
A Comprehensive Survey on Affinity Analysis, Bibliomining, and Technology Mining: Past, Present, and Future Research

 ,
,  ,
,  , and
, and
Abstract
:1. Introduction
1.1. Affinity Analysis
1.2. Bibliomining
- Determining the areas of focus;
- Identifying the internal and external data sources;
- Selecting appropriate analysis tools;
- Discovering patterns through data mining;
- Analyzing results.
1.3. Technology Mining
1.4. Organization
2. Related Literature Reviews
Research Gaps
- There are no existing reviews dedicated to affinity analysis;
- No approaches exist for reviewing affinity analysis-based research papers, according to their application domains;
- No effort has been made to review technology mining literature.
3. Review Methodology
3.1. Analyses of Related Surveys
3.2. Definition of Research Questions
- RQ1: what are the different types of application domains of affinity analysis?
- RQ2: how are affinity measures incorporated to improve itemset mining?
- RQ3: what are the key bibliomining practices and technologies available for academic libraries?
- RQ4: what are the existing techniques and approaches for technology mining?
- RQ5: what are the existing open issues, key challenges, and future research directions in the fields of affinity analysis, bibliomining, and technology mining?
3.3. Identification of Studies
3.4. Study Selection
3.4.1. Primary Selection
3.4.2. Final Selection
3.5. Data Extraction and Synthesis
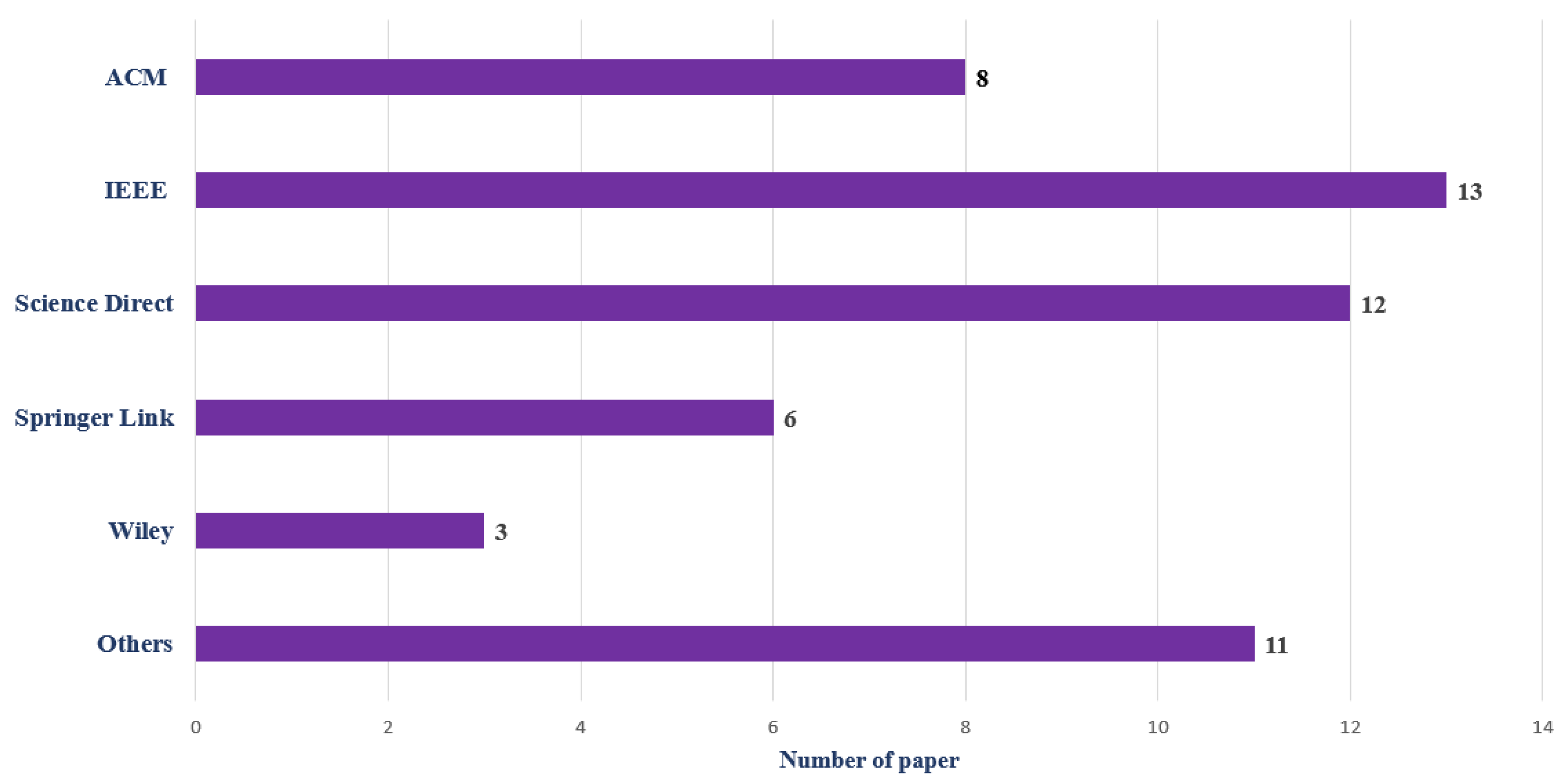
4. Publication Distribution
5. Affinity Analysis Review
5.1. E-Commerce
5.2. Social Network Analysis
Blog Analysis
5.3. Natural Language Processing
5.4. Video Data
5.5. Healthcare
5.6. Affinity Propagation
5.7. Utilities
6. Review of Bibliomining
7. Review of Technology Mining
8. Discussion
8.1. Answers to the Research Questions
- Kao et al. [82] utilized bibliomining as an essential tool to uncover useful library information from historical data to aid decision-making; however, a systematic procedure was missing for appropriate knowledge discovery. Bibliomining was used in conjunction with other measurement and assessment methods to generate complete reports on library systems, in [28,78].
- Different types of data mining approaches, such as association, classification, regression, clustering, and neural network methods have been applied for the analysis of library data. An association rule-based method was proposed by Wu et al. [98] to evaluate the usefulness of a library collection.
- One of the prime fields of technology mining is bibliometric analysis or text mining. Several approaches were found for technology-based text mining. Madani et al. [31] proposed a method based on articles found in the Web of Science database. Another approach based on the Web of Science core collection database was proposed by Zeba et al. [81].
8.2. Challenges
8.3. Open Issues and Future Research Directions
- The need for a systematic comparison method for an affinity-based model is still a major open issue. Research is required for the development of appropriate comparison criteria.
- An affinity analysis in social media is an emerging and very crucial application domain [49,52,53]. Most research studies have focused on the affinity within a single social media platform. This research can be extended to incorporate the affinity measure of a user (or group) between multiple social media platforms.
- Applying affinity analysis methodologies in developing fields of study (e.g., sentiment analysis, text classification, Internet of Things, and sensor networks) could open up new possibilities.
- Data privacy and security have always been prime concerns in data mining approaches. This is a crucial issue, especially in bibliomining and technology mining. Various types of data are associated with academic libraries, such as user credentials, digital article copies, billing information, and subscription data. The privacy and security of these data need to be guaranteed. Few approaches regarding privacy and security in bibliomining can be found in the literature. Securing data privacy can be considered a potentially fruitful research direction.
- The application of blockchains in various aspects of technology mining is still in the emerging phase. Blockchain is a cryptography-based decentralized database system, which can be very handy for securely storing associated data and managing authentication schemes.
