1. Introduction
In today’s context, video cameras can be easily accessed by everyone. These video cameras can be mobile-based cameras or other static cameras like surveillance cameras, smartphone cameras, Raspberry-Pi cameras, or laptops, etc. With the help of these cameras, it is easy to capture human faces from any location at any place. This kind of freedom has enabled the research community to implement these smart systems for understanding the behavior of humans in real-time. To understand the behavior of a human being, expression plays the most important role. Various surveys have already been done to understand different components that play major roles in understanding human emotions. The outcome of those surveys concluded that non-verbal components, facial expressions, play the most important role during interpersonal communication [
1]. Research in the field of emotive facial recognition has gathered attention in the last couple of decades, as the applications are not only limited to computer science but can be implemented in the field of affective computing, computer animation, cognitive science, and perceptual sciences etc. [
2]. The major mode of exchanging feelings and emotions in daily life is facial expressions. Small facial gestures are strong enough to pass on the message to another person about one’s feelings. Facial emotion is more important than verbal communication, as the emotions are an actual spontaneous reflection of a person’s feelings. Lots of research is being carried out to develop such robots that are capable of understanding the facial emotions of human beings and could understand different moods of people [
3]. To automate the facial emotion recognition system, various techniques have been used. With the help of such systems, facial expressions can be detected and the system has been applied during interviews [
4], for surveillance systems [
5], and for detection of aggression [
6]. When it comes to computer vision and artificial intelligence, facial emotion recognition is one of the most important topics. For detection of facial emotions, various sensors can be used but facial images are more important because they carry enough information to understand interpersonal communication. Various research has been conducted over the last couple of years, out of which deep-learning-based FER approaches along with detailed algorithms have been proposed. In addition there are various hybrid and deep-learning approaches that are a combination of convolutional neural networks that combine the spatial and temporal features of frames [
7].
Facial emotion recognition systems have gained popularity over the decades because of their diverse applications, and the majority of those applications are applicable in real-world activities like smart supervision for suspicious activities, marketing, group emotion analysis, etc. In the same field, a cost-effective system has been proposed by Muhammad Sajjad et al. that will help to implement a smart security system for law enforcement. This system has been proposed using Raspberry-Pi with Pi-cam, that also makes it cost effective and compact [
8]. With the advancement of technology and the availability of various compact devices like Raspberry-Pi, it becomes easy to equip police and security officers with compact systems that can detect facial images in real-time. In addition to that, with the development of cloud-based technology, the captured images can be sent to cloud for future action. Such a cloud-assisted facial recognition framework has been proposed by Muhammad Sajjad et al. that can help to identify criminals and provide ease for police and security people to identify criminals quickly and easily with this proposed framework [
9].
A smart home based on Raspberry-Pi has also been proposed that is completely automated. Chowdhury et al. has proposed this system to automate and provide access via web to carry out everyday work [
10]. An energy efficient and smart water management system has been proposed to provide cost-effective solutions over existing irrigation systems. Agrawal et al. has proposed a system that could initially water around 50 pots kept in the garden and proposed a strong system that could further be extended for bigger fields [
11]. Another application based on face recognition has been proposed by [
12]. This system provides access only to those who were identified by the system and makes the system more secure. The proposed system is also based on Raspberry-Pi and Pi-Camera that again is a cost-effective and user-friendly hardware to work with. Various challenges like pose mismatching [
13] and usage of strong descriptors [
14] have been mentioned in the literature and several alternatives have been provided in the literature to handle such issues. Various classification techniques are available in the literature and a few of them are amazingly effective to extract important information from those images like HFR (Hybrid face regions) [
15]. Implementation of deep networks for smartphones has allowed facial detection along with gender classification, and a pixel pattern-based gender classification has also been proposed on the FERRET dataset, with an accuracy of 90% with frontal faces [
16]. Various architectures are proposed in the literature to implement emotion recognition in real-time with multiple faces in videos [
17]. It becomes a challenge to detect faces and emotions in critical situations. To manage such situations, a fast and accurate system based on ORFs has been proposed that provides results by working on multiple components like backgrounds, pose estimation, face patches, etc. [
18] The contributions of study are as follows:
The implementation of hardware prototype for real time facial emotion detection with Raspberry-Pi.
A deep convolutional neural network known as Mini-Xception is used for training, validation, and testing of emotive facial images.
Support vector machine (SVM) classification is implemented in the Raspberry-Pi hardware for classifying the persons.
The organization of the study is as follows:
Section 2 presents the overview of AI and CNN;
Section 3 presents the proposed methodology where the methodology for real time face emotion detection is covered.
