
Rolling Bearing Health Indicator Extraction and RUL Prediction Based on Multi-Scale Convolutional Autoencoder


Abstract
:1. Introduction
- (1)
- A novel autoencoder-based HI construction method, called MSCAE, is proposed. Compared with the traditional HI construction method, it can effectively use local and global temporal information to obtain a more robust HI and, at the same time, realize the automatic HI extraction.
- (2)
- The HI obtained by MSCAE is compared with single-scale convolutional autoencoders with different convolutional kernel sizes, and the superiority of the proposed method is verified by a comprehensive evaluation index consisting of monotonicity, correlation and robustness.
- (3)
- The HI obtained by MSCAE does not require artificial determination of the failure threshold, which is directly set to 0 and can be directly used for RUL prediction.
2. Related Theory
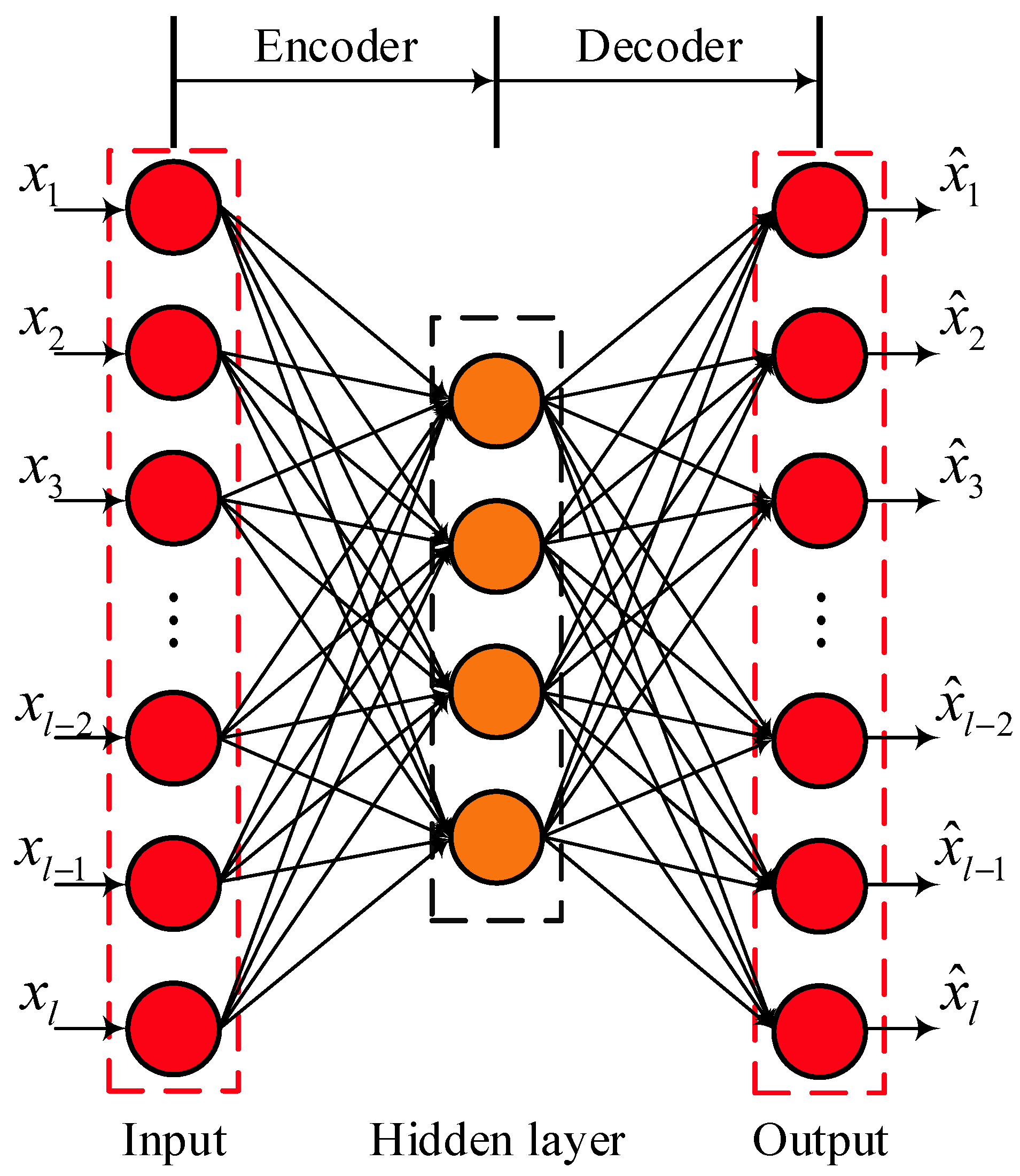
2.1. AE
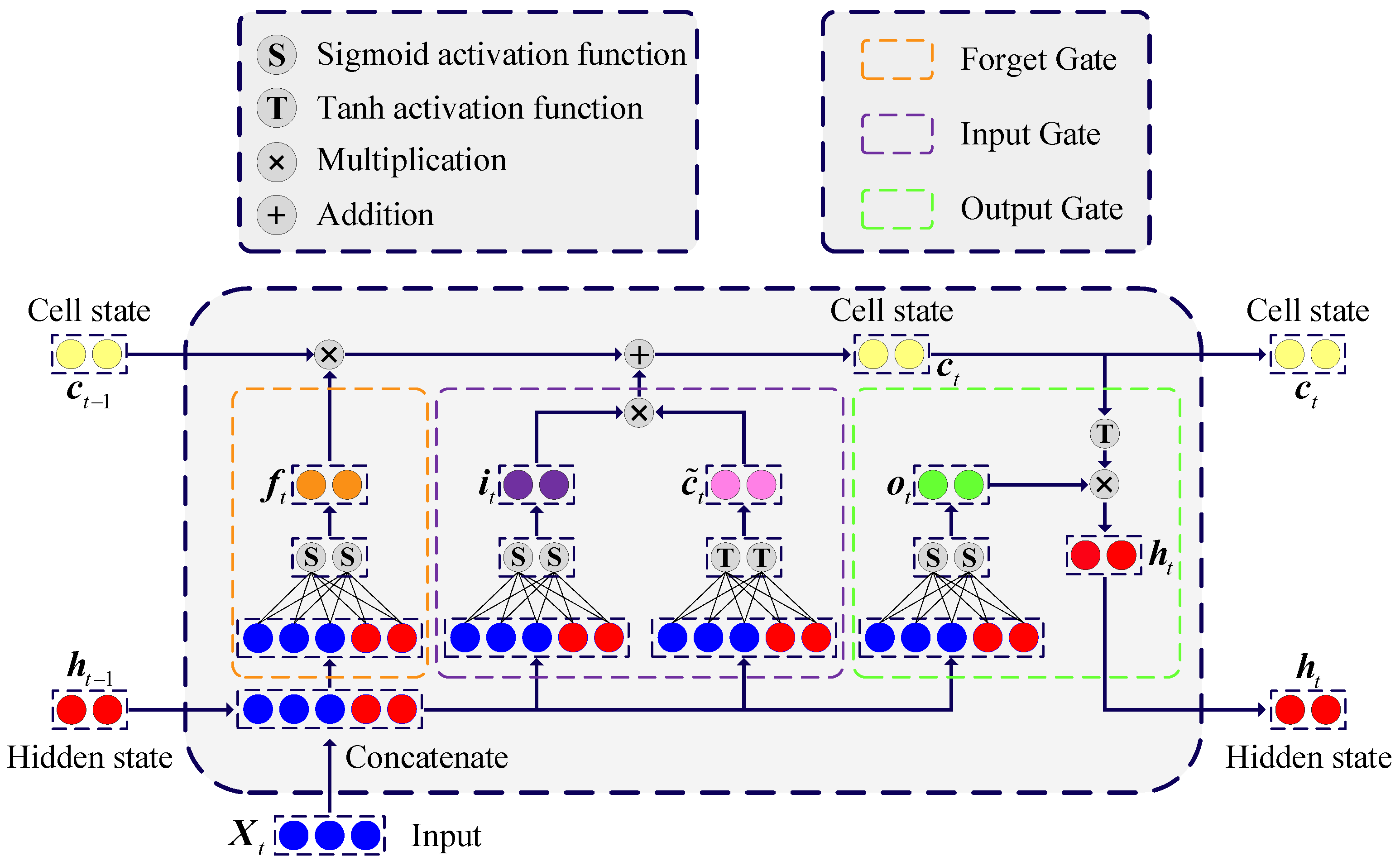
2.2. LSTM Neural Network
3. The Proposed Method
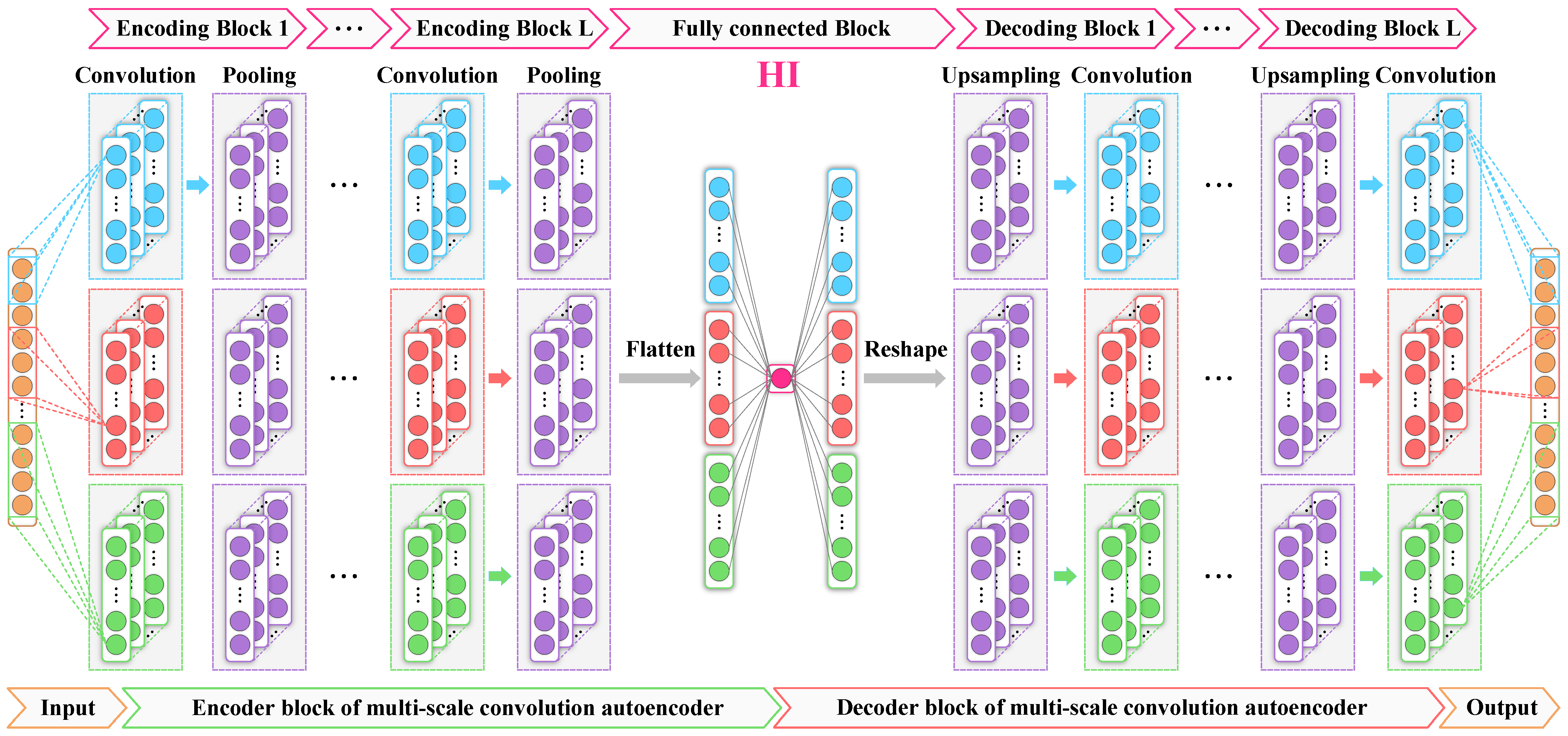
3.1. MSCAE
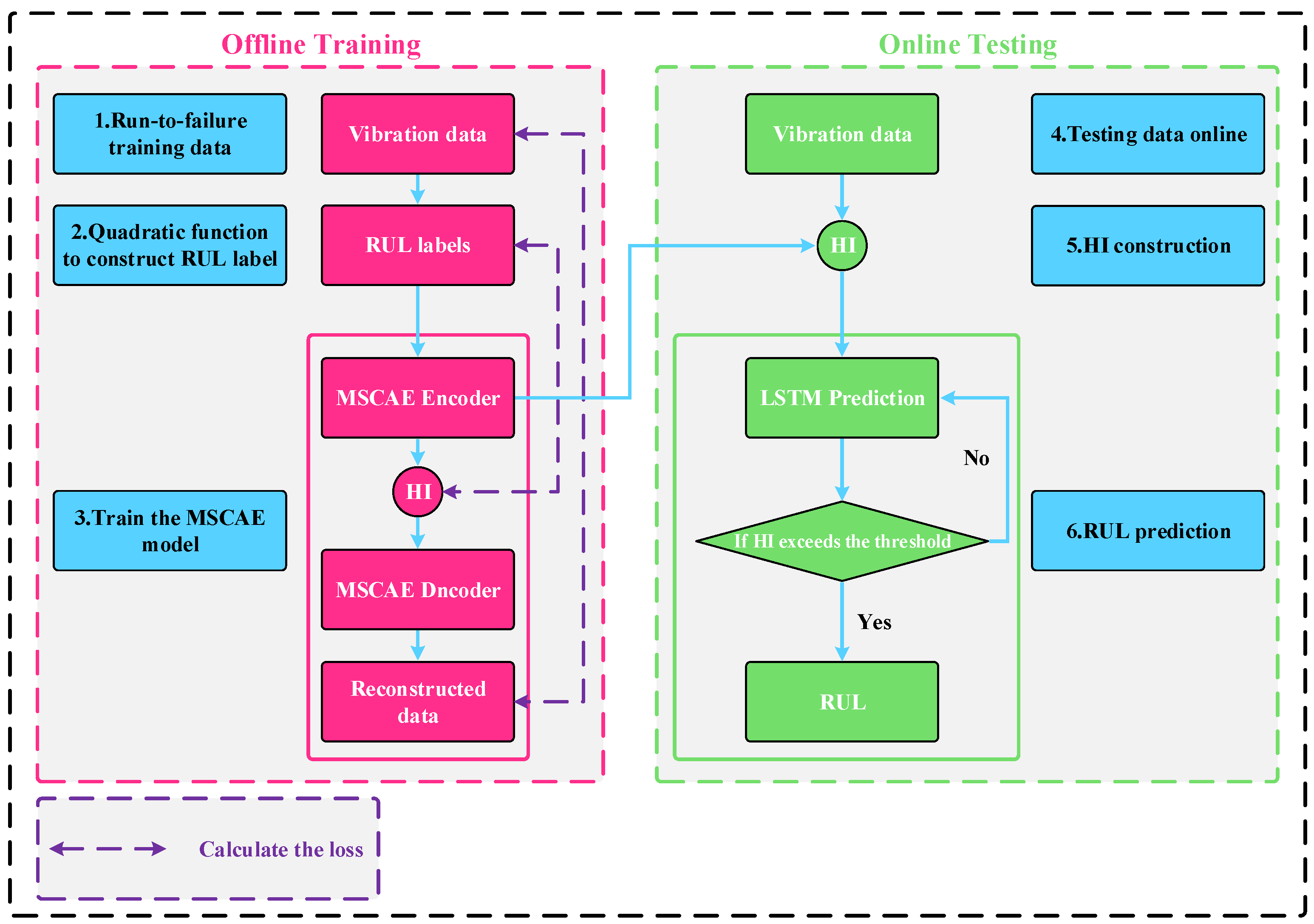
3.2. HI Extraction and RUL Prediction Process
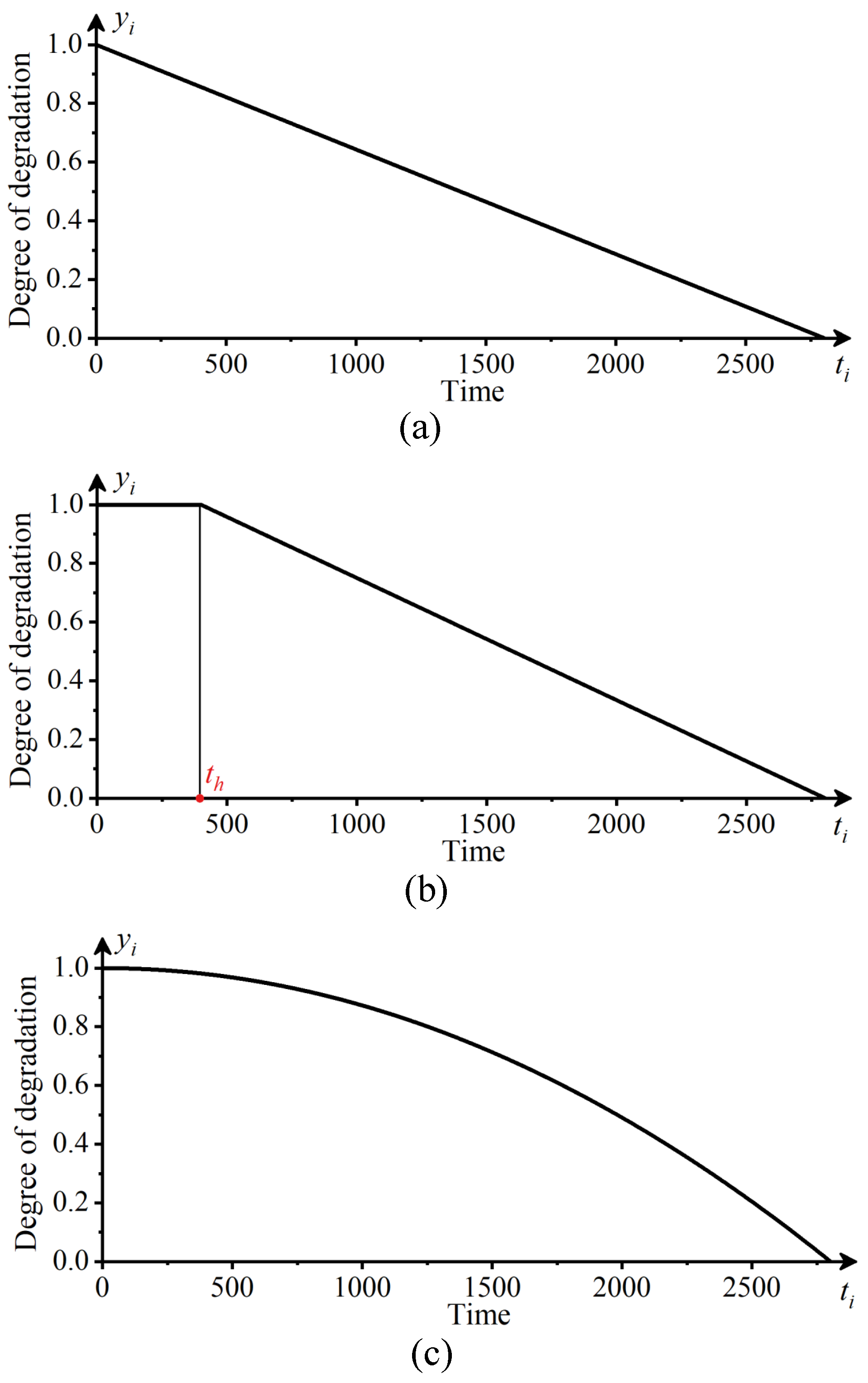
3.2.1. Construction Method of Degradation Labels
3.2.2. Overall Framework Flow
- Vibration data from training bearing operation to failure are obtained using vibration sensors. Suppose the vibration data are , , represents the vibration data at the moment , , B is the total time of bearing operation, and l is the length of the data.
- The degenerate labels for each moment of the vibration data are calculated using Equation (19), and the labels are obtained by the calculation.
- Training the proposed MSCAE model. First, the vibration datum X of the training bearing is input to the model, and the output of the MSCAE encoding part is the extracted HI, which is denoted as . After that, HI is used as an input to the decoding part of MSCAE to obtain the reconstructed data of the vibration data X. Finally, the composite loss function is calculated using Equation (16), and the internal parameters of the model are updated using the back-propagation algorithm. After the MSCAE is trained offline, it moves to the online testing phase.