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, B.; Hsu, W.; Ma, Y. Mining association rules with multiple minimum supports. In Proceedings of the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 337–341. [Google Scholar]
- Wang, C.Y.; Tseng, S.S.; Hong, T.P. Flexible online association rule mining based on multidimensional pattern relations. Inf. Sci. 2006, 176, 1752–1780. [Google Scholar] [CrossRef]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 26–28 May 1993; pp. 207–216. [Google Scholar]
- Hsu, P.Y.; Chen, Y.L.; Ling, C.C. Algorithms for mining association rules in bag databases. Inf. Sci. 2004, 166, 31–47. [Google Scholar] [CrossRef]
- Yun, U. Mining lossless closed frequent patterns with weight constraints. Knowl. Based Syst. 2007, 20, 86–97. [Google Scholar] [CrossRef]
- Gade, K.; Wang, J.; Karypis, G. Efficient closed pattern mining in the presence of tough block constraints. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 138–147. [Google Scholar]
- Fang, G.; Wu, Y.; Li, M.; Chen, J. An efficient algorithm for mining frequent closed itemsets. Informatica 2015, 39, 1. [Google Scholar]
- Wang, J.; Han, J.; Pei, J. CLOSET+ searching for the best strategies for mining frequent closed itemsets. In Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 236–245. [Google Scholar]
- Bonchi, F.; Lucchese, C. Pushing tougher constraints in frequent pattern mining. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2005; pp. 114–124. [Google Scholar]
- Bucilă, C.; Gehrke, J.; Kifer, D.; White, W. Dualminer: A dual-pruning algorithm for itemsets with constraints. Data Min. Knowl. Discov. 2003, 7, 241–272. [Google Scholar] [CrossRef]
- Lee, A.J.; Lin, W.c.; Wang, C.s. Mining association rules with multi-dimensional constraints. J. Syst. Softw. 2006, 79, 79–92. [Google Scholar] [CrossRef]
- Grahne, G.; Lakshmanan, L.V.; Wang, X. Efficient mining of constrained correlated sets. In Proceedings of the 16th International Conference on Data Engineering (Cat. No. 00CB37073), San Diego, CA, USA, 28 February–3 March 2000; pp. 512–521. [Google Scholar]
- Huang, Y.; Xiong, H.; Wu, W.; Deng, P.; Zhang, Z. Mining maximal hyperclique pattern: A hybrid search strategy. Inf. Sci. 2007, 177, 703–721. [Google Scholar] [CrossRef]
- Lee, Y.K.; Kim, W.Y.; Cai, Y.D.; Han, J. CoMine: Efficient Mining of Correlated Patterns. In Proceedings of the Third IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003; Volume 3, pp. 581–584. [Google Scholar]
- Ma, S.; Hellerstein, J.L. Mining mutually dependent patterns. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 409–416. [Google Scholar]
- Changchien, S.W.; Lu, T.C. Mining association rules procedure to support on-line recommendation by customers and products fragmentation. Expert Syst. Appl. 2001, 20, 325–335. [Google Scholar] [CrossRef]
- Layton, R. Learning Data Mining with Python; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Strzelecka, A.; Stachura, M.; Wójcik, T.; Pacian, A.B.; Kulik, T.; Pacian, J.; Kaczoruk, M.; Galinska, E.M.; Kawiak-Jawor, E.; Nowak-Starz, G. Using affinity analysis in diagnosing the needs of patients as regards e-Health. Ann. Agric. Environ. Med. 2020, 27, 3. [Google Scholar] [CrossRef]
- Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Karthiyayini, R.; Balasubramanian, R. Affinity analysis and association rule mining using apriori algorithm in market basket analysis. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2016, 6, 241–246. [Google Scholar]
- Nicholson, S. The basis for bibliomining: Frameworks for bringing together usage-based data mining and bibliometrics through data warehousing in digital library services. Inf. Process. Manag. 2006, 42, 785–804. [Google Scholar] [CrossRef] [Green Version]
- Nicholson, S.; Hwang, S.Y.; Keezer, P.; O’Neill, E.T. The bibliomining process: Data warehousing and data mining for libraries. Sponsored by SIG LT. Proc. Am. Soc. Inf. Sci. Technol. 2003, 40, 478–479. [Google Scholar] [CrossRef]
- Hajek, P.; Stejskal, J. Bibliomining analysis of the portfolio of services of public libraries: The case of the Municipal Library of Prague. In Proceedings of the 3rd International Conference on Arts and Culture, Moscow, Russia, 29–30 May 2012; pp. 345–350. [Google Scholar]
- Shieh, J.C. The integration system for librarians’ bibliomining. Electron. Libr. 2010, 28, 709–721. [Google Scholar] [CrossRef] [Green Version]
- Azam, I.; Sohrawardi, S.J.; Das, H.S.; Alam, M.S.; Alvy, M.S.; Rahman, R.M. Bibliomining on North South University library data. In Proceedings of the Eighth International Conference on Digital Information Management (ICDIM 2013), Islamabad, Pakistan, 10–12 September 2013; pp. 235–240. [Google Scholar]
- Nicholson, S.; Stanton, J. Gaining Strategic Advantage Through Bibliomining: Data Mining for Management Decisions in Corporate, Special, Digital and, Traditional Libraries. In Data Warehousing and Mining: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2008; pp. 2673–2687. [Google Scholar]
- Deshpande, A.S. Usage of Library books among UnderGraduate Computer Applications students using Bibliomining. Int. J. Inform. Syst. 2013, IV, 17–20. [Google Scholar]
- Nicholson, S. Bibliomining for automated collection development in a digital library setting: Using data mining to discover Web-based scholarly research works. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 1081–1090. [Google Scholar] [CrossRef]
- Porter, A.L.; Detampel, M.J. Technology opportunities analysis. Technol. Forecast. Soc. Change 1995, 49, 237–255. [Google Scholar] [CrossRef]
- Trumbach, C.C.; Payne, D.; Kongthon, A. Technology mining for small firms: Knowledge prospecting for competitive advantage. Technol. Forecast. Soc. Change 2006, 73, 937–949. [Google Scholar] [CrossRef]
- Madani, F. ‘Technology Mining’ bibliometrics analysis: Applying network analysis and cluster analysis. Scientometrics 2015, 105, 323–335. [Google Scholar] [CrossRef]
- Ceglar, A.; Roddick, J.F. Association mining. ACM Comput. Surv. (CSUR) 2006, 38, 5-es. [Google Scholar] [CrossRef]
- Maske, A.; Joglekar, B. Survey on Frequent Item-Set Mining Approaches in Market Basket Analysis. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–5. [Google Scholar]
- Fournier-Viger, P.; Chun-Wei Lin, J.; Truong-Chi, T.; Nkambou, R. A survey of high utility itemset mining. In High-Utility Pattern Mining; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–45. [Google Scholar]
- Almoqbily, R.S.; Rauf, A.; Quradaa, F.H. A survey of correlated high utility pattern mining. IEEE Access 2021, 9, 42786–42800. [Google Scholar] [CrossRef]
- Cheng, H.; Han, M.; Zhang, N.; Li, X.; Wang, L. A Survey of incremental high-utility pattern mining based on storage structure. J. Intell. Fuzzy Syst. 2021, 41, 1–26. [Google Scholar] [CrossRef]
- Siguenza-Guzman, L.; Saquicela, V.; Avila-Ordóñez, E.; Vandewalle, J.; Cattrysse, D. Literature review of data mining applications in academic libraries. J. Acad. Librariansh. 2015, 41, 499–510. [Google Scholar] [CrossRef] [Green Version]
- Al-Barashdi, H.; Al-Karousi, R. Big Data in academic libraries: Literature review and future research directions. J. Inf. Stud. Technol. 2019, 2018, 13. [Google Scholar] [CrossRef]
- Hamad, F.; Fakhuri, H.; Abdel Jabbar, S. Big data opportunities and challenges for analytics strategies in Jordanian Academic Libraries. New Rev. Acad. Librariansh. 2020, 28, 37–60. [Google Scholar] [CrossRef]
- Huancheng, L.; Tingting, W.; Rocha, Á. An analysis of research trends on data mining in Chinese academic libraries. J. Grid Comput. 2019, 17, 591–601. [Google Scholar] [CrossRef]
- Keele, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report; EBSE: Durham, UK, 2007. [Google Scholar]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Kitchenham, B. Procedures for Performing Systematic Reviews; Keele University: Keele, UK, 2004; Volume 33, pp. 1–26. [Google Scholar]
- Brereton, P.; Kitchenham, B.A.; Budgen, D.; Turner, M.; Khalil, M. Lessons from applying the systematic literature review process within the software engineering domain. J. Syst. Softw. 2007, 80, 571–583. [Google Scholar] [CrossRef] [Green Version]
- Shyu, M.L.; Chen, S.C.; Kashyap, R.L. Generalized affinity-based association rule mining for multimedia database queries. Knowl. Inf. Syst. 2001, 3, 319–337. [Google Scholar] [CrossRef] [Green Version]
- Yun, U.; Leggett, J.J. WIP: Mining Weighted Interesting Patterns with a strong weight and/or support affinity. In Proceedings of the 2006 SIAM International Conference on Data Mining, SIAM, Bethesda, MD, USA, 20–22 April 2006; pp. 624–628. [Google Scholar]
