
Improving the Accuracy of Predictive Models for Outcomes of Antidepressants by Using an Ontological Adjustment Approach


Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Source of Data
2.2. Sample
2.3. Measure of Antidepressant Effectiveness
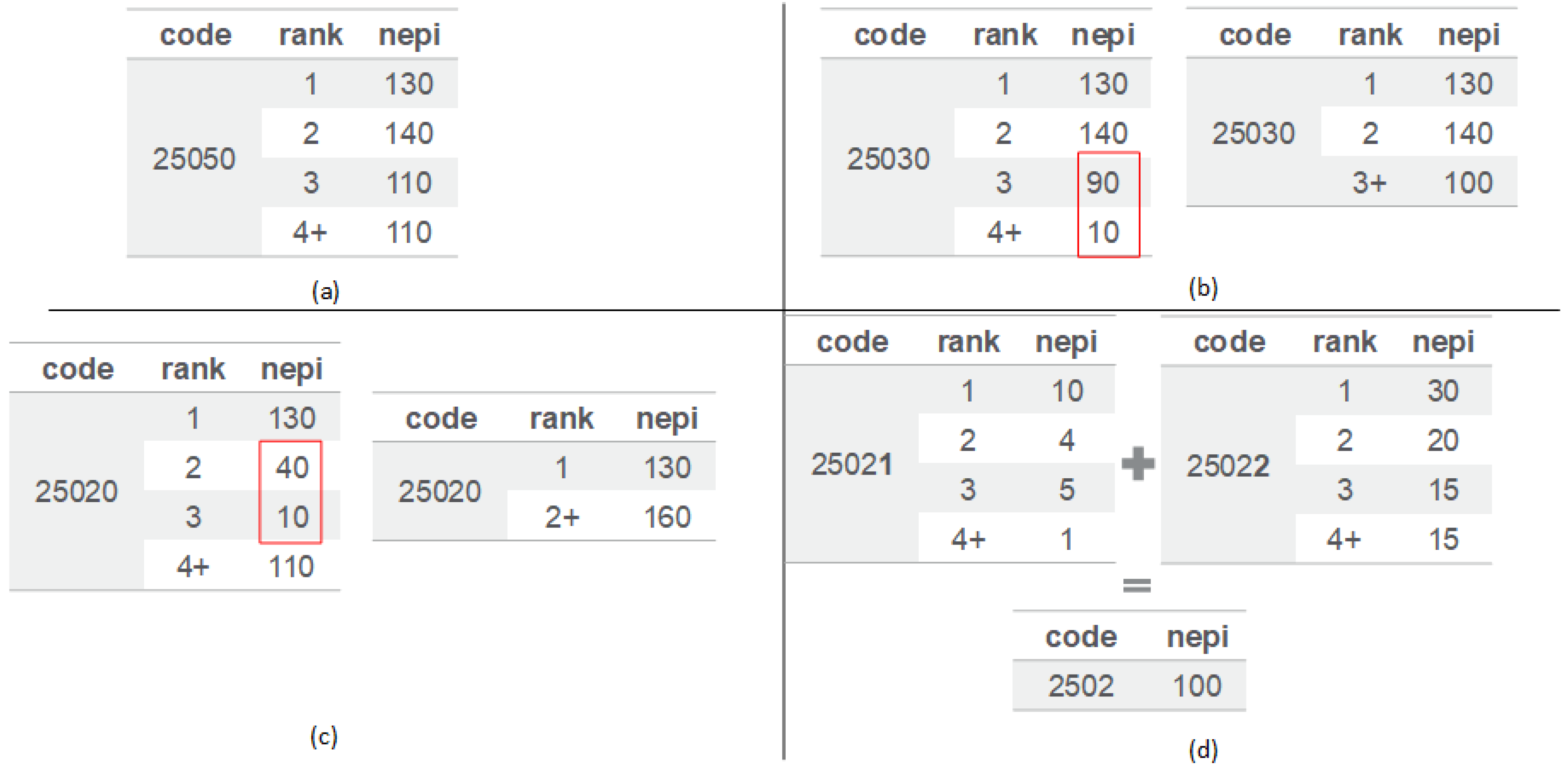
2.4. Methods of Ontological Adjustment
2.5. Measure of Accuracy of Estimated Treatment Effectiveness
3. Results
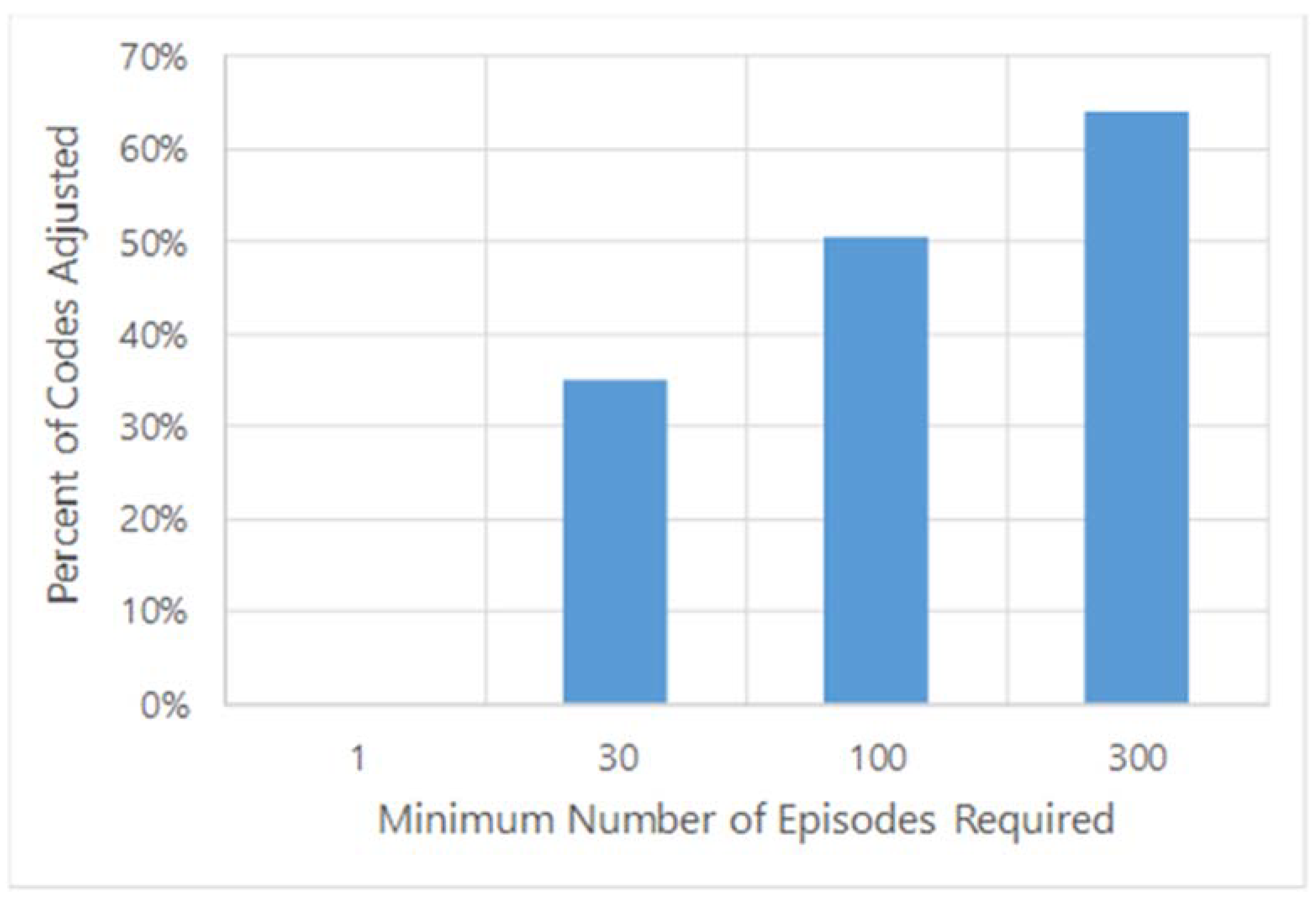
3.1. Threshold for Adjustments
3.2. Comparison of AROC Gaps between Models with and without OA
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICD | International Classification of Disease |
| OLDW | OptumLabs® Data Warehouse |
| AROC | Area under the receiver operating curves |
| OA | Ontological adjustment |
References
- Barth, J.; Schumacher, M.; Herrmann-Lingen, C. Depression as a risk factor for mortality in patients with coronary heart disease, a meta-analysis. Psychosom. Med. 2004, 66, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Fan, H.; Yu, W.; Zhang, Q.; Cao, H.; Li, J.; Wang, J.; Shao, Y.; Hu, X. Depression after heart failure and risk of cardiovascular and all-cause mortality, a meta-analysis. Prev. Med. 2014, 63, 36–42. [Google Scholar] [CrossRef] [PubMed]
- Farrokhi, F.; Abedi, N.; Beyene, J.; Kurdyak, P.; Jassal, S.V. Association between depression and mortality in patients receiving long-term dialysis, a systematic review and meta-analysis. Am. J. Kidney Dis. 2014, 63, 623–635. [Google Scholar] [CrossRef] [PubMed]
- Van Dooren, F.E.; Nefs, G.; Schram, M.T.; Verhey, F.R.; Denollet, J.; Pouwer, F. Depression and risk of mortality in people with diabetes mellitus, a systematic review and meta-analysis. PLoS ONE 2013, 8, e57058. [Google Scholar] [CrossRef] [Green Version]
