1. Introduction
With the growing demand for transportation in modern society, concern about road safety and traffic congestion is increasing [
1,
2]. Intelligent transportation systems are regarded as a promising solution to these challenges due to their potential to significantly increase road capacity, enhance safety, and reduce fuel consumption [
3,
4]. As a representative application for intelligent transportation, adaptive cruise control (ACC) systems have been extensively studied by academia and industry and are commercially available in a wide range of passenger vehicles. ACC utilizes a range sensor (camera and/or radar) to measure the inter-vehicle range, and the relative velocity and controls the longitudinal motion of the host vehicle to maintain a safe distance from the preceding vehicle [
5]. As a result, the driver is free from frequent acceleration and deceleration operation, and driving comfort and safety are improved. In recent years, the development of vehicle-to-vehicle (V2V) communication technologies, such as DSRC and LTE-V [
6,
7], has provided an opportunity for the host vehicle to exchange information with its surrounding vehicles. The resulting functionality, named cooperative adaptive cruise control (CACC), utilizes information on the forward vehicle or vehicles via V2V, as well as the inter-vehicle distance and relative velocity. Compared with conventional ACC, the wireless communication devices for CACC system increase cost of on-board hardwares. The control strategy becomes more complicated due to additional system state variables and the topological variety for platoons, which are even more critical when considering time delay, packet loss, and quantization error in the communications [
8,
9]. In [
10], it is demonstrated that the string stability domains shrink when the packet drop ratio or the sampling time of communication increases and above a critical limit string stability cannot be achieved. In [
11], an optimal control strategy is employed to develop a synthesis strategy for both distributed controllers and the communication topology that guarantees string stability. In another hand, CACC is more attractive than conventional autonomous ACC, because the system behavior is more responsive to changes in the preceding vehicle speed, thereby enabling shorter following gaps and enhancing traffic throughput, fuel economy, and road safety [
12]. Simulation results revealed that the freeway capacity increases quadratically as the CACC market penetration increases, with a maximum value of 3080 veh/h/lane at 100% market penetration, which is roughly 63% higher than at 0% market penetration [
13,
14].
The earliest research on CACC dates to the PATH program [
15] in the US, which was followed by the SARTRE project [
16,
17] in Europe and the Energy ITS project [
18] in Japan. Another demonstration of CACC is the Grand Cooperative Driving Challenge (GCDC), which has been held twice in 2011 and 2016 in the Netherlands. In GCDC, several vehicles cooperated in both urban and highway driving scenarios to facilitate the deployment and research of cooperative driving systems based on a combination of communication and state-of-the-art sensor fusion and control [
19,
20]. Most research on CACC has focused on vehicle dynamics control in the longitudinal direction to achieve stable following and coordination of the platoon. Linear feedforward and feedback controllers are widely used due to their advantages of simple structure and convenience in hardware implementation [
21,
22,
23]. In this approach, the controller uses the acceleration of the preceding vehicle and tracking errors as the feedforward and feedback signals, respectively, to determine the desired acceleration of the host vehicle. However, due to the nonlinearity of vehicle dynamics and uncertainty of the environment, sets of controller parameters need to be tuned manually, and it is difficult for controllers to be adaptive and robust to unknown disturbances. Model predictive control (MPC) has also been introduced for CACC by forecasting system dynamics and explicitly handling actuator and state constraints to generate an optimal control command [
19,
24,
25,
26,
27]. By solving the optimal control problem over a finite horizon in a receding manner, multi control objectives, such as tracking accuracy, driver comfort, and fuel economy can be balanced with the cost function. MPC is also superior in terms of constraint satisfaction. However, the MPC design involves more parameters and thus requires more time to adjust [
19,
25]. In addition, a detailed system dynamics model with high fidelity is needed to predict system states accurately, and solving the nonlinear optimization problem causes relatively high computational cost, which impedes real-time implementation with a short control sampling time [
27]. Moreover, due to CACC’s characteristics of a shorter inter-vehicle gap and quicker response, some researchers have pointed out that it is necessary to consider driver psychology and driving habits in the controller design to gain better human acceptance [
9,
28]. In [
29], a human-aware autonomous control scheme for CACC is proposed by blending a data-driven self-learning algorithm with MPC. The simulation results showed that vehicle jerk can be reduced while maintaining a safe following distance.
