
Modelling Place Visit Probability Sequences during Trajectory Data Gaps Based on Movement History


Abstract
:1. Introduction
2. Background
3. Probabilistic Space-Time Model from Historical Trajectories
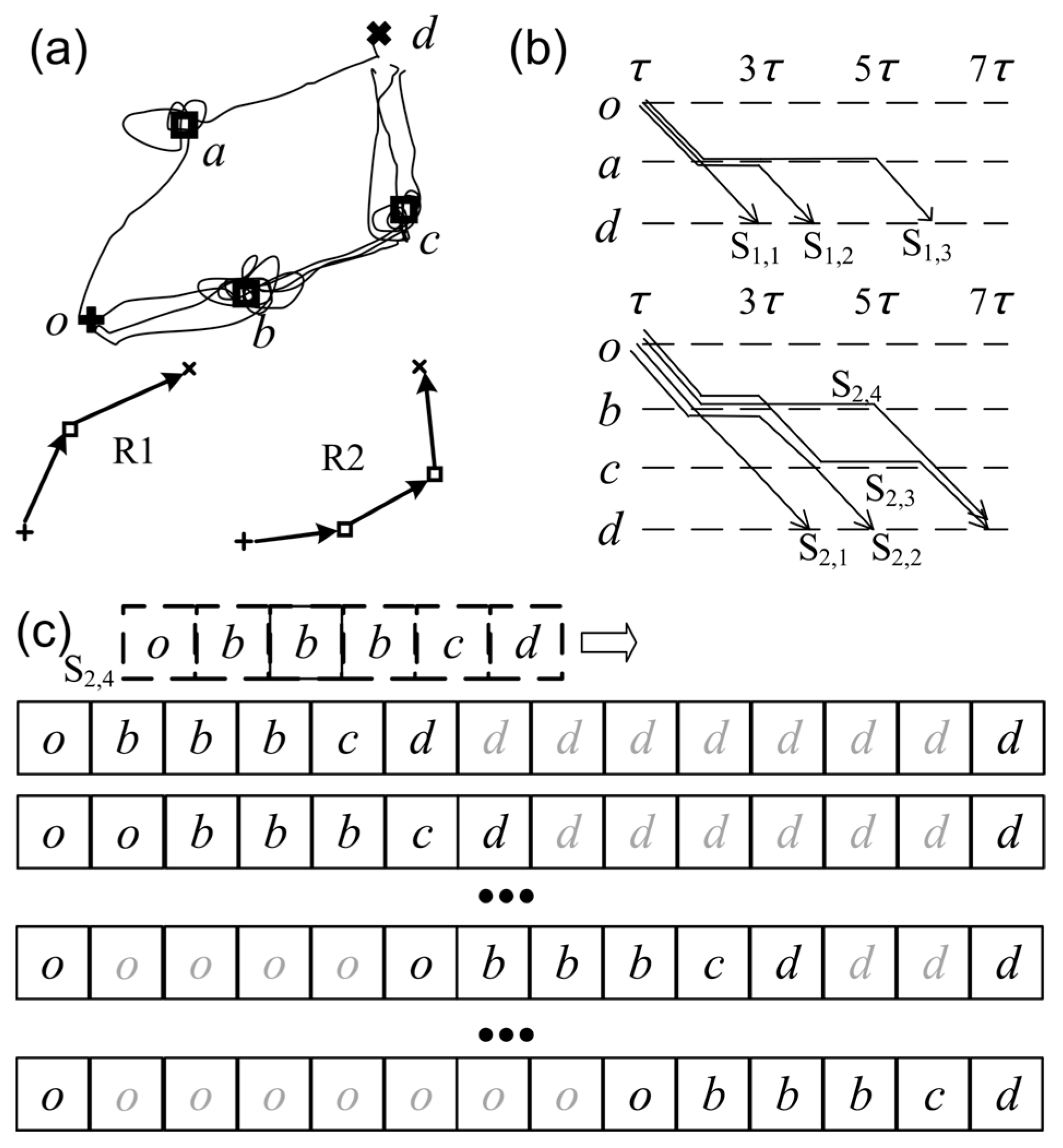
3.1. Mobility Patterns
3.2. Routes and Schedules
3.3. Visit Probability Estimation
4. Experiment and Results
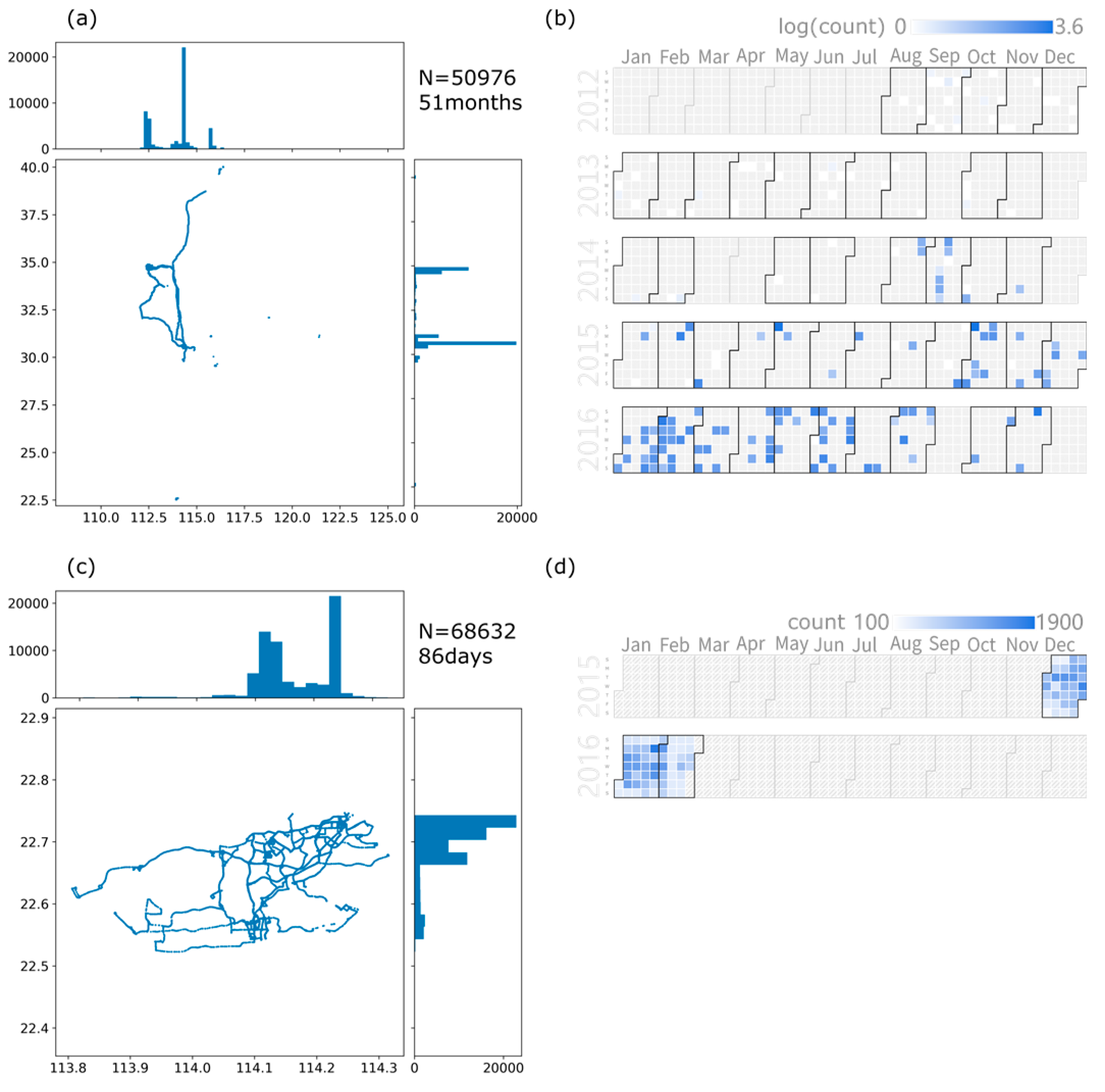
4.1. Datasets
4.2. Experiment Setting
4.3. Results
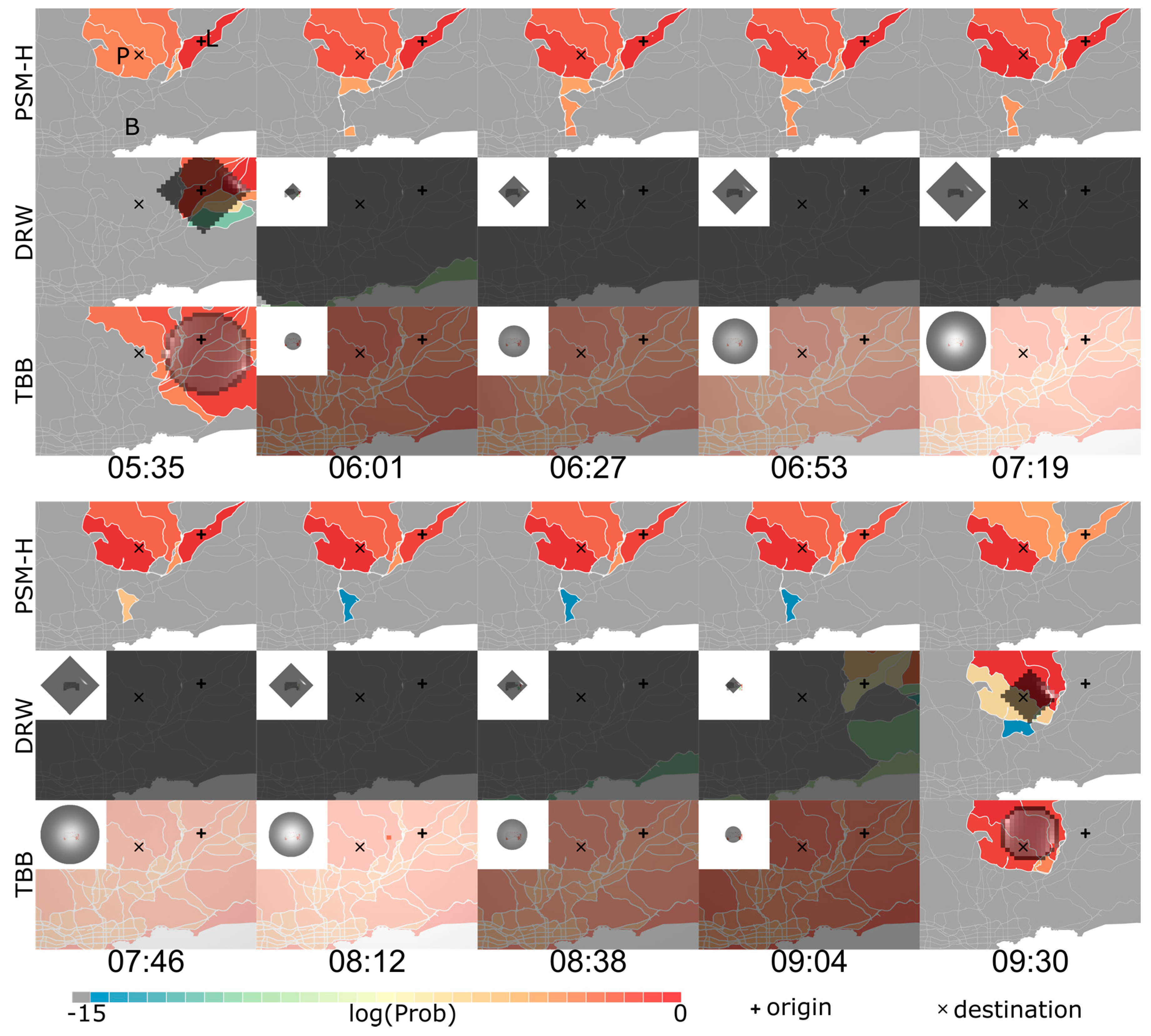
4.3.1. Visit Probability Distributions
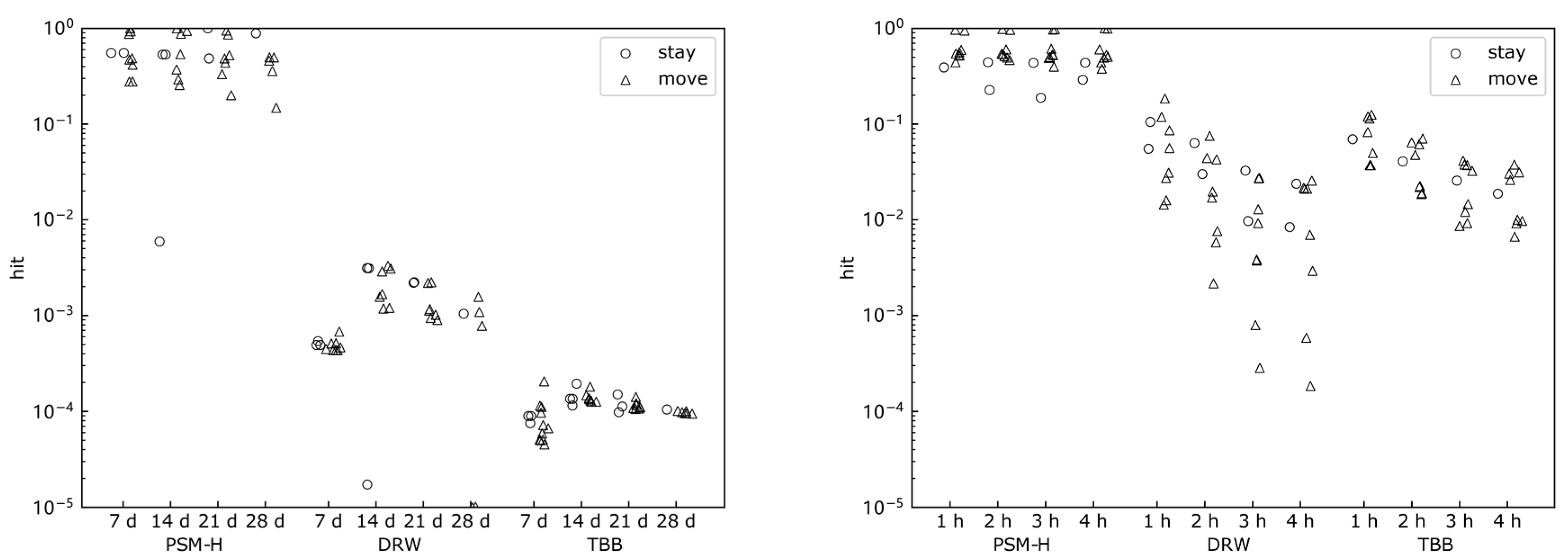
4.3.2. Metrics
4.4. Analysis
5. Discussion
5.1. Influence of Mobility Patterns
5.2. Choice of Spatial Units and Temporal Scales
5.3. Reliability in Varied Contexts
5.4. Scalability for Extrapolation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Demšar, U.; Buchin, K.; Cagnacci, F.; Safi, K.; Speckmann, B.; Van de Weghe, N.; Weiskopf, D.; Weibel, R. Analysis and Visualisation of Movement: An Interdisciplinary Review. Mov. Ecol. 2015, 3, 1–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, Y.; Gao, S.; Liang, Y.; Li, M.; Rao, J.; Kruse, J. Multiscale Dynamic Human Mobility Flow Dataset in the U.S. during the COVID-19 Epidemic. Sci. Data 2020, 7, 390. [Google Scholar] [CrossRef]
- Sharma, M.; Sharma, S.; Singh, G. Remote Monitoring of Physical and Mental State of 2019-NCoV Victims Using Social Internet of Things, Fog and Soft Computing Techniques. Comput. Methods Programs Biomed. 2020, 196, 105609. [Google Scholar] [CrossRef]
- Wan, S.; Xu, X.; Wang, T.; Gu, Z. An Intelligent Video Analysis Method for Abnormal Event Detection in Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2020, 1–9. [Google Scholar] [CrossRef]
- Sadilek, A.; Krumm, J. Far out: Predicting Long-Term Human Mobility. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 26. [Google Scholar]
- Parent, C.; Spaccapietra, S.; Renso, C.; Andrienko, G.; Andrienko, N.; Bogorny, V.; Damiani, M.L.; Gkoulalas-Divanis, A.; Macedo, J.; Pelekis, N.; et al. Semantic Trajectories Modeling and Analysis. ACM Comput. Surv. CSUR 2013, 45, 42. [Google Scholar] [CrossRef]
- Baratchi, M.; Meratnia, N.; Havinga, P.J.M.; Skidmore, A.K.; Toxopeus, B.A.K.G. A Hierarchical Hidden Semi-Markov Model for Modeling Mobility Data. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 401–412. [Google Scholar]