- The vibration data from test bearing operation to failure are obtained, which are defined as , and T is the total operating time of the testing bearing.
- The vibration signal of the testing bearing is input to the encoder of the MSCAE trained in step 3 to obtain in HI of the test bearing.
- After obtaining the HI of the testing bearing, the first N points of are taken to construct the training data for training the LSTM model. The training matrix can be expressed as follows.where M is the neurons number of the LSTM output layer, . The LSTM is trained by taking the first M vectors of the training matrix as the input of the LSTM and the last vector as the output. Assuming that the mapping function of the trained LSTM is denoted as f, the last M vectors of the matrix are passed as input to the trained LSTM to obtain the first prediction result , and the specific expression is:Then, the matrix can be updated as follows:
4. Experimental Analysis
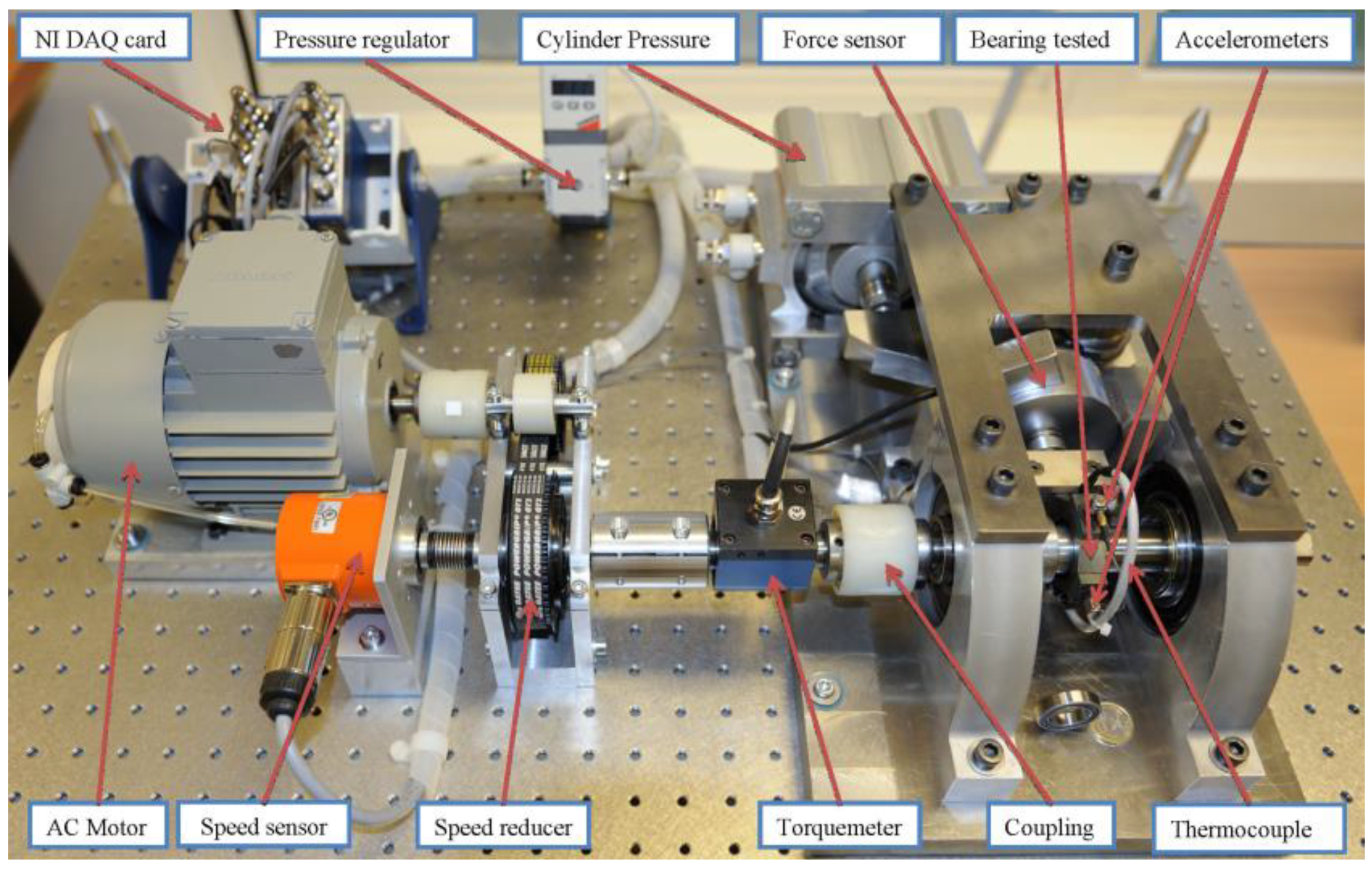
4.1. Data Introduction
4.2. Evaluation Metrics
- Monotonicity: It aims to assess the tendency of HI to increase monotonically or decrease monotonically as the running time increases. The stronger the monotonicity of HI, the closer it is to 1. The specific formula for monotonicity can be expressed as:where denotes the first-order derivative between two HI values and T denotes the number of HI and also the number of sensor samples.
- Correlation: It aims to measure the correlation between HI and runtime. The more correlated the two are, the closer the value of correlation is to 1, and vice versa. The formula for correlation can be expressed as:where and .