As an important approach for solving complex sequential decision or control problems, reinforcement learning (RL) has been widely studied in the community of artificial intelligence and machine learning [
30,
31,
32]. Recently, RL has been increasingly used in vehicle dynamics control to derive near-optimal or suboptimal control policies. In [
33], an RL-based real-time and robust energy management approach is proposed for reducing the fuel consumption of a hybrid vehicle. The power request is modeled as a Markov chain, and the Q-learning algorithm is applied to calculate a discrete, near-optimal policy table. In [
34], RL is used to design a full-range ACC system, in which the inducing region technique is introduced to guide the learning process for fast convergence. In [
35], a novel actor-critic approach that uses a PD controller to pre-train the actor at each step is proposed, and it is proved that the estimation error is uniformly ultimate bounded. Charles et al. use function approximation along with gradient-descent learning algorithms as a means of directly modifying a control policy for CACC [
36]. The simulation results showed that this approach can result in an efficient policy, but the oscillatory behavior of the control policy must be further addressed by using continuous actions. In [
37], a parameterized batch RL algorithm for near-optimal longitudinal velocity tracking is proposed, in which parameterized feature vectors based on kernels are learned from collected samples to approximate the value functions and policies, and the effectiveness of the controller is validated on an autonomous vehicle platform.
In this paper, we propose a supervised reinforcement learning (SRL) algorithm for the CACC problem, in which an actor-critic architecture is adopted, because it can map continuous state space to the control command and the policy can be updated directly by standard supervised learning methods [
38]. The main contributions of this study are the following:
- (1)
A supervisor network trained by collected driving samples of the human-driver is combined with the actor-critic algorithm to guide the reinforcement learning process.
- (2)