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban Computing: Concepts, Methodologies, and Applications. ACM Trans. Intell. Syst. Technol. 2014, 5, 1–55. [Google Scholar] [CrossRef]
- Dodge, S.; Weibel, R.; Ahearn, S.C.; Buchin, M.; Miller, J.A. Analysis of Movement Data. Int. J. Geogr. Inf. Sci. 2016, 30, 825–834. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.-C.; Krumm, J. Trajectory Preprocessing. In Computing with Spatial Trajectories; Zheng, Y., Zhou, X., Eds.; Springer: New York, NY, USA, 2011; pp. 3–33. ISBN 978-1-4614-1629-6. [Google Scholar]
- Shen, L.; Stopher, P.R. Review of GPS Travel Survey and GPS Data-Processing Methods. Transp. Rev. 2014, 34, 316–334. [Google Scholar] [CrossRef]
- Siła-Nowicka, K.; Vandrol, J.; Oshan, T.; Long, J.A.; Demšar, U.; Fotheringham, A.S. Analysis of Human Mobility Patterns from GPS Trajectories and Contextual Information. Int. J. Geogr. Inf. Sci. 2016, 30, 881–906. [Google Scholar] [CrossRef] [Green Version]
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and Mobility: User Movement in Location-Based Social Networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090. [Google Scholar]
- Rahmani, M.; Koutsopoulos, H.N. Path Inference from Sparse Floating Car Data for Urban Networks. Transp. Res. Part C Emerg. Technol. 2013, 30, 41–54. [Google Scholar] [CrossRef]
- Hoteit, S.; Chen, G.; Viana, A.; Fiore, M. Filling the Gaps: On the Completion of Sparse Call Detail Records for Mobility Analysis. In Proceedings of the Eleventh ACM Workshop on Challenged Networks, New York, NY, USA, 3–7 October 2016; pp. 45–50. [Google Scholar]
- Liu, Z.; Ma, T.; Du, Y.; Pei, T.; Yi, J.; Peng, H. Mapping Hourly Dynamics of Urban Population Using Trajectories Reconstructed from Mobile Phone Records. Trans. GIS 2018, 22, 494–513. [Google Scholar] [CrossRef]
- Li, M.; Gao, S.; Lu, F.; Zhang, H. Reconstruction of Human Movement Trajectories from Large-Scale Low-Frequency Mobile Phone Data. Comput. Environ. Urban Syst. 2019, 77, 101346. [Google Scholar] [CrossRef]
- Purves, R.S.; Laube, P.; Buchin, M.; Speckmann, B. Moving beyond the Point: An Agenda for Research in Movement Analysis with Real Data. Comput. Environ. Urban Syst. 2014, 47, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Schafer, J.L.; Graham, J.W. Missing Data: Our View of the State of the Art. Psychol. Methods 2002, 7, 147–177. [Google Scholar] [CrossRef] [PubMed]
- Stovel, K.; Bolan, M. Residential Trajectories: Using Optimal Alignment to Reveal The Structure of Residential Mobility. Sociol. Methods Res. 2004, 32, 559–598. [Google Scholar] [CrossRef] [Green Version]
