
Non-Standard Address Parsing in Chinese Based on Integrated CHTopoNER Model and Dynamic Finite State Machine


Abstract
:1. Introduction
- The existing methods for Chinese address element recognition segregate at the character level, without considering traditional Chinese word segmentation techniques commonly used in natural language processing. Consequently, the acquired semantic representations are at the character level and fail to capture the word-level features inherent in the Chinese language.
- Previous studies on Chinese address element recognition rarely consider the integration of local and global features during feature extraction. Hence, during feature extraction, problems such as missing global or local semantic information arise.
- Furthermore, after the address parsing process, the traditional finite state machines heavily rely on pre-recorded keywords of address elements or require threshold settings when ordering and combining these elements. While finite state machines (FSMs) and bidirectional FSMs perform well in handling standardized addresses, they struggle to effectively process address information descriptions present in web texts, characterized by hierarchical element disorder and omissions.
- This study proposes the CHTopoNER model for identifying hierarchical address elements in online text. The innovation of this model is derived from the improved SoftLexicon approach and the integration of BiLSTM and Iterated Dilated Convolutional Neural Network (IDCNN) models to form a Two Channel Neural Network (TCNN) layer. Specifically, the enhanced SoftLexicon approach is utilized to acquire word-level semantic information while avoiding potential out-of-vocabulary issues, resulting in more accurate identification of Chinese toponyms’ word boundaries. The TCNN layer comprehensively considers both character- and word-level local semantic features as well as global semantic features from the input text, thus minimizing the loss of semantic information and effectively addressing the ambiguity of Chinese address entity elements.
- This study introduces a dynamic FSM. In comparison to the traditional FSM, the dynamic FSM is capable of adjusting its state set based on the types of address elements. This adaptation avoids the limitations of depending heavily on the collected keywords of address elements and the threshold settings inherent to the FSM. Consequently, it can more effectively handle address information descriptions in network text that exhibit issues such as hierarchical element disorder and omission.
2. Related Work
2.1. Relevant Research on Chinese Address Parsing
2.1.1. Dictionary-Based Address Parsing
2.1.2. Rule-Based Address Parsing
2.1.3. Statistical-Based Address Parsing
2.1.4. Deep Learning-Based Address Parsing
2.2. Sorting and Combination of Chinese Addresses Based on FSM
3. Data and Methodology
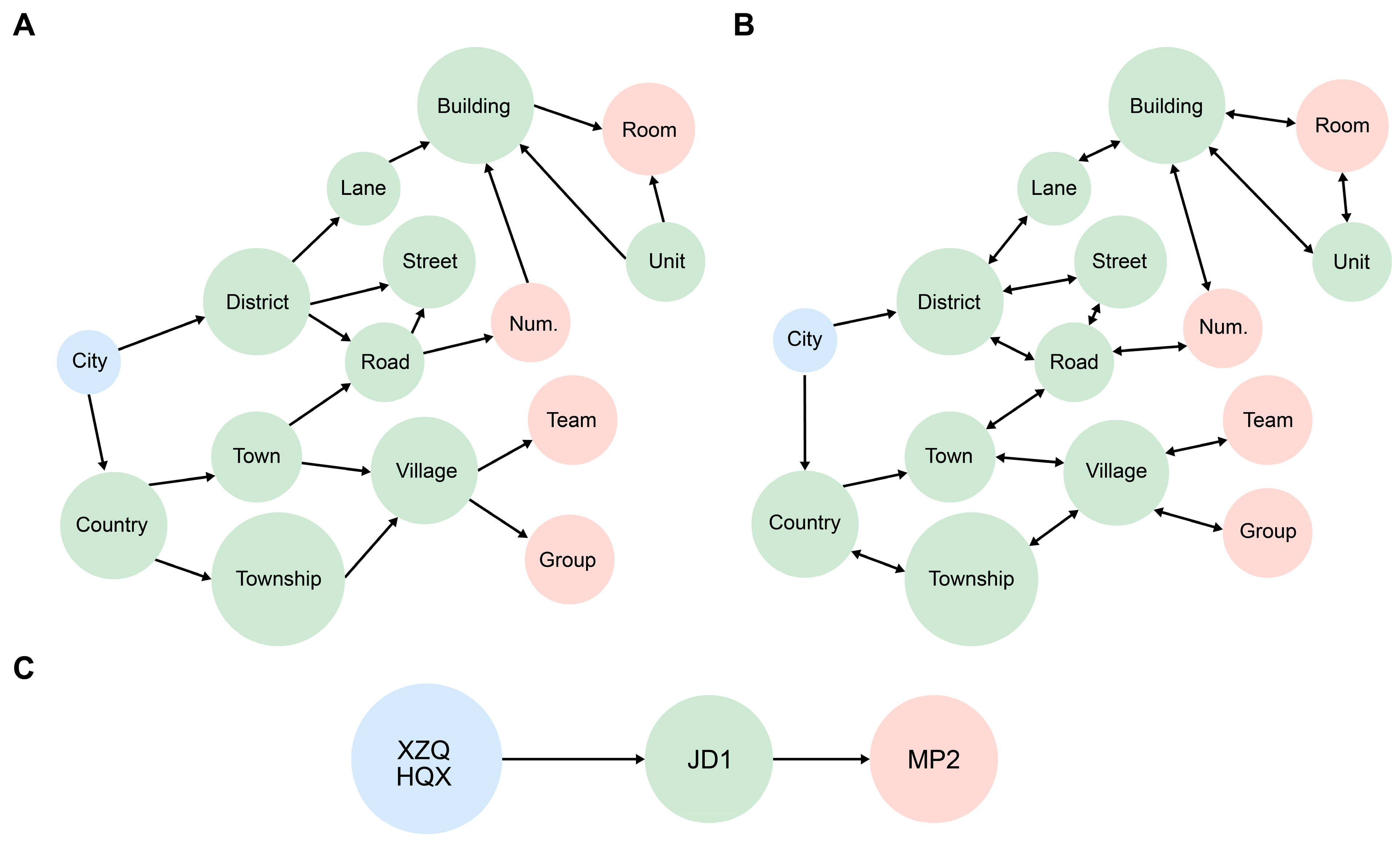
3.1. Data
3.2. Methodology
3.2.1. CHTopoNER Model
3.2.2. Dynamic FSM
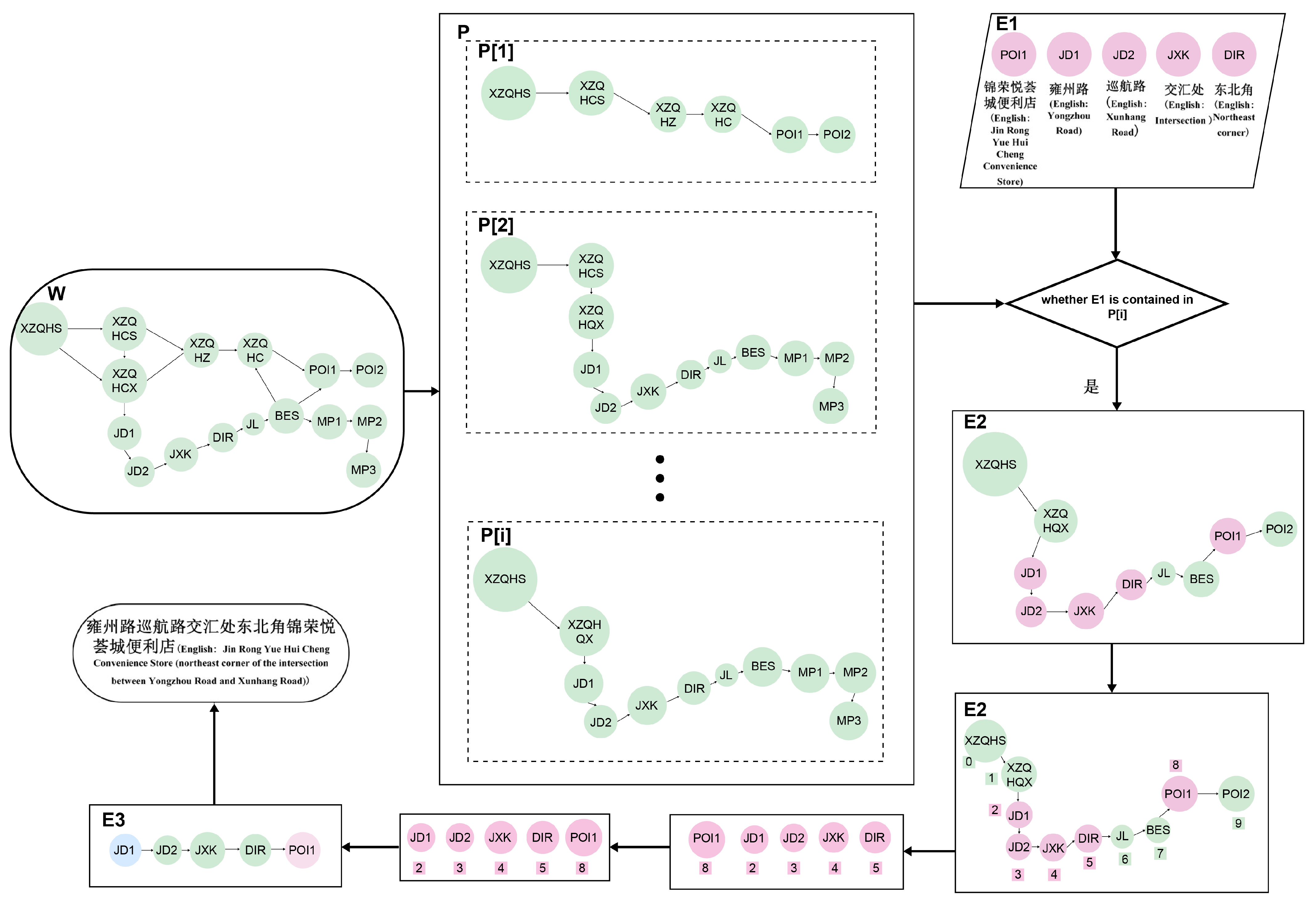
| Algorithm 1: Dynamic FSM algorithm. |
| Input: entity labels E1 of address elements, global FSM set W
Output: dynamic FSM E3 |
| function generateDynamicFSM(E1, W):