- Wang, B.; Rahal, I.; Dong, A. Parallel hierarchical clustering using weighted confidence affinity. Int. J. Data Mining, Model. Manag. 2011, 3, 110–129. [Google Scholar] [CrossRef]
- Li, H.; Bhowmick, S.S.; Sun, A.; Cui, J. Affinity-driven blog cascade analysis and prediction. Data Min. Knowl. Discov. 2014, 28, 442–474. [Google Scholar] [CrossRef]
- Rezgui, A.; Fahey, D.; Smith, I. Affinityfinder: A system for deriving hidden affinity relationships on twitter utilizing sentiment analysis. In Proceedings of the 2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Vienna, Austria, 22–24 August 2016; pp. 212–215. [Google Scholar]
- Tshimula, J.M.; Chikhaoui, B.; Wang, S. Har-search: A method to discover hidden affinity relationships in online communities. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Vancouver, BC, Canada, 27–30 August 2019; pp. 176–183. [Google Scholar]
- Yun, U. Efficient mining of weighted interesting patterns with a strong weight and/or support affinity. Inf. Sci. 2007, 177, 3477–3499. [Google Scholar] [CrossRef]
- Panigrahy, R.; Najork, M.; Xie, Y. How user behavior is related to social affinity. In Proceedings of the 5th ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; pp. 713–722. [Google Scholar]
- Li, L.; Peng, W.; Kataria, S.; Sun, T.; Li, T. Recommending users and communities in social media. ACM Trans. Knowl. Discov. Data 2015, 10, 1–27. [Google Scholar] [CrossRef]
- Hong, M.; Jung, J.J.; Lee, M. Social affinity-based group recommender system. In Proceedings of the 4th International Conference on Context-Aware Systems and Applications, Vung Tau, Vietnam, 26–27 November 2015; pp. 111–121. [Google Scholar]
- Butt, N.S. Bibliomining and Comparison of Q4 and ESCI Indexed journals under Statistics and Probability Category. Pak. J. Stat. Oper. Res. 2021, 17, 25–34. [Google Scholar] [CrossRef]
- Xiong, H.; Tan, P.N.; Kumar, V. Mining strong affinity association patterns in data sets with skewed support distribution. In Proceedings of the 3rd IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003; pp. 387–394. [Google Scholar]
- Wang, B.; Rahal, I. WC-clustering: Hierarchical clustering using the weighted confidence affinity measure. In Proceedings of the 7th IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 355–360. [Google Scholar]
- Subbiah, A.; Ibrahim, O. Implementing affinity analysis in determining critical factors on e-service systems in Malaysia. In Proceedings of the 2011 International Conference on Research and Innovation in Information Systems, Kuala Lumpur, Malaysia, 23–24 November 2011; pp. 1–6. [Google Scholar]
- Al Masum, A.; Rafy, M.H.; Rahman, S.M. Video-based affinity group detection using trajectories of multiple subjects. In Proceedings of the 8th International Conference on Electrical and Computer Engineering, Dhaka, Bangladesh, 20–22 December 2014; pp. 120–123. [Google Scholar]
- Moraes, S.; Godbole, A.; Gharpure, P. Affinity analysis for context-free grammars. In Proceedings of the 2017 IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), Chennai, India, 21–22 September 2017; pp. 2471–2474. [Google Scholar]
- Li, X.; Song, H.; Zhang, X.; Xu, Q. Fine-grained Construction of Semantic Technology Network for Technology Evolution Analysis. In Proceedings of the 3rd International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2019; pp. 1–7. [Google Scholar]
- Shyu, M.L.; Chen, S.C.; Chen, M.; Rubin, S.H. Affinity-based similarity measure for Web document clusteringh. In Proceedings of the 2004 IEEE International Conference on Information Reuse and Integration, (IRI 2004), Las Vegas, NV, USA, 8–10 November 2004; pp. 247–252. [Google Scholar]
- Chen, Y.W.; Larbani, M.; Hsieh, C.Y.; Chen, C.W. Introduction of affinity set and its application in data-mining example of delayed diagnosis. Expert Syst. Appl. 2009, 36, 10883–10889. [Google Scholar] [CrossRef]
- Liu, D.; Jiang, M. Affinity propagation clustering on oral conversation texts. In Proceedings of the 2012 IEEE 11th International Conference on Signal Processing, Beijing, China, 21–25 October 2012; Volume 3, pp. 2279–2282. [Google Scholar]
- Zhang, X.; Furtlehner, C.; Germain-Renaud, C.; Sebag, M. Data stream clustering with affinity propagation. IEEE Trans. Knowl. Data Eng. 2013, 26, 1644–1656. [Google Scholar] [CrossRef] [Green Version]
- Sadiq, S.; Yan, Y.; Taylor, A.; Shyu, M.L.; Chen, S.C.; Feaster, D. Aafa: Associative affinity factor analysis for bot detection and stance classification in twitter. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 356–365. [Google Scholar]
- Srilatha, G.; Chandra, N.S. Robust frequency affinity-based high utility itemset mining approach using multiple minimum utility. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Shen, X.; Gao, Y.; Ding, C.; Archambault, R. Lightweight reference affinity analysis. In Proceedings of the 19th Annual International Conference on Supercomputing, Cambridge, MA, USA, 20–22 June 2005; pp. 131–140. [Google Scholar]
- Li, H.; Bhowmick, S.S.; Sun, A. Blog cascade affinity: Analysis and prediction. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 1117–1126. [Google Scholar]
- Hájek, P.; Stejskal, J. Library user behavior analysis–use in economics and management. WSEAS Trans. Bus. Econ. 2014, 11, 107–116. [Google Scholar]
- Zhang, Z.; Gao, W.; Mo, W.; Wang, H.; Luan, L. Data-based affinity analysis of power transformer defects with adaptive frequent itemset mining algorithm. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 2850–2854. [Google Scholar]
- Swofford, M.; Peruzzi, J.; Tsoi, N.; Thompson, S.; Martín-Martín, R.; Savarese, S.; Vázquez, M. Improving social awareness through dante: Deep affinity network for clustering conversational interactants. Proc. ACM Hum. Comput. Interact. 2020, 4, 1–23. [Google Scholar] [CrossRef]
- Pitkaranta, T. Affinity analysis of coded data sets. In Proceedings of the 2009 EDBT/ICDT Workshops, Saint-Petersburg, Russia, 22 March 2009; pp. 177–184. [Google Scholar]
- Chen, C.; Xing, Z. Mining technology landscape from stack overflow. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real, Spain, 8–9 September 2016; pp. 1–10. [Google Scholar]
- Yadav, R.K.; Abhishek; Yadav, V.K.; Verma, S.; Venkatesan, S. HSIC-based affinity measure for learning on graphs. Pattern Anal. Appl. 2021, 24, 1667–1683. [Google Scholar] [CrossRef]
- Bao, F.; Mao, L.; Zhu, Y.; Xiao, C.; Xu, C. An improved evaluation methodology for mining association rules. Axioms 2021, 11, 17. [Google Scholar] [CrossRef]
- Prakash, K.; Chand, P.; Gohel, U. Application of data mining in library and information services. In Proceedings of the 2nd Convention PLANNER, Imphal, India, 4–5 November 2004; pp. 168–177. [Google Scholar]
- Nicholson, S. Approaching librarianship from the data: Using bibliomining for evidence-based librarianship. Library Hi Tech 2006, 24, 369–375. [Google Scholar] [CrossRef] [Green Version]
- Wen, Q.J.; Ren, Z.J.; Lu, H.; Wu, J.F. The progress and trend of BIM research: A bibliometrics-based visualization analysis. Autom. Constr. 2021, 124, 103558. [Google Scholar] [CrossRef]
- Kostoff, R.N.; del Rio, J.A.; Humenik, J.A.; Garcia, E.O.; Ramirez, A.M. Citation mining: Integrating text mining and bibliometrics for research user profiling. J. Am. Soc. Inf. Sci. Technol. 2001, 52, 1148–1156. [Google Scholar] [CrossRef]
- Zeba, G.; Dabić, M.; Čičak, M.; Daim, T.; Yalcin, H. Technology mining: Artificial intelligence in manufacturing. Technol. Forecast. Soc. Change 2021, 171, 120971. [Google Scholar] [CrossRef]
- Kao, S.C.; Chang, H.C.; Lin, C.H. Decision support for the academic library acquisition budget allocation via circulation database mining. Inf. Process. Manag. 2003, 39, 133–147. [Google Scholar] [CrossRef]
- Wu, C.H. Data mining applied to material acquisition budget allocation for libraries: Design and development. Expert Syst. Appl. 2003, 25, 401–411. [Google Scholar] [CrossRef]
- Yoon, B.; Park, Y. A text-mining-based patent network: Analytical tool for high-technology trend. J. High Technol. Manag. Res. 2004, 15, 37–50. [Google Scholar] [CrossRef]
- Adomavicius, G.; Bockstedt, J.C.; Gupta, A.; Kauffman, R.J. Technology roles and paths of influence in an ecosystem model of technology evolution. Inf. Technol. Manag. 2007, 8, 185–202. [Google Scholar] [CrossRef]
