
Anomaly Segmentation Based on Depth Image for Quality Inspection Processes in Tire Manufacturing


Abstract
:1. Introduction
1.1. Depth Image
1.2. Deep Learning Segmentation
1.3. Anomaly Detection
1.4. Summary
2. Materials and Methods
2.1. System Process
2.2. Step 1: Image Input
2.3. Step 2: Highlight Image Creation
2.3.1. Histogram Equalization
| ALGORITHM 1: 16BIT IMAGE HISTOGRAM EQUALIZATION |
 |
2.3.2. Histogram Heatmap
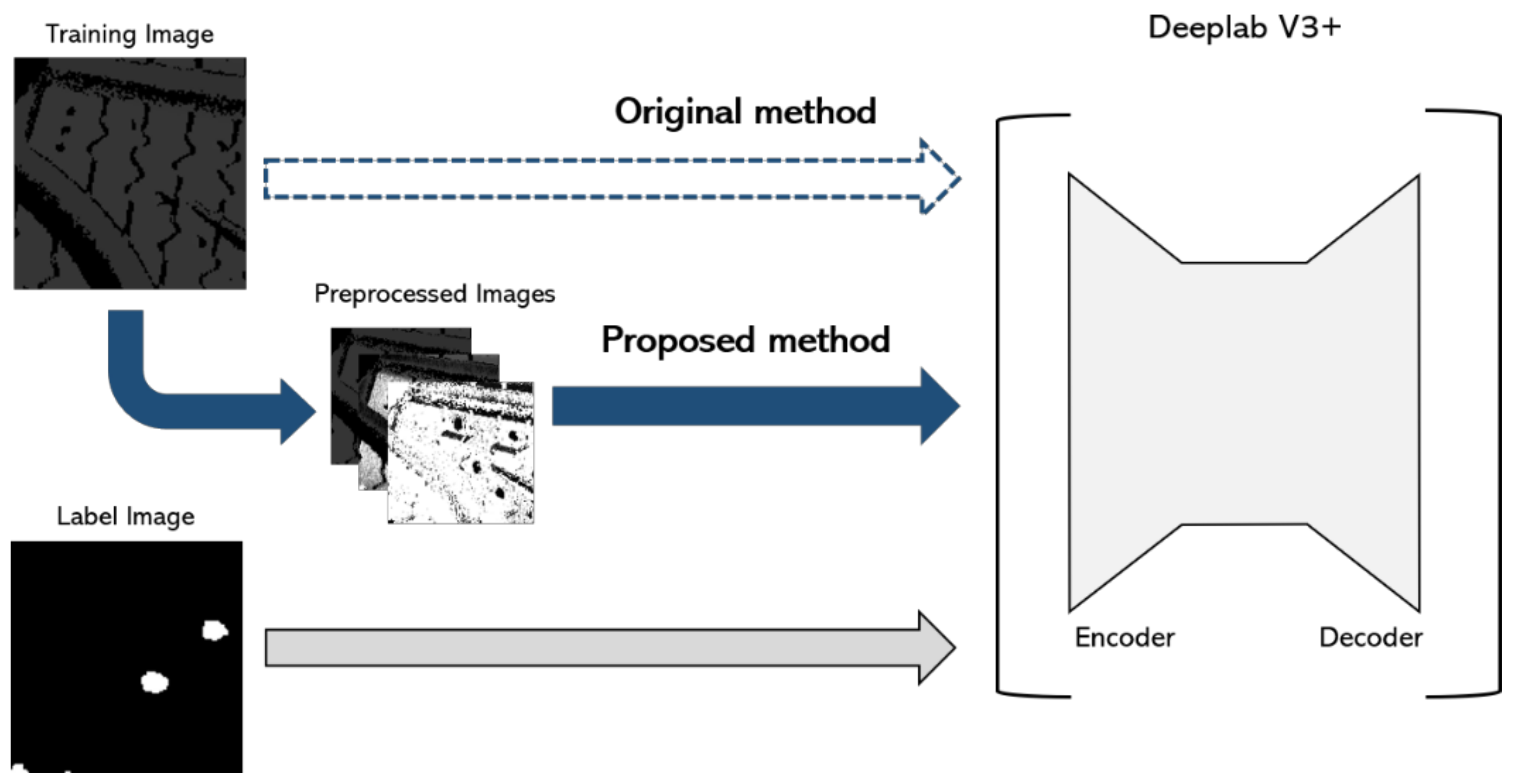
2.4. Step 3: Image Stacking
2.5. Step 4: Image Training
2.6. System Architecture
2.6.1. Depth Image Scan and Labeling
2.6.2. Tire Fault Inspection System
- Data loader
- Inspector
- Visualizer
3. Experimental Evaluation
3.1. Evaluation Methods for the Segmentation
3.1.1. Precision, Recall, and F1-Score Analysis
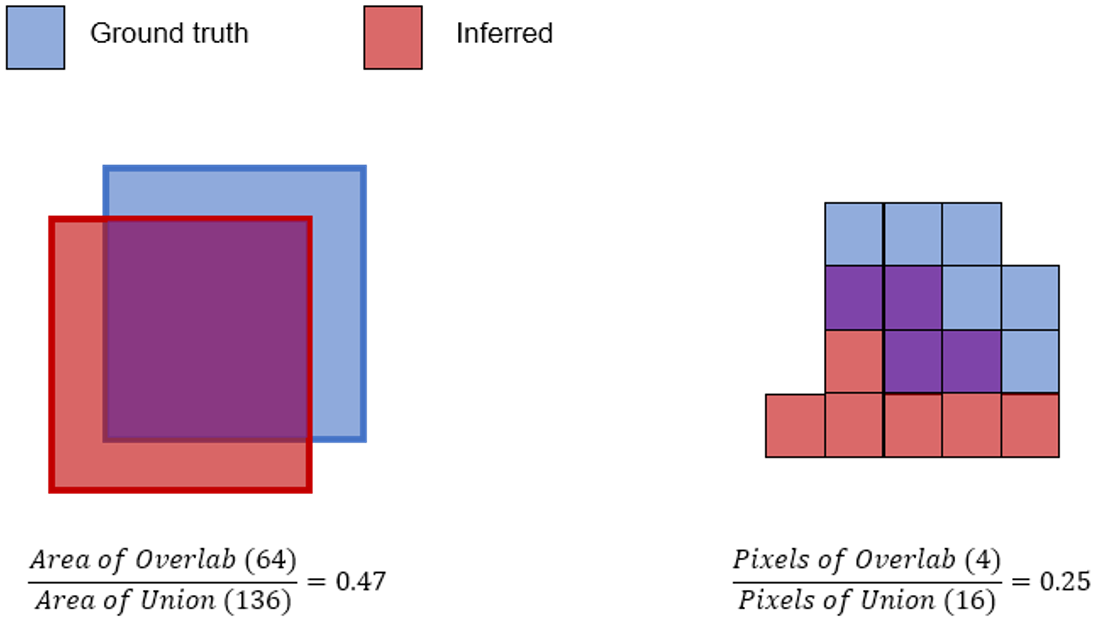
3.1.2. Intersection of Union (IoU)
3.2. Training Results
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Uysal, M.P.; Mergen, A.E. Smart manufacturing in intelligent digital mesh: Integration of enterprise architecture and software product line engineering. J. Ind. Inf. Integr. 2021, 22, 100202. [Google Scholar] [CrossRef]
- Gao, G.; Zhou, D.; Tang, H.; Hu, X. An intelligent health diagnosis and maintenance decision-making approach in smart manufacturing. Reliab. Eng. Syst. Saf. 2021, 216, 107965. [Google Scholar] [CrossRef]
- Kang, H.S.; Lee, J.Y.; Choi, S.; Kim, H.; Park, J.H.; Son, J.Y.; Kim, B.H.; Do Noh, S. Smart manufacturing: Past research, present findings, and future directions. Int. J. Precis. Eng. Manuf. Green Technol. 2016, 3, 111–128. [Google Scholar] [CrossRef]
- Davis, J.; Edgar, T.; Porter, J.; Bernaden, J.; Sarli, M. Smart manufacturing, manufacturing intelligence and demand-dynamic performance. Comput. Chem. Eng. 2012, 47, 145–156. [Google Scholar] [CrossRef]
- Mittal, S.; Khan, M.A.; Romero, D.; Wuest, T. Smart manufacturing: Characteristics, technologies and enabling factors. Mech. Eng. Part B J. Eng. Manuf. 2019, 233, 1342–1361. [Google Scholar] [CrossRef]
- Li, Q.; Wang, L.; Shi, L.; Wang, C. A data based production planning method for multi-variety and small-batch production. In Proceedings of the 2nd International Conference on Big Data Analysis, Beijing, China, 1–12 March 2017; pp. 420–425. [Google Scholar]
- Wang, Y.; Ma, H.-S.; Yang, J.-H.; Wang, K.-S. Industry 4.0: A way from mass customization to mass personalization production. Adv. Manuf. 2017, 5, 311–320. [Google Scholar] [CrossRef]
- Wu, Z.-G.; Lin, C.-Y.; Chang, H.-W.; Lin, P.T. Inline inspection with an industrial robot (IIIR) for mass-customization production line. Sensors 2020, 20, 3008. [Google Scholar] [CrossRef]