Section 4 presents the hardware setup, experimental results, and comparison of proposed hardware with previous studies. Finally, the study concluded in the final section.
2. Background
Artificial Intelligence (AI) refers to the representation of human intelligence of machines designed to think and recreate human actions [
19]. The concept can also be extended to any system that demonstrates characteristics consistent with a human mind such as learning and problem-solving. AI is interdisciplinary, however advancements in machine learning and deep learning are triggering a shift in perspective for nearly all sectors [
20]. Computer vision is an artificial intelligence area that concentrates on image issues. Convolutional neural networks (CNNs) and computer vision combined can perform complex operations from image recognition to resolving scientific problems [
21]. CNNs are well known for the capability of image recognition and classification. In general, a basic convolutional neural network consists of neurons connected via multiple layers. These layers collect the input images and process them in different layers. A simple CNN consists of three types of layers: the convolutional layer, the max-pooling layer, and the fully connected layer. The first two layers are responsible for feature extraction, introducing non-linearity and feature reduction to reduce overfitting. The last layer, known as a fully connected layer, helps in the classification based on the features that are extracted in the previous layers. The fully connected layer contains the majority of the parameters. The number of parameters has also been reduced, presented in architectures like Inception V3 [
22] in which the last layer is added, i.e., Global Average Pooling operation. This layer reduces the feature map by taking the average and converting the feature map into a scalar value. To further reduce the parameters, modern CNN architectures have presented the use of residual modules [
23] and depth wise-separable convolutions [
5]. The depth wise-separable CNNs works by separating the task of feature extraction and combining it within the convolutional layer, hence the parameters are further reduced. So, we have used a Mini-Xception CNN proposed by [
24] which reduces the parameters by using depth wise-separable convolution layers instead of simple convolution layers and eliminates fully connected layers.
3. Proposed Methodology
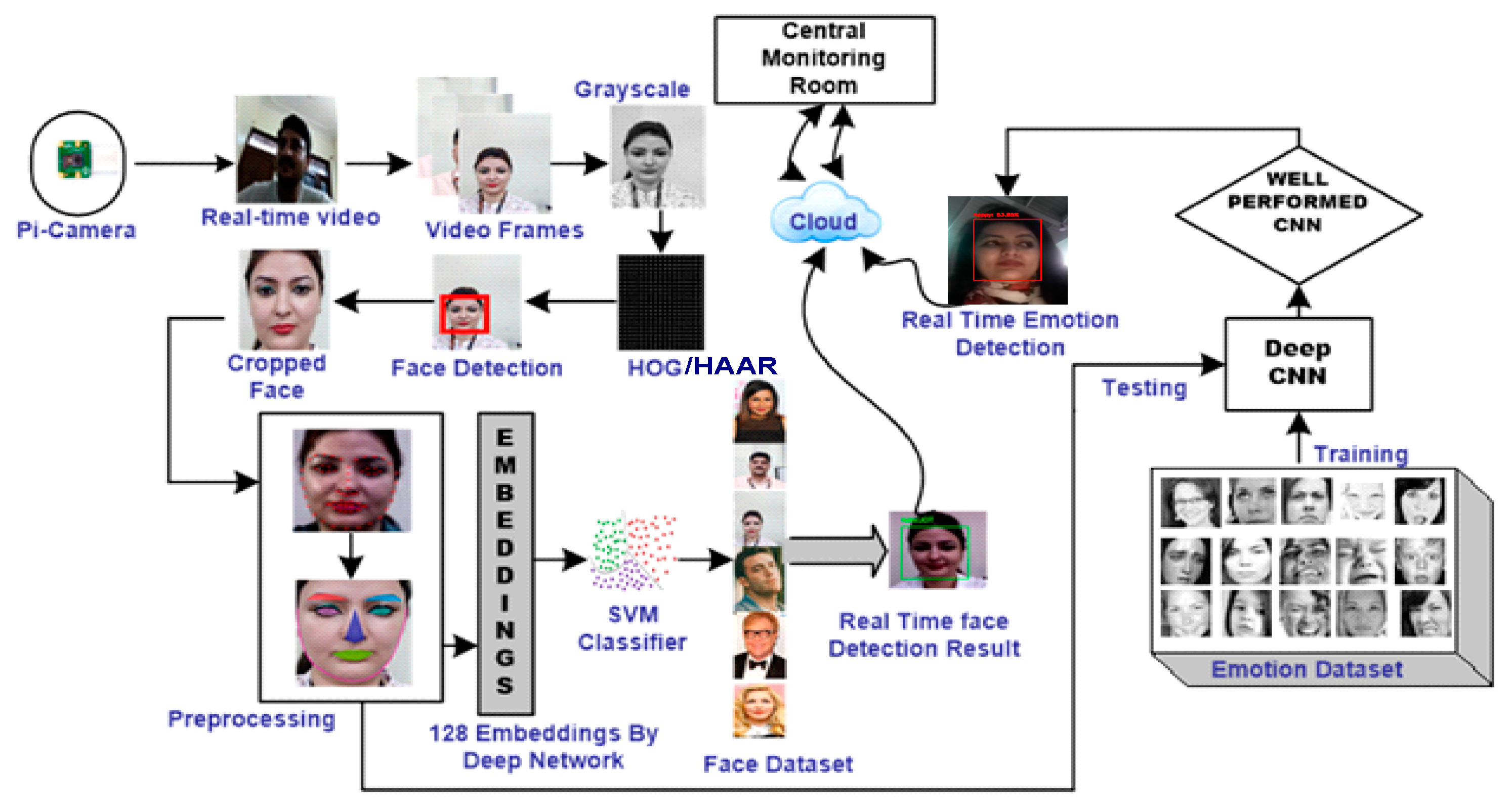
This section discerns the proposed framework. The elucidation of each step is elaborated on in the next sections. The entire process is divided into three tightly coupled tasks. The first task is to train the pertained deep network after dividing the dataset into training, validation, and testing. The entire dataset of emotive facial images is divided into an 8:1:1 ratio. A dataset with N images will be divided into ԺTR for training, ԺVD for cross validation and ԺT for testing purposes. This means a training set of N number of images I will consist of as training images, as validation images and as testing images. A deep convolutional neural network known as Mini-Xception is used for training, validation, and testing of emotive facial images. Training, validation, and testing is done on Google-CoLab with 12GB NVIDIA Tesla K80 GPU using FER 2013 dataset.