- Yun, U.; Leggett, J.J. WFIM: Weighted frequent itemset mining with a weight range and a minimum weight. In Proceedings of the 2005 SIAM International Conference on Data Mining, Newport Beach, CA, USA, 21–23 April 2005; pp. 636–640. [Google Scholar]
- Zhong, Y.; Orlovich, M.; Shen, X.; Ding, C. Array regrouping and structure splitting using whole-program reference affinity. ACM SIGPLAN Not. 2004, 39, 255–266. [Google Scholar] [CrossRef] [Green Version]
- Zen, G.; Lepri, B.; Ricci, E.; Lanz, O. Space speaks: Towards socially and personality aware visual surveillance. In Proceedings of the 1st ACM International Workshop on Multimodal Pervasive Video Analysis, Firenze, Italy, 29 October 2010; pp. 37–42. [Google Scholar]
- Alameda-Pineda, X.; Staiano, J.; Subramanian, R.; Batrinca, L.; Ricci, E.; Lepri, B.; Lanz, O.; Sebe, N. Salsa: A novel dataset for multimodal group behavior analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1707–1720. [Google Scholar] [CrossRef] [Green Version]
- Cristani, M.; Bazzani, L.; Paggetti, G.; Fossati, A.; Tosato, D.; Del Bue, A.; Menegaz, G.; Murino, V. Social interaction discovery by statistical analysis of F-formations. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; Volume 2, p. 4. [Google Scholar]
- Kaya, M.; Binli, M.K.; Ozbay, E.; Yanar, H.; Mishchenko, Y. A large electroencephalographic motor imagery dataset for electroencephalographic brain computer interfaces. Sci. Data 2018, 5, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thoma, M. The hasyv2 dataset. arXiv 2017, arXiv:1701.08380. [Google Scholar]
- Roy, P.; Ghosh, S.; Bhattacharya, S.; Pal, U. Effects of degradations on deep neural network architectures. arXiv 2018, arXiv:1807.10108. [Google Scholar]
- Quattoni, A.; Torralba, A. Recognizing indoor scenes. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 413–420. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Gama, A.W.O.; Widnyani, N.M. Simple Modification for an Apriori Algorithm with Combination Reduction and Iteration Limitation Technique. Knowl. Eng. Data Sci. 2021, 3, 89–98. [Google Scholar] [CrossRef]
- Akas, M.F.; Zaman, A.; Khan, A. Combined item sets generation using modified apriori algorithm. In Proceedings of the International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 January 2020; pp. 1–3. [Google Scholar]
- Wu, C.H.; Lee, T.Z.; Kao, S.C. Knowledge discovery applied to material acquisitions for libraries. Inf. Process. Manag. 2004, 40, 709–725. [Google Scholar] [CrossRef]


{kind=link}
| ID | Inclusion Criteria |
|---|---|
| InC1 | The article is published in conference proceedings or in a journal. |
| InC2 | The main contribution(s) of the study focus on affinity analysis, bibliomining, or technology mining. |
| InC3 | The article is published between the year 2000 and December 2021. |
| InC4 | The article proposes at least one affinity analysis method or applies any affinity analysis method to solve any real-world problem. |
| InC5 | The article proposes at least one method for bibliomining or applies any method to solve any real-world bibliomining problem. |
| InC6 | The article proposes at least one method for technology mining or applies the method to solve any real-world problem related |
| to technology mining. | |
| Exclusion criteria | |
| ExC1 | The article is a poster, editorial, report, summary, or book review. |
| ExC2 | The article is not in the English language. |
| ExC3 | The main focus of the study is not relevant to affinity analysis, bibliomining, or technology mining. |
| ExC4 | The major contribution of the study is unclear. |
| ExC5 | Duplicate study or article. |
| ExC6 | The article is unavailable in electronic format. |
| Before 2005 | 2006–2010 | 2011–2012 | 2013–2015 | 2016–2018 | 2019–Dec 2021 |
|---|---|---|---|---|---|
| Shyu et al. [45] | Yun et al. [46] | Wang et al. [47] | Li et al. [48] | Rezgui et al. [49] | Tshimula et al. [50] |
| Changchien et al. [16] | Yun et al. [51] | Panigrahy et al. [52] | Li et al. [53] | Hong et al. [54] | Butt et al. [55] |
| Xiong et al. [56] | Wang et al. [57] | Subbiah et al. [58] | Masum et al. [59] | Moraes et al. [60] | Li et al. [61] |
| Shyu et al. [62] | Chen et al. [63] | Liu et al. [64] | Zhang et al. [65] | Sadiq et al. [66] | Srilatha et al. [67] |
| Shen et al. [68] | Li et al. [69] | Hajek et al. [70] | Azam et al. [25] | Zhang et al. [71] | Swofford et al. [72] |
| Nicholson et al. [28] | Pitkaranta et al. [73] | Hajek et al. [23] | Deshpande et al. [27] | Chen et al. [74] | Yadav et al. [75] |
| Nicholsen et al. [22] | Nicholson [21] | Madani et al. [31] | Bao et al. [76] | ||
| Prakash et al. [77] | Nicholson [78] | Wen et al. [79] | |||
| Kostoff et al. [80] | Shieh et al. [24] | Zeba et al. [81] | |||
| Kao et al. [82] | Nicholson et al. [26] | ||||
| Wu et al. [83] | Courseault et al. [30] | ||||
| Yoon et al. [84] | Adomavicius et al. [85] | ||||
| Porter et al. [29] |
| Paper | Major Contribution | Data Set Used | Implementation Environment and Evaluation | Limitations |
|---|---|---|---|---|
| Shyu et al. [45] | The authors proposed an algorithm for affinity-based association rule mining for discovering quasi-equivalence relations in database queries. | Experimented on the Purdue University financial database management system with 22 media objects accessed by 17,222 queries. | Conducted two empirical studies, which showed that their proposed approach performed better than the traditional association rule mining approach in discovering quasi-equivalence relationships. | As the structural similarity link between two media objects cannot be automatically discovered, the query execution speed of this approach is still slower. |
| Xiong et al. [56] | To capture the degree of affinity in a pattern and remove cross-support patterns, they created a metric called h-confidence and proposed an algorithm called the hyperclique miner. | They evaluated their proposed algorithm on the Pumsb data set containing 49,046 records, S&P 500 data set (716 records), and the Retail data set (57,671 records). | All tests were conducted on a Sun Ultra 10 workstation running the SunOS 5.7 operating system with a 440 MHz CPU and 128 Mbytes of memory. They performed better than existing algorithms used for identifying patterns at very low support levels. | In practice, cross-support patterns, which contain elements with varying amounts of support, are loosely related and are not suitable for real-world purposes. |
| Yun et al. [46,51] | A new algorithm called weighted interesting pattern mining (WIP) was proposed, in which a new metric—weight-confidence—was created to produce weighted hyperclique patterns of similar weight levels. | Three real data sets were used: Connect, Pumsb, and Mushroom. | The WIP algorithm was implemented in C++ and experiments were performed on a Unix platform. The algorithm was compared with WFIM [86] and hyperclique miner [56]. | This technique is centered on the support confidence structure. However, it does not take into account the actual preferences of users. |
| Changchien et al. [16] | The authors proposed an association rule mining mechanism based on the self-organization map (SOM), a neural network for affinity grouping, and then a rough set for the extraction of association rules. | Experimented on purchase records of an e-commerce store containing 1120 products and 35 customer records. They only considered records for one whole day of transactions, comprising 2000 records. | The radius and learning rate of SOM clustering were set to 2.0 and 1.0, respectively. The change rate for both radius and learning rate was set to 0.98. The error rate of the clustering was lower than 0.1. For rule extraction, the minimum confidence was set to 0.2. | This strategy cannot be used for dynamic assessment (i.e., it cannot automatically add feedback and attributes). One should consider more variables, such as customer and product profiles, purchasing purposes, and so on. |
| Shyu et al. [62] | The authors proposed a new metric of similarity based on affinity to facilitate web document clustering. | Microsoft Anonymous Web, also known as the UCI KDD data set, contains 294 URLs and about 38,000 anonymous user accesses. | Four experiments were performed to validate the efficiency of the proposed affinity-based similarity measure. The experimental findings reveal that the suggested metric of the affinity-based similarity (AFFINITY) performs better in terms of generating the smallest number of inter-cluster accesses. | It requires a training data set, which intensely conditions the clustering results. This represents the main drawback of the approach. |
