Co-Occurrence Network of High-Frequency Words in the Bioinformatics Literature: Structural Characteristics and Evolution


Abstract
:Featured Application
Abstract
1. Introduction
2. Methods
2.1. Datasets
2.2. Word Segmentation and High-Frequency Words
2.3. High-Frequency Word Co-Occurrence Matrix and Co-Occurrence Network
2.4. Average Path Length
2.4.1. Rich-Club Coefficient
2.4.2. Neighbour Average Degree
3. Results and Discussion
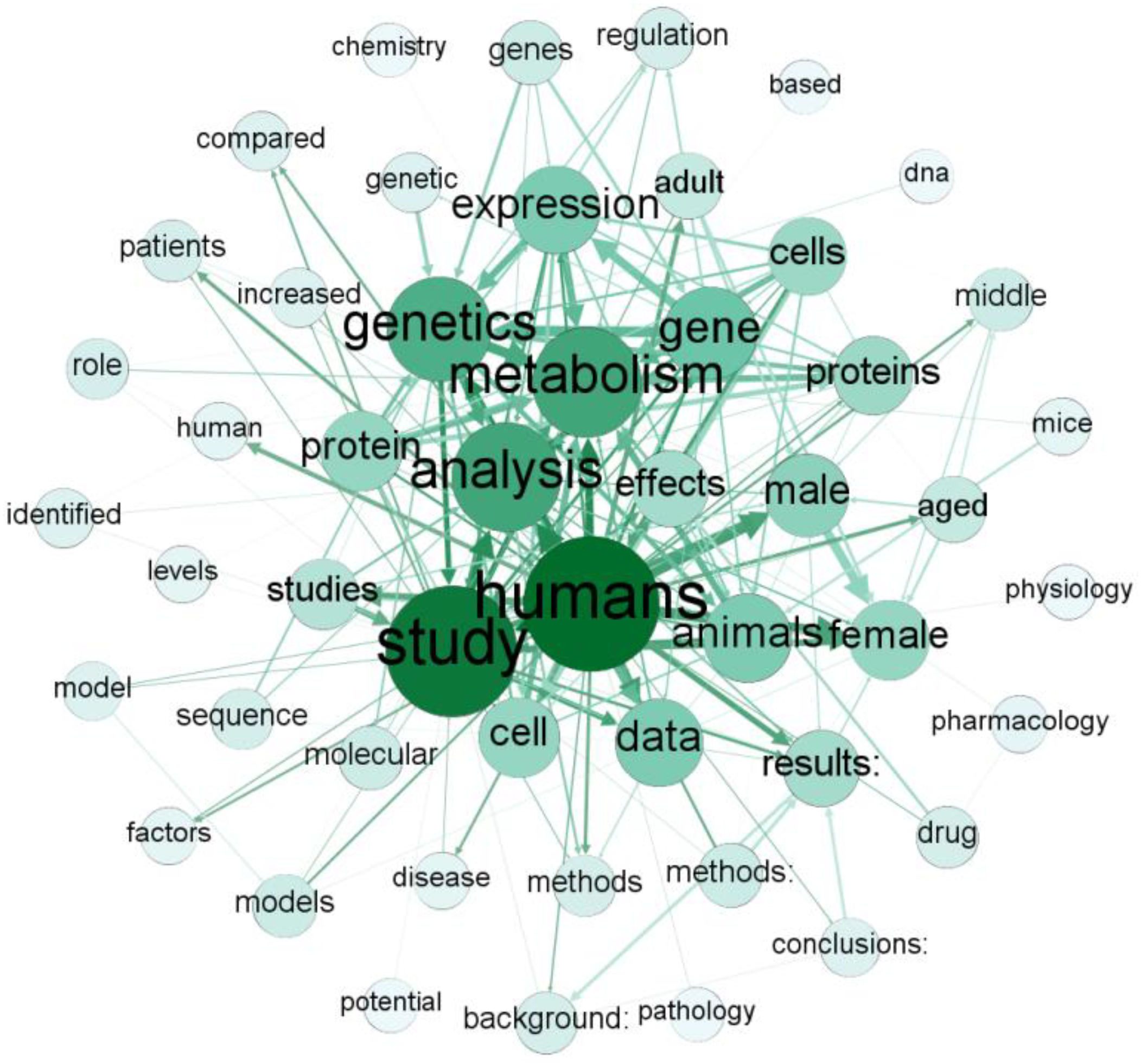
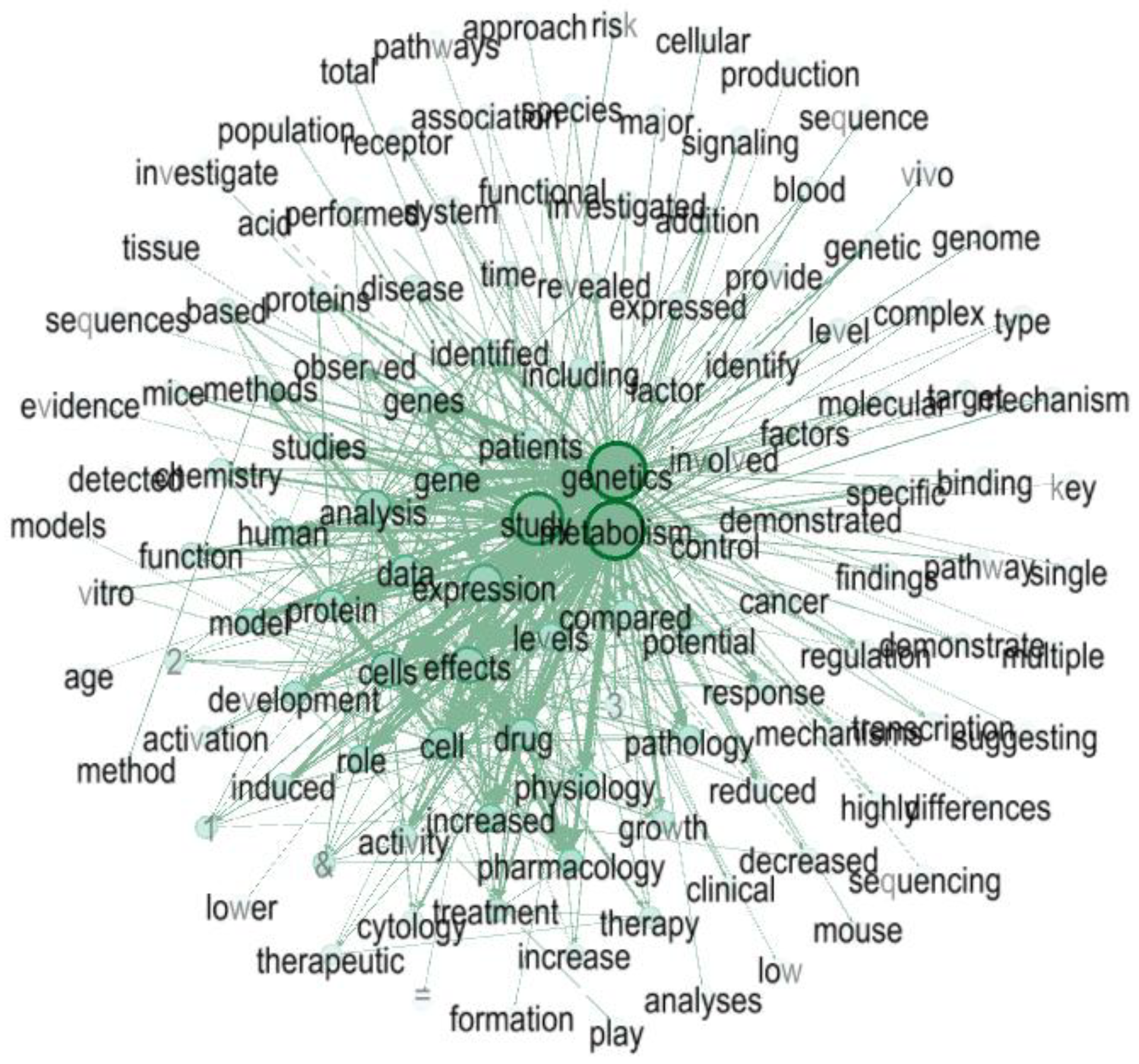
3.1. Co-Occurrence Network of High-Frequency Words in the Bioinformatics Literature
3.2. Small-World Network Characteristics
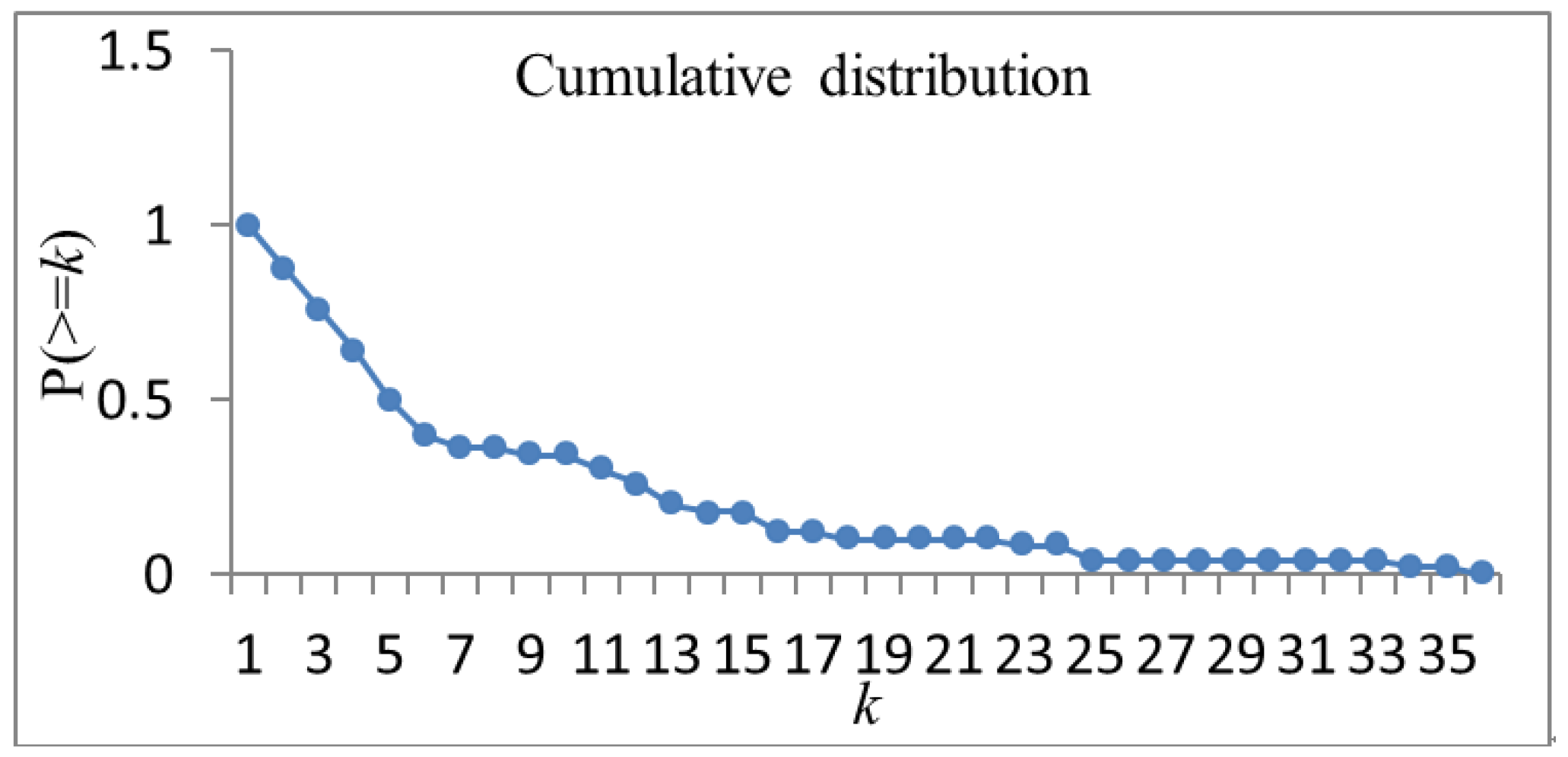
3.3. Degree Distribution Characteristics
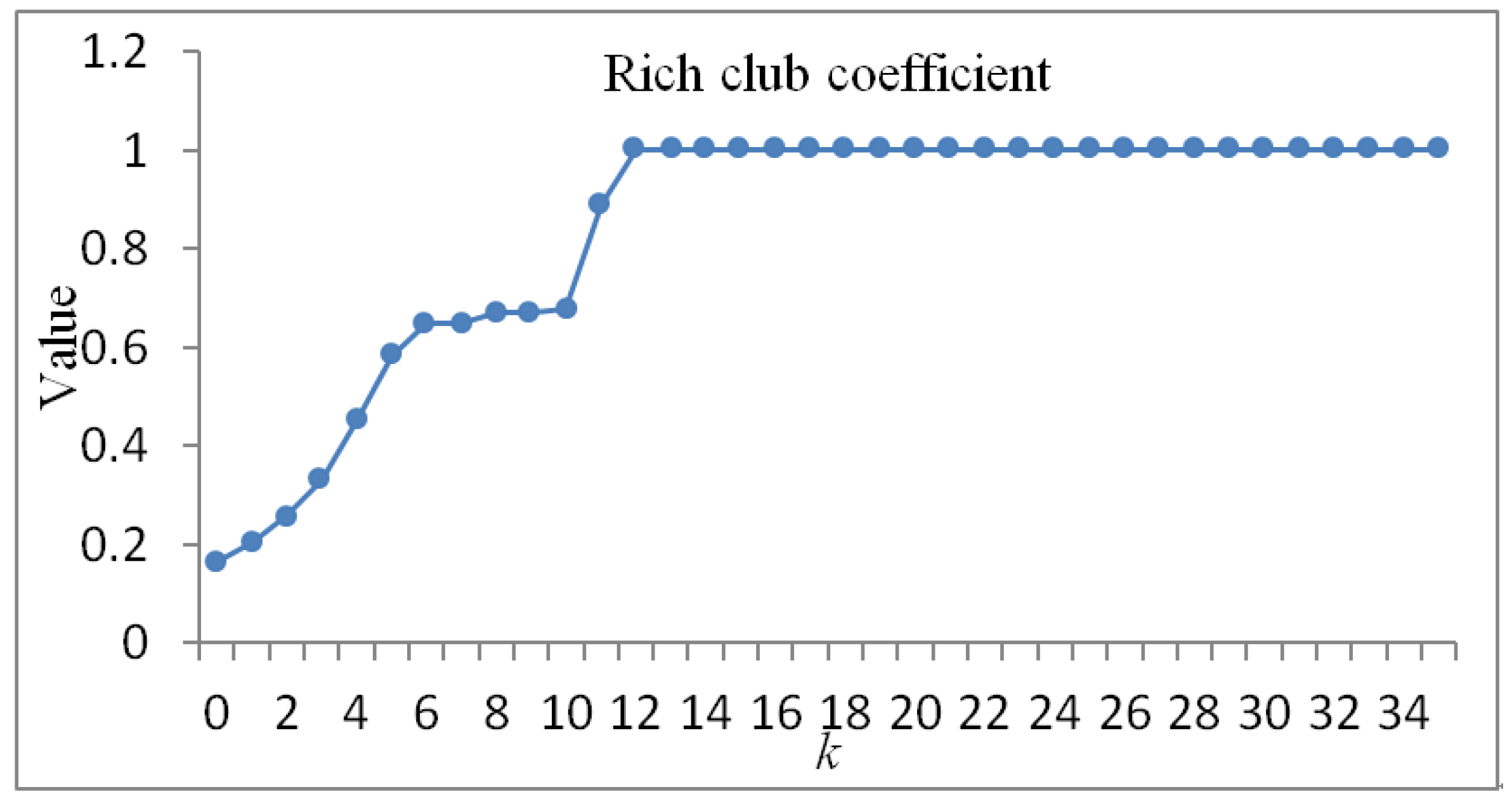
3.4. Rich-Club Phenomenon Characteristics
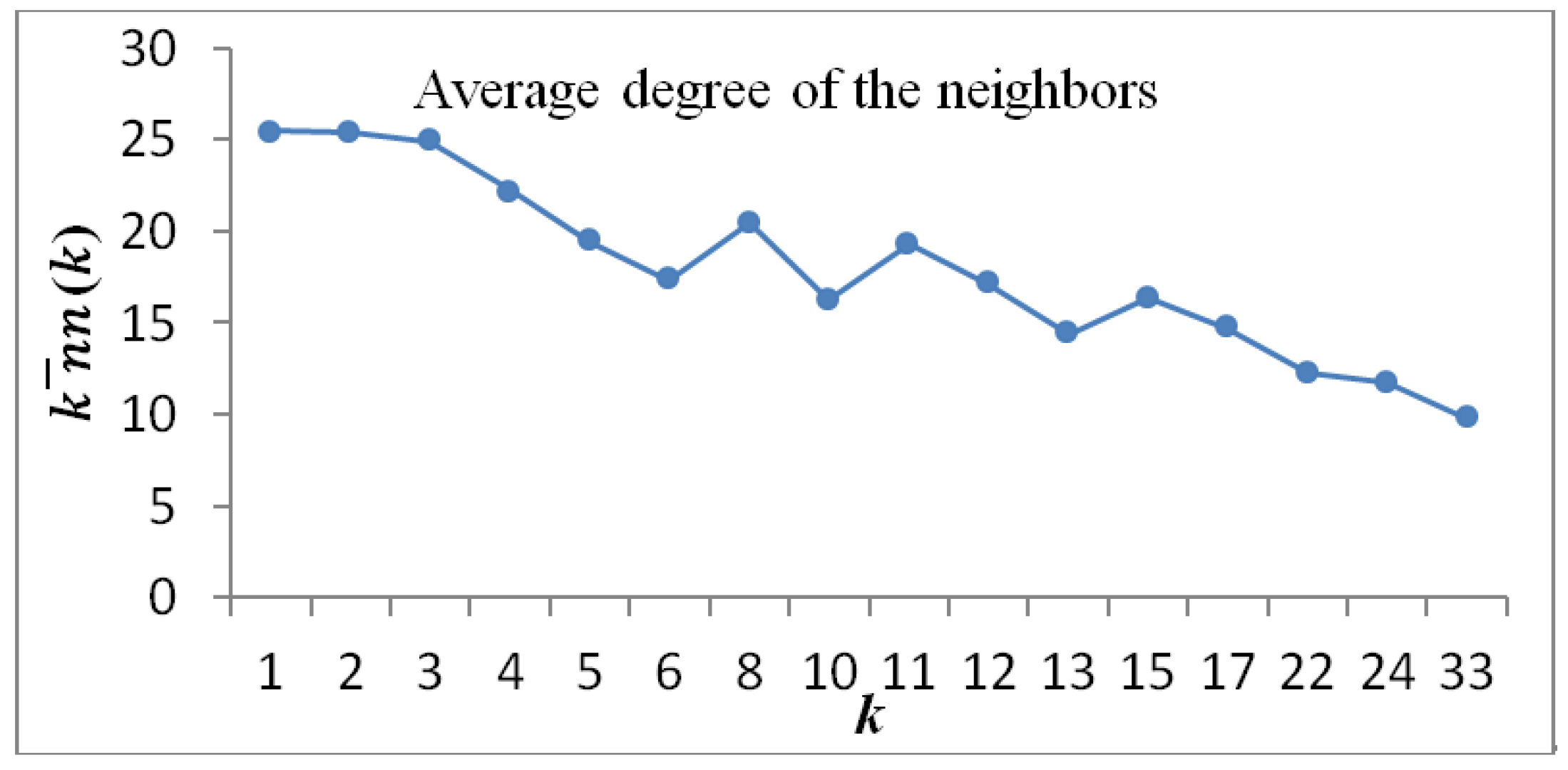
3.5. Matching form Characteristics
3.6. Evolution of the Co-Occurrence Network of High-Frequency Words in the Bioinformatics Literature
4. Conclusions
- The co-occurrence network of high-frequency words in bioinformatics literature is a small world network. The co-occurrence relationship between any two high-frequency words needed to be transferred at most once, and more than half of the high-frequency words in the bioinformatics literature had direct co-occurrence relationships.
- The degree distribution of the co-occurrence network of high-frequency words in the bioinformatics literature was scale-free, and the connectivity of a small number of nodes in the network was large, which had a leading role in the network. On the contrary, the connectivity of most nodes was small, indicating that the factors explored by the authors of the bioinformatics literature were more concentrated.
- The co-occurrence network of high-frequency words in the bioinformatics literature had the rich-club phenomenon. The high-frequency words in the club were the core words in the bioinformatics literature and they expressed the author’s attention to the bioinformatics literature.
- The co-occurrence network of high-frequency words in the bioinformatics literature had the characteristics of disassortative network. High-connectivity nodes were easily connected to nodes with low connectivity.
