
Improved Apple Fruit Target Recognition Method Based on YOLOv7 Model
Abstract
:1. Introduction
2. Image Data Collection and Preprocessing
2.1. Apple Image Data Collection
2.2. Dataset Production
2.3. Apple Image Data Amplification
3. Design and Training of the Identification Model
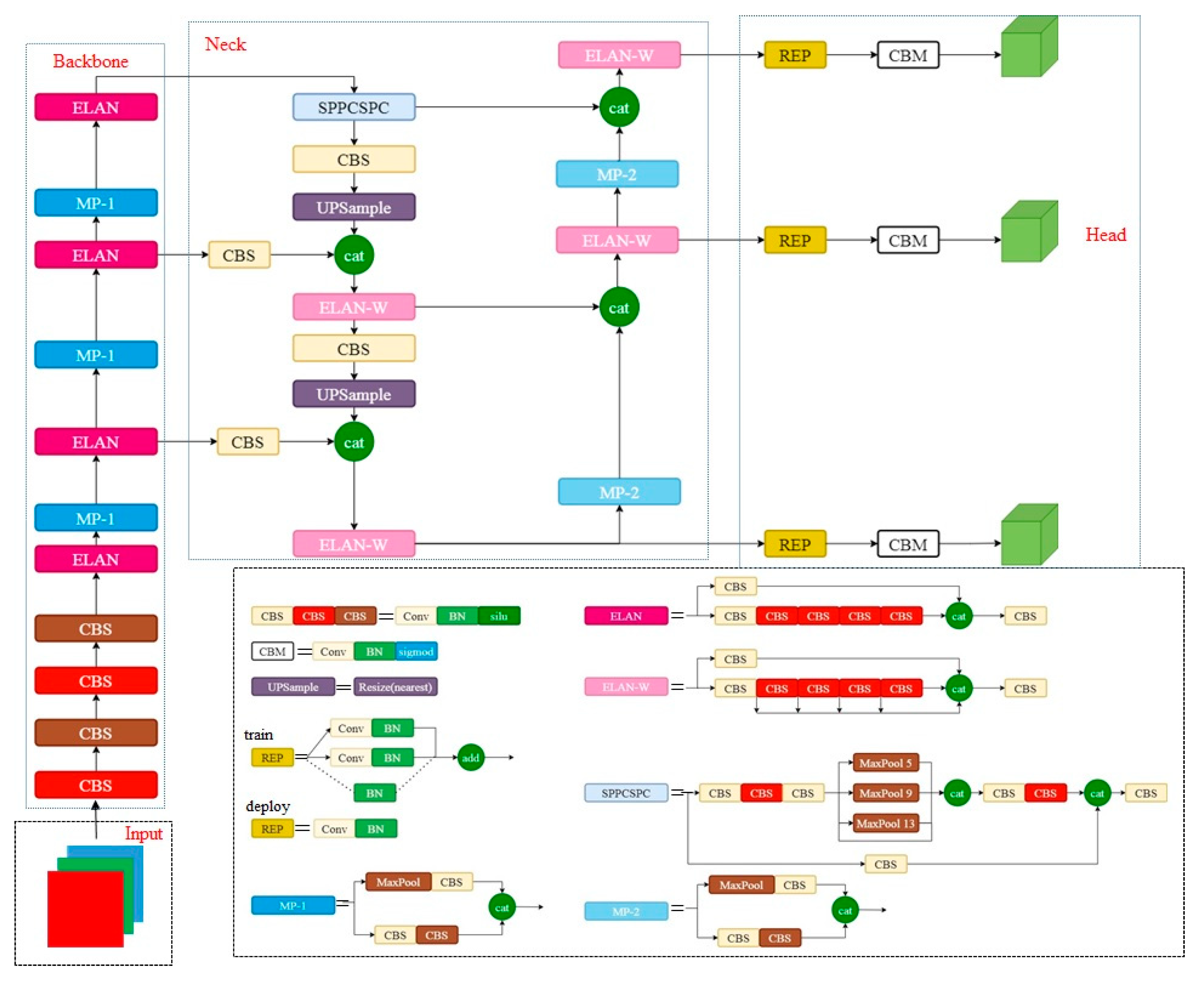
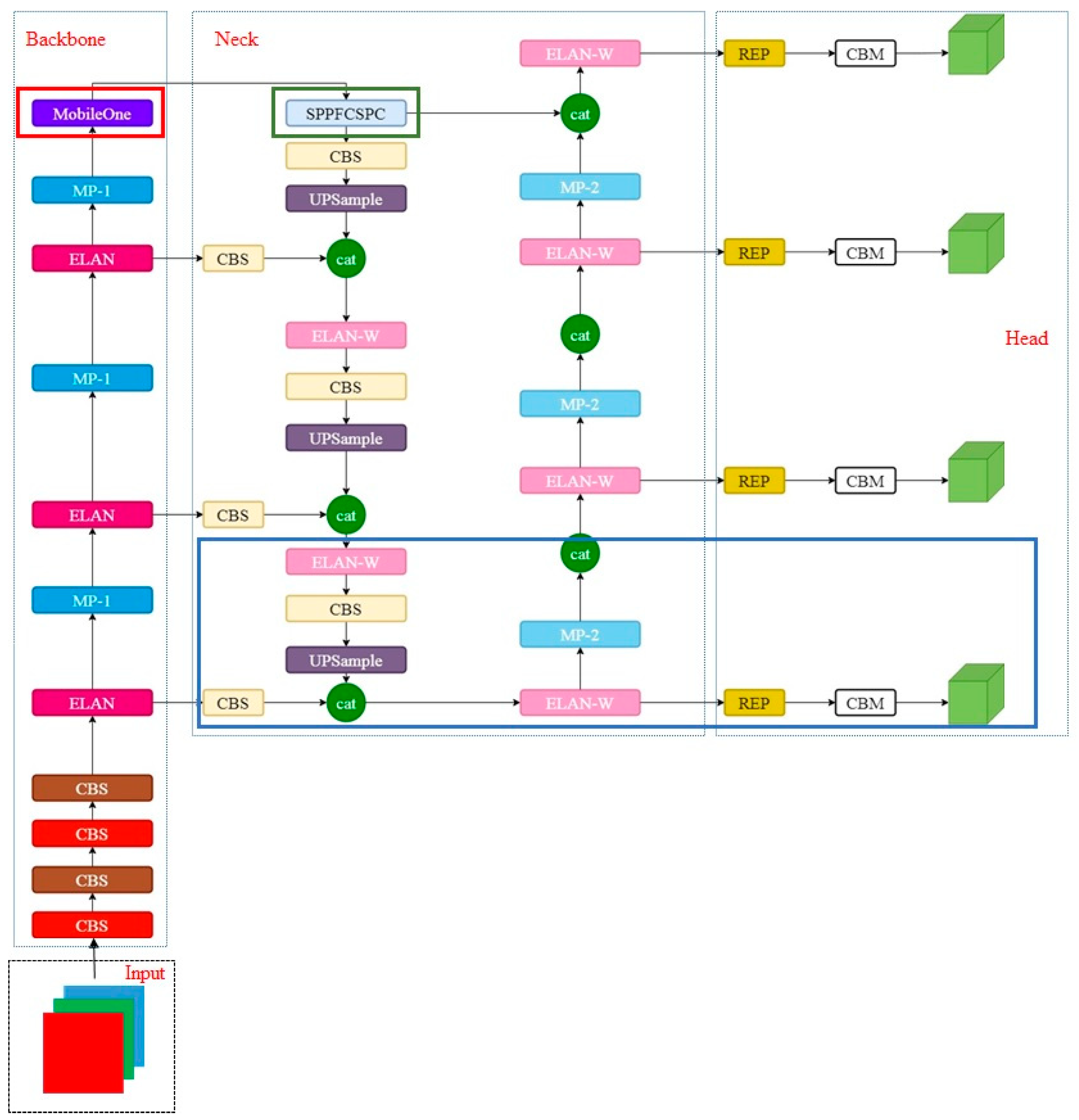
3.1. MobileOne-YOLOv7 Network
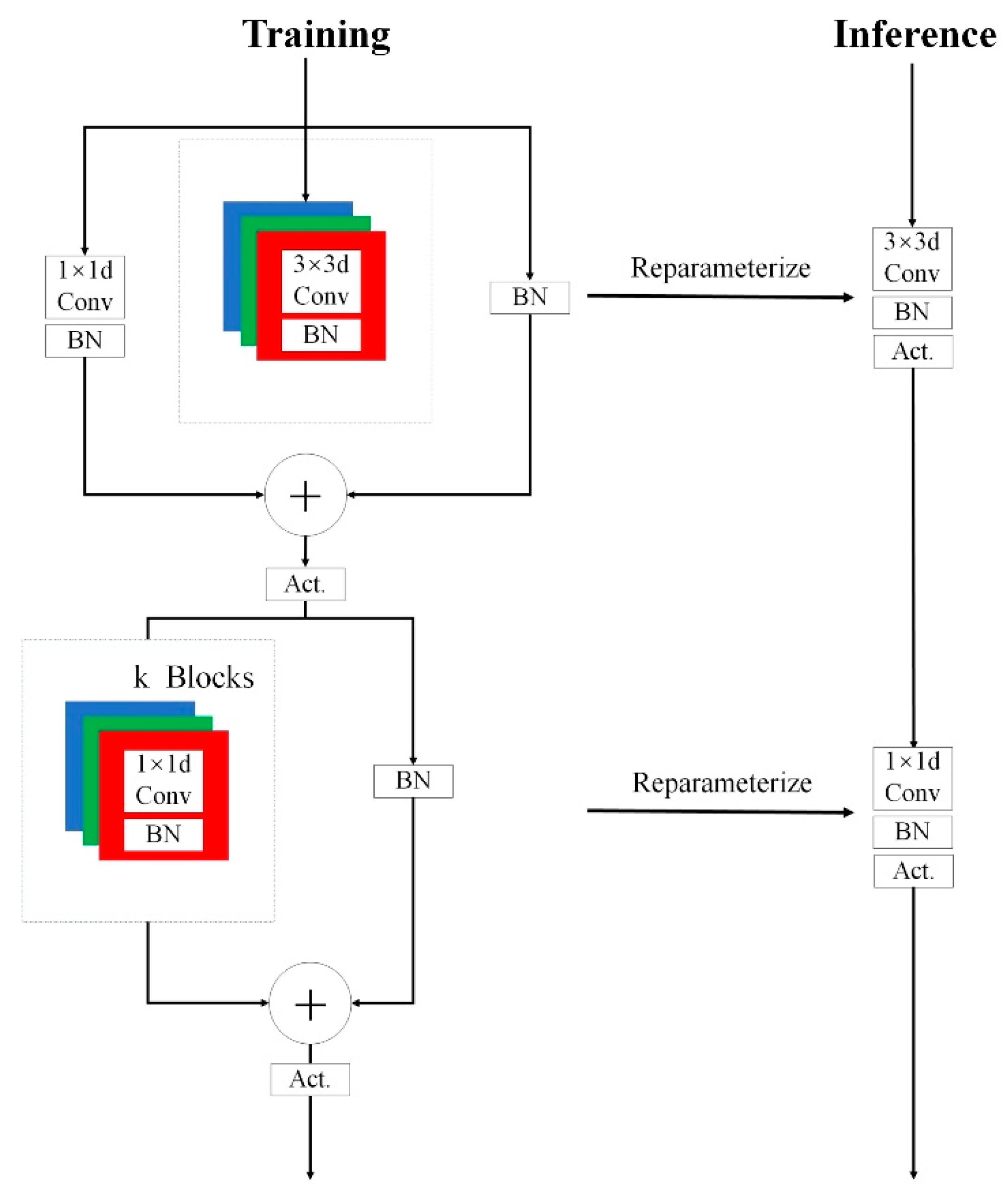
3.2. MobileOne Network
3.3. SPPFCSPC Module
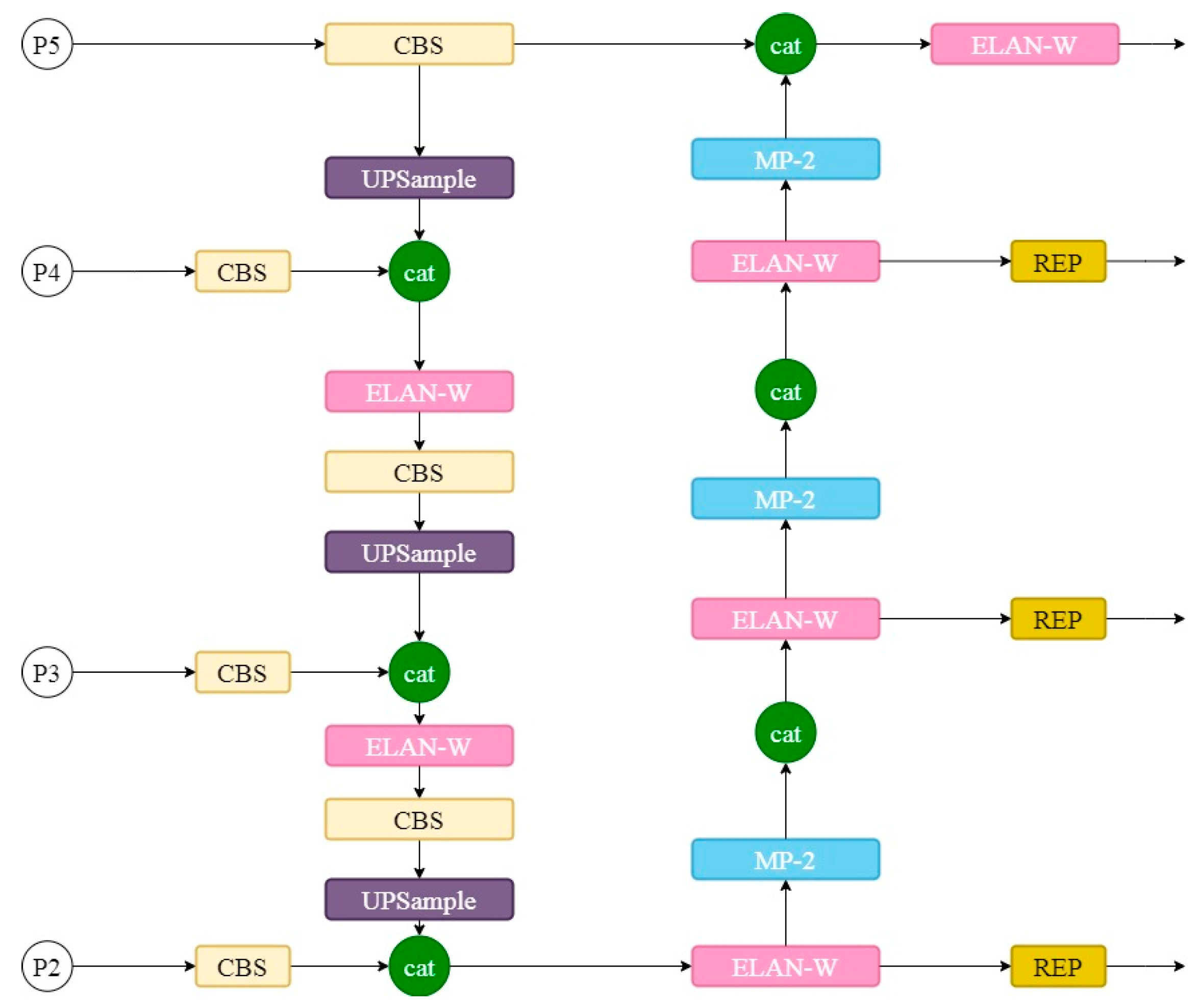
3.4. Add an Auxiliary Detection Head
3.5. Multi-Scale Training
3.6. Optimization of Loss Function
3.7. Model Training
3.7.1. Test Platform
3.7.2. Evaluation Indicators
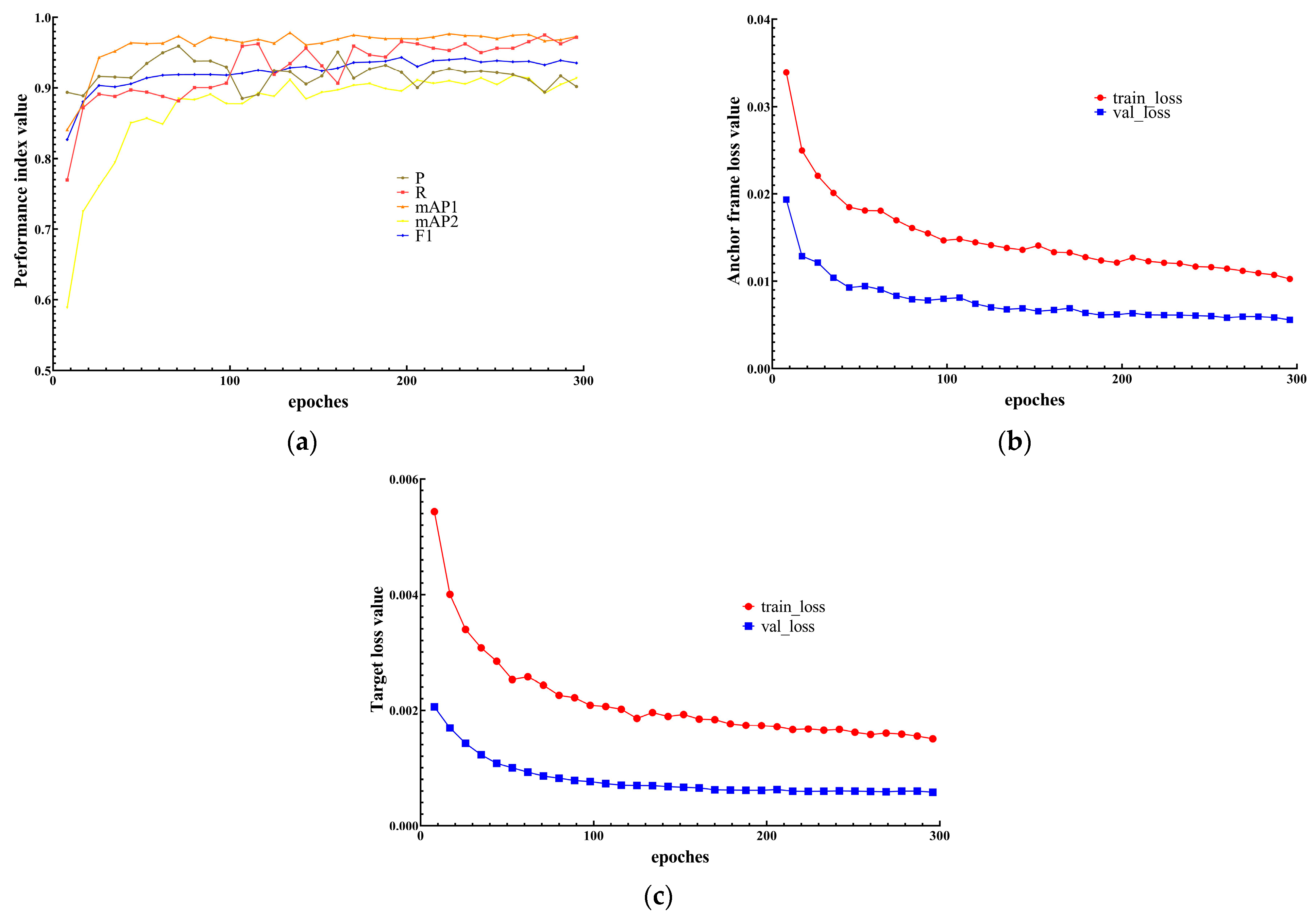
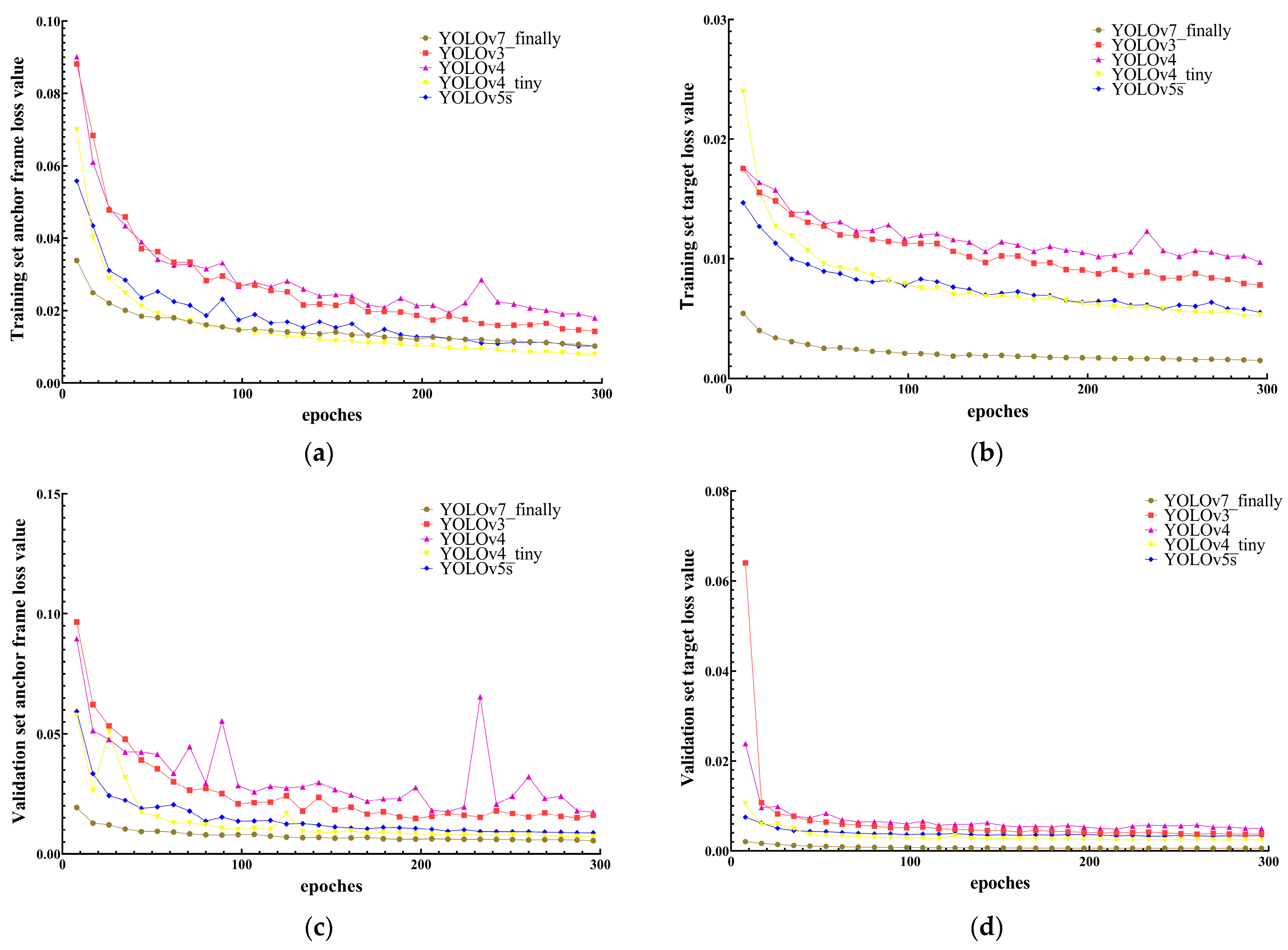
3.7.3. Training Process
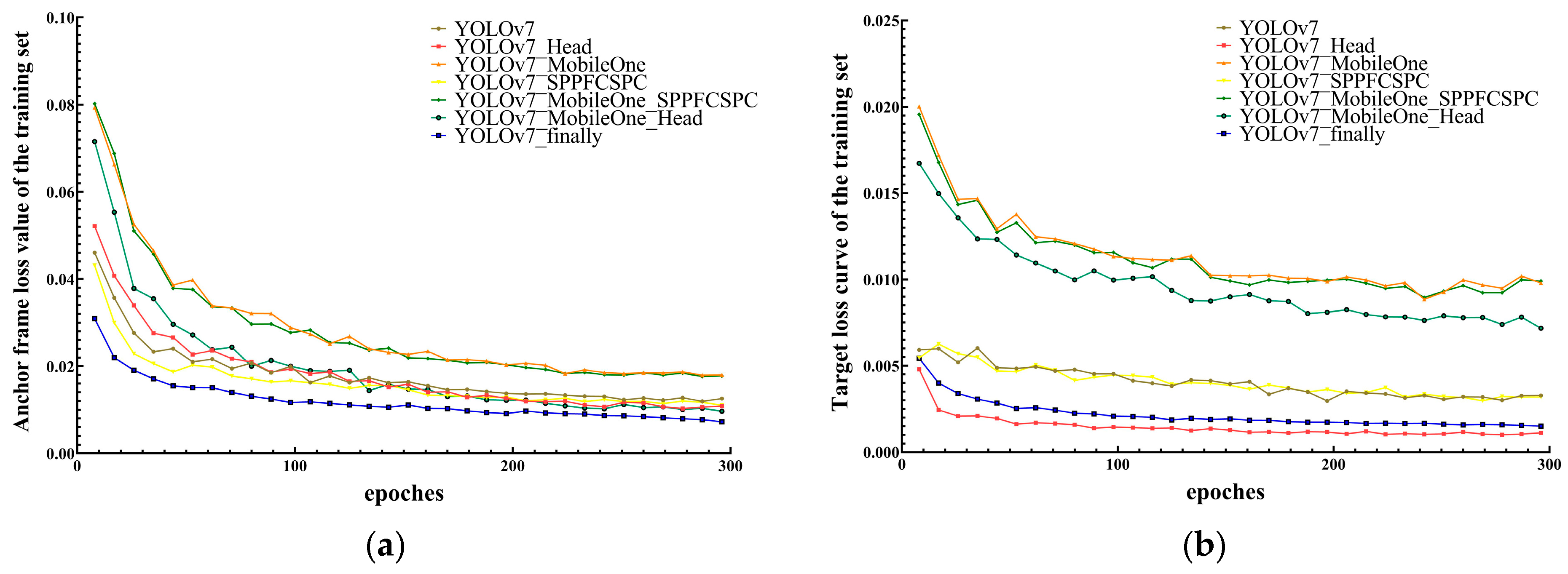
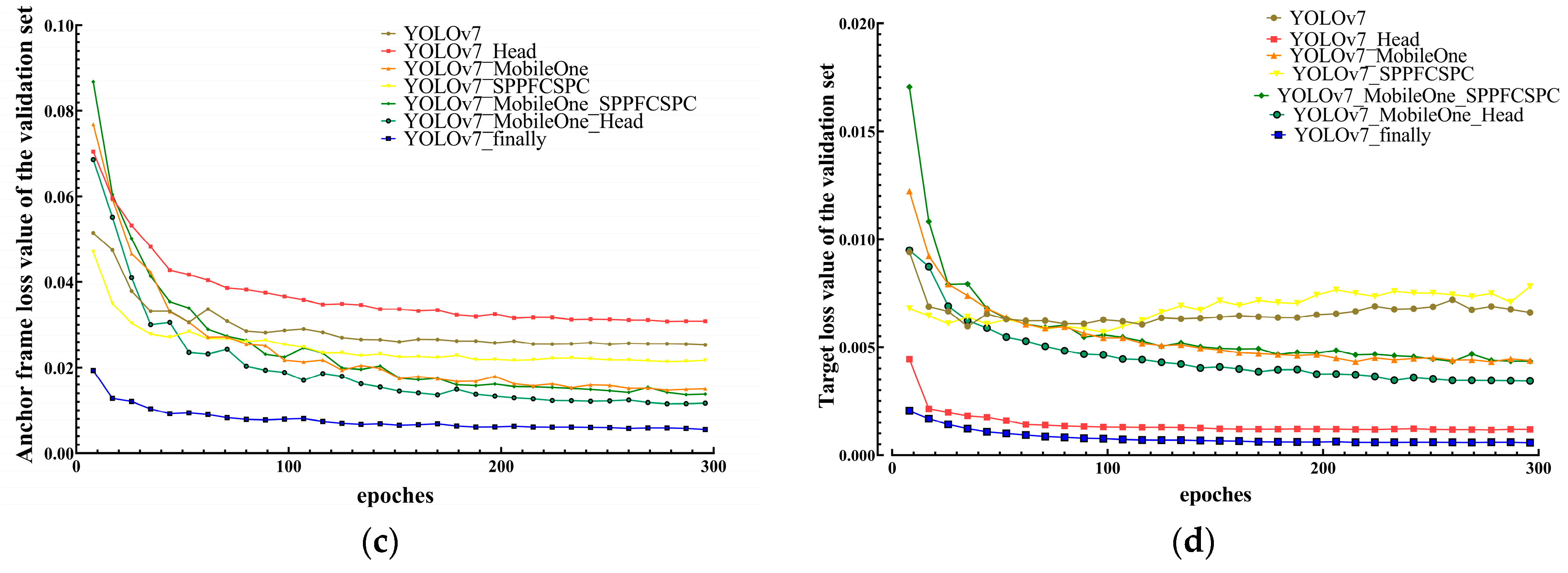
3.7.4. Analysis of Training Data of Different Optimization Algorithms
4. Experimental Analysis
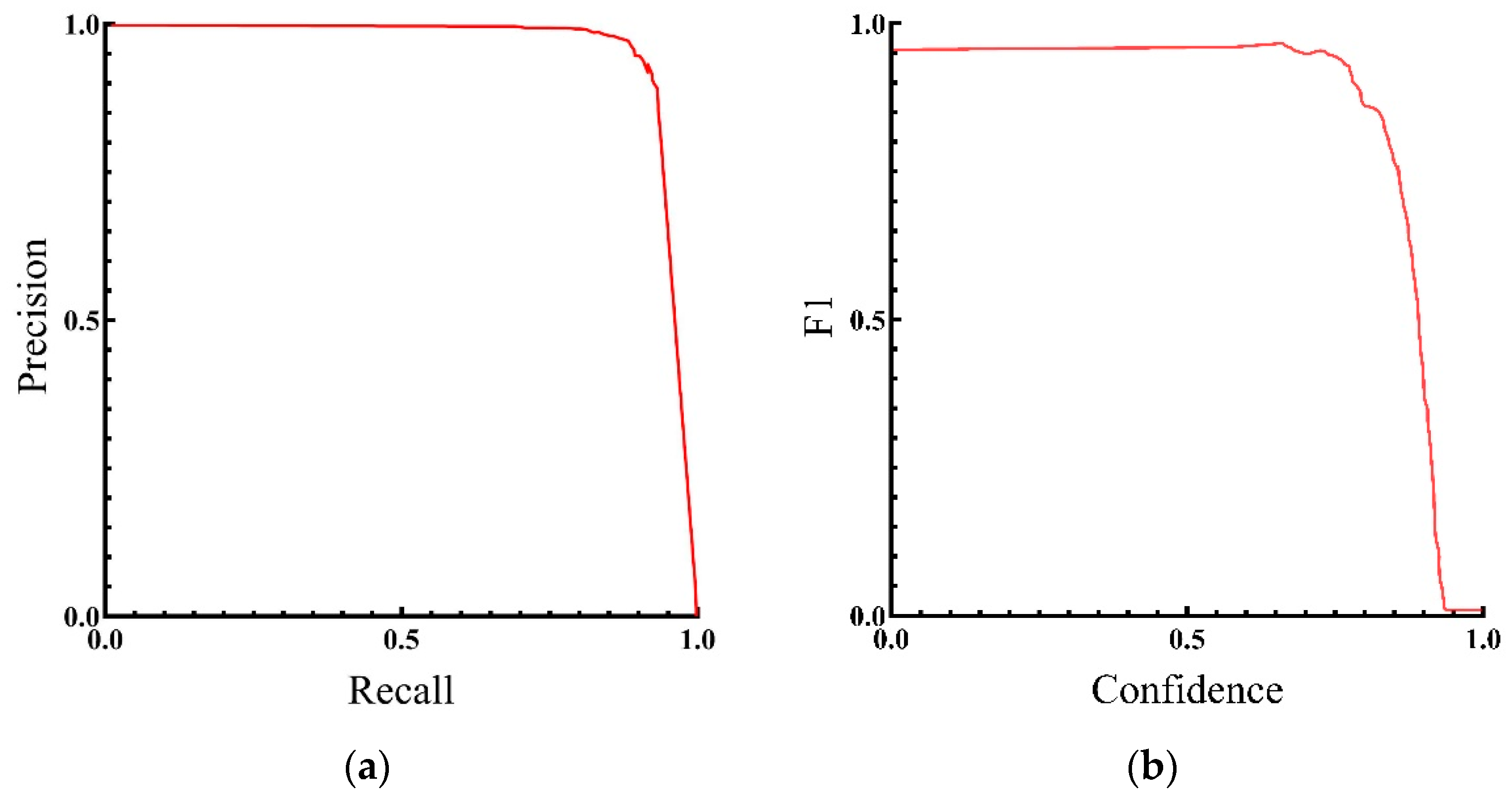
4.1. Evaluation of Test Results
4.2. Comparison of Recognition Results of Different Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Otani, T.; Itoh, A.; Mizukami, H.; Murakami, M.; Yoshida, S.; Terae, K.; Tanaka, T.; Masaya, K.; Aotake, S.; Funabashi, M.; et al. Agricultural Robot under Solar Panels for Sowing, Pruning, and Harvesting in a Synecoculture Environment. Agriculture 2022, 13, 18. [Google Scholar] [CrossRef]
- Vrochidou, E.; Tsakalidou, V.N.; Kalathas, I.; Gkrimpizis, T.; Pachidis, T.; Kaburlasos, V.G. An Overview of End Effectors in Agricultural Robotic Harvesting Systems. Agriculture 2022, 12, 1240. [Google Scholar] [CrossRef]