The composite output of the supervisor and the actor is applied to the system, and the proportion between supervised learning and reinforcement learning is adjusted by the gain scheduler during the training process. Using this method, the success rate of the training process is improved, and the driver characteristics are incorporated into the obtained control policy to achieve a human-like CACC controller.
- (3)
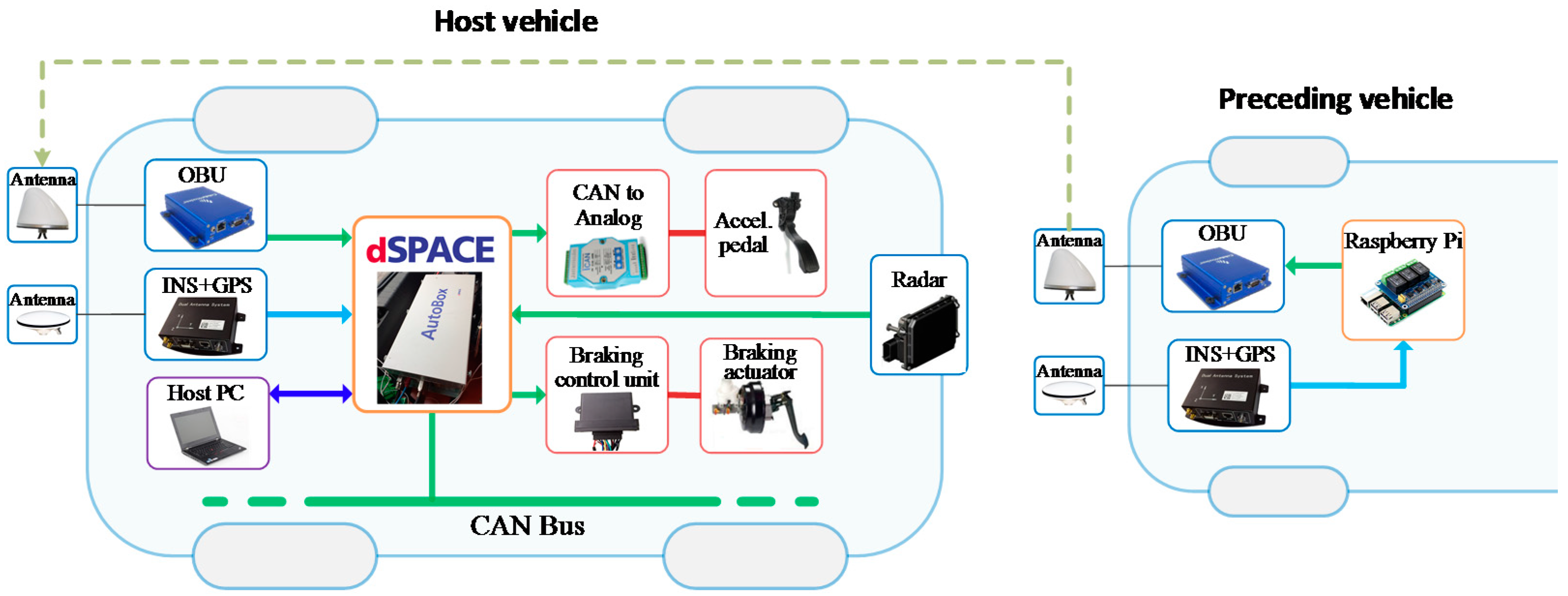
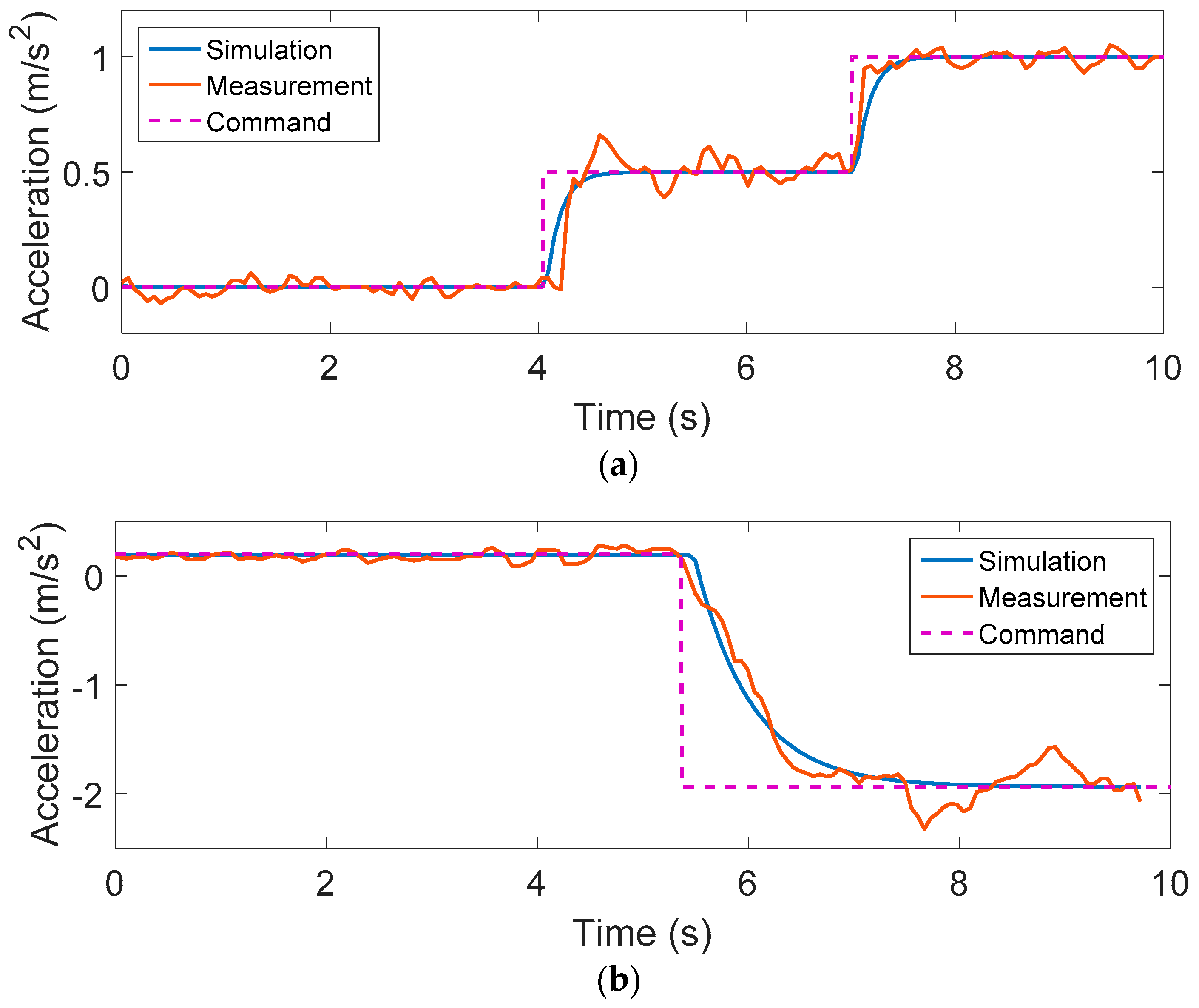
The CACC test platform is developed based on two electric vehicles (EV) and a rapid control prototyping system. The performance and learning ability of the SRL-based control policy are effectively validated by simulations and real vehicle-following experiments.
The rest of the paper is organized as follows.
Section 2 describes the control framework and the test platform.
Section 3 presents the SRL-based control approach for solving the CACC problem. The simulation and experimental results for a real vehicle following control are illustrated in
Section 4.
Section 5 concludes the paper.
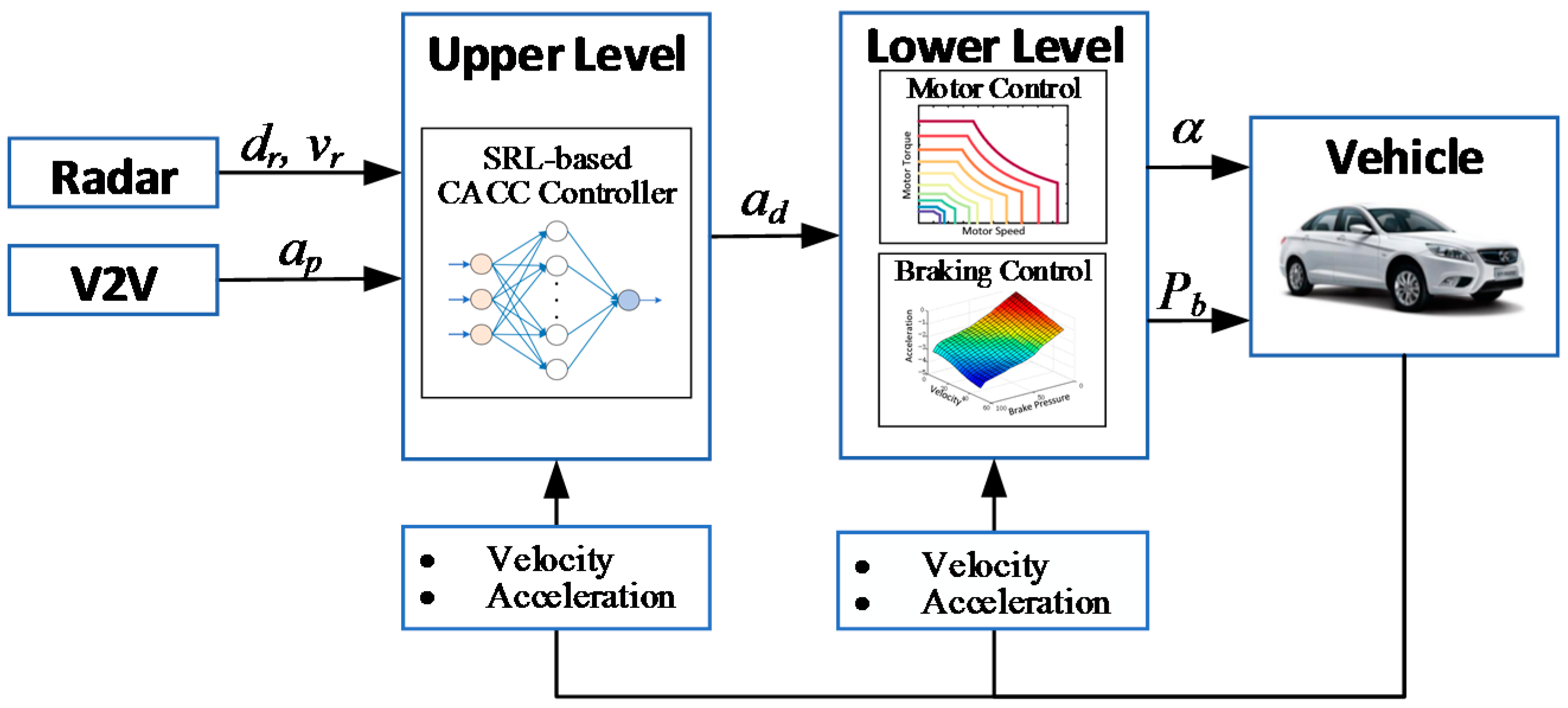
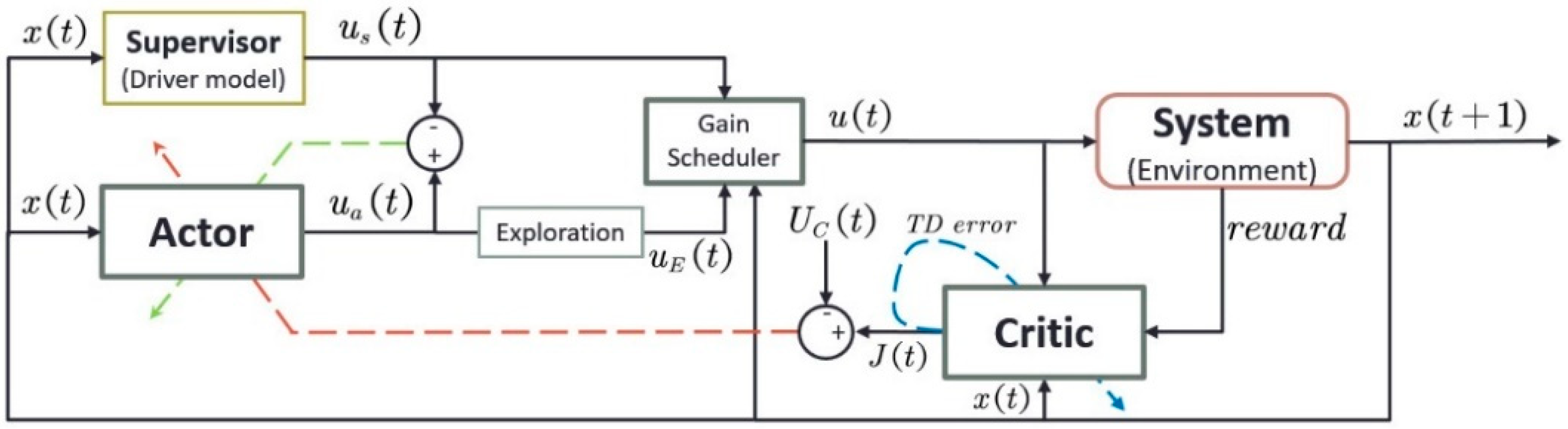
3. The SRL-Based Control Strategy for CACC
The principle of RL is learning an optimal policy, i.e., a mapping from states to actions that optimizes some performance criterion. Relying on RL alone, the learner is not told which actions to take but instead must discover which actions yield the greatest reward by trial and error [
30]. Some researchers have proposed that the use of supervisory information can effectively make a learning problem easier to solve [
38]. For a vehicle dynamics control problem, the richness of the human driver’s operation data can be employed to supervise the learning process of RL. In this section, an SRL-based control algorithm for CACC is proposed, as shown in
Figure 3. The actor-critic architecture is used to establish the continuous relationships between states and actions and the relationships among states, actions, and the control performance [
39,
40]. The supervisor provides the actor with hints about which action may or may not be promising for a specific state, and the composite action blending the actions from the supervisor and the actor by the gain scheduler is sent to the system. The system responds to the input action with a transition from the current state to the next state and gives a reward to the action. More details about each module are described as follows.
