1. Introduction
Socio-demographic datasets provide information about the population in a certain area. Besides others, they provide measures for the evaluation of age and family structures, gender distribution, and household size as well as educational level, employment, income, purchasing power, religious beliefs, and cultural heritage on different scales [
1]. Especially for political decision-making and urban planning, this information is of great value. Spatial economic information is also of particular interest to companies. With this, advertising can not only be developed and placed in a more targeted way, butalso, for example, a new branch of a business can be located, much more precisely adapted to the income of the population living in a respective area.
North Rhine-Westphalia (NRW) is the most populated state of Germany and exhibits a population with distinct economic statuses and opportunities. Hence, it is particularly suitable to establish a reproducible methodological approach that can be applied to other urban areas in other countries. Detailed socio-demographic datasets are very often collected by private enterprises (e.g., microm GmbH, Michael Bauer Micromarketing GmbH) and are commercially published in many different formats, covering a lot of different variables [
2]. Numerous spatial approaches focus on a more global scale for which the resolution and the size of the spatial units do not fall below urban statistical districts (e.g., [
3,
4,
5,
6]). The scope of available initial spatial datasets varies from very coarse (e.g., whole cities) to moderate (e.g., urban statistical districts), and results are often simply visualised in table form [
7] or diagrams that only establish borders between statistically generated classes [
8]. Since the early 1990s [
9], there have been numerous international studies and other publications that address the combination of spatial and statistical datasets and suggest how to ideally deal with this inter-methodological approach [
10,
11,
12,
13,
14]. However, socioeconomic properties are usually assigned to area-covering, gap-less administrative polygons, neglecting the fact, that people do not live equally spread throughout the area covered by such polygons. This leads to wrong spatially related numbers such as density for those polygons, wherein people gather only on a small part (e.g., block of buildings) of their respective area. This methodological limitation has been overcome by the submitted approach. The application of the proposed workflow using broadly available data to gain disaggregated relocated large-scale socioeconomic datasets has not yet been fully utilised.
In 2016, Ref. [
15] conducted a study to detect and classify hotspots of socioeconomic disadvantages for urban statistical districts in the city of Dortmund. Until then, this was the highest level of spatial detail one could find in social science studies that deal with socioeconomic values stored rather in individually shaped vector features instead of uniform raster cells. This study proposes to fill the gap between the expertise of using spatial data on the one hand and statistical socio-demographic data analysis on the other hand. It leads to a sophisticated disaggregation and relocation concept that can be broadly applied with a certain set of source data. The aim is to come to new conclusions by enhancing the spatial precision and to find new ways to incorporate social data into spatial analyses, such as the clustering and recognition of regional and local patterns, developed based on a case study for Dortmund, NRW. Finally, it is about the visualisation of such data in adequate and revealing maps to provide an auxiliary for visual validation and interpretation.
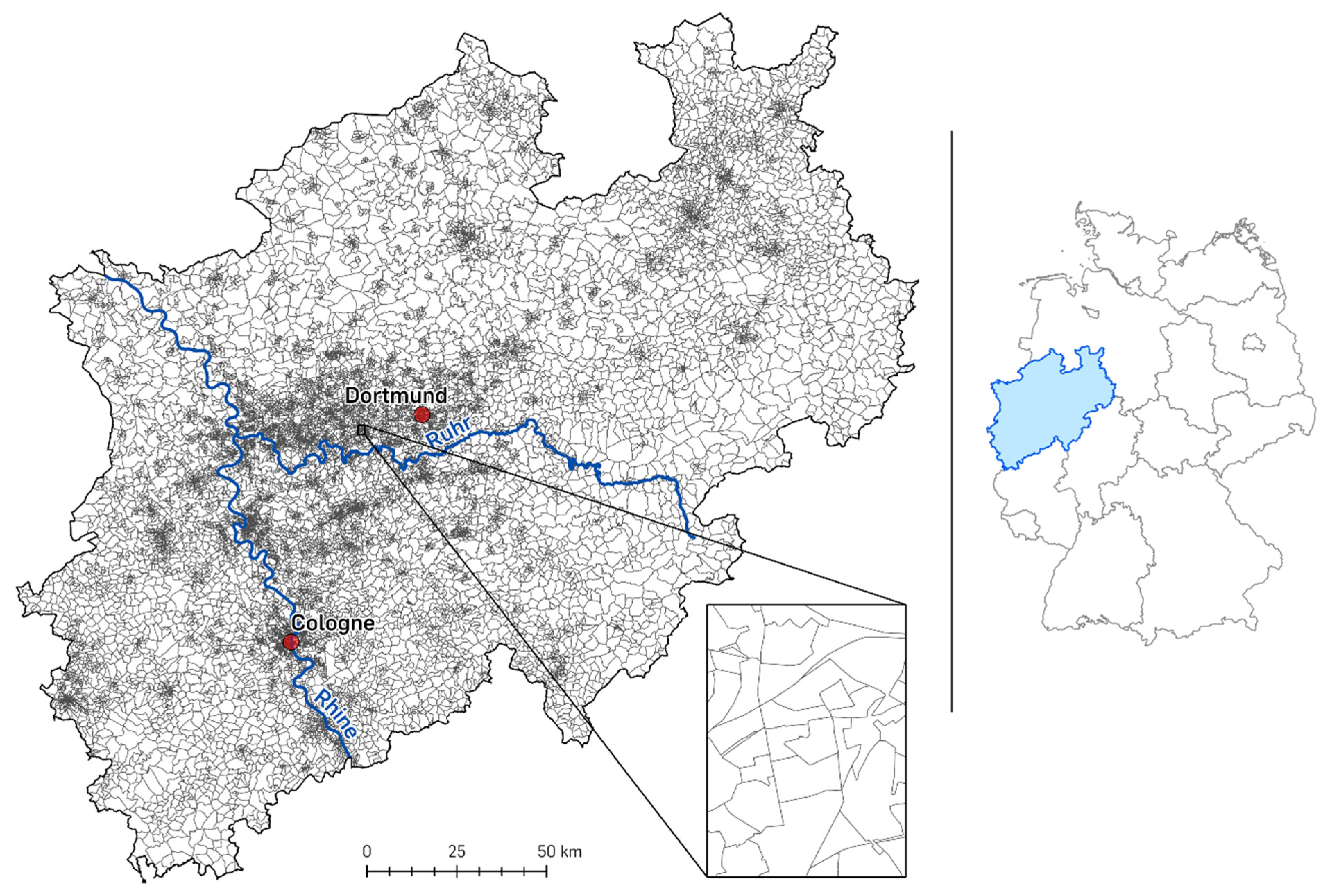
One of the common spatial units for geo-spatial representations of socioeconomic datasets in Germany are postcode polygons. These can be compared to any other kind of gapless spatial unit in terms of global transferability. Those postcode polygons are split up to even more detailed postal units with eight-digit pseudo-postcode polygons (PLZ8) that are provided by the company microm GmbH. Each of the polygons covers about 500 households. Hence, this dataset delivers a uniform basis for comparing different regions while still neglecting the fact that the distribution of people in a given polygon is never homogeneous and, consequently, partly contains areas where no people live. Yet, those homogeneous numbers of inhabitants per unit reliably allow to compare certain attributes in between any selection of polygons ([
16], see
Figure 1).
In this paper, the general concept of the three-class dasymetric mapping disaggregation will be introduced, illustrated, and applied to income and population data from the city of Dortmund. The resulting disaggregated datasets will be used for spatial comparison of the relationship between the population density and annual income [
17] on a city block level. Subsequently, the results will be compared to the initial postal code units through a correlation analysis followed by an individual clustering of both kinds of units for the final identification of respective hot spots of the highest correlation.