The entire architecture is divided into two tightly coupled tasks, i.e., face recognition and facial emotion recognition in real time. For face recognition, a pre-trained deep network known as OpenFace is used. To begin with, a real time image from video is captured as
. The total number of images captured in real time is
=
. To train the deep network, 6 images of each subject have been used and the network is trained with single triplet method of training for 20 different people with
N images and denoted as
. Once the training is complete, for the real time captured image,
, the very first task is to find the face inside the captured image and discard the unwanted information. The description of parameters used in the proposed architecture is given in
Table 1.
A well-known method known as HOG (Histogram of Oriented Gradients) has been used to find the faces. After the detection of the face, the facial image
has been cropped, which is further preprocessed in order to remove the effects of bad lighting, tilted face, and skewness, etc., in the cropped image
. The cropped image is preprocessed with the face landmark estimation algorithm. This algorithm locates 68 landmarks on the cropped image
and, with the help of simple affine transformations, the image is preprocessed
using rotation, shear, and scale to center the eyes and mouth of the cropped image
at best. The preprocessed image
is fed to the pre-trained network to extract the features from
image and generate 128 embeddings that are measurements of the face. The feature of the preprocessed image
is generated with the help of the neural network that will generate a feature vector of 128 embeddings as
. The last step is to classify the image by measuring the closest match of 128 embeddings
by comparing it with the database images. The feature vector
is passed through the simple SVM classifier Š, to recognize the face. The entire architecture with its detailed framework is represented in
Figure 1.
The second task is to transmit the output of preprocessing stage to the cloud where a pre-trained network of emotive facial recognition system is already available. This image is again passed through all the layers of the mini-Xception deep network, which is a fast and depth-wise separable convolutional neural network for the recognition of emotion captured in image. The deep network on the cloud is trained on seven basic emotions and is labelled as where the basic classes of seven emotions is represented as c.
3.1. Face Detection
After capturing the facial images in real time using Pi-cam, the first and foremost task is to separate the faces. To remove the unwanted and redundant information from the facial images like the background, a variety of methods are available. The most well-known method was the Viola Jones algorithm that was invented in the early 20s. We are using another method known as Histogram of Oriented Gradients, or HOG, to detect the facial images. Raspberry-Pi captures the emotive facial images in real-time via Pi-Cam from real time video frames. This image is real-time captured input image
which is converted to grayscale to extract HOG features to extract the facial part in the input image
. Finally the facial image is cropped,
, and is fed to a feature extraction unit to recognize faces in real time.
Figure 2a shows the basic steps of face detection using HOG. As shown in
Figure 2, the gradients are calculated for the entire grayscale image, and this is done by calculating the gradients for 16 × 16 pixels at a time.
