
A Technique of Recursive Reliability-Based Missing Data Imputation for Collaborative Filtering

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose an effective method for missing data imputation that improves the poor recommendation accuracy of CF caused by the data sparsity problem. The proposed method, k-RRI, first selects data with high reliability and then recursively imputes data with additional selection while gradually lowering the reliability criterion. Existing methods replaced the data with a small amount of real data at once; however, we replaced the data with real and reliable virtual data to alleviate the data sparsity problem.
- We also propose a new similarity measure that weights common interests and indifferences between users and items. This enables us to determine the similarities between user and items more accurately.
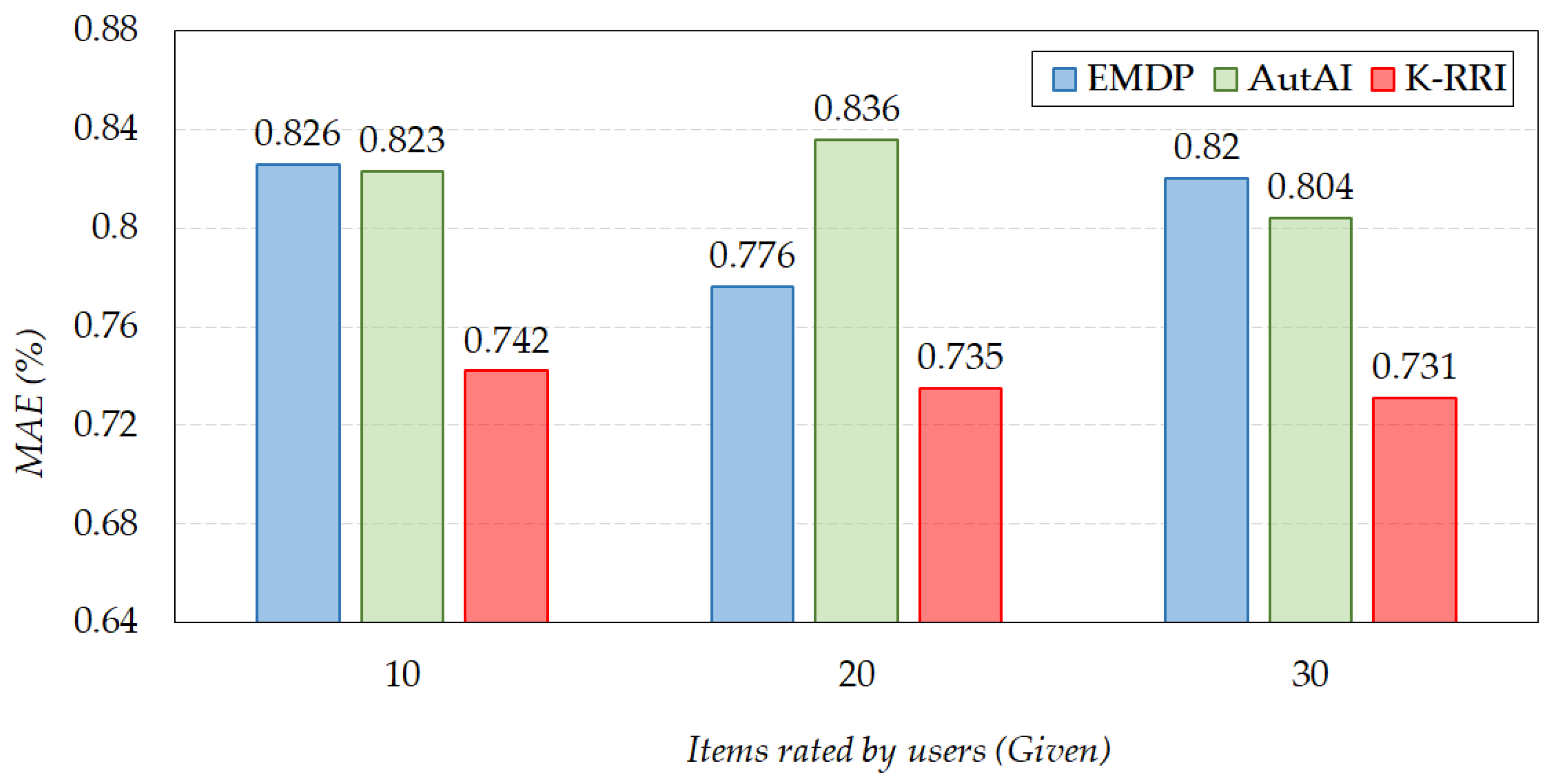
- We evaluated the performance of the proposed approach through experiments with state-of-the-art methods: EMDP and AutAI. The experimental results demonstrate that the proposed approach using a new similar measure significantly improves recommendation accuracy compared to those resulting from the state-of-the-art methods while demanding less computational complexity.