Univariate and bivariate choropleth maps are well-suited to give an extensive overview of how people of different economic statuses are distributed in Germany’s most populated state NRW and where certain characteristics and values peak locally. In this case, this comparative visualisation focuses on the two agglomerations of the Rhineland and the Ruhr area with their respective biggest cities of Cologne and Dortmund. They are known to be the densest populated areas in NRW. However, they differ in various social aspects, as, e.g., [
18,
19,
20] have already pointed out. Here, they provide an ideal use case for large-scale disaggregated socioeconomic datasets. A spatial comparison of these two areas reveals patterns that confirm and underline differences, allowing a better understanding of the causes for regional disparities.
The comprehensive disaggregation approach tested for the city of Dortmund refines the PLZ8-wide information to much smaller spatial units representing only residential housing blocks or even single houses and leaving out all unpopulated parts between them. Consequently, disaggregated values can provide the possibility to not only rate the gapless and coarse polygons coming from, e.g., postal codes or administrative units. With them, one can also obtain a visual impression of how the bivariate choropleth map results of the precedent analysis refer to the real living location of the population [
21].
2. Materials and Methods
2.1. PLZ8 Polygons
Countries are subdivided into smaller administrative units (states, districts, municipalities, etc.) as well as postal tracts on different levels of spatial detail. The postal code 8 level (PLZ8) is an artificial spatial unit developed for German conditions by microm GmbH. It subdivides the regular German five-digit postal code polygons into smaller areas representing an average of 500 inhabitants per polygon. Advantageously, the PLZ8 data product matches with existing administrative spatial units. Hence, its comparability is directly dependent on the spatial scale of the scientific approach (see
Figure 1). In urban areas, one identifies smaller PLZ8 polygons, whereas in rural areas, the extent of PLZ8 polygons is much larger. This means, in effect, that values between two different polygons—e.g., one in an urban and one in a rather rural area—can be reasonably compared with one another while the extent of the respective polygons may differ widely.
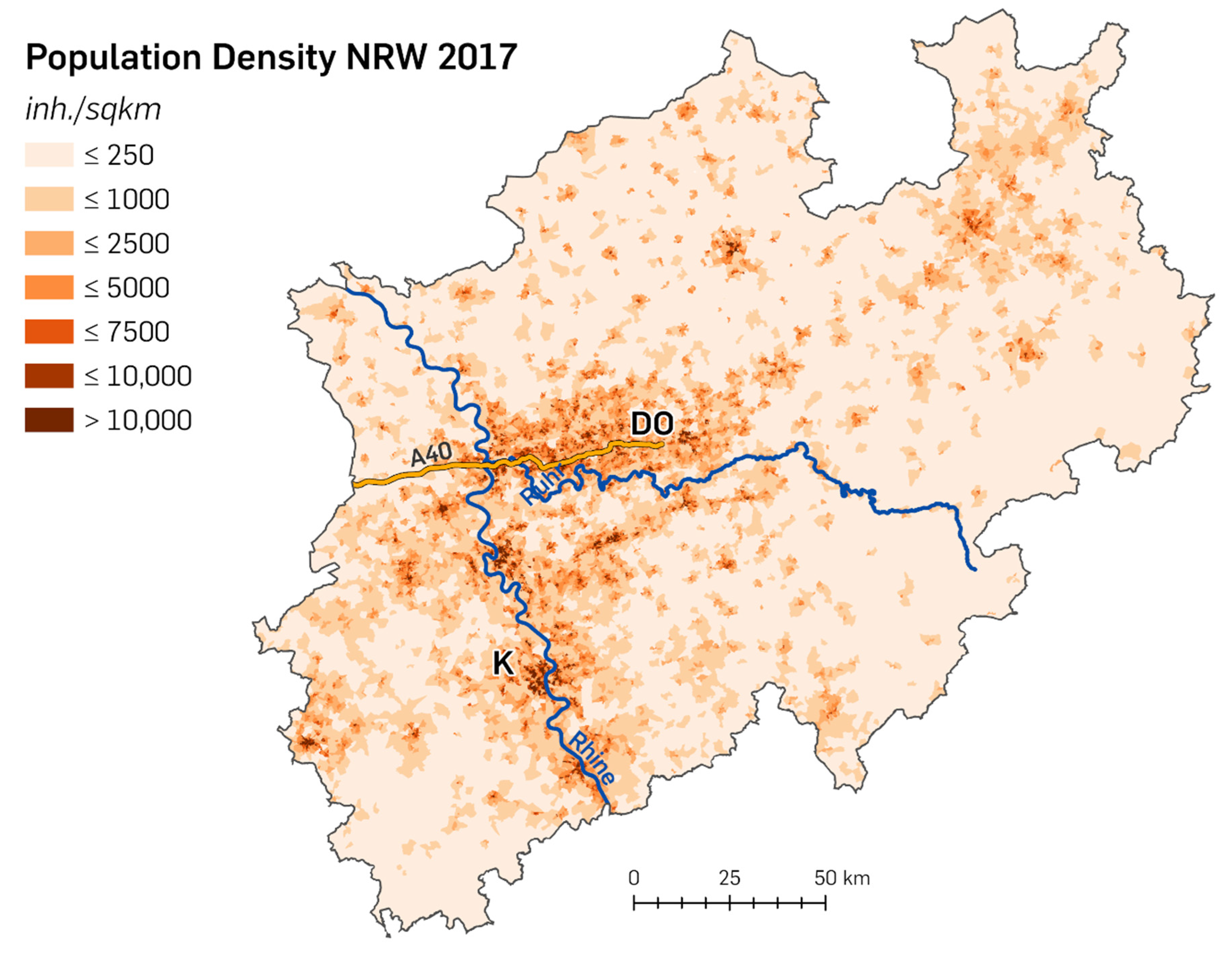
2.2. Population Density
To visualise the population density for each PLZ8 polygon in NRW, the absolute numbers of inhabitants (inh.) must be linked to the extent of the respective polygons in order to be able to calculate the number of inhabitants per square kilometre (sqkm) for each area. After that, the values can be categorised into classes for better comparability [
24] and then be visualised in a map (see
Figure 2).
The map reveals the more densely populated areas in NRW in darker colours, as there is the Rhine–Ruhr area in its centre with Dortmund (DO) north of the river Ruhr, continuing south across the river Rhine with the city of Cologne (K). All other cities are not named on the map.