- Fan, P.; Lang, G.; Guo, P.; Liu, Z.; Yang, F.; Yan, B.; Lei, X. Multi-Feature Patch-Based Segmentation Technique in the Gray-Centered RGB Color Space for Improved Apple Target Recognition. Agriculture 2021, 11, 273. [Google Scholar] [CrossRef]
- Fan, P.; Lang, G.; Yan, B.; Lei, X.; Guo, P.; Liu, Z.; Yang, F. A Method of Segmenting Apples Based on Gray-Centered RGB Color Space. Remote Sens. 2021, 13, 1211. [Google Scholar] [CrossRef]
- Fan, P.; Yan, B.; Wang, M.; Lei, X.; Liu, Z.; Yang, F. Three-finger grasp planning and experimental analysis of picking patterns for robotic apple harvesting. Comput. Electron. Agric. 2021, 188, 106353. [Google Scholar] [CrossRef]
- Fu, L.; Gao, F.; Wu, J.; Li, R.; Karkee, M.; Zhang, Q. Application of consumer RGB-D cameras for fruit detection and localization in field: A critical review. Comput. Electron. Agric. 2020, 177, 105687. [Google Scholar] [CrossRef]
- Duan, L.; Yang, F.; Yan, B.; Shi, S.; Qin, J. Research progress of apple production intelligent chassis and weeding and harvesting equipment technology. Smart Agric. 2022, 4, 24–41. [Google Scholar]
- Wang, N.; Joost, W.; Zhang, F. Towards sustainable intensification of apple production in China-Yield gaps and nutrient use efficiency in apple farming systems. J. Integr. Agric. 2016, 15, 716–725. [Google Scholar] [CrossRef] [Green Version]
- Bulanon, D.; Kataoka, T. Fruit detection system and an end effector for robotic harvesting of Fuji apples. Agric. Eng. Int. CIGR E-J. 2010, 12, 203–210. [Google Scholar]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Lv, J.; Zhao, D.; Ji, W. Fast tracing recognition method of target fruit for apple harvesting robot. Trans. Chin. Soc. Agric. Mach. 2014, 45, 65–72. [Google Scholar]
