
A Novel Bayesian Linear Regression Model for the Analysis of Neuroimaging Data

 , , , and
, , , and
Abstract
:1. Introduction
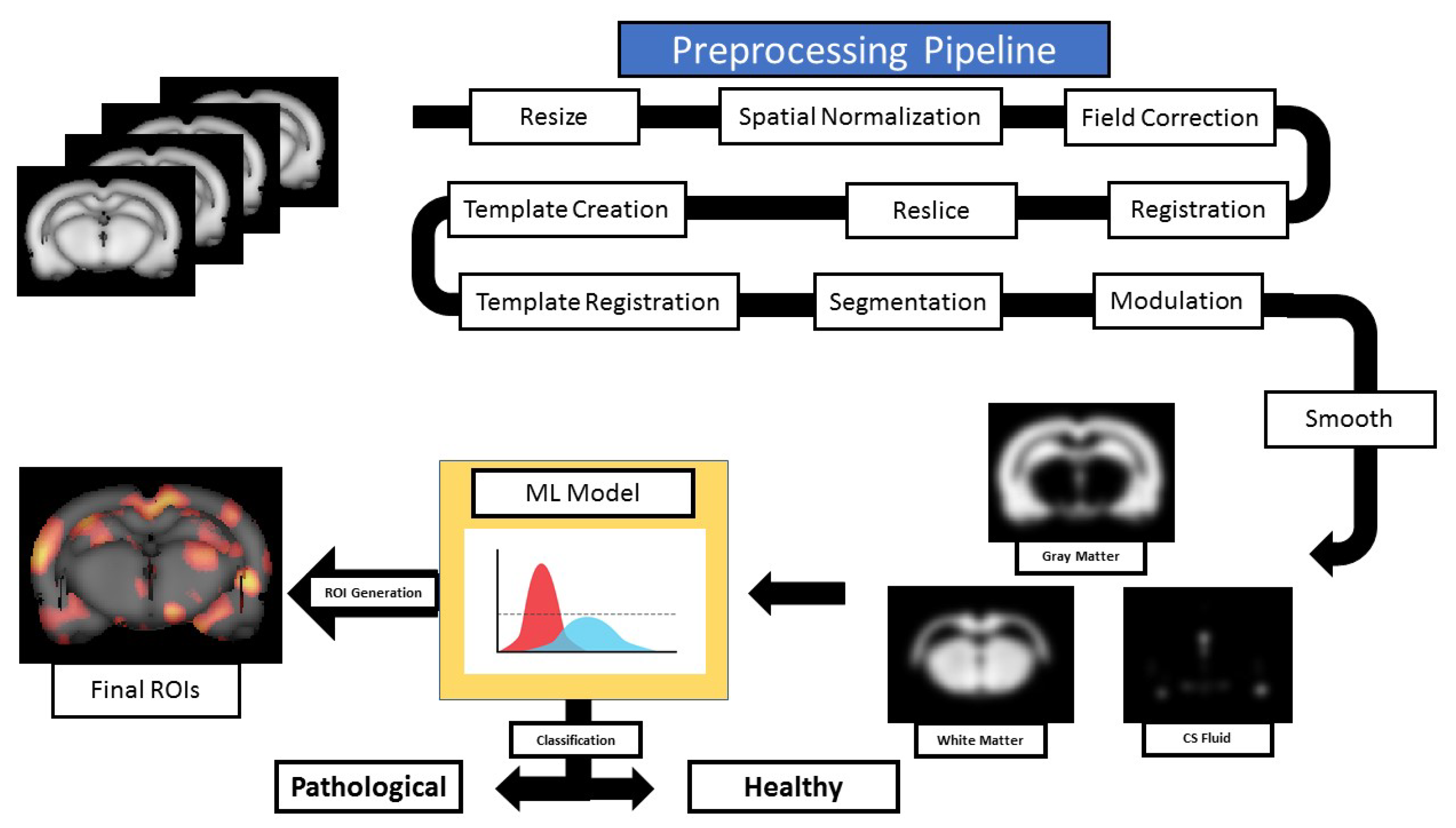
2. Materials
3. Methods
3.1. A Dual Bayesian Linear Regression Model with Feature Selection