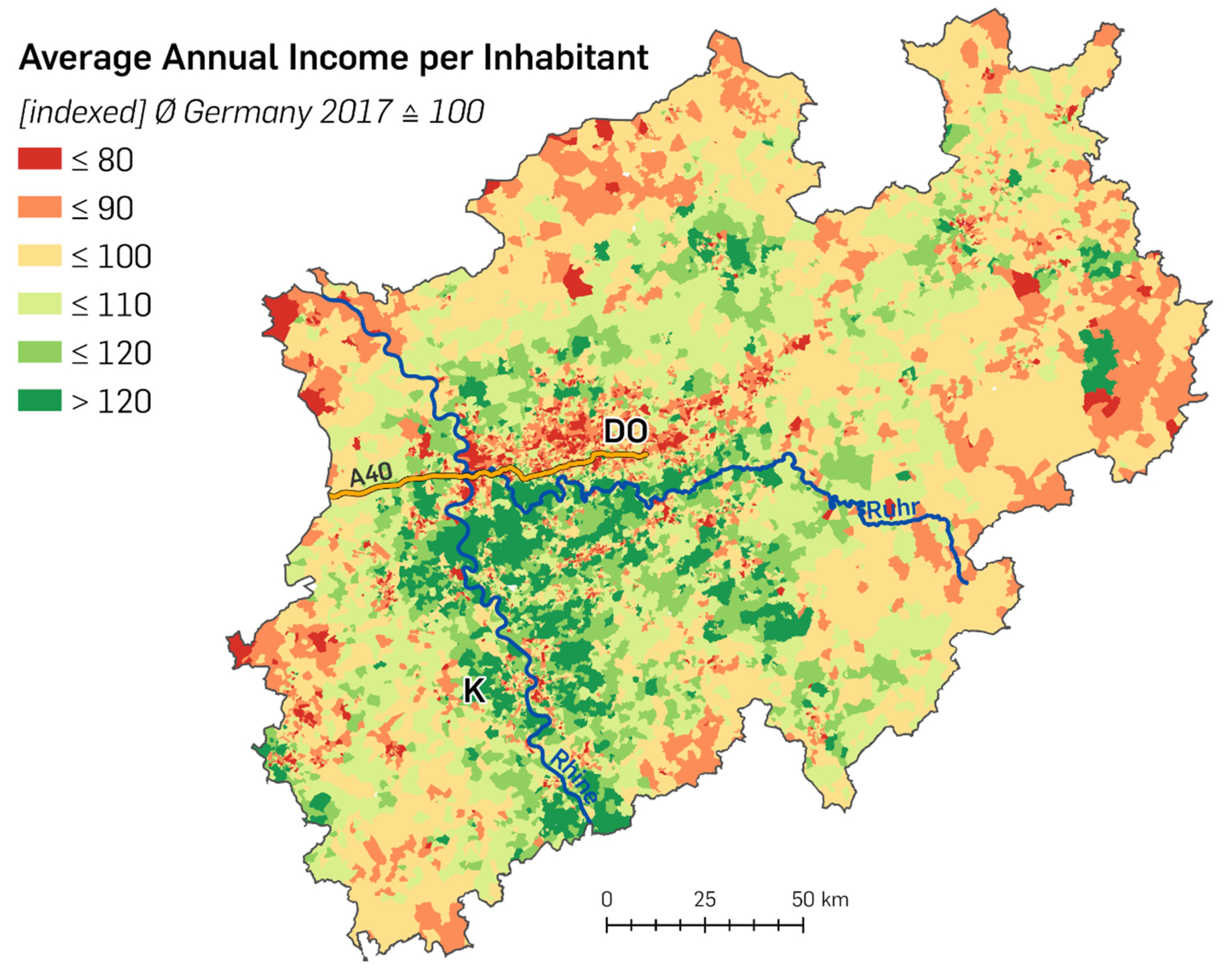
2.3. Average Annual Income per Inhabitant
The average annual income per inhabitant can be represented by the monetary sum of money per inhabitant or—better suited for comparisons—by an index that transforms the mean annual income of all inhabitants within a certain year to the value of 100. Income values higher or lower than the average are represented by values above or below 100, respectively. The microm datasets offer a variable called purchasing power index (PPI). It reflects the mean net inhabitant income [
27] during the period of 1 year within a spatial unit and can be used as a proxy to assess income factors such as salary, capital assets, lettings, etc., including tax deductions. Periodic expenses such as rent, electricity, and insurances are not taken into account [
28]. For Germany, the average income in 2017 is 21,220 EUR per inhabitant and is represented by a PPI value of 100 for that year [
17].
The choropleth map of the PPI—more suitable called average annual income per inhabitant hereinafter—for NRW in
Figure 3 was created in the same way based upon the same spatial units (PLZ8) as the population density map in
Figure 2. It varies the colour scheme for the different classes to point out regions characterised by average, lower, or higher income values (see
Figure 3).
As stated before, each PLZ8 unit does not necessarily reflect the real situation of the distribution of inhabitants, as there are areas within each polygon that are not occupied by residents. In order to move these values into those particular sub-polygons, representing the actual location of residential blocks, in the following chapters, a disaggregation approach will be applied. The aim is to confirm the hypothesis that large-scale units, selected as residential areas by their type of usage, provide a significantly better basis for a valuation concerning scientific problems with a spatial socioeconomic background.
2.4. Disaggregation Approach
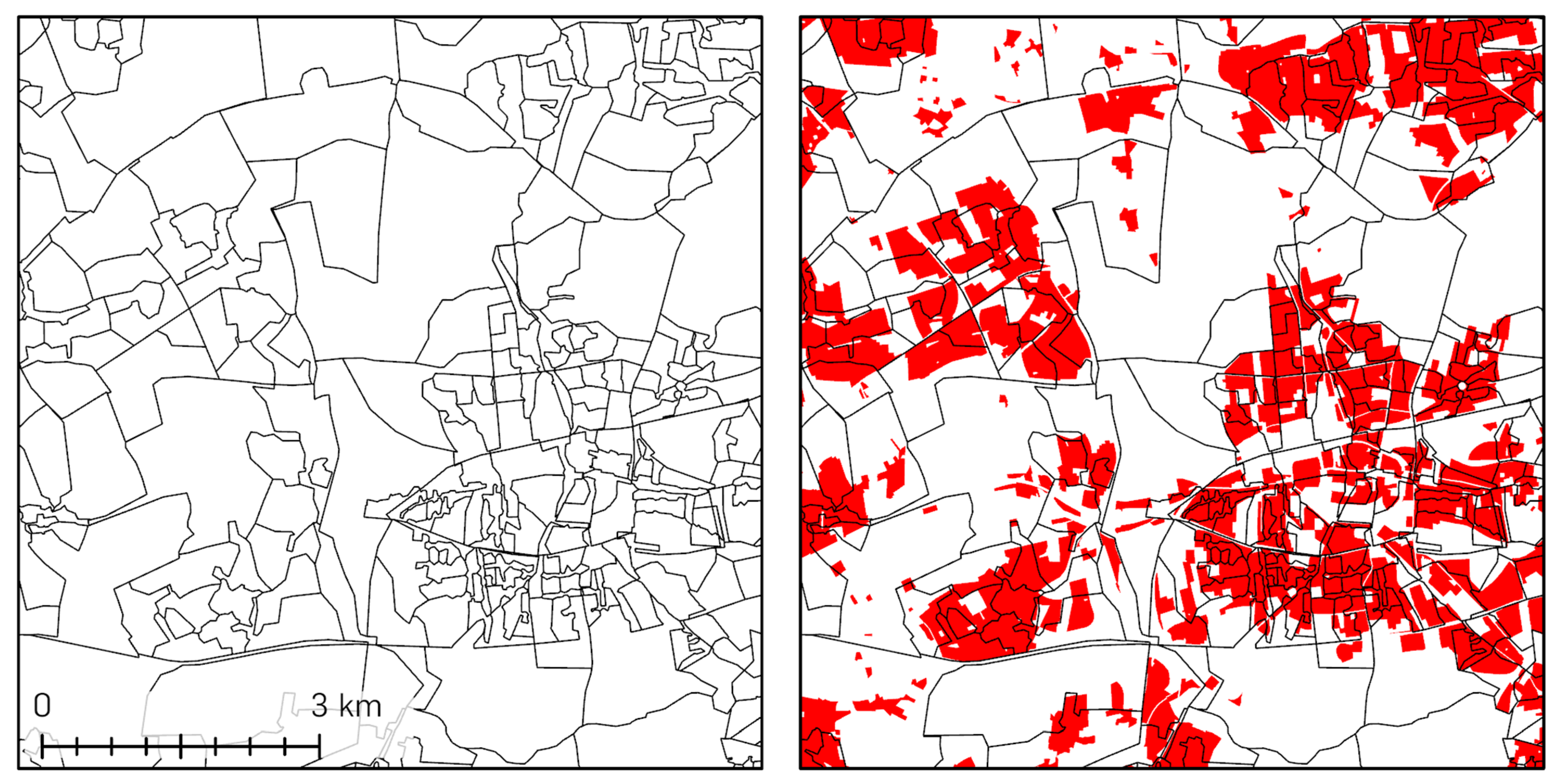
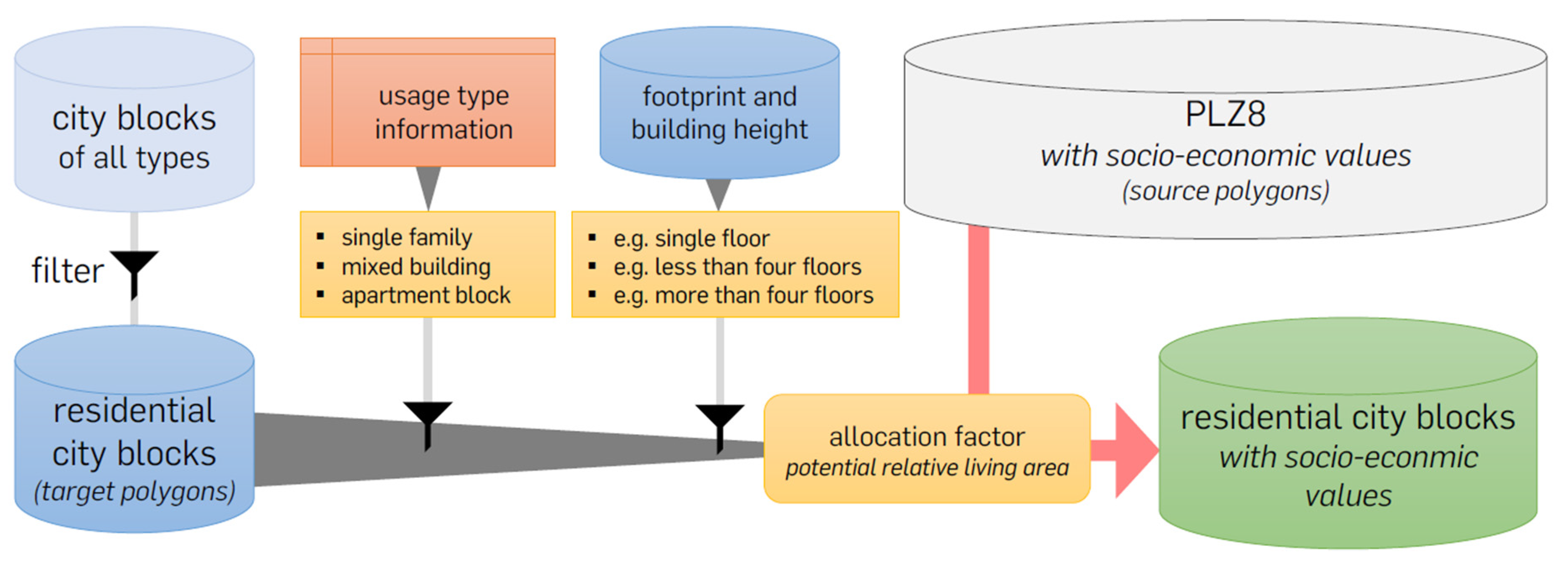
The disaggregation of spatial data is a problem that widely occurs in science and in planning practice. The primary goal is to distribute values from higher-level, larger spatial units to the smaller spatial units within. Thus, using a suitable procedure that achieves a realistic reassignment of attribute values describing the actual state of the respective smaller spatial units. The method used to assign the aggregated characteristics from the large spatial units—source polygons—to the smaller spatial units—target polygons (see
Figure 4)—is crucial for the reliability of a spatial disaggregation on the one hand. On the other hand, the consistency of the input data required for the respective methods has an even higher influence on the quality of the results [
29].
Numerous studies conduct a disaggregation using the areal interpolation approach, which is one of the simplest disaggregation techniques (e.g., [
31,
32]). In contrast, this study applies the three-class dasymetric mapping method as a methodology for further studies in other countries that might be based on it. This approach was evaluated as the best and most accurate one in various studies [
29,
33,
34,
35,
36]. It is applied by incorporating certain additional datasets that shape and qualify the target areas according to their usage: the outline of city blocks, their individual type of residential use (such as residential, mixed use, etc.), and the coverage of the area by buildings within the respective spatial unit. With this information added to the target polygons, for each of them, a weighting factor can be determined that defines the proportional assignment of inhabitants from the superior PLZ8 polygon. It is also dependent on the extent of each new and smaller spatial unit. The lack of ubiquitous, available, large-scale datasets holding the necessary information for the determination of the weighting factors might be one of the main reasons why so many past studies rather use the much simpler areal interpolation.
Since the availability of datasets required for this approach has strongly improved in a lot of countries over the past years [
37,
38], with this study, a methodology is developed utilising certain types of broadly available datasets necessary for a dasymetric mapping in three classes. It also aims to advertise this approach for a broader application in socio-geomatic research.