- Bostwick, J.M.; Pankratz, V.S. Affective disorders and suicide risk, a reexamination. Am. J. Psychiatry 2000, 157, 1925–1932. [Google Scholar] [CrossRef]
- Osby, U.; Brandt, L.; Correia, N.; Ekbom, A.; Sparén, P. Excess mortality in bipolar and unipolar disorder in Sweden. Arch. Gen. Psychiatry 2001, 58, 844–850. [Google Scholar] [CrossRef] [Green Version]
- Rotermann, M. Marital breakdown and subsequent depression. Health Rep. 2007, 18, 33–44. [Google Scholar]
- Bennett, H.A.; Einarson, A.; Taddio, A.; Koren, G.; Einarson, T.R. Prevalence of depression during pregnancy, systematic review. Obstet. Gynecol. 2004, 103, 698–709. [Google Scholar] [CrossRef]
- Gavrielov-Yusim, N.; Friger, M. Use of administrative medical databases in population-based research. J. Epidemiol. Community Health 2014, 683, 283–287. [Google Scholar] [CrossRef]
- Jain, S.H.; Rosenblatt, M.; Duke, J. Is big data the new frontier for academic-industry collaboration? JAMA 2014, 31121, 2171–2172. [Google Scholar] [CrossRef]
- Strom, J.B.; Faridi, K.F.; Butala, N.M.; Zhao, Y.; Tamez, H.; Valsdottir, L.R.; Brennan, J.M.; Shen, C.; Popma, J.J.; Kazi, D.S.; et al. Use of Administrative Claims to Assess Outcomes and Treatment Effect in Randomized Clinical Trials for Transcatheter Aortic Valve Replacement, Findings from the EXTEND Study. Circulation 2020, 142, 203–213. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Cook, J.A.; Ranstam, J. Overfitting. Br. J. Surg. 2016, 103, 1814. [Google Scholar] [CrossRef] [PubMed]
- Hoehndorf, R.; Schofield, P.N.; Gkoutos, G.V. The role of ontologies in biological and biomedical research, a functional perspective. Brief Bioinform. 2015, 16, 1069–1080. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arnaud, E.; Laporte, M.A.; Kim, S.; Aubert, C.; Leonelli, S.; Miro, B.; Cooper, L.; Jaiswal, P.; Kruseman, G.; Shrestha, R.; et al. The Ontologies Community of Practice, A CGIAR Initiative for Big Data in Agrifood Systems. Patterns 2020, 1, 100105. [Google Scholar] [CrossRef] [PubMed]
