Classification of Categorical Data Based on the Chi-Square Dissimilarity and t-SNE

 ,
,  , and
, and
Abstract
:1. Introduction
2. State of the Art
3. Materials and Methods
3.1. Chi-Square Distance
3.2. T-Distributed Stochastic Neighbor Embedding
3.3. Standard Classification Techniques
3.3.1. Support Vector Machines (SVMs)
- Separation of classes: It is about finding the optimal separating hyperplane between the two classes by maximizing the margin between the closest points of the classes.
- Overlapping classes: The incorrect data points of the discriminating margin are weighted to reduce their influence (soft margin).
- Non-linearity: When a linear separator cannot be found, the points are mapped to another dimensional space where the data can be separated linearly (this projection is realized via kernel techniques).
- Solution of the problem: The whole task can be formulated as a quadratic optimization problem that can be solved by known methods.
3.3.2. Bayesian Classifier
3.3.3. K-Nearest Neighbor (K-nn)
- The training data with labels (being N the number of data samples) are stored in memory.
- For a new sample ∈, where D is the number of attributes, it is found the k-nearest neighbors using a distance d in the whole training set (k can be ).
- It is performed a voting procedure for selecting the class of the new sample .
- Common distances d are:
- -
- Mahalanobis:where is the covariance matrix between and .
- -
- Euclidean:
- -
- Manhattan:
In this work, we employ the Mahalanobis distance. Also, we tested k = 3, 5, and 7 neighbors, but we report the best results obtained for k = 3.
4. Datasets and Experimental Setup
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Janert, P.K. Data Analysis with Open Source Tools: A Hands-On Guide for Programmers and Data Scientists; O’Reilly Media, Inc.: Newton, MA, USA, 2010. [Google Scholar]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2002; pp. 849–856. [Google Scholar]
- Meyer, D.; Wien, F.T. Support vector machines. R News 2001, 1, 23–26. [Google Scholar]
- Rasmussen, C.E. Gaussian processes in machine learning. In Advanced Lectures on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2004; pp. 63–71. [Google Scholar]
- Wang, Y.; Zhu, L. Research on improved text classification method based on combined weighted model. Concurr. Comput. Pract. Exp. 2020, 32, e5140. [Google Scholar] [CrossRef]
- Huang, Z.; Ng, M.K. A fuzzy k-modes algorithm for clustering categorical data. IEEE Trans. Fuzzy Syst. 1999, 7, 446–452. [Google Scholar] [CrossRef] [Green Version]
- Gower, J.C. A general coefficient of similarity and some of its properties. Biometrics 1971, 27, 857–871. [Google Scholar] [CrossRef]
- Gowda, K. Symbolic clustering using a new dissimilarity measure. Pattern Recognit. 1991, 24, 567–578. [Google Scholar] [CrossRef]
- Kaufman, L. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley and Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Michalski, R.S. Automated construction of classifications: Conceptual clustering versus numerical taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 1983, 4, 396–410. [Google Scholar] [CrossRef]
- Bonanomi, A.; Nai Ruscone, M.; Osmetti, S.A. Dissimilarity measure for ranking data via mixture of copulae. Stat. Anal. Data Min. ASA Data Sci. J. 2019, 12, 412–425. [Google Scholar] [CrossRef]
- Seshadri, K.; Iyer, K.V. Design and evaluation of a parallel document clustering algorithm based on hierarchical latent semantic analysis. Concurr. Comput. Pract. Exp. 2019, 31, e5094. [Google Scholar] [CrossRef]
- Alexandridis, A.; Chondrodima, E.; Giannopoulos, N.; Sarimveis, H. A fast and efficient method for training categorical radial basis function networks. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2831–2836. [Google Scholar] [CrossRef]
- Zheng, Z.; Cai, Y.; Yang, Y.; Li, Y. Sparse Weighted Naive Bayes Classifier for Efficient Classification of Categorical Data. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 691–696. [Google Scholar]
- Villuendas-Rey, Y.; Rey-Benguría, C.F.; Ferreira-Santiago, Á.; Camacho-Nieto, O.; Yáñez-Márquez, C. The naïve associative classifier (NAC): A novel, simple, transparent, and accurate classification model evaluated on financial data. Neurocomputing 2017, 265, 105–115. [Google Scholar] [CrossRef]
- Computation, Special Issue “Explainable Computational Intelligence, Theory, Methods and Applications”. 2020. Available online: https://0-www-mdpi-com.brum.beds.ac.uk/journal/computation/special_issues/explainable_computational_intelligence (accessed on 5 September 2020).