2. Preliminaries
2.1. Similarity Measures
2.2. Rating Prediction Method
3. Related Studies
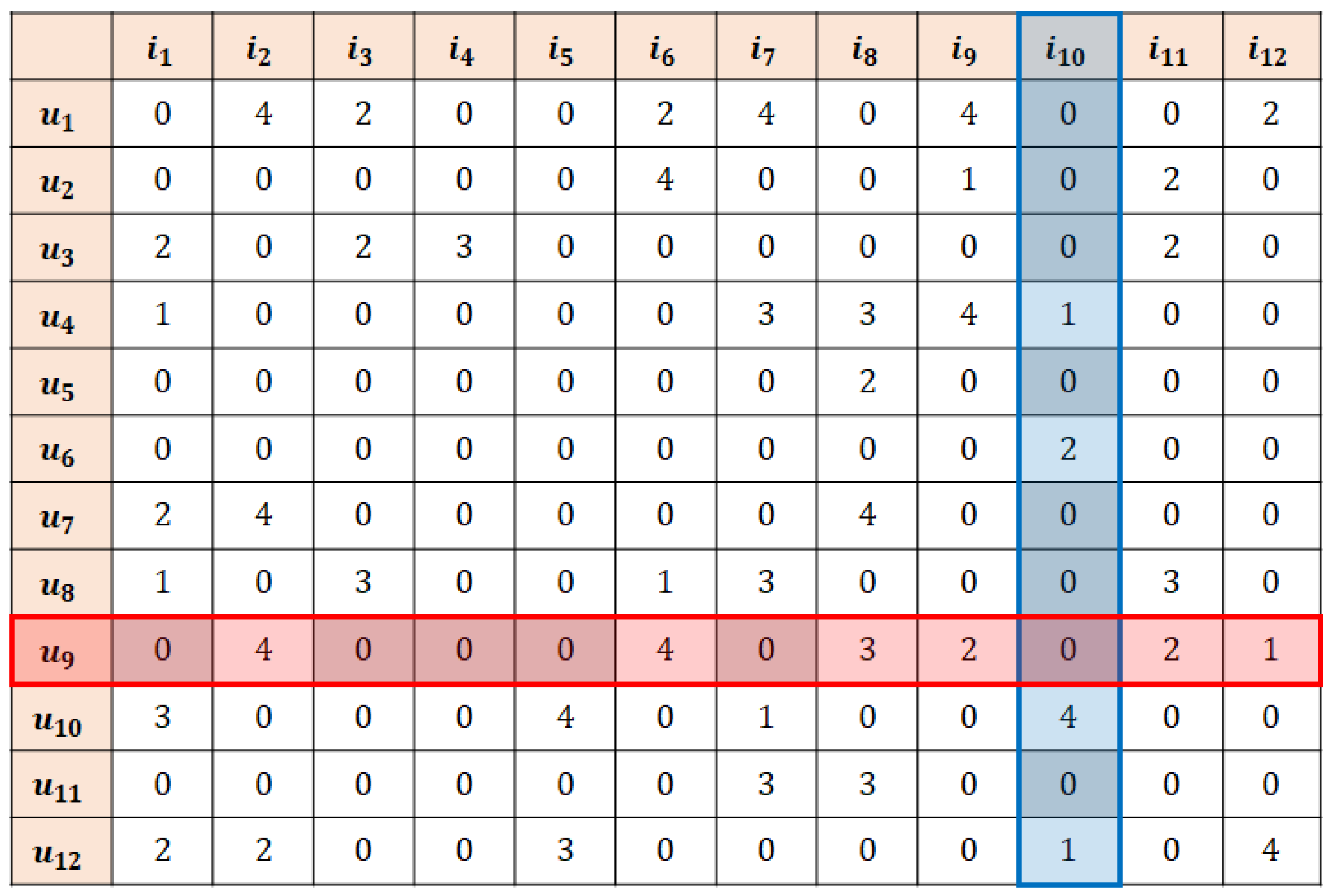
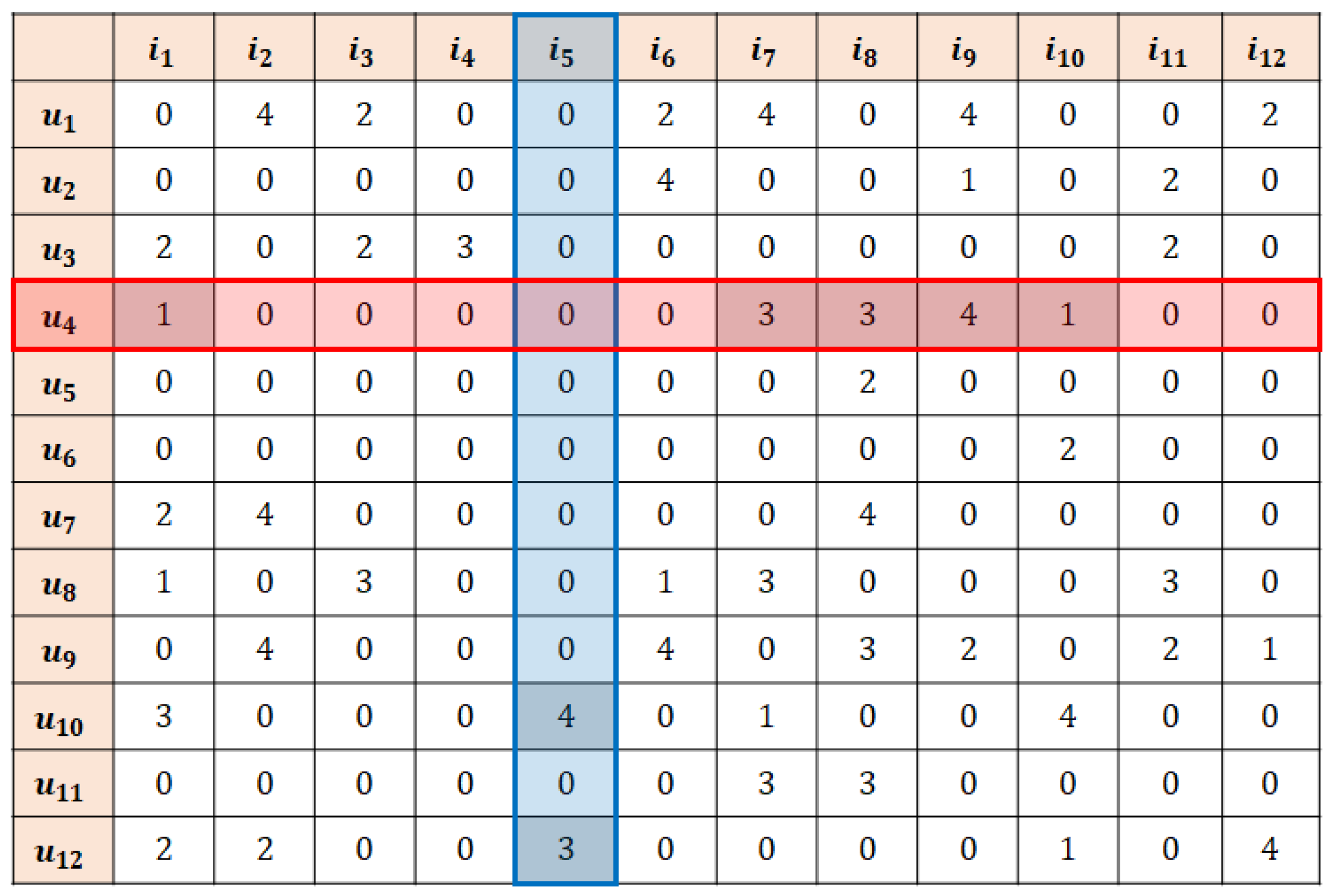
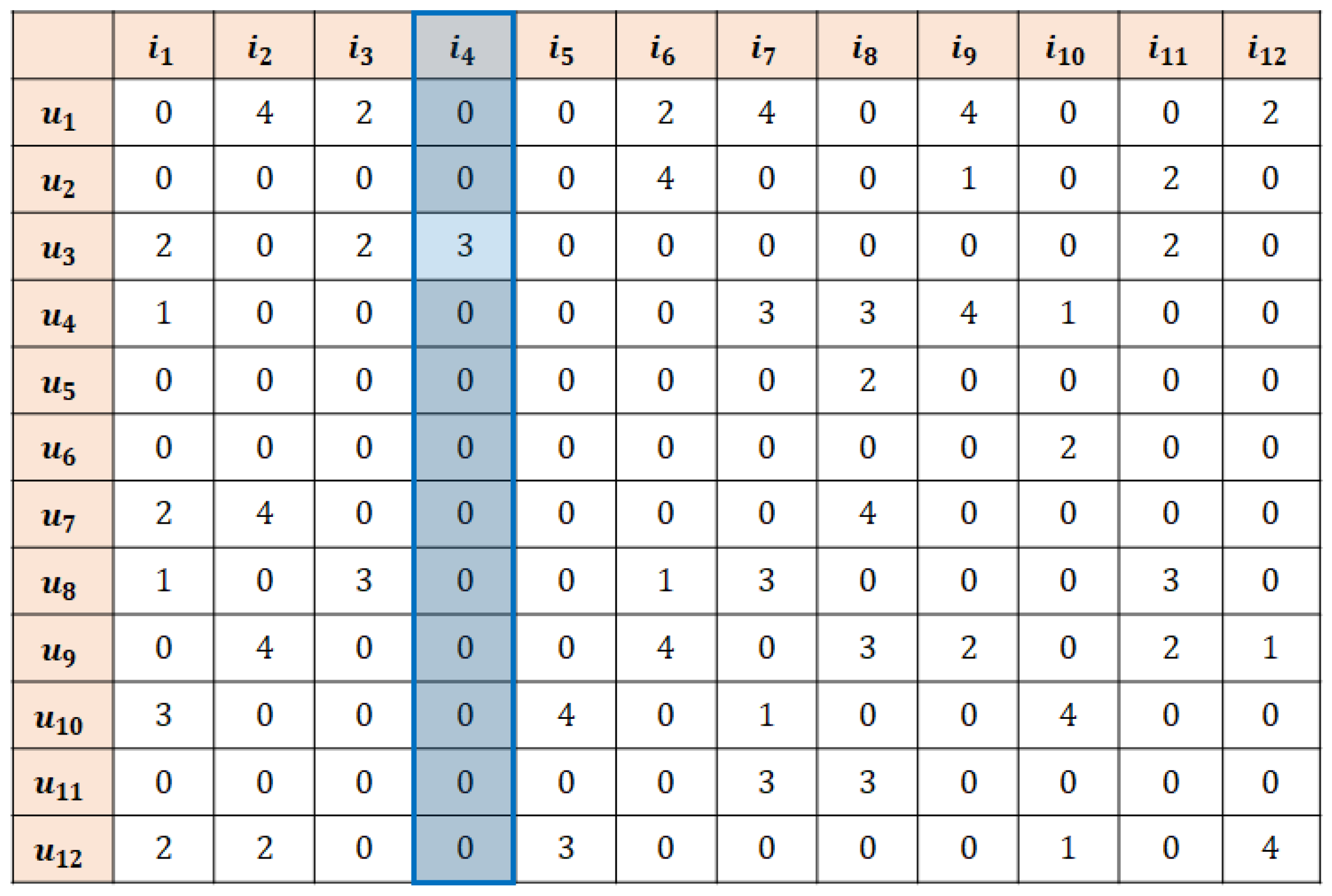