This calculation is repeated for the entire grayscale image, and we will end up with an image of gradients. The next step is to calculate the strongest gradients in 16 × 16 windows of pixels and replace the gradients in that window with the strongest gradient. These will result in a basic image that consists of basic structure of face. To locate the face in the real-time captured input image or on real time video, we only located that part of the image which looks remarkably like a known HOG pattern and crop that part of the input image , as a result we get the cropped facial image .
3.2. Face Alignment
As the face is captured in real-time, the image captured can have faces turned in different direction. To deal with such situations, we wrapped each picture so that our system can locate the eyes and lips in a sample place. To perform this operation, we have used an algorithm proposed by [
23] which is known as face landmark estimation. The main work of this algorithm is to locate 68 specific points known as facial landmarks, as shown in
Figure 2b, of all faces.
These landmarks locate the eyes, nose, chin, lips, and eyebrows etc., on any face. As explained by [
19],
is the vector that represents the p number of facial landmarks in image
I. The main aim is to perform the estimation of
S to the best possible estimate, which is nearest to the true shape and is denoted by
(t). This is done with the help of a cascade of regressors, where each regressor keeps on predicting and continuously updating the vector so that the estimation is accurate.
is the method in which the regressor
is being used in a cascade for prediction and updating the vector
.
3.3. Face Encoding
The next important step is to extract the features from the exactly centered image. The best way to get the unique features of any facial image is to measure the face. The dimensions of each face are different. The main challenge is about which measurement plays a vital role in recognition of captured image. This task can be difficult to achieve if performed with the traditional method of feature extraction. To achieve accuracy and raise the speed, a deep network is trained as machines have been proven to be better than humans when it comes to prediction. Training a deep network requires a lot of computation and power from a system. So, we used a pre-trained network which is provided by OpenFace [
20]. Now, we just give the input and the Deep network that measures the 128 measurements for each face instead of single face; the network has been trained on 3 facial images at an instant as shown in
Figure 3. This is achieved by training the first image (Image anchor) of person with a second image (positive) of the same person, with a completely different image (Image negative) of another person, as shown in
Figure 4. The main purpose is to have the image anchor closer to image positive, as compared to any other image, called image negative. The selection of a triplet to carry out 128 measurements is important. Machine learning experts call these measurements of every individual face “embedding”. Training on face embedding using a large set of images called dataset will improve the accuracy and decrease the error rate eventually. This process requires huge CPU power and lot of time. To understand triplet loss, consider the representation as
which is representing an image
into s-dimensional Euclidean space. We oblige this implanting to live on the s-dimensional hypersphere.
2 = 1. As shown in
Figure 3a, the main aim is to achieve minimum distance between
(Anchor) of a specific person with all the other images
(Positive) of the same person as compared to the image of any other person
(Negative).
So, we want to have the following:
where
β is the enforced margin between negative and positive pair of images and
is the set of all the possible triplets and has numbers equal to number
P.
Generation of multiple triplets will help to overcome the issue faced in Equation (1) and selection of suitable and complex triplets will result in the improvement of the deep learning model.
3.4. SVM Based Classification
The last step is the most important step of finding the names of persons from the encodings. Different techniques have been presented that will help in the evaluation of various classifiers. A variety of machine learning classification algorithms can be used to classify the faces but the most simple and efficient one has been used for classification of faces, known as support vector machine (SVM). We kept it simple because we only want the output to be the face with the name of the person. Moreover, we are implementing this on Raspberry-Pi, so we want our system to be fast and accurate. Running this classifier on hardware takes milliseconds, which what we want, and the result of this classifier is the name of the person.
3.5. Dataset
The training of the network is illustrated in the
Figure 4, here we have mapped the unique images from a single network into triplets. The gradient of the triplet loss is back propagated to the unique images through the mapping. The dataset that we have used consists of 35,888 images of facial emotions with seven categories (0 = Angry, 1 = Disgust, 2 = Fear, 3 = Happy, 4 = Sad, 5 = Surprise, 6 = Neutral). The FER 2013 dataset consist of 48 × 48 pixel gray scale images (
https://www.kaggle.com/msambare/fer2013 (accessed on 11 May 2021)). The dataset that we have used is in csv format, consisting of only two columns, i.e., “emotions” and “pixels” and is kept in Google drive. The entire data is divided into an 8:1:1 ratio for training
, validation
and testing
.