3.1. System Dynamics
The primary control objective is to make the host vehicle follow the preceding vehicle at a desired distance
. The constant time headway spacing policy, which is the most commonly used, is adopted here [
22,
23,
24]. The desired inter-vehicle distance is proportional to velocity:
in which
is the desired safe distance at standstill,
is the time headway, and
is the velocity of the host vehicle.
The longitudinal dynamics model for the host vehicle must consider the powertrain, braking system, aerodynamic drag, longitudinal tire forces, and rolling resistances, etc. The following assumptions are made to obtain a suitable control-oriented model: (1) The tire longitudinal slip is negligible, and the lower level dynamics are lumped into a first order inertial system; (2) The vehicle body is rigid; (3) The influence of pitch and yaw motions is neglected. Then, the nonlinear longitudinal dynamics can be described as
in which
is the position of the host vehicle;
is the vehicle mass;
is the efficiency of the driveline;
and
are the actual and desired driving/braking torque, respectively;
is the wheel radius;
is the aerodynamic coefficient;
is the frontal area;
is the acceleration of gravity;
is the rolling resistance coefficient; and
is the inertial delay of vehicle longitudinal dynamics.
With the exact feedback linearization technique [
41], the nonlinear model (2) is converted to
in which
is the control input after linearization, i.e., the desired acceleration, and we have
in which
denotes the acceleration of the host vehicle. The third-order state space model for the vehicle’s longitudinal dynamics is derived as
Using the Euler discretization approach, the state equation of continuous system (5) is discretized with a fixed sampling time
as follows:
Considering the vehicle following system of CACC, we define the system state variables as
.
,
, and
are the inter-vehicle distance error, relative velocity, and relative acceleration, respectively, denoted as
in which
,
, and
are the position, velocity, and acceleration of the preceding vehicle, respectively.
After taking the action
in state
, the system will go to the next state
according to the following transition equations:
3.2. The SRL Control Algorithm
There are three neural networks in the proposed SRL control algorithm: the actor, the critic, and the supervisor. The actor network is responsible for generating the control command according to the states. The critic network is used to approximate the discounted total reward-to-go and evaluate the performance of the control signal. The supervisor is used to model a human driver’s behavior and provide the predicted control signal of the driver to guide the training process of the actor and critic.
3.2.1. The Actor Network
The input of the actor network is the system state
, and the output is the optimal action. A simple three-layered feed-forward neural network is adopted for both the actor and critic according to [
39]. The output of the actor network is depicted as
in which
is the hyperbolic tangent activation function;
,
denote the inputs of the actor network;
represent the weights connecting the input layer to the hidden layer;
represent the weights connecting the hidden layer to the output layer;
is the number of neurons in the hidden layer of the actor network; and
is the number of state variables.
3.2.2. The Critic Network
The inputs of the critic network are the system state
and the composite action
. The output of the critic, the
function, approximates the future accumulative reward-to-go value
at time
. Specifically,
is defined as
in which
is the discount factor for the infinite-horizon problem (
). The discount factor determines the present value of future rewards: a reward received
k time steps in the future is worth
times what it would be worth if it were received immediately [
30].
is the final time step.
is the reward provided from the environment given by
in which
,
, and
are positive weighting factors. For the sake of control accuracy and driving comfort,
is formulated as the negative weighted sum of the quadratic forms of the distance error, the relative velocity, and the fluctuation of the host vehicle’s acceleration. Thus, a higher accumulative reward-to-go value
indicates the better performance of the action.
