
GP-Net: Image Manipulation Detection and Localization via Long-Range Modeling and Transformers

 ,
,
Abstract
:1. Introduction
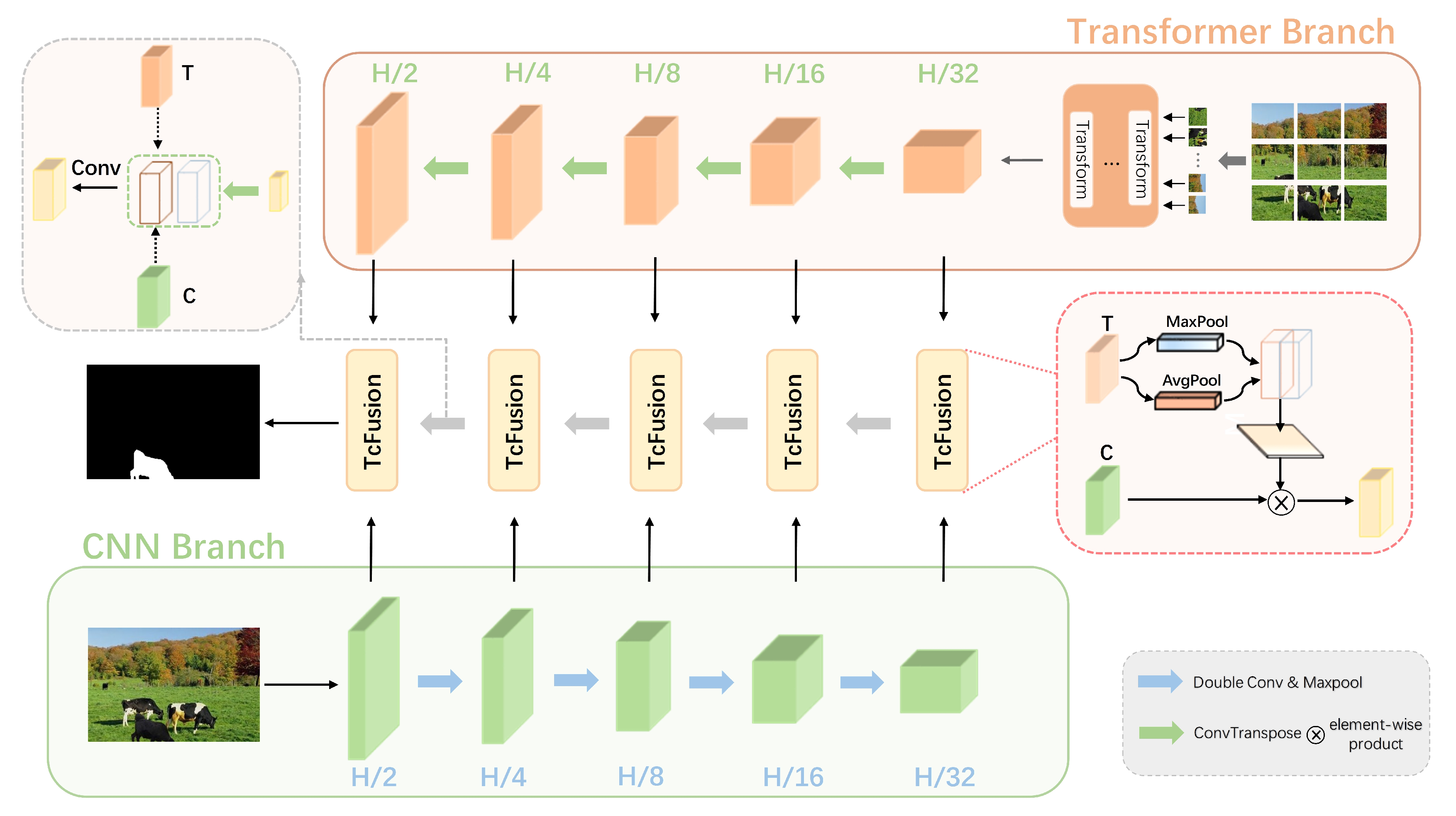
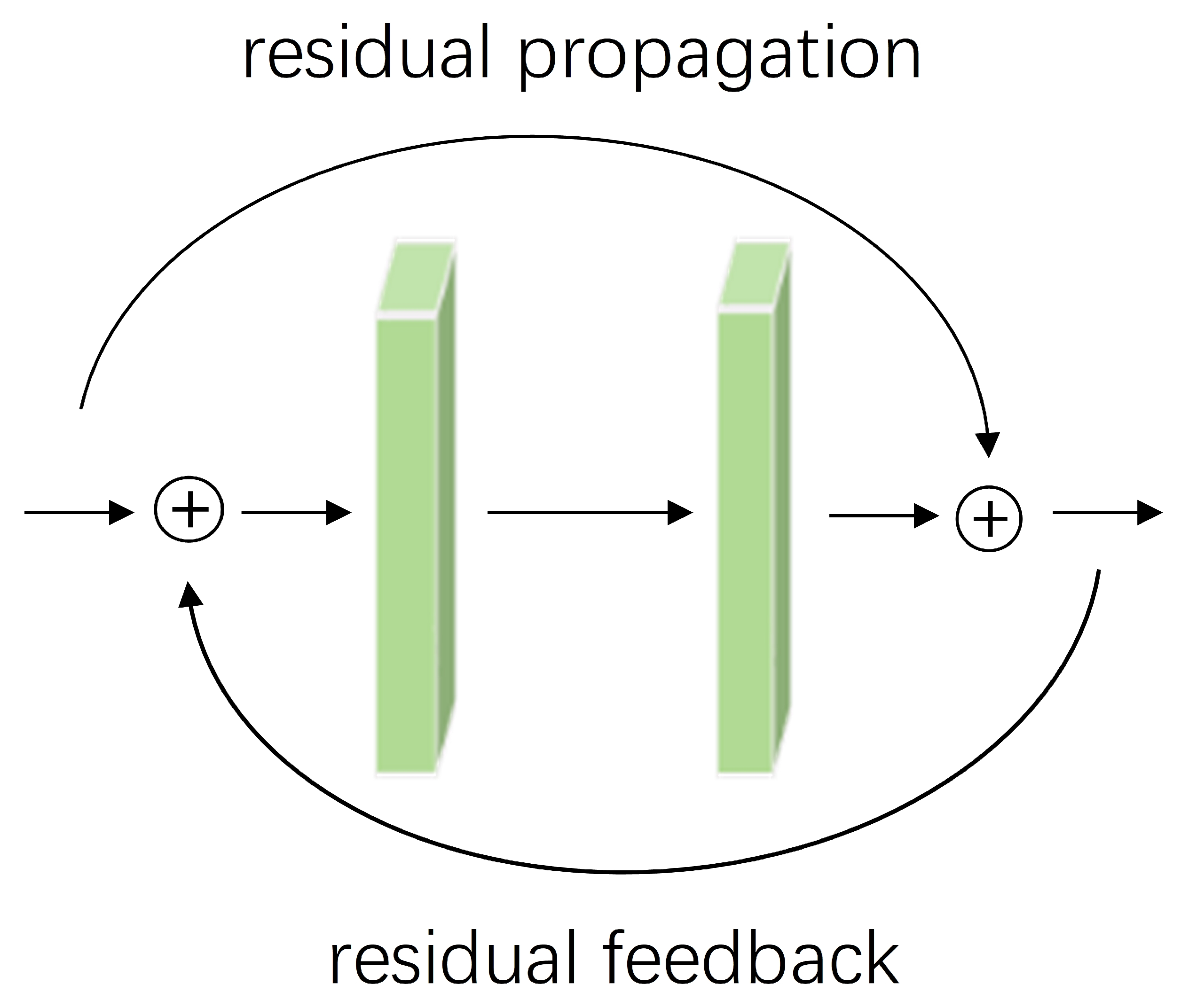
- GPNet represents a two-branch network which integrates CNNs and Transformers for image manipulation detection. It overcomes the limitations of excessively deep networks, addressing issues such as gradient vanishing and feature diminishment.