- Robertson, I.D.; Yourdkhani, M.; Centellas, P.J.; Aw, J.E.; Ivanoff, D.G.; Goli, E.; Lloyd, E.M.; Dean, L.M.; Sottos, N.R.; Geubelle, P.H.; et al. Rapid energy-efficient manufacturing of polymers and composites via frontal polymerization. Nat. Cell Biol. 2018, 557, 223–227. [Google Scholar] [CrossRef]
- Schleinkofer, U.; Laufer, F.; Zimmermann, M.; Roth, D.; Bauernhansl, T. Resource-efficient manufacturing systems through lightweight construction by using a combined development approach. Procedia CIRP 2018, 72, 856–861. [Google Scholar] [CrossRef]
- Wu, B.; Hu, B.; Lin, H. Toward efficient manufacturing systems: A trust based human robot collaboration. In Proceedings of the 2017 American Control Conference, Seattle, WA, USA, 24–26 May 2017. [Google Scholar]
- Mourtzis, D. Simulation in the design and operation of manufacturing systems: State of the art and new trends. Int. J. Prod. Res. 2020, 58, 1927–1949. [Google Scholar] [CrossRef]
- Hu, H.; Wu, Q.; Zhang, Z.; Han, S. Effect of the manufacturer quality inspection policy on the supply chain decision-making and profits. Adv. Prod. Eng. Manag. 2019, 14, 472–482. [Google Scholar] [CrossRef]
- Lopes, R. Integrated model of quality inspection, preventive maintenance and buffer stock in an imperfect production system. Comput. Ind. Eng. 2018, 126, 650–656. [Google Scholar] [CrossRef]
- Iglesias, C.; Martínez, J.; Taboada, J. Automated vision system for quality inspection of slate slabs. Comput. Ind. 2018, 99, 119–129. [Google Scholar] [CrossRef]
- Chen, S.; Xiong, J.; Guo, W.; Bu, R.; Zheng, Z.; Chen, Y.; Yang, Z.; Lin, R. Colored rice quality inspection system using machine vision. J. Cereal Sci. 2019, 88, 87–95. [Google Scholar] [CrossRef]
- Lee, S.; Kim, J.; Lim, H.; Ahn, S.C. Surface reflectance estimation and segmentation from single depth image of ToF camera. Signal Process. Image Commun. 2016, 47, 452–462. [Google Scholar] [CrossRef]
- Frangez, V.; Salido-Monzú, D.; Wieser, A. Surface finish classification using depth camera data. Autom. Constr. 2021, 129, 103799. [Google Scholar] [CrossRef]
- Du Plessis, A.; Yadroitsava, I.; Yadroitsev, I. Effects of defects on mechanical properties in metal additive manufacturing: A review focusing on X-ray tomography insights. Mater. Des. 2020, 187, 108385. [Google Scholar] [CrossRef]
- Liu, W.; Chen, C.; Shuai, S.; Zhao, R.; Liu, L.; Wang, X.; Hu, T.; Xuan, W.; Li, C.; Yu, J.; et al. Study of pore defect and mechanical properties in selective laser melted Ti6Al4V alloy based on X-ray computed tomography. Mater. Sci. Eng. A 2020, 797, 139981. [Google Scholar] [CrossRef]
- Millon, C.; Vanhoye, A.; Obaton, A.-F.; Penot, J.-D. Development of laser ultrasonics inspection for online monitoring of additive manufacturing. Weld. World 2018, 62, 653–661. [Google Scholar] [CrossRef]