However, still, the general availability of additional datasets depends strongly on the location of the study area and the respective national or regional players that collect and provide the corresponding data. Not only the acquisition of the data itself is important, but also the underlying structure of it. In some three-class approaches, no distinction is made between populated and non-populated target areas. Instead, regardless of whether it is used for, e.g., agricultural, industrial, or residential purposes—a corresponding value of socio-demographic and -economic properties is assigned to each area. While the decision about the weighting factors based on use classes is always subject-driven, it gives degrees of freedom for applying the principle and deriving a suitable allocation factor. Thus creating a need for testing and refinement [
35].
As it is known that people use to live in buildings, one could come to more prominent results by focusing the socioeconomic data to build up populated structures. To achieve this, the disaggregation approach is based on remotes-ensing imagery and additional datasets from regional authorities.
2.5. Disaggregation of Population Density and Annual Individual Income
The disaggregation of the socio-demographic values from the source polygons into the target polygons is conducted in four major steps (see
Figure 5): first, the additional datasets that constitute the target polygons in an extended dataset are selected, restructured, and adjusted to obtain a structure that matches the one of the source dataset. In this case, the source polygons are derived from the microm PLZ8 units. The target polygons representing city blocks are taken from the Urban Atlas 2012 dataset provided by the Copernicus program [
39]. The official digital landscape model that supplies the building geometries for this case study can be retrieved from Geobasis.NRW [
40].
The temporal gap between the datasets is disregarded in this context, since the Urban Atlas and the digital landscape model, besides the target-geometries, only contribute information for the classification of residential use types. A divergent acquisition time of only a few years for these datasets is not expected to cause significant inconsistencies.
In the second step, representing the second class of the three-class dasymetric mapping process, the extended datasets are filtered according to the requirements for the disaggregation, leaving only the target polygons that are appropriate for the current analysis. In this case study, the residential urban areas providing space for living are of major interest. This leads to preselection of only houses and city blocks whose purpose is habitation as rural, industrial, and commercial sites usually do not provide a place for living. There are several buildings that can be identified as mixed usage, e.g., shops on ground level and several flats on the floors above. This leads to step three, and the third and last class of the disaggregation is where the polygons of the preselected residential areas are classified according to their respective kind of apartment structure and their number of floors [
41]. The structure varies from one- or two-floor single homes for single families over mixed buildings with few shops and more apartments to large apartment blocks such as multi-family houses or dormitories for students, pupils, or seniors. Each usage type represents a different amount of people per area unit defining the density of inhabitants in the respective building blocks. This makes it inevitable to distinguish between all these classes, ensuring the values from the source polygons are transferred to the target polygons most appropriately. For this, an allocation factor is determined based on the developed classification of usage types, again based on the additional datasets. This is a crucial step, since the potential relative living area of all subdivided polygons is the only value where all polygons differ from each other.
After the preselection and classification of the target polygons, all source polygons are intersected with these prepared target polygons. This step is followed by assigning the weighted source values to the target polygons according to the two steps before. As the PLZ8 and the building block polygons do not match exactly, a lot of target polygons are subdivided into smaller pieces that were assigned with values from different source polygons. These values are assigned to the target polygons depending on their respective potential living area compared to the overall living area in the respective source zones.