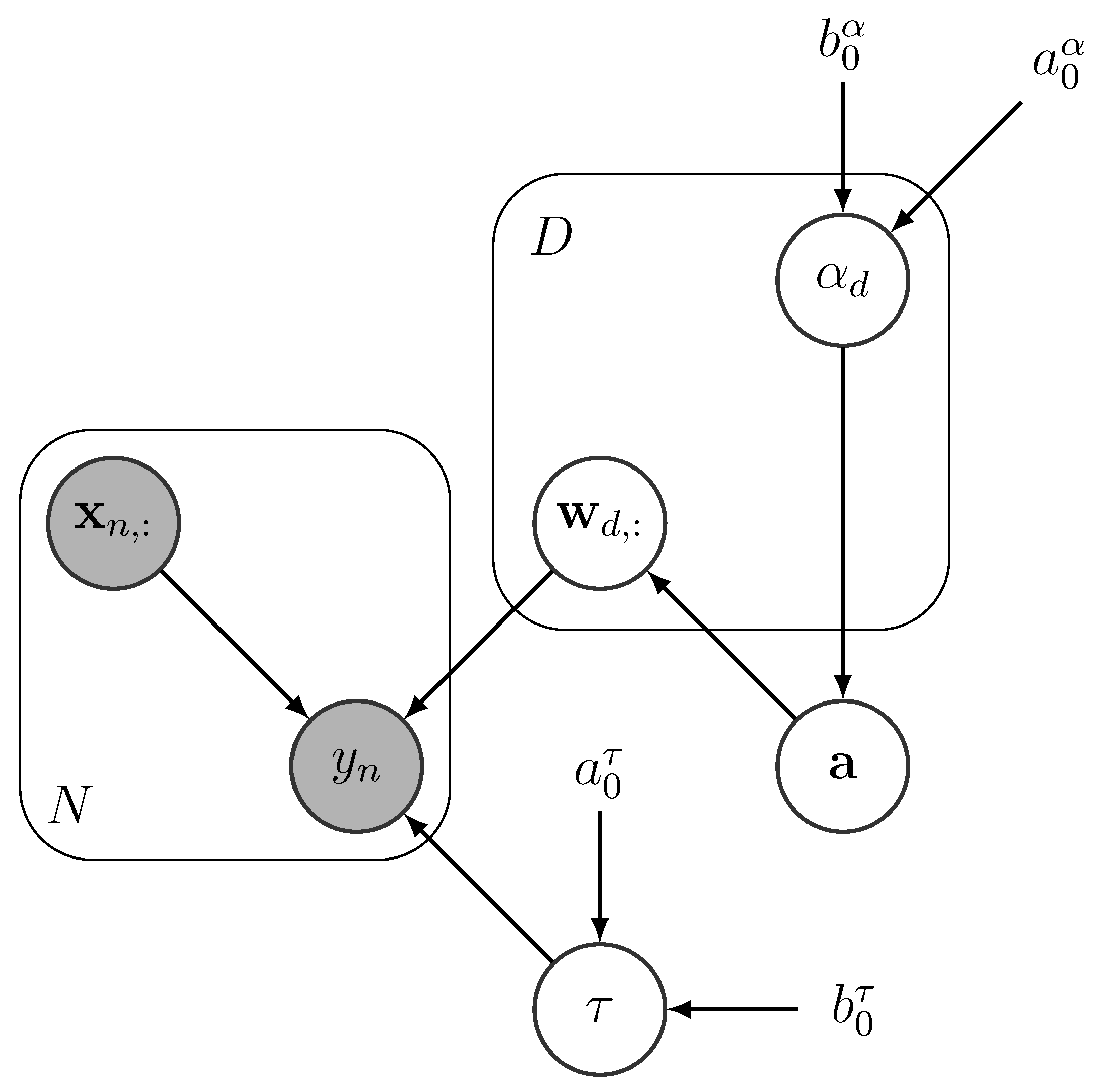
3.1.1. Model Definition
3.1.2. Generative Model
3.1.3. Variational Inference
3.2. Baselines
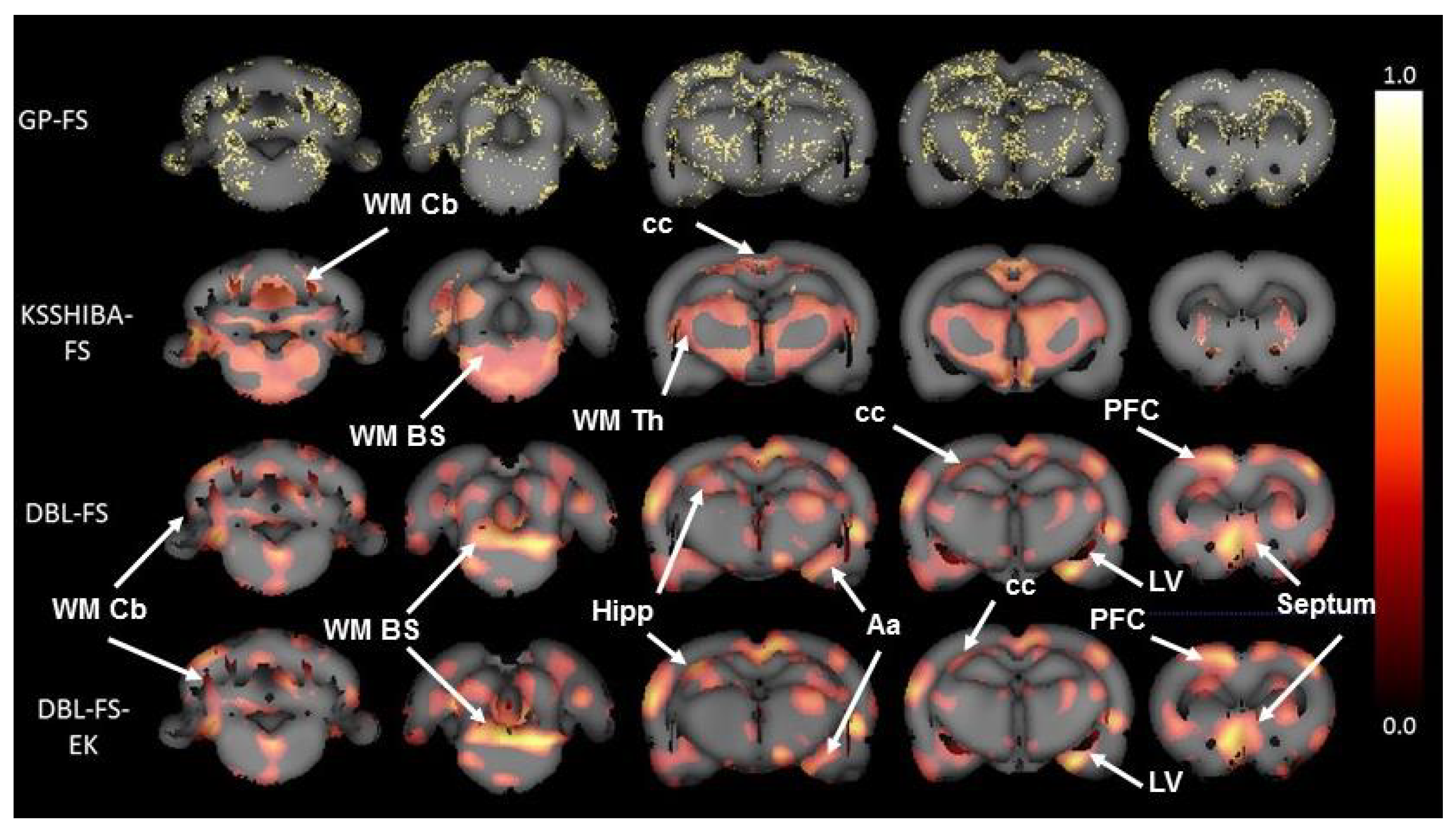
- As the first baseline, we included a regression Gaussian Process (GP) [35], using the implementation provided by the GPy library (available at github accessed on 9 December 2021). We have selected this model since it allows us to define lineal kernels with ARD, so that we can work in the dual space and learn the relevance of the different input features.