- Kerr, G.; Ruskin, H.J.; Crane, M.; Doolan, P. Techniques for clustering gene expression data. Comput. Biol. Med. 2008, 38, 283–293. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kustra, R.; Zagdanski, A. Incorporating Gene Ontology in Clustering Gene Expression Data. In Proceedings of the IEEE Symposium on Computer-Based Medical Systems, Salt Lake City, UT, USA, 22–23 June 2006; pp. 555–563. [Google Scholar]
- Liu, J.; Wang, W.; Yang, J. Gene Ontology Friendly Biclustering of Expression Profiles. In Proceedings of the 3rd International IEEE Computer Society Computational Systems Bioinformatics Conference (CSB 2004), Stanford, CA, USA, 16–19 August 2004; pp. 436–447. [Google Scholar] [CrossRef]
- Wei, W.Q.; Bastarache, L.A.; Carroll, R.J.; Marlo, J.E.; Osterman, T.J.; Gamazon, E.R.; Cox, N.J.; Roden, D.M.; Denny, J.C. Evaluating phecodes, clinical classification software, and ICD-9-CM codes for phenome-wide association studies in the electronic health record. PLoS ONE. 2017, 12, e0175508. [Google Scholar] [CrossRef]
- Leader, J.B.; Pendergrass, S.A.; Verma, A.; Carey, D.J.; Hartzel, D.N.; Ritchie, M.D.; Kirchner, H.L. Contrasting Association Results between Existing PheWAS Phenotype Definition Methods and Five Validated Electronic Phenotypes. AMIA Ann. Symp. Proc. 2015, 2015, 824–832. [Google Scholar]
- Cai, M.C.; Xu, Q.; Pan, Y.J.; Pan, W.; Ji, N.; Li, Y.B.; Jin, H.J.; Liu, K.; Ji, Z.L. ADReCS, an ontology database for aiding standardization and hierarchical classification of adverse drug reaction terms. Nucleic Acids Res. 2015, 43, D907–D913. [Google Scholar] [CrossRef] [Green Version]