- Mayer, K.U. New Directions in Life Course Research. Annu. Rev. Sociol. 2009, 35, 413–433. [Google Scholar] [CrossRef] [Green Version]
- Halpin, B. Multiple Imputation for Categorical Time Series. Stata J. 2016, 16, 590–612. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.-Z.; Kobayashi, H. A Hidden Semi-Markov Model with Missing Data and Multiple Observation Sequences for Mobility Tracking. Signal Process. 2003, 83, 235–250. [Google Scholar] [CrossRef]
- Crivellari, A.; Beinat, E. LSTM-Based Deep Learning Model for Predicting Individual Mobility Traces of Short-Term Foreign Tourists. Sustainability 2020, 12, 349. [Google Scholar] [CrossRef] [Green Version]
- Downs, J.A.; Horner, M.W. Probabilistic Potential Path Trees for Visualizing and Analyzing Vehicle Tracking Data. J. Transp. Geogr. 2012, 23, 72–80. [Google Scholar] [CrossRef]
- Ahearn, S.C.; Dodge, S.; Simcharoen, A.; Xavier, G.; Smith, J.L.D. A Context-Sensitive Correlated Random Walk: A New Simulation Model for Movement. Int. J. Geogr. Inf. Sci. 2017, 31, 867–883. [Google Scholar] [CrossRef]
- Song, Y.; Song, T.; Kuang, R. Path Segmentation for Movement Trajectories with Irregular Sampling Frequency Using Space-Time Interpolation and Density-Based Spatial Clustering. Trans. GIS 2019, 23, 558–578. [Google Scholar] [CrossRef]
- Loraamm, R.W. Incorporating Behavior into Animal Movement Modeling: A Constrained Agent-Based Model for Estimating Visit Probabilities in Space-Time Prisms. Int. J. Geogr. Inf. Sci. 2020, 34, 1607–1627. [Google Scholar] [CrossRef]
- An, L.; Tsou, M.-H.; Crook, S.E.; Chun, Y.; Spitzberg, B.; Gawron, J.M.; Gupta, D.K. Space–Time Analysis: Concepts, Quantitative Methods, and Future Directions. Ann. Assoc. Am. Geogr. 2015, 105, 891–914. [Google Scholar] [CrossRef]
- Kwan, M.-P. The Uncertain Geographic Context Problem. Ann. Assoc. Am. Geogr. 2012, 102, 958–968. [Google Scholar] [CrossRef]
- Miller, H.J. Time Geography and Space-Time Prism. In The International Encyclopedia of Geography; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Winter, S.; Yin, Z.-C. Directed Movements in Probabilistic Time Geography. Int. J. Geogr. Inf. Sci. 2010, 24, 1349–1365. [Google Scholar] [CrossRef]
- Winter, S.; Yin, Z.-C. The Elements of Probabilistic Time Geography. GeoInformatica 2011, 15, 417–434. [Google Scholar] [CrossRef]