- Xiang, Y.; Zhang, C.; Guo, Q. A dictionary-based method for tire defect detection. In Proceedings of the 2014 IEEE International Conference on Information and Automation, Cluj-Napoca, Romania, 22–24 May 2014; pp. 519–523. [Google Scholar]
- Li, J.; Huang, Y.; Junfeng, L. Automatic inspection of tire geometry with machine vision. In Proceedings of the 2015 IEEE International Conference on Mechatronics and Automation, Beijing, China, 2–5 August 2015; pp. 1950–1954. [Google Scholar]
- Fachada, S.; Bonatto, D.; Schenkel, A.; Lafruit, G. Depth image based view synthesis with multiple reference views for virtual reality. In Proceedings of the 3DTV-Conference: The True Vision—Capture, Transmission and Display of 3D Video, Piscataway, NJ, USA, 3–5 June 2018; pp. 1–4. [Google Scholar]
- Han, T.; Nunes, V.X.; Souza, L.F.D.F.; Marques, A.G.; Silva, I.C.L.; Junior, M.A.A.F.; Sun, J.; Filho, P.P.R. Internet of medical things—Based on deep learning techniques for segmentation of lung and stroke regions in CT scans. IEEE Access 2020, 8, 71117–71135. [Google Scholar] [CrossRef]
- Du, Z.; Hu, Y.; Buttar, N.A.; Mahmood, A. X-ray computed tomography for quality inspection of agricultural products: A review. Food Sci. Nutr. 2019, 7, 3146–3160. [Google Scholar] [CrossRef]
- Zhang, G.; Jiang, S.; Yang, Z.; Gong, L.; Ma, X.; Zhou, Z.; Bao, C.; Liu, Q. Automatic nodule detection for lung cancer in CT images: A review. Comput. Biol. Med. 2018, 103, 287–300. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Zhuo, L.; Zhang, H.; Zhang, Y.; Kim, J.; Yin, H.; Zhao, P.; Wang, Z. Vestibule segmentation from CT images with integration of multiple deep feature fusion strategies. Comput. Med. Imaging Graph. 2021, 89, 101872. [Google Scholar] [CrossRef] [PubMed]
- Gudsoorkar, U.; Bindu, R. Fatigue crack growth characterization of re-treaded tire rubber. Mater. Today Proc. 2021, 43, 2303–2310. [Google Scholar] [CrossRef]
- Liu, H.; Lei, D.; Zhu, Q.; Sui, H.; Zhang, H.; Wang, Z. Single-image depth estimation by refined segmentation and consistency reconstruction. Signal Process. Image Commun. 2021, 90, 116048. [Google Scholar] [CrossRef]
- Turkoglu, M. COVID-19 detection system using chest CT images and multiple kernels-extreme learning machine based on deep neural network. IRBM 2021, 42, 207–214. [Google Scholar] [CrossRef] [PubMed]
- Grundy, L.; Ghimire, C.; Snow, V. Characterisation of soil micro-topography using a depth camera. MethodsX 2020, 7, 101144. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.-B.; Li, A.-J.; Ci, Q.-P.; Shi, M.; Jing, T.-L.; Zhao, W.-Z. The study on tire tread depth measurement method based on machine vision. Adv. Mech. Eng. 2019, 11, 1–12. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, S.; Yu, B.; Li, Q.; Zhang, Y. Defect inspection in tire radiographic image using concise semantic segmentation. IEEE Access 2020, 8, 112674–112687. [Google Scholar] [CrossRef]
