Knowledge Management for Open Innovation: Bayesian Networks through Machine Learning



Abstract
:1. Introduction
1.1. Relevance between Knowledge Management and Open Innovation
1.2. Bayesian Networks Through Machine Learning
2. Materials and Methods
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nonaka, I.; Teece, D.J. (Eds.) Managing Industrial Knowledge: Creation, Transfer, and Utilization; Sage Publications Ltd.: New York, NY, USA, 2001. [Google Scholar]
- Teece, D. Human Capital, Capabilities, and the Firm: Literati, Numerati, and Entrepreneurs in the Twenty-First-Century Enterprise. In The Oxford Handbook of Human Capital; Burton-Jones, A.J.-C., Ed.; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Hajric, E. Knowledge Management System and Practices. A Theoretical and Practical Guide for Knowledge Management in Your Organization; Helpjuice: Jacksonville, FL, USA, 2018. [Google Scholar]
- Chesbrough, H.; Vanhaverbeke, W.; West, J. (Eds.) Open Innovation: Researching a New Paradigm; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Chesbrough, H. The future of open innovation: The future of open innovation is more extensive, more collaborative, and more engaged with a wider variety of participants. Res. Technol. Manag. 2017, 60, 35–38. [Google Scholar] [CrossRef]
- Ellen, E.; Bogers, M.; Chesbrough, H. Exploring open innovation in the digital age: A maturity model and future research directions. R&D Manag. 2020, 50, 161–168. [Google Scholar]
- Chesbrough, H.; Bogers, M. Explicating Open Innovation: Clarifying an Emerging Paradigm for Understanding Innovation. In New Frontiers in Open Innovation; Chesbrough, H., Vanhaverbeke, W., West, J., Eds.; Oxford University Press: New York, NY, USA, 2014; pp. 3–28. Available online: https://ssrn.com/abstract=2427233 (accessed on 16 January 2021).
- Davenport, T.H.; Prusak, L. Working Knowledge: How Organizations Manage What They Know; Harvard Business School Press: Boston, MA, USA, 1998. [Google Scholar]
- Koenig, M.; Neveroski, K. The Origins and Development of Knowledge Management. J. Inform. Knowl. Manag. 2008, 7, 243–254. [Google Scholar] [CrossRef]
- von Hayek, F.A. The use of knowledge in society. Am. Econ. Rev. 1945, 35, 519–530. [Google Scholar] [CrossRef]
- Nonaka, I.; Takeuchi, H. The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Bueno, E. Dirección del Conocimiento en las Organizaciones; Documento. Núm 16; AECA: Madrid, Spain, 2004. [Google Scholar]
- Lahaba, Y.N.; Santos, M.L. La gestión del conocimiento: Una nueva perspectiva en la gerencia de las organizaciones. Acimed 2001, 9, 121–126. [Google Scholar]
- Solleiro, J.L.; Escalante, F.; Herrera, A.; Castañón, R.; Luna, K.; Sánchez, G.; González, E. Gestión del conocimiento en Centros de Investigación y Desarrollo de México, Brasil y Chile; FLACSO México; Centro Internacional de Investigaciones para el Desarrollo: Avenida, Brasil, 2010. [Google Scholar]
- Bryson, J.M.; Berry, F.S.; Yang, K. The state of public strategic management research: A selective literature review and set of future directions. Am. Rev. Public Adm. 2010, 40, 495–521. [Google Scholar] [CrossRef] [Green Version]
- Guillen, I.; Montoya, T.; Rendón, M.; Montaño, L. Aprendizaje y cultura en las organizaciones: Un acercamiento al caso mexicano. Adm. Organ. 2002, 4, 53–83. [Google Scholar]
- Ekboir, J.; Dutrénit, G.; Martínez, G.; Torres, A.; Vera-Cruz, A. Successful Organizational Learning in the Management of Agricultural Research and Innovation the Mexican Produce Foundations; Research Report; IFPRI (International Food Policy Research Institute): Washington, DC, USA, 2009; p. 153. [Google Scholar]
- Fearnley, P.; Horder, M. What is knowledge management? Knowledge Management in the Oil and Gas Industry. In London Conference Proceedings Notes; IGI Global: London, UK, 1997. [Google Scholar]
- Solleiro, J.L.; Terán-Bustamante, A. Buenas Prácticas de Gestión de la Innovación en Centros de Investigación Tecnológica; Universidad Autónoma de México e Instituto de Investigaciones Eléctricas: Mexico City, México, 2012. [Google Scholar]
- Fernández, V. Gestión del Conocimiento versus Gestión de la Información. Investig. Bibliotecol. 2006, 20, 42–62. [Google Scholar] [CrossRef] [Green Version]