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Field, A. Discovering Statistics Using IBM SPSS Statistics; Sage: Newcastle upon Tyne, UK, 2013. [Google Scholar]
- Wang, C.; Dong, X.; Zhou, F.; Cao, L.; Chi, C.H. Coupled attribute similarity learning on categorical data. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 781–797. [Google Scholar] [CrossRef] [PubMed]
- Polato, M.; Lauriola, I.; Aiolli, F. A novel boolean kernels family for categorical data. Entropy 2018, 20, 444. [Google Scholar] [CrossRef] [Green Version]
- Baati, K.; Hamdani, T.M.; Alimi, A.M.; Abraham, A. A new classifier for categorical data based on a possibilistic estimation and a novel generalized minimum-based algorithm. J. Intell. Fuzzy Syst. 2017, 33, 1723–1731. [Google Scholar] [CrossRef]
- Ralambondrainy, H. A conceptual version of the k-means algorithm. Pattern Recognit. Lett. 1995, 16, 1147–1157. [Google Scholar] [CrossRef]
- Max, A. Woodbury and Jonathan Clive. Clinical pure types as a fuzzy partition. J. Cybern. 1974, 4, 111–121. [Google Scholar]
- Ahmad, A.; Dey, L. A method to compute distance between two categorical values of same attribute in unsupervised learning for categorical data set. Pattern Recognit. Lett. 2007, 28, 110–118. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Wilson, D.R.; Martinez, T.R. Improved heterogeneous distance functions. J. Artif. Intell. Res. 1997, 6, 1–34. [Google Scholar] [CrossRef]
- Qian, Y.; Li, F.; Liang, J.; Liu, B.; Dang, C. Space structure and clustering of categorical data. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2047–2059. [Google Scholar] [CrossRef]
- Huang, Z. A fast clustering algorithm to cluster very large categorical data sets in data mining. DMKD 1997, 3, 34–39. [Google Scholar]
- Chan, E.Y.; Ching, W.K.; Ng, M.K.; Huang, J.Z. An optimization algorithm for clustering using weighted dissimilarity measures. Pattern Recognit. 2004, 37, 943–952. [Google Scholar] [CrossRef]
- Bai, L.; Liang, J.; Dang, C.; Cao, F. The impact of cluster representatives on the convergence of the k-modes type clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1509–1522. [Google Scholar] [CrossRef]