- Mai, C.; Zheng, L.; Xiao, C.; Li, M. Comparison of apple recognition methods under natural light. J. China Agric. Univ. 2016, 21, 43–50. [Google Scholar]
- Si, Y.; Qiao, J.; Liu, G.; Gao, R.; He, B. Recognition and location of fruits for appleharvesting robot. Trans. Chin. Soc. Agric. Mach. 2010, 41, 148–153. [Google Scholar]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast implementation of real-time fruit detection in apple orchards using deep learning. Comput. Electron. Agric. 2020, 168, 105108. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Solimani, F.; Dimauro, G.; Petrozza, A.; Summerer, S.; Cellini, F.; Renò, V. Detection of tomato plant phenotyping traits using YOLOv5-based single stage detectors. Comput. Electron. Agric. 2023, 207, 107757. [Google Scholar] [CrossRef]
- Sekharamantry, P.K.; Melgani, F.; Malacarne, J. Deep Learning-Based Apple Detection with Attention Module and Improved Loss Function in YOLO. Remote Sens. 2023, 15, 1516. [Google Scholar] [CrossRef]
- Altaheri, H.; Alsulaiman, M.; Muhammad, G. Date fruit classification for robotic harvesting in a natural environment using deep learning. IEEE Access 2019, 7, 117115–117133. [Google Scholar] [CrossRef]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A Real-Time Apple Targets Detection Method for Picking Robot Based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Zhao, H.; Qiao, Y.; Wang, H.; Yue, Y. Apple fruit recognition in complex orchard environment based on improved YOLOv3. Trans. Chin. Soc. Agric. Eng. 2021, 37, 127–135. [Google Scholar]
