu, Z.; Lin, J.; Gao, C.; Xin, C.; Zhang, Q.; Chen, C.-L.; Roisman, L.; Gregori, G.; Rosenfeld, P.J.; Wang, R.K. Quantitative assessment of the retinal microvasculature using optical coherence tomography angiography. J. Biomed. Opt. 2016, 21, 066008. [Google Scholar] [CrossRef] [Green Version]
- Kim, A.Y.; Chu, Z.; Shahidzadeh, A.; Wang, R.K.; Puliafito, C.A.; Kashani, A.H. Quantifying Microvascular Density and Morphology in Diabetic Retinopathy Using Spectral-Domain Optical Coherence Tomography Angiography. Investig. Ophthalmol. Vis. Sci. 2016, 57, OCT362. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, H.; Cao, T.; Chen, R.; Qiu, H.; Gu, Y.; Li, P. Automatic 3D adaptive vessel segmentation based on linear relationship between intensity and complex-decorrelation in optical coherence tomography angiography. Quant. Imaging Med. Surg. 2021, 11, 895–906. [Google Scholar] [CrossRef] [PubMed]
- Alam; Le; Lim; Chan; Yao Supervised Machine Learning Based Multi-Task Artificial Intelligence Classification of Retinopathies. J. Clin. Med. 2019, 8, 872. [CrossRef] [PubMed] [Green Version]
- Rabiolo, A.; Gelormini, F.; Sacconi, R.; Cicinelli, M.V.; Triolo, G.; Bettin, P.; Nouri-Mahdavi, K.; Bandello, F.; Querques, G. Comparison of methods to quantify macular and peripapillary vessel density in optical coherence tomography angiography. PLoS ONE 2018, 13, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Mehta, N.; Braun, P.X.; Gendelman, I.; Alibhai, A.Y.; Arya, M.; Duker, J.S.; Waheed, N.K. Repeatability of binarization thresholding methods for optical coherence tomography angiography image quantification. Sci. Rep. 2020, 10, 15368. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Samek, W.; Wiegand, T.; Müller, K.-R. Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models. arXiv 2017, arXiv:1708.08296. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Lecture Notes in Computer Science (Including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics). Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Hormel, T.T.; Xiong, H.; Wang, B.; Camino, A.; Wang, J.; Huang, D.; Hwang, T.S.; Jia, Y. Development and validation of a deep learning algorithm for distinguishing the nonperfusion area from signal reduction artifacts on OCT angiography. Biomed. Opt. Express 2019, 10, 3257–3268. [Google Scholar] [CrossRef]
- Lo, J.; Heisler, M.; Vanzan, V.; Karst, S.; Zadro, I.; Matovinović, M.; Lončarić, S.L.; Navajas, E.V.; Faisal Beg, M.; Šarunić, M. V Microvasculature Segmentation and Intercapillary Area Quantification of the Deep Vascular Complex Using Transfer Learning. Transl. Vis. Sci. Technol. 2020, 9, 38. [Google Scholar] [CrossRef]
- Pissas, T.; Bloch, E.; Cardoso, M.J.; Flores, B.; Georgiadis, O.; Jalali, S.; Ravasio, C.; Stoyanov, D.; Da Cruz, L.; Bergeles, C. Deep iterative vessel segmentation in OCT angiography. Biomed. Opt. Express 2020, 11, 2490. [Google Scholar] [CrossRef]
- Yu, S.; Xie, J.; Hao, J.; Zheng, Y.; Zhang, J.; Hu, Y.; Liu, J.; Zhao, Y. 3D vessel reconstruction in OCT-angiography via depth map estimation. In Proceedings of the International Symposium on Biomedical Imaging, Nice, France, 13–16 April 2021; pp. 1609–1613. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Li, M.; Chen, Y.; Ji, Z.; Xie, K.; Yuan, S.; Chen, Q.; Li, S. Image Projection Network: 3D to 2D Image Segmentation in OCTA Images. IEEE Trans. Med. Imaging 2020, 39, 3343–3354. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Y.; Ji, Z.; Xie, K.; Yuan, S.; Liu, Q.; Chen, Q. IPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation. arXiv 2020, arXiv:2012.07261. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, M.; Zhao, M.; Cheong, A.M.; Corvi, F.; Chen, X.; Chen, S.; Zhou, Y.; Lam, A.K. Can deep learning improve the automatic segmentation of deep foveal avascular zone in optical coherence tomography angiography? Biomed. Signal Process. Control 2021, 66, 102456. [Google Scholar] [CrossRef]