4. k-Recursive Reliability-Based Imputation (k-RRI)
4.1. k-RRI
- Active user: the user of the data targeted for prediction.
- Active item: the item of the data targeted for prediction.
- Key neighbors: a set of data necessary for predicting the active user and the active item. Each imputation algorithm will define the key neighbors and impute the missing data, i.e., unrated data, among them.
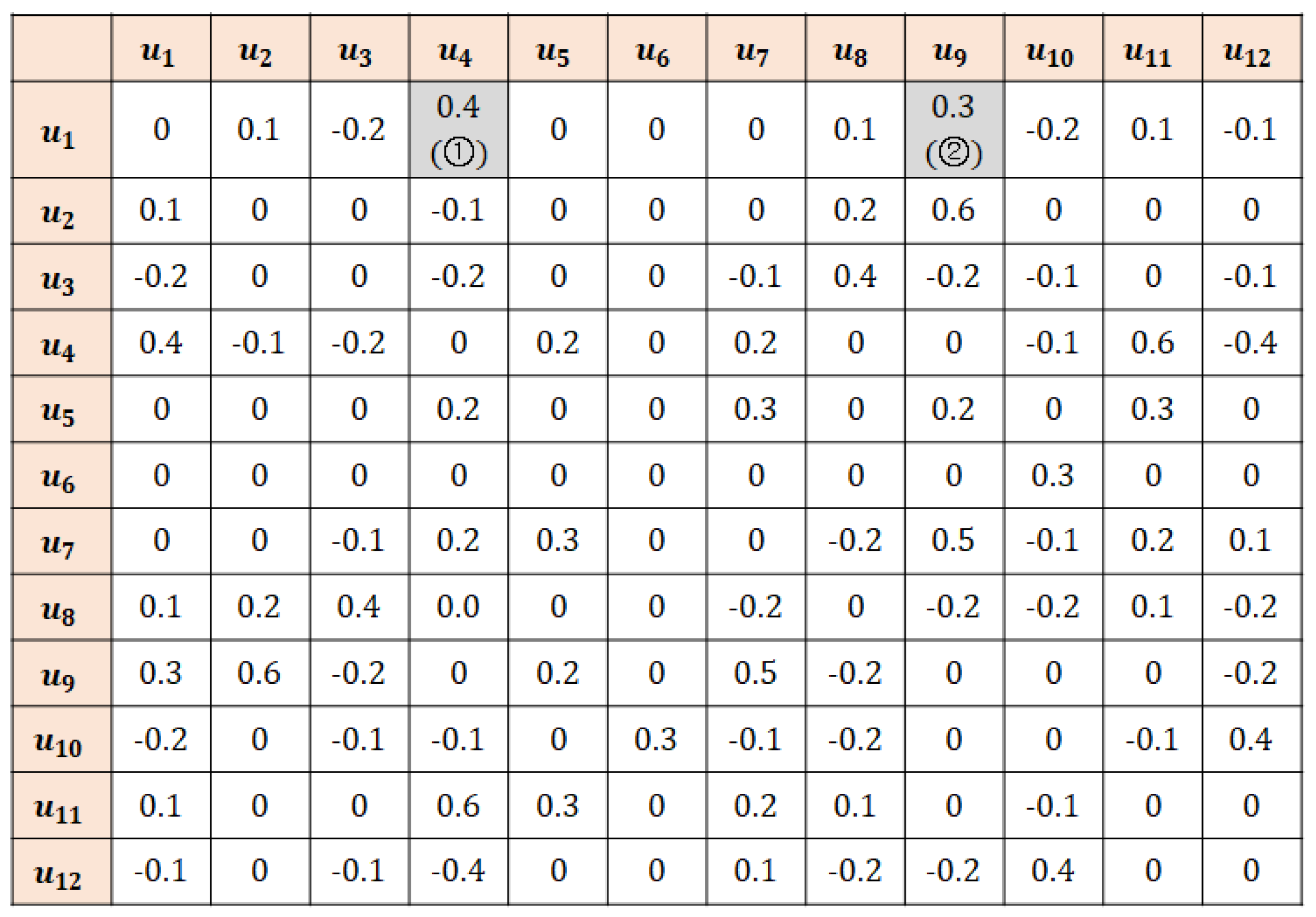
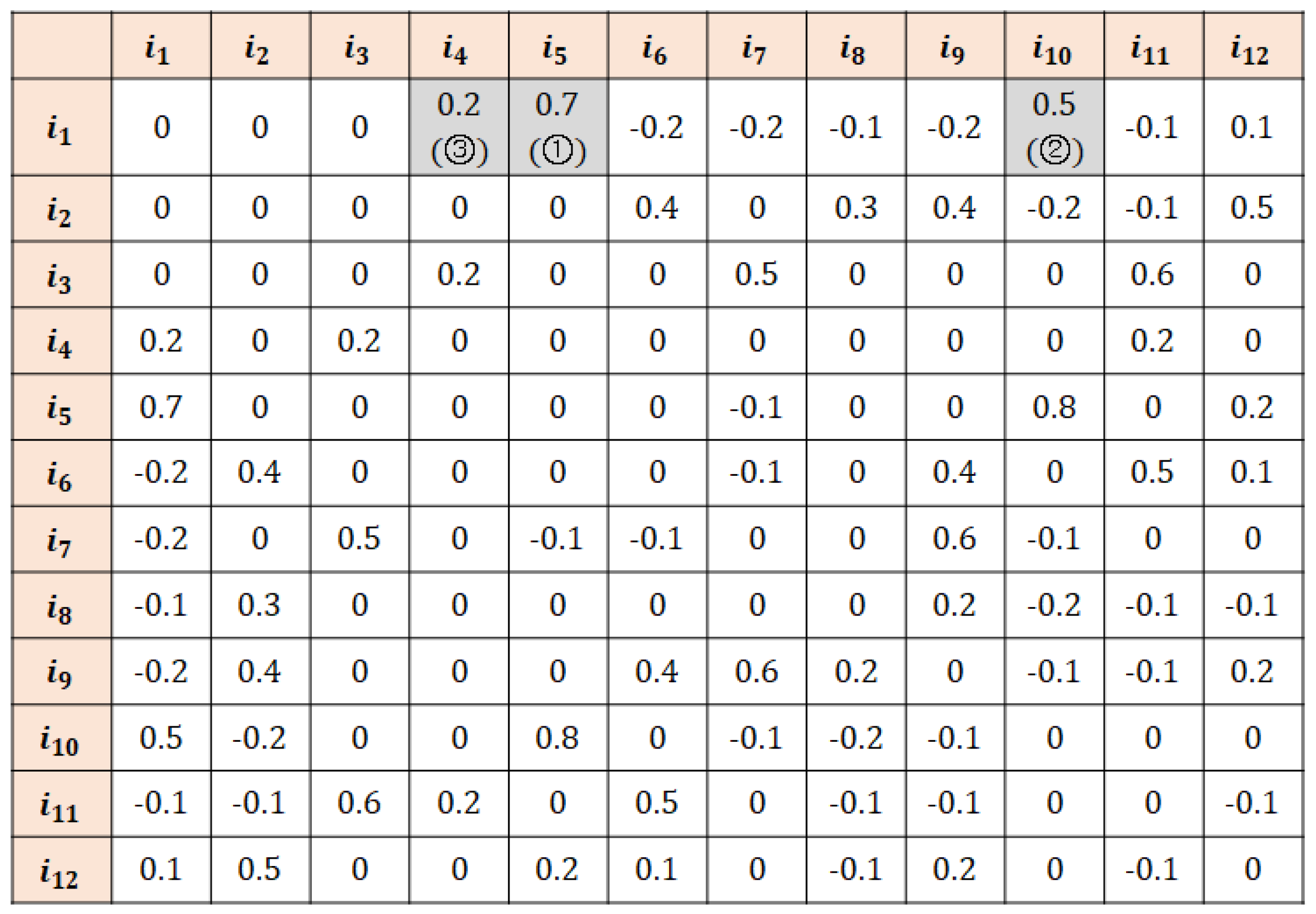
- High-reliability data: a set of data whose similarity with the active user and active item exceeds the given threshold.