Using the specific ID of each single target polygon, these broken parts can be dissolved into a final, coherent city block while aggregating up all property values of the respective subparts. This results in a new patchy dataset covering only those areas where actually people are living.
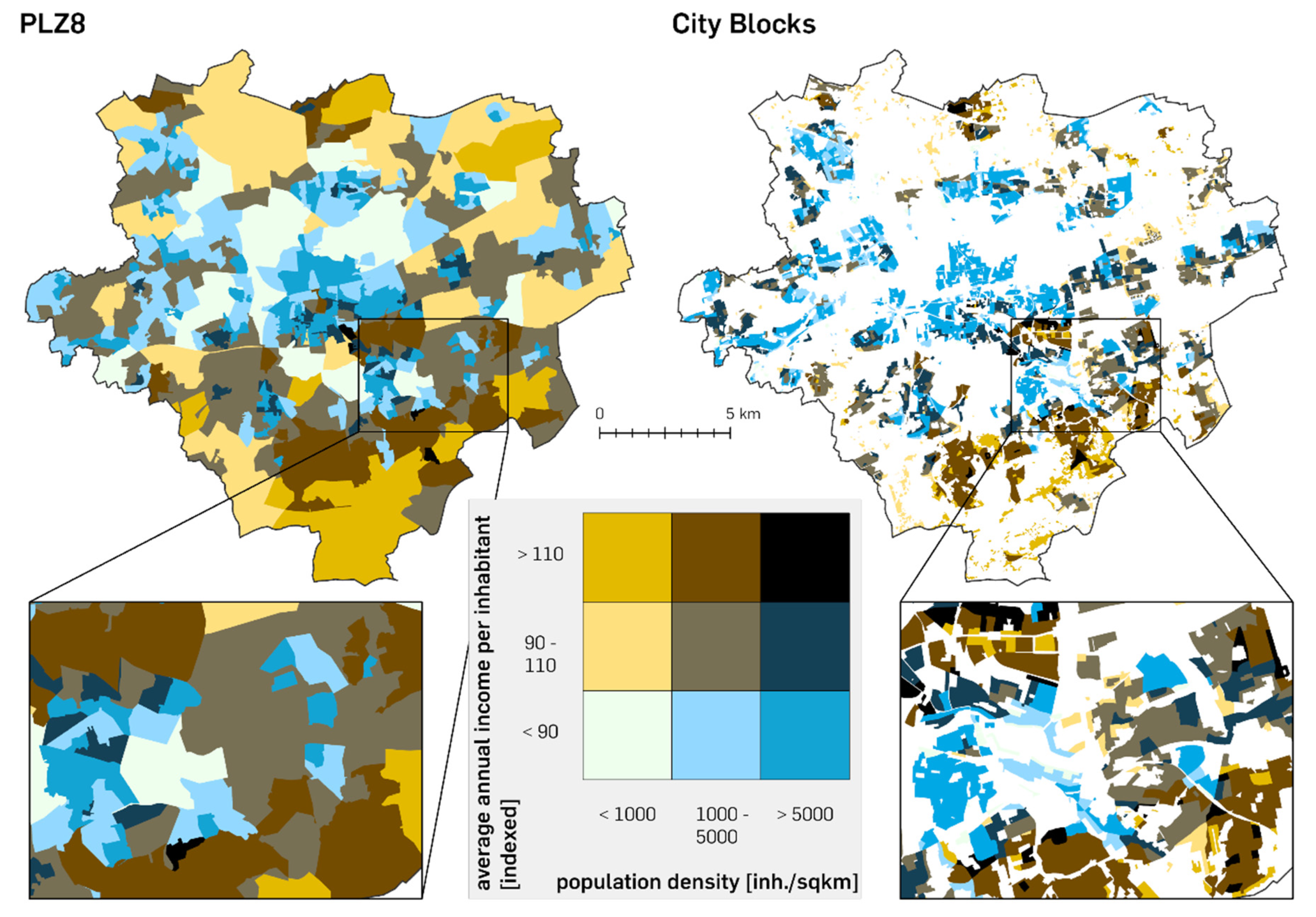
2.6. Concept of Bivariate Choropleth Maps
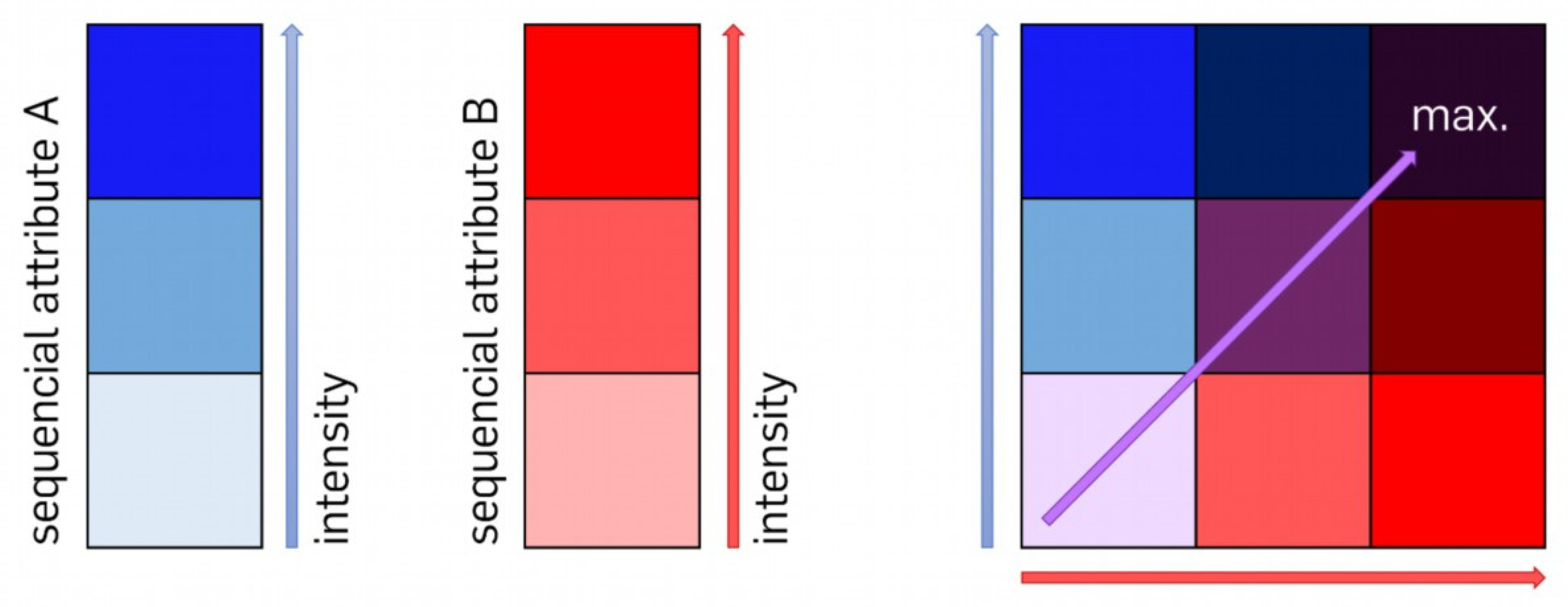
To illustrate the relationship between two quantitative parameters of polygons in a map, a combined matrix legend can be applied. This supports the recognition of patterns created by the combination of the characteristics of the two variables [
42,
43]. It is built by combining two different colour scales, each representing one variable by graded brightness. The saturation of the colour assigned to each variable increases with higher values and iss divided into three classes. For easy identification of the displayed correlation, by assigning the resulting colours in the polygons to the combined classes of both variables, a matrix legend with all nine possible colour combinations is used. Therefore, the classes of both characteristics are grouped by a specific selection. This results in an individual associative colour for each possible combination of the two values (see
Figure 6). Further applications for bivariate choropleth maps are provided by, e.g., [
21,
44].