- Kobayashi, Y.; Song, L.; Tomita, M.; Chen, P. Automatic Fault Detection and Isolation Method for Roller Bearing Using Hybrid-GA and Sequential Fuzzy Inference. Sensors 2019, 19, 3553. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ali, J.B.; Fnaiech, N.; Saidi, L.; Chebel-Morello, B.; Fnaiech, F. Application of empirical mode decomposition and artificial neural network for automatic bearing fault diagnosis based on vibration signals. Appl. Acoust. 2015, 89, 16–27. [Google Scholar]
- Tian, Y.; Wang, Z.; Lu, C. Self-adaptive bearing fault diagnosis based on permutation entropy and manifold-based dynamic time warping. Mech. Syst. Signal Process. 2019, 114, 658–673. [Google Scholar] [CrossRef]
- Tan, J.; Fu, W.; Wang, K.; Xue, X.; Hu, W.; Shan, Y. Fault Diagnosis for Rolling Bearing Based on Semi-Supervised Clustering and Support Vector Data Description with Adaptive Parameter Optimization and Improved Decision Strategy. Appl. Sci. 2019, 9, 1676. [Google Scholar] [CrossRef] [Green Version]
- Kaden, M.; Lange, M.; Nebel, D.; Riedel, M.; Geweniger, T.; Villmann, T. Aspects in classification Learning—Review of recent developments in learning vector quantization. Found. Comput. Decis. Sci. 2014, 39, 79–105. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Ma, J.; Lu, C.; Wang, Z. Rolling bearing fault diagnosis under variable conditions using LMD-SVD and extreme learning machine. Mech. Mach. Theory 2015, 90, 175–186. [Google Scholar] [CrossRef]
- Zhou, P.; Lu, S.; Liu, F.; Liu, Y.; Li, G.; Zhao, J. Novel synthetic index-based adaptive stochastic resonance method and its application in bearing fault diagnosis. J. Sound Vib. 2017, 391, 194–210. [Google Scholar] [CrossRef]
- Yang, Y.; Pan, H.; Ma, L.; Cheng, J. A fault diagnosis approach for roller bearing based on improved intrinsic timescale decomposition de-noising and kriging-variable predictive model-based class discriminate. J. Vib. Control 2016, 22, 1431–1446. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, T.; Zhao, W.; Luo, Z.; Sun, K. Fault Diagnosis of Rolling Bearing Using Multiscale Amplitude-Aware Permutation Entropy and Random Forest. Algorithms 2019, 12, 184. [Google Scholar] [CrossRef] [Green Version]
- Fei, S.W. Kurtosis forecasting of bearing vibration signal based on the hybrid model of empirical mode decomposition and RVM with artificial bee colony algorithm. Expert Syst. Appl. 2015, 42, 5011–5018. [Google Scholar] [CrossRef]