- Yang, F.; Lei, X.; Liu, Z.; Fan, P.; Yan, B. Fast Recognition Method for Multiple Apple Targets in Dense Scenes Based on CenterNet. Trans. Chin. Soc. Agric. Mach. 2022, 53, 265–273. [Google Scholar]
- Zheng, T.; Jiang, M.; Feng, M. Vision based target recognition and location for picking robot: A review. Chin. J. Sci. Instrum. 2021, 42, 28–51. [Google Scholar]
- Wu, W.; Yang, T.; Li, R.; Chen, C.; Zhou, K.; Sun, M.; Li, C.; Zhu, X.; Guo, W. Detection and enumeration of wheat grains based on a deep learning method under various scenarios and scales. J. Integr. Agric. 2020, 19, 1998–2008. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once:unified, realtime object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 91, pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition IEEE, Honolulu, HI, USA, 21–26 June 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Computer Vision and Pattern Recongintion; Springer: Berlin/Heidelberg, Germany, 2018; Volume 276, pp. 126–134. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. Comput. Vis. Pattern Recognit. 2020, 10, 34–51. [Google Scholar]
- Mekhalfi, M.L.; Nicolò, C.; Bazi, Y.; Al Rahhal, M.M.; Alsharif, N.A.; Al Maghayreh, E. Contrasting YOLOv5, Transformer, and EfficientDet Detectors for Crop Circle Detection in Desert. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yasushi, Y. An attribution-based pruning method for real-time mango detection with YOLO network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Ying, S.; Huang, S.; Chang, S.; Yang, Z.; Feng, Z.; Guo, N. Convolutional and Transformer Based Deep Neural Network for Automatic Modulation Classification. China Commun. 2023, 20, 135–147. [Google Scholar] [CrossRef]
