
Cycle Generative Adversarial Network Based on Gradient Normalization for Infrared Image Generation
 , ,
, ,
Abstract
:1. Introduction
2. Related Theoretical Work
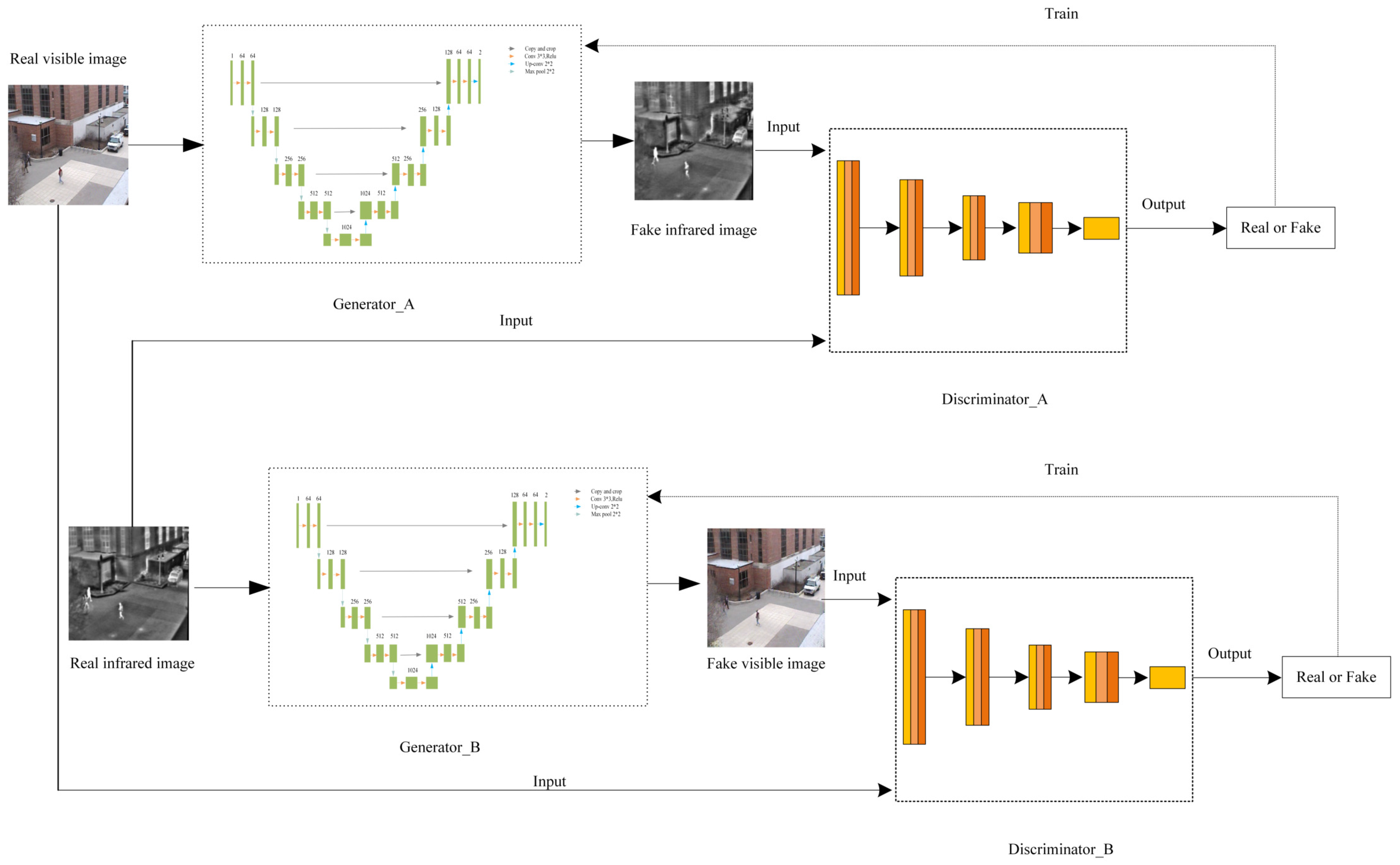
2.1. Cycle Generation of Adversarial Networks
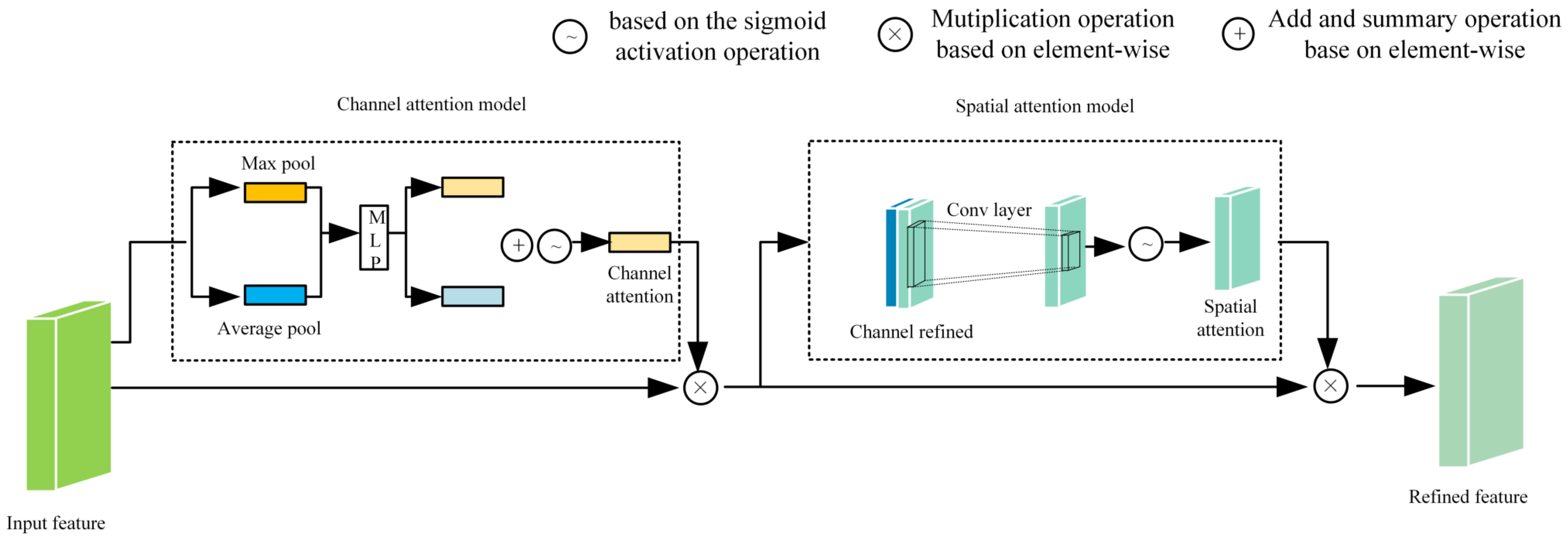
2.2. Channel Attention Mechanism and Spatial Attention Mechanism
2.3. Gradient Normalization
2.4. Loss Functions
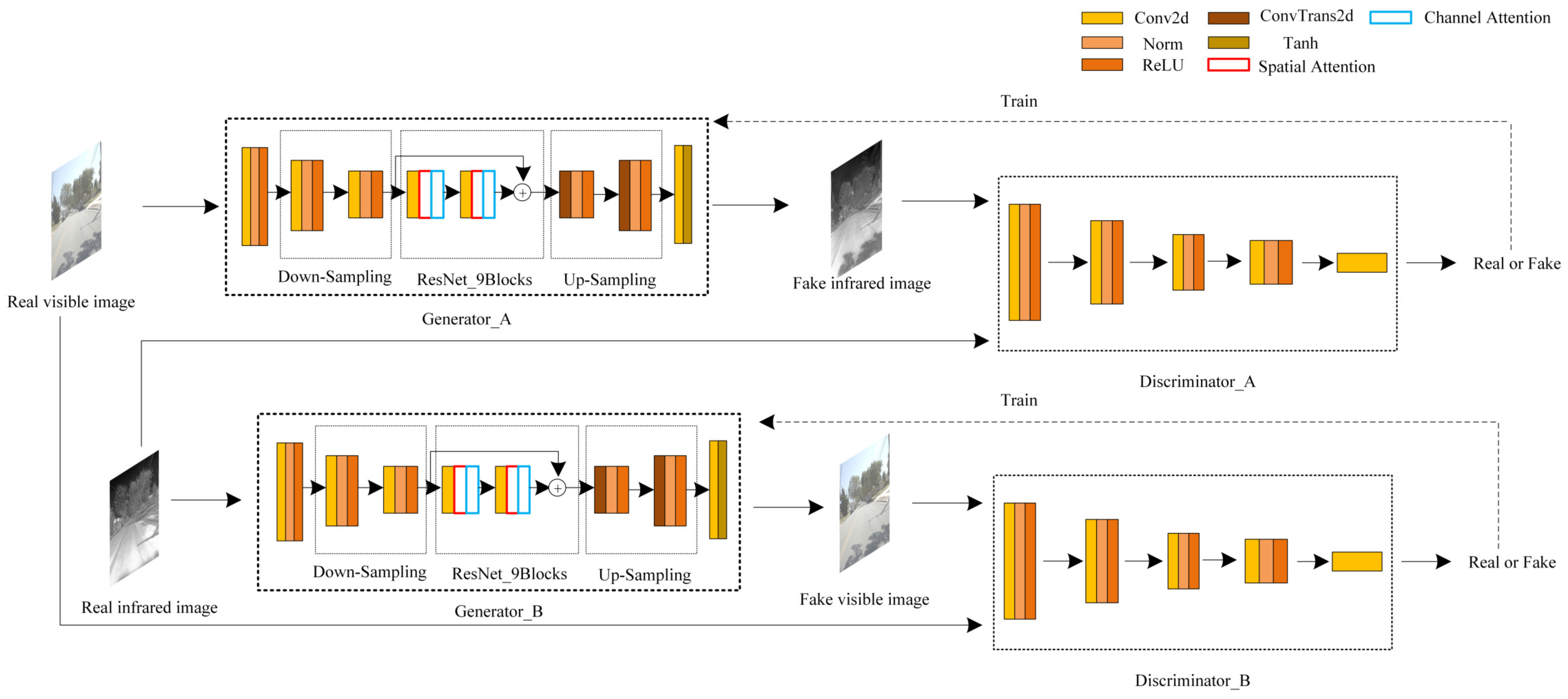
3. Methodologies
Network Framework Structure
4. Analysis of Experimental Results
4.1. Dataset and Experimental Procedure
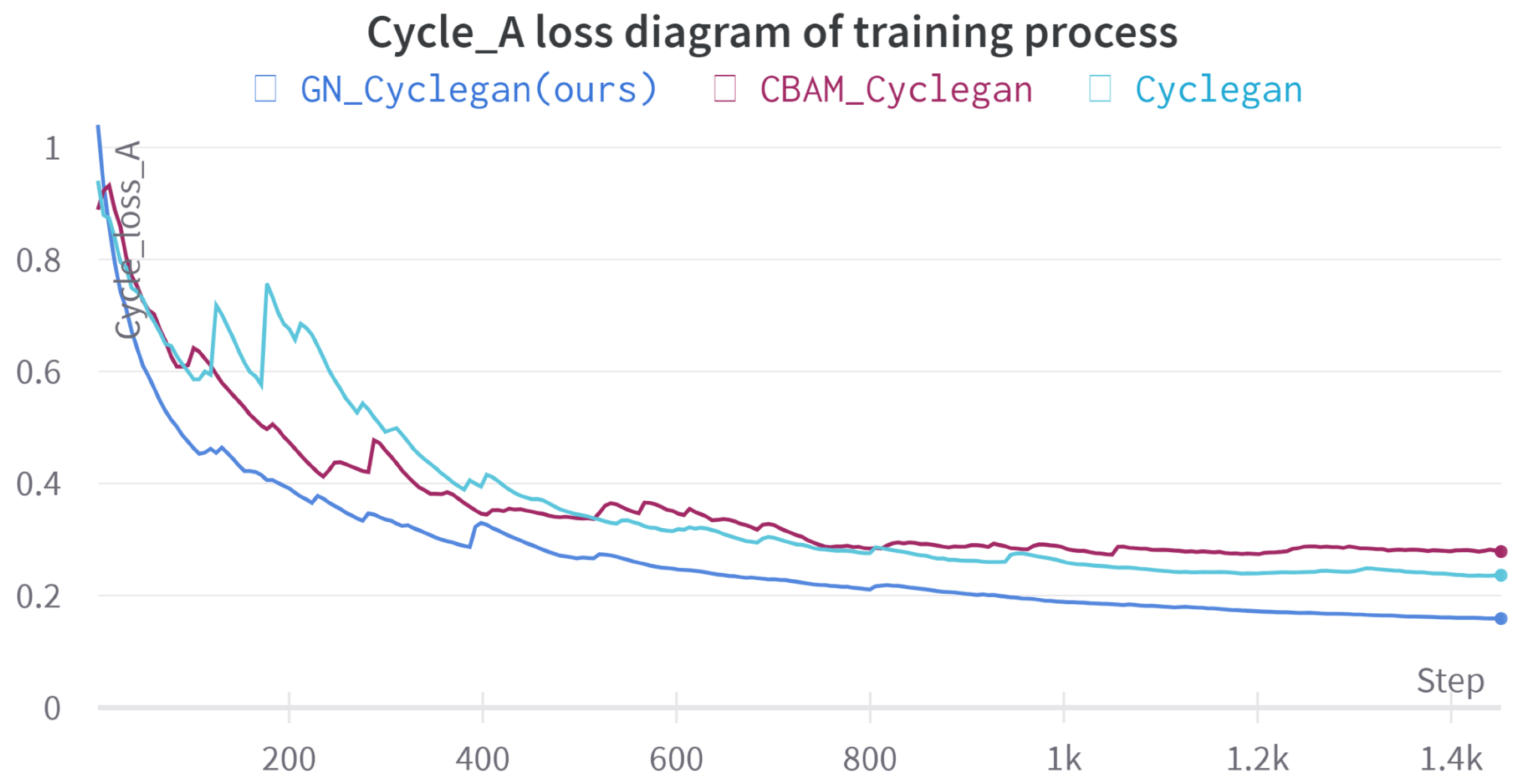
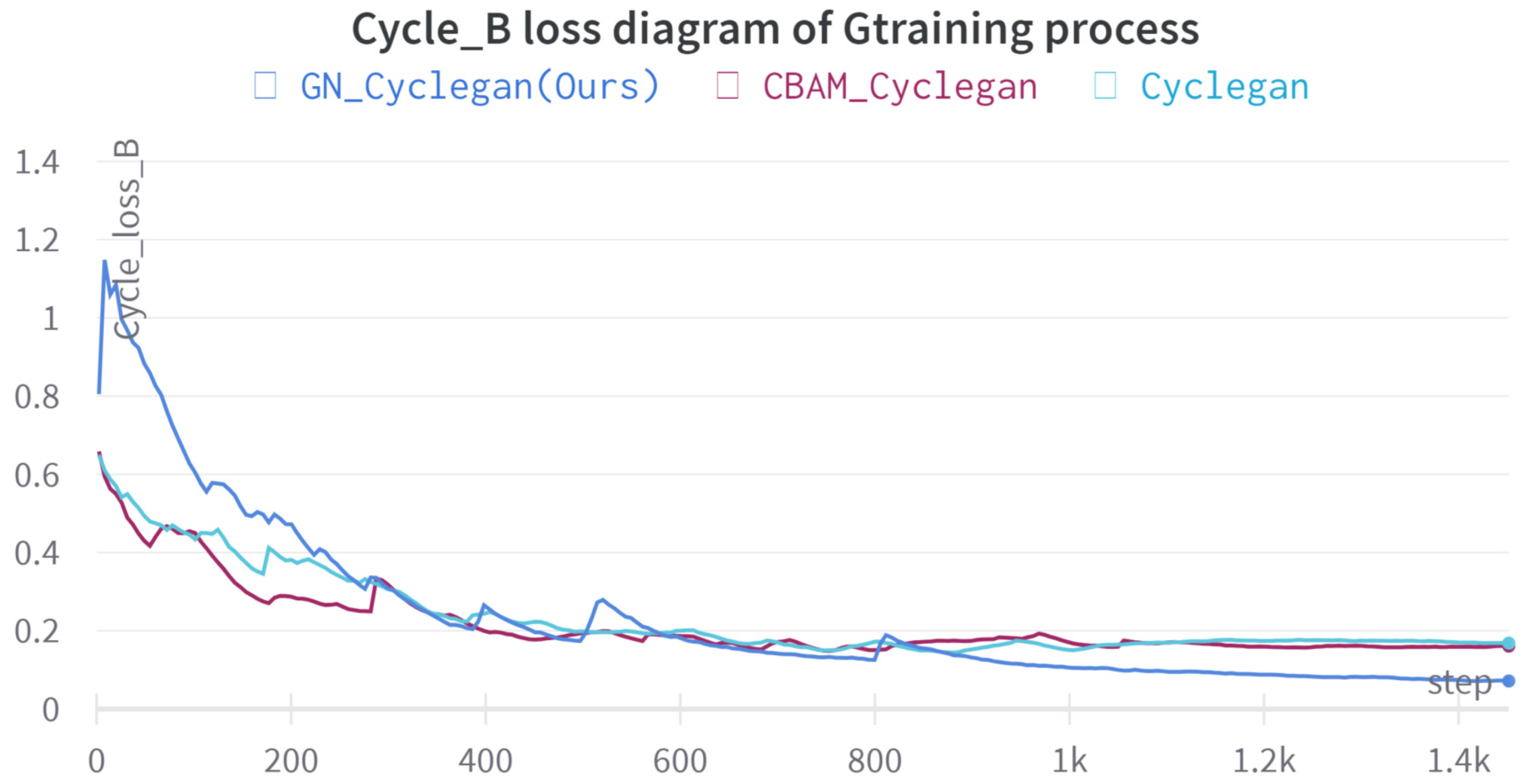
4.2. Experimental Results
4.3. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y. Survey on Deep Multi-modal Data Analytics: Collaboration, Rivalry, and Fusion. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, J.; Wang, H.; Wang, M. Progressive Learning with Multi-scale Attention Network for Cross-domain Vehicle Re-identification. Sci. China Inf. Sci. 2022, 65, 16103. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–7. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Singh, N.K.; Raza, K. Medical image generation using generative adversarial networks: A review. Health Inform. 2021, 932, 77–96. [Google Scholar]
- Suárez, P.L.; Sappa, A.D.; Vintimilla, B.X. Infrared image colorization based on a triplet dcgan architecture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018. [Google Scholar]