- Song, Y.; Miller, H.J. Simulating Visit Probability Distributions within Planar Space-Time Prisms. Int. J. Geogr. Inf. Sci. 2014, 28, 104–125. [Google Scholar] [CrossRef]
- Long, J.A.; Nelson, T.A.; Nathoo, F.S. Toward a Kinetic-Based Probabilistic Time Geography. Int. J. Geogr. Inf. Sci. 2014, 28, 855–874. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Miller, H.J.; Zhou, X.; Proffitt, D. Modeling Visit Probabilities within Network-Time Prisms Using Markov Techniques. Geogr. Anal. 2016, 48, 18–42. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.-L. Understanding Individual Human Mobility Patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef]
- Abbott, A. Sequence Analysis: New Methods for Old Ideas. Annu. Rev. Sociol. 1995, 21, 93–113. [Google Scholar] [CrossRef]
- Gauthier, J.-A.; Bühlmann, F.; Blanchard, P. Introduction: Sequence Analysis in 2014. In Advances in Sequence Analysis: Theory, Method, Applications; Blanchard, P., Bühlmann, F., Gauthier, J.-A., Eds.; Life Course Research and Social Policies; Springer International Publishing: Cham, Switzerland, 2014; pp. 1–17. ISBN 978-3-319-04969-4. [Google Scholar]
- Gabadinho, A.; Ritschard, G.; Studer, M.; Müller, N.S. Extracting and Rendering Representative Sequences. In Knowledge Discovery, Knowlege Engineering and Knowledge Management; Fred, A., Dietz, J.L.G., Liu, K., Filipe, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 94–106. [Google Scholar]
- Barban, N.; Billari, F.C. Classifying Life Course Trajectories: A Comparison of Latent Class and Sequence Analysis. J. R. Stat. Soc. Ser. C Appl. Stat. 2012, 61, 765–784. [Google Scholar] [CrossRef]
- Baumann, P.; Kleiminger, W.; Santini, S. How Long Are You Staying? Predicting Residence Time from Human Mobility Traces. In Proceedings of the 19th Annual International Conference on Mobile Computing & Networking, Miami, FL, USA, 30 September–4 October 2013; pp. 231–234. [Google Scholar]
- Wei, L.-Y.; Zheng, Y.; Peng, W.-C. Constructing Popular Routes from Uncertain Trajectories. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China 12–16 August 2012; pp. 195–203. [Google Scholar]
- Su, H.; Zheng, K.; Wang, H.; Huang, J.; Zhou, X. Calibrating Trajectory Data for Similarity-Based Analysis. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 833–844. [Google Scholar]
- Luo, W.; Tan, H.; Chen, L.; Ni, L.M. Finding Time Period-Based Most Frequent Path in Big Trajectory Data. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 713–724. [Google Scholar]