- Shen, C.; Xie, J.; Wang, D.; Jiang, X.; Shi, J. Improved Hierarchical Adaptive Deep Belief Network for Bearing Fault Diagnosis. Appl. Sci. 2019, 9, 3374. [Google Scholar] [CrossRef] [Green Version]
- Anbu, S.; Thangavelu, A.; Ashok, S.D. Fuzzy C-Means Based Clustering and Rule Formation Approach for Classification of Bearing Faults Using Discrete Wavelet Transform. Computation 2019, 7, 54. [Google Scholar] [CrossRef] [Green Version]
- Cang, S.; Yu, H. Mutual information based input feature selection for classification problems. Decis. Support Syst. 2012, 54, 691–698. [Google Scholar] [CrossRef]
- Sani, L.; Pecori, R.; Mordonini, M.; Cagnoni, S. From Complex System Analysis to Pattern Recognition: Experimental Assessment of an Unsupervised Feature Extraction Method Based on the Relevance Index Metrics. Computation 2019, 7, 39. [Google Scholar] [CrossRef] [Green Version]
- Weber, M. Implications of PCCA+ in molecular simulation. Computation 2018, 6, 20. [Google Scholar] [CrossRef] [Green Version]
- Serna, L.A.; Hernández, K.A.; González, P.N. A K-Means Clustering Algorithm: Using the Chi-Square as a Distance. In International Conference on Human Centered Computing; Tang, Y., Zu, Q., Rodríguez García, J., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11354. [Google Scholar]
- Hinton, G.E.; Roweis, S.T. Stochastic neighbor embedding. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2003; pp. 857–864. [Google Scholar]
- Van Der Maaten, L. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector network. Mach. Learn. 1995, 20, 1–25. [Google Scholar] [CrossRef]
- Hu, M.; Chen, Y.; Kwok, J.T.Y. Building sparse multiple-kernel SVM classifiers. Learning (MKL) 2009, 3, 26. [Google Scholar]
- Büyüköztürk, Ş.; Çokluk-Bökeoğlu, Ö. Discriminant function analysis: Concept and application. Eğitim Araştırmaları Dergisi 2008, 33, 73–92. [Google Scholar]
- Li, W.; Zhao, J. Wasserstein information matrix. arXiv 2020, arXiv:1910.11248. [Google Scholar]
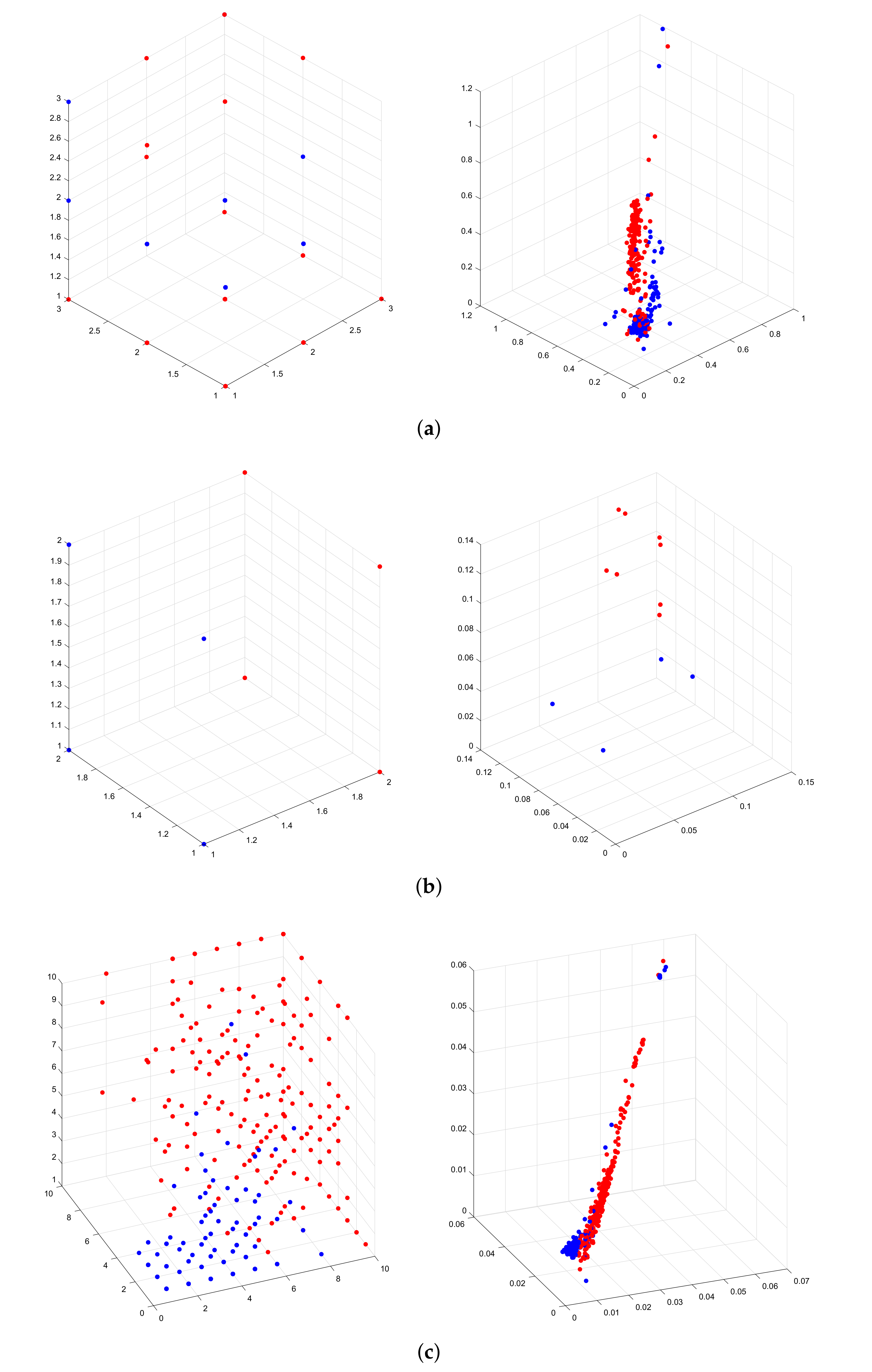

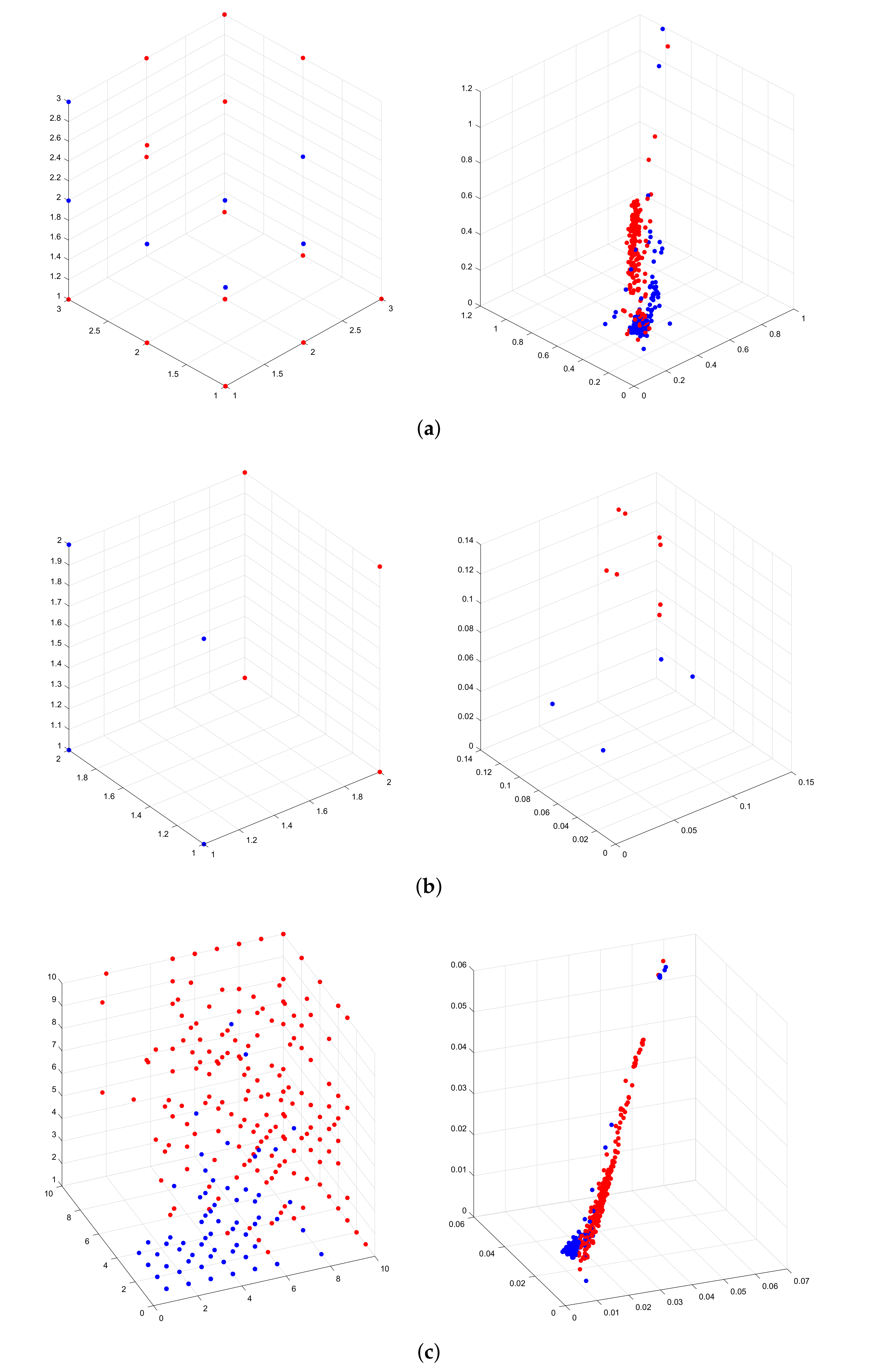{kind=link}
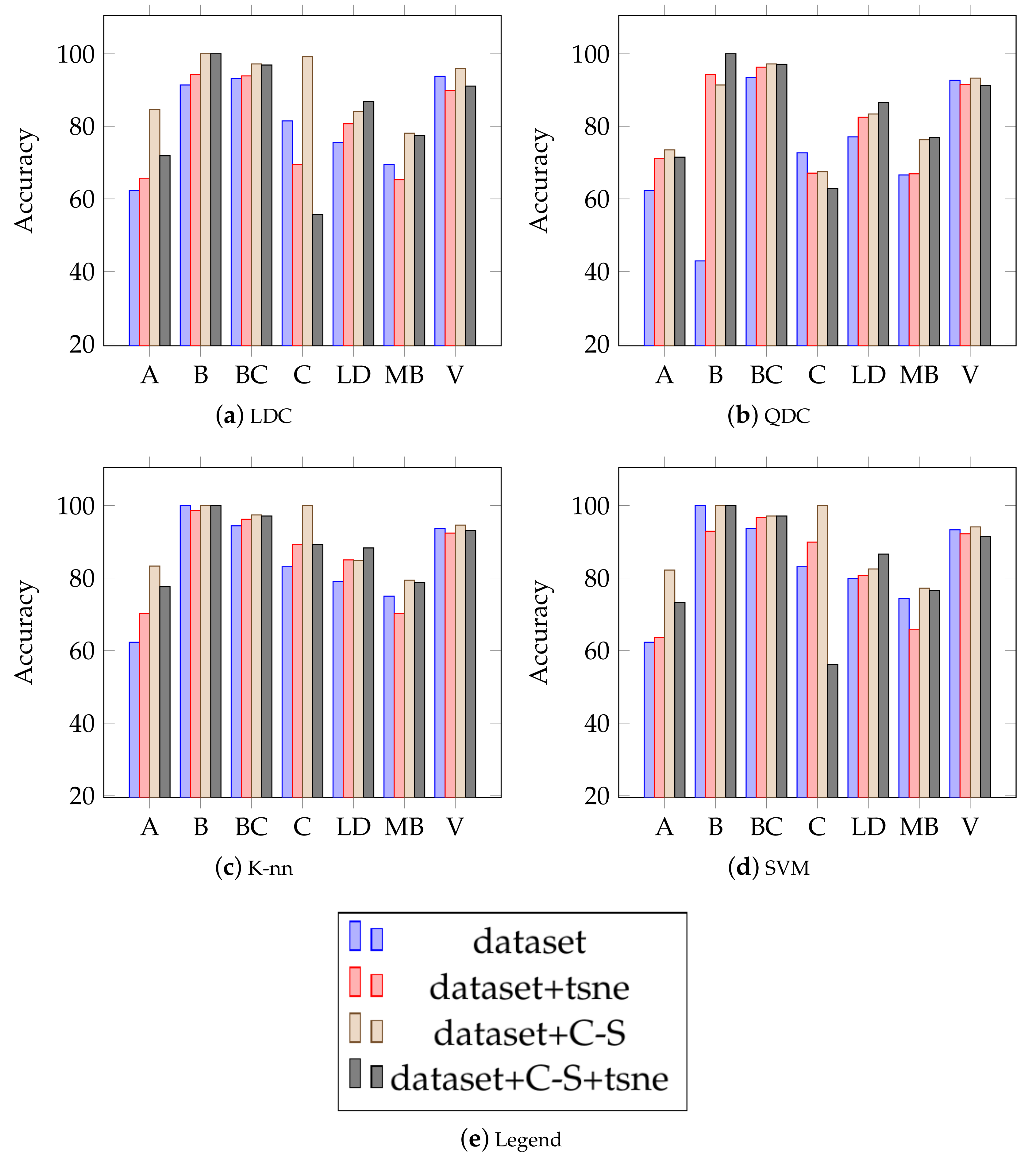
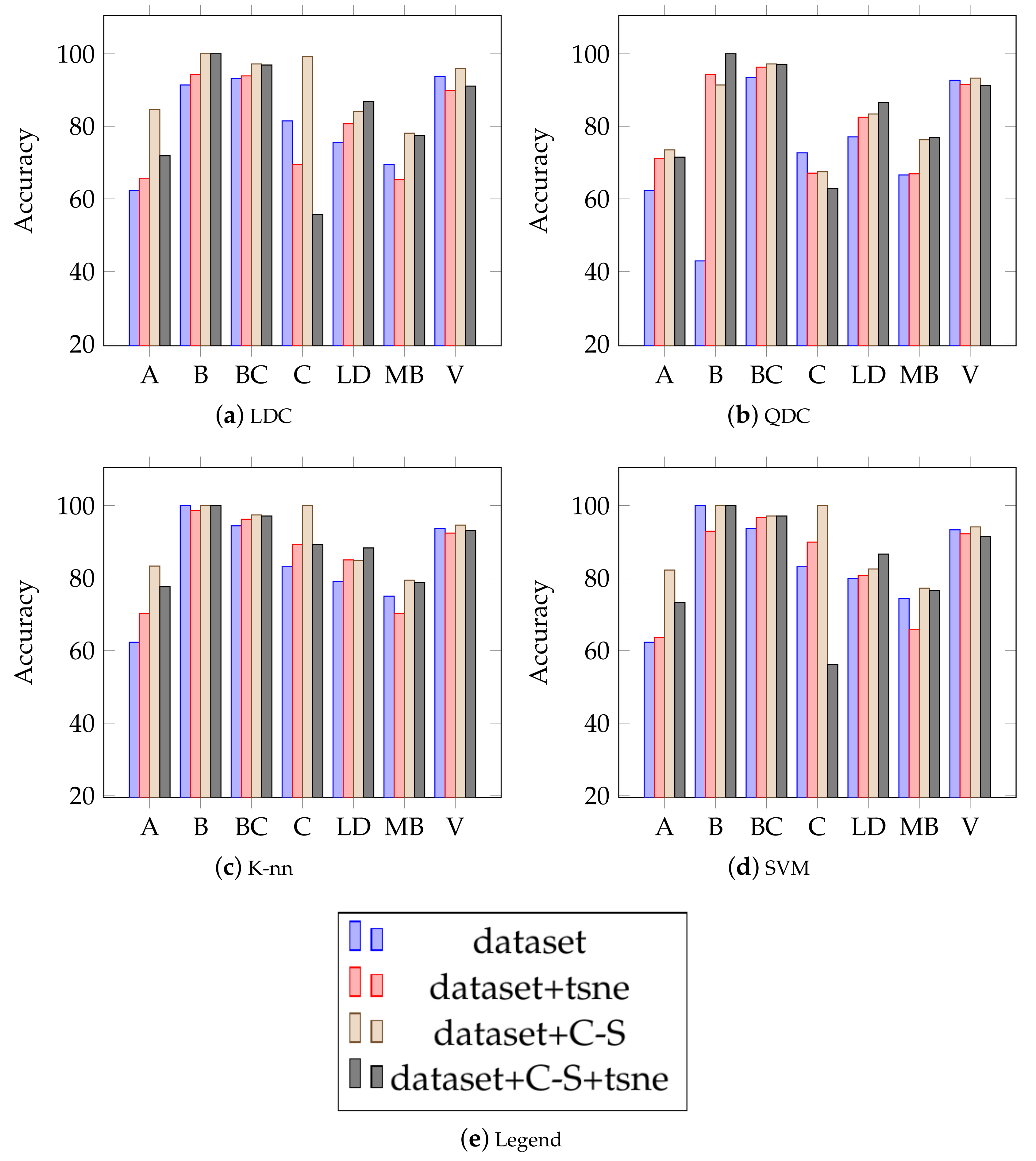{kind=link}
