1. Introduction
In recent years, geosensor networks and the sensor web have rapidly expanded in smart cities. Geosensors, such as card and bus GPS terminals, produce massive datastreams every day. These data from crowdsensing [
1] are of high value in some fields and can be mined to produce useful knowledge for decision-making purposes. As a city expands and its population increases, the city’s public transit system bears significant pressure. For example, commuters usually have to deal with crowded buses or subways in order to get to work, which is inconvenient and unpleasant. Additionally, it can be difficult for both private sector and government transit providers to arrange reasonable routes and predict the potential future flow of passengers. Therefore, the ability to forecast public transit needs is beneficial.
Luckily, government departments are increasingly willing to provide open access to city data (e.g., through data.org ), which is useful for researchers who aim to tackle real-world problems. The provincial government of Guangdong and the Ridge Nantong Limited bus company held a competition to predict passenger boarding choices and flow on the Alibaba platform [
2], which provides millions of user behavior datastreams along several public transport routes. Predicting passengers’ boarding choices is a user behavior analysis that may provide residents with a more intelligent public transport service and better timing of directional advertising. Moreover, passenger flow prediction in public transit is helpful for traffic control decision-making by the transit provider and government.
Issues related to mining frequent patterns in mobile users’ trajectories that have been discussed in the existing studies mostly consider the geographic features of trajectories [
3,
4]. However, patterns based on geographic trajectories are constrained by geographic data and do not work well when considering unvisited locations. Conversely, semantic trajectories have been proposed by Bogorny et al. [
5]. Practically, a semantic trajectory consists of a list of locations labeled with semantic tags that may indicate the activities being carried out in these trajectories. For instance, we may mine user trajectories with semantic tags like <Community, Education, Community>, which reveal the semantic behaviors of the user. However, different people have different travel requirements. For example, there is a rigid demand for office workers to go to work in the morning and back home at night (i.e., during rush hours); while for the elderly, travel times are usually more uncertain. Moreover, different weather conditions and district or neighborhood functions have different impacts on traveling. For example, office workers must go to work and back home on weekdays, no matter how bad the weather is; however, when the weather is bad during the weekend, they will not go out. In contrast, the elderly may go out on nice days whether it is a weekend or a weekday. Additionally, a district’s function may constrain passengers’ actions. For instance, office workers normally get off the bus near a city’s central business district in the morning, while the elderly usually arrive at a station near a park or supermarket.
In this paper, we propose a method for forecasting public transit in the coming week. We first preprocess the raw data (using a schema illustrated in the
Appendix), filtering out dirty data and discretizing what remains. Then, we annotate the data with semantic information. We construct several feature vectors and train the data with XGBoost [
6]. We present two case studies: (1) Forecasting the boarding choices of passengers, predicting whether a passenger will or will not take the bus; (2) Forecasting public transit passenger flow, predicting how many passengers will take the bus.
The major contributions of this paper are as follows:
- (1)
We present a approach for forecasting public transit using crowdsensing.
- (2)
We present two case studies of forecasting public transit boarding choices and passenger flow.
- (3)
We evaluate our approach using various data sources, including point of interest (POI), weather condition, and public bus information in Guangzhou to demonstrate its effectiveness.
The remainder of this paper is organized as follows.
Section 1 briefly reviews existing studies on trajectory prediction.
Section 2 contains the framework, data preprocessing, semantic trajectories mining, and feature information. In
Section 3, we present the results of our experiments. Finally,
Section 4 summarizes our findings and concludes the paper with a brief discussion of the scope of our future work.
3. Approach
3.1. Framework
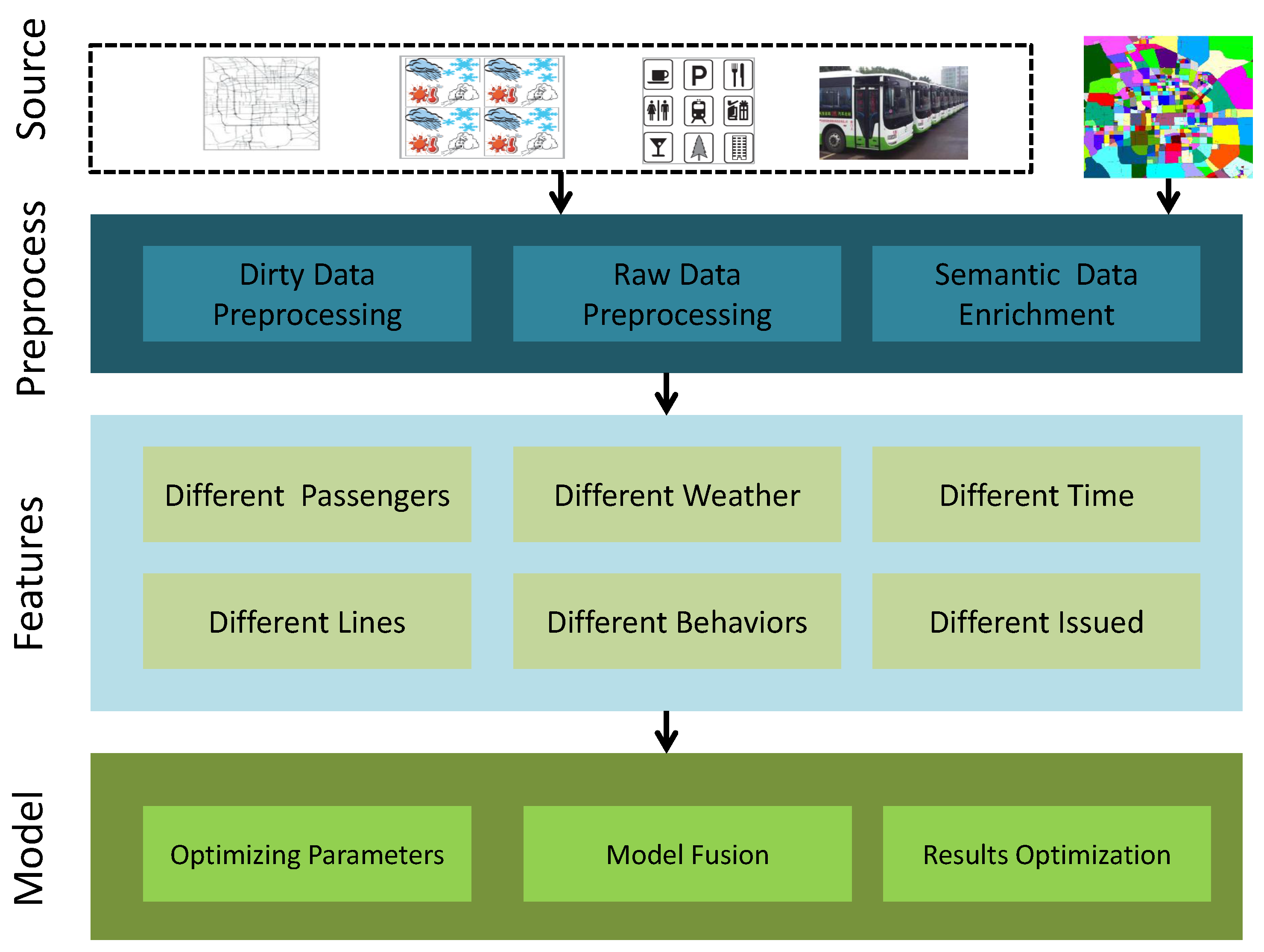
As
Figure 1 shows, our framework consists of two parts: feature engineering and model building. We first preprocess the raw data to filter out dirty data and discretize the dataset. Then, we annotate the data with semantic information. We construct several feature vectors and train with these data.