// initialize the sextuple of dynamic FSM E3 Qi = {} Σi = set of all entity labels in E1 δi = {} // state transition function, initialized as an empty set qi = {} // initial state set, initialized as an empty set Fi = {} // final state set, initialized as an empty set E3 = (W, Qi, Σi, δi, qi, Fi) // on each path P in W, do for each Pi in W: // obtain the entity labels E2 of the address elements of the path P E2 = entity labels in path Pi // determine whether every element in E1 is contained in E2 if all entity labels in E1 are in E2: // select this path P for the sorting and organizing the entity labels // traverse E1 in E2 and record the positions of the entity elements of E1 with respect to E2 indices = [] for each e in E1: index = index of e in E2 append index to indices // sort the entity elements of E1 according to the index in indices sorted_E1 = [E1[i] for i in sorted(indices)] // sort the entity elements of E2 according to the index in indices sorted_E2 = [E2[i] for i in sorted(indices)] // add the sorted entity elements to the state set Qi as new states qi = (sorted_E2, P) add qi to Qi // update the state transition function δ for i in range(len(sorted_E2)−1): s = (sorted_E2[i], sorted_E2[i + 1]) s_next = (sorted_E2[i + 1],) if s not in δ: δi [s] = set() δi [s].add(s_next) return E3 |
- (1)
- Traverse path P in W to obtain the entity label of the address element (P[i]) of each path.
- (2)
- Determine whether each element in E1 is contained in P[i]. If yes, the path was selected as E2.
- (3)
- Traverse from E1 to E2. If the label element in E1 was consistent with that in E2, the index of the element was recorded.
- (4)
- Finally, the indices were sorted from small to large to obtain a new dynamic FSM (E3; blue represents the initial state of the dynamic FSM, and pink represents the final state).