- Huang, Q. Mining Online Footprints to Predict User’s next Location. Int. J. Geogr. Inf. Sci. 2017, 31, 523–541. [Google Scholar] [CrossRef]
- Zheng, K.; Zheng, Y.; Xie, X.; Zhou, X. Reducing Uncertainty of Low-Sampling-Rate Trajectories. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1144–1155. [Google Scholar]
- Baratchi, M.; Meratnia, N.; Havinga, P.J. Finding Frequently Visited Paths: Dealing with the Uncertainty of Spatio-Temporal Mobility Data. In Proceedings of the 2013 IEEE Eighth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Melbourne, Australia, 2–5 April 2013; pp. 479–484. [Google Scholar]
- Huang, Q.; Wong, D.W. Modeling and Visualizing Regular Human Mobility Patterns with Uncertainty: An Example Using Twitter Data. Ann. Assoc. Am. Geogr. 2015, 105, 1179–1197. [Google Scholar] [CrossRef]
- Daintith, J.; Wright, E. Run-length encoding. In A Dictionary of Computing; Oxford University Press: Oxford, UK, 2008; ISBN 978-0-19-923400-4. [Google Scholar]
- Du Mouza, C.; Rigaux, P. Multiscale Classification of Moving Objects Trajectories. In Proceedings of the 16th International Conference on Scientific and Statistical Database Management, Santorini Island, Greece, 21–23 June 2004; pp. 307–316. [Google Scholar]
- Tao, Y.; Both, A.; Duckham, M. Analytics of Movement through Checkpoints. Int. J. Geogr. Inf. Sci. 2018, 32, 1282–1303. [Google Scholar] [CrossRef]
- Long, J.A.; Nelson, T.A. Time Geography and Wildlife Home Range Delineation. J. Wildl. Manag. 2012, 76, 407–413. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Ferreira, J.; González, M.C. Clustering Daily Patterns of Human Activities in the City. Data Min. Knowl. Discov. 2012, 25, 478–510. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Liu, X.; Zhou, J.; Chai, Y. Early Birds, Night Owls, and Tireless/Recurring Itinerants: An Exploratory Analysis of Extreme Transit Behaviors in Beijing, China. Habitat Int. 2016, 57, 223–232. [Google Scholar] [CrossRef] [Green Version]
- Furtado, A.S.; Alvares, L.O.C.; Pelekis, N.; Theodoridis, Y.; Bogorny, V. Unveiling Movement Uncertainty for Robust Trajectory Similarity Analysis. Int. J. Geogr. Inf. Sci. 2018, 32, 140–168. [Google Scholar] [CrossRef]
- Zheng, Y.; Xie, X.; Ma, W.-Y. GeoLife: A Collaborative Social Networking Service among User, Location and Trajectory. IEEE Data Eng. Bull. 2010, 33, 32–40. [Google Scholar]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.-L. Limits of Predictability in Human Mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [Green Version]