Problem statement: Given bus card record datasets over a period of several months (1 August 2014–31 December 2014), each of which includes the bus card ID, terminal ID (bus stop ID), travel time, etc., our problem is (1) a binary classification and (2) a regression task. We aim to predict, for the following week (1 January 2015–7 January 2015) (1) whether a specific passenger will take a specific bus, by predicting the existence label in these records (), and (2) the passenger numbers for a bus line, as ().
3.2. Data Preprocessing
3.2.1. Dirty Data Preprocessing
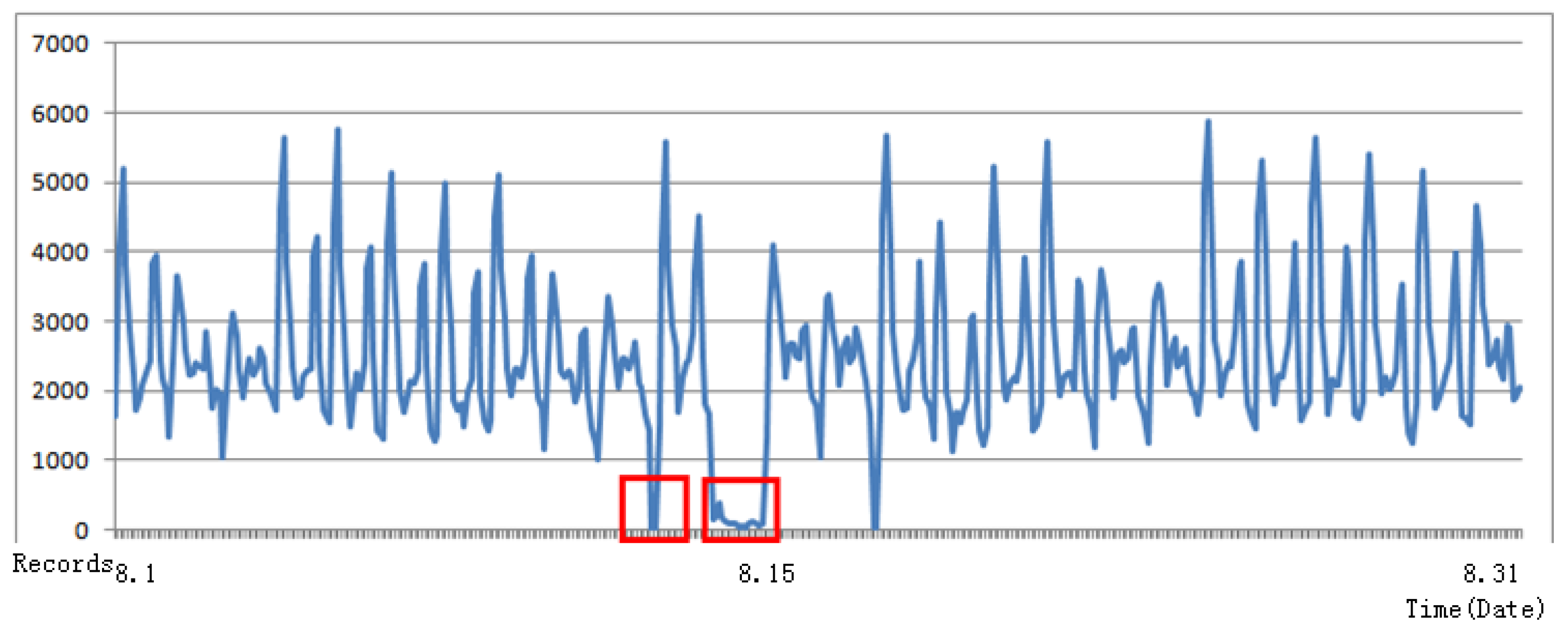
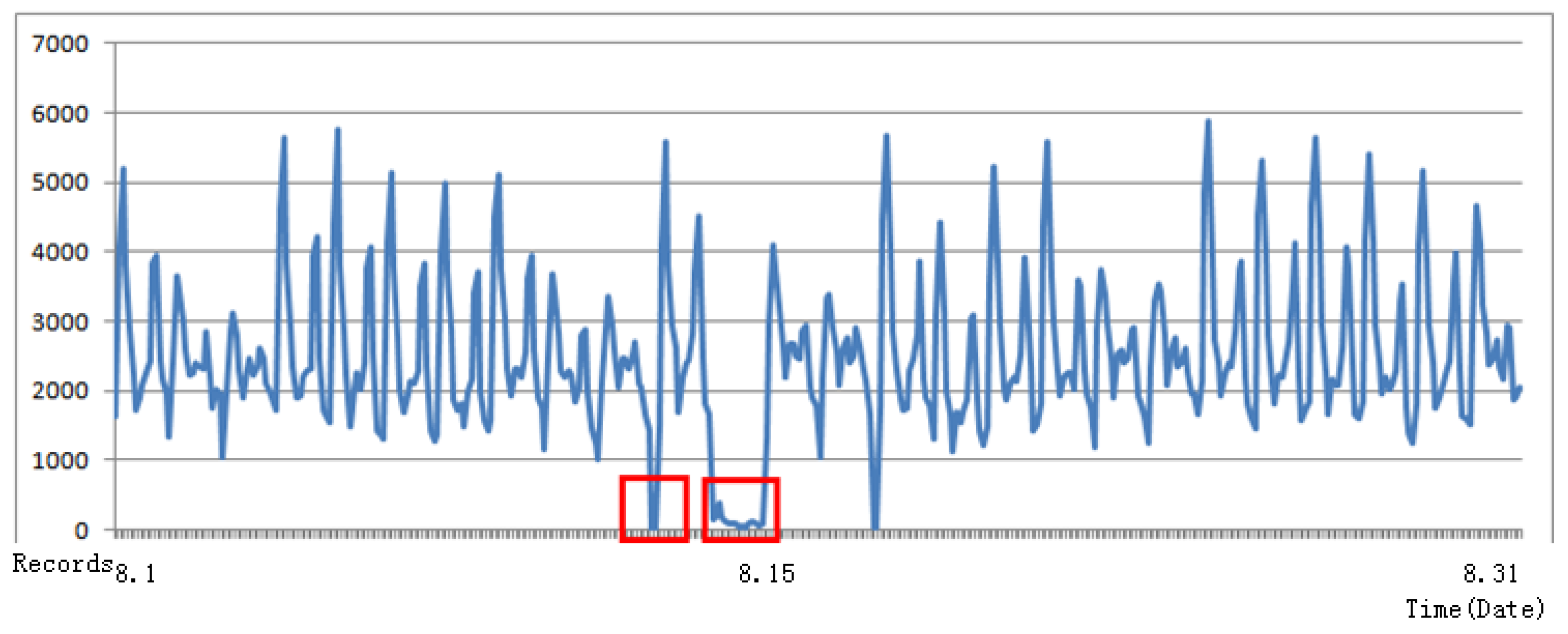
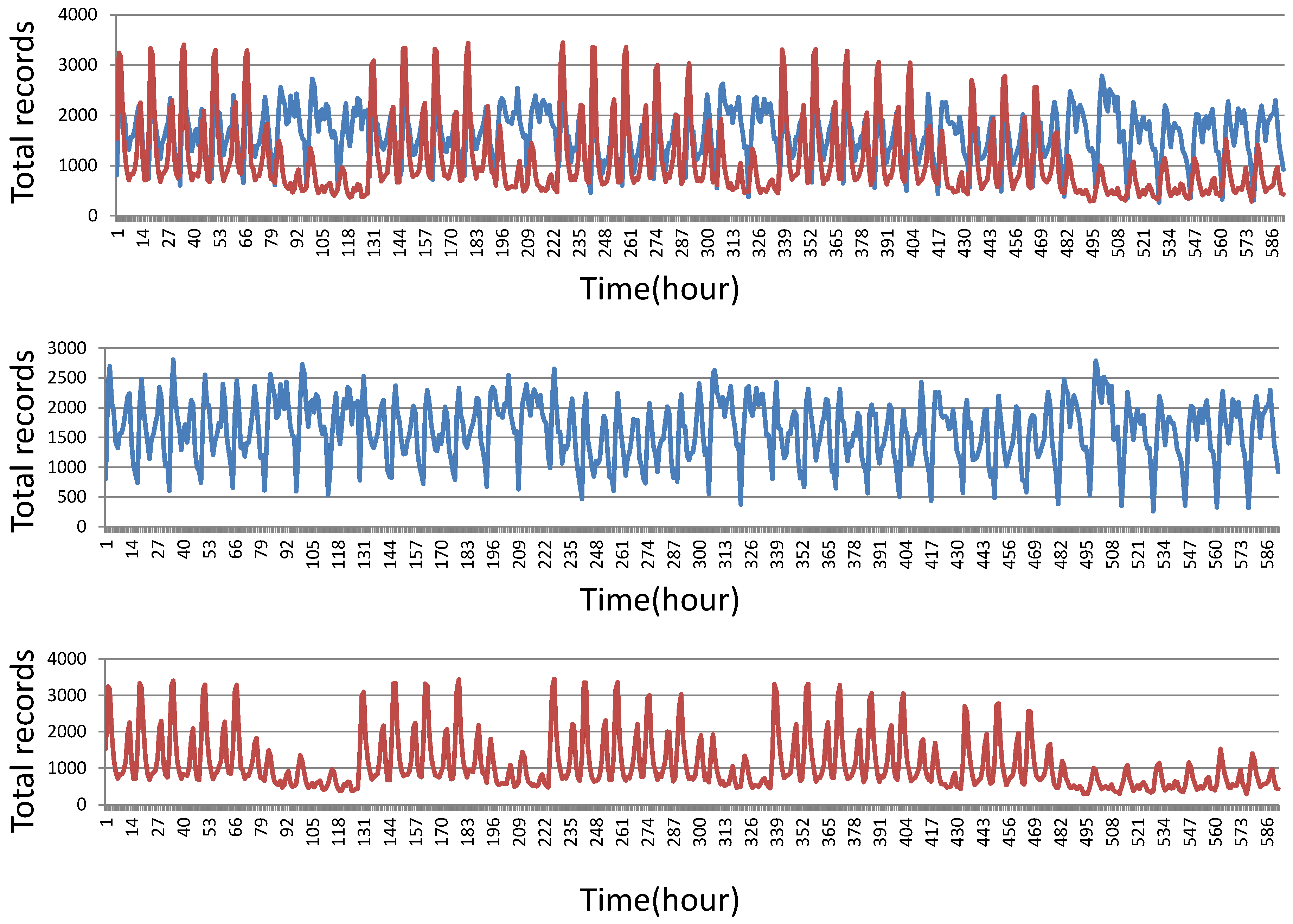
Figure 2 shows the different kinds of dirty data that exist in practice. The horizontal coordinate is time and the vertical coordinate is the total number of records of Bus Line 1. Entering this raw data into the training model will not produce a reasonable result, so it is of key importance to preprocess the data. About
of the raw data have a
that corresponds with more than two
values. We divide the
into two categories:
with one
and those with two or more values of
. This procedure has practical significance, because it filters out the passengers with regular bus lines. All the features are generated separately. Moreover, there exist some data for which the same
has more than two records in the same
at the same time. This is very abnormal and may be caused by terminal equipment or data transmission failures. We rank these
records in the same
at the same time and filter out all duplicate records.
3.2.2. Raw Data Preprocessing
In addition to dirty data, many kinds of data cannot be used directly for training, such as weather condition, time, and so on. We have to consider records with the same conditions (e.g., weather, time, etc.) of records and and construct the features. Take weather as an example: we have to calculate the number of records of the same weather condition in the last few hours, days, and so on, which can measure the difference of passengers in different weather conditions. In many machine learning tasks, the feature is not always a continuous value, but it is likely to be the value of the classification. For example, the temperature classes can describe the temperature in certain weather