4. Evaluation Metrics and Experimental Results
4.1. Evaluation Metrics
4.2. Experimental Setup and Parameters
4.3. Experimental Results and Analysis
4.3.1. Experimental Results
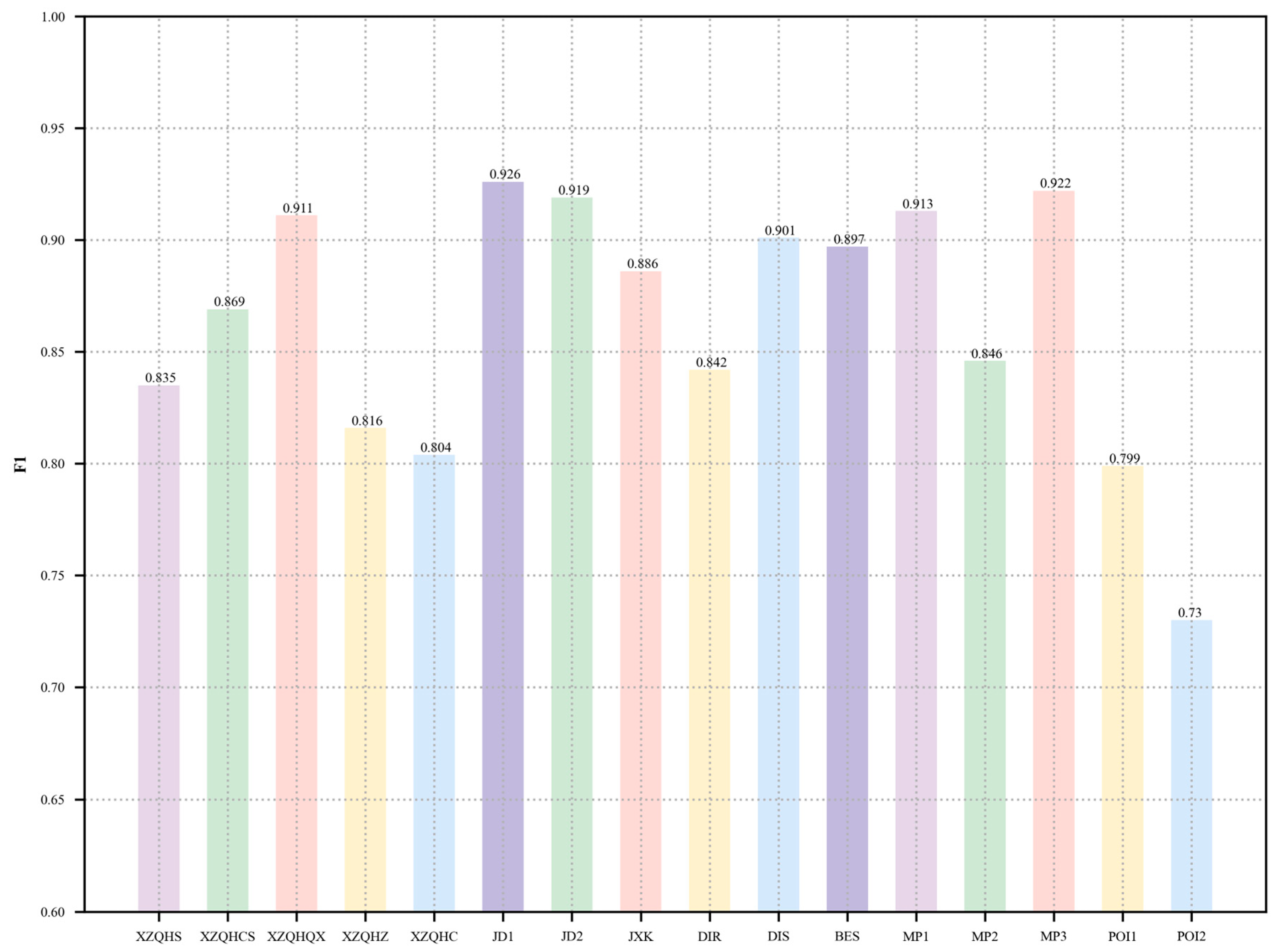
4.3.2. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tian, Q.; Ren, F.; Hu, T.; Liu, J.; Li, R.; Du, Q. Using an optimized Chinese address matching method to develop a geocoding service: A case study of Shenzhen, China. ISPRS Int. J. Geo Inf. 2021, 5, 65. [Google Scholar] [CrossRef]
- Kang, M.; Du, Q.; Wang, M. The Chinese address extraction method based on the address tree model. J. Surv. Mapp. 2015, 44, 99–107. [Google Scholar]
- Melo, F.; Martins, B. Automated geocoding of textual documents: A survey of current approaches. Trans. GIS 2017, 21, 3–38. [Google Scholar] [CrossRef]
- Lin, Y.; Kang, M.; He, B. Spatial pattern analysis of address quality: A study on the impact of rapid urban expansion in China. Environ. Plan. B Urb. Anal. City Sci. 2021, 48, 724–740. [Google Scholar] [CrossRef]
- Qiu, Q.; Xie, Z.; Wu, L.; Li, W. Geoscience keyphrase extraction algorithm using enhanced word embedding. Expert Syst. Appl. 2019, 125, 157–169. [Google Scholar] [CrossRef]
- Wu, K.; Zhang, X.; Ye, P.; Huai, A.; Zhang, H. The Chinese address parsing method based on BERT-BiLSTM-CRF. Geo Geogr. Inf. Sci. 2021, 37, 10–15. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pretraining of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ma, M. Study on Key Techniques of Data Organization for Spatiotemporal Information of Internet News; National University of Defense Technology: Changsha, China, 2016. [Google Scholar]
- Cheng, B.; Li, W.; Tong, H. Chinese hierarchical address segmentation based on BiLSTM-CRF. J. Geo-Inf. Sci. 2019, 21, 1143–1151. [Google Scholar]
- Song, Z. Chinese address matching algorithm for natural language understanding. J. Remote Sens. 2013, 17, 788–801. [Google Scholar]
- Hu, X.; Hu, Y.; Resch, B.; Kersten, J. Geographic Information Extraction from Texts (GeoExT). In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 2–6 April 2023; Springer Nature: Cham, Switzerland, 2023; pp. 398–404. [Google Scholar]
- Zhu, S.M. Research and Implementation of Chinese Word Segmentation Algorithms. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2011. [Google Scholar]
- Guo, Y.C. Research on Technology for Chinese Address Services. Master’s Thesis, Wuhan University, Wuhan, China, 2017. [Google Scholar]
- Ye, P.; Zhang, X.Y.; Du, M. Query Method of Chinese Gazetteer Based on the Character Features. J. Geo-Inf. Sci. 2018, 20, 880–886. [Google Scholar]
- Li, J.; Zhu, G.X.; Zhou, L.; Zheng, X.C. Address Segmentation Algorithm Based on Forward Adaptive Length Matching by Mark Words and Supplementary Method of Missing Address Elements. China Med. Devices 2019, 34, 112–114+130. [Google Scholar]