- Zhang, Y.; Cui, X.; Liu, Y.; Yu, B. Tire defects classification using convolution architecture for fast feature embedding. Int. J. Comput. Intell. Syst. 2018, 11, 1056–1066. [Google Scholar] [CrossRef] [Green Version]
- Noh, H.; Seunghoon, H.; Bohyung, H. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- Ban, K.D.; Kim, J.H.; Yoon, H.S. Gender Classification of Low-Resolution Facial Image Based on Pixel Classifier Boosting. ETRI J. 2016, 38, 347–355. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Yin, P.; Yuan, R.; Cheng, Y.; Wu, Q. Deep guidance network for biomedical image segmentation. IEEE Access 2020, 8, 116106–116116. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive medical image segmentation using deep learning with image-specific fine tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Advances in Autonomous Robotics; Springer: Berlin, Germany, 2018; pp. 833–851. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Al-Amri, R.; Murugesan, R.; Man, M.; Abdulateef, A.; Al-Sharafi, M.; Alkahtani, A. A review of machine learning and deep learning techniques for anomaly detection in IoT data. Appl. Sci. 2021, 11, 5320. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Wen, L.; Weixin, L.; Dongze, L.; Shenghua, G. Future frame prediction for anomaly detection—A new Baseline. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018. [Google Scholar]
- Lindemann, B.; Fesenmayr, F.; Jazdi, N.; Weyrich, M. Anomaly detection in discrete manufacturing using self-learning approaches. Procedia CIRP 2019, 79, 313–318. [Google Scholar] [CrossRef]
- He, Z.; Yuexiang, L.; Nanjun, H.; Kai, M.; Leyuan, F.; Huiqi, L.; Yefeng, Z. Anomaly detection for medical images using self-supervised and translation-consistent features. IEEE Trans. Med. Imaging 2021. [Google Scholar]
- Himeur, Y.; Ghanem, K.; Alsalemi, A.; Bensaali, F.; Amira, A. Artificial intelligence based anomaly detection of energy consumption in buildings: A review, current trends and new perspectives. Appl. Energy 2021, 287, 116601. [Google Scholar] [CrossRef]
- Pustokhina, I.V.; Pustokhin, D.A.; Vaiyapuri, T.; Gupta, D.; Kumar, S.; Shankar, K. An automated deep learning based anomaly detection in pedestrian walkways for vulnerable road users safety. Saf. Sci. 2021, 142, 105356. [Google Scholar] [CrossRef]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 3 November 2017; pp. 1285–1298. [Google Scholar]
- Lee, S.; Kwak, M.; Tsui, K.-L.; Kim, S.B. Process monitoring using variational autoencoder for high-dimensional nonlinear processes. Eng. Appl. Artif. Intell. 2019, 83, 13–27. [Google Scholar] [CrossRef]