- The last selected baseline is the recently proposed adaptation of Sparse Semi-supervised Heterogeneous Interbattery Bayesian Analysis (SSHIBA) [38] to work in the dual space, the Kernelized SSHIBA (KSSHIBA) [39] is available at github accessed on 29 March 2021. This algorithm can simultaneously combine different data sources or views (in our case, different tissues) in a common latent space providing a low-dimensional representation of the data. In addition, this model can also include an additional output view to categorically model the target variable (patient or control sample), as well as a linear kernel with ARD coefficients over the input features (equivalent to the GP configuration).
3.3. Experimental Setup
4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. DBL-FS Variational Inference
Appendix A.1. Mean Field Approximation of a
Appendix A.2. Mean Field Approximation of α
Appendix A.3. Mean Field Approximation of τ
Appendix B. Lower Bound Inference
Appendix B.1. Terms Associated to
Appendix B.2. Terms of Entropy
Appendix B.3. Complete Lower Bound
References
- Carvalho, A.F.; Solmi, M.; Sanches, M.; Machado, M.O.; Stubbs, B.; Ajnakina, O.; Sherman, C.; Sun, Y.R.; Liu, C.S.; Brunoni, A.R.; et al. Evidence-based umbrella review of 162 peripheral biomarkers for major mental disorders. Transl. Psychiatry 2020, 10, 152. [Google Scholar] [CrossRef] [PubMed]
- Widing, L.; Simonsen, C.; Flaaten, C.B.; Haatveit, B.; Vik, R.K.; Wold, K.F.; Åsbø, G.; Ueland, T.; Melle, I. Symptom Profiles in Psychotic Disorder Not Otherwise Specified. Front. Psychiatry 2020, 11, 580444. [Google Scholar] [CrossRef] [PubMed]
- Correll, C.U.; Brevig, T.; Brain, C. Patient characteristics, burden and pharmacotherapy of treatment-resistant schizophrenia: Results from a survey of 204 US psychiatrists. BMC Psychiatry 2019, 19, 362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roberts, L.W.; Chan, S.; Torous, J. New tests, new tools: Mobile and connected technologies in advancing psychiatric diagnosis. NPJ Digit. Med. 2018, 1, 20176. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Li, W.; Wei, Y.; Gui, G.; Zhang, R.; Liu, H.; Chen, Y.; Jiang, Y. Deep learning based automatic diagnosis of first-episode psychosis, bipolar disorder and healthy controls. Comput. Med. Imaging Graph. 2021, 89, 101882. [Google Scholar] [CrossRef] [PubMed]
- Trakadis, Y.J.; Sardaar, S.; Chen, A.; Fulginiti, V.; Krishnan, A. Machine learning in schizophrenia genomics, a case-control study using 5090 exomes. Am. J. Med. Genet. Part B Neuropsychiatr. Genet. 2019, 180, 103–112. [Google Scholar] [CrossRef]
- Hettige, N.C.; Nguyen, T.B.; Yuan, C.; Rajakulendran, T.; Baddour, J.; Bhagwat, N.; Bani-Fatemi, A.; Voineskos, A.N.; Chakravarty, M.M.; De Luca, V. Classification of suicide attempters in schizophrenia using sociocultural and clinical features: A machine learning approach. Gen. Hosp. Psychiatry 2017, 47, 20–28. [Google Scholar] [CrossRef]
- Xiao, Y.; Yan, Z.; Zhao, Y.; Tao, B.; Sun, H.; Li, F.; Yao, L.; Zhang, W.; Chandan, S.; Liu, J.; et al. Support vector machine-based classification of first episode drug-naïve schizophrenia patients and healthy controls using structural MRI. Schizophr. Res. 2019, 214, 11–17. [Google Scholar] [CrossRef]
- Guo, Y.; Qiu, J.; Lu, W. Support Vector Machine-Based Schizophrenia Classification Using Morphological Information from Amygdaloid and Hippocampal Subregions. Brain Sci. 2020, 10, 562. [Google Scholar] [CrossRef]