| Wang et al. [57] | The authors proposed a hierarchical technique, named weighted confidence (WC) clustering, for grouping market-basket data items based on a weighted confidence affinity measure and vertical data structures. | Standard market basket data sets and properties include transactions and itemsets. | The suggested weighted confidence affinity measure gives much more compact results than other concurrent affinity measures. Further, it determines the proximity between clusters more effectively than other affinity measurement approaches. | The PH-clustering scheme employs a larger number of processors to expedite the sequential clustering process. Due to the trade-off between computing time and communication time, it was noticed that expanding the amount of used processors does not really speed up clustering. |
| Chen et al. [63] | Addressed the problem of delayed diagnosis and, in order to decrease error probability, used the affinity set (through the topological concept) to classify/focus on key attributes that caused a delayed diagnosis (missed injury). | Clinical ER data of Kaohsiung Medical University and Chung-Ho Memorial Hospital, Taiwan. | Achieved accuracy of 89.4% when compared with the Rough Set, SVM, logistic regression, and neural network models. | Lack of implementation details and performance evaluation measures. |
| Li et al. [69] | The authors proposed a group of content-abstracted items that induced a blogger’s cascade joining behavior. | Data set consisting of blog posts published from June to September 2008. | It uses an SVM-based classification technique. Five properties—the number of friends, the number of candidates, the popularity of candidates, the time passed since the genesis of the cascade, and the citing factor of the blog—have notable impacts on the cascade affinity, helping to point out the bloggers who could easily influence. | As there are significant variations between retweeting in microblogs and blog cascades, the proposed solution employed in this paper may not be directly applicable in a microblogging environment. |
| Wang et al. [47] | The authors proposed a parallelized hierarchical clustering technique for market basket data and introduced a new WC affinity measure to enumerate the resemblance between clusters while reducing the impact of low-support items. | Market basket data properties include transactions and itemsets. | After they conducted an experiment on market basket data, it was evident that the recommended weighted confidence affinity measure produces much more compact results than several modern affinity measurement schemes. | This strategy cannot function in a dynamic context. It is performed on static data inputs and, so, is unable to generate real-time relationships and behavior patterns. |
| Panigrahy et al. [52] | The authors introduced a sketch-based new affinity measure in social networks that considers both the space between two individuals and total edge-separated paths between them. | The first experiment (Hotmail experiment) used three data sets: a) an anonymized data set with a pair of user ID hashes for any two email users, b) a data set consisting of basic demographic information, and c) a data set that includes the Bing query history. The second experiment evaluated one month’s worth of Twitter posts. | In this sketch-based social affinity measure approach, affinity queries could be responded to much more effectively than others. | Given that the measure relies on metrics, e.g., the number of interactions between individuals, it may fail to capture the set of components that may better explain the affinity. |
| Li et al. [48] | The authors proposed a group of content-abstracted properties (considering large-scale and small-scale) that induce a blog’s tendency to enter into a cascade. | The data set contains blog posts published from June to September 2008. | Their approach identified a total of seven properties that played a significant role in predicting affinity in the blog cascade, pointing out the bloggers who could easily influence. | To adapt this model to the microblog domain, some parameters may need to be modified, and other characteristics specific to microblogs must be considered. |
| Li et al. [53] | The authors proposed a framework, FRec, recommending prominent users and topic-related interactive communities that are very compatible with the given user, depending on the presumed outcome of the topic model. | Data set was an accumulation of tweets linked with presidential campaigns between Barack Obama and Mitt Romney, ranging from March to May 2012. | Based on the input, the proposed framework, FRec, could suggest an array of prominent or interactive users that correlate with the context, and those most compatible with a given user or keyword. | It does not provide any viable strategy to filter out the noise within the social media data. |
| Rezgui et al. [49] | The authors introduced a system named AffinityFinder that utilizes sentiment analysis to avoid the complexity in finding potential hidden associations among Twitter users. | The data set included around 12,000 directed tweets by approximately 600 users. | The proposed system, AffinityFinder, is capable of deriving probable friendship connections with high accuracy and, according to non-traditional information, it can make a more relevant supposition about the association. | The proposed method is not a real-time system, the MongoDB database is not updated regularly with newer tweets, and the relationship scores are not refreshed periodically. |
| Hong et al. [54] | The authors proposed a novel recommendation technique to determine social affinity based on the closeness between two community members. | Synthetic data sets. | After evaluating the synthetic data sets, it was shown that the recommended scheme could efficiently discover social affinities. | The system lacks experiments with a broader consumer group (rather than 18 people). Additionally, a virtual network that mirrors the real world using a standard theory needs to be created. |
| Tshimula et al. [50] | The authors proposed a method to detect hidden affinity associations between individuals on the web. | Used four online discussion data sets: 1) WhatsApp group data (WGD); 2) R community data on Twitter; 3) FreeCodeCamp Gitter chat data (FCC); and 4) internet argument corpus. | HAR-search comprises much more properties than AffinityFinder and could notice every detail to observe the context thoroughly. Moreover, HAR-search produced more effective results compared to AffinityFinder on the experimental data sets. | HAR-search models only positive interaction sequence(s) (PIS) based on the text context in the conversation history. |
| Moraes et al. [60] | The authors introduced an algorithm to analyze the context-free grammar affinity using test sentences originating automatically and randomly. | The set of all sentences that could be obtained from grammar. | After the evaluation, it was shown that the recommended trial and error-based algorithm could effectively analyze context-free grammar affinity and produce the desired output. | This algorithm is not fully capable of being applied to practical systems as its computational cost is high. |
| Pitkaranta et al. [73] | The authors introduced an information retrieval-based model that employs kernel methods and vector distance functions for systematic analysis of coded data sets. | Artificial coded data sets to which some renowned domains were added, namely healthcare and market basket analyses. | This model can perform smoothly for modifiable queries with vast amounts of coded data sets, generating rapid results. | The proposed information retrieval model mainly focuses on achieving a high performance, rather than accuracy; hence, it does not deliver high accuracy. |
| Shen et al. [68] | The authors proposed a frequency-based similarity analysis to group arrays. An interdisciplinary analysis strategy was also utilized to reconstruct this array based on the access frequency. | Used 11 benchmarks: eight from SPEC CPU2000 and three from the distance-based affinity analysis programs by Zhong et al. [87]. | After the evaluation, the experimental results showed that the authentic compiler-based array rearrangement improved most of the program’s performance compared to the others; no further improvement was required through code or data categorization. | Their static estimation only works for loops with regular structures and cannot accurately analyze irregular loops, indirect memory references, and complex dataflow with aliases. |