conditions while the continuous variables cannot. We make these data discrete by adopting dummy variables to handle them data. For instance, the daytime temperature is recorded as "0001" for the condition in which 10 C and 20 C , which is widely used in category features and has two advantages: (1) solve the problem of the classifier is not good to deal with attribute data and, (2) to a certain extent, it expands the characteristic of features. We thus transform the weather condition and time data. The daytime temperature is divided into (10 C–20 C), (20 C–30 C), and (>30 C) and the nighttime temperature is divided into (0 C–10 C), (10 C–20 C), and (20 C–30 C). The time data are divided into weekday, weekend, holiday, and rush hour.
3.3. Semantic Trajectory Mining
We divide a city into disjointed blocks [
17], assuming that placement in a block
g is uniform. The road network is usually composed of a number of major roads, such as the ring road, and the city is divided into areas [
18]. We map the projection of the vector-based road network onto a plane and convert it to a raster model [
19]. Each pixel of the image of the projected map can be viewed as a block element of the corresponding raster map. Consequently, the road network is converted into a binary image. Then, we extract the skeleton of the road, while retaining the original two-value image topology. Finally, we obtain the blocks
g of the cities.
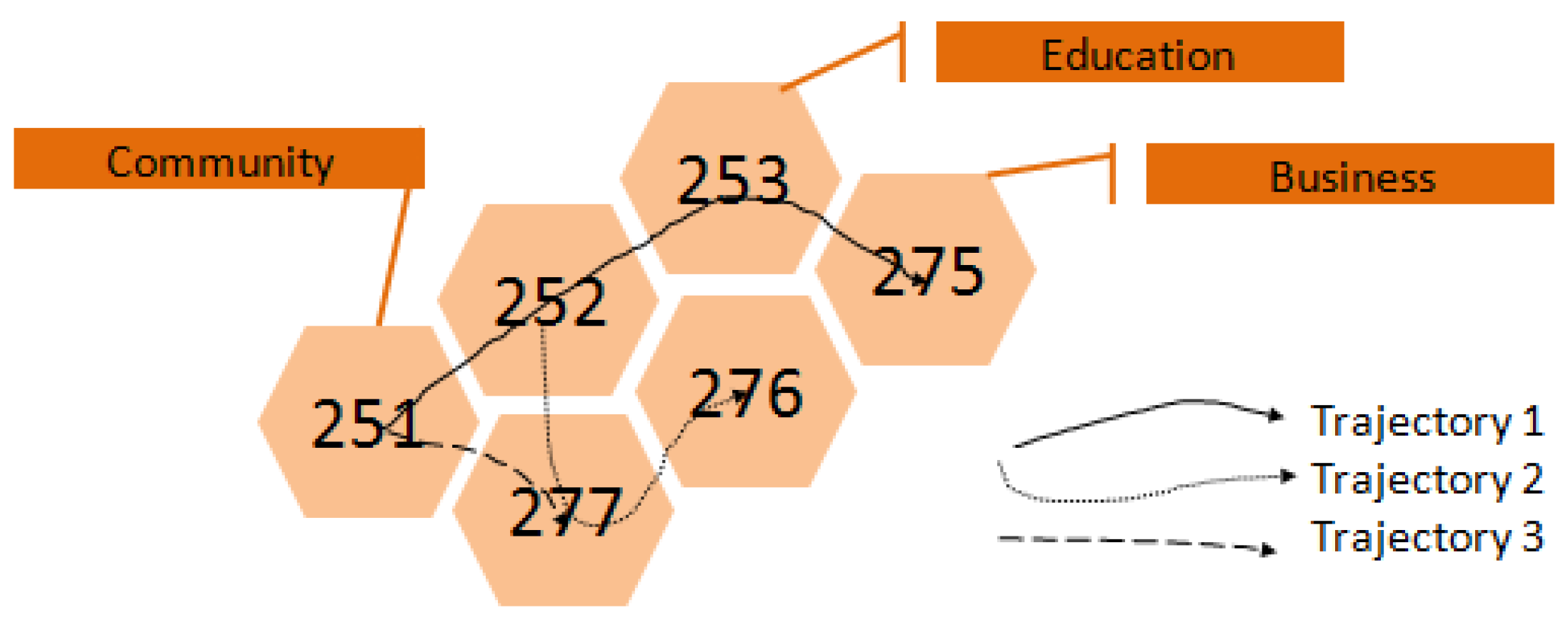
Each bus stop has latent semantic meaning due to its surroundings, such as POIs and neighborhood function. For example, a passenger who gets on the bus at a station in a residential area and gets off near a school every day may be going to school at a fixed time. We can formulate these records as <Community, Education>. The "Community" refers to the region of residential quarters with many people living there. We follow the approach of Ying et al. [
13] to mine semantic patterns from each user’s records. Semantic location information is labeled from the Baidu Map API (data schema shown in the
Appendix). We use some general categories, such as POI type and neighborhood function, as semantic labels. If a record location overlaps one or several areas with semantic labels, the semantic meanings of these areas are assigned to this record.