- Definition 1: Missing data are selectively imputed in a stepwise and decreasing order of reliability.
- Definition 2: Data imputed in the preceding step can be used for imputation in the succeeding step.
- Definition 3: The threshold cutoff value decreases as the algorithm progresses. That is, the reliability-based threshold cutoff criteria are strict in earlier recursive steps and become increasingly relaxed toward the end.
| Algorithm 1: k-RRI | |
| Input: | the user–item rating matrix . |
| the similarity set . | |
| the active user . the active item . | |
| the number of steps . | |
| the user’s final similarity threshold . | |
| the item’s final similarity threshold . | |
| Output: | the imputed matrix . |
| 1: | ; // initialize the imputed matrix |
| 2: | foruntildo |
| 3: | calculate , ; |
| 4: | ; |
| 5: | ; |
| 6: | ; |
| 7: | for each do |
| 8: | if then |
| 9: | calculate ; |
| 10: | ; |
| 11: | end if |
| 12: | end for |
| 13: | end for |
4.2. Threshold Reset Process
4.3. Comparison of Computational Complexity
- Key neighbor selection stage: selection of the key neighbors of interest.
- Missing data imputation stage [30]: identification of the missing data from the key neighbors and implementation of missing data imputation.
5. Performance Evaluation
5.1. Experimental Setup
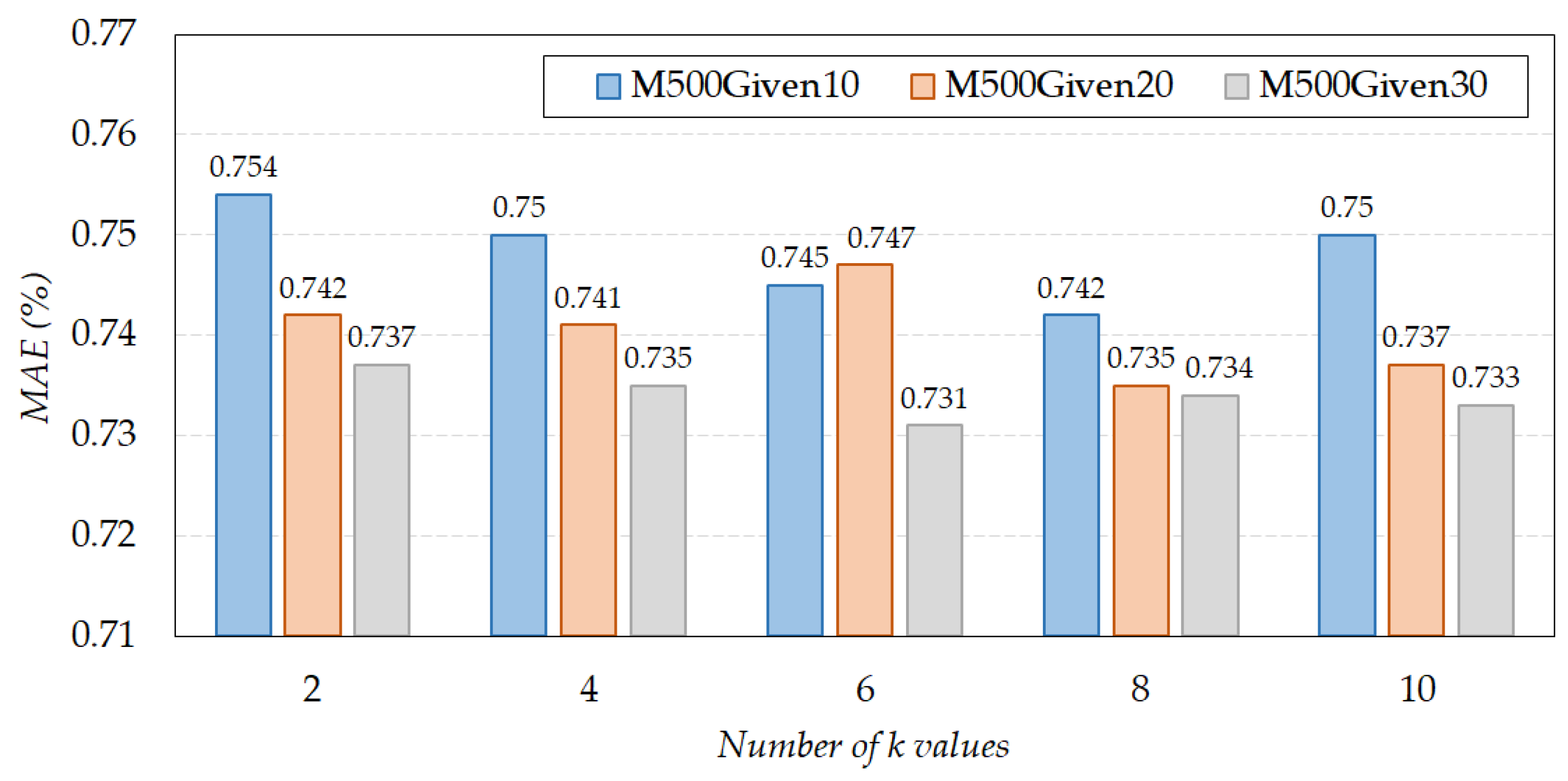
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adomavicius, G.; Tuzhilin, A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Trans. Knowl. Data Eng. 2015, 17, 734–749. [Google Scholar] [CrossRef]
- Rendle, S.; Krichene, W.; Zhang, L.; Anderson, J. Neural Collaborative Filtering vs. Matrix Factorization Revisited. In Proceedings of the ACM Conference on Recommender Systems, Rio de Janeiro, Brazil, 22–26 September 2020; pp. 240–248. [Google Scholar]
- Wang, Q.; Yin, H.; Wang, H.; Nguyen, Q.V.H.; Huang, Z.; Cui, L. Enhancing Collaborative Filtering with Generative Augmentation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 548–556. [Google Scholar]
- Musa, J.M.; Zhihong, X. Item Based Collaborative Filtering Approach in Movie Recommendation System Using Different Similarity Measures. In Proceedings of the 6th International Conference on Computer and Technology Applications, Antalya, Turkey, 14–16 April 2020; pp. 31–34. [Google Scholar]
- Cohen, W.W.; Fan, W. Web-collaborative filtering: Recommending music by crawling the web. Comput. Netw. 2000, 33, 685–698. [Google Scholar] [CrossRef]
- Logesh, R.; Subramaniyaswamy, V. Exploring hybrid recommender systems for personalized travel applications. Cogn. Inform. Soft Comput. 2019, 768, 535–544. [Google Scholar]
- Logesh, R.; Subramaniyaswamy, V.; Vijayakumar, V.; Li, X. Efficient user profiling based intelligent travel recommender system for individual and group of users. Mob. Netw. Appl. 2019, 24, 1018–1033. [Google Scholar] [CrossRef]
- Zhao, G.; Lei, X.; Qian, X.; Mei, T. Exploring users’ internal influence from reviews for social recommendation. IEEE Trans. Multimed. 2018, 21, 771–781. [Google Scholar] [CrossRef]