| Database | Samples | Features | Classes | Class Distribution |
|---|---|---|---|---|
| Audiology (Standardized) (A) | 226 | 69 | 2 | |
| Balloons (B) | 16 | 4 | 2 | |
| Breast Cancer (diagnosis) (BC) | 699 | 9 | 2 | |
| Chess (King-Rook vs. King-Pawn) (C) | 3196 | 36 | 2 | |
| Lymphography Domain (LD) | 148 | 18 | 2 | |
| Molecular Biology (Promoter Gene Sequences) (MB) | 106 | 57 | 2 | |
| Congressional Voting Records (V) | 435 | 16 | 2 |
| Experiment | Description |
|---|---|
| (A) | Database (A) + classifiers |
| (B) | Database (B) + classifiers |
| (BC) | Database (BC) + classifiers |
| (C) | Database (C) + classifiers |
| (LD) | Database (LD) + classifiers |
| (MB) | Database (MB) + classifiers |
| (V) | Database (V) + classifiers |
| (A) + (C-S) | Database (A) + Chi-Square Mapping + classifiers |
| (B) + (C-S) | Database (B) Chi-Square Mapping + classifiers |
| (BC) + (C-S) | Database (BC) + Chi-Square Mapping + classifiers |
| (C) + (C-S) | Database (C) + Chi-Square Mapping + classifiers |
| (LD) + (C-S) | Database (LD) + Chi-Square Mapping + classifiers |
| (MB) + (C-S) | Database (MB) + Chi-Square Mapping + classifiers |
| (V) + (C-S) | Database (V) + Chi-Square Mapping + classifiers |
| (A) + (C-S) + (t-SNE) | Database (A) + Chi-Square Mapping + t-SNE + classifiers |
| (B) + (C-S) + (t-SNE) | Database (B) + Chi-Square Mapping + t-SNE + classifiers |
| (BC) + (C-S) + (t-SNE) | Database (BC) + Chi-Square Mapping + t-SNE + classifiers |
| (C) + (C-S) + (t-SNE) | Database (C) + Chi-Square Mapping + t-SNE + classifiers |
| (LD) + (C-S) + (t-SNE) | Database (LD) + Chi-Square Mapping + t-SNE + classifiers |
| (MB) + (C-S) + (t-SNE) | Database (MB) + Chi-Square Mapping + t-SNE + classifiers |
| (V) + (C-S) + (t-SNE) | Database (V) + Chi-Square Mapping + t-SNE + classifiers |
| (A) + (t-SNE) | Database (A) + t-SNE + classifiers |
| (B) + (t-SNE) | Database (B) + t-SNE + classifiers |
| (BC) + (t-SNE) | Database (BC) + t-SNE + classifiers |
| (C) + (t-SNE) | Database (C) + t-SNE + classifiers |
| (LD) + (t-SNE) | Database (LD) + t-SNE + classifiers |
| (MB) + (t-SNE) | Database (MB) + t-SNE + classifiers |
| (V) + (t-SNE) | Database (V) + t-SNE + classifiers |