- We introduce the TcFusion module, a novel feature fusion mechanism that effectively combines features from the CNN branch and the Transformer branch. This fusion module enables the integration of complementary information from both branches.
- Through extensive experiments conducted on multiple baselines, we prove that our approach achieves SOAT performance in both detection and localization of image manipulations.
2. Related Work
2.1. Image Manipulation Detection
2.2. Image Manipulation Localization
3. Method
3.1. CNN Branch
3.2. Transformer Branch
3.3. TcFusion Module
4. Experiments
4.1. Experimental Settings
4.2. Compared Detection Methods
4.3. Image Manipulation Detection
4.4. Robustness Evaluation
4.5. Ablation Study
4.6. Limitation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Razavi, A.; Oord, A.; Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M. Generative adversarial nets. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Park, T.; Zhu, J.-Y.; Wang, O. Swapping autoencoder for deep image manipulation. In Proceedings of the Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Dhamo, H.; Farshad, A.; Laina, I. Semantic image manipulation using scene graphs. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T. Manigan: Text-guided image manipulation. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, B.; Pun, C.-M. Deep fusion network for splicing forgery localization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 237–251. [Google Scholar]
- Bi, X.; Wei, Y.; Xiao, B.; Li, W. The Ringed Residual U-Net for Image Splicing Forgery Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Bi, X.; Zhang, Z.; Liu, Y. Multi-task wavelet corrected network for image splicing forgery detection and localization. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Kwon, M.J.; Yu, I.J.; Nam, S.H.K. CAT-Net: Compression artifact tracing network for detection and localization of image splicing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision 2021, Waikoloa, HI, USA, 3–8 January 2021; pp. 375–384. [Google Scholar]
- Xiao, B.; Wei, Y.; Bi, X.; Li, W. Image splicing forgery detection combining coarse to refined convolutional neural network and adaptive clustering. Inf. Sci. 2020, 511, 172–191. [Google Scholar] [CrossRef]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Busternet: Detecting copy-move image forgery with source/target localization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 168–184. [Google Scholar]
- Zhu, Y.; Chen, C.; Yan, G.; Guo, Y. AR-Net: Adaptive attention and residual refinement network for copy-move forgery detection. IEEE Trans. Ind. Inform. 2020, 16, 6714–6723. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, G.; Wang, X. CNN-Transformer Based Generative Adversarial Network for Copy-Move Source/Target Distinguishment. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2019–2032. [Google Scholar] [CrossRef]
- Zhu, X.; Qian, Y.; Zhao, X. A deep learning approach to patch-based image inpainting forensics. Signal Process. Image Commun. 2018, 67, 90–99. [Google Scholar] [CrossRef]
- Li, H.; Huang, J. Localization of deep inpainting using high-pass fully convolutional network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8301–8310. [Google Scholar]
- Zhou, P.; Han, X.T.; Morariu, V.I. Learning rich features for image manipulation detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1053–1061. [Google Scholar]
- Zhou, P.; Chen, B.C.; Han, X. Generate, segment, and refine: Towards generic manipulation segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New York Midtown, NY, USA, 7–12 February 2020; Volume 32, pp. 13058–13065. [Google Scholar]
- Chen, X.; Dong, C.; Ji, J.; Cao, J. Image manipulation detection by multi-view multi-scale supervision. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Hu, X.; Zhang, Z.; Jiang, Z. Span: Spatial pyramid attention network forimage manipulation localization. In Proceedings of the European Conference on Computer Vision, ECCV 2020, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Liu, X.; Liu, Y.; Chen, J.; Liu, X. PSCC-Net: Progressive spatio-channel correlation network for image manipulation detection and localization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7505–7517. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); NIPS Foundation: La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Wang, J.; Wu, Z.; Chen, J. ObjectFormer for Image Manipulation Detection and Localization. In Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Sun, Y.; Ni, R. ET: Edge-enhanced Transformer for Image Splicing Detection. IEEE Signal Process. Lett. 2022, 29, 1232–1236. [Google Scholar] [CrossRef]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting fake news: Image splice detection via learned self-consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dong, J.; Wang, W.; Tan, T.N. CASIA image tampering detection evaluation database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013. [Google Scholar]
- Nist. Nimble 2016 Datasets. Available online: https://www.nist.gov/itl/iad/mig/nimble-challenge-2017-evaluation (accessed on 5 February 2016).