- Robustness: It aims to measure the ability of HI to resist outlier interference; the stronger its ability, the closer the robustness is to 1, and vice versa. The extracted HI can be seen as a superposition of the average trend and noise, whereby H can be expressed as:where denotes the average trend of HI at the moment T, and denotes the noise disturbance of HI at the moment T. Then, the robustness is calculated by the formula:
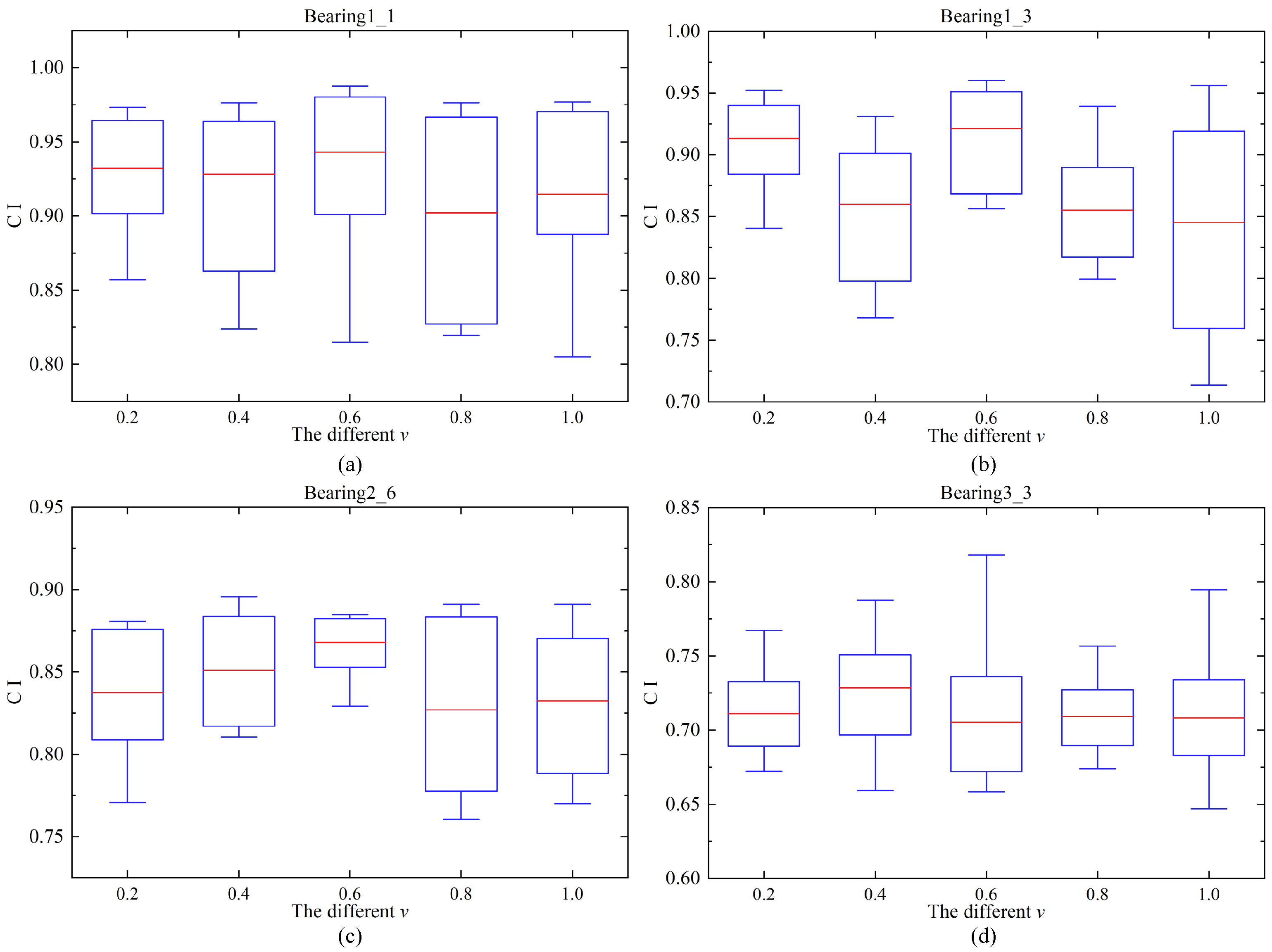
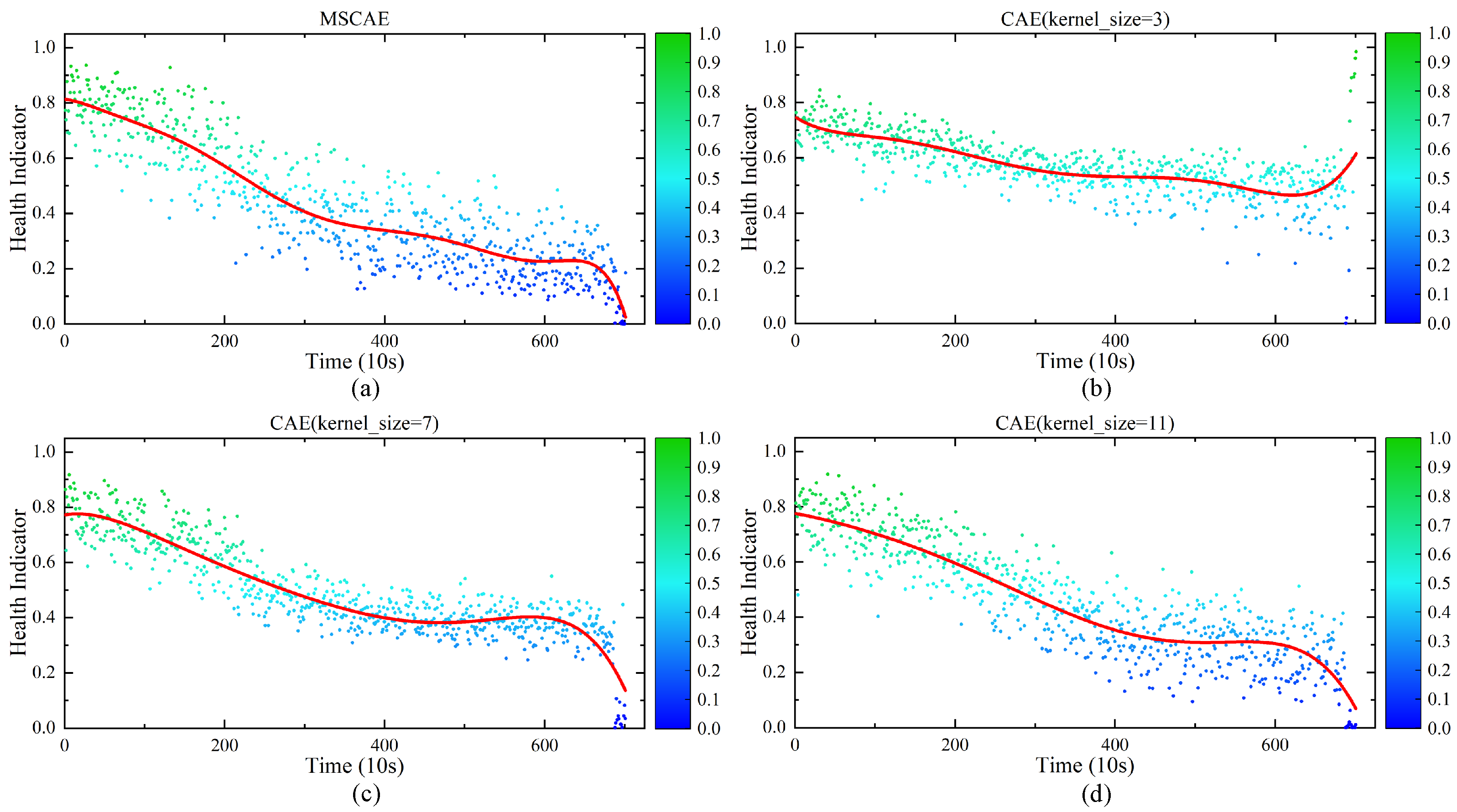
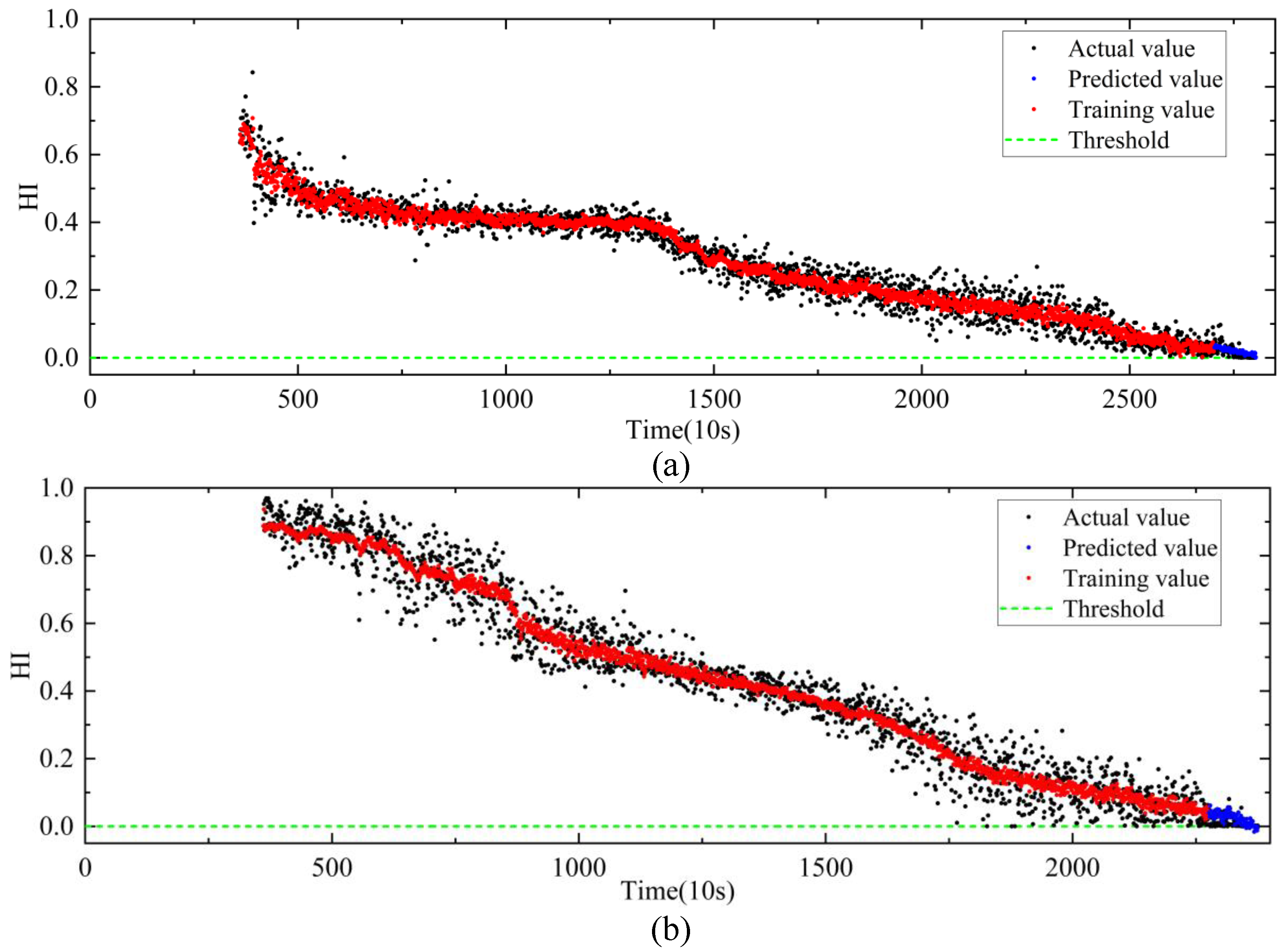
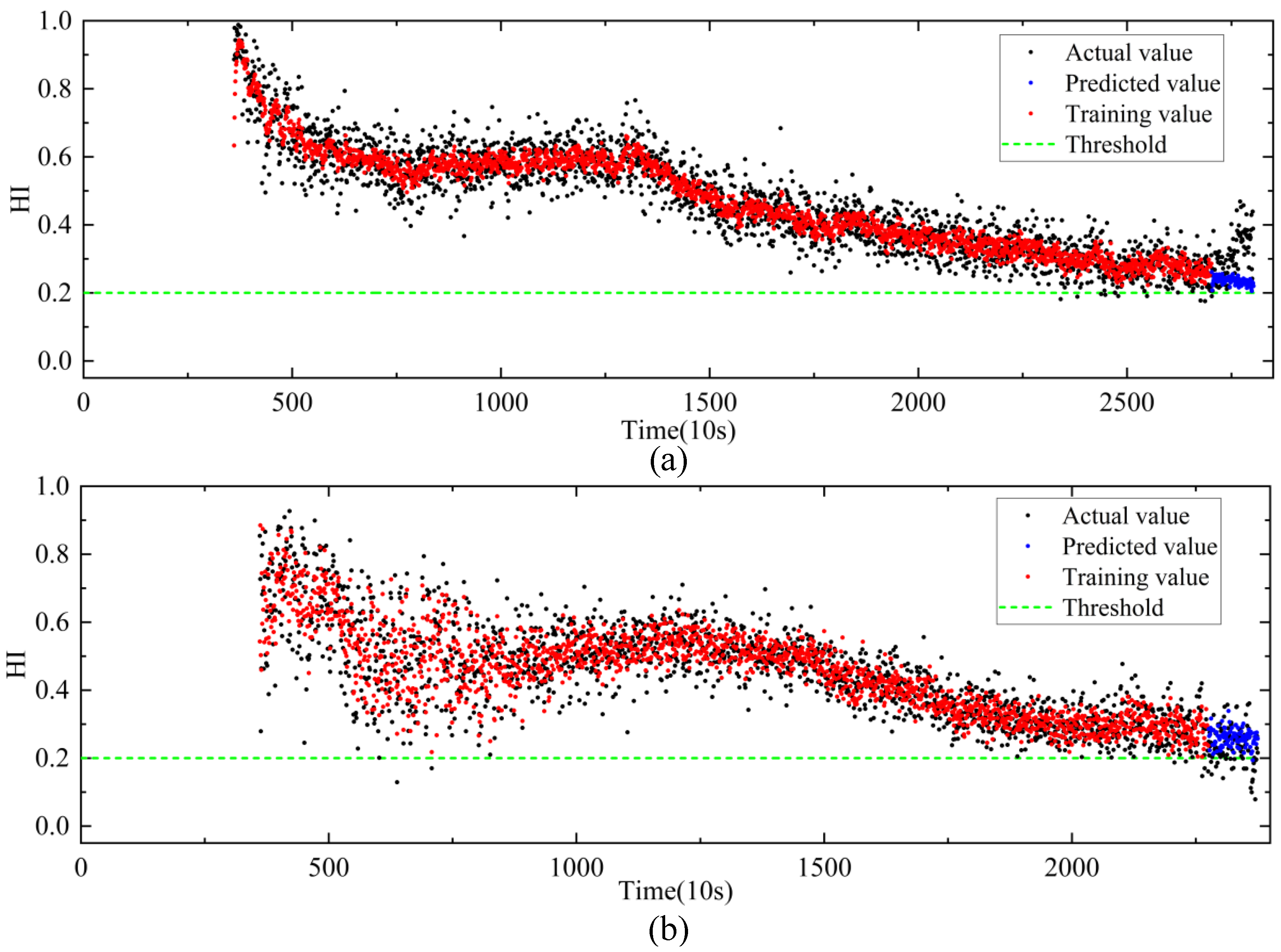
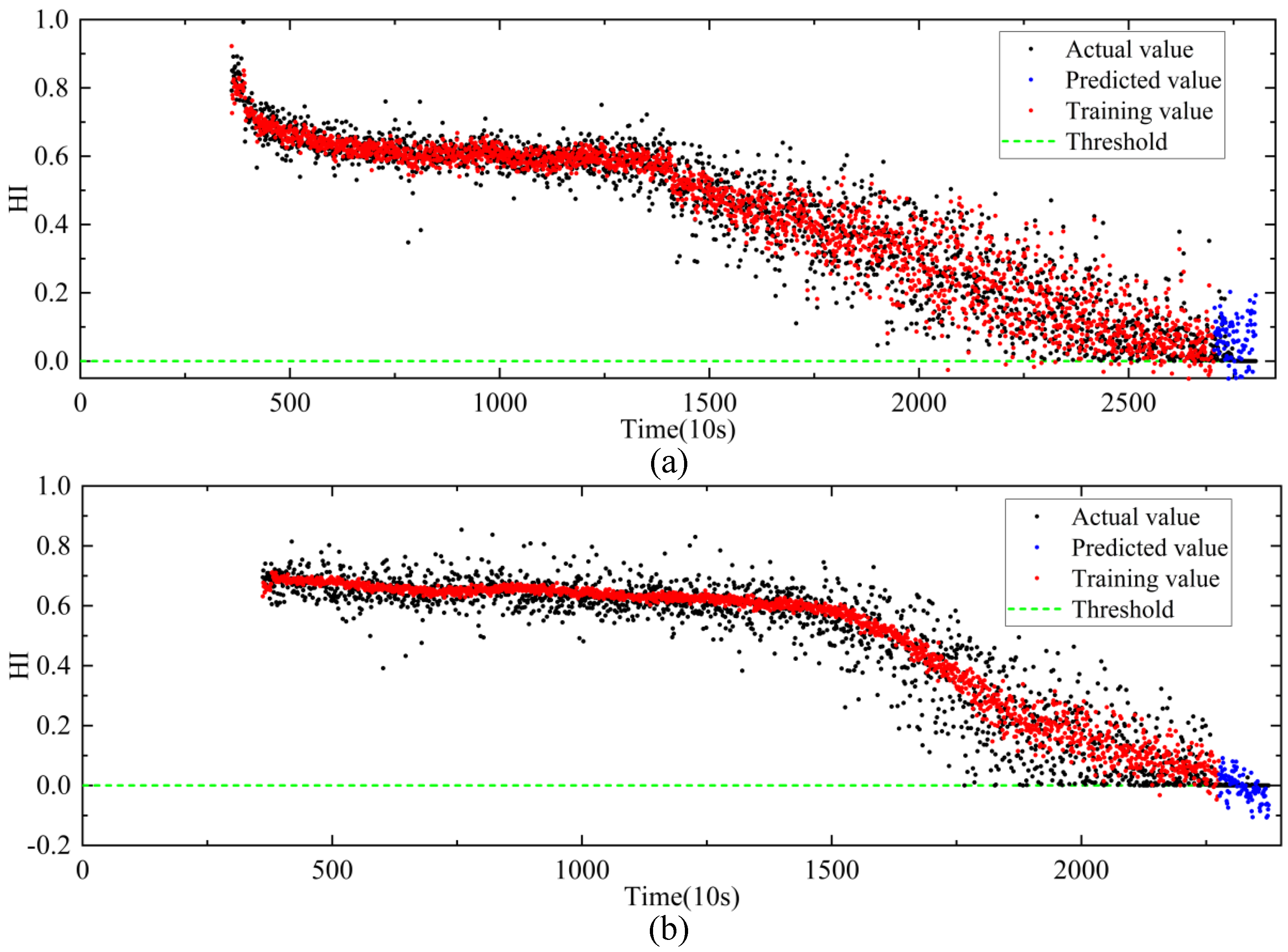
4.3. The Validity of MSCAE
4.4. RUL Prediction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ren, L.; Cui, J.; Sun, Y.; Cheng, X. Multi-bearing remaining useful life collaborative prediction: A deep learning approach. J. Manuf. Syst. 2017, 43, 248–256. [Google Scholar] [CrossRef]
- Pan, Z.; Meng, Z.; Chen, Z.; Gao, W.; Shi, Y. A two-stage method based on extreme learning machine for predicting the remaining useful life of rolling-element bearings. Mech. Syst. Signal Process. 2020, 144, 106899. [Google Scholar] [CrossRef]
- Gao, S.; Han, Q.; Zhou, N.; Pennacchi, P.; Chatterton, S.; Qing, T.; Zhang, J.; Chu, F. Experimental and theoretical approaches for determining cage motion dynamic characteristics of angular contact ball bearings considering whirling and overall skidding behaviors. Mech. Syst. Signal Process. 2022, 168, 108704. [Google Scholar] [CrossRef]
- Ambrożkiewicz, B.; Syta, A.; Gassner, A.; Georgiadis, A.; Litak, G.; Meier, N. The influence of the radial internal clearance on the dynamic response of self-aligning ball bearings. Mech. Syst. Signal Process. 2022, 171, 108954. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Du, H.; Yin, P. Error Evaluation of the Crown Profile of Logarithmic Generatrix Roller. J. Phys. Conf. Ser. 2021, 1948, 012065. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Peng, W. Estimation of Bearing Remaining Useful Life Based on Multiscale Convolutional Neural Network. IEEE Trans. Ind. Electron. 2019, 66, 3208–3216. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, H.; Jin, Y.; Dang, X.; Deng, W. Feature Extraction for Data-driven Remaining Useful Life Prediction of Rolling Bearings. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Deng, K.; Zhang, X.; Cheng, Y.; Zheng, Z.; Peng, J. A remaining useful life prediction method with long-short term feature processing for aircraft engines. Appl. Soft Comput. 2020, 93, 106344. [Google Scholar] [CrossRef]