| Dataset (A) | cosine | jaccard | mahalanobis | chebychev | minkowski | cityblock | seuclidean | euclidean | (A) Chi |
| LDC | 62.5 ± 0.0 | 70.3 ± 0.1 | 71.1 ± 0.1 | 60.0 ± 0.4 | 69.2 ± 0.0 | 62.8 ± 0.0 | 61.2 ± 0.0 | 66.4 ± 0.0 | 73.4 ± 0.1 |
| QDC | 72.8 ± 0.1 | 83.1 ± 0.0 | 70.7 ± 0.0 | 58.5 ± 0.1 | 73.6 ± 0.3 | 73.9 ± 0.0 | 55.6 ± 0.0 | 69.3 ± 0.0 | 84.6 ± 0.0 |
| K-nn | 82.8 ± 0.0 | 84.8 ± 0.1 | 77.2 ± 0.0 | 79.3 ± 0.1 | 84.4 ± 0.1 | 85.1 ± 0.0 | 63.9 ± 0.1 | 80.8 ± 0.0 | 88.9 ± 0.0 |
| SVM | 62.3 ± 0.0 | 70.8 ± 0.1 | 71.1 ± 0.0 | 62.3 ± 0.0 | 62.6 ± 0.0 | 60.3 ± 0.0 | 62.3 ± 0.0 | 64.3 ± 0.0 | 76.7 ± 0.1 |
| Average | 70.1 | 77.2 | 72.5 | 65.0 | 72.5 | 70.5 | 60.7 | 70.2 | 80.9 |
| Dataset (B) | cosine | jaccard | mahalanobis | chebychev | minkowski | cityblock | seuclidean | euclidean | (A) Chi |
| LDC | 74.3 ± 0.2 | 82.9 ± 0.1 | 75.7 ± 0.2 | 78.6 ± 0.2 | 72.9 ± 0.1 | 92.9 ± 0.1 | 54.3 ± 0.1 | 92.9 ± 0.1 | 97.1 ± 0.1 |
| QDC | 71.4 ± 0.2 | 74.3 ± 0.1 | 71.4 ± 0.1 | 75.7 ± 0.2 | 84.3 ± 0.1 | 84.3 ± 0.1 | 75.7 ± 0.2 | 81.4 ± 0.2 | 91.4 ± 0.0 |
| K-nn | 75.7 ± 0.1 | 85.7 ± 0.1 | 88.6 ± 0.1 | 78.6 ± 0.2 | 85.7 ± 0.1 | 94.3 ± 0.1 | 67.1 ± 0.1 | 95.7 ± 0.0 | 100 ± 0.0 |
| SVM | 72.9 ± 0.1 | 84.3 ± 0.1 | 85.7 ± 0.2 | 78.6 ± 0.2 | 70.0 ± 0.1 | 94.3 ± 0.1 | 58.6 ± 0.1 | 90.0 ± 0.1 | 97.1 ± 0.1 |
| Average | 73.6 | 81.8 | 80.4 | 77.9 | 78.2 | 91.5 | 63.9 | 90.0 | 96.4 |
| Dataset (BC) | cosine | jaccard | mahalanobis | chebychev | minkowski | cityblock | seuclidean | euclidean | (A) Chi |
| LDC | 88.3 ± 0.0 | 94.3 ± 0.0 | 78.3 ± 0.0 | 96.3 ± 0.0 | 95.6 ± 0.0 | 96.6 ± 0.0 | 96.5 ± 0.0 | 96.4 ± 0.0 | 96.9 ± 0.0 |
| QDC | 90.6 ± 0.0 | 93.4 ± 0.0 | 89.2 ± 0.0 | 96.8 ± 0.0 | 96.6 ± 0.0 | 97.3 ± 0.0 | 96.5 ± 0.0 | 96.4 ± 0.0 | 97.3 ± 0.0 |
| K-nn | 90.1 ± 0.0 | 95.3 ± 0.1 | 91.8 ± 0.0 | 96.6 ± 0.0 | 96.7 ± 0.0 | 97.5 ± 0.0 | 96.7 ± 0.0 | 97.1 ± 0.0 | 97.4 ± 0.0 |
| SVM | 88.1 ± 0.0 | 94.4 ± 0.0 | 79.1 ± 0.0 | 96.4 ± 0.0 | 95.5 ± 0.0 | 96.6 ± 0.0 | 96.5 ± 0.0 | 96.5 ± 0.0 | 97.2 ± 0.0 |
| Average | 89.3 | 94.4 | 84.6 | 96.5 | 96.1 | 95.7 | 96.5 | 96.6 | 97.2 |
| Dataset (C) | cosine | jaccard | mahalanobis | chebychev | minkowski | cityblock | seuclidean | euclidean | (A) Chi |
| LDC | 60.8 ± 0.0 | 59.7 ± 0.0 | 57.8 ± 0.0 | 50.3 ± 0.0 | 60.9 ± 0.0 | 55.3 ± 0.0 | 62.4 ± 0.0 | 60.8 ± 0.0 | 68.2 ± 0.0 |