- Rajalakshmi, S.; Banu, R.W. Analysis of Tacit Knowledge Sharing and Codification in Higher Education. In Proceedings of the 2012 International Conference on Computer Communication and Informatics, Coimbatore, India, 10–12 January 2012. [Google Scholar]
- Dorji, S.; Kirikova, M. Data, Information, and Knowledge Modeling in Work System Networks; Faculty of Computer Science and Information Technology, Institute of Applied Computer Systems, Kalku 1, Riga Technical University: Riga, Latvia, 2012. [Google Scholar]
- Liew, A. DIKIW: Data, information, knowledge, intelligence, wisdom, and their interrelationships. Bus. Manag Dynam. 2013, 2, 49. [Google Scholar]
- Liew, A. Data, information, knowledge, and their interrelationships. J. Knowl. Manag. Prac. 2007, 7, 2. [Google Scholar]
- Zins, C. Conceptual approaches for defining data, information, and knowledge. J. Am. Soc. Inform. Sci. Technol. 2007, 58, 479–493. [Google Scholar] [CrossRef]
- Davenport, T.; Long, D.; Beers, M. Successful Knowledge Management Projects. Sloan Manag. Rev. 1998, 39, 43–57. [Google Scholar]
- Manzano, O.; González, Y. La gestión del conocimiento como generador de valor agregado en las organizaciones: Análisis de un sector empresarial. Libre Empresa 2011, 8, 69–80. [Google Scholar]
- Plaz, R. Gestión del conocimiento: Una visión integradora del aprendizaje organizacional. MadrI + D51. 2003, 7, 51–58. [Google Scholar]
- Plaz, R.; González, N. La gestión del conocimiento organizativo: Dinámicas de agregación de valor en la organización. Econ. Ind. 2005, 357, 41–54. [Google Scholar]
- Choo, P. Innovation and Knowledge Creation: How are these Concepts Related? Int. J. Inform. Manag. 2006, 26, 302–312. [Google Scholar]
- Marchiori, D.; Mendes, L. Knowledge management, and total quality management: Foundations, intellectual structures, insights regarding the evolution of the literature. Total Qual. Manag. Bus. Excell. 2020, 31, 1135–1169. [Google Scholar] [CrossRef]
- Choo, C.W. Information Management for the Intelligent Organization, 3rd ed.; Information Today Inc.: Medford, NJ, USA, 2001. [Google Scholar]
- Gold, A.H.; Malhotra, A.; Segars, A.H. Knowledge management: An organizational capabilities perspective. J. Manag. Inform. Syst. 2001, 18, 185–214. [Google Scholar] [CrossRef]
- Koentjoro, S.; Gunawan, S. Managing Knowledge, Dynamic Capabilities, Innovative Performance, and Creating Sustainable Competitive Advantage in Family Companies: A Case Study of a Family Company in Indonesia. J. Open Innov. Technol. Mark. Complex. 2020, 6, 90. [Google Scholar] [CrossRef]
- Chung-Jen, C.; Huang, J.; Hsiao, Y. Knowledge management and innovativeness. Int. J. Manpow. 2010, 31, 848–870. [Google Scholar] [CrossRef]
- Lee, V.-H.; Leong, L.-Y.; Hew, T.-S.; Ooi, K.-B. Knowledge management: A key determinant in advancing technological innovation? J. Knowl. Manag. 2013, 17, 848–872. [Google Scholar] [CrossRef]
- Sveiby, K.E. The New Organizational Wealth: Managing and Measuring Knowledge-Based Assets; Berrett-Koehler: San Francisco, CA, USA, 1997. [Google Scholar]
- Sveiby, K.E. A knowledge-based theory of the firm to guide in strategy formulation. J. Intellect. Cap. 2001, 2, 44–358. [Google Scholar] [CrossRef] [Green Version]
- Sveiby, K.E. The Intangible Assets Monitor. J. Hum. Resour. Costing Account. 1997, 2, 73–97. [Google Scholar] [CrossRef]
- Hannu, R.; Sveiby, K.E. Are Turn to Practice. In The Routledge Companion to Intellectual Capital; Guthrie, J., Dumay, J., Ricceri, F., Nielsen, C., Eds.; The Routledge Companion to Intellectual Capital; Routledge: London, UK, 2017. [Google Scholar] [CrossRef]
- McInerney, C.R.; Koenig, M.E. Knowledge management (KM) processes in organizations: Theoretical foundations and practice. Synthesis Lectures on Information Concepts. Retr. Serv. 2011, 3, 1–96. [Google Scholar]
- Luga, V.; Kifor, C.V. Information and knowledge management and their inter-relationship within lean organizations. Sci. Bull. Nicolae Balcescu Land Forces Acad. 2014, 19, 31. [Google Scholar]
- Durant-Law, G.Y.; Byrne, P. The Tardis Knowledge Productivity System. Australian Government. 2007. Available online: http://www.durantlaw.info/sites/durantlaw.info/files/TARDIS%20Manual.pdf (accessed on 16 January 2021).