- Cui, J.; Zhong, S.; Chai, J. Colorization method of high resolution anime sketch with Pix2PixHD. In Proceedings of the 2021 5th Asian Conference on Artificial Intelligence Technology (ACAIT), Haikou, China, 29–31 October 2021. [Google Scholar]
- Dash, A.; Ye, J.; Wang, G. High Resolution Solar Image Generation using Generative Adversarial Networks. Ann. Data Sci. 2022, 1–17. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 11–15 August 2017. [Google Scholar]
- Zhou, C.; Zhang, J.; Liu, J. Lp-WGAN: Using Lp-norm normalization to stabilize Wasserstein generative adversarial networks. Knowl.-Based Syst. 2018, 161, 415–424. [Google Scholar] [CrossRef]
- Zhang, H.; Goodfellow, I.; Metaxas, D. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach Convention Center, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N. A structured self-attentive sentence embedding, Computing Research Repository. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. Adv. Neural Inf. Process. Syst. 2016, 29, 469–477. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised cross-domain image generation. arXiv 2016, arXiv:1611.02200. [Google Scholar]
- Mao, X.; Wang, S.; Zheng, L. Semantic invariant cross-domain image generation with generative adversarial networks. Neurocomputing 2018, 293, 55–63. [Google Scholar] [CrossRef]