| QDC | 65.4 ± 0.0 | 60.1 ± 0.0 | 58.9 ± 0.0 | 53.9 ± 0.0 | 62.1 ± 0.0 | 63.1 ± 0.0 | 64.1 ± 0.0 | 65.2 ± 0.0 | 65.5 ± 0.0 |
| K-nn | 88.5 ± 0.0 | 70.8 ± 0.0 | 84.3 ± 0.0 | 53.0 ± 0.0 | 89.4 ± 0.0 | 89.5 ± 0.0 | 85.9 ± 0.0 | 89.1 ± 0.0 | 89.7 ± 0.0 |
| SVM | 62.6 ± 0.0 | 60.7 ± 0.0 | 58.6 ± 0.0 | 52.2 ± 0.0 | 61.5 ± 0.0 | 60.8 ± 0.0 | 62.5 ± 0.0 | 61.1 ± 0.0 | 68.7 ± 0.0 |
| Average | 69.3 | 62.8 | 64.9 | 52.4 | 68.5 | 67.2 | 68.7 | 69.1 | 73.8 |
| Dataset (LD) | cosine | jaccard | mahalanobis | chebychev | minkowski | cityblock | seuclidean | euclidean | (A) Chi |
| LDC | 76.6 ± 0.0 | 71.6 ± 0.1 | 68.9 ± 0.1 | 64.3 ± 0.1 | 65.9 ± 0.1 | 76.1 ± 0.0 | 76.6 ± 0.0 | 72.0 ± 0.1 | 81.6 ± 0.1 |
| QDC | 77.3 ± 0.1 | 76.1 ± 0.0 | 64.1 ± 0.1 | 67.5 ± 0.1 | 67.0 ± 0.1 | 77.5 ± 0.0 | 78.6 ± 0.0 | 73.6 ± 0.1 | 81.1 ± 0.1 |
| K-nn | 79.1 ± 0.1 | 76.4 ± 0.1 | 79.1 ± 0.1 | 72.5 ± 0.1 | 74.8 ± 0.1 | 80.7 ± 0.0 | 83.4 ± 0.0 | 78.6 ± 0.1 | 84.0 ± 0.1 |
| SVM | 75.0 ± 0.0 | 71.1 ± 0.1 | 68.1 ± 0.1 | 66.1 ± 0.1 | 68.6 ± 0.1 | 75.9 ± 0.5 | 78.9 ± 0.0 | 70.7 ± 0.0 | 81.8 ± 0.1 |
| Average | 77.0 | 73.8 | 70.0 | 67.6 | 69.1 | 77.6 | 79.4 | 73.7 | 82.9 |
| Dataset (MB) | cosine | jaccard | mahalanobis | chebychev | minkowski | cityblock | seuclidean | euclidean | (A) Chi |
| LDC | 47.8 ± 0.1 | 56.2 ± 0.1 | 60.0 ± 0.1 | 43.1 ± 0.1 | 60.3 ± 0.1 | 72.5 ± 0.1 | 62.5 ± 0.1 | 55.0 ± 0.1 | 76.2 ± 0.1 |
| QDC | 57.2 ± 0.1 | 71.2 ± 0.1 | 54.1 ± 0.1 | 57.5 ± 0.1 | 68.7 ± 0.1 | 74.7 ± 0.1 | 65.3 ± 0.1 | 58.4 ± 0.1 | 78.7 ± 0.1 |
| K-nn | 62.5 ± 0.1 | 70.9 ± 0.1 | 65.6 ± 0.1 | 50.9 ± 0.1 | 66.2 ± 0.0 | 75.6 ± 0.1 | 68.1 ± 0.1 | 70.6 ± 0.1 | 80.3 ± 0.1 |
| SVM | 52.2 ± 0.1 | 55.9 ± 0.1 | 61.6 ± 0.1 | 44.4 ± 0.1 | 56.6 ± 0.1 | 70.3 ± 0.1 | 63.7 ± 0.1 | 54.1 ± 0.1 | 76.6 ± 0.1 |
| Average | 54.9 | 63.6 | 60.3 | 49.0 | 63.0 | 73.3 | 64.9 | 59.7 | 78.0 |
| Dataset (V) | cosine | jaccard | mahalanobis | chebychev | minkowski | cityblock | seuclidean | euclidean | (A) Chi |
| LDC | 90.5 ± 0.0 | 88.9 ± 0.0 | 90.0 ± 0.0 | 73.7 ± 0.0 | 90.2 ± 0.0 | 91.4 ± 0.0 | 80.8 ± 0.0 | 90.1 ± 0.0 | 91.5 ± 0.0 |
| QDC | 90.5 ± 0.0 | 90.9 ± 0.0 | 90.0 ± 0.0 | 74.5 ± 0.0 | 92.1 ± 0.0 | 91.7 ± 0.0 | 81.4 ± 0.0 | 90.6 ± 0.0 | 91.4 ± 0.0 |