- Openshaw, S. Ecological Fallacies and the Analysis of Areal Census Data. Environ. Plan. Econ. Space 1984, 16, 17–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, T.; Adepeju, M. Modifiable Temporal Unit Problem (MTUP) and Its Effect on Space-Time Cluster Detection. PLoS ONE 2014, 9, e100465. [Google Scholar] [CrossRef] [Green Version]
- Laube, P.; Purves, R.S. How Fast Is a Cow? Cross-Scale Analysis of Movement Data. Trans. GIS 2011, 15, 401–418. [Google Scholar] [CrossRef]
- Hwang, S.; VanDeMark, C.; Dhatt, N.; Yalla, S.V.; Crews, R.T. Segmenting Human Trajectory Data by Movement States While Addressing Signal Loss and Signal Noise. Int. J. Geogr. Inf. Sci. 2018, 32, 1391–1412. [Google Scholar] [CrossRef] [Green Version]
- Goodchild, M.F. Formalizing Place in Geographic Information Systems. In Communities, Neighborhoods, and Health: Expanding the Boundaries of Place; Burton, L.M., Matthews, S.A., Leung, M., Kemp, S.P., Takeuchi, D.T., Eds.; Social Disparities in Health and Health Care; Springer: New York, NY, USA, 2011; pp. 21–33. ISBN 978-1-4419-7482-2. [Google Scholar]
- Revilla, E.; Wiegand, T. Individual Movement Behavior, Matrix Heterogeneity, and the Dynamics of Spatially Structured Populations. Proc. Natl. Acad. Sci. USA 2008, 105, 19120–19125. [Google Scholar] [CrossRef] [Green Version]
- Huber, D.L.; Church, R.L. Transmission Corridor Location Modeling. J. Transp. Eng. 1985, 111, 114–130. [Google Scholar] [CrossRef]
- Shirabe, T. A Method for Finding a Least-Cost Wide Path in Raster Space. Int. J. Geogr. Inf. Sci. 2016, 30, 1469–1485. [Google Scholar] [CrossRef]
- Liao, L.; Fox, D.; Kautz, H. Extracting Places and Activities from GPS Traces Using Hierarchical Conditional Random Fields. Int. J. Robot. Res. 2007, 26, 119–134. [Google Scholar] [CrossRef]
- Meentemeyer, V. Geographical Perspectives of Space, Time, and Scale. Landsc. Ecol. 1989, 3, 163–173. [Google Scholar] [CrossRef]
- Schneider, C.M.; Belik, V.; Couronné, T.; Smoreda, Z.; González, M.C. Unravelling Daily Human Mobility Motifs. J. R. Soc. Interface 2013, 10, 20130246. [Google Scholar] [CrossRef] [Green Version]
- Kuijpers, B.; Othman, W. Modeling Uncertainty of Moving Objects on Road Networks via Space-Time Prisms. Int. J. Geogr. Inf. Sci. 2009, 23, 1095–1117. [Google Scholar] [CrossRef]