- Asiedu, E. A Critical Review on the Various Factors that Influence Successful Implementation of Knowledge Management Projects within Organizations. Int. J. Econ. 2015, 4, 7. [Google Scholar] [CrossRef]
- Omotayo, F. Knowledge Management as an important tool in Organisational Management: A Review of Literature. Libr. Philos. Prac. 2015, 1, 1–23. [Google Scholar]
- Mugellesi Dow, R.; Pallaschke, S. Managing knowledge for spacecraft operations at ESOC. J. Knowl. Manag. 2010, 14, 659–677. [Google Scholar] [CrossRef]
- Chesbrough, H.; Bogers, M. Explicating Open Innovation: Clarifying an Emerging Paradigm for Understanding Innovation. In Open Innovation: New Frontiers and Applications; Chesbrough, H., Vanhaverbeke, W., West, J., Eds.; Oxford University Press: Oxford, UK, 2014. [Google Scholar] [CrossRef] [Green Version]
- Zahra, S.A.; George, G. Absorptive capacity: A review, reconceptualization, and extension. Acad. Manag. Rev. 2002, 27, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.O.; Hart, P.E. DG Stork Pattern Classification; John Wiely and Sons, Inc.: Hoboken, NJ, USA, 2001. [Google Scholar]
- Bernardo, J.M.; Smith, A.F. Bayesian Theory; Wiley Series in Probability and Mathematical Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 405. [Google Scholar]
- Pearl, J. Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach; Cognitive Systems Laboratory, School of Engineering and Applied Science, University of California: Los Angeles, CA, USA, 1982; pp. 133–136. [Google Scholar]
- Pearl, J. Fusion, Propagation, and Structuring in BAYESIAN Networks; University of California, Computer Science Department: Los Angeles, CA, USA, 1985. [Google Scholar]
- Rivera, M.M. El Papel de las Redes Bayesianas en la Toma de Decisiones. 2011. Available online: http://www.urosario.edu.co/Administracion/documentos/investigacion/laboratorio/miller_2_3.pdf (accessed on 16 January 2021).
- Koshi, T.; Noble, J. Bayesian Networks an Introduction; Wiley Series in Probability and Statistics; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Clark, J.S. Why environmental scientists are becoming Bayesians. Ecol. Lett. 2005, 8, 2–14. [Google Scholar] [CrossRef]
- Bolker, B. Ecological Models and Data in R; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis, 3rd ed.; Chapman and Hall/CRC Press: New York, NY, USA, 2013. [Google Scholar]
- Ruiz-Benito, P.; Andivia, E.; Archambeaou, J.; Astigarraga, J.; Barrientos, R.; Cruz-Alonso, V.; Florencio, M.; Gómez, D.; Martínez-Baroja, L.; Quiles, P.; et al. Ventajas de la estadística bayesiana frente a la frecuentista: ¿por qué nos resistimos a usarla? Ecosistemas 2018, 27, 136–139. [Google Scholar] [CrossRef] [Green Version]
- Pearl, J. Bayesian networks, causal inference, and knowledge discovery. UCLA Cognitive Systems Laboratory. Tech. Rep. 2001, 1–9. Available online: ftp://pike.cs.ucla.edu/pub/stat_ser/R281.ps (accessed on 16 January 2021).
- Kjærulff, U.B.; Madsen, A.L. Probabilistic Networks. Bayesian Networks and Influence Diagrams: A Guide to Construction and Analysis; Springer: Berlin, Germany, 2008; pp. 63–106. [Google Scholar] [CrossRef]
- Beltrán, M.; Muñoz, A.; Muñoz, Á. Redes Bayesianas aplicadas a problemas de credit scoring. Una aplicación práctica. Cuad. Econ. 2014, 37, 73–86. [Google Scholar] [CrossRef] [Green Version]
- Terán-Bustamante, A.; Davila, G.; Castañon, R. Management of Technology and Innovation: A Bayesian Network Model. Ecoo. Teória Práct. 2019, 50, 63–100. [Google Scholar] [CrossRef]
- García, C.A. Selección de Instancias y Atributos en Conjuntos de Datos Mediante Algoritmos Sobre Grafos; Universidad de Sevilla: Sevilla, Spain, 2012; Available online: https://idus.us.es/bitstream/handle/11441/15361/O_Tesis-PROV25.pdf;jsessionid=45ADCE0BADE3179EDE0B60EAF9989776?sequence=1 (accessed on 16 January 2021).
- Huete, J.F. Sistemas Expertos Probabilísticos: Modelos Gráficos. 1998. Available online: https://ruidera.uclm.es/xmlui/handle/10578/6097 (accessed on 16 January 2021).
- Lavrač, N.; Kavšek, B.; Flach, P.; Todorovski, L. Subgroup discovery with CN2-SD. J. Mach. Learn. Res. 2004, 5, 153–188. [Google Scholar]
- López Puga, J. Modelos Predictivos en Actitudes Emprendedoras: Análisis Comparativo de las Condiciones de Ejecución de las Redes Bayesianas y la Regresión Logística. Master’s Thesis, Universidad de Almería, Almería, Spain, 2011. [Google Scholar]
- CONSAR. Información estadística. Cuentas Administradas por las Afores. México. (Cifras al cierre de Noviembre de 2020). 2020. Available online: https://www.consar.gob.mx/gobmx/aplicativo/siset/CuadroInicial.aspx?md=5 (accessed on 16 January 2021).