- Li, P.P. Research on Self-Learning Construction Method of Chinese Address Element Library Based on Internet POI. Master’s Thesis, Lanzhou Jiaotong University, Lanzhou, China, 2019. [Google Scholar]
- Zhu, J. Key Techniques for Chinese Standard Address Database Construction. Master’s Thesis, Nanjing Normal University, Nanjing, China, 2013. [Google Scholar]
- Zhuang, H.D.; Zhang, H.E. Rule-based Chinese Address Matching System. J. Fujian Comput. 2013, 29, 130–132+146. [Google Scholar]
- Zhang, X.Y.; Lv, G.N.; Li, B.Q.; Chen, W. Rule-based Approach to Semantic Resolution of Chinese Addresses. J. Geo-Inf. Sci. 2010, 12, 9–16. [Google Scholar] [CrossRef]
- Tan, K.K. Rule-Based Chinese Address Segmentation and Matching Methods. Master’s Dissertation, Shandong University of Science and Technology, Jinan, China, 2011. [Google Scholar]
- Zhao, Y.; Zhan, B.B.; Jia, P.Z.; Li, Y.H. Address Matching Algorithm Based on Rules and Dictionaries. Beijing Surv. Mapp. 2017, 5, 50–54. [Google Scholar] [CrossRef]
- Hong, Y. Study and Experiments on Urban Geocoding Method. Master’s Thesis, Liaoning Technical University, Dalian, China, 2008. [Google Scholar]
- Mao, R.C. Research on Address Standardization and Semantic Model Construction Based on Deep Neural Network. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2019. [Google Scholar]
- Jian, R.J. Building Standardization Model of Address Based on Statistical Methods. Master’s Thesis, Yunnan University, Kunming, China, 2015. [Google Scholar]
- Quan, Y.X. New Progress in Research on Chinese Word Segmentation Techniques in China. J. Intell. 2002, 11, 29–30. [Google Scholar]
- Zhang, X.Y.; Wang, T.; Chen, H.W. Research on Named Entity Recognition. Comput. Sci. 2005, 32, 5. [Google Scholar] [CrossRef]
- Zhu, F.; Zhao, T.; Liu, Y.; Zhao, Y. Research on Chinese Address Resolution Model Based on Conditional Random Field. J. Phys. Conf. Ser. 2018, 1087, 052040. [Google Scholar] [CrossRef]
- Tang, X.R.; Chen, X.H.; Zhang, X.Y. Research on Toponym Resolution in Chinese Text. Geomat. Inf. Sci. Wuhan Univ. 2010, 35, 930–935+982. [Google Scholar]
- Wei, Y.; Li, H.F.; Hu, D.L.; Li, X.; Ma, L. A Method of Chinese Place Name Recognition Based on Composite Features. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 17–23. [Google Scholar]
- Yuan, X.D. Design and Implementation of Segmentation System for Chinese Address Based on Statistics and Rules. Master’s Thesis, Southeast University, Nanjing, China, 2018. [Google Scholar]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and word2vec for text classification with semantic features. In Proceedings of the IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Beijing, China, 6–8 July 2015; IEEE: Manhattan, NY, USA, 2015; pp. 136–140. [Google Scholar]
- Li, H.; Lu, W.; Xie, P.; Li, L. Neural Chinese address parsing. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 3421–3431. [Google Scholar]
- Ling, G.; Mu, X.; Wang, C.; Xu, A. Enhancing Chinese Address Parsing in Low-Resource Scenarios through In-Context Learning. ISPRS Int. J. Geo Inf. 2023, 12, 296. [Google Scholar] [CrossRef]