- Xiang, S.; Qin, Y.; Luo, J.; Pu, H.; Tang, B. Multicellular LSTM-based deep learning model for aero-engine remaining useful life prediction. Reliab. Eng. Syst. Saf. 2021, 216, 107927. [Google Scholar] [CrossRef]
- Zeng, F.; Li, Y.; Jiang, Y.; Song, G. A deep attention residual neural network-based remaining useful life prediction of machinery. Measurement 2021, 181, 109642. [Google Scholar] [CrossRef]
- Song, Y.; Gao, S.; Li, Y.; Jia, L.; Pang, F. Distributed Attention-Based Temporal Convolutional Network for Remaining Useful Life Prediction. IEEE Internet Things J. 2020, 8, 9594–9602. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, M.; Zhao, R.; Guretno, F.; Li, X. Machine Remaining Useful Life Prediction via an Attention Based Deep Learning Approach. IEEE Trans. Ind. Electron. 2020, 68, 2521–2531. [Google Scholar] [CrossRef]
- Que, Z.; Jin, X.; Xu, Z. Remaining Useful Life Prediction for Bearings Based on a Gated Recurrent Unit. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Meng, Z.; Li, J.; Yin, N.; Pan, Z. Remaining useful life prediction of rolling bearing using fractal theory. Measurement 2020, 156, 107572. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Reliab. 2018, 69, 1–12. [Google Scholar] [CrossRef]
- Ren, L.; Sun, Y.; Cui, J.; Zhang, L. Bearing remaining useful life prediction based on deep autoencoder and deep neural networks. J. Manuf. Syst. 2018, 48, 71–77. [Google Scholar] [CrossRef]
- Liu, L.; Song, X.; Chen, K.; Hou, B.; Ning, H. An enhanced encoder–decoder framework for bearing remaining useful life prediction. Measurement 2020, 170, 108753. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Wang, W. Multi-Scale Convolutional Attention Network for Predicting Remaining Useful Life of Machinery. IEEE Trans. Ind. Electron. 2020, 68, 7496–7504. [Google Scholar] [CrossRef]
- Meng, M.; Zhu, M. Deep Convolution-based LSTM Network for Remaining Useful Life Prediction. IEEE Trans. Ind. Inform. 2020, 17, 1658–1667. [Google Scholar]