- Zhao, G.; Lou, P.; Qian, X.; Hou, X. Personalized location recommendation by fusing sentimental and spatial context. Knowl. Based Syst. 2020, 196, 105849. [Google Scholar] [CrossRef]
- Zou, L.; Xia, L.; Ding, Z.; Song, J.; Liu, W.; Yin, D. Reinforcement learning to optimize long-term user engagement in recommender systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2810–2818. [Google Scholar]
- Chen, X.; Deng, H. Research on Personalized Recommendation Methods for Online Video Learning Resources. Appl. Sci. 2021, 11, 1–11. [Google Scholar]
- Ma, H.; King, I.; Lyu, M.R. Effective missing data prediction for collaborative filtering. In Proceedings of the ACM SIGIR International Conference on Theory of Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 39–46. [Google Scholar]
- Özbal, G.; Karaman, H.; Alpaslan, F.N. A content-boosted collaborative filtering approach for movie recommendation based on local and global similarity and missing data prediction. Comput. J. 2011, 54, 1535–1546. [Google Scholar] [CrossRef]
- Agarwal, V.; Bharadwaj, K.K. A collaborative filtering framework for friends recommendation in social networks based on interaction intensity and adaptive user similarity. Soc. Netw. Anal. Min. 2013, 3, 359–379. [Google Scholar] [CrossRef]
- Shin, Y.S.; Kim, H.I.; Chang, J.W. A content-aware expert recommendation scheme in social network services. In Advanced Multimedia and Ubiquitous Engineering; Springer: Singapore, 2016; Volume 393, pp. 45–54. [Google Scholar]
- Inan, E.; Tekbacak, F.; Ozturk, C. Moreopt: A goal programming based movie recommender system. J. Comput. Sci. 2018, 28, 43–50. [Google Scholar] [CrossRef]
- Dong, J.; Tang, R.; Lian, G. Cooperative Filtering Program Recommendation Algorithm Based on User Situations and Missing Values Estimation. In Proceedings of the International Conference on Intelligent Information Processing, Guilin, China, 12–15 October 2018; pp. 247–258. [Google Scholar]
- Ren, Y.; Zhang, J.; Zhou, W. The Efficient Imputation Method for Neighborhood-based Collaborative Filtering. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 684–693. [Google Scholar]
- Ren, Y.; Li, G.; Zhang, J.; Zhou, W. Lazy collaborative filtering for data sets with missing values. IEEE Trans. Cybern. 2013, 43, 1822–1834. [Google Scholar] [CrossRef]
- Ren, Y.; Li, G.; Zhang, J.; Zhou, W. AdaM: Adaptive-maximum imputation for neighborhood-based collaborative filtering. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, New York, NY, USA, 25–28 August 2013; pp. 628–635. [Google Scholar]
- Ren, Y.; Li, G.; Zhang, J.; Zhou, W. The maximum imputation framework for neighborhood-based collaborative filtering. Soc. Netw. Anal. Min. 2014, 4, 207. [Google Scholar] [CrossRef]