- Zhang, H.; Du, Q.; Chen, Z.; Zhang, C. A Chinese address parsing method using RoBERTa-BiLSTM-CRF. J. Wuhan Univ. 2022, 47, 665–672. [Google Scholar]
- Zhang, H. Study on the Parsing and Matching Methods of Chinese Addresses Based on BERT Pretrained Model. Ph.D. Thesis, Nanjing Normal University, Nanjing, China, 2021. [Google Scholar] [CrossRef]
- Liu, X.; Li, Y.; Yin, B.; Tian, Q. Chinese address parsing integrating neural network with spatial relationship. Sci. Surv. 2021, 46, 165–171+212. [Google Scholar] [CrossRef]
- Lee, D.; Yannakakis, M. Principles and methods of testing finite state machines-a survey. Proc. IEEE 1996, 84, 1090–1123. [Google Scholar] [CrossRef]
- Gu, J. A Spatiotemporal Information Parsing Method for Cases and Events in Chinese. Ph.D. Dissertation, Nanjing Normal University, Nanjing, China, 2016. [Google Scholar]
- Luo, M.; Huang, H. A Chinese address standardization method based on finite state machine. Appl. Res. Comput. 2016, 33, 3691–3695. [Google Scholar]
- Wang, Y.; Liu, S.; Wang, Z. A Chinese address parsing model based on Trie and finite state automaton. Comput. Mod. 2016, 7, 60–67. [Google Scholar]
- Tan, T.C. Finite State Machines and Its Application. Master’s Thesis, South China University of Technology, Guangzhou, China, 2013. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; Wei, Z.; Huang, X. Simplify the usage of lexicon in Chinese NER. arXiv 2019, arXiv:1908.05969. [Google Scholar] [CrossRef]
- Levow, G.A. The third international Chinese language processing bakeoff: Word segmentation and named entity recognition. In Proceedings of the 5th SIGHAN Workshop on Chinese Language Processing, Sydney, Australia, 22–23 July 2006; pp. 108–117. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and accurate entity recognition with iterated dilated convolutions. arXiv 2017, arXiv:1702.02098. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Manhattan, NY, USA, 2013; pp. 6645–6649. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning, San Francisco, CA, USA, 28 June 2001. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Grishman, R.; Sundheim, B.M. Message understanding conference-6: A brief history. In Proceedings of the COLING 1996: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996; Volume 1. [Google Scholar]
- Di, L.; Ling, X.; Guangwen, W. Design of Chinese named entity recognition algorithm based on BiLSTM-CRF model. In Proceedings of the IEEE Conference on Telecommunications, Optics and Computer Science (TOCS), Shenyang, China, 10–11 December 2021; IEEE: Manhattan, NY, USA, 2021; pp. 37–41. [Google Scholar]
- Yu, B.; Wei, J. IDCNN-CRF-based domain named entity recognition method. In Proceedings of the IEEE 2nd International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Weihai, China, 14–16 October 2020; IEEE: Manhattan, NY, USA, 2020; pp. 542–546. [Google Scholar]