- Prentašic, P.; Heisler, M.; Mammo, Z.; Lee, S.; Merkur, A.; Navajas, E.; Beg, M.F.; Šarunic, M.; Loncaric, S. Segmentation of the foveal microvasculature using deep learning networks. J. Biomed. Opt. 2016, 21, 075008. [Google Scholar] [CrossRef]
- Mou, L.; Zhao, Y.; Chen, L.; Cheng, J.; Gu, Z.; Hao, H.; Qi, H.; Zheng, Y.; Frangi, A.; Liu, J. CS-Net: Channel and Spatial Attention Network for Curvilinear Structure Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 721–730. [Google Scholar]
- Guo, M.; Zhao, M.; Cheong, A.M.Y.; Dai, H.; Lam, A.K.C.; Zhou, Y. Automatic quantification of superficial foveal avascular zone in optical coherence tomography angiography implemented with deep learning. Vis. Comput. Ind. Biomed. Art 2019, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Hormel, T.T.; Gao, L.; Zang, P.; Guo, Y.; Wang, X.; Bailey, S.T.; Jia, Y. Automated diagnosis and segmentation of choroidal neovascularization in OCT angiography using deep learning. Biomed. Opt. Express 2020, 11, 927–944. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Clustering Methods. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2005; pp. 321–352. [Google Scholar]
- Chavan, A.; Mago, G.; Balaji, J.J.; Lakshminarayanan, V. A New Method for Quantification of Retinal Blood Vessel Characteristics. In Proceedings of the Ophthalmic Technologies XXXI, International Society for Optics and Photonics, Online Virtual Conference. 5 March 2021; Volume 1162320. [Google Scholar]
- Khansari, M.M.; O’Neill, W.; Lim, J.; Shahidi, M. Method for quantitative assessment of retinal vessel tortuosity in optical coherence tomography angiography applied to sickle cell retinopathy. Biomed. Opt. Express 2017, 8, 3796. [Google Scholar] [CrossRef] [PubMed]
- Cano, J.; O’neill, W.D.; Penn, R.D.; Blair, N.P.; Kashani, A.H.; Ameri, H.; Kaloostian, C.L.; Shahidi, M. Classification of advanced and early stages of diabetic retinopathy from non-diabetic subjects by an ordinary least squares modeling method applied to OCTA images. Biomed. Opt. Express 2020, 11, 4666. [Google Scholar] [CrossRef] [PubMed]
- Taibouni, K.; Chenoune, Y.; Miere, A.; Colantuono, D.; Souied, E.; Petit, E. Automated quantification of choroidal neovascularization on Optical Coherence Tomography Angiography images. Comput. Biol. Med. 2019, 114, 103450. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Yan, S.; Wang, Y.; Liu, T.; Qi, F.; Zhang, H.; Qiu, C.; Qu, J.; Liu, X.; Li, D. Unsupervised Segmentation of Choroidal Neovascularization for Optical Coherence Tomography Angiography by Grid Tissue-Like Membrane Systems. IEEE Access 2019, 143058–143066. [Google Scholar] [CrossRef]
- Engberg, A.M.E.; Erichsen, J.H.; Sander, B.; Kessel, L.; Dahl, A.B.; Dahl, V.A. Automated Quantification of Retinal Microvasculature from OCT Angiography using Dictionary-Based Vessel Segmentation. In Medical Image Understanding and Analysis; Springer: Berlin/Heidelberg, Germany, 2019; pp. 257–269. ISBN 9783030393427. [Google Scholar]
- Eladawi, N.; Elmogy, M.; Helmy, O.; Aboelfetouh, A.; Riad, A.; Sandhu, H.; Schaal, S.; El-Baz, A. Automatic blood vessels segmentation based on different retinal maps from OCTA scans. Comput. Biol. Med. 2017, 89, 150–161. [Google Scholar] [CrossRef]
- Sandhu, H.S.; Eladawi, N.; Elmogy, M.; Keynton, R.; Helmy, O.; Schaal, S.; El-Baz, A. Automated diabetic retinopathy detection using optical coherence tomography angiography: A pilot study. Br. J. Ophthalmol. 2018, 102, 1564–1569. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Gao, D.; Williams, B.M.; Stylianides, A.; Zheng, Y.; Jin, Z. Joint Destriping and Segmentation of OCTA Images. In Proceedings of the Annual Conference on Medical Image Understanding and Analysis, Online Virtual Conference. 15–17 July 2020; Volume 1065, pp. 423–435. [Google Scholar]