- Wen, B.; Zhu, Y.; Subramanian, R. Coverage—A novel database for copy-move forgery detection. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 161–165. [Google Scholar]
- Korus, P.; Huang, J. Evaluation of random field models in multi-modal unsupervised tampering localization. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Abu Dhabi, United Arab Emirates, 4–7 December 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datast | Number | Type | |||
|---|---|---|---|---|---|
| Train | Test | Splicing | Copy | Removal | |
| Coverage | 80 | 20 | ✗ | ✓ | ✗ |
| CASIA | 5078 | 532 | ✓ | ✓ | ✗ |
| NIST | 457 | 107 | ✓ | ✓ | ✓ |
| Methods | CASIA | NIST16 | Coverage |
|---|---|---|---|
| SPAN [21] | 38.2/83.8 | 58.2/96.1 | 55.8/93.7 |
| RGB-N [18] | 40.8/79.5 | 72.2/93.7 | 43.7/81.7 |
| RRU-Net [7] | 45.2/79.8 | 79.8/92.3 | 61.3/80.5 |
| PSCCNet [19] | 55.4/87.5 | 81.9/99.6 | 72.3/94.1 |
| ObjectFormer [22] | 57.9/88.2 | 82.4/99.6 | 75.8/95.7 |
| Ours | 61.4/88.4 | 91.2/99.7 | 72.4/94.5 |
| Dataset | Number | F1 | AUC |
|---|---|---|---|
| CASIA [28] | 500 | 78.1 | 88.7 |
| NIST [29] | 300 | 84.8 | 92.2 |
| RTD [31] | 220 | 69.2 | 71.3 |
| Distortion | F1 | AUC |
|---|---|---|
| No distortion | 91.2 | 99.7 |
| Resize (0.78×) | 90.8 | 96.5 |
| Resize (0.25×) | 87.7 | 92.4 |
| GaussianBlur ( = 3) | 88.4 | 96.8 |
| GaussianBlur ( = 7) | 85.1 | 90.1 |
| JPEGCompress ( = 100) | 90.8 | 98.4 |
| JPEGCompress ( = 80) | 90.2 | 98.1 |
| Variants | NIST16 | CASIA | ||
|---|---|---|---|---|
| F1 | AUC | F1 | AUC | |
| CNN Branch | 83.7 | 96.0 | 49.8 | 80.3 |
| Transformer Branch | 74.3 | 86.5 | 49.3 | 76.7 |
| w/o TcFusion | 86.8 | 94.3 | 57.5 | 83.3 |
| Ours | 91.2 | 99.7 | 61.4 | 88.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, J.; Liu, C.; Pang, H.; Gao, X.; Cheng, G.; Hao, B. GP-Net: Image Manipulation Detection and Localization via Long-Range Modeling and Transformers. Appl. Sci. 2023, 13, 12053. https://0-doi-org.brum.beds.ac.uk/10.3390/app132112053
Peng J, Liu C, Pang H, Gao X, Cheng G, Hao B. GP-Net: Image Manipulation Detection and Localization via Long-Range Modeling and Transformers. Applied Sciences. 2023; 13(21):12053. https://0-doi-org.brum.beds.ac.uk/10.3390/app132112053
Chicago/Turabian StylePeng, Jin, Chengming Liu, Haibo Pang, Xiaomeng Gao, Guozhen Cheng, and Bing Hao. 2023. "GP-Net: Image Manipulation Detection and Localization via Long-Range Modeling and Transformers" Applied Sciences 13, no. 21: 12053. https://0-doi-org.brum.beds.ac.uk/10.3390/app132112053