- Suganeshwari, G.; Ibrahim, S.S. Rule-based effective collaborative recommendation using unfavorable preference. IEEE Access 2020, 8, 128116–128123. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, S.W.; Park, S.; Xie, X. How to Impute Missing Ratings? Claims, Solution, and Its Application to Collaborative Filtering. In Proceedings of the 20th International Conference on World Wide Web, New York, NY, USA, 28 March–1 April 2018; pp. 783–792. [Google Scholar]
- Ahmadian, S.; Afsharchi, M.; Meghdadi, M. A novel approach based on multi-view reliability measures to alleviate data sparsity in recommender systems. Multimed. Tools Appl. 2019, 78, 17763–17798. [Google Scholar] [CrossRef]
- Chae, D.K.; Kim, J.; Chau, D.H.; Kim, S.W. AR-CF: Augmenting Virtual Users and Items in Collaborative Filtering for Addressing Cold-Start Problems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2020; pp. 1251–1260. [Google Scholar]
- Margaris, D.; Spiliotopoulos, D.; Karagiorgos, G.; Vassilakis, C. An Algorithm for Density Enrichment of Sparse Collaborative Filtering Datasets Using Robust Predictions as Derived Ratings. Algorithms 2020, 13, 174. [Google Scholar] [CrossRef]
- Herlocker, J.; Konstan, J.A.; Riedl, J. An empirical analysis of design choices in neighborhood-based collaborative filtering algorithms. Inf. Retr. 2002, 5, 287–310. [Google Scholar] [CrossRef]
- Luo, H.; Nju, C.; Shen, R.; Ullrich, C. A collaborative filtering framework based on both local user similarity and global user similarity. Mach. Learn. 2008, 72, 231–245. [Google Scholar] [CrossRef] [Green Version]
- Cover, T. Estimation by the nearest neighbor rule. IEEE Trans. Inf. Theory 1968, 14, 50–55. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, F.; Zheng, C. A precise SVM classification model for predictions with missing data. In Proceedings of the 4th National Conference on Applied Research in Electrical, Mechanical Computer and IT Engineering, Tehran, Iran, 4 October 2018. [Google Scholar]
- Wang, W.; Lu, Y. Analysis of the Mean Absolute Error (MAE) and the Root Mean Square Error (RMSE) in Assessing Rounding Model. Mater. Sci. Eng. 2018, 324, 012049. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Hong, M.S.; Jung, J.J.; Sohn, B.S. Cognitive Similarity-Based Collaborative Filtering Recommendation System. Appl. Sci. 2020, 10, 4183. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ihm, S.-Y.; Lee, S.-E.; Park, Y.-H.; Nasridinov, A.; Kim, M.; Park, S.-H. A Technique of Recursive Reliability-Based Missing Data Imputation for Collaborative Filtering. Appl. Sci. 2021, 11, 3719. https://0-doi-org.brum.beds.ac.uk/10.3390/app11083719
Ihm S-Y, Lee S-E, Park Y-H, Nasridinov A, Kim M, Park S-H. A Technique of Recursive Reliability-Based Missing Data Imputation for Collaborative Filtering. Applied Sciences. 2021; 11(8):3719. https://0-doi-org.brum.beds.ac.uk/10.3390/app11083719
Chicago/Turabian StyleIhm, Sun-Young, Shin-Eun Lee, Young-Ho Park, Aziz Nasridinov, Miyeon Kim, and So-Hyun Park. 2021. "A Technique of Recursive Reliability-Based Missing Data Imputation for Collaborative Filtering" Applied Sciences 11, no. 8: 3719. https://0-doi-org.brum.beds.ac.uk/10.3390/app11083719