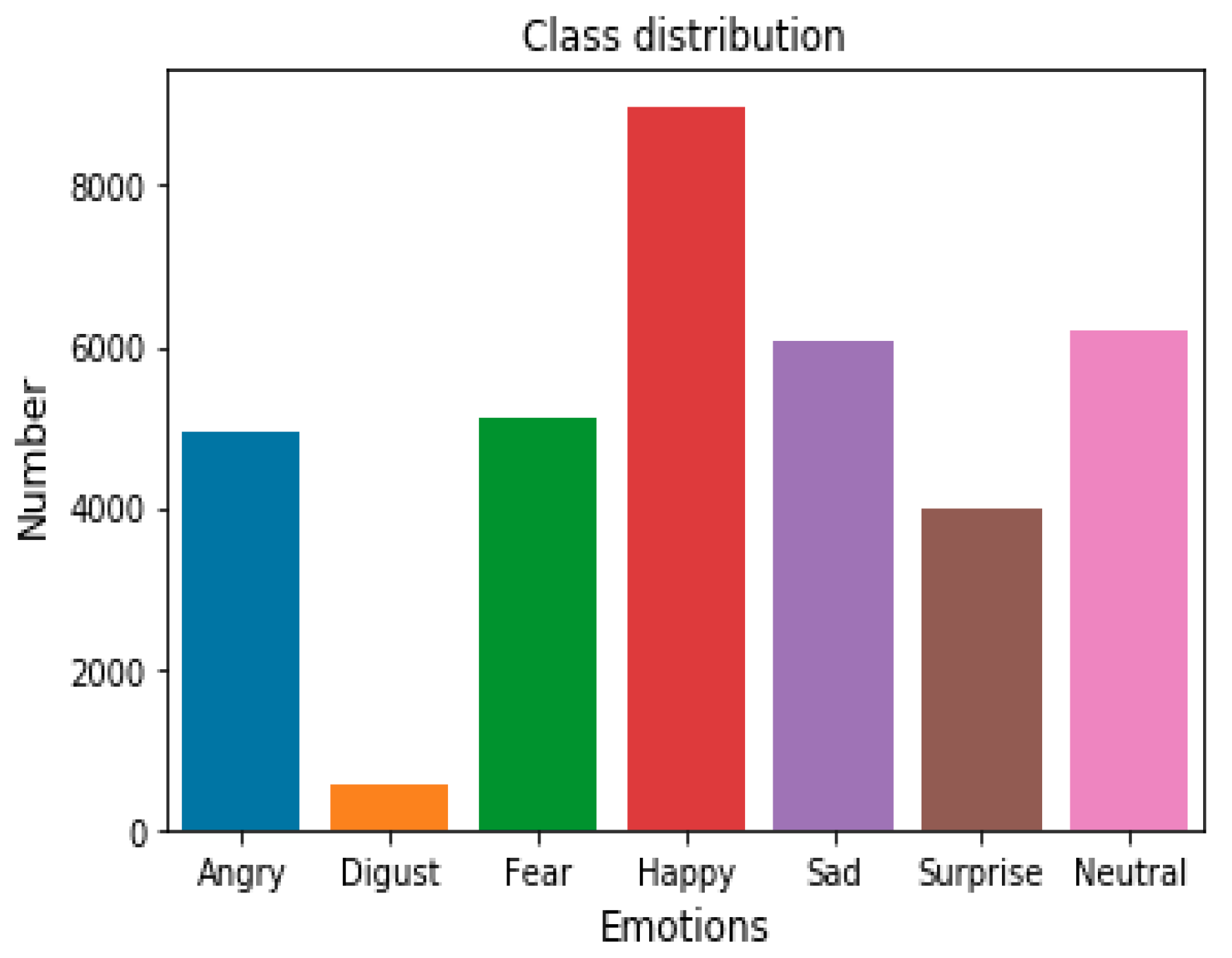
The number of images available in the dataset has been categorized as per the expression, and the total number of images under each category is shown in
Table 2 and the graphical representation of dataset is shown in
Figure 5. The FER 2013 dataset is not a uniform dataset, and it does not contain a uniform number of images under each category.
Figure 6 shows the sample images from the FER 2013 dataset. A large number of datasets is available to detect facial emotions.
3.6. Training CNN Model: Mini Xception
The dataset has been kept on Google drive and the training has been done on Google-CoLab with 12GB NVIDIA Tesla K80 GPU. The CNN has been trained with 80% of training data from the FER dataset and the remaining 10% of dataset is kept for validation. The architecture of Mini-Xception proposed by [
24] is shown in
Figure 7. Testing has been done on the remaining 10% of data as shown in
Figure 8 and on the input given by Raspberry-Pi after detecting the face and converting the cropped and pre-processed images into 48 × 48 sizes. This architecture is trained on the FER 2013 dataset because we want the response to be quick and the proposed architecture of Mini-Xception has been proved to be quick and light because of its unique architecture and replacement of convolutional layers with depth wise convolutional layers, which will reduce the number of parameters and make it reliable to implement for real time emotion recognition. The results of training are shown in
Figure 9 and training loss is represented in
Figure 10. As our system is based on Raspberry-Pi, which has certain constraints in-terms of memory and processing capability, so a smaller number of parameters will be helpful in future advancement of this system. We have achieved an accuracy of 66% on FER 2013 dataset (without augmentation), as mentioned in the state-of-the-art, and 68% after data augmentation. The main reason behind this accuracy is variation in the dataset and non-uniformity of images under each category.