- Benaim, S.; Wolf, L. One-shot unsupervised cross domain translation. Adv. Neural Inf. Process. Syst. 2018, 31, 2108–2118. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 21–30 October 2017. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–21 June 2018. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, M.Y.; Huang, X.; Mallya, A. Few-shot unsupervised image-to-image translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Murez, Z.; Kolouri, S.; Kriegman, D.; Ramamoorthi, R.; Kim, K. Image to Image Translation for Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–21 June 2018. [Google Scholar]
- Wang, M.; Li, H.; Li, F. Generative adversarial network based on resnet for conditional image restoration. arXiv 2017, arXiv:1707.04881. [Google Scholar]
- Cao, K.; Zhang, X. An improved res-unet model for tree species classification using airborne high-resolution images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Demir, U.; Unal, G. Patch-based image inpainting with generative adversarial networks. arXiv 2018, arXiv:1803.07422. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ma, B.; Wang, X.; Zhang, H.; Li, F.; Dan, J. CBAM-GAN: Generative adversarial networks based on convolutional block attention module. In Proceedings of the International Conference on Artificial Intelligence and Security, New York, NY, USA, 26–28 July 2019. [Google Scholar]
- Gul, M.S.K.; Mukati, M.U.; Bätz, M. LightField View Synthesis Using A Convolutional Block Attention Module. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021. [Google Scholar]