- OptumLabs and OptumLabs Data Warehouse (OLDW). Descriptions and Citation; OptumLabs: Eden Prairie, MN, USA, 2019. [Google Scholar]
- Nori, V.S.; Hane, C.A.; Martin, D.C.; Kravetz, A.D.; Sanghavi, D.M. Identifying incident dementia by applying machine learning to a very large administrative claims dataset. PLoS ONE 2019, 14, e0203246. [Google Scholar] [CrossRef] [Green Version]
- Alemi, F.; Aljuaid, M.; Durbha, N.; Yousefi, M.; Min, H.; Sylvia, L.G.; Nierenberg, A.A. A surrogate measure for patient reported symptom remission in administrative data. BMC Psychiatry 2021, 21, 121. [Google Scholar] [CrossRef] [PubMed]
- Tuck, M.G.; Alemi, F.; Shortle, J.F.; Avramovic, S.; Hesdorffer, C. A Comprehensive Index for Predicting Risk of Anemia from Patients’ Diagnoses. Big Data 2017, 5, 42–52. [Google Scholar] [CrossRef] [PubMed]
- Min, H.; Avramovic, S.; Wojtusiak, J.; Khosla, R.; Fletcher, R.D.; Alemi, F.; Kheirbek, R.E. A Comprehensive Multimorbidity Index for Predicting Mortality in Intensive Care Unit Patients. J. Palliat. Med. 2017, 20, 35–41. [Google Scholar] [CrossRef] [PubMed]
- Alemi, F.; Levy, C.R.; Kheirbek, R.E. The Multimorbidity Index, A Tool for Assessing the Prognosis of Patients from Their History of Illness. EGEMS 2016, 4, 1235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tabatabaie, M.; Sarrami, A.H.; Didehdar, M.; Tasorian, B.; Shafaat, O.; Sotoudeh, H. Accuracy of Machine Learning Models to Predict Mortality in COVID-19 Infection Using the Clinical and Laboratory Data at the Time of Admission. Cureus 2021, 13, e18768. [Google Scholar] [CrossRef] [PubMed]
- Agency for Healthcare Research and Quality (AHRQ). Available online: https://www.hcup-us.ahrq.gov/toolssoftware/ccs/ccsfactsheet.jsp (accessed on 7 January 2022).