- Zhang, S.; Zhu, H.; Xu, H.; Zhu, G.; Li, K.-C. A named entity recognition method towards product reviews based on BiLSTM-attention-CRF. Int. J. Comput. Sci. Eng. 2022, 25, 479–489. [Google Scholar]
- Li, X.; Zhang, H.; Zhou, X.H. Chinese clinical named entity recognition with variant neural structures based on BERT methods. J. Biomed. Inform. 2020, 107, 103422. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep structured output learning for unconstrained text recognition. arXiv 2014, arXiv:1412.5903. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Meaning | Example |
|---|---|---|
| XZQHS | Provincial administrative divisions | 河南省 (in English: Henan Province) |
| XZQHCS | Municipal administrative divisions | 郑州市 (in English: Zhengzhou City) |
| XZQHQX | County (district) administrative divisions | 中牟县 (in English: Zhongmu County) |
| XZQHZ | Town (township) administrative divisions | 白沙镇 (in English: Baisha Town) |
| XZQHC | Village | 高庄村 (in English: Gaozhuang Village) |
| JD1 | Road 1 | 商都路 (in English: Shangdu Road) |
| JD2 | Road 2 | 万山公里 (in English: Wansan Highway) |
| JXK | Intersection | 交叉路 (in English: Intersection) |
| DIR | Direction | 西北方向 (in English: Northwest) |
| DIS | Distance | 50 m (in English: 50 m) |
| BES | Blur shift | 附近 (in English: Nearby) |
| MP1 | Local area 1 | 489号 (in English: No. 489) |
| MP2 | Local area 2 | 博士嘉园 (in English: Boshi Jiayuan) |
| MP3 | Local area 3 | 25幢 (in English: Building 25) |
| POI1 | Point of interest 1 | 白沙商贸城 (in English: Baisha Trade City) |
| POI2 | Point of interest 2 | 茶百道 (in English: Chabaidao) |
| Component | Details |
|---|---|
| Central Processing Unit (CPU) | Intel(R) Core(TM) i9-12900H |
| Graphics Card (GPU) | NVIDIA GeForce RTX 3080 Ti |
| Operating System | Ubuntu 18.04 |
| Programming Language | Python 3.7 |
| Deep Learning Framework | TensorFlow1.14.0 |
| Precision | Recall | F1 | |
|---|---|---|---|
| BiLSTM-CRF (baseline) | 0.912 | 0.774 | 0.837 |
| IDCNN-CRF1 | 0.992 | 0.773 | 0.869 |
| IDCNN-CRF2 | 0.994 | 0.790 | 0.883 |
| BiLSTM-Attention-CRF | 0.938 | 0.740 | 0.827 |
| BERT-BiLSTM-CRF | 0.996 | 0.891 | 0.940 |
| CHTopoNER | 0.997 | 0.953 | 0.975 |
| Precision | Recall | F1 | |
|---|---|---|---|
| BiLSTM-CRF (baseline) | 0.990 | 0.890 | 0.864 |
| IDCNN-CRF1 | 0.994 | 0.889 | 0.864 |
| IDCNN-CRF2 | 0.995 | 0.916 | 0.875 |
| BiLSTM-Attention-CRF | 0.989 | 0.840 | 0.840 |
| BERT-BiLSTM-CRF | 0.989 | 0.895 | 0.940 |
| CHTopoNER | 0.999 | 0.965 | 0.981 |
| Precision | Recall | F1 | |
|---|---|---|---|
| BiLSTM-CRF (baseline) | 0.961 | 0.710 | 0.817 |
| IDCNN-CRF1 | 0.976 | 0.736 | 0.839 |
| IDCNN-CRF2 | 0.988 | 0.729 | 0.839 |
| BiLSTM-Attention-CRF | 0.936 | 0.703 | 0.809 |
| BERT-BiLSTM-CRF | 0.989 | 0.735 | 0.843 |
| CHTopoNER | 0.991 | 0.743 | 0.849 |
| Model | Accuracy |
|---|---|
| CHTopoNER + FSM | 0.777 |
| CHTopoNER + bidirectional FSM | 0.781 |
| CHTopoNER + Algorithm 1 (dynamic FSM) | 0.839 |
| Model | Accuracy |