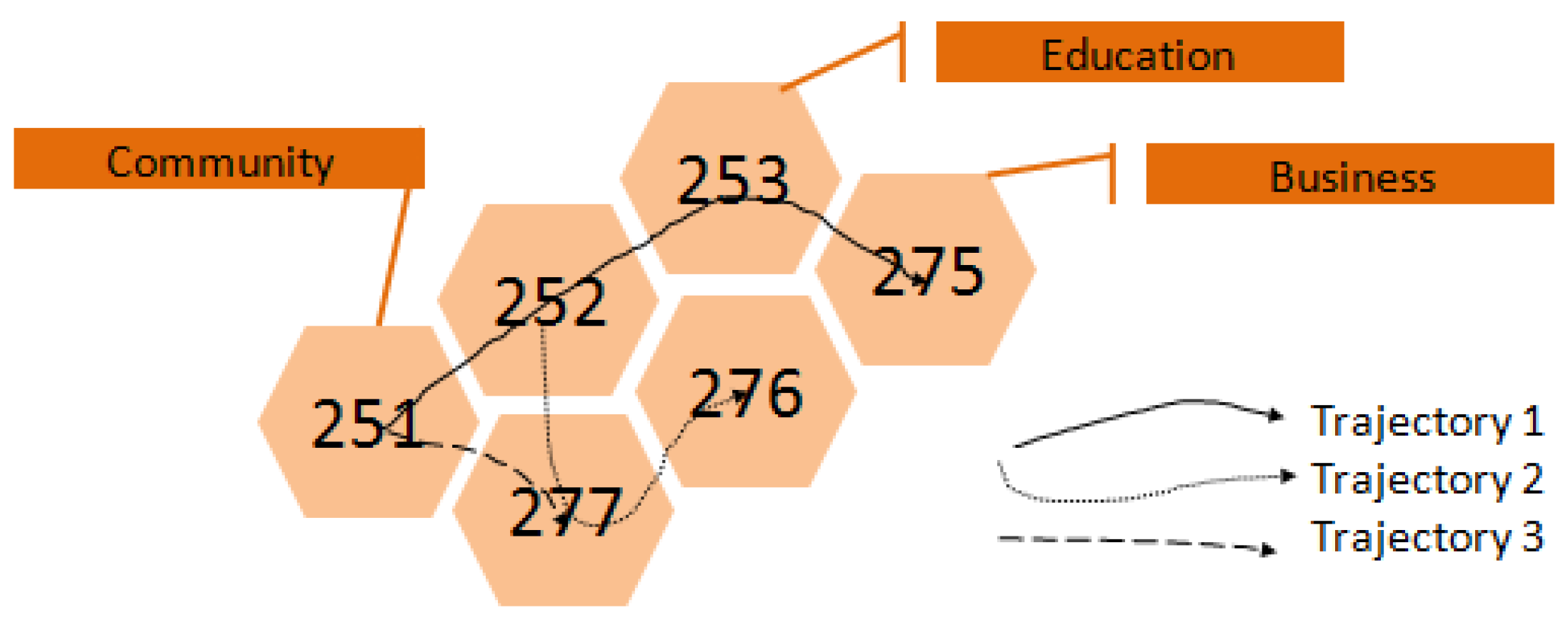
Figure 3 shows that the semantic label of block 253 (Block ID) is Education. We transform each passenger record to a semantic record, like <
>. Primary user behaviors may exhibit some patterns, and thus can be predicted. Formally, there are
n categories (including both POIs and neighborhood function) of blocks
, where
is a category such as Education (function) or Coffee Shop (POI). The bus records of passengers are represented in such combinations (231 combinations in this paper)
. Each combination represents a different user travel behavior.
3.4. Forecasting Passenger Boarding Choice
For this task, we consider the combinations of features
and
, and the association of a particular bus card with this bus line. Our features consist of seven categories: (1) Passenger (2) Bus Line (3) Time (4) Weather (5) Bus Card Issuing Location (6) Bus Card and (7) Latent Semantic User Behavior features. Specifically, we calculate these features for each day. We calculate the total number of records; the number of hours, days, and weeks that have records; and the number of times the card appears at different terminals (bus stops) over the past 1, 3, 7, 28, 70 and 126 days for the combination of
and
. The specific days are chosen because the data have periodicity over a week. Take the weather feature as an example. We consider records with the same weather condition of records
and
and calculate the features. Formally, we have:
where
is calculated considering the feature type. For instance, if
i is
(we divide time into in four categories, described in
Section 3.2.2), we consider records with the same time condition (e.g., rush hour, weekday) as
and
.