- Charlson, M.E.; Pompei, P.; Ales, K.L.; MacKenzie, C.R. A new method of classifying prognostic comorbidity in longitudinal studies, development and validation. J. Chronic. Dis. 1987, 40, 373–383. [Google Scholar] [CrossRef]
- Elixhauser, A.; Steiner, C.; Harris, D.R.; Coffey, R.M. Comorbidity measures for use with administrative data. Med. Care 1998, 36, 8–27. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Antidepressant | Threshold 1 (No Adjustment) | Threshold 100 (Adjusted Data) | ||||
|---|---|---|---|---|---|---|
| Training | Test | Gap | Training | Test | Gap | |
| AMITRIPTYLINE | 80.2% | 68.4% | 11.9% | 72.3% | 68.0% | 4.4% |
| BUPROPION | 73.9% | 67.3% | 6.6% | 69.8% | 67.3% | 2.5% |
| CITALOPRAM | 65.4% | 63.2% | 2.2% | 63.9% | 63.3% | 0.7% |
| DESVENLAFAXINE | 76.5% | 68.9% | 7.5% | 70.2% | 69.2% | 1.0% |
| DOXEPIN | 79.9% | 64.6% | 15.4% | 67.4% | 64.2% | 3.2% |
| DULOXETINE | 67.3% | 61.9% | 5.3% | 64.0% | 62.3% | 1.6% |
| ESCITALOPRAM | 63.7% | 60.5% | 3.2% | 61.5% | 60.3% | 1.2% |
| FLUOXETINE | 66.2% | 64.8% | 1.4% | 65.3% | 64.8% | 0.5% |
| FLUVOXAMINE | 89.2% | 63.5% | 25.7% | 69.3% | 62.1% | 7.2% |
| IMIPRAMINE | 94.7% | 64.9% | 29.8% | 77.9% | 67.8% | 10.2% |
| MIRTAZAPINE | 72.0% | 59.6% | 12.4% | 63.6% | 59.6% | 4.0% |
| NEFAZODONE | 88.7% | 58.4% | 30.3% | 68.1% | 59.9% | 8.2% |
| NORTRIPTYLINE | 85.1% | 63.9% | 21.2% | 70.9% | 65.4% | 5.5% |
| PAROXETINE | 65.0% | 62.1% | 2.9% | 62.9% | 62.1% | 0.8% |
| PRAMIPEXOLE | 76.0% | 58.6% | 17.4% | 64.0% | 58.9% | 5.0% |
| ROPINIROLE | 77.1% | 58.4% | 18.7% | 64.4% | 59.0% | 5.4% |
| SERTRALINE | 65.6% | 64.2% | 1.4% | 64.7% | 64.2% | 0.5% |
| TRAZODONE | 84.3% | 72.5% | 11.8% | 78.1% | 73.7% | 4.4% |
| VENLAFAXINE | 67.8% | 64.2% | 3.6% | 65.4% | 64.4% | 1.1% |
| VORTIOXETINE | 85.6% | 66.2% | 19.4% | 70.3% | 68.9% | 1.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Min, H.; Alemi, F.; Hane, C.A.; Nori, V.S. Improving the Accuracy of Predictive Models for Outcomes of Antidepressants by Using an Ontological Adjustment Approach. Appl. Sci. 2022, 12, 1479. https://0-doi-org.brum.beds.ac.uk/10.3390/app12031479
Min H, Alemi F, Hane CA, Nori VS. Improving the Accuracy of Predictive Models for Outcomes of Antidepressants by Using an Ontological Adjustment Approach. Applied Sciences. 2022; 12(3):1479. https://0-doi-org.brum.beds.ac.uk/10.3390/app12031479
Chicago/Turabian StyleMin, Hua, Farrokh Alemi, Christopher A. Hane, and Vijay S. Nori. 2022. "Improving the Accuracy of Predictive Models for Outcomes of Antidepressants by Using an Ontological Adjustment Approach" Applied Sciences 12, no. 3: 1479. https://0-doi-org.brum.beds.ac.uk/10.3390/app12031479