4. Experimental Results
The detailed results are shown in this section. We have divided the entire architecture to carry out two main tasks. The first task of face recognition has achieved an accuracy of 100%, as all the faces that were trained are recognized correctly, as open face has provided near-human accuracy [
20] on the LFW benchmark. So, we have used it and implemented it in real time video with the help of the Raspberry-Pi 3 B+ model. We have used Python with OpenCV and with the help of Pi-Cam we acquired the live video and recognize the faces in those live videos. The proposed framework can locate multiple faces in the frames but is able to recognize only those that are already trained and present in the dataset. Face recognition has given correct results even with different objects like spectacles. We have installed the setup along with the biometric attendance area so that, at the time of punching in and punching out, the expression on the faces of employees can be recorded and, after collecting the data of the fortnight, the recorded faces with names and recognized expressions can be analysed. This analysis can be useful to recognize the consistent behavior of the employees in private organizations. For example, an employee with a constant sad or disgusted expression on his face can be identified and can be reported to a happiness cell or psychological support cell for helping such employees and making them feel good and comfortable in the workplace. The hardware setup of the proposed system is shown in
Figure 8.
The comaparison with various models is shown in
Table 3 and specifications of the system are given in
Table 4, and the detailed algorithm is explained in Algorithm 1 and Algorithm 2. After detecting the face in real time, the cropped and pre-processed image is given to the pre-trained deep network which is trained on the FER 2013 dataset using Python and Keras. The results after classification are shown in the confusion matrix, as shown in the
Table 5. Several misclassifications have been found as “disgust” is misclassified as “Angry”. From the dataset one can easily locate that the count of disgusted faces in the dataset is least 547. This simply indicates that the number of features that the network has been trained to classify as a disgusted face is less compared to other classes. Hence, the misclassification took place.
The total number of parameters for which the network has been trained is 2,134,407. When tested on real time video, 110 out of 120 images with expressions are recognized correctly.
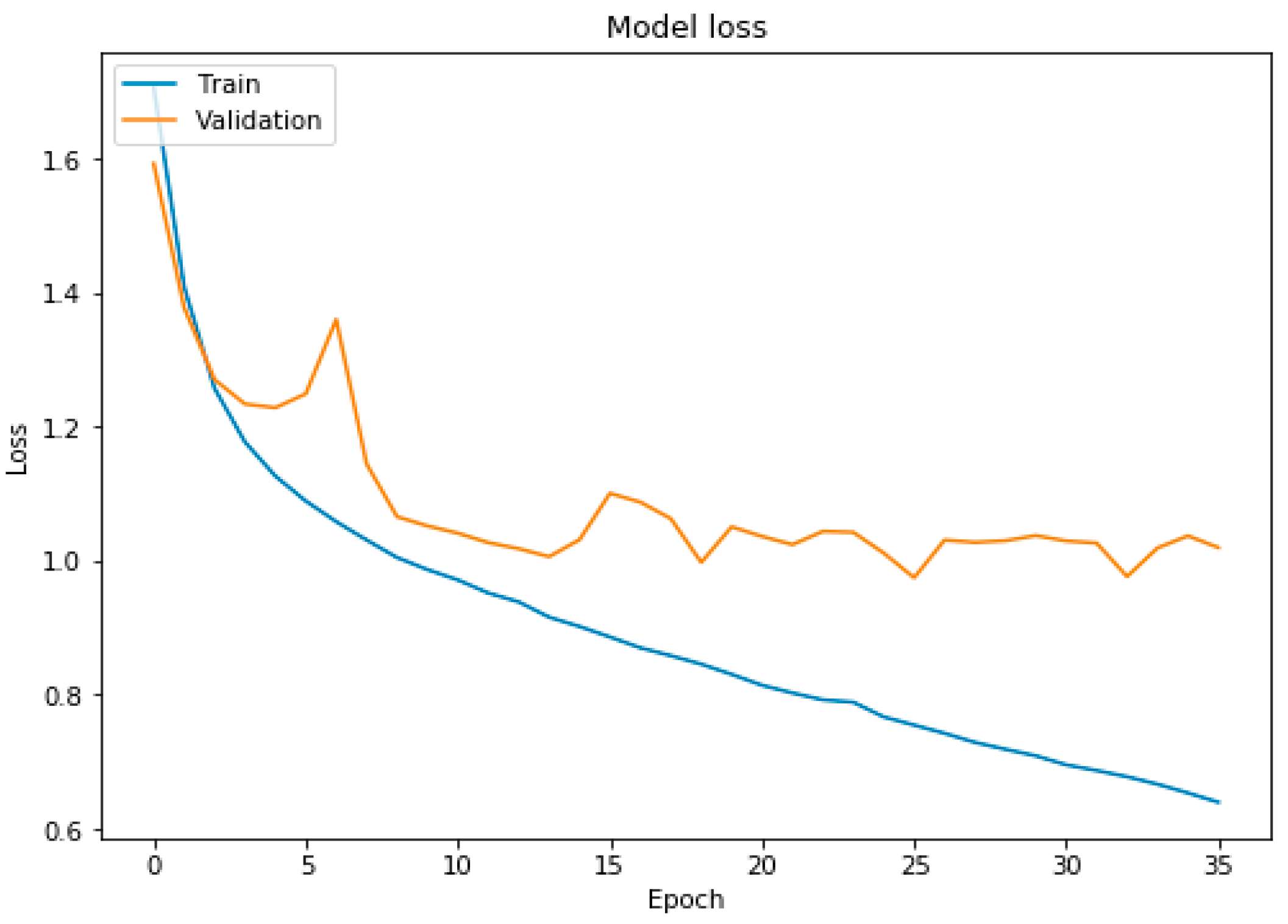
Figure 10 is the graphical representation of model accuracy and
Figure 11 is the graphical representation of model loss.
Figure 12 shows the real time face recognition result.
Table 3 shows the comparison of available models.
| | Algorithm 1. Face Detection in Real-Time. |
| 1 | \ Input: Real time video of subjects |
| 2 | I. Capture the real time image from the real time video frames |
| 3 | II. Facial Dataset creation |
| 4 | For k = 1 to size of = ℕ, ℕ is the count of each subjects sample and n is the total number of subjects captured |
| 5 | a. Select an image from |
| 6 | b. Convert the image
to grayscale image: Gray Scale |
| 7 | c. Detect the face region using Histogram of Oriented Gradients (HOG):
HOG |
| 8 | d. Crop the facial region Cropped |
| 9 | e. Preprocess the cropped image by applying facial landmark and affine transform:
Pre-processing |
| 10 | f. Repeat the sub steps a to e of II of database creation for n x Ď times |
| 11 | End |
| 12 | III. Label all images of dataset with the name of the subjects:
Labeled |
| 13 | IV. Training and feature extraction: |
| 14 | For k = 1 to size of ,where l represents labelled data |
| 15 | a. Select the anchor image of first subject |
| 16 | b. Select the positive image = of the same subject |
| 17 | c. Select the negative image.= of the second subject |
| 18 | d. Feed the images ,, to the pre-trained deep network |
| 19 | e. Repeat the training to achieve ,where β is the enforced margin between negative and positive pair of images and is the set of all the possible triplets and has numbers equal to number M |
| 20 | f. Generate multiple triplets to improve deep learning by |
| 21 | g. Generate the feature vector ,where n is the number of embedding’s generated by deep network |
| 22 | End |
| 23 | V. Cross validate by capturing image in real time |
| 24 | i. Repeat the substeps a to e of II Facial Dataset creation for |
| 25 | ii. Repeat the substeps a to f of IV Training step and feature extraction |
| 26 | VI. Feed the image to classifier to classify the image in real time by passing all the feature vectors called embedding’s that were generated in the substeps a to g of IV Training step and the Output: Prediction of the face of the subject with name in real-time\ |
| | |
| | Algorithm 2. Emotion Detection in Real-Time. |
| 1 | \Input Emotive facial dataset Ժ |
| 2 | I. Divide the dataset into training ,validation and testing |
| 3 | II. Training and feature extraction: |
| 4 | For j = 1 to size of ) = ,where N is the total number of images in Ժ |
| 5 | a. Select the image from |
| 6 | b. Feed the input to the deep network |
| 7 | c. Train the network by passing the ) with their labels and let the network extract all the parameter |
| 8 | End |
| 9 | III. Cross Validate: |
| 10 | For j = 1 to size of ( |
| 11 | a. Select the image from |
| 12 | b. Repeat the substeps b and c from II Training and feature extraction for images |
| 13 | c. Use validation images the reduction of overfitting |
| 14 | End |
| 15 | IV. Testing: |
| 16 | For j = 1 to size of |
| 17 | i. Select the image from |
| 18 | ii. Repeat the substeps b and c from II Training and feature extraction for images |
| 19 | iii. Use testing images to test the trained network for efficiency |
| 20 | End |
| 21 | V. Real time testing: |
| 22 | Take the input from subset e of II from Algorithm 1 |
| 23 | For k = 1 to size of = ℕ, ℕ is the count of each subjects sample and nis the total number of subjects captured |
| 24 | i.Resize the image Pre-processing
Resize |
| 25 | ii. Repeat the substeps b and c from II Training and feature extraction for images |
| 26 | End |
| 27 | VI. Predict the facial expression where the basic classis of seven emotions is represented as c = [Angry, disgust, fear, Happy, Sad, Surprise and Neutral].Output: Prediction of facial emotion of subject in real-time\ |
| | |
To evaluate the performance and effectiveness of proposed edge device, we have compared with the previous studies on facial emotional detection. It has been realized that the hardware implementation for facial emotion detection and recognition is less implemented. A few studies that have implemented this hardware recorded lower accuracy, like 51.28% and 47.44%, when compared with the proposed model, i.e., 68%.