- Wang, Y.; Ye, Z.; Wan, P.; Zhao, J. A survey of dynamic spectrum allocation based on reinforcement learning algorithms in cognitive radio networks. Artif. Intell. Rev. 2019, 51, 493–506. [Google Scholar] [CrossRef]
- Kim, H.; Park, Y. The effects of open innovation activity on performance of SMEs: The case of Korea. Int. J. Technol. Manag. 2010, 52, 236–256. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data > Information Management | Knowledge Creation | Knowledge Management | |
|---|---|---|---|
| Concept | |||
| The information is an organized set of processed data, which constitutes a message about a certain entity or phenomenon. | To share mentally, emotionally, and actively knowledge and ideas in such a way that added value is generated. The function of knowledge management is (i) to create new knowledge; (ii) to capture knowledge; (iii) transfer, distribute, and share knowledge; and (iv) assimilate. The conditions that make it feasible are sources, results, and measurement. | It includes defining how information is internalized and externalized, as well as the application of knowledge within the organization and how it is disseminated to the outside. | |
| Type | Tacit Explicitly Cultural |
|
| Perspective | The individual, group, organizational, inter-organizational. | ||
| Principles | Sharing experiences and learning | ||
| Time | Continuous—never ends- | ||
| Specific classification | Individual–collective | ||
| Based on the value chain. | |||
| Promoters | Processual, causal, conditional, relational | ||
| Process | Planning, decision-making, learning, awareness, understanding, adaptation, interaction, need for innovation, and crisis. | ||
| Where did it happen? | Socialization, externalization, internalization, combination. Creation and justification of concepts, construction of prototypes, cross-leveling knowledge. | ||
| # | Variable | Concept | Dimension |
|---|---|---|---|