3.5. Passenger Flow Forecasting
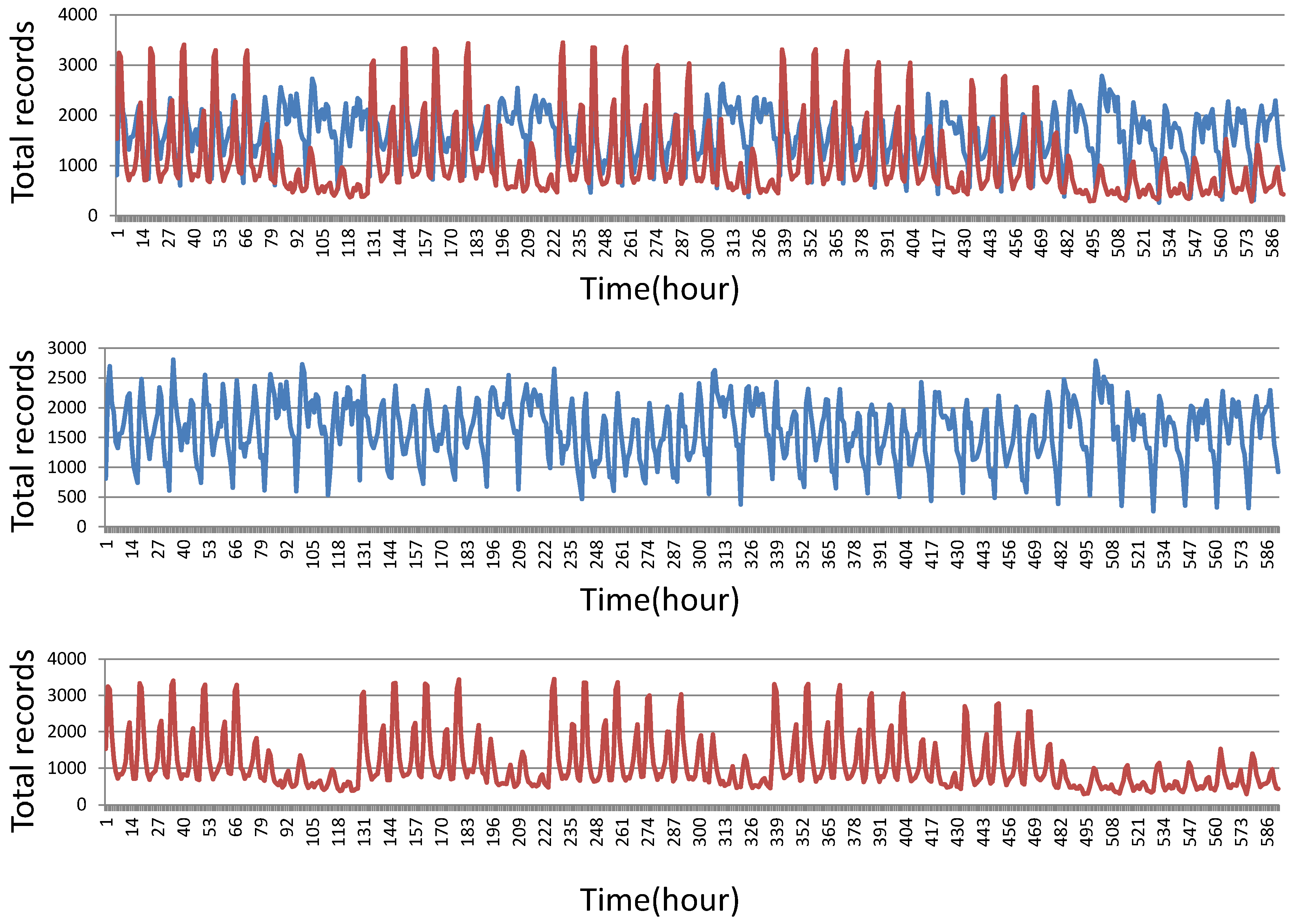
Three methods for passenger flow forecasting exist: (1) directly gathering all passenger boarding choice forecasting data to get the total number of bus passengers; (2) making the daily regression prediction using total passenger numbers; and (3) user group classification and data gathering. We adopt the third approach because of the great individual differences in bus records. The simple superposition of user records cannot be a good reflection of overall data trends because there are two kinds of passengers, as shown in
Figure 4. The red line shows occasional passengers and the blue line shows frequent passengers from 1 September 2014 to 7 October 2014. The records of frequent passengers are regular while the records of occasional passengers are random. We build different models for these different kinds of passengers. The
is the prediction result of random passenger model while the
is the prediction result of frequent passenger model. We have to combine the two results and get the final result. However, on different days (weekend/holiday and weekday), the portion of random passengers or frequent passengers in the total passengers are different. We use the variable
α and
β to adjust this deviation. Formally, we have:
We calculate the total number of passengers in each hour of each line and adopt one-hot encoding of weather conditions and semantic user behaviors as features for regression.
4. Experiments
4.1. Setup
All of our experimental data are available online. The dates of the public transit data range from 1 August 2014 to 31 December 2014. We use the data from 1 December 2014 to 31 December 2014 as the training data and from 1 January 2015 to 7 January 2015 as test data. The data ranged from 06:00 to 20:00 each day and data schema description details are in the
Appendix. We obtain POI and district function data from the Baidu Map API [
20]. We obtain free-text place descriptions using geoparsing [
21] to convert text into unambiguous geographic identifiers (latitude and longitude coordinates). We train our data with XGBoost [
22], optimizing its parameters by a linear weighted method. We set
and