- Jahmunah, V.; Oh, S.L.; Rajinikanth, V.; Ciaccio, E.J.; Cheong, K.H.; Arunkumar, N.; Acharya, U.R. Automated detection of schizophrenia using nonlinear signal processing methods. Artif. Intell. Med. 2019, 100, 101698. [Google Scholar] [CrossRef]
- Brownlee, J. Recursive Feature Elimination (RFE) for Feature Selection in Python. Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/rfe-feature-selection-in-python/ (accessed on 25 May 2020).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Chen, W.; Zhang, Q.; Wu, L. Building auto-encoder intrusion detection system based on random forest feature selection. Comput. Secur. 2020, 95, 101851. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Amini, F.; Hu, G. A two-layer feature selection method using genetic algorithm and elastic net. Expert Syst. Appl. 2021, 166, 114072. [Google Scholar] [CrossRef]
- Shen, L.; Qi, Y.; Kim, S.; Nho, K.; Wan, J.; Risacher, S.L.; Saykin, A.J. Sparse bayesian learning for identifying imaging biomarkers in AD prediction. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Beijing, China, 20–24 September 2010; pp. 611–618. [Google Scholar]
- Sabuncu, M.R.; Van Leemput, K. The relevance voxel machine (RVoxM): A self-tuning Bayesian model for informative image-based prediction. IEEE Trans. Med. Imaging 2012, 31, 2290–2306. [Google Scholar] [CrossRef] [Green Version]
- Sabuncu, M.R. A sparse Bayesian learning algorithm for longitudinal image data. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 411–418. [Google Scholar]
- Parrado-Hernández, E.; Gómez-Verdejo, V.; Martínez-Ramón, M.; Shawe-Taylor, J.; Alonso, P.; Pujol, J.; Menchón, J.M.; Cardoner, N.; Soriano-Mas, C. Discovering brain regions relevant to obsessive–compulsive disorder identification through bagging and transduction. Med. Image Anal. 2014, 18, 435–448. [Google Scholar] [CrossRef]
- Gómez-Verdejo, V.; Parrado-Hernández, E.; Tohka, J. Sign-consistency based variable importance for machine learning in brain imaging. Neuroinformatics 2019, 17, 593–609. [Google Scholar] [CrossRef] [Green Version]
- Sevilla-Salcedo, C.; Gómez-Verdejo, V.; Tohka, J. Regularized Bagged Canonical Component Analysis for Multiclass Learning in Brain Imaging. Neuroinformatics 2020, 18, 641–659. [Google Scholar] [CrossRef]
- Grimm, O.; Gass, N.; Weber-Fahr, W.; Sartorius, A.; Schenker, E.; Spedding, M.; Risterucci, C.; Schweiger, J.I.; Böhringer, A.; Zang, Z.; et al. Acute ketamine challenge increases resting state prefrontal-hippocampal connectivity in both humans and rats. Psychopharmacology 2015, 232, 4231–4241. [Google Scholar] [CrossRef]
- Hadar, R.; Soto-Montenegro, M.L.; Götz, T.; Wieske, F.; Sohr, R.; Desco, M.; Hamani, C.; Weiner, I.; Pascau, J.; Winter, C. Using a maternal immune stimulation model of schizophrenia to study behavioral and neurobiological alterations over the developmental course. Schizophr. Res. 2015, 166, 238–247. [Google Scholar] [CrossRef] [Green Version]
- Romero-Miguel, D.; Casquero-Veiga, M.; MacDowell, K.S.; Torres-Sanchez, S.; Garcia-Partida, J.A.; Lamanna-Rama, N.; Romero-Miranda, A.; Berrocoso, E.; Leza, J.C.; Desco, M.; et al. A Characterization of the Effects of Minocycline Treatment During Adolescence on Structural, Metabolic, and Oxidative Stress Parameters in a Maternal Immune Stimulation Model of Neurodevelopmental Brain Disorders. Int. J. Neuropsychopharmacol. 2021, 24, 734–748. [Google Scholar] [CrossRef] [PubMed]
- Ozawa, K.; Hashimoto, K.; Kishimoto, T.; Shimizu, E.; Ishikura, H.; Iyo, M. Immune activation during pregnancy in mice leads to dopaminergic hyperfunction and cognitive impairment in the offspring: A neurodevelopmental animal model of schizophrenia. Biol. Psychiatry 2006, 59, 546–554. [Google Scholar] [CrossRef] [PubMed]