| 1 | Competitive and technological intelligence | Those are activities that are carried out to monitor the technological environment of an organization | Yes/No |
| 2 | Strategic and Technological Planning | It is the plan that presents the technological strategy, defined for the organization, as the guiding thread. It allows us to identify the products/services that a company can offer to respond to market needs. | Yes/No |
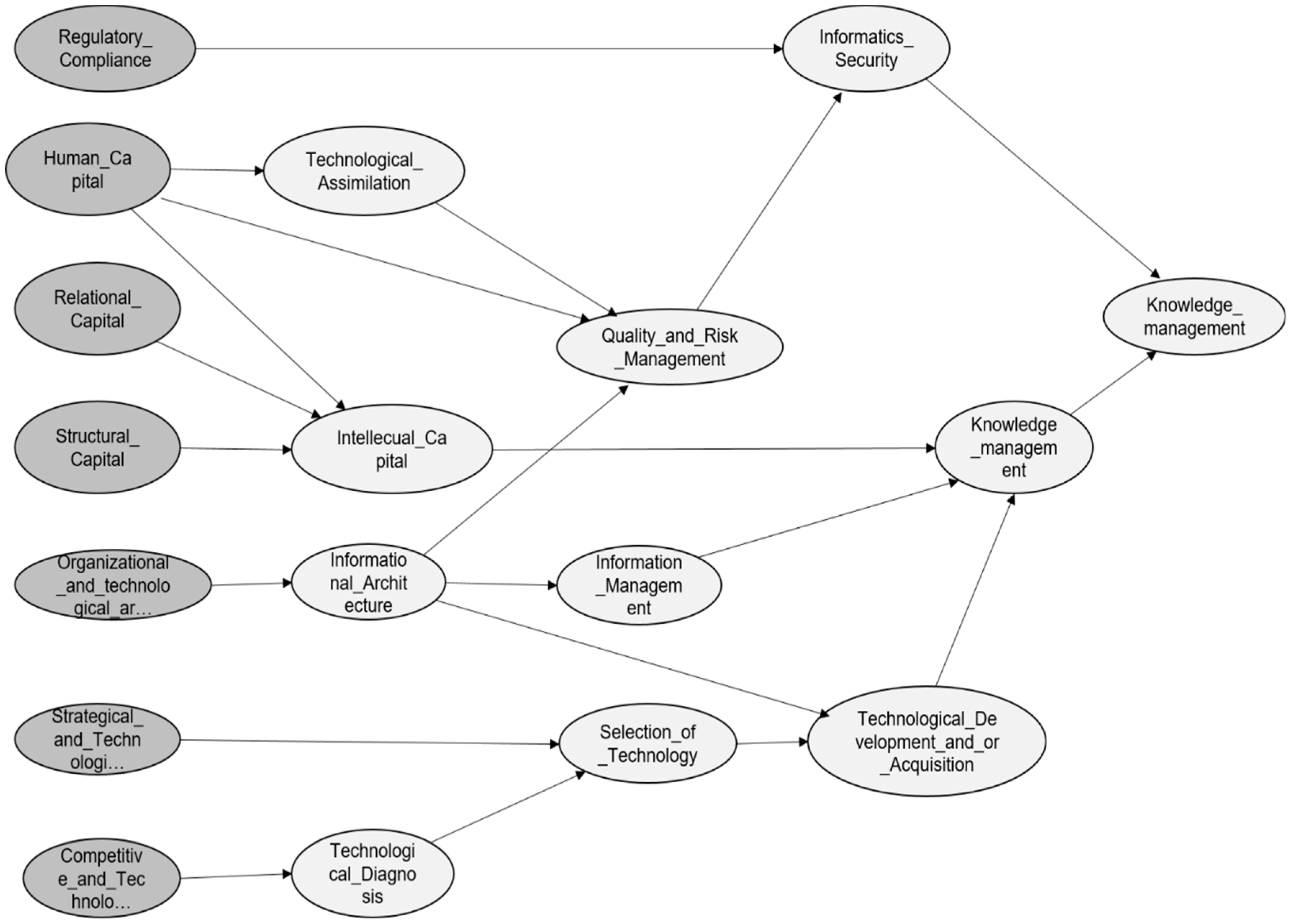
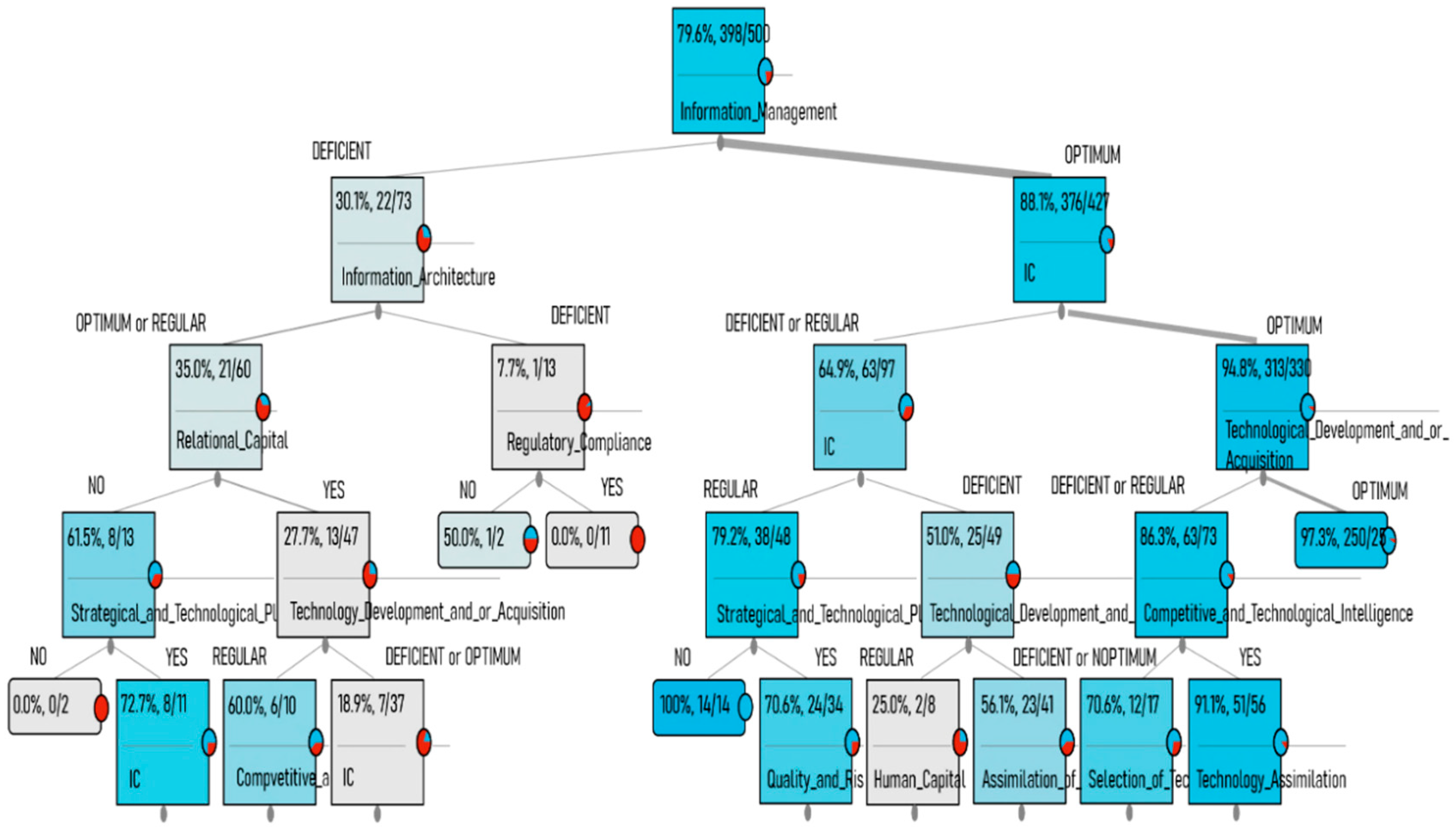
| 3 | Organizational and Technological Architecture | It is the design, organization, and distribution of computer systems, to satisfy information needs effectively. | Optimum Regular Deficient |
| 4 | Regulatory Compliance | Focuses on complying with legal aspects and the corresponding regulations. | Yes/No |
| 5 | Human Capital | It is a set of knowledge (tacit and explicit). There are a set of attitudes, abilities, motivations, and values that people possess. It is the talent of people. | Qualified |
| 6 | Relational Capital | It is the value that a company has the set of relationships that it maintains with the outside. | Not Qualified |
| 7 | Structural Capital | The knowledge that the company has internalized, generating value for it and that remains in the organization either in its structure, its processes, or in its culture. | With intellectual property No intellectual property |
| 8 | Technological Diagnosis | A tool that allows knowing the degree of development for innovation capabilities. It allows generating initiatives and being an instrument to generate knowledge. | Adequate/Inadequate |
| 9 | Technological Architecture | The conceptual model defines the structure, behavior, governance, and relationships between hardware, software, networks, data, human interaction, and the ecosystem that surrounds business processes. | Optimum Regular Deficient |