| Sadiq et al. [66] | The authors introduced a framework named the associative affinity factor analysis (AAFA) for position analysis and bot spotting; it recognizes actual users from bots and detects the positions within inconsistent affinities. | The 2016 U.S. presidential election campaign tweets were used as an experimental data set. | Their experimental results showed that the correctness of the suggested framework is very high when compared to various existing modern methods. | Other related information in tweets, such as resources, retweets, favorites, and so on, should be taken into account for enhanced stance recognition and bot categorization. |
| Subbiah et al. [58] | Conducted a pilot study to determine the most relevant critical factor that led to dissatisfaction among the users in providing e-services. | A pilot study: 3 groups of 8 people were formed, for a total of 24 participants comprising residents from 13 states in Malaysia. | By using the affinity analysis, they determined the critical factors of qualitative data. According to the findings of the affinity analysis, 80% of the problem was caused by 20% of the overall functionality of the serving system. | This paper was a pilot study that involved only 24 participants; surveying with fewer data is more likely to produce misconceptions and erroneous results. |
| Zhang et al. [71] | The authors introduced an adaptive repeated itemset mining algorithm, which was improved based on the Apriori algorithm in order to obtain the precise requirements of mining fault information, thereby supporting an insightful condition evaluation system for power transformers. | A total of 11,266 authentic records from in-service power transformers were used in the experimental data set. | The recommended algorithm can effectively specify the similarities among manufacturers, operating years, the voltage grades of transformers, and their defective parts. | Lack of implementation details and performance evaluation measures. |
| Masum et al. [59] | The authors introduced a supervised learning technique to detect affinity based on assumptions acquired by tracing trajectories of the human context captured in a video series. | Used 30 video clips, each with a length of at least 6 seconds, as a data set. | After evaluation, this assumption-based similarity identification scheme showed optimal results regarding accuracy in similarity identification when compared with other similarity measurement schemes. | The proposed algorithm has high computational requirements. |
| Liu et al. [64] | The authors proposed an algorithm named Affinity propagation (AP) to cluster oral conversational text. | Used textual corpus as an experimental data set. | After performing affinity propagation on text clustering, it was shown that, if the Kullback–Leibler (KL) divergence and affinity propagation are jointly applied, a better outcome could be obtained, compared to when using the default measure (Euclidean). Furthermore, it can effectively handle noisy data. | This paper applies the AP–KL method only on a textual corpus; it needs to be investigated further in other data sets to demonstrate its performance. |
| Zhang et al. [65] | The authors introduced the STRAP algorithm, blending affinity propagation (AP) with a statistical change point identification test to group data sets according to the best exemplars. | Two benchmark data sets. | The recommended method can accurately identify the best exemplars from the flow of data, and then build clusters according to these exemplars. | The proposed STRAP algorithms take a long time to compute. The question was raised as to whether or not this performance is compatible with real-time applications. |
| Srilatha et al. [67] | The authors proposed a unique high-utility pattern (HUP) discovery approach for progressive transactional databases by considering a resilient frequency affiliation (FA) and knowledge weight utilization, thus preserving the downward closure principle. | Three data samples—retail, food mart, and chess data information. | Experiments showed that the proposed itemset extraction method is excellent and scalable for mining intriguing HUP data. | The proposed data mining approach mainly focuses on improving the run-time and memory usage; other features, such as output accuracy and data security, were not considered |
| Swofford et al. [72] | A unique Deep Affinity Network (DANTE)-based approach for detecting conversational groups; it forecasts the affinity that two people in a situation are in the same conversational group based on the social environment. | This paper considers three publicly available data sets of social interactions for evaluation: the Cocktail Party data set [88], the SALSA data set [89], and the Coffee Break data set [90]. | In comparison with earlier work, this algorithm outperformed in conversational group identification, general group identification, and graph clustering tasks, when evaluated against the existing benchmarks. | The suggested technique ignores the temporal relationship of spatial data recorded by a sensor located anywhere. DANTE scales quadratically with the scene size; this could be a problem when used in a more crowded environment. |
| Yadav et al. [75] | The authors proposed an HSIC-based affiliation approach for learning non-linear relationships between data points, which subsequently identifies and connects related data points. | Synthetic data sets comprising 3D manifold shapes with known lower-dimensional 2D representations: punctured sphere, sine on a hyperboloid, Swiss roll with hole, twin peak with hole. Real-world data sets: BCI 5F [91], BCI HaLT [91], Hasy_v2 [92], natural images [93], CVPR’09 [94], and fashion MNIST [95] | The presented HSIC-based affinity successfully binds identical data points together and separates different data points to give a more explicit portrayal of resemblance, compared to the Euclidean distance, and it yields high precision under several dimensionality reduction approaches, such as LE, LLE, and LTSA | Although HSIC may be a suitable affiliation indicator, the precision of classification relies on other factors, such as the number of neighbors in the graph, the choice of the classification scheme, and so on, which also need to be experimentally evaluated. |
| Bao et al. [76] | The authors introduced four new assessment measures (Bi-support, Bi-lift, Bi-improvement, and Bi-confidence) for mining association rules. | Two types of data sets were utilized in the evaluation: the IBM SPSS modeler data set, which has over 1000 shopping entries, including 11 items, and the groceries data set, which consists of a total of 9835 purchase records and 169 items. | The suggested Bi-support and Bi-confidence paradigms outperformed previous models, in terms of objective evaluation, extensive definition, and application in practice, with excellent precision and reliability for filtering and choosing frequent patterns. | They did not test for large amounts of data (e.g., zettabyte-scale). The second issue is that experimental results in different relevant domains were inadequate. |
| Paper | Major Contribution | Data Set Used | Implementation Environment and Evaluation | Limitations |
|---|---|---|---|---|
| Azam et al. [25] | The authors proposed different stages and techniques for mining the North South University (NSU) library information, concentrating on helpful examples. | Experimented with a database based on MySQL to determine the relationships between book classes. | Analyzed the NSU library database, successfully using bibliomining techniques (with 97% accuracy). | This article discusses different techniques for mining data and extracting patterns with respect to only one private university (North South University) library in Bangladesh. The system lacks application in a large domain. |