- Zhang, Q.; Ma, W.; Wang, Y.; Zhang, Y.; Shi, Z.; Li, Y. Backdoor Attacks on Image Classification Models in Deep Neural Networks. Chin. J. Electron. 2022, 31, 199–212. [Google Scholar] [CrossRef]
- Dai, G.; Fan, J.; Tian, Z.; Wang, C. PPLC-Net:Neural network-based plant disease identification model supported by weather data augmentation and multi-level attention mechanism. J. King Saud Univ.—Comput. Inf. Sci. 2023, 35, 101555. [Google Scholar] [CrossRef]
- Wei, J.; Wang, Q.; Song, X.; Zhao, Z. The Status and Challenges of Image Data Augmentation Algorithms. J. Phys. Conf. Ser. 2023, 2456, 012041. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, Y.; Wang, J. A Dragon Fruit Picking Detection Method Based on YOLOv7 and PSP-Ellipse. Sensors 2023, 23, 3803. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. Real-time growth stage detection model for high degree of occultation using DenseNet-fused YOLOv4. Comput. Electron. Agric. 2022, 193, 106694. [Google Scholar] [CrossRef]
- Piao, Y.; Jiang, Y.; Zhang, M.; Wang, J.; Lu, H. PANet: Patch-Aware Network for Light Field Salient Object Detection. IEEE Trans. Cybern. 2021, 53, 379–391. [Google Scholar] [CrossRef]
- Hong, F.; Tay, D.; Wei, L.; Ang, A. Intelligent Pick-and-Place System Using MobileNet. Electronics 2023, 12, 621. [Google Scholar] [CrossRef]
- Li, X.; Ye, H.; Qiu, S. Cloud Contaminated Multispectral Remote Sensing Image Enhancement Algorithm Based on MobileNet. Remote Sens. 2022, 14, 4815. [Google Scholar] [CrossRef]
- Sheng, G.; Sun, S.; Liu, C.; Yang, Y. Food recognition via an efficient neural network with transformer grouping. Int. J. Intell. Syst. 2022, 37, 11465–11481. [Google Scholar] [CrossRef]