| 10 | Quality and Risk Management | A set of techniques and tools to support and help make the appropriate decisions, considering uncertainty, the possibility of future events, and the effects on the agreed objectives. | Optimum Deficient |
| 11 | Technology Selection | Process of identification, selection, and obtaining outside the organization of the necessary technology for its current and future operation | Optimum Regular Deficient |
| 12 | Technological Development and/or Acquisition | It is the process for the adequate development or acquisition of the necessary technology for the current and future operation of the organization. | Optimum Regular Deficient |
| 13 | Information Management | It is managing data. Set of activities aimed at the generation, coordination, storage or conservation, search and recovery of information both internally and externally contained in any medium. | Optimum Deficient |
| 14 | Computer Security | The process to protect the use and access to the organization’s computer resources. Considering confidentiality, integrity, availability, and authentication. | Optimum Deficient |
| 15 | Assimilation of Technology | The process that allows an organization to adapts the technology it acquires and gain the capacity to use it appropriately. | Optimum Regular Deficient |
| 16 | Intellectual Capital | Identification of intellectual assets, referring to the stock of knowledge that the organization possesses. The knowledge that can translate into value extraction and creation. | Optimum Regular Deficient |
| 17 | Knowledge Management | A systematic process of generation, documentation, dissemination, exchange, use, and improvement of individual and organizational knowledge. | Optimum Deficient |
| Variable | Score |
|---|---|
| Information Management | 0.204 |
| Relational Capital | 0.136 |
| Intellectual Capital | 0.080 |
| Quality and Risk Management | 0.048 |
| Technology Assimilation | 0.040 |
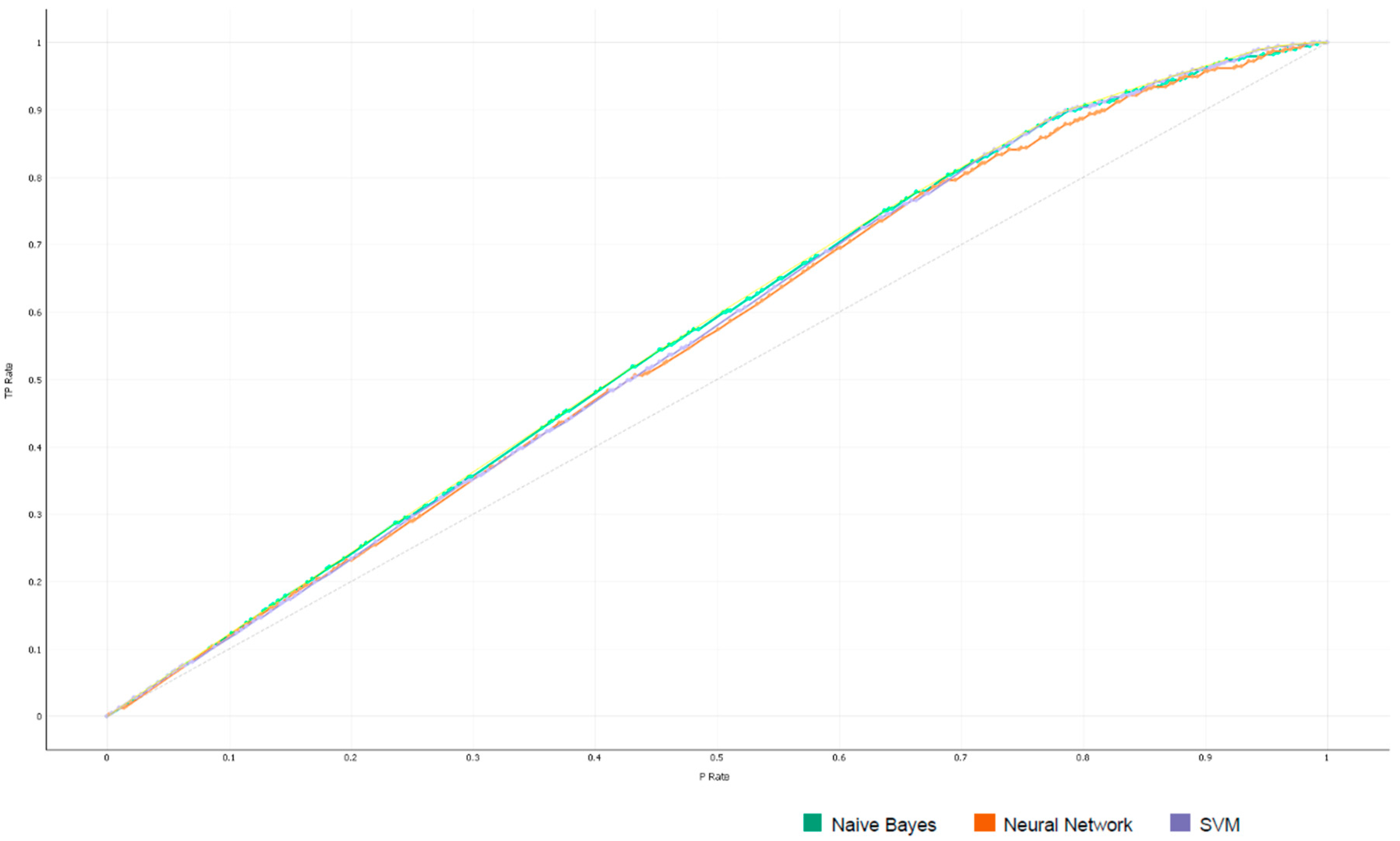