- The analysis on the evolution of the co-occurrence network of high-frequency words in the bioinformatics literature revealed that the high-frequency words in the bioinformatics literature changed little in 2–3 years. However, the state-of-the-art technology was introduced gradually with time. Consequently, the authors’ wording also changed, such as passion for big data and data analysis.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A





References
- Zhang, X.C.; Huang, D.S.; Li, F. Cancer nursing research output and topics in the first decade of the 21st century: Results of a bibliometric and co-word cluster analysis. Asian Pac. J. Cancer Prev. 2011, 12, 2055–2058. [Google Scholar] [PubMed]
- Kendrick, L.; Musial, K.; Gabrys, B. Change point detection in social networks—Critical review with experiments. Comput Sci. Rev. 2018, 29, 1–13. [Google Scholar] [CrossRef]
- Bahri, L.; Carminati, B.; Ferrari, E. Decentralized privacy preserving services for online social networks. Online Soc. Netw. Media 2018, 6, 18–25. [Google Scholar] [CrossRef]
- Bidarta, C.; Degenne, A.; Grossetti, M. Personal networks typologies: A structural approach. Soc. Netw. 2018, 54, 1–11. [Google Scholar] [CrossRef]
- Houston, J.F.; Lee, J.; Suntheim, F. Social networks in the global banking sector. J. Account. Econ. 2018, 65, 237–269. [Google Scholar] [CrossRef]
- Kim, J.; Hastak, M. Social network analysis: Characteristics of online social networks after a disaster. Int. J. Inf. Manag. 2018, 38, 86–96. [Google Scholar] [CrossRef]
- Growieca, K.; Growiec, J.; Kaminski, B. Social network structure and the trade-off between social utility and economic performance. Soc. Netw. 2018, 55, 31–46. [Google Scholar] [CrossRef]
- Manchin, M.; Orazbayev, S. Social networks and the intention to migrate. World Dev. 2018, 109, 360–374. [Google Scholar] [CrossRef]
- Ye, W. The rich-club phenomenon of China’s population flow network during the country’s spring festival. Appl. Geogr. 2018, 96, 77–85. [Google Scholar]
- Rutenberg, A.D.; Mitnitski, A.B.; Farrell, S.G.; Rockwood, K. Unifying aging and frailty through complex dynamical networks. Exp. Gerontol. 2018, 107, 126–129. [Google Scholar] [CrossRef] [PubMed]
- Shanmukhappa, T.; Iwh, H.; Chi, K.T. Spatial analysis of bus transport networks using network theory. Phys. A 2018, 502, 295–314. [Google Scholar] [CrossRef]
- Xu, X.; Chen, A.; Jansuwan, S.; Yang, C.; Ryu, S. Transportation network redundancy: Complementary measures and computational methods. Transp. Res. Part B 2018, 114, 68–85. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, S.; Wang, X. Comparison analysis on vulnerability of metro networks based on complex network. Phys. A 2018, 496, 72–78. [Google Scholar] [CrossRef]
- Lu, K.; Yu, S.; Yu, M. Bibliometric analysis of tumor immunotherapy studies. Med. Sci. Monit. 2018, 24, 3405–3414. [Google Scholar] [CrossRef] [PubMed]
- Zarandi, F.D.; Rafsanjani, M.K. Community detection in complex networks using structural similarity. Phys. A 2018, 503, 882–891. [Google Scholar] [CrossRef]
- İlhan, N.; Öğüdücü, Ş.G. Feature identification for predicting community evolution in dynamic social networks. Eng. Eng. Appl. Artif. Intell. 2016, 55, 202–218. [Google Scholar] [CrossRef]
- Zhao, J. Research on the characteristics of evolution in knowledge flow networks of strategic alliance under different resource allocation. Expert Syst. Appl. 2018, 98, 242–256. [Google Scholar]
- Li, H. The evolution of the network structure in tin-fluoro-phosphate glass with increasing temperature. J. Non-Cryst. Solids 2018, 492, 84–93. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, Q.; Liu, W. The structural evolution of an online discussion network. Phys. A 2010, 389, 5871–5877. [Google Scholar] [CrossRef]
- Wang, X.S.; Yang-Yang, G.U.; Cheng, Y.H. Construction of delay gene regulatory network based on complex network. Acta Electron. Sin. 2010, 38, 2518–2522. [Google Scholar]
- Van Rijsbergen, C.J. A theoretical basis for the use of co-occurrence data in information retrieval. J. Doc. 1977, 33, 106–119. [Google Scholar] [CrossRef]