As discussed in the above section, the FER 2013 dataset is not a balanced dataset. A total of 35,887 images of 7 classes are present in this dataset. The unbalanced dataset gave the results which are very low, specifically for disgust, fear, and sad emotion. So, a data balancing technique is used for balancing the data. Keras API helps to increase the data set by applying various techniques by using the Image Data Generator function. This mainly includes five functions, i.e., rotation at a certain angle, shearing, zooming, rescale, and horizontal flip. Before data augmentation, a total of 35,887 images were used, out of which only 547 images were of disgusted expressions. After applying data augmentation, a total of 41,904 images were used, of which 6564 were of disgusted faces. The confusion matrix after data augmentation is shown in
Table 6.
Table 6 shows the confusion matrix after data augmentation. It can be noticed that prediction for disgust and fear has improved. The overall efficiency of system after data augmentation has been raised by 2% and came out as 68%.
Table 7 shows the comparison of proposed edge device with previous studies.
6. Conclusions
Real time detection of any kind of activity that is suspicious in nature is difficult to identify without any actual interaction with the subject or suspect. Reading the face of a person in real time is a challenging task. With the help of compact and portable devices, it becomes easy for the majority of organizations to understand the behavior of their employees and resolve some of the minor and major issues at an early stage. To achieve that, a framework has been tested and proposed that can be implemented in any organization to understand employee behavior. The proposed framework is a cost-effective and compact alternative over all those heavy and bulky systems that are difficult to implement in real time. The system has been tested for 20 different people with all 7 emotions, and out of total 120 images, 110 images were identified with correct emotions in real time. The proposed framework has been implemented using the Mini-Xception Deep Network because of its computational efficiency in a shorter time as compared to other networks.
Facial expression representation plays an important role in facial expression recognition. It can be viewed as generating good features for describing the appearance, structure, and motion of facial expressions. More specifically, facial expression features attempt to effectively describe the facial muscle or facial motion for static or dynamic facial images. Numerous works have already done this and, although different proposed methods for facial expression recognition have achieved good results, there remain different problems that need to be addressed by the research community. The most important one is face variability in a single person. There are many factors that can cause two pictures from the same person to look totally different, such as light, face expression, or occlusion. Another problem to be taken into account is the environment. Except in controlled scenarios, face pictures have very different backgrounds, which can make the problem of face recognition more difficult. To address this issue, many of the most successful systems focus on treating the face alone, discarding all the surroundings. Smart meeting, video conferencing, and visual surveillance are some of the real-world applications that require a facial expression recognition system that works adequately on low resolution images. There exist lots of methods for facial expression recognition but very few of those methods provide results or work adequately on low resolution images. More research effort is required to be put forth for recognizing more complex facial expressions than the six classical ones, such as fatigue, pain, and mental states such as agreeing, disagreeing, lying, frustration, thinking, as they have numerous application areas. Other problems include expression intensity estimation, spontaneous expression recognition, micro expression recognition (brief, involuntary facial expression, lasts only 1/25 to 1/15 of a second), mis-alignment problems, illumination, and face pose variation. Moreover, studies proved that visual captures of facial expressions alone are not sufficient to identify the exact human emotions discussed in this section. This research can be further carried out by combining FER systems with various physiological sensors to identify the exact mental state of a person.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}