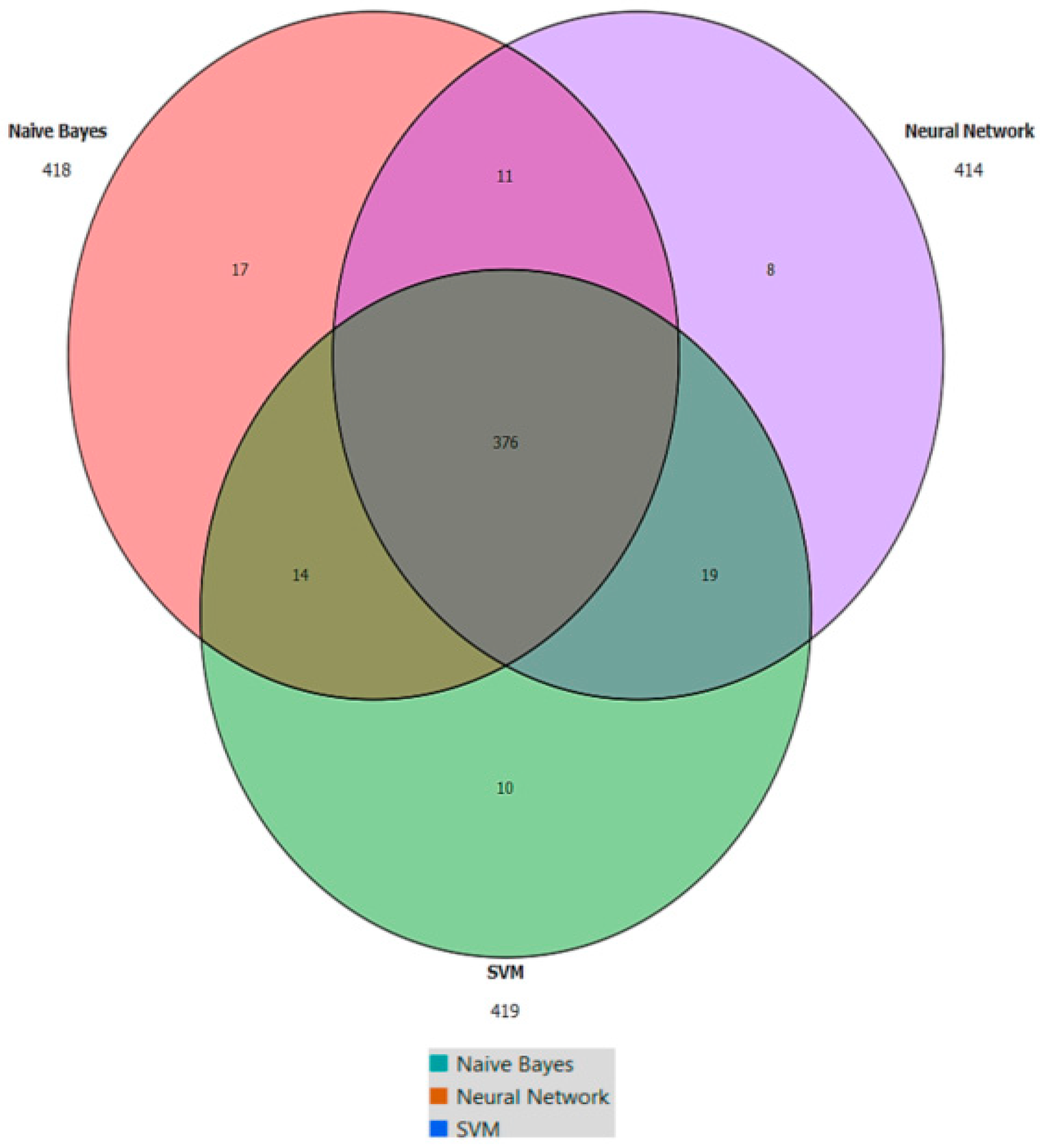
| Model | AUC | CA | F1 | Precision | Recall |
|---|---|---|---|---|---|
| Naive Bayes | 0.83 | 0.84 | 0.83 | 0.82 | 0.84 |
| Neural Network | 0.79 | 0.83 | 0.82 | 0.82 | 0.83 |
| SVM | 0.81 | 0.84 | 0.82 | 0.82 | 0.84 |
| Item Sets | % |
|---|---|
| Technological Diagnosis = Adequate | 93 |
| Regulatory Compliance = Yes | 85 |
| Human Capital = Capable | 84 |
| Technology Selection = Optimum | 86 |
| Informatics Security = Optimum | 79 |
| Strategic and Technological Planning = Yes | 80 |
| Technology Assimilation = Optimum | 81 |
| Organizational and technological architecture = Optimum | 80 |
| Regulatory Compliance = Yes | 92 |
| informatics’ Security = Optimum | 80 |
| Competitive and technological intelligence = Yes | 91 |
| Regulatory Compliance = Yes | 83 |
| Technological Diagnosis = Adequate | 87 |
| Regulatory Compliance = Yes | 79 |
| Human Capital = Capable | 79 |
| Technology Selection = Optimum | 60 |
| Human Capital = Capable | 83 |
| Technology Selection = Optimum | 82 |
| Human Capital = Capable | 90 |
| Regulatory Compliance = Yes | 82 |
| Technology Selection = Optimum | 80 |
| Technology Selection = Optimum | 90 |
| Regulatory Compliance = Yes | 82 |
| Strategic and Technological Planning = Yes | 79 |
| Informatics’ Security = Optimum | 86 |
| Strategic and Technological Planning = Yes | 86 |
| Regulatory Compliance = Yes | 79 |
| Technology Assimilation = Optimum | 85 |
| Human Capital = Capable | 82 |
| Organizational and technological architecture = Optimum | 85 |
| Information Management = Optimum | 82 |
| Technological architecture = Optimum | 81 |
| Quality and risk management = Optimum | 80 |
| Development or Technology Acquisition = Optimum | 79 |