- Timmermans, H.J.P.; Zhang, J. Modeling Household Activity Travel Behavior: Examples of State of the Art Modeling Approaches and Research Agenda. Transp. Res. Part B Methodol. 2009, 43, 187–190. [Google Scholar] [CrossRef]
- Avgar, T.; Mosser, A.; Brown, G.S.; Fryxell, J.M. Environmental and Individual Drivers of Animal Movement Patterns across a Wide Geographical Gradient. J. Anim. Ecol. 2013, 82, 96–106. [Google Scholar] [CrossRef]
- Shoval, N.; Isaacson, M. Sequence Alignment as a Method for Human Activity Analysis in Space and Time. Ann. Assoc. Am. Geogr. 2007, 97, 282–297. [Google Scholar] [CrossRef]
- Kjærgaard, M.B.; Bhattacharya, S.; Blunck, H.; Nurmi, P. Energy-Efficient Trajectory Tracking for Mobile Devices. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services, Bethesda, MD, USA, 28 June–1 July 2011; pp. 307–320. [Google Scholar]
- Greenwood, J.A.; Sandomire, M.M. Sample Size Required for Estimating the Standard Deviation as a Per Cent of Its True Value. J. Am. Stat. Assoc. 1950, 45, 257–260. [Google Scholar] [CrossRef]
- Seaman, D.E.; Millspaugh, J.J.; Kernohan, B.J.; Brundige, G.C.; Raedeke, K.J.; Gitzen, R.A. Effects of Sample Size on Kernel Home Range Estimates. J. Wildl. Manag. 1999, 63, 739–747. [Google Scholar] [CrossRef]
- Wang, Y.; Yuan, N.J.; Lian, D.; Xu, L.; Xie, X.; Chen, E.; Rui, Y. Regularity and Conformity: Location Prediction Using Heterogeneous Mobility Data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1275–1284. [Google Scholar]
- Miller, J.C. Embodied Architectural Geographies of Consumption and the Mall Paseo Chiloe Controversy in Southern Chile. Ann. Am. Assoc. Geogr. 2019, 109, 1300–1316. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| pidl | id of l-th place | J | total number of points |
| polygonl | geometry of l-th polygon | K | number of MLE episodes |
| <xj, yj, tj> | geographic coordinates and timestamp of j-th point | L | total number of defined places |
| Nk | number of location fixes in an MLE episode | M | total number of stops |
| tsk, tek | start and end time of k-th episode | N | total number of moves |
| sidm | id of m-th stop episode | R | set of place subsequence representing stops between a pair of places |
| spidm | place id associated with m-th stop episode | r, r’ | sample stop sequences from set R |
| midn | id of n-th move episode | S | set of place subsequences representing paths between a pair of places |