- Zhu, F.; Zheng, Y.; Liu, Y.; Zhang, X.; Zhao, J. Minocycline alleviates behavioral deficits and inhibits microglial activation in the offspring of pregnant mice after administration of polyriboinosinic–polyribocytidilic acid. Psychiatry Res. 2014, 219, 680–686. [Google Scholar] [CrossRef] [PubMed]
- Meyer, U.; Feldon, J. To poly (I: C) or not to poly (I: C): Advancing preclinical schizophrenia research through the use of prenatal immune activation models. Neuropharmacology 2012, 62, 1308–1321. [Google Scholar] [CrossRef]
- Casquero-Veiga, M.; Garcia-Garcia, D.; MacDowell, K.S.; Perez-Caballero, L.; Torres-Sanchez, S.; Fraguas, D.; Berrocoso, E.; Leza, J.C.; Arango, C.; Desco, M.; et al. Risperidone administered during adolescence induced metabolic, anatomical and inflammatory/oxidative changes in adult brain: A pet and mri study in the maternal immune stimulation animal model. Eur. Neuropsychopharmacol. 2019, 29, 880–896. [Google Scholar] [CrossRef]
- Valdes Hernandez, P.A.; Sumiyoshi, A.; Nonaka, H.; Haga, R.; Aubert Vasquez, E.; Ogawa, T.; Iturria Medina, Y.; Riera, J.J.; Kawashima, R. An in vivo MRI template set for morphometry, tissue segmentation, and fMRI localization in rats. Front. Neuroinform. 2011, 5, 26. [Google Scholar]
- Bishop, C.M. Bayesian PCA. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 1999; pp. 382–388. [Google Scholar]
- Klami, A.; Virtanen, S.; Kaski, S. Bayesian canonical correlation analysis. J. Mach. Learn. Res. 2013, 14, 965–1003. [Google Scholar]
- Bishop, C.M. Pattern recognition. Mach. Learn. 2006, 128, 1–39. [Google Scholar]
- Schölkopf, B.; Herbrich, R.; Smola, A.J. A generalized representer theorem. In Proceedings of the International Conference on Computational Learning Theory, Amsterdam, The Netherlands, 16–19 July 2001; pp. 416–426. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: New York, NY, USA, 2008. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Sevilla-Salcedo, C.; Gómez-Verdejo, V.; Olmos, P.M. Sparse semi-supervised heterogeneous interbattery bayesian analysis. Pattern Recognit. 2021, 120, 108141. [Google Scholar] [CrossRef]
- Sevilla-Salcedo, C.; Guerrero-López, A.; Olmos, P.M.; Gómez-Verdejo, V. Bayesian Sparse Factor Analysis with Kernelized Observations. arXiv 2020, arXiv:2006.00968. [Google Scholar]
- Styner, M.; Lieberman, J.A.; McClure, R.K.; Weinberger, D.R.; Jones, D.W.; Gerig, G. Morphometric analysis of lateral ventricles in schizophrenia and healthy controls regarding genetic and disease-specific factors. Proc. Natl. Acad. Sci. USA 2005, 102, 4872–4877. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rapado-Castro, M.; Villar-Arenzana, M.; Janssen, J.; Fraguas, D.; Bombin, I.; Castro-Fornieles, J.; Mayoral, M.; González-Pinto, A.; de la Serna, E.; Parellada, M.; et al. Fronto-Parietal Gray Matter Volume Loss Is Associated with Decreased Working Memory Performance in Adolescents with a First Episode of Psychosis. J. Clin. Med. 2021, 10, 3929. [Google Scholar] [CrossRef]
- Wen, D.; Wang, J.; Yao, G.; Liu, S.; Li, X.; Li, J.; Li, H.; Xu, Y. Abnormality of subcortical volume and resting functional connectivity in adolescents with early-onset and prodromal schizophrenia. J. Psychiatr. Res. 2021, 140, 282–288. [Google Scholar] [CrossRef]
- Guo, S.; Kendrick, K.M.; Zhang, J.; Broome, M.; Yu, R.; Liu, Z.; Feng, J. Brain-wide functional inter-hemispheric disconnection is a potential biomarker for schizophrenia and distinguishes it from depression. Neuroimage Clin. 2013, 2, 818–826. [Google Scholar] [CrossRef] [Green Version]