- Aytekin, C.; Ni, X.; Cricri, F. Clustering and unsupervised anomaly detection with L2 normalized deep auto-encoder representations. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazi, 8–13 July 2018. [Google Scholar]
- Wu, Y.L.; Shuai, H.H.; Tam, Z.R. Gradient normalization for generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–18 October 2021. [Google Scholar]
- Bhaskara, V.S.; Aumentado-Armstrong, T.; Jepson, A.D. GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 2–5 March 2022. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T.A. style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Davis, J.; Sharma, V. Background-Subtraction using Contour-based Fusion of Thermal and Visible Imagery. Comput. Vis. Image Underst. 2007, 106, 162–182. [Google Scholar] [CrossRef]
- Sagan, V.; Maimaitijiang, M.; Sidike, P. UAV-based high resolution thermal imaging for vegetation monitoring, and plant phenotyping using ICI 8640 P, FLIR Vue Pro R 640, and thermomap cameras. Remote Sens. 2019, 11, 330. [Google Scholar] [CrossRef] [Green Version]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Winkler, S.; Mohandas, P. The evolution of video quality measurement: From PSNR to hybrid metrics. IEEE Trans. Broadcast. 2008, 54, 660–668. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef] [Green Version]
- Setiadi, D.I.M. PSNR vs SSIM: Imperceptibility quality assessment for image steganography. Multimed Too. PSNR vs. SSIM: Imperceptibility quality assessment for image steganography. Multimed. Tools Appl. 2021, 80, 8423–8444. [Google Scholar] [CrossRef]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 319–345. [Google Scholar]
- Qian, X.; Zhang, M.; Zhang, F. Sparse gans for thermal infrared image generation from optical image. IEEE Access 2020, 8, 180124–180132. [Google Scholar] [CrossRef]
- Chen, F.; Zhu, F.; Wu, Q. InfraRed Images Augmentation Based on Images Generation with Generative Adversarial Networks. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: Infrared image ,visible image | |
| Output: False infrared image generated from visible image | |
| step 1 | For M epochs do |
| step 2 | For K steps do |
| step 3 | n samples taken from the IR image distribution |
| step 4 | n samples taken from the visible image distribution |
| step 5 | Training the discriminator Discriminator_A and updating the parametric model. |
| step 6 | Training the discriminator Discriminator_B and updating the parametric model. |
| step 7 | End for |
| step 8 | Training the generator Generator_A and updating the model parameters. |
| step 9 | Training the generator Generator_B and updating the model parameters. |
| step 10 | End for |
| Mathod | OSU | Flir | ||
|---|---|---|---|---|
| Evaluation indicators | PSNR/dB | SSIM | PSNR/dB | SSIM |