. We mainly tune the parameters, including the maximum depth of tree and the step size shrinkage used in updates, to prevent overfitting and to minimize the sum of the instance (Hessian) weight needed in a child node. Finally, we set the maximum depth to 10, step size to 0.3, and the minimum instance weight sum to 2.0 in our experiments. Logistic regression [
23] and linear regression are used as weak classifier in our experiment.
4.2. Metrics
First, we use the set of baselines to justify the necessity of each component of our method by, for example, not utilizing user behavior () or the weather ().
To forecast passenger boarding choice, we adopt logistic regression [
23], GBDTs [
24], and Random Forests [
25] as baselines. For passenger flow forecasting, we use Autoregressive-moving Average (ARMA) [
26], a single layer artificial neural network (ANN), and linear regression as baselines.
We evaluate the final result with F1 scores, where , for the passenger boarding choice forecasting.
For passenger flow forecasting, we adopt the root mean square error (RMSE), defined as , where is a prediction and is the ground truth.
4.3. Data Insight
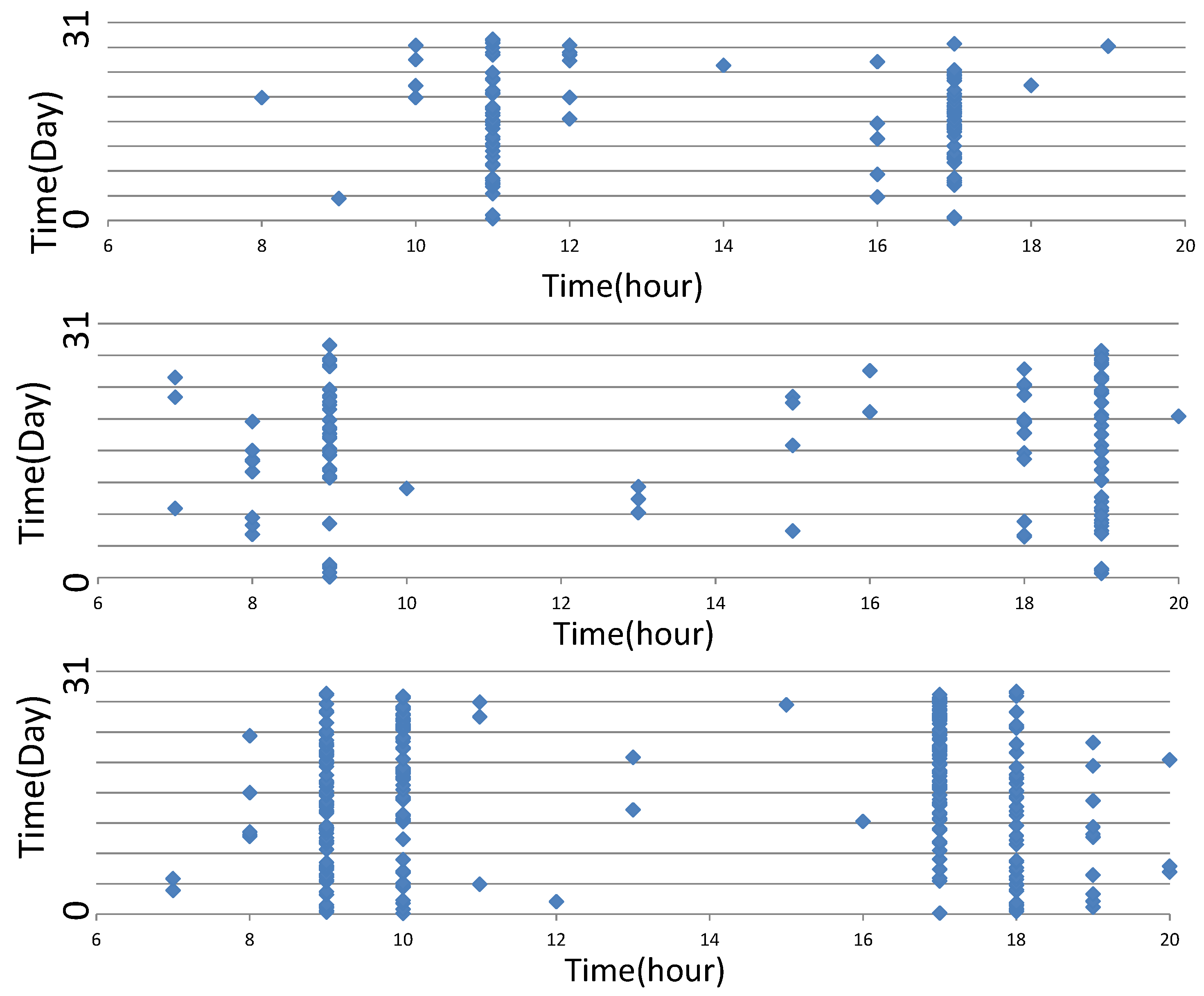
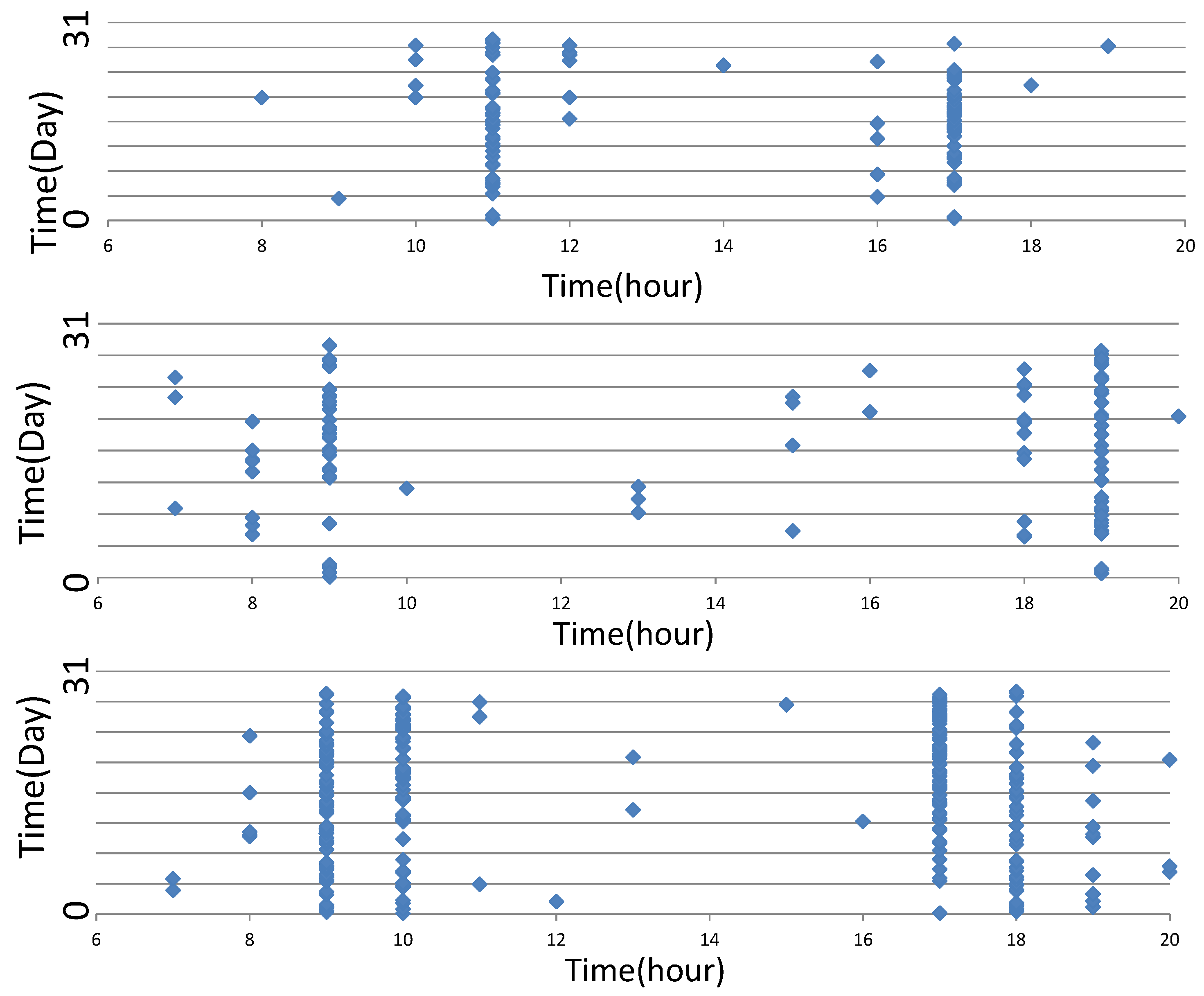
We first analyze individual public transit records. As
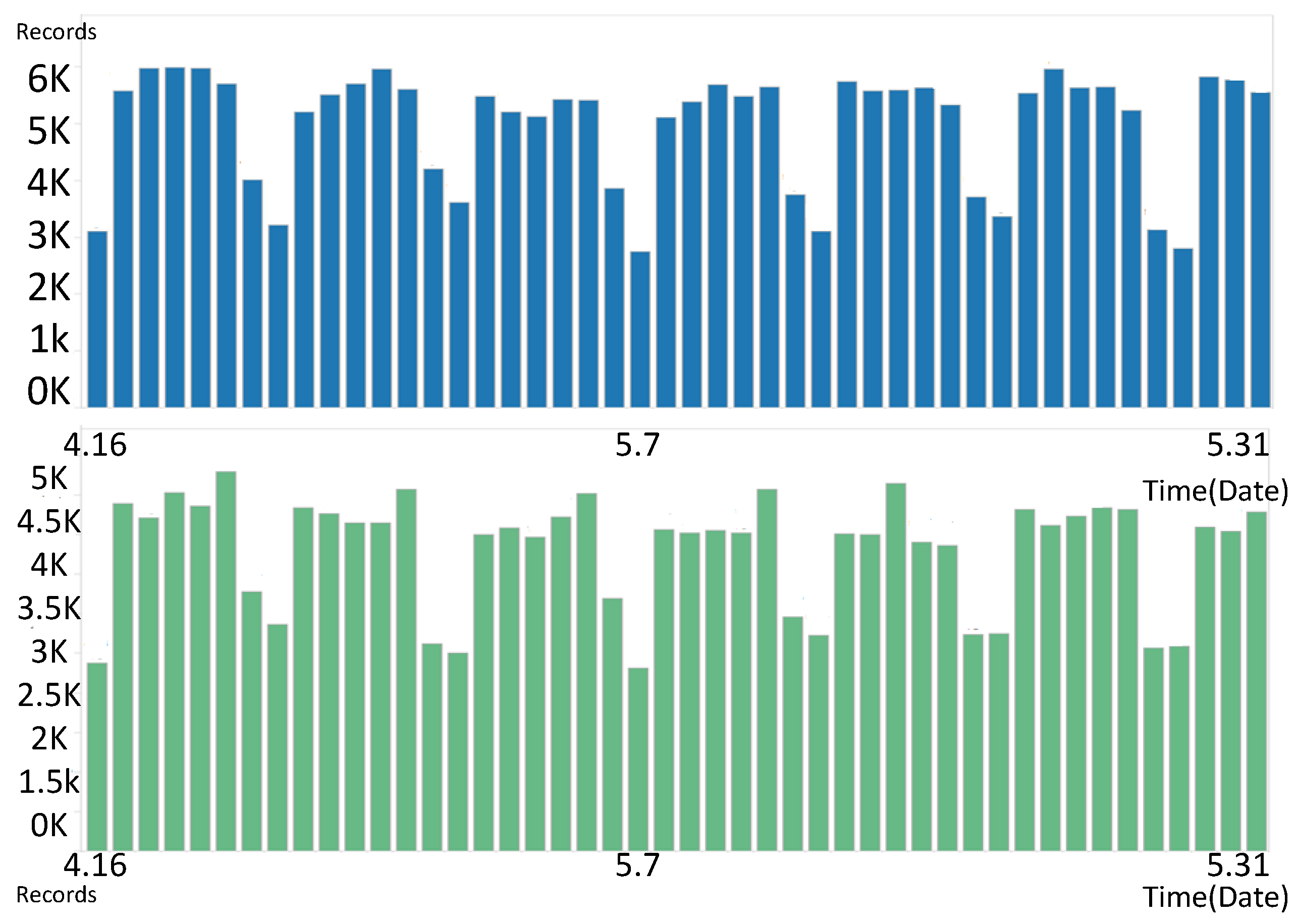
Figure 5 depicts, the horizontal coordinates represent the hour (06:00–20:00) of travel and the vertical coordinates represent the travel date (the 1st–31st day of the month). There exist significant differences between individuals. Take Line 1 as an example: there are 19,513,511 passengers and 6,738,391 records over five months, meaning that there are 3.45 passengers per record over this period. This result indicates that there are many passengers who rarely take the bus. We then divide those passengers by their travel record frequency. Passengers with more than eight records each week are treated as frequent passengers, while the others are occasional passengers. As
Figure 6 shows, the blue histogram represents the flow of frequent passengers and the green, occasional passengers. Clearly, the two groups follow different rules regarding travel times. Hence, we build different passenger flow forecasting models for frequent and occasional passengers.