|---|---|
| CHTopoNER + FSM | 0.532 |
| CHTopoNER + bidirectional FSM | 0.698 |
| CHTopoNER + Algorithm 1 (dynamic FSM) | 0.836 |
| Model | Example | Processing of Address Elements |
|---|---|---|
| CHTopoNER + FSM | Xinyuan Modern Cheng (Cheng has the same meaning as city but uses a different Chinese character. In this study, Cheng is used to differentiate from city), No. 17 Qingfeng Street, Erqi District, Zhengzhou City | Zhengzhou City (XZQHCS)/Erqi District (XZQHQX)/Qingfeng Street (JD1)/No.17 (MP1)/Xinyuan Modern Cheng |
| CHTopoNER + bidirectional FSM | Xinyuan Modern Cheng, No. 17 Qingfeng Street, Erqi District, Zhengzhou City | Zhengzhou City (XZQHCS)/Erqi District (XZQHQX)/Qingfeng Street (JD1)/No.17 (MP1)/Xinyuan Modern Cheng (MP2) |
| CHTopoNER + Algorithm 1 (dynamic FSM) | Xinyuan Modern Cheng, No. 17 Qingfeng Street, Erqi District, Zhengzhou City | Zhengzhou City (XZQHCS)/Erqi District (XZQHQX)/Qingfeng Street (JD1)/No.17 (MP1)/Xinyuan Modern Cheng (MP2) |
| Model | Example | Processing of Address Elements |
|---|---|---|
| CHTopoNER + FSM | No. 132 Wangwu Road, Zheng Shang Ming Zuan | Invalid address |
| CHTopoNER + bidirectional FSM | No. 132 Wangwu Road, Zheng Shang Ming Zuan | Wangwu Road, Zheng Shang Ming Zuan (JD1)/No. 132 (MP1) |
| CHTopoNER + Algorithm 1 (dynamic FSM) | No. 132 Wangwu Road, Zheng Shang Ming Zuan | Wangwu Road (JD1)/No. 132 (MP1)/Zheng Shang Ming Zuan (MP2) |
| Model | Example | Processing of Address Elements |
|---|---|---|
| CHTopoNER + FSM | Jin Rong Yue Hui Cheng Convenience Store (northeast corner of the intersection of Yongzhou Road and Xunhang Road) | Invalid address |
| CHTopoNER + bidirectional FSM | Jin Rong Yue Hui Cheng Convenience Store (northeast corner of the intersection of Yongzhou Road and Xunhang Road) | Invalid address |
| CHTopoNER + Algorithm 1 (dynamic FSM) | Jin Rong Yue Hui Cheng Convenience Store (northeast corner of the intersection of Yongzhou Road and Xunhang Road) | Yongzhou Road (JD1)/Xunhang Road (JD2)/Intersection (JXK)/Northeast Corner (DIR)/Jin Rong Yue Hui Cheng Convenience Store (POI1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Liu, X.; Ma, J.; Zhang, Z.; Qiu, Y.; Jiang, Z. Non-Standard Address Parsing in Chinese Based on Integrated CHTopoNER Model and Dynamic Finite State Machine. Appl. Sci. 2023, 13, 9855. https://0-doi-org.brum.beds.ac.uk/10.3390/app13179855
Zhang M, Liu X, Ma J, Zhang Z, Qiu Y, Jiang Z. Non-Standard Address Parsing in Chinese Based on Integrated CHTopoNER Model and Dynamic Finite State Machine. Applied Sciences. 2023; 13(17):9855. https://0-doi-org.brum.beds.ac.uk/10.3390/app13179855
Chicago/Turabian StyleZhang, Mengwei, Xingui Liu, Jingzhen Ma, Zheng Zhang, Yue Qiu, and Zhipeng Jiang. 2023. "Non-Standard Address Parsing in Chinese Based on Integrated CHTopoNER Model and Dynamic Finite State Machine" Applied Sciences 13, no. 17: 9855. https://0-doi-org.brum.beds.ac.uk/10.3390/app13179855