| pidon, piddn | place ids of the origin and destination of n-th move episode | s | sample paths from set S |
| ton, tdn | times at the origin and destination of n-th move episode | su, su’ | u-th and u’-th place from path s |
| a, b, i, i’ | sample place ids | AC(a,b) | count of adjacent occurrence of places a and b |
| o, d | place id of origin and destination | SD(Δs;a) | frequency distribution of stay duration Δs at place a |
| Δs | duration of a stop episode | TT(Δt;a,b) | frequency distribution of travel time Δt from place a to b |
| Δt | duration of a move episode | SF(r) | frequency distribution of stop sequence r for a trip |
| spid[m,m’] | subsequence of sequence spid from m-th to m’-th element | MD(a,b|o,d) | count of occurrence of place a ahead of b for a trip from place o to d |
| |∙| | cardinality operator, number of elements in a set | {element| condition} | a set of elements satisfying condition specified after the vertical bar |
| ^ | logical ‘and’ operator |
| Student Dataset | Clerk Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| ΔT | 7 d | 14 d | 21 d | 28 d | 60 min | 120 min | 180 min | 240 min |
| N(OD) | 14 | 12 | 11 | 7 | 10 | 10 | 10 | 10 |
| N0(OD) 1 | 4 | 2 | 2 | 1 | 1 | 0 | 0 | 0 |
| PSM-H | 42% ± 35% | 45% ± 36% | 48% ± 35% | 41% ± 28% | 55% ± 27% | 58% ± 23% | 56% ± 24% | 57% ± 24% |
| DRW | 0.04% ± 0.02% | 0.20% ± 0.12% | 0.13% ± 0.08% | 0.06% ± 0.06% | 7% ± 5% | 3% ± 3% | 1% ± 1% | 1% ± 1% |
| TBB | 0.01% ± 0.00% | 0.01% ± 0.00% | 0.01% ± 0.00% | 0.01% ± 0.00% | 8% ± 4% | 4% ± 2% | 2% ± 1% | 2% ± 1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, C.; Tang, L.; Long, J.; Kan, Z.; Yang, X. Modelling Place Visit Probability Sequences during Trajectory Data Gaps Based on Movement History. ISPRS Int. J. Geo-Inf. 2021, 10, 456. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10070456
Ren C, Tang L, Long J, Kan Z, Yang X. Modelling Place Visit Probability Sequences during Trajectory Data Gaps Based on Movement History. ISPRS International Journal of Geo-Information. 2021; 10(7):456. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10070456
Chicago/Turabian StyleRen, Chang, Luliang Tang, Jed Long, Zihan Kan, and Xue Yang. 2021. "Modelling Place Visit Probability Sequences during Trajectory Data Gaps Based on Movement History" ISPRS International Journal of Geo-Information 10, no. 7: 456. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10070456