- Lin, A.; Fang, D.; Li, C.; Cheung, C.Y.; Chen, H. Improved Automated Foveal Avascular Zone Measurement in Cirrus Optical Coherence Tomography Angiography Using the Level Sets Macro. Transl. Vis. Sci. Technol. 2020, 9, 20. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Simonett, J.M.; Wang, J.; Zhang, M.; Hwang, T.; Hagag, A.M.; Huang, D.; Li, D.; Jia, Y. Evaluation of automatically quantified foveal avascular zone metrics for diagnosis of diabetic retinopathy using optical coherence tomography angiography. Investig. Ophthalmol. Vis. Sci. 2018, 59, 2212–2221. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef]
- Díaz, M.; Novo, J.; Cutrín, P.; Gómez-Ulla, F.; Penedo, M.G.; Ortega, M. Automatic segmentation of the foveal avascular zone in ophthalmological OCT-A images. PLoS ONE 2019, 14, 1–22. [Google Scholar] [CrossRef]
- Liew, Y.M.; McLaughlin, R.A.; Gong, P.; Wood, F.M.; Sampson, D.D. In vivo assessment of human burn scars through automated quantification of vascularity using optical coherence tomography. J. Biomed. Opt. 2012, 18, 061213. [Google Scholar] [CrossRef]
- Gao, S.S.; Patel, R.C.; Jain, N.; Zhang, M.; Weleber, R.G.; Huang, D.; Pennesi, M.E.; Jia, Y. Choriocapillaris evaluation in choroideremia using optical coherence tomography angiography. Biomed. Opt. Express 2017, 8, 48. [Google Scholar] [CrossRef] [Green Version]
- Alam, M.; Le, D.; Son, T.; Lim, J.I.; Yao, X. AV-Net: Deep learning for fully automated artery-vein classification in optical coherence tomography angiography. Biomed. Opt. Express 2020, 11, 5249. [Google Scholar] [CrossRef]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505–515. [Google Scholar] [CrossRef] [PubMed]
- Saha, P.K.; Borgefors, G.; Sanniti di Baja, G. A survey on skeletonization algorithms and their applications. Pattern Recognit. Lett. 2016, 76, 3–12. [Google Scholar] [CrossRef]
- Meiburger, K.M.; Nam, S.Y.; Chung, E.; Suggs, L.J.; Emelianov, S.Y.; Molinari, F. Skeletonization algorithm-based blood vessel quantification using in vivo 3D photoacoustic imaging. Phys. Med. Biol. 2016, 61, 7994–8009. [Google Scholar] [CrossRef] [PubMed]
- Molinari, F.; Meiburger, K.M.; Giustetto, P.; Rizzitelli, S.; Boffa, C.; Castano, M.; Terreno, E. Quantitative Assessment of Cancer Vascular Architecture by Skeletonization of High-resolution 3-D Contrast-enhanced Ultrasound Images: Role of Liposomes and Microbubbles. Technol. Cancer Res. Treat. 2014, 13, 541–550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alfahaid, A.; Morris, T. An Automated Age-Related Macular Degeneration Classification Based on Local Texture Features in Optical Coherence Tomography Angiography. In Proceedings of the Annual Conference on Medical Image Understanding and Analysis, Southampton, UK, 9–11 July 2018; pp. 189–200. [Google Scholar]
- Liu, Z.; Wang, C.; Cai, X.; Jiang, H.; Wang, J. Discrimination of Diabetic Retinopathy from Optical Coherence Tomography Angiography Images Using Machine Learning Methods. IEEE Access 2021, 9, 51689–51694. [Google Scholar] [CrossRef]
- Hearst, M.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support Vector Machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Heisler, M.; Karst, S.; Lo, J.; Mammo, Z.; Yu, T.; Warner, S.; Maberley, D.; Faisal Beg, M.; Navajas, E.V.; Sarunic, M. V Ensemble Deep Learning for Diabetic Retinopathy Detection Using Optical Coherence Tomography Angiography. Transl. Vis. Sci. Technol. 2020, 9, 20. [Google Scholar] [CrossRef] [Green Version]
- Alam, M.; Thapa, D.; Lim, J.I.; Cao, D.; Yao, X. Computer-aided classification of sickle cell retinopathy using quantitative features in optical coherence tomography angiography. Biomed. Opt. Express 2017, 8, 4206. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Le, D.; Alam, M.N.; Lim, J.I.; Chan, R.V.P.; Yao, X. Deep learning for objective OCTA detection of diabetic retinopathy. In Proceedings of the Ophthalmic Technologies XXX, International Society for Optics and Photonics, San Francisco, CA, USA, 19 February 2020; p. 60. [Google Scholar]
- Zang, P.; Gao, L.; Hormel, T.T.; Wang, J.; You, Q.; Hwang, T.S.; Jia, Y. DcardNet: Diabetic Retinopathy Classification at Multiple Levels Based on Structural and Angiographic Optical Coherence Tomography. IEEE Trans. Biomed. Eng. 2021, 68, 1859–1870. [Google Scholar] [CrossRef]