| Nicholson et al. [28] | Various bibliomining procedures were used to decide the best arrangement of rules to discriminate the different works; the best model delivered by every strategy was tested using an alternative arrangement of web pages. | Different data criteria were used for web pages. Then, a model was created, the data were queried and cleaned manually, and a data set was prepared for development and testing. The final data set was composed of 1000 documents that were selected for testing. | Used different models, such as classification tree, discriminant analysis, neural network, and logistic regression, for classification. Every model had a different accuracy and return. | The data used in this method were not real web data, and the amount of data were small. The precision of existing models could be improved by considering more real web data and applying feature reduction techniques. |
| Nicholson et al. [21,22] | The origin of the term bibliomining was investigated; the authors explored the link between bibliomining and its two key components: bibliometrics and data mining. A conceptual framework for library and information scientists was proposed. | Different analysis tools and data mining algorithms used in the data warehouse. | In two contexts—digital library administration and digital library research—the conceptual positioning of bibliomining (with respect to other types of evaluation) was discussed. Finally, a research plan was devised to address frequent concerns and to support the systematic expansion of bibliomining. | Data mining and bibliometric techniques were integrated to facilitate digital library services, but the implementation of these techniques was absent. |
| Nicholson et al. [26] | The authors investigated how data mining may be used by libraries and information management to better understand the behavioral patterns among library users and staff, as well as the design of information resources used across an institution. | Available data sources, such as integrated library system (ILS) data sources and external data sources, were used. | Data sources and potential data mining applications were investigated, as well as the legal and ethical aspects of bibliomining. | No mention about the utilization of library information to help vital administration choices for libraries and their host establishments. |
| Nicholson et al. [78] | Presented a new approach to evidence-based librarianship (EBL) concepts. | Used multi-library data warehouses for traditional evidence-based librarianship. | For the measurement and evaluation of library services, they presented a different approach for combining data mining and data warehousing with bibliometrics. Standards for data collections and associated tools different from traditional EBL were proposed. | The main challenge of this article was to allow librarians to carve out the opportunities to gather information. |
| Hajek et al. [70] | Built a model of bibliomining considering the characteristics of the different stages of the process. | Used empirical data to determine a strategy to scrutinize the respondents regarding their singular preferences of public administrations given by the library, considering the inquiries for the valuation of their significance. | The k-means clustering algorithm was used to identify the services of public libraries. The clustering accuracy was higher (37% of users in total) when compared to other clustering approaches (10%). | A strategy was built for bibliomining, but the technique has numerous obstructions to its utilization. One significant drawback is the lack of a comprehensive analysis of the services provided by public libraries. |
| Hajek et al. [23] | The authors proposed a function for the grouping of strategies and extraction of characteristics from genuine public library information. | Used empirical data to check strategies for scrutinizing respondents based on their singular preferences of public administration given by the library, taking into account inquiries to account their significance. | For the identification of library services, data were collected, pre-processed, extracted, and then subjected to clustering methods. The results of ten components contributed to 54.45% of the variance of the main data. The results were obtained by using Ward’s algorithm and statistical methods, according to the needs of the users. | The proposed method was not created exhaustively in the area of public administration, even though it is expected to help in the main itemized examination of the arrangement and provide information for streamlining executive processes in the association. |
| Shieh et al. [24] | The authors proposed a bibliomining model that constructs an integrated arrangement for librarian bibliomining, ensuring the versatile and straightforward operations of library data mining activities. | Various data sources, including different databases and data files, were used. The data sources can include MS Access, MS Excel, SQL Server, and text. | Based on the bibliomining application model, a prototype for the integration system was developed in order to test and verify its feasibility. | Used a rapid prototyping development procedure to construct an integration system for librarians, which has lower accuracy and is more expensive. |
| Deshpande et al. [27] | Analyzed the usage of library books among undergraduate computer science students using a library book data set captured from an automated library | Considered 482 volumes of books from the library database between 2010 and 2013. XLminer, a data mining tool, was used for data analysis | Using the bibliomining technique in a year-wise manner, the library books among undergraduate computer science students were considered, such that the students could optimally utilize the library books. | Library use was lower in the year 2011, even though there was an expansion in library utilization in 2012. |
| Prakash et al. [77] | Provided an overview of data sourcing and essential functions of the data mining process in a library. | Used library data sources. | Data mining approaches work with classes, clusters, patterns, associations, and sequences. Different levels of analyses, such as ANN, DT, data visualization, genetic algorithms, rule induction, and k-nearest neighbor methods are available. | An outline of information sources and potential utilization of information mining in the library is presented, but any implementation is absent. |
| Kostoff et al. [80] | The authors proposed a novel approach for recognizing the pathways through which exploration may affect research and technology development as well as to recognize specialized framework attributes. | Selected 307 articles accessed in the Science Citation Index (SCI) database. | Applied text mining for the taxonomy of citing articles. Bibliometrics was applied to profile user characteristics. Different types of cluster analysis techniques were performed on the information extracted from the 307 first-generation cited articles. | Did not consider second- or higher-order citations. Moreover, the proposed approach was only applied to 307 fundamental physics articles. More domains and articles needed to be considered for better understanding and applicability. |
| Kao et al. [82] | Presented a methodology (ABAMDM; acquisition budget allocation model via data mining) that specifically addressed the use of descriptive information acquired in historical circulation data to aid in library acquisition budget allocation. | Used a circulation database with various attributes, in which the circulation data were first pre-processed and in which performance and descriptive knowledge could be derived. | The proposed library budget assignment arrangement model could be used by an originator in developing a choice decision support network. ABAMDM and ARPM were applied in 17 departments and successfully found the number of records and final budgets of these 17 departments. | Information assortment through daily dissemination work is incredibly impacted by how a client utilizes web-based materials, thus making the budget plan portion of the activity considerably more troublesome. |
| Wu et al. [83] | A data mining model named DMBA was proposed to assist in apportioning library information to obtain a spending plan. | Used a data table that incorporated departments, materials used, and etymological strength (regarding the extent that a used material was identified with a department). | Developed an algorithm consisting of SQL statements. The outcomes with ARPM, DeC(Dpt), UGain(Dpt), BAWeight(Dpt), and the last library assigned procurement financial plan for divisions exhibited the utilization of DMBA and the outlined function for LKSUT. | The proposed budget plan assignment is complex, troublesome, and based on historical data. Their budget assignment methodology is outdated with respect to modern library requirements. |