4.4. Results
4.4.1. Forecasting Passenger Boarding Choices
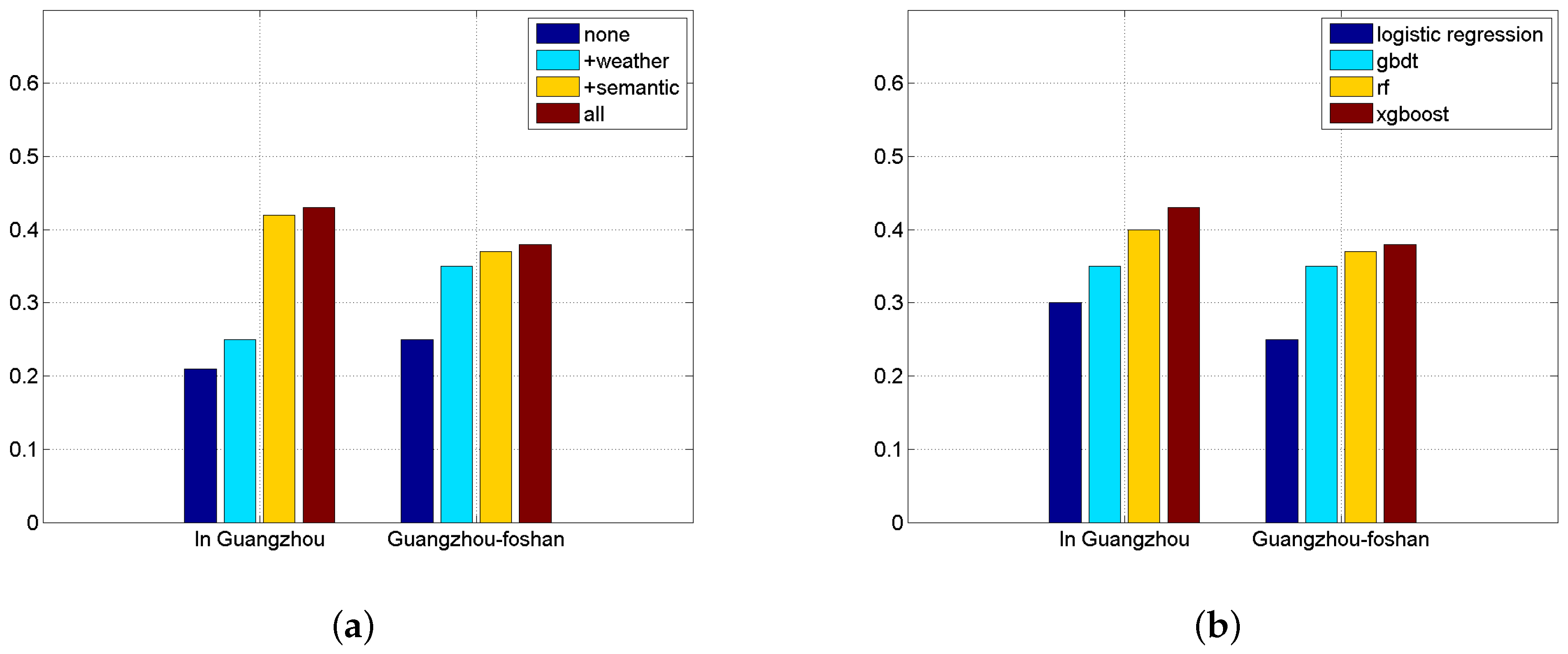
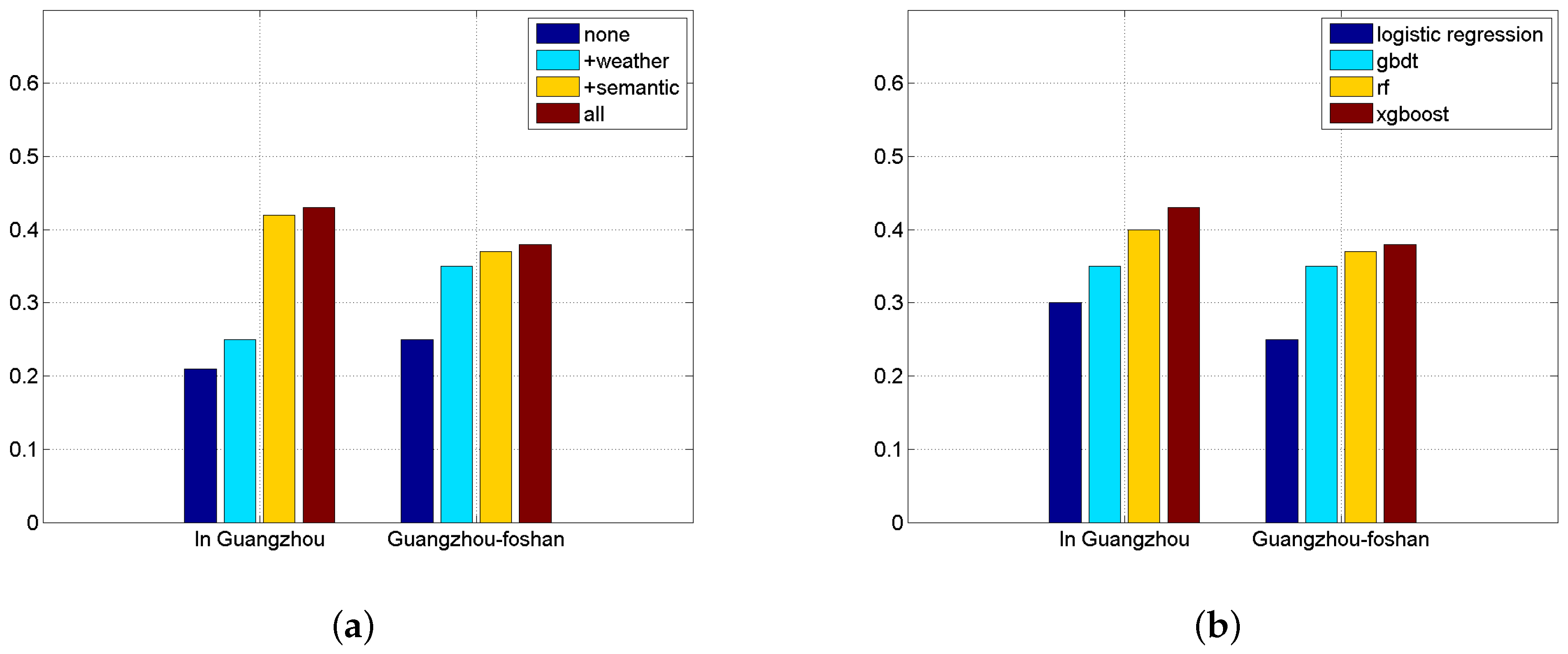
Figure 7a demonstrates the necessity of each component of our method for forecasting passenger boarding choices. The “none” case adopts only time features and has the worst results. By adding weather and semantic features, F1 scores increase rapidly. The “all” case utilizes all the features of our method and gets the best results.