- Wang, Q.; Cheng, M.; Huang, S.; Cai, Z.; Zhang, J.; Yuan, H. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings. Comput. Electron. Agric. 2022, 199, 107194. [Google Scholar] [CrossRef]
- Wei, D.; Chen, J.; Luo, T.; Long, T.; Wang, H. Classification of crop pests based on multi-scale feature fusion. Comput. Electron. Agric. 2022, 194, 106736. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yang, N.; Wang, B. Multi-scale receptive fields: Graph attention neural network for hyperspectral image classification. Expert Syst. Appl. 2023, 223, 119858. [Google Scholar] [CrossRef]
- Yang, Y.; Sun, S.; Huang, J.; Huang, T.; Liu, K. Large-Scale Aircraft Pose Estimation System Based on Depth Cameras. Appl. Sci. 2023, 13, 3736. [Google Scholar] [CrossRef]
- Ding, J.; Cao, H.; Ding, X.; An, C. High Accuracy Real-Time Insulator String Defect Detection Method Based on Improved YOLOv5. Front. Energy Res. 2022, 10, 898. [Google Scholar] [CrossRef]
- Gao, J.; Yang, T. Face detection algorithm based on improved TinyYOLOv3 and attention mechanism. Comput. Commun. 2021, 181, 329–337. [Google Scholar] [CrossRef]
- Qi, J.; Zhang, J.; Meng, Q. Auxiliary Equipment Detection in Marine Engine Rooms Based on Deep Learning Model. J. Mar. Sci. Eng. 2021, 9, 1006. [Google Scholar] [CrossRef]
- Amarasingam, N.; Gonzalez, F.; Salgadoe, A.S.A.; Sandino, J.; Powell, K. Detection of White Leaf Disease in Sugarcane Crops Using UAV-Derived RGB Imagery with Existing Deep Learning Models. Remote Sens. 2022, 14, 6137. [Google Scholar] [CrossRef]