| CycleGAN+unet_128 | 13.6867 | 0.2479 | 13.2131 | 0.4167 |
| CycleGAN+unet_256 | 13.7892 | 0.2686 | 12.7318 | 0.4444 |
| CycleGAN+resnet_6blocks | 17.3956 | 0.7071 | 13.3745 | 0.4700 |
| CycleGAN+resnet_9blocks | 17.0300 | 0.6900 | 13.3275 | 0.4368 |
| CUT [42] | 13.3502 | 0.3168 | 13.1813 | 0.4214 |
| Ours(GN_CycleGAN) | 18.0699 | 0.7491 | 13.5195 | 0.4572 |
| Method | PSNR/dB | SSIM |
|---|---|---|
| Baseline(CycleGAN) | 13.2131 | 0.4167 |
| CycleGAN+ResNet | 13.3275 | 0.4368 |
| CycleGAN+ResNet+CBAM | 13.2403 | 0.4530 |
| Ours (GN_CycleGAN) | 13.5195 | 0.4572 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, X.; Pan, H.; Zhao, H.; Liu, P.; Zhang, C.; Wang, J.; Wang, H. Cycle Generative Adversarial Network Based on Gradient Normalization for Infrared Image Generation. Appl. Sci. 2023, 13, 635. https://0-doi-org.brum.beds.ac.uk/10.3390/app13010635
Yi X, Pan H, Zhao H, Liu P, Zhang C, Wang J, Wang H. Cycle Generative Adversarial Network Based on Gradient Normalization for Infrared Image Generation. Applied Sciences. 2023; 13(1):635. https://0-doi-org.brum.beds.ac.uk/10.3390/app13010635
Chicago/Turabian StyleYi, Xing, Hao Pan, Huaici Zhao, Pengfei Liu, Canyu Zhang, Junpeng Wang, and Hao Wang. 2023. "Cycle Generative Adversarial Network Based on Gradient Normalization for Infrared Image Generation" Applied Sciences 13, no. 1: 635. https://0-doi-org.brum.beds.ac.uk/10.3390/app13010635