In the critic network, the hyperbolic tangent and linear-type activation function are used in the hidden layer and the output layer, respectively. The output
has the following form:
in which
denote the inputs of the critic network,
represent the weights connecting the input layer to the hidden layer,
represent the weights connecting the hidden layer to the output layer, and
is the number of neurons in the hidden layer of the actor network.
3.2.3. The Supervisor
Driver behavior can be modeled with parametric models, such as the SUMO model and the Intelligent Driver Model, and non-parametric models, such as the Gaussian Mixture Regression model and artificial neural network model [
42]. In [
43,
44], a neural network-based approach for modelling driver behavior is investigated. In this part, the driver behavior is modeled by a feed-forward neural network with the same structure as the actor network. The driver’s operation data in a real vehicle-following scenario can be collected to form a dataset
. Note that here we use the desired acceleration
as the driver’s command instead of the accelerator pedal signal
and braking pressure
. The supervisor network can be trained with dataset
to predict the driver’s command
according to a given state
. The weights are updated by prediction error back-propagation, and the Levenberg-Marquardt method is employed to train the network until the weights converge.
3.2.4. The Gain Scheduler
As mentioned above, the actor network, the supervisor network, and the gain scheduler generate a composite action to the host vehicle. The gain scheduler computes a weighted sum of the actions from the supervisor and the actor as follows:
in which
is the output of the supervisor, i.e., the prediction of the driver’s desired acceleration with regard to the current state.
is normalized within the range [−1, 1] m/s
2.
is the exploratory action of the actor,
.
denotes a random noise with zero mean and variance
. The parameter
weights the control proportion between the actor and the supervisor,
. This parameter is important for the supervised learning process, because it determines the autonomy level of the actor or the guidance intensity of the supervisor. Generally, the value of
varies with the state. It can be adjusted by the actor, the supervisor, or a third party. Considering the control requirement and comfort of the driver and passengers, the range of
, which is within the range [−1, 1], is transformed into the range [−2, 2] m/s
2 before applying to the system.
3.2.5. SRL Learning
During the learning process, the weights of the actor and critic are updated with error back-propagation at each time step. After taking the composite action
, the system transits to the next state
and gives a reward
. For the critic network, the prediction error has the same expression with the temporal difference (TD) error as follows:
The squared error objective function is calculated as
The objective function is minimized by the gradient descent approach as
in which
is the learning rate of the critic network at time
,
.
The adaptation of the actor network is regulated by the gain scheduler. The weights of the actor are updated according to the following rule as
in which
and
are the updates based on RL and the supervised learning, respectively. The error and objective function of RL are defined as
in which
is the desired control objective. Here,
is set to 0, because the reward tends to zero if optimal actions are being taken.
The supervisory error and its objective function are calculated as
The RL and supervisory objective functions are minimized by the gradient descent approach, and thus the reinforcement-based update and the supervisory update are calculated as
in which
is the learning rate of the actor network at time
,
.
The complete SRL algorithm is described in detail with the pseudocode as Algorithm 1.
| Algorithm 1. Supervised Reinforcement Learning algorithm. |
| 1: Collect driving samples from a human driver in an infinite time horizon |
| 2: Train the supervisor network with using the Levenberg-Marquardt method |
| 3: Input the actor and critic learning rate ; the discount factor ; the exploration size ; and the interpolation parameter |
| 4: Initialize the weights of the actor and critic randomly |
| 5: Repeat for each trial |
| 6: initial state of the trial |
| 7: repeat for each step of the trial |
| 8: action given by the supervisor |
| 9: action given by the actor |
| 10: |
| 11: interpolation parameter from the gain scheduler |
| 12: |
| 13: execute action and observe the reward and new state |
| 14: |
| 15: update the weights of the critic by (16) and (17) |
| 16: |
| 17: |
| 18: update the weights of the actor by (18), (23) and (24) |
| 19: |
| 20: until is terminal |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}