2.7. Population Density vs. Annual Individual Income in Bivariate Choropleth Maps
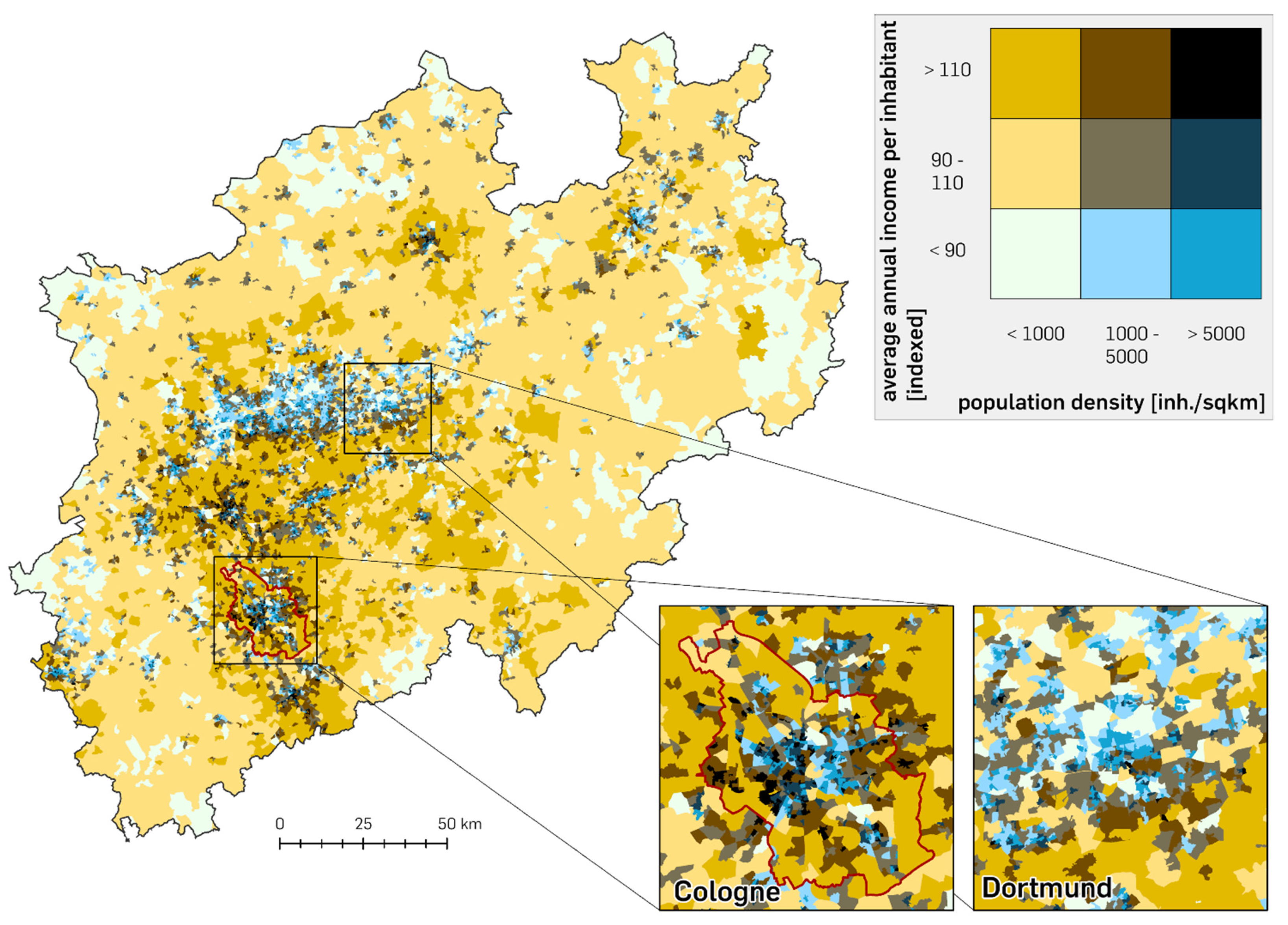
The univariate choropleth maps shown in
Figure 2 and
Figure 3 can now be transformed into one bivariate choropleth map. For this reasonable class, breaks for each attribute need to be set, and a colour scheme must be selected that emphasises the essence of this analysis.
The resulting
Figure 7 gives a decent insight into the spatial pattern of the two variables used. It shows less saturation in the combination of the two different colours where values tend to be lower, and vice versa.
2.8. Correlation and Multivariate Cluster Analysis
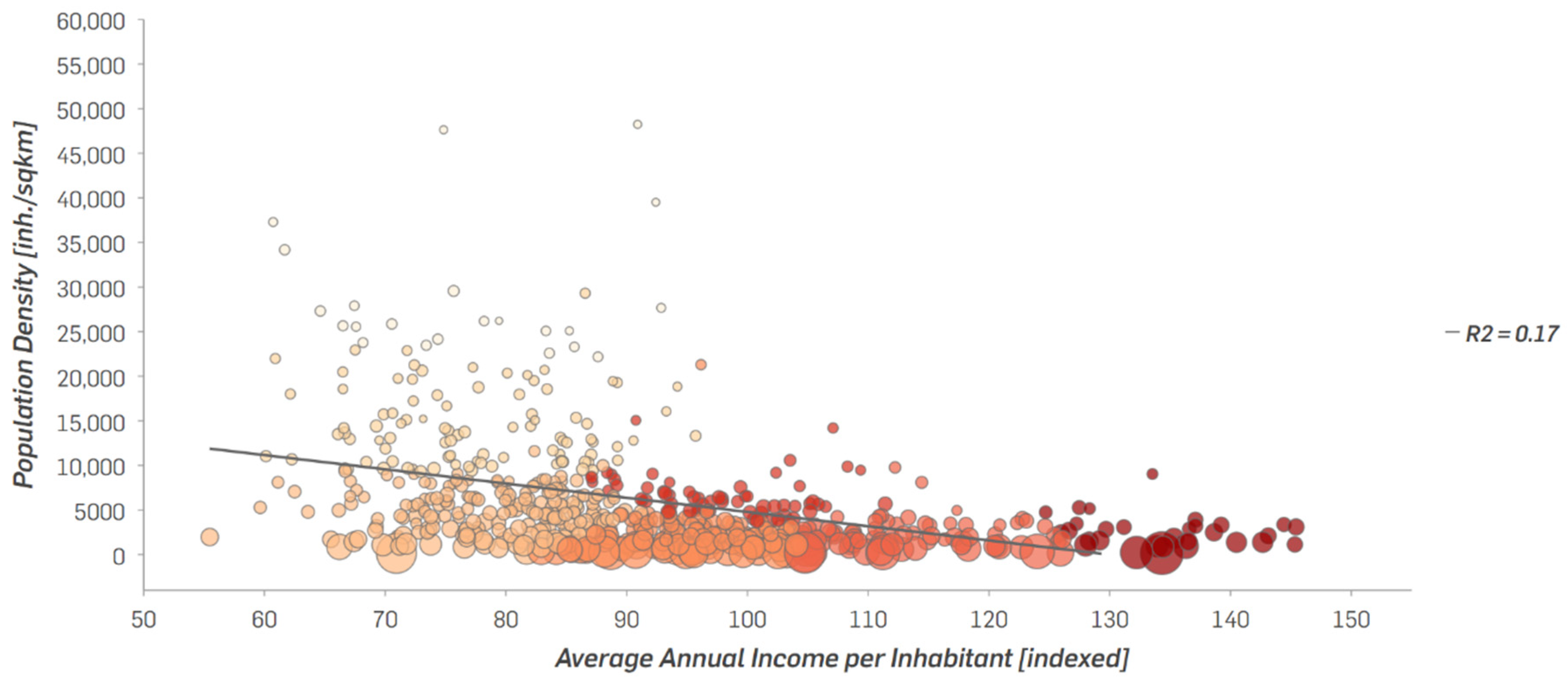
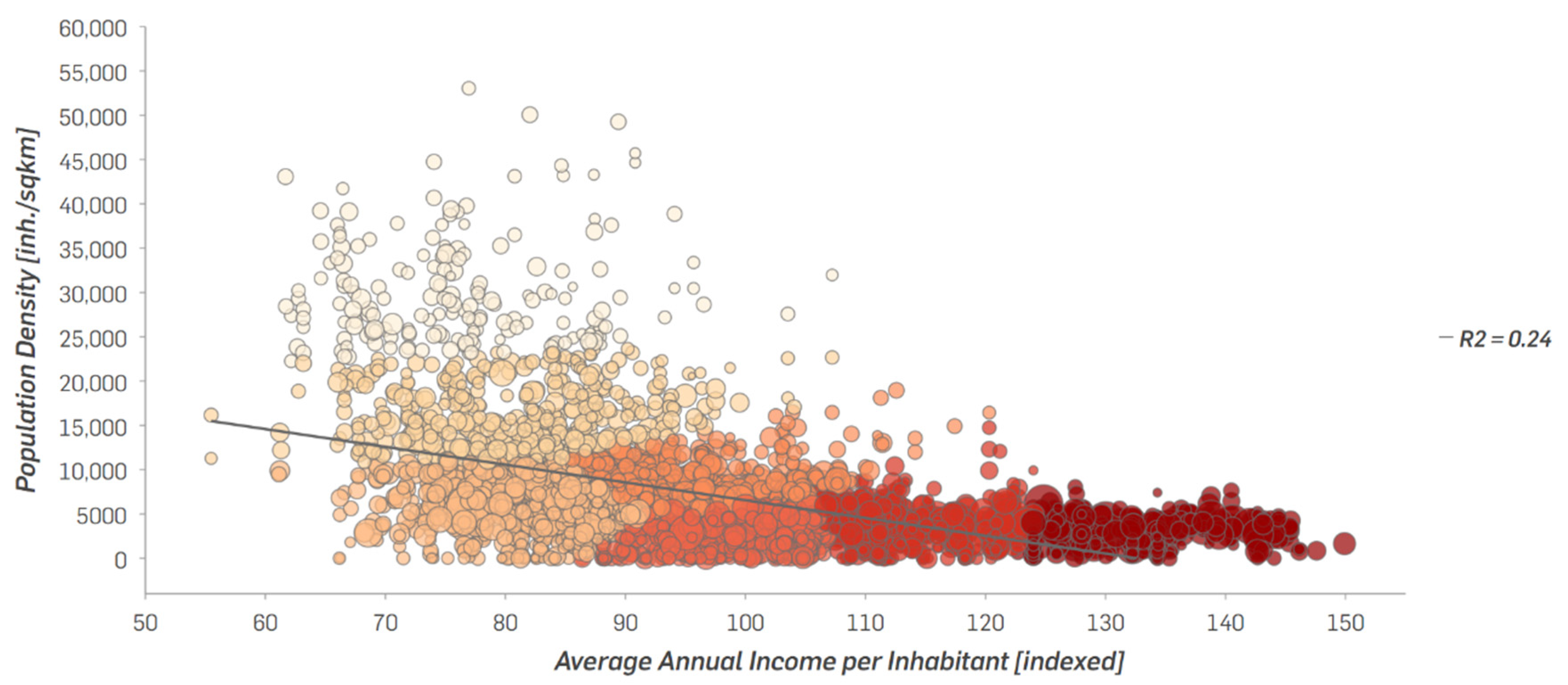
The correlation analysis of the two attributes, population density and average annual income per inhabitant, on the PLZ8 level reveals, respectively, a low R2 value with an excessive scattering (see
Figure 8).
Calculating the same correlation for the disaggregated city block polygons, the R2 value becomes significantly higher while the scattering is reduced (see
Figure 9).
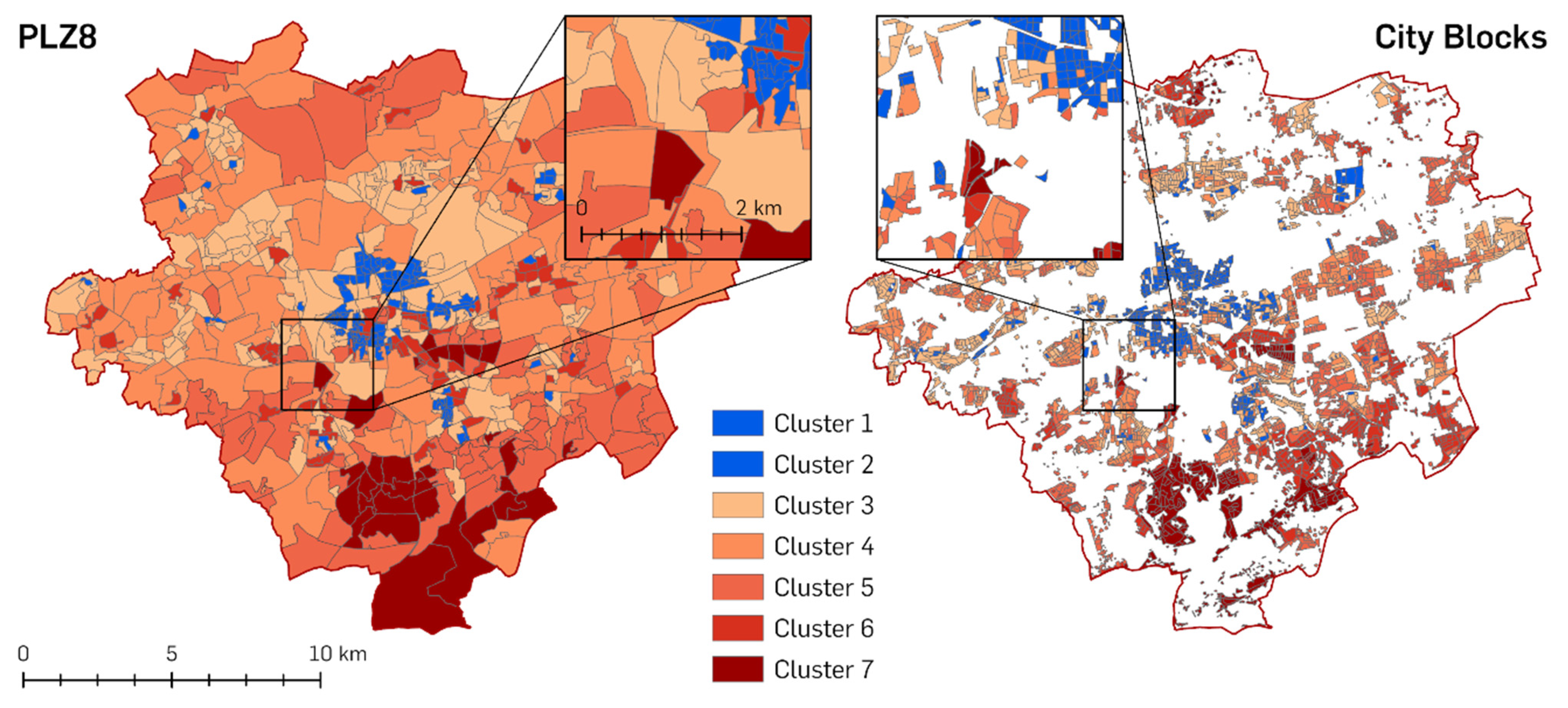
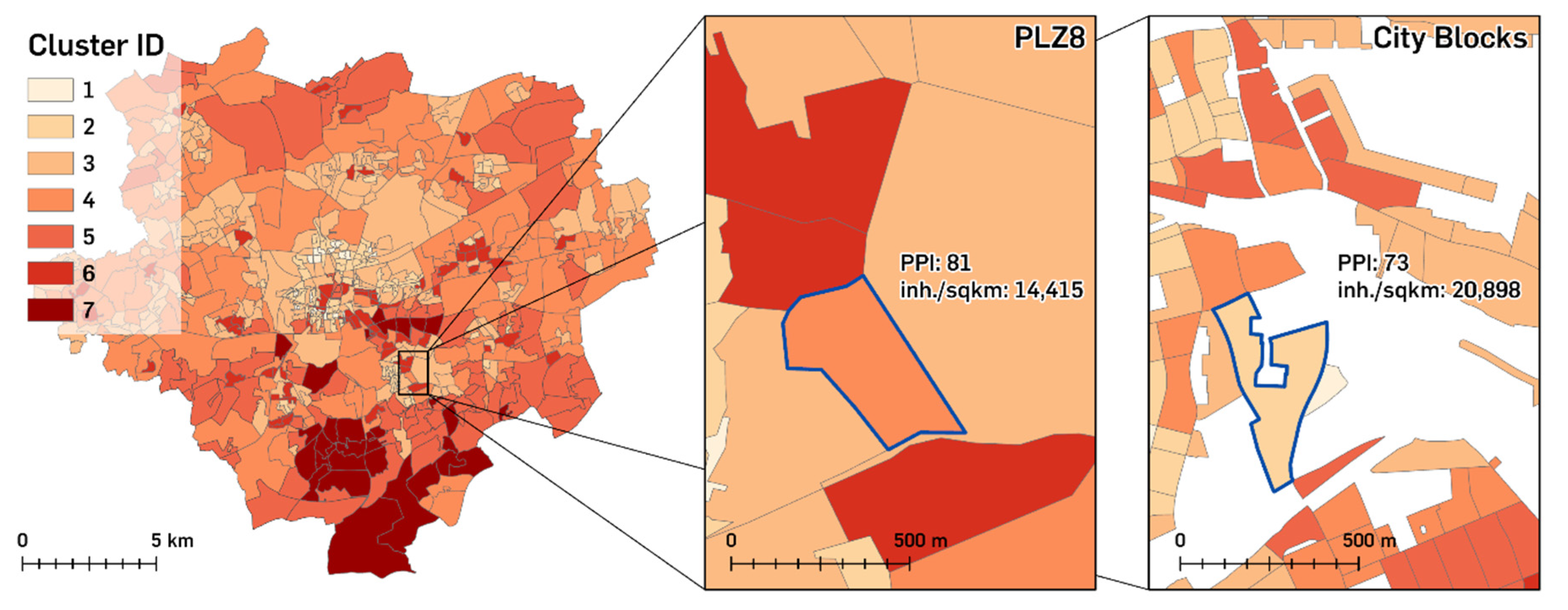
The two regressions already show that the disaggregation has led to an improvement in the correlation of the two values. In the following step, a multivariate cluster analysis is conducted with the two attributes for both spatial units in order to generate new classes, compare the results, and provide a better mean to see if the results can reveal new patterns and insights into large-scale city areas, using the disaggregated city blocks as the smaller spatial unit. The multivariate cluster analysis used in this study is based on the K means algorithm, which aims to partition features based on seeds that grow into clusters, minimising the differences among the features within each cluster [
45,
46]. This is the basis for the map shown in
Figure 10 displaying the clustered values spatially that are shown statistically in the scatterplots of
Figure 8 and
Figure 9.
4. Discussion
The primary methodological goal of this study was to develop a transferable methodology to be able to analyse socio-demographic variables in much more spatial detail to gain more spatially precise information on the living circumstances of residential areas, embedded in the context of political decision making, geo-marketing, and for further socioeconomic research and urban planning. The results facilitate a distinctly new perspective on certain urban areas, where large-scale city block polygons have replaced the area covering PLZ8 polygons, assigned with respective matching and adjusted values. These allow a much more detailed assessment of fine-grained regional questions.