Figure 7b shows the results of logistic regression, GBDT, Random Forest, and XGBoost. XGBoost shows good performance compared with the other methods.
4.4.2. Passenger Flow Forecasting
Figure 8a shows the necessity of each component of our method for passenger flow forecasting. The “none” case adopts only time features and has the worst results. By adding weather and semantic features, F1 scores increase rapidly. The “all” case adopts all the possible features of our method and gets the best results.
Figure 8b shows the results of linear regression, ANN, ARMA, and XGBoost. XGBoost has superior performance compared to the other methods.
4.5. Case Studies: Public Transport in Guangzhou
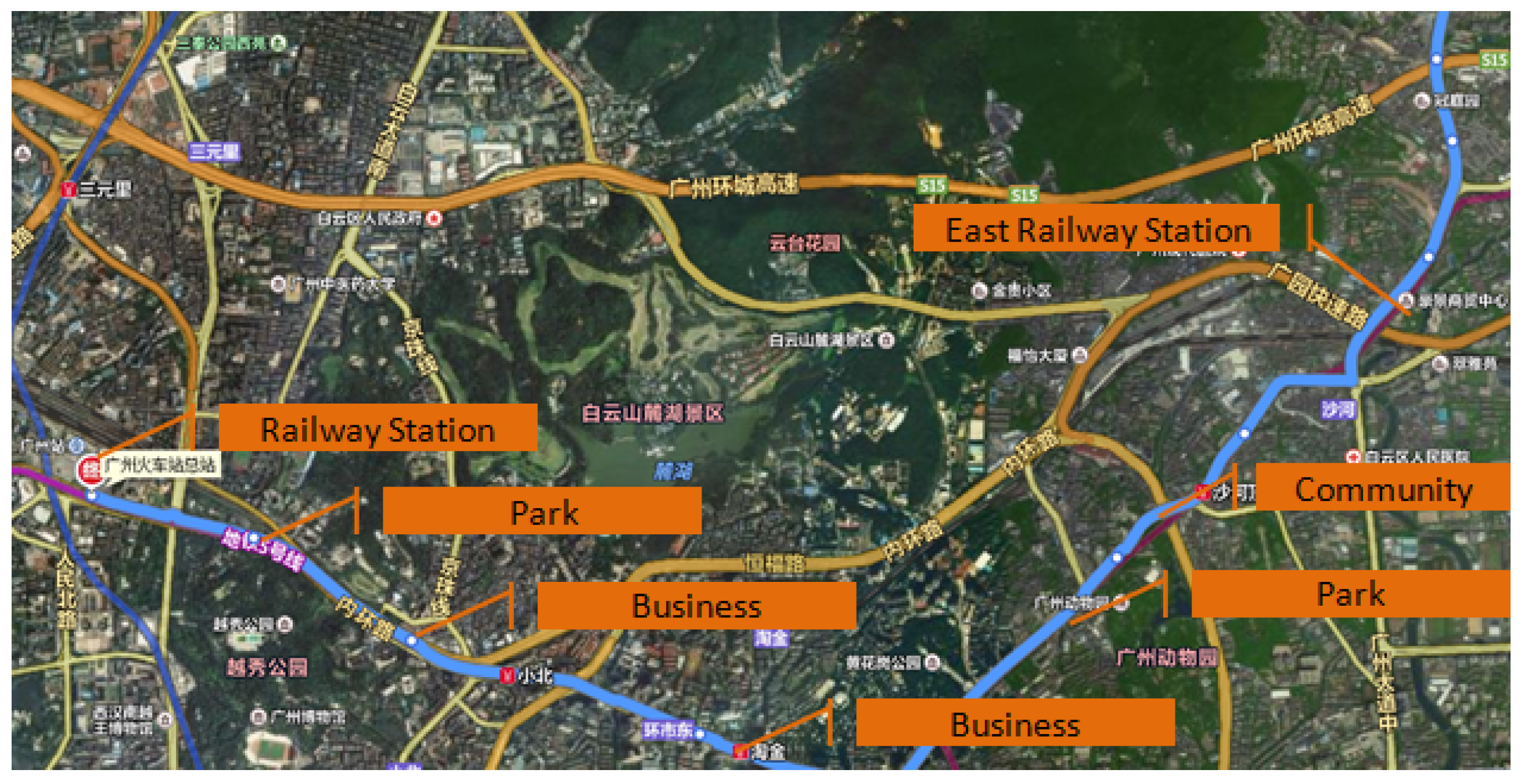
Bus data is not just traffic data. It can reveal users’ potential travel needs. As
Figure 9 shows, passengers who get on a bus at the Railway Station and get off at the East Railway Station may want to change trains. The passengers from a Shahe (Community) to Xiaobei (Business) may be going to work, while those who travel from Shahe (Community) to the Zoo (Park) may be traveling for entertainment purposes. The frequency and timing of public transit trips can also indicate potential reasons for traveling and reflect the pulse of a city.
4.6. Discussion
Good solutions are derived from a thorough understanding of business and detailed data analysis. Today, the significance of mobile applications such as Uber and Didi (an Uber-like app in China) lies in connecting people and travel tools. However, this shared economic model is far from economic. Imagine that when Uber and Didi were launched, the frequency of car travel increased significantly, leading to a decline in the frequency of public transit use and a consequent increase in traffic congestion and environmental pollution. Public transit is much more economic and environmentally friendly than private car travel and there still exist severe traffic congestion and environmental problems in big cities. Hence, the development of public transit is more urgent than that of private cars, even though travellers may find public transit less convenient and comfortable. Based on the analysis of big datasets, such as public transport and road network data from smart cities, we can improve the convenience, comfort, ease, and speed of travel via public transit. Moreover, directional advertising timing can be provided by passenger behavior analysis. In recent years, more data have become accessible through web services in order to mine their potential value. Analyzing these data can improve social efficiency.
5. Conclusions
In this study, we propose an approach for forecasting public transit using crowdsensing data, which is helpful for public transit companies and government decision-making, but had not previously been investigated. In this framework, we first preprocess the raw data to filter out dirty data to discretize the dataset. Next, we annotate the data with semantic information, construct several feature vectors, and train with those data.
There are some limitations to this study, which should be addressed in future work. One major limitation lies in the partially missing data from some users and the limited availability of open data. For example, there exist many records that do not record when the passenger got off the bus (passengers should use their bus card both to get on and off the bus/subway). We would like to mine the passenger behaviors more deeply in the future. The adaptability of this approach to real-world circumstances will also be considered in our future work. First, some visual analytics functions will be added to our ongoing demonstration system. Through presenting similar historical circumstances or forecasting results according to different features, the system will be able to provide more information for flexible decision-making. We are also investigating a new prediction model that utilizes data from similar historical circumstances through understanding the underlying semantics of the data.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}