- Boklage, C.E. Schizophrenia, brain asymmetry development, and twinning: Cellular relationship with etiological and possibly prognostic implications. Biol. Psychiatry 1977, 12, 19–35. [Google Scholar]
- Casquero-Veiga, M.; Romero-Miguel, D.; MacDowell, K.S.; Torres-Sanchez, S.; Garcia-Partida, J.A.; Lamanna-Rama, N.; Gómez-Rangel, V.; Romero-Miranda, A.; Berrocoso, E.; Leza, J.C.; et al. Omega-3 fatty acids during adolescence prevent schizophrenia-related behavioural deficits: Neurophysiological evidences from the prenatal viral infection with PolyI: C. Eur. Neuropsychopharmacol. 2021, 46, 14–27. [Google Scholar] [CrossRef]
- Bortz, D.M.; Grace, A.A. Medial septum activation produces opposite effects on dopamine neuron activity in the ventral tegmental area and substantia nigra in MAM vs. normal rats. NPJ Schizophr. 2018, 4, 17. [Google Scholar] [CrossRef] [Green Version]
- Takeuchi, Y.; Nagy, A.; Barcsai, L.; Li, Q.; Ohsawa, M.; Mizuseki, K.; Berényi, A. The medial septum as a potential target for treating brain disorders associated with oscillopathies. Front. Neural Circuits 2021, 15, 701080. [Google Scholar] [CrossRef] [PubMed]
- McGlinchey, E.M.; Aston-Jones, G. Dorsal hippocampus drives context-induced cocaine seeking via inputs to lateral septum. Neuropsychopharmacology 2018, 43, 987–1000. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pantazis, C.B.; Aston-Jones, G. Lateral septum inhibition reduces motivation for cocaine: Reversal by diazepam. Addict. Biol. 2020, 25, e12742. [Google Scholar] [CrossRef] [PubMed]
- Gárate-Pérez, M.F.; Méndez, A.; Bahamondes, C.; Sanhueza, C.; Guzmán, F.; Reyes-Parada, M.; Sotomayor-Zárate, R.; Renard, G.M. Vasopressin in the lateral septum decreases conditioned place preference to amphetamine and nucleus accumbens dopamine release. Addict. Biol. 2021, 26, e12851. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Gao, S.; Zhang, X. Cognitive deficits and white matter abnormalities in never-treated first-episode schizophrenia. Transl. Psychiatry 2020, 10, 368. [Google Scholar] [CrossRef]
- Kim, S.E.; Jung, S.; Sung, G.; Bang, M.; Lee, S.H. Impaired cerebro-cerebellar white matter connectivity and its associations with cognitive function in patients with schizophrenia. NPJ Schizophr. 2021, 7, 38. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Experiment | Accuracy | # Selected Voxels |
|---|---|---|
| GP | 67.9% | 1,077,656 (100%) |
| GP+FS | 67.9% | 269,414 (25%) |
| SVM | 71.6% | 1,077,656 (100%) |
| MKL-SVM | 67.9% | 1,077,656 (100%) |
| KSSHIBA | 69.8% | 1,077,656 (100%) |
| KSSHIBA+FS | 64.1% | 269,414 (25%) |
| DBL-FS | 77.3% | 287,996 (26.72%) |
| DBL-FS+EK | 77.3% | 242,754 (22.52%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belenguer-Llorens, A.; Sevilla-Salcedo, C.; Desco, M.; Soto-Montenegro, M.L.; Gómez-Verdejo, V. A Novel Bayesian Linear Regression Model for the Analysis of Neuroimaging Data. Appl. Sci. 2022, 12, 2571. https://0-doi-org.brum.beds.ac.uk/10.3390/app12052571
Belenguer-Llorens A, Sevilla-Salcedo C, Desco M, Soto-Montenegro ML, Gómez-Verdejo V. A Novel Bayesian Linear Regression Model for the Analysis of Neuroimaging Data. Applied Sciences. 2022; 12(5):2571. https://0-doi-org.brum.beds.ac.uk/10.3390/app12052571
Chicago/Turabian StyleBelenguer-Llorens, Albert, Carlos Sevilla-Salcedo, Manuel Desco, Maria Luisa Soto-Montenegro, and Vanessa Gómez-Verdejo. 2022. "A Novel Bayesian Linear Regression Model for the Analysis of Neuroimaging Data" Applied Sciences 12, no. 5: 2571. https://0-doi-org.brum.beds.ac.uk/10.3390/app12052571