- Mika, P. Ontologies are us: A unified model of social networks and semantics. Web Semant: Sci. Serv. Agents Word Wide Web 2007, 5, 522–536. [Google Scholar] [CrossRef]
- Barberán, A.; Bates, S.T.; Casamayor, E.O.; Fierer, N. Using network analysis to explore co-occurrence patterns in soil microbial communities. ISME J. 2012, 6, 343–351. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamneva, O.K. Genome composition and phylogeny of microbes predict their co-occurrence in the environment. PLoS Comput. Biol. 2017, 13, e1005366. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Cao, R.Z.; Cheng, J.L. Three-level prediction of protein function by combining profile-sequence search, profile-profile search, and domain co-occurrence networks. BMC Bioinf. 2013, 14 (Suppl. 3), S3. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, X.C.; Le, M.H.; Xu, D.; Stacey, G.; Cheng, J.L. A protein domain co-occurrence network approach for predicting protein function and inferring species phylogeny. PLoS ONE 2011, 6, e17906. [Google Scholar] [CrossRef] [PubMed]
- Li, L.G.; Xia, Y.; Zhang, T. Co-occurrence of antibiotic and metal resistance genes revealed in complete genome collection. ISME J. 2017, 11, 651–662. [Google Scholar] [CrossRef] [PubMed]
- Li, T.Y.; Li, F.; Chen, Y.; Lv, X.N. Fast clustering for sparse network of retail products associated big data. Control Decis. 2018, 33, 1117–1122. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Mondragón, R.J. The rich-club phenomenon in the internet topology. IEEE Commun. Lett. 2004, 8, 180–182. [Google Scholar] [CrossRef]
- Newman, M.E.J. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Liu, Y.S.; Zeng, X.; He, Z.; Zou, Q. Inferring microRNA-disease associations by random walk on a heterogeneous network with multiple data sources. IEEE/ACM Trans. Comput. Biol. Bioinf. 2016, 14, 905–915. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Guo, M.; Wang, C.; Liu, X.; Zou, Q. An overview of SNP interactions in genome-wide association studies. Briefings Funct. Genomics 2015, 14, 143–155. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Journal Name | IF (5 Year) | Rank | Area(s) | Press |
|---|---|---|---|---|---|
| 1 | Algorithms for Molecular Biology | 1.617 | JCR4 | Mathematical and Computational Biology | Biomed Central Ltd. |
| 2 | Analytical Biochemistry | 2.160 | JCR3 | Biochemistry and Molecular Biology | Elsevier Sci Ltd. |
| 3 | Bioinformatics | 8.561 | JCR2 | Mathematical and Computational Biology | Oxford Univ Press |
| 4 | Biosystems | 1.460 | JCR4 | Mathematical and Computational Biology | Elsevier Sci Ltd. |
| 5 | BMC Bioinformatics | 3.114 | JCR3 | Mathematical and Computational Biology | Biomed Central Ltd. |
| 6 | BMC Biology | 7.436 | JCR1 | Biology | Biomed Central Ltd. |
| 7 | BMC Genomics | 4.257 | JCR2 | Biotechnology and Applied Microbiology | Biomed Central Ltd. |
| 8 | BMC Systems Biology | 2.505 | JCR3 | Mathematical and Computational Biology | Biomed Central Ltd. |
| 9 | Briefings in Bioinformatics | 7.065 | JCR1 | Biochemical Research Methods | Oxford Univ Press |
| 10 | Bulletin of Mathematical Biology | 1.536 | JCR4 | Biology | Springer |
| 11 | Computational Biology and Chemistry | 1.345 | JCR4 | Biology | Elsevier Sci Ltd. |
| 12 | Computers in Biology and Medicine | 2.168 | JCR3 | Engineering, Biomedical | Elsevier Science Bv Science Ltd. |
| 13 | EURASIP Journal on Bioinformatics and Systems Biology | Mathematical and Computational Biology | Springer Heidelberg | ||
| 14 | Journal of Biomedical Semantics | 1.883 | JCR3 | Mathematical and Computational Biology | Springer Nature |
| 15 | Gene | 3.286 | JCR3 | Genetics and Heredity | Elsevier Science Bv |
| 16 | Genome Biology | 16.497 | JCR1 | Biotechnology and Applied Microbiology | Biomed Central Ltd. |
| 17 | IEEE/ACM Transactions on Computational Biology and Bioinformatics | 2.064 | JCR3 | Engineering | IEEE Computer Soc |
| 18 | IET Systems Biology | 0.972 | JCR4 | Mathematical and Computational Biology | Inst Engineering Technology |