| K-nn | 92.6 ± 0.0 | 91.7 ± 0.0 | 91.4 ± 0.0 | 76.6 ± 0.0 | 92.3 ± 0.0 | 93.3 ± 0.0 | 82.7 ± 0.0 | 92.3 ± 0.0 | 93.8 ± 0.0 |
| SVM | 91.4 ± 0.0 | 90.9 ± 0.0 | 89.8 ± 0.0 | 75.2 ± 0.0 | 91.9 ± 0.0 | 92.3 ± 0.0 | 81.7 ± 0.0 | 90.8 ± 0.0 | 92.6 ± 0.0 |
| Average | 91.2 | 90.6 | 90.4 | 75.0 | 91.6 | 92.2 | 81.6 | 90.9 | 93.1 |
| Experimental Setup | Computational Time (Seconds) | Experimental Setup t-SNE | Computational Time (Seconds) |
|---|---|---|---|
| (A) + C-S | 33.8 | (A) + C-S + t-SNE | 24.6 |
| (B) + C-S | 1.4 | (B) + C-S + t-SNE | 0.2 |
| (BC) + C-S | 397.0 | (BC) + C-S + t-SNE | 86.0 |
| (C) + C-S | 30.9 | (C) + C-S + t-SNE | 21.5 |
| (LD) + C-S | 25.9 | (LD) + C-S + t-SNE | 18.3 |
| (MB) + C-S | 155.4 | (MB) + C-S + t-SNE | 52.6 |
| (V) + C-S | 2530.5 | (V) + C-S + t-SNE | 523.5 |
| Database | SWNBC | C4.5 | BK | NPC | C-S |
|---|---|---|---|---|---|
| Chess | 87.59 ± 1.23 | 97.48 ± 1.85 | 97.22 ± 1.94 | 88.67 ± 1.72 | 100.0 ± 0.00 |
| Congressional Voting | 90.08 ± 3.71 | 93.28 ± 3.18 | 92.36 ± 3.23 | 94.23 ± 3.62 | 94.53 ± 1.60 |
| Breast Cancer | 72.50 ± 7.71 | 71.33 ± 6.33 | 66.45 ± 6.92 | 73.81 ± 7.11 | 97.35 ± 1.30 |
| Lymphography Domain | 83.60 ± 9.82 | 73.12 ± 8.63 | 73.82 ± 8.47 | 87.76 ± 9.60 | 88.30 ± 4.80 |
| Balloons | 100.0 ± 0.00 | 100.0 ± 0.00 | 100.0 ± 0.00 | 100.0 ± 0.00 | 100.0 ± 0.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cardona, L.A.S.; Vargas-Cardona, H.D.; Navarro González, P.; Cardenas Peña, D.A.; Orozco Gutiérrez, Á.Á. Classification of Categorical Data Based on the Chi-Square Dissimilarity and t-SNE. Computation 2020, 8, 104. https://0-doi-org.brum.beds.ac.uk/10.3390/computation8040104
Cardona LAS, Vargas-Cardona HD, Navarro González P, Cardenas Peña DA, Orozco Gutiérrez ÁÁ. Classification of Categorical Data Based on the Chi-Square Dissimilarity and t-SNE. Computation. 2020; 8(4):104. https://0-doi-org.brum.beds.ac.uk/10.3390/computation8040104
Chicago/Turabian StyleCardona, Luis Ariosto Serna, Hernán Darío Vargas-Cardona, Piedad Navarro González, David Augusto Cardenas Peña, and Álvaro Ángel Orozco Gutiérrez. 2020. "Classification of Categorical Data Based on the Chi-Square Dissimilarity and t-SNE" Computation 8, no. 4: 104. https://0-doi-org.brum.beds.ac.uk/10.3390/computation8040104