- Li, J.; Chen, L.; Shen, J.; Xiao, X.; Liu, X.; Sun, X.; Wang, X. Improved Neural Network with Spatial Pyramid Pooling and Online Datasets Preprocessing for Underwater Target Detection Based on Side Scan Sonar Imagery. Remote Sens. 2023, 15, 440. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Size (Pixel) | Date | Framework | Backbone | [email protected] | [email protected]–0.95 |
|---|---|---|---|---|---|---|
| YOLOv3 | 640 | 2018 | Darknet | Darknet53 | 83.4 | 51.9 |
| YOLOv4 | 640 | 2020 | Darknet | CSPD Darknet53 | 81.6 | 56.5 |
| YOLOv5s | 640 | 2020 | PyTorch | Modified CSP v7 | 85.7 | 56.7 |
| YOLOv6s | 640 | 2022 | PyTorch | EfficientRep | 87.7 | 58.4 |
| YOLOv7 | 640 | 2022 | PyTorch | RepConvN | 92.0 | 62.8 |
| Number of Weight Model | P/% | R/% | mAP1/% | mAP2/% | F1/% |
|---|---|---|---|---|---|
| 49 | 81.78 | 79.71 | 87.48 | 74.42 | 80.73 |
| 99 | 87.02 | 96.26 | 96.16 | 88.56 | 91.41 |
| 149 | 90.69 | 94.07 | 95.24 | 88.19 | 92.35 |
| 199 | 90.92 | 97.19 | 96.95 | 89.82 | 93.95 |
| 249 | 91.70 | 96.43 | 96.38 | 90.08 | 94.01 |
| 299 | 92.25 | 96.57 | 97.14 | 90.23 | 94.36 |
| 283 | 96.31 | 92.96 | 97.28 | 91.76 | 94.61 |
| YOLOv7 Network | MobileOne | SPPFCSPC | Detection Head | P/% | R/% | mAP1/% | mAP2/% | F1/% |
|---|---|---|---|---|---|---|---|---|
| √ | × | × | × | 89.8 | 86.6 | 91.5 | 88.5 | 88.2 |
| √ | √ | × | × | 90.3 | 80.5 | 92.5 | 87.3 | 85.1 |
| √ | × | √ | × | 89.8 | 89.6 | 96.3 | 94.1 | 89.7 |
| √ | × | × | √ | 92.0 | 83.8 | 92.2 | 89.6 | 87.7 |
| √ | √ | √ | × | 91.4 | 92.4 | 86.8 | 85.6 | 91.9 |
| √ | √ | × | √ | 94.4 | 86.2 | 93.8 | 84.1 | 90.1 |
| √ | √ | √ | √ | 96.7 | 96.6 | 96.5 | 92.3 | 96.6 |
| Algorithm Model. | Scene Conditions | Actual Fruit Count | Correct Number to Check Out | Missing Count | Missed Detection Rate/% |
|---|---|---|---|---|---|
| YOLOv7 | Close-range smooth light | 6 | 6 | 0 | 0 |