- Thakoor, K.; Bordbar, D.; Yao, J.; Moussa, O.; Chen, R.; Sajda, P. Hybrid 3D-2D deep learning for detection of neovascularage-related macular degeneration using optical coherence tomography B-scans and angiography volumes. In Proceedings of the International Symposium on Biomedical Imaging, Nice, France, 13–16 April 2021; pp. 1600–1604. [Google Scholar]
- Aoyama, Y.; Maruko Id, I.; Kawano, T.; Yokoyama, T.; Ogawa, Y.; Maruko, R.; Iida, T. Diagnosis of central serous chorioretinopathy by deep learning analysis of en face images of choroidal vasculature: A pilot study. PLoS ONE 2021, 16, e0244469. [Google Scholar] [CrossRef]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. DenseNet: Implementing Efficient ConvNet Descriptor Pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Iafe, N.A.; Phasukkijwatana, N.; Chen, X.; Sarraf, D. Retinal capillary density and foveal avascular zone area are age-dependent: Quantitative analysis using optical coherence tomography angiography. Investig. Ophthalmol. Vis. Sci. 2016, 57, 5780–5787. [Google Scholar] [CrossRef] [Green Version]
- Salvi, M.; Acharya, U.R.; Molinari, F.; Meiburger, K.M. The impact of pre- and post-image processing techniques on deep learning frameworks: A comprehensive review for digital pathology image analysis. Comput. Biol. Med. 2021, 128, 104129. [Google Scholar] [CrossRef]
- Frangi, A.; Niessen, W. Multiscale vessel enhancement filtering. Med. Image Comput. Comput. Interv. MICCAI 1998, 1496, 130–137. [Google Scholar]
- Law, M.W.K.; Chung, A.C.S. Three Dimensional Curvilinear Structure Detection Using Optimally Oriented Flux. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 368–382. [Google Scholar]
- Soares, J.V.B.; Leandro, J.J.G.; Cesar, R.M.; Jelinek, H.F.; Cree, M.J. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Trans. Med. Imaging 2006, 25, 1214–1222. [Google Scholar] [CrossRef] [Green Version]
- Annunziata, R.; Trucco, E. Accelerating Convolutional Sparse Coding for Curvilinear Structures Segmentation by Refining SCIRD-TS Filter Banks. IEEE Trans. Med. Imaging 2016, 35, 2381–2392. [Google Scholar] [CrossRef]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Falavarjani, K.G.; Al-Sheikh, M.; Akil, H.; Sadda, S.R. Image artefacts in swept-source optical coherence tomography angiography. Br. J. Ophthalmol. 2017, 101, 564–568. [Google Scholar] [CrossRef]
- Hormel, T.T.; Huang, D.; Jia, Y. Artifacts and artifact removal in optical coherence tomographic angiography. Quant. Imaging Med. Surg. 2021, 11, 1120–1133. [Google Scholar] [CrossRef]
- Untracht, G.R.; Matos, R.; Dikaios, N.; Bapir, M.; Durrani, A.K.; Butsabong, T.; Campagnolo, P.; David, D.; Heiss, C.; Sampson, D.M. OCTAVA: An open-source toolbox for quantitative analysis of optical coherence tomography angiography images. arXiv 2021, arXiv:2109.01835. [Google Scholar]
- Goel, S.; Duda, D.G.; Xu, L.; Munn, L.L.; Boucher, Y.; Fukumura, D.; Jain, R.K. Normalization of the vasculature for treatment of cancer and other diseases. Physiol. Rev. 2011, 91, 1071–1121. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meiburger, K.M.; Salvi, M.; Rotunno, G.; Drexler, W.; Liu, M. Automatic Segmentation and Classification Methods Using Optical Coherence Tomography Angiography (OCTA): A Review and Handbook. Appl. Sci. 2021, 11, 9734. https://0-doi-org.brum.beds.ac.uk/10.3390/app11209734
Meiburger KM, Salvi M, Rotunno G, Drexler W, Liu M. Automatic Segmentation and Classification Methods Using Optical Coherence Tomography Angiography (OCTA): A Review and Handbook. Applied Sciences. 2021; 11(20):9734. https://0-doi-org.brum.beds.ac.uk/10.3390/app11209734
Chicago/Turabian StyleMeiburger, Kristen M., Massimo Salvi, Giulia Rotunno, Wolfgang Drexler, and Mengyang Liu. 2021. "Automatic Segmentation and Classification Methods Using Optical Coherence Tomography Angiography (OCTA): A Review and Handbook" Applied Sciences 11, no. 20: 9734. https://0-doi-org.brum.beds.ac.uk/10.3390/app11209734