This becomes obvious by combining the two different socio-demographic attributes of population density and average annual income per inhabitant. This is useful to not only analyse how these two variables may affect each other in terms of numbers but also to dissipate them into appropriate spatial units. Their spatial visualisation can reveal certain segmentations that are perfect for preliminary analyses of the underlying data. By completing this, the results in
Figure 7 reveal a distinct pattern that allows for the evaluation and comparison of certain regions about their characteristics in both variables. The K means algorithm and the resulting multivariate statistical and spatial clusters for both spatial levels of detail evidently illustrate the added value of more precise new spatial units that can lead to a better understanding of where to find socially disadvantaged people on the one hand and how to improve economic approaches that incorporate the social status of people on the other hand. They provide an enhanced reference for further studies that deal with a smaller area of investigation and thus require smaller units to evaluate not broadly but in great detail.
Looking at the two regions of the Rhineland and the Ruhr area, it is noticeable that even though both regions stand out in NRW in terms of population density, the Rhineland is obviously inhabited by more people that have an average income or above while the inhabitants of the Ruhr area seem to be below the German average of the respective year (2017). A reason for this could be the diverging demographic structures of the two regions. The Ruhr area has always been a melting pot for miners and factory employees due to the history of the region with a high density of coal and steel factories. Once the industrial sector was obliterated by the structural transformation of the Ruhr area due to the end of the mining era, a lot of people—especially foreign guest workers—were forced to look for new professions while the area was still looking for its future purpose [
53]. Apart from that, the Ruhr area had and still has a reputation that suggests a dirty image caused by industrial smoke, coal mining, air pollution, and missing recreational sites such as green areas and forests. This led to the fact that the Rhineland seemed to be more attractive not only for citizens but also for industry and commerce [
20] while the Ruhr area was still in the process of handling the downfall of the industrial era and hence is still looking for new perspectives to provide jobs for the many inhabitants.