| Close-range backlight | 3 | 3 | 0 | 0 | |
| Smooth light in a dense scene | 58 | 29 | 29 | 50.00 | |
| Backlight in dense scenes | 51 | 21 | 30 | 58.82 | |
| Large field-of-view scenes | 93 | 24 | 69 | 74.19 | |
| Proposed algorithm | Close-range smooth light | 6 | 6 | 0 | 0 |
| Close-range backlight | 3 | 3 | 0 | 0 | |
| Smooth light in a dense scene | 58 | 47 | 11 | 23.40 | |
| Backlight in dense scenes | 51 | 50 | 1 | 1.96 | |
| Large field-of-view scenes | 93 | 87 | 6 | 6.45 |
| Performance Indicators | YOLOv7-Finally | YOLOv3 | YOLOv4 | YOLOv4-Tiny | YOLOv5s |
|---|---|---|---|---|---|
| P/% | 96.7 | 93.2 | 82.7 | 87.6 | 90.2 |
| R/% | 96.6 | 91.0 | 81.6 | 88.4 | 92.8 |
| mAP1/% | 96.5 | 95.8 | 84.4 | 91.5 | 90.9 |
| mAP2/% | 92.3 | 86.4 | 70.5 | 89.7 | 83.6 |
| F1/% | 96.7 | 92.1 | 82.2 | 88.0 | 91.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Liu, Y.; Wang, S.; Qu, H.; Li, N.; Wu, J.; Yan, Y.; Zhang, H.; Wang, J.; Qiu, J. Improved Apple Fruit Target Recognition Method Based on YOLOv7 Model. Agriculture 2023, 13, 1278. https://0-doi-org.brum.beds.ac.uk/10.3390/agriculture13071278
Yang H, Liu Y, Wang S, Qu H, Li N, Wu J, Yan Y, Zhang H, Wang J, Qiu J. Improved Apple Fruit Target Recognition Method Based on YOLOv7 Model. Agriculture. 2023; 13(7):1278. https://0-doi-org.brum.beds.ac.uk/10.3390/agriculture13071278
Chicago/Turabian StyleYang, Huawei, Yinzeng Liu, Shaowei Wang, Huixing Qu, Ning Li, Jie Wu, Yinfa Yan, Hongjian Zhang, Jinxing Wang, and Jianfeng Qiu. 2023. "Improved Apple Fruit Target Recognition Method Based on YOLOv7 Model" Agriculture 13, no. 7: 1278. https://0-doi-org.brum.beds.ac.uk/10.3390/agriculture13071278