| 19 | In Silico Biology | Biochemistry | IOS Press | ||
| 20 | International Journal of Data Mining and Bioinformatics | 0.585 | JCR4 | Mathematical and Computational Biology | Inderscience Enterprises Ltd. |
| 21 | Chemical Biology and Drug Design | 2.404 | JCR3 | Biochemistry and Molecular Biology | Wiley-Blackwell Publishing |
| 22 | Acta Biotheoretica | 0.907 | JCR4 | Mathematical and Computational Biology | Springer |
| 23 | International Journal of Functional Informatics and Personalized Medicine | Biomedical Sciences | Inderscience Enterprises Ltd. | ||
| 24 | International Journal of Molecular Sciences | 3.878 | JCR3 | Biochemistry and Molecular Biology | Mdpi |
| 25 | Journal of Bioinformatics and Computational Biology | 0.959 | JCR4 | Mathematical and Computational Biology | World Scientific Publishing Co Pte Ltd. |
| 26 | Journal of Biological Systems | 0.686 | JCR4 | Mathematical and Computational Biology | World Scientific Publishing Co Pte Ltd. |
| 27 | Journal of Biomedical Informatics | 3.120 | JCR3 | Medical Informatics | Academic Press Inc Elsevier Science |
| 28 | Journal of Biomolecular Structure and Dynamics | 2.443 | JCR3 | Biochemistry and Molecular Biology | Adenine Press |
| 29 | Journal of Computational Biology | 3.118 | JCR4 | Mathematical and Computational Biology | Mary Ann Liebert Inc |
| 30 | Journal of Computational Neuroscience | 1.763 | JCR4 | Mathematical and Computational Biology | Springer |
| 31 | Journal of Integrative Bioinformatics | Biomedicine And Biotechnology | Imbio Association | ||
| 32 | Journal of Theoretical Biology | 1.980 | JCR3 | Mathematical and Computational Biology | Elsevier Science Ltd. |
| 33 | Mathematical Biosciences | 1.617 | JCR4 | Mathematical and Computational Biology | Elsevier Science Inc |
| 34 | Mathematical Biosciences and Engineering | 1.260 | JCR4 | Mathematical and Computational Biology | Amer Inst Mathematical Sciences |
| 35 | Methods | 3.936 | JCR2 | Biochemistry and Molecular Biology | Academic Press Inc Elsevier Science |
| 36 | Molecular Biosystems | 2.838 | JCR3 | Biochemistry and Molecular Biology | Royal Soc Chemistry |
| 37 | Nature Communications | 13.691 | JCR1 | Multidisciplinary Sciences | Nature Publishing Group |
| 38 | Nucleic Acids Research | 10.235 | JCR1 | Biochemistry and Molecular Biology | Oxford Univ Press |
| 39 | Online Journal of Bioinformatics | Computational Biology | Online Journal Of Bioinformatics | ||
| 40 | PeerJ | 2.469 | JCR3 | Multidisciplinary Sciences | Peerj, Inc. |
| 41 | PLoS Computational Biology | 4.834 | JCR2 | Mathematical and Computational Biology | Public Library Science |
| 42 | Plos One | 3.352 | JCR3 | Multidisciplinary Sciences | Public Library Science |
| 43 | Protein and peptide letters | 1.052 | JCR4 | Biochemistry and Molecular Biology | Bentham Science Publ Ltd. |
| 44 | Scientific Reports | 4.609 | JCR3 | Multidisciplinary Sciences | Springer Nature |
| 45 | Source Code for Biology and Medicine | Bioinformatics | Springer Nature | ||
| 46 | StaProteins: Structure, Function and Bioinformatics | 2.328 | JCR3 | Biochemistry and Molecular Biology | Wiley-Liss |
| 47 | Statistical Applications in Genetics and Molecular Biology | 1.104 | JCR4 | Mathematical and Computational Biology | De Gruyter |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Bai, J.; Yang, X.; Liu, Q.; Chen, Y. Co-Occurrence Network of High-Frequency Words in the Bioinformatics Literature: Structural Characteristics and Evolution. Appl. Sci. 2018, 8, 1994. https://0-doi-org.brum.beds.ac.uk/10.3390/app8101994
Li T, Bai J, Yang X, Liu Q, Chen Y. Co-Occurrence Network of High-Frequency Words in the Bioinformatics Literature: Structural Characteristics and Evolution. Applied Sciences. 2018; 8(10):1994. https://0-doi-org.brum.beds.ac.uk/10.3390/app8101994
Chicago/Turabian StyleLi, Taoying, Jie Bai, Xue Yang, Qianyu Liu, and Yan Chen. 2018. "Co-Occurrence Network of High-Frequency Words in the Bioinformatics Literature: Structural Characteristics and Evolution" Applied Sciences 8, no. 10: 1994. https://0-doi-org.brum.beds.ac.uk/10.3390/app8101994