- Mei, S.; Wang, Y.; Wen, G. Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aguilar, J.J.C.; Carrillo, J.A.C.; Fernández, A.J.G.; Pozo, S.P. Optimization of an optical test bench for tire properties measurement and tread defects characterization. Sensors 2017, 17, 707. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kansal, S.; Purwar, S.; Tripathi, R.K. Image contrast enhancement using unsharp masking and histogram equalization. Multimed. Tools Appl. 2018, 77, 26919–26938. [Google Scholar] [CrossRef]
- Khan, M.F.; Khan, E.; Abbasi, Z. Segment dependent dynamic multi-histogram equalization for image contrast enhancement. Digit. Signal Process. 2014, 25, 198–223. [Google Scholar] [CrossRef]
- Wang, C.; Ye, Z. Brightness preserving histogram equalization with maximum entropy: A variational perspective. IEEE Trans. Consum. Electron. 2005, 51, 1326–1334. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Rong, G.; Sham, M.K.; Rahul, K.; Praneeth, N. The step decay schedule: A near optimal, geometrically decaying learning rate procedure for least squares. arXiv 2019, arXiv:1904.12838. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title 1 | Title 2 |
|---|---|
| CPU | Intel Core i9-10980XE |
| GPU | NVIDIA GeForce RTX 3090, 24 GB Memory |
| Memory | DDR4, 128 GB |
| Framework | PyTorch 1.8.0, CUDA 11.1, CUDNN 11.2 |
| Original | Proposed | |||||
|---|---|---|---|---|---|---|
| Mobilenet | Resnet-50 | Resnet-101 | Mobilenet | Resnet-50 | Resnet-101 | |
| Mean IoU | 0.6066 | 0.6362 | 0.6230 | 0.6289 | 0.6670 | 0.6791 |
| Class IoU (Vent spew error) | 0.2192 | 0.2773 | 0.2671 | 0.2624 | 0.3383 | 0.3621 |
| Precision | 0.3769 | 0.4235 | 0.5967 | 0.3664 | 0.4817 | 0.5010 |
| Recall | 0.3437 | 0.4478 | 0.3260 | 0.4801 | 0.5319 | 0.5662 |
| F1-Score | 0.3595 | 0.4342 | 0.4217 | 0.4157 | 0.5055 | 0.5316 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ko, D.; Kang, S.; Kim, H.; Lee, W.; Bae, Y.; Park, J. Anomaly Segmentation Based on Depth Image for Quality Inspection Processes in Tire Manufacturing. Appl. Sci. 2021, 11, 10376. https://0-doi-org.brum.beds.ac.uk/10.3390/app112110376
Ko D, Kang S, Kim H, Lee W, Bae Y, Park J. Anomaly Segmentation Based on Depth Image for Quality Inspection Processes in Tire Manufacturing. Applied Sciences. 2021; 11(21):10376. https://0-doi-org.brum.beds.ac.uk/10.3390/app112110376
Chicago/Turabian StyleKo, Dongbeom, Sungjoo Kang, Hyunsuk Kim, Wongok Lee, Yousuk Bae, and Jeongmin Park. 2021. "Anomaly Segmentation Based on Depth Image for Quality Inspection Processes in Tire Manufacturing" Applied Sciences 11, no. 21: 10376. https://0-doi-org.brum.beds.ac.uk/10.3390/app112110376