- Cao, Y.; Ding, Y.; Jia, M.; Tian, R. A novel temporal convolutional network with residual self-attention mechanism for remaining useful life prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2021, 215, 107813. [Google Scholar] [CrossRef]
- Yao, D.; Li, B.; Liu, H.; Yang, J.; Jia, L. Remaining useful life prediction of roller bearings based on improved 1D-CNN and simple recurrent unit. Measurement 2021, 175, 109166. [Google Scholar] [CrossRef]
- Hai, Q.; Lee, J.; Jing, L.; Gang, Y. Robust performance degradation assessment methods for enhanced rolling element bearing prognostics. Adv. Eng. Inform. 2003, 17, 127–140. [Google Scholar]
- Qin, Y.; Chen, D.; Xiang, S.; Zhu, C. Gated Dual Attention Unit Neural Networks for Remaining Useful Life Prediction of Rolling Bearings. IEEE Trans. Ind. Inform. 2021, 17, 6438–6447. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, G.; Zhu, Z.; Li, S. A novel deep learning method based on attention mechanism for bearing remaining useful life prediction. Appl. Soft Comput. 2019, 86, 105919. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.; Li, N.; Yan, T.; Li, N. Machinery health indicator construction based on convolutional neural networks considering trend burr. Neurocomputing 2018, 292, 142–150. [Google Scholar] [CrossRef]
- Li, N.; Lei, Y.; Lin, J.; Ding, S.X. An Improved Exponential Model for Predicting Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Ind. Electron. 2015, 62, 7762–7773. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.; Jia, F.; Lei, Y.; Lin, J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Chen, D.; Qin, Y.; Luo, J.; Xiang, S. Gated Adaptive Hierarchical Attention Unit Neural Networks for the Life Prediction of Servo Motors. IEEE Trans. Ind. Electron. 2022, 69, 9451–9461. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClelland, J.L. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations; MIT Press: Cambridge, MA, USA, 1987; pp. 318–362. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chen, D.; Qin, Y.; Wang, Y.; Zhou, J. Health indicator construction by quadratic function-based deep convolutional auto-encoder and its application into bearing RUL prediction. ISA Trans. 2021, 114, 44–56. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, San Francisco, CA, USA, 17–20 June 2012. [Google Scholar]