| Butt et al. [55] | This article focused on a bibliometric examination and correlation of all distributed archives from 2015 to 2019, considering diaries in the review subject class of ’Statistics and Probability’ under the classifications of Q4-IF and the Emerging Source Citation Index (ESCI) of the Web of Science (WoS). | All published documents from journals in the study topic category of ’Statistics and Probability’ for Q4 Impact Factor (IF) journals and Web of Science’s Emerging Source Citation Index (ESCI) journals from 2015 to 2019. | The greater part of the distributed records were multi-creator archives, yet a somewhat larger number of single-wrote records (23% and 22%, respectively) was noticed in both Q4-IF and ESCI journals. | This article used limited data from the literature; the time frame was also limited. |
| Wen et al. [79] | Mapping of the knowledge domain was employed as an analytical approach to conduct a systematic analysis of the literature concerning building information modeling (BIM) research from 2010 to 2019. | A total of 1369 relevant published studies on BIM in the core Web of Science database. | For the analysis of data, the proposed method employed cluster analysis, co-citation analysis, and co-word analysis. The mapping of the knowledge domain was performed using CiteSpace software. The findings demonstrate that BIM research is still in its early stages. In addition, BIM research is primarily spread over nine domains. | They worked with a few specific fields; in their study, there was difficulty in summing up the turn-of-events pattern of BIM, which was obtainable from the small review test. |
| Paper | Major Contribution | Data Set Used | Implementation Environment and Evaluation | Limitations |
|---|---|---|---|---|
| Madani et al. [31] | Provided an in-depth analysis for detecting and visualizing emerging trends in technology mining. | Applied appropriate queries on the Web of Science database; 143 papers were selected for analyses. | Applied a Java application named CiteSpace to sort out, recognize, and visualize patterns for envisioning, breaking down references, and evaluating substances in analytical writing. The analysis was divided into eight different clusters, based on five aspects. | The cluster analysis was performed based on only five aspects. More important aspects, such as evaluation and accuracy, need to be considered. |
| Trumbach et al. [30] | The authors proposed technology mining as a means of assisting smaller firms in staying informed about new ideas. | Tested the data regarding some typical issues of a fleet management company (FMC), comprising common zones for development in small innovative firms. | Identified the problems in high-tech small firms and developed recommendations that should benefit FMCs or any small business. The recommendations focused on how technology mining strategies could improve some of the recognized problems. | No mention of the scalability of the work for a larger company than a FMC. |
| Li et al. [61] | The authors proposed building a fine-grained technological network that could aid in identifying fundamental and emergent innovations in the nano-fertilizer field. | Utilized a patent database to gather patent information, including unstructured information and organized information. Nano-fertilizer licenses were chosen as part of a case study. | Technical information using subject–action–object (SAO) structures taken from patent filings were categorized; the semantic links between different forms of technical information were analyzed. Finally, a fine-grained method for the construction of a technology network was proposed. | The input data analyzed for the study were not sufficient. |
| Yoon et al. [84] | The authors proposed a network-based patent examination method, which is an elective strategy for a reference investigation. | Used networks of WDM-related patent documents mined from the U.S. Patent and Trademark Office (USPTO: www.uspto.gov) database. | Actualized an organization-based patent investigation strategy; the initial steps involved data assortment and data pre-processing. The patent organization was produced with hubs and connections. Finally, the patent investigation was completed. | It can be difficult to generate a patent community if the dimensions of the patent files are too large. The improvements of different quantifiable indices are required to amplify and spread the evaluations. |
| Chen et al. [74] | Suggested applying affiliation rule mining and network recognition strategies to mine the innovation scene from the Stack Overflow question labels, where the mined innovation scene was referred to as a graphical technology associative network (TAN). | Utilized the Stack Overflow information dump delivered in March 2015, with information from 2008–07–31 to 2015–03–08, containing 7.89 million inquiries that were joined with at least two labels, and 39,948 remarkable labels from these inquiries. | The study showed that the mined TAN caught a wide scope of innovations, the intricate connections among the advances, and the pattern of the advances in the conversations of engineers on the Stack Overflow. | To enhance the website design, it was necessary to gather extra fine-grained consumer interplay information, provided along with a cursor hover and a right-click inside the TAN. |
| Porter et al. [29] | The authors proposed a semi-automatic trend detection system named technology opportunities analysis (TOA) for the analysis of technological opportunities relating to emerging technologies. | INSPEC was used as the database for the sample searches, which is a very rich abstract database. | Documents were extracted from the INSPEC database using keywords. Then, the formed queries were provided to custom software, Technology Opportunities Analysis Knowbot (TOAK). Finally, the bibliometric analysis was performed for TOA. | TOAK is designed to be utilized interactively and iteratively by a human expert, which makes it unsuitable for general use. |
| Adomavicius et al. [85] | The authors introduced a model to understand innovation development through the perspective of an innovative biological system. | Considered technology classes, such as desktop PCs (Dell XPS 600 gaming PC), wireless networking (Wi-Fi) technologies, and a business mini-case on the digital music industry. | Utilized various levels of ideas to distinguish the structures of related innovations. The perspectives on biological systems of PC advances incorporate PCs as contending innovations and supporting advances. The advancements were quickly distinguished, identified through the central innovation inside a given setting, dependent on the three jobs that advance play in an environment. | It could be fruitful to broaden a few new modeling factors in the framework in order to symbolize era function shifts over time. |
| Zeba et al. [81] | Incorporated a precise audit of logical writing utilizing bibliometric and content examination in an attempt to distinguish research trends and give examples of research points on artificial intelligence in the assembling field. | Bibliometric examinations of the obtained articles were first performed for the periods 1975–2010 and 2011–2019. | For the two time frames, they performed bibliometric and content investigations. For content investigations, they utilized WordStat 8 programming. | They only utilized the terms ‘producing’ and ‘fake knowledge’ in the inquiry. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, M.R.; Arefin, M.S.; Rahman, S.; Ahmed, A.; Islam, T.; Dhar, P.K.; Kwon, O.-J. A Comprehensive Survey on Affinity Analysis, Bibliomining, and Technology Mining: Past, Present, and Future Research. Appl. Sci. 2022, 12, 5227. https://0-doi-org.brum.beds.ac.uk/10.3390/app12105227
Rahman MR, Arefin MS, Rahman S, Ahmed A, Islam T, Dhar PK, Kwon O-J. A Comprehensive Survey on Affinity Analysis, Bibliomining, and Technology Mining: Past, Present, and Future Research. Applied Sciences. 2022; 12(10):5227. https://0-doi-org.brum.beds.ac.uk/10.3390/app12105227
Chicago/Turabian StyleRahman, Md. Rashadur, Mohammad Shamsul Arefin, Sanjida Rahman, Afsana Ahmed, Tahsina Islam, Pranab Kumar Dhar, and Oh-Jin Kwon. 2022. "A Comprehensive Survey on Affinity Analysis, Bibliomining, and Technology Mining: Past, Present, and Future Research" Applied Sciences 12, no. 10: 5227. https://0-doi-org.brum.beds.ac.uk/10.3390/app12105227