| CI = Optimum | 79 |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture ==MEDIUM THEN Knowledge management =HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture ==MEDIUM AND Competitive and Technological Intelligence! =NO THEN Knowledge management =HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUMAND Competitive and Technological Intelligence! =YES THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUM AND Technological Diagnosis==Appropriate THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUM AND Technological Diagnosis! =Appropriate THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUM AND Strategic and Technological Planning==NO THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUM AND Strategic and Technological Planning! = NO THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUM AND Technology Selection! = DEFICIENT THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUM AND Technology Selection==OPTIMUM THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture==MEDIUM AND Technology Selection! = MEDIUM THEN Knowledge management=HIGH |
| IF Information Management! =DEFICIENT AND CI==Optimum AND Information Architecture ==MEDIUM THEN Knowledge management =HIGH |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Terán-Bustamante, A.; Martínez-Velasco, A.; Dávila-Aragón, G. Knowledge Management for Open Innovation: Bayesian Networks through Machine Learning. J. Open Innov. Technol. Mark. Complex. 2021, 7, 40. https://0-doi-org.brum.beds.ac.uk/10.3390/joitmc7010040
Terán-Bustamante A, Martínez-Velasco A, Dávila-Aragón G. Knowledge Management for Open Innovation: Bayesian Networks through Machine Learning. Journal of Open Innovation: Technology, Market, and Complexity. 2021; 7(1):40. https://0-doi-org.brum.beds.ac.uk/10.3390/joitmc7010040
Chicago/Turabian StyleTerán-Bustamante, Antonia, Antonieta Martínez-Velasco, and Griselda Dávila-Aragón. 2021. "Knowledge Management for Open Innovation: Bayesian Networks through Machine Learning" Journal of Open Innovation: Technology, Market, and Complexity 7, no. 1: 40. https://0-doi-org.brum.beds.ac.uk/10.3390/joitmc7010040