Due to the successful disaggregation, now inhabitants can be evaluated according to their density and their average annual income—not only for large PLZ8 polygons but for detailed polygons that represent residential city blocks.
Many disaggregation techniques have already been tested, evaluated, and established in various studies (see
Section 2.3). However, the one that [
21] was adopted and improved for his case study of NRW can easily be transferred to almost every spatial unit in other countries with a comparable data basis without further adaptation. This indicates that socio-geomatic approaches are of great value to combine fine spatial structures with socio-demographic and -economic data to enhance their spatial resolution in order to more accurately analyse their spatial patterns.
5. Conclusions
This paper exemplarily investigates the spatial relationship between population density and annual income to identify hotspots of imbalance by visualising them in bivariate choropleth maps. This approach is carried forward and followed by applying a spatial disaggregation technique to then perform a statistical multivariate cluster analysis on both spatial resolutions for the two attributes into a certain hierarchy for the study area of Dortmund (see
Figure 8,
Figure 9 and
Figure 10).
The comparison of both the clusters and bivariate choropleth maps of the starting and the resulting scales after the disaggregation revealed several improvements. It was demonstrated that the scattering of the cluster combinations has been substantially decreased while the coefficient of determination of the two attributes has been increased, and hence, the usability of socio-demographic values stored in postal code features could be significantly improved.
The empirical acquisition and commercial or scientific distribution of statistical values for the huge variety of different socio-demographic variables is often carried out in coarse and gapless spatial datasets (e.g., regular rasters or postcode polygons). These datasets can help to characterise regions based on their structure and distribution, but their mediocre level of detail and the fact that they do not distinguish between inhabited and uninhabited areas reveal a great potential for improvement concerning the spatial resolution and suitability of the variable containing features. This especially takes effect when dealing with sociological research questions that are analysed spatially, as the results of a sophisticated disaggregation can raise possible interpretations to the next level.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}