- Chen, L.; Xu, G.; Zhang, S.; Yan, W.; Wu, Q. Health indicator construction of machinery based on end-to-end trainable convolution recurrent neural networks. J. Manuf. Syst. 2020, 54, 1–11. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Test Set | |
|---|---|---|
| Condition 1 | Bearing1_2 Bearing1_4 Bearing1_5 Bearing1_6 Bearing1_7 | Bearing1_1 Bearing1_3 |
| Condition 2 | Bearing2_1 Bearing2_2 Bearing2_3 Bearing2_4 Bearing2_5 Bearing2_7 | Bearing2_6 |
| Condition 3 | Bearing3_1 Bearing3_2 | Bearing3_3 |
| Hyperparameter | Value |
|---|---|
| Batch size | 128 |
| Epoch | 100 |
| Learning rate | Adam (0.0001) |
| Number of Encoding Block | 3 |
| Number of Decoding Block | 3 |
| Kernel size | |
| Pooling size | 8 |
| Upsampling size | 8 |
| Number of fully connected layer units |
| Parameters | Value |
|---|---|
| The number of neurons in the input layer | 360 |
| The number of neurons in the hidden layer | 29 |
| The number of neurons in the output layer | 1 |
| Learning rate | 0.07 |
| Optimizer | Adam |
| Score | |||
|---|---|---|---|
| MSCAE-HI | CRNN-HI | CNN-HI | |
| Bearing1_1 | 0.2334 | 0.1379 | |
| Bearing1_3 | 0.1366 | 0.0712 | |
| MAE | |||
| MSCAE-HI | CRNN-HI | CNN-HI | |
| Bearing1_1 | 276 | 602 | |
| Bearing1_3 | 356 | 808 | |
| NRMSE | |||
| MSCAE-HI | CRNN-HI | CNN-HI | |
| Bearing1_1 | 0.2601 | 1.5480 | |
| Bearing1_3 | 0.3596 | 4.2882 | |
| RMSE | |||
| MSCAE-HI | CRNN-HI | CNN-HI | |
| Bearing1_1 | 296.58 | 616.13 | |
| Bearing1_3 | 378.31 | 823.33 | |
| MAPE | |||
| MSCAE-HI | CRNN-HI | CNN-HI | |
| Bearing1_1 | 27.6 | 60.2 | |
| Bearing1_3 | 35.6 | 80.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Z.; Zhang, Q.; Shao, S.; Niu, T.; Zhao, Y. Rolling Bearing Health Indicator Extraction and RUL Prediction Based on Multi-Scale Convolutional Autoencoder. Appl. Sci. 2022, 12, 5747. https://0-doi-org.brum.beds.ac.uk/10.3390/app12115747
Ye Z, Zhang Q, Shao S, Niu T, Zhao Y. Rolling Bearing Health Indicator Extraction and RUL Prediction Based on Multi-Scale Convolutional Autoencoder. Applied Sciences. 2022; 12(11):5747. https://0-doi-org.brum.beds.ac.uk/10.3390/app12115747
Chicago/Turabian StyleYe, Zijian, Qiang Zhang, Siyu Shao, Tianlin Niu, and Yuwei Zhao. 2022. "Rolling Bearing Health Indicator Extraction and RUL Prediction Based on Multi-Scale Convolutional Autoencoder" Applied Sciences 12, no. 11: 5747. https://0-doi-org.brum.beds.ac.uk/10.3390/app12115747